

تخيل أن أمامك كومةً ضخمةً من ملفات PDF، وأنك بحاجة إلى إجابة سريعة على سؤال محدد. البحث اليدوي قد يستغرق ساعات، ولكن ماذا لو كان بالإمكان طرح سؤال على الآلة والحصول على إجابة دقيقة في ثوانٍ؟ أو ربما الحصول على تلخيص نصوص طويلة بلمسة زر واحدة؟
في الواقع، يمكن القيام بالأمر بسهولة، إذ لم يعد العثور على المعلومات الدقيقة واستخراجها أمرًا معقدًا بفضل تقنيات الذكاء الاصطناعي المتقدمة، وأحد أبرزها أنظمة RAG.
أنظمة التوليد المعزز بالاسترجاع أو ما يُعرف اختصارًا بأنظمة RAG هي تقنية متقدمة في الذكاء الاصطناعي تجمع بين استرجاع المعلومات من مصادر خارجية وتوليد النصوص، مما يتيح تقديم إجابات أكثر دقة وأمان. تعمل هذه الأنظمة كوسيط ذكي بين البحث والتوليد، مما يسمح بفهم أعمق للمحتوى، والإجابة على الأسئلة المعقدة، وتلخيص النصوص الطويلة بكفاءة عالية، دون الحاجة إلى إعادة تدريب النموذج على بيانات جديدة باستمرار.
فكرة المشروع الذي تحتويه المقالة
يهدف هذا المشروع إلى تطوير نظام RAG يمكننا من الحصول على المعلومات المطلوبة بسرعة والحصول على ملخصات دقيقة للمفاهيم التي نحتاجها من كتاب طريقك إلى العمل الحر عبر الإنترنت، ويسمح بطرح الأسئلة حول محتوى الكتاب والحصول على إجابات موجزة، مما يسهل مراجعة المعلومات واستذكارها بكفاءة.
سنعتمد في العمل على النظام على DeepSeek لاسترجاع المعلومات من الكتاب بدقة، بينما يُستخدم Ollama لإنشاء ردود ذكية قائمة على السياق المسترجع.
مع ذلك هناك أمر مهم جدًا يجب توضيحه، رغم قوة DeepSeek-R1 الذي سنستخدمه في المقال مع اللغات الأجنبية، إلا أنه وللأسف لا يقدم أداءً مثاليًا مع اللغة العربية بسبب محدودية التدريب على النصوص العربية مقارنةً باللغات الأخرى مثل الإنجليزية. ولحل هذه المشكلة، تطلب منا الأمر استخدام نماذج أكبر مثل DeepSeek R1-70B للحصول على النتائج الدقيقة عالية الجودة التي ستجدها بالمقال، لكن تطبيقك لشبيه به، سيعتمد على توفر موارد حاسوبية كافية؛ أما في حال لم تكن هذه الموارد متاحة، فيمكن الاستفادة من نفس الطريقة لتطبيق النظام على نماذج أخرى تدعم اللغة العربية بكفاءة أكبر مثل Qwen، أو استخدامه مع لغات أخرى مثل الإنجليزية التي تتمتع بدعم أفضل.
