

يُعد فلاسك إطار عمل للويب مبني بلغة بايثون، ويتميز بكونه صغير الحجم وسهل المعالجة، ويوفّر أيضًا عدة أدوات وميزات من شأنها إنشاء تطبيقات ويب في لغة بايثون.
أمّا SQLAlchemy فهي أداة في محرك قواعد البيانات SQL تؤمن وصولًا فعالًا وعالي الأداء إلى قواعد البيانات العلاقية، كما توفّر طرقًا للتخاطب مع العديد من محركات قواعد البيانات، مثل SQLite و MySQL و PostgreSQ، مانحةً إمكانية الوصول إلى آليات SQL الخاصة بقواعد البيانات، كما توفّر رابط الكائن بالعلاقات Object Relational Mapper -أو اختصارًا ORM- الذي يتيح إمكانية إنشاء الاستعلامات والتعامل مع البيانات باستخدام توابع وكائنات بسيطة في بايثون.
تعدّ Flask-SQLAlchemy إضافةً لفلاسك تسهّل استخدام SQLAlchemy ضمنها وتؤمّن الأدوات والوسائل المناسبة للتعامل مع قاعدة البيانات في تطبيقات فلاسك من خلال SQLAlchemy.
سنستخدم في هذا المقال كلًا من إطار العمل فلاسك والإضافة Flask-SQLAlchemy لإنشاء نظام إدارة موظفين مع قاعدة بيانات تضم جدولًا خاصًّا بكل موظف، ليتضمّن هذا الجدول المعرّف الفريد ID للموظف واسمه الأوّل ونسبته وبريده الإلكتروني الفريد، إضافةً إلى عددٍ صحيح يدل على عمره وقيمة تاريخ تشير إلى تاريخ انضمامه إلى الشركة (تاريخ تعيّينه) وقيمةٍ منطقية تُحدّد ما إذا كان هذا الموظف متواجد حاليًا في مكتبه أم لا.
إذ سنستخدم صَدَفَة فلاسك للاستعلام عن جدول ما والحصول على سجلاتٍ معيّنة وفقًا لقيمة عمود منه (مثل البريد الإلكتروني)، أي سنجلب سجلات الموظفين المُحقّقة لشروط مُحدّدة، كأن نجلب فقط الموظفين المتواجدين حاليًا أو أن نُنشئ قائمةً بالموظفين غير المتواجدين، كما سنرتّب النتائج وفقًا لقيم أحد الأعمدة، بما يتضمّن تحديد نتائج الاستعلام وحساب عددها، وسنستخدم نهايةً الترقيم Pagination بغية عرض عدد مُحدّد من الموظفين في الصفحة الواحدة ضمن تطبيق الويب.
مستلزمات العمل
قبل المتابعة في هذا المقال لا بدّ من:
- توفُّر بيئة برمجة بايثون 3 محلية، مثبّتة على حاسوبك، وسنفترض في مقالنا أن اسم مجلد المشروع هو "flask_app".
- الفهم الجيد لأساسيات فلاسك، مثل مفهوم الوجهات ودوال العرض، ويمكنك في هذا الصدد الاطلاع على المقالين كيفية بناء موقعك الإلكتروني الأول باستخدام إطار عمل فلاسك Flask من لغة بايثون وكيفية استخدام القوالب في تطبيقات فلاسك Flask لفهم مبادئ فلاسك.
- فهم أساسيات لغة HTML.
- فهم أساسيات الإضافة Flask-SQLAlchemy، مثل إعداد قاعدة البيانات وإنشاء نماذجها وإدخال البيانات إليها، وننصحك في هذا الصدد بقراءة المقال استخدام الإضافة Flask-SQLAlchemy للتخاطب مع قواعد البيانات في تطبيقات فلاسك لفهم مبادئ هذه الإضافة.
الخطوة 1: إعداد قاعدة البيانات والنموذج
سنثبّت في هذه الخطوة كافّة الحزم اللازمة، كما سنعدّ كلًا من تطبيق فلاسك وقاعدة البيانات Flask-SQLAlchemy ونموذج الموظف المُمثّل للجدول employee، حيث سنخزّن بيانات الموظف، كما سنضيف وجهة وصفحة، حيث سنعرض كافّة الموظفين ضمن الصفحة الرئيسية للتطبيق.
لذا، وبعد التأكّد من كون البيئة الافتراضية مُفعّلة، سنستخدم أمر تثبيت الحزم pip لتثبيت كل من فلاسك والإضافة Flask-SQLAlchemy على النحو التالي:
(env)user@localhost:$ pip install Flask Flask-SQLAlchemy
بمجرّد انتهاء التثبيت بنجاح، سيظهر في السطر الأخير من الخرج ما يشبه التالي:
Successfully installed Flask-2.1.2 Flask-SQLAlchemy-2.5.1 Jinja2-3.1.2 MarkupSafe-2.1.1 SQLAlchemy-1.4.37 Werkzeug-2.1.2 click-8.1.3 greenlet-1.1.2 itsdangerous-2.1.2
الآن وبعد تثبيت الحزم اللازمة، سننشئ ملفًا جديدًا باسم "app.py" ضمن المجلد "flask.app" والذي سيحتوي على الشيفرات الخاصة بإعداد قاعدة البيانات ووجهات فلاسك اللازمة لعمل التطبيق:
(env)user@localhost:$ nano app.py
ونكتب ضمنه الشيفرة التالية، التي ستُعِدّ قاعدة بياناتٍ من نوع SQLite ونموذج قاعدة بيانات للموظف مُمثّلًا للجدول employee الذي سنستخدمه لتخزين بيانات كل موظف:
import os from flask import Flask, render_template, request, url_for, redirect from flask_sqlalchemy import SQLAlchemy basedir = os.path.abspath(os.path.dirname(__file__)) app = Flask(__name__) app.config['SQLALCHEMY_DATABASE_URI'] =\ 'sqlite:///' + os.path.join(basedir, 'database.db') app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False db = SQLAlchemy(app) class Employee(db.Model): id = db.Column(db.Integer, primary_key=True) firstname = db.Column(db.String(100), nullable=False) lastname = db.Column(db.String(100), nullable=False) email = db.Column(db.String(100), unique=True, nullable=False) age = db.Column(db.Integer, nullable=False) hire_date = db.Column(db.Date, nullable=False) active = db.Column(db.Boolean, nullable=False) def __repr__(self): return f'<Employee {self.firstname} {self.lastname}>'
نحفظ الملف ونغلقه.
استوردنا في الشيفرة السابقة الوحدة os التي تُمكنّنا من الوصول إلى واجهات نظام التشغيل المختلفة، والتي سنستخدمها في بناء مسار ملف قاعدة البيانات database.db، كما استوردنا من حزمة فلاسك كافّة المُساعدات اللازمة للتطبيق، مثل الصنف فلاسك Flask المُستخدم في إنشاء النسخة الفعلية من التطبيق، والدالة ()render_template لتصيير قوالب HTML، والكائن request المسؤول عن التعامل مع الطلبات، والدالة ()url_for لبناء روابط الوجهات، والدالة ()redirect لإعادة توجيه المُستخدمين من صفحة لأُخرى.
استوردنا بعد ذلك الصنف SQLAlchemy من الإضافة Flask-SQLAlchemy، والذي يسمح لنا بالوصول إلى جميع الدوال والأصناف الخاصة بالأداة SQLAlchemy، إضافةً إلى المُساعدات والآليات التي تدعم عمل فلاسك مع هذه الأداة، والتي سنستخدمها لإنشاء كائن قاعدة بيانات يتصل مع تطبيق فلاسك.
بهدف إنشاء مسار لملف قاعدة البيانات، حدّدنا المجلد الحالي ليكون المجلد الرئيسي، كما استخدمنا الدالة ()os.path.abspath للحصول على المسار المطلق لمجلد الملف الحالي، إذ يتضمّن المتغير الخاص __file__ اسم مسار الملف الحالي app.py، وخزنّا المسار المطلق للمجلد الأساسي ضمن المتغير basedir.
بعد ذلك، أنشأنا نسخةً فعليةً من تطبيق فلاسك باسم app والتي سنستخدمها لضبط مفتاحي إعدادات خاصّين بالإضافة Flask-SQLAlchemy، هما:
-
SQLALCHEMY_DATABASE_URI: وهو معرّف الموارد الموحّد الخاص بقاعدة البيانات database URI، وهو مسؤول عن تحديد قاعدة البيانات المراد إنشاء اتصال معها، وفي هذه الحالة تكون صيغة هذا المعرّف على النحوsqlite://path/to/database.db، إذ تُستخدم الدالة()op.path.joinلتحقيق الربط المدروس ما بين المجلد الأساسي الذي أنشاناه وخزنّا مساره في المتغيرbasedir، وبين اسم الملفdatabase.db، الأمر الذي يسمح بالاتصال مع ملف قاعدة البيانات "database.db" الموجود في المجلد "flask.app"، إذ سيُنشَئ هذا الملف فور تهيئة قاعدة البيانات. -
SQLALCHEMY_TRACK_MODIFICATIONS: وهو إعداد لتمكين أو إلغاء تمكين ميزة تتبع تغيرات الكائنات، وقد عيّناه إلى القيمةfalseلإلغاء التتبع وبالتالي تحقيق استخدام أقل لموارد الذاكرة.
بعد الانتهاء من ضبط إعدادات الأداة SQLAIchemy من خلال تعيين معرّف الموارد الموحّد لقاعدة البيانات وإلغاء تمكين ميزة تتبّع التغييرات، أنشأنا كائن قاعدة بيانات باستخدام صنف الأداة SQLAIchemy، ممررين إليه نسخة التطبيق بغية ربط تطبيق فلاسك مع الأداة SQLAIchemy، مخزنين كائن قاعدة البيانات هذا ضمن متغير باسم db والذي سنستخدمه في التخاطب مع قاعدة البيانات.
