

كانت لحظة مرعبة حينما جلست على حاسوبي بعد أن «عضّ القرش» كبل الإنترنت وانقطع، وأدركت حينها كم أقضي وقتًا على الإنترنت حينما أستعمل حاسوبي؛ فلدي عادة أن أتحقق من بريدي يدويًا (مع أن التنبيهات تصلني أولًا بأول!) وأفتح تويتر (إكس، سمهِّ ما شئت) وأنظر ما آخر المستجدات.
كثيرٌ من عملنا على الحاسوب يتطلب وصولًا إلى الانترنت، ومصطلح «استخراج البيانات من الويب» Web scraping يستعمل مع البرامج التي تنزل المحتوى من الإنترنت وتعالجه. فمثلًا لدى غوغل عدد من البوتات لتنزيل محتوى صفحات الويب وفهرستها وأرشفتها لتستعملها في محرك البحث.
سنتعلم في هذا المقال عن عددٍ من الوحدات في بايثون التي تسهل علينا استخراج البيانات من الويب:
-
webbrowser: حزمة تأتي مع بايثون وتفتح متصفحًا على صفحة ويب معينة. -
requests: تنزل الملفات وصفحات الويب من الإنترنت. -
bs4: تفسّر شيفرات HTML التي تكتب فيها صفحات الويب. -
selenium: تشغل وتتحمل في متصفح ويب، والوحدةseleniumقادرة على ملء الاستمارات ومحاكاة ضغطات الفأرة في المتصفح.
مشروع: برنامج mapIt.py مع وحدة webbrowser
الدالة open() في الوحدة webbrowser تفتح صفحة ويب معينة في نافذة متصفح جديدة. جرب ما يلي في الصدفة التفاعلية:
>>> import webbrowser >>> webbrowser.open('https://academy.hsoub.com/')
ستجد أكاديمية حسوب مفتوحةً في لسانٍ جديد في المتصفح. هذا كل ما تستطيع الوحدة webbrowser فعله، لكن مع ذلك يمكننا أن نجري بعض الأمور اللطيفة مع الدالة open()، فمثلًا قد تكون مهمة فتح خرائط جوجل والبحث عن عنوان معين أمرًا مملًا، ونستطيع التخلص من بضع خطوات لو كتبنا سكربتًا يفتح خرائط جوجل ويوجهها إلى عنوان الشارع المنسوخ في الحافظة لديك، وبالتالي سيكون عليك أن تنسخ العنوان إلى الحافظة وتشغل السكربت، وستفتح الخريطة لديك.
هذا ما يفعله البرنامج: يحصل على عنوان الشارع من وسائط سطر الأوامر أو من الحافظة يفتح نافذة متصفح ويوجهها إلى صفحة خرائط جوجل المرتبطة بعنوان الشارع.
هذا يعني أن على الشيفرة البرمجية أن تفعل ما يلي: تقرأ وسائط سطر الأوامر تقرأ محتويات الحافظة تستدعي الدالة webbrowser.open() لتفتح صفحة الويب.
احفظ ملفًا جديدًا باسم mapIt.py، ولنبدأ برمجته.
الخطوة 1: معرفة الرابط الصحيح
اعتمادًا على التعليمات الموجودة في الملحق ب، اضبط برنامج mapIt.py ليعمل من سطر الأوامر كما في المثال الآتي:
C:\> mapit 870 Valencia St, San Francisco, CA 94110
سيستخدم البرنامج وسائط سطر الأوامر بدلًا من الحافظة، وإذا لم نمرر إليه أيّة وسائط فحينها سيقرأ محتويات الحافظة.
علينا بدايةً أن نحصِّل ما هو عنوان URL الذي يجب فتحه للعثور على شارع معين. إذا فتحت خرائط جوجل في المتصفح وبحثت عن عنوان فسيكون الرابط في الشريط العلوي يشبه:
https://www.google.com/maps/place/870+Valencia+St/@37.7590311,-122.4215096,17z/data=!3m1!4b1!4m2!3m1!1s0x808f7e3dadc07a37:0xc86b0b2bb93b73d8
نعم العنوان في الرابط، لكن هنالك نص كثير إضافي غيره.
تضيف المواقع عادةً بيانات إضافية لتتبع الزوار أو تخصيص المواقع. لكن إن حاولت الذهاب إلى الرابط التالي:
https://www.google.com/maps/place/870+Valencia+St+San+Francisco+CA/
فسترى العنوان مفتوحًا أمامك. وبهذا كل ما نحتاج إليه هو فتح صفحة ويب ذات العنوان التالي:
https://www.google.com/maps/place/your_address_string
حيث your_address_string هو العنوان الذي تريد عرضه في الخريطة.
الخطوة 2: التعامل مع وسائط سطر الأوامر
يجب أن تبدو الشيفرة لديك كما يلي:
#! python3 # mapIt.py - تشغيل خريطة في المتصفح باستخدام عنوان # من سطر الأوامر أو الحافظة. import webbrowser, sys if len(sys.argv) > 1: # Get address from command line. address = ' '.join(sys.argv[1:]) # TODO: الحصول على العنوان من الحافظة.
بعد سطر !# سنستورد الوحدة webbrowser لتشغيل المتصفح والوحدة sys لمحاولة قراءة وسائط سطر الأوامر.
يخزن المتغير sys.argv اسم الملف ووسائط سطر الأوامر، وإذا احتوت هذه القائمة على أكثر من عنصر واحد (الذي هو اسم الملف) فيجب أن تكون قيمة استدعاء len(sys.argv) أكبر من 1، وهذا يعني أن هنالك وسائط في سطر الأوامر.
عادةً ما يُفصَل بين وسائط سطر الأوامر بفراغات، لكن في هذه الحالة نريد أن نفسر جميع الوسائط على أنها سلسلة نصية واحدة، ولما كانت قيمة sys.argv هي قائمة تحتوي على سلاسل نصية، فيمكننا استخدام التابع join() معها، مما يعيد سلسلة نصية واحدة؛ لكن انتبه أننا لا نريد اسم الملف ضمن تلك السلسلة النصية، فعلينا استخدام sys.arv[1:] لإزالة أول عنصر في القائمة، ثم سنتخزن تلك القيمة في المتغير address.
يمكنك تشغيل البرنامج بكتابة ما يلي في سطر الأوامر:
mapit 870 Valencia St, San Francisco, CA 94110
وستكون قيمة المتغير sys.argv هي القائمة:
['mapIt.py', '870', 'Valencia', 'St, ', 'San', 'Francisco, ', 'CA', '94110']
وبالتالي تكون قيمة المتغير address هي السلسلة النصية '870 Valencia St, San Francisco, CA 94110'.
الخطوة 3: التعامل مع محتويات الحافظة وتشغيل المتصفح
تأكد أن الشيفرة الخاصة بك تشبه الشيفرة الآتية:
#! python3 # mapIt.py - تشغيل خريطة في المتصفح باستخدام عنوان # من سطر الأوامر أو الحافظة. import webbrowser, sys, pyperclip if len(sys.argv) > 1: # Get address from command line. address = ' '.join(sys.argv[1:]) else: # الحصول على العنوان من الحافظة. address = pyperclip.paste() webbrowser.open('https://www.google.com/maps/place/' + address)
إذا لم تكن هنالك وسائط ممررة عبر سطر الأوامر، فسيفترض البرنامج أن العنوان منسوخ إلى الحافظة، ويمكننا الحصول على محتوى الحافظة باستخدام pyperclip.paste() وتخزينها في المتغير address. آخر خطوة هي تشغيل المتصفح مع توفير رابط URL صحيح لخرائط غوغل عبر webbrowser.open().
ستوفر عليك بعض البرامج التي ستطورها ساعات من العمل، لكن بعض قد يكون بسيطًا ويوفر عليك بضع ثوانٍ في كل مرة تجري فيها مهمة تكرارية مثل فتح عنوان ما على الخريطة، الجدول التالي يقارن بين الخطوات اللازمة لعرض الخريطة:
| فتح الخريطة يدويًا |
استخدام سكربت mapIt.py
|
|---|---|
|
تحديد العنوان نسخ العنوان فتح متصفح الويب الذهاب إلى خرائط غوغل الضغط على حقل الإدخال لصق العنوان الضغط على enter |
تحديد العنوان نسخ العنوان
تشغيل |
مقارنة الخطوات اللازمة لعرض الخريطة
أفكار لبرامج مشابهة
تساعدك الوحدة webbrowser إذا كان لديك عنوان URL لصفحة معينة تريد اختصار عملية فتح المتصفح والتوجه إليها، يمكنك أن تستفيد منها لإنشاء:
- برنامج يفتح جميع الروابط المذكورة في مستند نصي في ألسنة جديدة.
- برنامج يفتح المتصفح على صفحة الطقس لمدينتك.
- برنامج يفتح مواقع التواصل الاجتماعي التي تزورها عادة.
تنزيل الملفات من الويب باستخدام الوحدة requests
تسمح لك الوحدة requests بتنزيل الملفات من الويب دون أن تفكر في مشاكل الشبكة أو الاتصال أو ضغط البيانات. لا تأتي الوحدة requests مضمنةً في بايثون، وإنما عليك تثبيتها أولًا من سطر الأوامر بتشغيل الأمر pip install --user requests.
