
البحث في الموقع
المحتوى عن 'ubuntu'.
-
 يمكن شرح مبدأ نظام التكامل المستمر Continuous Integration System في هندسة البرمجيات ببساطة على أنه دمج مجهود أفراد فريق عمل بشكل مستمر ويومي، فكل مرة تضيف شفرة جديدة لفرع master مثلًا، يحاول خادم CI أن يبني البرنامج (يجمّع البرنامج ويختبر الوحدات والتكامل ويحلل الجودة، إلخ). نظام Concourse للتكامل المستمر تحدث أخطاء غير مقصودة في المتغيرات التي لديك أثناء انتقالك من أحد أنظمة التكامل المستمر إلى غيره لمجرد استخدام واجهة النظام الجديد، ولأن عدد تلك المتغيرات كبير فإن احتمال حدوث الخطأ كبير أيضًا. وهنا يأتي Concourse CI، حيث يهدف إلى توفير نظام تكامل بسيط وقابل للتوسع وبه أقل عدد ممكن من الأجزاء المتحركة، عبر استخدام بنية تفسيرية Declarative syntax يمكن من خلالها نمذجة أي أنبوب pipeline سواء كان بسيطًا مثل (الوحدة unit، التكامل integration ، التطبيق deploy، الشحن ship)، أو كان أنبوبًا معقدًا مثل إجراء اختبارات على بنى تحتية infrastructures متعددة. وسنعرف في هذا المقال طريقة تثبيت Concourse CI على خادم أوبنتو 16.04 باستخدام PostgreSQL. الخطوة الأولى – تثبيت PostgreSQL نبدأ أولًا وقبل أي شيء بتثبيت PostgreSQL على الخادم، حيث سيستخدمها Concourse لتخزين بيانات الأنبوب الخاص به: # apt-get install postgresql postgresql-contrib ثم ننشئ مستخدم PostgreSQL، سيدير هذا المستخدم بيانات Concourse في قاعدة البيانات: $ sudo -u postgres createuser concourseusr يبحث Concourse بشكل افتراضي عن قاعدة بيانات اسمها atc، وسيحاول الاتصال بها، فننشئ قاعدة بيانات جديدة: $ sudo -u postgres createdb --owner=concourse atc تثبيت Concourse CI سنحمّل الآن الملفات التنفيذية الخاصة بلينكس في مجلد tmp (نُشر المقال في 3 أغسطس من هذا العام، واستخدم إصدار 3.3.2 من Concourse، وسنستخدم إصدار 3.4.1 في هذا المقال حيث أنه آخر إصدار متوفر إلى الآن، اطّلع على صفحة التحميلات وانظر الإصدار المناسب لك وغيّر رقم الإصدار في أوامر التحميل التالية: للذهاب إلى tmp: # cd /tmp والآن نفذ الأمر التالي لتحميل إصدار 3.4.1 : # curl -LO https://github.com/concourse/concourse/releases/download/v3.4.1/concourse_linux_amd64 ثم نحمّل الإصدار الأخير المتوفر من fly (إصدار 3.4.1) في مجلد tmp أيضًا: # curl -LO https://github.com/concourse/concourse/releases/download/v3.4.1/fly_linux_amd64 بعد تحميل الملفين، ننقلهما إلى هذا مجلد bin: # mv concourse* /usr/local/bin/concourse # mv fly* /usr/local/bin/fly نتأكد الآن من سلامة الملفات بفحص إصدارها $ concourse --version $ fly –version ويجب أن يظهر لك أن الإصدار هو 3.4.1 (هذا آخر إصدار متوفر وقت ترجمة المقال، وهو الذي استخدمناه). ضبط وإعداد Concourse CI ننشئ أولًا مجلدًا لضبط وإعداد Concourse: # mkdir /etc/concourse 1. إنشاء مفاتيح تشفير تحتاج العناصر التي يتكون منها concourse إلى التواصل فيما بينها بأمان، خاصة TSA وWorkers TSA: خادم SSH بني خصيصًا لتسجيل workers مع ATC Workers: آلات تستخدم خوادم Garden وbaggageclaim وتسجّل نفسها من خلال TSA ولضمان أمان ذلك التواصل فإننا نحتاج إلى إنشاء هذه المفاتيح: مفاتيح لـ Worker مفاتيح لـ TSA مفاتيح تسجيل الجلسة (Session Signing Keys) من أجل تسجيل الرموز (Tokens) ستُستخدم تلك المفاتيح تلقائيًا حين يبدأ عنصر ما، لذا من المهم ألا تستخدم كلمة مرور لقفل المفاتيح. والآن، سننشئ تلك المفاتيح اللازمة، عبر هذه الأوامر: # ssh-keygen -t rsa -q -N '' -f /etc/concourse/worker_key # ssh-keygen -t rsa -q -N '' -f /etc/concourse/tsa_key # ssh-keygen -t rsa -q -N '' -f /etc/concourse/session_key سيقرر خادم TSA آلات workers التي يسمح لها بالاتصال بالنظام، لذا يجب أن نمنح تلك الصلاحية لمفتاح worker العام، وسنكتفي في حالتنا بتنفيذ هذا الأمر: # cp /etc/concourse/worker_key.pub /etc/concourse/authorized_worker_keys 2. تهيئة البيئة Environment Configuration لا يقرأ ملف Concourse التنفيذي أي ملفات تهيئة (Configuration)، لكن هذا لا يعني أنه لا يمكن تهيئته، فهو يأخذ قِيَمه من متغيرات البيئة التي أُدخلت في بداية العملية. 1- أنشئ ملفًا جديدًا لتهيئة عملية web: # $EDITOR /etc/concourse/web_env 2- ألصق هذا المحتوى داخل الملف: CONCOURSE_SESSION_SIGNING_KEY=/etc/concourse/session_key CONCOURSE_TSA_HOST_KEY=/etc/concourse/tsa_key CONCOURSE_TSA_AUTHORIZED_KEYS=/etc/concourse/authorized_worker_keys CONCOURSE_POSTGRES_SOCKET=/var/run/postgresql # Match your environment CONCOURSE_BASIC_AUTH_USERNAME=your_usr_name CONCOURSE_BASIC_AUTH_PASSWORD=strong_pwd CONCOURSE_EXTERNAL_URL=http://server_IP:8080 3- احفظ الملف وأغلقه. 4- أنشئ ملفًا جديدًا من أجل worker # $EDITOR /etc/concourse/worker_env 5- ألصق هذا المحتوى فيه: CONCOURSE_WORK_DIR=/var/lib/concourse CONCOURSE_TSA_WORKER_PRIVATE_KEY=/etc/concourse/worker_key CONCOURSE_TSA_PUBLIC_KEY=/etc/concourse/tsa_key.pub CONCOURSE_TSA_HOST=127.0.0.1 6- عدّل الصلاحيات لملفات البيئة: # chmod 600 /etc/concourse/w*_env 3. إنشاء المستخدم 1- سننشئ مستخدمًا جديدًا لتشغيل عملية web، ويجب أن يطابق هذا المستخدم اسم المستخدم الذي أنشأناه لـ PostgreSQL من قبل: # adduser --system --group concourseusr 2- أعط هذا المستخدم ملكية مجلد تهيئة Concourse CI: chown -R concourse:concourse /etc/concourse 3- أنشئ ملف concourse-web.service في مجلد system: # $EDITOR /etc/systemd/system/concourse-web.service 4- ألصق هذا المحتوى فيه: [Unit] Description=Concourse CI web process (ATC and TSA) After=postgresql.service [Service] User=concourse Restart=on-failure EnvironmentFile=/etc/concourse/web_env ExecStart=/usr/local/bin/concourse web [Install] WantedBy=multi-user.target 5- احفظ وأغلق الملف. 6- أنشئ ملفًا من أجل عملية Worker # $EDITOR /etc/systemd/system/concourse-worker.service 7- ألصق فيه هذا المحتوى: [Unit] Description=Concourse CI worker process After=concourse-web.service [Service] User=root Restart=on-failure EnvironmentFile=/etc/concourse/worker_env ExecStart=/usr/local/bin/concourse worker [Install] WantedBy=multi-user.target 4. ضبط (UFW (Uncomplicated FireWall تستمع عملية web للاتصالات التي على منفذ 8080، لذلك سنتيح الدخول إلى هذا المنفذ بتنفيذ أمر ufw: # ufw allow 8080 وسنحتاج إلى السماح بتصدير الدخول (forwarding access): # ufw default allow routed 5. بدء الخدمات هنا نصل إلى خطوة تشغيل كلا الخدمتين: # systemctl start concourse-worker concourse-web ثم نضبطهما ليعملا في وقت إقلاع الخادم (Server Boot Time): # systemctl enable concourse-worker concourse-web والآن صار الخادم جاهزًا لتنفيذ كل مزايا التكامل المستمر التي يوفرها Concourse CI في أوبنتو 16.04. ترجمة -بتصرف- لمقال Continuous Integration: Concourse CI on Ubuntu 16.04 لصاحبه Giuseppe Molica
يمكن شرح مبدأ نظام التكامل المستمر Continuous Integration System في هندسة البرمجيات ببساطة على أنه دمج مجهود أفراد فريق عمل بشكل مستمر ويومي، فكل مرة تضيف شفرة جديدة لفرع master مثلًا، يحاول خادم CI أن يبني البرنامج (يجمّع البرنامج ويختبر الوحدات والتكامل ويحلل الجودة، إلخ). نظام Concourse للتكامل المستمر تحدث أخطاء غير مقصودة في المتغيرات التي لديك أثناء انتقالك من أحد أنظمة التكامل المستمر إلى غيره لمجرد استخدام واجهة النظام الجديد، ولأن عدد تلك المتغيرات كبير فإن احتمال حدوث الخطأ كبير أيضًا. وهنا يأتي Concourse CI، حيث يهدف إلى توفير نظام تكامل بسيط وقابل للتوسع وبه أقل عدد ممكن من الأجزاء المتحركة، عبر استخدام بنية تفسيرية Declarative syntax يمكن من خلالها نمذجة أي أنبوب pipeline سواء كان بسيطًا مثل (الوحدة unit، التكامل integration ، التطبيق deploy، الشحن ship)، أو كان أنبوبًا معقدًا مثل إجراء اختبارات على بنى تحتية infrastructures متعددة. وسنعرف في هذا المقال طريقة تثبيت Concourse CI على خادم أوبنتو 16.04 باستخدام PostgreSQL. الخطوة الأولى – تثبيت PostgreSQL نبدأ أولًا وقبل أي شيء بتثبيت PostgreSQL على الخادم، حيث سيستخدمها Concourse لتخزين بيانات الأنبوب الخاص به: # apt-get install postgresql postgresql-contrib ثم ننشئ مستخدم PostgreSQL، سيدير هذا المستخدم بيانات Concourse في قاعدة البيانات: $ sudo -u postgres createuser concourseusr يبحث Concourse بشكل افتراضي عن قاعدة بيانات اسمها atc، وسيحاول الاتصال بها، فننشئ قاعدة بيانات جديدة: $ sudo -u postgres createdb --owner=concourse atc تثبيت Concourse CI سنحمّل الآن الملفات التنفيذية الخاصة بلينكس في مجلد tmp (نُشر المقال في 3 أغسطس من هذا العام، واستخدم إصدار 3.3.2 من Concourse، وسنستخدم إصدار 3.4.1 في هذا المقال حيث أنه آخر إصدار متوفر إلى الآن، اطّلع على صفحة التحميلات وانظر الإصدار المناسب لك وغيّر رقم الإصدار في أوامر التحميل التالية: للذهاب إلى tmp: # cd /tmp والآن نفذ الأمر التالي لتحميل إصدار 3.4.1 : # curl -LO https://github.com/concourse/concourse/releases/download/v3.4.1/concourse_linux_amd64 ثم نحمّل الإصدار الأخير المتوفر من fly (إصدار 3.4.1) في مجلد tmp أيضًا: # curl -LO https://github.com/concourse/concourse/releases/download/v3.4.1/fly_linux_amd64 بعد تحميل الملفين، ننقلهما إلى هذا مجلد bin: # mv concourse* /usr/local/bin/concourse # mv fly* /usr/local/bin/fly نتأكد الآن من سلامة الملفات بفحص إصدارها $ concourse --version $ fly –version ويجب أن يظهر لك أن الإصدار هو 3.4.1 (هذا آخر إصدار متوفر وقت ترجمة المقال، وهو الذي استخدمناه). ضبط وإعداد Concourse CI ننشئ أولًا مجلدًا لضبط وإعداد Concourse: # mkdir /etc/concourse 1. إنشاء مفاتيح تشفير تحتاج العناصر التي يتكون منها concourse إلى التواصل فيما بينها بأمان، خاصة TSA وWorkers TSA: خادم SSH بني خصيصًا لتسجيل workers مع ATC Workers: آلات تستخدم خوادم Garden وbaggageclaim وتسجّل نفسها من خلال TSA ولضمان أمان ذلك التواصل فإننا نحتاج إلى إنشاء هذه المفاتيح: مفاتيح لـ Worker مفاتيح لـ TSA مفاتيح تسجيل الجلسة (Session Signing Keys) من أجل تسجيل الرموز (Tokens) ستُستخدم تلك المفاتيح تلقائيًا حين يبدأ عنصر ما، لذا من المهم ألا تستخدم كلمة مرور لقفل المفاتيح. والآن، سننشئ تلك المفاتيح اللازمة، عبر هذه الأوامر: # ssh-keygen -t rsa -q -N '' -f /etc/concourse/worker_key # ssh-keygen -t rsa -q -N '' -f /etc/concourse/tsa_key # ssh-keygen -t rsa -q -N '' -f /etc/concourse/session_key سيقرر خادم TSA آلات workers التي يسمح لها بالاتصال بالنظام، لذا يجب أن نمنح تلك الصلاحية لمفتاح worker العام، وسنكتفي في حالتنا بتنفيذ هذا الأمر: # cp /etc/concourse/worker_key.pub /etc/concourse/authorized_worker_keys 2. تهيئة البيئة Environment Configuration لا يقرأ ملف Concourse التنفيذي أي ملفات تهيئة (Configuration)، لكن هذا لا يعني أنه لا يمكن تهيئته، فهو يأخذ قِيَمه من متغيرات البيئة التي أُدخلت في بداية العملية. 1- أنشئ ملفًا جديدًا لتهيئة عملية web: # $EDITOR /etc/concourse/web_env 2- ألصق هذا المحتوى داخل الملف: CONCOURSE_SESSION_SIGNING_KEY=/etc/concourse/session_key CONCOURSE_TSA_HOST_KEY=/etc/concourse/tsa_key CONCOURSE_TSA_AUTHORIZED_KEYS=/etc/concourse/authorized_worker_keys CONCOURSE_POSTGRES_SOCKET=/var/run/postgresql # Match your environment CONCOURSE_BASIC_AUTH_USERNAME=your_usr_name CONCOURSE_BASIC_AUTH_PASSWORD=strong_pwd CONCOURSE_EXTERNAL_URL=http://server_IP:8080 3- احفظ الملف وأغلقه. 4- أنشئ ملفًا جديدًا من أجل worker # $EDITOR /etc/concourse/worker_env 5- ألصق هذا المحتوى فيه: CONCOURSE_WORK_DIR=/var/lib/concourse CONCOURSE_TSA_WORKER_PRIVATE_KEY=/etc/concourse/worker_key CONCOURSE_TSA_PUBLIC_KEY=/etc/concourse/tsa_key.pub CONCOURSE_TSA_HOST=127.0.0.1 6- عدّل الصلاحيات لملفات البيئة: # chmod 600 /etc/concourse/w*_env 3. إنشاء المستخدم 1- سننشئ مستخدمًا جديدًا لتشغيل عملية web، ويجب أن يطابق هذا المستخدم اسم المستخدم الذي أنشأناه لـ PostgreSQL من قبل: # adduser --system --group concourseusr 2- أعط هذا المستخدم ملكية مجلد تهيئة Concourse CI: chown -R concourse:concourse /etc/concourse 3- أنشئ ملف concourse-web.service في مجلد system: # $EDITOR /etc/systemd/system/concourse-web.service 4- ألصق هذا المحتوى فيه: [Unit] Description=Concourse CI web process (ATC and TSA) After=postgresql.service [Service] User=concourse Restart=on-failure EnvironmentFile=/etc/concourse/web_env ExecStart=/usr/local/bin/concourse web [Install] WantedBy=multi-user.target 5- احفظ وأغلق الملف. 6- أنشئ ملفًا من أجل عملية Worker # $EDITOR /etc/systemd/system/concourse-worker.service 7- ألصق فيه هذا المحتوى: [Unit] Description=Concourse CI worker process After=concourse-web.service [Service] User=root Restart=on-failure EnvironmentFile=/etc/concourse/worker_env ExecStart=/usr/local/bin/concourse worker [Install] WantedBy=multi-user.target 4. ضبط (UFW (Uncomplicated FireWall تستمع عملية web للاتصالات التي على منفذ 8080، لذلك سنتيح الدخول إلى هذا المنفذ بتنفيذ أمر ufw: # ufw allow 8080 وسنحتاج إلى السماح بتصدير الدخول (forwarding access): # ufw default allow routed 5. بدء الخدمات هنا نصل إلى خطوة تشغيل كلا الخدمتين: # systemctl start concourse-worker concourse-web ثم نضبطهما ليعملا في وقت إقلاع الخادم (Server Boot Time): # systemctl enable concourse-worker concourse-web والآن صار الخادم جاهزًا لتنفيذ كل مزايا التكامل المستمر التي يوفرها Concourse CI في أوبنتو 16.04. ترجمة -بتصرف- لمقال Continuous Integration: Concourse CI on Ubuntu 16.04 لصاحبه Giuseppe Molica -

 إن بروتوكول ضبط المضيف ديناميكيًّا (Dynamic Host Configuration Protocol) هو خدمة شبكة تُفعِّل إسناد إعدادات الشبكة إلى الحواسيب المضيفة من خادوم بدلًا من إعداد كل مضيف شبكي يدويًا؛ حيث لا تملك الحواسيب المُعدَّة كعملاءٍ لخدمة DHCP أيّة تحكم بالإعدادات التي تحصل عليها من خادوم DHCP. إن أشهر الإعدادات الموفَّرة من خادوم DHCP إلى عملاء DHCP تتضمن: عنوان IP وقناع الشبكة.عنوان IP للبوابة الافتراضية التي يجب استخدامها.عناوين IP لخواديم DNS التي يجب استعمالها.لكن يمكن أيضًا أن يوفِّر خادوم DHCP خاصيات الضبط الآتية: اسم المضيف.اسم النطاق.خادوم الوقت.خادوم الطباعة.من مزايا استخدام DHCP هو أن أي تغييرٍ في إعدادات الشبكة -على سبيل المثال تغيير عنوان خادوم DNS- سيتم في خادوم DHCP فقط، وسيُعاد ضبط جميع مضيفي الشبكة في المرة القادمة التي سيَطلُبُ فيها عملاء DHCP معلومات الإعدادات من خادوم DHCP؛ ويُسهِّل استعمال خادوم DHCP إضافة حواسيب جديدة إلى الشبكة، فلا حاجة للتحقق من توفر عنوان IP؛ وسيقل أيضًا التضارب في حجز عناوين IP. يمكن أن يُوفِّر خادوم DHCP إعدادات الضبط باستخدام الطرق الآتية: التوزيع اليدوي (Manual allocation) عبر عنوان MACتتضمن هذه الطريقة استخدام DHCP للتعرف على عنوان مميز لعتاد كل كرت شبكة متصل إلى الشبكة، ثم سيوفِّر إعدادات ضبطٍ ثابتةً في كل مرة يتصل فيها عميل DHCP إلى خادوم DHCP باستخدام بطاقة الشبكة المعيّنة مسبقًا؛ وهذا يضمن أن يُسنَد عنوان معيّن إلى بطاقةٍ شبكيّةٍ معيّنة وذلك وفقًا لعنوان MAC. التوزيع الديناميكي (Dynamic allocation)سيُسنِد خادوم DHCP -في هذه الطريقة- عنوان IP من مجموعة من العناوين (تسمى pool، أو في بعض الأحيان range أو scope) لمدة من الزمن (يسمى ذلك بالمصطلح lease) التي تُضبَط في الخادوم، أو حتى يخبر العميل الخادوم أنه لم يعد بحاجةٍ للعنوان بعد الآن؛ وسيحصل العملاء في هذه الطريقة على خصائص الضبط ديناميكيًّا وفق المبدأ «الذي يأتي أولًا، يُخدَّم أولًا»؛ وعندما لا يكون عميل DHCP متواجدًا على الشبكة لفترة محددة، فسينتهي وقت الضبط المخصص له، وسيعود العنوان المسند إليه إلى مجموعة العناوين لاستخدامه من عملاء DHCP الآخرين؛ أي أنَّه في هذه الطريقة، يمكن «تأجير» أو استخدام العنوان لفترة من الزمن؛ وبعد هذه المدة، يجب أن يطلب العميل من الخادوم أن يعيد تأجيره إياه. التوزيع التلقائي (Automatic allocation)سيُسنِد خادوم DHCP -في هذه الطريقة- عنوان IP إسنادًا دائمًا إلى جهاز معين، ويتم اختيار هذه العنوان من مجموعة العناوين المتوفرة؛ يُضبَط عادةً DHCP لكي يُسنِد عنوانًا مؤقتًا إلى الخادوم، لكن يمكن أن يسمح خادوم DHCP بزمن تأجير «لا نهائي». يمكن اعتبار آخر طريقتين «تلقائيتَين»، ﻷنه في كل حالة يُسنِد خادوم DHCP العنوان دون تدخل إضافي مباشر، الفرق الوحيد بينهما هو مدة تأجير عنوان IP؛ بكلماتٍ أخرى، هل ستنتهي صلاحية عنوان العميل بعد فترة من الزمن أم لا. يأتي أوبنتو مع خادوم وعميل DHCP، الخادوم هو dhcpd (dynamic host configuration protocol daemon)، والعميل الذي يأتي مع أوبنتو هو dhclient، ويجب أن يثبَّت على جميع الحواسيب التي تريدها أن تُعَدّ تلقائيًا، كلا البرنامجين سهلُ التثبيت، وسيبدآن تلقائيًا عند إقلاع النظام. التثبيتاكتب الأمر الآتي في مِحَث الطرفية لتثبيت dhcpd: sudo apt-get install isc-dhcp-serverربما تحتاج إلى تغيير الضبط الافتراضي بتعديل ملف /etc/dhcp/dhcpd.conf ليلائم احتياجاتك والضبط الخاص الذي تريده. ربما تحتاج أيضًا إلى تعديل /etc/default/isc-dhcp-server لتحديد البطاقات الشبكية التي يجب أن «يستمع» (listen) إليها عفريت dhcpd. ملاحظة: رسالة عفريت dhcpd تُرسَل إلى syslog، انظر هناك لرسائل التشخيص. الضبطربما سيربكك ظهور رسالة خطأ عند انتهاء التثبيت، لكن الخطوات الآتية ستساعدك في ضبط الخدمة: في الحالات الأكثر شيوعًا، كل ما تريد أن تفعله هو إسناد عناوين IP إسنادًا عشوائيًا، يمكن أن يُفعَل ذلك بالإعدادات الآتية: # minimal sample /etc/dhcp/dhcpd.conf default-lease-time 600; max-lease-time 7200; subnet 192.168.1.0 netmask 255.255.255.0 { range 192.168.1.150 192.168.1.200; option routers 192.168.1.254; option domain-name-servers 192.168.1.1, 192.168.1.2; option domain-name "mydomain.example"; }نتيجة الإعدادات السابقة هي ضبط خادوم DHCP لإعطاء العملاء عناوين IP تتراوح من 192.168.1.150 إلى 192.168.1.200، وسيُأجَّر عنوان IP لمدة 600 ثانية إذا لم يطلب العميل وقتًا محددًا؛ عدا ذلك، فسيكون وقت الإيجار الأقصى للعنوان هو 7200 ثانية؛ و«سينصح» الخادومُ العميلَ أن يستخدم 192.168.1.254 كبوابة افتراضية، و 192.168.1.1 و 192.168.1.2 كخادومَيّ DNS. عليك إعادة تشغيل خدمة dhcpd بعد تعديل ملف الضبط: sudo service isc-dhcp-server restartمصادرتوجد بعض المعلومات المفيدة في صفحة ويكي أوبنتو «dhcp3-server».للمزيد من خيارات ملف /etc/dhcp/dhcpd.conf، راجع صفحة الدليل man dhcpd.conf.مقالة في ISC: «dhcp-server».ترجمة -وبتصرف- للمقال Ubuntu Server Guide: Dynamic Host Configuration Protocol - DHCP. حقوق الصورة البارزة: Designed by Freepik.
إن بروتوكول ضبط المضيف ديناميكيًّا (Dynamic Host Configuration Protocol) هو خدمة شبكة تُفعِّل إسناد إعدادات الشبكة إلى الحواسيب المضيفة من خادوم بدلًا من إعداد كل مضيف شبكي يدويًا؛ حيث لا تملك الحواسيب المُعدَّة كعملاءٍ لخدمة DHCP أيّة تحكم بالإعدادات التي تحصل عليها من خادوم DHCP. إن أشهر الإعدادات الموفَّرة من خادوم DHCP إلى عملاء DHCP تتضمن: عنوان IP وقناع الشبكة.عنوان IP للبوابة الافتراضية التي يجب استخدامها.عناوين IP لخواديم DNS التي يجب استعمالها.لكن يمكن أيضًا أن يوفِّر خادوم DHCP خاصيات الضبط الآتية: اسم المضيف.اسم النطاق.خادوم الوقت.خادوم الطباعة.من مزايا استخدام DHCP هو أن أي تغييرٍ في إعدادات الشبكة -على سبيل المثال تغيير عنوان خادوم DNS- سيتم في خادوم DHCP فقط، وسيُعاد ضبط جميع مضيفي الشبكة في المرة القادمة التي سيَطلُبُ فيها عملاء DHCP معلومات الإعدادات من خادوم DHCP؛ ويُسهِّل استعمال خادوم DHCP إضافة حواسيب جديدة إلى الشبكة، فلا حاجة للتحقق من توفر عنوان IP؛ وسيقل أيضًا التضارب في حجز عناوين IP. يمكن أن يُوفِّر خادوم DHCP إعدادات الضبط باستخدام الطرق الآتية: التوزيع اليدوي (Manual allocation) عبر عنوان MACتتضمن هذه الطريقة استخدام DHCP للتعرف على عنوان مميز لعتاد كل كرت شبكة متصل إلى الشبكة، ثم سيوفِّر إعدادات ضبطٍ ثابتةً في كل مرة يتصل فيها عميل DHCP إلى خادوم DHCP باستخدام بطاقة الشبكة المعيّنة مسبقًا؛ وهذا يضمن أن يُسنَد عنوان معيّن إلى بطاقةٍ شبكيّةٍ معيّنة وذلك وفقًا لعنوان MAC. التوزيع الديناميكي (Dynamic allocation)سيُسنِد خادوم DHCP -في هذه الطريقة- عنوان IP من مجموعة من العناوين (تسمى pool، أو في بعض الأحيان range أو scope) لمدة من الزمن (يسمى ذلك بالمصطلح lease) التي تُضبَط في الخادوم، أو حتى يخبر العميل الخادوم أنه لم يعد بحاجةٍ للعنوان بعد الآن؛ وسيحصل العملاء في هذه الطريقة على خصائص الضبط ديناميكيًّا وفق المبدأ «الذي يأتي أولًا، يُخدَّم أولًا»؛ وعندما لا يكون عميل DHCP متواجدًا على الشبكة لفترة محددة، فسينتهي وقت الضبط المخصص له، وسيعود العنوان المسند إليه إلى مجموعة العناوين لاستخدامه من عملاء DHCP الآخرين؛ أي أنَّه في هذه الطريقة، يمكن «تأجير» أو استخدام العنوان لفترة من الزمن؛ وبعد هذه المدة، يجب أن يطلب العميل من الخادوم أن يعيد تأجيره إياه. التوزيع التلقائي (Automatic allocation)سيُسنِد خادوم DHCP -في هذه الطريقة- عنوان IP إسنادًا دائمًا إلى جهاز معين، ويتم اختيار هذه العنوان من مجموعة العناوين المتوفرة؛ يُضبَط عادةً DHCP لكي يُسنِد عنوانًا مؤقتًا إلى الخادوم، لكن يمكن أن يسمح خادوم DHCP بزمن تأجير «لا نهائي». يمكن اعتبار آخر طريقتين «تلقائيتَين»، ﻷنه في كل حالة يُسنِد خادوم DHCP العنوان دون تدخل إضافي مباشر، الفرق الوحيد بينهما هو مدة تأجير عنوان IP؛ بكلماتٍ أخرى، هل ستنتهي صلاحية عنوان العميل بعد فترة من الزمن أم لا. يأتي أوبنتو مع خادوم وعميل DHCP، الخادوم هو dhcpd (dynamic host configuration protocol daemon)، والعميل الذي يأتي مع أوبنتو هو dhclient، ويجب أن يثبَّت على جميع الحواسيب التي تريدها أن تُعَدّ تلقائيًا، كلا البرنامجين سهلُ التثبيت، وسيبدآن تلقائيًا عند إقلاع النظام. التثبيتاكتب الأمر الآتي في مِحَث الطرفية لتثبيت dhcpd: sudo apt-get install isc-dhcp-serverربما تحتاج إلى تغيير الضبط الافتراضي بتعديل ملف /etc/dhcp/dhcpd.conf ليلائم احتياجاتك والضبط الخاص الذي تريده. ربما تحتاج أيضًا إلى تعديل /etc/default/isc-dhcp-server لتحديد البطاقات الشبكية التي يجب أن «يستمع» (listen) إليها عفريت dhcpd. ملاحظة: رسالة عفريت dhcpd تُرسَل إلى syslog، انظر هناك لرسائل التشخيص. الضبطربما سيربكك ظهور رسالة خطأ عند انتهاء التثبيت، لكن الخطوات الآتية ستساعدك في ضبط الخدمة: في الحالات الأكثر شيوعًا، كل ما تريد أن تفعله هو إسناد عناوين IP إسنادًا عشوائيًا، يمكن أن يُفعَل ذلك بالإعدادات الآتية: # minimal sample /etc/dhcp/dhcpd.conf default-lease-time 600; max-lease-time 7200; subnet 192.168.1.0 netmask 255.255.255.0 { range 192.168.1.150 192.168.1.200; option routers 192.168.1.254; option domain-name-servers 192.168.1.1, 192.168.1.2; option domain-name "mydomain.example"; }نتيجة الإعدادات السابقة هي ضبط خادوم DHCP لإعطاء العملاء عناوين IP تتراوح من 192.168.1.150 إلى 192.168.1.200، وسيُأجَّر عنوان IP لمدة 600 ثانية إذا لم يطلب العميل وقتًا محددًا؛ عدا ذلك، فسيكون وقت الإيجار الأقصى للعنوان هو 7200 ثانية؛ و«سينصح» الخادومُ العميلَ أن يستخدم 192.168.1.254 كبوابة افتراضية، و 192.168.1.1 و 192.168.1.2 كخادومَيّ DNS. عليك إعادة تشغيل خدمة dhcpd بعد تعديل ملف الضبط: sudo service isc-dhcp-server restartمصادرتوجد بعض المعلومات المفيدة في صفحة ويكي أوبنتو «dhcp3-server».للمزيد من خيارات ملف /etc/dhcp/dhcpd.conf، راجع صفحة الدليل man dhcpd.conf.مقالة في ISC: «dhcp-server».ترجمة -وبتصرف- للمقال Ubuntu Server Guide: Dynamic Host Configuration Protocol - DHCP. حقوق الصورة البارزة: Designed by Freepik. -
![مزيد من المعلومات حول "[فيديو] تثبيت وضبط خادم Nginx"](https://academy.hsoub.com/uploads/monthly_2019_04/Nginx.png.f74f35f5f20e6db14333232f5570eb3e.png) نشرح طريقة تثبيت وإعداد خادم Nginx على توزيعة أوبنتو، وسنستعمله لتخديم صفحات HTML الخاصة بنا. لتثبيت خادم أباتشي راجع فيديو تثبيت وضبط خادم Apache في أكاديمية حسوب. قسم خوادم الويب في أكاديمية حسوب غني بالمقالات المفيدة للتعامل معها.
نشرح طريقة تثبيت وإعداد خادم Nginx على توزيعة أوبنتو، وسنستعمله لتخديم صفحات HTML الخاصة بنا. لتثبيت خادم أباتشي راجع فيديو تثبيت وضبط خادم Apache في أكاديمية حسوب. قسم خوادم الويب في أكاديمية حسوب غني بالمقالات المفيدة للتعامل معها. -
![مزيد من المعلومات حول "[فيديو] نشر تطبيق روبي على خادم لينكس"](https://academy.hsoub.com/uploads/monthly_2019_03/rails.png.280265319ac7d011f7faff8db72a6527.png) بعد برمجتك لموقعك باستخدام روبي وإطار ريلز، حان الوقت الآن لنشر التطبيق على خادم (server) ليستطيع زوارك الوصول إليه. سنعتمد في هذا الفيديو على أحد التطبيقات الذي طورناه في دورة تعلم تطوير تطبيقات الويب باستخدام روبي: https://academy.hsoub.com/learn/ruby-web-application-development/ مستودع التطبيق: https://github.com/HsoubAcademy/rails-twitter-web-app نوفر في موسوعة حسوب توثيقًا كاملًا للغة روبي وإطار العمل ريلز باللغة العربية: https://wiki.hsoub.com/Ruby https://wiki.hsoub.com/Rails
بعد برمجتك لموقعك باستخدام روبي وإطار ريلز، حان الوقت الآن لنشر التطبيق على خادم (server) ليستطيع زوارك الوصول إليه. سنعتمد في هذا الفيديو على أحد التطبيقات الذي طورناه في دورة تعلم تطوير تطبيقات الويب باستخدام روبي: https://academy.hsoub.com/learn/ruby-web-application-development/ مستودع التطبيق: https://github.com/HsoubAcademy/rails-twitter-web-app نوفر في موسوعة حسوب توثيقًا كاملًا للغة روبي وإطار العمل ريلز باللغة العربية: https://wiki.hsoub.com/Ruby https://wiki.hsoub.com/Rails -
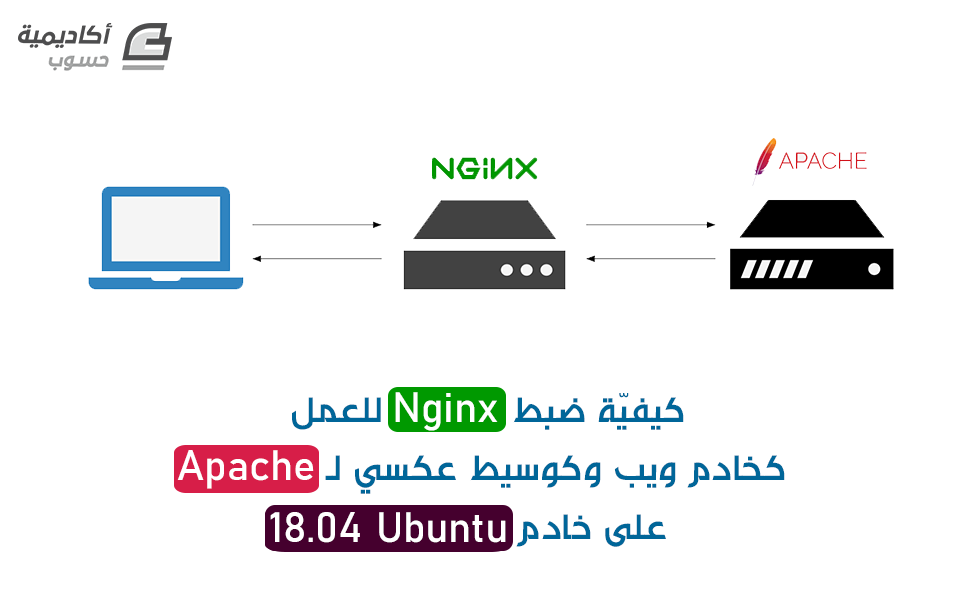 مقدّمة يُعتبر Apache و Nginx اثنين من أشهر خوادم الويب مفتوحة المصدر ويُستخدمان غالباً مع PHP. قد يكون من المفيد تشغيل كل منهما على نفس الجهاز الإفتراضي virtual machine عند استضافة مواقع ويب متعددة ذات متطلباتٍ متنوعة. إنّ الحل العام لتشغيل خوادم الويب على نظام واحد هو استخدام عناوين IP متعددة أو أرقام منافذ مختلفة. بالإمكان ضبط الخوادم التي تملك كلّا من عناوين IPv4 و IPv6 لخدمة مواقع Apache على أحد البروتوكولين ومواقع Nginx على البروتوكول الآخر، ولكن عمليًا هذا غير مُطبّق حاليًا، نظرًا لأن تبنّي مزودي خدمات الإنترنت لـ IPv6 لا يزال غير شائع. حيث يعدّ وجود رقم منفذ مختلف مثل 81 أو 8080 لخادم الويب الثاني حلاً آخر، ولكن مشاركة عناوين URL بأرقام المنافذ (مثل http://example.com:81) ليس منطقيًّا أو مثاليًّا دائمًا. سنتعلّم في هذه الدورة كيفيّة ضبط Nginx كخادم ويب وكذلك كوسيط عكسي Reverse Proxy لـ Apache - كل ذلك على خادم واحد. قد تكون هنالك حاجة اعتمادًا على تطبيق الويب إلى تغييرات في الشفرة ليبقى Apache مُدركًا بالوسيط العكسي، وخاصّة عند ضبط مواقع SSL. سنتجنّب ذلك بتثبيت module وحدة Apache تسمى mod_rpaf والتي تُعيد كتابة متغيرات بيئة معيّنة بحيث يبدو أن Apache يتعامل مباشرة مع الطلبات من عملاء الويب. ستُضاف أربعة أسماء نِطاقات domain names على خادم واحد. وسيُخدَّم اثنين منهما بواسطة Nginx هما:example.com (المُضيف الظاهري الافتراضي) و sample.org. والاثنين المتبقيين، foobar.net و test.io، سيُخدّمان من قبل Apache. سنُعدّ أيضًا Apache لخدمة تطبيقات PHP باستخدام PHP-FPM، والذي يقدّم أداء أفضل عبر mod_php. المتطلبات المُسبقة ستحتاج لإكمال هذه الدورة التعليميّة إلى ما يلي: خادم Ubuntu 18.04 جديد تم إعداده من خلال اتباع خطوات الإعداد الأولي للخادم في Ubuntu 18.4، مع مستخدم sudo عادي (non-root) و جدار ناري. ضبط أربعة أسماء نطاق مؤهلة بالكامل للإشارة لعنوان IP الخاص بخادمك. انظر الخطوة 3 من كيفية إعداد اسم مضيف فيDigitalOcean كمِثال لكيفية القيام بذلك. إذا كنت تستضيف DNS للنطاقات الخاصّة بك في مكان آخر، فعليك إنشاء سجلات A مناسبة هناك بدلاً من ذلك. الخطوة 1 - تثبيت Apache و PHP-FPM لنبدأ بتثبيت Apache و PHP-FPM. سنثبّت أيضًا بالإضافة إلى تثبيت Apache و PHP-FPM، وحدة PHP FastCGI Apache وهيlibapache2-mod-fastcgi، لدعم تطبيقات ويب FastCGI. أولاً، يجب تحديث قائمة الحزم package الخاصّة بك للتأكد من حصولك على أحدث الحزم. $ sudo apt update يجب بعد ذلك تثبيت حزم Apache و PHP-FPM: $ sudo apt install apache2 php-fpm يجب تنزيل وحدة FastCGI Apache من kernel.org وتثبيتها باستخدام الأمر dpkg لأنّها غير متوفرة في مستودع Ubuntu: $ Wget https://mirrors.edge.kernel.org/ubuntu/pool/multiverse/liba/ libapache-mod-fastcgi/libapache2-mod-fastcgi_2.4.7~0910052141-1.2_amd64.deb $ sudo dpkg -i libapache2-mod-fastcgi_2.4.7~0910052141-1.2_amd64.deb علينا بعد ذلك تغيير الضبط الافتراضي لخادم Apache من أجل استخدام PHP-FPM. الخطوة 2 - ضبط Apache و PHP-FPM سنغيّر في هذه الخطوة رقم منفذ Apache إلى 8080 وضبطه للعمل مع PHP-FPM باستخدام الوحدة mod_fastcgi. أعد تسمية ملف ضبط ports.conf لمخدم Apache: $ sudo mv /etc/apache2/ports.conf /etc/apache2/ports.conf.default أنشئ ملف ports.conf جديد مع تعيين المنفذ إلى 8080: $ echo "Listen 8080" | sudo tee /etc/apache2/ports.conf ملاحظة: تُضبط خوادم الويب بشكل عام للتنصت على المنفذ 127.0.0.1:8080 عند ضبط الوكيل العكسي، ولكن القيام بذلك سيؤدي إلى ضبط قيمة متغير بيئة (PHP (SERVER_ADDR إلى عنوان IP الاسترجاع بدلاً من عنوان الـ IP العام للخادم. هدفنا هو إعداد Apache بطريقة لا ترى مواقعه على الويب الوكيل العكسي أمامها. لذلك، سنضبطه للتنصت على المنفذ 8080 لجميع عناوين IP. سننشئ بعد ذلك ملف مضيف افتراضي لـ Apache. سيعدّ التوجيه في هذا الملف ليخدّم المواقع فقط على المنفذ 8080. عطّل المضيف الظاهري الافتراضي: $ sudo a2dissite 000-default ثم أنشئ ملف مضيف افتراضي جديد، باستخدام الموقع الافتراضي الموجود: $ sudo cp /etc/apache2/sites-available/000-default.conf /etc/apache2/sites-available/001-default.conf افتح الآن ملف الضبط الجديد: $ sudo nano /etc/apache2/sites-available/001-default.conf غيّرمنفذ التنصت إلى 8080: /etc/apache2/sites-available/000-default.conf ServerAdmin webmaster@localhost DocumentRoot /var/www/html ErrorLog ${APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined احفظ الملف وقم بتنشيط ملف الضبط الجديد: $ sudo a2ensite 001-default ثم أعد تحميل Apache: $ sudo systemctl reload apache2 تحقّق من أن Apache يتنصت الآن على 8080: $ sudo netstat -tlpn يجب أن يبدو الخرج output كالمثال التالي، حيث يتنصّت apache2 على المنفذ 8080: output Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1086/sshd tcp6 0 0 :::8080 :::* LISTEN 4678/apache2 tcp6 0 0 :::22 :::* LISTEN 1086/sshd يمكنك إعداد دعم PHP و FastCGI بمجرّد التحقق من أن Apache يتنصت على المنفذ الصحيح. الخطوة 3 - ضبط Apache لاستخدام mod_fastcgi يخدّم Apache صفحات PHP باستخدام mod_php افتراضيًا، ولكنه يتطلب إعدادًا إضافيًّا للعمل مع PHP-FPM. ملاحظة: إذا كنت تجرّب هذا الدرس على نسخة موجودة مسبقًا من LAMP مع mod_php، عطّله أولاً باستخدام sudo a2dismod php7.2. سنضيف كتلة ضبط لوحدة mod_fastcgi التي تعتمد على mod_action. يُعطّل mod_action بشكل افتراضي، لذلك نحتاج أولاً إلى تفعيله: $ sudo a2enmod action أعد تسمية ملف ضبط FastCGI الموجود: $ sudo mv /etc/apache2/mods-enabled/fastcgi.conf/etc/apache2/mods -enabled/fastcgi.conf.default أنشئ ملف ضبط جديد: $ sudo nano /etc/apache2/mods-enabled/fastcgi.conf أضف التوجيهات التالية إلى الملف لتمرير طلبات ملفات php. إلى مقبس PHP-FPM UNIX: /etc/apache2/mods-enabled/fastcgi.conf AddHandler fastcgi-script .fcgi FastCgiIpcDir /var/lib/apache2/fastcgi AddType application/x-httpd-fastphp .php Action application/x-httpd-fastphp /php-fcgi Alias /php-fcgi /usr/lib/cgi-bin/php-fcgi FastCgiExternalServer /usr/lib/cgi-bin/php-fcgi -socket /run/php/php7.2-fpm.sock -pass-header Authorization Require all granted احفظ التغييرات واختبر الضبط: $ sudo apachectl -t إذا ظهرت عبارة Syntax OK، أعد تحميل Apache: $ sudo systemctl reload apache2 إذا رأيت رسالة التحذير التالية، يمكنك تجاهلها الآن بشكل آمن. سنَضبط أسماء الخادم في وقت لاحق: Could not reliably determine the server's fully qualified domain name, using 127.0.1.1. Set the 'ServerName' directive globally to suppress this message. دعنا نتأكد الآن من أنّه بإمكاننا تخديم PHP من Apache. الخطوة 4 - التحقق من عمل PHP سَنتأكّد من أن PHP يعمل، وذلك من خلال إنشاء ملف ()phpinfo والوصول إليه من متصفح الويب. أنشئ الملف var/www/html/info.php/ والذي يحتوي على استدعاء للدّالة phpinfo: $ echo "" | sudo tee /var/www/html/info.php انتقل في المتصفح إلى http: // your_server_ip: 8080 / info.php لاستعراض هذا الملف. ستظهر لك قائمة إعدادات الضبط التي يستخدمها PHP. كما في الشكل التالي: تحقّق من أن الخيار Server API يأخذ القيمة FPM/FastCGI وذلك في أعلى الصفحة كما في الصورة السابقة. سترى كذلك في أسفل الصفحة تقريبًا في القسم PHP Variables بأنّ قيمة SERVER_SOFTWARE هي Apache على Ubuntu. وهذا يؤكّد أنّ الوحدة mod_fastcgi مُفعّلة وأنّ Apache يستخدم PHP-FPM لمعالجة ملفات PHP. الخطوة 5 - إنشاء مضيفات افتراضيّة لـ Apache دعونا ننشئ ملفات المضيف الافتراضي لـ Apache للنطاقين foobar.net و test.io. سنقوم لعمل ذلك أولاً بإنشاء الأدلّة الجذر للمستند في كِلا الموقعين ووضع بعض الملفات الافتراضيّة في هذه الأدلة حتى نتمكن من اختبار الضبط لدينا بسهولة. أولاً، أنشئ الأدلّة الجذر للمستند: $ sudo mkdir -v /var/www/foobar.net /var/www/test.io أنشئ بعد ذلك ملف index لكل موقع: $ echo "<h1 style='color: green;'>Foo Bar</h1>" | sudo tee /var/www/foobar.net/index.html $ echo "<h1 style='color: red;'>Test IO</h1>" | sudo tee /var/www/test.io/index.html " | sudo tee /var/www/test.io/index.html ثم أنشئ ملف ()phpinfo لكل موقع حتى نتمكن من اختبار فيما إذا ضُبط PHP بشكل صحيح. $ echo "" | sudo tee /var/www/foobar.net/info.php $ echo "" | sudo tee /var/www/test.io/info.php الآن أنشئ ملف المضيف الافتراضي للنطاق foobar.net: $ sudo nano /etc/apache2/sites-available/foobar.net.conf أضف الشفرة التالية إلى الملف لتعريف المضيف: /etc/apache2/sites-available/foobar.net.conf ServerName foobar.net ServerAlias www.foobar.net DocumentRoot /var/www/foobar.net AllowOverride All يتيح السطر AllowOverride All تفعيل دعم htaccess. احفظ وأغلق الملف. ثم أنشئ ملف ضبط مماثل لـ test.io. أولاً أنشئ الملف: $ sudo nano /etc/apache2/sites-available/test.io.conf ثم أضف الضبط إلى الملف: /etc/apache2/sites-available/test.io.conf ServerName test.io ServerAlias www.test.io DocumentRoot /var/www/test.io AllowOverride All احفظ الملف وإغلاق المحرّر. والآن بعد إعداد كل من مضيفي Apache الافتراضيين، فعّل المواقع باستخدام الأمر a2ensite. والذي يُنشئ رابط رمزي لمَلف المضيف الافتراضي في الدليل sites-enabled: $ sudo a2ensite foobar.net $ sudo a2ensite test.io تحقّق من Apache للتأكّد من وجود أخطاء في الضبط مرّة أخرى: $ sudo apachectl –t سترى عبارة Syntax OK إذا لم يكن هناك أخطاء. إذا رأيت أي شيء آخر، فتحقّق من الضبط وحاول مرّة أخرى. قم بإعادة تحميل Apache لتطبيق التغييرات بمجرّد أن يكون الضبط الخاص بك خاليًا من الأخطاء: $ sudo systemctl reload apache2 افتح http://foobar.net:8080 و http://test.io:8080 في متصفحك للتأكّد من عمل المواقع والتحقّق من أنّ كل موقع يعرض ملف index.html الخاص به. سترى النتائج التالية: تأكّد أيضًا من أن PHP تعمل وذلك عن طريق الوصول إلى ملفات info.php لكل موقع. افتح http://foobar.net:8080/info.php و http://test.io:8080/info.php في متصفحك. سترى قائمة مواصفات ضبط PHP نفسها على كل موقع كما رأيت في الخطوة 4. لدينا الآن موقعين مُستضافين على Apache على المنفذ 8080. فلنَضبط بعد ذلك Nginx. الخطوة 6 - تثبيت وضبط Nginx سنقوم في هذه الخطوة بتثبيت Nginx وإعداد ضبط النطاقات example.com و sample.org كمضيفين افتراضيين لـ Nginx. ثبّت Nginx باستخدام مدير الحزم: $ sudo apt install nginx أزل الرابط الرمزي الافتراضي للمضيف الافتراضي حيث أننا لن نستخدمه بعد الآن: $ sudo rm /etc/nginx/sites-enabled/default سنُنشئ الموقع الافتراضي الخاص بنا فيما بعد (example.com). سنُنشئ الآن مضيفين افتراضيين لـ Nginx باستخدام نفس الإجرائيّة التي استخدمناها من أجل Apache. أنشئ أولاً الأدلّة للمستند الجذر لكل من موقعي الويب: $ sudo mkdir -v /usr/share/nginx/example.com /usr/share/nginx/sample.org سنحتفظ بمواقع الويب الخاصّة بـ Nginx في /usr/share/nginx، وهو المسار الافتراضي الذي سيختاره Nginx. يمكنك وضع هذه المواقع في /var/www/html مع مواقع Apache، لكن هذا الفصل بينها قد يساعدك على ربط المواقع بـ Nginx. كما فعلت مع مضيفي Apache الافتراضيين، أنشئ ملفات index و ()phpinfo من أجل الاختبار بعد اكتمال الإعداد: $ echo "<h1 style='color: green;'>Example.com</h1>" | sudo tee /usr/share/nginx/example.com/index.html $ echo "<h1 style='color: red;'>Sample.org</h1>" | sudo tee /usr/share/nginx/sample.org/index.html $ echo "<?php phpinfo(); ?>" | sudo tee /usr/share/nginx/example.com/info.php $ echo "<?php phpinfo(); ?>" | sudo tee /usr/share/nginx/sample.org/info.php الآن أنشئ ملف مضيف افتراضي للنطاق example.com: $ sudo nano /etc/nginx/sites-available/example.com يستدعي Nginx كتل server {. . .} من ملف الضبط server blocks. أنشئ كتلة خادم من أجل المضيف الافتراضي الأساسي example.com. تجعل ضبط التوجيه default_server هذا المضيف كمضيف افتراضي افتراضي لمعالجة طلبات HTTP التي لا تتطابق مع أي مضيف افتراضي آخر. /etc/nginx/sites-available/example.com server { listen 80 default_server; root /usr/share/nginx/example.com; index index.php index.html index.htm; server_name example.com www.example.com; location / { try_files $uri $uri/ /index.php; } location ~ \.php$ { fastcgi_pass unix:/run/php/php7.2-fpm.sock; include snippets/fastcgi-php.conf; } } احفظ وأغلق الملف. أنشئ الآن ملف مضيف Nginx افتراضي للنطاق الثاني، sample.org: $ sudo nano etc/nginx/sites-available/sample.org أضف ما يلي إلى الملف: /etc/nginx/sites-available/sample.org server { root /usr/share/nginx/sample.org; index index.php index.html index.htm; server_name sample.org www.sample.org; location / { try_files $uri $uri/ /index.php; } location ~ \.php$ { fastcgi_pass unix:/run/php/php7.2-fpm.sock; include snippets/fastcgi-php.conf; } } احفظ وأغلق الملف. ثم فعّل كِلا الموقعين من خلال إنشاء روابط رمزيّة للدّليل sites-enabled: $ sudo ln -s /etc/nginx/sites-available/example.com /etc/nginx/sites-enabled/example.com $ sudo ln -s /etc/nginx/sites-available/sample.org /etc/nginx/sites-enabled/sample.org اختبر بعد ذلك ضبط Nginx لضمان عدم وجود أخطاء في الضبط: $ sudo nginx -t ثم أعد تحميل Nginx إذا لم يكن هناك أخطاء: $ sudo systemctl reload nginx الآن قم بالوصول إلى ملف ()phpinfo الخاص بمُضيفي Nginx الافتراضيين من متصفح الويب من خلال زيارة http://sample.org/info.php و http://example.com/info.php. انظر مجدّدًا إلى الصورة في الأسفل إلى قسم المتغيرات PHP Variables. يجب أن يحوي["SERVER_SOFTWARE"] على القيمة Nginx، مشيرًا إلى أنّ الملفات خُدّمت بشكل مباشر بواسطة Nginx. يجب أن يشير["DOCUMENT_ROOT"] إلى الدليل الذي أنشأته مُسبقًا في هذه الخطوة لكل موقع من مواقع Nginx. ثبّتنا في هذه المرحلة Nginx وأنشأنا مضيفين افتراضيين.سنقوم بعد ذلك بضبط Nginx على طلبات الوكيل المخصّصة للنطاقات المستضافة على Apache. الخطوة 7 - ضبط Nginx لمضيفي Apache الافتراضيين لنُنشئ مضيف Nginx افتراضي إضافي مع أسماء نطاقات متعددة في توجيهات server_name. سيتم توكيل طلبات هذه النطاقات إلى Apache. أنشئ ملف مضيف Nginx افتراضي جديد لإعادة توجيه الطلبات إلى Apache: $ sudo nano /etc/nginx/sites-available/apache أضف كتلة الشفرة التالية التي تحدد أسماء نطاقات كلاً من مضيفي Apache الاتراضيين وتوكل طلباتها إلى Apache. تذكّر استخدام عنوان IP العام في proxy_pass: /etc/nginx/sites-available/apache server { listen 80; server_name foobar.net www.foobar.net test.io www.test.io; location / { proxy_pass http://your_server_ip:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } } قم بحفظ الملف وتفعيل هذا المضيف الافتراضي الجديد عن طريق إنشاء رابط رمزي: $ sudo ln -s /etc/nginx/sites-available/apache /etc/nginx/sites-enabled/apache اختبر الضبط للتأكد من عدم وجود أخطاء: $ sudo nginx -t إذا لم يكن هنالك أخطاء، أعد تحميل Nginx: $ sudo systemctl reload nginx افتح متصفحك وقم بالوصول إلى العنوان http://foobar.net/info.php. انتقل لأسفل إلى قسم PHP Variables وتحقق من القيم المعروضة كما في الصورة. يؤكّد المتغيران ERVER_SOFTWARE و DOCUMENT_ROOT أنّ هذا الطلب عُولج بواسطة Apache. وأضيفت المتغيرات HTTP_X_REAL_IP و HTTP_X_FORWARDED_FOR بواسطة Nginx ويجب أن تُظهر عنوان IP العام للحاسب الذي تستخدمه للوصول إلى عنوان URL. لقد أعددنا Nginx بنجاح ليوكل بطلبات نطاقات محدّدة إلى Apache. بعد ذلك، لنقم بضبط Apache لضبط المتغير REMOTE_ADDR كما لو أنه يتعامل مع هذه الطلبات مباشرة. الخطوة 8 - تثبيت وضبط mod_rpaf سنُثبّت في هذه الخطوة وحدة Apache تسمى mod\_rpaf والتي تعيد كتابة قيم REMOTE_ADDR، HTTPS و HTTP_PORT استنادًا إلى القيم المقدّمة من قبل وسيط عكسي. وبدون هذه الوحدة، تتطلب بعض تطبيقات PHP تغييرات في الشفرة للعمل بسلاسة من خلفْ الخادم الوكيل. هذه الوحدة موجودة في مستودع Ubuntu باسم libapache2-mod-rpaf ولكنها قديمة ولا تدعم توجيهات ضبط معينة. سنقوم بدلاً من ذلك بتثبيتها من المصدر. تثبيت الحزم اللازمة لبناء الوحدة: $ sudo apt install unzip build-essential apache2-dev نزّل أحدث إصدار مستقر من GitHub: $ wget https://github.com/gnif/mod_rpaf/archive/stable.zip استخراج الملف الذي نزل: $ unzip stable.zip انتقل إلى المجلد الجديد الذي يحتوي على الملفات: $ cd mod_rpaf-stable ترجم Compile الوحدة ثم ثبّتها: $ make $ sudo make install أنشئ بعد ذلك ملف في المجلد mods-available والذي سيُحمّل وحدة rpaf: $ sudo nano /etc/apache2/mods-available/rpaf.load أضف الشفرة التالية إلى الملف لتحميل الوحدة: /etc/apache2/mods-available/rpaf.load LoadModule rpaf_module /usr/lib/apache2/modules/mod_rpaf.so احفظ الملف وأغلق المحرر. أنشئ ملف آخر في نفس الدليل وسمّه rpaf.conf والذي سوف يحتوي على توجيهات الضبط للوحدة mod_rpaf: $ sudo nano /etc/apache2/mods-available/rpaf.conf أضف كتلة الشفرة التالية لضبط mod_rpaf، مع التأكّد من تحديد عنوان IP الخاص بخادمك: /etc/apache2/mods-available/rpaf.conf RPAF_Enable On RPAF_Header X-Real-Ip RPAF_ProxyIPs your_server_ip RPAF_SetHostName On RPAF_SetHTTPS On RPAF_SetPort On فيما يلي وصف موجز لكل توجيه. لمزيد من المعلومات، راجع ملف mod_rpaf README. RPAF_Header - الترويسة المراد استخدامها لعنوان IP الحقيقي للعميل. RPAF_ProxyIPs - عنوان IP للوكيل لضبط طلبات HTTP من أجله. RPAF_SetHostName - يقوم بتحديث اسم المضيف الافتراضي بحيث يعمل كل من ServerName و ServerAlias. RPAF_SetHTTPS - يضبط متغير بيئة HTTPS استنادًا إلى القيمة الموجودة في X-Forwarded-Proto. RPAF_SetPort - يضبط متغير بيئة SERVER_PORT. يكون مفيد عندما يكون Apache يعمل خلف وكيل SSL. احفظ الملف rpaf.conf وقم بتفعيل الوحدة: $ sudo a2enmod rpaf يؤدي هذا إلى إنشاء روابط رمزيّة من الملفات rpaf.load و rpaf.conf في الدليل mods-enabled. الآن قم بإجراء اختبار الضبط: $ sudo apachectl -t أعد تحميل Apache إذا لم يكن هنالك أخطاء: $ sudo systemctl reload apache2 قم بالوصول إلى الملف ()phpinfo في الصفحات http://foobar.net/info.php و http://test.io/info.php من متصفحك وتحقق من قسم PHP Variables. الآن سيكون المتغير REMOTE_ADDR هو أيضًا عنوان IP العام للحاسب المحلي لديك. الآن دعنا نعد تشفير TLS / SSL لكل موقع. الخطوة 9 - إعداد مواقع HTTPS باستخدام Let's Encrypt (اختياري) سنضبط في هذه الخطوة شهادات TLS / SSL لكل من النطاقات المُستضافة على Apache. سوف نحصل على الشهادات بواسطة [Let's Encrypt](https://letsencrypt.org]. يدعم Nginx إنهاء SSL، لذا من الممكن إعداد SSL بدون تعديل ملفات ضبط Apache. تَضمنْ الوحدة mod_rpaf أن يتم تعيين متغيرات البيئة المطلوبة على Apache لجعل التطبيقات تعمل بسلاسة خلفْ وكيل عكسي لـ SSL. أولاً سنفصل كتل الخادم {...}server من كِلا النطاقين بحيث يمكن أن يكون لكلٍ منهما شهادات SSL خاصّة به. افتح الملف etc/nginx/sites-available/apache/ في المحرّر الخاص بك: $ sudo nano /etc/nginx/sites-available/apache عدّل الملف بحيث يبدو مثل هذا، مع foobar.net و test.io في كتل الخادم الخاصّة بهم: /etc/nginx/sites-available/apache server { listen 80; server_name foobar.net www.foobar.net; location / { proxy_pass http://your_server_ip:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } } server { listen 80; server_name test.io www.test.io; location / { proxy_pass http://your_server_ip:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } } سنستخدم Certbot لإنشاء شهادات TLS/SSL الخاصّة بنا. ستتولى إضافة Nginx plugin" Nginx" مُهمة إعادة ضبط Nginx وإعادة تحميل الضبط عند الضرورة. أولاً، أضف مستودع Certbot المرخّص: $ sudo add-apt-repository ppa:certbot/certbot اضغط على ENTER عند مطالبتك بتأكيد رغبتك في إضافة المستودع الجديد. ثم قم بتحديث قائمة الحزم للحصول على معلومات حزمة المستودع الجديدة: $ sudo apt update ثم ثبّت حزمة Nginx الخاصّة بـ Certbot باستخدام apt: $ sudo apt install python-certbot-nginx وبمجرّد تثبيته، استخدم أمر certbot لإنشاء الشهادات لـ foobar.net و www.foobar.net: $ sudo certbot --nginx -d foobar.net -d www.foobar.net يخبر هذا الأمر Certbot ليستخدم ملحق nginx، وباستخدم –d لتحديد الأسماء التي نودّ أن تكون الشهادة صالحة لها. إذا كانت هذه هي المرة الأولى التي تُشغّل فيها certbot، فسَتتم مطالبتك بإدخال عنوان بريد إلكتروني والموافقة على شروط الخدمة. سيتصل بعد القيام بذلك certbot بخادم Let's Encrypt، ثم يشغّل ردّا للتحقق من أنّك تتحكم في النطاق الذي تطلب الحصول على شهادة له. سَيسألك Certbot بعد ذلك عن الطريقة التي ترغب في ضبط إعدادات HTTPS الخاصّة بك: Output Please choose whether or not to redirect HTTP traffic to HTTPS, removing HTTP access. ------------------------------------------------------------------------------- 1: No redirect - Make no further changes to the webserver configuration. 2: Redirect - Make all requests redirect to secure HTTPS access. Choose this for new sites, or if you're confident your site works on HTTPS. You can undo this change by editing your web server's configuration. ------------------------------------------------------------------------------- Select the appropriate number [1-2] then [enter] (press 'c' to cancel): حدّد خيارك، ثم اضغط على ENTER. سيتم تحديث الضبط، وإعادة تحميل Nginx لتفعيل الإعدادات الجديدة. الآن، نفّذ الأمر للنطاق الثاني: $ sudo certbot --nginx -d test.io -d www.test.io انظر في قسم PHP Variables. تم تعيين المتغير SERVER_PORT على القيمة 443 وضبط HTTPS على القيمة on، كما لو أنّه تم الوصول إلى Apache مباشرةً عبر HTTPS. مع ضبط هذه المتغيرات، لن تحتاج تطبيقات PHP إلى إعداد خاص للعمل خلف وسيط عكسي. سنقوم الآن بتعطيل الوصول المباشر إلى Apache. الخطوة 10 - حظر الوصول المباشر إلى Apache (اختياري) بما أن Apache يستمع على المنفذ 8080 على عنوان IP العام، فإنّه بإمكان الجميع الوصول إليه. ويمكن حظره من خلال عمل الأمر IPtables التالي في مجموعة قواعد الجدار الناري. $ sudo iptables -I INPUT -p tcp --dport 8080 ! -s your_server_ip -j REJECT --reject-with tcp-reset تأكّد من استخدام عنوان IP لخَادمك مكان اللون الأحمر في المثال السابق. بمجرد حظر المنفذ 8080 في الجدار الناري، اختبر عدم إمكانية الوصول إلى Apache. افتح متصفح الويب الخاص بك وحاول الوصول إلى أحد أسماء نطاقات Apache على المنفذ 8080. على سبيل المثال: http://example.com:8080 يجب أن يعرض المتصفح رسالة خطأ "غير قادر على الاتصال" أو "صفحة الويب غير متوفرة". وبضبط خيار IPtables tcp-reset، لن يرى أحد أي اختلاف بين المنفذ 8080 والمنفذ الذي لا يحتوي أيّ خدمةٍ عليه. ملاحظة: عند إعادة تشغيل النظام وبشكل افتراضي لن تبقى قواعد IPtables كما حدّدناها. هناك طرق متعددة للحفاظ على قواعد IPtables، ولكن أسهلها هو استخدام iptables-persistent في مستودع Ubuntu. استكشف هذه المقالة لمعرفة المزيد حول كيفيّة ضبط IPTables. لنضبط الآن Nginx لخدمة ملفات ثابتة لمواقع Apache. الخطوة 11 - تخديم الملفات الثابتة باستخدام Nginx (اختياري) عندما يقدم وسيط Nginx طلبات لنطاقات Apache، فإنّه يرسل كل ملف طلب لهذا النطاق إلى Apache. Nginx أسرع من Apache في خدمة الملفات الثابتة مثل الصور، وجافا سكريبت وأوراق الأنماط. لذلك دعونا نضبط ملف مضيف apache افتراضي خاص بـ Nginx لتخديم الملفات الثابتة مباشرة ولكن مع إرسال طلبات PHP إلى Apache. افتح الملف etc/nginx/sites-available/apache/ في محرّرك الخاص: $ sudo nano /etc/nginx/sites-available/apache ستحتاج إلى إضافة موضعين location إضافيين لكل كتلة خادم، بالإضافة إلى تعديل أقسام location الموجودة. بالإضافة إلى ذلك، ستحتاج إلى إخبار Nginx بمكان تواجد الملفات الثابتة لكل موقع. إذا قرّرت عدم استخدام شهادات SSL و TLS، فعدّل ملفك بحيث يبدو كالتالي: /etc/nginx/sites-available/apache server { listen 80; server_name test.io www.test.io; root /var/www/test.io; index index.php index.htm index.html; location / { try_files $uri $uri/ /index.php; } location ~ \.php$ { proxy_pass http://your_server_ip:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } location ~ /\.ht { deny all; } } server { listen 80; server_name foobar.net www.foobar.net; root /var/www/foobar.net; index index.php index.htm index.html; location / { try_files $uri $uri/ /index.php; } location ~ \.php$ { proxy_pass http://your_ip_address:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } location ~ /\.ht { deny all; { { إذا كنت تريد بأن يكون HTTPS متوفرًا أيضًا، فاستخدم الضبط التالي بدلاً من ذلك: server { listen 80; server_name test.io www.test.io; root /var/www/test.io; index index.php index.htm index.html; location / { try_files $uri $uri/ /index.php; } location ~ \.php$ { proxy_pass http://your_server_ip:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } location ~ /\.ht { deny all; } listen 443 ssl; ssl_certificate /etc/letsencrypt/live/test.io/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/test.io/privkey.pem; include /etc/letsencrypt/options-ssl-nginx.conf; ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; } server { listen 80; server_name foobar.net www.foobar.net; root /var/www/foobar.net; index index.php index.htm index.html; location / { try_files $uri $uri/ /index.php; } location ~ \.php$ { proxy_pass http://your_ip_address:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } location ~ /\.ht { deny all; } listen 443 ssl; ssl_certificate /etc/letsencrypt/live/foobar.net/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/foobar.net/privkey.pem; include /etc/letsencrypt/options-ssl-nginx.conf; ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; { إنّ التوجيه try_files يجعل Nginx يبحث عن الملفات في المستند الجذر ويقدّمها مباشرةً. إذا كان الملف له امتداد php.، سيتم تمرير الطلب إلى Apache. حتى إذا لم يُعثر على الملف في المستند الجذر، يُمرّر الطلب إلى Apache لتعمل ميزات التطبيق مثل permalinks بدون أخطاء. تحذير: إنّ التوجيه location ~ /\.ht مهم جداً؛ حيث يمنع Nginx من عرض محتويات ملفات الضبط Apache مثل htaccess. و htpasswd. التي تحتوي على معلومات حساسة. احفظ الملف وقم بإجراء اختبار الضبط: $ sudo nginx -t أعد تحميل Nginx إذا نجح الاختبار: $ sudo service nginx reload يمكنك للتحقّق من أن العمل تم بشكل صحيح فحص ملفات سجل Apache في var/log/apache2/ ومشاهدة طلبات GET لملفات info.php من test.io و foobar.net. استخدم الأمر tail لمشاهدة الأسطر القليلة الأخيرة من الملف، واستخدم رمز التبديل f- لمشاهدة الملف من أجل التغييرات: $ sudo tail -f /var/log/apache2/other_vhosts_access.log قم الآن بزيارة http://test.io/info.php في مستعرض الويب الخاص بك ثم انظر إلى خرج السجل. سترى أن Apache يجيب بالفعل: Output test.io:80 your_server_ip - - [01/Jul/2016:18:18:34 -0400] "GET /info.php HTTP/1.0" 200 20414 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36" ثم قم بزيارة صفحة index.html لكل موقع ولن ترى أي إدخالات للسجّل من قبل Apache. لأن Nginx هو من يخدّمهم. عند الانتهاء من معاينة ملف السجل، اضغط على CTRL + C لإيقاف تعقبّه. باستخدام هذا الإعداد، لن يكون Apache قادرًا على تقييد الوصول إلى الملفّات الثابتة. وللتَحكم في الوصول إلى الملفّات الثابتة تحتاج إلى ضبط في ملف المضيف apache الافتراضي الخاص بـ Nginx، ولكن هذا خارج نطاق هذه الدورة التعليميّة. الخلاصة لديك الآن خادم Ubuntu مع Nginx يُخدّم example.com و sample.org، جنبًا إلى جنب مع Apache والذي يُخدّم foobar.net و test.io. على الرغم من أن Nginx يعمل كوكيل عكسي لـ Apache، إلا أن خدمة الوكيل في Nginx تتسم بالشفافية وتُظهر اتصالها بنطاقات Apache كما لو أنها مخدّمة مباشرةً من Apache. يمكنك استخدام هذه الطريقة لتخديم مواقع آمنة وثابتة. ترجمة بتصرف للمقال How To Configure Nginx as a Web Server and Reverse Proxy for Apache on One Ubuntu 18.04 Server لصاحبه Jesin A.
