
البحث في الموقع
المحتوى عن 'sql'.
-
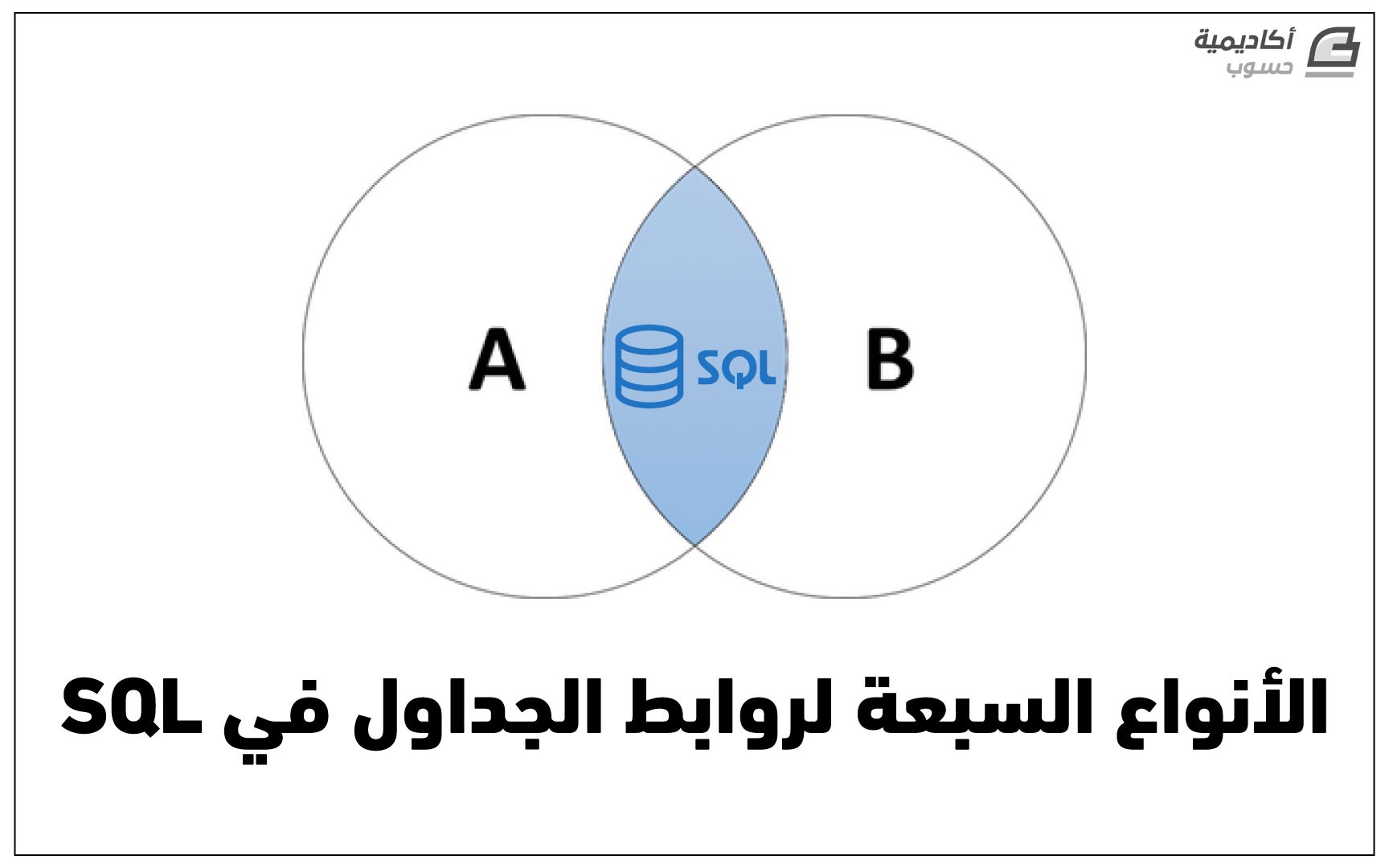 من المُستبعد احتمال أنّك ستعمل مع بيانات من جدول واحد فقط، لذا ستحتاج إلى الحصول على البيانات من جداول مُتعدّدة. استعمال الروابط (Joins) أحد الخيارات للقيام بالأمر، وفي قواعد البيانات العلائقيّة (Relational databases)، فالروابط هي التي تجعل قواعد البيانات علائقيّة. يوفّر هذا الدّرس تذكيرا سريعا بالأنواع الأربعة الأساسيّة لروابط SQL وثلاثة من فروعها. ما هو الرابط؟ الرابط طريقة للربط بين البيانات من جدولين أو أكثر اعتمادا على عمود مُشترك بين الجداول. على سبيل المثال، يُمكن ربط جدول عناوين مع جدول أرقام الهواتف حسب اسم شخص مُعيّن (أعطني عنوان ورقم هاتف الشّخص المُسمّى مُحمّد أحمد). لماذا تعد الروابط مهمة؟ تُمكّن الروابط من الحصول على البيانات من عدّة جداول باستعلام (query) واحد. من المُستبعد بأنّك ستعمل مع جدول واحد فقط. استعمال جدول واحد فقط يعني بأنّك إمّا تحدّ نفسك في كميّة البيانات التي تحصل عليها أو أنّك تمتلك الكثير من البيانات التي قد تجعل من الجدول صعب المراس. تُنشئ الروابط علاقة بين جدول وآخر (ومنه جاء مُصطلح “قواعد البيانات العلائقيّة”). ما هي أنواع روابط SQL الموجودة؟ ما يلي عبارة عن قائمة من أنواع روابط SQL الأربعة الرّئيسية (إضافة إلى ثلاثة أشكال فرعيّة)، مُرتبة من أكثرها حصرا إلى أكثرها شمولا. أضفنا كذلك عينات SQL إلى الشروحات المكتوبة لتجربتها والنظر إلى نتيجة استعمال رابط مُعيّن في الاستعلام الخاص بك. الرابط الدّاخلي Inner Join رُبما يعتبر الرّابط الدّاخلي من أكثر أنواع روابط SQL استعمالا. ويُرجِع الرابط الداخلي جميع الصفوف التي تُحقّق شرط الرّبط (join condition) من جدولين أو أكثر. عينة SQL SELECT columns FROM TableA INNER JOIN TableB ON A.columnName = B.columnName; الربط اليساري (الخارجي) يُرجع الرّبط اليساري الخارجي (أحيانا يُختصر إلى الرّبط اليساري) جميع الصفوف من الجدول المُحدّد يسار الشّرط ON والصفوف التي تًحقّق شرط الرّبط فقط من الجدول في اليمين. عينة SQL SELECT columns FROM TableA LEFT OUTER JOIN TableB ON A.columnName = B.columnName الربط اليساري (الخارجي) دون تقاطع هذا الرّبط فرع من فروع الرّبط اليساري، ويُرجع جميع الصفوف من الجدول على يسار الشّرط ON والتي تُحقّق شرط الرّبط كذلك، دون الصفوف التي تُحقّق شرط الرّبط من الجدول على اليمين. عينة SQL SELECT columns FROM TableA LEFT OUTER JOIN TableB ON A.columnName = B.columnName WHERE