أتت الوحدة requests لتقدم حلًا بديلًا لوحدة urllib2 في بايثون لأنها معقدة زيادة عن اللزوم، وأنصحك أن تزيل الوحدة urllib2 من ذهنك تمامًا، لأنها وحدة صعبة دون داعٍ، وعليك استخدام الوحدة requests دومًا.
لنجرب الآن أن الحزمة requests مثبتة صحيحًا بإدخال ما يلي في الصدفة التفاعلية:
import requests>>> import requests
إذا لم تظهر أي رسالة خطأ فهذا يعني أن الحزمة requests مثبتة عندك.
تنزيل صفحة ويب باستخدام الدالة requests.get()
الدالة requests.get() تقبل سلسلةً نصيةً فيها رابط URL لتنزيلها. إذا استعملت الدالة type() على القيمة المعادة من الدالة requests.get() فسترى أن الناتج هو كائن Response، الذي يحتوي على الرد الذي تلقاه برنامجك بعد إتمام الطلبية إلى خادم الويب. سنستكشف سويةً الكائن Response بالتفصيل لاحقًا، لكن لنكتب الآن الأسطر الآتية في الطرفية التفاعلية على حاسوب متصل بالإنترنت:
>>> import requests ➊ >>> res = requests.get('https://automatetheboringstuff.com/files/rj.txt') >>> type(res) <class 'requests.models.Response'> ➋ >>> res.status_code == requests.codes.ok True >>> len(res.text) 178981 >>> print(res.text[:250]) The Project Gutenberg EBook of Romeo and Juliet, by William Shakespeare This eBook is for the use of anyone anywhere at no cost and with almost no restrictions whatsoever. You may copy it, give it away or re-use it under the terms of the Proje
الرابط الذي طلبناه هو مستند نصي لمسرحية روميو وجولييت على موقع الكتاب الأصلي ➊، يمكنك أن ترى نجاح الطلبية إلى صفحة الويب بالنظر إلى السمة status_code من الكائن Response، إذا كانت القيمة الخاصة بها تساوي requests.codes.ok فهذا يعني أن كل شيء على ما يرام ➋.
بالمناسبة، رمز الاستجابة الذي يدل على أن الأمور على ما يرام OK في HTTP هو 200، ومن المرجح أنك تعرف الحالة 404 التي تشير إلى رابط غير موجود. يمكنك العثور على قائمة برموز الاستجابة في HTTP ومعانيها في الصفحة قائمة رموز الاستجابة في HTTP من ويكيبيديا.
إذا نجحت الطلبية، فستخزن صفحة الويب التي نزلناها كسلسلة نصية في المتغير text في كائن Response. يحتوي هذا المتغير على سلسلة نصية طويلة فيها المسرحية كاملةً. وإذا استدعيت len(res.text) فسترى أنها أطول من 178,000 محرف. استدعينا في النهاية print(res.text[:250]) لعرض أول 250 محرف.
إذا فشل الطلب وظهرت رسالة خطأ مثل "Failed to establish a new connection" أو "Max retries exceeded" فتأكد من اتصالك بالإنترنت. لا نستطيع نقاش جميع أسباب عدم القدرة على الاتصال بالخوادم لتعقيد الموضوع، لكن أنصحك بالبحث في الويب عن المشكلة التي تواجهك لترى حلها.
التأكد من عدم وجود مشاكل
كما رأينا سويةً، يملك الكائن Response السمة status_code التي تأكدنا أنها تساوي requests.codes.ok (وهو متغير فيه القيمة الرقمية 200) للتحقق من نجاح عملية التنزيل.
هنالك طريقة أخرى سهلة للتحقق من نجاح التنفيذ هو استدعاء التابع raise_for_status() على الكائن Response، التي ستؤدي إلى إطلاق استثناء إذا حدث خطأ حين تنزيل الملف، ولن تفعل شيئًا إن سارت الأمور على ما يرام. جرب ما يلي في الصدفة التفاعلية:
>>> res = requests.get('https://inventwithpython.com/page_that_does_not_exist') >>> res.raise_for_status() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "C:\Users\Al\AppData\Local\Programs\Python\Python37\lib\site-packages\requests\models .py", line 940, in raise_for_status raise HTTPError(http_error_msg, response=self) requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://inventwithpython .com/page_that_does_not_exist.html
يضمن لنا التابع ()raise_for_status أن البرنامج سيتوقف إذا حدثت مشكلة في التنزيل، وهذا مناسب جدًا إذا أردنا إيقاف البرنامج حين حصول مشكلة في التنزيل. أما لو كنا نريد استمرار البرنامج حتى لو فشل تنزيل الملف فيمكننا حينئذٍ أن نحيط التابع raise_for_status() بالتعبيرات try و except لمعالجة هذا الاستثناء:
import requests res = requests.get('https://inventwithpython.com/page_that_does_not_exist') try: res.raise_for_status() except Exception as exc: print('There was a problem: %s' % (exc))
التابع raise_for_status() في الشيفرة السابقة سيؤدي إلى طباعة ما يلي:
There was a problem: 404 Client Error: Not Found for url: https:// inventwithpython.com/page_that_does_not_exist.html
احرص دومًا على استدعاء التابع raise_for_status() بعد استدعاء requests.get() لتضمن أن برنامجك قد نزَّل الملف دون مشاكل قبل إكمال التنفيذ.
حفظ الملفات المنزلة إلى نظام الملفات
يمكنك الآن حفظ صفحة الويب إلى نظام الملفات لديك باستخدام الدالة open() والتابع write()، هنالك بعض الاختلافات البسيطة عمّا فعلناه سابقًا: علينا أن نفتح الملف في وضع الكتابة بالنظام الثنائي write binary بتمرير السلسلة النصية 'wb' كوسيط ثانٍ إلى الدالة open() حتى لو كان الملف المنزل نصيًا (مثل مسرحية روميو وجولييت في المثال أعلاه)، لأننا نريد كتابة البيانات الثنائية بدلًا من البيانات النصية للحفاظ على ترميز النص encoding.
لنستعمل حلقة for مع التابع iter_content() للكائن Response لكتابة صفحة الويب إلى ملف:
>>> import requests >>> res = requests.get('https://automatetheboringstuff.com/files/rj.txt') >>> res.raise_for_status() >>> playFile = open('RomeoAndJuliet.txt', 'wb') >>> for chunk in res.iter_content(100000): playFile.write(chunk) 100000 78981 >>> playFile.close()
يعيد التابع iter_content() قطعًا من النص في كل تكرار لحلقة التكرار، وكل قطعة يكون لها نوع البيانات bytes وتحدد لها كم بايتًا يجب أن يكون طول كل قطعة، وأرى أن مئة ألف بايت هو حجم مناسب، لذا لنمرر 100000 إلى التابع iter_content().
أنشأنا الآن الملف RomeoAndJuliet.txt في مجلد العمل الحالي، لاحظ أن اسم الملف في موقع الويب هو rj.txt بينما اسم الملف المحفوظ لدينا مختلف. تذكر أن الوحدة requests تنزل محتويات صفحات الويب لديك، وبعد تنزيلها يكون على عاتقك التعامل معها وحفظها إن شئت أينما تشاء.
اقتباسترميز يونيكود Unicode encoding: ترميز يونيكود خارج عن نطاق هذه السلسلة، لكن يمكنك قراءة المزيد عنه في مقال The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets ومقال Pragmatic Unicode.
يعيد التابع
()writeعدد البايتات المكتوبة إلى ملف، وكتبنا في المثال السابق 100,000 بايت إلى الملف في أول «قطعة» chunk وبقي له 78,981 بايت للكتابة للمرة الثانية.
للمراجعة، هذه هي الخطوات الكاملة لتنزيل وحفظ ملف:
-
استدعاء التابع
requests.get()لتنزيل ملف. -
استدعاء
open()مع الخيار'wb'لإنشاء ملف جديد وفتحه للكتابة في الوضع الثنائي. -
المرور على التابع
iter_content()للكائنResponse. -
استدعاء التابع
write()في كل تكرار لكتابة المحتوى إلى الملف. -
إغلاق الملف
close().
هذا كل ما يتعلق بالوحدة requests! قد تبدو لك حلقة for مع iter_content() معقدةً مقارنةً باستخدام open() و write() و close() التي استخدمناها لكتابة الملفات النصية؛ لكننا فعلنا ذلك لنضمن أن برنامجنا لن يستهلك ذاكرة كثيرة إذا نزلنا ملفات ضخمة. يمكنك قراءة المزيد حول ميزات الوحدة requests الأخرى من requests.readthedocs.org.
لغة HTML
قبل أن نستخلص المعلومات من صفحات الويب، لنتعلم بعض أساسيات HTML أولًا، ولنرى كيف نصل إلى أدوات المطور في متصفح الويب، التي ستجعل عملية استخراج البيانات من الويب أمرًا سهلًا جدًا.
مصادر لتعلم HTML
لغة HTML هي الصيغة التي تكتب فيها صفحات الويب، ويفترض هذا المقال أن لديك بعض الأساسيات حول HTML، لكن إن كنت تريد البدء من الصفر فأنصحك أن تراجع:
- توثيق HTML في موسوعة حسوب.
- قسم HTML في أكاديمية حسوب.
تذكرة سريعة
في حال لم تلمس HTML من مدة، سأخبرك بملخص بسيط عنها.