مقدّمة يُعتبر Apache و Nginx اثنين من أشهر خوادم الويب مفتوحة المصدر ويُستخدمان غالباً مع PHP. قد يكون من المفيد تشغيل كل منهما على نفس الجهاز الإفتراضي virtual machine عند استضافة مواقع ويب متعددة ذات متطلباتٍ متنوعة. إنّ الحل العام لتشغيل خوادم الويب على نظام واحد هو استخدام عناوين IP متعددة أو أرقام منافذ مختلفة. بالإمكان ضبط الخوادم التي تملك كلّا من عناوين IPv4 و IPv6 لخدمة مواقع Apache على أحد البروتوكولين ومواقع Nginx على البروتوكول الآخر، ولكن عمليًا هذا غير مُطبّق حاليًا، نظرًا لأن تبنّي مزودي خدمات الإنترنت لـ IPv6 لا يزال غير شائع. حيث يعدّ وجود رقم منفذ مختلف مثل 81 أو 8080 لخادم الويب الثاني حلاً آخر، ولكن مشاركة عناوين URL بأرقام المنافذ (مثل http://example.com:81) ليس منطقيًّا أو مثاليًّا دائمًا. سنتعلّم في هذه الدورة كيفيّة ضبط Nginx كخادم ويب وكذلك كوسيط عكسي Reverse Proxy لـ Apache - كل ذلك على خادم واحد. قد تكون هنالك حاجة اعتمادًا على تطبيق الويب إلى تغييرات في الشفرة ليبقى Apache مُدركًا بالوسيط العكسي، وخاصّة عند ضبط مواقع SSL. سنتجنّب ذلك بتثبيت module وحدة Apache تسمى mod_rpaf والتي تُعيد كتابة متغيرات بيئة معيّنة بحيث يبدو أن Apache يتعامل مباشرة مع الطلبات من عملاء الويب. ستُضاف أربعة أسماء نِطاقات domain names على خادم واحد. وسيُخدَّم اثنين منهما بواسطة Nginx هما:example.com (المُضيف الظاهري الافتراضي) و sample.org. والاثنين المتبقيين، foobar.net و test.io، سيُخدّمان من قبل Apache. سنُعدّ أيضًا Apache لخدمة تطبيقات PHP باستخدام PHP-FPM، والذي يقدّم أداء أفضل عبر mod_php. المتطلبات المُسبقة ستحتاج لإكمال هذه الدورة التعليميّة إلى ما يلي: خادم Ubuntu 18.04 جديد تم إعداده من خلال اتباع خطوات الإعداد الأولي للخادم في Ubuntu 18.4، مع مستخدم sudo عادي (non-root) و جدار ناري. ضبط أربعة أسماء نطاق مؤهلة بالكامل للإشارة لعنوان IP الخاص بخادمك. انظر الخطوة 3 من كيفية إعداد اسم مضيف فيDigitalOcean كمِثال لكيفية القيام بذلك. إذا كنت تستضيف DNS للنطاقات الخاصّة بك في مكان آخر، فعليك إنشاء سجلات A مناسبة هناك بدلاً من ذلك. الخطوة 1 - تثبيت Apache و PHP-FPM لنبدأ بتثبيت Apache و PHP-FPM. سنثبّت أيضًا بالإضافة إلى تثبيت Apache و PHP-FPM، وحدة PHP FastCGI Apache وهيlibapache2-mod-fastcgi، لدعم تطبيقات ويب FastCGI. أولاً، يجب تحديث قائمة الحزم package الخاصّة بك للتأكد من حصولك على أحدث الحزم. $ sudo apt update يجب بعد ذلك تثبيت حزم Apache و PHP-FPM: $ sudo apt install apache2 php-fpm يجب تنزيل وحدة FastCGI Apache من kernel.org وتثبيتها باستخدام الأمر dpkg لأنّها غير متوفرة في مستودع Ubuntu: $ Wget https://mirrors.edge.kernel.org/ubuntu/pool/multiverse/liba/ libapache-mod-fastcgi/libapache2-mod-fastcgi_2.4.7~0910052141-1.2_amd64.deb $ sudo dpkg -i libapache2-mod-fastcgi_2.4.7~0910052141-1.2_amd64.deb علينا بعد ذلك تغيير الضبط الافتراضي لخادم Apache من أجل استخدام PHP-FPM. الخطوة 2 - ضبط Apache و PHP-FPM سنغيّر في هذه الخطوة رقم منفذ Apache إلى 8080 وضبطه للعمل مع PHP-FPM باستخدام الوحدة mod_fastcgi. أعد تسمية ملف ضبط ports.conf لمخدم Apache: $ sudo mv /etc/apache2/ports.conf /etc/apache2/ports.conf.default أنشئ ملف ports.conf جديد مع تعيين المنفذ إلى 8080: $ echo "Listen 8080" | sudo tee /etc/apache2/ports.conf ملاحظة: تُضبط خوادم الويب بشكل عام للتنصت على المنفذ 127.0.0.1:8080 عند ضبط الوكيل العكسي، ولكن القيام بذلك سيؤدي إلى ضبط قيمة متغير بيئة (PHP (SERVER_ADDR إلى عنوان IP الاسترجاع بدلاً من عنوان الـ IP العام للخادم. هدفنا هو إعداد Apache بطريقة لا ترى مواقعه على الويب الوكيل العكسي أمامها. لذلك، سنضبطه للتنصت على المنفذ 8080 لجميع عناوين IP. سننشئ بعد ذلك ملف مضيف افتراضي لـ Apache. سيعدّ التوجيه في هذا الملف ليخدّم المواقع فقط على المنفذ 8080. عطّل المضيف الظاهري الافتراضي: $ sudo a2dissite 000-default ثم أنشئ ملف مضيف افتراضي جديد، باستخدام الموقع الافتراضي الموجود: $ sudo cp /etc/apache2/sites-available/000-default.conf /etc/apache2/sites-available/001-default.conf افتح الآن ملف الضبط الجديد: $ sudo nano /etc/apache2/sites-available/001-default.conf غيّرمنفذ التنصت إلى 8080: /etc/apache2/sites-available/000-default.conf ServerAdmin webmaster@localhost DocumentRoot /var/www/html ErrorLog ${APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined احفظ الملف وقم بتنشيط ملف الضبط الجديد: $ sudo a2ensite 001-default ثم أعد تحميل Apache: $ sudo systemctl reload apache2 تحقّق من أن Apache يتنصت الآن على 8080: $ sudo netstat -tlpn يجب أن يبدو الخرج output كالمثال التالي، حيث يتنصّت apache2 على المنفذ 8080: output Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1086/sshd tcp6 0 0 :::8080 :::* LISTEN 4678/apache2 tcp6 0 0 :::22 :::* LISTEN 1086/sshd يمكنك إعداد دعم PHP و FastCGI بمجرّد التحقق من أن Apache يتنصت على المنفذ الصحيح. الخطوة 3 - ضبط Apache لاستخدام mod_fastcgi يخدّم Apache صفحات PHP باستخدام mod_php افتراضيًا، ولكنه يتطلب إعدادًا إضافيًّا للعمل مع PHP-FPM. ملاحظة: إذا كنت تجرّب هذا الدرس على نسخة موجودة مسبقًا من LAMP مع mod_php، عطّله أولاً باستخدام sudo a2dismod php7.2. سنضيف كتلة ضبط لوحدة mod_fastcgi التي تعتمد على mod_action. يُعطّل mod_action بشكل افتراضي، لذلك نحتاج أولاً إلى تفعيله: $ sudo a2enmod action أعد تسمية ملف ضبط FastCGI الموجود: $ sudo mv /etc/apache2/mods-enabled/fastcgi.conf/etc/apache2/mods -enabled/fastcgi.conf.default أنشئ ملف ضبط جديد: $ sudo nano /etc/apache2/mods-enabled/fastcgi.conf أضف التوجيهات التالية إلى الملف لتمرير طلبات ملفات php. إلى مقبس PHP-FPM UNIX: /etc/apache2/mods-enabled/fastcgi.conf AddHandler fastcgi-script .fcgi FastCgiIpcDir /var/lib/apache2/fastcgi AddType application/x-httpd-fastphp .php Action application/x-httpd-fastphp /php-fcgi Alias /php-fcgi /usr/lib/cgi-bin/php-fcgi FastCgiExternalServer /usr/lib/cgi-bin/php-fcgi -socket /run/php/php7.2-fpm.sock -pass-header Authorization Require all granted احفظ التغييرات واختبر الضبط: $ sudo apachectl -t إذا ظهرت عبارة Syntax OK، أعد تحميل Apache: $ sudo systemctl reload apache2 إذا رأيت رسالة التحذير التالية، يمكنك تجاهلها الآن بشكل آمن. سنَضبط أسماء الخادم في وقت لاحق: Could not reliably determine the server's fully qualified domain name, using 127.0.1.1. Set the 'ServerName' directive globally to suppress this message. دعنا نتأكد الآن من أنّه بإمكاننا تخديم PHP من Apache. الخطوة 4 - التحقق من عمل PHP سَنتأكّد من أن PHP يعمل، وذلك من خلال إنشاء ملف ()phpinfo والوصول إليه من متصفح الويب. أنشئ الملف var/www/html/info.php/ والذي يحتوي على استدعاء للدّالة phpinfo: $ echo "" | sudo tee /var/www/html/info.php انتقل في المتصفح إلى http: // your_server_ip: 8080 / info.php لاستعراض هذا الملف. ستظهر لك قائمة إعدادات الضبط التي يستخدمها PHP. كما في الشكل التالي: تحقّق من أن الخيار Server API يأخذ القيمة FPM/FastCGI وذلك في أعلى الصفحة كما في الصورة السابقة. سترى كذلك في أسفل الصفحة تقريبًا في القسم PHP Variables بأنّ قيمة SERVER_SOFTWARE هي Apache على Ubuntu. وهذا يؤكّد أنّ الوحدة mod_fastcgi مُفعّلة وأنّ Apache يستخدم PHP-FPM لمعالجة ملفات PHP. الخطوة 5 - إنشاء مضيفات افتراضيّة لـ Apache دعونا ننشئ ملفات المضيف الافتراضي لـ Apache للنطاقين foobar.net و test.io. سنقوم لعمل ذلك أولاً بإنشاء الأدلّة الجذر للمستند في كِلا الموقعين ووضع بعض الملفات الافتراضيّة في هذه الأدلة حتى نتمكن من اختبار الضبط لدينا بسهولة. أولاً، أنشئ الأدلّة الجذر للمستند: $ sudo mkdir -v /var/www/foobar.net /var/www/test.io أنشئ بعد ذلك ملف index لكل موقع: $ echo "<h1 style='color: green;'>Foo Bar</h1>" | sudo tee /var/www/foobar.net/index.html $ echo "<h1 style='color: red;'>Test IO</h1>" | sudo tee /var/www/test.io/index.html " | sudo tee /var/www/test.io/index.html ثم أنشئ ملف ()phpinfo لكل موقع حتى نتمكن من اختبار فيما إذا ضُبط PHP بشكل صحيح. $ echo "" | sudo tee /var/www/foobar.net/info.php $ echo "" | sudo tee /var/www/test.io/info.php الآن أنشئ ملف المضيف الافتراضي للنطاق foobar.net: $ sudo nano /etc/apache2/sites-available/foobar.net.conf أضف الشفرة التالية إلى الملف لتعريف المضيف: /etc/apache2/sites-available/foobar.net.conf ServerName foobar.net ServerAlias www.foobar.net DocumentRoot /var/www/foobar.net AllowOverride All يتيح السطر AllowOverride All تفعيل دعم htaccess. احفظ وأغلق الملف. ثم أنشئ ملف ضبط مماثل لـ test.io. أولاً أنشئ الملف: $ sudo nano /etc/apache2/sites-available/test.io.conf ثم أضف الضبط إلى الملف: /etc/apache2/sites-available/test.io.conf ServerName test.io ServerAlias www.test.io DocumentRoot /var/www/test.io AllowOverride All احفظ الملف وإغلاق المحرّر. والآن بعد إعداد كل من مضيفي Apache الافتراضيين، فعّل المواقع باستخدام الأمر a2ensite. والذي يُنشئ رابط رمزي لمَلف المضيف الافتراضي في الدليل sites-enabled: $ sudo a2ensite foobar.net $ sudo a2ensite test.io تحقّق من Apache للتأكّد من وجود أخطاء في الضبط مرّة أخرى: $ sudo apachectl –t سترى عبارة Syntax OK إذا لم يكن هناك أخطاء. إذا رأيت أي شيء آخر، فتحقّق من الضبط وحاول مرّة أخرى. قم بإعادة تحميل Apache لتطبيق التغييرات بمجرّد أن يكون الضبط الخاص بك خاليًا من الأخطاء: $ sudo systemctl reload apache2 افتح http://foobar.net:8080 و http://test.io:8080 في متصفحك للتأكّد من عمل المواقع والتحقّق من أنّ كل موقع يعرض ملف index.html الخاص به. سترى النتائج التالية: تأكّد أيضًا من أن PHP تعمل وذلك عن طريق الوصول إلى ملفات info.php لكل موقع. افتح http://foobar.net:8080/info.php و http://test.io:8080/info.php في متصفحك. سترى قائمة مواصفات ضبط PHP نفسها على كل موقع كما رأيت في الخطوة 4. لدينا الآن موقعين مُستضافين على Apache على المنفذ 8080. فلنَضبط بعد ذلك Nginx. الخطوة 6 - تثبيت وضبط Nginx سنقوم في هذه الخطوة بتثبيت Nginx وإعداد ضبط النطاقات example.com و sample.org كمضيفين افتراضيين لـ Nginx. ثبّت Nginx باستخدام مدير الحزم: $ sudo apt install nginx أزل الرابط الرمزي الافتراضي للمضيف الافتراضي حيث أننا لن نستخدمه بعد الآن: $ sudo rm /etc/nginx/sites-enabled/default سنُنشئ الموقع الافتراضي الخاص بنا فيما بعد (example.com). سنُنشئ الآن مضيفين افتراضيين لـ Nginx باستخدام نفس الإجرائيّة التي استخدمناها من أجل Apache. أنشئ أولاً الأدلّة للمستند الجذر لكل من موقعي الويب: $ sudo mkdir -v /usr/share/nginx/example.com /usr/share/nginx/sample.org سنحتفظ بمواقع الويب الخاصّة بـ Nginx في /usr/share/nginx، وهو المسار الافتراضي الذي سيختاره Nginx. يمكنك وضع هذه المواقع في /var/www/html مع مواقع Apache، لكن هذا الفصل بينها قد يساعدك على ربط المواقع بـ Nginx. كما فعلت مع مضيفي Apache الافتراضيين، أنشئ ملفات index و ()phpinfo من أجل الاختبار بعد اكتمال الإعداد: $ echo "<h1 style='color: green;'>Example.com</h1>" | sudo tee /usr/share/nginx/example.com/index.html $ echo "<h1 style='color: red;'>Sample.org</h1>" | sudo tee /usr/share/nginx/sample.org/index.html $ echo "<?php phpinfo(); ?>" | sudo tee /usr/share/nginx/example.com/info.php $ echo "<?php phpinfo(); ?>" | sudo tee /usr/share/nginx/sample.org/info.php الآن أنشئ ملف مضيف افتراضي للنطاق example.com: $ sudo nano /etc/nginx/sites-available/example.com يستدعي Nginx كتل server {. . .} من ملف الضبط server blocks. أنشئ كتلة خادم من أجل المضيف الافتراضي الأساسي example.com. تجعل ضبط التوجيه default_server هذا المضيف كمضيف افتراضي افتراضي لمعالجة طلبات HTTP التي لا تتطابق مع أي مضيف افتراضي آخر. /etc/nginx/sites-available/example.com server { listen 80 default_server; root /usr/share/nginx/example.com; index index.php index.html index.htm; server_name example.com www.example.com; location / { try_files $uri $uri/ /index.php; } location ~ \.php$ { fastcgi_pass unix:/run/php/php7.2-fpm.sock; include snippets/fastcgi-php.conf; } } احفظ وأغلق الملف. أنشئ الآن ملف مضيف Nginx افتراضي للنطاق الثاني، sample.org: $ sudo nano etc/nginx/sites-available/sample.org أضف ما يلي إلى الملف: /etc/nginx/sites-available/sample.org server { root /usr/share/nginx/sample.org; index index.php index.html index.htm; server_name sample.org www.sample.org; location / { try_files $uri $uri/ /index.php; } location ~ \.php$ { fastcgi_pass unix:/run/php/php7.2-fpm.sock; include snippets/fastcgi-php.conf; } } احفظ وأغلق الملف. ثم فعّل كِلا الموقعين من خلال إنشاء روابط رمزيّة للدّليل sites-enabled: $ sudo ln -s /etc/nginx/sites-available/example.com /etc/nginx/sites-enabled/example.com $ sudo ln -s /etc/nginx/sites-available/sample.org /etc/nginx/sites-enabled/sample.org اختبر بعد ذلك ضبط Nginx لضمان عدم وجود أخطاء في الضبط: $ sudo nginx -t ثم أعد تحميل Nginx إذا لم يكن هناك أخطاء: $ sudo systemctl reload nginx الآن قم بالوصول إلى ملف ()phpinfo الخاص بمُضيفي Nginx الافتراضيين من متصفح الويب من خلال زيارة http://sample.org/info.php و http://example.com/info.php. انظر مجدّدًا إلى الصورة في الأسفل إلى قسم المتغيرات PHP Variables. يجب أن يحوي["SERVER_SOFTWARE"] على القيمة Nginx، مشيرًا إلى أنّ الملفات خُدّمت بشكل مباشر بواسطة Nginx. يجب أن يشير["DOCUMENT_ROOT"] إلى الدليل الذي أنشأته مُسبقًا في هذه الخطوة لكل موقع من مواقع Nginx. ثبّتنا في هذه المرحلة Nginx وأنشأنا مضيفين افتراضيين.سنقوم بعد ذلك بضبط Nginx على طلبات الوكيل المخصّصة للنطاقات المستضافة على Apache. الخطوة 7 - ضبط Nginx لمضيفي Apache الافتراضيين لنُنشئ مضيف Nginx افتراضي إضافي مع أسماء نطاقات متعددة في توجيهات server_name. سيتم توكيل طلبات هذه النطاقات إلى Apache. أنشئ ملف مضيف Nginx افتراضي جديد لإعادة توجيه الطلبات إلى Apache: $ sudo nano /etc/nginx/sites-available/apache أضف كتلة الشفرة التالية التي تحدد أسماء نطاقات كلاً من مضيفي Apache الاتراضيين وتوكل طلباتها إلى Apache. تذكّر استخدام عنوان IP العام في proxy_pass: /etc/nginx/sites-available/apache server { listen 80; server_name foobar.net www.foobar.net test.io www.test.io; location / { proxy_pass http://your_server_ip:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } } قم بحفظ الملف وتفعيل هذا المضيف الافتراضي الجديد عن طريق إنشاء رابط رمزي: $ sudo ln -s /etc/nginx/sites-available/apache /etc/nginx/sites-enabled/apache اختبر الضبط للتأكد من عدم وجود أخطاء: $ sudo nginx -t إذا لم يكن هنالك أخطاء، أعد تحميل Nginx: $ sudo systemctl reload nginx افتح متصفحك وقم بالوصول إلى العنوان http://foobar.net/info.php. انتقل لأسفل إلى قسم PHP Variables وتحقق من القيم المعروضة كما في الصورة. يؤكّد المتغيران ERVER_SOFTWARE و DOCUMENT_ROOT أنّ هذا الطلب عُولج بواسطة Apache. وأضيفت المتغيرات HTTP_X_REAL_IP و HTTP_X_FORWARDED_FOR بواسطة Nginx ويجب أن تُظهر عنوان IP العام للحاسب الذي تستخدمه للوصول إلى عنوان URL. لقد أعددنا Nginx بنجاح ليوكل بطلبات نطاقات محدّدة إلى Apache. بعد ذلك، لنقم بضبط Apache لضبط المتغير REMOTE_ADDR كما لو أنه يتعامل مع هذه الطلبات مباشرة. الخطوة 8 - تثبيت وضبط mod_rpaf سنُثبّت في هذه الخطوة وحدة Apache تسمى mod\_rpaf والتي تعيد كتابة قيم REMOTE_ADDR، HTTPS و HTTP_PORT استنادًا إلى القيم المقدّمة من قبل وسيط عكسي. وبدون هذه الوحدة، تتطلب بعض تطبيقات PHP تغييرات في الشفرة للعمل بسلاسة من خلفْ الخادم الوكيل. هذه الوحدة موجودة في مستودع Ubuntu باسم libapache2-mod-rpaf ولكنها قديمة ولا تدعم توجيهات ضبط معينة. سنقوم بدلاً من ذلك بتثبيتها من المصدر. تثبيت الحزم اللازمة لبناء الوحدة: $ sudo apt install unzip build-essential apache2-dev نزّل أحدث إصدار مستقر من GitHub: $ wget https://github.com/gnif/mod_rpaf/archive/stable.zip استخراج الملف الذي نزل: $ unzip stable.zip انتقل إلى المجلد الجديد الذي يحتوي على الملفات: $ cd mod_rpaf-stable ترجم Compile الوحدة ثم ثبّتها: $ make $ sudo make install أنشئ بعد ذلك ملف في المجلد mods-available والذي سيُحمّل وحدة rpaf: $ sudo nano /etc/apache2/mods-available/rpaf.load أضف الشفرة التالية إلى الملف لتحميل الوحدة: /etc/apache2/mods-available/rpaf.load LoadModule rpaf_module /usr/lib/apache2/modules/mod_rpaf.so احفظ الملف وأغلق المحرر. أنشئ ملف آخر في نفس الدليل وسمّه rpaf.conf والذي سوف يحتوي على توجيهات الضبط للوحدة mod_rpaf: $ sudo nano /etc/apache2/mods-available/rpaf.conf أضف كتلة الشفرة التالية لضبط mod_rpaf، مع التأكّد من تحديد عنوان IP الخاص بخادمك: /etc/apache2/mods-available/rpaf.conf RPAF_Enable On RPAF_Header X-Real-Ip RPAF_ProxyIPs your_server_ip RPAF_SetHostName On RPAF_SetHTTPS On RPAF_SetPort On فيما يلي وصف موجز لكل توجيه. لمزيد من المعلومات، راجع ملف mod_rpaf README. RPAF_Header - الترويسة المراد استخدامها لعنوان IP الحقيقي للعميل. RPAF_ProxyIPs - عنوان IP للوكيل لضبط طلبات HTTP من أجله. RPAF_SetHostName - يقوم بتحديث اسم المضيف الافتراضي بحيث يعمل كل من ServerName و ServerAlias. RPAF_SetHTTPS - يضبط متغير بيئة HTTPS استنادًا إلى القيمة الموجودة في X-Forwarded-Proto. RPAF_SetPort - يضبط متغير بيئة SERVER_PORT. يكون مفيد عندما يكون Apache يعمل خلف وكيل SSL. احفظ الملف rpaf.conf وقم بتفعيل الوحدة: $ sudo a2enmod rpaf يؤدي هذا إلى إنشاء روابط رمزيّة من الملفات rpaf.load و rpaf.conf في الدليل mods-enabled. الآن قم بإجراء اختبار الضبط: $ sudo apachectl -t أعد تحميل Apache إذا لم يكن هنالك أخطاء: $ sudo systemctl reload apache2 قم بالوصول إلى الملف ()phpinfo في الصفحات http://foobar.net/info.php و http://test.io/info.php من متصفحك وتحقق من قسم PHP Variables. الآن سيكون المتغير REMOTE_ADDR هو أيضًا عنوان IP العام للحاسب المحلي لديك. الآن دعنا نعد تشفير TLS / SSL لكل موقع. الخطوة 9 - إعداد مواقع HTTPS باستخدام Let's Encrypt (اختياري) سنضبط في هذه الخطوة شهادات TLS / SSL لكل من النطاقات المُستضافة على Apache. سوف نحصل على الشهادات بواسطة [Let's Encrypt](https://letsencrypt.org]. يدعم Nginx إنهاء SSL، لذا من الممكن إعداد SSL بدون تعديل ملفات ضبط Apache. تَضمنْ الوحدة mod_rpaf أن يتم تعيين متغيرات البيئة المطلوبة على Apache لجعل التطبيقات تعمل بسلاسة خلفْ وكيل عكسي لـ SSL. أولاً سنفصل كتل الخادم {...}server من كِلا النطاقين بحيث يمكن أن يكون لكلٍ منهما شهادات SSL خاصّة به. افتح الملف etc/nginx/sites-available/apache/ في المحرّر الخاص بك: $ sudo nano /etc/nginx/sites-available/apache عدّل الملف بحيث يبدو مثل هذا، مع foobar.net و test.io في كتل الخادم الخاصّة بهم: /etc/nginx/sites-available/apache server { listen 80; server_name foobar.net www.foobar.net; location / { proxy_pass http://your_server_ip:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } } server { listen 80; server_name test.io www.test.io; location / { proxy_pass http://your_server_ip:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } } سنستخدم Certbot لإنشاء شهادات TLS/SSL الخاصّة بنا. ستتولى إضافة Nginx plugin" Nginx" مُهمة إعادة ضبط Nginx وإعادة تحميل الضبط عند الضرورة. أولاً، أضف مستودع Certbot المرخّص: $ sudo add-apt-repository ppa:certbot/certbot اضغط على ENTER عند مطالبتك بتأكيد رغبتك في إضافة المستودع الجديد. ثم قم بتحديث قائمة الحزم للحصول على معلومات حزمة المستودع الجديدة: $ sudo apt update ثم ثبّت حزمة Nginx الخاصّة بـ Certbot باستخدام apt: $ sudo apt install python-certbot-nginx وبمجرّد تثبيته، استخدم أمر certbot لإنشاء الشهادات لـ foobar.net و www.foobar.net: $ sudo certbot --nginx -d foobar.net -d www.foobar.net يخبر هذا الأمر Certbot ليستخدم ملحق nginx، وباستخدم –d لتحديد الأسماء التي نودّ أن تكون الشهادة صالحة لها. إذا كانت هذه هي المرة الأولى التي تُشغّل فيها certbot، فسَتتم مطالبتك بإدخال عنوان بريد إلكتروني والموافقة على شروط الخدمة. سيتصل بعد القيام بذلك certbot بخادم Let's Encrypt، ثم يشغّل ردّا للتحقق من أنّك تتحكم في النطاق الذي تطلب الحصول على شهادة له. سَيسألك Certbot بعد ذلك عن الطريقة التي ترغب في ضبط إعدادات HTTPS الخاصّة بك: Output Please choose whether or not to redirect HTTP traffic to HTTPS, removing HTTP access. ------------------------------------------------------------------------------- 1: No redirect - Make no further changes to the webserver configuration. 2: Redirect - Make all requests redirect to secure HTTPS access. Choose this for new sites, or if you're confident your site works on HTTPS. You can undo this change by editing your web server's configuration. ------------------------------------------------------------------------------- Select the appropriate number [1-2] then [enter] (press 'c' to cancel): حدّد خيارك، ثم اضغط على ENTER. سيتم تحديث الضبط، وإعادة تحميل Nginx لتفعيل الإعدادات الجديدة. الآن، نفّذ الأمر للنطاق الثاني: $ sudo certbot --nginx -d test.io -d www.test.io انظر في قسم PHP Variables. تم تعيين المتغير SERVER_PORT على القيمة 443 وضبط HTTPS على القيمة on، كما لو أنّه تم الوصول إلى Apache مباشرةً عبر HTTPS. مع ضبط هذه المتغيرات، لن تحتاج تطبيقات PHP إلى إعداد خاص للعمل خلف وسيط عكسي. سنقوم الآن بتعطيل الوصول المباشر إلى Apache. الخطوة 10 - حظر الوصول المباشر إلى Apache (اختياري) بما أن Apache يستمع على المنفذ 8080 على عنوان IP العام، فإنّه بإمكان الجميع الوصول إليه. ويمكن حظره من خلال عمل الأمر IPtables التالي في مجموعة قواعد الجدار الناري. $ sudo iptables -I INPUT -p tcp --dport 8080 ! -s your_server_ip -j REJECT --reject-with tcp-reset تأكّد من استخدام عنوان IP لخَادمك مكان اللون الأحمر في المثال السابق. بمجرد حظر المنفذ 8080 في الجدار الناري، اختبر عدم إمكانية الوصول إلى Apache. افتح متصفح الويب الخاص بك وحاول الوصول إلى أحد أسماء نطاقات Apache على المنفذ 8080. على سبيل المثال: http://example.com:8080 يجب أن يعرض المتصفح رسالة خطأ "غير قادر على الاتصال" أو "صفحة الويب غير متوفرة". وبضبط خيار IPtables tcp-reset، لن يرى أحد أي اختلاف بين المنفذ 8080 والمنفذ الذي لا يحتوي أيّ خدمةٍ عليه. ملاحظة: عند إعادة تشغيل النظام وبشكل افتراضي لن تبقى قواعد IPtables كما حدّدناها. هناك طرق متعددة للحفاظ على قواعد IPtables، ولكن أسهلها هو استخدام iptables-persistent في مستودع Ubuntu. استكشف هذه المقالة لمعرفة المزيد حول كيفيّة ضبط IPTables. لنضبط الآن Nginx لخدمة ملفات ثابتة لمواقع Apache. الخطوة 11 - تخديم الملفات الثابتة باستخدام Nginx (اختياري) عندما يقدم وسيط Nginx طلبات لنطاقات Apache، فإنّه يرسل كل ملف طلب لهذا النطاق إلى Apache. Nginx أسرع من Apache في خدمة الملفات الثابتة مثل الصور، وجافا سكريبت وأوراق الأنماط. لذلك دعونا نضبط ملف مضيف apache افتراضي خاص بـ Nginx لتخديم الملفات الثابتة مباشرة ولكن مع إرسال طلبات PHP إلى Apache. افتح الملف etc/nginx/sites-available/apache/ في محرّرك الخاص: $ sudo nano /etc/nginx/sites-available/apache ستحتاج إلى إضافة موضعين location إضافيين لكل كتلة خادم، بالإضافة إلى تعديل أقسام location الموجودة. بالإضافة إلى ذلك، ستحتاج إلى إخبار Nginx بمكان تواجد الملفات الثابتة لكل موقع. إذا قرّرت عدم استخدام شهادات SSL و TLS، فعدّل ملفك بحيث يبدو كالتالي: /etc/nginx/sites-available/apache server { listen 80; server_name test.io www.test.io; root /var/www/test.io; index index.php index.htm index.html; location / { try_files $uri $uri/ /index.php; } location ~ \.php$ { proxy_pass http://your_server_ip:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } location ~ /\.ht { deny all; } } server { listen 80; server_name foobar.net www.foobar.net; root /var/www/foobar.net; index index.php index.htm index.html; location / { try_files $uri $uri/ /index.php; } location ~ \.php$ { proxy_pass http://your_ip_address:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } location ~ /\.ht { deny all; { { إذا كنت تريد بأن يكون HTTPS متوفرًا أيضًا، فاستخدم الضبط التالي بدلاً من ذلك: server { listen 80; server_name test.io www.test.io; root /var/www/test.io; index index.php index.htm index.html; location / { try_files $uri $uri/ /index.php; } location ~ \.php$ { proxy_pass http://your_server_ip:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } location ~ /\.ht { deny all; } listen 443 ssl; ssl_certificate /etc/letsencrypt/live/test.io/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/test.io/privkey.pem; include /etc/letsencrypt/options-ssl-nginx.conf; ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; } server { listen 80; server_name foobar.net www.foobar.net; root /var/www/foobar.net; index index.php index.htm index.html; location / { try_files $uri $uri/ /index.php; } location ~ \.php$ { proxy_pass http://your_ip_address:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } location ~ /\.ht { deny all; } listen 443 ssl; ssl_certificate /etc/letsencrypt/live/foobar.net/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/foobar.net/privkey.pem; include /etc/letsencrypt/options-ssl-nginx.conf; ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; { إنّ التوجيه try_files يجعل Nginx يبحث عن الملفات في المستند الجذر ويقدّمها مباشرةً. إذا كان الملف له امتداد php.، سيتم تمرير الطلب إلى Apache. حتى إذا لم يُعثر على الملف في المستند الجذر، يُمرّر الطلب إلى Apache لتعمل ميزات التطبيق مثل permalinks بدون أخطاء. تحذير: إنّ التوجيه location ~ /\.ht مهم جداً؛ حيث يمنع Nginx من عرض محتويات ملفات الضبط Apache مثل htaccess. و htpasswd. التي تحتوي على معلومات حساسة. احفظ الملف وقم بإجراء اختبار الضبط: $ sudo nginx -t أعد تحميل Nginx إذا نجح الاختبار: $ sudo service nginx reload يمكنك للتحقّق من أن العمل تم بشكل صحيح فحص ملفات سجل Apache في var/log/apache2/ ومشاهدة طلبات GET لملفات info.php من test.io و foobar.net. استخدم الأمر tail لمشاهدة الأسطر القليلة الأخيرة من الملف، واستخدم رمز التبديل f- لمشاهدة الملف من أجل التغييرات: $ sudo tail -f /var/log/apache2/other_vhosts_access.log قم الآن بزيارة http://test.io/info.php في مستعرض الويب الخاص بك ثم انظر إلى خرج السجل. سترى أن Apache يجيب بالفعل: Output test.io:80 your_server_ip - - [01/Jul/2016:18:18:34 -0400] "GET /info.php HTTP/1.0" 200 20414 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36" ثم قم بزيارة صفحة index.html لكل موقع ولن ترى أي إدخالات للسجّل من قبل Apache. لأن Nginx هو من يخدّمهم. عند الانتهاء من معاينة ملف السجل، اضغط على CTRL + C لإيقاف تعقبّه. باستخدام هذا الإعداد، لن يكون Apache قادرًا على تقييد الوصول إلى الملفّات الثابتة. وللتَحكم في الوصول إلى الملفّات الثابتة تحتاج إلى ضبط في ملف المضيف apache الافتراضي الخاص بـ Nginx، ولكن هذا خارج نطاق هذه الدورة التعليميّة. الخلاصة لديك الآن خادم Ubuntu مع Nginx يُخدّم example.com و sample.org، جنبًا إلى جنب مع Apache والذي يُخدّم foobar.net و test.io. على الرغم من أن Nginx يعمل كوكيل عكسي لـ Apache، إلا أن خدمة الوكيل في Nginx تتسم بالشفافية وتُظهر اتصالها بنطاقات Apache كما لو أنها مخدّمة مباشرةً من Apache. يمكنك استخدام هذه الطريقة لتخديم مواقع آمنة وثابتة. ترجمة بتصرف للمقال How To Configure Nginx as a Web Server and Reverse Proxy for Apache on One Ubuntu 18.04 Server لصاحبه Jesin A. -
 مقدمة صُممت أنظمة إدارة الضبط لتجعل من التحكم في عددٍ كبيرٍ من الخوادم أمرًا سهلًا للمدراء وفِرق العمليات. فهي تسمح بالتحكم في العديد من الأنظمة المختلفة بطريقةٍ آلية ومن موقع مركزي واحد. وعلى الرغم من وجود العديد من أنظمة إدارة الضبط الشائعة المتوفرة لأنظمة Linux، مثل Chef وPuppet، إلاّ أنّ هذه الأنظمة غالباً ما تكون أكثر تعقيدًا مما يريده أو يحتاجه الكثير من الأشخاص. يُعدّ Ansible بديلاً هامًا لهذه الخيارات نظرًا لأنّه يتطلب عبئا أقل بكثير للبدء. سنناقش في هذا الدليل كيفيّة تثبيت Ansible على خادم Ubuntu 18.04 وسنتحدّث عن بعض الأساسيّات حول كيفيّة استخدام البرنامج. كيف يعمل Ansible؟ يعمل Ansible عن طريق ضبط أجهزة العميل من خلال حاسب يحوي مكوّنات Ansible مُثبّتة ومُهيأة. يتصل عبر قنوات SSH الاعتيادية لاسترداد المعلومات من الأجهزة البعيدة، وإصدار الأوامر، ونسخ الملفات. ولذلك لا يتطلب نظام Ansible تثبيت أيّة برمجيّات إضافيّة على أجهزة حواسب العملاء. هذه هي إحدى الطرق التي يّبسط فيها Ansible إدارة الخوادم. يمكن ضم أي خادم لديه منفذ SSH مكشوف تحت مظلة ضبط Ansible بغض النظر عن الطور الذي يتواجد فيه ضمن دورة حياته. وهذا يعني أن أي حاسب يمكنك إدارته من خلال SSH، يمكنك إدارته أيضًا من خلال Ansible. يتخذ Ansible نهجًا معياريًا، جاعلًا من السهل التوسع لاستخدام وظائف النظام الرئيسي للتعامل مع سيناريوهات محدّدة. يمكن كتابة الوحدات باستخدام أيّة لغة وتتواصل في JSON القياسيّة. إن ملفات الضبط مكتوبة بشكل أساسي بصيغة تسلسل بيانات YAML بسبب طبيعتها الدلاليّة وتشابهها مع لغات الترميز الشائعة. ويمكن أن يتفاعل Ansible مع المضيفات hosts إما عبر أدوات سطر الأوامر أو من خلال سكربتات الضبط ، والتي تُعرف باسم Playbooks. المتطلبات المسبقة ستحتاج لمتابعة هذه الدورة التعليميّة إلى: اثنين أو أكثر من خوادم Ubuntu 18.04. سيُستخدم واحد منها كخادم Ansible الخاص بك، بينما سيُستخدم الباقي كمضيفين Ansible الخاصين بك. يجب أن يكون لكل منهم مستخدم غير جذري non-root بامتيازات sudo وجدار ناري firewall أساسي مُهيئ. يمكنك إعداد ذلك باتباع دليل إعداد الخادم المبدئي لـ Ubuntu 18.04. ويرجى ملاحظة أنّ الأمثلة في هذا الدليل تحدّد ثلاثة مضيفين Ansible، ولكن يمكن ضبط الأوامر لأيّ عدد تريده من العملاء. أُنشئت مفاتيح SSH للمستخدم الغير جذري non-root user على خادم Ansible الخاص بك. وللقيام بذلك، تابع الخطوة 1 من دليلنا حول كيفية إعداد مفاتيح SSH على Ubuntu 18.04. يمكنك من أجل هذه الدورة التعليميّة حفظ زوج المفاتيح إلى الموقع الافتراضي (ssh/id_rsa./~) ولا تحتاج إلى حماية بكلمة المرور. الخطوة 1 - تثبيت Ansible يجب تثبيت برنامج Ansible على جهاز واحد على الأقل لبدء استخدامه كوسيلة لإدارة الخوادم المختلفة. يمكنك إضافة أرشيف الحزمة الشخصيّة للمشروع (PPA (personal package archive إلى النظام الخاص بك للحصول على أحدث إصدار من Ansible على نظام Ubuntu. عليك قبل القيام بذلك أولاً تحديث فهرس الحزمة وتثبيت حزمة software-properties-common. حيث تسهّل هذه البرمجية إدارة هذا المستودع ومستودعات البرمجيات المستقلة الأخرى: $ sudo apt update $ sudo apt install software-properties-common ثم أضف PPA Ansible عن طريق كتابة الأمر التالي: $ sudo apt-add-repository ppa: ansible / ansible اضغط ENTER لقبول إضافة PPA. بعدها، حدّث فهرس حزمة النظام مرّةً أخرى حتى يصبح على معرفةٍ بالحزم المتاحة في PPA: $ sudo apt update يمكنك تثبيت برمجيّة Ansible بعد هذا التحديث: $ sudo apt install ansible يحتوي الآن خادم Ansible على جميع البرمجيّات المطلوبة لإدارة المضيفات hosts. الخطوة 2 - تهيئة الـ SSH للوصول إلى مضيفات Ansible يتصل Ansible كما ذُكر سابقًا بشكل أساسي مع أجهزة الحواسب العميلة من خلال SSH. وعلى الرغم من أن لديها بالتأكيد القدرة على التعامل مع استيثاق SSH المعتمد على كلمة المرور، إلاّ أن استخدام مفاتيح SSH يمكن أن يساعد في إبقاء الأمور بسيطة. استخدم أمر cat على خادم Ansible خاصتك لطباعة محتويات ملف مفتاح SSH العام للمستخدم الغير جذري non-root الخاص بك إلى خرْج الطرفيّة terminal: $ cat ~ / .ssh / id_rsa.pub انسخ الخرج الناتج إلى حافظتك، ثم افتح طرفيّة جديدة terminal واتصل بأحد مضيفي Ansible مُستخدمًا SSH: $ ssh sammy @ ansible_host_ip بدّل إلى المستخدم الجذري root لجهاز العميل: $ su – افتح الدليل authorized_keys ضمن المسار ~/.ssh كمستخدم جذر root : # nano ~/.ssh/authorized_keys الصق مفتاح SSH لمستخدم Ansible server في الملف، ثم احفظ الملف وأغلق المحرر (, اضغط CTRL + X, Y، ثم ENTER). ثم شغِّل الأمر exit للرجوع إلى المستخدم العادي للمضيف: # exit أخيرًا، ونظرًا لأن Ansible يستخدم مُفسّر بايثون python interpreter الموجود في المسار / usr / bin / python لتشغيل وحداته، فستحتاج إلى تثبيت Python 2 على المضيف حتى يتمكن Ansible من الاتصال به. شغّل الأوامر التالية لتحديث فهرس حزمة المضيف وتثبيت حزمة python: $ sudo apt update $sudo apt install python يمكنك بعد ذلك تشغيل أمر exit مرّةً أخرى لإغلاق الاتصال بالعميل: $ exit كرّر هذه العملية من أجل كل خادم تنوي التحكم فيه باستخدام خادم Ansible الخاص بك. بعد ذلك، سنُهيئ خادم Ansible للاتصال بالمضيفات باستخدام ملف (hosts)الخاص بـ Ansible. الخطوة 3 - إعداد مضيفات Ansible يتتبع Ansible كافة الخوادم الذي يتعرف عليها من خلال ملف المضيفات hosts. نحتاج أولًا إلى إعداد هذا الملف قبل أن نتمكن من بدء الاتصال بحواسبنا الأخرى: $ sudo nano /etc/ansible/hosts سترى ملفًا يحوي عددًا من أمثلة "نماذج" الضبط المُعقّب عليها (بإشارة # تسبق كل سطر). لن تعمل هذه الأمثلة فعليًا في حالتنا نظرًا لأن المضيفات المُدرجات في كل منها وهميّة. بكافة الأحوال سنحتفظ بهذه الأمثلة في الملف لمساعدتنا في الضبط في حال أردنا تنفيذ حالات أكثر تعقيدًا في المستقبل. إن ملف hosts مرن إلى حدّ ما ويمكن ضبطته بعدّة بطرق مختلفة. وبناءً عليه، ستبدو الصياغة التي سنستخدمها كما يلي: [group_name] alias ansible_ssh_host=your_server_ip في هذا المثال، إن group_name وسم تنظيمي يتيح لك الإشارة إلى أي خادم مدرج تحته بكلمة واحدة، بينما alias هو مجرد اسم للإشارة إلى خادم معيّن. نعتبر في حالتنا أن لدينا ثلاثة خوادم سنتحكم بهم باستخدام Ansible. يمكن عند هذه النقطة الوصول إلى هذه الخوادم من خادم Ansible بكتابة: $ ssh root@ansible_host_ip إذا أعددت هذا بشكل صحيح فلا يجب أن تُطالب بكلمة مرور. سنفترض هنا لأغراض العرض التوضيحي أن عناوين IP لمضيفاتنا هي 203.0.113.1 و 203.0.113.2 و 203.0.113.3. وسنضبط ذلك بحيث يمكننا الإشارة إليها بشكل فردي كـ host1، و host2، و host3، أو كمجموعة باسم servers. و لإتمام ذلك يتوجب إضافة هذه الكتلة إلى ملف hosts الخاص بنا: [servers] host1 ansible_ssh_host=203.0.113.1 host2 ansible_ssh_host=203.0.113.2 host3 ansible_ssh_host=203.0.113.3 يمكن أن تكون المضيفات في مجموعاتٍ متعددة، ويمكن للمجموعات ضبط المعاملات parameters من أجل جميع أعضائها. فلنجرّب هذا الآن. إن حاولنا باستخدام إعداداتنا الحاليّة الاتصال بأي من هذه الأجهزة المضيفة hosts من خلال Ansible، فسيفشل الأمر (على افتراض أنك لا تعمل كمستخدم جذر root). يحدث هذا لأنّه تم تضمين مفاتيح SSH من أجل المستخدم الجذر على الأنظمة البعيدة وسيحاول Ansible الاتصال بشكل افتراضي بواسطة المستخدم الحالي، ستعطينا محاولة الاتصال هذا الخطأ: [servers] Output host1 | UNREACHABLE! => { "changed": false, "msg": "Failed to connect to the host via ssh.", "unreachable": true } نستخدم على خادم Ansible مستخدمًا اسمه sammy. سيحاول Ansible الاتصال بكل مضيف باستخدام ssh sammy @ server. ولن يعمل هذا إذا لم يكن المستخدم sammy موجودًا على النظام البعيد أيضًا. يمكننا إنشاء ملف يخبر جميع الخوادم في مجموعة "servers " للاتصال كمستخدم جذر root. سننشئ لعمل ذلك دليلًا في بنية ضبط Ansible يدعى group_vars. ويمكننا ضمن هذا المجلد إنشاء ملفات بتنسيق YAML لكل مجموعة نريد ضبطها: $ sudo mkdir /etc/ansible/group_vars $sudo nano /etc/ansible/group_vars/servers يمكننا وضع ضبطنا هنا. تبدأ ملفات YAML بـ "---"، لذا تأكد من عدم نسيان هذا الجزء. /etc/ansible/group_vars/servers --- ansible_ssh_user: root احفظ وأغلق هذا الملف عند الانتهاء. إذا كنت تريد تحديد تفاصيل الضبط لكل خادم، بغض النظر عن المجموعة المرتبط بها، فيمكنك وضع هذه التفاصيل في ملف في المسار etc/ansible/group_vars/all/. يمكن ضبط المضيفات بشكل فردي عن طريق إنشاء ملفات مُسماة بالاسم البديل alias تحت الدليل في /etc/ansible/host_vars. الخطوة 4 - استخدام أوامر Ansible بسيطة يمكننا الآن -وبعد أن أعددنا مضيفاتنا و ضبطنا تفاصيل تهيئة كافية للسماح لنا بالاتصال بنجاح مع مضيفاتنا- تجربة الأمر الأول. عمل اختبار ping لجميع خوادمنا المُهيئة وذلك بكتابة: $ anmible -m ping all ستكون المخرجات كالتالي: host1 | SUCCESS => { "changed": false, "ping": "pong" } host3 | SUCCESS => { "changed": false, "ping": "pong" } host2 | SUCCESS => { "changed": false, "ping": "pong" } وهو اختبار بسيط للتأكّد من أنّ Ansible يتصل بجميع مضيفاته. تعني all جميع المضيفات. ويمكننا بسهولة تحديد مجموعة معيّنة كما يلي: $ ansible -m ping servers يمكننا أيضًا تحديد مضيف بشكل فردي: $ anmible -m ping host1 يمكننا تحديد عدّة مضيفات من خلال فصلها باستخدام النقطتين: $ anmible -m ping host1: host2 إنّ المقطع -m ping من الأمر عبارة عن تعليمة لـ Ansible لاستخدام الوحدة "ping". وهي في الأساس أوامر يمكنك تشغيلها على المضيفات عن بعد. تعمل وحدة ping بعدّة طرق مثل أداة ping العادية في Linux، ولكنها بدلاً من ذلك تتحقق من اتصال Ansible. لا تأخذ وحدة ping في الواقع أيّة وسائط arguments، لكن يمكننا تجربة أمر آخر لمعرفة كيفيّة عمل ذلك. نمرّر المعاملات في تدوين نصي "سكريبت" عن طريق كتابة -a. تتيح لنا الوحدة "shell" إرسال أمر طرفيّة terminal command إلى المضيف البعيد واسترداد النتائج. على سبيل المثال، يمكننا استخدام الأمر التالي لمعرفة استخدام الذاكرة على جهاز host1: $ ansible -m shell -a 'free -m' host1 ستكون مخرجات Shell كالتالي: host1 | SUCCESS | rc=0 >> total used free shared buffers cached Mem: 3954 227 3726 0 14 93 -/+ buffers/cache: 119 3834 Swap: 0 0 0 وبذلك أصبح خادم Ansible الخاص بك مُهيئًا ويمكنك الاتصال والتحكم في المضيفات بنجاح. الخلاصة ضبطنا في هذه الدورة التعليميّة Ansible وتأكّدنا من إمكانية اتصاله مع كل مضيف. واستخدمنا أيضًا الأمر ansible لتنفيذ مهام بسيطة عن بُعد. وعلى الرغم من أن هذا مفيد، إلا أنّنا لم نُغطّي أهم ميزة لـ Ansible في هذا المقال وهي الـ Playbooks. تعتبر Ansible Playbooks طريقةً قويّة وبَسيطة لإدارة عمليات تهيئة الخادم وعمليات النشر المتعدّدة الأجهزة. للحصول على تمهيد حول كتب Playbook، راجع هذا الدليل. بالإضافة إلى ذلك، فإننا نشجعك على مراجعة توثيق Ansible الرسميّة لمعرفة المزيد عن الأداة ترجمة وبتصرّف للمقال How to Install and Configure Ansible on Ubuntu 18.04 لصاحبيه Stephen Rees-Carter و Mark Drake
مقدمة صُممت أنظمة إدارة الضبط لتجعل من التحكم في عددٍ كبيرٍ من الخوادم أمرًا سهلًا للمدراء وفِرق العمليات. فهي تسمح بالتحكم في العديد من الأنظمة المختلفة بطريقةٍ آلية ومن موقع مركزي واحد. وعلى الرغم من وجود العديد من أنظمة إدارة الضبط الشائعة المتوفرة لأنظمة Linux، مثل Chef وPuppet، إلاّ أنّ هذه الأنظمة غالباً ما تكون أكثر تعقيدًا مما يريده أو يحتاجه الكثير من الأشخاص. يُعدّ Ansible بديلاً هامًا لهذه الخيارات نظرًا لأنّه يتطلب عبئا أقل بكثير للبدء. سنناقش في هذا الدليل كيفيّة تثبيت Ansible على خادم Ubuntu 18.04 وسنتحدّث عن بعض الأساسيّات حول كيفيّة استخدام البرنامج. كيف يعمل Ansible؟ يعمل Ansible عن طريق ضبط أجهزة العميل من خلال حاسب يحوي مكوّنات Ansible مُثبّتة ومُهيأة. يتصل عبر قنوات SSH الاعتيادية لاسترداد المعلومات من الأجهزة البعيدة، وإصدار الأوامر، ونسخ الملفات. ولذلك لا يتطلب نظام Ansible تثبيت أيّة برمجيّات إضافيّة على أجهزة حواسب العملاء. هذه هي إحدى الطرق التي يّبسط فيها Ansible إدارة الخوادم. يمكن ضم أي خادم لديه منفذ SSH مكشوف تحت مظلة ضبط Ansible بغض النظر عن الطور الذي يتواجد فيه ضمن دورة حياته. وهذا يعني أن أي حاسب يمكنك إدارته من خلال SSH، يمكنك إدارته أيضًا من خلال Ansible. يتخذ Ansible نهجًا معياريًا، جاعلًا من السهل التوسع لاستخدام وظائف النظام الرئيسي للتعامل مع سيناريوهات محدّدة. يمكن كتابة الوحدات باستخدام أيّة لغة وتتواصل في JSON القياسيّة. إن ملفات الضبط مكتوبة بشكل أساسي بصيغة تسلسل بيانات YAML بسبب طبيعتها الدلاليّة وتشابهها مع لغات الترميز الشائعة. ويمكن أن يتفاعل Ansible مع المضيفات hosts إما عبر أدوات سطر الأوامر أو من خلال سكربتات الضبط ، والتي تُعرف باسم Playbooks. المتطلبات المسبقة ستحتاج لمتابعة هذه الدورة التعليميّة إلى: اثنين أو أكثر من خوادم Ubuntu 18.04. سيُستخدم واحد منها كخادم Ansible الخاص بك، بينما سيُستخدم الباقي كمضيفين Ansible الخاصين بك. يجب أن يكون لكل منهم مستخدم غير جذري non-root بامتيازات sudo وجدار ناري firewall أساسي مُهيئ. يمكنك إعداد ذلك باتباع دليل إعداد الخادم المبدئي لـ Ubuntu 18.04. ويرجى ملاحظة أنّ الأمثلة في هذا الدليل تحدّد ثلاثة مضيفين Ansible، ولكن يمكن ضبط الأوامر لأيّ عدد تريده من العملاء. أُنشئت مفاتيح SSH للمستخدم الغير جذري non-root user على خادم Ansible الخاص بك. وللقيام بذلك، تابع الخطوة 1 من دليلنا حول كيفية إعداد مفاتيح SSH على Ubuntu 18.04. يمكنك من أجل هذه الدورة التعليميّة حفظ زوج المفاتيح إلى الموقع الافتراضي (ssh/id_rsa./~) ولا تحتاج إلى حماية بكلمة المرور. الخطوة 1 - تثبيت Ansible يجب تثبيت برنامج Ansible على جهاز واحد على الأقل لبدء استخدامه كوسيلة لإدارة الخوادم المختلفة. يمكنك إضافة أرشيف الحزمة الشخصيّة للمشروع (PPA (personal package archive إلى النظام الخاص بك للحصول على أحدث إصدار من Ansible على نظام Ubuntu. عليك قبل القيام بذلك أولاً تحديث فهرس الحزمة وتثبيت حزمة software-properties-common. حيث تسهّل هذه البرمجية إدارة هذا المستودع ومستودعات البرمجيات المستقلة الأخرى: $ sudo apt update $ sudo apt install software-properties-common ثم أضف PPA Ansible عن طريق كتابة الأمر التالي: $ sudo apt-add-repository ppa: ansible / ansible اضغط ENTER لقبول إضافة PPA. بعدها، حدّث فهرس حزمة النظام مرّةً أخرى حتى يصبح على معرفةٍ بالحزم المتاحة في PPA: $ sudo apt update يمكنك تثبيت برمجيّة Ansible بعد هذا التحديث: $ sudo apt install ansible يحتوي الآن خادم Ansible على جميع البرمجيّات المطلوبة لإدارة المضيفات hosts. الخطوة 2 - تهيئة الـ SSH للوصول إلى مضيفات Ansible يتصل Ansible كما ذُكر سابقًا بشكل أساسي مع أجهزة الحواسب العميلة من خلال SSH. وعلى الرغم من أن لديها بالتأكيد القدرة على التعامل مع استيثاق SSH المعتمد على كلمة المرور، إلاّ أن استخدام مفاتيح SSH يمكن أن يساعد في إبقاء الأمور بسيطة. استخدم أمر cat على خادم Ansible خاصتك لطباعة محتويات ملف مفتاح SSH العام للمستخدم الغير جذري non-root الخاص بك إلى خرْج الطرفيّة terminal: $ cat ~ / .ssh / id_rsa.pub انسخ الخرج الناتج إلى حافظتك، ثم افتح طرفيّة جديدة terminal واتصل بأحد مضيفي Ansible مُستخدمًا SSH: $ ssh sammy @ ansible_host_ip بدّل إلى المستخدم الجذري root لجهاز العميل: $ su – افتح الدليل authorized_keys ضمن المسار ~/.ssh كمستخدم جذر root : # nano ~/.ssh/authorized_keys الصق مفتاح SSH لمستخدم Ansible server في الملف، ثم احفظ الملف وأغلق المحرر (, اضغط CTRL + X, Y، ثم ENTER). ثم شغِّل الأمر exit للرجوع إلى المستخدم العادي للمضيف: # exit أخيرًا، ونظرًا لأن Ansible يستخدم مُفسّر بايثون python interpreter الموجود في المسار / usr / bin / python لتشغيل وحداته، فستحتاج إلى تثبيت Python 2 على المضيف حتى يتمكن Ansible من الاتصال به. شغّل الأوامر التالية لتحديث فهرس حزمة المضيف وتثبيت حزمة python: $ sudo apt update $sudo apt install python يمكنك بعد ذلك تشغيل أمر exit مرّةً أخرى لإغلاق الاتصال بالعميل: $ exit كرّر هذه العملية من أجل كل خادم تنوي التحكم فيه باستخدام خادم Ansible الخاص بك. بعد ذلك، سنُهيئ خادم Ansible للاتصال بالمضيفات باستخدام ملف (hosts)الخاص بـ Ansible. الخطوة 3 - إعداد مضيفات Ansible يتتبع Ansible كافة الخوادم الذي يتعرف عليها من خلال ملف المضيفات hosts. نحتاج أولًا إلى إعداد هذا الملف قبل أن نتمكن من بدء الاتصال بحواسبنا الأخرى: $ sudo nano /etc/ansible/hosts سترى ملفًا يحوي عددًا من أمثلة "نماذج" الضبط المُعقّب عليها (بإشارة # تسبق كل سطر). لن تعمل هذه الأمثلة فعليًا في حالتنا نظرًا لأن المضيفات المُدرجات في كل منها وهميّة. بكافة الأحوال سنحتفظ بهذه الأمثلة في الملف لمساعدتنا في الضبط في حال أردنا تنفيذ حالات أكثر تعقيدًا في المستقبل. إن ملف hosts مرن إلى حدّ ما ويمكن ضبطته بعدّة بطرق مختلفة. وبناءً عليه، ستبدو الصياغة التي سنستخدمها كما يلي: [group_name] alias ansible_ssh_host=your_server_ip في هذا المثال، إن group_name وسم تنظيمي يتيح لك الإشارة إلى أي خادم مدرج تحته بكلمة واحدة، بينما alias هو مجرد اسم للإشارة إلى خادم معيّن. نعتبر في حالتنا أن لدينا ثلاثة خوادم سنتحكم بهم باستخدام Ansible. يمكن عند هذه النقطة الوصول إلى هذه الخوادم من خادم Ansible بكتابة: $ ssh root@ansible_host_ip إذا أعددت هذا بشكل صحيح فلا يجب أن تُطالب بكلمة مرور. سنفترض هنا لأغراض العرض التوضيحي أن عناوين IP لمضيفاتنا هي 203.0.113.1 و 203.0.113.2 و 203.0.113.3. وسنضبط ذلك بحيث يمكننا الإشارة إليها بشكل فردي كـ host1، و host2، و host3، أو كمجموعة باسم servers. و لإتمام ذلك يتوجب إضافة هذه الكتلة إلى ملف hosts الخاص بنا: [servers] host1 ansible_ssh_host=203.0.113.1 host2 ansible_ssh_host=203.0.113.2 host3 ansible_ssh_host=203.0.113.3 يمكن أن تكون المضيفات في مجموعاتٍ متعددة، ويمكن للمجموعات ضبط المعاملات parameters من أجل جميع أعضائها. فلنجرّب هذا الآن. إن حاولنا باستخدام إعداداتنا الحاليّة الاتصال بأي من هذه الأجهزة المضيفة hosts من خلال Ansible، فسيفشل الأمر (على افتراض أنك لا تعمل كمستخدم جذر root). يحدث هذا لأنّه تم تضمين مفاتيح SSH من أجل المستخدم الجذر على الأنظمة البعيدة وسيحاول Ansible الاتصال بشكل افتراضي بواسطة المستخدم الحالي، ستعطينا محاولة الاتصال هذا الخطأ: [servers] Output host1 | UNREACHABLE! => { "changed": false, "msg": "Failed to connect to the host via ssh.", "unreachable": true } نستخدم على خادم Ansible مستخدمًا اسمه sammy. سيحاول Ansible الاتصال بكل مضيف باستخدام ssh sammy @ server. ولن يعمل هذا إذا لم يكن المستخدم sammy موجودًا على النظام البعيد أيضًا. يمكننا إنشاء ملف يخبر جميع الخوادم في مجموعة "servers " للاتصال كمستخدم جذر root. سننشئ لعمل ذلك دليلًا في بنية ضبط Ansible يدعى group_vars. ويمكننا ضمن هذا المجلد إنشاء ملفات بتنسيق YAML لكل مجموعة نريد ضبطها: $ sudo mkdir /etc/ansible/group_vars $sudo nano /etc/ansible/group_vars/servers يمكننا وضع ضبطنا هنا. تبدأ ملفات YAML بـ "---"، لذا تأكد من عدم نسيان هذا الجزء. /etc/ansible/group_vars/servers --- ansible_ssh_user: root احفظ وأغلق هذا الملف عند الانتهاء. إذا كنت تريد تحديد تفاصيل الضبط لكل خادم، بغض النظر عن المجموعة المرتبط بها، فيمكنك وضع هذه التفاصيل في ملف في المسار etc/ansible/group_vars/all/. يمكن ضبط المضيفات بشكل فردي عن طريق إنشاء ملفات مُسماة بالاسم البديل alias تحت الدليل في /etc/ansible/host_vars. الخطوة 4 - استخدام أوامر Ansible بسيطة يمكننا الآن -وبعد أن أعددنا مضيفاتنا و ضبطنا تفاصيل تهيئة كافية للسماح لنا بالاتصال بنجاح مع مضيفاتنا- تجربة الأمر الأول. عمل اختبار ping لجميع خوادمنا المُهيئة وذلك بكتابة: $ anmible -m ping all ستكون المخرجات كالتالي: host1 | SUCCESS => { "changed": false, "ping": "pong" } host3 | SUCCESS => { "changed": false, "ping": "pong" } host2 | SUCCESS => { "changed": false, "ping": "pong" } وهو اختبار بسيط للتأكّد من أنّ Ansible يتصل بجميع مضيفاته. تعني all جميع المضيفات. ويمكننا بسهولة تحديد مجموعة معيّنة كما يلي: $ ansible -m ping servers يمكننا أيضًا تحديد مضيف بشكل فردي: $ anmible -m ping host1 يمكننا تحديد عدّة مضيفات من خلال فصلها باستخدام النقطتين: $ anmible -m ping host1: host2 إنّ المقطع -m ping من الأمر عبارة عن تعليمة لـ Ansible لاستخدام الوحدة "ping". وهي في الأساس أوامر يمكنك تشغيلها على المضيفات عن بعد. تعمل وحدة ping بعدّة طرق مثل أداة ping العادية في Linux، ولكنها بدلاً من ذلك تتحقق من اتصال Ansible. لا تأخذ وحدة ping في الواقع أيّة وسائط arguments، لكن يمكننا تجربة أمر آخر لمعرفة كيفيّة عمل ذلك. نمرّر المعاملات في تدوين نصي "سكريبت" عن طريق كتابة -a. تتيح لنا الوحدة "shell" إرسال أمر طرفيّة terminal command إلى المضيف البعيد واسترداد النتائج. على سبيل المثال، يمكننا استخدام الأمر التالي لمعرفة استخدام الذاكرة على جهاز host1: $ ansible -m shell -a 'free -m' host1 ستكون مخرجات Shell كالتالي: host1 | SUCCESS | rc=0 >> total used free shared buffers cached Mem: 3954 227 3726 0 14 93 -/+ buffers/cache: 119 3834 Swap: 0 0 0 وبذلك أصبح خادم Ansible الخاص بك مُهيئًا ويمكنك الاتصال والتحكم في المضيفات بنجاح. الخلاصة ضبطنا في هذه الدورة التعليميّة Ansible وتأكّدنا من إمكانية اتصاله مع كل مضيف. واستخدمنا أيضًا الأمر ansible لتنفيذ مهام بسيطة عن بُعد. وعلى الرغم من أن هذا مفيد، إلا أنّنا لم نُغطّي أهم ميزة لـ Ansible في هذا المقال وهي الـ Playbooks. تعتبر Ansible Playbooks طريقةً قويّة وبَسيطة لإدارة عمليات تهيئة الخادم وعمليات النشر المتعدّدة الأجهزة. للحصول على تمهيد حول كتب Playbook، راجع هذا الدليل. بالإضافة إلى ذلك، فإننا نشجعك على مراجعة توثيق Ansible الرسميّة لمعرفة المزيد عن الأداة ترجمة وبتصرّف للمقال How to Install and Configure Ansible on Ubuntu 18.04 لصاحبيه Stephen Rees-Carter و Mark Drake -
 إن UFW، أو Uncomplicated Firewall (الجدار الناري غير المعقَّد)، هو واجهة للجدار الناري iptables الذي يجنح لتبسيط عملية ضبط جدار ناري؛ وعلى الرغم من أنَّ iptables هو أداةٌ قويةٌ ومرنة، لكن قد يكون من الصعب على المبتدئين أن يتعلموا استخدامه ليضبطوا جدارًا ناريًا ضبطًا سليمًا. إذا كنت تطمح إلى أن تبدأ بتأمين شبكتك، ولكنك لست متأكدًا من أيّ أداةٍ ستختار، فربما يكون UFW هو الخيار المناسب لك. سيريك هذا الدرس كيفية ضبط جدارٍ ناريٍ في أوبنتو 14.04 بوساطة UFW. المتطلبات المسبقةقبل أن تبدأ في تطبيق هذا الدرس، يجب أن تملك حسابَ مستخدمٍ ليس جذرًا لكنه يستطيع الحصول على امتيازات الجذر عبر الأمر sudo. يمكنك تعلم كيف يتم ذلك عبر تطبيق الخطوات من 1 إلى 3 على الأقل في درس الإعداد الابتدائي لخادوم أوبنتو 14.04. يكون UFW مُثبَّتًا افتراضيًا في أوبنتو؛ إذا ألغي تثبيته لسببٍ ما، فيمكنك إعادة تثبيته باستخدام الأمر: sudo apt-get install ufw استخدام IPv6 مع UFWإذا كان IPv6 مفعّلًا على خادومك، فتأكد أن UFW مضبوطٌ لدعم IPv6 كي تستطيع إدارة قواعد الجدار الناري الخاصة بعناوين IPv6 بالإضافة إلى IPv4؛ ولفعل ذلك، عدِّل ضبط UFW بمحررك النصي المفضّل؛ سنستخدم nano هنا: sudo nano /etc/default/ufw تأكد من أن قيمة «IPV6» مساويةٌ للقيمة «yes»؛ إذ يجب أن يبدو الملف كما يلي: /etc/default/ufw excerpt … IPV6=yes … احفظ واخرج، اضغط Ctrl-X للخروج من الملف، ثم Y لحفظ التعديلات التي أجريتها، ثم اضغط Enter لتأكيد اسم الملف. عندما يفعَّل UFW، فسيُضبَط لكتابة قواعد جدار ناري لعناوين IPv4 و IPv6. كُتِبَ هذا الدرس مع أخذ IPv4 بعين الاعتبار، لكنه قابل للتطبيق على IPv6 طالما كنت مفعِّلًا إياه. التحقق من حالة وقواعد UFWفي أي وقتٍ تريد، تستطيع التحقق من حالة UFW باستخدام هذا الأمر: sudo ufw status verbose افتراضيًا، يكون UFW معطّلًا لذلك سيظهر عندك شيءٌ شبيهٌ بما يلي: Status: inactive إذا كان UFW مفعّلًا، فسيخبرك الناتج ذلك، وسيُظهِر أيّة قواعد قد ضُبِطَت؛ على سبيل المثال، إذا ضُبِطَ الجدار الناري للسماح بالاتصالات من أيّ مكانٍ إلى SSH (المنفذ 22)، فسيكون الناتج شيئًا شبيهًا بما يلي: Status: active Logging: on (low) Default: deny (incoming), allow (outgoing), disabled (routed) New profiles: skip To Action From -- ------ ---- 22/tcp ALLOW IN Anywhereيمكنك استخدام الأمر status في أي وقتٍ إذا أردت أن تعرف كيف ضَبَطَ UFW الجدارَ الناري. قبل تفعيل UFW، ربما تريد أن تتأكد أن جدارك الناري مضبوطٌ للسماح لك بالاتصال عبر SSH. لنبدأ بضبط السياسات الافتراضية (default policies). ضبط السياسات الافتراضيةإذا كنت قد بدأت لتوِّك مع جدارك الناري، فإن أولى القواعد التي عليك تعريفها هي السياسات الافتراضية؛ تتحكم هذه القواعد بطريقة معالجة البيانات الشبكية التي لم تُطابَق بدقّة مع أيّة قواعد أخرى؛ افتراضيًا، UFW مضبوطٌ لمنع جميع الاتصالات الواردة والسماح لكل الاتصالات الصادرة. هذا يعني أن أي شخصٍ يحاول أن يصل إلى خادومك السحابي لن يستطيع الاتصال، بينما يستطيع أيُ تطبيقٍ على خادومك أن يصل إلى «العالم الخارجي». لنرجع الضبط الافتراضي لقواعد UFW لكي نتأكد أنك تستطيع الإكمال مع هذا الدرس؛ استخدم الأمرين الآتيين لإعادة ضبط القيم الافتراضية المُستخدَمة من UFW: sudo ufw default deny incoming sudo ufw default allow outgoing وكما توقّعتَ، يعيد الأمران السابقان ضبط UFW إلى القيم الافتراضية بمنع الاتصالات الواردة والسماح للاتصالات الصادرة؛ قد تكون هذه القيم الافتراضية كافيةً للحواسيب الشخصية لكن تحتاج الخواديم إلى الرد على الطلبيات (requests) القادمة من المستخدمين الخارجيين؛ سنلقي نظرةً على ذلك لاحقًا. السماح لاتصالات SSHإذا فعّلنا جدار UFW الآن، فسيحجب جميع الاتصالات الواردة؛ هذا يعني أننا سنحتاج إلى إنشاء قواعد تسمح (وبدقّة) للاتصالات الشرعيّة (مثل اتصالات SSH أو HTTP) إذا أردنا أن يجيب خادومنا إلى ذاك النوع من الطلبيات؛ إذا كنت تستخدم خادومًا سحابيًا، فربما تريد السماح لاتصالات SSH الواردة كي تستطيع الاتصال وإدارة خادومك عن بُعد. لضبط خادومك للسماح باتصالات SSH، فاستخدم أمر UFW الآتي: sudo ufw allow ssh ينُشِئ الأمر السابق قواعد جدار ناري تسمح لجميع الاتصالات على المنفذ 22، الذي هو المنفذ الذي يستمع إليه «عفريت» (daemon) SSH؛ يعلم UFW ما هو «ssh» (بالإضافة إلى عدد كبير من أسماء الخدمات الأخرى) ولذلك لأنه مذكورٌ كخدمةٍ تَستخدمُ المنفذ 22 في ملف /etc/services. نستطيع كتابة قاعدة مكافئة للقاعدة السابقة بتحديد المنفذ بدلًا من اسم الخدمة؛ على سبيل المثال، سيعمل هذا الأمر عمل الأمر السابق تمامًا: sudo ufw allow 22 إذا ضبطتَ عفريت SSH ليستخدم منفذًا آخر، فربما عليك تحديد المنفذ الملائم؛ على سبيل المثال، إذا كان يستمع خادم SSH إلى المنفذ 2222، فيمكنك استخدام الأمر الآتي للسماح للاتصالات على ذاك المنفذ: sudo ufw allow 2222 الآن، وبعد أن ضبطتَ جدارك الناري للسماح لاتصالات SSH القادمة، فعلينا تفعيله. تفعيل UFWاستخدم الأمر الآتي لتفعيل UFW: sudo ufw enable سيظهر لك تحذيرٌ يقول: «قد يقطع هذا الأمر اتصالات SSH الموجودة»؛ لكننا قد ضبطنا مسبقًا قاعدةً تسمح لاتصالات SSH، لذلك لا بأس من الإكمال، أجب بكتابة y. قد فعَّلتَ الجدار الناري الآن، تستطيع تنفيذ الأمر: sudo ufw status verbose لمعرفة القواعد المضبوطة. السماح لبقية الاتصالاتعليك الآن السماح لبقية الاتصالات التي يجب على خادومك الإجابة عليها؛ الاتصالات التي ستَسمح لها تتعلق باحتياجاتك. ولحسن الحظ، لقد تعلمت كيف تكتب قواعدًا تسمح للاتصالات بناءً على اسم الخدمة أو المنفذ (حيث فعلنا ذلك لخدمة SSH على المنفذ 22)؛ سنريك عدّة أمثلة لخدماتٍ شائعةٍ جدًا ربما تريد أن تسمح لها في جدارك الناري. إذا كانت لديك أيّة خدمات أخرى تريد السماح لاتصالاتها الواردة، فاتّبِع تلك الصيغة. خدمة HTTP – المنفذ 80يمكن السماح لاتصالات HTTP التي تستخدمها خوادم الويب غير المشفَّرة (unencrypted) بالأمر الآتي: sudo ufw allow http أو إذا كنت تفضِّل استخدام رقم المنفذ (80)، فنفِّذ هذا الأمر: sudo ufw allow 80 خدمة HTTPS – المنفذ 443يمكن السماح لاتصالات HTTPS التي تستخدمها خوادم الويب المشفَّرة (encrypted) بالأمر الآتي: sudo ufw allow https أو إذا كنت تفضِّل استخدام رقم المنفذ (443)، فنفِّذ هذا الأمر: sudo ufw allow 443 خدمة FTP – المنفذ 21يمكن السماح لاتصالات FTP التي تُستخدَم لنقل الملفات دون تشفير (والتي لا يجدر بك استخدامها على أيّة حال) بالأمر الآتي: sudo ufw allow ftp أو إذا كنت تفضِّل استخدام رقم المنفذ (21)، فنفِّذ هذا الأمر: sudo ufw allow 21/tcp السماح لمجالات منافذ معيّنةيمكنك تحديد مجالات منافذ عبر UFW؛ حيث تَستخدِم بعض التطبيقات عدِّة منافذ، بدلًا من منفذٍ واحد. على سبيل المثال، للسماح لاتصالات X11، التي تستخدم المنافذ 6000-6007، فاستخدم هذين الأمرين: sudo ufw allow 6000:6007/tcp sudo ufw allow 6000:6007/udp عند تحديد مجالات للمنافذ مع UFW، فيجب عليك تحديد البروتوكول (tcp أو udp) الذي تُطبَّق عليه القاعدة؛ لم نذكر ذلك من قبل لأنه عدم تحديد البروتوكول يسمح ببساطة بالاتصالات لكلي البروتوكولَين، وهذا مقبولٌ في أغلبية الحالات. السماح لعناوين IP محددةعند العمل مع UFW، تستطيع تحديد عناوين IP؛ على سبيل المثال، إذا أردت السماح للاتصالات من عنوان IP محدد، مثل عنوان IP للعمل أو المنزل الذي هو 15.15.15.51، فعليك استخدام الكلمة «from» ثم عنوان IP: sudo ufw allow from 15.15.15.51 تستطيع تحديد منفذ معيّن يُسمَح لعنوان IP بالاتصال إليه عبر كتابة «to any port» متبوعةً برقم المنفذ؛ على سبيل المثال، إذا أردت السماح لعنوان 15.15.15.51 بالاتصال إلى المنفذ 22 (SSH)، فاستخدم هذا الأمر: sudo ufw allow from 15.15.15.51 to any port 22 السماح للشبكات الفرعيةإذا أردت السماح لشبكة فرعية من عناوين IP، فيمكنك استخدام «ترميز CIDR» (CIDR notation) لتحديد شبكة فرعية؛ فعلى سبيل المثال، إذا أردت السماح لجميع عناوين IP التي تتراوح بين 15.15.15.1 إلى 15.15.15.254 فيمكنك استخدام هذا الأمر: sudo ufw allow from 15.15.15.0/24وبشكلٍ مشابه، تستطيع أيضًا تحديد منفذ يُسمَح للشبكة الفرعية 15.15.15.0/24 بالاتصال إليه؛ سنستخدم أيضًا المنفذ 22 (SSH) كمثال: sudo ufw allow from 15.15.15.0/24 to any port 22 السماح بالاتصالات إلى بطاقة شبكية محددةإذا أردت إنشاء قاعدة جدار ناري تُطبَّق فقط على بطاقةٍ شبكيّةٍ محددة، فيمكنك فعل ذلك عبر كتابة «allow in on» متبوعةً باسم البطاقة الشبكيّة. ربما تريد أن تبحث عن بطاقاتك الشبكيّة قبل الإكمال؛ استخدم هذا الأمر لفعل ذلك: ip addr الناتج: … 2: eth0: حجب الاتصالاتإذا لم تعدِّل السياسة الافتراضية للاتصالات الواردة، فإن UFW مضبوطٌ ليحجب كل الاتصالات الواردة؛ عمومًا، هذا يُبسِّط عملية إنشاء سياسة جدار ناري آمنة وذلك بتطلّب إنشاء قواعد تحدد بدقة المنافذ وعناوين IP التي يسمح لها «بالعبور»؛ لكن في بعض الأحيان، تريد أن تحجب اتصالاتٍ معينة بناءً على عنوان IP المصدري أو الشبكة الفرعية، ربما لأنك تعلم أن خادومك يتعرض للهجوم من هناك. وأيضًا لو حوّلت سياسة التعامل الافتراضية مع الاتصالات الواردة إلى «السماح» (والذي ليس مستحسنًا لصالح الأمان)، فعليك إنشاء قيود «حجب» لأي خدمة أو عناوين IP لا تريد السماح بمرور الاتصالات إليها. يمكنك استخدام الأوامر المشروحة آنفًا لكتابة قيود الحجب، لكن مع استبدال «deny» بالكلمة «allow». على سبيل المثال، لحجب اتصالات HTTP، فعليك استخدام الأمر: sudo ufw deny http أو إذا أردت حجب جميع الاتصالات من 15.15.15.51 فيمكنك استخدام هذا الأمر: sudo ufw deny from 15.15.15.51 إذا أردت مساعدةً في كتابة قواعد الحجب، فانظر إلى قواعد السماح السابقة وعدِّلها بما يلائمها. لنلقِ الآن نظرةً على طريقة حذف القواعد. حذف القواعدمعرفة كيفية حذف قواعد الجدار الناري بنفس أهمية معرفة كيفية إنشائها؛ هنالك طريقتان لتحديد أيّة قواعد لتحذف: عبر رقم القاعدة أو عبر القاعدة نفسها (بشكلٍ شبيه لطريقة تحديد القاعدة عندما أُنشِئت). سنبدأ بطريقة الحذف عبر رقم القاعدة لأنها أسهل، مقارنةً بكتابة القواعد نفسها، خصوصًا إن كنتَ حديث العهد بالتعامل مع UFW. عبر رقم القاعدةإذا كنت تستخدم رقم القاعدة لحذف قواعد الجدار الناري، فإن أول شيء تريد فعله هو الحصول على قائمة بقواعد جدارك الناري؛ يملك أمر UFW status خيارًا لعرض الأرقام بجوار قواعدها، كما هو مبيّن هنا: sudo ufw status numbered الناتج: Status: active To Action From -- ------ ---- [ 1] 22 ALLOW IN 15.15.15.0/24 [ 2] 80 ALLOW IN Anywhereإذا قررت أنك تريد حذف القاعدة 2، التي تسمح بالاتصالات إلى المنفذ 80 (HTTP)، فيمكنك ذلك عبر تمرير رقمها إلى أمر UFW delete كما يلي: sudo ufw delete 2 ما سبق سيُظهِر محثًا (prompt) ليطلب موافقتك، ثم سيحذف القاعدة 2 التي تسمح باتصالات HTTP. الحظ أنك إن كنت قد فعَّلت IPv6، فعليك أن تحذف قاعدة IPv6 المناظرة لها. عبر القاعدة نفسهاالبديل عن تحديد رقم القاعدة هو تحديد القاعدة نفسها؛ على سبيل المثال، إذا أردت حذف قاعدة «allow http»، فيمكنك كتابة الأمر كما يلي: sudo ufw delete allow http يمكنك أيضًا تحديد القاعدة مستعملًا «allow 80»، بدلًا من اسم الخدمة: sudo ufw delete allow 80 ستَحذُف هذه الطريقة قواعد IPv4 و IPv6 إن كانت موجودةً. كيفية تعطيل UFW (خطوة اختيارية)إذا قررت أنّك لا تريد استعمال UFW لأي سببٍ كان، فيمكنك تعطيله عبر هذا الأمر: sudo ufw disable ستُعطَّل أيّة قواعد أنشَأتها باستخدام UFW، يمكنك بأي وقتٍ تنفيذ: sudo ufw enable إذا احتجت لتفعيله لاحقًا. إعادة ضبط قواعد UFW (خطوة اختيارية)إذا كانت لديك قواعد UFW مضبوطة، لكنك قررت أن تبدأ من الصفر، فيمكنك استخدام الأمر reset: sudo ufw reset سيُعطِِّل الأمر السابق UFW ويحذف أيّة قواعد عرَّفتَها سابقًا. أبقِ في بالك أن السياسات الافتراضية لن يُعاد ضبطها إلى إعداداتها الافتراضية إذا كنت قد عدَّلتها. الخلاصةيجب أن يكون قد ضُبِطَ جدارك الناري للسماح (على الأقل) لاتصالات SSH؛ تأكد أن تسمح لأيّة اتصالات واردة أخرى لخادومك بينما تقيّد أيّة اتصالات غير ضرورية، كي يكون خادومك آمنًا ويعمل عملًا صحيحًا. ترجمة -وبتصرّف- للمقال How To Set Up a Firewall with UFW on Ubuntu 14.04 لصاحبه Mitchell Anicas.