وبعد إعداد كل من نسخة التطبيق الفعلية وكائن قاعدة البيانات، أنشأنا نموذج قاعدة بيانات باسم Employee الوارث للصنف db.Model، إذ يُمثّل هذا النموذج جدول الموظفين employee المُتضمّن للأعمدة التالية:
-
id: وهو معرّف الموظف، ويحتوي على بياناتٍ من نوع رقم صحيح، ويمثّل المفتاح الأساسي. -
firstname: الاسم الأول للموظف، وهو سلسلة نصية بعدد محارف أعظمي يساوي 100، وتشير التعليمةnullable=Falseإلى أن هذا العمود لا يجب أن يحتوي على قيمٍ فارغة. -
lastname: الاسم الأخير للموظف، وهو سلسلة نصية بعدد محارف أعظمي يساوي 100، وتشير التعليمةnullable=Falseإلى أن هذا العمود لا يجب أن يحتوي على قيمٍ فارغة. -
email: عنوان البريد الإلكتروني للموظف، وهو سلسلة نصية بعدد محارف أعظمي يساوي 100، وتشير التعليمةunique=Trueإلى أنّ البريد الإلكتروني يجب أن يكون فريدًا لكل موظف، كما تشير التعليمةnullable=Falseإلى أن هذا العمود لا يجب أن يحتوي على قيمٍ فارغة. -
age: عمر الموظف، ويحتوي على بياناتٍ من نوع رقم صحيح. -
hire_date: يحتوي على تاريخ تعيين الموظف، وقد عيّنا نمط العمود ليكونdb.dateبغية التصريح عن كون هذا العمود يحتوي على تواريخ. -
active: يتضمّن قيمة منطقية تدل على ما إذا كان الموظف متواجد حاليًا في مكتبه أم لا.
تمكّننا الدالة الخاصة __repr__ من تمثيل كل كائن بصيغة سلسلة نصية، الأمر الذي يساعد في التعرّف على هذا الكائن لأغراض التنقيح، واستخدمنا في حالتنا الاسم الأوّل والأخير للموظف لتمثيل كائنات الموظفين.
الآن وبعد الانتهاء من إعداد كل من الاتصال مع قاعدة البيانات ونموذج الموظف، سنكتب برنامجًا في بايثون لإنشاء قاعدة البيانات والجدول employee وملء هذا الجدول ببعضٍ من بيانات الموظفين.
لذا، سننشئ ملفًا جديدًا باسم "init_db.py" ضمن المجلد "flask_app":
(env)user@localhost:$ nano init_db.py
ونكتب ضمنه الشيفرة التالية بغية حذف أي جداول حالية في قاعدة البيانات والبدء بقاعدة بيانات فارغة، كما سننشئ الجدول employee وسنملؤه ببيانات تسعة موظفين:
from datetime import date from app import db, Employee db.drop_all() db.create_all() e1 = Employee(firstname='John', lastname='Doe', email='jd@example.com', age=32, hire_date=date(2012, 3, 3), active=True ) e2 = Employee(firstname='Mary', lastname='Doe', email='md@example.com', age=38, hire_date=date(2016, 6, 7), active=True ) e3 = Employee(firstname='Jane', lastname='Tanaka', email='jt@example.com', age=32, hire_date=date(2015, 9, 12), active=False ) e4 = Employee(firstname='Alex', lastname='Brown', email='ab@example.com', age=29, hire_date=date(2019, 1, 3), active=True ) e5 = Employee(firstname='James', lastname='White', email='jw@example.com', age=24, hire_date=date(2021, 2, 4), active=True ) e6 = Employee(firstname='Harold', lastname='Ishida', email='hi@example.com', age=52, hire_date=date(2002, 3, 6), active=False ) e7 = Employee(firstname='Scarlett', lastname='Winter', email='sw@example.com', age=22, hire_date=date(2021, 4, 7), active=True ) e8 = Employee(firstname='Emily', lastname='Vill', email='ev@example.com', age=27, hire_date=date(2019, 6, 9), active=True ) e9 = Employee(firstname='Mary', lastname='Park', email='mp@example.com', age=30, hire_date=date(2021, 8, 11), active=True ) db.session.add_all([e1, e2, e3, e4, e5, e6, e7, e8, e9]) db.session.commit()
استوردنا في الشيفرة السابقة الصنف ()date من الوحدة datetime لاستخدامه في ضبط تواريخ تعيّين الموظفين.
استوردنا أيضًا كلًا من كائن قاعدة البيانات والنموذج Employee، واستدعينا الدالة ()db.drop_all بغية حذف كافّة الجداول الموجودة أصلًا في قاعدة البيانات متجنبين بذلك فرصة وجود جدول مملوء باسم "employee" سابقًا فيها، الأمر الذي قد يسبب أخطاءً.
من الجدير بالملاحظة أنّ البرنامج "init_db.py" سيحذف كامل محتويات قاعدة البيانات في كل مرة نشغّله فيها، وللمزيد حول كيفية إنشاء وتعديل وحذف جداول قاعدة البيانات، ننصحك بقراءة المقال استخدام الإضافة Flask-SQLAlchemy للتخاطب مع قواعد البيانات في تطبيقات فلاسك.
استنسخنا بعد ذلك النموذج Emolyee عدّة مرات بغية تمثيل كافّة الموظفين الذين سنستعلم عنهم في هذا المقال، ثم أضفنا هذه النسخ إلى قاعدة البيانات باستخدام الدالة ()db.session.add_all، ونهايةً استخدمنا التابع ()db.session.commit لتأكيد العمليات وتطبيق التغييرات على قاعدة البيانات.
نحفظ الملف ونغلقه.
سننفذ الآن البرنامج "init_db.py":
(env)user@localhost:$ python init_db.py
للاطلاع على البيانات المُضافة إلى قاعدة البيانات، نفتح صَدفة فلاسك بعد التأكّد من كون البيئة الافتراضية مُفعّلة بغية الاستعلام عن كافّة الموظفين وعرض بيانات كل منهم، على النحو التالي:
(env)user@localhost:$ flask shell
ثمّ نشغّل الشيفرة التالية المسؤولة عن الاستعلام عن كافّة الموظفين وعرض بياناتهم:
>>> from app import db, Employee >>> >>> >>> employees = Employee.query.all() >>> >>> for employee in employees: >>> print(employee.firstname, employee.lastname) >>> print('Email:', employee.email) >>> print('Age:', employee.age) >>> print('Hired:', employee.hire_date) >>> if employee.active: >>> print('Active') >>> else: >>> print('Out of Office') >>> print('----')
استخدمنا في الشيفرة السابقة التابع ()all من السمة query للحصول على كافّة الموظفين، واستخدمنا حلقةً تكراريةً للمرور على كافّة نتائج الاستعلام؛ أمّا بالنسبة للعمود "active"، فقد استخدمنا جملةً شرطيةً لإظهار الحالة الراهنة للموظف، سواءٌ كان متواجدًا "Active" أم خارج مكتبه "Out of Office".
نحصل على خرجٍ على النحو التالي:
John Doe Email: jd@example.com Age: 32 Hired: 2012-03-03 Active ---- Mary Doe Email: md@example.com Age: 38 Hired: 2016-06-07 Active ---- Jane Tanaka Email: jt@example.com Age: 32 Hired: 2015-09-12 Out of Office ---- Alex Brown Email: ab@example.com Age: 29 Hired: 2019-01-03 Active ---- James White Email: jw@example.com Age: 24 Hired: 2021-02-04 Active ---- Harold Ishida Email: hi@example.com Age: 52 Hired: 2002-03-06 Out of Office ---- Scarlett Winter Email: sw@example.com Age: 22 Hired: 2021-04-07 Active ---- Emily Vill Email: ev@example.com Age: 27 Hired: 2019-06-09 Active ---- Mary Park Email: mp@example.com Age: 30 Hired: 2021-08-11 Active ----
وبذلك نجد أنه قد جرى عرض كافة الموظفين المُضافين إلى قاعدة البيانات على نحوٍ سليم.
نُغلق الآن صَدَفة فلاسك:
>>> exit()
أمّا الآن، فسننشئ وجهة فلاسك المسؤولة عن عرض الموظفين، لذا سنفتح الملف app.py لتحريره:
(env)user@localhost:$ nano app.py
ونكتب الوجهة التالية في نهايته:
... @app.route('/') def index(): employees = Employee.query.all() return render_template('index.html', employees=employees)
نحفظ الملف ونغلقه.
ستستعلم الوجهة السابقة عن كافّة الموظفين، وتُصيّر قالب HTML للصفحة الرئيسية للتطبيق باسم "index.html" مُمررةً إليه نتائج الاستعلام.
ننشئ الآن مجلدًا للقوالب باسم "templates" وقالبًا رئيسيًا باسم "base.html":
(env)user@localhost:$ mkdir templates (env)user@localhost:$ nano templates/base.html
ونكتب التالي ضمن القالب الرئيسي:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>{% block title %} {% endblock %} - FlaskApp</title> <style> .title { margin: 5px; } .content { margin: 5px; width: 100%; display: flex; flex-direction: row; flex-wrap: wrap; } .employee { flex: 20%; padding: 10px; margin: 5px; background-color: #f3f3f3; inline-size: 100%; } .name { color: #00a36f; text-decoration: none; } nav a { color: #d64161; font-size: 3em; margin-left: 50px; text-decoration: none; } .pagination { margin: 0 auto; } .pagination span { font-size: 2em; margin-right: 10px; } .page-number { color: #d64161; padding: 5px; text-decoration: none; } .current-page-number { color: #666 } </style> </head> <body> <nav> <a href="{{ url_for('index') }}">FlaskApp</a> <a href="#">About</a> </nav> <hr> <div class="content"> {% block content %} {% endblock %} </div> </body> </html>
نحفظ الملف ونغلقه.
استخدمنا في الشيفرة السابقة كتلة عنوان، كما أضفنا بعضًا من تنسيقات CSS لتنسيق مظهر المكونات.