ملفات HTML هي ملفات نصية لها اللاحقة html، وتكون النصوص فيها محادثة بالوسوم tags، وكل وسم يكون ضمن قوسي زاوية <>، وتخبر هذه الوسوم المتصفحات كيف يجب أن تعرض الصفحة.
يمكن أن يكون هنالك نص بين وسم البداية ووسم النهاية، وهذا ما يؤلف عنصرًا element. فمثلًا، الشيفرة الآتية تعرض لك Hello, world! في المتصفح، وتكون كلمة Hello بخط عريض:
<strong>Hello</strong>, world!
وستبدو في المتصفح كما في الشكل الآتي:
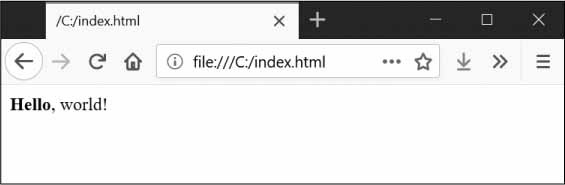
مثال Hello, world! معروضة في متصفح
وسم البداية <strong> يخبر المتصفح أن النص سيكون بخط عريض، ووسم النهاية </strong> يخبر المتصفح أين هي نهاية النص العريض. هنالك وسوم متنوعة في HTML، ولبعض تلك الوسوم خاصيات تُذكَر ضمن قوسَي الزاوية <>، مثلًا الوسم <a> يعني أن النص هو رابط، وتكون قيمة هذا الرابط محددة بالخاصية href. مثال:
Al's free <a href="https://inventwithpython.com">Python books</a>.
ستبدو صفحة الويب كما في الشكل الآتي:
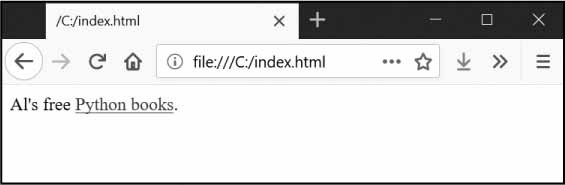
رابط معروض في متصفح.
تمتلك بعض العناصر الخاصية id التي تستخدم لتعريف عناصر الصفحة بشكل فريد، ويمكنك أن تطلب من برامجك البحث عن عنصر ما باستخدام معرفه id، لهذا تكون معرفة قيمة id لأحد العناصر من أهم الأمور التي سنستعمل فيها أدوات المطور أثناء كتابة برامج استخلاص البيانات من صفحات الويب.
عرض مصدر صفحة HTML
إذا أردت إلقاء نظرة على مصدر صفحة HTML لإحدى الصفحات التي تزورها، اضغط على الزر الأيمن للفأرة واختر View page source كما في الشكل التالي. هذا النص هو ما يحصل عليه متصفحك وهو يعرف كيف يعرض الصفحة اعتمادًا على ذاك النص.
عرض مصدر صفحة ويب
أنصح -وبشدة- أن تجرب عرض مصدر صفحات HTML لبعض مواقعك المفضلة، حتى لو لم تفهم تمامًا كل ما تراها أمامك، فلست بحاجة إلى احتراف HTML لتعرف كيف تكتب برامج لاستخراج البيانات؛ فليس المطلوب منك برمجة موقعك الشخصي وإنما أن يكون لديك ما يكفي لتحصل البيانات المطلوبة.
فتح أدوات المطور
إضافةً إلى عرض المصدر، يمكنك أن تلقي نظرة على صفحات HTML باستخدام أدوات المطور في متصفحك. يمكنك أن تضغط الزر F12 في كروم لإظهارها، أو الضغط على F12 مرة أخرى لإخفائها. يمكنك أيضًا فتحها من القائمة الجانبية ثم Developer Tools، أو الضغط على ⌘-⌥-I في ماك.
أدوات المطور في متصفح كروم
أما في فايرفكس، فيمكنك فتح أدوات المطور بالضغط على Ctrl+Shift+C في ويندوز ولينكس، أو ⌘-⌥-C في ماك، وأدوات المطور هنا تشبه كروم كثيرًا.
بعد تفعيل أدوات المطور في متصفحك، يمكنك الضغط بالزر الأيمن للفأرة على أي عنصر واختيار Inspect Element في القائمة المنبثقة لترى شيفرة HTML المسؤولة عن ذاك الجزء من الصفحة. ستستفيد من ذلك كثيرًا عندما تبدأ تفسير صفحات HTML لاستخراج البيانات منها.
اقتباسلا تستعمل التعابير النمطية لتفسير HTML: قد تظن أن التعابير النمطية هي الأداة الأمثل العثور على سلسلة نصية معينة في HTML، لكنني أنصحك بعدم فعل ذلك، لأن هنالك طرائق كثيرة يمكننا كتابة شيفرات HTML سليمة، ومحاولة تغطية جميع حالات الاستخدام يدويًا باستخدام التعابير النمطية هو أمر مرهق ومعرض للخطأ كثيرًا. هنالك وحدات مطورة خصيصًا لتفسير شيفرات HTML مثل
bs4، التي ستقلل كثيرًا من العلل والأخطاء وتسهل عليك العمل.
استخدام أدوات المطور للعثور على عناصر HTML
بعد أن نزل برنامج صفحة الويب باستخدام الوحدة requests فسيكون لدينا صفحة الويب كاملةً كسلسلة نصية واحدة، وعلينا أن نجد طريقة لمعرفة ما هي عناصر HTML التي تحتوي على المعلومات التي نريد استخراجها من الصفحة.
ستساعدنا هنا أدوات المطور في ذلك. لنقل مثلًا أننا نريد كتابة برنامج لجلب بيانات الطقس من موقع weather.gov. لكن قبل أن نبدأ بكتابة الشيفرات فعلينا القيام ببعض التحريات أولًا. إذا زرنا الموقع وبحثنا عن الرمز البريدي 94105 فستحصل على صفحة تظهر لك الطقس في تلك المنطقة.
ماذا إن كانت مهتمًا باستخراج بيانات الطقس لهذا العنوان البريدي؟ اضغط بالزر الأيمن على مكان معلومات الطقس في تلك الصفحة واختر Inspect Element من القائمة، وستظهر لك نافذة أدوات المطور، التي تريك شيفرات HTML المسؤولة عن ذاك الجزء من الصفحة كما يظهر في الشكل التالي. انتبه إلى أن الموقع قد يتغير دوريًا وقد تظهر لك عناصر مختلفة وعليك اتباع نفس الخطوات لتفحص العناصر الجديدة.
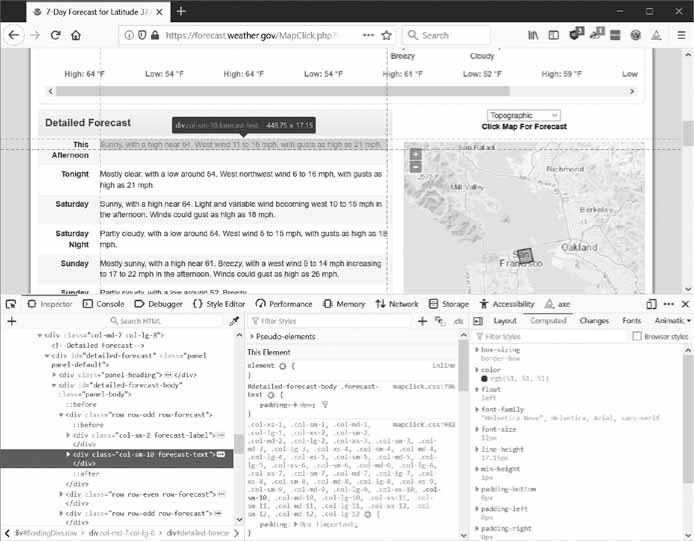
تفحص عناصر صفحة الطقس باستخدام أدوات المطور
يمكننا أن نرى ما هي شيفرة HTML المسؤولة عن عرض الطقس في الصفحة السابقة، وهي:
<div class="col-sm-10 forecast-text">Sunny, with a high near 64. West wind 11 to 16 mph, with gusts as high as 21 mph.</div>
هذا ما نبحث عنه تمامًا، يبدو أن معلومات الطقس موجودة داخل عنصر <div> له صنف CSS باسم forecast-text. اضغط بالزر الأيمن على العنصر في أدوات المطور واختر من القائمة Copy ▸ CSS Selector، وستُنسَخ لك سلسلة نصية مثل الآتية إلى الحافظة:
'div.row-odd:nth-child(1) > div:nth-child(2)'
ويمكنك أن تستخدم تلك السلسلة النصية مع التابع ذ في BS4 أو find_element_by_css_selector() في Selenium كما هو مشروح في هذا المقال.
الآن وبعد أن عرفت ما الذي تبحث عنه تحديدًا، يمكن لوحدة Beautiful Soup أن تساعدك في العثور عليه.
تفسير HTML مع وحدة BS4
تستخدم الوحدة Beautiful Soup في استخراج المعلومات من صفحة HTML، واسم الوحدة في بايثون هو bs4 للإشارة إلى الإصدار الرابع منها، ويمكننا تثبيتها عبر الأمر pip install --user beautifulsoup4 (راجع الملحق أ لتعليمات حول تثبيت الوحدات). صحيح أننا استخدمنا beautifulsoup4 لتثبيت الوحدة، لكن حين استيرادها في بايثون سنستعمل import bs4.