خطوات العمل على المشروع
يعتمد مشروعنا على دمج مرحلتين أساسيتين:
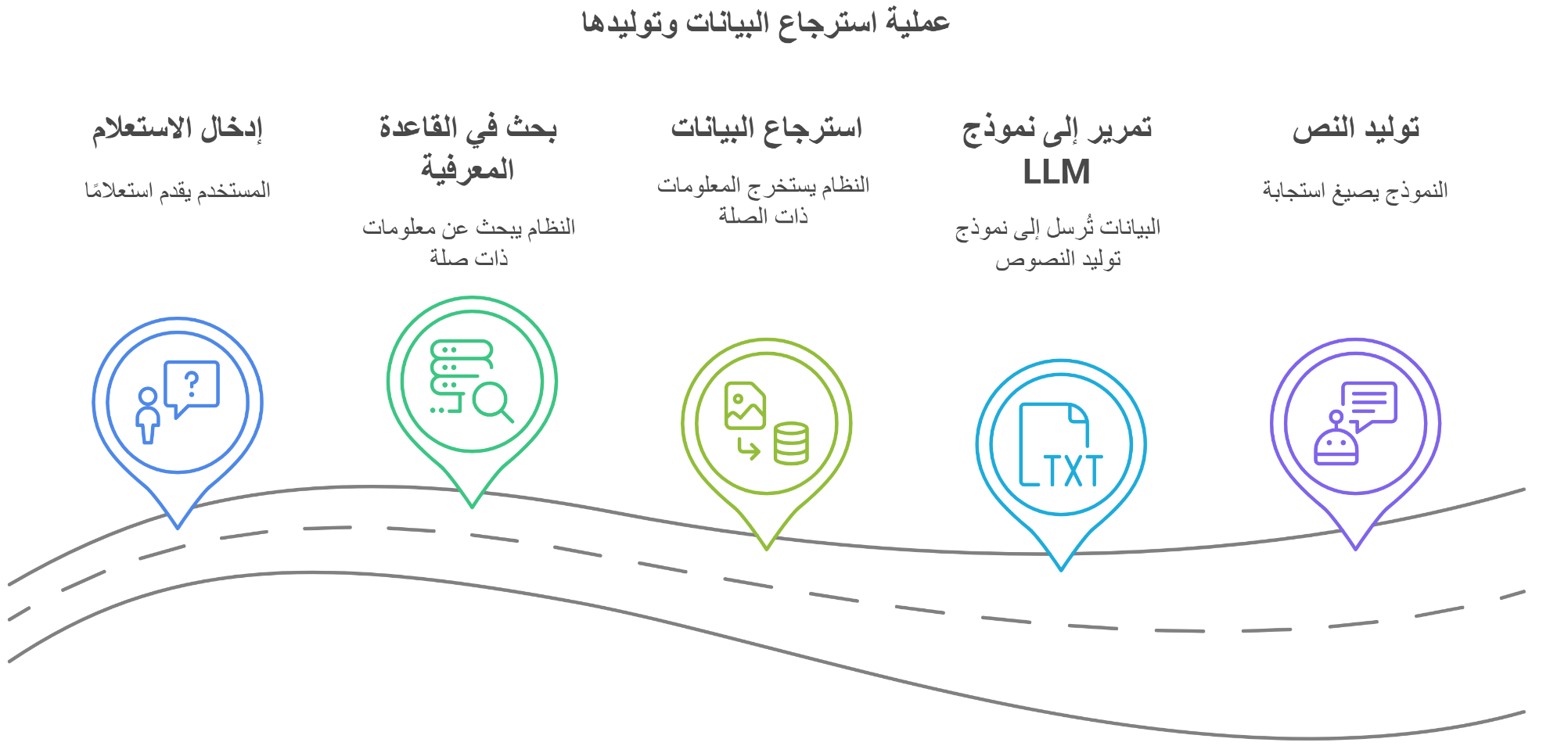
- إسترجاع المعلومات: عند إدخال سؤال، يبدأ النظام بالبحث في قاعدة البيانات التي استخرجها من الكتاب عن أكثر المعلومات ذات الصلة، والتي تساعد في الإجابة على السؤال توليد
- توليد النصوص: بعد استرجاع المعلومات من قاعدة البيانات الخاصة بالكتاب، تُنقل لنموذج توليد النص، لينشئ لنا إجابة دقيقة تعتمد على المعلومات المسترجعة من الكتاب فقط
تحضير بيئة العمل على المشروع
من أجل تنفيذ هذا المشروع، سنحتاج إلى الأدوات الآتية:
تحميل مكتبات وأطر عمل لغة بايثون المطلوبة
سنستعمل في نظامنا المكتبات التالية:
- مكتبة HuggingFace Embeddings: وهي المكتبة المسئولة عن البصمات الرقمية للنصوص، حجمها خفيف وتلائم الأجهزة الضعيفة نسبيًا
- مكتبة PyPDFLoader: وهي المكتبة المسئولة عن التعامل مع ملفات PDF، سريعة المعالجة ولا تستهلك الكثير من الوقت
- مكتبة Faiss: وهي المكتبة المسئولة عن إنشاء قاعدة بيانات تخزن فيها المعلومات واسترجاعها عند الحاجة، وهي أشهر مكتبة حاليا
وسنستعمل أطر العمل Frameworks التالية:
- إطار العمل Langchain: وهو البيئة المسئولة عن بناء تطبيقات الذكاء الاصطناعي المتكاملة
- إطار العمل Streamlit: المسئول عن توفير واجهة ويب تفاعلية لعرض النتائج بوضوح، نستعملها لبساطتها ولأنها توفر في ذاكرة الوصول العشوائي RAM
إذا كنا نستعمل مثبّت conda أو mini-conda، فيمكننا تثبيت المكتبات والأطر المطلوبة عبر سطر الأوامر Terminal مباشرةً على النحو الآتي:
# تثبيت المكتبات وأطر العمل التي نحتاجها للعمل عبر مثبِّت conda conda install -c conda-forge streamlit pdfplumber langchain faiss-cpu sentence-transformers pytorch huggingface_hub -y pip install langchain-community langchain-huggingface langchain-ollama arabic-support
أما إذا كنا نستخدم pip، فيمكن تثبيت المكتبات والأطر المشار المطلوبة عبر سطر الأوامر على النحو الآتي:
# تثبيت المكتبات وأطر العمل التي نحتاجها عبر مثبِّت pip pip install streamlit pdfplumber langchain langchain-community langchain-huggingface langchain-ollama faiss-cpu sentence-transformers torch huggingface_hub arabic-support
تحميل Ollama و DeepSeek
Ollama هو أداة تتيح إمكانية تشغيل نماذج الذكاء الاصطناعي محليًا بسهولة دون الحاجة إلى إعدادات معقدة ويناسب مكتبة Langchain للتنزيل يمكن التوجه إلى الموقع الرسمي لـ Ollama والضغط على خيار التنزيل Download من الواجهة الرئيسية كما هو موضح في الصورة الآتية.

بعد ذلك نضغط على خيار DeepSeek-R1 من نفس الواجهة ونختار النموذج المناسب لنا، وننسخ إعداداته التي نحتاجها لمقالنا من أجل تحميل DeepSeek، وهي في هذا المقال على النحو الآتي:
ollama pull deepseek-r1:70b
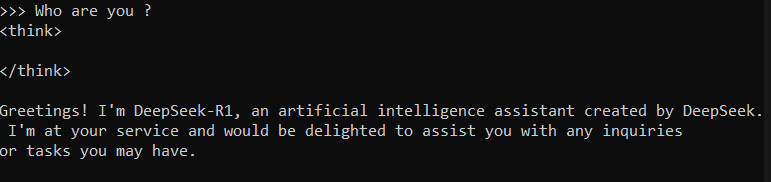
ننسخها إلى سطر الأوامر Terminal، وبعد تحميله نتأكد من أنه قد حُمل بنجاح، بإجراء اختبار ببسيط له نسأله من خلاله عمن يكون، لنحصل على الرد الآتي الذي يوضح أن عملية التثبيت قد تمت بنجاح تام.
بدء كتابة كود المشروع
سنكتب الكود الآن بتدرج، وأول ما سنفعله هو استدعاء المكتبات والأُطر التي سنحتاجها، والتي سبق وثبتناها مع بداية المقال.
# استدعاء المكتبات والأُطر التي سنحتاجها import tempfile import re import streamlit as st from langchain_community.document_loaders import PDFPlumberLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_huggingface import HuggingFaceEmbeddings from langchain_community.vectorstores import FAISS from langchain_ollama import OllamaLLM from langchain.prompts import PromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_core.runnables import RunnablePassthrough
بعد ذلك، سنهيّء الواجهة التي سنعرض من خلالها نتائجنا لتتوافق مع اللغة العربية لضمان أن تكون واجهة النظام ستكون من اليمين لليسار.
# تهيئة الواجهة لتتوافق مع اللغة العربية from arabic_support import support_arabic_text support_arabic_text(all=True)
بعد ذلك سنتبع ما يلي.