أضفنا أيضًا شريط تصفّح بعنصرين، الأوّل للصفحة الرئيسية للتطبيق، والثاني لصفحة عرض معلومات حول التطبيق إلا أننا سنتركها غير فعالة حاليًا، إذ سيُستخدم شريط التصفّح هذا في التطبيق في كافّة القوالب الوارثة للقالب الرئيسي، كما ستُستبدل كتلة المحتوى من القالب الرئيسي بالمحتوى الموافق لكل صفحة موظف.
نفتح الآن قالب الصفحة الرئيسية "index.html" الذي صيّرناه في الملف "app.py":
(env)user@localhost:$ nano templates/index.html
ونكتب ضمنه الشيفرة التالية:
{% extends 'base.html' %} {% block content %} <h1 class="title">{% block title %} Employees {% endblock %}</h1> <div class="content"> {% for employee in employees %} <div class="employee"> <p><b>#{{ employee.id }}</b></p> <b> <p class="name">{{ employee.firstname }} {{ employee.lastname }}</p> </b> <p>{{ employee.email }}</p> <p>{{ employee.age }} years old.</p> <p>Hired: {{ employee.hire_date }}</p> {% if employee.active %} <p><i>(Active)</i></p> {% else %} <p><i>(Out of Office)</i></p> {% endif %} </div> {% endfor %} </div> {% endblock %}
مررنا في الشيفرة السابقة على كافّة الموظفين باستخدام حلقةٍ تكرارية، لنعرض معلومات كل منهم، إذ أضفنا العنوان التوضيحي "Active" في حال كون الموظف متواجد حاليًا، وفيما عدا ذلك يُعرَض العنوان "Out of Office" دلالةً على عدم تواجده.
نحفظ الملف ونغلقه.
الآن ومع وجودنا ضمن المجلد "flask_app" ومع كون البيئة الافتراضية مُفعّلة، سنُعلم فلاسك بالتطبيق المراد تشغيله (وهو في حالتنا الملف "app.py") باستخدام متغير البيئة FLASK_APP، في حين يحدّد متغير البيئة FLASK_ENV وضع التشغيل وهنا قد اخترنا وضع development ما يعني أنّ التطبيق سيعمل في وضع التطوير مع تشغيل مُنقّح الأخطاء، وللمزيد من المعلومات حول مُنقّح الأخطاء في فلاسك ننصحك بقراءة المقال كيفية التعامل مع الأخطاء في تطبيقات فلاسك، ولتنفيذ ما سبق سنشغّل الأوامر التالية:
(env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ export FLASK_ENV=development
والآن سنشغّل التطبيق باستخدام الأمر flask run:
(env)user@localhost:$ flask run
وبعد التأكد من كون خادم التطوير ما يزال قيد التشغيل، نذهب إلى الرابط التالي باستخدام المتصفح:
http://127.0.0.1:5000/
فيظهر الموظفون المضافون إلى قاعدة البيانات في صفحة مشابهة للصورة التالية:
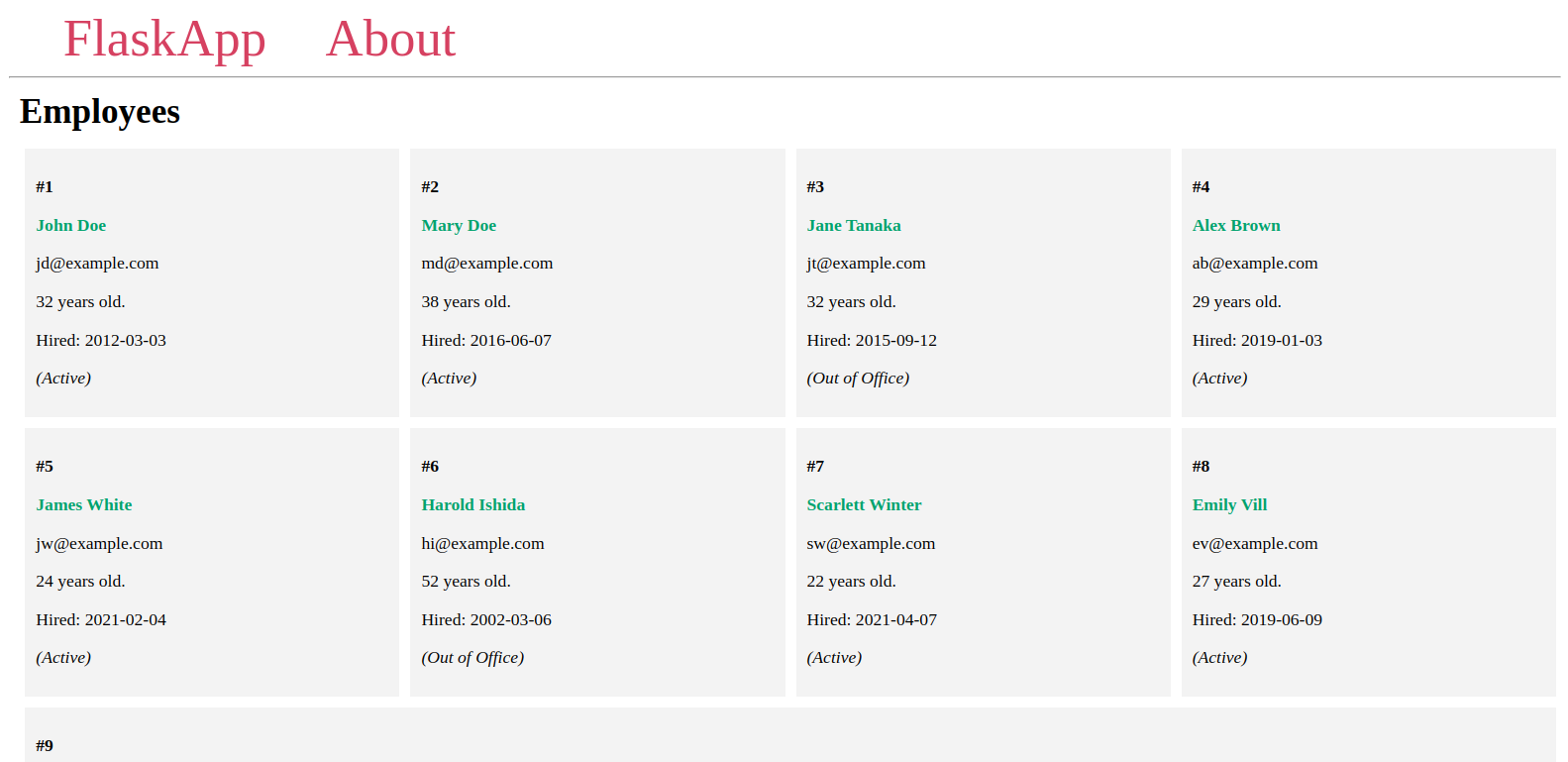
أما الآن، نترك الخادم قيد التشغيل، ونفتح نافذة طرفية جديدة استعدادًا للخطوة التالية، ومع نهاية هذه الخطوة نكون قد عرضنا الموظفين المدخلين في قاعدة البيانات على الصفحة الرئيسية للتطبيق، وسنستخدم في الخطوة التالية صَدَفة فلاسك للاستعلام عن الموظفين باستخدام توابع مختلفة.
الخطوة 2: الاستعلام عن السجلات
سنستخدم في هذه الخطوة صَدَفة فلاسك للاستعلام عن السجلات، لنجلب النتائج ونرشّحها باستخدام توابع مختلفة تحت شروط مختلفة.
سنضبط بدايةً متغيرات البيئة FLASK_APP و FLASK_ENV أثناء كون البيئة البرمجية مُفعّلة، ثم نفتح صَدَفة فلاسك:
(env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ export FLASK_ENV=development (env)user@localhost:$ flask shell
ثم نستورد كلًا من الكائن db والنموذج Employee:
>>> from app import db, Employee
استرجاع كافة السجلات
كما رأينا في الخطة السابقة، من الممكن استخدام التابع ()all من السمة query للحصول على كافّة سجلات الجدول، على النحو التالي:
>>> all_employees = Employee.query.all() >>> print(all_employees)
وعندها سيكون الخرج قائمةً بالكائنات المُمثلّة لكل الموظفين:
[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>, <Employee Alex Brown>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>, <Employee Emily Vill>, <Employee Mary Park>]
استرجاع السجل الأول
من المُمكن استخدام التابع ()first للحصول على السجل الأوّل بصورةٍ مشابهة لما سبق، على النحو التالي:
>>> first_employee = Employee.query.first() >>> print(first_employee)
وعندها سيكون الخرج هو الكائن المُتضمّن لبيانات الموظف الأوّل:
<Employee John Doe>
استرجاع سجل وفق معرفه
تُعرَّفُ السجلات في معظم جداول قواعد البيانات باستخدام معرّفٍ فريد ID، وتتيح الإضافة Flask-SQLAlchemy جلبَ سجلٍ ما وفقًا لمعرّفه باستخدام التابع ()get على النحو التالي:
>>> employee5 = Employee.query.get(5) >>> employee3 = Employee.query.get(3) >>> print(f'{employee5} | ID: {employee5.id}') >>> print(f'{employee3} | ID: {employee3.id}')
ويكون الخرج بالشكل:
<Employee James White> | ID: 5 <Employee Jane Tanaka> | ID: 3
استرجاع سجل أو عدة سجلات وفقا لقيمة عمود
من الممكن استخدام تابع الترشيح ()filter_by بغية الحصول على سجل محدّد وفقًا لقيمة أحد أعمدته، فمثلًا لجلب سجل ما وفقًا لقيمة معرفّه بما يشبه مبدأ عمل التابع ()get، نكتب:
>>> employee = Employee.query.filter_by(id=1).first() >>> print(employee)
ويكون الخرج بالشكل:
<Employee John Doe>
استخدمنا التابع ()first في الشيفرة السابقة لأنّ التابع ()filter_by قد يعيد عدّة نتائج، وبذلك نجلب الأولى منها فقط.
ملاحظة: في حال رغبتك بجلب سجلٍ ما وفقًا لمعرّفه، فإن المنهجية الأفضل هي استخدام التابع ()get.