ستكون أمثلتنا عن BS4 عن تفسير ملف HTML (أي تحليلها والتعرف على أجزائها) مخزن محليًا على حاسوبنا. افتح لسانًا جديدًا في محرر Mu وأدخل ما يلي فيه واحفظه باسم example.html:
<!-- This is the example.html example file. --> <html><head><title>The Website Title</title></head> <body> <p>Download my <strong>Python</strong> book from <a href="https:// inventwithpython.com">my website</a>.</p> <p class="slogan">Learn Python the easy way!</p> <p>By <span id="author">Al Sweigart</span></p> </body></html>
نعم، حتى ملفات HTML البسيطة فيها مختلف العناصر والخاصيات، وستكون الأمور أعقد بكثير في المواقع الكبيرة، لكن مكتبة BS4 هنا لمساعدتنا وتسهيل الأمر علينا.
إنشاء كائن BeautifulSoup من سلسلة HTML نصية
يمكننا استدعاء الدالة bs4.BeautifulSoup() مع تمرير سلسلة نصية تحتوي على شيفرة HTML التي ستفسر. تعيد الدالة bs4.BeautifulSoup() كائن BeautifulSoup. جرب ما يلي في الصدفة التفاعلية على حاسوبك مع وجود إنترنت:
>>> import requests, bs4 >>> res = requests.get('https://academy.hsoub.com') >>> res.raise_for_status() >>> academySoup = bs4.BeautifulSoup(res.text, 'html.parser') >>> type(academySoup) <class 'bs4.BeautifulSoup'>
هذه الشيفرة تستعمل requests.get() لتنزيل صفحة الويب من موقع أكاديمية حسوب ثم تمرر قيمة السمة text للرد إلى الدالة bs4.BeautifulSoup() التي تعيد كائن BeautifulSoup نخزنه في المتغير academySoup.
يمكننا أيضًا تحميل ملف HTML من القرص لدينا بتمرير كائن File إلى الدالة bs4.BeautifulSoup() مع وسيط ثانٍ يخبر وحدة BS4 ما المفسر الذي عليها استعماله لتفسير الملف.
أدخل ما يلي في الصدفة التفاعلية مع التأكد أنك في نفس المجلد الذي يحتوي على ملف example.html:
>>> exampleFile = open('example.html') >>> exampleSoup = bs4.BeautifulSoup(exampleFile, 'html.parser') >>> type(exampleSoup) <class 'bs4.BeautifulSoup'>
المفسر 'html.parser' المستخدم هنا يأتي مع بايثون، لكن يمكنك استخدام المفسر 'lxml' الأسرع إذا ثبتت الوحدة الخارجية lxml. اتبع التعليمات الموجودة في الملحق أ لتثبيت الوحدة باستخدام الأمر pip install --user lxml. إذا لم نضمِّن الوسيط الثاني الذي يحدد المفسر فسيظهر التحذير: UserWarning: No parser was explicitly specified.
بعد أن يكون لدينا كائن BeautifulSoup سنتمكن من استخدام توابعه لتحديد أجزاء معينة من مستند HTML.
العثور على عنصر باستخدام التابع select()
يمكنك الحصول على عنصر من عناصر صفحة الويب في الكائن BeatuifulSoup باستدعاء التابع select() وتمرير محدد CSS (أي CSS Selector) للعنصر الذي تبحث عنه. المحددات تشبه التعابير النمطية في وظيفتها: تحدد نمطًا يمكن البحث عنه في صفحات الويب.
نقاش محددات CSS خارج سياق هذه السلسلة، لكن هذه مقدمة مختصرة عنها في الجدول التالي، وأنصحك بالاطلاع على توثيق المحددات في موسوعة حسوب.
| المحدد الذي يمرر إلى التابع ()select | سيطابق |
|---|---|
| soup.select('div') |
جميع عناصر <div>
|
| soup.select('#author') |
جميع العناصر التي لها الخاصية id وقيمتها author
|
| soup.select('.notice') |
جميع العناصر التي لها خاصية class ولها صنف CSS باسم notice
|
| soup.select('div span') |
جميع عناصر <span> الموجود داخل عناصر <div>
|
| soup.select('div > span') |
جميع العناصر <span> الموجودة مباشرةً داخل عناصر <div> بدون وجود أي عنصر بينهما
|
| soup.select('input[name]') |
جميع عناصر <input> التي لها الخاصية name بغض النظر عن قيمتها
|
| soup.select('input[type="button"]') |
جميع عناصر <input> التي لها الخاصية type وتكون مساوية إلى button
|
أمثلة عن محددات CSS
يمكن دمج مختلف أنماط المحددات مع بعضها لمطابقة أنماط أكثر تعقيدًا، فمثلًا soup.select('p #author') ستطابق أي عنصر له خاصية id قيمتها author لكن يجب أن يكون هذا العنصر موجودًا داخل عنصر <p>.
بدلًا من محاولة كتابة المحددات بنفسك، يمكنك الضغط بالزر الأيمن على أي عنصر في صفحة الويب واختيار Inspect Element، وحينما تفتح أدوات المطور اضغط بالزر الأيمن على عنصر HTML واختر Copy ▸ CSS Selector لنسخ محدد CSS إلى الحافظة لتستطيع لصقه في الشيفرة لديك.
التابع select() سيعيد قائمةً بعناصر Tag، وهذا ما تفعله وحدة BS4 لتمثيل عنصر HTML. هذه القائمة ستحتوي على كائن Tag لكل مطابقة للمحدد في كائن BeautifulSoup. يمكن تمرير كائن Tag إلى الدالة str() لعرض وسوم HTML التي تمثلها.
تمتلك قيم Tag أيضًا السمة attrs التي تظهر جميع خاصيات HTML للعنصر ممثلةً كقاموس. لنجرب على ملف example.html بإدخال ما يلي في الصدفة التفاعلية:
>>> import bs4 >>> exampleFile = open('example.html') >>> exampleSoup = bs4.BeautifulSoup(exampleFile.read(), 'html.parser') >>> elems = exampleSoup.select('#author') >>> type(elems) # elems هي قائمة من كائنات Tag <class 'list'> >>> len(elems) 1 >>> type(elems[0]) <class 'bs4.element.Tag'> >>> str(elems[0]) # تحويل الكائن إلى سلسلة نصية. '<span id="author">Al Sweigart</span>' >>> elems[0].getText() 'Al Sweigart' >>> elems[0].attrs {'id': 'author'}
ستستخرج الشيفرة السابقة العنصر الذي له id="author" في مستند HTML. سنستخدم select('#author') للحصول على قائمة بجميع العناصر التي لها id="author"، وسنخزن قائمة كائنات Tag في المتغير elems، وسيخبرنا التعبير len(elems) أن لدينا كائن Tag وحيد في القائمة، أي جرت عملية المطابقة لعنصر HTML وحيد.
استدعاء التابع getText() على العناصر سيعيد النص الموجود في العنصر، أي السلسلة النصية الموجودة بين وسم البدء والإغلاق.
أما تمرير الكائن إلى الدالة str() سيعيد سلسلة نصيةً فيها وسمَي البداية والنهاية مع نص العنصر؛ أما السمة attrs فستعطينا قاموسًا فيه خاصيات العنصر كاملةً.
يمكنك أيضًا استخراج جميع عناصر <p> من كائن BeautifulSoup كما في المثال الآتي:
>>> pElems = exampleSoup.select('p') >>> str(pElems[0]) '<p>Download my <strong>Python</strong> book from <a href="https:// inventwithpython.com">my website</a>.</p>' >>> pElems[0].getText() 'Download my Python book from my website.' >>> str(pElems[1]) '<p class="slogan">Learn Python the easy way!</p>' >>> pElems[1].getText() 'Learn Python the easy way!' >>> str(pElems[2]) '<p>By <span id="author">Al Sweigart</span></p>' >>> pElems[2].getText() 'By Al Sweigart'
ستعطينا select() ثلاث مطابقات، والتي ستخزن في المتغير pElems. سنجرب استخدام str() على الكائنات pElems[0] و pElems[1] و pElems[2] لعرض العناصر كسلاسل نصية، وسنجرب أيضًا التابع getText() لإظهار نص تلك العناصر فقط.
الحصول على معلومات من خاصيات العنصر
يسهل علينا التابع get() الخاص بكائنات Tag الوصول إلى خاصيات العناصر، ونمرر لهذا التابع سلسلةً نصيةً باسم الخاصية attribute وسيعيد لنا قيمتها. لنجرب المثال الآتي على الملف example.html:
>>> import bs4 >>> soup = bs4.BeautifulSoup(open('example.html'), 'html.parser') >>> spanElem = soup.select('span')[0] >>> str(spanElem) '<span id="author">Al Sweigart</span>' >>> spanElem.get('id') 'author' >>> spanElem.get('some_nonexistent_addr') == None True >>> spanElem.attrs {'id': 'author'}
يمكننا استخدام select() للعثور على أي عناصر <span> ثم تخزين أول عنصر مطابق في المتغير spanElem، الذي سنمرر للتابع get() القيمة 'id' للحصول على قيمة المعرف الخاصة به، وهي 'author' في مثالنا.