تهيئة الكتاب لإسترجاع المعلومات
من أجل استرجاع المعلومات ذات الصلة من ملف الكتاب، سنحتاج لاتّباع الخطوات الآتية:
- تحميل المستند: بحيث يتم رفع ملف PDF وتحميل محتوياته باستخدام PDFPlumberLoader لسرعته في القراءة
- تقسيم النصوص: حيث تُجزَّأ المحتويات إلى مقاطع باستخدام أداة RecursiveCharacterTextSplitter لنحافظ على السياق ونحسن دقة البحث
- إرسال البيانات الى مكتبة HuggingFaceEmbeddings: وذلك لانشاء البصمات للنصوص لتُخزن في قاعدة البيانات FAISS
وقد اتبعنا هذه الخطوات لأنه عند كتابنا للسؤال، يجب أن يعمل النظام على البحث في البيانات ذات الصلة، لذا يتم ذلك عبر تحويل النصوص إلى تمثيلات رقمية، إذ نحوّل كل جزء من النص إلى أرقام تعبّر عن معناه، تمامًا مثل بصمة رقمية للنص، ثم نبحث في البيانات عن أقرب تضمينات مطابقة.
ويكون الكود المكتوب على النحو الآتي:
# تحميل وقراءة محتوى الملف docs = PDFPlumberLoader(temp_pdf_path).load() # تحويل الكتاب إلى نصوص حاسوبية يمكنه فهمها والبحث فيها بكفاءة embedder = HuggingFaceEmbeddings(model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2") chunk_size = max(500, min(1000, len(docs) // 10)) # تحديد حجم المقطع حسب طول المستند documents = RecursiveCharacterTextSplitter( chunk_size=chunk_size, # تحديد حجم كل مقطع نصي chunk_overlap=chunk_size // 5 # السماح بتداخل بين المقاطع بنسبة 20% للحفاظ على السياق ).split_documents(docs) تنفيذ عملية التقسيم على المستند المحمّل # انشاء مخزن البيانات ووضع البيانات التي استخرجت من الكتاب في المخزن الخاص بالنظام retriever = FAISS.from_documents(documents, embedder).as_retriever(search_kwargs={"k": 4})
وحتى هذه العملية، نكون قد عالجنا الكتاب وأكملنا تهيئته لإسترجاع المعلومات ذات الصلة منه.
توليد الإجابات النهائية من ملف الكتاب
لكي نُولد الإجابة النهائية، يجب علينا أولًا تحليل السياق وفهم المعنى المقصود من السؤال، لذا يُستخدم نموذج اللغة لتوليد استجابة مناسبة. يتم أيضًا تعزيز جودة الإجابة من خلال دمج المعلومات المسترجعة مسبقًا مع المعرفة المخزنة داخل النموذج، وأخيرًا نُطبق تقنيات تحسين الصياغة لضمان وضوح الإجابة. وتتم العملية بعدة خطوات وهي:
- تهيئة نموذج اللغة في الكود: حيث يتم استخدام OllamaLLM وضبط DeepSeek R1 ليكون المصدر الأساسي للإجابة على الأسئلة.
- إعداد الأوامر Prompt Engineering: حيث يتم تصميم إنشاء قالب تعليمات باستخدام PromptTemplate لتوجيه النموذج حول كيفية الإجابة عند البحث في محتوى الكتاب
- انشاء سلسلة معالجة الإجابات: عن طريق دمج نموذج LLM مع تنقية FAISS Retriever لنضمن توليد النموذج الإجابات بناءً على المعلومات المسترجعة فقط، وهذا يوفر دقة الإجابات ويقلل احتمالية توليد معلومات غير صحيحة
# تهيئة نموذج اللغة llm = OllamaLLM(model="deepseek-r1:70b") # إعداد الأوامر، تعريف الأوامر التي يتبعها النظام أثناء البحث في الكتاب template = """ Use the following context to answer the question concisely in 3-4 sentences. If the answer is unknown, respond with "I don't know" without making anything up. Answer in Arabic if the given question is in Arabic. Context: {context} Question: {question} Answer: """ rag_chain = ( {"context": retriever, "question": RunnablePassthrough()} # تمرير السياق والسؤال | PromptTemplate.from_template(template) # تجهيز السؤال بالتنسيق المطلوب | llm # إرسال البيانات إلى نموذج اللغة لمعالجتها | StrOutputParser() # استخراج الإجابة بصيغة نصية )
حتى هذه العملية تم توليد الإجابه بناءً على المعلومات المسترجعة.
انشاء واجهة الويب
استخدمنا في هذا المقال إطار العمل Streamlit لإنشاء واجهة الويب من أجل تسهيل عملية العرض والاستخدام.