من المُمكن أيضًا جلب موظف ما وفقًا لعمره، كما يلي:
>>> employee = Employee.query.filter_by(age=52).first() >>> print(employee)
فيكون الخرج بالشكل:
<Employee Harold Ishida>
لنأخذ مثالًا على حالة تتضمن فيها نتائج الاستعلام عدّة سجلات، إذ سنستعلم عندها وفقًا لاسم الموظف الأول firstname، وبقيمة "Mary"، وهنا توجد موظفتان بهذا الاسم في قاعدة البيانات لدينا:
>>> mary = Employee.query.filter_by(firstname='Mary').all() >>> print(mary)
فيكون الخرج بالشكل:
[<Employee Mary Doe>, <Employee Mary Park>]
استخدمنا التابع ()all في الشيفرة السابقة للحصول على قائمة نتائج الاستعلام كاملةً، كما من الممكن استخدام التابع ()first للحصول على النتيجة الأولى فقط، على النحو التالي:
>>> mary = Employee.query.filter_by(firstname='Mary').first() >>> print(mary)
ويكون الخرج عندها بالشكل:
<Employee Mary Doe>
وبذلك نكون قد جلبنا سجلاتٍ وفقًا لقيم أعمدة فيها، أما في الخطوة التالية فسنستعلم عن السجلات مُستخدمين شروطًا منطقية.
الخطوة 3: ترشيح السجلات باستخدام الشروط المنطقية
نحتاج غالبًا في تطبيقات الويب المعقدة كاملة الميزات إلى الاستعلام عن السجلات من قاعدة البيانات تحت شروطٍ معقدة، كأن نجلب الموظفين اعتمادًا على مجموعة من الشروط التي تأخذ في الحسبان مواقعهم وتوافرهم ودورهم الوظيفيّ ومسؤولياتهم.
ستتدرب في هذه الخطوة على كيفية استخدام المعاملات الشرطية، كما ستستخدم تابع الترشيح ()filter من سمة الاستعلام query بغية ترشيح نتائج الاستعلامات وفقًا لشروط منطقية تربط فيما بينها معاملاتٍ مُختلفة، إذ يمكن مثلًا استخدام المعاملات المنطقية لجلب قائمة بالموظفين غير المتواجدين في مكاتبهم حاليًا، أو أولئك الذين يستحقون ترقيةً، أو حتى لتوفير جدولة لمواعيد إجازات الموظفين وغيرها.
معامل التساوي
لعلّ أبسط معامل منطقي يمكن أن نستخدمه هو معامل المساواة ==، والذي يعمل بآلية مُشابهة للتابع ()filter_by، فللحصول مثلًا على كافّة السجلات التي قيمة عمود الاسم الأول firstname فيها تساوي "Mary"، يمكننا استخدام التابع ()filter على النحو التالي:
>>> mary = Employee.query.filter(Employee.firstname == 'Mary').all() >>> print(mary)
استخدمنا في الشيفرة السابقة التعليمة Model.column == value وسيطًا للتابع ()filter، ويعدّ التابع ()filter_by اختصارًا لهذه الطريقة، وستكون النتيجة نفسها كما في حالة استخدام التابع ()filter_by تحت نفس الشرط، وهي:
[<Employee Mary Doe>, <Employee Mary Park>]
وكما هو الحال لدى استخدام التابع ()filter_by، من الممكن جلب نتيجة الاستعلام الأولى فقط باستخدام التابع ()first، على النحو التالي:
>>> mary = Employee.query.filter(Employee.firstname == 'Mary').first() >>> print(mary)
فيصبح الخرج على الشّكل التالي:
<Employee Mary Doe>
معامل عدم التساوي
يتيح التابع ()filter إمكانية استخدام معامل عدم التساوي =! من بايثون في الحصول على السجلات، إذ يمكن مثلًا استخدام المنهجية التالية بغية الحصول على قائمة بالموظفين غير المتواجدين في مكاتبهم حاليًا:
>>> out_of_office_employees = Employee.query.filter(Employee.active != True).all() >>> print(out_of_office_employees)
فيكون الخرج بالشكل التالي:
[<Employee Jane Tanaka>, <Employee Harold Ishida>]
استخدمنا في الشيفرة السابقة الشرط Employee.active != True لترشيح نتائج الاستعلام.
معامل الأصغر تماما
من الممكن استخدام المعامل > للحصول على سجل وفقًا لشرط كون قيمة أحد أعمدته أصغر تمامًا من قيمة معينة، إذ يمكن مثلًا الحصول على قائمة بالموظفين الذين أعمارهم أصغر تمامًا من 32 عامًا على النحو التالي:
>>> employees_under_32 = Employee.query.filter(Employee.age < 32).all() >>> >>> for employee in employees_under_32: >>> print(employee.firstname, employee.lastname) >>> print('Age: ', employee.age) >>> print('----')
فيكون الخرج بالشكل التالي:
Alex Brown Age: 29 ---- James White Age: 24 ---- Scarlett Winter Age: 22 ---- Emily Vill Age: 27 ---- Mary Park Age: 30 ----
كما من الممكن استخدام المعامل => للحصول على السجلات الأصغر من قيمة معينة أو تساويها، فمثلًا لتضمين الموظفين الذين أعمارهم تساوي 32 عامًا بنتائج الاستعلام السابق، نكتب:
>>> employees_32_or_younger = Employee.query.filter(Employee.age <=32).all() >>> >>> for employee in employees_32_or_younger: >>> print(employee.firstname, employee.lastname) >>> print('Age: ', employee.age) >>> print('----')
فيصبح الخرج بالشّكل:
John Doe Age: 32 ---- Jane Tanaka Age: 32 ---- Alex Brown Age: 29 ---- James White Age: 24 ---- Scarlett Winter Age: 22 ---- Emily Vill Age: 27 ---- Mary Park Age: 30 ----
معامل الأكبر تماما
من الممكن استخدام المعامل < للحصول على سجل وفقًا لشرط كون قيمة أحد أعمدته أكبر تمامًا من قيمة معينة. فعلى سبيل المثال، للحصول على قائمة بالموظفين الذين أعمارهم أكبر تمامًا من 32 عامًا، نكتب:
>>> employees_over_32 = Employee.query.filter(Employee.age > 32).all() >>> >>> for employee in employees_over_32: >>> print(employee.firstname, employee.lastname) >>> print('Age: ', employee.age) >>> print('----')
فيكون الخرج بالشكل:
Mary Doe Age: 38 ---- Harold Ishida Age: 52 ----
كما من الممكن استخدام المعامل =< للحصول على السجلات الأكبر من قيمة معينة أو تساويها. فمثلًا لتضمين الموظفين الذين أعمارهم تساوي 32 عامًا بنتائج الاستعلام السابق، نكتب:
>>> employees_32_or_older = Employee.query.filter(Employee.age >=32).all() >>> >>> for employee in employees_32_or_older: >>> print(employee.firstname, employee.lastname) >>> print('Age: ', employee.age) >>> print('----')
فيصبح الخرج بالشّكل:
John Doe Age: 32 ---- Mary Doe Age: 38 ---- Jane Tanaka Age: 32 ---- Harold Ishida Age: 52 ----
تابع الانتماء In
تتيح الإضافة SQLAlchemy إمكانية الحصول على السجلات التي توافق قيمة أحد أعمدتها قيمةً ضمن قائمة معطاة وذلك باستخدام التابع ()_in على العمود المطلوب على النحو التالي:
>>> names = ['Mary', 'Alex', 'Emily'] >>> employees = Employee.query.filter(Employee.firstname.in_(names)).all() >>> print(employees)
فيكون الخرج بالشكل:
[<Employee Mary Doe>, <Employee Alex Brown>, <Employee Emily Vill>, <Employee Mary Park>]
استخدمنا في الشيفرة السابقة شرطًا وفق الصيغة (Model.column.in_(iterable، إذ تشير العبارة iterable لأي نوع تكراري من الكائنات (أي كائن يمكن المرور على عناصره، مثل القائمة). لنأخذ مثال آخر، إذ من الممكن استخدام دالة بايثون ()range للحصول على الموظفين المُنتمين لمجال معيّن من العمر، والاستعلام التالي يجلب كافّة الموظفين الذين أعمارهم في الثلاثينات:
>>> employees_in_30s = Employee.query.filter(Employee.age.in_(range(30, 40))).all() >>> for employee in employees_in_30s: >>> print(employee.firstname, employee.lastname) >>> print('Age: ', employee.age) >>> print('----')
فيكون الخرج بالشّكل:
John Doe Age: 32 ---- Mary Doe Age: 38 ---- Jane Tanaka Age: 32 ---- Mary Park Age: 30 ----
تابع عدم الانتماء Not in
من الممكن استخدام تابع عدم الانتماء ()not_in بصورةٍ مشابهة لآلية استخدام التابع السابق ()_in بغية الحصول على السجلات التي لا تنتمي قيمة أحد أعمدتها لمجموعة قيم ضمن كائن تكراري ما، كما في المثال التالي:
>>> names = ['Mary', 'Alex', 'Emily'] >>> employees = Employee.query.filter(Employee.firstname.not_in(names)).all() >>> print(employees)
فيكون الخرج بالشّكل:
[<Employee John Doe>, <Employee Jane Tanaka>, <Employee James White>, <Employee Harold Ishida>, <Employee Scarlett Winter>]
إذ حصلنا على كافّة الموظفين عدا أولئك الذي أسماؤهم الأولى موجودة ضمن القائمة المُسمّاة names.
معامل And
من الممكن ربط عدّة شروط منطقية مع بعضها بعضًا باستخدام الدالة ()_db.and التي تعمل بنفس آلية المعامل and في بايثون.