مشروع: فتح جميع نتائج البحث
في كل مرة أبحث فيها في جوجل، لا أريد أن أرى نتيجة بحث واحدة فقط ثم أنتقل إلى النتيجة التي بعدها، بل أضغط بسرعة على الزر الأوسط للفأرة على كل الروابط (أو الضغط عليها مع زر Ctrl) لفتحها في لسان جديد وأقرؤها معًا لاحقًا. فعلت هذا الأمر كثيرًا في جوجل لدرجة أنني مللت من البحث ثم الضغط على كل الروابط واحدًا واحدًا. ماذا لو كتبت برنامجًا أستطيع عبره كتابة عبارة البحث وسيفتح لي متصفحًا فيه كل نتائج البحث الأولى مفتوحةً كل واحد منها في لسان في المتصفح؟
لنكتب سكربتًا يفعل ذلك مع صفحة نتائج بحث فهرس حزم بايثون. يمكن تعديل هذا البرنامج ليعمل على الكثير من المواقع الأخرى، لكن انتبه إلى أن محركات البحث غوغل و DockDockGo عادةً ما تصعب عملية استخراج نتائج البحث من مواقعها.
هذا ما يفعله البرنامج:
- الحصول على عبارة البحث من سطر الأوامر
- الحصول على صفحة نتائج البحث
- فتح لسان متصفح جديد لكل نتيجة
هذا يعني أن على برنامجك أن يفعل ما يلي:
-
قراءة وسائط سطر الأوامر من
sys.argv. -
الحصول على صفحة نتائج البحث عبر الوحدة
requests. - العثور على جميع روابط نتائج البحث.
-
استدعاء الدالة
webbrowser.open()لفتحها في المتصفح.
لنبدأ البرمجة بفتح ملف جديد باسم searchpypi.py في محررنا.
الخطوة 1: الحصول على وسائط سطر الأوامر وطلب صفحة نتائج البحث
قبل أن نبدأ بالبرمجة، علينا أن نعرف ما هو رابط URL لصفحة نتائج البحث. انظر إلى شريط العنوان في المتصفح بعد إتمامك لعملية البحث، وسترى أن الرابط يشبه https://pypi.org/search/?q=SEARCH_TERM_HERE. يمكننا استخدام الوحدة requests لتنزيل هذه الصفحة، ثم استخدام BS4 للبحث عن الروابط في مستند HTML. يمكننا في النهاية أن نستعمل وحدة webbrowser لفتح تلك الروابط في ألسنة جديدة.
يحب أن تكون الشيفرة كما يلي:
#! python3 # searchpypi.py - فتح عدة نتائج بحث. import requests, sys, webbrowser, bs4 print('Searching...') # عرض النص ريثما تحمل الصفحة res = requests.get('https://pypi.org/search/?q=' + ' '.join(sys.argv[1:])) res.raise_for_status() # TODO: Retrieve top search result links. # TODO: فتح لسان لكل نتيجة.
سيحدد المستخدم كلمات البحث عبر تمريرها إلى سطر الأوامر أثناء تشغيل البرنامج، وستخزن في sys.argv كما رأينا في المقالات السابقة لهذه السلسلة.
الخطوة 2: العثور على كل النتائج
ستحتاج الآن إلى وحدة BS4 لاستخراج نتائج البحث من مستند HTML المنزل. لكن كيف يمكننا معرفة المحدد المناسب لحالتنا؟ ليس من المنطقي مثلًا البحث عن جميع عناصر <a> لوجود روابط كثيرة لا تهمنا؛ والحل هنا أن نفتح أدوات المطور في المتصفح وننظر إلى المحدد المناسب الذي سينتقي لنا الروابط التي نريدها فقط.
بعد أن نبحث فسنجد بعض العناصر التي تشبه التالي:
<a class="package-snippet" href="/project/pyautogui/">
ولا يهمنا إن كانت تلك العناصر معقدة، وإنما نحتاج إلى النمط الذي علينا استخدامه للبحث عن الروابط.
لنعدل شيفرتنا إلى:
#! python3 # searchpypi.py - Opens several google results. import requests, sys, webbrowser, bs4 --snip-- # Retrieve top search result links. soup = bs4.BeautifulSoup(res.text, 'html.parser') # فتح لسان لكل نتيجة. linkElems = soup.select('.package-snippet')
إذا ألقيت نظرةً إلى عناصر <a> فستجد أن جميع نتائج البحث لها الخاصية class="package-snippet" وإذا بحثنا في كامل مصدر الصفحة فسنتأكد أن الصنف package-snippet ليس مستخدمًا إلا لروابط نتائج البحث. لا يهمنا ما هو الصنف package-snippet ولا ما يفعل، وإنما يهمنا كيف سنستفيد منه لتحديد عناصر <a> التي نبحث عنها.
لننشِئ كائن BeautifulSoup من صفحة HTML التي نزلناها ونستخدم المحدد '.package-snippet' لتحديد جميع عناصر <a> التي لها صنف CSS المحدد؛ ضع في ذهنك أن موقع PyPI قد يحدث واجهته الرسومية وقد تحتاج إلى استخدام محدد CSS مختلف مستقبلًا، إن حدث ذلك فمرر المحدد الجديد إلى التابع soup.select() وسيعمل البرنامج على ما يرام.
الخطوة 3: فتح نتائج البحث في المتصفح
لنخبر برنامجنا الآن أن يفتح لنا النتائج الأولى في متصفح الويب. أضف ما يلي إلى برنامجك:
#! python3 # searchpypi.py - فتح عدة نتائج بحث. import requests, sys, webbrowser, bs4 --snip-- # فتح لسان لكل نتيجة. linkElems = soup.select('.package-snippet') numOpen = min(5, len(linkElems)) for i in range(numOpen): urlToOpen = 'https://pypi.org' + linkElems[i].get('href') print('Opening', urlToOpen) webbrowser.open(urlToOpen)
سيفتح البرنامج افتراضيًا أول خمسة روابط في المتصفح باستخدام الوحدة webbrowser، لكن قد يكون ناتج بحث المستخدم أقل من خمس نتائج، فحينها ننظر أيهما أقل، 5 أم عدد عناصر القائمة المعادة من استدعاء التابع soup.select().
الدالة المضمنة في بايثون min() تعيد العدد الأصغر من الوسائط الممررة إليها (والدالة max() تفعل العكس). يمكنك أن تستخدم الدالة min() لمعرفة إذا كان عدد الروابط أقل من 5 وتخزين الناتج في المتغير numOpen، والذي ستستفيد منه في حلقة for عبر range(numOpen).
سنستخدم الدالة webbrowser.open() في كل تكرار لحلقة for لفتح الرابط في المتصفح. لاحظ أن قيمة الخاصية href في عناصر <a> لا تحتوي على https://pypi.org لذا علينا إضافتها بأنفسنا إلى قيمة الخاصية href قبل فتح الرابط.
يمكنك الآن فتح أول 5 نتائج بحث عن «boring stuff» في محرك بحث PyPI بكتابة الأمر searchpypi boring stuff في سطر الأوامر.
أفكار لبرامج مشابهة
من الجميل أن يكون لدينا برنامج يفتح لنا عدة ألسنة في المتصفح لأي عملية روتينية مكررة، مثل:
- فتح جميع صفحات المنتجات في متجر أمازون بعد البحث عن منتج معين.
- فتح كل روابط المراجعات لمنتج ما.
- فتح الصور الناتجة بعد إجراء عملية بحث سريعة على أحد مواقع الصور مثل Flickr.
مشروع: تنزيل كل رسمات XKCD
عادةً ما تحدث المواقع والمدونات الصفحة الرئيسية لها بعرض آخر منشور فيها، مع وجود زر «السابق» الذي يأخذك إلى المنشور السابق، ثم تجد في المنشور السابق زرًا يأخذك للمنشور الذي قبله، وهلم جرًا، مما ينشِئ سلسلةً من الصفحات التي تأخذك من الصفحة الرئيسية إلى صفحة أول منشور في الموقع.
إذا أردت نسخةً من محتوى موقعٍ ما لتقرأها وأنت غير متصل بالإنترنت، فيمكنك أن تفتح بنفسك كل صفحة وتحفظها، لكن هذا الأمر ممل جدًا ومن المناسب كتابة برنامج لأتمتة هذه المهمة.
موقع XKCD هو موقع كوميكس له نفس البنية المذكورة. وصفحته الرئيسية فيها زر Prev للعودة إلى الكوكميس السابقة، لكن عملية تنزيل كل الكوميكس واحدةً واحدةً تأخذ وقتًا كثيرًا، لكننا نستطيع كتابة سكربت لأتمتة ذلك في ثوانٍ معدودة.
هذا ما سيفعله برنامجنا:
- فتح صفحة XKCD الرئيسية
- حفظ صورة الكوميكس في تلك الصفحة
- الانتقال إلى صفحة الكوميكس السابق
- تكرار العملية حتى الوصول إلى أول صورة كوميكس.
هذا يعني أن الشيفرة البرمجية ستفعل ما يلي:
-
تنزيل الصفحات باستخدام الوحدة
requests. -
العثور على رابط URL لصورة الكوميكس باستخدام وحدة
BS4. -
تنزيل وحفظ صورة الكوميكس إلى نظام الملفات باستخدام
iter_content(). - العثور على رابط صورة الكوميكس السابقة، وتكرار العملية كلها.
افتح ملفًا جديدًا في محررك وسمِّه باسم downloadXkcd.py.