# إعداد واجهة التطبيق st.markdown("<h2 style='text-align: right;'>Ollama و Deepseek بإستخدام Pdf البحث ضمن ملف</h2>", unsafe_allow_html=True) uploaded_file = st.file_uploader("Pdf رفع ملف", type="pdf") if uploaded_file is not None: with st.spinner("..جاري المعالجة"): with tempfile.NamedTemporaryFile(delete=False, suffix=".pdf") as temp_pdf: temp_pdf.write(uploaded_file.getvalue()) temp_pdf_path = temp_pdf.name # إدخال المستخدم للسؤال st.markdown(f'<div style="direction: rtl; font-size: 16px; font-weight: bold;">أدخل سؤالك هنا..</div>', unsafe_allow_html=True) user_input = st.text_input(" ", key="user_question", label_visibility="hidden")
تحسين المخرجات
في هذا الجزء، ركزنا على تحسين جودة المخرجات الناتجة عن نظام RAG لضمان تقديم إجابات واضحة ومباشرة، ويتم ذلك من خلال تعديل الكود لإزالة أي نصوص تحليلية أو تعليمات غير ضرورية قد تظهر في الاستجابة، مما يجعل النتيجة أكثر تركيزًا على المعلومات المطلوبة فقط
ولتسهيل العملية استخدمنا تعبير نمطي Regular Expression للبحث عن أي نص موجود بين العلامتين <think> و </think> داخل الإجابة في سطر cleaned_response، ثم يٌحذف لضمان عرض المحتوى النهائي فقط. بعد ذلك، يتم تنظيف النص وإزالة أي فراغات زائدة باستخدام .strip().
# معالجة إدخال المستخدم if user_input: with st.spinner("..جاري البحث"): response = rag_chain.invoke(user_input) # استرجاع البيانات ثم توليد الإجابة cleaned_response = re.sub(r"<think>.*?</think>", "", response, flags=re.DOTALL).strip() st.markdown("### Answer:") st.write(cleaned_response) # عرض الإجابة النهائية else: st.info("Pdf من فضلك قم برفع ملف")
ولنفتح واجهة الويب، لا بد من كتابة الأمر التالي في Terminal الخاص بالبرنامج:
# فتح واجهة الويب streamlit run Project.py
ملاحظة: سنغير كلمة Project بناءً على اسم الملف.
اختبار كفاءة النظام
عند هذه المرحلة جربنا اختبار النظام للتأكد من دقة استرجاع المعلومات، وتوليد الإجابات، وقدرته على تقديم إجابات نموذجية، لضمان إنتاج النموذج أفضل إجابة وأدق تفاصيل.
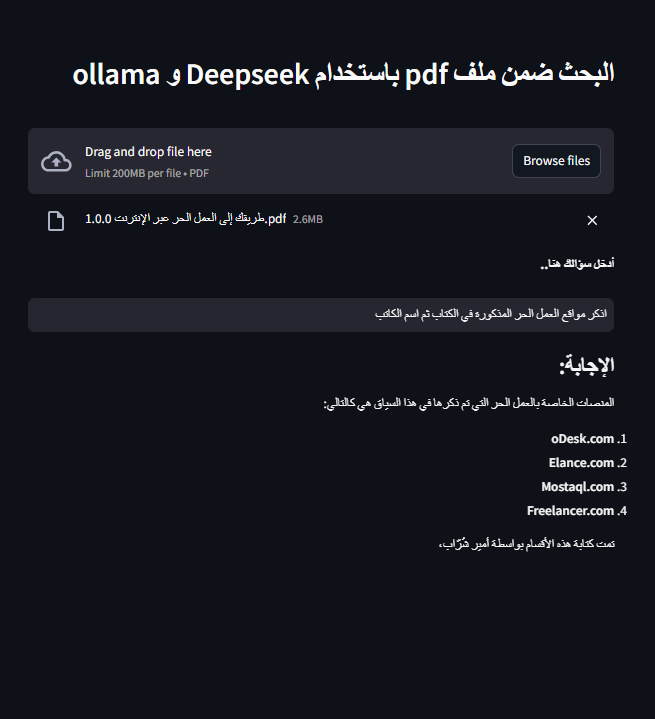
ملاحظة: نود لفت الانتباه مجددًا إلى أن النظام في شكله الحالي لا يزال يواجه صعوبةً في دعم اللغة العربية بشكل مثالي، وهو ما دفعنا إلى استخدام موارد حاسوبية عالية في مشروعنا، مثل وحدات معالجة رسومية قوية وذاكرة وصول عشوائي كبيرة، لضمان أداء دقيق. إذا لم تكن هذه الموارد متاحة لبناء نظام مشابه فيمكن بسهولة تطبيق نفس الخطوات التي شرحناها على نماذج أخرى تدعم اللغة العربية بكفاءة أكبر، أو حتى استخدامها مع لغات أخرى مثل الإنجليزية التي تتطلب موارد أقل بكثير للحصول على نتائج مماثلة، مما يتيح إمكانية تحقيق أهدافك بما يتناسب مع إمكانياتك المتوفرة.