لنفرض مثلًا أننا نريد الحصول على جميع الموظفين الذين تبلغ أعمارهم 32 عامًا والمتواجدين في مكاتبهم حاليًا، ففي هذه الحالة، سنتحقق بدايةً من الموظفين البالغة أعمارهم 32 عامًا باستخدام التابع ()filter_by (أو التابع ()filter إذا أردت)، على النحو:
>>> for employee in Employee.query.filter_by(age=32).all(): >>> print(employee) >>> print('Age:', employee.age) >>> print('Active:', employee.active) >>> print('-----')
فيكون الخرج على النحو التالي:
<Employee John Doe> Age: 32 Active: True ----- <Employee Jane Tanaka> Age: 32 Active: False -----
حصلنا في الخرج السابق على موظَفيْن تبلغ أعمارهما 32 عامًا، أحدهما متواجد في مكتبه حاليًا والآخر قد غادره، وللحصول على الموظفين البالغة أعمارهم 32 عامًا والمتواجدين في مكاتبهم حاليًا، فلا بدّ من استخدام شرطين ضمن التابع ()filter، هما:
-
Employee.age == 32 -
Employee.active == True
ولربط الشرطين معًا، من الممكن استخدام الدالة ()_db.and كما يلي:
>>> active_and_32 = Employee.query.filter(db.and_(Employee.age == 32, >>> Employee.active == True)).all() >>> print(active_and_32)
فيكون الخرج على النحو التالي:
[<Employee John Doe>]
استخدمنا في الشيفرة السابقة الصيغة ((filter(db.and_(condition1, condition2 للربط بين الشرطين.
ومع تطبيق التابع ()all على نتائج الاستعلام نحصل على قائمة بكافّة النتائج المُحقّقة لكلا الشرطين، كما من الممكن استخدام التابع ()first للحصول على النتيجة الأولى فقط من نتائج الاستعلام.
>>> active_and_32 = Employee.query.filter(db.and_(Employee.age == 32, >>> Employee.active == True)).first() >>> print(active_and_32)
فيكون الخرج على النحو التالي:
<Employee John Doe>
لنأخذ مثالًا أكثر تعقيدًا، لنفرض أننا نريد الاستعلام عن الموظفين الذين جرى تعيينهم خلال فترة زمنية معينة، عندها من الممكن استخدام الدالة ()db.and مع الدالة ()date، كما في المثال التالي الهادف للحصول على كافّة الموظفين المُعينين خلال عام 2019:
>>> from datetime import date >>> >>> hired_in_2019 = Employee.query.filter(db.and_(Employee.hire_date >= date(year=2019, month=1, day=1), Employee.hire_date < date(year=2020, month=1, day=1))).all() >>> >>> for employee in hired_in_2019: >>> print(employee, ' | Hired: ', employee.hire_date)
فيكون الخرج على النحو التالي:
<Employee Alex Brown> | Hired: 2019-01-03 <Employee Emily Vill> | Hired: 2019-06-09
استوردنا في الشيفرة السابقة الدالة ()date، كما رشّحنا نتائج الاستعلام باستخدام الدالة ()_db.and بغية ربط شرطين، هما:
-
(Employee.hire_date >= date(year=2019, month=1, day=1: وهو مُحقّق "True" من أجل الموظفين المُعينين بدءًا من الأول من كانون الثاني لعام 2019 فما بعد. -
(Employee.hire_date < date(year=2020, month=1, day=1: وهو مُحقّق "True" من أجل الموظفين المُعينين قبل الأول من كانون الثاني لعام 2020.
حصلنا من خلال الربط بين الشرطين على الموظفين المُعينين بدءًا من بداية عام 2019 وحتى نهايته.
معامل Or
تعمل الدالة ()_db.or على ربط شرطين منطقيين كما تفعل الدالة ()_db.and، إلا أنها تشابه آلية عمل المعامل or في بايثون، إذ تعمل على جلب كافّة السجلات التي تحقق شرطًا على الأقل من الشرطين المُمررين إليها، فعلى سبيل المثال، للحصول على الموظفين البالغة أعمارهم 32 عامًا أو 52 عامًا، من الممكن الربط بين هذين الشرطين باستخدام الدالة ()_db.or بالشكل:
>>> employees_32_or_52 = Employee.query.filter(db.or_(Employee.age == 32, Employee.age == 52)).all() >>> >>> for e in employees_32_or_52: >>> print(e, '| Age:', e.age)
فيكون الخرج على النحو التالي:
<Employee John Doe> | Age: 32 <Employee Jane Tanaka> | Age: 32 <Employee Harold Ishida> | Age: 52
يمكن استخدام التابعين ()startswith (الذي يشترط على السلسة النصية البدء بمحرف معيّن) و ()endswith (الذي يشترط على السلسة النصية الانتهاء بمحرف معيّن) على السلاسل النصية في الشروط المُمرّرة إلى التابع ()filter، فعلى سبيل المثال، لجلب كافة الموظفين الذين يبدأ اسمهم الأول بالحرف 'M' وأولئك الذين ينتهي اسمهم الأخير بالحرف 'e' نكتب:
>>> employees = Employee.query.filter(db.or_(Employee.firstname.startswith('M'), Employee.lastname.endswith('e'))).all() >>> >>> for e in employees: >>> print(e)
فنحصل على الخرج التالي:
<Employee John Doe> <Employee Mary Doe> <Employee James White> <Employee Mary Park>
ربطنا في الشيفرة السابقة الشرطين التاليين:
-
('Employee.firstname.startswith('M: للحصول على الموظفين الذين يبدأ اسمهم الأول بالحرف'M'. -
('Employee.lastname.endswith('e: للحصول على الموظفين الذين ينتهي اسمهم الأخير بالحرف'e'.
وبذلك أصبح من الممكن الآن ترشيح نتائج الاستعلام باستخدام الشروط المنطقية في تطبيقات Flask-SQLAlchemy، أمّا في الخطوة التالية فسنعمل على ترتيب وتحديد وحساب عدد النتائج التي نحصل عليها من قاعدة البيانات.
الخطوة 4: ترتيب وتحديد وحساب عدد النتائج
غالبًا ما نضطر إلى ترتيب السجلات عند عرضها في تطبيقات الويب، فمن الممكن مثلًا أن يكون لدينا صفحةٌ لعرض التعيينات الأخيرة في كل قسم، وهذا يجعل باقي أعضاء فريق العمل يتعرّفون على زملائهم الجدد؛ كما من الممكن ترتيب عرض الموظفين بحيث يظهر الموظفين الأقدم أولًا بهدف معرفة أطول الموظفين خدمةً؛ وقد تحتاج أيضًا في بعض الحالات إلى تحديد النتائج، كما في حال رغبتك بعرض أحدث ثلاث موظفين ضمن شريط جانبي صغير، وغالبًا ما نضطر إلى حساب عدد نتائج الاستعلام، لعرض مثلًا عدد الموظفين المتواجدين في مكاتبهم حاليًا. ستتعرف في هذه الخطوة على كيفية ترتيب وتحديد وحساب عدد نتائج الاستعلامات.
ترتيب النتائج
نستخدم التابع ()order_by لترتيب النتائج وفقًا لقيم عمود ما، فعلى سبيل المثال، لترتيب النتائج حسب الاسم الأول للموظف نكتب:
>>> employees = Employee.query.order_by(Employee.firstname).all() >>> print(employees)
فنحصل على الخرج التالي:
[<Employee Alex Brown>, <Employee Emily Vill>, <Employee Harold Ishida>, <Employee James White>, <Employee Jane Tanaka>, <Employee John Doe>, <Employee Mary Doe>, <Employee Mary Park>, <Employee Scarlett Winter>]
نلاحظ من الخرج السابق أنّ النتائج مُرتّبة أبجديًا وفق الاسم الأول للموظف، كما من الممكن ترتيب النتائج وفقًا لقيم عمود آخر، كأن نستخدم الاسم الأخير للترتيب، كما يلي:
>>> employees = Employee.query.order_by(Employee.lastname).all() >>> print(employees)
فيصبح الخرج على النحو التالي:
[<Employee Alex Brown>, <Employee John Doe>, <Employee Mary Doe>, <Employee Harold Ishida>, <Employee Mary Park>, <Employee Jane Tanaka>, <Employee Emily Vill>, <Employee James White>, <Employee Scarlett Winter>]
كما من الممكن ترتيب الموظفين وفقًا لتواريخ تعيّينهم، على النحو:
>>> em_ordered_by_hire_date = Employee.query.order_by(Employee.hire_date).all() >>> >>> for employee in em_ordered_by_hire_date: >>> print(employee.firstname, employee.lastname, employee.hire_date)
فيكون الخرج على النحو التالي:
Harold Ishida 2002-03-06 John Doe 2012-03-03 Jane Tanaka 2015-09-12 Mary Doe 2016-06-07 Alex Brown 2019-01-03 Emily Vill 2019-06-09 James White 2021-02-04 Scarlett Winter 2021-04-07 Mary Park 2021-08-11
نلاحظ من الخرج السابق ترتيب تواريخ التعيين تصاعديًا من الأقدم إلى الأحدث، ومن الممكن عكس هذا الترتيب وجعله تنازلي أي من الأحدث إلى الأقدم باستخدام التابع ()desc على النحو التالي:
>>> em_ordered_by_hire_date_desc = Employee.query.order_by(Employee.hire_date.desc()).all() >>> >>> for employee in em_ordered_by_hire_date_desc: >>> print(employee.firstname, employee.lastname, employee.hire_date)
فيصبح الخرج كما يلي:
Mary Park 2021-08-11 Scarlett Winter 2021-04-07 James White 2021-02-04 Emily Vill 2019-06-09 Alex Brown 2019-01-03 Mary Doe 2016-06-07 Jane Tanaka 2015-09-12 John Doe 2012-03-03 Harold Ishida 2002-03-06
كما من الممكن ربط كلا تابعي الترشيح ()filter والترتيب ()order_by معًا بغية ترتيب النتائج بعد ترشيحها، إذ تجلب الشيفرة التالية مثلًا كافّة الموظفين المُعينين خلال عام 2021 ثمّ ترتبهم حسب أعمارهم:
>>> from datetime import date >>> hired_in_2021 = Employee.query.filter(db.and_(Employee.hire_date >= date(year=2021, month=1, day=1), Employee.hire_date < date(year=2022, month=1, day=1))).order_by(Employee.age).all() >>> >>> for employee in hired_in_2021: >>> print(employee.firstname, employee.lastname, >>> employee.hire_date, '| Age', employee.age)
فيكون الخرج كما يلي:
Scarlett Winter 2021-04-07 | Age 22 James White 2021-02-04 | Age 24 Mary Park 2021-08-11 | Age 30
استخدمنا في الشيفرة السابقة الدالة ()_db.and للربط بين شرطين مطلوب تحققهما معًا، الأول لتحديد الموظفين المُعينين بدءًا من الأول من كانون الثاني لعام 2021 فما بعد:
Employee.hire_date >= date(year=2021, month=1, day=1)
والثاني لتحديد الموظفين المُعينين قبل اليوم الأول من عام 2022:
Employee.hire_date < date(year=2022, month=1, day=(1)
ومن ثمّ استخدمنا التابع ()order_by لترتيب الموظفين المُحققين للشرطين السابقين وفق أعمارهم.