الخطوة 1: تصميم البرنامج
إذا فتحت أدوات المطور في المتصفح ونظرت إلى عناصر الصفحة، فسترى ما يلي:
-
رابط URL لملف صورة الكوميكس في الخاصية
hrefفي العنصر <img>. -
العنصر
<img>موجود داخل العنصر<div id="comic">. -
الزر
Pervله الخاصيةrelوقيمتهاprev. -
صفحة أول صورة كوميكس يشير فيها الزر
Prevإلى الرابطhttps://xkcd.com/#مما يشير إلى عدم وجود صفحات سابقة. عدّل الشيفرة لتبدو كما يلي:
#! python3 # downloadXkcd.py - تنزيل كل صورة كوميكس في XKCD. import requests, os, bs4 url = 'https://xkcd.com' # starting url os.makedirs('xkcd', exist_ok=True) # store comics in ./xkcd while not url.endswith('#'): # TODO: Download the page. # TODO: Find the URL of the comic image. # TODO: Download the image. # TODO: حفظ الصورة إلى ./xkcd. # TODO: الحصول على رابط الصفحة السابقة. print('Done.')
سيكون لدينا متغير اسمه url يبدأ بالقيمة 'https://xkcd.com' وتحدث قيمته دوريًا ضمن حلقة for لتصبح الرابط الموجود في الزر Prev للصفحة الحالية. وسننزل صورة الكوميكس في كل تكرار من تكرارات حلقة for الموجودة في الرابط url، وسننتهي من حلقة التكرار حينما تنتهي قيمة url بالعلامة '#'.
سننزل ملفات الصور إلى مجلد موجود في مجلد العمل الحالي باسم xkcd، وسنتأكد من أن المجلد موجود باستدعاء os.makedirs() مع تمرير وسيط الكلمات المفتاحية exist_ok=True الذي يمنع الدالة من رمي استثناء إن كان المجلد موجودًا مسبقًا. بقية الشيفرة هو تعليقات سنملؤها في الأقسام القادمة.
الخطوة 2: تنزيل صفحة الويب
لنكتب الشيفرة الآتية التي ستنزل الصفحة:
#! python3 # downloadXkcd.py - تنزيل كل صورة كوميكس في XKCD. import requests, os, bs4 url = 'https://xkcd.com' # starting url os.makedirs('xkcd', exist_ok=True) # store comics in ./xkcd while not url.endswith('#'): # Download the page. print('Downloading page %s...' % url) res = requests.get(url) res.raise_for_status() soup = bs4.BeautifulSoup(res.text, 'html.parser') # TODO: Find the URL of the comic image. # TODO: Download the image. # TODO: حفظ الصورة إلى ./xkcd. # TODO: الحصول على رابط الصفحة السابقة. print('Done.')
لنطبع بدايةً قيمة url ليعرف المستخدم ما هو رابط URL الذي يحاول البرنامج تنزيله، ثم سنستخدم الدالة requests.get() في الوحدة requests لتنزيل الصفحة. ثم سنستدعي التابع raise_for_status() كالعادة لرمي استثناء إن حدثت مشكلة ما في التنزيل؛ ثم إن سارت الأمور على ما يرام فسننشِئ كائن BeautifulSoup من نص الصفحة المنزلة.
الخطوة 3: البحث عن صورة الكوميكس وتنزيلها
لنعدل شيفرة برنامجنا:
#! python3 # downloadXkcd.py - تنزيل كل صورة كوميكس في XKCD. import requests, os, bs4 --snip-- # Find the URL of the comic image. comicElem = soup.select('#comic img') if comicElem == []: print('Could not find comic image.') else: comicUrl = 'https:' + comicElem[0].get('src') # Download the image. print('Downloading image %s...' % (comicUrl)) res = requests.get(comicUrl) res.raise_for_status() # TODO: حفظ الصورة إلى ./xkcd. # TODO: الحصول على رابط الصفحة السابقة. print('Done.')
بعد تفحص صفحة XKCD عبر أدوات المطور، سنعرف أن عنصر <img> لصورة الكوميكس موجود داخل عنصر <div> له الخاصية id التي قيمتها هي comic، وبالتالي سيكون المحدد '#comic img' صحيحًا لتحديد العنصر <img> عبر كائن BeautifulSoup.
تمتلك بعض صفحات موقع XKCD على محتوى خاص لا يمثل صورة بسيطة، لكن لا بأس فيمكننا تخطي تلك الصفحات، فإن لم يطابِق المحدد الخاص بنا أي عنصر فسيعيد استدعاء soup.select('#comic img') قائمة فارغة، وحينها سيظهر برنامجنا رسالة خطأ ويتجاوز الصفحة دون تنزيل الصورة.
عدا ذلك، فسيعيد المحدد السابق قائمةً فيها عنصر <img> وحيد، ويمكننا الحصول على قيمة الخاصية src لعنصر <img>ونمررها إلى requests.get() لتنزيل صورة الكوميكس.
الخطوة 4: حفظ الصورة والعثور على الصفحة السابقة
لنعدل الشيفرة لتصبح كما يلي:
#! python3 # downloadXkcd.py - تنزيل كل صورة كوميكس في XKCD. import requests, os, bs4 --snip-- # حفظ الصورة إلى ./xkcd. imageFile = open(os.path.join('xkcd', os.path.basename(comicUrl)), 'wb') for chunk in res.iter_content(100000): imageFile.write(chunk) imageFile.close() # الحصول على رابط الصفحة السابقة. prevLink = soup.select('a[rel="prev"]')[0] url = 'https://xkcd.com' + prevLink.get('href') print('Done.')
أصبح لدينا ملف صورة الكوميكس مخزنًا في المتغير res، وعلينا كتابة بيانات هذه الصورة إلى ملف في نظام الملفات المحلي لدينا. سنحدد اسم الملف المحلي للصورة ونمرره إلى الدالة open()، لاحظ أن المتغير comicUrl يحتوي على قيمة تشبه القيمة الآتية:
'https://imgs.xkcd.com/comics/heartbleed_explanation.png'
ويبدو أنك لاحظت وجود مسار الملف فيها.
يمكنك استخدام الدالة os.path.basename() مع comicUrl لإعادة آخر جزء من رابط URL السابق، أي 'heartbleed_explanation.png'، ويمكنك حينها استخدام هذا الاسم حين حفظ الصورة إلى نظام الملفات المحلي.
يمكنك أن تضيف هذا الاسم إلى اسم مجلد xkcd باستخدام الدالة os.path.join() كما تعلمنا سابقًا لكي يستخدم برنامجك الفاصل الصحيح (الخط المائل الخلفي \ في ويندوز، والخط المائل / في لينكس وماك). أصبح لدينا الآن اسم ملف صحيح، ويمكننا استدعاء الدالة open() لفتح ملف جديد بوضع الكتابة الثنائية 'wb'.
إذا كنت تذكر حينما حفظنا الملفات التي نزلناها عبر الوحدة requests في بداية المقال كنا نمر بحلقة تكرار على القيمة المعادة من التابع iter_content()، وستكتب الشيفرة الموجودة في حلقة for قطعًا من بيانات الصورة (كحد أقصى 100,000 بايت كل مرة) إلى الملف، ثم تغلق الملف. أصبحت الصورة محفوظة لديك محليًا الآن!
علينا بعدئذٍ استخدام المحدد 'a[rel="prev"]' لتحديد العنصر <a> الذي له العلاقة rel مضبوطةً إلى prev. يمكنك استخدام قيمة الخاصية href لعنصر <a> المحدد للحصول على رابط صورة الكوميكس السابقة، والتي ستخزن في المتغير url، ثم ستدور حلقة while مرة أخرى وتعيد تنفيذ عملية التنزيل من جديد على الصفحة الجديدة.
سيبدو ناتج تنفيذ البرنامج كما يلي:
Downloading page https://xkcd.com... Downloading image https://imgs.xkcd.com/comics/phone_alarm.png... Downloading page https://xkcd.com/1358/... Downloading image https://imgs.xkcd.com/comics/nro.png... Downloading page https://xkcd.com/1357/... Downloading image https://imgs.xkcd.com/comics/free_speech.png... Downloading page https://xkcd.com/1356/... Downloading image https://imgs.xkcd.com/comics/orbital_mechanics.png... Downloading page https://xkcd.com/1355/... Downloading image https://imgs.xkcd.com/comics/airplane_message.png... Downloading page https://xkcd.com/1354/... Downloading image https://imgs.xkcd.com/comics/heartbleed_explanation.png... --snip–
هذا المشروع هو مثال ممتاز لبرامج تتبع الروابط تلقائًا لاستخراج كمية معلومات كبيرة من الويب. يمكنك تعلم المزيد من المعلومات حول ميزات Beautiful Soup الأخرى من توثيقها الرسمي.
أفكار لبرامج مشابهة
تنزيل صفحات الويب وتتبع الروابط فيها هو أساس أي برنامج زحف crawler. يمكنك أن تبرمج برامج تفعل ما يلي:
- تنسخ موقعًا كاملًا احتياطيًا.
- تنسخ جميع التعليقات من أحد المنتديات.
- تعرض قائمة بجميع المنتجات التي عليها تخفيضات في أحد المتاجر.
الوحدتان requests و bs4 رائعتين جدًا، لكن عليك أن تعرف ما هو رابط URL المناسب لتمريره إلى requests.get()، لكن في بعض الأحيان قد لا يكون ذلك سهلًا؛ أو ربما عليك تسجيل الدخول إلى أحد المواقع قبل بدء عملية الاستخراج، لهذا السبب سنستكشف سويةً الوحدة selenium لأداء مهام معقدة.