إن UFW، أو Uncomplicated Firewall (الجدار الناري غير المعقَّد)، هو واجهة للجدار الناري iptables الذي يجنح لتبسيط عملية ضبط جدار ناري؛ وعلى الرغم من أنَّ iptables هو أداةٌ قويةٌ ومرنة، لكن قد يكون من الصعب على المبتدئين أن يتعلموا استخدامه ليضبطوا جدارًا ناريًا ضبطًا سليمًا. إذا كنت تطمح إلى أن تبدأ بتأمين شبكتك، ولكنك لست متأكدًا من أيّ أداةٍ ستختار، فربما يكون UFW هو الخيار المناسب لك. سيريك هذا الدرس كيفية ضبط جدارٍ ناريٍ في أوبنتو 14.04 بوساطة UFW. المتطلبات المسبقةقبل أن تبدأ في تطبيق هذا الدرس، يجب أن تملك حسابَ مستخدمٍ ليس جذرًا لكنه يستطيع الحصول على امتيازات الجذر عبر الأمر sudo. يمكنك تعلم كيف يتم ذلك عبر تطبيق الخطوات من 1 إلى 3 على الأقل في درس الإعداد الابتدائي لخادوم أوبنتو 14.04. يكون UFW مُثبَّتًا افتراضيًا في أوبنتو؛ إذا ألغي تثبيته لسببٍ ما، فيمكنك إعادة تثبيته باستخدام الأمر: sudo apt-get install ufw استخدام IPv6 مع UFWإذا كان IPv6 مفعّلًا على خادومك، فتأكد أن UFW مضبوطٌ لدعم IPv6 كي تستطيع إدارة قواعد الجدار الناري الخاصة بعناوين IPv6 بالإضافة إلى IPv4؛ ولفعل ذلك، عدِّل ضبط UFW بمحررك النصي المفضّل؛ سنستخدم nano هنا: sudo nano /etc/default/ufw تأكد من أن قيمة «IPV6» مساويةٌ للقيمة «yes»؛ إذ يجب أن يبدو الملف كما يلي: /etc/default/ufw excerpt … IPV6=yes … احفظ واخرج، اضغط Ctrl-X للخروج من الملف، ثم Y لحفظ التعديلات التي أجريتها، ثم اضغط Enter لتأكيد اسم الملف. عندما يفعَّل UFW، فسيُضبَط لكتابة قواعد جدار ناري لعناوين IPv4 و IPv6. كُتِبَ هذا الدرس مع أخذ IPv4 بعين الاعتبار، لكنه قابل للتطبيق على IPv6 طالما كنت مفعِّلًا إياه. التحقق من حالة وقواعد UFWفي أي وقتٍ تريد، تستطيع التحقق من حالة UFW باستخدام هذا الأمر: sudo ufw status verbose افتراضيًا، يكون UFW معطّلًا لذلك سيظهر عندك شيءٌ شبيهٌ بما يلي: Status: inactive إذا كان UFW مفعّلًا، فسيخبرك الناتج ذلك، وسيُظهِر أيّة قواعد قد ضُبِطَت؛ على سبيل المثال، إذا ضُبِطَ الجدار الناري للسماح بالاتصالات من أيّ مكانٍ إلى SSH (المنفذ 22)، فسيكون الناتج شيئًا شبيهًا بما يلي: Status: active Logging: on (low) Default: deny (incoming), allow (outgoing), disabled (routed) New profiles: skip To Action From -- ------ ---- 22/tcp ALLOW IN Anywhereيمكنك استخدام الأمر status في أي وقتٍ إذا أردت أن تعرف كيف ضَبَطَ UFW الجدارَ الناري. قبل تفعيل UFW، ربما تريد أن تتأكد أن جدارك الناري مضبوطٌ للسماح لك بالاتصال عبر SSH. لنبدأ بضبط السياسات الافتراضية (default policies). ضبط السياسات الافتراضيةإذا كنت قد بدأت لتوِّك مع جدارك الناري، فإن أولى القواعد التي عليك تعريفها هي السياسات الافتراضية؛ تتحكم هذه القواعد بطريقة معالجة البيانات الشبكية التي لم تُطابَق بدقّة مع أيّة قواعد أخرى؛ افتراضيًا، UFW مضبوطٌ لمنع جميع الاتصالات الواردة والسماح لكل الاتصالات الصادرة. هذا يعني أن أي شخصٍ يحاول أن يصل إلى خادومك السحابي لن يستطيع الاتصال، بينما يستطيع أيُ تطبيقٍ على خادومك أن يصل إلى «العالم الخارجي». لنرجع الضبط الافتراضي لقواعد UFW لكي نتأكد أنك تستطيع الإكمال مع هذا الدرس؛ استخدم الأمرين الآتيين لإعادة ضبط القيم الافتراضية المُستخدَمة من UFW: sudo ufw default deny incoming sudo ufw default allow outgoing وكما توقّعتَ، يعيد الأمران السابقان ضبط UFW إلى القيم الافتراضية بمنع الاتصالات الواردة والسماح للاتصالات الصادرة؛ قد تكون هذه القيم الافتراضية كافيةً للحواسيب الشخصية لكن تحتاج الخواديم إلى الرد على الطلبيات (requests) القادمة من المستخدمين الخارجيين؛ سنلقي نظرةً على ذلك لاحقًا. السماح لاتصالات SSHإذا فعّلنا جدار UFW الآن، فسيحجب جميع الاتصالات الواردة؛ هذا يعني أننا سنحتاج إلى إنشاء قواعد تسمح (وبدقّة) للاتصالات الشرعيّة (مثل اتصالات SSH أو HTTP) إذا أردنا أن يجيب خادومنا إلى ذاك النوع من الطلبيات؛ إذا كنت تستخدم خادومًا سحابيًا، فربما تريد السماح لاتصالات SSH الواردة كي تستطيع الاتصال وإدارة خادومك عن بُعد. لضبط خادومك للسماح باتصالات SSH، فاستخدم أمر UFW الآتي: sudo ufw allow ssh ينُشِئ الأمر السابق قواعد جدار ناري تسمح لجميع الاتصالات على المنفذ 22، الذي هو المنفذ الذي يستمع إليه «عفريت» (daemon) SSH؛ يعلم UFW ما هو «ssh» (بالإضافة إلى عدد كبير من أسماء الخدمات الأخرى) ولذلك لأنه مذكورٌ كخدمةٍ تَستخدمُ المنفذ 22 في ملف /etc/services. نستطيع كتابة قاعدة مكافئة للقاعدة السابقة بتحديد المنفذ بدلًا من اسم الخدمة؛ على سبيل المثال، سيعمل هذا الأمر عمل الأمر السابق تمامًا: sudo ufw allow 22 إذا ضبطتَ عفريت SSH ليستخدم منفذًا آخر، فربما عليك تحديد المنفذ الملائم؛ على سبيل المثال، إذا كان يستمع خادم SSH إلى المنفذ 2222، فيمكنك استخدام الأمر الآتي للسماح للاتصالات على ذاك المنفذ: sudo ufw allow 2222 الآن، وبعد أن ضبطتَ جدارك الناري للسماح لاتصالات SSH القادمة، فعلينا تفعيله. تفعيل UFWاستخدم الأمر الآتي لتفعيل UFW: sudo ufw enable سيظهر لك تحذيرٌ يقول: «قد يقطع هذا الأمر اتصالات SSH الموجودة»؛ لكننا قد ضبطنا مسبقًا قاعدةً تسمح لاتصالات SSH، لذلك لا بأس من الإكمال، أجب بكتابة y. قد فعَّلتَ الجدار الناري الآن، تستطيع تنفيذ الأمر: sudo ufw status verbose لمعرفة القواعد المضبوطة. السماح لبقية الاتصالاتعليك الآن السماح لبقية الاتصالات التي يجب على خادومك الإجابة عليها؛ الاتصالات التي ستَسمح لها تتعلق باحتياجاتك. ولحسن الحظ، لقد تعلمت كيف تكتب قواعدًا تسمح للاتصالات بناءً على اسم الخدمة أو المنفذ (حيث فعلنا ذلك لخدمة SSH على المنفذ 22)؛ سنريك عدّة أمثلة لخدماتٍ شائعةٍ جدًا ربما تريد أن تسمح لها في جدارك الناري. إذا كانت لديك أيّة خدمات أخرى تريد السماح لاتصالاتها الواردة، فاتّبِع تلك الصيغة. خدمة HTTP – المنفذ 80يمكن السماح لاتصالات HTTP التي تستخدمها خوادم الويب غير المشفَّرة (unencrypted) بالأمر الآتي: sudo ufw allow http أو إذا كنت تفضِّل استخدام رقم المنفذ (80)، فنفِّذ هذا الأمر: sudo ufw allow 80 خدمة HTTPS – المنفذ 443يمكن السماح لاتصالات HTTPS التي تستخدمها خوادم الويب المشفَّرة (encrypted) بالأمر الآتي: sudo ufw allow https أو إذا كنت تفضِّل استخدام رقم المنفذ (443)، فنفِّذ هذا الأمر: sudo ufw allow 443 خدمة FTP – المنفذ 21يمكن السماح لاتصالات FTP التي تُستخدَم لنقل الملفات دون تشفير (والتي لا يجدر بك استخدامها على أيّة حال) بالأمر الآتي: sudo ufw allow ftp أو إذا كنت تفضِّل استخدام رقم المنفذ (21)، فنفِّذ هذا الأمر: sudo ufw allow 21/tcp السماح لمجالات منافذ معيّنةيمكنك تحديد مجالات منافذ عبر UFW؛ حيث تَستخدِم بعض التطبيقات عدِّة منافذ، بدلًا من منفذٍ واحد. على سبيل المثال، للسماح لاتصالات X11، التي تستخدم المنافذ 6000-6007، فاستخدم هذين الأمرين: sudo ufw allow 6000:6007/tcp sudo ufw allow 6000:6007/udp عند تحديد مجالات للمنافذ مع UFW، فيجب عليك تحديد البروتوكول (tcp أو udp) الذي تُطبَّق عليه القاعدة؛ لم نذكر ذلك من قبل لأنه عدم تحديد البروتوكول يسمح ببساطة بالاتصالات لكلي البروتوكولَين، وهذا مقبولٌ في أغلبية الحالات. السماح لعناوين IP محددةعند العمل مع UFW، تستطيع تحديد عناوين IP؛ على سبيل المثال، إذا أردت السماح للاتصالات من عنوان IP محدد، مثل عنوان IP للعمل أو المنزل الذي هو 15.15.15.51، فعليك استخدام الكلمة «from» ثم عنوان IP: sudo ufw allow from 15.15.15.51 تستطيع تحديد منفذ معيّن يُسمَح لعنوان IP بالاتصال إليه عبر كتابة «to any port» متبوعةً برقم المنفذ؛ على سبيل المثال، إذا أردت السماح لعنوان 15.15.15.51 بالاتصال إلى المنفذ 22 (SSH)، فاستخدم هذا الأمر: sudo ufw allow from 15.15.15.51 to any port 22 السماح للشبكات الفرعيةإذا أردت السماح لشبكة فرعية من عناوين IP، فيمكنك استخدام «ترميز CIDR» (CIDR notation) لتحديد شبكة فرعية؛ فعلى سبيل المثال، إذا أردت السماح لجميع عناوين IP التي تتراوح بين 15.15.15.1 إلى 15.15.15.254 فيمكنك استخدام هذا الأمر: sudo ufw allow from 15.15.15.0/24وبشكلٍ مشابه، تستطيع أيضًا تحديد منفذ يُسمَح للشبكة الفرعية 15.15.15.0/24 بالاتصال إليه؛ سنستخدم أيضًا المنفذ 22 (SSH) كمثال: sudo ufw allow from 15.15.15.0/24 to any port 22 السماح بالاتصالات إلى بطاقة شبكية محددةإذا أردت إنشاء قاعدة جدار ناري تُطبَّق فقط على بطاقةٍ شبكيّةٍ محددة، فيمكنك فعل ذلك عبر كتابة «allow in on» متبوعةً باسم البطاقة الشبكيّة. ربما تريد أن تبحث عن بطاقاتك الشبكيّة قبل الإكمال؛ استخدم هذا الأمر لفعل ذلك: ip addr الناتج: … 2: eth0: حجب الاتصالاتإذا لم تعدِّل السياسة الافتراضية للاتصالات الواردة، فإن UFW مضبوطٌ ليحجب كل الاتصالات الواردة؛ عمومًا، هذا يُبسِّط عملية إنشاء سياسة جدار ناري آمنة وذلك بتطلّب إنشاء قواعد تحدد بدقة المنافذ وعناوين IP التي يسمح لها «بالعبور»؛ لكن في بعض الأحيان، تريد أن تحجب اتصالاتٍ معينة بناءً على عنوان IP المصدري أو الشبكة الفرعية، ربما لأنك تعلم أن خادومك يتعرض للهجوم من هناك. وأيضًا لو حوّلت سياسة التعامل الافتراضية مع الاتصالات الواردة إلى «السماح» (والذي ليس مستحسنًا لصالح الأمان)، فعليك إنشاء قيود «حجب» لأي خدمة أو عناوين IP لا تريد السماح بمرور الاتصالات إليها. يمكنك استخدام الأوامر المشروحة آنفًا لكتابة قيود الحجب، لكن مع استبدال «deny» بالكلمة «allow». على سبيل المثال، لحجب اتصالات HTTP، فعليك استخدام الأمر: sudo ufw deny http أو إذا أردت حجب جميع الاتصالات من 15.15.15.51 فيمكنك استخدام هذا الأمر: sudo ufw deny from 15.15.15.51 إذا أردت مساعدةً في كتابة قواعد الحجب، فانظر إلى قواعد السماح السابقة وعدِّلها بما يلائمها. لنلقِ الآن نظرةً على طريقة حذف القواعد. حذف القواعدمعرفة كيفية حذف قواعد الجدار الناري بنفس أهمية معرفة كيفية إنشائها؛ هنالك طريقتان لتحديد أيّة قواعد لتحذف: عبر رقم القاعدة أو عبر القاعدة نفسها (بشكلٍ شبيه لطريقة تحديد القاعدة عندما أُنشِئت). سنبدأ بطريقة الحذف عبر رقم القاعدة لأنها أسهل، مقارنةً بكتابة القواعد نفسها، خصوصًا إن كنتَ حديث العهد بالتعامل مع UFW. عبر رقم القاعدةإذا كنت تستخدم رقم القاعدة لحذف قواعد الجدار الناري، فإن أول شيء تريد فعله هو الحصول على قائمة بقواعد جدارك الناري؛ يملك أمر UFW status خيارًا لعرض الأرقام بجوار قواعدها، كما هو مبيّن هنا: sudo ufw status numbered الناتج: Status: active To Action From -- ------ ---- [ 1] 22 ALLOW IN 15.15.15.0/24 [ 2] 80 ALLOW IN Anywhereإذا قررت أنك تريد حذف القاعدة 2، التي تسمح بالاتصالات إلى المنفذ 80 (HTTP)، فيمكنك ذلك عبر تمرير رقمها إلى أمر UFW delete كما يلي: sudo ufw delete 2 ما سبق سيُظهِر محثًا (prompt) ليطلب موافقتك، ثم سيحذف القاعدة 2 التي تسمح باتصالات HTTP. الحظ أنك إن كنت قد فعَّلت IPv6، فعليك أن تحذف قاعدة IPv6 المناظرة لها. عبر القاعدة نفسهاالبديل عن تحديد رقم القاعدة هو تحديد القاعدة نفسها؛ على سبيل المثال، إذا أردت حذف قاعدة «allow http»، فيمكنك كتابة الأمر كما يلي: sudo ufw delete allow http يمكنك أيضًا تحديد القاعدة مستعملًا «allow 80»، بدلًا من اسم الخدمة: sudo ufw delete allow 80 ستَحذُف هذه الطريقة قواعد IPv4 و IPv6 إن كانت موجودةً. كيفية تعطيل UFW (خطوة اختيارية)إذا قررت أنّك لا تريد استعمال UFW لأي سببٍ كان، فيمكنك تعطيله عبر هذا الأمر: sudo ufw disable ستُعطَّل أيّة قواعد أنشَأتها باستخدام UFW، يمكنك بأي وقتٍ تنفيذ: sudo ufw enable إذا احتجت لتفعيله لاحقًا. إعادة ضبط قواعد UFW (خطوة اختيارية)إذا كانت لديك قواعد UFW مضبوطة، لكنك قررت أن تبدأ من الصفر، فيمكنك استخدام الأمر reset: sudo ufw reset سيُعطِِّل الأمر السابق UFW ويحذف أيّة قواعد عرَّفتَها سابقًا. أبقِ في بالك أن السياسات الافتراضية لن يُعاد ضبطها إلى إعداداتها الافتراضية إذا كنت قد عدَّلتها. الخلاصةيجب أن يكون قد ضُبِطَ جدارك الناري للسماح (على الأقل) لاتصالات SSH؛ تأكد أن تسمح لأيّة اتصالات واردة أخرى لخادومك بينما تقيّد أيّة اتصالات غير ضرورية، كي يكون خادومك آمنًا ويعمل عملًا صحيحًا. ترجمة -وبتصرّف- للمقال How To Set Up a Firewall with UFW on Ubuntu 14.04 لصاحبه Mitchell Anicas. -
.png.d93d3a4a1230d3805e04118b5e89c9cb.png) نتابع عملنا في هذه السلسلة بتنصيب ماجنتو على نظام التشغيل Ubuntu 16.04.1 LTS. لقد اخترت طريقة سهلة وعمليّة لتنصيب ماجنتو واستثماره. يعتمد ماجنتو في عمله على وجود خادوم الويب Apache بالإضافة إلى لغة PHP وقواعد بيانات MySQL. سنستخدم الإصدار الأخير من ماجنتو وهو 2.1. يحتاج هذا الإصدار إلى الإصدارات التالية من البرمجيّات السابقة: Apache 2.2 أو Apache 2.4. MySQL 5.6 PHP 5.6.x حيث من الممكن أن يكون x أي رقم. لا يُعتبر تجهيز البرمجيات السابقة بالشكل الملائم أمرا يسيرا في الواقع. لذلك فقد آثرت استخدام توزيعة اسمها XAMPP، وهي توزيعة مشهورة تسمح بتنصيب البرمجيّات السابقة (وأكثر) دفعةً واحدةً. تأتي توزيعة XAMPP من مجموعة تُدعى Apache Friends. المثير في الأمر أنّ هذه المجموعة تتعاون مع شركة اسمها Bitnami وهي شركة متخصّصة بالحوسبة السحابيّة، حيث توفّر هذه الشركة العديد من التطبيقات المهمّة التي تعمل بشكل سلس على توزيعة XAMPP. من بين هذه التطبيقات هو تطبيق ماجنتو Magento. يمكننا بإجراءات بسيطة للغاية تجهيز ماجنتو وتشغليه على XAMPP. سنبدأ بتحميل وتنصيب توزيعة XAMPP وما تحويه من برمجيّات ضروريّة لعمل ماجنتو، ثمّ سنعمل على تحميل وتنصيب تطبيق ماجنتو. يفترض هذا الدرس أنّه لديك خبرة أساسيّة بطريقة التعامل مع أنظمة تشغيل Linux بشكل عام، مثل استخدام الطرفية Terminal والوصول عن طريقها إلى المجلّدات المختلفة، وتنفيذ الأوامر. تحميل وتنصيب توزيعة XAMPP انتقل إلى الحاسوب الذي يشغّلUbuntu . ثم استخدم المتصفّح للانتقال إلى موقع التحميل الخاص بتوزيعة XAMPP. استخدم شريط التمرير لتصل إلى القسم الخاص بلينوكس كما في الشكل التالي: حمّل النسخة التي تتضمّن PHP 5.6.23 (في الوسط) مع معمارية 64 بت. عند الانتهاء من تحميل الملف، انتقل إلى الطرفية Terminal ومنها إلى المكان الذي حمّلت إليه الملف السابق. بالنسبة إليّ كان الملف يحمل الاسم التالي وهو موجود ضمن المجلّد Documents: xampp-linux-x64-5.6.23-0-installer.run نفّذ الأمرين التاليين: sudo chmod 755 xampp-linux-x64-5.6.23-0-installer.run sudo ./xampp-linux-x64-5.6.23-0-installer.run كما يظهر في الشكل التالي: لاحظ أنّ الطرفية تطلب إدخال كلمة المرور الخاصة بالمستخدم الحالي بعد تنفيذ الأمر الأوّل مباشرةً، وذلك بسبب استخدام الأمر sudo. بعد تنفيذ الأمر الثاني سيبدأ برنامج الإعداد الخاص بالتوزيعة XAMPP بالعمل، حيث سيُظهر رسالة ترحيبيّة كما في الشكل التالي: انقر الزر Next للمتابعة لتصل إلى النافذة الخاصة بالمكوّنات الأساسيّة التي سيتم تنصيبها كما يلي: تأكّد من صناديق الاختيار، ثم انقر الزر Next. ستخبرك النافذة التالية عن المكان الذي سيتم فيه حفظ الملفات وهو /opt/lampp انقر زر Next لتحصل على نافذة دعائيّة للخدمات التي من الممكن أن تحصل عليها مع Bitnami. تابع نقر Next حتى تبدأ عملية التنصيب. ستأخذ عملية التنصيب قليلًا من الوقت، وبعد أن تنتهي، ستحصل على نافذة شبيهة بما يلي: احرص على اختيار تشغيل XAMPP من تحديد صندوق الاختيار إن لم يكن كذلك، ثم انقر الزر Finish ليعمل تطبيق الإدارة الخاص بـ XAMPP كما يظهر من الشكل التالي: انقر لسان التبويب Manage Servers من الأعلى لتحصل على شكل شبيه بما يلي: نلاحظ من الشكل السابق أنّ كل من الخادومين MySQL Database و Apache Web Server هما حاليًا في طور التشغيل Running. إن لم يكونا كذلك، فيمكنك تحديد كل منهما على حدة ونقر زر Start الذي يظهر في الجهة اليمنى من الشكل السابق. للتأكّد من نجاح عمليّة التنصيب السابقة، افتح متصفّح الانترنت لديك، ثم اكتب ضمن شريط العنوان ما يلي: http://ubuntu ثم اضغط الزر Enter، يجب أن تحصل على شكل شبيه بالشكل التالي: نكون عند هذه النقطة قد انتهينا من تنصيب XAMPP وبتنا مستعدّين لتنصيب ماجنتو. تحميل وتنصيب ماجنتو انتقل بمتصفّح الويب إلى العنوان التالي https://bitnami.com/stack/xampp لعرض التطبيقات التي توفرها Bitnami لتوزيعة XAMPP. ثم استخدام شريط التمرير حتى تصل إلى ماجنتو Magento كما في الشكل التالي: انقر زر Download الخاص بنظام التشغيل لينكس مع معمارية 64 بت كما في الشكل السابق لتبدأ عملية التحميل. بعد الانتهاء من التحميل، انتقل باستخدام الطرفية Terminal إلى المجلّد الذي يحوي الملف المُحمَّل. بالنسبة إليّ كان الملف يحمل الاسم التالي وهو موجود ضمن المجلّد Documents: bitnami-magento-2.1.0-2-module-linux-x64-installer.run نفّذ الأمرين التاليين ضمن الطرفية: sudo chmod 755 bitnami-magento-2.1.0-2-module-linux-x64-installer.run sudo ./bitnami-magento-2.1.0-2-module-linux-x64-installer.run كما في الشكل التالي: لاحظ من الشكل السابق أنّ الطرفية قد طلبت كلمة المرور للمستخدم الحالي، كما هو الحال عند تنصيب XAMPP وذلك لأنّني أعدت تشغيل الطرفية من جديد. بمجرّد تنفيذ الأمر الثاني سيبدأ عمل برنامج التنصيب الخاص بماجنتو، حيث ستظهر لك رسالة ترحيبيّة من برنامج الإعداد كما يلي: انقر Next ليعرض لك برنامج الإعداد نافذة تفيد بالمكوّنات المراد تنصيبها. يوجد مكوّن واحد هو ماجنتو Magento يجب أن يكون في حالة اختيار. انقر Next لتصل إلى النافذة التي تحدّد المسار الذي سيتم فيه نسخ الملفات. يجب أن يكون هذا المسار هو /opt/lampp انقر زر Next مرّة أخرى لتصل إلى النافذة التالية: ستطلب هذه النافذة بعض المعلومات الشخصيّة مثل الاسم المرغوب لتسجيل الدخول على ماجنتو (Login) والاسم الحقيقي والبريد الإلكتروني. كما ستطلب منك تعيين كلمة المرور الخاصة بتطبيق ماجنتو. بعد أن تنتهي من كتابة البيانات المطلوبة انقر Next لتصل إلى النافذة التالية: تطلب منك النافذة السابقة تحديد عنوان المضيف لإنشاء الروابط الداخلية. وهنا ينبغي أن تكتب العنوان الخاص بموقعك. في حالتنا هذه، استخدمت العنوان المحلّي 127.0.1.1 فحسب. يمكن بالتأكيد تغيير هذا العنوان فيما بعد. انقر الآن الزر Next لتصل إلى النافذة الخاصة بإعدادات خادوم البريد الصادر SMTP الذي سيستخدمه ماجنتو لإرسال رسائل البريد الإلكتروني. انظر الشكل التالي: لاحظ أنّني قد اخترت مزوّد خدمة GMail للبريد الصادر SMTP. أدخل البريد الإلكتروني الذي ترغب استخدامه مع هذه الخدمة، ثم زوّد برنامج الإعداد بكلمة المرور لهذا الحساب. انقر Next لتصل إلى نافذة تعرض عليك نشر deploy نسخة ماجنتو هذه إلى الخدمة السحابية الخاصة بشركة Bitnami كما في الشكل التالي: أزل الاختيار من الصندوق ثم انقر زر Next. سيعرض برنامج الإعداد رسالة تفيد بأنّه جاهز لبدء عمليّة التنصيب. انقر Next للبدء. سيستغرق الأمر بعض الوقت، وبعد الانتهاء سيعرض برنامج الإعداد رسالة تفيد بانتهاء عمليّة التنصيب ويعرض عليك تشغيل ماجنتو فورًا. كما في الشكل التالي: انقر على زر Finish لتختفي هذه النافذة وتظهر نافذة متصفّح الويب وقد انتقلت لتعرض الصفحة الرئيسيّة لمتجر ماجنتو: نكون بذلك قد انتهينا من تنصيب ماجنتو وبات جاهزًا للعمل. الخلاصة تعلّمنا في هذا الدرس كيفيّة تنصيب تطبيق ماجنتو بشكل عمليّ وسهل. حيث مررنا بخطوتين رئيسيتين. الأولى هي تنصيب توزيعة XAMPP التي تتضمن خادوم الويب Apache وخادوم قاعدة البيانات MySQL. أمّا الخطوة الثانية فكانت تنصيب ماجنتو من خلال برنامج إعداد مخصّص من Bitnami لكي ينصّب ماجنتو بوجود التوزيعة XAMPP. سنتابع عملنا في الدرس القادم في إلقاء نظرة على المنتجات في ماجنتو.
نتابع عملنا في هذه السلسلة بتنصيب ماجنتو على نظام التشغيل Ubuntu 16.04.1 LTS. لقد اخترت طريقة سهلة وعمليّة لتنصيب ماجنتو واستثماره. يعتمد ماجنتو في عمله على وجود خادوم الويب Apache بالإضافة إلى لغة PHP وقواعد بيانات MySQL. سنستخدم الإصدار الأخير من ماجنتو وهو 2.1. يحتاج هذا الإصدار إلى الإصدارات التالية من البرمجيّات السابقة: Apache 2.2 أو Apache 2.4. MySQL 5.6 PHP 5.6.x حيث من الممكن أن يكون x أي رقم. لا يُعتبر تجهيز البرمجيات السابقة بالشكل الملائم أمرا يسيرا في الواقع. لذلك فقد آثرت استخدام توزيعة اسمها XAMPP، وهي توزيعة مشهورة تسمح بتنصيب البرمجيّات السابقة (وأكثر) دفعةً واحدةً. تأتي توزيعة XAMPP من مجموعة تُدعى Apache Friends. المثير في الأمر أنّ هذه المجموعة تتعاون مع شركة اسمها Bitnami وهي شركة متخصّصة بالحوسبة السحابيّة، حيث توفّر هذه الشركة العديد من التطبيقات المهمّة التي تعمل بشكل سلس على توزيعة XAMPP. من بين هذه التطبيقات هو تطبيق ماجنتو Magento. يمكننا بإجراءات بسيطة للغاية تجهيز ماجنتو وتشغليه على XAMPP. سنبدأ بتحميل وتنصيب توزيعة XAMPP وما تحويه من برمجيّات ضروريّة لعمل ماجنتو، ثمّ سنعمل على تحميل وتنصيب تطبيق ماجنتو. يفترض هذا الدرس أنّه لديك خبرة أساسيّة بطريقة التعامل مع أنظمة تشغيل Linux بشكل عام، مثل استخدام الطرفية Terminal والوصول عن طريقها إلى المجلّدات المختلفة، وتنفيذ الأوامر. تحميل وتنصيب توزيعة XAMPP انتقل إلى الحاسوب الذي يشغّلUbuntu . ثم استخدم المتصفّح للانتقال إلى موقع التحميل الخاص بتوزيعة XAMPP. استخدم شريط التمرير لتصل إلى القسم الخاص بلينوكس كما في الشكل التالي: حمّل النسخة التي تتضمّن PHP 5.6.23 (في الوسط) مع معمارية 64 بت. عند الانتهاء من تحميل الملف، انتقل إلى الطرفية Terminal ومنها إلى المكان الذي حمّلت إليه الملف السابق. بالنسبة إليّ كان الملف يحمل الاسم التالي وهو موجود ضمن المجلّد Documents: xampp-linux-x64-5.6.23-0-installer.run نفّذ الأمرين التاليين: sudo chmod 755 xampp-linux-x64-5.6.23-0-installer.run sudo ./xampp-linux-x64-5.6.23-0-installer.run كما يظهر في الشكل التالي: لاحظ أنّ الطرفية تطلب إدخال كلمة المرور الخاصة بالمستخدم الحالي بعد تنفيذ الأمر الأوّل مباشرةً، وذلك بسبب استخدام الأمر sudo. بعد تنفيذ الأمر الثاني سيبدأ برنامج الإعداد الخاص بالتوزيعة XAMPP بالعمل، حيث سيُظهر رسالة ترحيبيّة كما في الشكل التالي: انقر الزر Next للمتابعة لتصل إلى النافذة الخاصة بالمكوّنات الأساسيّة التي سيتم تنصيبها كما يلي: تأكّد من صناديق الاختيار، ثم انقر الزر Next. ستخبرك النافذة التالية عن المكان الذي سيتم فيه حفظ الملفات وهو /opt/lampp انقر زر Next لتحصل على نافذة دعائيّة للخدمات التي من الممكن أن تحصل عليها مع Bitnami. تابع نقر Next حتى تبدأ عملية التنصيب. ستأخذ عملية التنصيب قليلًا من الوقت، وبعد أن تنتهي، ستحصل على نافذة شبيهة بما يلي: احرص على اختيار تشغيل XAMPP من تحديد صندوق الاختيار إن لم يكن كذلك، ثم انقر الزر Finish ليعمل تطبيق الإدارة الخاص بـ XAMPP كما يظهر من الشكل التالي: انقر لسان التبويب Manage Servers من الأعلى لتحصل على شكل شبيه بما يلي: نلاحظ من الشكل السابق أنّ كل من الخادومين MySQL Database و Apache Web Server هما حاليًا في طور التشغيل Running. إن لم يكونا كذلك، فيمكنك تحديد كل منهما على حدة ونقر زر Start الذي يظهر في الجهة اليمنى من الشكل السابق. للتأكّد من نجاح عمليّة التنصيب السابقة، افتح متصفّح الانترنت لديك، ثم اكتب ضمن شريط العنوان ما يلي: http://ubuntu ثم اضغط الزر Enter، يجب أن تحصل على شكل شبيه بالشكل التالي: نكون عند هذه النقطة قد انتهينا من تنصيب XAMPP وبتنا مستعدّين لتنصيب ماجنتو. تحميل وتنصيب ماجنتو انتقل بمتصفّح الويب إلى العنوان التالي https://bitnami.com/stack/xampp لعرض التطبيقات التي توفرها Bitnami لتوزيعة XAMPP. ثم استخدام شريط التمرير حتى تصل إلى ماجنتو Magento كما في الشكل التالي: انقر زر Download الخاص بنظام التشغيل لينكس مع معمارية 64 بت كما في الشكل السابق لتبدأ عملية التحميل. بعد الانتهاء من التحميل، انتقل باستخدام الطرفية Terminal إلى المجلّد الذي يحوي الملف المُحمَّل. بالنسبة إليّ كان الملف يحمل الاسم التالي وهو موجود ضمن المجلّد Documents: bitnami-magento-2.1.0-2-module-linux-x64-installer.run نفّذ الأمرين التاليين ضمن الطرفية: sudo chmod 755 bitnami-magento-2.1.0-2-module-linux-x64-installer.run sudo ./bitnami-magento-2.1.0-2-module-linux-x64-installer.run كما في الشكل التالي: لاحظ من الشكل السابق أنّ الطرفية قد طلبت كلمة المرور للمستخدم الحالي، كما هو الحال عند تنصيب XAMPP وذلك لأنّني أعدت تشغيل الطرفية من جديد. بمجرّد تنفيذ الأمر الثاني سيبدأ عمل برنامج التنصيب الخاص بماجنتو، حيث ستظهر لك رسالة ترحيبيّة من برنامج الإعداد كما يلي: انقر Next ليعرض لك برنامج الإعداد نافذة تفيد بالمكوّنات المراد تنصيبها. يوجد مكوّن واحد هو ماجنتو Magento يجب أن يكون في حالة اختيار. انقر Next لتصل إلى النافذة التي تحدّد المسار الذي سيتم فيه نسخ الملفات. يجب أن يكون هذا المسار هو /opt/lampp انقر زر Next مرّة أخرى لتصل إلى النافذة التالية: ستطلب هذه النافذة بعض المعلومات الشخصيّة مثل الاسم المرغوب لتسجيل الدخول على ماجنتو (Login) والاسم الحقيقي والبريد الإلكتروني. كما ستطلب منك تعيين كلمة المرور الخاصة بتطبيق ماجنتو. بعد أن تنتهي من كتابة البيانات المطلوبة انقر Next لتصل إلى النافذة التالية: تطلب منك النافذة السابقة تحديد عنوان المضيف لإنشاء الروابط الداخلية. وهنا ينبغي أن تكتب العنوان الخاص بموقعك. في حالتنا هذه، استخدمت العنوان المحلّي 127.0.1.1 فحسب. يمكن بالتأكيد تغيير هذا العنوان فيما بعد. انقر الآن الزر Next لتصل إلى النافذة الخاصة بإعدادات خادوم البريد الصادر SMTP الذي سيستخدمه ماجنتو لإرسال رسائل البريد الإلكتروني. انظر الشكل التالي: لاحظ أنّني قد اخترت مزوّد خدمة GMail للبريد الصادر SMTP. أدخل البريد الإلكتروني الذي ترغب استخدامه مع هذه الخدمة، ثم زوّد برنامج الإعداد بكلمة المرور لهذا الحساب. انقر Next لتصل إلى نافذة تعرض عليك نشر deploy نسخة ماجنتو هذه إلى الخدمة السحابية الخاصة بشركة Bitnami كما في الشكل التالي: أزل الاختيار من الصندوق ثم انقر زر Next. سيعرض برنامج الإعداد رسالة تفيد بأنّه جاهز لبدء عمليّة التنصيب. انقر Next للبدء. سيستغرق الأمر بعض الوقت، وبعد الانتهاء سيعرض برنامج الإعداد رسالة تفيد بانتهاء عمليّة التنصيب ويعرض عليك تشغيل ماجنتو فورًا. كما في الشكل التالي: انقر على زر Finish لتختفي هذه النافذة وتظهر نافذة متصفّح الويب وقد انتقلت لتعرض الصفحة الرئيسيّة لمتجر ماجنتو: نكون بذلك قد انتهينا من تنصيب ماجنتو وبات جاهزًا للعمل. الخلاصة تعلّمنا في هذا الدرس كيفيّة تنصيب تطبيق ماجنتو بشكل عمليّ وسهل. حيث مررنا بخطوتين رئيسيتين. الأولى هي تنصيب توزيعة XAMPP التي تتضمن خادوم الويب Apache وخادوم قاعدة البيانات MySQL. أمّا الخطوة الثانية فكانت تنصيب ماجنتو من خلال برنامج إعداد مخصّص من Bitnami لكي ينصّب ماجنتو بوجود التوزيعة XAMPP. سنتابع عملنا في الدرس القادم في إلقاء نظرة على المنتجات في ماجنتو. -
 يؤمن تطبيق المفكرة Jupyter Notebook موجه أوامر تفاعلي شبيه بتطبيقات الويب، والذي يمكن استخدامه مع العديد من لغات البرمجة مثل Python و Julia و R و Haskell و Ruby، وذلك في التطبيقات الخاصة بالبيانات والإحصاء والذكاء الصناعي. سيتم في هذه المقالة شرح طريقة تهيئة وإعداد تطبيق المفكرة Jupyter Notebook للعمل مع أكواد لغة البرمجة Python 3 محليًا أو من الخادم Ubuntu 16.04 server. إن تطبيق المفكرة Jupyter Notebook هو عبارة عن برنامج مفكرة يقوم بتوليد المستندات المتضمنة على الأكواد البرمجية والشروحات والصور والمخططات البيانية والمعادلات الرياضية، لاستخدامها في عرض وتطوير ومشاركة الأبحاث العلمية. المتطلبات قبل البدء يجب توفر بيئة برمجية مهيّأة محليًا (على الحاسب الشخصي) أو على الخادم Ubuntu 16.04 مع امتلاك صلاحية مدير النظام (المستخدم الجذر root) أو استخدام الأمر sudo عند تنفيذ الأوامر في موجه أوامر لينكس. الخطوة الأولى- تنصيب تطبيق المفكرة Jupyter Notebook سيتم استخدام أداة إدارة الحزم pip لتنصيب تطبيق المفكرة Jupyter Notebook في بيئة Python البرمجية المُنشأة مسبقًا. لكن يجب في البداية الانتقال إلى المجلدenvironments الخاص ببيئة Python البرمجية my_env المُنشأة مسبقًا وتفعيلها، وذلك بتنفيذ الأوامر التالية في موجه أوامر النظام: sammy@ubuntu:~$ cd ~/environments sammy@ubuntu:~/environments$ . my_env/bin/activate (my_env) sammy@ubuntu:~/environments$ ثم علينا التأكد من أن الأداة pip محدّثة لآخر إصدار وذلك بتنفيذ الأمر التالي: (my_env) sammy@ubuntu:~/environments$ pip install --upgrade pip ثم نقوم عن طريق الأداة pip بتنصيب تطبيق المفكرة Jupyter Notebook في البيئة البرمجية my_env، وذلك بتنفيذ الأمر التالي: (my_env) sammy@ubuntu:~/environments$ pip install jupyter وهكذا تم تنصيب تطبيق المفكرة Jupyter Notebook في البيئة البرمجية. الخطوة التالية وهي اختيارية للذين يريدون الاتصال عبر قناة الاتصال SSH بواجهة الويب التفاعلية لتطبيق المفكرة Jupyter Notebook المنصَّب على الخادم. الخطوة الثانية (اختيارية)- الاتصال بتطبيق المفكرة Jupyter Notebook المنصَّب على الخادم عبر قناة الاتصال SSH سيتم في هذه الخطوة شرح طريقة الاتصال بواجهة الويب التفاعلية لتطبيق المفكرة Jupyter Notebook المنصَّب مسبقًا على الخادم، وذلك عبر قناة الاتصال SSH. حيث تؤمن قناة الاتصال SSH اتصالاً آمنًا بتطبيق المفكرة Jupyter Notebook كونه يستخدم منفذ محدد في الخادم (مثل المنفذ :8888 أو :8889 الخ). سيتم في الفقرتين التاليتين شرح طريقة إنشاء قناة الاتصال SSH. الأولى من نظام التشغيل ماكنتوش أو لينكس، والثانية من نظام التشغيل ويندوز. طريقة إنشاء قناة الاتصال SSH من نظام التشغيل ماكنتوش أو لينكس سيتم في هذه الفقرة شرح طريقة إنشاء قناة اتصال SSH من نظام التشغيل ماكنتوش أو لينكس، باستخدام الأمر ssh مع مجموعة من المعاملات التي تؤمن نجاح عملية الاتصال. يمكن إنشاء قناة اتصال SSH جديدة بتنفيذ الأمر التالي في نافذة جديدة لموجه أوامر النظام: $ ssh -L 8888:localhost:8888 your_server_username@your_server_ip حيث يستخدم الأمر ssh من أجل فتح اتصال SSH، في حين يستخدم العلم -L لتحديد المنفذ المعطى في المضيف المحلي (العميل) الذي سيتم توجيهه إلى المنفذ والمضيف البعيد (الخادم) المعطى، أي أن أي شيء سيعمل على المنفذ الثاني (مثلا 8888) على الخادم، سيظهر على المنفذ الأول (مثلا 8888) على العميل (الحاسب الشخصي). ويفضل تغيير رقم المنفذ 8888 إلى أي رقم آخر اختياري لتجنب وجود عملية أخرى تعمل على نفس المنفذ. إن المُعامل your_server_username هو اسم المستخدم (مثلا sammy) الذي تم إنشاؤه مسبقًا على الخادم، والمُعامل your_server_ip هو عنوان IP للخادم (مثلا 203.0.113.0). أي يصبح الأمر السابق بعد إدخال اسم المستخدم وعنوان IP للخادم كما يلي: $ ssh -L 8888:localhost:8888 sammy@203.0.113.0 وفي حال نجاح عملية الاتصال بالخادم وعدم حدوث أي خطأ، ينتقل موجه أوامر النظام إلى البيئة البرمجية المهيّأة مسبقًا على الخادم كما يلي: (my_env) sammy@ubuntu:~/environments$ ثم نقوم بتشغيل تطبيق المفكرة Jupyter Notebook المنصَّب مسبقًا في بيئتنا البرمجية كما يلي: (my_env) sammy@ubuntu:~/environments$ jupyter notebook والآن أصبح بالإمكان التفاعل مع تطبيق المفكرة Jupyter Notebook من خلال واجهة الويب التفاعلية الخاصة به، وذلك بإدخال العنوان الالكتروني http://localhost:8888 في المتصفح، كما يجب إدخال السلسلة الرمزية token الخاصة بالتصديق عند طلبها من قبل المتصفح، أو كتابتها بعد العنوان في المتصفح. طريقة إنشاء قناة الاتصال SSH من نظام التشغيل ويندوز عن طريق Putty تستخدم الأداة Putty لإنشاء قناة اتصال SSH في نظام التشغيل ويندوز، لذا يجب في البداية تنصيبها، وعند فتحها تظهر واجهة الأداة كما هو موضح بالشكل التالي: حيث يتم إدخال العنوان الإلكتروني URL للخادم أو عنوان IP ضمن حقل اسم المضيف Host Name، ثم الضغط على الخيار SSH في أسفل النافذة اليسارية من واجهة الأداة، فتظهر قائمة منسدلة من الخيارات، نختار منها الخيار Tunnels فتظهر في النافذة اليمينية مجموعة من خيارات التحكم بقناة الاتصال SSH كما هو موضح بالشكل التالي: ثم نقوم بإدخال رقم منفذ الحاسب الشخصي المراد استخدامه لتطبيق المفكرة Jupyter Notebook (مثلًا 8888)، ضمن حقل منفذ المصدر Source port، ويفضل أن يكون رقم هذا المنفذ أكبر من 8888 لضمان عدم وجود أي تطبيق أخر يعمل على هذا المنفذ. ثم ندخل العنوان localhost:8888 في حقل الهدف Distination حيث :8888 هو رقم المنفذ الذي يعمل عليه تطبيق المفكرة Jupyter Notebook في الخادم، ثم نضغط على زر الإضافة Add، فيظهر المنفذ في قائمة المنافذ الموجَّهة Forwarded ports. وأخيرًا نضغط على زر الفتح Open من أجل الاتصال بالخادم عن طريق قناة الاتصال SSH، ثم ندخل العنوان localhost:8888 (طبعًا يجب أن يكون رقم المنفذ موافقًا لرقم المنفذ الذي تم اختياره) في متصفح الويب من أجل الاتصال بتطبيق المفكرة Jupyter Notebook العامل على الخادم، كما يجب إدخال السلسلة الرمزية token الخاصة بالتصديق عند طلبها من قبل المتصفح، أو كتابتها بعد العنوان في المتصفح. الخطوة الثالثة- تشغيل تطبيق المفكرة Jupyter Notebook بعد الانتهاء من تنصيب تطبيق المفكرة Jupyter Notebook، يصبح بالإمكان تشغيله من موجه أوامر النظام بتنفيذ الأمر التالي: (my_env) sammy@ubuntu:~/environments$ jupyter notebook فيُطبع في نافذة موجه الأوامر سجل معلومات تشغيل تطبيق المفكرة Jupyter Notebook كما يلي: [I NotebookApp] Serving notebooks from local directory: /home/sammy [I NotebookApp] 0 active kernels [I NotebookApp] The Jupyter Notebook is running at: http://localhost:8888/ [I NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation). ... حيث تتضمن هذه المعلومات على رقم المنفذ الذي يعمل عليه التطبيق، وعند تشغيل التطبيق لأول مرة سيكون رقم المنفذ 8888. يقوم المتصفح الافتراضي تلقائياً بفتح واجهة الويب التفاعلية الخاصة بتطبيق المفكرة Jupyter Notebook عند تشغيله على الحاسب الشخصي (ليس على الخادم)، وفي حال لم يتم ذلك أو تم إغلاق المتصفح، يمكن إعادة فتحه من جديد بإدخال عنوانه http://localhost:8888/ الظاهر في سجل معلومات التطبيق في المتصفح. يتم إنهاء تطبيق المفكرة Jupyter Notebook بالضغط على المفاتيح CTRL و C ثم ضغط المفتاح y (نعم) عند السؤال عن تأكيد عملية الإنهاء، ثم ضغط المفتاح ENTER، فتُطبع رسالة تأكيد عملية إنهاء التطبيق التالية في نافذة موجه الأوامر: [C 12:32:23.792 NotebookApp] Shutdown confirmed [I 12:32:23.794 NotebookApp] Shutting down kernels الخطوة الرابعة- استخدام تطبيق المفكرة Jupyter Notebook سيتم في هذه الفقرة شرح أساسيات استخدام تطبيق المفكرة Jupyter Notebook، لكن يجب في البداية تشغيله إن لم يكن في حالة العمل، وذلك بتنفيذ الأمر التالي: (my_env) sammy@ubuntu:~/environments$ jupyter notebook نستطيع الآن الإتصال به والتفاعل معه من خلال واجهة الويب التفاعلية. يمتاز تطبيق المفكرة Jupyter Notebook بالقوة حيث يحتوي على الكثير من الميزات، لكن سيقتصر الشرح على بعض الميزات الأساسية التي تسمح بمباشرة العمل على هذا التطبيق. يعرض تطبيق المفكرة Jupyter Notebook جميع الملفات والمجلدات الواقعة ضمن المسار الذي تم تشغيله منه، لذا يجب تشغيله دائمًا من مسار المشروع البرمجي الذي يتم العمل عليه. يتم إنشاء ملف مفكرة Jupyter Notebook جديد بالضغط على خيار جديد New الموجود في الزاوية اليمينية العُلوية من واجهة الويب التفاعلية، فتظهر قائمة منسدلة نختار منها Python 3 كما هو موضح بالشكل التالي: فيُفتح الملف الجديد المُنشأ ضمن واجهة الويب التفاعلية. نستطيع الآن كتابة وتنفيذ كود Python ضمن خليّة الكود البرمجي. كما يمكن تغيير هذه الخلية لتقبل لغة التوصيف Markdown، وذلك بالضغط على خيار الخلية Cell ثم خيار نوع الخلية Cell Type ثم خيار التوصيف Markdown من الشريط العلوي، فيصبح بالإمكان الآن استخدام هذه الخلية لكتابة الملاحظات وحتى تضمين المعادلات الرياضية المكتوبة بلغة LaTeX بعد وضعها بين الرمزين ($$)، فمثلا يمكن كتابة كود التوصيف التالي ضمن الخلية بعد تحويلها لخلية توصيف: # Simple Equation Let us now implement the following equation: $$ y = x^2$$ where $x = 2$ يتم تحويل هذا الكود إلى نص بضغط المفاتيح CTRL و ENTER فنحصل على النتيجة التالية: وهكذا نلاحظ أنه يمكن استخدام خلايا التوصيف من أجل توثيق الكود البرمجي. سنقوم الآن بإنشاء معادلة رياضية بسيطة ونطبع نتيجة تنفيذها، وذلك بالضغط على الخلية العلوية ثم الضغط على المفاتيح ALT و CTRL من أجل إنشاء خلية جديدة تحتها ثم ندخل فيها الكود التالي: x = 2 y = x**2 print(y) ثم نقوم بتنفيذ الكود بضغط المفاتيح CTRL و ENTER فنحصل على النتيجة التالية: أصبح بمقدورك الآن وبعد أن تعلمت أساسيات تطبيق المفكرة Jupyter Notebook ، أن تقوم باستيراد النماذج البرمجية، وأن تستخدم هذه المفكرة كما تريد مع أي بيئة برمجية أخرى. ملخص أصبحت قادرا الآن على كتابة أكواد Python والملاحظات القابلة للتطوير والمشاركة، بعد أن تعلمت كيفية تنصيب وتشغيل والعمل على تطبيق المفكرة Jupyter Notebook. يمكن الحصول على مزيد من المعلومات والمساعدة حول كيفية استخدام هذه المفكرة، بالدخول إلى User Interface Tour عن طريق الخيار Help الموجود في الشريط العلوي من واجهة الويب التفاعلية. ترجمة المقال How To Set Up Jupyter Notebook for Python 3 لصاحبته Lisa Tagliaferri
يؤمن تطبيق المفكرة Jupyter Notebook موجه أوامر تفاعلي شبيه بتطبيقات الويب، والذي يمكن استخدامه مع العديد من لغات البرمجة مثل Python و Julia و R و Haskell و Ruby، وذلك في التطبيقات الخاصة بالبيانات والإحصاء والذكاء الصناعي. سيتم في هذه المقالة شرح طريقة تهيئة وإعداد تطبيق المفكرة Jupyter Notebook للعمل مع أكواد لغة البرمجة Python 3 محليًا أو من الخادم Ubuntu 16.04 server. إن تطبيق المفكرة Jupyter Notebook هو عبارة عن برنامج مفكرة يقوم بتوليد المستندات المتضمنة على الأكواد البرمجية والشروحات والصور والمخططات البيانية والمعادلات الرياضية، لاستخدامها في عرض وتطوير ومشاركة الأبحاث العلمية. المتطلبات قبل البدء يجب توفر بيئة برمجية مهيّأة محليًا (على الحاسب الشخصي) أو على الخادم Ubuntu 16.04 مع امتلاك صلاحية مدير النظام (المستخدم الجذر root) أو استخدام الأمر sudo عند تنفيذ الأوامر في موجه أوامر لينكس. الخطوة الأولى- تنصيب تطبيق المفكرة Jupyter Notebook سيتم استخدام أداة إدارة الحزم pip لتنصيب تطبيق المفكرة Jupyter Notebook في بيئة Python البرمجية المُنشأة مسبقًا. لكن يجب في البداية الانتقال إلى المجلدenvironments الخاص ببيئة Python البرمجية my_env المُنشأة مسبقًا وتفعيلها، وذلك بتنفيذ الأوامر التالية في موجه أوامر النظام: sammy@ubuntu:~$ cd ~/environments sammy@ubuntu:~/environments$ . my_env/bin/activate (my_env) sammy@ubuntu:~/environments$ ثم علينا التأكد من أن الأداة pip محدّثة لآخر إصدار وذلك بتنفيذ الأمر التالي: (my_env) sammy@ubuntu:~/environments$ pip install --upgrade pip ثم نقوم عن طريق الأداة pip بتنصيب تطبيق المفكرة Jupyter Notebook في البيئة البرمجية my_env، وذلك بتنفيذ الأمر التالي: (my_env) sammy@ubuntu:~/environments$ pip install jupyter وهكذا تم تنصيب تطبيق المفكرة Jupyter Notebook في البيئة البرمجية. الخطوة التالية وهي اختيارية للذين يريدون الاتصال عبر قناة الاتصال SSH بواجهة الويب التفاعلية لتطبيق المفكرة Jupyter Notebook المنصَّب على الخادم. الخطوة الثانية (اختيارية)- الاتصال بتطبيق المفكرة Jupyter Notebook المنصَّب على الخادم عبر قناة الاتصال SSH سيتم في هذه الخطوة شرح طريقة الاتصال بواجهة الويب التفاعلية لتطبيق المفكرة Jupyter Notebook المنصَّب مسبقًا على الخادم، وذلك عبر قناة الاتصال SSH. حيث تؤمن قناة الاتصال SSH اتصالاً آمنًا بتطبيق المفكرة Jupyter Notebook كونه يستخدم منفذ محدد في الخادم (مثل المنفذ :8888 أو :8889 الخ). سيتم في الفقرتين التاليتين شرح طريقة إنشاء قناة الاتصال SSH. الأولى من نظام التشغيل ماكنتوش أو لينكس، والثانية من نظام التشغيل ويندوز. طريقة إنشاء قناة الاتصال SSH من نظام التشغيل ماكنتوش أو لينكس سيتم في هذه الفقرة شرح طريقة إنشاء قناة اتصال SSH من نظام التشغيل ماكنتوش أو لينكس، باستخدام الأمر ssh مع مجموعة من المعاملات التي تؤمن نجاح عملية الاتصال. يمكن إنشاء قناة اتصال SSH جديدة بتنفيذ الأمر التالي في نافذة جديدة لموجه أوامر النظام: $ ssh -L 8888:localhost:8888 your_server_username@your_server_ip حيث يستخدم الأمر ssh من أجل فتح اتصال SSH، في حين يستخدم العلم -L لتحديد المنفذ المعطى في المضيف المحلي (العميل) الذي سيتم توجيهه إلى المنفذ والمضيف البعيد (الخادم) المعطى، أي أن أي شيء سيعمل على المنفذ الثاني (مثلا 8888) على الخادم، سيظهر على المنفذ الأول (مثلا 8888) على العميل (الحاسب الشخصي). ويفضل تغيير رقم المنفذ 8888 إلى أي رقم آخر اختياري لتجنب وجود عملية أخرى تعمل على نفس المنفذ. إن المُعامل your_server_username هو اسم المستخدم (مثلا sammy) الذي تم إنشاؤه مسبقًا على الخادم، والمُعامل your_server_ip هو عنوان IP للخادم (مثلا 203.0.113.0). أي يصبح الأمر السابق بعد إدخال اسم المستخدم وعنوان IP للخادم كما يلي: $ ssh -L 8888:localhost:8888 sammy@203.0.113.0 وفي حال نجاح عملية الاتصال بالخادم وعدم حدوث أي خطأ، ينتقل موجه أوامر النظام إلى البيئة البرمجية المهيّأة مسبقًا على الخادم كما يلي: (my_env) sammy@ubuntu:~/environments$ ثم نقوم بتشغيل تطبيق المفكرة Jupyter Notebook المنصَّب مسبقًا في بيئتنا البرمجية كما يلي: (my_env) sammy@ubuntu:~/environments$ jupyter notebook والآن أصبح بالإمكان التفاعل مع تطبيق المفكرة Jupyter Notebook من خلال واجهة الويب التفاعلية الخاصة به، وذلك بإدخال العنوان الالكتروني http://localhost:8888 في المتصفح، كما يجب إدخال السلسلة الرمزية token الخاصة بالتصديق عند طلبها من قبل المتصفح، أو كتابتها بعد العنوان في المتصفح. طريقة إنشاء قناة الاتصال SSH من نظام التشغيل ويندوز عن طريق Putty تستخدم الأداة Putty لإنشاء قناة اتصال SSH في نظام التشغيل ويندوز، لذا يجب في البداية تنصيبها، وعند فتحها تظهر واجهة الأداة كما هو موضح بالشكل التالي: حيث يتم إدخال العنوان الإلكتروني URL للخادم أو عنوان IP ضمن حقل اسم المضيف Host Name، ثم الضغط على الخيار SSH في أسفل النافذة اليسارية من واجهة الأداة، فتظهر قائمة منسدلة من الخيارات، نختار منها الخيار Tunnels فتظهر في النافذة اليمينية مجموعة من خيارات التحكم بقناة الاتصال SSH كما هو موضح بالشكل التالي: ثم نقوم بإدخال رقم منفذ الحاسب الشخصي المراد استخدامه لتطبيق المفكرة Jupyter Notebook (مثلًا 8888)، ضمن حقل منفذ المصدر Source port، ويفضل أن يكون رقم هذا المنفذ أكبر من 8888 لضمان عدم وجود أي تطبيق أخر يعمل على هذا المنفذ. ثم ندخل العنوان localhost:8888 في حقل الهدف Distination حيث :8888 هو رقم المنفذ الذي يعمل عليه تطبيق المفكرة Jupyter Notebook في الخادم، ثم نضغط على زر الإضافة Add، فيظهر المنفذ في قائمة المنافذ الموجَّهة Forwarded ports. وأخيرًا نضغط على زر الفتح Open من أجل الاتصال بالخادم عن طريق قناة الاتصال SSH، ثم ندخل العنوان localhost:8888 (طبعًا يجب أن يكون رقم المنفذ موافقًا لرقم المنفذ الذي تم اختياره) في متصفح الويب من أجل الاتصال بتطبيق المفكرة Jupyter Notebook العامل على الخادم، كما يجب إدخال السلسلة الرمزية token الخاصة بالتصديق عند طلبها من قبل المتصفح، أو كتابتها بعد العنوان في المتصفح. الخطوة الثالثة- تشغيل تطبيق المفكرة Jupyter Notebook بعد الانتهاء من تنصيب تطبيق المفكرة Jupyter Notebook، يصبح بالإمكان تشغيله من موجه أوامر النظام بتنفيذ الأمر التالي: (my_env) sammy@ubuntu:~/environments$ jupyter notebook فيُطبع في نافذة موجه الأوامر سجل معلومات تشغيل تطبيق المفكرة Jupyter Notebook كما يلي: [I NotebookApp] Serving notebooks from local directory: /home/sammy [I NotebookApp] 0 active kernels [I NotebookApp] The Jupyter Notebook is running at: http://localhost:8888/ [I NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation). ... حيث تتضمن هذه المعلومات على رقم المنفذ الذي يعمل عليه التطبيق، وعند تشغيل التطبيق لأول مرة سيكون رقم المنفذ 8888. يقوم المتصفح الافتراضي تلقائياً بفتح واجهة الويب التفاعلية الخاصة بتطبيق المفكرة Jupyter Notebook عند تشغيله على الحاسب الشخصي (ليس على الخادم)، وفي حال لم يتم ذلك أو تم إغلاق المتصفح، يمكن إعادة فتحه من جديد بإدخال عنوانه http://localhost:8888/ الظاهر في سجل معلومات التطبيق في المتصفح. يتم إنهاء تطبيق المفكرة Jupyter Notebook بالضغط على المفاتيح CTRL و C ثم ضغط المفتاح y (نعم) عند السؤال عن تأكيد عملية الإنهاء، ثم ضغط المفتاح ENTER، فتُطبع رسالة تأكيد عملية إنهاء التطبيق التالية في نافذة موجه الأوامر: [C 12:32:23.792 NotebookApp] Shutdown confirmed [I 12:32:23.794 NotebookApp] Shutting down kernels الخطوة الرابعة- استخدام تطبيق المفكرة Jupyter Notebook سيتم في هذه الفقرة شرح أساسيات استخدام تطبيق المفكرة Jupyter Notebook، لكن يجب في البداية تشغيله إن لم يكن في حالة العمل، وذلك بتنفيذ الأمر التالي: (my_env) sammy@ubuntu:~/environments$ jupyter notebook نستطيع الآن الإتصال به والتفاعل معه من خلال واجهة الويب التفاعلية. يمتاز تطبيق المفكرة Jupyter Notebook بالقوة حيث يحتوي على الكثير من الميزات، لكن سيقتصر الشرح على بعض الميزات الأساسية التي تسمح بمباشرة العمل على هذا التطبيق. يعرض تطبيق المفكرة Jupyter Notebook جميع الملفات والمجلدات الواقعة ضمن المسار الذي تم تشغيله منه، لذا يجب تشغيله دائمًا من مسار المشروع البرمجي الذي يتم العمل عليه. يتم إنشاء ملف مفكرة Jupyter Notebook جديد بالضغط على خيار جديد New الموجود في الزاوية اليمينية العُلوية من واجهة الويب التفاعلية، فتظهر قائمة منسدلة نختار منها Python 3 كما هو موضح بالشكل التالي: فيُفتح الملف الجديد المُنشأ ضمن واجهة الويب التفاعلية. نستطيع الآن كتابة وتنفيذ كود Python ضمن خليّة الكود البرمجي. كما يمكن تغيير هذه الخلية لتقبل لغة التوصيف Markdown، وذلك بالضغط على خيار الخلية Cell ثم خيار نوع الخلية Cell Type ثم خيار التوصيف Markdown من الشريط العلوي، فيصبح بالإمكان الآن استخدام هذه الخلية لكتابة الملاحظات وحتى تضمين المعادلات الرياضية المكتوبة بلغة LaTeX بعد وضعها بين الرمزين ($$)، فمثلا يمكن كتابة كود التوصيف التالي ضمن الخلية بعد تحويلها لخلية توصيف: # Simple Equation Let us now implement the following equation: $$ y = x^2$$ where $x = 2$ يتم تحويل هذا الكود إلى نص بضغط المفاتيح CTRL و ENTER فنحصل على النتيجة التالية: وهكذا نلاحظ أنه يمكن استخدام خلايا التوصيف من أجل توثيق الكود البرمجي. سنقوم الآن بإنشاء معادلة رياضية بسيطة ونطبع نتيجة تنفيذها، وذلك بالضغط على الخلية العلوية ثم الضغط على المفاتيح ALT و CTRL من أجل إنشاء خلية جديدة تحتها ثم ندخل فيها الكود التالي: x = 2 y = x**2 print(y) ثم نقوم بتنفيذ الكود بضغط المفاتيح CTRL و ENTER فنحصل على النتيجة التالية: أصبح بمقدورك الآن وبعد أن تعلمت أساسيات تطبيق المفكرة Jupyter Notebook ، أن تقوم باستيراد النماذج البرمجية، وأن تستخدم هذه المفكرة كما تريد مع أي بيئة برمجية أخرى. ملخص أصبحت قادرا الآن على كتابة أكواد Python والملاحظات القابلة للتطوير والمشاركة، بعد أن تعلمت كيفية تنصيب وتشغيل والعمل على تطبيق المفكرة Jupyter Notebook. يمكن الحصول على مزيد من المعلومات والمساعدة حول كيفية استخدام هذه المفكرة، بالدخول إلى User Interface Tour عن طريق الخيار Help الموجود في الشريط العلوي من واجهة الويب التفاعلية. ترجمة المقال How To Set Up Jupyter Notebook for Python 3 لصاحبته Lisa Tagliaferri -
.png.534d167cf9accdae320717169306444a.png) في هذا الدرس، ستتعلم كيفية استخدام خُطّافات (Git (Git hooks لأتمتة نشر بيئة الإنتاج لتطبيقات Rails على خادم أوبونتو 14.04 عن بُعد. باستخدام خُطّافات Git ستتمكن من نشر التطبيقات عن طريق دفع التغييرات إلى خادم الإنتاج production server، وبدلًا من أن تقوم بكل شيء يدويًّا (مثل ترحيل قاعدة البيانات) فالاستعانة بأحد أشكال النشر الآلي، مثل خُطّافات Git، سيوفر عليك الكثير من الوقت على المدى الطويل. في هذا الدرس سنستخدم خُطّافGit من نوعpost-receive ، بالإضافة إلىPuma كخادم للتطبيق،Nginx كوكيل عكسي لـ Puma و PostgreSQL كقاعدة بيانات. المتطلبات الأساسية سوف تحتاج صلاحيات مستخدم غير جذري non-root والذي يملك امتيازات مستخدم أساسي superuser على خادم أوبونتو. في هذا المثال، سيكون اسم المستخدم deploy. يمكنك تعلم كيفية فعل ذلك في هذا الدرس: الإعداد الابتدائي لخادوم أوبنتو 14.04. إذا كنت ترغب في النشر دون الحاجة لإدخال كلمة المرور، فتأكد من إعداد مفاتيح SSH. سوف تحتاج إلى تثبيت Ruby على خادمك. إذا لم تكن قد فعلت ذلك سلفًا، يمكنك تثبيته جنبًا إلى جنب مع Rails باستخدام rbenv أو RVM. سوف تحتاج أيضًا إلى تطبيق Rails مُدار في مستودع git على جهازك. إذا لم يكن لديك تطبيق في git، فسوف نقدم لك تطبيقًا بسيطًا كمثال لتعمل عليه. لنبدأ على بركة الله. تثبيت PostgreSQL معظم بيئات Rails تستخدم PostgreSQL كقاعدة بيانات، لذلك عليك تثبيته على خادمك الآن. على خادم الإنتاج، قم بتحديث apt-get: sudo apt-get update ثم قم بتثبيت PostgreSQL بهذه التعليمات: sudo apt-get install postgresql postgresql-contrib libpq-dev إنشاء قاعدة بيانات الإنتاج الخاصة بالمستخدم لإبقاء الأمور بسيطةً، سنسمي قاعدة بيانات الإنتاج الخاصة بالمستخدم بنفس اسم التطبيق خاصتك. على سبيل المثال، إذا كان اسم تطبيقك “appname”، فيجب عليك إنشاء مستخدم PostgreSQL بهذه الطريقة: sudo -u postgres createuser -s appname لتعيين كلمة مرور لقاعدة بيانات المستخدم، ادخُل سطر أوامر PostgreSQL هكذا: sudo -u postgres psql بعد ذلك قم بتعيين كلمة المرور لقاعدة بيانات المستخدم “appname” هكذا: \password appname قم بإدخال كلمة المرور التي تريد ثم قم بتأكيدها. اخرج من سطر أوامر PostgreSQL بهذه التعليمة: \q الآن نحن على استعداد لتزويد تطبيقك بمعلومات الاتصال الخاصة بقاعدة البيانات. إعداد تطبيق Rails على جهاز التطوير خاصتك، ستقوم بإعداد تطبيقك لأجل النشر. اختياري: إنشاء تطبيق Rails إن كان لديك تطبيق Rails جاهز للنشر. فيمكنك تخطي هذا القسم والقيام بالتغييرات المناسبة لاحقًا. أمّا إن لم يكن لديك تطبيق جاهز، فإن الخطوة الأولى هي إنشاء تطبيق Rails جديدة. هذه التعليمات ستنشئ تطبيق Rails جديد تحت اسم “appname” في المجلد الرئيسي. لا تتردد في استبدال “appname” بالاسم الذي تريد: cd ~ rails new appname ثم تحوّل إلى مجلد التطبيق: cd appname لأجل تطبيقنا هذا، سوف نقوم بتوليد سقالة scaffold controller لكي يجد تطبيقنا شيءً ليعرضه: rails generate scaffold Task title:string note:text لنتأكدْ الآن من أن تطبيقنا موجود في مستودعgit . تهيئة Git Repo إن لم يكن تطبيقك موجودًا بالفعل في مستودع git لسبب ما، قم بتهيئته وإجراء إلزام أولي initial commit. قم بالتحوّل إلى مجلد التطبيق. في مثالنا، التطبيق يسمى " appname" وهو موضوع في المجلد الرئيسي home directory: cd ~/appname git init git add -A git commit -m 'initial commit' الآن دعونا نُجهّز تطبيقنا لربط الاتصال بقاعدة بيانات الإنتاج لـ PostgreSQL. تحديث إعدادات قاعدة البيانات تحوّل إلى مجلد تطبيقك إن لم تكن بالفعل هناك. في مثالنا، التطبيق يسمى “appname” وهو موضوع في المجلد الرئيسي home directory: cd ~/appname الآن افتح ملف إعداد قاعدة البيانات في محرر النصوص المفضل لديك: vi config/database.yml اعثر على مقطع الإنتاج production section في إعدادات قاعدة بيانات تطبيقك، وقم باستبداله بمعلومات الاتصال بقاعدة بيانات الإنتاج خاصتك. من المفروض أن يبدو كشيء من هذا القبيل (قم باستبدال القيم عند الاقتضاء): config/database.yml excerpt production: <<: *default host: localhost adapter: postgresql encoding: utf8 database: appname_production pool: 5 username: <%= ENV['APPNAME_DATABASE_USER'] %> password: <%= ENV['APPNAME_DATABASE_PASSWORD'] %> احفظ واخرج. هذا الملف يؤكد على أن بيئة الإنتاج الخاصة بالتطبيق ينبغي أن تستخدم قاعدة بيانات PostgreSQL تحت مُسمّى “appname_production” على المضيف المحلي localhost. لاحظ أنه تم إحالة اسم المستخدم وكلمة مرور قاعدة البيانات إلى متغيرات البيئة environment variables. سنقوم بتحديدها على الخادم في وقت لاحق. تحديث Gemfile إذا لم يكن لدى Gemfile خاصتك المكتبة pg (PostgreSQL adapter gem)، ولم تكن المكتبة Puma مُحددة، فيجب عليك إضافتهما الآن. افتح Gemfile الخاص بتطبيقك في المحرّر المفضل لديك: vi Gemfile أضف الأسطر التالية إلىGemfile : Gemfile excerpt group :production do gem 'pg' gem 'puma' end احفظ واخرج. سيحدد هذا النص البرمجي أن بيئة الإنتاج production environment يجب أن تستخدم المكتبات pgوpuma : إعداد Puma قبل إعداد Puma، يجب عليك أن تتحقق من عدد وحدات المعالجة المركزية التي يملكها خادمك. يمكنك بسهولة فعل ذلك على خادمك بهذه التعليمة: grep -c processor /proc/cpuinfo الآن، على جهاز التطوير خاصتك، قم بإضافة إعدادات Puma إلى الإعداد config/puma.rb . افتح الملف في محرر النصوص: vi config/puma.rb انسخ وألصق هذه الإعدادات في الملف: config/puma.rb # Change to match your CPU core count workers 2 # Min and Max threads per worker threads 1, 6 app_dir = File.expand_path("../..", __FILE__) shared_dir = "#{app_dir}/shared" # Default to production rails_env = ENV['RAILS_ENV'] || "production" environment rails_env # Set up socket location bind "unix://#{shared_dir}/sockets/puma.sock" # Logging stdout_redirect "#{shared_dir}/log/puma.stdout.log", "#{shared_dir}/log/puma.stderr.log", true # Set master PID and state locations pidfile "#{shared_dir}/pids/puma.pid" state_path "#{shared_dir}/pids/puma.state" activate_control_app on_worker_boot do require "active_record" ActiveRecord::Base.connection.disconnect! rescue Ac-tiveRecord::ConnectionNotEstablished Ac-tiveRecord::Base.establish_connection(YAML.load_file("#{app_dir}/config/database.yml")[rails_env]) end قم بتغيير العددworkers إلى عدد وحدات المعالجة المركزية لخادمك. يفترض المثال أن لديك اثنان. احفظ واخرج. الآن تم إعداد Puma بموضعlocation تطبيقك وموضع مقبسه socket والمذكرات logs ومعرّفات العمليات PIDS. لا تتردد في تعديل الملف، أو إضافة الخيارات التي تناسبك. ألزمCommit التغييرات الأخيرة: git add -A git commit -m 'added pg and puma' قبل الاستمرار، قم بتوليد المفتاح السري والذي سيتم استخدامه لبيئة الإنتاج الخاصة بتطبيقك: rake secret rake secret sample output: 29cc5419f6b0ee6b03b717392c28f5869eff0d136d8ae388c68424c6e5dbe52c1afea8fbec305b057f4b071db1646473c1f9a62f803ab8386456ad3b29b14b89 سوف تنسخ المُخرجات وتستخدمها لتحديد القيمة SECRET_KEY_BASE الخاصة بتطبيقك في الخطوة التالية. إنشاء النص البرمجي لإطلاق Puma سنقوم بإنشاء نص برمجي للإطلاق (Upstart init script). حتى نتمكن من تشغيل وإيقاف Puma بسهولة، وللتأكد من أنه سيبدأ عند بدء التشغيل. على خادم الإنتاج خاصتك، حمّل أداة Jungle Upstart من مستودع Puma على GitHub وضعها في المجلد الرئيسي: cd ~ wget https://raw.githubusercontent.com/puma/puma/master/tools/jungle/upstart/puma-manager.conf wget https://raw.githubusercontent.com/puma/puma/master/tools/jungle/upstart/puma.conf الآن افتح الملف puma.conf حتى تتمكن من تحرير إعدادات النشر الخاصة بمستخدمPuma : vi puma.conf ابحث عن السطرين الذين يحددان setuid و setgid، و قم باستبدال “apps” باسم النشر الخاص بالمستخدم أو المجموعة خاصتك. على سبيل المثال، إذا كان اسم مستخدم النشر “deploy”، فينبغي أن تكون الأسطر هكذا: puma.conf excerpt 1 of 2 setuid deploy setgid deploy الآن ابحث عن السطر الذي يحتوي:exec /bin/bash <<'EOT'. أضف الأسطر التالية تحته، وتأكد من استبدال اسم المستخدم وكلمة المرور الخاصة ب PostgreSQL، وأضف كذلك rake secret الذي قمت بإنشائه سابقًا: puma.conf excerpt 2 of 2 export APPNAME_DATABASE_USER='appname' export APPNAME_DATABASE_PASSWORD='appname_password' export SECRET_KEY_BASE='rake_secret_generated_above' احفظ واخرج. الآن انسخ النصوص في مجلد خدمات الإطلاق Upstart services: sudo cp puma.conf puma-manager.conf /etc/init النص البرمجي puma-manager.conf يُحدد /etc/puma.conf كمرجع لمعرفة التطبيقات التي يجب إدارتها. دعونا ننشئ ونحرّر هذا الملف الآن: sudo vi /etc/puma.conf كل أسطر هذا الملف يجب أن تتضمن مسارات التطبيقات التي تريد من Puma أن يُديرها. سنقوم بنشر تطبيقنا في مجلد يُسمى “appname” داخل المجلد الرئيسي. في هذا المثال، سيكون كما يلي (تأكد من تعديل المسار ليتناسب مع المكان الذي يتواجد فيه تطبيقك): /etc/puma.conf /home/deploy/appname احفظ واخرج الآن تمّ إعداد تطبيقك لينطلق عند بدء التشغيل بمساعدة Upstart, وهذا يعني أن تطبيقك سيبدأ حتى بعد إعادة إقلاع خادمك. لا تنسى أننا لم ننشر التطبيق حتى الآن، لذلك لسنا جاهزين لتشغيله بعد. تثبيت وإعداد Nginx لجعل التطبيق متاحًا على شبكة الإنترنت، يجب أن تستخدم Nginx كخادم. قم بتثبيت Nginx باستخدام apt-get: sudo apt-get install nginx الآن افتح كتلة الخادم الافتراضي default server block بمحرر النصوص: sudo vi /etc/nginx/sites-available/default استبدل محتويات الملف بالتعليمات البرمجية التالية. تأكد من استبدال الأجزاء الملوّنة باسم المستخدم واسم التطبيق المناسبين. /etc/nginx/sites-available/default upstream app { # Path to Puma SOCK file, as defined previously server unix:/home/deploy/appname/shared/sockets/puma.sock fail_timeout=0; } server { listen 80; server_name localhost; root /home/deploy/appname/public; try_files $uri/index.html $uri @app; location @app { proxy_pass http://app; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; } error_page 500 502 503 504 /500.html; client_max_body_size 4G; keepalive_timeout 10; } احفظ واخرج. سيقوم هذا النص البرمجي بإعداد Nginx كوكيل عكسي، لذلك طلبات HTTP ستُرسل إلى الخادم Puma عبر مقبس يونيكس Unix socket. لا تتردد في إجراء التغييرات التي تراها مناسبةً. لن نقوم بإعادة تشغيل Nginx, فالتطبيق غير موجود بعدُ على الخادم. سنقوم بإعداد التطبيق فيما يلي. إعداد مستودع الإنتاج (git (Prepare Production Git Remote على خادم الإنتاج، قم بتثبيت git بواسطة apt-get: sudo apt-get install git ثم قم بإنشاء مجلد للمستودع البعيد remote repository. سنقوم بإنشاء مجلد git أوّلي في المجلد الرئيسي وسنسميه “appname_production”. يمكنك تسمية المستودع البعيد كما تريد (ولكن لا تضعه في ~/appnameلأنه المكان الذي سننشر فيه التطبيق): mkdir ~/appname_production cd ~/appname_production git init –bare بما أن هذا المستودع أوّلي، فلا يوجد مجلّد عمل بعدُ وجميع الملفات الموجودة في .git موجودة في المجلد الرئيسي نفسه. نحن بحاجة إلى إنشاء خُطّاف git من نوعpost-receive ، والذي هو النص البرمجي الذي سيتم تشغيله عندما يتلقى خادم الإنتاج دفعةً من git(git push). افتح الملف hooks/post-receive في محرر النصوص: vi hooks/post-receive انسخ وألصق النص التالي في الملف post-receive: hooks/post-receive #!/bin/bash GIT_DIR=/home/deploy/appname_production WORK_TREE=/home/deploy/appname export APPNAME_DATABASE_USER='appname' export APPNAME_DATABASE_PASSWORD='appname_password' export RAILS_ENV=production . ~/.bash_profile while read oldrev newrev ref do if [[ $ref =~ .*/master$ ]]; then echo "Master ref received. Deploying master branch to produc-tion..." mkdir -p $WORK_TREE git --work-tree=$WORK_TREE --git-dir=$GIT_DIR checkout -f mkdir -p $WORK_TREE/shared/pids $WORK_TREE/shared/sockets $WORK_TREE/shared/log # start deploy tasks cd $WORK_TREE bundle install rake db:create rake db:migrate rake assets:precompile sudo restart puma-manager sudo service nginx restart # end deploy tasks echo "Git hooks deploy complete" else echo "Ref $ref successfully received. Doing nothing: only the mas-ter branch may be deployed on this server." fi done تأكد من تحديث القيم التالية: GIT_DIR :مجلد المستودع الأولي لـ (git (bare git repository الذي قمت بإنشائه في وقت سابق WORK_TREE : المجلد حيث تريد نشر تطبيقك (يجب أن يتطابق مع الموضع الذي قمت بتحديده في إعدادات Puma) APPNAME_DATABASE_USER :اسم مستخدم PostgreSQL (ضروري لمهام rake ) APPNAME_DATABASE_PASSWORD : كلمة مرور PostgreSQL (ضروري لمهام rake ) بعد ذلك، يجب عليك مراجعة التعليمات الموجودة بين التعليقين # start deploy tasks و # end deploy tasks. هذه هي التعليمات التي سيتم تشغيلها في كل مرة يتم دفع push الشعبة الرئيسية master branch إلى مستودع الإنتاج في(git (appname_production. إذا تركتها كما هي، فسيحاول الخادم القيام بما يلي بالنسبة لبيئة الإنتاج الخاصة بتطبيقك: تشغيل المُحزّم bundler إنشاء قاعدة بيانات ترحيل قاعدة البيانات الترجمة الأوليةPrecompile للأصول assets إعادة تشغيل Puma إعادة تشغيل Nginx إذا كنت ترغب في إجراء أية تغييرات أو أي إضافات للتحقق من الأخطاء، لا تتردد في القيام بذلك. بمجرد الانتهاء من مراجعة النص البرمجي احفظه واخرج. بعد ذلك، اجعل البرنامج النصي قابلًا للتنفيذ: chmod +x hooks/post-receive Sudo بلا كلمة مرور Passwordless Sudo لأن الخُطّاف post-receive يحتاج إلى تشغيل تعليماتsudo ، فسنسمح للمستخدم deploy باستخدام sudo بدون كلمة مرور(استبدل اسم المستخدمdeploy في حال اخترت اسمًا مختلفًا): sudo sh -c 'echo "deploy ALL=(ALL) NOPASSWD:ALL" > /etc/sudoers.d/90-deploy' هذا سيسمح للمستخدم deploy بتشغيل التعليمة sudo دون الحاجة لإعطاء كلمة المرور. ربما تريد أن تُقيّد التعليمات التي يمكن للمستخدمdeploy القيام بها. وكحد أدنى، عليك استخدام مفتاح المصادقة SSH كما عليك تعطيل المصادقة بكلمة المرور password authentication. إضافة Production Git Remote الآن بعد أن أعددنا كل شيء لخادم الإنتاج، دعونا نضيف production git remote لمستودع التطبيق خاصتنا. على جهاز التطوير خاصتك، تأكد من أنك في مجلد التطبيق: cd ~/appname ثم قم بإضافة مستودع git بعيد (git remote) جديد تحت اسم “production” والذي يشير إلى مستودع git الأولي appname_production الذي أنشأته على خادم الإنتاج. استبدل اسم المستخدم (deploy) وعنوان الـ IP الخاص بالخادم واسم المستودع البعيد (appname_production): git remote add production deploy@production_server_public_IP:appname_production لقد صار تطبيقك الآن جاهزًا للنشر بواسطة git push. النشر للإنتاج Deploy to Production بعد كل الإعدادات التي قمنا بها، يمكنك الآن نشر تطبيقك على الخادم خاصتك عن طريق تشغيل تعليمات git التالية: git push production master هذا سيدفع push شعبتك الرئيسية المحلية local master branch إلى مستودع الإنتاج البعيد production remote الذي قمت بإنشائه سابقًا. عندما يتلقى production remote أمر الدفع، فسينفّذ النصَّ البرمجي post-receive الذي أعددناه في وقت سابق. إذا قمت بكل شيء بشكل صحيح، فيجب أن يكون تطبيقك متاحًا الآن على عنوان الـ IP العام لخادم الإنتاج خاصتك. إذا كنت تستخدم التطبيق التعليمي لهذا الدرس، فمن المفروض أن تكون قادرًا على الوصول إلى http://production_server_IP/tasks من أيّ متصفح و من المفروض أن ترى شيئًا من هذا القبيل: الخلاصة في أي وقت تقوم بإجراء تغيير على تطبيقك، يمكنك تشغيل نفس التعليمة git push للنشر على خادم الإنتاج خاصتك. هذا لوحده من المفروض أن يوفر عليك الكثير من الوقت على مدى عمر المشروع. لقد شمل هذا الدرس فقط الخطّافات من نوع “post-receive”، ولكن هناك عدة أنواع أخرى من الخطّافات التي يمكن أن تساعدك على تحسين أتمتة عملية النشر. ترجمة -وبتصرّف- للمقال How To Deploy a Rails App with Git Hooks on Ubuntu 14.04 لصاحبه Mitchell Anicas