تحديد النتائج
قد نحصل في معظم حالات الاستعلام عن جداول قواعد البيانات في التطبيقات الحقيقية على ملايين النتائج الموافقة، ما يجعل من تحديد عدد النتائج برقم معيّن أمرًا ضروريًا، ولتحقيق ذلك في تطبيقات Flask-SQLAlchemy، نستخدم التابع ()limit. يبين المثال التالي كيفية الاستعلام عن البيانات في جدول الموظفين employee، ليعيد أول ثلاث نتائج موافقة فقط:
>>> employees = Employee.query.limit(3).all() >>> print(employees)
فيكون الخرج على النحو التالي:
[<Employee John Doe>, <Employee Mary Doe>, <Employee Jane Tanaka>]
كما من الممكن استخدام التابع ()limit مع توابع أُخرى، مثل filter و order_by، إذ يمكن مثلًا الحصول على آخر موظَفيْن مُعيَنيْن لعام 2021 باستخدام التابع ()limit على النحو التالي:
>>> from datetime import date >>> hired_in_2021 = Employee.query.filter(db.and_(Employee.hire_date >= date(year=2021, month=1, day=1), Employee.hire_date < date(year=2022, month=1, day=1))).order_by(Employee.age).limit(2).all() >>> >>> for employee in hired_in_2021: >>> print(employee.firstname, employee.lastname, >>> employee.hire_date, '| Age', employee.age)
فنحصل على الخرج التالي:
Scarlett Winter 2021-04-07 | Age 22 James White 2021-02-04 | Age 24
استخدمنا في الشيفرة السابقة نفس الاستعلام الوارد في القسم السابق ولكن مع استدعاء للتابع (limit(2.
حساب عدد النتائج
يمكننا استخدام التابع ()count لحساب عدد نتائج استعلام ما، فعلى سبيل المثال، للحصول على عدد الموظفين الموجودين في قاعدة البيانات نكتب:
>>> employee_count = Employee.query.count() >>> print(employee_count)
فنحصل على الخرج التالي:
9
كما من الممكن استخدام التابع ()count جنبًا إلى جنب مع توابع استعلام أُخرى مثل ()limit. للحصول على عدد الموظفين المُعينين خلال عام 2021 مثلًا نكتب:
>>> from datetime import date >>> hired_in_2021_count = Employee.query.filter(db.and_(Employee.hire_date >= date(year=2021, month=1, day=1), Employee.hire_date < date(year=2022, month=1, day=1))).order_by(Employee.age).count() >>> print(hired_in_2021_count)
فنحصل على الخرج التالي:
3
استخدمنا في هذه الشيفرة نفس الاستعلام السابق الخاص بالحصول على الموظفين المُعينين خلال عام 2021 ولكن مع استخدام التابع ()count للحصول على عددهم (عدد السجلات الموافقة) وهو 3.
ومع نهاية هذه الخطوة نكون قد تعرّفنا على كيفية ترتيب وتحديد وحساب عدد نتائج استعلام في Flask-SQLAlchemy، أمّا في الخطوة التالية فسنتعرف على كيفية تقسيم نتائج الاستعلام على صفحاتٍ مُتعدّدة، إضافةً إلى كيفية إنشاء نظام ترقيم في تطبيقات فلاسك.
الخطوة 5: كيفية عرض قوائم السجلات الطويلة على صفحات متعددة
سنعمل في هذه الخطوة على تعديل الوجهة الرئيسية للتطبيق لتجعل الصفحة الرئيسية تعرض سجلات الموظفين على صفحاتٍ مُتعدّدة، ما يجعل من تصفّح قائمة الموظفين أسهل.
سنستخدم بدايةً صَدَفة فلاسك لنوضّح كيفية استخدام ميزة الترقيم pagination في الإضافة Flask-SQLAlchemy، لذا نفتح صَدَفة فلاسك (إن لم تكن مفتوحة أصلًا):
(env)user@localhost:$ flask shell
وبفرض أنّنا نريد توزيع سجلات جدول الموظفين على صفحاتٍ مُتعدّدة، من خلال عرض عنصرين اثنين فقط في كل صفحة، فمن الممكن إنجاز ذلك باستخدام تابع الاستعلام ()paginate كما يلي:
>>> page1 = Employee.query.paginate(page=1, per_page=2) >>> print(page1) >>> print(page1.items)
فيكون الخرج على النحو التالي:
<flask_sqlalchemy.Pagination object at 0x7f1dbee7af80> [<Employee John Doe>, <Employee Mary Doe>]
استخدمنا في الشيفرة السابقة معامل الصفحة page من تابع الاستعلام ()paginate بغية تحديد الصفحة المراد الوصول إليها، وهي الصفحة الأولى في حالتا، أمّا المعامل per_page فيُحدّد عدد العناصر المعروضة في كل صفحة، وقد عيّنا قيمته لتكون "2" لتعرض كل صفحة عنصرين فقط، أمّا المتغير page1 فما هو إلا كائن ترقيم يمكّننا من الوصول إلى السمات والتوابع المُستخدمة في إدارة عملية الترقيم.
استخدمنا السمة items للوصول إلى عناصر الصفحة؛ أما للوصول إلى الصفحة التالية، فمن الممكن استخدام التابع ()next من كائن الترقيم على النحو التالي، إذ ستكون النتيجة المُعادة كائن ترقيم أيضًا:
>>> page2 = page1.next() >>> >>> print(page2.items) >>> print(page2)
فيكون الخرج على النحو التالي:
[<Employee Jane Tanaka>, <Employee Alex Brown>] <flask_sqlalchemy.Pagination object at 0x7f1dbee799c0>
كما من الممكن الحصول على كائن ترقيم خاص بالصفحة السابقة باستخدام التابع ()prev، ففي المثال التالي، نحصل على كائن الترقيم الخاص بالصفحة الرابعة، ومنه نصل إلى كائن ترقيم الصفحة السابقة، أي الصفحة رقم 3، على النحو التالي:
>>> page4 = Employee.query.paginate(page=4, per_page=2) >>> print(page4.items) >>> page3 = page4.prev() >>> print(page3.items)
فيكون الخرج كما يلي:
[<Employee Scarlett Winter>, <Employee Emily Vill>] [<Employee James White>, <Employee Harold Ishida>]
كما من الممكن الوصول إلى رقم الصفحة الحالية باستخدام السمة page على النحو:
>>> print(page1.page) >>> print(page2.page)
فنحصل على الخرج التالي:
1 2
كما من الممكن استخدام السمة pages من كائن الترقيم للحصول على العدد الإجمالي من الصفحات، ففي المثال التالي، تعيد كلًا من التعليمتين page1.pages و page2.pages نفس القيمة لأن العدد الإجمالي للصفحات ثابت:
>>> print(page1.pages) >>> print(page2.pages)
ويكون الخرج على النحو التالي:
5 5
أمّا للحصول على العدد الكلي من العناصر، فنستخدم السمة total من كائن الترقيم، على النحو التالي:
>>> print(page1.total) >>> print(page2.total)
فنحصل على الخرج التالي:
9 9
نلاحظ في الخرج السابق وطالما أنّنا استعلمنا عن كافّة الموظفين، سيكون العدد الإجمالي للعناصر في كائن الترقيم هو 9، نظرًا لوجود تسعة موظفين في قاعدة البيانات.
وفيما يلي قائمة ببعض السمات الأخرى التي تملكها كائنات الترقيم:
-
prev_num: رقم الصفحة السابقة. -
next_num: رقم الصفحة التالية. -
has_next: تعيد القيمة "True" في حال وجود صفحة تالية. -
has_prev: تعيد القيمة "True" في حال وجود صفحة سابقة. -
per_page: عدد العناصر في الصفحة.
كما يمتلك كائن الترقيم تابعًا باسم ()iter_pages للمرور على أرقام الصفحات، إذ من الممكن مثلًا طباعة أرقام الصفحات على النحو:
>>> pagination = Employee.query.paginate(page=1, per_page=2) >>> >>> for page_num in pagination.iter_pages(): >>> print(page_num)
فيكون الخرج كما يلي:
1 2 3 4 5
وفيما يلي مثال لتوضيح كيفية الوصول إلى جميع الصفحات وعناصرها باستخدام كل من كائن الترقيم والتابع ()iter_pages:
>>> pagination = Employee.query.paginate(page=1, per_page=2) >>> >>> for page_num in pagination.iter_pages(): >>> print('PAGE', pagination.page) >>> print('-') >>> print(pagination.items) >>> print('-'*20) >>> pagination = pagination.next()
فنحصل على الخرج التالي:
PAGE 1 - [<Employee John Doe>, <Employee Mary Doe>] -------------------- PAGE 2 - [<Employee Jane Tanaka>, <Employee Alex Brown>] -------------------- PAGE 3 - [<Employee James White>, <Employee Harold Ishida>] -------------------- PAGE 4 - [<Employee Scarlett Winter>, <Employee Emily Vill>] -------------------- PAGE 5 - [<Employee Mary Park>] --------------------
أنشأنا في الشيفرة السابقة كائن ترقيم يبدأ من الصفحة الأولى، ثمّ مررنا على الصفحات باستخدام حلقة for تكرارية عن طريق تابع الترقيم ()iter_pages، لنطبع رقم وعناصر الصفحة، ثم أسندنا قيمة كائن الترقيم الخاص بالصفحة التالية إلى كائن الترقيم pagination باستخدام التابع ()next.