التحكم في المتصفح عبر الوحدة selenium
تسمح الوحدة selenium لبايثون بالتحكم برمجيًا بالمتصفح بضغط الروابط وتعبئة الاستمارات، مثلها كمثل أي تفاعل من مستخدم بشري. يمكننا أن نتفاعل مع صفحات الويب بطرائق أكثر تقدمًا في الوحدة selenium مقارنة مع requests و bs4، لكنها قد تكون أبطأ وأصعب بالتشغيل في الخلفية لأننا نفتح متصفح ويب كامل مقارنة بتنزيل بعض الصفحات من الويب.
لكن إن كان علينا التعامل مع صفحات الويب بطريقة تعتمد على شيفرات JavaScript التي تحدث الصفحة، فعلينا استخدام selenium بدلًا من requests. أضف إلى ذلك أن المواقع الشهيرة مثل أمازون تستخدم برمجيات للتعرف على الزيارات الآتية من سكربتات التي تحاول استخراج البيانات من صفحاتها أو إنشاء عدّة حسابات مجانية، ومن المرجح أن تحجب هذه المواقع برامجك بعد فترة؛ وهنا تأتي الوحدة selenium التي تعمل مثل متصفحات الويب العادية.
أحد أشهر العلامات التي تتعرف فيها المواقع أن الزيارات آتية من برنامج (أو سكربت script) هي عبارة user-agent، التي تُعرِّف متصفح الويب المستخدم وتضمَّن في كل طلبيات HTTP. فمثلًا تكون عبارة user-agent للوحدة requests شيء يشبه 'python-requests/2.21.0'.
يمكنك زيارة موقع مثل whatsmyua.info لتعرف ما هي user-agent الخاصة بك. أما الوحدة selenium فمن المرجح أن تظن المواقع أنها مستخدم بشري، لأنها تستخدم user-agent شبيه بالمتصفحات العادية مثل:
Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0
ولأن نمط التصفح فيها يشبه المتصفحات الأخرى، فستُنزَّل الصور والإعلانات وملفات تعريف الارتباط والمتتبعات كما في المتصفحات العادية. لكن يمكن للمواقع كشف selenium وتحاول شركات شراء بطاقات الدخول والمتاجر الإلكترونية حجب أي سكربتات تستعمل متصفح selenium.
تشغيل متصفح تتحكم فيه selenium
سنرى في الأمثلة القادمة كيفية التحكم في متصفح فيرفكس من selenium، إذا لم يكن مثبتًا لديك فيمكنك تنزيله من getfirefox.com، ويمكنك تثبيت selenium،من سطر الأوامر بتشغيل pip install --user selenium، وأذكرك بالذهاب إلى الملحق أ لمزيد من المعلومات.
قد يكون استيراد مكونات selenium مختلفًا عليك، فبدلًا من import selenium سنستعمل from selenium import webdriver (سبب فعل selenium لذلك خارج نطاق هذه السلسلة لا تقلق حوله). يمكنك بعد ذلك تشغيل فايرفوكس مع selenium بكتابة ما يلي في الصدفة التفاعلية:
>>> from selenium import webdriver >>> browser = webdriver.Firefox() >>> type(browser) <class 'selenium.webdriver.firefox.webdriver.WebDriver'> >>> browser.get('https://inventwithpython.com')
ستلاحظ أن متصفح فايرفوكس قد بدأ بالعمل حين استدعاء webdriver.Firefox(). استدعاء type() على webdriver.Firefox() سيظهر أنها من نوع البيانات WebDrive، واستدعاء التالي:
browser.get('https://inventwithpython.com')
سيوجه المتصفح إلى https://inventwithpython.com/.
_get()_.jpg.93f20ae1a36f5a4b6eb7f7eaeffb12e3.jpg)
بعد استدعاء webdriver.Firefox() و get() ستفتح الصفحة في متصفح فايرفوكس
إذا واجهت مشكلة من قبيل 'geckodriver' executable needs to be in PATH فهذا يعني أن عليك تنزيل محرك فايرفوكس يدويًا قبل استخدام selenium للتحكم به. يمكنك التحكم بمتصفحات أخرى غير فيرفكس إذا ثبتت محرك الويب لهم webdriver.
لمتصفح فايرفوكس، اذهب إلى github.com وثبت محرك geckodriver لنظام تشغيلك. (كلمة «Gecko» هي اسم محرك المتصفح engine في فيرفكس). سيحتوي الملف المضغوط المنزل على geckodriver.exe في ويندوز أو geckodriver في ماك ولينكس، وعليك وضعه في مسار PATH الخاص في نظامك، راجع الإجابة الآتية stackoverflow.com.
أما لمتصفح كروم فاذهب إلى chromium.org ونزل الملف المضغوط المناسب لنظامك، وضع الملف chromedriver.exe أو chromedriver في مسار PATH كما ذكرنا أعلاه.
يمكن فعل نفس الأمر لبقية المتصفحات الرئيسية، ابحث سريعًا في الويب عن اسم المتصفح متبوعًا بالكلمة webdriver وستجدها.
قد تواجه مشاكل في تشغيل المتصفحات الجديدة في selenium، بسبب عدم التوافقية بينهما، لكن يمكنك إجراء حل التفافي بتثبيت نسخة قديمة من المتصفح أو من وحدة selenium. يمكنك معرفة تاريخ الإصدارات من pypi.org. للأسف قد تحدث مشاكل توافقية بين selenium وبعض إصدارات المتصفحات، وأنصحك حينها بالبحث في الويب عن الحلول المقترحة، وراجع الملحق أ لمعلومات حول تثبيت إصدار محدد من selenium (مثل تثبيت pip install --user -U selenium==3.14.1).
العثور على عناصر في الصفحة
توفر كائنات WebDriver عددًا من التوابع للعثور على عناصر صفحة، ويمكن تقسيمها إلى قسمين من التوابع find_element_ و find_elements_*. توابع find_element_* تعيد كائن WebElement وحيد يمثل أول عنصر في الصفحة يطابق الطلبية التي حددتها، بينما تعيد توابع _find_elements قائمة من كائنات WebElement_* لكل عنصر مطابق في الصفحة.
يظهر الجدول الموالي أمثلة على التوابع find_element_ و find_elements_ المستدعاة على كائن WebDriver مخزن في المتغير browser.
| اسم التابع | كائن/قائمة كائنات WebElement |
|---|---|
browser.find_element_by_class_name(name) browser.find_elements_by_class_name(name)
|
العناصر التي تستخدم صنف CSS باسم name |
browser.find_element_by_css_selector(selector) browser.find_elements_by_css_selector(selector)
|
العناصر التي تطابق محدد CSS معين |
browser.find_element_by_id(id) browser.find_elements_by_id(id)
|
العناصر التي تطابق id معين |
|
browser.find |
عناصر <a> التي يطابق محتواها القيمة text كاملةً
|
browser.find_element_by_partial_link_text(text) browser.find_elements_by_partial_link_text(text)
|
عناصر <a> التي يطابق محتواها القيمة text جزئيًا
|
browser.find_element_by_name(name) browser.find_elements_by_name(name)
|
العناصر التي لها الخاصية name وتطابق قيمة معينة
|
browser.find_element_by_tag_name(name) browser.find_elements_by_tag_name(name)
|
العناصر التي تطابق وسمًا معينًا، وهي غير حساسة لحالة الأحرف (أي <a> يمكن أن يطابق عبر 'a' أو 'A')
|
توابع WebDriver للعثور على العناصر في selenium
باستثناء التوابع *_by_tag_name() تكون جميع الوسائط الممررة إلى الدوال حساسةً لحالة الأحرف، وإذا لم تكن العناصر موجودة في الصفحة فستطلق selenium الاستثناء NoSuchElement، وعليك استخدام عبارات try و except إذا لم ترغب بتوقف برنامج عن العمل عند ذلك.
بعد أن تحصل على كائن WebElement فيمكنك أن تتعرف على المزيد حوله بقراءة سماته أو استدعاء توابع المذكورة في الجدول التالي:
| السمة أو التابع | الوصف |
|---|---|
| tag_name |
اسم الوسم، مثل 'a' لعنصر <a>
|
| get_attribute(name) |
قيمة خاصية name للعنصر
|
| text |
النص الموجود داخل العنصر، مثل 'hello' في <span>hello</span>
|
| clear() | مسح النص المكتوب في الحقول النصية |
| is_displayed() |
إعادة True إذا كان العنصر ظاهرًا، وإلا فيعيد False
|
| is_enabled() |
إعادة True إذا كان حقل الإدخال مفعلًا، وإلا فيعيد False
|
| is_selected() |
لأزرار الانتقاء radio ومربعات التأشير checkbox ستعيد True إذا كان العنصر مختار، وإلا فتعيد False
|
| location |
قاموس فيه المفاتيح 'x' و 'y' لمكان العنصر في الصفحة
|
سمات وتوابع الكائن WebElement
مثلًا، افتح ملفًا جديدًا واكتب البرنامج الآتي:
from selenium import webdriver browser = webdriver.Firefox() browser.get('https://inventwithpython.com') try: elem = browser.find_element_by_class_name(' cover-thumb') print('Found <%s> element with that class name!' % (elem.tag_name)) except: print('Was not able to find an element with that name.')