في هذا الدرس، ستتعلم كيفية استخدام خُطّافات (Git (Git hooks لأتمتة نشر بيئة الإنتاج لتطبيقات Rails على خادم أوبونتو 14.04 عن بُعد. باستخدام خُطّافات Git ستتمكن من نشر التطبيقات عن طريق دفع التغييرات إلى خادم الإنتاج production server، وبدلًا من أن تقوم بكل شيء يدويًّا (مثل ترحيل قاعدة البيانات) فالاستعانة بأحد أشكال النشر الآلي، مثل خُطّافات Git، سيوفر عليك الكثير من الوقت على المدى الطويل. في هذا الدرس سنستخدم خُطّافGit من نوعpost-receive ، بالإضافة إلىPuma كخادم للتطبيق،Nginx كوكيل عكسي لـ Puma و PostgreSQL كقاعدة بيانات. المتطلبات الأساسية سوف تحتاج صلاحيات مستخدم غير جذري non-root والذي يملك امتيازات مستخدم أساسي superuser على خادم أوبونتو. في هذا المثال، سيكون اسم المستخدم deploy. يمكنك تعلم كيفية فعل ذلك في هذا الدرس: الإعداد الابتدائي لخادوم أوبنتو 14.04. إذا كنت ترغب في النشر دون الحاجة لإدخال كلمة المرور، فتأكد من إعداد مفاتيح SSH. سوف تحتاج إلى تثبيت Ruby على خادمك. إذا لم تكن قد فعلت ذلك سلفًا، يمكنك تثبيته جنبًا إلى جنب مع Rails باستخدام rbenv أو RVM. سوف تحتاج أيضًا إلى تطبيق Rails مُدار في مستودع git على جهازك. إذا لم يكن لديك تطبيق في git، فسوف نقدم لك تطبيقًا بسيطًا كمثال لتعمل عليه. لنبدأ على بركة الله. تثبيت PostgreSQL معظم بيئات Rails تستخدم PostgreSQL كقاعدة بيانات، لذلك عليك تثبيته على خادمك الآن. على خادم الإنتاج، قم بتحديث apt-get: sudo apt-get update ثم قم بتثبيت PostgreSQL بهذه التعليمات: sudo apt-get install postgresql postgresql-contrib libpq-dev إنشاء قاعدة بيانات الإنتاج الخاصة بالمستخدم لإبقاء الأمور بسيطةً، سنسمي قاعدة بيانات الإنتاج الخاصة بالمستخدم بنفس اسم التطبيق خاصتك. على سبيل المثال، إذا كان اسم تطبيقك “appname”، فيجب عليك إنشاء مستخدم PostgreSQL بهذه الطريقة: sudo -u postgres createuser -s appname لتعيين كلمة مرور لقاعدة بيانات المستخدم، ادخُل سطر أوامر PostgreSQL هكذا: sudo -u postgres psql بعد ذلك قم بتعيين كلمة المرور لقاعدة بيانات المستخدم “appname” هكذا: \password appname قم بإدخال كلمة المرور التي تريد ثم قم بتأكيدها. اخرج من سطر أوامر PostgreSQL بهذه التعليمة: \q الآن نحن على استعداد لتزويد تطبيقك بمعلومات الاتصال الخاصة بقاعدة البيانات. إعداد تطبيق Rails على جهاز التطوير خاصتك، ستقوم بإعداد تطبيقك لأجل النشر. اختياري: إنشاء تطبيق Rails إن كان لديك تطبيق Rails جاهز للنشر. فيمكنك تخطي هذا القسم والقيام بالتغييرات المناسبة لاحقًا. أمّا إن لم يكن لديك تطبيق جاهز، فإن الخطوة الأولى هي إنشاء تطبيق Rails جديدة. هذه التعليمات ستنشئ تطبيق Rails جديد تحت اسم “appname” في المجلد الرئيسي. لا تتردد في استبدال “appname” بالاسم الذي تريد: cd ~ rails new appname ثم تحوّل إلى مجلد التطبيق: cd appname لأجل تطبيقنا هذا، سوف نقوم بتوليد سقالة scaffold controller لكي يجد تطبيقنا شيءً ليعرضه: rails generate scaffold Task title:string note:text لنتأكدْ الآن من أن تطبيقنا موجود في مستودعgit . تهيئة Git Repo إن لم يكن تطبيقك موجودًا بالفعل في مستودع git لسبب ما، قم بتهيئته وإجراء إلزام أولي initial commit. قم بالتحوّل إلى مجلد التطبيق. في مثالنا، التطبيق يسمى " appname" وهو موضوع في المجلد الرئيسي home directory: cd ~/appname git init git add -A git commit -m 'initial commit' الآن دعونا نُجهّز تطبيقنا لربط الاتصال بقاعدة بيانات الإنتاج لـ PostgreSQL. تحديث إعدادات قاعدة البيانات تحوّل إلى مجلد تطبيقك إن لم تكن بالفعل هناك. في مثالنا، التطبيق يسمى “appname” وهو موضوع في المجلد الرئيسي home directory: cd ~/appname الآن افتح ملف إعداد قاعدة البيانات في محرر النصوص المفضل لديك: vi config/database.yml اعثر على مقطع الإنتاج production section في إعدادات قاعدة بيانات تطبيقك، وقم باستبداله بمعلومات الاتصال بقاعدة بيانات الإنتاج خاصتك. من المفروض أن يبدو كشيء من هذا القبيل (قم باستبدال القيم عند الاقتضاء): config/database.yml excerpt production: <<: *default host: localhost adapter: postgresql encoding: utf8 database: appname_production pool: 5 username: <%= ENV['APPNAME_DATABASE_USER'] %> password: <%= ENV['APPNAME_DATABASE_PASSWORD'] %> احفظ واخرج. هذا الملف يؤكد على أن بيئة الإنتاج الخاصة بالتطبيق ينبغي أن تستخدم قاعدة بيانات PostgreSQL تحت مُسمّى “appname_production” على المضيف المحلي localhost. لاحظ أنه تم إحالة اسم المستخدم وكلمة مرور قاعدة البيانات إلى متغيرات البيئة environment variables. سنقوم بتحديدها على الخادم في وقت لاحق. تحديث Gemfile إذا لم يكن لدى Gemfile خاصتك المكتبة pg (PostgreSQL adapter gem)، ولم تكن المكتبة Puma مُحددة، فيجب عليك إضافتهما الآن. افتح Gemfile الخاص بتطبيقك في المحرّر المفضل لديك: vi Gemfile أضف الأسطر التالية إلىGemfile : Gemfile excerpt group :production do gem 'pg' gem 'puma' end احفظ واخرج. سيحدد هذا النص البرمجي أن بيئة الإنتاج production environment يجب أن تستخدم المكتبات pgوpuma : إعداد Puma قبل إعداد Puma، يجب عليك أن تتحقق من عدد وحدات المعالجة المركزية التي يملكها خادمك. يمكنك بسهولة فعل ذلك على خادمك بهذه التعليمة: grep -c processor /proc/cpuinfo الآن، على جهاز التطوير خاصتك، قم بإضافة إعدادات Puma إلى الإعداد config/puma.rb . افتح الملف في محرر النصوص: vi config/puma.rb انسخ وألصق هذه الإعدادات في الملف: config/puma.rb # Change to match your CPU core count workers 2 # Min and Max threads per worker threads 1, 6 app_dir = File.expand_path("../..", __FILE__) shared_dir = "#{app_dir}/shared" # Default to production rails_env = ENV['RAILS_ENV'] || "production" environment rails_env # Set up socket location bind "unix://#{shared_dir}/sockets/puma.sock" # Logging stdout_redirect "#{shared_dir}/log/puma.stdout.log", "#{shared_dir}/log/puma.stderr.log", true # Set master PID and state locations pidfile "#{shared_dir}/pids/puma.pid" state_path "#{shared_dir}/pids/puma.state" activate_control_app on_worker_boot do require "active_record" ActiveRecord::Base.connection.disconnect! rescue Ac-tiveRecord::ConnectionNotEstablished Ac-tiveRecord::Base.establish_connection(YAML.load_file("#{app_dir}/config/database.yml")[rails_env]) end قم بتغيير العددworkers إلى عدد وحدات المعالجة المركزية لخادمك. يفترض المثال أن لديك اثنان. احفظ واخرج. الآن تم إعداد Puma بموضعlocation تطبيقك وموضع مقبسه socket والمذكرات logs ومعرّفات العمليات PIDS. لا تتردد في تعديل الملف، أو إضافة الخيارات التي تناسبك. ألزمCommit التغييرات الأخيرة: git add -A git commit -m 'added pg and puma' قبل الاستمرار، قم بتوليد المفتاح السري والذي سيتم استخدامه لبيئة الإنتاج الخاصة بتطبيقك: rake secret rake secret sample output: 29cc5419f6b0ee6b03b717392c28f5869eff0d136d8ae388c68424c6e5dbe52c1afea8fbec305b057f4b071db1646473c1f9a62f803ab8386456ad3b29b14b89 سوف تنسخ المُخرجات وتستخدمها لتحديد القيمة SECRET_KEY_BASE الخاصة بتطبيقك في الخطوة التالية. إنشاء النص البرمجي لإطلاق Puma سنقوم بإنشاء نص برمجي للإطلاق (Upstart init script). حتى نتمكن من تشغيل وإيقاف Puma بسهولة، وللتأكد من أنه سيبدأ عند بدء التشغيل. على خادم الإنتاج خاصتك، حمّل أداة Jungle Upstart من مستودع Puma على GitHub وضعها في المجلد الرئيسي: cd ~ wget https://raw.githubusercontent.com/puma/puma/master/tools/jungle/upstart/puma-manager.conf wget https://raw.githubusercontent.com/puma/puma/master/tools/jungle/upstart/puma.conf الآن افتح الملف puma.conf حتى تتمكن من تحرير إعدادات النشر الخاصة بمستخدمPuma : vi puma.conf ابحث عن السطرين الذين يحددان setuid و setgid، و قم باستبدال “apps” باسم النشر الخاص بالمستخدم أو المجموعة خاصتك. على سبيل المثال، إذا كان اسم مستخدم النشر “deploy”، فينبغي أن تكون الأسطر هكذا: puma.conf excerpt 1 of 2 setuid deploy setgid deploy الآن ابحث عن السطر الذي يحتوي:exec /bin/bash <<'EOT'. أضف الأسطر التالية تحته، وتأكد من استبدال اسم المستخدم وكلمة المرور الخاصة ب PostgreSQL، وأضف كذلك rake secret الذي قمت بإنشائه سابقًا: puma.conf excerpt 2 of 2 export APPNAME_DATABASE_USER='appname' export APPNAME_DATABASE_PASSWORD='appname_password' export SECRET_KEY_BASE='rake_secret_generated_above' احفظ واخرج. الآن انسخ النصوص في مجلد خدمات الإطلاق Upstart services: sudo cp puma.conf puma-manager.conf /etc/init النص البرمجي puma-manager.conf يُحدد /etc/puma.conf كمرجع لمعرفة التطبيقات التي يجب إدارتها. دعونا ننشئ ونحرّر هذا الملف الآن: sudo vi /etc/puma.conf كل أسطر هذا الملف يجب أن تتضمن مسارات التطبيقات التي تريد من Puma أن يُديرها. سنقوم بنشر تطبيقنا في مجلد يُسمى “appname” داخل المجلد الرئيسي. في هذا المثال، سيكون كما يلي (تأكد من تعديل المسار ليتناسب مع المكان الذي يتواجد فيه تطبيقك): /etc/puma.conf /home/deploy/appname احفظ واخرج الآن تمّ إعداد تطبيقك لينطلق عند بدء التشغيل بمساعدة Upstart, وهذا يعني أن تطبيقك سيبدأ حتى بعد إعادة إقلاع خادمك. لا تنسى أننا لم ننشر التطبيق حتى الآن، لذلك لسنا جاهزين لتشغيله بعد. تثبيت وإعداد Nginx لجعل التطبيق متاحًا على شبكة الإنترنت، يجب أن تستخدم Nginx كخادم. قم بتثبيت Nginx باستخدام apt-get: sudo apt-get install nginx الآن افتح كتلة الخادم الافتراضي default server block بمحرر النصوص: sudo vi /etc/nginx/sites-available/default استبدل محتويات الملف بالتعليمات البرمجية التالية. تأكد من استبدال الأجزاء الملوّنة باسم المستخدم واسم التطبيق المناسبين. /etc/nginx/sites-available/default upstream app { # Path to Puma SOCK file, as defined previously server unix:/home/deploy/appname/shared/sockets/puma.sock fail_timeout=0; } server { listen 80; server_name localhost; root /home/deploy/appname/public; try_files $uri/index.html $uri @app; location @app { proxy_pass http://app; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; } error_page 500 502 503 504 /500.html; client_max_body_size 4G; keepalive_timeout 10; } احفظ واخرج. سيقوم هذا النص البرمجي بإعداد Nginx كوكيل عكسي، لذلك طلبات HTTP ستُرسل إلى الخادم Puma عبر مقبس يونيكس Unix socket. لا تتردد في إجراء التغييرات التي تراها مناسبةً. لن نقوم بإعادة تشغيل Nginx, فالتطبيق غير موجود بعدُ على الخادم. سنقوم بإعداد التطبيق فيما يلي. إعداد مستودع الإنتاج (git (Prepare Production Git Remote على خادم الإنتاج، قم بتثبيت git بواسطة apt-get: sudo apt-get install git ثم قم بإنشاء مجلد للمستودع البعيد remote repository. سنقوم بإنشاء مجلد git أوّلي في المجلد الرئيسي وسنسميه “appname_production”. يمكنك تسمية المستودع البعيد كما تريد (ولكن لا تضعه في ~/appnameلأنه المكان الذي سننشر فيه التطبيق): mkdir ~/appname_production cd ~/appname_production git init –bare بما أن هذا المستودع أوّلي، فلا يوجد مجلّد عمل بعدُ وجميع الملفات الموجودة في .git موجودة في المجلد الرئيسي نفسه. نحن بحاجة إلى إنشاء خُطّاف git من نوعpost-receive ، والذي هو النص البرمجي الذي سيتم تشغيله عندما يتلقى خادم الإنتاج دفعةً من git(git push). افتح الملف hooks/post-receive في محرر النصوص: vi hooks/post-receive انسخ وألصق النص التالي في الملف post-receive: hooks/post-receive #!/bin/bash GIT_DIR=/home/deploy/appname_production WORK_TREE=/home/deploy/appname export APPNAME_DATABASE_USER='appname' export APPNAME_DATABASE_PASSWORD='appname_password' export RAILS_ENV=production . ~/.bash_profile while read oldrev newrev ref do if [[ $ref =~ .*/master$ ]]; then echo "Master ref received. Deploying master branch to produc-tion..." mkdir -p $WORK_TREE git --work-tree=$WORK_TREE --git-dir=$GIT_DIR checkout -f mkdir -p $WORK_TREE/shared/pids $WORK_TREE/shared/sockets $WORK_TREE/shared/log # start deploy tasks cd $WORK_TREE bundle install rake db:create rake db:migrate rake assets:precompile sudo restart puma-manager sudo service nginx restart # end deploy tasks echo "Git hooks deploy complete" else echo "Ref $ref successfully received. Doing nothing: only the mas-ter branch may be deployed on this server." fi done تأكد من تحديث القيم التالية: GIT_DIR :مجلد المستودع الأولي لـ (git (bare git repository الذي قمت بإنشائه في وقت سابق WORK_TREE : المجلد حيث تريد نشر تطبيقك (يجب أن يتطابق مع الموضع الذي قمت بتحديده في إعدادات Puma) APPNAME_DATABASE_USER :اسم مستخدم PostgreSQL (ضروري لمهام rake ) APPNAME_DATABASE_PASSWORD : كلمة مرور PostgreSQL (ضروري لمهام rake ) بعد ذلك، يجب عليك مراجعة التعليمات الموجودة بين التعليقين # start deploy tasks و # end deploy tasks. هذه هي التعليمات التي سيتم تشغيلها في كل مرة يتم دفع push الشعبة الرئيسية master branch إلى مستودع الإنتاج في(git (appname_production. إذا تركتها كما هي، فسيحاول الخادم القيام بما يلي بالنسبة لبيئة الإنتاج الخاصة بتطبيقك: تشغيل المُحزّم bundler إنشاء قاعدة بيانات ترحيل قاعدة البيانات الترجمة الأوليةPrecompile للأصول assets إعادة تشغيل Puma إعادة تشغيل Nginx إذا كنت ترغب في إجراء أية تغييرات أو أي إضافات للتحقق من الأخطاء، لا تتردد في القيام بذلك. بمجرد الانتهاء من مراجعة النص البرمجي احفظه واخرج. بعد ذلك، اجعل البرنامج النصي قابلًا للتنفيذ: chmod +x hooks/post-receive Sudo بلا كلمة مرور Passwordless Sudo لأن الخُطّاف post-receive يحتاج إلى تشغيل تعليماتsudo ، فسنسمح للمستخدم deploy باستخدام sudo بدون كلمة مرور(استبدل اسم المستخدمdeploy في حال اخترت اسمًا مختلفًا): sudo sh -c 'echo "deploy ALL=(ALL) NOPASSWD:ALL" > /etc/sudoers.d/90-deploy' هذا سيسمح للمستخدم deploy بتشغيل التعليمة sudo دون الحاجة لإعطاء كلمة المرور. ربما تريد أن تُقيّد التعليمات التي يمكن للمستخدمdeploy القيام بها. وكحد أدنى، عليك استخدام مفتاح المصادقة SSH كما عليك تعطيل المصادقة بكلمة المرور password authentication. إضافة Production Git Remote الآن بعد أن أعددنا كل شيء لخادم الإنتاج، دعونا نضيف production git remote لمستودع التطبيق خاصتنا. على جهاز التطوير خاصتك، تأكد من أنك في مجلد التطبيق: cd ~/appname ثم قم بإضافة مستودع git بعيد (git remote) جديد تحت اسم “production” والذي يشير إلى مستودع git الأولي appname_production الذي أنشأته على خادم الإنتاج. استبدل اسم المستخدم (deploy) وعنوان الـ IP الخاص بالخادم واسم المستودع البعيد (appname_production): git remote add production deploy@production_server_public_IP:appname_production لقد صار تطبيقك الآن جاهزًا للنشر بواسطة git push. النشر للإنتاج Deploy to Production بعد كل الإعدادات التي قمنا بها، يمكنك الآن نشر تطبيقك على الخادم خاصتك عن طريق تشغيل تعليمات git التالية: git push production master هذا سيدفع push شعبتك الرئيسية المحلية local master branch إلى مستودع الإنتاج البعيد production remote الذي قمت بإنشائه سابقًا. عندما يتلقى production remote أمر الدفع، فسينفّذ النصَّ البرمجي post-receive الذي أعددناه في وقت سابق. إذا قمت بكل شيء بشكل صحيح، فيجب أن يكون تطبيقك متاحًا الآن على عنوان الـ IP العام لخادم الإنتاج خاصتك. إذا كنت تستخدم التطبيق التعليمي لهذا الدرس، فمن المفروض أن تكون قادرًا على الوصول إلى http://production_server_IP/tasks من أيّ متصفح و من المفروض أن ترى شيئًا من هذا القبيل: الخلاصة في أي وقت تقوم بإجراء تغيير على تطبيقك، يمكنك تشغيل نفس التعليمة git push للنشر على خادم الإنتاج خاصتك. هذا لوحده من المفروض أن يوفر عليك الكثير من الوقت على مدى عمر المشروع. لقد شمل هذا الدرس فقط الخطّافات من نوع “post-receive”، ولكن هناك عدة أنواع أخرى من الخطّافات التي يمكن أن تساعدك على تحسين أتمتة عملية النشر. ترجمة -وبتصرّف- للمقال How To Deploy a Rails App with Git Hooks on Ubuntu 14.04 لصاحبه Mitchell Anicas -

 تزيد أحجام قواعد البيانات مع الوقت حتى تتجاوز أحيانًا المساحة اﻷصلية التي خُصِّصت لها، وقد تواجهك مشاكل في المدخلات والمخرجات I/O إن كانت قاعدة البيانات موجودة في نفس القسم “Partition” الموجود به بقية نظام التشغيل. وسنتعلم في هذا الدليل كيفية نقل مجلد البيانات في نظام PostgreSQL لإدارة قواعد البيانات إلى مكان جديد في حالة كنت تريد إضافة مساحة جديدة أو تبحث في طرق لتحسين الأداء، أو الاستفادة من مزايا التخزين الأخرى التي توفرها أنظمة مصفوفات الأقراص المستقلة RAID، أو عُقّدُ التخزين الشبكية “Network Block Storages”، أو غيرها من الأجهزة وأنظمة التخزين. المتطلبات خادم يعمل بتوزيعة أوبنتو 16.04، عليها مستخدم له صلاحية sudo -انتبه، ليس المستخدم الجذر root-. خادم PostgreSQL، يمكنك قراءة كيفية تثبيت واستخدام PostgreSQL على أوبنتو في هذا المقال. وسننقل البيانات إلى وحدة تخزينية “Block Storage Device” لها نقطة الضم التالية /mnt/volume-nyc1-01. فائدة: تكون اﻷقراص أو اﻷجهزة/الوحدات “Devices”بشكل عام في أنظمة لينكس عبارة عن ملفات، وكل جهاز “قسم/partition من القرص الصلب مثلًا” له نقطة ضم “mount point” يكون فيها محتواه. الخطوة الأولى: نقل مجلد بيانات PostgreSQL سنبدأ جلسة PostgreSQL تفاعلية أولًا كي نتحقق من المكان الحالي للمجلد، وسنستخدم أمر psql للدخول إلى شاشة تفاعلية “interactive monitor”، ثم نضيفu postgres- لتخبر sudo أن ينفِّذ أمر psql كمستخدم postgre. $ sudo -u postgres psql وبمجرد دخولك إلى الشاشة، اطلب عرض مجلد البيانات: postgres=# SHOW data_directory; وسيكون الخرج في حالتنا هكذا: data_directory ------------------------------ /var/lib/postgresql/9.5/main (1 row) ويؤكد هذا الخرج أن PostgreSQL مُعدَّ لاستخدام مجلد البيانات الافتراضي main الموجود في المسار ذي اللون الأحمر بالأعلى، إذًا هذا هو المجلد الذي سننقله. اكتب q\ للخروج بمجرد أن تتأكد من وجود المجلد في النظام. سنوقف PostgreSQL لضمان سلامة البيانات، قبل أن نغيّر شيئًا في مجلد main: $ sudo systemctl stop postgresql ثم نستعلم عن حالة PostgreSQL لنتأكد أنها أُوقِفَت، إذ أن systemctl ﻻ يعرض نتائج أوامر إدارة الخدمات في النظام: $ sudo systemctl status postgresql وتتأكد أنها أوقفت إن كان السطر الأخير في الخرج يقول لك إن الخادم قد توقف: . . . Jul 22 16:22:44 ubuntu-512mb-nyc1-01 systemd[1]: Stopped PostgreSQL RDBMS. والآن، سننسخ مجلد البيانات الحالي إلى مكان جديد باستخدام rsync، مع استخدام لاحقة a- للحفاظ على الصلاحيات وبقية خصائص المجلد، وv- لعرض خرج مفصّل كي تتابع ما يحدث. ملاحظة: تأكد من عدم وجود شرطة مائلة بعد اسم المجلد، والتي قد تضاف تلقائيًا إن استخدمت زر tab لإكمال النصوص، إذ أن rsync سيضع محتوى المجلد في نقطة الضم بدلًا من مجلد محتوي لـ PostgreSQL. سنبدأ rsync من مجلد postgresql من أجل محاكاة هيكل المجلد الأصلي في المكان الجديد، وسنتجنب مشاكل الصلاحيات للترقيات المستقبلية عبر إنشاء مجلد postgresql داخل نقطة الضم “mount point” والإبقاء على ملكيته لمستخدم PostgreSQL. ونحن لا نحتاج هنا إلى مجلد الإصدار 9.5 بما أننا حددنا مكان المجلد بوضوح في ملفpostgresql.conf، لكن ﻻ بأس باتباع أسلوب المشروع خاصة إن كانت هناك حاجة في المستقبل لتشغيل عدة إصدارات من PostgreSQL: $ sudo rsync -av /var/lib/postgresql /mnt/volume-nyc1-01 وسنعيد تسمية المجلد الحالي مع امتداد bak. ونبقي عليه حتى نتأكد أن النقل تم بنجاح، ونحن نعيد تسميته من أجل تجنب أي لبس قد يحدث من ملفات موجودة في كلا من المكان القديم والجديد: $ sudo mv /var/lib/postgresql/9.5/main /var/lib/postgresql/9.5/main.bak وبهذا نكون جاهزين لننتقل إلى ضبط إعدادات PostgreSQL. الخطوة الثانية: التوجيه إلى المكان الجديد للبيانات تُضبط القيمة الافتراضية لـ data_directory في إعدادات PostgreSQL على أنه موجود في هذا المسار: /var/lib/postgresql/9.5/main وتوجد هذه الإعدادات في ملف postgresql.conf، وسنغيّر الآن تلك الإعدادات لنضع المكان الجديد لمجلد البيانات: $ sudo nano /etc/postgresql/9.5/main/postgresql.conf ابحث عن السطر الذي يبدأ بكلمة data_directory وغيّر مساره إلى المسار الموجود فيه المجلد الجديد، وفي حالتنا فإن هذا السطر يجب أن يبدو هكذا بعد تغيير المسار: . . . data_directory = '/mnt/volume-nyc1-01/postgresql/9.5/main' . . . الخطوة الثالثة: إعادة تشغيل PostgreSQL نحن الآن جاهزون لتشغيل PostgreSQL، الصق الأمر الأول لتشغيله، والثاني لمعرفة حالته: $ sudo systemctl start postgresql $ sudo systemctl status postgresql افتح شاشة PostgreSQL التفاعلية: $ sudo -u postgres psql اطلب عرض قيمة data_directory لنتأكد أن مجلد البيانات الجديد هو المستخدَم الآن: postgres=# SHOW data_directory; يجب أن يكون الخرج هكذا في حالتنا: data_directory ----------------------------------------- /mnt/volume-nyc1-01/postgresql/9.5/main (1 row) وننتهز هذه الفرصة بما أننا أعدنا تشغيل PostgreSQL وتأكدنا أنه يستخدم المكان الجديد، كي نتأكد أن قاعدة البيانات تعمل بكفاءة. احذف مجلد البيانات الاحتياطي -القديم- بمجرد أن تتأكد من سلامة أي بيانات موجودة مسبقًا: $ sudo rm -Rf /var/lib/postgresql/9.5/main.bak أعد تشغيل PostgreSQL مرة أخيرة للتأكد من أنها تعمل كما يجب: $ sudo systemctl start postgresql $ sudo systemctl status postgresql الخلاصة يجب أن تستخدم قاعدةُ بياناتك الآن المجلدَ الجديد في المكان الذي اخترتَه له، وهذا يعني أنك تستطيع الآن زيادة حجم قاعدة البيانات بما أنك نقلتها من المكان القديم ذي المساحة المحدودة. ترجمة -بتصرف- لمقال How To Move a PostgreSQL Data Directory to a New Location on Ubuntu 16.04 لصاحبته Melissa Anderson
تزيد أحجام قواعد البيانات مع الوقت حتى تتجاوز أحيانًا المساحة اﻷصلية التي خُصِّصت لها، وقد تواجهك مشاكل في المدخلات والمخرجات I/O إن كانت قاعدة البيانات موجودة في نفس القسم “Partition” الموجود به بقية نظام التشغيل. وسنتعلم في هذا الدليل كيفية نقل مجلد البيانات في نظام PostgreSQL لإدارة قواعد البيانات إلى مكان جديد في حالة كنت تريد إضافة مساحة جديدة أو تبحث في طرق لتحسين الأداء، أو الاستفادة من مزايا التخزين الأخرى التي توفرها أنظمة مصفوفات الأقراص المستقلة RAID، أو عُقّدُ التخزين الشبكية “Network Block Storages”، أو غيرها من الأجهزة وأنظمة التخزين. المتطلبات خادم يعمل بتوزيعة أوبنتو 16.04، عليها مستخدم له صلاحية sudo -انتبه، ليس المستخدم الجذر root-. خادم PostgreSQL، يمكنك قراءة كيفية تثبيت واستخدام PostgreSQL على أوبنتو في هذا المقال. وسننقل البيانات إلى وحدة تخزينية “Block Storage Device” لها نقطة الضم التالية /mnt/volume-nyc1-01. فائدة: تكون اﻷقراص أو اﻷجهزة/الوحدات “Devices”بشكل عام في أنظمة لينكس عبارة عن ملفات، وكل جهاز “قسم/partition من القرص الصلب مثلًا” له نقطة ضم “mount point” يكون فيها محتواه. الخطوة الأولى: نقل مجلد بيانات PostgreSQL سنبدأ جلسة PostgreSQL تفاعلية أولًا كي نتحقق من المكان الحالي للمجلد، وسنستخدم أمر psql للدخول إلى شاشة تفاعلية “interactive monitor”، ثم نضيفu postgres- لتخبر sudo أن ينفِّذ أمر psql كمستخدم postgre. $ sudo -u postgres psql وبمجرد دخولك إلى الشاشة، اطلب عرض مجلد البيانات: postgres=# SHOW data_directory; وسيكون الخرج في حالتنا هكذا: data_directory ------------------------------ /var/lib/postgresql/9.5/main (1 row) ويؤكد هذا الخرج أن PostgreSQL مُعدَّ لاستخدام مجلد البيانات الافتراضي main الموجود في المسار ذي اللون الأحمر بالأعلى، إذًا هذا هو المجلد الذي سننقله. اكتب q\ للخروج بمجرد أن تتأكد من وجود المجلد في النظام. سنوقف PostgreSQL لضمان سلامة البيانات، قبل أن نغيّر شيئًا في مجلد main: $ sudo systemctl stop postgresql ثم نستعلم عن حالة PostgreSQL لنتأكد أنها أُوقِفَت، إذ أن systemctl ﻻ يعرض نتائج أوامر إدارة الخدمات في النظام: $ sudo systemctl status postgresql وتتأكد أنها أوقفت إن كان السطر الأخير في الخرج يقول لك إن الخادم قد توقف: . . . Jul 22 16:22:44 ubuntu-512mb-nyc1-01 systemd[1]: Stopped PostgreSQL RDBMS. والآن، سننسخ مجلد البيانات الحالي إلى مكان جديد باستخدام rsync، مع استخدام لاحقة a- للحفاظ على الصلاحيات وبقية خصائص المجلد، وv- لعرض خرج مفصّل كي تتابع ما يحدث. ملاحظة: تأكد من عدم وجود شرطة مائلة بعد اسم المجلد، والتي قد تضاف تلقائيًا إن استخدمت زر tab لإكمال النصوص، إذ أن rsync سيضع محتوى المجلد في نقطة الضم بدلًا من مجلد محتوي لـ PostgreSQL. سنبدأ rsync من مجلد postgresql من أجل محاكاة هيكل المجلد الأصلي في المكان الجديد، وسنتجنب مشاكل الصلاحيات للترقيات المستقبلية عبر إنشاء مجلد postgresql داخل نقطة الضم “mount point” والإبقاء على ملكيته لمستخدم PostgreSQL. ونحن لا نحتاج هنا إلى مجلد الإصدار 9.5 بما أننا حددنا مكان المجلد بوضوح في ملفpostgresql.conf، لكن ﻻ بأس باتباع أسلوب المشروع خاصة إن كانت هناك حاجة في المستقبل لتشغيل عدة إصدارات من PostgreSQL: $ sudo rsync -av /var/lib/postgresql /mnt/volume-nyc1-01 وسنعيد تسمية المجلد الحالي مع امتداد bak. ونبقي عليه حتى نتأكد أن النقل تم بنجاح، ونحن نعيد تسميته من أجل تجنب أي لبس قد يحدث من ملفات موجودة في كلا من المكان القديم والجديد: $ sudo mv /var/lib/postgresql/9.5/main /var/lib/postgresql/9.5/main.bak وبهذا نكون جاهزين لننتقل إلى ضبط إعدادات PostgreSQL. الخطوة الثانية: التوجيه إلى المكان الجديد للبيانات تُضبط القيمة الافتراضية لـ data_directory في إعدادات PostgreSQL على أنه موجود في هذا المسار: /var/lib/postgresql/9.5/main وتوجد هذه الإعدادات في ملف postgresql.conf، وسنغيّر الآن تلك الإعدادات لنضع المكان الجديد لمجلد البيانات: $ sudo nano /etc/postgresql/9.5/main/postgresql.conf ابحث عن السطر الذي يبدأ بكلمة data_directory وغيّر مساره إلى المسار الموجود فيه المجلد الجديد، وفي حالتنا فإن هذا السطر يجب أن يبدو هكذا بعد تغيير المسار: . . . data_directory = '/mnt/volume-nyc1-01/postgresql/9.5/main' . . . الخطوة الثالثة: إعادة تشغيل PostgreSQL نحن الآن جاهزون لتشغيل PostgreSQL، الصق الأمر الأول لتشغيله، والثاني لمعرفة حالته: $ sudo systemctl start postgresql $ sudo systemctl status postgresql افتح شاشة PostgreSQL التفاعلية: $ sudo -u postgres psql اطلب عرض قيمة data_directory لنتأكد أن مجلد البيانات الجديد هو المستخدَم الآن: postgres=# SHOW data_directory; يجب أن يكون الخرج هكذا في حالتنا: data_directory ----------------------------------------- /mnt/volume-nyc1-01/postgresql/9.5/main (1 row) وننتهز هذه الفرصة بما أننا أعدنا تشغيل PostgreSQL وتأكدنا أنه يستخدم المكان الجديد، كي نتأكد أن قاعدة البيانات تعمل بكفاءة. احذف مجلد البيانات الاحتياطي -القديم- بمجرد أن تتأكد من سلامة أي بيانات موجودة مسبقًا: $ sudo rm -Rf /var/lib/postgresql/9.5/main.bak أعد تشغيل PostgreSQL مرة أخيرة للتأكد من أنها تعمل كما يجب: $ sudo systemctl start postgresql $ sudo systemctl status postgresql الخلاصة يجب أن تستخدم قاعدةُ بياناتك الآن المجلدَ الجديد في المكان الذي اخترتَه له، وهذا يعني أنك تستطيع الآن زيادة حجم قاعدة البيانات بما أنك نقلتها من المكان القديم ذي المساحة المحدودة. ترجمة -بتصرف- لمقال How To Move a PostgreSQL Data Directory to a New Location on Ubuntu 16.04 لصاحبته Melissa Anderson -
 حاوية لينكس هي مجموعة من العمليات المعزولة عن بقية النظام من خلال استخدام ميزات أمان نواة لينكس، مثل مساحات الأسماء ومجموعات التحكم. إنها بناء مماثل للآلة الافتراضية، و لكنه أكثر خفة منها، فإن لم يكن لديك النفقات الكافية لتشغيل أنوية إضافية أو آلات افتراضية فلا تقلق من ذلك، لأنه يمكنك بسهولة إنشاء حاويات متعددة على نفس الخادوم. على سبيل المثال، تخيل أن لديك خادوم يقوم بتشغيل مواقع ويب متعددة لعملائك. في حال التثبيت التقليدي سيكون كل موقع على شبكة الانترنت مضيفًا افتراضيًا من نفس حالة خادوم apache أو Nginx. ولكن مع حاويات لينكس يمكن لكل موقع على شبكة الإنترنت أن يثبت في حاوية خاصة به مع خادوم الويب الخاص بها. باستخدام حاويات لينكس يمكنك تجميع التطبيق الخاص بك واعتمادياته في حاوية دون التأثير على بقية النظام. يتيح لك LXD إنشاء هذه الحاويات وإدارتها. يوفر LXD خدمة مراقب الأجهزة الافتراضية لإدارة دورة الحياة الكاملة للحاويات. في هذا الدرس سوف نقوم بإعداد LXD واستخدامه لتشغيل Nginx في حاوية. وستقوم بعد ذلك بتوجيه حركة المرور إلى الحاوية من أجل جعل موقع الويب ممكن الوصول إليه من الإنترنت. المتطلبات الأساسية لإكمال هذا الدرس ستحتاج إلى ما يلي: خادوم أوبونتو 16.04 مُعَد مسبقا ، يمكنك الرجوع إلى هذه المقال لتعرف كيف تفعل ذلك: الإعداد الابتدائي لخادوم أوبنتو 14.04 مستخدم غير جذر يملك صلاحيات الجذر وجدار الحماية. اختياريًا أضف 20 جيغا أو أكثر من مساحة التخزين ، يمكنك استخدام ذلك لتخزين كافة البيانات المتعلقة بالحاويات. الخطوة 1 : إعداد LXD تم تثبيت LXD بالفعل على أوبونتو، ولكن يجب أن يتم إعداده بشكل مناسب قبل أن تتمكن من استخدامه على الخادوم. يجب عليك إعداد حساب المستخدم لإدارة الحاويات، ثم إعداد نوع قاعدة التخزين لتخزين الحاويات وإعداد الشبكة. قم بتسجيل الدخول إلى الخادوم باستخدام حساب المستخدم غير الجذر. ثم أضف المستخدم إلى مجموعة LXD بحيث يمكنك استخدامه لأداء جميع مهام إدارة الحاويات: sudo usermod --append --groups lxd Sammy قم بتسجيل الخروج من الخادوم وتسجيل الدخول مرة أخرى لكي يتم تحديث جلسة SSH الجديدة الخاصة بك مع عضوية المجموعة الجديدة. بعد تسجيل الدخول يمكنك البدء في تهيئة LXD. الآن قم بإعداد قاعدة التخزين. قاعدة التخزين الموصى بها ل LXD هو نظام ملفات ZFS، المخزنة إما في ملف مخصص مسبقًا أو باستخدام كتلة التخزين . لاستفادة من دعم ZFS في LXD حدّث قائمة الحزم الخاصة بك ثم ثبت الحزمة zfsutils-linux : sudo apt-get update sudo apt-get install zfsutils-linux يمكنك الآن إعداد LXD. ابدأ بعملية تهيئة LXD مع الأمر LXD init : sudo lxd init ستتم مطالبتك بتعيين تفاصيل قاعدة التخزين. بعد الانتهاء من هذا الإعداد يتوجب عليك إعداد الشبكة من أجل الحاويات. أولاً سوف يُقترح عليك أن تختار بشأن قاعدة التخزين، وستُخَير بين أمرين: dir أو zfs . الخيار dir يخبر LXD بتخزين الحاويات في مجلدات تابعة لنظام ملفات الخادوم. وأما الخيار zfs فيستخدم نظام الملفات zfs ونظام إدارة القرص الصلب LVM. اختر zfs. باستخدام zfs نحصل على كلٍّ من كفاءة التخزين وتحسين الاستجابة. على سبيل المثال إذا أنشأنا عشرة حاويات من نفس صورة الحاوية الأولية، فإنها جميعا تستخدم من القرص مساحةَ حاوية واحدة فقط. وبعد ذلك سيتم فقط تخزين التغييرات على صورة الحاوية الأولى في قاعدة التخزين. Name of the storage backend to use (dir or zfs) [default=zfs]: zfs بعد اختيار zfs سيُطلَب منك إنشاء تجمع (pool) zfs جديد واسم لهذا التجمع. اختر نعم لإنشاء التجمع، وسمه ب lxd : Create a new ZFS pool (yes/no) [default=yes]? yes Name of the new ZFS pool [default=lxd]: lxd ثم ستُسأل إذا كنت ترغب في استخدام عتاد التخزين الموجود: Would you like to use an existing block device (yes/no) [default=no] إذا أجبت بنعم فعليك أن تخبر LXD أين يجد هذا العتاد. إذا أجبت بلا فسوف يقوم LXD باستخدام ملف مخصص مسبقًا. مع هذا الخيار سوف تستخدم المساحة الفارغة على الخادوم نفسه. هناك حالتان يتبعان ذلك اعتمادًا على ما إذا كنت تريد استخدام ملف مخصص مسبقًا أو عتاد التخزين. اتبع الخطوة المناسبة لحالتك. بعد تحديد آلية التخزين ستعمل على تهيئة خيارات الشبكة من أجل حاوياتك. الخيار 1 : استخدام التخصيص المسبق يمكنك استخدام ملف مخصص مسبقًا إذا لم تتمكن من الوصول إلى عتاد التخزين من أجل تخزين الحاويات. اتبع هذه الخطوات لإعداد LXD لكي يستخدم ملف مخصص مسبقًا لتخزين الحاويات. أولًا، عندما يطلب منك استخدام عتاد التخزين الموجود أجب بلا : Would you like to use an existing block device (yes/no) [default=no]? no بعد ذلك، سيطلب منك تحديد حجم loop device ، الذي يستدعيه الملف المخصص مسبقًا من LXD. استخدام الحجم الافتراضي المقترح للملف المخصص مسبقًا : Size in GB of the new loop device (1GB minimum) [default=15]: 15 وكقاعدة عامة 15 جيغا هو أصغر حجم يجب عليك إنشاؤه. فأنت تريد تخصيص مساحة كافية لكي يكون لديك 10 غيغابايت على الأقل من المساحة المتبقية بعد إنشاء الحاويات الخاصة بك. بعد تهيئة الجهاز سيطلب منك إعداد الشبكة. انتقل إلى الخطوة 2 لمتابعة الإعداد. الخيار 2 : استخدام عتاد التخزين إذا كنت تريد استخدام عتاد التخزين قاعدةً للتخزين فستحتاج إلى العثور على العتاد الذي يتوافق مع حجم كتلة التخزين التي قمت بإنشائها في تهيئة LXD. انتقل إلى تبويب المجلدات في لوحة التحكم الخاصة ب DigitalOcean، ثم حدد موقع وحدة التخزين الخاصة بك، انقر فوق المزيد من القائمة المنبثقة، ثم انقر فوق تعليمات الإعداد. حدد موقع العتاد بتطبيق أمر تهيئة وحدة التخزين. بعبارة أدق ابحث عن المسار المحدد بتنفيذ الأمر sudo mkfs.ext4 -F . لا تقم بتشغيل أيٍّ من الأوامر الظاهرة في تلك الصفحة، نحن لا نريد سوى العثور على اسم الجهاز الصحيح لإعطاءه لـ LXD. يوضح الشكل التالي مثالا عن اسم الجهاز الخاص بوحدة التخزين. تحتاج فقط إلى الجزء المسطر عليه بالأحمر: يمكنك أيضا تحديد اسم الجهاز بالأمر التالي: ls -l /dev/disk/by-id/ total 0 lrwxrwxrwx 1 root root 9 Sep 16 20:30 scsi-0DO_Volume_volume-fra1-01 -> ../../sda في هذه الحالة اسم الجهاز لوحدة التخزين هو /dev/disk/by-id/scsi-0D0_Volume_volume-fra1-01 وقد يختلف الأمر لديك. بعد تحديد اسم عتاد وحدة التخزين تابع مع تثبيت LXD . عندما تُسأل هل تود أن تستخدم عتاد التخزين الموجود، اختر نعم وقدّم المسار الذي وجدته سابقا: Would you like to use an existing block device (yes/no) [default=no]? yes Path to the existing block device: /dev/disk/by-id/scsi-0DO_Volume_volume-fra1-01 بعد تحديد القرص الصلب سيطلب منك إعداد خيارات الشبكة. الخطوة 2 : إعدادات الشبكة بعد تهيئة وحدة التخزين ستتم مطالبتك بتهيئة الشبكة وإعدادها. أولاً سيسألك LXD عما إذا كنت تريد جعله متاحًا عبر الشبكة. اختيار “نعم” سوف يمكّنك من إدارة LXD من جهاز الكمبيوتر المحلي الخاص بك، دون الحاجة إلى جلسة SSH للوصول إلى هذا الخادوم. اقبل القيمة الافتراضية “لا” : Output of the "lxd init" command — LXD over the network Would you like LXD to be available over the network (yes/no) [default=no]? no ثم سيطلب منك إنشاء جسر الشبكة من أجل حاويات LXD. وهذا يتيح لك الميزات التالية: كل حاوية تحصل تلقائيًا على عنوان IP خاص. يمكن للحاويات التواصل مع بعضها البعض عبر الشبكة الخاصة. يمكن لكل حاوية انشاء اتصال بالإنترنت. تبقى الحاويات التي تقوم بإنشائها غير قابلة للوصول إليها من الإنترنت. لا يمكنك إجراء اتصال من الإنترنت والوصول إلى حاوية إلا إذا قمت بتمكينه صراحة. سوف تتعلم كيفية السماح بالوصول إلى حاوية معينة في الخطوة التالية. عندما يطلب منك تكوين جسر LXD، اختر نعم : Output of the "lxd init" command — Networking for the containers Do you want to configure the LXD bridge (yes/no) [default=yes]? Yes سيتم عرض الرسالة التالية: أكّد أنك تريد إعداد جسر الشبكة. سيطلب منك تسمية الجسر. اقبل القيمة الافتراضية. سيطلب منك إجراء تهيئة الشبكة لكلٍّ من IPv4 و IPv6. في هذا الدرس سنعمل فقط مع IPv4. عندما يطلب منك إعداد شبكة فرعية IPv4 اختر نعم . سوف يتم إعلامك بأنه تم إنشاء شبكة فرعية عشوائية بالنسبة لك. اختر موافق للمتابعة. عند المطالبة بعنوان IPv4 صحيح قم بقبول القيمة الافتراضية. عندما يطلب منك قناع CIDR صحيح، اقبل القيمة الافتراضية. عند المطالبة بعنوان DHCP الأول اقبل القيمة الافتراضية. افعل الشيء نفسه مع عنوان DHCP الأخير وذلك حسب الحد الأقصى لعدد عملاء DHCP. اختر نعم عندما يطلب إلى NAT حركة مرور IPv4. عندما يطلب منك إعداد شبكة فرعية لـ IPv6 اختر “لا” . ستشاهد المخرجات التالية بعد اكتمال إعداد الشبكات: Warning: Stopping lxd.service, but it can still be activated by: lxd.socket LXD has been successfully configured. أنت مستعد الآن لإعداد حاوياتك. الخطوة 3 : إنشاء حاوية Nginx لقد نجحت في تهيئة LXD وأصبحت الآن جاهزا لإنشاء الحاوية الأولى وإدارتها. يمكنك إدارة الحاويات مع الأمر lxc. استخدم lxc list لعرض الحاويات المثبتة المتاحة: lxc list سترى الإخراج التالي: Generating a client certificate. This may take a minute... If this is your first time using LXD, you should also run: sudo lxd init To start your first container, try: lxc launch ubuntu:16.04 +------+-------+------+------+------+-----------+ | NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS | +------+-------+------+------+------+-----------+ وبما أن هذه هي المرة الأولى التي يتواصل فيها الأمر lxc مع مراقب الأجهزة الافتراضية لـ LXD تتيح لك مخرجاته معرفة أنه قام تلقائيًا بإنشاء شهادة للعميل من أجل الاتصال الآمن مع LXD، وبعض المعلومات حول كيفية تشغيل حاوية، وقائمة فارغة من الحاويات، وهو أمر متوقع لأننا لم ننشئ أي واحدة حتى الآن. دعنا ننشئ حاوية تقوم بتشغيل Nginx. للقيام بذلك سوف نستخدم الأمر lxc launch لإنشاء وبدء حاوية أوبونتو 16.04 اسمها webserver. لإنشاء الحاوية webserver ننفذ الأمر: lxc launch ubuntu:x webserver x في ubuntu:x هو اختصار للحرف الأول من Xenial ، الاسم الرمزي لأوبونتو 16.04. ubuntu: هو معرف للمستودع الذي تم تكوينه مسبقا لصور LXD . يمكنك أيضا استخدام ubuntu:16.04 لاسم الصورة. ملاحظة : يمكنك العثور على القائمة الكاملة لجميع صور ubuntu المتاحة عن طريق تشغيل الأمر: lxc image list Ubuntu: وفي التوزيعات الأخرى عن طريق تشغيل الأمر: lxc image list images: نظرًا لأن هذه هي المرة الأولى التي تقوم فيها بإنشاء حاوية ينزّل هذا الأمرُ صورةَ الحاوية من الإنترنت ويخزنها محليًا بحيث إذا أنشأت حاوية جديدة فسيتم إنشاؤها بسرعة أكبر. سترى هذه المخرجات عند إنشاء الحاوية الجديدة: Generating a client certificate. This may take a minute... If this is your first time using LXD, you should also run: sudo lxd init To start your first container, try: lxc launch ubuntu:16.04 Creating webserver Retrieving image: 100% Starting webserver الآن ..بعد تشغيل الحاوية استخدم الأمر lxc list لعرض معلومات حولها: lxc list تظهر المخرجات جدولًا يحمل اسم كل حاوية وحالتها الحالية وعنوان IP خاص بها ونوعها وما إذا كانت هناك لقطات مأخوذة. Output +-----------+---------+-----------------------+------+------------+-----------+ | NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS | +-----------+---------+-----------------------+------+------------+-----------+ | webserver | RUNNING | 10.10.10.100 (eth0) | | PERSISTENT | 0 | +-----------+---------+-----------------------+------+------------+-----------+ ملاحظة: إذا قمت بتمكين IPv6 في LXD فقد يكون مخرج أمر lxc list كبيرًا جدًا عن أن تسعه الشاشة. يمكنك أن تستخدم بدلا عن ذلك الأمر lxc list –columns ns4tS الذي يظهر فقط الاسم والحالة و IPv4 والنوع وما إذا كانت هناك لقطات متاحة. لاحظ عنوان IPv4 للحاوية. ستحتاج إلى تهيئة الجدار الناري للسماح بالزيارات الواردة من العالم الخارجي. سنتابع في الدرس القادم كيفية تكوين وتوجيه وإزالة حاوية Nginx. ترجمة -وبتصرّف- للمقال How to Set Up and Use LXD on Ubuntu 16.04 لصاحبه Simos Xenitellis
حاوية لينكس هي مجموعة من العمليات المعزولة عن بقية النظام من خلال استخدام ميزات أمان نواة لينكس، مثل مساحات الأسماء ومجموعات التحكم. إنها بناء مماثل للآلة الافتراضية، و لكنه أكثر خفة منها، فإن لم يكن لديك النفقات الكافية لتشغيل أنوية إضافية أو آلات افتراضية فلا تقلق من ذلك، لأنه يمكنك بسهولة إنشاء حاويات متعددة على نفس الخادوم. على سبيل المثال، تخيل أن لديك خادوم يقوم بتشغيل مواقع ويب متعددة لعملائك. في حال التثبيت التقليدي سيكون كل موقع على شبكة الانترنت مضيفًا افتراضيًا من نفس حالة خادوم apache أو Nginx. ولكن مع حاويات لينكس يمكن لكل موقع على شبكة الإنترنت أن يثبت في حاوية خاصة به مع خادوم الويب الخاص بها. باستخدام حاويات لينكس يمكنك تجميع التطبيق الخاص بك واعتمادياته في حاوية دون التأثير على بقية النظام. يتيح لك LXD إنشاء هذه الحاويات وإدارتها. يوفر LXD خدمة مراقب الأجهزة الافتراضية لإدارة دورة الحياة الكاملة للحاويات. في هذا الدرس سوف نقوم بإعداد LXD واستخدامه لتشغيل Nginx في حاوية. وستقوم بعد ذلك بتوجيه حركة المرور إلى الحاوية من أجل جعل موقع الويب ممكن الوصول إليه من الإنترنت. المتطلبات الأساسية لإكمال هذا الدرس ستحتاج إلى ما يلي: خادوم أوبونتو 16.04 مُعَد مسبقا ، يمكنك الرجوع إلى هذه المقال لتعرف كيف تفعل ذلك: الإعداد الابتدائي لخادوم أوبنتو 14.04 مستخدم غير جذر يملك صلاحيات الجذر وجدار الحماية. اختياريًا أضف 20 جيغا أو أكثر من مساحة التخزين ، يمكنك استخدام ذلك لتخزين كافة البيانات المتعلقة بالحاويات. الخطوة 1 : إعداد LXD تم تثبيت LXD بالفعل على أوبونتو، ولكن يجب أن يتم إعداده بشكل مناسب قبل أن تتمكن من استخدامه على الخادوم. يجب عليك إعداد حساب المستخدم لإدارة الحاويات، ثم إعداد نوع قاعدة التخزين لتخزين الحاويات وإعداد الشبكة. قم بتسجيل الدخول إلى الخادوم باستخدام حساب المستخدم غير الجذر. ثم أضف المستخدم إلى مجموعة LXD بحيث يمكنك استخدامه لأداء جميع مهام إدارة الحاويات: sudo usermod --append --groups lxd Sammy قم بتسجيل الخروج من الخادوم وتسجيل الدخول مرة أخرى لكي يتم تحديث جلسة SSH الجديدة الخاصة بك مع عضوية المجموعة الجديدة. بعد تسجيل الدخول يمكنك البدء في تهيئة LXD. الآن قم بإعداد قاعدة التخزين. قاعدة التخزين الموصى بها ل LXD هو نظام ملفات ZFS، المخزنة إما في ملف مخصص مسبقًا أو باستخدام كتلة التخزين . لاستفادة من دعم ZFS في LXD حدّث قائمة الحزم الخاصة بك ثم ثبت الحزمة zfsutils-linux : sudo apt-get update sudo apt-get install zfsutils-linux يمكنك الآن إعداد LXD. ابدأ بعملية تهيئة LXD مع الأمر LXD init : sudo lxd init ستتم مطالبتك بتعيين تفاصيل قاعدة التخزين. بعد الانتهاء من هذا الإعداد يتوجب عليك إعداد الشبكة من أجل الحاويات. أولاً سوف يُقترح عليك أن تختار بشأن قاعدة التخزين، وستُخَير بين أمرين: dir أو zfs . الخيار dir يخبر LXD بتخزين الحاويات في مجلدات تابعة لنظام ملفات الخادوم. وأما الخيار zfs فيستخدم نظام الملفات zfs ونظام إدارة القرص الصلب LVM. اختر zfs. باستخدام zfs نحصل على كلٍّ من كفاءة التخزين وتحسين الاستجابة. على سبيل المثال إذا أنشأنا عشرة حاويات من نفس صورة الحاوية الأولية، فإنها جميعا تستخدم من القرص مساحةَ حاوية واحدة فقط. وبعد ذلك سيتم فقط تخزين التغييرات على صورة الحاوية الأولى في قاعدة التخزين. Name of the storage backend to use (dir or zfs) [default=zfs]: zfs بعد اختيار zfs سيُطلَب منك إنشاء تجمع (pool) zfs جديد واسم لهذا التجمع. اختر نعم لإنشاء التجمع، وسمه ب lxd : Create a new ZFS pool (yes/no) [default=yes]? yes Name of the new ZFS pool [default=lxd]: lxd ثم ستُسأل إذا كنت ترغب في استخدام عتاد التخزين الموجود: Would you like to use an existing block device (yes/no) [default=no] إذا أجبت بنعم فعليك أن تخبر LXD أين يجد هذا العتاد. إذا أجبت بلا فسوف يقوم LXD باستخدام ملف مخصص مسبقًا. مع هذا الخيار سوف تستخدم المساحة الفارغة على الخادوم نفسه. هناك حالتان يتبعان ذلك اعتمادًا على ما إذا كنت تريد استخدام ملف مخصص مسبقًا أو عتاد التخزين. اتبع الخطوة المناسبة لحالتك. بعد تحديد آلية التخزين ستعمل على تهيئة خيارات الشبكة من أجل حاوياتك. الخيار 1 : استخدام التخصيص المسبق يمكنك استخدام ملف مخصص مسبقًا إذا لم تتمكن من الوصول إلى عتاد التخزين من أجل تخزين الحاويات. اتبع هذه الخطوات لإعداد LXD لكي يستخدم ملف مخصص مسبقًا لتخزين الحاويات. أولًا، عندما يطلب منك استخدام عتاد التخزين الموجود أجب بلا : Would you like to use an existing block device (yes/no) [default=no]? no بعد ذلك، سيطلب منك تحديد حجم loop device ، الذي يستدعيه الملف المخصص مسبقًا من LXD. استخدام الحجم الافتراضي المقترح للملف المخصص مسبقًا : Size in GB of the new loop device (1GB minimum) [default=15]: 15 وكقاعدة عامة 15 جيغا هو أصغر حجم يجب عليك إنشاؤه. فأنت تريد تخصيص مساحة كافية لكي يكون لديك 10 غيغابايت على الأقل من المساحة المتبقية بعد إنشاء الحاويات الخاصة بك. بعد تهيئة الجهاز سيطلب منك إعداد الشبكة. انتقل إلى الخطوة 2 لمتابعة الإعداد. الخيار 2 : استخدام عتاد التخزين إذا كنت تريد استخدام عتاد التخزين قاعدةً للتخزين فستحتاج إلى العثور على العتاد الذي يتوافق مع حجم كتلة التخزين التي قمت بإنشائها في تهيئة LXD. انتقل إلى تبويب المجلدات في لوحة التحكم الخاصة ب DigitalOcean، ثم حدد موقع وحدة التخزين الخاصة بك، انقر فوق المزيد من القائمة المنبثقة، ثم انقر فوق تعليمات الإعداد. حدد موقع العتاد بتطبيق أمر تهيئة وحدة التخزين. بعبارة أدق ابحث عن المسار المحدد بتنفيذ الأمر sudo mkfs.ext4 -F . لا تقم بتشغيل أيٍّ من الأوامر الظاهرة في تلك الصفحة، نحن لا نريد سوى العثور على اسم الجهاز الصحيح لإعطاءه لـ LXD. يوضح الشكل التالي مثالا عن اسم الجهاز الخاص بوحدة التخزين. تحتاج فقط إلى الجزء المسطر عليه بالأحمر: يمكنك أيضا تحديد اسم الجهاز بالأمر التالي: ls -l /dev/disk/by-id/ total 0 lrwxrwxrwx 1 root root 9 Sep 16 20:30 scsi-0DO_Volume_volume-fra1-01 -> ../../sda في هذه الحالة اسم الجهاز لوحدة التخزين هو /dev/disk/by-id/scsi-0D0_Volume_volume-fra1-01 وقد يختلف الأمر لديك. بعد تحديد اسم عتاد وحدة التخزين تابع مع تثبيت LXD . عندما تُسأل هل تود أن تستخدم عتاد التخزين الموجود، اختر نعم وقدّم المسار الذي وجدته سابقا: Would you like to use an existing block device (yes/no) [default=no]? yes Path to the existing block device: /dev/disk/by-id/scsi-0DO_Volume_volume-fra1-01 بعد تحديد القرص الصلب سيطلب منك إعداد خيارات الشبكة. الخطوة 2 : إعدادات الشبكة بعد تهيئة وحدة التخزين ستتم مطالبتك بتهيئة الشبكة وإعدادها. أولاً سيسألك LXD عما إذا كنت تريد جعله متاحًا عبر الشبكة. اختيار “نعم” سوف يمكّنك من إدارة LXD من جهاز الكمبيوتر المحلي الخاص بك، دون الحاجة إلى جلسة SSH للوصول إلى هذا الخادوم. اقبل القيمة الافتراضية “لا” : Output of the "lxd init" command — LXD over the network Would you like LXD to be available over the network (yes/no) [default=no]? no ثم سيطلب منك إنشاء جسر الشبكة من أجل حاويات LXD. وهذا يتيح لك الميزات التالية: كل حاوية تحصل تلقائيًا على عنوان IP خاص. يمكن للحاويات التواصل مع بعضها البعض عبر الشبكة الخاصة. يمكن لكل حاوية انشاء اتصال بالإنترنت. تبقى الحاويات التي تقوم بإنشائها غير قابلة للوصول إليها من الإنترنت. لا يمكنك إجراء اتصال من الإنترنت والوصول إلى حاوية إلا إذا قمت بتمكينه صراحة. سوف تتعلم كيفية السماح بالوصول إلى حاوية معينة في الخطوة التالية. عندما يطلب منك تكوين جسر LXD، اختر نعم : Output of the "lxd init" command — Networking for the containers Do you want to configure the LXD bridge (yes/no) [default=yes]? Yes سيتم عرض الرسالة التالية: أكّد أنك تريد إعداد جسر الشبكة. سيطلب منك تسمية الجسر. اقبل القيمة الافتراضية. سيطلب منك إجراء تهيئة الشبكة لكلٍّ من IPv4 و IPv6. في هذا الدرس سنعمل فقط مع IPv4. عندما يطلب منك إعداد شبكة فرعية IPv4 اختر نعم . سوف يتم إعلامك بأنه تم إنشاء شبكة فرعية عشوائية بالنسبة لك. اختر موافق للمتابعة. عند المطالبة بعنوان IPv4 صحيح قم بقبول القيمة الافتراضية. عندما يطلب منك قناع CIDR صحيح، اقبل القيمة الافتراضية. عند المطالبة بعنوان DHCP الأول اقبل القيمة الافتراضية. افعل الشيء نفسه مع عنوان DHCP الأخير وذلك حسب الحد الأقصى لعدد عملاء DHCP. اختر نعم عندما يطلب إلى NAT حركة مرور IPv4. عندما يطلب منك إعداد شبكة فرعية لـ IPv6 اختر “لا” . ستشاهد المخرجات التالية بعد اكتمال إعداد الشبكات: Warning: Stopping lxd.service, but it can still be activated by: lxd.socket LXD has been successfully configured. أنت مستعد الآن لإعداد حاوياتك. الخطوة 3 : إنشاء حاوية Nginx لقد نجحت في تهيئة LXD وأصبحت الآن جاهزا لإنشاء الحاوية الأولى وإدارتها. يمكنك إدارة الحاويات مع الأمر lxc. استخدم lxc list لعرض الحاويات المثبتة المتاحة: lxc list سترى الإخراج التالي: Generating a client certificate. This may take a minute... If this is your first time using LXD, you should also run: sudo lxd init To start your first container, try: lxc launch ubuntu:16.04 +------+-------+------+------+------+-----------+ | NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS | +------+-------+------+------+------+-----------+ وبما أن هذه هي المرة الأولى التي يتواصل فيها الأمر lxc مع مراقب الأجهزة الافتراضية لـ LXD تتيح لك مخرجاته معرفة أنه قام تلقائيًا بإنشاء شهادة للعميل من أجل الاتصال الآمن مع LXD، وبعض المعلومات حول كيفية تشغيل حاوية، وقائمة فارغة من الحاويات، وهو أمر متوقع لأننا لم ننشئ أي واحدة حتى الآن. دعنا ننشئ حاوية تقوم بتشغيل Nginx. للقيام بذلك سوف نستخدم الأمر lxc launch لإنشاء وبدء حاوية أوبونتو 16.04 اسمها webserver. لإنشاء الحاوية webserver ننفذ الأمر: lxc launch ubuntu:x webserver x في ubuntu:x هو اختصار للحرف الأول من Xenial ، الاسم الرمزي لأوبونتو 16.04. ubuntu: هو معرف للمستودع الذي تم تكوينه مسبقا لصور LXD . يمكنك أيضا استخدام ubuntu:16.04 لاسم الصورة. ملاحظة : يمكنك العثور على القائمة الكاملة لجميع صور ubuntu المتاحة عن طريق تشغيل الأمر: lxc image list Ubuntu: وفي التوزيعات الأخرى عن طريق تشغيل الأمر: lxc image list images: نظرًا لأن هذه هي المرة الأولى التي تقوم فيها بإنشاء حاوية ينزّل هذا الأمرُ صورةَ الحاوية من الإنترنت ويخزنها محليًا بحيث إذا أنشأت حاوية جديدة فسيتم إنشاؤها بسرعة أكبر. سترى هذه المخرجات عند إنشاء الحاوية الجديدة: Generating a client certificate. This may take a minute... If this is your first time using LXD, you should also run: sudo lxd init To start your first container, try: lxc launch ubuntu:16.04 Creating webserver Retrieving image: 100% Starting webserver الآن ..بعد تشغيل الحاوية استخدم الأمر lxc list لعرض معلومات حولها: lxc list تظهر المخرجات جدولًا يحمل اسم كل حاوية وحالتها الحالية وعنوان IP خاص بها ونوعها وما إذا كانت هناك لقطات مأخوذة. Output +-----------+---------+-----------------------+------+------------+-----------+ | NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS | +-----------+---------+-----------------------+------+------------+-----------+ | webserver | RUNNING | 10.10.10.100 (eth0) | | PERSISTENT | 0 | +-----------+---------+-----------------------+------+------------+-----------+ ملاحظة: إذا قمت بتمكين IPv6 في LXD فقد يكون مخرج أمر lxc list كبيرًا جدًا عن أن تسعه الشاشة. يمكنك أن تستخدم بدلا عن ذلك الأمر lxc list –columns ns4tS الذي يظهر فقط الاسم والحالة و IPv4 والنوع وما إذا كانت هناك لقطات متاحة. لاحظ عنوان IPv4 للحاوية. ستحتاج إلى تهيئة الجدار الناري للسماح بالزيارات الواردة من العالم الخارجي. سنتابع في الدرس القادم كيفية تكوين وتوجيه وإزالة حاوية Nginx. ترجمة -وبتصرّف- للمقال How to Set Up and Use LXD on Ubuntu 16.04 لصاحبه Simos Xenitellis -