في حال عدم توفر الموارد يمكن استعمال النظام باللغة الإنجليزية مثلًا، وبكل بسهولة عن طريق استعمال نموذج لغة أصغر مثل Deepseek R1-7b، عن طريق تحميله عبر سطر الأوامر Terminal: ollama pull deepseek-r1
وبعد التأكد من تحميله، نغير سطر نموذج اللغة في الكود
# تهيئة نموذج اللغة llm = OllamaLLM(model="deepseek-r1")
ثم نحذف الجزء المتعلق بتهيئة واجهة اللغة العربية من الكود وتصبح هذه هي النتيجة:
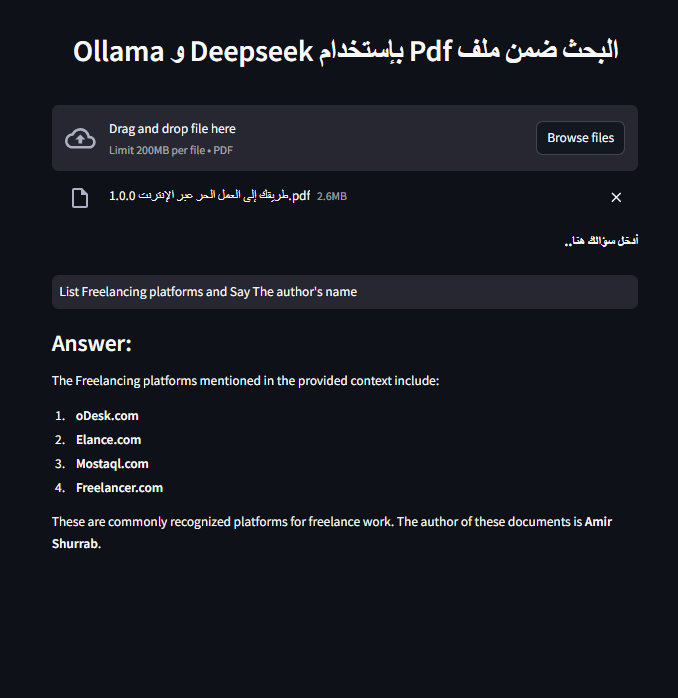
وكما هو واضح، فالنموذج قادر على فهم الكتاب العربي الذي شاركناه إياه كمدخلات للبحث ضمنها عن جواب، وقد تمكن الإجابة علينا بلغة إنجليزية سليمة بعد أن سألناه باللغة الإنجليزية.
خاتمة
بهذا نكون قد وصلنا إلى نهاية المقال الذي تعرفنا فيه على كيفية بناء نظام RAG قادر على اختصار الوقت علينا ومساعدتنا في الحصول على ردود دقيقة وسريعة من الملفات التي تحتاج منا عادة لساعات من القراءة والبحث، ووضحنا كيفية تحسين نموذج اللغة لتوليد استجابات ذكية عبر عدة مراحل، بدءًا من إعداد التوجيهات وتصميم قالب الأوامر، مرورًا بتطبيق المشروع ضمن السياق وإنشاء مسارات معالجة، مع التركيز على تعزيز الدقة والترابط لضمان استجابات متسقة وواضحة.
المصادر
- ?What is RAG (Retrieval-Augmented Generation)
- Developing Retrieval Augmented Generation (RAG) based LLM Systems
- How to build a RAG Using Langchain, Ollama, and Streamlit
- Building RAG-based LLM Applications
- Streamlit Arabic Support









أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.