يمكن استخدام كلًا من تابعي الترشيح ()filter والترتيب ()order_by جنبًا إلى جنب مع تابع الترقيم ()paginate لترقيم نتائج الاستعلام بعد ترشيحها وترتيبها، فعلى سبيل المثال، يمكننا الحصول على الموظفين ممن تجاوزوا الثلاثين من عمرهم ونرتّب النتائج وفقًا للعمر وننفّذ على النتائج عملية ترقيم كما يلي:
>>> pagination = Employee.query.filter(Employee.age > 30).order_by(Employee.age).paginate(page=1, per_page=2) >>> >>> for page_num in pagination.iter_pages(): >>> print('PAGE', pagination.page) >>> print('-') >>> for employee in pagination.items: >>> print(employee, '| Age: ', employee.age) >>> print('-'*20) >>> pagination = pagination.next()
فنحصل على خرجٍ بالشّكل التالي:
PAGE 1 - <Employee John Doe> | Age: 32 <Employee Jane Tanaka> | Age: 32 -------------------- PAGE 2 - <Employee Mary Doe> | Age: 38 <Employee Harold Ishida> | Age: 52 --------------------
الآن وبعد أن تعرفنا على آلية عمل ميزة الترقيم في Flask-SQLAlchemy بوضوح، سنحرّر صفحة التطبيق الرئيسية لعرض الموظفين على صفحاتٍ مُتعدّدة، وهذا ما يجعل تصفحهم أسهل على المُستخدم.
نخرج من صَدَفة فلاسك:
>>> exit()
سنستخدم معاملات الروابط URL المعروفة باسم سلاسل الاستعلام عن الروابط URL query strings للوصول إلى صفحاتِ الموظفين المُختلفة، وهي طريقة لتمرير المعلومات إلى التطبيق من خلال الروابط، إذ تُمرّر المعاملات إلى التطبيق بعد الرمز ? في الرابط. على سبيل المثال، من الممكن استخدام الروابط التالية لتمرير معامل الصفحة page بقيمٍ مُختلفة:
http://127.0.0.1:5000/?page=1 http://127.0.0.1:5000/?page=3
إذ يمرِّر هنا الرابط الأوّل القيمة "1" إلى معامل الرابط page، بينما يمرّر الرابط الثاني القيمة "3" لنفس المعامل.
نفتح الآن الملف app.py:
(env)user@localhost:$ nano app.py
ونعدّل الوجهة الرئيسية index لتصبح على النحو التالي:
@app.route('/') def index(): page = request.args.get('page', 1, type=int) pagination = Employee.query.order_by(Employee.firstname).paginate( page, per_page=2) return render_template('index.html', pagination=pagination)
حصلنا في الشيفرة السابقة على قيمة معامل الرابط للصفحة المسمّى page باستخدام كل من الكائن request.args وتابعه ()get. فعلى سبيل المثال، نأخذ من الجزء page=1?/ من الرابط القيمة "1" الخاصّة بمعامل الرابط للصفحة المسمّى page، لتُمرّر هذه القيمة "1" مثل قيمة افتراضية، ونمرّر نمط البيانات int من بايثون مثل وسيط لمعامل النوع type لضمان كون القيمة المُمررة من النوع عدد صحيح.
ثمّ أنشأنا الكائن pagination، ورتّبنا نتائج الاستعلام وفق الاسم الأول للموظف، كما مرّرنا قيمة معامل الرابط page إلى التابع ()paginate، ووزّعنا النتائج على عنصرين لكل صفحة عبر تمرير القيمة "2" إلى المعامل per_page، ومرّرنا نهايةً كائن الترقيم المُنشأ pagination إلى القالب المُصيّر index.html.
نحفظ الملف ونغلقه.
أمّا الآن، سنحرر القالب index.html بغية عرض عناصر الترقيم:
(env)user@localhost:$ nano templates/index.html
سنعدّل وسم التقسيم div الخاص بالمحتوى ليتضمّن عنوانًا من المستوى الثاني h2 للدلالة على الصفحة الحالية، كما سنعدّل حلقة for التكرارية لتمر على الكائن pagination.items بدلًا من الكائن employees الذي لم يعد موجودًا.
<div class="content"> <h2>(Page {{ pagination.page }})</h2> {% for employee in pagination.items %} <div class="employee"> <p><b>#{{ employee.id }}</b></p> <b> <p class="name">{{ employee.firstname }} {{ employee.lastname }}</p> </b> <p>{{ employee.email }}</p> <p>{{ employee.age }} years old.</p> <p>Hired: {{ employee.hire_date }}</p> {% if employee.active %} <p><i>(Active)</i></p> {% else %} <p><i>(Out of Office)</i></p> {% endif %} </div> {% endfor %} </div>
نحفظ الملف ونغلقه.
الآن، سنضبط كلًا من متغيري البيئة FLASK_APP و FLASK_ENV، كما سنشغّل خادم التطوير (وذلك في حال عدم إنجاز هذه الخطوات مُسبقًا):
(env)user@localhost:$ export FLASK_APP=app (env)user@localhost:$ export FLASK_ENV=development (env)user@localhost:$ flask run
ننتقل الآن إلى الصفحة الرئيسية للتطبيق باستخدام قيمٍ مُختلفة لمعامل الرابط page، على النحو التالي:
http://127.0.0.1:5000/ http://127.0.0.1:5000/?page=2 http://127.0.0.1:5000/?page=4 http://127.0.0.1:5000/?page=19
فسيظهر في كل مرة صفحة جديدة، يتضمّن كل منها عنصرين مُختلفين بما يُشبه النتيجة التي رأيناها سابقًا ضمن صَدَفة فلاسك.

وفي حال كون الرقم المُمرّر إلى معامل الرابط غير موجود، فعندها سيُعرض خطأ HTTP من النوع "404 Not Found"، كما هو الحال مع الرابط الأخير من قائمة الروابط أعلاه.
أمّا الآن، فسننشئ عنصر واجهة مستخدم widget خاص بالترقيم لنسمح للمستخدم بالتنقّل بين الصفحات، إذ سنستخدم بعض سمات وتوابع كائن الترقيم بغية عرض أرقام كافّة الصفحات، إذ سيمثّل كل رقم رابطًا إلى صفحته الموافقة، كما سنعرض الزر >>> للرجوع في حال كانت الصفحة الحالية تمتلك صفحة سابقة، وزر <<< للانتقال إلى الصفحة التالية في حال كانت الصفحة الحالية تمتلك صفحة تليها.
وسيبدو عنصر واجهة المستخدم الخاص بالترقيم بالشكل التالي:
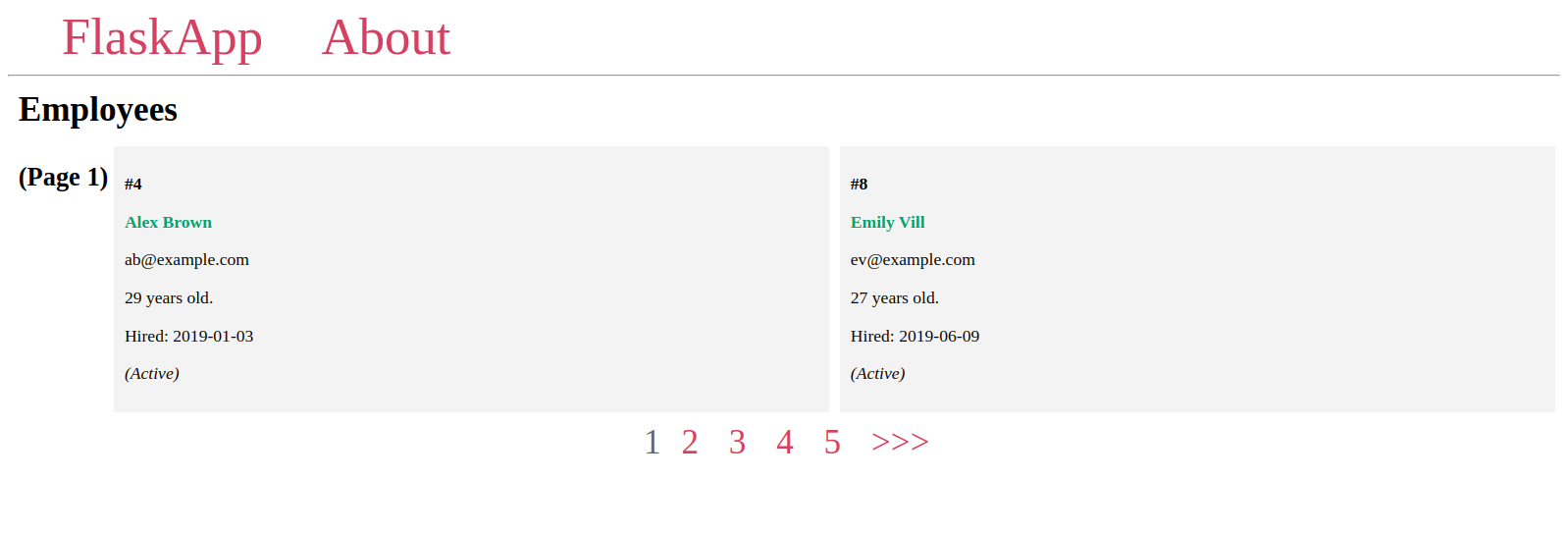

ولإضافته، نفتح الملف index.html:
(env)user@localhost:$ nano templates/index.html
ونعدّله بإضافة وسم تقسيم div جديد أسفل وسم div السابق الخاص بالمحتوى، على النحو:
<div class="content"> {% for employee in pagination.items %} <div class="employee"> <p><b>#{{ employee.id }}</b></p> <b> <p class="name">{{ employee.firstname }} {{ employee.lastname }}</p> </b> <p>{{ employee.email }}</p> <p>{{ employee.age }} years old.</p> <p>Hired: {{ employee.hire_date }}</p> {% if employee.active %} <p><i>(Active)</i></p> {% else %} <p><i>(Out of Office)</i></p> {% endif %} </div> {% endfor %} </div> <div class="pagination"> {% if pagination.has_prev %} <span> <a class='page-number' href="{{ url_for('index', page=pagination.prev_num) }}"> {{ '<<<' }} </a> </span> {% endif %} {% for number in pagination.iter_pages() %} {% if pagination.page != number %} <span> <a class='page-number' href="{{ url_for('index', page=number) }}"> {{ number }} </a> </span> {% else %} <span class='current-page-number'>{{ number }}</span> {% endif %} {% endfor %} {% if pagination.has_next %} <span> <a class='page-number' href="{{ url_for('index', page=pagination.next_num) }}"> {{ '>>>' }} </a> </span> {% endif %} </div>
نحفظ الملف ونغلقه.