 تعلمنا في الدرس السابق كيفية إعداد LXD وإعداد الشبكة بالإضافة إلى إنشاء حاوية Nginx والآن لنقم بإعداد Nginx داخل الحاوية: الخطوة 4 : تكوين حاوية Nginx لِنتصلْ بالحاوية webserver ولنقم بإعداد خادوم الويب. اتصل بالحاوية بالأمر lxc exec الذي يأخذ اسم الحاوية وأوامر التنفيذ كمدخلات: lxc exec webserver -- sudo --login --user ubuntu يشير المحرف “–” الأول إلى أن مدخلات الأمر lxc يجب أن تتوقف عندها وسيتم تمرير بقية السطر كأمر يتم تنفيذه داخل الحاوية. الأمر هو sudo --login –user Ubuntu وهو الذي سوف يوفر صدفة تسجيل الدخول للحساب ubuntu السابق الإعداد داخل الحاوية. ملاحظة: إذا كنت بحاجة إلى الاتصال بالحاوية باعتبارك جذرًا استخدم الأمر lxc exec webserver -- /bin/bash بدلًا من ذلك. بعدما تدخل إلى الحاوية ستبدو الصدفة الآن كما يلي. ubuntu@webserver:~$ المستخدم ubuntu في الحاوية لديه صلاحيات sudo مُعَدَّة مسبقًا ويمكنه تنفيذ أوامر بصلاحيات الجذر دون المطالبة بإدخال كلمة السر. تقتصر هذه الصدفة على حدود الحاوية. أيُّ شيء تقوم بتشغيله في هذه الصدفة سيبقى في الحاوية ولا يمكن الذهاب به إلى الخادوم المضيف. لنقم بإعداد Nginx في هذه الحاوية. حدّث قائمة حزم ubuntu داخل الحاوية وثبت Nginx: sudo apt-get update sudo apt-get install nginx ثم قم بتحرير صفحة الويب الافتراضية لهذا الموقع وأضف بعض الجمل التي تجعل من الواضح أن هذا الموقع يتم استضافته في الحاوية webserver . افتح الملف : sudo nano /var/www/html/index.nginx-debian.html أدخل التغيير التالي على الملف: <!DOCTYPE html> <html> <head> <title>Welcome to nginx on LXD container webserver!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx on LXD container webserver!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> لقد قمنا بتحرير الملف في مكانين، وعلى وجه التحديد أضفنا العبارة ” on LXD container webserver”. احفظ الملف وأغلق المحرر. الآن سجل الخروج من الحاوية وعُد إلى الخادوم المضيف: Logout استخدم الأمر curl لاختبار أن خادوم الويب في الحاوية يعمل. ستحتاج إلى عناوين IP لحاويات الويب التي يمكنك أن تجدها بتنفيذ الأمر lxd list. curl http://10.10.10.100/ يجب أن تكون المخرجات: <!DOCTYPE html> <html> <head> <title>Welcome to nginx on LXD container webserver!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx on LXD container webserver!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> خادوم الويب يعمل، ولكن لا يمكننا الوصول إليه إلا من خلال الـ IP الخاص. لِنوجِّهْ الطلبات الخارجية إلى هذه الحاوية حتى يتمكن العالم من الدخول إلى موقعنا على الويب. الخطوة 5 : إعادة توجيه الاتصالات الواردة إلى حاوية Nginx الجزء الأخير من اللغز هو ربط حاوية خادوم الويب بالإنترنت. Nginx مثبت في حاوية، وبشكل افتراضي لا يمكن الوصول إليه من الإنترنت. نحتاج إلى إعداد الخادوم المضيف لإعادة توجيه أيّ اتصالات قد يتلقاها من الإنترنت على المنفذ 80 إلى الحاوية webserver . للقيام بذلك سننشئ قاعدة iptables لإعادة توجيه الاتصالات. يتطلب الأمر iptables اثنين من عناوين IP: عنوان IP العام للخادوم (your_server_ip) وعنوان IP الخاص بحاوية nginx (your_webserver_container_ip) ، والذي يمكنك الحصول عليه باستخدام الأمر lxc list . نفذ هذا الأمر لإنشاء القاعدة: PORT=80 PUBLIC_IP=your_server_ip CONTAINER_IP=your_container_ip \ sudo -E bash -c 'iptables -t nat -I PREROUTING -i eth0 -p TCP -d $PUBLIC_IP --dport $PORT -j DNAT --to-destination $CONTAINER_IP:$PORT -m comment --comment "forward to the Nginx container"' وإليك شرح هذا الأمر: -t nat يعني أننا نستخدم جدول nat لترجمة العنوان. -I PREROUTING يعني أننا نقوم بإضافة القاعدة إلى سلسلة PREROUTING. -i eth0 يعني الواجهة eth0، وهي الواجهة العامة الافتراضية في Droplets. -p TCP يعني أننا نستخدم البروتوكول TCP. -d $PUBLIC_IP يحدد عنوان IP الوجهة . --dport $PORT : يحدد منفذ الوجهة (مثل 80 ). -j DNAT تعني أننا نريد إجراء قفزة إلى الوجهة NAT (DNAT). --to-destination $CONTAINER_IP:$PORT تعني أننا نريد الذهاب إلى عنوان IP الخاص بالحاوية المذكورة ومنفذ الوجهة. ملاحظة: يمكنك إعادة استخدام هذا الأمر لإعداد قواعد إعادة التوجيه ببساطة عن طريق تعيين متغيرات PORT و PUBLIC_IP و CONTAINER_IP في بداية السطر. فقط قم بتغيير القيم الملونة بالأحمر. يمكنك الاطلاع على قواعد IPTables عن طريق تشغيل هذا الأمر: sudo iptables -t nat -L PREROUTING سترى مخرجًا مماثلًا لهذا: Chain PREROUTING (policy ACCEPT) target prot opt source destination DNAT tcp -- anywhere your_server_ip tcp dpt:http /* forward to this container */ to:your_container_ip:80 ... اختبر الآن إمكانية الوصول إلى خادوم الويب، وذلك بالدخول إليه من جهاز الكمبيوتر المحلي باستخدام الأمر curl مثل هذا: curl --verbose 'http://your_server_ip' سترى رأس صفحة الويب التي أنشأتها في الحاوية متبوعًا بمحتوياتها: * Trying your_server_ip... * Connected to your_server_ip (your_server_ip) port 80 (#0) > GET / HTTP/1.1 > User-Agent: curl/7.47.0 > Accept: */* > < HTTP/1.1 200 OK < Server: nginx/1.10.0 (Ubuntu) ... <!DOCTYPE html> <html> <head> <title>Welcome to nginx on LXD container webserver!</title> <style> body { ... هذا يؤكد أن الطلبات ستذهب إلى الحاوية. وأخيرًا .. لحفظ قاعدة جدار الحماية ثبت الحزمة iptables-persistent الحماية لكي يتم إعادة تطبيقها بعد إعادة التشغيل sudo apt-get install iptables-persistent عند تثبيت الحزمة ستتم مطالبتك بحفظ قواعد جدار الحماية الحالية. اقبل واحفظ جميع القواعد الحالية. عند إعادة تشغيل جهازك ستكون قاعدة جدار الحماية موجودة. بالإضافة إلى ذلك سيتم إعادة تشغيل خدمة Nginx في الحاوية الخاصة بك تلقائيا. الآن بعد أن قمنا بإعداد كل شيء لننظر في كيفية إزالته. الخطوة 6 : إيقاف وإزالة الحاوية ربما تقرر إزالة الحاوية واستبدالها. لنعرف كيف نقوم بذلك: لإيقاف الحاوية استخدم lxc stop : lxc stop webserver استخدم الأمر lxc list للتحقق من الحالة، ستكون المخرجات: +-----------+---------+------+------+------------+-----------+ | NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS | +-----------+---------+------+------+------------+-----------+ | webserver | STOPPED | | | PERSISTENT | 0 | +-----------+---------+------+------+------------+-----------+ لإزالة الحاوية استخدم lxc delete : lxc delete webserver نفذ الأمر lxc list مرة أخرى ليظهر لك أنه لا يوجد حاوية قيد التشغيل: +------+-------+------+------+------+-----------+ | NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS | +------+-------+------+------+------+-----------+ استخدم الأمر lxc help للاطلاع على خيارات إضافية. لإزالة قاعدة الجدار الناري التي توجه حركة المرور إلى الحاوية حدد أولا القاعدة في قائمة القواعد بهذا الأمر والذي يربط رقم سطر مع كل قاعدة: sudo iptables -t nat -L PREROUTING --line-numbers سترى القاعدة، مسبوقة برقم سطر، كما يلي: Chain PREROUTING (policy ACCEPT) num target prot opt source destination 1 DNAT tcp -- anywhere your_server_ip tcp dpt:http /* forward to the Nginx container */ to:your_container_ip استخدم رقم السطر هذا لإزالة القاعدة: sudo iptables -t nat -D PREROUTING 1 تأكد من إلغاء القاعدة من خلال مشاهدة القواعد مرة أخرى بالأمر: `sudo iptables -t nat -L PREROUTING --line-numbers` سترى أنه تمت إزالة القاعدة: Chain PREROUTING (policy ACCEPT) num target prot opt source destination احفظ التغييرات الآن حتى لا يتم العمل بالقاعدة بعد إعادة تشغيل الخادوم: sudo netfilter-persistent save يمكنك الآن إنشاء حاوية أخرى مع الإعدادات الخاصة بك وإضافة قاعدة جدار حماية جديدة لإعادة توجيه حركة المرور إليها. خلاصة لقد قمت بإعداد موقع ويب باستخدام Nginx في حاوية LXD. يمكنك من هنا إعداد المزيد من مواقع الويب حيث يقتصر كل واحد منها على حاويته الخاصة به، ويمكنك ايضا استخدام بروكسي عكسي لتوجيه حركة المرور إلى الحاوية المناسبة. سيعلمك كيف تفعل ذلك هذا المقال: كيف تستضيف مجموعة مواقع بشكل آمن باستخدام Nginx و Php-fpm على أوبنتو 14.04 يتيح لك LXD أيضا التقاط لقطات من الحالة الكاملة للحاويات، مما يجعل من السهل إنشاء نسخ احتياطية من أجل الرجوع إليها لاحقا. وإذا قمت بتثبيت LXD على خادومين مختلفين فمن الممكن توصيل الحاويات بعضها ببعض وترحيلها بين الخوادم عبر الإنترنت. لمعرفة المزيد عن LXD اقرأ هذه التدوينات عن LXD التي كتبها مطورو LXD يمكنك أيضا تجربة LXD على الانترنت واتباع البرنامج التعليمي على شبكة الإنترنت للحصول على مزيد من الممارسة. ترجمة -وبتصرّف- للمقال How to Set Up and Use LXD on Ubuntu 16.04 لصاحبه Simos Xenitellis
تعلمنا في الدرس السابق كيفية إعداد LXD وإعداد الشبكة بالإضافة إلى إنشاء حاوية Nginx والآن لنقم بإعداد Nginx داخل الحاوية: الخطوة 4 : تكوين حاوية Nginx لِنتصلْ بالحاوية webserver ولنقم بإعداد خادوم الويب. اتصل بالحاوية بالأمر lxc exec الذي يأخذ اسم الحاوية وأوامر التنفيذ كمدخلات: lxc exec webserver -- sudo --login --user ubuntu يشير المحرف “–” الأول إلى أن مدخلات الأمر lxc يجب أن تتوقف عندها وسيتم تمرير بقية السطر كأمر يتم تنفيذه داخل الحاوية. الأمر هو sudo --login –user Ubuntu وهو الذي سوف يوفر صدفة تسجيل الدخول للحساب ubuntu السابق الإعداد داخل الحاوية. ملاحظة: إذا كنت بحاجة إلى الاتصال بالحاوية باعتبارك جذرًا استخدم الأمر lxc exec webserver -- /bin/bash بدلًا من ذلك. بعدما تدخل إلى الحاوية ستبدو الصدفة الآن كما يلي. ubuntu@webserver:~$ المستخدم ubuntu في الحاوية لديه صلاحيات sudo مُعَدَّة مسبقًا ويمكنه تنفيذ أوامر بصلاحيات الجذر دون المطالبة بإدخال كلمة السر. تقتصر هذه الصدفة على حدود الحاوية. أيُّ شيء تقوم بتشغيله في هذه الصدفة سيبقى في الحاوية ولا يمكن الذهاب به إلى الخادوم المضيف. لنقم بإعداد Nginx في هذه الحاوية. حدّث قائمة حزم ubuntu داخل الحاوية وثبت Nginx: sudo apt-get update sudo apt-get install nginx ثم قم بتحرير صفحة الويب الافتراضية لهذا الموقع وأضف بعض الجمل التي تجعل من الواضح أن هذا الموقع يتم استضافته في الحاوية webserver . افتح الملف : sudo nano /var/www/html/index.nginx-debian.html أدخل التغيير التالي على الملف: <!DOCTYPE html> <html> <head> <title>Welcome to nginx on LXD container webserver!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx on LXD container webserver!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> لقد قمنا بتحرير الملف في مكانين، وعلى وجه التحديد أضفنا العبارة ” on LXD container webserver”. احفظ الملف وأغلق المحرر. الآن سجل الخروج من الحاوية وعُد إلى الخادوم المضيف: Logout استخدم الأمر curl لاختبار أن خادوم الويب في الحاوية يعمل. ستحتاج إلى عناوين IP لحاويات الويب التي يمكنك أن تجدها بتنفيذ الأمر lxd list. curl http://10.10.10.100/ يجب أن تكون المخرجات: <!DOCTYPE html> <html> <head> <title>Welcome to nginx on LXD container webserver!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx on LXD container webserver!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> خادوم الويب يعمل، ولكن لا يمكننا الوصول إليه إلا من خلال الـ IP الخاص. لِنوجِّهْ الطلبات الخارجية إلى هذه الحاوية حتى يتمكن العالم من الدخول إلى موقعنا على الويب. الخطوة 5 : إعادة توجيه الاتصالات الواردة إلى حاوية Nginx الجزء الأخير من اللغز هو ربط حاوية خادوم الويب بالإنترنت. Nginx مثبت في حاوية، وبشكل افتراضي لا يمكن الوصول إليه من الإنترنت. نحتاج إلى إعداد الخادوم المضيف لإعادة توجيه أيّ اتصالات قد يتلقاها من الإنترنت على المنفذ 80 إلى الحاوية webserver . للقيام بذلك سننشئ قاعدة iptables لإعادة توجيه الاتصالات. يتطلب الأمر iptables اثنين من عناوين IP: عنوان IP العام للخادوم (your_server_ip) وعنوان IP الخاص بحاوية nginx (your_webserver_container_ip) ، والذي يمكنك الحصول عليه باستخدام الأمر lxc list . نفذ هذا الأمر لإنشاء القاعدة: PORT=80 PUBLIC_IP=your_server_ip CONTAINER_IP=your_container_ip \ sudo -E bash -c 'iptables -t nat -I PREROUTING -i eth0 -p TCP -d $PUBLIC_IP --dport $PORT -j DNAT --to-destination $CONTAINER_IP:$PORT -m comment --comment "forward to the Nginx container"' وإليك شرح هذا الأمر: -t nat يعني أننا نستخدم جدول nat لترجمة العنوان. -I PREROUTING يعني أننا نقوم بإضافة القاعدة إلى سلسلة PREROUTING. -i eth0 يعني الواجهة eth0، وهي الواجهة العامة الافتراضية في Droplets. -p TCP يعني أننا نستخدم البروتوكول TCP. -d $PUBLIC_IP يحدد عنوان IP الوجهة . --dport $PORT : يحدد منفذ الوجهة (مثل 80 ). -j DNAT تعني أننا نريد إجراء قفزة إلى الوجهة NAT (DNAT). --to-destination $CONTAINER_IP:$PORT تعني أننا نريد الذهاب إلى عنوان IP الخاص بالحاوية المذكورة ومنفذ الوجهة. ملاحظة: يمكنك إعادة استخدام هذا الأمر لإعداد قواعد إعادة التوجيه ببساطة عن طريق تعيين متغيرات PORT و PUBLIC_IP و CONTAINER_IP في بداية السطر. فقط قم بتغيير القيم الملونة بالأحمر. يمكنك الاطلاع على قواعد IPTables عن طريق تشغيل هذا الأمر: sudo iptables -t nat -L PREROUTING سترى مخرجًا مماثلًا لهذا: Chain PREROUTING (policy ACCEPT) target prot opt source destination DNAT tcp -- anywhere your_server_ip tcp dpt:http /* forward to this container */ to:your_container_ip:80 ... اختبر الآن إمكانية الوصول إلى خادوم الويب، وذلك بالدخول إليه من جهاز الكمبيوتر المحلي باستخدام الأمر curl مثل هذا: curl --verbose 'http://your_server_ip' سترى رأس صفحة الويب التي أنشأتها في الحاوية متبوعًا بمحتوياتها: * Trying your_server_ip... * Connected to your_server_ip (your_server_ip) port 80 (#0) > GET / HTTP/1.1 > User-Agent: curl/7.47.0 > Accept: */* > < HTTP/1.1 200 OK < Server: nginx/1.10.0 (Ubuntu) ... <!DOCTYPE html> <html> <head> <title>Welcome to nginx on LXD container webserver!</title> <style> body { ... هذا يؤكد أن الطلبات ستذهب إلى الحاوية. وأخيرًا .. لحفظ قاعدة جدار الحماية ثبت الحزمة iptables-persistent الحماية لكي يتم إعادة تطبيقها بعد إعادة التشغيل sudo apt-get install iptables-persistent عند تثبيت الحزمة ستتم مطالبتك بحفظ قواعد جدار الحماية الحالية. اقبل واحفظ جميع القواعد الحالية. عند إعادة تشغيل جهازك ستكون قاعدة جدار الحماية موجودة. بالإضافة إلى ذلك سيتم إعادة تشغيل خدمة Nginx في الحاوية الخاصة بك تلقائيا. الآن بعد أن قمنا بإعداد كل شيء لننظر في كيفية إزالته. الخطوة 6 : إيقاف وإزالة الحاوية ربما تقرر إزالة الحاوية واستبدالها. لنعرف كيف نقوم بذلك: لإيقاف الحاوية استخدم lxc stop : lxc stop webserver استخدم الأمر lxc list للتحقق من الحالة، ستكون المخرجات: +-----------+---------+------+------+------------+-----------+ | NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS | +-----------+---------+------+------+------------+-----------+ | webserver | STOPPED | | | PERSISTENT | 0 | +-----------+---------+------+------+------------+-----------+ لإزالة الحاوية استخدم lxc delete : lxc delete webserver نفذ الأمر lxc list مرة أخرى ليظهر لك أنه لا يوجد حاوية قيد التشغيل: +------+-------+------+------+------+-----------+ | NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS | +------+-------+------+------+------+-----------+ استخدم الأمر lxc help للاطلاع على خيارات إضافية. لإزالة قاعدة الجدار الناري التي توجه حركة المرور إلى الحاوية حدد أولا القاعدة في قائمة القواعد بهذا الأمر والذي يربط رقم سطر مع كل قاعدة: sudo iptables -t nat -L PREROUTING --line-numbers سترى القاعدة، مسبوقة برقم سطر، كما يلي: Chain PREROUTING (policy ACCEPT) num target prot opt source destination 1 DNAT tcp -- anywhere your_server_ip tcp dpt:http /* forward to the Nginx container */ to:your_container_ip استخدم رقم السطر هذا لإزالة القاعدة: sudo iptables -t nat -D PREROUTING 1 تأكد من إلغاء القاعدة من خلال مشاهدة القواعد مرة أخرى بالأمر: `sudo iptables -t nat -L PREROUTING --line-numbers` سترى أنه تمت إزالة القاعدة: Chain PREROUTING (policy ACCEPT) num target prot opt source destination احفظ التغييرات الآن حتى لا يتم العمل بالقاعدة بعد إعادة تشغيل الخادوم: sudo netfilter-persistent save يمكنك الآن إنشاء حاوية أخرى مع الإعدادات الخاصة بك وإضافة قاعدة جدار حماية جديدة لإعادة توجيه حركة المرور إليها. خلاصة لقد قمت بإعداد موقع ويب باستخدام Nginx في حاوية LXD. يمكنك من هنا إعداد المزيد من مواقع الويب حيث يقتصر كل واحد منها على حاويته الخاصة به، ويمكنك ايضا استخدام بروكسي عكسي لتوجيه حركة المرور إلى الحاوية المناسبة. سيعلمك كيف تفعل ذلك هذا المقال: كيف تستضيف مجموعة مواقع بشكل آمن باستخدام Nginx و Php-fpm على أوبنتو 14.04 يتيح لك LXD أيضا التقاط لقطات من الحالة الكاملة للحاويات، مما يجعل من السهل إنشاء نسخ احتياطية من أجل الرجوع إليها لاحقا. وإذا قمت بتثبيت LXD على خادومين مختلفين فمن الممكن توصيل الحاويات بعضها ببعض وترحيلها بين الخوادم عبر الإنترنت. لمعرفة المزيد عن LXD اقرأ هذه التدوينات عن LXD التي كتبها مطورو LXD يمكنك أيضا تجربة LXD على الانترنت واتباع البرنامج التعليمي على شبكة الإنترنت للحصول على مزيد من الممارسة. ترجمة -وبتصرّف- للمقال How to Set Up and Use LXD on Ubuntu 16.04 لصاحبه Simos Xenitellis -
 تستخدِم محركات البحث تقنية بحث النصوص الكاملة (Full-Text Search (FTS للبحث عن نتائج في قاعدة بيانات ما، وهي تقنية مفيدة في تقوية نتائج البحث في مواقع مثل المتاجر الرقمية ومحركات البحث والجرائد وغيرها. ويتلخص ما تفعله FTS في جلب المستندات “documents” وهي وحدات من قواعد البيانات تحتوي بيانات نصية ﻻ تتطابق بشكل كامل مع نصوص البحث، فمثلًا حين يبحث مستخدم ما عن “cats and dogs” فإن التطبيق المزوّد بـتقنية بحث النصوص الكاملة سيُظهر نتائج تحتوي الكلمتين dogs وcats بشكل منفصل، أو بترتيب معكوس “dogs and cats”، أو صور مختلفة من هذه الكلمات (cat أو dog)، وذلك يعطي أفضلية للتطبيقات في تخمين قصد المستخدم وإظهار نتائج بحث مرتبطة بما يريده وبسرعة أكبر. وتسمح أنظمة إدارة قواعد البيانات مثل PostgreSQL بعمليات بحث نصية بشكل جزئي باستخدام بنود LIKE، لكن هذه العمليات تعطي عادةً أداء دون المستوى مع البيانات الكبيرة، كما أنها مقيَّدة بمطابقة مدخلات المستخدم الحرفية، وهذا يعني أن استعلامًا ما أو بحثًا عن بيانات معينة قد ﻻ يعطي أي نتائج، حتى لو كانت هناك مستندات عن معلومات مرتبطة بهذا البحث. أما باستخدام FTS فيمكنك بناء محرك بحث قوي للنصوص دون الحاجة لاعتماديات جديدة على أدوات أكثر تطورًا، وسنستخدم نظام PostgreSQL في هذا المقال لتخزين بيانات تحتوي مقالات لموقع أخبار افتراضي، ثم نتعلم كيف نبحث في قاعدة البيانات باستخدام FTS، واختيار أفضل النتائج فقط. ثم سنقوم ببعض التحسينات في الأداء لعمليات بحث النصوص الكاملة. المتطلبات خادم مثبت عليه أوبنتو 16.04 به مستخدم يملك صلاحيات `sudo`، ﻻ أن يكون هو المستخدم الجذر. خادمPostgreSQL، وسنستخدم نحن قاعدة بيانات ومستخدم باسم `sammy` كمثال. ملاحظة: تأكد أن يكون لديك حزمة postgresql-conrib عبر تنفيذ الأمر التالي في الطرفية: sudo apt-get list postgresql-contrib الخطوة الأولى: إنشاء بيانات وهمية من أجل الشرح سنحتاج إلى بعض البيانات من أجل استخدامها في اختبار إضافة FTS، لكن إن كان لديك جدول به قيم نصية جاهزة فيمكنك أن تنتقل إلى الخطوة التالية مباشرة وتستبدل قيمك بالقيم الموجودة هنا، أما إن لم يكن لديك فاتبع ما يلي: اتصل بقاعدة بيانات PostgreSQL من خلال الخادم الخاص بها، ولن تحتاج كلمة مرور لأنك تتصل من نفس المضيف “host”: sudo -u postgres psql sammy وهذا الأمر سيفتح جلسة PostgreSQL تفاعلية ظاهر بها اسم قاعدة البيانات الذي نعمل عليها -sammy في حالتنا-، فيجب أن ترى =#sammy في محث قاعدة البيانات. أنشئ جدولًا وسمّه news، وسيمثِّل كل مدخل في هذا الجدول مقالًا بعنوان وجزء من المحتوى والكاتب، إضافة إلى معرّف فريد: sammy=# CREATE TABLE news ( sammy=# id SERIAL PRIMARY KEY, sammy=# title TEXT NOT NULL, sammy=# content TEXT NOT NULL, sammy=# author TEXT NOT NULL sammy=# ); إن نظرنا للجدول السابق، فإن id هو معرّف الجدول الأساسي مع النوع الخاص SERIAL المسؤول عن زيادة هذا المعرف بشكل تلقائي للجدول، وذلك معرّف فريد سنتحدث عنه أكثر في الخطوة الثالثة حين ننظر في تحسينات الأداء. واﻵن أضف بعض البيانات للجدول باستخدام أمر INESRT، ستمثل هذه البيانات الوهمية بالأسفل بعض مقالات الأخبار: sammy=# INSERT INTO news (id, title, content, author) VALUES sammy=# (1, 'Pacific Northwest high-speed rail line', 'Currently there are only a few options for traveling the 140 miles between Seattle and Vancouver and none of them are ideal.', 'Greg'), sammy=# (2, 'Hitting the beach was voted the best part of life in the region', 'Exploring tracks and trails was second most popular, followed by visiting the shops and then checking out local parks.', 'Ethan'), sammy=# (3, 'Machine Learning from scratch', 'Bare bones implementations of some of the foundational models and algorithms.', 'Jo'); سنجرب الآن بعض عمليات البحث بما أننا أدخلنا بعض البيانات التي يمكن البحث والاستعلام عنها. الخطوة الثانية: تجهيز المستندات والبحث فيها أول خطوة هنا هي بناء مستند واحد بأعمدة نصوص متعددة من جدول قاعدة البيانات، ثم يمكننا تحويل النتائج بعدها إلى متَّجَه من الكلمات نستخدمه في عمليات البحث. ملاحظة: يستخدم خرج psql في هذا الدليل تهيئة expanded display والتي تعرض كل عمود من الخرج في سطر جديد لتسهيل عرضها على الشاشة. يمكننا تفعيلها كما يلي: sammydb=# \x يجب أن يكون الخرج هكذا: Expanded display is on. سنحتاج أولًا إلى جمع كل الأعمدة معًا باستخدام دالتي التسلسل `||` والتحويل `()to_tsvector` في PostgreSQL: sammy=# SELECT title || '. ' || content as document, to_tsvector(title || '. ' || content) as metadata FROM news WHERE id = 1; سيخرج لنا هذا أول سجلّ كمستند كامل باﻹضافة إلى نسخته التي سنستخدمها في البحث: -[ RECORD 1 ]----------------------------------------------------- document | Pacific Northwest high-speed rail line. Currently there are only a few options for traveling the 140 miles between Seattle and Vancouver and none of them are ideal. metadata | '140':18 'current':8 'high':4 'high-spe':3 'ideal':29 'line':7 'mile':19 'none':25 'northwest':2 'option':14 'pacif':1 'rail':6 'seattl':21 'speed':5 'travel':16 'vancouv':23 ربما تلاحظ أن هناك كلمات أقل في النسخة المحوّلة metadata في الخرج السابق عن النسخة الأصلية document، وبعض الكلمات مختلفة، وكل كلمة لديها فاصلة منقوطة ; ورقم ملحق بها، وذلك ﻷن دالة ()to_tsvector تنسّق كل كلمة كي نستطيع إيجاد صور مختلفة منها، ثم تصنف النتائج أبجديًا، وذلك الرقم هو موضع الكلمة في document، قد تكون هناك مواضع أخرى للكلمة بينها فواصل , إن كانت الكلمة المنسّقة تظهر أكثر من مرة. يمكننا الآن استغلال إمكانيات FTS عبر استخدام هذا المستند المحوّل في البحث عن كلمة “Explorations”: sammy=# SELECT * FROM news WHERE to_tsvector(title || '. ' || content) @@ to_tsquery('Explorations'); وسنقوم الآن بتحليل الدوال والمشغِّلات التي استخدمناها في اﻷمر أعلاه: تترجم دالةُ ()to_tsquery المعاملَ “parameter” -الذي يمكن أن يكون تعديلًا مباشرًا أو طفيفًا في بحث المستخدم- إلى معيار بحث نصي يقلل المدخلات بنفس طريقة ()to_tsvector. وإضافة إلى ذلك فإن الدالة تتيح لك تحديد اللغة التي تريد استخدامها وما إن يجب أن تكون كل الكلمات موجودة في النتائج أو واحدة منهم فقط. ويحدد مشغِّل @@ ما إن كان tsvector مماثلًا لـ tsquery أم لـ tsvector آخر، عبر عرض إحدى نتيجتين (true أو false)، مما يسهّل استخدامه كجزء من معيار WHERE. الخرج: -[ RECORD 1 ]----------------------------------------------------- id | 2 title | Hitting the beach was voted the best part of life in the region content | Exploring tracks and trails was second most popular, followed by visiting the shops and then checking out local parks. author | Ethan أظهرت عمليةُ البحث المستندَ الذي يحتوي كلمة Exploring، رغم أن الكلمة التي بحثنا عنها هي Exploration، أما لو استخدمنا مشغّل LIKE لكنّا حصلنا على نتيجة فارغة. واﻵن بما أننا عرفنا كيفية تجهيز المستندات لها وكيفية هيكلة المستندات، فسننظر في كيفية تحسين أداء FTS. الخطوة الثالثة: تحسين أداء FTS قد يشكّل توليد مستند في كل مرة نستخدم فيها استعلام FTS مشكلة في الأداء إن كنا نستخدم خوادم صغيرة أو بيانات كبيرة. وأحد الحلول الجيدة لهذا الأمر هو توليد المستند المحوّل أثناء إدخال المستند الأصلي وتخزينه مع البيانات الأخرى، وبهذه الطريقة يمكننا استرجاعه باستعلام صغير عوضًا عن توليده في كل مرة. أولًا ننشئ عمودًا إضافيًا اسمه document في جدول news الذي أنشأناه قبل قليل: sammy=# ALTER TABLE news ADD "document" tsvector; سنحتاج الآن أن نستخدم استعلامًا جديدًا ﻹدخال البيانات في الجدول، لكن على عكس الخطوة الثانية، سنحتاج هنا إلى تجهيز المستند المحوّل وإضافته إلى عمود document الجديد: sammy=# INSERT INTO news (id, title, content, author, document) sammy=# VALUES (4, 'Sleep deprivation curing depression', 'Clinicians have long known that there is a strong link between sleep, sunlight and mood.', 'Patel', to_tsvector('Sleep deprivation curing depression' || '. ' || 'Clinicians have long known that there is a strong link between sleep, sunlight and mood.')); تتطلب إضافة عمود جديد إلى الجدول الموجود مسبقًا أن نضيف قيمًا فارغة لعمود document أولًا، وسنحدّثه الآن بالقيم المولَّدة. استخدم أمر UPDATE لإضافة البيانات الناقصة. sammy=# UPDATE news SET document = to_tsvector(title || '. ' || content) WHERE document IS NULL; وهذه الأسطر التي أضفناها إلى جدولنا تحسّن من أداء FTS، لكن قد نواجه مشاكل أخرى في حالة البيانات الكبيرة بسبب أن قاعدة البيانات ﻻ تزال في حاجة إلى فحص الجدول كله ﻹيجاد الأسطر التي توافق مدخلات البحث، وحل هذا أن نستخدم الفهارس “indexes”. فهرس قاعدة البيانات database index هو هيكل بيانات يخزّن البيانات بشكل منفصل من البيانات الأساسية التي تحسّن عمليات استرجاع البيانات، ويتم تحديثها بعد أي تغيّر في محتوى الجدول وﻻ تتكلف إﻻ الكتابة الجديدة ومساحة تخزين صغيرة نسبيًا. وتسمح المساحة الصغيرة وهيكل البيانات المهيّأ جيدًا للفهارس أن تعمل بكفاءة أكبر من استخدام مساحة الجدول لاختيار الاستعلامات. وبشكل عام، فإن الفهارس تسرّع إيجاد قواعد البيانات للصفوف من خلال البحث باستخدام خوارزميات وهياكل بيانات خاصة. ويمتاز نظام PostgreSQL بأن به عدة أنواع من الفهارس التي تناسب أنواعًا محددة من الاستعلامات، وأقرب هذه الأنواع إلى حالتنا هنا هي فهارس GiST وGIN. والفرق البارز بينهما هو السرعة التي يجلب كل منهما البيانات من الجدول، فـGIN أبطأ أثناء إضافة بيانات جديدة لكنه أسرع في الاستعلام، أما GiST فأسرع في بناء البيانات الجديدة لكنه يحتاج إلى قراءات إضافية للبيانات. وسننشئ فهرس GIN هنا ﻷن GiST أبطأ بثلاث مرات في جلب البيانات: sammy=# CREATE INDEX idx_fts_search ON news USING gin(document); وسيصبح استعلام SELECT أبسط باستخدام عمود document المفهرس: sammy=# SELECT title, content FROM news WHERE document @@ to_tsquery('Travel | Cure'); ويجب أن يكون الخرج شيئًا كهذا: -[ RECORD 1 ]----------------------------------------------------- title | Sleep deprivation curing depression content | Clinicians have long known that there is a strong link between sleep, sunlight and mood. -[ RECORD 2 ]----------------------------------------------------- title | Pacific Northwest high-speed rail line content | Currently there are only a few options for traveling the 140 miles between Seattle and Vancouver and none of them are ideal. واﻵن يمكنك الخروج من لوحة التحكم الخاصة بقاعدة البيانات عبر كتابة q\. الخلاصة يغطي هذا الدليل كيفية استخدام تقنية بحث النصوص الكاملة في PostgreSQL، بما في ذلك تجهيز وتخزين مستند البيانات الوصفية metadata واستخدام فهرس لتحسين أداء البحث. وإن أردت مزيدًا من الشرح حول FTS في PostgreSQL فألق نظرة على التوثيق الرسمي لنظام PostgreSQL حول بحث النصوص الكاملة. ترجمة -بتصرف- لمقال How to Use Full-Text Search in PostgreSQL on Ubuntu 16.04 لصاحبه Ilya Kotov
تستخدِم محركات البحث تقنية بحث النصوص الكاملة (Full-Text Search (FTS للبحث عن نتائج في قاعدة بيانات ما، وهي تقنية مفيدة في تقوية نتائج البحث في مواقع مثل المتاجر الرقمية ومحركات البحث والجرائد وغيرها. ويتلخص ما تفعله FTS في جلب المستندات “documents” وهي وحدات من قواعد البيانات تحتوي بيانات نصية ﻻ تتطابق بشكل كامل مع نصوص البحث، فمثلًا حين يبحث مستخدم ما عن “cats and dogs” فإن التطبيق المزوّد بـتقنية بحث النصوص الكاملة سيُظهر نتائج تحتوي الكلمتين dogs وcats بشكل منفصل، أو بترتيب معكوس “dogs and cats”، أو صور مختلفة من هذه الكلمات (cat أو dog)، وذلك يعطي أفضلية للتطبيقات في تخمين قصد المستخدم وإظهار نتائج بحث مرتبطة بما يريده وبسرعة أكبر. وتسمح أنظمة إدارة قواعد البيانات مثل PostgreSQL بعمليات بحث نصية بشكل جزئي باستخدام بنود LIKE، لكن هذه العمليات تعطي عادةً أداء دون المستوى مع البيانات الكبيرة، كما أنها مقيَّدة بمطابقة مدخلات المستخدم الحرفية، وهذا يعني أن استعلامًا ما أو بحثًا عن بيانات معينة قد ﻻ يعطي أي نتائج، حتى لو كانت هناك مستندات عن معلومات مرتبطة بهذا البحث. أما باستخدام FTS فيمكنك بناء محرك بحث قوي للنصوص دون الحاجة لاعتماديات جديدة على أدوات أكثر تطورًا، وسنستخدم نظام PostgreSQL في هذا المقال لتخزين بيانات تحتوي مقالات لموقع أخبار افتراضي، ثم نتعلم كيف نبحث في قاعدة البيانات باستخدام FTS، واختيار أفضل النتائج فقط. ثم سنقوم ببعض التحسينات في الأداء لعمليات بحث النصوص الكاملة. المتطلبات خادم مثبت عليه أوبنتو 16.04 به مستخدم يملك صلاحيات `sudo`، ﻻ أن يكون هو المستخدم الجذر. خادمPostgreSQL، وسنستخدم نحن قاعدة بيانات ومستخدم باسم `sammy` كمثال. ملاحظة: تأكد أن يكون لديك حزمة postgresql-conrib عبر تنفيذ الأمر التالي في الطرفية: sudo apt-get list postgresql-contrib الخطوة الأولى: إنشاء بيانات وهمية من أجل الشرح سنحتاج إلى بعض البيانات من أجل استخدامها في اختبار إضافة FTS، لكن إن كان لديك جدول به قيم نصية جاهزة فيمكنك أن تنتقل إلى الخطوة التالية مباشرة وتستبدل قيمك بالقيم الموجودة هنا، أما إن لم يكن لديك فاتبع ما يلي: اتصل بقاعدة بيانات PostgreSQL من خلال الخادم الخاص بها، ولن تحتاج كلمة مرور لأنك تتصل من نفس المضيف “host”: sudo -u postgres psql sammy وهذا الأمر سيفتح جلسة PostgreSQL تفاعلية ظاهر بها اسم قاعدة البيانات الذي نعمل عليها -sammy في حالتنا-، فيجب أن ترى =#sammy في محث قاعدة البيانات. أنشئ جدولًا وسمّه news، وسيمثِّل كل مدخل في هذا الجدول مقالًا بعنوان وجزء من المحتوى والكاتب، إضافة إلى معرّف فريد: sammy=# CREATE TABLE news ( sammy=# id SERIAL PRIMARY KEY, sammy=# title TEXT NOT NULL, sammy=# content TEXT NOT NULL, sammy=# author TEXT NOT NULL sammy=# ); إن نظرنا للجدول السابق، فإن id هو معرّف الجدول الأساسي مع النوع الخاص SERIAL المسؤول عن زيادة هذا المعرف بشكل تلقائي للجدول، وذلك معرّف فريد سنتحدث عنه أكثر في الخطوة الثالثة حين ننظر في تحسينات الأداء. واﻵن أضف بعض البيانات للجدول باستخدام أمر INESRT، ستمثل هذه البيانات الوهمية بالأسفل بعض مقالات الأخبار: sammy=# INSERT INTO news (id, title, content, author) VALUES sammy=# (1, 'Pacific Northwest high-speed rail line', 'Currently there are only a few options for traveling the 140 miles between Seattle and Vancouver and none of them are ideal.', 'Greg'), sammy=# (2, 'Hitting the beach was voted the best part of life in the region', 'Exploring tracks and trails was second most popular, followed by visiting the shops and then checking out local parks.', 'Ethan'), sammy=# (3, 'Machine Learning from scratch', 'Bare bones implementations of some of the foundational models and algorithms.', 'Jo'); سنجرب الآن بعض عمليات البحث بما أننا أدخلنا بعض البيانات التي يمكن البحث والاستعلام عنها. الخطوة الثانية: تجهيز المستندات والبحث فيها أول خطوة هنا هي بناء مستند واحد بأعمدة نصوص متعددة من جدول قاعدة البيانات، ثم يمكننا تحويل النتائج بعدها إلى متَّجَه من الكلمات نستخدمه في عمليات البحث. ملاحظة: يستخدم خرج psql في هذا الدليل تهيئة expanded display والتي تعرض كل عمود من الخرج في سطر جديد لتسهيل عرضها على الشاشة. يمكننا تفعيلها كما يلي: sammydb=# \x يجب أن يكون الخرج هكذا: Expanded display is on. سنحتاج أولًا إلى جمع كل الأعمدة معًا باستخدام دالتي التسلسل `||` والتحويل `()to_tsvector` في PostgreSQL: sammy=# SELECT title || '. ' || content as document, to_tsvector(title || '. ' || content) as metadata FROM news WHERE id = 1; سيخرج لنا هذا أول سجلّ كمستند كامل باﻹضافة إلى نسخته التي سنستخدمها في البحث: -[ RECORD 1 ]----------------------------------------------------- document | Pacific Northwest high-speed rail line. Currently there are only a few options for traveling the 140 miles between Seattle and Vancouver and none of them are ideal. metadata | '140':18 'current':8 'high':4 'high-spe':3 'ideal':29 'line':7 'mile':19 'none':25 'northwest':2 'option':14 'pacif':1 'rail':6 'seattl':21 'speed':5 'travel':16 'vancouv':23 ربما تلاحظ أن هناك كلمات أقل في النسخة المحوّلة metadata في الخرج السابق عن النسخة الأصلية document، وبعض الكلمات مختلفة، وكل كلمة لديها فاصلة منقوطة ; ورقم ملحق بها، وذلك ﻷن دالة ()to_tsvector تنسّق كل كلمة كي نستطيع إيجاد صور مختلفة منها، ثم تصنف النتائج أبجديًا، وذلك الرقم هو موضع الكلمة في document، قد تكون هناك مواضع أخرى للكلمة بينها فواصل , إن كانت الكلمة المنسّقة تظهر أكثر من مرة. يمكننا الآن استغلال إمكانيات FTS عبر استخدام هذا المستند المحوّل في البحث عن كلمة “Explorations”: sammy=# SELECT * FROM news WHERE to_tsvector(title || '. ' || content) @@ to_tsquery('Explorations'); وسنقوم الآن بتحليل الدوال والمشغِّلات التي استخدمناها في اﻷمر أعلاه: تترجم دالةُ ()to_tsquery المعاملَ “parameter” -الذي يمكن أن يكون تعديلًا مباشرًا أو طفيفًا في بحث المستخدم- إلى معيار بحث نصي يقلل المدخلات بنفس طريقة ()to_tsvector. وإضافة إلى ذلك فإن الدالة تتيح لك تحديد اللغة التي تريد استخدامها وما إن يجب أن تكون كل الكلمات موجودة في النتائج أو واحدة منهم فقط. ويحدد مشغِّل @@ ما إن كان tsvector مماثلًا لـ tsquery أم لـ tsvector آخر، عبر عرض إحدى نتيجتين (true أو false)، مما يسهّل استخدامه كجزء من معيار WHERE. الخرج: -[ RECORD 1 ]----------------------------------------------------- id | 2 title | Hitting the beach was voted the best part of life in the region content | Exploring tracks and trails was second most popular, followed by visiting the shops and then checking out local parks. author | Ethan أظهرت عمليةُ البحث المستندَ الذي يحتوي كلمة Exploring، رغم أن الكلمة التي بحثنا عنها هي Exploration، أما لو استخدمنا مشغّل LIKE لكنّا حصلنا على نتيجة فارغة. واﻵن بما أننا عرفنا كيفية تجهيز المستندات لها وكيفية هيكلة المستندات، فسننظر في كيفية تحسين أداء FTS. الخطوة الثالثة: تحسين أداء FTS قد يشكّل توليد مستند في كل مرة نستخدم فيها استعلام FTS مشكلة في الأداء إن كنا نستخدم خوادم صغيرة أو بيانات كبيرة. وأحد الحلول الجيدة لهذا الأمر هو توليد المستند المحوّل أثناء إدخال المستند الأصلي وتخزينه مع البيانات الأخرى، وبهذه الطريقة يمكننا استرجاعه باستعلام صغير عوضًا عن توليده في كل مرة. أولًا ننشئ عمودًا إضافيًا اسمه document في جدول news الذي أنشأناه قبل قليل: sammy=# ALTER TABLE news ADD "document" tsvector; سنحتاج الآن أن نستخدم استعلامًا جديدًا ﻹدخال البيانات في الجدول، لكن على عكس الخطوة الثانية، سنحتاج هنا إلى تجهيز المستند المحوّل وإضافته إلى عمود document الجديد: sammy=# INSERT INTO news (id, title, content, author, document) sammy=# VALUES (4, 'Sleep deprivation curing depression', 'Clinicians have long known that there is a strong link between sleep, sunlight and mood.', 'Patel', to_tsvector('Sleep deprivation curing depression' || '. ' || 'Clinicians have long known that there is a strong link between sleep, sunlight and mood.')); تتطلب إضافة عمود جديد إلى الجدول الموجود مسبقًا أن نضيف قيمًا فارغة لعمود document أولًا، وسنحدّثه الآن بالقيم المولَّدة. استخدم أمر UPDATE لإضافة البيانات الناقصة. sammy=# UPDATE news SET document = to_tsvector(title || '. ' || content) WHERE document IS NULL; وهذه الأسطر التي أضفناها إلى جدولنا تحسّن من أداء FTS، لكن قد نواجه مشاكل أخرى في حالة البيانات الكبيرة بسبب أن قاعدة البيانات ﻻ تزال في حاجة إلى فحص الجدول كله ﻹيجاد الأسطر التي توافق مدخلات البحث، وحل هذا أن نستخدم الفهارس “indexes”. فهرس قاعدة البيانات database index هو هيكل بيانات يخزّن البيانات بشكل منفصل من البيانات الأساسية التي تحسّن عمليات استرجاع البيانات، ويتم تحديثها بعد أي تغيّر في محتوى الجدول وﻻ تتكلف إﻻ الكتابة الجديدة ومساحة تخزين صغيرة نسبيًا. وتسمح المساحة الصغيرة وهيكل البيانات المهيّأ جيدًا للفهارس أن تعمل بكفاءة أكبر من استخدام مساحة الجدول لاختيار الاستعلامات. وبشكل عام، فإن الفهارس تسرّع إيجاد قواعد البيانات للصفوف من خلال البحث باستخدام خوارزميات وهياكل بيانات خاصة. ويمتاز نظام PostgreSQL بأن به عدة أنواع من الفهارس التي تناسب أنواعًا محددة من الاستعلامات، وأقرب هذه الأنواع إلى حالتنا هنا هي فهارس GiST وGIN. والفرق البارز بينهما هو السرعة التي يجلب كل منهما البيانات من الجدول، فـGIN أبطأ أثناء إضافة بيانات جديدة لكنه أسرع في الاستعلام، أما GiST فأسرع في بناء البيانات الجديدة لكنه يحتاج إلى قراءات إضافية للبيانات. وسننشئ فهرس GIN هنا ﻷن GiST أبطأ بثلاث مرات في جلب البيانات: sammy=# CREATE INDEX idx_fts_search ON news USING gin(document); وسيصبح استعلام SELECT أبسط باستخدام عمود document المفهرس: sammy=# SELECT title, content FROM news WHERE document @@ to_tsquery('Travel | Cure'); ويجب أن يكون الخرج شيئًا كهذا: -[ RECORD 1 ]----------------------------------------------------- title | Sleep deprivation curing depression content | Clinicians have long known that there is a strong link between sleep, sunlight and mood. -[ RECORD 2 ]----------------------------------------------------- title | Pacific Northwest high-speed rail line content | Currently there are only a few options for traveling the 140 miles between Seattle and Vancouver and none of them are ideal. واﻵن يمكنك الخروج من لوحة التحكم الخاصة بقاعدة البيانات عبر كتابة q\. الخلاصة يغطي هذا الدليل كيفية استخدام تقنية بحث النصوص الكاملة في PostgreSQL، بما في ذلك تجهيز وتخزين مستند البيانات الوصفية metadata واستخدام فهرس لتحسين أداء البحث. وإن أردت مزيدًا من الشرح حول FTS في PostgreSQL فألق نظرة على التوثيق الرسمي لنظام PostgreSQL حول بحث النصوص الكاملة. ترجمة -بتصرف- لمقال How to Use Full-Text Search in PostgreSQL on Ubuntu 16.04 لصاحبه Ilya Kotov -
 مقدمة: إطار التحليل الشبكي Bro هو إطار عمل مفتوح المصدر لتحليل الشبكات يركز على مراقبة أمانها، وهو نتاج خمس عشرة سنة من البحث واستخدمته جامعات كثيرة ومعامل بحثية ومراكز حواسيب خارقة وعدد من مجتمعات العلوم المفتوحة-Open Science. وقد بدأ تطويره بشكل أساسي في المعهد الدولي لعلوم الحاسوب في بيركلي والمركز الوطني لتطبيقات الحواسيب الخارقة في أوربانا-شامبين في إيلينوي. وتتلخص مزايا Bro فيما يلي: سياسات مراقبة خاصة بكل موقع، إذ تسمح لغة Bro النصية-scripting language بذلك استهداف الشبكات عالية الأداء. محللات للعديد من البروتوكولات، مما يسمح بالتحليل الدلالي عالي المستوى-High Level Semantic Analysis حتى على مستوى التطبيق. جمع إحصائيات شاملة على مستوى التطبيق للشبكة التي يراقبها. تسجّيل كل شيء يراقبه، ويوفّر أرشيفًا عالي المستوى لنشاط الشبكة. متطلبات Bro للعمل على الخادم يحتاج Bro إلى الاعتماديات-Dependencies التالية: Libpcap مكتبات Open SSL مكتبة BIND8 Libz Bash (نحتاجها من أجل BroControl) Python إصدار 2.6 أو أحدث (من أجل BroControl) كما يتطلب بناؤه من المصدر ما يلي: CMake 2.8 أو أحدث Make GCC 4.8 فأحدث، أو Clang 3.3 فأحدث SWIG GNU Bison Flex Libpcap headers OpenSSL headers zlib headers بدء العمل ثبّت الاعتماديات المطلوبة بتنفيذ الأمر التالي: # apt-get install cmake make gcc g++ flex bison libpcap-dev libssl-dev python-dev swig zlib1g-dev تثبيت قاعدة بيانات GeoIP من أجل موقع IP الجغرافي يعتمد Bro على GeoIP لتحديد الموقع الجغرافي للعنوان، فثبّت إصدارات IPv4، وIPv6 عبر هذه الأوامر: $ wget http://geolite.maxmind.com/download/geoip/database/GeoLiteCity.dat.gz $ wget http://geolite.maxmind.com/download/geoip/database/GeoLiteCityv6-beta/GeoLiteCityv6.dat.gz فُكّ ضغط تلك الأرشيفات التي حملناها: $ gzip -d GeoLiteCity.dat.gz $ gzip -d GeoLiteCityv6.dat.gz انقل الملفات التي فككناها إلى مجلد GeoIP: # mvGeoLiteCity.dat /usr/share/GeoIP/GeoIPCity.dat # mv GeoLiteCityv6.dat /usr/share/GeoIP/GeoIPCityv6.dat بناء Bro من المصدر سنحصل على احدث إصدار من مستودعات git (اقرأ هذا المقال لتثبيتgit وإعداده إن لم يكن مثبتًا لديك)، عبر الأمر التالي: $ git clone --recursive git://git.bro.org/bro نذهب إلى هذا المجلد المنسوخ-cloned directory، ونبني bro بهذه الأوامر: $ cd bro $ ./configure $ make سيستغرق أمر make بعض الوقت للبناء، ويتوقف هذا الوقت على قوة الخادم نفسه. ويمكن تنفيذ شفرة configure النصية مع بعض المعاملات-arguments لتحديد أي الاعتماديات تريد بناءها، خاصة خيارات (–with-*) تثبيت Bro داخل مجلد bro سابق الذكر، نفذ الأمر التالي، حيث سيكون مجلد التثبيت هو usr/local/bro/ # make install تهيئة وإعداد Bro تقع ملفات تهيئة Bro وضبطه في مجلد etc، في مسار usr/local/bro/etc/، وستجد ثلاثة ملفات: node.cfg، يستخدم لتحديد أي عقدة-node أو مجموعة عُقّد سيراقبها (العقدة في الشبكات هي جهاز يتلقى/يشكّل/يحوّل المعلومات الواردة عبره). broctl.cfg، ملف تهيئة BroControl. networks.cgf، يحتوي قائمة بالشبكات في ترميز التوجيه غير الفئوي-CIDR Notation. ضبط إعدادات البريد افتح ملف broctl.cfg، حيث تستبدل $EDITOR في الأمر التالي بالمحرر النصي الذي تفضله: # $EDITOR /usr/local/bro/etc/broctl.cfg ابحث في الملف عن قسم Mail Options، وعدل سطر MailTo كما يلي: # Recipient address for emails sent out by Bro and BroControl MailTo = admin@example.com استبدل عنوان البريد بالعنوان الذي تريد، ثم احفظ الملف وأغلقه. لديك الكثير من الخيارات هنا، لكن الخيارات الافتراضية جيدة ولا تحتاج تعديلات. اختيار العُقَد التي ستُراقَب إن Bro مجهز افتراضيًا ليعمل في الوضع المستقل-Standalone، وهو ما نشرحه في هذا المقال، لذا لن تحتاج إلى تغيير الكثير، لكن سننظر على أي حال في ملف node.cfg: # $EDITOR /usr/local/bro/etc/node.cfg يجب أن ترى شيئًا كهذا في قسم [bro]: [bro] type=standalone host=localhost interface=eth0 تأكد أن تكون الواجهة-interface مطابقة لواجهة خادم أوبنتو 16.04، ثم احفظ الملف وأغلقه. ضبط شبكات العقدة-Node’s Networks آخر ملف سنعدّل فيه هو network.cfg، افتحه باستخدام المحرر النصي الذي تفضله: # $EDITOR /usr/local/bro/etc/networks.cfg يجب أن ترى المحتوى التالي: # List of local networks in CIDR notation, optionally followed by a # descriptive tag. # For example, "10.0.0.0/8" or "fe80::/64" are valid prefixes. 10.0.0.0/8 Private IP space 172.16.0.0/12 Private IP space 192.168.0.0/16 Private IP space احذف المدخلات الثلاثة (التي هي أمثلة فقط لكيفية استخدام الملف)، وأدخل مساحةIP العامة والخاصة للخادم الخاص بك، على هذه الهيئة: X.X.X.X/X مساحة IP العامة X.X.X.X/X مساحة IP الخاصة احفظ الملف وأغلقه. إدارة تثبيت Bro باستخدام BroControl تحتاج إلى استخدام BroControl من أجل إدارة Bro، وهو يأتي في صورة صَدفة تفاعلية-interactive shell وأداة سطر أوامر، افتح الصدفة بالآتي: # /usr/local/bro/bin/broctl ولتستخدمها كأداة سطر أوامر، أضف معاملًا-argument إلى الأمر السابق، مثال: # /usr/local/bro/bin/broctl status سيتحقق هذا الأمر من حالة Bro بإخراج نتيجة كهذه: Name Type Host Status Pid Started bro standalone localhost running 6807 20 Jul 12:30:50 خاتمة ما شرحناه في هذا المقال يلخص دليل تثبيت Bro، وقد استخدمنا طريقة التثبيت من المصدر لأنها أكفأ طريقة ممكنة للحصول على آخر إصدار متوفر، لكن اعلم أن أداة تحليل الشبكات هذه يمكن تحميلها أيضًا في صورة ملف ثنائي/تنفيذي إن لم ترغب ببنائها من الصفر. ترجمة -بتصرف- لمقال Network Analysis: How To Install Bro On Ubuntu 16.04 لصاحبه Giuseppe Molica حقوق الصورة البارزة محفوظة لـ Freepik
مقدمة: إطار التحليل الشبكي Bro هو إطار عمل مفتوح المصدر لتحليل الشبكات يركز على مراقبة أمانها، وهو نتاج خمس عشرة سنة من البحث واستخدمته جامعات كثيرة ومعامل بحثية ومراكز حواسيب خارقة وعدد من مجتمعات العلوم المفتوحة-Open Science. وقد بدأ تطويره بشكل أساسي في المعهد الدولي لعلوم الحاسوب في بيركلي والمركز الوطني لتطبيقات الحواسيب الخارقة في أوربانا-شامبين في إيلينوي. وتتلخص مزايا Bro فيما يلي: سياسات مراقبة خاصة بكل موقع، إذ تسمح لغة Bro النصية-scripting language بذلك استهداف الشبكات عالية الأداء. محللات للعديد من البروتوكولات، مما يسمح بالتحليل الدلالي عالي المستوى-High Level Semantic Analysis حتى على مستوى التطبيق. جمع إحصائيات شاملة على مستوى التطبيق للشبكة التي يراقبها. تسجّيل كل شيء يراقبه، ويوفّر أرشيفًا عالي المستوى لنشاط الشبكة. متطلبات Bro للعمل على الخادم يحتاج Bro إلى الاعتماديات-Dependencies التالية: Libpcap مكتبات Open SSL مكتبة BIND8 Libz Bash (نحتاجها من أجل BroControl) Python إصدار 2.6 أو أحدث (من أجل BroControl) كما يتطلب بناؤه من المصدر ما يلي: CMake 2.8 أو أحدث Make GCC 4.8 فأحدث، أو Clang 3.3 فأحدث SWIG GNU Bison Flex Libpcap headers OpenSSL headers zlib headers بدء العمل ثبّت الاعتماديات المطلوبة بتنفيذ الأمر التالي: # apt-get install cmake make gcc g++ flex bison libpcap-dev libssl-dev python-dev swig zlib1g-dev تثبيت قاعدة بيانات GeoIP من أجل موقع IP الجغرافي يعتمد Bro على GeoIP لتحديد الموقع الجغرافي للعنوان، فثبّت إصدارات IPv4، وIPv6 عبر هذه الأوامر: $ wget http://geolite.maxmind.com/download/geoip/database/GeoLiteCity.dat.gz $ wget http://geolite.maxmind.com/download/geoip/database/GeoLiteCityv6-beta/GeoLiteCityv6.dat.gz فُكّ ضغط تلك الأرشيفات التي حملناها: $ gzip -d GeoLiteCity.dat.gz $ gzip -d GeoLiteCityv6.dat.gz انقل الملفات التي فككناها إلى مجلد GeoIP: # mvGeoLiteCity.dat /usr/share/GeoIP/GeoIPCity.dat # mv GeoLiteCityv6.dat /usr/share/GeoIP/GeoIPCityv6.dat بناء Bro من المصدر سنحصل على احدث إصدار من مستودعات git (اقرأ هذا المقال لتثبيتgit وإعداده إن لم يكن مثبتًا لديك)، عبر الأمر التالي: $ git clone --recursive git://git.bro.org/bro نذهب إلى هذا المجلد المنسوخ-cloned directory، ونبني bro بهذه الأوامر: $ cd bro $ ./configure $ make سيستغرق أمر make بعض الوقت للبناء، ويتوقف هذا الوقت على قوة الخادم نفسه. ويمكن تنفيذ شفرة configure النصية مع بعض المعاملات-arguments لتحديد أي الاعتماديات تريد بناءها، خاصة خيارات (–with-*) تثبيت Bro داخل مجلد bro سابق الذكر، نفذ الأمر التالي، حيث سيكون مجلد التثبيت هو usr/local/bro/ # make install تهيئة وإعداد Bro تقع ملفات تهيئة Bro وضبطه في مجلد etc، في مسار usr/local/bro/etc/، وستجد ثلاثة ملفات: node.cfg، يستخدم لتحديد أي عقدة-node أو مجموعة عُقّد سيراقبها (العقدة في الشبكات هي جهاز يتلقى/يشكّل/يحوّل المعلومات الواردة عبره). broctl.cfg، ملف تهيئة BroControl. networks.cgf، يحتوي قائمة بالشبكات في ترميز التوجيه غير الفئوي-CIDR Notation. ضبط إعدادات البريد افتح ملف broctl.cfg، حيث تستبدل $EDITOR في الأمر التالي بالمحرر النصي الذي تفضله: # $EDITOR /usr/local/bro/etc/broctl.cfg ابحث في الملف عن قسم Mail Options، وعدل سطر MailTo كما يلي: # Recipient address for emails sent out by Bro and BroControl MailTo = admin@example.com استبدل عنوان البريد بالعنوان الذي تريد، ثم احفظ الملف وأغلقه. لديك الكثير من الخيارات هنا، لكن الخيارات الافتراضية جيدة ولا تحتاج تعديلات. اختيار العُقَد التي ستُراقَب إن Bro مجهز افتراضيًا ليعمل في الوضع المستقل-Standalone، وهو ما نشرحه في هذا المقال، لذا لن تحتاج إلى تغيير الكثير، لكن سننظر على أي حال في ملف node.cfg: # $EDITOR /usr/local/bro/etc/node.cfg يجب أن ترى شيئًا كهذا في قسم [bro]: [bro] type=standalone host=localhost interface=eth0 تأكد أن تكون الواجهة-interface مطابقة لواجهة خادم أوبنتو 16.04، ثم احفظ الملف وأغلقه. ضبط شبكات العقدة-Node’s Networks آخر ملف سنعدّل فيه هو network.cfg، افتحه باستخدام المحرر النصي الذي تفضله: # $EDITOR /usr/local/bro/etc/networks.cfg يجب أن ترى المحتوى التالي: # List of local networks in CIDR notation, optionally followed by a # descriptive tag. # For example, "10.0.0.0/8" or "fe80::/64" are valid prefixes. 10.0.0.0/8 Private IP space 172.16.0.0/12 Private IP space 192.168.0.0/16 Private IP space احذف المدخلات الثلاثة (التي هي أمثلة فقط لكيفية استخدام الملف)، وأدخل مساحةIP العامة والخاصة للخادم الخاص بك، على هذه الهيئة: X.X.X.X/X مساحة IP العامة X.X.X.X/X مساحة IP الخاصة احفظ الملف وأغلقه. إدارة تثبيت Bro باستخدام BroControl تحتاج إلى استخدام BroControl من أجل إدارة Bro، وهو يأتي في صورة صَدفة تفاعلية-interactive shell وأداة سطر أوامر، افتح الصدفة بالآتي: # /usr/local/bro/bin/broctl ولتستخدمها كأداة سطر أوامر، أضف معاملًا-argument إلى الأمر السابق، مثال: # /usr/local/bro/bin/broctl status سيتحقق هذا الأمر من حالة Bro بإخراج نتيجة كهذه: Name Type Host Status Pid Started bro standalone localhost running 6807 20 Jul 12:30:50 خاتمة ما شرحناه في هذا المقال يلخص دليل تثبيت Bro، وقد استخدمنا طريقة التثبيت من المصدر لأنها أكفأ طريقة ممكنة للحصول على آخر إصدار متوفر، لكن اعلم أن أداة تحليل الشبكات هذه يمكن تحميلها أيضًا في صورة ملف ثنائي/تنفيذي إن لم ترغب ببنائها من الصفر. ترجمة -بتصرف- لمقال Network Analysis: How To Install Bro On Ubuntu 16.04 لصاحبه Giuseppe Molica حقوق الصورة البارزة محفوظة لـ Freepik -
 تزداد شعبية Go، وهي لغة برمجة حديثة تطوّرها شركة Google، تزداد كثيرا في التطبيقات والشركات؛ كما توفّر مجموعة متناسقة من المكتبات البرمجية. يشرح هذا الدرس خطوات تثبيت الإصدار 1.8 (الإصدار المستقر الأحدث حتى الآن) على توزيعة لينكس أوبونتو 16.04. سننفّذ في الخطوة الأخيرة من هذا الدرس تطبيق “أهلا بالعالم” صغيرا للتأكد من تثبيت مصرّف اللغة Compiler وعمله. المتطلّبات يفترض هذا الدرس توفّر نظام أوبونتو 16.04 معدًّا للعمل مع مستخدم إداري غير المستخدم الجذر بالطريقة التي يشرحها الإعداد الابتدائي لخادوم أوبونتو. الخطوة الأولى: تثبيت Go نبدأ بتثبيت Go على الخادوم. اتّصل - إن دعت الحاجة لذلك - بالخادوم عن طريق SSH: ssh sammy@your_server_ip اذهب إلى صفحة التنزيلات على الموقع الرسمي لـGo واعثُر على رابط الملف المضغوط لآخر إصدار مستقر، مع قيمة تجزئة SHA256 الخاصة به. تأكد من أنك في المجلّد الشخصي للمستخدم ثم نزّل الإصدار انطلاقا من الرابط الذي تحصّلت عليه في الفقرة الماضية: cd ~ curl -O https://storage.googleapis.com/golang/go1.8.3.linux-amd64.tar.gz استخدم الأمر sha256sum للتحقّق من الملف المضغوط: sha256sum go1.8.3.linux-amd64.tar.gz مثال على المُخرجات: 1862f4c3d3907e59b04a757cfda0ea7aa9ef39274af99a784f5be843c80c6772 go1.8.3.linux-amd64.tar.gz ستحصُل على قيمة تجزئة Hash مثل تلك الموجودة في المُخرجات السابقة. تأكد من أنها توافق قيمة التجزئة الخاصة بالملف التي تحصّلت عليها من صفحة التنزيلات. سنستخدم الآن الأمر tar لفك ضغط الملف. يطلُب الخيار x استخراج محتوى الملف المضغوط، يُظهر الخيار v مخرجات مفصَّلة ويحدّد الخيار f أننا سنمرّر للأمر tar اسم الملف المضغوط: tar xvf go1.6.linux-amd64.tar.gz ستحصُل الآن على مجلّد باسم go في المجلّد الشخصي للمستخدم. نفّذ الأمرين التاليين لتعديل ملكية المجلّد go ثم نقله إلى المسار usr/local/ : sudo chown -R root:root ./go sudo mv go /usr/local ملحوظة: المسار usr/local/go/ هو المسار المنصوح به رسميا لتثبيت Go إلا أن بعض الحالات قد تتطلّب تثبيته على مسار مختلف. الخطوة الثانية: ضبط مسارات Go سنضبُط في هذه الخطوة المسارات الخاصّة بـGo في بيئة النظام. نفتح الملف profile./~ لتحريره: sudo nano ~/.profile نضيف السطرين التاليّين في نهاية الملف لضبط قيمة المتغيّر GOPATH، الذي يحدّد المسار الذي يجب على المصرّف البحثُ فيه عن الملفات المكتوبة بـGo، ولإضافة هذا المسار إلى متغيّر النظام PATH: export GOPATH=$HOME/work export PATH=$PATH:/usr/local/go/bin:$GOPATH/bin أضف الأسطر أدناه إلى الملف بدلا من الأسطر السابقة إن اخترت مسارا غير الذي اخترناه لتثبيت Go. يفترض المثال أن Go مثبَّت في المجلّد الشخصي للمستخدم: export GOROOT=$HOME/go export GOPATH=$HOME/work export PATH=$PATH:$GOROOT/bin:$GOPATH/bin نغلق الملف بعد التحرير ونعتمد التغيير بتنفيذ الأمر source: source ~/.profile الخطوة الثالثة: اختبار التثبيت نتأكّد بعد أن ثبّتنا Go وضبطنا مساراته من عمله. أنشئ مجلّدا جديدا لحفظ ملفات Go. مسار هذا الملف هو نفس المسار الذي حدّدناه في المتغيّر GOPATHضمن الخطوة السابقة: mkdir $HOME/work أنشئ مجلّدات مشاريع Go ضمن هذا المجلد كما في المثال التالي. يمكنك إبدال user في المسار أدناه باسم المستخدم الخاصّ بك على GitHub إن كنت تخطّط لاستخدام Git لإيداع شفرتك البرمجية على GitHub. إن لم تكن تخطّط لذلك فيمكن اختيار تسميات أخرى مثل my_project. mkdir -p work/src/github.com/user/hello ننشئ ملفّ Go بسيطا للتجربة، ونسميه hello: nano ~/work/src/github.com/user/hello/hello.go ألصق شفرة Go التالية ضمن محرّر النصوص. تستخدم هذه الشفرة حزمة main في Go، تستورد مكتبة fmt لدوالّ الإدخال والإخراج وتضبُط دالة جديدة لطباعة الجملة hello, world. package main import "fmt" func main() { fmt.Printf("hello, world\n") } يطبع البرنامج السابق عند تنفيذه بنجاح العبارة hello, world، وهو ما يدلّ على نجاح تصريف Compiling شفرة Go. احفظ الملف ثم أغلقه؛ ثم صرّفه باستدعاء الأمر go install: go install github.com/user/hello يمكننا الآن تشغيل البرنامج بتنفيذ الأمر hello: hello إن تمّ كل شيء على ما يُرام فستُطبَع العبارة hello, world. يمكنك معرفة أين يوجد الملف التنفيذي للبرنامج (ناتج التصريف) بتمرير اسمه إلى الأمر which: which hello مثال على المُخرجات: /home/user/work/bin/hello خاتمة يصبح لديك بعد تنزيل حزمة Go وتثبيتها وضبط مساراتها نظام جاهز لاستخدامه في التطوير بلغة Go. يمكنك الآن البدء بتعلم كتابة البرامج بهذه اللغة، راجع قسم البرمجة بلغة Go للمزيد. ترجمة - بتصرّف - للمقال How to Install Go 1.6 on Ubuntu 16.04 لصاحبه Brennen Bearnes.