فتحنا هنا متصفح فيرفكس ووجهناه إلى رابط URL معين، وحاولنا العثور على العناصر التي لها الصنف bookcover، وإذا عثرنا على أحد العناصر فسنطبع اسم الوسم عبر السمة tag_name؛ أما لو لم يعثر على أي عنصر فسنطبع رسالة مختلفة. سيعيد البرنامج الناتج الآتي:
Found <img> element with that class name!
أي عثرنا على عنصر <img> له اسم الصنف 'bookcover'.
الضغط على عناصر الصفحة
تمتلك كائنات WebElement المعادة من التوابع find_element_* و find_elements_* التابع click() الذي يحاكي ضغطات الفأرة على العنصر، ويمكن استخدام هذا التابع للضغط على رابط أو تحديد زر انتقاء أو الضغط على زر الإرسال أو أي حدث آخر يُطلَق عند الضغط على أحد العناصر. جرب المثال الآتي في الطرفية التفاعلية:
>>> from selenium import webdriver >>> browser = webdriver.Firefox() >>> browser.get('https://inventwithpython.com') >>> linkElem = browser.find_element_by_link_text('Read Online for Free') >>> type(linkElem) <class 'selenium.webdriver.remote.webelement.FirefoxWebElement'> >>> linkElem.click() # follows the "Read Online for Free" link
سيفتح متصفح فيرفكس الصفحة ويحصل على العنصر <a> الذي يحتوي على النص Read it Online ويحاكي الضغط على الرابط كما لو ضغطته بنفسك.
تعبئة وإرسال الاستمارات
يمكن تعبئة الحقول النصية مثل <input> أو <textarea> بالبحث عنها ثم استدعاء التابع send_keys(). جرب ما يلي في الطرفية التفاعلية:
>>> from selenium import webdriver >>> browser = webdriver.Firefox() >>> browser.get('https://login.metafilter.com') >>> userElem = browser.find_element_by_id('user_name) >>> userElem.send_keys('your_real_username_here') >>> passwordElem = browser.find_element_by_id('user_pass') >>> passwordElem.send_keys('your_real_password_here') >>> passwordElem.submit()
لطالما لم تغيّر صفحة MetaFilter المعرف id لحقول اسم المستخدم وكلمة المرور بعد نشر هذا الكتاب، فيمكنك استخدام الشيفرة السابقة لملء تلك الحقول النصية (تذكر أنك تستطيع استخدام أدوات المطور للتأكد من المعرف id للحقول في أي وقت).
استدعاء التابع submit() على أي عنصر في الاستمارة له نفس تأثير الضغط على زر الإرسال.
تحذير: ابتعد عن تخزين كلمات المرور الخاصة بك في الشيفرة المصدرية لبرامجك قدر الإمكان، فمن السهل تسريب كلمات المرور إذا تركناها دون تشفير. يمكن لبرنامجك أن يطلب كلمة المرور من المستخدم أثناء التشغيل كما ناقشنا في مقال سابق.
إرسال المفاتيح الخاصة
تمتلك selenuim وحدةً للمفاتيح الخاصة التي لا يمكن كتابتها كسلسلة نصية، مثل زر Tab أو الأسهم. تلك القيم مخزنة كسمات في الوحدة selenium.webdriver.common.keys، ولأن اسم الوحدة طويل جدًا فمن الأسهل كتابة from selenium.webdriver.common.keys import Keys في بداية البرنامج، وحينها تستطيع استخدام Keys في أي مكان تريد أن تكتب فيه selenium.webdriver.common.keys. يعرض الجدول 12-5 أشهر القيم المستخدمة.
الجدول 12-5: أشهر القيم المستخدمة في الوحدة selenium.webdriver.common.keys.
| السمة | الشرح |
|---|---|
| Keys.DOWN و Keys.UP و Keys.LEFT و Keys.RIGHT | الأسهم في لوحة المفاتيح |
| Keys.ENTER و Keys.RETURN | زر Enter |
| Keys.HOME و Keys.END و Keys.PAGE_DOWN و Keys.PAGE_UP | أزرار Home و End و PageDown و PageUp على التوالي |
| Keys.ESCAPE و Keys.BACK_SPACE و Keys.DELETE | أزرار Escape و Backspace و Delete على التوالي |
| Keys.F1 و Keys.F2 و . . . و Keys.F12 | الأزرار F1 حتى F12 في الصف العلوي من لوحة المفاتيح |
| Keys.TAB | زر Tab |
فمثلًا لو لم يكن المؤشر موجودًا داخل حقل نصي، فالضغط على زر Home و End سيؤدي إلى التمرير إلى بداية ونهاية الصفحة على التوالي. جرب ما يلي على الصدفة التفاعلية ولاحظ كيف يؤدي استدعاء send_keys() إلى تمرير الصفحة:
>>> from selenium import webdriver >>> from selenium.webdriver.common.keys import Keys >>> browser = webdriver.Firefox() >>> browser.get('https://nostarch.com') >>> htmlElem = browser.find_element_by_tag_name('html') >>> htmlElem.send_keys(Keys.END) # scrolls to bottom >>> htmlElem.send_keys(Keys.HOME) # scrolls to top
العنصر <html> موجود في كل ملفات HTML، ويكون كامل محتوى مستند HTML داخله؛ وتحديد هذا العنصر مفيد لو أردنا إرسال المفاتيح إلى صفحة الويب عمومًا، وهذا بدوره مفيد إذا كانت الصفحة تحمِّل محتوى جديد عند التمرير إلى أسفل الصفحة.
الضغط على أزرار المتصفح
يمكن أن تحاكي الوحدة selenium الضغط على أزرار المتصفح المختلفة:
-
التابع
browser.back()يضغط على زر الرجوع -
التابع
browser.forward()يضغط على زر إلى الأمام -
التابع
browser.refresh()يضغط على زر التحديث -
التابع
browser.quit()يضغط على زر إغلاق النافذة
المزيد من المعلومات حول Selenium
يمكن للوحدة selenium فعل الكثير مما لم نذكره هنا، فيمكنك أن تعدل محتوى ملفات تعريف الارتباط، وتأخذ لقطة شاشة، وتشغل سكربت JavaScript مخصص …إلخ. لمزيد من المعلومات حول تلك الخصائص فأنصحك أن تزور التوثيق الرسمي.
الخلاصة
المهام المملة ليست متعلقة بالملفات المحلية على حاسوبك. إذا كنت قادرًا على تنزيل صفحات الويب برمجيًا فستستطيع أتمتة أي مهمة تردك! تسهل الوحدة requests تنزيل صفحات الويب، وبعد تعلم أساسيات HTML فيمكنك أن تستخدم الوحدة BeautifulSoup لتفسير الصفحات التي تنزلها. لكن إن كانت تريد أتمتة أي مهمة متعلقة بالويب أيًا كانت، فيمكنك التحكم برمجيًا مباشرةً بمتصفح الويب عبر الوحدة selenium، التي تسمح لك بفتح المواقع وملء الاستمارات كما لو كان برنامجك كائنًا بشريًا يتصفح المواقع.
مشاريع تدريبية
لكي تتدرب، اكتب برامج لتنفيذ المهام الآتية.
إرسال البريد الإلكتروني من سطر الأوامر
اكتب برنامج يقبل عنوان بريد إلكتروني وسلسلة نصية في سطر الأوامر، ثم يستخدم selenium للدخول إلى حسابك البريدي وإرسال بريد إلكتروني إلى العنوان المحدد (أنصحك بإنشاء حساب تجريبي مختلف عن حسابك الأساسي). اكتب برامج أخرى لإضافة منشورات إلى فيسبوك أو تويتر (إكس، سمه ما شئت!).
منزِّل الصور
اكتب برنامج يفتح أحد مواقع مشاركة الصور مثل Flickr ويبحث عن تصنيف معين من الصور وينزل جميع نتائج البحث في الصفحة الأولى. يمكنك أن تكتب برنامج يعمل على أي موقع مشاركة صور ولديه خاصية البحث.
لعبة 2048
لعبة 2048 هي لعبة بسيطة تسمح لك بجمع مربعات بجعلها تنزلق إلى أحد الاتجاهات باستخدام أزرار الأسهم. يمكنك أن تحصل على نتيجة عالية إذا جعلت الانزلاق بهذا الترتيب مرارًا وتكرارًا: الأعلى ثم اليمين ثم الأسفل ثم اليسار. اكتب برنامج بسيط يفتح اللعبة gabrielecirulli.github.io وينفذ النمط السابق للعب اللعبة تلقائيًا.
التحقق من الروابط
اكتب برنامج يأخذ رابط URL من صفحة ويب، ويحاول أن ينزل كل صفحة مرتبطة فيها، ويُعلِّم كل الصفحات التي تعيد 404 وتؤشر عليها أنها روابط مكسورة.
ترجمة -بتصرف- للمقال Web Scraping من كتاب Automate the Boring Stuff with Python.
اقرأ أيضًا
- المقال السابق: تنقيح أخطاء Debugging شيفرتك البرمجية باستخدام لغة بايثون
- برمجة عملاء ويب باستخدام بايثون
- أهم 10 مكتبات بايثون تستخدم في المشاريع الصغيرة
- مشاريع بايثون عملية تناسب المبتدئين
- النسخة العربية الكاملة لكتاب البرمجة بلغة بايثون











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.