استخدمنا في الشيفرة السابقة الشرط if pagination.has_prev بغية إضافة رابط لزر الرجوع إلى الصفحة السابقة >>> وذلك فقط في حال لم تكن الصفحة الحالية هي الصفحة الأولى، إذ ربطنا الزر مع الصفحة السابقة من خلال استدعاء الدالة التالية:
url_for('index', page=pagination.prev_num)
وفيها يُربط الزر بدالة العرض الرئيسية index ممررين القيمة pagination.prev_num إلى معامل الرابط page.
لعرض روابط لكل أرقام الصفحات المتوفرة، مررنا باستخدام حلقة تكرارية على كافّة عناصر التابع ()pagination.iter_pages الذي يزودنا برقم صفحة عند كل تكرار، واستخدمنا الشرط if pagination.page != number لنتحقق ما إذا كان رقم الصفحة الحالي مغاير للرقم في التكرار الحالي؛ فعند تحقق الشرط، ننشئ رابطًا يُمكّن المستخدم من تغيّير الصفحة الحالية إلى صفحة أخرى، وإلّا فإنّنا نعرض رقم الصفحة دون رابط، إذ تكون الصفحة الحالية في هذه الحالة موافقة للرقم الحالي في التكرار، وهذا ما سيساعد المستخدمين على معرفة رقم الصفحة الحالية من خلال عنصر واجهة المستخدم الخاص بالترقيم.
استخدمنا نهايةً الشرط pagination.has_next لنتحقّق من وجود صفحة تلي الصفحة الحالية، وفي حال تحقُّق هذا الشرط، نُنشئ رابطًا إليها من خلال استدعاء التابع وربطه بالزر <<<:
url_for('index', page=pagination.next_num)
الآن وبالانتقال إلى الصفحة الرئيسية للتطبيق عبر المتصفح باستخدام الرابط:
http://127.0.0.1:5000/
سنجد عنصر واجهة المستخدم الخاص بالترقيم يعمل بنجاح، كما في الشكل التالي:
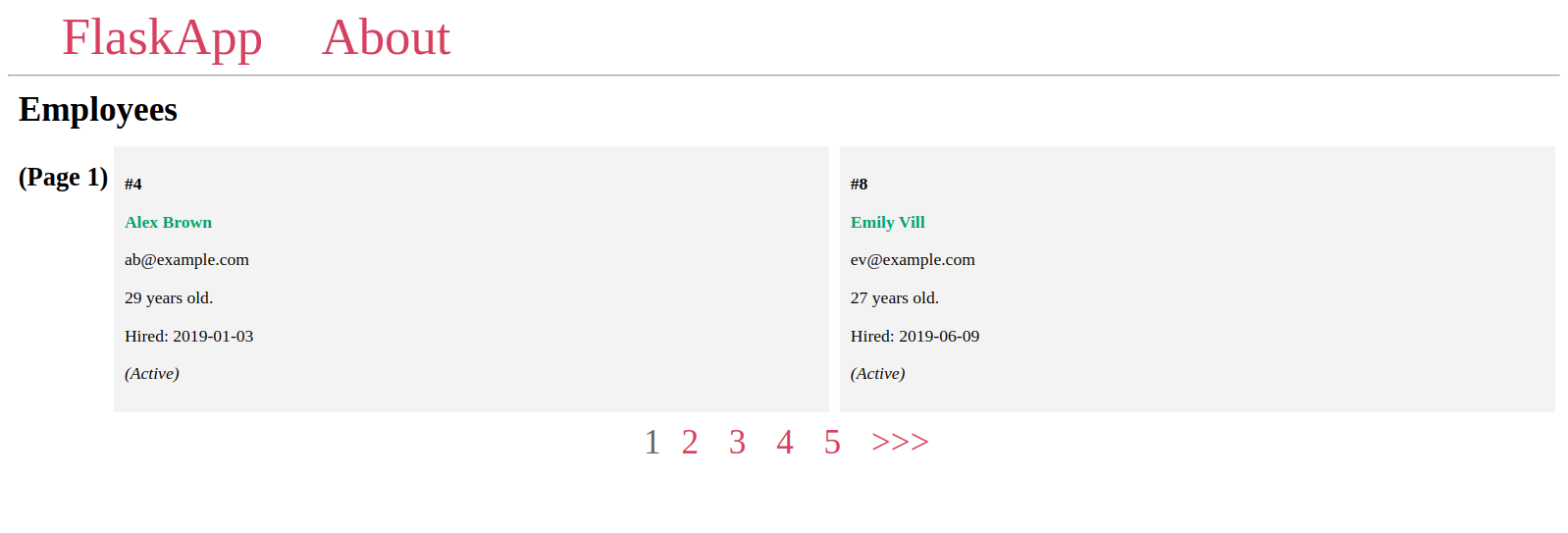
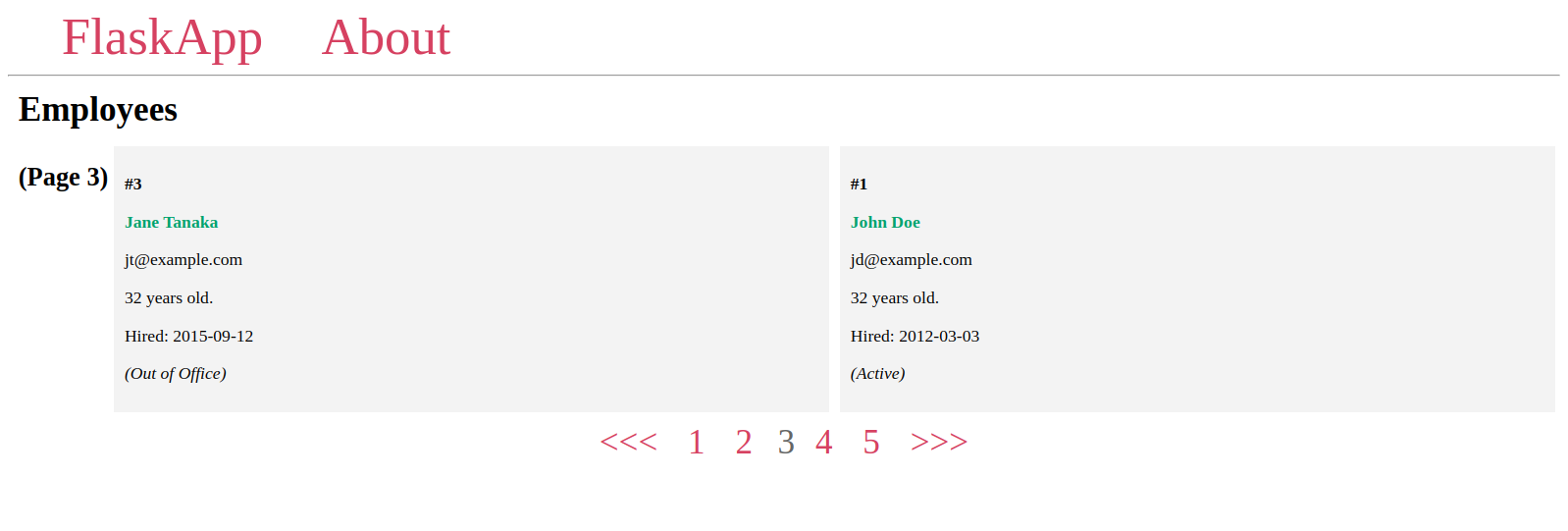
استخدمنا هنا الرمز <<< للدلالة على الانتقال إلى الصفحة التالية، والرمز >>> للدلالة على الانتقال إلى الصفحة السابقة، ولكن من الممكن استخدام أي رمز آخر مثل > و <، أو حتى صور باستخدام وسم الصورة <img>.
مع نهاية هذه الخطوة نكون قد عرضنا بيانات الموظفين على صفحاتٍ مُتعدّدة، وتعلّمنا كيفية التعامل مع مفهوم الترقيم في Flask-SQLAlchemy، ومن الآن أصبح بإمكانك استخدام عنصر واجهة المستخدم الخاص بالترقيم الذي أنشأناه في أي تطبيقات فلاسك أخرى تُنشئها.
الخاتمة
استخدمنا في هذا المقال الإضافة Flask-SQLAlchemy لإنشاء نظام إدارة موظفين، إذ استعرضنا كيفية الاستعلام عن جدول وترشيح نتائجه وفق قيم أحد أعمدته أو وفق شروطٍ منطقية بسيطة ومُركّبة، كما بيّنا كيفية ترتيب نتائج الاستعلامات وتحديدها وحساب عددها، وأنشأنا أيضًا نظام ترقيم بغية عرض عددٍ مُحدّد من السجلات في كل صفحة من صفحات تطبيق الويب، مع إمكانية التنقّل بين هذه الصفحات.
ترجمة -وبتصرف- للمقال How To Query Tables and Paginate Data in Flask-SQLAlchemy لصاحبه Abdelhadi Dyouri.










أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.