تزداد شعبية Go، وهي لغة برمجة حديثة تطوّرها شركة Google، تزداد كثيرا في التطبيقات والشركات؛ كما توفّر مجموعة متناسقة من المكتبات البرمجية. يشرح هذا الدرس خطوات تثبيت الإصدار 1.8 (الإصدار المستقر الأحدث حتى الآن) على توزيعة لينكس أوبونتو 16.04. سننفّذ في الخطوة الأخيرة من هذا الدرس تطبيق “أهلا بالعالم” صغيرا للتأكد من تثبيت مصرّف اللغة Compiler وعمله. المتطلّبات يفترض هذا الدرس توفّر نظام أوبونتو 16.04 معدًّا للعمل مع مستخدم إداري غير المستخدم الجذر بالطريقة التي يشرحها الإعداد الابتدائي لخادوم أوبونتو. الخطوة الأولى: تثبيت Go نبدأ بتثبيت Go على الخادوم. اتّصل - إن دعت الحاجة لذلك - بالخادوم عن طريق SSH: ssh sammy@your_server_ip اذهب إلى صفحة التنزيلات على الموقع الرسمي لـGo واعثُر على رابط الملف المضغوط لآخر إصدار مستقر، مع قيمة تجزئة SHA256 الخاصة به. تأكد من أنك في المجلّد الشخصي للمستخدم ثم نزّل الإصدار انطلاقا من الرابط الذي تحصّلت عليه في الفقرة الماضية: cd ~ curl -O https://storage.googleapis.com/golang/go1.8.3.linux-amd64.tar.gz استخدم الأمر sha256sum للتحقّق من الملف المضغوط: sha256sum go1.8.3.linux-amd64.tar.gz مثال على المُخرجات: 1862f4c3d3907e59b04a757cfda0ea7aa9ef39274af99a784f5be843c80c6772 go1.8.3.linux-amd64.tar.gz ستحصُل على قيمة تجزئة Hash مثل تلك الموجودة في المُخرجات السابقة. تأكد من أنها توافق قيمة التجزئة الخاصة بالملف التي تحصّلت عليها من صفحة التنزيلات. سنستخدم الآن الأمر tar لفك ضغط الملف. يطلُب الخيار x استخراج محتوى الملف المضغوط، يُظهر الخيار v مخرجات مفصَّلة ويحدّد الخيار f أننا سنمرّر للأمر tar اسم الملف المضغوط: tar xvf go1.6.linux-amd64.tar.gz ستحصُل الآن على مجلّد باسم go في المجلّد الشخصي للمستخدم. نفّذ الأمرين التاليين لتعديل ملكية المجلّد go ثم نقله إلى المسار usr/local/ : sudo chown -R root:root ./go sudo mv go /usr/local ملحوظة: المسار usr/local/go/ هو المسار المنصوح به رسميا لتثبيت Go إلا أن بعض الحالات قد تتطلّب تثبيته على مسار مختلف. الخطوة الثانية: ضبط مسارات Go سنضبُط في هذه الخطوة المسارات الخاصّة بـGo في بيئة النظام. نفتح الملف profile./~ لتحريره: sudo nano ~/.profile نضيف السطرين التاليّين في نهاية الملف لضبط قيمة المتغيّر GOPATH، الذي يحدّد المسار الذي يجب على المصرّف البحثُ فيه عن الملفات المكتوبة بـGo، ولإضافة هذا المسار إلى متغيّر النظام PATH: export GOPATH=$HOME/work export PATH=$PATH:/usr/local/go/bin:$GOPATH/bin أضف الأسطر أدناه إلى الملف بدلا من الأسطر السابقة إن اخترت مسارا غير الذي اخترناه لتثبيت Go. يفترض المثال أن Go مثبَّت في المجلّد الشخصي للمستخدم: export GOROOT=$HOME/go export GOPATH=$HOME/work export PATH=$PATH:$GOROOT/bin:$GOPATH/bin نغلق الملف بعد التحرير ونعتمد التغيير بتنفيذ الأمر source: source ~/.profile الخطوة الثالثة: اختبار التثبيت نتأكّد بعد أن ثبّتنا Go وضبطنا مساراته من عمله. أنشئ مجلّدا جديدا لحفظ ملفات Go. مسار هذا الملف هو نفس المسار الذي حدّدناه في المتغيّر GOPATHضمن الخطوة السابقة: mkdir $HOME/work أنشئ مجلّدات مشاريع Go ضمن هذا المجلد كما في المثال التالي. يمكنك إبدال user في المسار أدناه باسم المستخدم الخاصّ بك على GitHub إن كنت تخطّط لاستخدام Git لإيداع شفرتك البرمجية على GitHub. إن لم تكن تخطّط لذلك فيمكن اختيار تسميات أخرى مثل my_project. mkdir -p work/src/github.com/user/hello ننشئ ملفّ Go بسيطا للتجربة، ونسميه hello: nano ~/work/src/github.com/user/hello/hello.go ألصق شفرة Go التالية ضمن محرّر النصوص. تستخدم هذه الشفرة حزمة main في Go، تستورد مكتبة fmt لدوالّ الإدخال والإخراج وتضبُط دالة جديدة لطباعة الجملة hello, world. package main import "fmt" func main() { fmt.Printf("hello, world\n") } يطبع البرنامج السابق عند تنفيذه بنجاح العبارة hello, world، وهو ما يدلّ على نجاح تصريف Compiling شفرة Go. احفظ الملف ثم أغلقه؛ ثم صرّفه باستدعاء الأمر go install: go install github.com/user/hello يمكننا الآن تشغيل البرنامج بتنفيذ الأمر hello: hello إن تمّ كل شيء على ما يُرام فستُطبَع العبارة hello, world. يمكنك معرفة أين يوجد الملف التنفيذي للبرنامج (ناتج التصريف) بتمرير اسمه إلى الأمر which: which hello مثال على المُخرجات: /home/user/work/bin/hello خاتمة يصبح لديك بعد تنزيل حزمة Go وتثبيتها وضبط مساراتها نظام جاهز لاستخدامه في التطوير بلغة Go. يمكنك الآن البدء بتعلم كتابة البرامج بهذه اللغة، راجع قسم البرمجة بلغة Go للمزيد. ترجمة - بتصرّف - للمقال How to Install Go 1.6 on Ubuntu 16.04 لصاحبه Brennen Bearnes. -
.png.5db67f8c9021ccbe432b15b629890028.png) هل تريد الوصول إلى شبكة الإنترنت بشكلٍ آمن ومحمي من هاتفك الذكي أو حاسوبك المحمول عندما تقوم بالاتصال بشبكاتٍ غير موثوقة مثل الشبكات اللاسلكية العمومية لفندق أو مقهى؟ تسمح لك الشبكة الافتراضية الخاصّة (Virtual Private Network - VPN) بتصفّح الإنترنت بالشبكات غير الموثوقة بشكلٍ آمن ومجهول كما لو كنتَ على شبكةٍ آمنة وموثوقة. يتم تمرير تدفّق البيانات (traffic) من خادومك إلى وجهته ومن ثمّ يعود إليك حاملًا البيانات. يسمح لك هذا الإعداد عندما يتم ربطه مع [اتصال HTTPS] (https://en.wikipedia.org/wiki/HTTP_Secure) أن تقوم بتأمين عمليات تسجيل الدخول وعمليات الدفع وغيرها من العمليات التي تقوم بها عند تصفّحك للإنترنت. يمكنك تخطّي الحجب الذي يفرضه مزوّد الخدمة على مواقع معيّنة مثلًا وتخطّي تقييدات المنطقة الجغرافية لمواقع معيّنة، كما يمكنك تحصين موقعك وتدفّق HTTP الصادر من جهازك من الشبكات غير المحمية. OpenVPN هو عبارة عن شبكة افتراضية خاصّة لطبقة حِزَم البيانات الآمنة مفتوحة المصدر (SSL) ويقبل تشكيلةً واسعة من الإعدادات والتخصيصات. في هذا الدرس، سنقوم بإعداد خادوم OpenVPN على خادومنا ومن ثمّ نقوم بإعداده ليقبل الوصول إليه من نظام ويندوز، Mac OS X، iOS و Android. سنبقي خطوات التثبيت والإعداد أسهل ما يمكن في هذا الدرس. المتطلّباتالمتطلّبات الوحيدة اللازمة هي امتلاك خادوم يعمل بتوزيعة Ubuntu 14.04. يجب أن تمتلك الوصول إلى حساب المستخدم الجذر لإكمال هذا الدرس. إضافي: بعد إكمال هذا الدرس، سيكون من الجيد إنشاء حساب مستخدمٍ عادي بصلاحيات sudo لعمل صيانةٍ عامّة على خادومك في حال احتجتها مستقبلًا.الخطوة الأولى: تثبيت وإعداد بيئة خادوم OpenVPNإعداد OpenVPNقبل أن نقوم بتثبيت أيّ حزم، يجب أن نقوم بتحديث قوائم مستودعات توزيعة أوبونتو أولًا: apt-get updateومن ثمّ، يمكننا تثبيت OpenVPN و Easy-RSA: apt-get install openvpn easy-rsaيجب أن يتم استخراج ملفّ عيّنة إعدادات OpenVPN إلى المسار /etc/openvpn لكي نتمكّن من إضافته إلى عملية التثبيت الخاصّة بنا. يمكن القيام بهذا عبر الأمر: gunzip -c /usr/share/doc/openvpn/examples/sample-config-files/server.conf.gz > /etc/openvpn/server.confبمجرّد أن يتم استخراجه، افتح ملفّ server.conf في محرر نصوص. في هذا الدرس سنستخدم Vim ولكن يمكنك استخدم أيّ محرر نصوص تريده: vim /etc/openvpn/server.confهناك العديد من التغييرات التي يجب علينا تطبيقها على هذا الملفّ. سترى قسمًا يبدو هكذا: # Diffie hellman parameters. # Generate your own with: # openssl dhparam -out dh1024.pem 1024 # Substitute 2048 for 1024 if you are using # 2048 bit keys. dh dh1024.pemقم بتغيير dh1024.pem إلى: dh2048.pemسيقوم هذا بمضاعفة طول مفتاح RSA المُستخدم عندما يتم إنشاء مفاتيح الخادوم والعميل. ما نزال في ملفّ server.conf، والآن ابحث عن هذا القسم: # If enabled, this directive will configure # all clients to redirect their default # network gateway through the VPN, causing # all IP traffic such as web browsing and # and DNS lookups to go through the VPN # (The OpenVPN server machine may need to NAT # or bridge the TUN/TAP interface to the internet # in order for this to work properly). ;push "redirect-gateway def1 bypass-dhcp"قم بإلغاء تعليق السطر التالي (أزل إشارة # أو ; من قبله): ;push "redirect-gateway def1 bypass-dhcp" لكي يتمكّن خادوم OpenVPN الخاصّ بنا من تمرير التدفّق المطلوب من المستخدمين والعملاء إلى وجهته المطلوبة. يجب أن يبدو السطر هكذا بعد التعديل: push "redirect-gateway def1 bypass-dhcp"الآن ابحث عن هذا القسم: # Certain Windows-specific network settings # can be pushed to clients, such as DNS # or WINS server addresses. CAVEAT: # http://openvpn.net/faq.html#dhcpcaveats # The addresses below refer to the public # DNS servers provided by opendns.com. ;push "dhcp-option DNS 208.67.222.222" ;push "dhcp-option DNS 208.67.220.220"قم بإلغاء تعليق السطرين push "dhcp-option DNS 208.67.222.222" و push "dhcp-option DNS 208.67.220.220" . يجب أن يبدوا على هذا الشكل: push "dhcp-option DNS 208.67.222.222" push "dhcp-option DNS 208.67.220.220"يقوم هذا بإخبار الخادوم بأن يقوم بدفع OpenVPN ليتصل بالعملاء (clients) ليعطيهم عنوان الـDNS المخصص. يقوم هذا الأمر بحماية المستخدم من خروج طلبات DNS خارج اتصال الـVPN. وعلى كلّ حال، من المهم أن تقوم بتحديد عناوين الـDNS المطلوبة التي تريد استخدامها على كلّ جهازٍ من أجهزة العملاء. رغم أنّ OpenVPN يستخدم خدمة OpenDNS افتراضيًا إلّا أنّه يمكنك استخدامه أيّ خدمات DNS تريدها. القسم الأخير الذي يجب تغييره في ملفّ server.conf هو: # You can uncomment this out on # non-Windows systems. ;user nobody ;group nogroupقم بإلغاء تعليق كلٍّ من السطرين user nobody و group nobody. يجب أن يبدوا هكذا: user nobody group nogroupافتراضيًا، يقوم OpenVPN بالعمل باستخدام المستخدم الجذر (root) حيث يمتلك هذا الأخير وصولًا كاملًا إلى النظام. سنقوم عوضًا عن هذا بجعل OpenVPN يستخدم المستخدم nobody والمجموعة nobody. هذا المستخدم لا يمتلك صلاحيات ولا أيّ إمكانياتٍ للولوج، ويتم استخدامه عادةً لتشغيل التطبيقات غير الموثوقة مثل خواديم واجهات الويب. يمكنك الآن حفظ تغييراتك والخروج من VIM. توجيه حِزَم البياناتهذا الأمر هو عبارة عن خاصية sysctl تقوم بإخبار نواة الخادوم أن تقوم بتوجيه التدفّق من أجهزة العملاء إلى الإنترنت. إن لم يتم هذا الأمر، فإنّ التدفّق سيتوقف في الخادوم. يمكنك تفعيل توجيه حِزَم البيانات أثناء وقت التشغيل باستخدام الأمر التالي: echo 1 > /proc/sys/net/ipv4/ip_forwardنحتاج أن نقوم بجعل هذا الأمر دائمًا بحيث يبقى الخادوم يقوم بتوجيه التدفّق حتى بعد إعادة تشغيل الخادوم: vim /etc/sysctl.confفي بداية ملفّ sysctl ستجد: # Uncomment the next line to enable packet forwarding for IPv4 #net.ipv4.ip_forward=1قم بإلغاء تعليق net.ipv4.ip_forward. يجب أن يبدو ذاك السطر هكذا: # Uncomment the next line to enable packet forwarding for IPv4 net.ipv4.ip_forward=1احفظ تغييراتك واخرج. الجدار الناري غير المعقّد (ufw)ufw هو واجهة أمامية (front-end) لـiptables. إعداد ufw ليس صعبًا. وهو مُضمّن بشكلٍ افتراضي في Ubuntu 14.04، لذا يجب علين فقط إنشاء بضع قواعد (rules) وتعديل بعض الإعدادات ليعمل، ومن ثمّ سنقوم بتشغيله. للمزيد من المعلومات حول ufw يمكنك مراجعة كيفية إعداد جدارٍ ناري باستخدام UFW على خادوم أوبونتو ودبيان السحابي. أولًا قم بضبط ufw بحيث يسمح باتصال SSH. أدخل اﻷمر التالي: ufw allow sshسنستخدم OpenVPN عبر UDP في هذا الدرس، لذا يجب أن يسمح UFW بتدفّق UDP عبر المنفذ 1194: ufw allow 1194/udpيجب ضبط سياسة التوجيه في UFW كذلك. يمكنك القيام هذا عبر تعديل ملفّ إعدادات UFW الرئيسي: vim /etc/default/ufwابحث عن DEFAULTFORWARDPOLICY="DROP". يجب تغيير محتوى هذا السطر من DROP إلى ACCEPT. يجب أن يبدو السطر هكذا عندما تنتهي منه: DEFAULT_FORWARD_POLICY="ACCEPT"ثمّ سنقوم بإضافة بعض قواعد UFW الإضافية لترجمة عناوين الشبكة وتذكّر عناوين الـIP الخاصّة بالعملاء الحاليين: vim /etc/ufw/before.rulesقم بجعل بداية ملفّ before.rules الخاصّ بك تبدو هكذا كما بالمثال أدناه. القسم بعد START OPENVPN RULES وقبل END OPENVPN RULES هو ما يجب إضافته: # # rules.before # # Rules that should be run before the ufw command line added rules. Custom # rules should be added to one of these chains: # ufw-before-input # ufw-before-output # ufw-before-forward # # START OPENVPN RULES # NAT table rules *nat :POSTROUTING ACCEPT [0:0] # Allow traffic from OpenVPN client to eth0 -A POSTROUTING -s 10.8.0.0/8 -o eth0 -j MASQUERADE COMMIT # END OPENVPN RULES # Don't delete these required lines, otherwise there will be errors *filterبعدما تمّ تطبيق هذه التغييرات على UFW، يمكننا الآن تفعيله. أدخل اﻷمر التالي في سطر الأوامر: ufw enableوسيتم طباعة الخرج التالي: Command may disrupt existing ssh connections. Proceed with operation (y|n)?للتحقق من حالة قواعد الجدار الناري طبّق: ufw statusوالخرج يجب أن يكون: Status: active To Action From -- ------ ---- 22 ALLOW Anywhere 1194/udp ALLOW Anywhere 22 (v6) ALLOW Anywhere (v6) 1194/udp (v6) ALLOW Anywhere (v6)الخطوة الثانية: إنشاء استيثاق الشهادات و شهادة موقّعة من الخادوم ومفتاح لهايستخدم OpenVPN الشهادات ليقوم بتشفير التدفّق. إعداد وبناء استيثاق الشهاداتالآن هو وقت إعداد استيثاق الشهادات الخاصّ بنا (Certificate Authority - CA) وإنشاء شهادة ومفتاح لخادوم الـOpenVPN. يدعم OpenVPN الاستيثاق ثنائي الاتجاه (bidirectional authentication) باستخدام الشهادات، مما يعني أنّه يجب على العميل أن يقوم باستيثاق شهادة الخادوم ويجب على الخادوم أن يقوم باستيثاق شهادة العميل قبل أن يتم إنشاء الاتصال المشترك بينهما. سنستخدم سكربتات Easy RSA التي نسخناها مبكّرًا للقيام بهذا. أولًا، انسخ سكربتات Easy RSA إلى مكانها: cp -r /usr/share/easy-rsa/ /etc/openvpnثمّ قم بعمل مجلّد لتخزين المفاتيح: mkdir /etc/openvpn/easy-rsa/keysتمتلك Easy-RSA ملفّ متغيّرات يمكننا تعديله لإنشاء شهاداتٍ خاصّة بشخصنا، شركاتنا أو أيّ شيءٍ آخر نريده. يتم نسخ هذه المعلومات إلى الشهادات والمفاتيح، وستساعد هذه المعلومات على التعرّف على المفاتيح لاحقًا: vim /etc/openvpn/easy-rsa/varsالمتغيّرات بين علامتيّ تنصيص (") يجب أن تقوم بتغييرها بناءً على إعداداتك: export KEY_COUNTRY="US" export KEY_PROVINCE="TX" export KEY_CITY="Dallas" export KEY_ORG="My Company Name" export KEY_EMAIL="sammy@example.com" export KEY_OU="MYOrganizationalUnit"في نفس الملفّ vars، قم أيضًا بتعديل السطر الظاهر أدناه، سنستخدم server كاسم المفتاح. إذا أردت استخدام اسمٍ آخر، فسيجب عليك أيضًا تحديث ملفّات إعدادات OpenVPN التي تقوم بالإشارة إلى server.key و server.crt: export KEY_NAME="server"نحتاج إلى إنشاء مُعامِلات Diffie-Hellman; قد يأخذ هذا الأمر بضع دقائق: openssl dhparam -out /etc/openvpn/dh2048.pem 2048الآن فلنغيّر المسارات بحيث نعمل في المسارات الذي نقلنا سكربتات Easy-RSA إليه من قبل في الخطوة الثانية: cd /etc/openvpn/easy-rsaقم بتحليل ملفّ (PKI (Public Key Infrastructure. انتبه إلى النقطة (.) و المسافة (space) قبل الأمر vars/. حيثُ أنّ هذا الأمر قد يغيّر المسار الحالي كلّيًا (المصدر): . ./varsخرج الأمر أعلاه ظاهرٌ أدناه. بما أننا لم نقم بإنشاء أيّ شيء في مجلّد keys بعد، فإنّ رسالة التحذير ليست شيئًا لنقلق حوله الآن: NOTE: If you run ./clean-all, I will be doing a rm -rf on /etc/openvpn/easy-rsa/keysالآن سنقوم بتنظيف مسار عملنا الحالي من أيّ ملفّات عيّنة مفاتيح أو مفاتيح قديمة لكي تبقى المفاتيح الجديدة بالمسار فقط: ./clean-allسيبني هذا الأمر الأخير استيثاق الشهادات (CA) عبر استدعاء طرفيّة OpenSSL التفاعلية. سيسألك الخرج أن تقوم بتأكيد اسم المتغيرات الفريدة التي أدخلناها من قبل في ملفّ متغيّرات Easy-RSA (اسم البلد، المنظمة.. إلخ): ./build-caاضغط مفتاح Enter ببساطة لتتنقل عبر كلّ طرفية. إذا كان هناك شيءٌ يجب تغييره، فيمكنك القيام بذلك عبر سطر الأوامر. إنشاء شهادة ومفتاح للخادومما زلنا نعمل من المسار /etc/openvpn/easy-rsa ، الآن قم بإدخال الأمر التالي لبناء مفتاح الخادوم. حيث سترى أنّ server هو قيمة المتغيّر export KEY_NAME الذي أعددناه في ملفّ vars الخاصّ بـEasy-RSA من قبل بالخطوة الثانية: ./build-key-server serverيظهر خرج مشابه كالذي يظهر عندما طبّقنا ./build-ca ، ويمكنك مجددًا الضغط على مفتاح Enter لتأكيد كلّ سطرٍ من الأسماء الفريدة. على كلّ حال، هذه المرّة هناك إدخالان إضافيان: Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []: An optional company name []:يجب أن يتم تركهما كلاهما فارغين، لذا فقط اضغط Enter للمتابعة. هناك سؤالان إضافيان في النهاية، وهما يتطلبان إجابة ( y ) إيجابية فقط: Sign the certificate? [y/n] 1 out of 1 certificate requests certified, commit? [y/n]يجب أن يكتمل السؤال الأخير أعلاه بالتالي: Write out database with 1 new entries Data Base Updatedنقل شهادات الخادوم والمفاتيحيتوقّع OpenVPN أن يرى استيثاق شهادات الخادوم، الشهادات والمفاتيح في /etc/openvpn . فلننسخها إلى الموقع الصحيح: cp /etc/openvpn/easy-rsa/keys/{server.crt,server.key,ca.crt} /etc/openvpnيمكنك التحقق من نجاح العملية عبر: ls /etc/openvpnيجب أن ترى ملفّات الشهادات والمفاتيح الخاصّة بالخادوم. في هذه النقطة، أصبح خادوم OpenVPN جاهزًا للانطلاق. شغّله وتحقق من حالته باستخدام: service openvpn start service openvpn statusيجب أن يقوم أمر التحقق من الحالة بإرجاع الخرج التالي لك: VPN 'server' is runningتهانينا! أصبح خادوم OpenVPN الخاصّ بك عاملًا! إذا كانت رسالة الحالة تقول لك أنّ خادوم الـOpenVPN لا يعمل، فتحقق من ملفّ /var/log/syslog وابحث عن أخطاء مثل: Options error: --key fails with 'server.key': No such file or directoryوالتي تقوم أنّ ملفّ server.key لم يتم نسخه إلى المسار etc/openvpn/ بشكلٍ صحيح، مما يتوجب عليك إعادة نسخه مجددًا. الخطوة الثالثة: إنشاء الشهادات والمفاتيح الخاصّة بالعملاءلقد قمنا بتثبيت وإعداد خادوم OpenVPN، أنشأنا استيثاق الشهادات وشهادة ومفتاح الخادوم. في هذه الخطوة الآن، سنستخدم استيثاق شهادات الخادوم لنقوم بإنشاء الشهادات والمفاتيح الخاصّة بجهاز كلّ عميلٍ سيتصل بالخادوم على حدى. سيتم تثبيت هذه الملفّات لاحقًا إلى أجهزة العملاء كالهواتف الذكية والأجهزة المحمولة. بناء المفاتيح والشهاداتمن المناسب أن يمتلك كلّ عميلٍ يتصل بالخادوم شهادته ومفتاحه الخاصّين به. هذا الأمر مفضّل على إنشاء شهادة واحدة ومفتاح واحد وتوزيعهما على جميع أجهزة العملاء لأغراض تتعلق بالأمان. ملاحظة: افتراضيًا، لا يسمح OpenVPN بالاتصالات المتزامنة بنفس الوقت إلى الخادوم من أكثر من جهازٍ عميل باستخدام نفس الشهادة والمفتاح (انظر duplicate-cn في etc/openvpn/server.conf/). لإنشاء شهادات استيثاق منفصلة لكلّ جهاز عميل تنوي السماح له بالاتصال بخادوم الـOpenVPN، يجب عليك إكمال هذه الخطوة لكلّ جهاز، ولكن يمكنك تغيير الاسم client1 أدناه إلى شيءٍ مختلف مثل client2 أو iphone2. بفضل استخدام شهادةٍ منفصلة لكلّ جهاز عميل، يمكن لاحقًا منعهم بشكلٍ منفصل من الوصول إلى الخادوم إذا ما تمّ الاحتياج لذلك. سنستخدم client1 في الأمثلة الموجودة في هذا الدرس كاسم الجهاز العميل. كما فعلنا مع مفتاح الخادوم، فسنقوم الآن ببناء واحد لمثال client1. يجب أن تكون ما زلت تعمل في /etc/openvpn/easy-rsa: ./build-key client1مجددًا، سيتم سؤالك عمّا إذا كنتَ تريد تغيير أو تأكيد متغيّرات الأسماء الفريدة والحقول الإضافية التي تركناها فارغة من قبل. اضغط Enter لاختيار الخيارات الافتراضية: Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []: An optional company name []:وكما في السابق، سيسألك مرتين عن تأكيد بعض الخيارات، اكتب y: Sign the certificate? [y/n] 1 out of 1 certificate requests certified, commit? [y/n]إذا نجحت عملية بناء المفتاح فسيظهر التالي: Write out database with 1 new entries Data Base Updatedيجب على ملفّ عيّنة إعدادات العميل أن يتم نسخه إلى مجلّد Easy-RSA أيضًا. سنستخدمه كقالب يمكن تحميله إلى أجهزة العملاء ليتم تعديله. أثناء عملية النسخ، سنقوم بتغيير اسم ملفّ العيّنة من client.conf إلى client.ovpn لأنّ امتداد ملفّ .ovpn هو ما تتوقع أجهزة العملاء أن تراه باسم الملفّ وليس .conf: cp /usr/share/doc/openvpn/examples/sample-config-files/client.conf /etc/openvpn/easy-rsa/keys/client.ovpnيمكنك تكرار هذا القسم مجددًا لكلّ عميلٍ تريد السماح له بالوصول، ولا تنسى استبدال client1 باسم الجهاز الجديد. نقل الشهادات والمفاتيح إلى أجهزة العميلخلاصة ما طبقّناه أعلاه هو أننا أنشأنا شهادات ومفاتيح العملاء، وأننا قمنا بتخزينها على خادوم OpenVPN في المسار /etc/openvpn/easy-rsa/keys . نحتاج القيام بنقل شهادة العميل، المفتاح وقالب الملفّ الشخصي لكلّ عميلٍ نريد السماح له بالوصول إلى مجلّد محلّي على جهاز الحاسوب الخاصّ بنا أو أيّ جهاز عميل آخر. في هذا المثال، يتطلّب جهاز العميل client1 الشهادات والمفاتيح الخاصّة به والموجودة في المسارات: * /etc/openvpn/easy-rsa/keys/client1.crt * /etc/openvpn/easy-rsa/keys/client1.keyتكون ملفّات ca.crt و client.ovpn هي نفسها لجميع أجهزة العملاء مهما اختلفت. قمّ بتحميل هذه الملفّات أيضًا; لاحظ أنّ ملف ca.crt هو في مسارٍ مختلف عن الملفّات الأخرى: etc/openvpn/easy-rsa/keys/client.ovpn/etc/openvpn/ca.crt/بينما ستعتمد التطبيقات المُستخدمة لإكمال هذه المهمّة على اختيارك ونوع نظام التشغيل الخاصّ بك، فإنّك بحاجة إلى تطبيق يستخدم STFP (بروتوكول نقل الملفّات عبر SSH) أو SCP (النسخ الآمن) للوصول إلى الملفّات الموجودة في خلفية الخادوم. سينقل هذا ملفّات الاستيثاق الخاصّة بخادومك عبر اتصالٍ مشفّر. إليك مثالًا لأمر SCP باستخدام مثالنا من client1. إنّه يقوم بوضع الملفّ client1.key إلى المجلّد Downloads الموجود على حاسوبنا المحلّي: scp root@your-server-ip:/etc/openvpn/easy-rsa/keys/client1.key Downloads/إليك بضع أدوات ودروس يمكنك استخدامها لنقل الملفّات بشكلٍ آمن من الخادوم إلى الحاسوب المحلّي: WinSCPكيفية استخدام SFTP لنقل الملفّات بشكلٍ آمن من خادومٍ بعيد.كيفية استخدام FileZilla لنقل وإدارة الملفّات بشكلٍ آمن.في نهاية هذا القسم، تأكّد أنّ هذه الملفّات الأربعة أصبحت موجودة على جهاز المحلّي مهما كان نوعه: client1.crtclient1.keyclient.ovpnca.crtالخطوة الرابعة: إنشاء ملفٍّ شخصيٍ موحّد لجهاز العميلهناك العديد من الطرق المُستخدمة لإدارة ملفّات العملاء ولكن أسهلها يستخدم ملفّا شخصيًا موحّدًا. يتم إنشاء هذا الملفّ عبر تعديل قالب ملفّ client.ovpn ليتضمّن استيثاق شهادات الخادوم، شهادة العميل والمفتاح الخاصّ به. بمجرّد إضافته، فسيجب حينها فقط استيراد ملفّ client.ovpn إلى تطبيقات OpenVPN على أجهزة العميل. سنقوم بإنشاء ملفٍّ شخصيٍ وحيد لجهازنا المدعو client1 على الحاسوب المحلّي الذي قمنا بتحميل جميع الملفّات إليه. يمكن لهذا الحاسوب المحلّي بنفسه أن يكون جهازًا عميلًا أو مجرّد منطقة عمل مؤقّتة لدمج ملفّات الاستيثاق. يجب أن يتم نسخ قالب ملفّ client.ovpn وإعادة تسميته. كيفية قيامك بهذا الأمر ستعتمد على نظام التشغيل الخاصّة بجهازك المحلّي. ملاحظة: لا يجب على اسم ملفّ client.ovpn الخاصّ بك المنسوخ الجديد أن يكون مطابقًا لاسم جهاز العميل. تطبيق العميل لـOpenVPN سيستخدم اسم الملفّ كمُعرّف لاتصال VPN نفسه، حيث يجب عليك نسخ ملفّ client.ovpn إلى أيّ اسمٍ جديد تريد استخدامه على نظام التشغيل الخاصّ بك. كمثال: work.ovpn سيتم التعرّف عليه كـwork و school.ovpn سيتم التعرّف عليه كـschool. في هذا الدرس، سنقوم بتسمية اتصال VPN كـ HsoubAcademy ولذلك فسيكون اسم الملفّ هو HsoubAcademy.ovpn من الآن فصاعدًا. بمجرّد تسمية الملفّ الجديد المنسوخ، يجب علينا حينها فتح ملفّ HsoubAcademy.ovpn في محرر نصوص. أول نقطة سيقع عليها انتباهك هي مكان عنوان الـIP الخاصّ بخادومك. بالقرب من بداية الملفّ، قم بتغيير my-server-1 إلى عنوان IP الخاصّ بخادومك: # The hostname/IP and port of the server. # You can have multiple remote entries # to load balance between the servers. remote my-server-1 1194الآن، ابحث عن القسم الظاهر أدناه وقم بإلغاء تعليق user nobody و group nobody، كما فعلنا مع ملفّ server.conf في الخطوة الأولى. ملاحظة: هذا لا ينطبق على ويندوز لذا يمكنك تجاوزه. يجب أن يبدو هكذا عندما تنتهي: # Downgrade privileges after initialization (non-Windows only) user nobody group nogroupالقسم الظاهر أدناه يحتاج أن نقوم فيه بتعليق السطور الثلاثة الأخيرة لكي نتمكّن من تضمين الشهادة والمفتاح مباشرةً في ملفّ HsoubAcademy.ovpn، يجب أن يبدو هكذا: # SSL/TLS parms. # . . . #ca ca.crt #cert client.crt #key client.keyلدمج الملفّات المنفصلة إلى ملفٍّ شخصي واحدٍ موحّد، يجب أن يتم وضع محتويات الملفّات ca.crt, client1.crt, و client1.key مباشرةً في ملفّ .ovpn باستخدام هيكلة XML. يجب بالنهاية أن يبدو شكلها كالتالي: <ca> (أدخل محتويات ca.crt هنا) </ca> <cert> (أدخل محتويات client1.crt هنا) </cert> <key> (أدخل محتويات client1.key هنا) </key>عندما تنتهي، يجب أن تبدو نهاية الملفّ كالتالي: <ca> -----BEGIN CERTIFICATE----- . . . -----END CERTIFICATE----- </ca> <cert> Certificate: . . . -----END CERTIFICATE----- . . . -----END CERTIFICATE----- </cert> <key> -----BEGIN PRIVATE KEY----- . . . -----END PRIVATE KEY----- </key>يمتلك ملفّ client1.crt معلوماتٍ إضافية في داخله; لا بأس بتضمين الملفّ بأكمله. احفظ التغييرات واخرج. أصبح لدينا الآن ملفّ واحد موحّد لضبط جهازنا المحلّي client1. الخطوة الخامسة: تثبيت ملفّ العميلالآن سنناقش تثبيت ملفّ VPN على Windows, OS X, iOS, و Android. لا يعتمد أيٌّ من إرشادات هذه الأنظمة على الآخر لذا يمكنك التجاوز إلى الذي يطابق نظامك التشغيلي الحالي فقط. تذكّر أنّ الاتصال سيتم تسميته بحساب اسم ملفّ .ovpn الذي استخدمته. في مثالنا قمنا بتسمية الملفّ كـ HsoubAcademy.ovpn ولذلك سيكون اسم الاتصال هو HsoubAcademy. Windowsالتثبيتيمكن العثور على تطبيق عميل OpenVPN لنظام ويندوز من صفحة التحميلات الخاصّة بـOpenVPN. اختر المُثبّت المناسب لإصدارك من ويندوز. ملاحظة: يتطلّب OpenVPN الصلاحيات الإدارية ليتم تثبيته. بعد تثبيته، انسخ الملفّ HsoubAcademy.ovpn إلى: C:\Program Files\OpenVPN\configعندما تقوم بتشغيل OpenVPN، فسيقوم تلقائيًا برؤية الملفّ وجعله متاحًا. يجب أن يتم تشغيل OpenVPN بصلاحيات المسؤول في كلّ مرّة يتم تشغيله، حتى ولو كان يتم تشغيله على حسابات المستخدمين. لفعل هذا دون الحاجة إلى الضغط على زرّ الفأرة الأيمن واختيار التشغيل كمسؤول في كلّ مرّة تقوم باستعمال الـVPN، يمكنك ضبط هذا الأمر ولكنك ستحتاج إلى القيام به من حساب بصلاحياتٍ إدارية. هذا يعني أيضًا أنّه سيجب على المستخدمين إدخال كلمة مرور المستخدم المدير لاستخدام OpenVPN. على الناحية الأخرى، لن يتمكن المستخدمون من استخدام OpenVPN بشكلٍ صحيح دون أن يتم تشغيله على جهاز العميل بصلاحياتٍ إدارية، لذا فإنّ الصلاحيات الإدارة مطلوبة. لجعل تطبيق OpenVPN يتم تشغيله دومًا كمدير، اضغط بزرّ الفأرة الأيمن على أيقونة الاختصار الخاصّة به واذهب إلى خصائص. في نهاية لسان التوافقية، اضغط على الزرّ لتغيير الإعدادات لجميع المستخدمين. في النافذة الجديدة، اختر تشغيل هذا البرنامج كمدير. الاتصالفي كلّ مرّة تقوم بتشغيل واجهة OpenVPN الرسومية، سيسألك ويندوز عمّا إذا كنتَ تريد السماح للبرنامج بتطبيق التغييرات على نظامك. اضغط على موافق. تشغيل تطبيق عميل OpenVPN سيقوم فقط بوضع الأيقونة في تنبيهات النظام ويمكن الاتصال أو قطع الاتصال بخادوم OpenVPN عند الحاجة; وهو لا يقوم حقيقةً بالاتصال بـ VPN. بمجرّد بدء OpenVPN، قم بإنشاء اتصال عبر الذهاب إلى تنبيهات النظام والضغط بزرّ الفأرة الأيمن على أيقونة OpenVPN. هذا سيفتح لك قائمةً فرعية. اختر HsoubAcademy من أعلى القائمة (والذي هو عبارة عن HsoubAcademy.ovpn) واختر اتصال. سيتم فتح نافذة حالة جديدة تعرض لك الخرج أثناء تأسيس الاتصال، وسيتم طباعة رسالة بمجرّد اكتمال العملية. يمكنك إلغاء الاتصال من VPN بنفس الطريقة: اذهب إلى تنبيهات النظام وانقر بزرّ الفأرة الأيمن على أيقونة OpenVPN واختر قطع الاتصال. OS XالتثبيتTunnelblick هو تطبيق عميل OpenVPN مجاني ومفتوح المصدر لنظام MAC OS X. يمكنك تحميله من صفحة تحميلات Tunnelblick. انقر نقرتين على ملفّ .dmg المحمّل وتابع إرشادات التثبيت. إلى نهاية عملية التثبيت، سيسألك Tunnelblick عمّا إذا كنتَ تمتلك أيّ ملفّات إعدادات. الأسهل حاليًا هو اختيار لا وترك Tunnelblick ليتابع التثبيت. ابحث نافذة Finder وانقر على ملفّ HsoubAcademy.ovpn وسيتم تشغيل Tunnelblick باستخدام ذلك الملفّ، الصلاحيات الإدارية مطلوبة. الاتصالشغّل Tunnelblick عبر النقر مرّتين على مجلّد أيقونة التطبيقات. بمجرّد تشغيل Tunnelblick، سيكون هناك أيقونة Tunnelblick على شريط القائمة في أعلى يمين الشاشة للتحكّم بالاتصالات. اضغط على الأيقونة ومن ثمّ عنصر قائمة اتصال لبدء اتصالٍ جديد واختر HsoubAcademy. iOSالتثبيتمن متجر تطبيقات iTunes، ابحث وثبّت تطبيق OpenVPN Connect، والذي هو تطبيق عميل OpenVPN الرسمي لـiOS. لنقل ملفّ .ovpn الخاصّ بك إلى هاتفك، قم بتوصيله مباشرةً إلى حاسوب. إكمال النقل مع iTunes سيكون خارجيًا هنا. افتح iTunes من على الحاسوب واضغط على iPhone > apps. انتقل إلى الأسفل إلى قسم مشاركة الملفّات وانقر على تطبيق OpenVPN. النافذة الموجودة على اليمين، OpenVPN Documents هي لمشاركة الملفّات. اسحب ملفّ .ovpn وأفلته إلى النافذة أدناه. الآن شغّل تطبيق OpenVPN على iPhone. سيكون هناك إشعار أنّه هناك ملفّ جديد ليتم استيراده. انقر على إشارة الزائد الخضراء ليتمّ ذلك: الاتصالأصبح OpenVPN الآن جاهزًا للاستخدام مع الملفّ الجديد. ابدأ الاتصال عبر النقر على زرّ Connect وجعله On. ويمكنك قطع الاتصال عبر جعله Off. ملاحظة: لا يمكن استخدام محوّل VPN الموجود تحت الإعدادات للاتصال بـVPN. إذا حاولت، فسيصلك إشعار باستخدام تطبيق OpenVPN فقط. Androidالتثبيتافتح متجر Google Play. ابحث عن تطبيق Android OpenVPN Connect وثبّته، إنّه تطبيق OpenVPN الرسمي لأندرويد. يمكن نقل ملفّ .ovpn إلى الهاتف عبر إيصال جهاز الأندرويد الخاصّ بك إلى الحاسوب عبر USB ونقل الملفّ. بشكلٍ مغاير، إذا كنتَ تمتلك قارئ بطاقات SD، فيمكنك إزالة بطاقة SD من الجهاز، نسخ الملفّ إليها ومن ثمّ إدراجها مجددًا إلى جهاز الأندرويد. ابدأ تطبيق OpenVPN وانقر على القائمة للاستيراد: ثمّ تنقّل إلى موقع الملفّ المحفوظ (لقطة الشاشة تستخدم /sdcard/Download/) واختر الملفّ. وسيقوم التطبيق بإخبارك أنّ الملفّ تمّ استيراده: الاتصالللاتصال، قم ببساطة بالضغط على زرّ الاتصال الموجود أمامك. سيتم سؤالك عمّا إذا كنتَ تثق بالتطبيق، اضغط على موافق وتابع. لإلغاء الاتصال، انقر على زرّ قطع الاتصال بالتطبيق. الخطوة السادسة: اختبار اتصالك بـ VPNبمجرّد تثبيت كلّ شيء، يمكن لفحصٍ سريع أن يؤكّد لك أنّك تستعمل VPN الآن أو لا. أولًا قبل استخدام أيّ VPN، اذهب إلى موقع DNSLeakTest. سيعطيك الموقع عنوان الـIP الخاصّ بك عبر مزوّد الإنترنت لديك وستظهر أنت كما تبدو لبقية العالم. للتحقق من إعدادات DNS الخاصّ بك عبر نفس الموقع، انقر على Extended Test وسيخبرك عن خواديم DNS التي تستعملها. الآن، قم بالاتصال بخادوم OpenVPN الموجود على خادومك وحدّث الصفحة. وشاهد عنوان الـIP الجديد المختلف كليًا عن السابق. هذا سيكون هو عنوان الـIP الظاهر للعالم عند تصفّحك لمواقعهم. مجددًا، انقر على Extended Test وسيخبرك عن خواديم DNS التي تستعملها وسيؤكد لك أنّك تستخدم الآن خواديم الـDNS المُعدّة من قبل OpenVPN. تهانينا! يمكنك الآن التنقّل بأمان في الإنترنت وحماية خصوصيتك، موقعك وبياناتك من المراقبة والمُخترقين. ترجمة -وبتصرّف- للمقال: How To Set Up an OpenVPN Server on Ubuntu 14.04.
هل تريد الوصول إلى شبكة الإنترنت بشكلٍ آمن ومحمي من هاتفك الذكي أو حاسوبك المحمول عندما تقوم بالاتصال بشبكاتٍ غير موثوقة مثل الشبكات اللاسلكية العمومية لفندق أو مقهى؟ تسمح لك الشبكة الافتراضية الخاصّة (Virtual Private Network - VPN) بتصفّح الإنترنت بالشبكات غير الموثوقة بشكلٍ آمن ومجهول كما لو كنتَ على شبكةٍ آمنة وموثوقة. يتم تمرير تدفّق البيانات (traffic) من خادومك إلى وجهته ومن ثمّ يعود إليك حاملًا البيانات. يسمح لك هذا الإعداد عندما يتم ربطه مع [اتصال HTTPS] (https://en.wikipedia.org/wiki/HTTP_Secure) أن تقوم بتأمين عمليات تسجيل الدخول وعمليات الدفع وغيرها من العمليات التي تقوم بها عند تصفّحك للإنترنت. يمكنك تخطّي الحجب الذي يفرضه مزوّد الخدمة على مواقع معيّنة مثلًا وتخطّي تقييدات المنطقة الجغرافية لمواقع معيّنة، كما يمكنك تحصين موقعك وتدفّق HTTP الصادر من جهازك من الشبكات غير المحمية. OpenVPN هو عبارة عن شبكة افتراضية خاصّة لطبقة حِزَم البيانات الآمنة مفتوحة المصدر (SSL) ويقبل تشكيلةً واسعة من الإعدادات والتخصيصات. في هذا الدرس، سنقوم بإعداد خادوم OpenVPN على خادومنا ومن ثمّ نقوم بإعداده ليقبل الوصول إليه من نظام ويندوز، Mac OS X، iOS و Android. سنبقي خطوات التثبيت والإعداد أسهل ما يمكن في هذا الدرس. المتطلّباتالمتطلّبات الوحيدة اللازمة هي امتلاك خادوم يعمل بتوزيعة Ubuntu 14.04. يجب أن تمتلك الوصول إلى حساب المستخدم الجذر لإكمال هذا الدرس. إضافي: بعد إكمال هذا الدرس، سيكون من الجيد إنشاء حساب مستخدمٍ عادي بصلاحيات sudo لعمل صيانةٍ عامّة على خادومك في حال احتجتها مستقبلًا.الخطوة الأولى: تثبيت وإعداد بيئة خادوم OpenVPNإعداد OpenVPNقبل أن نقوم بتثبيت أيّ حزم، يجب أن نقوم بتحديث قوائم مستودعات توزيعة أوبونتو أولًا: apt-get updateومن ثمّ، يمكننا تثبيت OpenVPN و Easy-RSA: apt-get install openvpn easy-rsaيجب أن يتم استخراج ملفّ عيّنة إعدادات OpenVPN إلى المسار /etc/openvpn لكي نتمكّن من إضافته إلى عملية التثبيت الخاصّة بنا. يمكن القيام بهذا عبر الأمر: gunzip -c /usr/share/doc/openvpn/examples/sample-config-files/server.conf.gz > /etc/openvpn/server.confبمجرّد أن يتم استخراجه، افتح ملفّ server.conf في محرر نصوص. في هذا الدرس سنستخدم Vim ولكن يمكنك استخدم أيّ محرر نصوص تريده: vim /etc/openvpn/server.confهناك العديد من التغييرات التي يجب علينا تطبيقها على هذا الملفّ. سترى قسمًا يبدو هكذا: # Diffie hellman parameters. # Generate your own with: # openssl dhparam -out dh1024.pem 1024 # Substitute 2048 for 1024 if you are using # 2048 bit keys. dh dh1024.pemقم بتغيير dh1024.pem إلى: dh2048.pemسيقوم هذا بمضاعفة طول مفتاح RSA المُستخدم عندما يتم إنشاء مفاتيح الخادوم والعميل. ما نزال في ملفّ server.conf، والآن ابحث عن هذا القسم: # If enabled, this directive will configure # all clients to redirect their default # network gateway through the VPN, causing # all IP traffic such as web browsing and # and DNS lookups to go through the VPN # (The OpenVPN server machine may need to NAT # or bridge the TUN/TAP interface to the internet # in order for this to work properly). ;push "redirect-gateway def1 bypass-dhcp"قم بإلغاء تعليق السطر التالي (أزل إشارة # أو ; من قبله): ;push "redirect-gateway def1 bypass-dhcp" لكي يتمكّن خادوم OpenVPN الخاصّ بنا من تمرير التدفّق المطلوب من المستخدمين والعملاء إلى وجهته المطلوبة. يجب أن يبدو السطر هكذا بعد التعديل: push "redirect-gateway def1 bypass-dhcp"الآن ابحث عن هذا القسم: # Certain Windows-specific network settings # can be pushed to clients, such as DNS # or WINS server addresses. CAVEAT: # http://openvpn.net/faq.html#dhcpcaveats # The addresses below refer to the public # DNS servers provided by opendns.com. ;push "dhcp-option DNS 208.67.222.222" ;push "dhcp-option DNS 208.67.220.220"قم بإلغاء تعليق السطرين push "dhcp-option DNS 208.67.222.222" و push "dhcp-option DNS 208.67.220.220" . يجب أن يبدوا على هذا الشكل: push "dhcp-option DNS 208.67.222.222" push "dhcp-option DNS 208.67.220.220"يقوم هذا بإخبار الخادوم بأن يقوم بدفع OpenVPN ليتصل بالعملاء (clients) ليعطيهم عنوان الـDNS المخصص. يقوم هذا الأمر بحماية المستخدم من خروج طلبات DNS خارج اتصال الـVPN. وعلى كلّ حال، من المهم أن تقوم بتحديد عناوين الـDNS المطلوبة التي تريد استخدامها على كلّ جهازٍ من أجهزة العملاء. رغم أنّ OpenVPN يستخدم خدمة OpenDNS افتراضيًا إلّا أنّه يمكنك استخدامه أيّ خدمات DNS تريدها. القسم الأخير الذي يجب تغييره في ملفّ server.conf هو: # You can uncomment this out on # non-Windows systems. ;user nobody ;group nogroupقم بإلغاء تعليق كلٍّ من السطرين user nobody و group nobody. يجب أن يبدوا هكذا: user nobody group nogroupافتراضيًا، يقوم OpenVPN بالعمل باستخدام المستخدم الجذر (root) حيث يمتلك هذا الأخير وصولًا كاملًا إلى النظام. سنقوم عوضًا عن هذا بجعل OpenVPN يستخدم المستخدم nobody والمجموعة nobody. هذا المستخدم لا يمتلك صلاحيات ولا أيّ إمكانياتٍ للولوج، ويتم استخدامه عادةً لتشغيل التطبيقات غير الموثوقة مثل خواديم واجهات الويب. يمكنك الآن حفظ تغييراتك والخروج من VIM. توجيه حِزَم البياناتهذا الأمر هو عبارة عن خاصية sysctl تقوم بإخبار نواة الخادوم أن تقوم بتوجيه التدفّق من أجهزة العملاء إلى الإنترنت. إن لم يتم هذا الأمر، فإنّ التدفّق سيتوقف في الخادوم. يمكنك تفعيل توجيه حِزَم البيانات أثناء وقت التشغيل باستخدام الأمر التالي: echo 1 > /proc/sys/net/ipv4/ip_forwardنحتاج أن نقوم بجعل هذا الأمر دائمًا بحيث يبقى الخادوم يقوم بتوجيه التدفّق حتى بعد إعادة تشغيل الخادوم: vim /etc/sysctl.confفي بداية ملفّ sysctl ستجد: # Uncomment the next line to enable packet forwarding for IPv4 #net.ipv4.ip_forward=1قم بإلغاء تعليق net.ipv4.ip_forward. يجب أن يبدو ذاك السطر هكذا: # Uncomment the next line to enable packet forwarding for IPv4 net.ipv4.ip_forward=1احفظ تغييراتك واخرج. الجدار الناري غير المعقّد (ufw)ufw هو واجهة أمامية (front-end) لـiptables. إعداد ufw ليس صعبًا. وهو مُضمّن بشكلٍ افتراضي في Ubuntu 14.04، لذا يجب علين فقط إنشاء بضع قواعد (rules) وتعديل بعض الإعدادات ليعمل، ومن ثمّ سنقوم بتشغيله. للمزيد من المعلومات حول ufw يمكنك مراجعة كيفية إعداد جدارٍ ناري باستخدام UFW على خادوم أوبونتو ودبيان السحابي. أولًا قم بضبط ufw بحيث يسمح باتصال SSH. أدخل اﻷمر التالي: ufw allow sshسنستخدم OpenVPN عبر UDP في هذا الدرس، لذا يجب أن يسمح UFW بتدفّق UDP عبر المنفذ 1194: ufw allow 1194/udpيجب ضبط سياسة التوجيه في UFW كذلك. يمكنك القيام هذا عبر تعديل ملفّ إعدادات UFW الرئيسي: vim /etc/default/ufwابحث عن DEFAULTFORWARDPOLICY="DROP". يجب تغيير محتوى هذا السطر من DROP إلى ACCEPT. يجب أن يبدو السطر هكذا عندما تنتهي منه: DEFAULT_FORWARD_POLICY="ACCEPT"ثمّ سنقوم بإضافة بعض قواعد UFW الإضافية لترجمة عناوين الشبكة وتذكّر عناوين الـIP الخاصّة بالعملاء الحاليين: vim /etc/ufw/before.rulesقم بجعل بداية ملفّ before.rules الخاصّ بك تبدو هكذا كما بالمثال أدناه. القسم بعد START OPENVPN RULES وقبل END OPENVPN RULES هو ما يجب إضافته: # # rules.before # # Rules that should be run before the ufw command line added rules. Custom # rules should be added to one of these chains: # ufw-before-input # ufw-before-output # ufw-before-forward # # START OPENVPN RULES # NAT table rules *nat :POSTROUTING ACCEPT [0:0] # Allow traffic from OpenVPN client to eth0 -A POSTROUTING -s 10.8.0.0/8 -o eth0 -j MASQUERADE COMMIT # END OPENVPN RULES # Don't delete these required lines, otherwise there will be errors *filterبعدما تمّ تطبيق هذه التغييرات على UFW، يمكننا الآن تفعيله. أدخل اﻷمر التالي في سطر الأوامر: ufw enableوسيتم طباعة الخرج التالي: Command may disrupt existing ssh connections. Proceed with operation (y|n)?للتحقق من حالة قواعد الجدار الناري طبّق: ufw statusوالخرج يجب أن يكون: Status: active To Action From -- ------ ---- 22 ALLOW Anywhere 1194/udp ALLOW Anywhere 22 (v6) ALLOW Anywhere (v6) 1194/udp (v6) ALLOW Anywhere (v6)الخطوة الثانية: إنشاء استيثاق الشهادات و شهادة موقّعة من الخادوم ومفتاح لهايستخدم OpenVPN الشهادات ليقوم بتشفير التدفّق. إعداد وبناء استيثاق الشهاداتالآن هو وقت إعداد استيثاق الشهادات الخاصّ بنا (Certificate Authority - CA) وإنشاء شهادة ومفتاح لخادوم الـOpenVPN. يدعم OpenVPN الاستيثاق ثنائي الاتجاه (bidirectional authentication) باستخدام الشهادات، مما يعني أنّه يجب على العميل أن يقوم باستيثاق شهادة الخادوم ويجب على الخادوم أن يقوم باستيثاق شهادة العميل قبل أن يتم إنشاء الاتصال المشترك بينهما. سنستخدم سكربتات Easy RSA التي نسخناها مبكّرًا للقيام بهذا. أولًا، انسخ سكربتات Easy RSA إلى مكانها: cp -r /usr/share/easy-rsa/ /etc/openvpnثمّ قم بعمل مجلّد لتخزين المفاتيح: mkdir /etc/openvpn/easy-rsa/keysتمتلك Easy-RSA ملفّ متغيّرات يمكننا تعديله لإنشاء شهاداتٍ خاصّة بشخصنا، شركاتنا أو أيّ شيءٍ آخر نريده. يتم نسخ هذه المعلومات إلى الشهادات والمفاتيح، وستساعد هذه المعلومات على التعرّف على المفاتيح لاحقًا: vim /etc/openvpn/easy-rsa/varsالمتغيّرات بين علامتيّ تنصيص (") يجب أن تقوم بتغييرها بناءً على إعداداتك: export KEY_COUNTRY="US" export KEY_PROVINCE="TX" export KEY_CITY="Dallas" export KEY_ORG="My Company Name" export KEY_EMAIL="sammy@example.com" export KEY_OU="MYOrganizationalUnit"في نفس الملفّ vars، قم أيضًا بتعديل السطر الظاهر أدناه، سنستخدم server كاسم المفتاح. إذا أردت استخدام اسمٍ آخر، فسيجب عليك أيضًا تحديث ملفّات إعدادات OpenVPN التي تقوم بالإشارة إلى server.key و server.crt: export KEY_NAME="server"نحتاج إلى إنشاء مُعامِلات Diffie-Hellman; قد يأخذ هذا الأمر بضع دقائق: openssl dhparam -out /etc/openvpn/dh2048.pem 2048الآن فلنغيّر المسارات بحيث نعمل في المسارات الذي نقلنا سكربتات Easy-RSA إليه من قبل في الخطوة الثانية: cd /etc/openvpn/easy-rsaقم بتحليل ملفّ (PKI (Public Key Infrastructure. انتبه إلى النقطة (.) و المسافة (space) قبل الأمر vars/. حيثُ أنّ هذا الأمر قد يغيّر المسار الحالي كلّيًا (المصدر): . ./varsخرج الأمر أعلاه ظاهرٌ أدناه. بما أننا لم نقم بإنشاء أيّ شيء في مجلّد keys بعد، فإنّ رسالة التحذير ليست شيئًا لنقلق حوله الآن: NOTE: If you run ./clean-all, I will be doing a rm -rf on /etc/openvpn/easy-rsa/keysالآن سنقوم بتنظيف مسار عملنا الحالي من أيّ ملفّات عيّنة مفاتيح أو مفاتيح قديمة لكي تبقى المفاتيح الجديدة بالمسار فقط: ./clean-allسيبني هذا الأمر الأخير استيثاق الشهادات (CA) عبر استدعاء طرفيّة OpenSSL التفاعلية. سيسألك الخرج أن تقوم بتأكيد اسم المتغيرات الفريدة التي أدخلناها من قبل في ملفّ متغيّرات Easy-RSA (اسم البلد، المنظمة.. إلخ): ./build-caاضغط مفتاح Enter ببساطة لتتنقل عبر كلّ طرفية. إذا كان هناك شيءٌ يجب تغييره، فيمكنك القيام بذلك عبر سطر الأوامر. إنشاء شهادة ومفتاح للخادومما زلنا نعمل من المسار /etc/openvpn/easy-rsa ، الآن قم بإدخال الأمر التالي لبناء مفتاح الخادوم. حيث سترى أنّ server هو قيمة المتغيّر export KEY_NAME الذي أعددناه في ملفّ vars الخاصّ بـEasy-RSA من قبل بالخطوة الثانية: ./build-key-server serverيظهر خرج مشابه كالذي يظهر عندما طبّقنا ./build-ca ، ويمكنك مجددًا الضغط على مفتاح Enter لتأكيد كلّ سطرٍ من الأسماء الفريدة. على كلّ حال، هذه المرّة هناك إدخالان إضافيان: Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []: An optional company name []:يجب أن يتم تركهما كلاهما فارغين، لذا فقط اضغط Enter للمتابعة. هناك سؤالان إضافيان في النهاية، وهما يتطلبان إجابة ( y ) إيجابية فقط: Sign the certificate? [y/n] 1 out of 1 certificate requests certified, commit? [y/n]يجب أن يكتمل السؤال الأخير أعلاه بالتالي: Write out database with 1 new entries Data Base Updatedنقل شهادات الخادوم والمفاتيحيتوقّع OpenVPN أن يرى استيثاق شهادات الخادوم، الشهادات والمفاتيح في /etc/openvpn . فلننسخها إلى الموقع الصحيح: cp /etc/openvpn/easy-rsa/keys/{server.crt,server.key,ca.crt} /etc/openvpnيمكنك التحقق من نجاح العملية عبر: ls /etc/openvpnيجب أن ترى ملفّات الشهادات والمفاتيح الخاصّة بالخادوم. في هذه النقطة، أصبح خادوم OpenVPN جاهزًا للانطلاق. شغّله وتحقق من حالته باستخدام: service openvpn start service openvpn statusيجب أن يقوم أمر التحقق من الحالة بإرجاع الخرج التالي لك: VPN 'server' is runningتهانينا! أصبح خادوم OpenVPN الخاصّ بك عاملًا! إذا كانت رسالة الحالة تقول لك أنّ خادوم الـOpenVPN لا يعمل، فتحقق من ملفّ /var/log/syslog وابحث عن أخطاء مثل: Options error: --key fails with 'server.key': No such file or directoryوالتي تقوم أنّ ملفّ server.key لم يتم نسخه إلى المسار etc/openvpn/ بشكلٍ صحيح، مما يتوجب عليك إعادة نسخه مجددًا. الخطوة الثالثة: إنشاء الشهادات والمفاتيح الخاصّة بالعملاءلقد قمنا بتثبيت وإعداد خادوم OpenVPN، أنشأنا استيثاق الشهادات وشهادة ومفتاح الخادوم. في هذه الخطوة الآن، سنستخدم استيثاق شهادات الخادوم لنقوم بإنشاء الشهادات والمفاتيح الخاصّة بجهاز كلّ عميلٍ سيتصل بالخادوم على حدى. سيتم تثبيت هذه الملفّات لاحقًا إلى أجهزة العملاء كالهواتف الذكية والأجهزة المحمولة. بناء المفاتيح والشهاداتمن المناسب أن يمتلك كلّ عميلٍ يتصل بالخادوم شهادته ومفتاحه الخاصّين به. هذا الأمر مفضّل على إنشاء شهادة واحدة ومفتاح واحد وتوزيعهما على جميع أجهزة العملاء لأغراض تتعلق بالأمان. ملاحظة: افتراضيًا، لا يسمح OpenVPN بالاتصالات المتزامنة بنفس الوقت إلى الخادوم من أكثر من جهازٍ عميل باستخدام نفس الشهادة والمفتاح (انظر duplicate-cn في etc/openvpn/server.conf/). لإنشاء شهادات استيثاق منفصلة لكلّ جهاز عميل تنوي السماح له بالاتصال بخادوم الـOpenVPN، يجب عليك إكمال هذه الخطوة لكلّ جهاز، ولكن يمكنك تغيير الاسم client1 أدناه إلى شيءٍ مختلف مثل client2 أو iphone2. بفضل استخدام شهادةٍ منفصلة لكلّ جهاز عميل، يمكن لاحقًا منعهم بشكلٍ منفصل من الوصول إلى الخادوم إذا ما تمّ الاحتياج لذلك. سنستخدم client1 في الأمثلة الموجودة في هذا الدرس كاسم الجهاز العميل. كما فعلنا مع مفتاح الخادوم، فسنقوم الآن ببناء واحد لمثال client1. يجب أن تكون ما زلت تعمل في /etc/openvpn/easy-rsa: ./build-key client1مجددًا، سيتم سؤالك عمّا إذا كنتَ تريد تغيير أو تأكيد متغيّرات الأسماء الفريدة والحقول الإضافية التي تركناها فارغة من قبل. اضغط Enter لاختيار الخيارات الافتراضية: Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []: An optional company name []:وكما في السابق، سيسألك مرتين عن تأكيد بعض الخيارات، اكتب y: Sign the certificate? [y/n] 1 out of 1 certificate requests certified, commit? [y/n]إذا نجحت عملية بناء المفتاح فسيظهر التالي: Write out database with 1 new entries Data Base Updatedيجب على ملفّ عيّنة إعدادات العميل أن يتم نسخه إلى مجلّد Easy-RSA أيضًا. سنستخدمه كقالب يمكن تحميله إلى أجهزة العملاء ليتم تعديله. أثناء عملية النسخ، سنقوم بتغيير اسم ملفّ العيّنة من client.conf إلى client.ovpn لأنّ امتداد ملفّ .ovpn هو ما تتوقع أجهزة العملاء أن تراه باسم الملفّ وليس .conf: cp /usr/share/doc/openvpn/examples/sample-config-files/client.conf /etc/openvpn/easy-rsa/keys/client.ovpnيمكنك تكرار هذا القسم مجددًا لكلّ عميلٍ تريد السماح له بالوصول، ولا تنسى استبدال client1 باسم الجهاز الجديد. نقل الشهادات والمفاتيح إلى أجهزة العميلخلاصة ما طبقّناه أعلاه هو أننا أنشأنا شهادات ومفاتيح العملاء، وأننا قمنا بتخزينها على خادوم OpenVPN في المسار /etc/openvpn/easy-rsa/keys . نحتاج القيام بنقل شهادة العميل، المفتاح وقالب الملفّ الشخصي لكلّ عميلٍ نريد السماح له بالوصول إلى مجلّد محلّي على جهاز الحاسوب الخاصّ بنا أو أيّ جهاز عميل آخر. في هذا المثال، يتطلّب جهاز العميل client1 الشهادات والمفاتيح الخاصّة به والموجودة في المسارات: * /etc/openvpn/easy-rsa/keys/client1.crt * /etc/openvpn/easy-rsa/keys/client1.keyتكون ملفّات ca.crt و client.ovpn هي نفسها لجميع أجهزة العملاء مهما اختلفت. قمّ بتحميل هذه الملفّات أيضًا; لاحظ أنّ ملف ca.crt هو في مسارٍ مختلف عن الملفّات الأخرى: etc/openvpn/easy-rsa/keys/client.ovpn/etc/openvpn/ca.crt/بينما ستعتمد التطبيقات المُستخدمة لإكمال هذه المهمّة على اختيارك ونوع نظام التشغيل الخاصّ بك، فإنّك بحاجة إلى تطبيق يستخدم STFP (بروتوكول نقل الملفّات عبر SSH) أو SCP (النسخ الآمن) للوصول إلى الملفّات الموجودة في خلفية الخادوم. سينقل هذا ملفّات الاستيثاق الخاصّة بخادومك عبر اتصالٍ مشفّر. إليك مثالًا لأمر SCP باستخدام مثالنا من client1. إنّه يقوم بوضع الملفّ client1.key إلى المجلّد Downloads الموجود على حاسوبنا المحلّي: scp root@your-server-ip:/etc/openvpn/easy-rsa/keys/client1.key Downloads/إليك بضع أدوات ودروس يمكنك استخدامها لنقل الملفّات بشكلٍ آمن من الخادوم إلى الحاسوب المحلّي: WinSCPكيفية استخدام SFTP لنقل الملفّات بشكلٍ آمن من خادومٍ بعيد.كيفية استخدام FileZilla لنقل وإدارة الملفّات بشكلٍ آمن.في نهاية هذا القسم، تأكّد أنّ هذه الملفّات الأربعة أصبحت موجودة على جهاز المحلّي مهما كان نوعه: client1.crtclient1.keyclient.ovpnca.crtالخطوة الرابعة: إنشاء ملفٍّ شخصيٍ موحّد لجهاز العميلهناك العديد من الطرق المُستخدمة لإدارة ملفّات العملاء ولكن أسهلها يستخدم ملفّا شخصيًا موحّدًا. يتم إنشاء هذا الملفّ عبر تعديل قالب ملفّ client.ovpn ليتضمّن استيثاق شهادات الخادوم، شهادة العميل والمفتاح الخاصّ به. بمجرّد إضافته، فسيجب حينها فقط استيراد ملفّ client.ovpn إلى تطبيقات OpenVPN على أجهزة العميل. سنقوم بإنشاء ملفٍّ شخصيٍ وحيد لجهازنا المدعو client1 على الحاسوب المحلّي الذي قمنا بتحميل جميع الملفّات إليه. يمكن لهذا الحاسوب المحلّي بنفسه أن يكون جهازًا عميلًا أو مجرّد منطقة عمل مؤقّتة لدمج ملفّات الاستيثاق. يجب أن يتم نسخ قالب ملفّ client.ovpn وإعادة تسميته. كيفية قيامك بهذا الأمر ستعتمد على نظام التشغيل الخاصّة بجهازك المحلّي. ملاحظة: لا يجب على اسم ملفّ client.ovpn الخاصّ بك المنسوخ الجديد أن يكون مطابقًا لاسم جهاز العميل. تطبيق العميل لـOpenVPN سيستخدم اسم الملفّ كمُعرّف لاتصال VPN نفسه، حيث يجب عليك نسخ ملفّ client.ovpn إلى أيّ اسمٍ جديد تريد استخدامه على نظام التشغيل الخاصّ بك. كمثال: work.ovpn سيتم التعرّف عليه كـwork و school.ovpn سيتم التعرّف عليه كـschool. في هذا الدرس، سنقوم بتسمية اتصال VPN كـ HsoubAcademy ولذلك فسيكون اسم الملفّ هو HsoubAcademy.ovpn من الآن فصاعدًا. بمجرّد تسمية الملفّ الجديد المنسوخ، يجب علينا حينها فتح ملفّ HsoubAcademy.ovpn في محرر نصوص. أول نقطة سيقع عليها انتباهك هي مكان عنوان الـIP الخاصّ بخادومك. بالقرب من بداية الملفّ، قم بتغيير my-server-1 إلى عنوان IP الخاصّ بخادومك: # The hostname/IP and port of the server. # You can have multiple remote entries # to load balance between the servers. remote my-server-1 1194الآن، ابحث عن القسم الظاهر أدناه وقم بإلغاء تعليق user nobody و group nobody، كما فعلنا مع ملفّ server.conf في الخطوة الأولى. ملاحظة: هذا لا ينطبق على ويندوز لذا يمكنك تجاوزه. يجب أن يبدو هكذا عندما تنتهي: # Downgrade privileges after initialization (non-Windows only) user nobody group nogroupالقسم الظاهر أدناه يحتاج أن نقوم فيه بتعليق السطور الثلاثة الأخيرة لكي نتمكّن من تضمين الشهادة والمفتاح مباشرةً في ملفّ HsoubAcademy.ovpn، يجب أن يبدو هكذا: # SSL/TLS parms. # . . . #ca ca.crt #cert client.crt #key client.keyلدمج الملفّات المنفصلة إلى ملفٍّ شخصي واحدٍ موحّد، يجب أن يتم وضع محتويات الملفّات ca.crt, client1.crt, و client1.key مباشرةً في ملفّ .ovpn باستخدام هيكلة XML. يجب بالنهاية أن يبدو شكلها كالتالي: <ca> (أدخل محتويات ca.crt هنا) </ca> <cert> (أدخل محتويات client1.crt هنا) </cert> <key> (أدخل محتويات client1.key هنا) </key>عندما تنتهي، يجب أن تبدو نهاية الملفّ كالتالي: <ca> -----BEGIN CERTIFICATE----- . . . -----END CERTIFICATE----- </ca> <cert> Certificate: . . . -----END CERTIFICATE----- . . . -----END CERTIFICATE----- </cert> <key> -----BEGIN PRIVATE KEY----- . . . -----END PRIVATE KEY----- </key>يمتلك ملفّ client1.crt معلوماتٍ إضافية في داخله; لا بأس بتضمين الملفّ بأكمله. احفظ التغييرات واخرج. أصبح لدينا الآن ملفّ واحد موحّد لضبط جهازنا المحلّي client1. الخطوة الخامسة: تثبيت ملفّ العميلالآن سنناقش تثبيت ملفّ VPN على Windows, OS X, iOS, و Android. لا يعتمد أيٌّ من إرشادات هذه الأنظمة على الآخر لذا يمكنك التجاوز إلى الذي يطابق نظامك التشغيلي الحالي فقط. تذكّر أنّ الاتصال سيتم تسميته بحساب اسم ملفّ .ovpn الذي استخدمته. في مثالنا قمنا بتسمية الملفّ كـ HsoubAcademy.ovpn ولذلك سيكون اسم الاتصال هو HsoubAcademy. Windowsالتثبيتيمكن العثور على تطبيق عميل OpenVPN لنظام ويندوز من صفحة التحميلات الخاصّة بـOpenVPN. اختر المُثبّت المناسب لإصدارك من ويندوز. ملاحظة: يتطلّب OpenVPN الصلاحيات الإدارية ليتم تثبيته. بعد تثبيته، انسخ الملفّ HsoubAcademy.ovpn إلى: C:\Program Files\OpenVPN\configعندما تقوم بتشغيل OpenVPN، فسيقوم تلقائيًا برؤية الملفّ وجعله متاحًا. يجب أن يتم تشغيل OpenVPN بصلاحيات المسؤول في كلّ مرّة يتم تشغيله، حتى ولو كان يتم تشغيله على حسابات المستخدمين. لفعل هذا دون الحاجة إلى الضغط على زرّ الفأرة الأيمن واختيار التشغيل كمسؤول في كلّ مرّة تقوم باستعمال الـVPN، يمكنك ضبط هذا الأمر ولكنك ستحتاج إلى القيام به من حساب بصلاحياتٍ إدارية. هذا يعني أيضًا أنّه سيجب على المستخدمين إدخال كلمة مرور المستخدم المدير لاستخدام OpenVPN. على الناحية الأخرى، لن يتمكن المستخدمون من استخدام OpenVPN بشكلٍ صحيح دون أن يتم تشغيله على جهاز العميل بصلاحياتٍ إدارية، لذا فإنّ الصلاحيات الإدارة مطلوبة. لجعل تطبيق OpenVPN يتم تشغيله دومًا كمدير، اضغط بزرّ الفأرة الأيمن على أيقونة الاختصار الخاصّة به واذهب إلى خصائص. في نهاية لسان التوافقية، اضغط على الزرّ لتغيير الإعدادات لجميع المستخدمين. في النافذة الجديدة، اختر تشغيل هذا البرنامج كمدير. الاتصالفي كلّ مرّة تقوم بتشغيل واجهة OpenVPN الرسومية، سيسألك ويندوز عمّا إذا كنتَ تريد السماح للبرنامج بتطبيق التغييرات على نظامك. اضغط على موافق. تشغيل تطبيق عميل OpenVPN سيقوم فقط بوضع الأيقونة في تنبيهات النظام ويمكن الاتصال أو قطع الاتصال بخادوم OpenVPN عند الحاجة; وهو لا يقوم حقيقةً بالاتصال بـ VPN. بمجرّد بدء OpenVPN، قم بإنشاء اتصال عبر الذهاب إلى تنبيهات النظام والضغط بزرّ الفأرة الأيمن على أيقونة OpenVPN. هذا سيفتح لك قائمةً فرعية. اختر HsoubAcademy من أعلى القائمة (والذي هو عبارة عن HsoubAcademy.ovpn) واختر اتصال. سيتم فتح نافذة حالة جديدة تعرض لك الخرج أثناء تأسيس الاتصال، وسيتم طباعة رسالة بمجرّد اكتمال العملية. يمكنك إلغاء الاتصال من VPN بنفس الطريقة: اذهب إلى تنبيهات النظام وانقر بزرّ الفأرة الأيمن على أيقونة OpenVPN واختر قطع الاتصال. OS XالتثبيتTunnelblick هو تطبيق عميل OpenVPN مجاني ومفتوح المصدر لنظام MAC OS X. يمكنك تحميله من صفحة تحميلات Tunnelblick. انقر نقرتين على ملفّ .dmg المحمّل وتابع إرشادات التثبيت. إلى نهاية عملية التثبيت، سيسألك Tunnelblick عمّا إذا كنتَ تمتلك أيّ ملفّات إعدادات. الأسهل حاليًا هو اختيار لا وترك Tunnelblick ليتابع التثبيت. ابحث نافذة Finder وانقر على ملفّ HsoubAcademy.ovpn وسيتم تشغيل Tunnelblick باستخدام ذلك الملفّ، الصلاحيات الإدارية مطلوبة. الاتصالشغّل Tunnelblick عبر النقر مرّتين على مجلّد أيقونة التطبيقات. بمجرّد تشغيل Tunnelblick، سيكون هناك أيقونة Tunnelblick على شريط القائمة في أعلى يمين الشاشة للتحكّم بالاتصالات. اضغط على الأيقونة ومن ثمّ عنصر قائمة اتصال لبدء اتصالٍ جديد واختر HsoubAcademy. iOSالتثبيتمن متجر تطبيقات iTunes، ابحث وثبّت تطبيق OpenVPN Connect، والذي هو تطبيق عميل OpenVPN الرسمي لـiOS. لنقل ملفّ .ovpn الخاصّ بك إلى هاتفك، قم بتوصيله مباشرةً إلى حاسوب. إكمال النقل مع iTunes سيكون خارجيًا هنا. افتح iTunes من على الحاسوب واضغط على iPhone > apps. انتقل إلى الأسفل إلى قسم مشاركة الملفّات وانقر على تطبيق OpenVPN. النافذة الموجودة على اليمين، OpenVPN Documents هي لمشاركة الملفّات. اسحب ملفّ .ovpn وأفلته إلى النافذة أدناه. الآن شغّل تطبيق OpenVPN على iPhone. سيكون هناك إشعار أنّه هناك ملفّ جديد ليتم استيراده. انقر على إشارة الزائد الخضراء ليتمّ ذلك: الاتصالأصبح OpenVPN الآن جاهزًا للاستخدام مع الملفّ الجديد. ابدأ الاتصال عبر النقر على زرّ Connect وجعله On. ويمكنك قطع الاتصال عبر جعله Off. ملاحظة: لا يمكن استخدام محوّل VPN الموجود تحت الإعدادات للاتصال بـVPN. إذا حاولت، فسيصلك إشعار باستخدام تطبيق OpenVPN فقط. Androidالتثبيتافتح متجر Google Play. ابحث عن تطبيق Android OpenVPN Connect وثبّته، إنّه تطبيق OpenVPN الرسمي لأندرويد. يمكن نقل ملفّ .ovpn إلى الهاتف عبر إيصال جهاز الأندرويد الخاصّ بك إلى الحاسوب عبر USB ونقل الملفّ. بشكلٍ مغاير، إذا كنتَ تمتلك قارئ بطاقات SD، فيمكنك إزالة بطاقة SD من الجهاز، نسخ الملفّ إليها ومن ثمّ إدراجها مجددًا إلى جهاز الأندرويد. ابدأ تطبيق OpenVPN وانقر على القائمة للاستيراد: ثمّ تنقّل إلى موقع الملفّ المحفوظ (لقطة الشاشة تستخدم /sdcard/Download/) واختر الملفّ. وسيقوم التطبيق بإخبارك أنّ الملفّ تمّ استيراده: الاتصالللاتصال، قم ببساطة بالضغط على زرّ الاتصال الموجود أمامك. سيتم سؤالك عمّا إذا كنتَ تثق بالتطبيق، اضغط على موافق وتابع. لإلغاء الاتصال، انقر على زرّ قطع الاتصال بالتطبيق. الخطوة السادسة: اختبار اتصالك بـ VPNبمجرّد تثبيت كلّ شيء، يمكن لفحصٍ سريع أن يؤكّد لك أنّك تستعمل VPN الآن أو لا. أولًا قبل استخدام أيّ VPN، اذهب إلى موقع DNSLeakTest. سيعطيك الموقع عنوان الـIP الخاصّ بك عبر مزوّد الإنترنت لديك وستظهر أنت كما تبدو لبقية العالم. للتحقق من إعدادات DNS الخاصّ بك عبر نفس الموقع، انقر على Extended Test وسيخبرك عن خواديم DNS التي تستعملها. الآن، قم بالاتصال بخادوم OpenVPN الموجود على خادومك وحدّث الصفحة. وشاهد عنوان الـIP الجديد المختلف كليًا عن السابق. هذا سيكون هو عنوان الـIP الظاهر للعالم عند تصفّحك لمواقعهم. مجددًا، انقر على Extended Test وسيخبرك عن خواديم DNS التي تستعملها وسيؤكد لك أنّك تستخدم الآن خواديم الـDNS المُعدّة من قبل OpenVPN. تهانينا! يمكنك الآن التنقّل بأمان في الإنترنت وحماية خصوصيتك، موقعك وبياناتك من المراقبة والمُخترقين. ترجمة -وبتصرّف- للمقال: How To Set Up an OpenVPN Server on Ubuntu 14.04. -
.png.eada42406f5456ed1eddf7676cc1b6fc.png) من المهم جدًا الحفاظ على دقة وقت النظام، سواءً فعلنا ذلك للحرص على دقة ترتيب السجلات (logs) أو أنَّ تحديثات قاعدة البيانات ستُطبَّق دون مشاكل؛ فإذا كان الوقت المضبوط على النظام غير صحيح، فقد يسبب ذلك أخطاءً أو تلفًا في البيانات أو مشاكل أخرى يصعب معرفة سببها بسهولة. ميزة مزامنة الوقت مضمّنةٌ ومفعّلةٌ في أوبنتو 16.04 افتراضيًا عبر خدمة timesyncd، وسنلقي في هذا الدرس نظرةً على الأوامر الأساسية المتعلقة بالوقت، ونتأكد أنَّ خدمة timesyncd مفعّلة، ونتعلم كيفية تثبيت خدمة بديلة لمزامنة الوقت والتاريخ. المتطلبات المسبقة يجب أن تملك قبل اتباع تعليمات هذا الدرس خادومًا يعمل بنظام أوبنتو 16.04 مع مستخدم ليس جذرًا لكنه يملك امتيازات الجذر عبر الأمر sudo؛ انظر إلى درس الإعداد الابتدائي لخادوم أوبنتو 14.04» لمزيدٍ من المعلومات. تعلّم الأوامر الأساسية للتعامل مع الوقت إنَّ أبسط الأوامر لمعرفة ما هو الوقت الحالي في نظامك هو date، يمكن لأي مستخدم كتابة هذا الأمر للحصول على الوقت والتاريخ الحاليين: date مثال على الناتج: Wed Apr 26 17:44:38 UTC 2017 من المرجح أنَّ المنطقة الزمنية المستعملة في خادومك هي UTC كما هو ظاهر في المثال أعلاه، كلمة UTC هي اختصار لعبارة Coordinated Universal Time (التوقيت العالمي الموحد) وهو الوقت عند مبدأ خطوط الطول، واستعمال توقيت UTC سيسهل عليك العمل إذا كانت خواديمك تمتد لأكثر من منطقة زمنية وحيدة. إذا أردت تغيير المنطقة الزمنية لأي سببٍ من الأسباب، فيمكنك استخدام الأمر timedatectl لفعل ذلك. اعرض أولًا قائمةً بالمناطق الزمنية المتاحة: timedatectl list-timezones ستُعرَض قائمة بجميع المناطق الزمنية، يمكنك الضغط على زر Space للتمرير إلى الأسفل وزر b للتمرير إلى الأعلى؛ وبعد أن تعثر على المنطقة الزمنية الصحيحة فدوِّنها عندك ثم اضغط على q للخروج من القائمة. يمكنك الآن ضبط القائمة الزمنية باستخدام الأمر timedatectl set-timezone، احرص على وضع منطقتك الزمنية بدلًا من تلك المذكورة في الأمر الآتي؛ لاحظ أنَّك ستحتاج إلى استخدام الأمر sudo مع الأمر timedatectl لإجراء هذا التعديل: sudo timedatectl set-timezone America/New_York يمكنك التحقق من التغييرات بتشغيل الأمر date مجددًا: date الناتج: Wed Apr 26 13:55:45 EDT 2017 يجب أن يشير الاختصار المذكور في الأمر السابق إلى المنطقة الزمنية التي اخترتها. تعلمنا كيف نتحقق من الوقت الحالي وكيف نضبط المناطق الزمنية، وسنتعلم الآن كيف نتأكد من مزامنة الوقت في نظامنا. التحكم بخدمة timesyncd بواسطة timedatectl كانت أغلبية عمليات مزامنة الوقت تتم عبر خدمة بروتوكول وقت الشبكة (Network Time Protocol daemon) ntpd، أي سيتصل الخادوم إلى مجموعة من خواديم NTP التي توفر الوقت بدقة كبيرة. لكن توزيعة أوبنتو تستعمل timesyncd بدلًا من ntpd لمزامنة الوقت، إذ تتصل خدمة timesyncd إلى خواديم الوقت نفسها وتعمل العمل نفسه تقريبًا، لكنها أخف وتندمج اندماجًا أفضل مع systemd وطريقة العمل الداخلية في توزيعة أوبنتو. يمكنك الحصول على حالة خدمة timesyncd بتشغيل الأمر timedatectl دون معاملات، ولن تحتاج إلى استخدام sudo في هذا الموضع: timedatectl الناتج: Local time: Wed 2017-04-26 17:20:07 UTC Universal time: Wed 2017-04-26 17:20:07 UTC RTC time: Wed 2017-04-26 17:20:07 Time zone: Etc/UTC (UTC, +0000) Network time on: yes NTP synchronized: yes RTC in local TZ: no سيطبع الأمر السابق الوقت المحلي والوقت العالمي (والذي يساوي الوقت المحلي في حال لم تغيّر المنطقة الزمنية)، وبعض معلومات عن حالة وقت الشبكة. السطر Network time on: yes يعني أنَّ خدمة timesyncd مفعّلة، والسطر NTP synchronized: yes يشير إلى نجاح مزامنة الوقت. إذا لم تكن خدمة timesyncd مفعلةً، فشغِّلها باستعمال الأمر timedatectl: sudo timedatectl set-ntp on شغِّل الأمر timedatectl مجددًا للتأكد من حالة وقت الشبكة؛ لاحظ أنَّ عملية التزامن تحتاج إلى بعض الوقت، لكن في النهاية يجب أن تكون قيمة السطرين Network time on: و NTP synchronized: تساوي yes. التحويل إلى خدمة ntpd على الرغم من أنَّ خدمة timesyncd مناسبة لغالبية الاحتياجات، لكن بعض التطبيقات حساسةٌ جدًا لأدنى اضطراب في الوقت ومن المستحسن استعمال ntpd في هذه الحالات، لأنه يستعمل تقنيات معقدة لإبقاء الوقت في النظام مزامنًا دومًا. علينا إيقاف خدمة timesyncd قبل تثبيت ntpd: sudo timedatectl set-ntp no للتأكد من إيقاف خدمة timesyncd: timedatectl ابحث عن السطر Network time on: no الذي يعني أنَّ خدمة timdsyncd متوقفة؛ يمكننا الآن تثبيت حزمة ntp باستعمال الأداة apt-get: sudo apt-get install ntp يجب أن يعمل خادوم ntpd تلقائيًا بعد التثبيت، يمكنك عرض حالة خدمة ntpd للتأكد أنَّ كل شيءٍ على ما يرام: sudo ntpq -p الناتج: remote refid st t when poll reach delay offset jitter ============================================================================== 0.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000 1.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000 2.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000 3.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000 ntp.ubuntu.com .POOL. 16 p - 64 0 0.000 0.000 0.000 -makaki.miuku.ne 210.23.25.77 2 u 45 64 3 248.007 -0.489 1.137 -69.10.161.7 144.111.222.81 3 u 43 64 3 90.551 4.316 0.550 +static-ip-85-25 130.149.17.21 2 u 42 64 3 80.044 -2.829 0.900 +zepto.mcl.gg 192.53.103.108 2 u 40 64 3 83.331 -0.385 0.391 ntpq هي أداة لطلب (query) معلومات حول خدمة ntpd، والخيار -p يطلب معلومات حول خواديم NTP (peers) التي اتصلت خدمة ntpd بها. قد يختلف الناتج عندك قليلًا، لكن يجب أن تتضمن القائمة على خواديم أوبنتو الافتراضية إضافةً إلى غيرها. أبقِ في ذهنك أنَّ خدمة ntpd تحتاج إلى بضع دقائق لتهيئة الاتصالات… الخلاصة رأينا في هذا الدرس طريقة عرض وقت النظام، وكيفية تغيير المناطق الزمنية، وطريقة التعامل مع خدمة timesyncd الموجودة افتراضيًا في أوبنتو، إضافةً إلى طريقة تثبيت ntpd. إذا كان نظامك ذو احتياجات خاصة لم نشرحها في هذا الدرس، فأنصحك بالرجوع إلى توثيق NTP الرسمي، وألقِ نظرةً على مشروع NTP Pool الذي هو مجموعةٌ من المتطوعين الذين يوفرون جزءًا كبيرًا من البنية التحتية التي يحتاج لها بروتوكول NTP في العالم. ترجمة –وبتصرّف– للمقال How To Set Up Time Synchronization on Ubuntu 16.04لصاحبه Brian Boucheron حقوق الصورة البارزة محفوظة لـ Freepik
من المهم جدًا الحفاظ على دقة وقت النظام، سواءً فعلنا ذلك للحرص على دقة ترتيب السجلات (logs) أو أنَّ تحديثات قاعدة البيانات ستُطبَّق دون مشاكل؛ فإذا كان الوقت المضبوط على النظام غير صحيح، فقد يسبب ذلك أخطاءً أو تلفًا في البيانات أو مشاكل أخرى يصعب معرفة سببها بسهولة. ميزة مزامنة الوقت مضمّنةٌ ومفعّلةٌ في أوبنتو 16.04 افتراضيًا عبر خدمة timesyncd، وسنلقي في هذا الدرس نظرةً على الأوامر الأساسية المتعلقة بالوقت، ونتأكد أنَّ خدمة timesyncd مفعّلة، ونتعلم كيفية تثبيت خدمة بديلة لمزامنة الوقت والتاريخ. المتطلبات المسبقة يجب أن تملك قبل اتباع تعليمات هذا الدرس خادومًا يعمل بنظام أوبنتو 16.04 مع مستخدم ليس جذرًا لكنه يملك امتيازات الجذر عبر الأمر sudo؛ انظر إلى درس الإعداد الابتدائي لخادوم أوبنتو 14.04» لمزيدٍ من المعلومات. تعلّم الأوامر الأساسية للتعامل مع الوقت إنَّ أبسط الأوامر لمعرفة ما هو الوقت الحالي في نظامك هو date، يمكن لأي مستخدم كتابة هذا الأمر للحصول على الوقت والتاريخ الحاليين: date مثال على الناتج: Wed Apr 26 17:44:38 UTC 2017 من المرجح أنَّ المنطقة الزمنية المستعملة في خادومك هي UTC كما هو ظاهر في المثال أعلاه، كلمة UTC هي اختصار لعبارة Coordinated Universal Time (التوقيت العالمي الموحد) وهو الوقت عند مبدأ خطوط الطول، واستعمال توقيت UTC سيسهل عليك العمل إذا كانت خواديمك تمتد لأكثر من منطقة زمنية وحيدة. إذا أردت تغيير المنطقة الزمنية لأي سببٍ من الأسباب، فيمكنك استخدام الأمر timedatectl لفعل ذلك. اعرض أولًا قائمةً بالمناطق الزمنية المتاحة: timedatectl list-timezones ستُعرَض قائمة بجميع المناطق الزمنية، يمكنك الضغط على زر Space للتمرير إلى الأسفل وزر b للتمرير إلى الأعلى؛ وبعد أن تعثر على المنطقة الزمنية الصحيحة فدوِّنها عندك ثم اضغط على q للخروج من القائمة. يمكنك الآن ضبط القائمة الزمنية باستخدام الأمر timedatectl set-timezone، احرص على وضع منطقتك الزمنية بدلًا من تلك المذكورة في الأمر الآتي؛ لاحظ أنَّك ستحتاج إلى استخدام الأمر sudo مع الأمر timedatectl لإجراء هذا التعديل: sudo timedatectl set-timezone America/New_York يمكنك التحقق من التغييرات بتشغيل الأمر date مجددًا: date الناتج: Wed Apr 26 13:55:45 EDT 2017 يجب أن يشير الاختصار المذكور في الأمر السابق إلى المنطقة الزمنية التي اخترتها. تعلمنا كيف نتحقق من الوقت الحالي وكيف نضبط المناطق الزمنية، وسنتعلم الآن كيف نتأكد من مزامنة الوقت في نظامنا. التحكم بخدمة timesyncd بواسطة timedatectl كانت أغلبية عمليات مزامنة الوقت تتم عبر خدمة بروتوكول وقت الشبكة (Network Time Protocol daemon) ntpd، أي سيتصل الخادوم إلى مجموعة من خواديم NTP التي توفر الوقت بدقة كبيرة. لكن توزيعة أوبنتو تستعمل timesyncd بدلًا من ntpd لمزامنة الوقت، إذ تتصل خدمة timesyncd إلى خواديم الوقت نفسها وتعمل العمل نفسه تقريبًا، لكنها أخف وتندمج اندماجًا أفضل مع systemd وطريقة العمل الداخلية في توزيعة أوبنتو. يمكنك الحصول على حالة خدمة timesyncd بتشغيل الأمر timedatectl دون معاملات، ولن تحتاج إلى استخدام sudo في هذا الموضع: timedatectl الناتج: Local time: Wed 2017-04-26 17:20:07 UTC Universal time: Wed 2017-04-26 17:20:07 UTC RTC time: Wed 2017-04-26 17:20:07 Time zone: Etc/UTC (UTC, +0000) Network time on: yes NTP synchronized: yes RTC in local TZ: no سيطبع الأمر السابق الوقت المحلي والوقت العالمي (والذي يساوي الوقت المحلي في حال لم تغيّر المنطقة الزمنية)، وبعض معلومات عن حالة وقت الشبكة. السطر Network time on: yes يعني أنَّ خدمة timesyncd مفعّلة، والسطر NTP synchronized: yes يشير إلى نجاح مزامنة الوقت. إذا لم تكن خدمة timesyncd مفعلةً، فشغِّلها باستعمال الأمر timedatectl: sudo timedatectl set-ntp on شغِّل الأمر timedatectl مجددًا للتأكد من حالة وقت الشبكة؛ لاحظ أنَّ عملية التزامن تحتاج إلى بعض الوقت، لكن في النهاية يجب أن تكون قيمة السطرين Network time on: و NTP synchronized: تساوي yes. التحويل إلى خدمة ntpd على الرغم من أنَّ خدمة timesyncd مناسبة لغالبية الاحتياجات، لكن بعض التطبيقات حساسةٌ جدًا لأدنى اضطراب في الوقت ومن المستحسن استعمال ntpd في هذه الحالات، لأنه يستعمل تقنيات معقدة لإبقاء الوقت في النظام مزامنًا دومًا. علينا إيقاف خدمة timesyncd قبل تثبيت ntpd: sudo timedatectl set-ntp no للتأكد من إيقاف خدمة timesyncd: timedatectl ابحث عن السطر Network time on: no الذي يعني أنَّ خدمة timdsyncd متوقفة؛ يمكننا الآن تثبيت حزمة ntp باستعمال الأداة apt-get: sudo apt-get install ntp يجب أن يعمل خادوم ntpd تلقائيًا بعد التثبيت، يمكنك عرض حالة خدمة ntpd للتأكد أنَّ كل شيءٍ على ما يرام: sudo ntpq -p الناتج: remote refid st t when poll reach delay offset jitter ============================================================================== 0.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000 1.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000 2.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000 3.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000 ntp.ubuntu.com .POOL. 16 p - 64 0 0.000 0.000 0.000 -makaki.miuku.ne 210.23.25.77 2 u 45 64 3 248.007 -0.489 1.137 -69.10.161.7 144.111.222.81 3 u 43 64 3 90.551 4.316 0.550 +static-ip-85-25 130.149.17.21 2 u 42 64 3 80.044 -2.829 0.900 +zepto.mcl.gg 192.53.103.108 2 u 40 64 3 83.331 -0.385 0.391 ntpq هي أداة لطلب (query) معلومات حول خدمة ntpd، والخيار -p يطلب معلومات حول خواديم NTP (peers) التي اتصلت خدمة ntpd بها. قد يختلف الناتج عندك قليلًا، لكن يجب أن تتضمن القائمة على خواديم أوبنتو الافتراضية إضافةً إلى غيرها. أبقِ في ذهنك أنَّ خدمة ntpd تحتاج إلى بضع دقائق لتهيئة الاتصالات… الخلاصة رأينا في هذا الدرس طريقة عرض وقت النظام، وكيفية تغيير المناطق الزمنية، وطريقة التعامل مع خدمة timesyncd الموجودة افتراضيًا في أوبنتو، إضافةً إلى طريقة تثبيت ntpd. إذا كان نظامك ذو احتياجات خاصة لم نشرحها في هذا الدرس، فأنصحك بالرجوع إلى توثيق NTP الرسمي، وألقِ نظرةً على مشروع NTP Pool الذي هو مجموعةٌ من المتطوعين الذين يوفرون جزءًا كبيرًا من البنية التحتية التي يحتاج لها بروتوكول NTP في العالم. ترجمة –وبتصرّف– للمقال How To Set Up Time Synchronization on Ubuntu 16.04لصاحبه Brian Boucheron حقوق الصورة البارزة محفوظة لـ Freepik -
 تعرّفنا في الجزأين السابقيْن من هذا الدليل على كيفية عرض معلومات عن مساحات التخزين وإنشاء مساحات تخزين جديدة وتحجيمها. سنكمل في هذا الجزأ - الأخير من الدليل - ما تعلمناه سابقا ونتعرّف على المهمة الأخيرة من بين المهمّات الأساسية في إدارة التخزين بآلية LVM. تنبيه: تأكّد من أنّ الأجهزة التّي تودّ تطبيق الأوامر المذكورة في هذا الدرس عليها لا تحتوي على بيانات مُهمّة. استخدام هذه الأجهزة مع LVM سيؤدّي إلى الكتابة فوق المحتويات الحاليّة. يُفضَّل أن تختبر الخطوات المعروضة أدناه في آلة افتراضية أو على خادوم خاصّ بأغراض التجربة والاختبار. إزالة أو تقليص مُكوّنات LVM بما أن تقليص مساحة التّخزين قد يؤدي إلى فقدان البيانات، فإجراءات تقليص المساحة المتوفّرة، سواءٌ بتقليص حجم أو حذف المكوّنات، أكثر تعقيدًا من بقية المهامّ. تخفيض حجم وحدة تخزين منطقيّة لتقليص وحدة تخزين منطقيّة، يجب عليك أولا أخذ نسخة احتياطية من بياناتك. فبما أن هذه العمليّة تقلّص مساحة التّخزين المُتوفّرة فإن أي خطأ يُمكن له أن يُؤدي إلى فقدان البيانات. إذا كنت جاهزا، تأكّد من حجم المساحة المُستخدمة حاليّا: df -h المُخرج: Filesystem Size Used Avail Use% Mounted on . . . /dev/mapper/LVMVolGroup-test 4.8G 521M 4.1G 12% /mnt/test في هذا المثال، يبدو بأنّنا نستخدم حاليّا حوالي 521M من المساحة. استعمل هذه المعلومة لتحديد الحجم الذي تريد تقليص وحدة التخزين إليه. تاليّا، أزل تركيب نظام الملفّات. فعلى عكس التوسيعات، يجب عليك تقليص مساحة نظام الملفّات أثناء إزالة التركيب: cd ~ sudo umount /dev/LVMVolGroup/test بعد إزالة التركيب، تأكّد من أن نظام الملفّات في حالة جيّدة. مرّر نوع نظام الملفّات عبر الخيار -t. سنستعمل الخيار -f للتّحقّق من أن كل شيء على ما يرام حتى ولو بدا كذلك: sudo fsck -t ext4 -f /dev/LVMVolGroup/test بعد التّحقّق من سلامة نظام الملفّات، يُمكنك تقليص مساحته باستخدام الأدوات الخاصّة، في حالة Ext4، فالأمر سيكون resize2fs. مرّر الحجم النّهائي لنظام الملفّات. تنبيه: أكثر خيار أمانا هو تمرير حجم نهائي أكبر بكثير من الحجم المُستخدم حاليا. أعط نفسك مساحة أمان لتجنّب فقدان البيانات وتأكّد من إنشاء نسخ احتياطيّة. sudo resize2fs -p /dev/LVMVolGroup/test 3G حالما تنتهي العمليّة، قلّص حجم وحدة التّخزين المنطقيّة عبر تمرير نفس الحجم (3G في هذه الحالة) إلى الأمر lvresize عبر الخيار -L. sudo lvresize -L 3G LVMVolGroup/test ستستقبل تنبيها حول فقدان البيانات، إن كنت جاهزا، فاكتب y للاستمرار. بعد تقليص حجم وحدة التّخزين المنطقيّة، تحقّق من سلامة نظام الملفّات مُجدّدا: sudo fsck -t ext4 -f /dev/LVMVolGroup/test إن سار كلّ شيء على ما يرام، فستستطيع إعادة وصل نظام الملفّات بالأمر المُعتاد: sudo mount /dev/LVMVolGroup/test /mnt/test ينبغي الآن على وحدة التّخزين المنطقيّة أن تُقلّص إلى الحجم المُحدّد. حذف وحدة تخزين منطقيّة إن لم تعد بحاجة إلى وحدة تخزين منطقيّة، يُمكنك حذفها باستعمال الأمر lvremove. أولا، أزل تركيب وحدة التخزين: cd ~ sudo umount /dev/LVMVolGroup/test بعدها، احذف وحدة التخزين بالأمر التّالي: sudo lvremove LVMVolGroup/test سيُطلب منك تأكيد العمليّة، إن كنت متأكّدا من رغبتك في حذف وحدة التّخزين، فاكتب y. حذف مجموعة تخزين لحذف مجموعة تخزين كاملة، بما في ذلك جميع وحدات التّخزين المنطقيّة المتواجدة بها، استعمل الأمر vgremove. قبل حذف مجموعة تخزين، عليك حذف وحدات التّخزين بداخلها بالعمليّة أعلاه. أو على الأقل، تأكّد من إزالة تركيب جميع وحدات التّخزين بداخل المجموعة: sudo umount /dev/LVMVolGroup/www sudo umount /dev/LVMVolGroup/projects sudo umount /dev/LVMVolGroup/db بعدها يُمكنك حذف مجموعة التّخزين عبر تمرير اسمها إلى الأمر vgremove: sudo vgremove LVMVolGroup سيُطلب منك تأكيد عمليّة حذف المجموعة. إذا كانت هناك أية وحدات تخزين منطقيّة مُتبقيّة، ستُسأل عن تأكيد حذفها واحدة واحدة قبل حذف المجموعة. حذف وحدة تخزين ماديّة إن أردت إزالة وحدة تخزين ماديّة من إدارة LVM، فسيعتمد الإجراء المطلوب على ما إذا كانت الوحدة مُستخدمة من طرف LVM أو لا. إن كانت وحدة التّخزين الماديّة مُستخدَمة، سيتوجّب عليك نقل المداءات الماديّة على الجهاز إلى مكان آخر. سيتطلّب ذلك وجود وحدات تخزين ماديّة أخرى لتحتضن المداءات الماديّة. إن كنت تستعمل أنواعا مُعقّدة من وحدات التّخزين المنطقيّة، فقد يتوجّب عليك الحصول على المزيد من وحدات التّخزين الماديّة حتى ولو كانت لديك مساحة تخزين كافيّة. إن كان لديك عدد كاف من وحدات التّخزين الماديّة في مجموعة التّخزين لاحتضان المداءات الماديّة، فانقلها إلى خارج وحدة التّخزين الماديّة التي ترغب في إزالتها عبر كتابة ما يلي: sudo pvmove /dev/sda يُمكن لهذه العمليّة أن تأخذ وقتا طويلا حسب حجم وحدات التّخزين وكميّة البيانات التي يتوجب نقلها. حالما تنتقل المداءات إلى وحدات تخزين أخرى، يُمكنك حذف وحدة التّخزين الماديّة من مجموعة التّخزين عبر الأمر التّالي: sudo vgreduce LVMVolGroup /dev/sda هذه العمليّة كفيلة بإزالة وحدات التّخزين التي أُخلِيت من مجموعة التّخزين. بعد انتهاء العمليّة، يُمكنك حذف علامة وحدة التّخزين الماديّة من جهاز التّخزين عبر الأمر: sudo pvremove /dev/sda ينبغي الآن أن تتمكّن من استعمال جهاز التّخزين المُزال لأغراض أخرى أو إزالته من النّظام بالكامل. ختاما إلى هذه النّقطة، يجب أن يكون لديك فهم لكيفيّة إدارة أجهزة التّخزين على أوبونتو 16.04 مع LVM. يجب أن تعرف كيفيّة الحصول على معلومات عن مكوّنات LVM، كيفيّة استخدام LVM لتركيب نظام تخزين خاص بك، وكيفيّة تعديل وحدات التّخزين لتلبيّة حاجاتك. يُمكنك اختبار هذه المبادئ في بيئة آمنة لفهم أعمق حول آليّة عمل LVM ومكوّناته. ترجمة – بتصرّف - للمقال How To Use LVM To Manage Storage Devices on Ubuntu 16.04 لكاتبه Justin Ellingwood.
تعرّفنا في الجزأين السابقيْن من هذا الدليل على كيفية عرض معلومات عن مساحات التخزين وإنشاء مساحات تخزين جديدة وتحجيمها. سنكمل في هذا الجزأ - الأخير من الدليل - ما تعلمناه سابقا ونتعرّف على المهمة الأخيرة من بين المهمّات الأساسية في إدارة التخزين بآلية LVM. تنبيه: تأكّد من أنّ الأجهزة التّي تودّ تطبيق الأوامر المذكورة في هذا الدرس عليها لا تحتوي على بيانات مُهمّة. استخدام هذه الأجهزة مع LVM سيؤدّي إلى الكتابة فوق المحتويات الحاليّة. يُفضَّل أن تختبر الخطوات المعروضة أدناه في آلة افتراضية أو على خادوم خاصّ بأغراض التجربة والاختبار. إزالة أو تقليص مُكوّنات LVM بما أن تقليص مساحة التّخزين قد يؤدي إلى فقدان البيانات، فإجراءات تقليص المساحة المتوفّرة، سواءٌ بتقليص حجم أو حذف المكوّنات، أكثر تعقيدًا من بقية المهامّ. تخفيض حجم وحدة تخزين منطقيّة لتقليص وحدة تخزين منطقيّة، يجب عليك أولا أخذ نسخة احتياطية من بياناتك. فبما أن هذه العمليّة تقلّص مساحة التّخزين المُتوفّرة فإن أي خطأ يُمكن له أن يُؤدي إلى فقدان البيانات. إذا كنت جاهزا، تأكّد من حجم المساحة المُستخدمة حاليّا: df -h المُخرج: Filesystem Size Used Avail Use% Mounted on . . . /dev/mapper/LVMVolGroup-test 4.8G 521M 4.1G 12% /mnt/test في هذا المثال، يبدو بأنّنا نستخدم حاليّا حوالي 521M من المساحة. استعمل هذه المعلومة لتحديد الحجم الذي تريد تقليص وحدة التخزين إليه. تاليّا، أزل تركيب نظام الملفّات. فعلى عكس التوسيعات، يجب عليك تقليص مساحة نظام الملفّات أثناء إزالة التركيب: cd ~ sudo umount /dev/LVMVolGroup/test بعد إزالة التركيب، تأكّد من أن نظام الملفّات في حالة جيّدة. مرّر نوع نظام الملفّات عبر الخيار -t. سنستعمل الخيار -f للتّحقّق من أن كل شيء على ما يرام حتى ولو بدا كذلك: sudo fsck -t ext4 -f /dev/LVMVolGroup/test بعد التّحقّق من سلامة نظام الملفّات، يُمكنك تقليص مساحته باستخدام الأدوات الخاصّة، في حالة Ext4، فالأمر سيكون resize2fs. مرّر الحجم النّهائي لنظام الملفّات. تنبيه: أكثر خيار أمانا هو تمرير حجم نهائي أكبر بكثير من الحجم المُستخدم حاليا. أعط نفسك مساحة أمان لتجنّب فقدان البيانات وتأكّد من إنشاء نسخ احتياطيّة. sudo resize2fs -p /dev/LVMVolGroup/test 3G حالما تنتهي العمليّة، قلّص حجم وحدة التّخزين المنطقيّة عبر تمرير نفس الحجم (3G في هذه الحالة) إلى الأمر lvresize عبر الخيار -L. sudo lvresize -L 3G LVMVolGroup/test ستستقبل تنبيها حول فقدان البيانات، إن كنت جاهزا، فاكتب y للاستمرار. بعد تقليص حجم وحدة التّخزين المنطقيّة، تحقّق من سلامة نظام الملفّات مُجدّدا: sudo fsck -t ext4 -f /dev/LVMVolGroup/test إن سار كلّ شيء على ما يرام، فستستطيع إعادة وصل نظام الملفّات بالأمر المُعتاد: sudo mount /dev/LVMVolGroup/test /mnt/test ينبغي الآن على وحدة التّخزين المنطقيّة أن تُقلّص إلى الحجم المُحدّد. حذف وحدة تخزين منطقيّة إن لم تعد بحاجة إلى وحدة تخزين منطقيّة، يُمكنك حذفها باستعمال الأمر lvremove. أولا، أزل تركيب وحدة التخزين: cd ~ sudo umount /dev/LVMVolGroup/test بعدها، احذف وحدة التخزين بالأمر التّالي: sudo lvremove LVMVolGroup/test سيُطلب منك تأكيد العمليّة، إن كنت متأكّدا من رغبتك في حذف وحدة التّخزين، فاكتب y. حذف مجموعة تخزين لحذف مجموعة تخزين كاملة، بما في ذلك جميع وحدات التّخزين المنطقيّة المتواجدة بها، استعمل الأمر vgremove. قبل حذف مجموعة تخزين، عليك حذف وحدات التّخزين بداخلها بالعمليّة أعلاه. أو على الأقل، تأكّد من إزالة تركيب جميع وحدات التّخزين بداخل المجموعة: sudo umount /dev/LVMVolGroup/www sudo umount /dev/LVMVolGroup/projects sudo umount /dev/LVMVolGroup/db بعدها يُمكنك حذف مجموعة التّخزين عبر تمرير اسمها إلى الأمر vgremove: sudo vgremove LVMVolGroup سيُطلب منك تأكيد عمليّة حذف المجموعة. إذا كانت هناك أية وحدات تخزين منطقيّة مُتبقيّة، ستُسأل عن تأكيد حذفها واحدة واحدة قبل حذف المجموعة. حذف وحدة تخزين ماديّة إن أردت إزالة وحدة تخزين ماديّة من إدارة LVM، فسيعتمد الإجراء المطلوب على ما إذا كانت الوحدة مُستخدمة من طرف LVM أو لا. إن كانت وحدة التّخزين الماديّة مُستخدَمة، سيتوجّب عليك نقل المداءات الماديّة على الجهاز إلى مكان آخر. سيتطلّب ذلك وجود وحدات تخزين ماديّة أخرى لتحتضن المداءات الماديّة. إن كنت تستعمل أنواعا مُعقّدة من وحدات التّخزين المنطقيّة، فقد يتوجّب عليك الحصول على المزيد من وحدات التّخزين الماديّة حتى ولو كانت لديك مساحة تخزين كافيّة. إن كان لديك عدد كاف من وحدات التّخزين الماديّة في مجموعة التّخزين لاحتضان المداءات الماديّة، فانقلها إلى خارج وحدة التّخزين الماديّة التي ترغب في إزالتها عبر كتابة ما يلي: sudo pvmove /dev/sda يُمكن لهذه العمليّة أن تأخذ وقتا طويلا حسب حجم وحدات التّخزين وكميّة البيانات التي يتوجب نقلها. حالما تنتقل المداءات إلى وحدات تخزين أخرى، يُمكنك حذف وحدة التّخزين الماديّة من مجموعة التّخزين عبر الأمر التّالي: sudo vgreduce LVMVolGroup /dev/sda هذه العمليّة كفيلة بإزالة وحدات التّخزين التي أُخلِيت من مجموعة التّخزين. بعد انتهاء العمليّة، يُمكنك حذف علامة وحدة التّخزين الماديّة من جهاز التّخزين عبر الأمر: sudo pvremove /dev/sda ينبغي الآن أن تتمكّن من استعمال جهاز التّخزين المُزال لأغراض أخرى أو إزالته من النّظام بالكامل. ختاما إلى هذه النّقطة، يجب أن يكون لديك فهم لكيفيّة إدارة أجهزة التّخزين على أوبونتو 16.04 مع LVM. يجب أن تعرف كيفيّة الحصول على معلومات عن مكوّنات LVM، كيفيّة استخدام LVM لتركيب نظام تخزين خاص بك، وكيفيّة تعديل وحدات التّخزين لتلبيّة حاجاتك. يُمكنك اختبار هذه المبادئ في بيئة آمنة لفهم أعمق حول آليّة عمل LVM ومكوّناته. ترجمة – بتصرّف - للمقال How To Use LVM To Manage Storage Devices on Ubuntu 16.04 لكاتبه Justin Ellingwood. -
.png.553efcc105da817644c1f29f1dcfb34c.png) بعد أن تعرّفنا في الجزء السابق على كيفية عرض معلومات عن مختلف العناصر في LVM، سنتطرّق في هذا الجزء من الدليل إلى كيفية التحكم في هذه المكوّنات بإنشاء مكوّنات جديدة أو إعادة تحجيم (توسيع أو تقليص) مكوّنات موجودة. إنشاء أو توسيع مكوّنات LVM سنتحدّث في هذه الفقرات عن كيفيّة إنشاء وتوسيع وحدات التّخزين الماديّة والمنطقيّة وكذا مجموعات التّخزين. إنشاء وحدات تخزين ماديّة من أجهزة تخزين خام لاستعمال أجهزة التّخزين مع LVM، يجب عليها أولا أن تُعلّم على أنها وحدات تخزين ماديّة. ما يُحدّد إمكانيّة استخدام الجهاز داخل مجموعة تخزين. أولا، استعمل الأمر lvmdiskscan لإيجاد جميع أجهزة التّخزين التي يُمكن لـLVM رؤيتها واستخدامها: sudo lvmdiskscan المُخرج: /dev/ram0 [ 64.00 MiB] /dev/sda [ 200.00 GiB] /dev/ram1 [ 64.00 MiB] . . . /dev/ram15 [ 64.00 MiB] /dev/sdb [ 100.00 GiB] 2 disks 17 partitions 0 LVM physical volume whole disks 0 LVM physical volumes في المُخرج أعلاه، بتجاهل أجهزة /dev/ram*، يُمكننا رؤية الأجهزة التّي يُمكن تحويلها إلى وحدات تخزين ماديّة لـLVM. تنبيه: تأكّد من أنّ الأجهزة التّي ترغب باستعمالها مع LVM لا تحتوي على أيّة بيانات مُهمّة. استخدام هذه الأجهزة مع LVM سيؤدّي إلى الكتابة فوق المحتويات الحاليّة. إذا كنت تمتلك بيانات مهمّة على خادومك فأنشئ نسخا احتياطية قبل الاستمرار في تطبيق الدّرس. لجعل أجهزة التّخزين وحدات تخزين ماديّة خاصّة بـLVM، استعمل الأمر pvcreate. يُمكنك تمرير عدّة أجهزة في نفس الوقت: sudo pvcreate /dev/sda /dev/sdb هذا الأمر سيكتب ترويسة LVM على جميع الأجهزة الهدف لتخصيصها كوحدات تخزين LVM ماديّة. إنشاء مجموعة تخزين من وحدات التّخزين الماديّة لإنشاء مجموعة تخزين جديدة من وحدات التّخزين الماديّة، استعمل الأمر vgcreate. سيتوجّب عليك تمرير اسم للمجموعة متبوعا بوحدة تخزين ماديّة واحدة على الأقل: sudo vgcreate volume_group_name /dev/sda استبدل volume_group_name باسم من اختيارك لمجموعة التّخزين. سينشئ المثال أعلاه مجموعة تخزين انطلاقا من وحدة تخزين ماديّة واحدة فقط. يُمكنك تمرير أكثر من وحدة تخزين ماديّة عند إنشاء المجموعة إن أردت ذلك: sudo vgcreate volume_group_name /dev/sda /dev/sdb /dev/sdc عادة ستحتاج إلى مجموعة تخزين واحدة فقط لكل خادوم. بحيث يُمكنك إضافة أي مساحة تخزين إضافيّة لمنطقة مُوحّدة ثمّ تخصيص وحدات تخزين منطقيّة منها. الحاجة إلى استخدام أحجام مداءات مُختلفة من الأسباب التّي قد تدفعك إلى إنشاء أكثر من مجموعة تخزين واحدة. في العادة، لن يتوجّب عليك تحديد حجم المدى (الحجم المبدئي هو 4M ويُعدّ كافيّا لمُعظم الاستخدامات)، لكنّ إن أردت، يُمكنك تحديد حجم المداءات عند إنشاء مجموعة التّخزين باستعمال الخيار -s: sudo vgcreate -s 8M volume_group_name /dev/sda سينشئ هذا الأمر مجموعة تخزين مع حجم مداءات يُساوي 8M. إضافة وحدة تخزين ماديّة إلى مجموعة تخزين موجودة مُسبقا لتوسيع مجموعة تخزين عبر إضافة وحدات تخزين ماديّة، استخدم الأمر vgextend. يأخذ هذا الأمر مجموعة تخزين متبوعة بوحدات التّخزين الماديّة التّي ترغب بإضافتها إلى المجموعة. يُمكنك كذلك تمرير أكثر من جهاز في نفس الوقت إن أردت: sudo vgextend volume_group_name /dev/sdb ستُضاف وحدة التّخزين الماديّة إلى مجموعة التّخزين موسّعة بذلك مساحة التّخزين المُتوفّرة على المجموعة. إنشاء وحدة تخزين منطقيّة بحجم مُحدّد لإنشاء وحدة تخزين منطقيّة من مجموعة تخزين، استعمل الأمر lvcreate. حدّد حجم وحدة التّخزين المنطقيّة باستخدام الخيار -L، وحدّد اسما عبر الخيار -n، ومرّر مجموعة التّخزين الأم. على سبيل المثال، لإنشاء وحدة تخزين منطقيّة تُسمّى test من مجموعة تخزين تُسمّى LVMVolGroup، اكتب: sudo lvcreate -L 10G -n test LVMVolGroup على افتراض أنّ بمجموعة التّخزين مساحة تخزين فارغة توافق حجم وحدة التّخزين، فإنشاء وحدة التّخزين الجديدة سيتمّ بنجاح. إنشاء وحدة تخزين منطقيّة من كامل باقي المساحة الفارغة إن أردت إنشاء وحدة تخزين من باقي المساحة الفارغة على مجموعة تخزين، استعمل الأمر vgcreate مع الخيار -n لتحديد اسم لها ثمّ مرّر مجموعة التّخزين كما في السّابق. عوضا عن تمرير حجم مُعيّن، استعمل الخيار -l 100%FREE لتحديد بقيّة المساحة الفارغة في المجموعة: sudo lvcreate -l 100%FREE -n test2 LVMVolGroup إنشاء وحدات تخزين منطقيّة مع خيارات مُتقدّمة يُمكنك إنشاء وحدات تخزين منطقيّة مع خيارات مُتقدّمة كذلك. التّالي بعض من الخيارات التي يُمكن أن تأخذها بعين الاعتبار: --type: يقوم هذا الخيار بتحديد نوع وحدة التّخزين المنطقيّة ما يُحدّد كيفيّة تخصيص مساحة له. بعض من هذه الأنواع لن تكون مُتوفّرة إن لم يكن لديك الحدّ الأدنى من وحدات التّخزين الماديّة التي يتطلّبها النّوع. بعض من أكثر هذه الأنواع شيوعا هي كما يلي: linear: النّوع المبدئي. أجهزة التّخزين المُستخدمة ستُضاف بعضها على بعض واحدا تلو الآخر. striped: مُشابه لـRAID 0، تُقسّم البيانات إلى قطع صغيرة وتُنشر على شكل قوس على وحدات التّخزين الماديّة المُستعملة. ما يؤدّي إلى تحسينات في الأداء، لكن يُمكن أن يؤدي إلى زيادة في قابليّة إصابة البيانات. لتحديد هذا النّوع، يجب عليك تمرير الخيار -i ويتطلّب وحدتي تخزين ماديّتين على الأقل. raid1: إنشاء وحدة تخزين RAID 1 مُنعكسة Mirrored. مبدئيًّا، سيكون للانعكاس نُسختان، لكن يُمكنك تحديد عدد أكبر عبر الخيار -m المشروح أسفله. هذا الخيار يتطلّب وحدتي تخزين ماديّتين على الأقل. raid5: إنشاء وحدة تخزين RAID 5. يتطلّب ثلاثة وحدات تخزين ماديّة على الأقل. raid6: إنشاء وحدة تخزين RAID 6. يتطلّب أربعة وحدات تخزين ماديّة على الأقل. -m: يحدّد عدد نُسخ البيانات الإضافيّة. إن مرّرت القيمة 1 فهذا يعني بأنّ نُسخة واحدة إضافيّة من البيانات ستُصان، بحيث يكون لديك مجموعتان من نفس البيانات. -i: يُحدّد عدد الشّرائط Stripes. هذا الخيار مطلوب للنوع striped، ويُمكن أن يُؤثّر على بعض خيارات RAID الأخرى. -s: يُحدّد بأنّ أخذ لقطة يجب أن يتمّ على مُستوى وحدة التّخزين المنطقيّة الحاليّة عوضا عن إنشاء وحدة تخزين منطقيّة جديدة ومُستقلّة. سنلقي نظرة على بضعة أمثلة لهذه الخيارات لنرى حالات الاستخدام الشّائعة. لإنشاء وحدة تخزين شريطيّة Striped volume، يجب عليك تحديد شريطين على الأقل. هذه العمليّة تحتاج إلى وحدتي تخزين ماديّتين على الأقل مع مساحة تخزين متوافقة مع الحجم المُراد: sudo lvcreate --type striped -i 2 -L 10G -n striped_vol LVMVolGroup لإنشاء مساحة تخزين مُنعكسة Mirrored volume، استخدم النّوع raid1. إن أردت أكثر من مجموعتي بيانات، استعمل الخيار -m. المثال التّالي يستعمل -m 2 لإنشاء ثلاث مجموعات من البيانات (يعتبر LVM بأنّها مجموعة واحدة من البيانات مع انعكاسين). ستحتاج إلى ثلاثة وحدات تخزين ماديّة على الأقل لنجاح العمليّة: sudo lvcreate --type raid1 -m 2 -L 20G -n mirrored_vol LVMVolGroup لإنشاء لقطة لوحدة تخزين ما، يجب عليك تحديد وحدة التّخزين المنطقيّة الأصل التي ستأخذ منها اللقطة وليس كامل مجموعة التّخزين. لا تحجز اللقطات الكثير من المساحة في البدء، لكنّ حجمها يزداد كلّما أُجرِيَت تغييرات على وحدة التّخزين المنطقيّة الأصليّة. عند إنشاء لقطة ما، فالحجم المُخصّص يكون أقصى حدّ يُمكن للقطة أن تصل إليه (اللقطات التي تزيد عن هذا الحجم مُعطّلة وغير قابلة للاستخدام؛ لكن يُمكن توسيع اللقطات التي تقترب من هذا الحجم): sudo lvcreate -s -L 10G -n snap_test LVMVolGroup/test تنبيه: لإعادة وحدة تخزين إلى الحالة التي تتواجد بها اللقطة، استخدم الأمر lvconvert --merge: sudo lvconvert --merge LVMVolGroup/snap_test سيقوم هذا الأمر بإعادة اللقطة إلى الحالة التي كانت عليها عندما تمّ إنشاؤها. كما ترى، هناك العديد من الخيارات التي يُمكن لها أن تُغيّر طريقة عمل وحدة التخزين المنطقيّة بشكل كبير. زيادة حجم وحدة تخزين منطقيّة المرونة في التّعامل مع وحدات التّخزين المنطقيّة من أكثر المميّزات المتوفّرة في LVM. إذ يُمكنك بسهولة تعديل عدد أو حجم وحدات التّخزين المنطقيّة دون إيقاف النّظام. لزيادة حجم وحدة تخزين منطقيّة أنشئت مُسبقا، استعمل الأمر lvresize. مرّر قيمة إلى الخيار -L لتحديد حجم جديد. يُمكنك كذلك استخدام أحجام نسبيّة عبر الرّمز +. في هذه الحالة سيقوم LVM بإضافة الكميّة المُحدّدة إلى الحجم الكلي لوحدة التّخزين. لتعديل حجم نظام الملفّات المُستخدم على وحدة التّخزين بشكل آلي، استعمل الخيار --resizefs. لتحديد اسم صحيح لوحدة التّخزين التي ترغب بتوسيعها، سيتوجّب عليك تحديد مجموعة التّخزين، ثمّ رمز / متبوعا باسم وحدة التّخزين المنطقيّة: sudo lvresize -L +5G --resizefs LVMVolGroup/test في هذا المثال، سيتمّ زيادة 5G لكل من وحدة التّخزين test ونظام الملفّات المُستخدم. إن أردت توسيع نظام الملفّات يدويًّا، يُمكنك حذف الخيار --resizefs واستعمال أداة توسيع نظام الملفّات الخاصّة. مثلا، لو كان نظام الملفّات هو Ext4 فيُمكن أن تكتب: sudo lvresize -L +5G LVMVolGroup/test sudo resize2fs /dev/LVMVolGroup/test سيكون لهذه العمليّة نفس تأثير ما سبق. ترجمة – بتصرّف - للمقال How To Use LVM To Manage Storage Devices on Ubuntu 16.04 لكاتبه Justin Ellingwood.
بعد أن تعرّفنا في الجزء السابق على كيفية عرض معلومات عن مختلف العناصر في LVM، سنتطرّق في هذا الجزء من الدليل إلى كيفية التحكم في هذه المكوّنات بإنشاء مكوّنات جديدة أو إعادة تحجيم (توسيع أو تقليص) مكوّنات موجودة. إنشاء أو توسيع مكوّنات LVM سنتحدّث في هذه الفقرات عن كيفيّة إنشاء وتوسيع وحدات التّخزين الماديّة والمنطقيّة وكذا مجموعات التّخزين. إنشاء وحدات تخزين ماديّة من أجهزة تخزين خام لاستعمال أجهزة التّخزين مع LVM، يجب عليها أولا أن تُعلّم على أنها وحدات تخزين ماديّة. ما يُحدّد إمكانيّة استخدام الجهاز داخل مجموعة تخزين. أولا، استعمل الأمر lvmdiskscan لإيجاد جميع أجهزة التّخزين التي يُمكن لـLVM رؤيتها واستخدامها: sudo lvmdiskscan المُخرج: /dev/ram0 [ 64.00 MiB] /dev/sda [ 200.00 GiB] /dev/ram1 [ 64.00 MiB] . . . /dev/ram15 [ 64.00 MiB] /dev/sdb [ 100.00 GiB] 2 disks 17 partitions 0 LVM physical volume whole disks 0 LVM physical volumes في المُخرج أعلاه، بتجاهل أجهزة /dev/ram*، يُمكننا رؤية الأجهزة التّي يُمكن تحويلها إلى وحدات تخزين ماديّة لـLVM. تنبيه: تأكّد من أنّ الأجهزة التّي ترغب باستعمالها مع LVM لا تحتوي على أيّة بيانات مُهمّة. استخدام هذه الأجهزة مع LVM سيؤدّي إلى الكتابة فوق المحتويات الحاليّة. إذا كنت تمتلك بيانات مهمّة على خادومك فأنشئ نسخا احتياطية قبل الاستمرار في تطبيق الدّرس. لجعل أجهزة التّخزين وحدات تخزين ماديّة خاصّة بـLVM، استعمل الأمر pvcreate. يُمكنك تمرير عدّة أجهزة في نفس الوقت: sudo pvcreate /dev/sda /dev/sdb هذا الأمر سيكتب ترويسة LVM على جميع الأجهزة الهدف لتخصيصها كوحدات تخزين LVM ماديّة. إنشاء مجموعة تخزين من وحدات التّخزين الماديّة لإنشاء مجموعة تخزين جديدة من وحدات التّخزين الماديّة، استعمل الأمر vgcreate. سيتوجّب عليك تمرير اسم للمجموعة متبوعا بوحدة تخزين ماديّة واحدة على الأقل: sudo vgcreate volume_group_name /dev/sda استبدل volume_group_name باسم من اختيارك لمجموعة التّخزين. سينشئ المثال أعلاه مجموعة تخزين انطلاقا من وحدة تخزين ماديّة واحدة فقط. يُمكنك تمرير أكثر من وحدة تخزين ماديّة عند إنشاء المجموعة إن أردت ذلك: sudo vgcreate volume_group_name /dev/sda /dev/sdb /dev/sdc عادة ستحتاج إلى مجموعة تخزين واحدة فقط لكل خادوم. بحيث يُمكنك إضافة أي مساحة تخزين إضافيّة لمنطقة مُوحّدة ثمّ تخصيص وحدات تخزين منطقيّة منها. الحاجة إلى استخدام أحجام مداءات مُختلفة من الأسباب التّي قد تدفعك إلى إنشاء أكثر من مجموعة تخزين واحدة. في العادة، لن يتوجّب عليك تحديد حجم المدى (الحجم المبدئي هو 4M ويُعدّ كافيّا لمُعظم الاستخدامات)، لكنّ إن أردت، يُمكنك تحديد حجم المداءات عند إنشاء مجموعة التّخزين باستعمال الخيار -s: sudo vgcreate -s 8M volume_group_name /dev/sda سينشئ هذا الأمر مجموعة تخزين مع حجم مداءات يُساوي 8M. إضافة وحدة تخزين ماديّة إلى مجموعة تخزين موجودة مُسبقا لتوسيع مجموعة تخزين عبر إضافة وحدات تخزين ماديّة، استخدم الأمر vgextend. يأخذ هذا الأمر مجموعة تخزين متبوعة بوحدات التّخزين الماديّة التّي ترغب بإضافتها إلى المجموعة. يُمكنك كذلك تمرير أكثر من جهاز في نفس الوقت إن أردت: sudo vgextend volume_group_name /dev/sdb ستُضاف وحدة التّخزين الماديّة إلى مجموعة التّخزين موسّعة بذلك مساحة التّخزين المُتوفّرة على المجموعة. إنشاء وحدة تخزين منطقيّة بحجم مُحدّد لإنشاء وحدة تخزين منطقيّة من مجموعة تخزين، استعمل الأمر lvcreate. حدّد حجم وحدة التّخزين المنطقيّة باستخدام الخيار -L، وحدّد اسما عبر الخيار -n، ومرّر مجموعة التّخزين الأم. على سبيل المثال، لإنشاء وحدة تخزين منطقيّة تُسمّى test من مجموعة تخزين تُسمّى LVMVolGroup، اكتب: sudo lvcreate -L 10G -n test LVMVolGroup على افتراض أنّ بمجموعة التّخزين مساحة تخزين فارغة توافق حجم وحدة التّخزين، فإنشاء وحدة التّخزين الجديدة سيتمّ بنجاح. إنشاء وحدة تخزين منطقيّة من كامل باقي المساحة الفارغة إن أردت إنشاء وحدة تخزين من باقي المساحة الفارغة على مجموعة تخزين، استعمل الأمر vgcreate مع الخيار -n لتحديد اسم لها ثمّ مرّر مجموعة التّخزين كما في السّابق. عوضا عن تمرير حجم مُعيّن، استعمل الخيار -l 100%FREE لتحديد بقيّة المساحة الفارغة في المجموعة: sudo lvcreate -l 100%FREE -n test2 LVMVolGroup إنشاء وحدات تخزين منطقيّة مع خيارات مُتقدّمة يُمكنك إنشاء وحدات تخزين منطقيّة مع خيارات مُتقدّمة كذلك. التّالي بعض من الخيارات التي يُمكن أن تأخذها بعين الاعتبار: --type: يقوم هذا الخيار بتحديد نوع وحدة التّخزين المنطقيّة ما يُحدّد كيفيّة تخصيص مساحة له. بعض من هذه الأنواع لن تكون مُتوفّرة إن لم يكن لديك الحدّ الأدنى من وحدات التّخزين الماديّة التي يتطلّبها النّوع. بعض من أكثر هذه الأنواع شيوعا هي كما يلي: linear: النّوع المبدئي. أجهزة التّخزين المُستخدمة ستُضاف بعضها على بعض واحدا تلو الآخر. striped: مُشابه لـRAID 0، تُقسّم البيانات إلى قطع صغيرة وتُنشر على شكل قوس على وحدات التّخزين الماديّة المُستعملة. ما يؤدّي إلى تحسينات في الأداء، لكن يُمكن أن يؤدي إلى زيادة في قابليّة إصابة البيانات. لتحديد هذا النّوع، يجب عليك تمرير الخيار -i ويتطلّب وحدتي تخزين ماديّتين على الأقل. raid1: إنشاء وحدة تخزين RAID 1 مُنعكسة Mirrored. مبدئيًّا، سيكون للانعكاس نُسختان، لكن يُمكنك تحديد عدد أكبر عبر الخيار -m المشروح أسفله. هذا الخيار يتطلّب وحدتي تخزين ماديّتين على الأقل. raid5: إنشاء وحدة تخزين RAID 5. يتطلّب ثلاثة وحدات تخزين ماديّة على الأقل. raid6: إنشاء وحدة تخزين RAID 6. يتطلّب أربعة وحدات تخزين ماديّة على الأقل. -m: يحدّد عدد نُسخ البيانات الإضافيّة. إن مرّرت القيمة 1 فهذا يعني بأنّ نُسخة واحدة إضافيّة من البيانات ستُصان، بحيث يكون لديك مجموعتان من نفس البيانات. -i: يُحدّد عدد الشّرائط Stripes. هذا الخيار مطلوب للنوع striped، ويُمكن أن يُؤثّر على بعض خيارات RAID الأخرى. -s: يُحدّد بأنّ أخذ لقطة يجب أن يتمّ على مُستوى وحدة التّخزين المنطقيّة الحاليّة عوضا عن إنشاء وحدة تخزين منطقيّة جديدة ومُستقلّة. سنلقي نظرة على بضعة أمثلة لهذه الخيارات لنرى حالات الاستخدام الشّائعة. لإنشاء وحدة تخزين شريطيّة Striped volume، يجب عليك تحديد شريطين على الأقل. هذه العمليّة تحتاج إلى وحدتي تخزين ماديّتين على الأقل مع مساحة تخزين متوافقة مع الحجم المُراد: sudo lvcreate --type striped -i 2 -L 10G -n striped_vol LVMVolGroup لإنشاء مساحة تخزين مُنعكسة Mirrored volume، استخدم النّوع raid1. إن أردت أكثر من مجموعتي بيانات، استعمل الخيار -m. المثال التّالي يستعمل -m 2 لإنشاء ثلاث مجموعات من البيانات (يعتبر LVM بأنّها مجموعة واحدة من البيانات مع انعكاسين). ستحتاج إلى ثلاثة وحدات تخزين ماديّة على الأقل لنجاح العمليّة: sudo lvcreate --type raid1 -m 2 -L 20G -n mirrored_vol LVMVolGroup لإنشاء لقطة لوحدة تخزين ما، يجب عليك تحديد وحدة التّخزين المنطقيّة الأصل التي ستأخذ منها اللقطة وليس كامل مجموعة التّخزين. لا تحجز اللقطات الكثير من المساحة في البدء، لكنّ حجمها يزداد كلّما أُجرِيَت تغييرات على وحدة التّخزين المنطقيّة الأصليّة. عند إنشاء لقطة ما، فالحجم المُخصّص يكون أقصى حدّ يُمكن للقطة أن تصل إليه (اللقطات التي تزيد عن هذا الحجم مُعطّلة وغير قابلة للاستخدام؛ لكن يُمكن توسيع اللقطات التي تقترب من هذا الحجم): sudo lvcreate -s -L 10G -n snap_test LVMVolGroup/test تنبيه: لإعادة وحدة تخزين إلى الحالة التي تتواجد بها اللقطة، استخدم الأمر lvconvert --merge: sudo lvconvert --merge LVMVolGroup/snap_test سيقوم هذا الأمر بإعادة اللقطة إلى الحالة التي كانت عليها عندما تمّ إنشاؤها. كما ترى، هناك العديد من الخيارات التي يُمكن لها أن تُغيّر طريقة عمل وحدة التخزين المنطقيّة بشكل كبير. زيادة حجم وحدة تخزين منطقيّة المرونة في التّعامل مع وحدات التّخزين المنطقيّة من أكثر المميّزات المتوفّرة في LVM. إذ يُمكنك بسهولة تعديل عدد أو حجم وحدات التّخزين المنطقيّة دون إيقاف النّظام. لزيادة حجم وحدة تخزين منطقيّة أنشئت مُسبقا، استعمل الأمر lvresize. مرّر قيمة إلى الخيار -L لتحديد حجم جديد. يُمكنك كذلك استخدام أحجام نسبيّة عبر الرّمز +. في هذه الحالة سيقوم LVM بإضافة الكميّة المُحدّدة إلى الحجم الكلي لوحدة التّخزين. لتعديل حجم نظام الملفّات المُستخدم على وحدة التّخزين بشكل آلي، استعمل الخيار --resizefs. لتحديد اسم صحيح لوحدة التّخزين التي ترغب بتوسيعها، سيتوجّب عليك تحديد مجموعة التّخزين، ثمّ رمز / متبوعا باسم وحدة التّخزين المنطقيّة: sudo lvresize -L +5G --resizefs LVMVolGroup/test في هذا المثال، سيتمّ زيادة 5G لكل من وحدة التّخزين test ونظام الملفّات المُستخدم. إن أردت توسيع نظام الملفّات يدويًّا، يُمكنك حذف الخيار --resizefs واستعمال أداة توسيع نظام الملفّات الخاصّة. مثلا، لو كان نظام الملفّات هو Ext4 فيُمكن أن تكتب: sudo lvresize -L +5G LVMVolGroup/test sudo resize2fs /dev/LVMVolGroup/test سيكون لهذه العمليّة نفس تأثير ما سبق. ترجمة – بتصرّف - للمقال How To Use LVM To Manage Storage Devices on Ubuntu 16.04 لكاتبه Justin Ellingwood. -
.png.7dd969d813ae0c442298b7807e01cb65.png) مُقدّمة LVM اختصار لعبارة Logical Volume Management، عبارة عن تقنيّة لإدارة أجهزة التّخزين تُمكّن المُستخدمين من توحيد وتجريد التّخطيط الماديّ لمكونات أجهزة التّخزين، لإدارتها بسهولة ومرونة. يُمكن استعمال النّسخة الحاليّة LVM2 بالاعتماد على إطار العمل الخاصّ بربط الأجهزة في نواة لينكس لجمع أجهزة التّخزين المُتوفّرة في مجموعات وتخصيص وحدات منطقيّة Logical units من المساحة المُركّبة حسب الطّلب. سنتعرّف في هذا الدليل على كيفية استخدام LVM لإدارة أجهزة التّخزين الخاصّة بك. سنرى كيفيّة عرض معلومات حول وحدات التّخزين وأهداف مُحتملة، كيفيّة إنشاء ومحو مُختلف أنواع وحدات التّخزين، وكيفيّة تعديل وحدات تخزينيّة متواجدة عبر إعادة تخصيص حجم لها وتحويلها. سنعتمد على Ubuntu 16.04 لأمثلة على تنفيذ هذه العمليّات. المُتطلّبات لمُتابعة الدّرس، يجب أن تكون قادرا على الوصول إلى خادوم Ubuntu 16.04. ستحتاج إلى مُستخدم ذي صلاحيّات sudo مع ضبط مُسبق لتمكينه من تنفيذ مهام إداريّة، غير المستخدم الجذر root. لأخذ فكرة حول مكوّنات LVM ومبادئه ولاختبار إعداد بسيط باستخدام LVM، اتّبع درس مدخل إلى LVM قبل الشّروع في هذا الدّرس. إن كنت جاهزا، ادخل إلى خادومك باستخدام حساب المُستخدم ذي صلاحيّات sudo. ملحوظة: يُفضَّل إن كانت هذه أول مرة تتعامل فيها مع LVM أو إن لم تكن متأكّدا من ما تريد فعله أن تختبر الخطوات المعروضة في هذا الدليل في آلة افتراضية أو على خادوم خاصّ بأغراض التجربة والاختبار. قد يؤدّي تنفيذ أوامر بطريقة غير صحيحة إلى ضياع البيانات. عرض معلومات حول وحدات التّخزين الماديّة، مجموعات التّخزين، ووحدات التّخزين المنطقيّة من المُهمّ أن تكون قادرا على الحصول على معلومات حول مُختلف مُكوّنات LVM في نظامك بسهولة. لحسن الحظّ، توفّر حزمة أدوات LVM كميّة وفيرة من الأدوات لعرض معلومات حول كلّ طبقة من طبقات كومة LVM. عرض معلومات حول جميع أجهزة التّخزين الكتليّة المتوافقة مع LVM لعرض جميع أجهزة التّخزين الكتليّة التي يُمكن لـLVM إدارتها، استخدم الأمر lvmdiskscan: sudo lvmdiskscan المُخرَج: /dev/ram0 [ 64.00 MiB] /dev/sda [ 200.00 GiB] /dev/ram1 [ 64.00 MiB] . . . /dev/ram15 [ 64.00 MiB] /dev/sdb [ 100.00 GiB] 2 disks 17 partitions 0 LVM physical volume whole disks 0 LVM physical volumes بتجاهل أجهزة /dev/ram* (التي تُعتبر جزءا من قرص الذاكرة العشوائيّة في لينكس)، يُمكننا مُلاحظة الأجهزة التي يُمكن استخدامها لتشكيل وحدات تخزين ماديّة لـLVM. ستكون هذه الخطوة في الغالب أول خطوة لتحديد أجهزة تخزين لاستعمالها مع LVM. عرض معلومات عن وحدات التّخزين الماديّة تُكتَب ترويسة Header على أجهزة التّخزين لتعليمها على أنها مكوّنات يُمكن لـLVM استخدامها. الأجهزة التي تحمل ترويسة تُسمّى بوحدات التّخزين الماديّة Physical Volumes. يُمكنك عرض جميع أجهزة التّخزين الماديّة على جهازك عبر استخدام الأمر lvmdiskscan مع خيار -l، ما سيُرجع وحدات التّخزين الماديّة فقط في نتيجة تنفيذ الأمر: sudo lvmdiskscan -l المُخرج: WARNING: only considering LVM devices /dev/sda [ 200.00 GiB] LVM physical volume /dev/sdb [ 100.00 GiB] LVM physical volume 2 LVM physical volume whole disks 0 LVM physical volumes الأمر pvscan مُشابه لما سبق، إذ يبحث عن جميع وحدات التّخزين الماديّة الخاصّة بـLVM. إلّا أنّ تنسيق المُخرج مُختلف نوعا ما، إذ يعرض معلومات إضافيّة: sudo pvscan المُخرج: PV /dev/sda VG LVMVolGroup lvm2 [200.00 GiB / 0 free] PV /dev/sdb VG LVMVolGroup lvm2 [100.00 GiB / 10.00 GiB free] Total: 2 [299.99 GiB] / in use: 2 [299.99 GiB] / in no VG: 0 [0 ] إن كنت ترغب بالحصول على المزيد من المعلومات، فاستعمال الأمرين pvs وpvdisplay خيار أفضل. يتميّز الأمر pvs بقابليّة تخصيصه وإمكانيّة استخدامه لعرض المعلومات في عدّة أشكال وتنسيقات مُختلفة. ولأنّ مُخرجات الأمر قابلة للتّخصيص، فاستخدامه شائع في السكريبتات أو عند الحاجة إلى أتمتة الأمور Automation. تُوفّر المُخرجات الأساسيّة للأمر خلاصة مُفيدة مُشابهة لما سبق: sudo pvs المُخرج: PV VG Fmt Attr PSize PFree /dev/sda LVMVolGroup lvm2 a-- 200.00g 0 /dev/sdb LVMVolGroup lvm2 a-- 100.00g 10.00g لمعلومات أكثر إسهابا وقابليّة للقراءة، فالأمر pvdisplay عادة ما يكون خيارا أفضل: sudo pvdisplay المُخرج: --- Physical volume --- PV Name /dev/sda VG Name LVMVolGroup PV Size 200.00 GiB / not usable 4.00 MiB Allocatable yes (but full) PE Size 4.00 MiB Total PE 51199 Free PE 0 Allocated PE 51199 PV UUID kRUOyU-0ib4-ujPh-kAJP-eeQv-ztRL-4EkaDQ --- Physical volume --- PV Name /dev/sdb VG Name LVMVolGroup PV Size 100.00 GiB / not usable 4.00 MiB Allocatable yes PE Size 4.00 MiB Total PE 25599 Free PE 2560 Allocated PE 23039 PV UUID udcuRJ-jCDC-26nD-ro9u-QQNd-D6VL-GEIlD7 كما ترى، فالأمر pvdisplay أسهل أمر للحصول على معلومات مُفصّلة عن وحدات التّخزين الماديّة. لاستكشاف المدااءات المنطقيّة المُرتبطة بكلّ وحدة تخزين، مرّر الخيار -m إلى الأمر pvdisplay: sudo pvdisplay -m المُخرج: --- Physical volume --- PV Name /dev/sda VG Name LVMVolGroup PV Size 200.00 GiB / not usable 4.00 MiB Allocatable yes PE Size 4.00 MiB Total PE 51199 Free PE 38395 Allocated PE 12804 PV UUID kRUOyU-0ib4-ujPh-kAJP-eeQv-ztRL-4EkaDQ --- Physical Segments --- Physical extent 0 to 0: Logical volume /dev/LVMVolGroup/db_rmeta_0 Logical extents 0 to 0 Physical extent 1 to 5120: Logical volume /dev/LVMVolGroup/db_rimage_0 Logical extents 0 to 5119 . . . يُمكن لهذا الأمر أن يكون مُفيدا لك عند الرّغبة في تحديد أي بيانات تتواجد في أي من الأقراص الماديّة لأغراض إداريّة. عرض معلومات عن مجموعات التّخزين Volume Groups يحتوي LVM على العديد من الأدوات التّي يُمكن بها عرض معلومات حول مجموعات التّخزين. يُستعملُ الأمر vgscan لفحص النّظام عن مجموعات التّخزين المتوفّرة. بالإضافة إلى إعادة بناء ملفّ التّخبئة Cache عند الحاجة. ويُعدّ أمرا جيّدا للاستخدام عند استيراد مجموعة تخزين إلى نظام جديد: sudo vgscan المُخرج: Reading all physical volumes. This may take a while... Found volume group "LVMVolGroup" using metadata type lvm2 المُخرج لا يُعطي الكثير من المعلومات، لكن يجب عليه أن يكون قادرا على إيجاد جميع مجموعات التّخزين على النّظام. لعرض المزيد من المعلومات، فالأمران vgs و vgdisplay مُتوفّران لذلك. تماما مثل مثيله المُخصّص لوحدات التّخزين الماديّة، فالأمر vgs مُتعدّد الاستعمالات ويُمكن له أن يعرض كميّة ضخمة من المعلومات في أشكال مُتعدّدة. ولأنّ إمكانيّة تخصيص مُخرجات الأمر عاليّة المرونة، فاستخدامه في برمجة السكريبتات والأتمتة أمر شائع. على سبيل المثال، من الأمور المُفيدة التي يُمكنك فعلها هي تخصيص المُخرج ليعرض فقط الأجهزة الماديّة ومسار وحدات التّخزين المنطقيّة: sudo vgs -o +devices,lv_path المُخرج: VG #PV #LV #SN Attr VSize VFree Devices Path LVMVolGroup 2 4 0 wz--n- 299.99g 10.00g /dev/sda(0) /dev/LVMVolGroup/projects LVMVolGroup 2 4 0 wz--n- 299.99g 10.00g /dev/sda(2560) /dev/LVMVolGroup/www LVMVolGroup 2 4 0 wz--n- 299.99g 10.00g /dev/sda(3840) /dev/LVMVolGroup/db LVMVolGroup 2 4 0 wz--n- 299.99g 10.00g /dev/sda(8960) /dev/LVMVolGroup/workspace LVMVolGroup 2 4 0 wz--n- 299.99g 10.00g /dev/sdb(0) /dev/LVMVolGroup/workspace لمُخرج أكثر إسهابا وقابليّة للقراءة، فالأمر vgdisplay عادة ما يكون خيارا أفضل. إضافة الخيار -v يُوفّر كذلك معلومات حول وحدات التّخزين الماديّة التّي تُشكّل مجموعة التّخزين، بالإضافة إلى وحدات التّخزين المنطقيّة التي تمّ إنشاءها باستخدام مجموعة التّخزين: sudo vgdisplay -v المُخرج: Using volume group(s) on command line. --- Volume group --- VG Name LVMVolGroup . . . --- Logical volume --- LV Path /dev/LVMVolGroup/projects . . . --- Logical volume --- LV Path /dev/LVMVolGroup/www . . . --- Logical volume --- LV Path /dev/LVMVolGroup/db . . . --- Logical volume --- LV Path /dev/LVMVolGroup/workspace . . . --- Physical volumes --- PV Name /dev/sda . . . PV Name /dev/sdb . . . الأمر vgdisplay مُفيد لقُدرته على الرّبط بين المعلومات حول مُختلف عناصر كومة LVM. عرض معلومات حول وحدات التّخزين المنطقيّة يمتلك LVM مجموعة من الأدوات لعرض معلومات عن وحدات التّخزين المنطقيّة كذلك. كما الحال مع مُكوّنات LVM الأخرى، يُمكن استعمال الأمر lvscan لفحص النّظام وعرض معلومات وجيزة حول وحدات التّخزين المنطقيّة التي يجدها: sudo lvscan المُخرج: ACTIVE '/dev/LVMVolGroup/projects' [10.00 GiB] inherit ACTIVE '/dev/LVMVolGroup/www' [5.00 GiB] inherit ACTIVE '/dev/LVMVolGroup/db' [20.00 GiB] inherit ACTIVE '/dev/LVMVolGroup/workspace' [254.99 GiB] inherit لمعلومات أكثر كمالا، يُمكنك استخدام الأمر lvs الذي يتمتّع بمرونة وقوّة بالإضافة إلى سهولة استخدامه في السكربتات: sudo lvs المُخرج: LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert db LVMVolGroup -wi-ao---- 20.00g projects LVMVolGroup -wi-ao---- 10.00g workspace LVMVolGroup -wi-ao---- 254.99g www LVMVolGroup -wi-ao---- 5.00g لإيجاد عدد شرائط Stripes وحدة التّخزين المنطقيّة ونوعها، استعمل الخيار --segments: sudo lvs --segments المُخرج: LV VG Attr #Str Type SSize db LVMVolGroup rwi-a-r--- 2 raid1 20.00g mirrored_vol LVMVolGroup rwi-a-r--- 3 raid1 10.00g test LVMVolGroup rwi-a-r--- 3 raid5 10.00g test2 LVMVolGroup -wi-a----- 2 striped 10.00g test3 LVMVolGroup rwi-a-r--- 2 raid1 10.00g يُمكن الحصول على أكثر مُخرج قابل للقراءة عبر الأمر lvdisplay. عند إضافة الخيار -m، فستعرض الأداة معلومات حول مكوّنات وحدة التّخزين المنطقيّة وكيفيّة توزيعها: sudo lvdisplay -m المُخرج: --- Logical volume --- LV Path /dev/LVMVolGroup/projects LV Name projects VG Name LVMVolGroup LV UUID IN4GZm-ePJU-zAAn-DRO3-1f2w-qSN8-ahisNK LV Write Access read/write LV Creation host, time lvmtest, 2016-09-09 21:00:03 +0000 LV Status available # open 1 LV Size 10.00 GiB Current LE 2560 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 252:0 --- Segments --- Logical extents 0 to 2559: Type linear Physical volume /dev/sda Physical extents 0 to 2559 . . . كما تُلاحظ من الجزء السّفلي للمُخرج أعلاه، فوحدة التّخزين المنطقيّة /dev/LVMVolGroup/projects متواجدة بالكامل على وحدة التّخزين الماديّة /dev/sda في هذا المثال. هذه المعلومة مُفيدة إن كنت ترغب بإزالة جهاز التّخزين المُعتمد عليه وتريد نقل البيانات إلى مكان مُحدّد. رأينا في هذا الجزء من الدليل كيفية عرض معلومات عن مختلف المكوّنات في LVM. سنكمل في الأجزاء التالية بقيّة المهام الإدارية. ترجمة – بتصرّف - للمقال How To Use LVM To Manage Storage Devices on Ubuntu 16.04 لكاتبه Justin Ellingwood.
مُقدّمة LVM اختصار لعبارة Logical Volume Management، عبارة عن تقنيّة لإدارة أجهزة التّخزين تُمكّن المُستخدمين من توحيد وتجريد التّخطيط الماديّ لمكونات أجهزة التّخزين، لإدارتها بسهولة ومرونة. يُمكن استعمال النّسخة الحاليّة LVM2 بالاعتماد على إطار العمل الخاصّ بربط الأجهزة في نواة لينكس لجمع أجهزة التّخزين المُتوفّرة في مجموعات وتخصيص وحدات منطقيّة Logical units من المساحة المُركّبة حسب الطّلب. سنتعرّف في هذا الدليل على كيفية استخدام LVM لإدارة أجهزة التّخزين الخاصّة بك. سنرى كيفيّة عرض معلومات حول وحدات التّخزين وأهداف مُحتملة، كيفيّة إنشاء ومحو مُختلف أنواع وحدات التّخزين، وكيفيّة تعديل وحدات تخزينيّة متواجدة عبر إعادة تخصيص حجم لها وتحويلها. سنعتمد على Ubuntu 16.04 لأمثلة على تنفيذ هذه العمليّات. المُتطلّبات لمُتابعة الدّرس، يجب أن تكون قادرا على الوصول إلى خادوم Ubuntu 16.04. ستحتاج إلى مُستخدم ذي صلاحيّات sudo مع ضبط مُسبق لتمكينه من تنفيذ مهام إداريّة، غير المستخدم الجذر root. لأخذ فكرة حول مكوّنات LVM ومبادئه ولاختبار إعداد بسيط باستخدام LVM، اتّبع درس مدخل إلى LVM قبل الشّروع في هذا الدّرس. إن كنت جاهزا، ادخل إلى خادومك باستخدام حساب المُستخدم ذي صلاحيّات sudo. ملحوظة: يُفضَّل إن كانت هذه أول مرة تتعامل فيها مع LVM أو إن لم تكن متأكّدا من ما تريد فعله أن تختبر الخطوات المعروضة في هذا الدليل في آلة افتراضية أو على خادوم خاصّ بأغراض التجربة والاختبار. قد يؤدّي تنفيذ أوامر بطريقة غير صحيحة إلى ضياع البيانات. عرض معلومات حول وحدات التّخزين الماديّة، مجموعات التّخزين، ووحدات التّخزين المنطقيّة من المُهمّ أن تكون قادرا على الحصول على معلومات حول مُختلف مُكوّنات LVM في نظامك بسهولة. لحسن الحظّ، توفّر حزمة أدوات LVM كميّة وفيرة من الأدوات لعرض معلومات حول كلّ طبقة من طبقات كومة LVM. عرض معلومات حول جميع أجهزة التّخزين الكتليّة المتوافقة مع LVM لعرض جميع أجهزة التّخزين الكتليّة التي يُمكن لـLVM إدارتها، استخدم الأمر lvmdiskscan: sudo lvmdiskscan المُخرَج: /dev/ram0 [ 64.00 MiB] /dev/sda [ 200.00 GiB] /dev/ram1 [ 64.00 MiB] . . . /dev/ram15 [ 64.00 MiB] /dev/sdb [ 100.00 GiB] 2 disks 17 partitions 0 LVM physical volume whole disks 0 LVM physical volumes بتجاهل أجهزة /dev/ram* (التي تُعتبر جزءا من قرص الذاكرة العشوائيّة في لينكس)، يُمكننا مُلاحظة الأجهزة التي يُمكن استخدامها لتشكيل وحدات تخزين ماديّة لـLVM. ستكون هذه الخطوة في الغالب أول خطوة لتحديد أجهزة تخزين لاستعمالها مع LVM. عرض معلومات عن وحدات التّخزين الماديّة تُكتَب ترويسة Header على أجهزة التّخزين لتعليمها على أنها مكوّنات يُمكن لـLVM استخدامها. الأجهزة التي تحمل ترويسة تُسمّى بوحدات التّخزين الماديّة Physical Volumes. يُمكنك عرض جميع أجهزة التّخزين الماديّة على جهازك عبر استخدام الأمر lvmdiskscan مع خيار -l، ما سيُرجع وحدات التّخزين الماديّة فقط في نتيجة تنفيذ الأمر: sudo lvmdiskscan -l المُخرج: WARNING: only considering LVM devices /dev/sda [ 200.00 GiB] LVM physical volume /dev/sdb [ 100.00 GiB] LVM physical volume 2 LVM physical volume whole disks 0 LVM physical volumes الأمر pvscan مُشابه لما سبق، إذ يبحث عن جميع وحدات التّخزين الماديّة الخاصّة بـLVM. إلّا أنّ تنسيق المُخرج مُختلف نوعا ما، إذ يعرض معلومات إضافيّة: sudo pvscan المُخرج: PV /dev/sda VG LVMVolGroup lvm2 [200.00 GiB / 0 free] PV /dev/sdb VG LVMVolGroup lvm2 [100.00 GiB / 10.00 GiB free] Total: 2 [299.99 GiB] / in use: 2 [299.99 GiB] / in no VG: 0 [0 ] إن كنت ترغب بالحصول على المزيد من المعلومات، فاستعمال الأمرين pvs وpvdisplay خيار أفضل. يتميّز الأمر pvs بقابليّة تخصيصه وإمكانيّة استخدامه لعرض المعلومات في عدّة أشكال وتنسيقات مُختلفة. ولأنّ مُخرجات الأمر قابلة للتّخصيص، فاستخدامه شائع في السكريبتات أو عند الحاجة إلى أتمتة الأمور Automation. تُوفّر المُخرجات الأساسيّة للأمر خلاصة مُفيدة مُشابهة لما سبق: sudo pvs المُخرج: PV VG Fmt Attr PSize PFree /dev/sda LVMVolGroup lvm2 a-- 200.00g 0 /dev/sdb LVMVolGroup lvm2 a-- 100.00g 10.00g لمعلومات أكثر إسهابا وقابليّة للقراءة، فالأمر pvdisplay عادة ما يكون خيارا أفضل: sudo pvdisplay المُخرج: --- Physical volume --- PV Name /dev/sda VG Name LVMVolGroup PV Size 200.00 GiB / not usable 4.00 MiB Allocatable yes (but full) PE Size 4.00 MiB Total PE 51199 Free PE 0 Allocated PE 51199 PV UUID kRUOyU-0ib4-ujPh-kAJP-eeQv-ztRL-4EkaDQ --- Physical volume --- PV Name /dev/sdb VG Name LVMVolGroup PV Size 100.00 GiB / not usable 4.00 MiB Allocatable yes PE Size 4.00 MiB Total PE 25599 Free PE 2560 Allocated PE 23039 PV UUID udcuRJ-jCDC-26nD-ro9u-QQNd-D6VL-GEIlD7 كما ترى، فالأمر pvdisplay أسهل أمر للحصول على معلومات مُفصّلة عن وحدات التّخزين الماديّة. لاستكشاف المدااءات المنطقيّة المُرتبطة بكلّ وحدة تخزين، مرّر الخيار -m إلى الأمر pvdisplay: sudo pvdisplay -m المُخرج: --- Physical volume --- PV Name /dev/sda VG Name LVMVolGroup PV Size 200.00 GiB / not usable 4.00 MiB Allocatable yes PE Size 4.00 MiB Total PE 51199 Free PE 38395 Allocated PE 12804 PV UUID kRUOyU-0ib4-ujPh-kAJP-eeQv-ztRL-4EkaDQ --- Physical Segments --- Physical extent 0 to 0: Logical volume /dev/LVMVolGroup/db_rmeta_0 Logical extents 0 to 0 Physical extent 1 to 5120: Logical volume /dev/LVMVolGroup/db_rimage_0 Logical extents 0 to 5119 . . . يُمكن لهذا الأمر أن يكون مُفيدا لك عند الرّغبة في تحديد أي بيانات تتواجد في أي من الأقراص الماديّة لأغراض إداريّة. عرض معلومات عن مجموعات التّخزين Volume Groups يحتوي LVM على العديد من الأدوات التّي يُمكن بها عرض معلومات حول مجموعات التّخزين. يُستعملُ الأمر vgscan لفحص النّظام عن مجموعات التّخزين المتوفّرة. بالإضافة إلى إعادة بناء ملفّ التّخبئة Cache عند الحاجة. ويُعدّ أمرا جيّدا للاستخدام عند استيراد مجموعة تخزين إلى نظام جديد: sudo vgscan المُخرج: Reading all physical volumes. This may take a while... Found volume group "LVMVolGroup" using metadata type lvm2 المُخرج لا يُعطي الكثير من المعلومات، لكن يجب عليه أن يكون قادرا على إيجاد جميع مجموعات التّخزين على النّظام. لعرض المزيد من المعلومات، فالأمران vgs و vgdisplay مُتوفّران لذلك. تماما مثل مثيله المُخصّص لوحدات التّخزين الماديّة، فالأمر vgs مُتعدّد الاستعمالات ويُمكن له أن يعرض كميّة ضخمة من المعلومات في أشكال مُتعدّدة. ولأنّ إمكانيّة تخصيص مُخرجات الأمر عاليّة المرونة، فاستخدامه في برمجة السكريبتات والأتمتة أمر شائع. على سبيل المثال، من الأمور المُفيدة التي يُمكنك فعلها هي تخصيص المُخرج ليعرض فقط الأجهزة الماديّة ومسار وحدات التّخزين المنطقيّة: sudo vgs -o +devices,lv_path المُخرج: VG #PV #LV #SN Attr VSize VFree Devices Path LVMVolGroup 2 4 0 wz--n- 299.99g 10.00g /dev/sda(0) /dev/LVMVolGroup/projects LVMVolGroup 2 4 0 wz--n- 299.99g 10.00g /dev/sda(2560) /dev/LVMVolGroup/www LVMVolGroup 2 4 0 wz--n- 299.99g 10.00g /dev/sda(3840) /dev/LVMVolGroup/db LVMVolGroup 2 4 0 wz--n- 299.99g 10.00g /dev/sda(8960) /dev/LVMVolGroup/workspace LVMVolGroup 2 4 0 wz--n- 299.99g 10.00g /dev/sdb(0) /dev/LVMVolGroup/workspace لمُخرج أكثر إسهابا وقابليّة للقراءة، فالأمر vgdisplay عادة ما يكون خيارا أفضل. إضافة الخيار -v يُوفّر كذلك معلومات حول وحدات التّخزين الماديّة التّي تُشكّل مجموعة التّخزين، بالإضافة إلى وحدات التّخزين المنطقيّة التي تمّ إنشاءها باستخدام مجموعة التّخزين: sudo vgdisplay -v المُخرج: Using volume group(s) on command line. --- Volume group --- VG Name LVMVolGroup . . . --- Logical volume --- LV Path /dev/LVMVolGroup/projects . . . --- Logical volume --- LV Path /dev/LVMVolGroup/www . . . --- Logical volume --- LV Path /dev/LVMVolGroup/db . . . --- Logical volume --- LV Path /dev/LVMVolGroup/workspace . . . --- Physical volumes --- PV Name /dev/sda . . . PV Name /dev/sdb . . . الأمر vgdisplay مُفيد لقُدرته على الرّبط بين المعلومات حول مُختلف عناصر كومة LVM. عرض معلومات حول وحدات التّخزين المنطقيّة يمتلك LVM مجموعة من الأدوات لعرض معلومات عن وحدات التّخزين المنطقيّة كذلك. كما الحال مع مُكوّنات LVM الأخرى، يُمكن استعمال الأمر lvscan لفحص النّظام وعرض معلومات وجيزة حول وحدات التّخزين المنطقيّة التي يجدها: sudo lvscan المُخرج: ACTIVE '/dev/LVMVolGroup/projects' [10.00 GiB] inherit ACTIVE '/dev/LVMVolGroup/www' [5.00 GiB] inherit ACTIVE '/dev/LVMVolGroup/db' [20.00 GiB] inherit ACTIVE '/dev/LVMVolGroup/workspace' [254.99 GiB] inherit لمعلومات أكثر كمالا، يُمكنك استخدام الأمر lvs الذي يتمتّع بمرونة وقوّة بالإضافة إلى سهولة استخدامه في السكربتات: sudo lvs المُخرج: LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert db LVMVolGroup -wi-ao---- 20.00g projects LVMVolGroup -wi-ao---- 10.00g workspace LVMVolGroup -wi-ao---- 254.99g www LVMVolGroup -wi-ao---- 5.00g لإيجاد عدد شرائط Stripes وحدة التّخزين المنطقيّة ونوعها، استعمل الخيار --segments: sudo lvs --segments المُخرج: LV VG Attr #Str Type SSize db LVMVolGroup rwi-a-r--- 2 raid1 20.00g mirrored_vol LVMVolGroup rwi-a-r--- 3 raid1 10.00g test LVMVolGroup rwi-a-r--- 3 raid5 10.00g test2 LVMVolGroup -wi-a----- 2 striped 10.00g test3 LVMVolGroup rwi-a-r--- 2 raid1 10.00g يُمكن الحصول على أكثر مُخرج قابل للقراءة عبر الأمر lvdisplay. عند إضافة الخيار -m، فستعرض الأداة معلومات حول مكوّنات وحدة التّخزين المنطقيّة وكيفيّة توزيعها: sudo lvdisplay -m المُخرج: --- Logical volume --- LV Path /dev/LVMVolGroup/projects LV Name projects VG Name LVMVolGroup LV UUID IN4GZm-ePJU-zAAn-DRO3-1f2w-qSN8-ahisNK LV Write Access read/write LV Creation host, time lvmtest, 2016-09-09 21:00:03 +0000 LV Status available # open 1 LV Size 10.00 GiB Current LE 2560 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 252:0 --- Segments --- Logical extents 0 to 2559: Type linear Physical volume /dev/sda Physical extents 0 to 2559 . . . كما تُلاحظ من الجزء السّفلي للمُخرج أعلاه، فوحدة التّخزين المنطقيّة /dev/LVMVolGroup/projects متواجدة بالكامل على وحدة التّخزين الماديّة /dev/sda في هذا المثال. هذه المعلومة مُفيدة إن كنت ترغب بإزالة جهاز التّخزين المُعتمد عليه وتريد نقل البيانات إلى مكان مُحدّد. رأينا في هذا الجزء من الدليل كيفية عرض معلومات عن مختلف المكوّنات في LVM. سنكمل في الأجزاء التالية بقيّة المهام الإدارية. ترجمة – بتصرّف - للمقال How To Use LVM To Manage Storage Devices on Ubuntu 16.04 لكاتبه Justin Ellingwood. -
 يتناول هذا المقال تثبيت بيئة تطوير Ruby on Rails على الإصدار 16.04 من أوبونتو. في أغلب الأحوال ستُنفَّذ الشفرة البرمجيّة التي تكتبها على خادوم لينكس، وأوبونتو هي إحدى توزيعات لينكس الأسهل استخداما وتوجد الكثير من الموارد عنها على الشبكة. تثبيت Ruby أول ما يجب علينا فعله هو تثبيت الاعتماديات Dependencies التي يحتاجها Ruby للعمل. نبدأ أولا بتحديث فهرس الحزم ثم تثبيت الاعتماديّات: sudo apt update sudo apt install git-core curl zlib1g-dev build-essential libssl-dev libreadline-dev libyaml-dev libsqlite3-dev sqlite3 libxml2-dev libxslt1-dev libcurl4-openssl-dev python-software-properties libffi-dev nodejs الخطوة الموالية هي تثبيت Ruby. توجد طرق عدّة للتثبيت، سنستخدم rbenv وهي أداة خفيفة وسريعة لإدارة إصدارات Ruby. نبدأ بتثبيت rbenv : cd git clone https://github.com/rbenv/rbenv.git ~/.rbenv echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bashrc echo 'eval "$(rbenv init -)"' >> ~/.bashrc exec $SHELL الأداة rbenv جاهزة الآن. سنثبّت ruby-build وهي إضافة تعمل مع الأداة rbenv وتتيح تثبيت إصدارات عدّة من Ruby في مجلّدات مختلفة على نفس النظام. git clone https://github.com/rbenv/ruby-build.git ~/.rbenv/plugins/ruby-build echo 'export PATH="$HOME/.rbenv/plugins/ruby-build/bin:$PATH"' >> ~/.bashrc exec $SHELL ثم نثبّت الإصدار 2.4.0 من Ruby: TMPDIR=~/tmp/ rbenv install 2.4.0 rbenv global 2.4.0 يُثبّت الأمر الأول الإصدار المطلوب ضمن مجلّد العمل حيث نُفِّذ الأمر؛ في ما يضبط الأمر الثاني إصدار Ruby المبدئي، أي الإصدار الذي سيُستخدَم عند عدم تحديد إصدار. للتأكد من تثبيت Ruby والإصدار المثبّت ننفذ الأمر: ruby -v الذي يُظهر نتيجة تشبه التالي: ruby 2.4.0p0 (2016-12-24 revision 57164) [x86_64-linux] الخطوة الأخيرة هي تثبيت Bundler الذي يوفّر بيئة تطوير متجانسة لـ Ruby عبر تتبّع الاعتماديات وتثبيت الإصدارات المطلوبة منها بالضبط: gem install bundler وتنفيذ الأمر لأخذ التثبيت الجديد في الحسبان: rbenv rehash تثبيت Rails يتضمّن إطار العمل Rails الكثير من الاعتماديات، لذا سنحتاج لبيئة تنفيذ JavaScript مثل NodeJS التي ستمكّننا من استخدام مكتبات تتيح إمكانيّة جمع وضغط ملفات جافاسكريبت من أجل الحصول على بيئة تطوير أسرع. نثبّت NodeJS من المستودع الرسمي على النحو التالي: curl -sL https://deb.nodesource.com/setup_4.x | sudo -E bash - sudo apt install -y nodejs ثم نثبّت Rails: gem install rails -v 5.0.1 ثم ننفذ الأمر التالي ليمكننا استخدام Rails: rbenv rehash Rails مثبّت الآن، يمكننا التأكّد من ذلك بتنفيذ الأمر التالي الذي يُظهر رقم الإصدار المثبت: rails -v إعداد قاعدة بيانات MySQL يأتي Rails مبدئيا بقاعدة بيانات sqlite3؛ إلا أن هذا النوع من قواعد البيانات لا يناسب تطبيقات كثيرة. يمكن في هذه الحالة إعداد Rails للعمل مع قاعدة بيانات MySQL (أو PostgreSQL). نثبّت خادوم وعميل MySQL من المستودعات الرسمية لأوبونتو: sudo apt install mysql-server mysql-client libmysqlclient-dev سيُطلَب منك خلال التثبيت إنشاءُ كلمة سر خاصة بالحساب الإداري root (انتبِه إلى أنّه حساب خاص بنظام MySQL لإدارة قواعد البيانات، وليس لنظام التشغيل أوبونتو). تتضمّن الحزمة libmysqlclient-dev الملفات الضرورية لتثبيت الاعتماديّات التي يحتاجها Rails للاتصال بقاعدة بيانات MySQL. ننفّذ بعد تثبيت MySQL الأمريْن التاليّيْن لتحضير قاعدة البيانات لبيئة الإنتاج (يمكنك تجاوز هذه الخطوة إن كنت تثبّت Rails على حاسوب شخصي): sudo mysql_install_db sudo mysql_secure_installation سيُطلب منك النّظام إدخال كلمة سرّ الحساب الجذر في MySQL؛ ثمّ يسألك ما إذا كنتَ تُريد تغييرها. أدخل حرف n (دلالةً على “no” أي “لا”) إن لم تكن ترغبُ في ذلك. بالنسبة لبقية الأسئلة يمكنك قبول القيم المبدئية بالنقر على زرّ Enter. أول تطبيق Rails حان الوقت الآن لتشغيل أول تطبيق Ruby on Rails. ننشئ تطبيقا باسم myapp يستخدم قاعدة البيانات MySQL: rails new myapp -d mysql انتظر اكتمال إنشاء التطبيق الذي قد يستغرق وقتا، ثم انتقل إلى مجلد التطبيق: cd myapp عدّل الملف config/database.yml بإضافة كلمة سر الحساب الإداري لقاعدة البيانات (أعددناها أثناء تثبيت MySQL، يمكنك تركها فارغة إن لم تكن أعددتَ كلمة سر لـ MySQL): default: &default adapter: mysql2 encoding: utf8 pool: 5 username: root password: socket: /var/run/mysqld/mysqld.sock اكتب كلمة السر أمام التعليمة password ضمن المقطع السابق الموجود أعلى الملف بعد التعليقات الأولى (تبدأ التعليقات بالعلامة #)؛ ثم نفّذ الأمر التالي لإنشاء قاعدة البيانات التي سيعمل عليها التطبيق: rake db:create النتيجة: Created database 'myapp_development' Created database 'myapp_test' إن واجهك خطأ Access denied for user 'root'@'localhost' (using password: NO) فهذا يعني أنك لم تكتب كلمة السر بطريقة صحيحة. نشغل خادوم التطوير: rails server يمكنك بعد تشغيل خادوم التطوير إدخال العنوان http://localhost:3000/ في المتصفح لمعاينة صفحة التطبيق المبدئي في Rails. إعداد Git هذه الخطوة اختيارية ولكنه تفيدك إن كنت تخطّط لاستعمال Git لإدارة إصدارات المشروع وربطه بحسابك على Github. أبدل YOUR NAME وYOUR@EMAIL.com في الأوامر أدناه على التوالي باسمك والبريد الذي استخدمته للتسجيل على Github. git config --global color.ui true git config --global user.name "YOUR NAME" git config --global user.email "YOUR@EMAIL.com" ssh-keygen -t rsa -b 4096 -C "YOUR@EMAIL.com" يُولّد الأمر الأخير في الأوامر أعلاه زوج مفاتيح SSH سنستخدمها في ما بعد للاتصال بحسابنا على Github. يضع الأمر ssh-keygen مبدئيا زوج المفاتيح على المسار ssh./~. نأخذ المفتاح العمومي الذي يوجد بملف المفتاح ذي الامتداد pub، ويُسمّى مبدئيا id_rsa.pub وننسخه ضمن مفاتيح SSH على حسابنا في Github الموجودة هنا. انقر على الزّر New SSH Key، أعط للمفتاح اسما تختاره ثم ألصق في الحقل الثاني محتوى الملف ssh/id_rsa.pub/~ الذي يمكن الحصول عليه بالأمر التالي، ثم انقر على زرّ Add SSH Key لاعتماد المفتاح: cat ~/.ssh/id_rsa.pub يمكنك التأكد من نجاح العملية بتنفيذ الأمر التالي: ssh -T git@github.com يجب أن تظهر لك رسالة تشبه التالي (يُذكَر فيها اسم حسابك على Github): Hi Zeine77! You've successfully authenticated, but GitHub does not provide shell access. ترجمة - بتصرّف - للمقال Setup Ruby On Rails on Ubuntu 16.04 Xenial Xerus.
يتناول هذا المقال تثبيت بيئة تطوير Ruby on Rails على الإصدار 16.04 من أوبونتو. في أغلب الأحوال ستُنفَّذ الشفرة البرمجيّة التي تكتبها على خادوم لينكس، وأوبونتو هي إحدى توزيعات لينكس الأسهل استخداما وتوجد الكثير من الموارد عنها على الشبكة. تثبيت Ruby أول ما يجب علينا فعله هو تثبيت الاعتماديات Dependencies التي يحتاجها Ruby للعمل. نبدأ أولا بتحديث فهرس الحزم ثم تثبيت الاعتماديّات: sudo apt update sudo apt install git-core curl zlib1g-dev build-essential libssl-dev libreadline-dev libyaml-dev libsqlite3-dev sqlite3 libxml2-dev libxslt1-dev libcurl4-openssl-dev python-software-properties libffi-dev nodejs الخطوة الموالية هي تثبيت Ruby. توجد طرق عدّة للتثبيت، سنستخدم rbenv وهي أداة خفيفة وسريعة لإدارة إصدارات Ruby. نبدأ بتثبيت rbenv : cd git clone https://github.com/rbenv/rbenv.git ~/.rbenv echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bashrc echo 'eval "$(rbenv init -)"' >> ~/.bashrc exec $SHELL الأداة rbenv جاهزة الآن. سنثبّت ruby-build وهي إضافة تعمل مع الأداة rbenv وتتيح تثبيت إصدارات عدّة من Ruby في مجلّدات مختلفة على نفس النظام. git clone https://github.com/rbenv/ruby-build.git ~/.rbenv/plugins/ruby-build echo 'export PATH="$HOME/.rbenv/plugins/ruby-build/bin:$PATH"' >> ~/.bashrc exec $SHELL ثم نثبّت الإصدار 2.4.0 من Ruby: TMPDIR=~/tmp/ rbenv install 2.4.0 rbenv global 2.4.0 يُثبّت الأمر الأول الإصدار المطلوب ضمن مجلّد العمل حيث نُفِّذ الأمر؛ في ما يضبط الأمر الثاني إصدار Ruby المبدئي، أي الإصدار الذي سيُستخدَم عند عدم تحديد إصدار. للتأكد من تثبيت Ruby والإصدار المثبّت ننفذ الأمر: ruby -v الذي يُظهر نتيجة تشبه التالي: ruby 2.4.0p0 (2016-12-24 revision 57164) [x86_64-linux] الخطوة الأخيرة هي تثبيت Bundler الذي يوفّر بيئة تطوير متجانسة لـ Ruby عبر تتبّع الاعتماديات وتثبيت الإصدارات المطلوبة منها بالضبط: gem install bundler وتنفيذ الأمر لأخذ التثبيت الجديد في الحسبان: rbenv rehash تثبيت Rails يتضمّن إطار العمل Rails الكثير من الاعتماديات، لذا سنحتاج لبيئة تنفيذ JavaScript مثل NodeJS التي ستمكّننا من استخدام مكتبات تتيح إمكانيّة جمع وضغط ملفات جافاسكريبت من أجل الحصول على بيئة تطوير أسرع. نثبّت NodeJS من المستودع الرسمي على النحو التالي: curl -sL https://deb.nodesource.com/setup_4.x | sudo -E bash - sudo apt install -y nodejs ثم نثبّت Rails: gem install rails -v 5.0.1 ثم ننفذ الأمر التالي ليمكننا استخدام Rails: rbenv rehash Rails مثبّت الآن، يمكننا التأكّد من ذلك بتنفيذ الأمر التالي الذي يُظهر رقم الإصدار المثبت: rails -v إعداد قاعدة بيانات MySQL يأتي Rails مبدئيا بقاعدة بيانات sqlite3؛ إلا أن هذا النوع من قواعد البيانات لا يناسب تطبيقات كثيرة. يمكن في هذه الحالة إعداد Rails للعمل مع قاعدة بيانات MySQL (أو PostgreSQL). نثبّت خادوم وعميل MySQL من المستودعات الرسمية لأوبونتو: sudo apt install mysql-server mysql-client libmysqlclient-dev سيُطلَب منك خلال التثبيت إنشاءُ كلمة سر خاصة بالحساب الإداري root (انتبِه إلى أنّه حساب خاص بنظام MySQL لإدارة قواعد البيانات، وليس لنظام التشغيل أوبونتو). تتضمّن الحزمة libmysqlclient-dev الملفات الضرورية لتثبيت الاعتماديّات التي يحتاجها Rails للاتصال بقاعدة بيانات MySQL. ننفّذ بعد تثبيت MySQL الأمريْن التاليّيْن لتحضير قاعدة البيانات لبيئة الإنتاج (يمكنك تجاوز هذه الخطوة إن كنت تثبّت Rails على حاسوب شخصي): sudo mysql_install_db sudo mysql_secure_installation سيُطلب منك النّظام إدخال كلمة سرّ الحساب الجذر في MySQL؛ ثمّ يسألك ما إذا كنتَ تُريد تغييرها. أدخل حرف n (دلالةً على “no” أي “لا”) إن لم تكن ترغبُ في ذلك. بالنسبة لبقية الأسئلة يمكنك قبول القيم المبدئية بالنقر على زرّ Enter. أول تطبيق Rails حان الوقت الآن لتشغيل أول تطبيق Ruby on Rails. ننشئ تطبيقا باسم myapp يستخدم قاعدة البيانات MySQL: rails new myapp -d mysql انتظر اكتمال إنشاء التطبيق الذي قد يستغرق وقتا، ثم انتقل إلى مجلد التطبيق: cd myapp عدّل الملف config/database.yml بإضافة كلمة سر الحساب الإداري لقاعدة البيانات (أعددناها أثناء تثبيت MySQL، يمكنك تركها فارغة إن لم تكن أعددتَ كلمة سر لـ MySQL): default: &default adapter: mysql2 encoding: utf8 pool: 5 username: root password: socket: /var/run/mysqld/mysqld.sock اكتب كلمة السر أمام التعليمة password ضمن المقطع السابق الموجود أعلى الملف بعد التعليقات الأولى (تبدأ التعليقات بالعلامة #)؛ ثم نفّذ الأمر التالي لإنشاء قاعدة البيانات التي سيعمل عليها التطبيق: rake db:create النتيجة: Created database 'myapp_development' Created database 'myapp_test' إن واجهك خطأ Access denied for user 'root'@'localhost' (using password: NO) فهذا يعني أنك لم تكتب كلمة السر بطريقة صحيحة. نشغل خادوم التطوير: rails server يمكنك بعد تشغيل خادوم التطوير إدخال العنوان http://localhost:3000/ في المتصفح لمعاينة صفحة التطبيق المبدئي في Rails. إعداد Git هذه الخطوة اختيارية ولكنه تفيدك إن كنت تخطّط لاستعمال Git لإدارة إصدارات المشروع وربطه بحسابك على Github. أبدل YOUR NAME وYOUR@EMAIL.com في الأوامر أدناه على التوالي باسمك والبريد الذي استخدمته للتسجيل على Github. git config --global color.ui true git config --global user.name "YOUR NAME" git config --global user.email "YOUR@EMAIL.com" ssh-keygen -t rsa -b 4096 -C "YOUR@EMAIL.com" يُولّد الأمر الأخير في الأوامر أعلاه زوج مفاتيح SSH سنستخدمها في ما بعد للاتصال بحسابنا على Github. يضع الأمر ssh-keygen مبدئيا زوج المفاتيح على المسار ssh./~. نأخذ المفتاح العمومي الذي يوجد بملف المفتاح ذي الامتداد pub، ويُسمّى مبدئيا id_rsa.pub وننسخه ضمن مفاتيح SSH على حسابنا في Github الموجودة هنا. انقر على الزّر New SSH Key، أعط للمفتاح اسما تختاره ثم ألصق في الحقل الثاني محتوى الملف ssh/id_rsa.pub/~ الذي يمكن الحصول عليه بالأمر التالي، ثم انقر على زرّ Add SSH Key لاعتماد المفتاح: cat ~/.ssh/id_rsa.pub يمكنك التأكد من نجاح العملية بتنفيذ الأمر التالي: ssh -T git@github.com يجب أن تظهر لك رسالة تشبه التالي (يُذكَر فيها اسم حسابك على Github): Hi Zeine77! You've successfully authenticated, but GitHub does not provide shell access. ترجمة - بتصرّف - للمقال Setup Ruby On Rails on Ubuntu 16.04 Xenial Xerus. -
 سنتعلّم في هذا الدّرس كيفيّة استخدام HAProxy (والذي يرمز إلى الوسيط عالي التوفّر High Availability Proxy) كمُوازِن حمل عن طريق الطبقة السّابعة layer 7 load balancer من أجل تخديم تطبيقات متعدّدة من اسم مجال واحد Single Domain أو عنوان IP، بإمكان موازنة الحمل أن تزيد أداء، توفّر، ومرونة بيئتنا. تكون موازنة الحمل والوسيط العكسي للطبقة 7 ملائمة لموقعك إن أردت أن تملك اسم نطاق واحد يقوم بتخديم تطبيقات متعدّدة، حيث يمكن تحليل طلبات http لتقرّر أي تطبيق ينبغي عليه أن يستقبل حركة مرور البيانات. تمّت كتابة هذا الدّرس باستخدام ووردبريس وموقع ثابت Static website كأمثلة، ولكن يمكن استخدام مفاهيمه العامّة مع تطبيقات أخرى للحصول على تأثير مماثل. المتطلبات الأساسية قبل متابعة هذا الدّرس ينبغي عليك أن تملك تطبيقين على الأقل يعملان على خادومين منفصلين، سنستخدم موقعًا ثابتًا مستضافًا على Nginx و ووردبريس كتطبيقين لدينا، وبالإضافة للبيئة الحاليّة لديك سنقوم بإنشاء الخواديم التالية: haproxy-www: وهو خادوم HAProxy لأجل موازنة الحمل والوسيط العكسي wordpress-2: وهو خادوم الويب الثاني لووردبريس (تحتاجه فقط إن أردت موازنة حمل مكونات ووردبريس في بيئتك) web-2: خادوم ويب Nginx الثاني (تحتاجه فقط إن أردت موازنة حمل مكونات Nginx في بيئتك) إن لم يسبق لك التّعامل مع المفاهيم أو المصطلحات الأساسيّة لموازنة الحمل، مثل موازنة الحمل عن طريق الطبقة 7 أو الواجهات الخلفيّة backends أو قوائم تحكّم الوصول ACLs فهذا هو الدّرس الذي يشرح الأساسيّات: مقدّمة إلى HAProxy ومبادئ موازنة الحمل (Load Balancing). هدفنا بنهاية هذا الدّرس نريد أن نحصل على بيئة تبدو كما يلي: أي سيقوم المستخدمون لديك بالنفاذ لكلا تطبيقيك عبر http://example.com، وسيتم تمرير كل الطلبات التي تبدأ بـ http://example.com/wordpress إلى خواديم ووردبريس، ويتم تمرير جميع باقي الطلبات إلى خواديم Nginx الأساسيّة، لاحظ أنّه لا تحتاج بالضرورة لموازنة حمل تطبيقاتك حتى تظهر على مجال واحد، ولكن سنقوم بتغطية موازنة الحمل في هذا الدّرس. تثبيت HAProxy نقوم بإنشاء خادوم جديد مع الشّبكات الخاصّة، سنسمّيه في هذا الدّرس haproxy-www. نقوم بتثبيت HAProxy على الخادوم haproxy-www باستخدام apt-get: sudo apt-get update sudo apt-get install haproxy نحتاج لتمكين سكريبت التهيئة init script لـ HAProxy كي يبدأ ويتوقف HAProxy مع الخادوم لدينا: sudo vi /etc/default/haproxy نغيّر قيمة ENABLED إلى 1 لتمكين سكريبت التهيئة لـ HAProxy: ENABLED=1 نقوم بالحفظ والخروج، سيبدأ ويتوقف HAProxy الآن مع خادومنا، نستطيع أيضًا الآن استخدام الأمر service للتحكّم بـ HAProxy، فلنتحقّق من أنّه قيد التشغيل: user@haproxy-www:/etc/init.d$ sudo service haproxy status haproxy not running. نجد أنّه لا يعمل، لا مشكلة لأنّه يحتاج إلى إعداده قبل أن نتمكّن من استخدامه، فلنقم الآن بإعداد HAProxy لأجل بيئتنا. إعداد HAProxy يكون ملف إعدادات HAProxy مُقسّمًا إلى قسمين رئيسيين: العمومي Global: يقوم بتعيين المُعامِلات parameters على نطاق العمليّة الوسطاء Proxies: يتكون من المُعامِلات الافتراضيّة defaults، الاستماع listen، الواجهة الأماميّة frontend، والواجهة الخلفيّة backend. مرّة أخرى إن لم يسبق لك أن سمعت عن مفاهيم أو المصطلحات الأساسيّة لموازنة الحمل، فقم بالرجوع إلى هذا الدّرس: مقدّمة إلى HAProxy ومبادئ موازنة الحمل (Load Balancing). إعداد HAProxy: العمومي يجب أن يتم ضبط إعدادات HAProxy على الخادوم haproxy-www. في البداية لنقم بعمل نسخة من الملف haproxy.cfg الافتراضي: cd /etc/haproxy; sudo cp haproxy.cfg haproxy.cfg.orig نقوم الآن بفتح الملف haproxy.cfg باستخدام مُحرِّر نصوص: sudo vi /etc/haproxy/haproxy.cfg سنشاهد وجود قسمين معرّفين مسبقًا: global و defaults، سنلقي نظرة في البداية على بعض المعاملات القياسية default. تحت القسم defaults نبحث عن الأسطر التالية: mode http option httplog يقوم اختيار http كوضع بضبط HAProxy ليعمل كموازن حمل عن طريق الطبقة 7 (أو طبقة التطبيقات)، يعني هذا أنّ موازن الحمل سينظر إلى محتوى طلبات http ويقوم بتمريرها إلى الخادوم المناسب اعتمادًا على القواعد المعرّفة في الواجهة الأماميّة frontend، إن لم يكن هذا المفهوم مألوفًا لديك فمن فضلك اقرأ قسم أنواع موازنة الحمل في درس مقدّمة إلى HAProxy. لا تقم بإغلاق ملف الإعدادات الآن، لأنّنا سنضيف إعدادات الوسيط. إعداد HAProxy: الوسطاء إعداد الواجهة الأماميّة أول شيء نريد إضافته هو واجهة أماميّة frontend، ولأجل إعداد أساسي لوسيط عكسي وموازنة حمل عن طريق الطبقة 7 سنحتاج لتعريف قائمة تحكّم وصول ACL تُستخدَم لتوجيه حركة مرور بياناتنا إلى خواديم الواجهة الخلفيّة المناسبة، هنالك العديد من قوائم تحكّم الوصول التي يُمكن استخدامها في HAProxy، سنغطي فقط واحدة منها في هذا الدّرس (وهي path_beg)، ولأجل الحصول على قائمة كاملة من قوائم تحكّم الوصول في HAProxy قم بمراجعة التّوثيق الرسميّ: HAProxy ACLs. نضيف واجهتنا الأماميّة www في نهاية الملف، تأكّد من أن تضع عنوان IP الخاص بخادوم haproxy-www لديك بدلًا من haproxy_www_public_IP: frontend www bind haproxy_www_public_IP:80 option http-server-close acl url_wordpress path_beg /wordpress use_backend wordpress-backend if url_wordpress default_backend web-backend وهذا شرح لما يعنيه كل سطر من المقطع السابق المأخوذ من إعدادات الواجهة الأماميّة: frontend www: يُعيِّن واجهة أماميّة اسمها "www"، حيث سنستخدمها للتعامل مع حركة مرور بيانات www الواردة. bind haproxy_www_public_IP:80: ضع عنوان IP خادوم haproxy-www لديك بدلًا من haproxy_www_public_IP، يُخبر هذا السطر HAProxy أنّ هذه الواجهة الأماميّة ستتعامل مع حركة مرور بيانات الشبكة الواردة إلى عنوان IP هذا على هذا المنفذ. option http-server-close: يقوم بتمكين وضع إغلاق اتصال HTTP على الخادوم، ويحافظ على القدرة على دعم ترويسة HTTP keep-alive وتقنيّة HTTP pipelining على العميل (وهي تقنيّة لإرسال العديد من طلبات HTTP ضمن اتصال TCP وحيد بدون انتظار الموافقة لها)، يسمح هذا الخيار بأن يقوم HAProxy بمعالجة طلبات متعدّدة للعميل ضمن اتصال وحيد، والذي عادة ما يزيد من الأداء. acl url_wordpress path_beg /wordpress: يُعيِّن قائمة تحكّم وصول ACL تُدعى url_wordpress والتي تكون قيمتها صحيحة true إن كان مسار الطلب يبدأ بـ "wordpress/"، على سبيل المثال http://example.com/wordpress/hello-world. use_backend wordpress-backend if url_wordpress: يقوم بإعادة توجيه أي حركة مرور بيانات تتوافق مع قائمة تحكّم الوصول url_wordpress إلى wordpress-backend، والتي سنقوم بتعريفها قريبًا. default_backend web-backend: يُحدِّد أنّه أي حركة مرور بيانات لا تتوافق مع قاعدة use_backend سيتم تمريرها إلى web-backend، والتي سنقوم بتعريفها في الخطوة القادمة. إعداد الواجهة الخلفية Backend بعد أن تنتهي من إعداد الواجهة الأماميّة، قم الآن إضافة واجهتك الخلفيّة الأولى عن طريق إضافة الأسطر التالية، تأكّد من أن تضع عنوان IP المناسب بدلًا من web_1_private_IP: backend web-backend server web-1 web_1_private_IP:80 check وهذا شرح لما يعنيه كل سطر من المقطع السابق المأخوذ من إعدادات الواجهة الخلفيّة: backend web-backend: يُعيِّن واجهة خلفيّة تُدعى web-backend. server web-1 ... : يُعيِّن خادوم واجهة خلفيّة يُدعى web-1، مع عنوان IP الخاص (وهو الذي يجب أن تستبدله) والمنفذ الذي يستمع عليه، وهو 80 في هذه الحالة، يُخبِر الخيار check مُوازِن الحمل أن يُجري دوريًّا تحقّق من السّلامة على هذا الخادوم. بعدها أضف الواجهة الخلفيّة لتطبيق ووردبريس لديك: backend wordpress-backend reqrep ^([^\ :]*)\ /wordpress/(.*) \1\ /\2 server wordpress-1 wordpress_1_private_IP:80 check وهذا شرح لما يعنيه كل سطر من المقطع السابق المأخوذ من إعدادات الواجهة الخلفيّة: backend wordpress-backend: يُعيِّن واجهة خلفيّة تُدعى wordpress-backend. reqrep ... : يعيد كتابة الطلبات من wordpress/ إلى / عند تمرير حركة مرور البيانات إلى خواديم ووردبريس، وهو ليس ضروريًّا إن كان تطبيق ووردبريس مُثبّتًا على جذر root الخادوم ولكن نحتاج إليه لقابلية النفاذ عبر wordpress/ على خادوم HAProxy. server wordpress-1 ... : يُعيِّن خادوم واجهة خلفيّة يُدعى wordpress-1، مع عنوان IP الخاص (وهو الذي يجب أن تستبدله) والمنفذ الذي يستمع عليه، وهو 80 في هذه الحالة، يُخبِر الخيار check مُوازِن الحمل أن يُجري دوريًّا تحقّق من السّلامة على هذا الخادوم. إعدادات HAProxy: الإحصائيات Stats إن أردت تمكين إحصائيّات HAProxy، والتي قد تكون مفيدة في تحديد كيفيّة تعامل HAProxy مع حركة مرور البيانات الواردة، ستحتاج إلى إضافة الأسطر التالية إلى إعداداتك: listen stats :1936 stats enable stats scope www stats scope web-backend stats scope wordpress-backend stats uri / stats realm Haproxy\ Statistics stats auth user:password وهذا شرح لما تعنيه الأسطر غير البديهيّة من المقطع السابق المأخوذ من إعدادات listen stats: listen stats :1936: يقوم بإعداد صفحة إحصائيّات HAProxy لتكون قابلة للنفاذ على المنفذ 1936 (أي http://haproxy_www_public_IP:1936). stats scope ... : يجمع الإحصائيّات على الواجهة المُحدّدة سواء كانت أماميّة أو خلفيّة. / stats uri: يُعيِّن رابط صفحة الإحصائيّات إلى / . stats realm Haproxy\ Statistics: يقوم بتمكين الإحصائيّات وتعيين اسم الاستيثاق realm Authentication (وهو استيثاق ذو نافذة منبثقة)، يُستخدَم بالترابط مع الخيار stats auth. stats auth haproxy:password: يُعيِّن اعتمادات credentials الاستيثاق لصفحة الإحصائيّات، قم بوضع اسم المستخدم وكلمة السّر الخاصّة بك. الآن قم بالحفظ والإغلاق، عند تشغيل HAProxy تكون صفحة الإحصائيّات متوفّرة عبر الرابط http://haproxy_www_public_ip:1936/ حالما تبدأ خدمة HAProxy لديك، تكون HAProxy جاهزة الآن لتشغيلها ولكن فلنقم بتمكين التسجيل logging أولًا. تمكين تسجيل HAProxy إنّ تمكين التسجيل في HAProxy بسيط جدًّا، قم في البداية بتحرير الملف rsyslog.conf: sudo vi /etc/rsyslog.conf ثم ابحث عن السطرين التاليين وأزل التعليق عنهما لتمكين استقبال UDP syslog، يجب أن تبدو كما يلي عند الفراغ منها: $ModLoad imudp $UDPServerRun 514 $UDPServerAddress 127.0.0.1 الآن أعد تشغيل rsyslog لتمكين الإعدادات الجديدة: sudo service rsyslog restart تم تمكين تسجيل HAProxy الآن، سيتم إنشاء ملف السّجل في المسار var/log/haproxy.log/ بعد أن يتم تشغيل HAProxy. تحديث إعدادات ووردبريس الآن وقد تم تغيير رابط تطبيق ووردبريس فيجب علينا تحديث بعض الإعدادات في ووردبريس. قم بتعديل الملف wp-config.php على أي خادوم ووردبريس، هذا الملف موجود في مكان تثبيت ووردبريس (في هذا الدّرس تم تثبيته على المسار var/www/example.com/ ولكن قد يكون مختلفًا لديك): cd /var/www/example.com; sudo vi wp-config.php ابحث عن السطر الموجود في بداية الملف الذي يحتوي على ('define('DB_NAME', 'wordpress وقم بإضافة الأسطر التالية فوقه مع استبدال http://haproxy_www_public_IP: define('WP_SITEURL', 'http://haproxy_www_public_IP'); define('WP_HOME', 'http://haproxy_www_public_IP'); قم بحفظ وإغلاق الملف، تمّ الآن إعداد روابط ووردبريس لتشير إلى موازن الحمل بدلًا من خادوم ووردبريس الأصلي والتي تلعب دورها عند محاولتك النفاذ إلى لوحة تحكم ووردبريس. تشغيل HAProxy قم بتشغيل HAProxy على الخادوم haproxy-www ليتم تطبيق تغييرات الإعدادات: sudo service haproxy restart إتمام الوسيط العكسي Reverse Proxy أصبحت الآن تطبيقاتنا قابلة للوصول إليها عبر نفس المجال، example.com، عبر الوسيط العكسي للطبقة 7، ولكن لم يتم تطبيق موازنة الحمل عليها بعد، تبدو الآن البيئة لدينا كالمخطط التالي: وفقًا للواجهة الأماميّة التي عرفناها سابقًا، هذا وصف حول كيفيّة تمرير HAProxy لحركة مرور البيانات: http://example.com/wordpress: سيتم إرسال أي طلب يبدأ بـ wordpress/ إلى wordpress-backend (والذي يتكون من الخادوم wordpress-1). http://example.com/: سيتم إرسال أيّة طلبات أخرى إلى web-backend (والذي يتكون من الخادوم web-1). إن كان كل ما تريد فعله هو استضافة تطبيقات متعدّدة على مجال وحيد فقد أنجزت هذا بنجاح، أمّا إن أردت موازنة حمل تطبيقاتك أكمل قراءة الدّرس. كيفية إضافة موازنة الحمل موازنة حمل الخادوم web-1 لموازنة حمل خادوم ويب أساسي، كل ما تحتاج إليه هو إنشاء خادوم ويب جديد يمتلك إعدادات ومحتوى مطابق لخادوم الأصلي، سندعو هذا الخادوم الجديد: web-2. لديك خياران عند إنشاء الخادوم الجديد: إن كنت تملك خيار إنشاء خادوم جديد انطلاقًا من صورة web-1، فهذه هي الطريقة الأبسط لإنشاء web-2. إنشاؤه من الصفر، تثبيت نفس البرمجيّات، إعداده بشكل مماثل، ومن ثمّ نسخ محتوى جذر خادوم Nginx من web-1 إلى web-2 باستخدام rsync (اقرأ درس كيف تستخدِم Rsync لمزامنة مجلّدات بين الجهاز المحلّي والخادوم). ملاحظة: إن كل من الطريقتين السابقتين تقوم بإنشاء نسخة لمحتويات جذر الخادوم مرّة وحيدة، لذلك إن قمت بتحديث أي من الملفّات على أحد خواديمك، web-1 أو web-2، فتأكّد من مزامنة الملفّات مرّة أخرى. بعد أن يتم إعداد خادوم ويب المماثل لديك، قم بإضافته إلى web-backend ضمن إعدادات HAProxy. على الخادوم haproxy-www قم بتحرير الملف haproxy.cfg: sudo vi /etc/haproxy/haproxy.cfg ابحث عن القسم web-backend من الإعدادات: backend web-backend server web-1 web_1_private_IP:80 check وبعدها أضف الخادوم web-2 في السطر التالي: server web-2 web_2_private_IP:80 check قم بحفظ وإغلاق الملف، وأعد تحميل HAProxy لتطبيق التغييرات: sudo service haproxy reload يمتلك web-backend الآن خادومين يتعاملان مع حركة مرور البيانات غير المرتبطة بووردبريس، أي تمّ إعداد موازنة الحمل عليه بنجاح. موازنة حمل الخادوم wordpress-1 إنّ موازنة حمل تطبيق مثل ووردبريس أكثر تعقيدًا بقليل من موازنة حمل خادوم ثابت، لأنّه يجب عليك الاهتمام بأشياء مثل مزامنة الملفّات المُحمّلة ومستخدمي قواعد البيانات الإضافيّين. أكمل الخطوات الثلاث التالية لإنشاء خادوم ووردبريس الثاني wordpress-2: إنشاء خادوم تطبيق ويب الثاني. مزامنة ملفّات تطبيق الويب. إنشاء مستخدم قاعدة بيانات جديد. بعد أن تقوم بإنشاء الخادوم wordpress-2 مع إعداد قاعدة البيانات بشكل صحيح فكل ما تبقى عليك فعله هو إضافته إلى wordpress-backend ضمن إعدادات HAProxy. على الخادوم haproxy-www قم بتحرير الملف haproxy.cfg: sudo vi /etc/haproxy/haproxy.cfg ابحث عن القسم wordpress-backend من الإعدادات: backend wordpress-backend server wordpress-1 wordpress_1_private_IP:80 check وبعدها أضف الخادوم wordpress-2 في السطر التالي: server wordpress-2 wordpress_2_private_IP:80 check قم بحفظ وإغلاق الملف، وأعد تحميل HAProxy لتطبيق التغييرات: sudo service haproxy reload يمتلك web-backend الآن خادومين يتعاملان مع حركة مرور البيانات غير المرتبطة بووردبريس، أي تمّ إعداد موازنة الحمل عليه بنجاح. الخاتمة بعد أن أتممت الآن هذا الدّرس يجب أن تكون قادرًا على توسيع موازنة الحمل والوسيط العكسي لإضافة المزيد من التطبيقات والخواديم لبيئتك لجعلها تتوافق بشكل أفضل مع احتياجاتك، تذكّر أنّه لا توجد حدود لطرق إعداد بيئتك، وربّما تحتاج إلى البحث في توثيق HAProxy إن أردت متطلبات أكثر تعقيدًا. ترجمة -وبتصرّف- للمقال How To Use HAProxy As A Layer 7 Load Balancer For WordPress and Nginx On Ubuntu 14.04 لصاحبه Mitchell Anicas.
سنتعلّم في هذا الدّرس كيفيّة استخدام HAProxy (والذي يرمز إلى الوسيط عالي التوفّر High Availability Proxy) كمُوازِن حمل عن طريق الطبقة السّابعة layer 7 load balancer من أجل تخديم تطبيقات متعدّدة من اسم مجال واحد Single Domain أو عنوان IP، بإمكان موازنة الحمل أن تزيد أداء، توفّر، ومرونة بيئتنا. تكون موازنة الحمل والوسيط العكسي للطبقة 7 ملائمة لموقعك إن أردت أن تملك اسم نطاق واحد يقوم بتخديم تطبيقات متعدّدة، حيث يمكن تحليل طلبات http لتقرّر أي تطبيق ينبغي عليه أن يستقبل حركة مرور البيانات. تمّت كتابة هذا الدّرس باستخدام ووردبريس وموقع ثابت Static website كأمثلة، ولكن يمكن استخدام مفاهيمه العامّة مع تطبيقات أخرى للحصول على تأثير مماثل. المتطلبات الأساسية قبل متابعة هذا الدّرس ينبغي عليك أن تملك تطبيقين على الأقل يعملان على خادومين منفصلين، سنستخدم موقعًا ثابتًا مستضافًا على Nginx و ووردبريس كتطبيقين لدينا، وبالإضافة للبيئة الحاليّة لديك سنقوم بإنشاء الخواديم التالية: haproxy-www: وهو خادوم HAProxy لأجل موازنة الحمل والوسيط العكسي wordpress-2: وهو خادوم الويب الثاني لووردبريس (تحتاجه فقط إن أردت موازنة حمل مكونات ووردبريس في بيئتك) web-2: خادوم ويب Nginx الثاني (تحتاجه فقط إن أردت موازنة حمل مكونات Nginx في بيئتك) إن لم يسبق لك التّعامل مع المفاهيم أو المصطلحات الأساسيّة لموازنة الحمل، مثل موازنة الحمل عن طريق الطبقة 7 أو الواجهات الخلفيّة backends أو قوائم تحكّم الوصول ACLs فهذا هو الدّرس الذي يشرح الأساسيّات: مقدّمة إلى HAProxy ومبادئ موازنة الحمل (Load Balancing). هدفنا بنهاية هذا الدّرس نريد أن نحصل على بيئة تبدو كما يلي: أي سيقوم المستخدمون لديك بالنفاذ لكلا تطبيقيك عبر http://example.com، وسيتم تمرير كل الطلبات التي تبدأ بـ http://example.com/wordpress إلى خواديم ووردبريس، ويتم تمرير جميع باقي الطلبات إلى خواديم Nginx الأساسيّة، لاحظ أنّه لا تحتاج بالضرورة لموازنة حمل تطبيقاتك حتى تظهر على مجال واحد، ولكن سنقوم بتغطية موازنة الحمل في هذا الدّرس. تثبيت HAProxy نقوم بإنشاء خادوم جديد مع الشّبكات الخاصّة، سنسمّيه في هذا الدّرس haproxy-www. نقوم بتثبيت HAProxy على الخادوم haproxy-www باستخدام apt-get: sudo apt-get update sudo apt-get install haproxy نحتاج لتمكين سكريبت التهيئة init script لـ HAProxy كي يبدأ ويتوقف HAProxy مع الخادوم لدينا: sudo vi /etc/default/haproxy نغيّر قيمة ENABLED إلى 1 لتمكين سكريبت التهيئة لـ HAProxy: ENABLED=1 نقوم بالحفظ والخروج، سيبدأ ويتوقف HAProxy الآن مع خادومنا، نستطيع أيضًا الآن استخدام الأمر service للتحكّم بـ HAProxy، فلنتحقّق من أنّه قيد التشغيل: user@haproxy-www:/etc/init.d$ sudo service haproxy status haproxy not running. نجد أنّه لا يعمل، لا مشكلة لأنّه يحتاج إلى إعداده قبل أن نتمكّن من استخدامه، فلنقم الآن بإعداد HAProxy لأجل بيئتنا. إعداد HAProxy يكون ملف إعدادات HAProxy مُقسّمًا إلى قسمين رئيسيين: العمومي Global: يقوم بتعيين المُعامِلات parameters على نطاق العمليّة الوسطاء Proxies: يتكون من المُعامِلات الافتراضيّة defaults، الاستماع listen، الواجهة الأماميّة frontend، والواجهة الخلفيّة backend. مرّة أخرى إن لم يسبق لك أن سمعت عن مفاهيم أو المصطلحات الأساسيّة لموازنة الحمل، فقم بالرجوع إلى هذا الدّرس: مقدّمة إلى HAProxy ومبادئ موازنة الحمل (Load Balancing). إعداد HAProxy: العمومي يجب أن يتم ضبط إعدادات HAProxy على الخادوم haproxy-www. في البداية لنقم بعمل نسخة من الملف haproxy.cfg الافتراضي: cd /etc/haproxy; sudo cp haproxy.cfg haproxy.cfg.orig نقوم الآن بفتح الملف haproxy.cfg باستخدام مُحرِّر نصوص: sudo vi /etc/haproxy/haproxy.cfg سنشاهد وجود قسمين معرّفين مسبقًا: global و defaults، سنلقي نظرة في البداية على بعض المعاملات القياسية default. تحت القسم defaults نبحث عن الأسطر التالية: mode http option httplog يقوم اختيار http كوضع بضبط HAProxy ليعمل كموازن حمل عن طريق الطبقة 7 (أو طبقة التطبيقات)، يعني هذا أنّ موازن الحمل سينظر إلى محتوى طلبات http ويقوم بتمريرها إلى الخادوم المناسب اعتمادًا على القواعد المعرّفة في الواجهة الأماميّة frontend، إن لم يكن هذا المفهوم مألوفًا لديك فمن فضلك اقرأ قسم أنواع موازنة الحمل في درس مقدّمة إلى HAProxy. لا تقم بإغلاق ملف الإعدادات الآن، لأنّنا سنضيف إعدادات الوسيط. إعداد HAProxy: الوسطاء إعداد الواجهة الأماميّة أول شيء نريد إضافته هو واجهة أماميّة frontend، ولأجل إعداد أساسي لوسيط عكسي وموازنة حمل عن طريق الطبقة 7 سنحتاج لتعريف قائمة تحكّم وصول ACL تُستخدَم لتوجيه حركة مرور بياناتنا إلى خواديم الواجهة الخلفيّة المناسبة، هنالك العديد من قوائم تحكّم الوصول التي يُمكن استخدامها في HAProxy، سنغطي فقط واحدة منها في هذا الدّرس (وهي path_beg)، ولأجل الحصول على قائمة كاملة من قوائم تحكّم الوصول في HAProxy قم بمراجعة التّوثيق الرسميّ: HAProxy ACLs. نضيف واجهتنا الأماميّة www في نهاية الملف، تأكّد من أن تضع عنوان IP الخاص بخادوم haproxy-www لديك بدلًا من haproxy_www_public_IP: frontend www bind haproxy_www_public_IP:80 option http-server-close acl url_wordpress path_beg /wordpress use_backend wordpress-backend if url_wordpress default_backend web-backend وهذا شرح لما يعنيه كل سطر من المقطع السابق المأخوذ من إعدادات الواجهة الأماميّة: frontend www: يُعيِّن واجهة أماميّة اسمها "www"، حيث سنستخدمها للتعامل مع حركة مرور بيانات www الواردة. bind haproxy_www_public_IP:80: ضع عنوان IP خادوم haproxy-www لديك بدلًا من haproxy_www_public_IP، يُخبر هذا السطر HAProxy أنّ هذه الواجهة الأماميّة ستتعامل مع حركة مرور بيانات الشبكة الواردة إلى عنوان IP هذا على هذا المنفذ. option http-server-close: يقوم بتمكين وضع إغلاق اتصال HTTP على الخادوم، ويحافظ على القدرة على دعم ترويسة HTTP keep-alive وتقنيّة HTTP pipelining على العميل (وهي تقنيّة لإرسال العديد من طلبات HTTP ضمن اتصال TCP وحيد بدون انتظار الموافقة لها)، يسمح هذا الخيار بأن يقوم HAProxy بمعالجة طلبات متعدّدة للعميل ضمن اتصال وحيد، والذي عادة ما يزيد من الأداء. acl url_wordpress path_beg /wordpress: يُعيِّن قائمة تحكّم وصول ACL تُدعى url_wordpress والتي تكون قيمتها صحيحة true إن كان مسار الطلب يبدأ بـ "wordpress/"، على سبيل المثال http://example.com/wordpress/hello-world. use_backend wordpress-backend if url_wordpress: يقوم بإعادة توجيه أي حركة مرور بيانات تتوافق مع قائمة تحكّم الوصول url_wordpress إلى wordpress-backend، والتي سنقوم بتعريفها قريبًا. default_backend web-backend: يُحدِّد أنّه أي حركة مرور بيانات لا تتوافق مع قاعدة use_backend سيتم تمريرها إلى web-backend، والتي سنقوم بتعريفها في الخطوة القادمة. إعداد الواجهة الخلفية Backend بعد أن تنتهي من إعداد الواجهة الأماميّة، قم الآن إضافة واجهتك الخلفيّة الأولى عن طريق إضافة الأسطر التالية، تأكّد من أن تضع عنوان IP المناسب بدلًا من web_1_private_IP: backend web-backend server web-1 web_1_private_IP:80 check وهذا شرح لما يعنيه كل سطر من المقطع السابق المأخوذ من إعدادات الواجهة الخلفيّة: backend web-backend: يُعيِّن واجهة خلفيّة تُدعى web-backend. server web-1 ... : يُعيِّن خادوم واجهة خلفيّة يُدعى web-1، مع عنوان IP الخاص (وهو الذي يجب أن تستبدله) والمنفذ الذي يستمع عليه، وهو 80 في هذه الحالة، يُخبِر الخيار check مُوازِن الحمل أن يُجري دوريًّا تحقّق من السّلامة على هذا الخادوم. بعدها أضف الواجهة الخلفيّة لتطبيق ووردبريس لديك: backend wordpress-backend reqrep ^([^\ :]*)\ /wordpress/(.*) \1\ /\2 server wordpress-1 wordpress_1_private_IP:80 check وهذا شرح لما يعنيه كل سطر من المقطع السابق المأخوذ من إعدادات الواجهة الخلفيّة: backend wordpress-backend: يُعيِّن واجهة خلفيّة تُدعى wordpress-backend. reqrep ... : يعيد كتابة الطلبات من wordpress/ إلى / عند تمرير حركة مرور البيانات إلى خواديم ووردبريس، وهو ليس ضروريًّا إن كان تطبيق ووردبريس مُثبّتًا على جذر root الخادوم ولكن نحتاج إليه لقابلية النفاذ عبر wordpress/ على خادوم HAProxy. server wordpress-1 ... : يُعيِّن خادوم واجهة خلفيّة يُدعى wordpress-1، مع عنوان IP الخاص (وهو الذي يجب أن تستبدله) والمنفذ الذي يستمع عليه، وهو 80 في هذه الحالة، يُخبِر الخيار check مُوازِن الحمل أن يُجري دوريًّا تحقّق من السّلامة على هذا الخادوم. إعدادات HAProxy: الإحصائيات Stats إن أردت تمكين إحصائيّات HAProxy، والتي قد تكون مفيدة في تحديد كيفيّة تعامل HAProxy مع حركة مرور البيانات الواردة، ستحتاج إلى إضافة الأسطر التالية إلى إعداداتك: listen stats :1936 stats enable stats scope www stats scope web-backend stats scope wordpress-backend stats uri / stats realm Haproxy\ Statistics stats auth user:password وهذا شرح لما تعنيه الأسطر غير البديهيّة من المقطع السابق المأخوذ من إعدادات listen stats: listen stats :1936: يقوم بإعداد صفحة إحصائيّات HAProxy لتكون قابلة للنفاذ على المنفذ 1936 (أي http://haproxy_www_public_IP:1936). stats scope ... : يجمع الإحصائيّات على الواجهة المُحدّدة سواء كانت أماميّة أو خلفيّة. / stats uri: يُعيِّن رابط صفحة الإحصائيّات إلى / . stats realm Haproxy\ Statistics: يقوم بتمكين الإحصائيّات وتعيين اسم الاستيثاق realm Authentication (وهو استيثاق ذو نافذة منبثقة)، يُستخدَم بالترابط مع الخيار stats auth. stats auth haproxy:password: يُعيِّن اعتمادات credentials الاستيثاق لصفحة الإحصائيّات، قم بوضع اسم المستخدم وكلمة السّر الخاصّة بك. الآن قم بالحفظ والإغلاق، عند تشغيل HAProxy تكون صفحة الإحصائيّات متوفّرة عبر الرابط http://haproxy_www_public_ip:1936/ حالما تبدأ خدمة HAProxy لديك، تكون HAProxy جاهزة الآن لتشغيلها ولكن فلنقم بتمكين التسجيل logging أولًا. تمكين تسجيل HAProxy إنّ تمكين التسجيل في HAProxy بسيط جدًّا، قم في البداية بتحرير الملف rsyslog.conf: sudo vi /etc/rsyslog.conf ثم ابحث عن السطرين التاليين وأزل التعليق عنهما لتمكين استقبال UDP syslog، يجب أن تبدو كما يلي عند الفراغ منها: $ModLoad imudp $UDPServerRun 514 $UDPServerAddress 127.0.0.1 الآن أعد تشغيل rsyslog لتمكين الإعدادات الجديدة: sudo service rsyslog restart تم تمكين تسجيل HAProxy الآن، سيتم إنشاء ملف السّجل في المسار var/log/haproxy.log/ بعد أن يتم تشغيل HAProxy. تحديث إعدادات ووردبريس الآن وقد تم تغيير رابط تطبيق ووردبريس فيجب علينا تحديث بعض الإعدادات في ووردبريس. قم بتعديل الملف wp-config.php على أي خادوم ووردبريس، هذا الملف موجود في مكان تثبيت ووردبريس (في هذا الدّرس تم تثبيته على المسار var/www/example.com/ ولكن قد يكون مختلفًا لديك): cd /var/www/example.com; sudo vi wp-config.php ابحث عن السطر الموجود في بداية الملف الذي يحتوي على ('define('DB_NAME', 'wordpress وقم بإضافة الأسطر التالية فوقه مع استبدال http://haproxy_www_public_IP: define('WP_SITEURL', 'http://haproxy_www_public_IP'); define('WP_HOME', 'http://haproxy_www_public_IP'); قم بحفظ وإغلاق الملف، تمّ الآن إعداد روابط ووردبريس لتشير إلى موازن الحمل بدلًا من خادوم ووردبريس الأصلي والتي تلعب دورها عند محاولتك النفاذ إلى لوحة تحكم ووردبريس. تشغيل HAProxy قم بتشغيل HAProxy على الخادوم haproxy-www ليتم تطبيق تغييرات الإعدادات: sudo service haproxy restart إتمام الوسيط العكسي Reverse Proxy أصبحت الآن تطبيقاتنا قابلة للوصول إليها عبر نفس المجال، example.com، عبر الوسيط العكسي للطبقة 7، ولكن لم يتم تطبيق موازنة الحمل عليها بعد، تبدو الآن البيئة لدينا كالمخطط التالي: وفقًا للواجهة الأماميّة التي عرفناها سابقًا، هذا وصف حول كيفيّة تمرير HAProxy لحركة مرور البيانات: http://example.com/wordpress: سيتم إرسال أي طلب يبدأ بـ wordpress/ إلى wordpress-backend (والذي يتكون من الخادوم wordpress-1). http://example.com/: سيتم إرسال أيّة طلبات أخرى إلى web-backend (والذي يتكون من الخادوم web-1). إن كان كل ما تريد فعله هو استضافة تطبيقات متعدّدة على مجال وحيد فقد أنجزت هذا بنجاح، أمّا إن أردت موازنة حمل تطبيقاتك أكمل قراءة الدّرس. كيفية إضافة موازنة الحمل موازنة حمل الخادوم web-1 لموازنة حمل خادوم ويب أساسي، كل ما تحتاج إليه هو إنشاء خادوم ويب جديد يمتلك إعدادات ومحتوى مطابق لخادوم الأصلي، سندعو هذا الخادوم الجديد: web-2. لديك خياران عند إنشاء الخادوم الجديد: إن كنت تملك خيار إنشاء خادوم جديد انطلاقًا من صورة web-1، فهذه هي الطريقة الأبسط لإنشاء web-2. إنشاؤه من الصفر، تثبيت نفس البرمجيّات، إعداده بشكل مماثل، ومن ثمّ نسخ محتوى جذر خادوم Nginx من web-1 إلى web-2 باستخدام rsync (اقرأ درس كيف تستخدِم Rsync لمزامنة مجلّدات بين الجهاز المحلّي والخادوم). ملاحظة: إن كل من الطريقتين السابقتين تقوم بإنشاء نسخة لمحتويات جذر الخادوم مرّة وحيدة، لذلك إن قمت بتحديث أي من الملفّات على أحد خواديمك، web-1 أو web-2، فتأكّد من مزامنة الملفّات مرّة أخرى. بعد أن يتم إعداد خادوم ويب المماثل لديك، قم بإضافته إلى web-backend ضمن إعدادات HAProxy. على الخادوم haproxy-www قم بتحرير الملف haproxy.cfg: sudo vi /etc/haproxy/haproxy.cfg ابحث عن القسم web-backend من الإعدادات: backend web-backend server web-1 web_1_private_IP:80 check وبعدها أضف الخادوم web-2 في السطر التالي: server web-2 web_2_private_IP:80 check قم بحفظ وإغلاق الملف، وأعد تحميل HAProxy لتطبيق التغييرات: sudo service haproxy reload يمتلك web-backend الآن خادومين يتعاملان مع حركة مرور البيانات غير المرتبطة بووردبريس، أي تمّ إعداد موازنة الحمل عليه بنجاح. موازنة حمل الخادوم wordpress-1 إنّ موازنة حمل تطبيق مثل ووردبريس أكثر تعقيدًا بقليل من موازنة حمل خادوم ثابت، لأنّه يجب عليك الاهتمام بأشياء مثل مزامنة الملفّات المُحمّلة ومستخدمي قواعد البيانات الإضافيّين. أكمل الخطوات الثلاث التالية لإنشاء خادوم ووردبريس الثاني wordpress-2: إنشاء خادوم تطبيق ويب الثاني. مزامنة ملفّات تطبيق الويب. إنشاء مستخدم قاعدة بيانات جديد. بعد أن تقوم بإنشاء الخادوم wordpress-2 مع إعداد قاعدة البيانات بشكل صحيح فكل ما تبقى عليك فعله هو إضافته إلى wordpress-backend ضمن إعدادات HAProxy. على الخادوم haproxy-www قم بتحرير الملف haproxy.cfg: sudo vi /etc/haproxy/haproxy.cfg ابحث عن القسم wordpress-backend من الإعدادات: backend wordpress-backend server wordpress-1 wordpress_1_private_IP:80 check وبعدها أضف الخادوم wordpress-2 في السطر التالي: server wordpress-2 wordpress_2_private_IP:80 check قم بحفظ وإغلاق الملف، وأعد تحميل HAProxy لتطبيق التغييرات: sudo service haproxy reload يمتلك web-backend الآن خادومين يتعاملان مع حركة مرور البيانات غير المرتبطة بووردبريس، أي تمّ إعداد موازنة الحمل عليه بنجاح. الخاتمة بعد أن أتممت الآن هذا الدّرس يجب أن تكون قادرًا على توسيع موازنة الحمل والوسيط العكسي لإضافة المزيد من التطبيقات والخواديم لبيئتك لجعلها تتوافق بشكل أفضل مع احتياجاتك، تذكّر أنّه لا توجد حدود لطرق إعداد بيئتك، وربّما تحتاج إلى البحث في توثيق HAProxy إن أردت متطلبات أكثر تعقيدًا. ترجمة -وبتصرّف- للمقال How To Use HAProxy As A Layer 7 Load Balancer For WordPress and Nginx On Ubuntu 14.04 لصاحبه Mitchell Anicas. -
 طوّرت شركة Sun Microsystems نظام الملفّات الشبكي Network file system, NFS سنة 1980 من أجل السماح بتشارك الملفّات والمجلّدات بين الأنظمة الشبيهة بيونكس (لينكس ويونكس). يتيح نظام NFS للملفّات تركيب Mounting ملفّات عبر الشّبكة والتعامل معها كما لو كانت مركَّبة محليًّا على نفس النظام. فوائد نظام NFS يسمح نظام NFS بالوصول إلى الملفّات عن بعد. يستخدم بنية عميل-خادوم Client/Server معيارية لتشارك الملفّات بين جميع الأجهزة العاملة بالأنظمة الشبيهة بيونكس. ليس ضروريًّا عند استخدام NFS أن تكون الأجهزة تعمل على نفس نظام التّشغيل. يمكن ضبط حلول للتخزين المركزيّ بمساعدة نظام NFS. يعثُر المستخدمون على بياناتهم مهما كان تواجدها الفعلي. لا توجد حاجة للتحيين Refresh اليدوي للحصول على الملفّات الجديدة. تدعم الإصدارات الحديثة من NFS قوائم التحكّم في الوصول ACL. يمكن تأمينه عبر الجدران الناريّة Firewalls وKerberos (ميثاق للاستيثاق عبر الشبكة). تدخلّ الملفّات التاليّة في إعداد NFS: ملفّ etc/exports/: وهو ملفّ الإعداد الرئيس؛ تعرّف فيه - على الخادوم - جميع الملفّات والمجلّدات المشاركة. ملفّ etc/fstab/: يجب إدراج سطر لكلّ نظام ملفّات مُركَّب ضمن هذا الملفّ حتى يكون التركيب دائما (يبقى بعد إعادة التشغيل). ملفّ etc/sysconfig/nfs/: يعرّف المنافذ التي تنصت الخدمات للاتّصالات الواردة عبرها. إعداد NFS على خادوم أوبونتو سنعتمد في هذا الدرس على جهازين يعملان بإحدى توزيعات لينكس التاليّة: دبيان، أوبونتو أو ردهات. سنثبّت على أحد الجهازين خادوم NFS وعلى الثاني عميلا له كالتالي: خادوم NFS على العنوان 192.168.2.200. عميل NFS على العنوان 192.168.2.150. يمكنك استخدام VirtualBox لإعداد بيئة عمل بالمواصفات أعلاه. تثبيت الخادوم والعميل سنحتاج لتثبيت حزم NFS على الخادوم والعميل: # apt-get update # apt-get install nfs-kernel-server nfs-common ملحوظة: يمكن الاكتفاء بالحزمة nfs-common على العميل. تشير العلامة # إلى أن الأمر ينفَّذ بصلاحيّات الجذر. إعداد خادوم NFS الخطوة الأولى هي تحديد المجلّد الذي نريد مشاركته؛ سننشئ واحدا لهذا الغرض (يمكنك اختيّار مجلّد موجود مسبقا): # mkdir /nfsshare ثم نغيّر ملكيّته إلى nobody:nogroup: # chown nobody:nogroup /nfsshare غيّرنا ملكيّة الملفّ إلى المستخدم nobody الذي هو حساب لا يملك سوى الصلاحيّات الدنيا ويُستخدَم عادة لتنفيذ سكربتات غير مأمونة المصدر حتى لا تلحق أي ضرر بالنظام. هذه الخطوة ضروريّة وإلا فلن يكون بمقدورك إضافة ملفّات إلى المجلّد انطلاقا من العميل؛ إلا إذا أضفت خيار no_root_squash كما هو مشروح أدناه (لا يُنصَح بذلك). ليمكن تشاركُ المجلّد يجب أن نضيفه إلى ملفّ الإعداد etc/exports/؛ نفتح هذا الملفّ (بصلاحيّات الجذر) ثم نضيف إليه السّطر التالي: /nfsshare 192.168.2.150(rw,sync) يسمح السّطر أعلاه بتشارك المجلّد nfsshare مع العميل على العنوان 192.168.2.150 مع تحديد خيارات التشارك. يمكن أن تكون الخيارات على النحو التالي: ro: الوصول عبر وضع القراءة فقط؛ أي أن العميل يمكنه الوصول إلى الملفات المتشاركة فقط دون أن يكون قادرا على التعديل عليها أو إنشاء ملفات جديدة. rw: يمنح العميل القدرة على الوصول إلى الملفّات والتعديل عليها. sync: مزامنة التعديلات. يعني هذا أن أي تعديل سيُحفَظ فورا على نظام الملفّات؛ قد يؤثّر هذا الخيار على الأداء في حالة وجود الكثير من التغييرات المتزامنة على ملفّات كبيرة. no_subtree_check: يفحص نظام NFS مبدئيّا جميع المجلدات التي يتفرّع منها المجلّد المتشارَك من أجل التحقّق من الأذون وتفاصيل أخرى. يؤدّي تفعيل هذه الخاصيّة إلى تعطيل الفحص ممّا يحسّن من الأداء ولكنّه يؤدّي التقليل من الأمان. no_root_squash: تسمح هذه الخاصيّة للمستخدم الجذر على الجهاز العميل بالوصول إلى الملفّات المتشاركة على الخادوم بصلاحيّات الجذر على الخادوم. لا يُنصَح لأسباب أمنيّة باستخدام هذا الخيار إلا في حالات خاصّة. نطبّق الأمر exportfs بعد الانتهاء من تحرير الملفّ exports من أجل اعتماد التعديلات: # exportfs -r ثم نشغّل خدمة NFS كالتالي: # service nfs-kernel-server start إعداد عميل NFS على أوبونتو يمكننا الآن تركيب مجلّد التشارك على العميل. تأكد من أنه يمكن التواصل عبر الشبكة بين الجهاز الخادوم والعميل؛ مثلا باستخدام الأمر ping على العميل (حيثُ 192.168.2.200 هو عنوان الخادوم): $ ping 192.168.2.200 PING 192.168.2.200 (192.168.2.200) 56(84) bytes of data. 64 bytes from 192.168.2.200: icmp_seq=7 ttl=52 time=363 ms 64 bytes from 192.168.2.200: icmp_seq=8 ttl=52 time=322 ms نبدأ أولا بالبحث عن الملفّات المتشاركة عبر NFS على الخادوم: $ showmount -e 192.168.2.200 Export list for 192.168.2.200: /nfsshare 192.168.2.150 يظهر من نتيجة الأمر أعلاه أن المجلّد nfsshare/ متاح للتشارك مع العميل ذي العنوان 192.168.2.150. تركيب المجلد على العميل سننشئ على العميل مجلّدًا باسم mnt/nfs/nfsshare_mount/ ونستخدمه لتركيب المجلّد nfsshare/ على العميل (المجلّد nfsshare/ الموجود على الخادوم): # mkdir -p /mnt/nfs/nfsshare_mount # mount -t nfs 192.168.2.200:/nfsshare /mnt/nfs/nfsshare_mount يمكننا التأكد من تركيب المجلّد بتنفيذ الأمر mount والبحث عن نوع الملفّات nfs: $ mount | grep nfs 192.168.2.200:/nfsshare on /mnt/nfs/nfsshare_mount type nfs (rw,vers=4,addr=192.168.2.200,clientaddr=192.168.2.150) يمكن الآن إضافة ملفّات إلى مجلّد التشارك عبر نقطة التركيب: # touch /mnt/nfs/nfsshare_mount/testfile.txt يمكن التأكد من على الخادوم بسرد محتويات المجلّد nfsshare/. إن أردت جعل التركيب دائما (لا يزول مع إقلاع النظام) فيمكنك إضافة السطر التالي إلى ملفّ etc/fstab/: 192.168.2.200:/nfsshare /mnt/nfs/nfsshare_mount nfs defaults 0 0 نفّذ الأمر mount -a بعد تعديل ملفّ fstab لاعتماد التغييرات فورا. ملحوظة: تأكد من إدخال القيم الصحيحة في ملفّ etc/fstab/؛ وجود أخطاء في صياغة السّطر يمكن أن يؤدي إلى عدم إقلاع النظام. فصل المجلد من العميل استخدم الأمر umount إن أردت فصل المجلّد المركَّب، تُمرّضر نقطة التركيب للأمر على النحو التالي: # umount /mnt/nfs/nfsshare_mount نفّذ الأمر mount | grep nfs للتأكد من فصل المجلّد. أوامر أساسية للتعامل مع ملفات NFS في ما يلي أوامر يكثُر استخدامها أثناء التعامل مع المجلّدات المشارَكة عبر نظام NFS: showmount -e: يعرض جميع المجلّدات المتشاركة المتاحة على الجهاز. showmount -e <server-ip>: يسرد قائمة بالمجلّدات المشاركة المتاحة على الخادوم ذي العنوان server-ip. showmount -d <server-ip>: سرد المجلّدات المشاركة المتاحة على الخادوم والمجلدات المتفرعة منها. exportfs -v: يعرض قائمة بالمجلّدات المتشاركة الموجوة على الخادوم. exportfs -a: يطلب من الخادوم مشاركة الملفّات المحدّدة في الملفّ etc/exports/. exportfs -u: يعمل عكسَ عمل الأمر السابق، إذ يوقف مشاركة المجلدات المحدّدة في etc/exports/. exportfs -r: يحدّث قائمة المشاركات بعد التعديل على الملفّ etc/exports/. يمكن اعتماد هذا المقال الذي يقدّم أساسيات تشارك الملفّات عبر نظام NFS للانتقال إلى تفاصيل أكثر تقدّما بخصوص NFS والميزات التي يقدّمها. ترجمة -وبتصرّف- للمقال How to Setup NFS (Network File System) on RHEL/CentOS/Fedora and Debian/Ubuntu لصاحبه Tarunika Shrivastava.
طوّرت شركة Sun Microsystems نظام الملفّات الشبكي Network file system, NFS سنة 1980 من أجل السماح بتشارك الملفّات والمجلّدات بين الأنظمة الشبيهة بيونكس (لينكس ويونكس). يتيح نظام NFS للملفّات تركيب Mounting ملفّات عبر الشّبكة والتعامل معها كما لو كانت مركَّبة محليًّا على نفس النظام. فوائد نظام NFS يسمح نظام NFS بالوصول إلى الملفّات عن بعد. يستخدم بنية عميل-خادوم Client/Server معيارية لتشارك الملفّات بين جميع الأجهزة العاملة بالأنظمة الشبيهة بيونكس. ليس ضروريًّا عند استخدام NFS أن تكون الأجهزة تعمل على نفس نظام التّشغيل. يمكن ضبط حلول للتخزين المركزيّ بمساعدة نظام NFS. يعثُر المستخدمون على بياناتهم مهما كان تواجدها الفعلي. لا توجد حاجة للتحيين Refresh اليدوي للحصول على الملفّات الجديدة. تدعم الإصدارات الحديثة من NFS قوائم التحكّم في الوصول ACL. يمكن تأمينه عبر الجدران الناريّة Firewalls وKerberos (ميثاق للاستيثاق عبر الشبكة). تدخلّ الملفّات التاليّة في إعداد NFS: ملفّ etc/exports/: وهو ملفّ الإعداد الرئيس؛ تعرّف فيه - على الخادوم - جميع الملفّات والمجلّدات المشاركة. ملفّ etc/fstab/: يجب إدراج سطر لكلّ نظام ملفّات مُركَّب ضمن هذا الملفّ حتى يكون التركيب دائما (يبقى بعد إعادة التشغيل). ملفّ etc/sysconfig/nfs/: يعرّف المنافذ التي تنصت الخدمات للاتّصالات الواردة عبرها. إعداد NFS على خادوم أوبونتو سنعتمد في هذا الدرس على جهازين يعملان بإحدى توزيعات لينكس التاليّة: دبيان، أوبونتو أو ردهات. سنثبّت على أحد الجهازين خادوم NFS وعلى الثاني عميلا له كالتالي: خادوم NFS على العنوان 192.168.2.200. عميل NFS على العنوان 192.168.2.150. يمكنك استخدام VirtualBox لإعداد بيئة عمل بالمواصفات أعلاه. تثبيت الخادوم والعميل سنحتاج لتثبيت حزم NFS على الخادوم والعميل: # apt-get update # apt-get install nfs-kernel-server nfs-common ملحوظة: يمكن الاكتفاء بالحزمة nfs-common على العميل. تشير العلامة # إلى أن الأمر ينفَّذ بصلاحيّات الجذر. إعداد خادوم NFS الخطوة الأولى هي تحديد المجلّد الذي نريد مشاركته؛ سننشئ واحدا لهذا الغرض (يمكنك اختيّار مجلّد موجود مسبقا): # mkdir /nfsshare ثم نغيّر ملكيّته إلى nobody:nogroup: # chown nobody:nogroup /nfsshare غيّرنا ملكيّة الملفّ إلى المستخدم nobody الذي هو حساب لا يملك سوى الصلاحيّات الدنيا ويُستخدَم عادة لتنفيذ سكربتات غير مأمونة المصدر حتى لا تلحق أي ضرر بالنظام. هذه الخطوة ضروريّة وإلا فلن يكون بمقدورك إضافة ملفّات إلى المجلّد انطلاقا من العميل؛ إلا إذا أضفت خيار no_root_squash كما هو مشروح أدناه (لا يُنصَح بذلك). ليمكن تشاركُ المجلّد يجب أن نضيفه إلى ملفّ الإعداد etc/exports/؛ نفتح هذا الملفّ (بصلاحيّات الجذر) ثم نضيف إليه السّطر التالي: /nfsshare 192.168.2.150(rw,sync) يسمح السّطر أعلاه بتشارك المجلّد nfsshare مع العميل على العنوان 192.168.2.150 مع تحديد خيارات التشارك. يمكن أن تكون الخيارات على النحو التالي: ro: الوصول عبر وضع القراءة فقط؛ أي أن العميل يمكنه الوصول إلى الملفات المتشاركة فقط دون أن يكون قادرا على التعديل عليها أو إنشاء ملفات جديدة. rw: يمنح العميل القدرة على الوصول إلى الملفّات والتعديل عليها. sync: مزامنة التعديلات. يعني هذا أن أي تعديل سيُحفَظ فورا على نظام الملفّات؛ قد يؤثّر هذا الخيار على الأداء في حالة وجود الكثير من التغييرات المتزامنة على ملفّات كبيرة. no_subtree_check: يفحص نظام NFS مبدئيّا جميع المجلدات التي يتفرّع منها المجلّد المتشارَك من أجل التحقّق من الأذون وتفاصيل أخرى. يؤدّي تفعيل هذه الخاصيّة إلى تعطيل الفحص ممّا يحسّن من الأداء ولكنّه يؤدّي التقليل من الأمان. no_root_squash: تسمح هذه الخاصيّة للمستخدم الجذر على الجهاز العميل بالوصول إلى الملفّات المتشاركة على الخادوم بصلاحيّات الجذر على الخادوم. لا يُنصَح لأسباب أمنيّة باستخدام هذا الخيار إلا في حالات خاصّة. نطبّق الأمر exportfs بعد الانتهاء من تحرير الملفّ exports من أجل اعتماد التعديلات: # exportfs -r ثم نشغّل خدمة NFS كالتالي: # service nfs-kernel-server start إعداد عميل NFS على أوبونتو يمكننا الآن تركيب مجلّد التشارك على العميل. تأكد من أنه يمكن التواصل عبر الشبكة بين الجهاز الخادوم والعميل؛ مثلا باستخدام الأمر ping على العميل (حيثُ 192.168.2.200 هو عنوان الخادوم): $ ping 192.168.2.200 PING 192.168.2.200 (192.168.2.200) 56(84) bytes of data. 64 bytes from 192.168.2.200: icmp_seq=7 ttl=52 time=363 ms 64 bytes from 192.168.2.200: icmp_seq=8 ttl=52 time=322 ms نبدأ أولا بالبحث عن الملفّات المتشاركة عبر NFS على الخادوم: $ showmount -e 192.168.2.200 Export list for 192.168.2.200: /nfsshare 192.168.2.150 يظهر من نتيجة الأمر أعلاه أن المجلّد nfsshare/ متاح للتشارك مع العميل ذي العنوان 192.168.2.150. تركيب المجلد على العميل سننشئ على العميل مجلّدًا باسم mnt/nfs/nfsshare_mount/ ونستخدمه لتركيب المجلّد nfsshare/ على العميل (المجلّد nfsshare/ الموجود على الخادوم): # mkdir -p /mnt/nfs/nfsshare_mount # mount -t nfs 192.168.2.200:/nfsshare /mnt/nfs/nfsshare_mount يمكننا التأكد من تركيب المجلّد بتنفيذ الأمر mount والبحث عن نوع الملفّات nfs: $ mount | grep nfs 192.168.2.200:/nfsshare on /mnt/nfs/nfsshare_mount type nfs (rw,vers=4,addr=192.168.2.200,clientaddr=192.168.2.150) يمكن الآن إضافة ملفّات إلى مجلّد التشارك عبر نقطة التركيب: # touch /mnt/nfs/nfsshare_mount/testfile.txt يمكن التأكد من على الخادوم بسرد محتويات المجلّد nfsshare/. إن أردت جعل التركيب دائما (لا يزول مع إقلاع النظام) فيمكنك إضافة السطر التالي إلى ملفّ etc/fstab/: 192.168.2.200:/nfsshare /mnt/nfs/nfsshare_mount nfs defaults 0 0 نفّذ الأمر mount -a بعد تعديل ملفّ fstab لاعتماد التغييرات فورا. ملحوظة: تأكد من إدخال القيم الصحيحة في ملفّ etc/fstab/؛ وجود أخطاء في صياغة السّطر يمكن أن يؤدي إلى عدم إقلاع النظام. فصل المجلد من العميل استخدم الأمر umount إن أردت فصل المجلّد المركَّب، تُمرّضر نقطة التركيب للأمر على النحو التالي: # umount /mnt/nfs/nfsshare_mount نفّذ الأمر mount | grep nfs للتأكد من فصل المجلّد. أوامر أساسية للتعامل مع ملفات NFS في ما يلي أوامر يكثُر استخدامها أثناء التعامل مع المجلّدات المشارَكة عبر نظام NFS: showmount -e: يعرض جميع المجلّدات المتشاركة المتاحة على الجهاز. showmount -e <server-ip>: يسرد قائمة بالمجلّدات المشاركة المتاحة على الخادوم ذي العنوان server-ip. showmount -d <server-ip>: سرد المجلّدات المشاركة المتاحة على الخادوم والمجلدات المتفرعة منها. exportfs -v: يعرض قائمة بالمجلّدات المتشاركة الموجوة على الخادوم. exportfs -a: يطلب من الخادوم مشاركة الملفّات المحدّدة في الملفّ etc/exports/. exportfs -u: يعمل عكسَ عمل الأمر السابق، إذ يوقف مشاركة المجلدات المحدّدة في etc/exports/. exportfs -r: يحدّث قائمة المشاركات بعد التعديل على الملفّ etc/exports/. يمكن اعتماد هذا المقال الذي يقدّم أساسيات تشارك الملفّات عبر نظام NFS للانتقال إلى تفاصيل أكثر تقدّما بخصوص NFS والميزات التي يقدّمها. ترجمة -وبتصرّف- للمقال How to Setup NFS (Network File System) on RHEL/CentOS/Fedora and Debian/Ubuntu لصاحبه Tarunika Shrivastava. -
 تم بشكل رسمي إطلاق الإصدار 16.04 LTS ذو الدعم طويل الأمد (الملقّب بـ Xerial Xerus) من توزيعة أوبونتو منذ عدّة أسابيع، ويتشوق الكثيرون إلى معرفة المزيد عن التغييرات التي طرأت والميزات الجديدة التي أضيفت، ويمكن القيام بذلك من خلال تثبيت نسخة نظيفة clean install أو تحديث نسخة قديمة من توزيعة لينوكس أوبونتو. سنتابع في المقال كيفية القيام بتحديث توزيعة أوبونتو من الإصدار 14.04 LTS إلى الإصدار الجديد وذلك خطوة بخطوة. تحذير: يجب أخذ الاحتياطات اللازمة وإنشاء نسخة احتياطية للبيانات كالمجلدات والمستندات والصور والكثير من الملفات الموجودة على النظام، ولا يجوز ترك الموضوع للحظ لأن في بعض الأحيان لا تجري عمليات التحديث كما هو متوقّع، وقد تصادف بعض الإشكالات التي قد تؤدي إلى تلف البيانات في حال فشلت عملية التحديث. تحديث توزيعة أوبونتو 14.04 إلى 16.04 على نسخة أوبونتو المكتبية Desktop Edition في البداية سنتحقق من أن النظام يملك آخر إصدار من البرمجيات المثبّتة، ونقوم بذلك من خلال فتح مدير تحديثات أوبونتو Ubuntu Update manager الموجود في لوحة القيادة Dashboard. رسم توضيحي 1 – البحث عن الإصدارات الجديدة لبرمجيات أوبونتو المثبّتة سيقوم مدير التحديثات بفحص النظام للتحقق فيما إذا كانت البرمجيات المثبتة تم تحديثها لآخر إصدار، وعند انتهائه يقوم بعرض قائمة بالبرمجيات التي سيتم تحديثها وتثبيت الإصدار الجديد منها. رسم توضيحي 2 - قائمة بالبرمجيات التي يتوفر إصدارات أحدث منها نقوم بالضغط على زر Install Now لتحميل وتثبيت التحديثات المعروضة. رسم توضيحي 3 - تحميل تحديثات برمجيات أوبونتو بعد انتهاء التحميل، سيتم البدء بتثبيت الإصدارات الجديدة: رسم توضيحي 4 - تثبيت تحديثات برمجيات أوبونتو بعد الانتهاء سيعُرض علينا إعادة التشغيل لإنهاء عملية تثبيت التحديثات، وسنقوم باختيار إعادة التشغيل Restart Now. رسم توضيحي 5 - إعادة التشغيل لإنهاء عملية تحديث البرمجيات أخيرًا، يمكن التحقق من أنه قد تم تثبيت جميع التحديثات على البرمجيات بفتح مدير التحديثات مجددًا ويُفترض أن تظهر الرسالة التالية التي تشير إلى عدم وجود تحديثات جديدة: رسم توضيحي 6 - جميع البرمجيات مثبتة بآخر إصداراتها سنباشر الآن بعملية تحديث التوزيعة، نقوم في البداية بفتح سطر الأوامر وتنفيذ الأمر التالي للبدء بعملية تحديث التوزيعة للإصدار الجديد 16.04 LTS: $ sudo update-manager -d تنبيه: انتبه إلى وجود مسافة ما بين update-manager و d- في الأمر السابق. بعد تنفيذ الأمر، سيطلب النظام إدخال كلمة مرور المستخدم، قم بإدخالها والضغط على مفتاح Enter وسيتم فتح مدير التحديث update-manager كما في الصورة: رسم توضيحي 7 - تحديث أوبونتو إلى الإصدار 16.04 أخيرًا، اضغط على زر Upgrade لتحديث نسخة التوزيعة. تحديث توزيعة أوبونتو 14.04 إلى 16.04 على نسخة أوبونتو الخاصة بالخوادم Server Edition سنقوم بتطبيق ذات الخطوات أيضًا، حيث سنبدأ بتحديث البرمجيات المثبتة من خلال تنفيذ الأمر: $ sudo apt-get update && sudo apt-get dist-upgrade وبعد الانتهاء قم بإعادة التشغيل لإنهاء تثبيت التحديثات: $ sudo init 6 بعد ذلك سنقوم بتثبيت حزمة update-manager-core باستخدام الأمر التالي إذا لم تكن مثبتة مسبقًا على الخادوم: $ sudo apt-get install update-manager-core بعد ذلك، سنقوم بفتح الملف etc/update-manager/release-upgrades/ باستخدام أي محرر نصوص نُفضّله (نستخدم vi في مثالنا)، وسنضيف عبارة Prompt=lts إلى نهايته كما في الصورة التالية: $ sudo vi /etc/update-manager/release-upgrades رسم توضيحي 8 - إعداد مدير تحديثات أوبونتو بعد ذلك، سنبدأ عملية التحديث بتنفيذ الأمر: $ sudo do-release-upgrade -d تنبيه: انتبه أيضًا إلى وجود مسافة ما بين do-release-upgrade و d- في الأمر السابق. رسم توضيحي 9 - عملية تحديث توزيعة أوبونتو 14.04 بعد أن يقوم مدير التحديثات بتحديد الحزم التي سيتم تحديثها وأفضل مصادر لها، سيطلب منك تأكيد العملية لذا سنقوم بالنقر على مفتاح y (الذي يشير إلى كلمة yes) ومن ثم نضغط على مفتاح Enter للبدء بعملية التحديث: رسم توضيحي 10 - تحديث أوبونتو للإصدار 16.04 سيُعرض أثناء عملية التحديث إعادة تشغيل بعض الخدمات، لذا نختار الموافقة yes حينها: رسم توضيحي 11 - إعداد الخدمات أثناء عملية تحديث توزيعة أوبونتو أخيرًا، سيُسأل فيما إذا كنا نرغب بإزالة الحزم القديمة التي تم تحديثها أو استبدالها، وسنقوم بالموافقة بالضغط على مفتاح y ومن ثم Enter. بعد انتهاء عملية التحديث نقوم بإعادة تشغيل الخادوم باستخدام الأمر: $ sudo init 6 ونكون قد انتهينا من تحديث توزيعة أوبونتو للإصدار 16.04 LTS. آمل أن تجدوا هذا الدليل مفيًدا ومساعدًا، وفي حال ظهور مشكلة أثناء العملية نظرًا لاختلاف خبرات المستخدمين أثناء عملية التحديث، فلا تترددوا بالسؤال في قسم التعليقات أدناه. ترجمة -وبتصرّف- للمقال How To Upgrade to Ubuntu 16.04 LTS from Ubuntu 14.04 LTS لصاحبه Aaron Kili.
تم بشكل رسمي إطلاق الإصدار 16.04 LTS ذو الدعم طويل الأمد (الملقّب بـ Xerial Xerus) من توزيعة أوبونتو منذ عدّة أسابيع، ويتشوق الكثيرون إلى معرفة المزيد عن التغييرات التي طرأت والميزات الجديدة التي أضيفت، ويمكن القيام بذلك من خلال تثبيت نسخة نظيفة clean install أو تحديث نسخة قديمة من توزيعة لينوكس أوبونتو. سنتابع في المقال كيفية القيام بتحديث توزيعة أوبونتو من الإصدار 14.04 LTS إلى الإصدار الجديد وذلك خطوة بخطوة. تحذير: يجب أخذ الاحتياطات اللازمة وإنشاء نسخة احتياطية للبيانات كالمجلدات والمستندات والصور والكثير من الملفات الموجودة على النظام، ولا يجوز ترك الموضوع للحظ لأن في بعض الأحيان لا تجري عمليات التحديث كما هو متوقّع، وقد تصادف بعض الإشكالات التي قد تؤدي إلى تلف البيانات في حال فشلت عملية التحديث. تحديث توزيعة أوبونتو 14.04 إلى 16.04 على نسخة أوبونتو المكتبية Desktop Edition في البداية سنتحقق من أن النظام يملك آخر إصدار من البرمجيات المثبّتة، ونقوم بذلك من خلال فتح مدير تحديثات أوبونتو Ubuntu Update manager الموجود في لوحة القيادة Dashboard. رسم توضيحي 1 – البحث عن الإصدارات الجديدة لبرمجيات أوبونتو المثبّتة سيقوم مدير التحديثات بفحص النظام للتحقق فيما إذا كانت البرمجيات المثبتة تم تحديثها لآخر إصدار، وعند انتهائه يقوم بعرض قائمة بالبرمجيات التي سيتم تحديثها وتثبيت الإصدار الجديد منها. رسم توضيحي 2 - قائمة بالبرمجيات التي يتوفر إصدارات أحدث منها نقوم بالضغط على زر Install Now لتحميل وتثبيت التحديثات المعروضة. رسم توضيحي 3 - تحميل تحديثات برمجيات أوبونتو بعد انتهاء التحميل، سيتم البدء بتثبيت الإصدارات الجديدة: رسم توضيحي 4 - تثبيت تحديثات برمجيات أوبونتو بعد الانتهاء سيعُرض علينا إعادة التشغيل لإنهاء عملية تثبيت التحديثات، وسنقوم باختيار إعادة التشغيل Restart Now. رسم توضيحي 5 - إعادة التشغيل لإنهاء عملية تحديث البرمجيات أخيرًا، يمكن التحقق من أنه قد تم تثبيت جميع التحديثات على البرمجيات بفتح مدير التحديثات مجددًا ويُفترض أن تظهر الرسالة التالية التي تشير إلى عدم وجود تحديثات جديدة: رسم توضيحي 6 - جميع البرمجيات مثبتة بآخر إصداراتها سنباشر الآن بعملية تحديث التوزيعة، نقوم في البداية بفتح سطر الأوامر وتنفيذ الأمر التالي للبدء بعملية تحديث التوزيعة للإصدار الجديد 16.04 LTS: $ sudo update-manager -d تنبيه: انتبه إلى وجود مسافة ما بين update-manager و d- في الأمر السابق. بعد تنفيذ الأمر، سيطلب النظام إدخال كلمة مرور المستخدم، قم بإدخالها والضغط على مفتاح Enter وسيتم فتح مدير التحديث update-manager كما في الصورة: رسم توضيحي 7 - تحديث أوبونتو إلى الإصدار 16.04 أخيرًا، اضغط على زر Upgrade لتحديث نسخة التوزيعة. تحديث توزيعة أوبونتو 14.04 إلى 16.04 على نسخة أوبونتو الخاصة بالخوادم Server Edition سنقوم بتطبيق ذات الخطوات أيضًا، حيث سنبدأ بتحديث البرمجيات المثبتة من خلال تنفيذ الأمر: $ sudo apt-get update && sudo apt-get dist-upgrade وبعد الانتهاء قم بإعادة التشغيل لإنهاء تثبيت التحديثات: $ sudo init 6 بعد ذلك سنقوم بتثبيت حزمة update-manager-core باستخدام الأمر التالي إذا لم تكن مثبتة مسبقًا على الخادوم: $ sudo apt-get install update-manager-core بعد ذلك، سنقوم بفتح الملف etc/update-manager/release-upgrades/ باستخدام أي محرر نصوص نُفضّله (نستخدم vi في مثالنا)، وسنضيف عبارة Prompt=lts إلى نهايته كما في الصورة التالية: $ sudo vi /etc/update-manager/release-upgrades رسم توضيحي 8 - إعداد مدير تحديثات أوبونتو بعد ذلك، سنبدأ عملية التحديث بتنفيذ الأمر: $ sudo do-release-upgrade -d تنبيه: انتبه أيضًا إلى وجود مسافة ما بين do-release-upgrade و d- في الأمر السابق. رسم توضيحي 9 - عملية تحديث توزيعة أوبونتو 14.04 بعد أن يقوم مدير التحديثات بتحديد الحزم التي سيتم تحديثها وأفضل مصادر لها، سيطلب منك تأكيد العملية لذا سنقوم بالنقر على مفتاح y (الذي يشير إلى كلمة yes) ومن ثم نضغط على مفتاح Enter للبدء بعملية التحديث: رسم توضيحي 10 - تحديث أوبونتو للإصدار 16.04 سيُعرض أثناء عملية التحديث إعادة تشغيل بعض الخدمات، لذا نختار الموافقة yes حينها: رسم توضيحي 11 - إعداد الخدمات أثناء عملية تحديث توزيعة أوبونتو أخيرًا، سيُسأل فيما إذا كنا نرغب بإزالة الحزم القديمة التي تم تحديثها أو استبدالها، وسنقوم بالموافقة بالضغط على مفتاح y ومن ثم Enter. بعد انتهاء عملية التحديث نقوم بإعادة تشغيل الخادوم باستخدام الأمر: $ sudo init 6 ونكون قد انتهينا من تحديث توزيعة أوبونتو للإصدار 16.04 LTS. آمل أن تجدوا هذا الدليل مفيًدا ومساعدًا، وفي حال ظهور مشكلة أثناء العملية نظرًا لاختلاف خبرات المستخدمين أثناء عملية التحديث، فلا تترددوا بالسؤال في قسم التعليقات أدناه. ترجمة -وبتصرّف- للمقال How To Upgrade to Ubuntu 16.04 LTS from Ubuntu 14.04 LTS لصاحبه Aaron Kili.