B.columnName IS NULL الربط اليميني (الخارجي) يُرجع الرّبط اليميني الخارجي (أحيانا يُختصر إلى الرّبط اليميني) جميع الصّفوف من يمين شرط ON والصفوف التي تحقّق شرط الرّبط فقط من الجدول على اليسار. عيّنة SQL SELECT columns FROM TableA RIGHT OUTER JOIN TableB ON A.columnName = B.columnName الربط اليميني (الخارجي) دون تقاطع هذا الرّبط فرع من فروع الرّبط اليميني، ويُرجع جميع الصفوف من الجدول على يمين الشّرط ON والتي تُحقّق شرط الرّبط كذلك، دون الصفوف التي تُحقّق شرط الرّبط من الجدول على اليسار. عيّنة SQL SELECT columns FROM TableA RIGHT OUTER JOIN TableB ON A.columnName = B.columnName WHERE A.columnName IS NULL الربط التام (الخارجي) يُرجع الرّبط التّام الخارجي (يُختصر أحيانا إلى الرّبط التّام) جميع الصفوف من كلا الجدولين المُحددين في الشّرط ON في حالة لم يتحقق شرط الرّبط (ما يشمل القيم الفارغة NULL). عيّنة SQL SELECT columns FROM TableA FULL JOIN TableB ON A.columnName = B.columnName الربط التام (الخارجي) دون تقاطع هذا فرع من الرّوابط التّامة الخارجية يُرجع جميع الصفوف من كلا الجدولين المُحدّدين في الشّرط ON في حالة لم يتحقّق شرط الرّبط (باستثناء القيم الفارغة NULL). عيّنة SQL SELECT columns FROM TableA FULL JOIN TableB ON A.columnName = B.columnName WHERE A.columnName IS NULL OR B.columnName IS NULL ختاما غطّى هذا الدّرس الأنواع الأربعة الأساسيّة لروابط SQL وثلاثة روابط مُتفرّعة منها. الروابط هي التي تجعل من قواعد البيانات العلائقيّة علاقية، لذا إن لم تحترف أنواع روابط SQL المختلفة، فاستعمل TeamSQL الآن واستخدم عينات SQL الموفَّرة في هذا الدّرس لتُلقي نظرة على كيفيّة الحصول على أجزاء مختلفة من البيانات الخاصة بك. ترجمة -بتصرّف- للمقال The Seven Types of SQL Joins لصاحبه Eren Baydemir.
من المُستبعد احتمال أنّك ستعمل مع بيانات من جدول واحد فقط، لذا ستحتاج إلى الحصول على البيانات من جداول مُتعدّدة. استعمال الروابط (Joins) أحد الخيارات للقيام بالأمر، وفي قواعد البيانات العلائقيّة (Relational databases)، فالروابط هي التي تجعل قواعد البيانات علائقيّة. يوفّر هذا الدّرس تذكيرا سريعا بالأنواع الأربعة الأساسيّة لروابط SQL وثلاثة من فروعها. ما هو الرابط؟ الرابط طريقة للربط بين البيانات من جدولين أو أكثر اعتمادا على عمود مُشترك بين الجداول. على سبيل المثال، يُمكن ربط جدول عناوين مع جدول أرقام الهواتف حسب اسم شخص مُعيّن (أعطني عنوان ورقم هاتف الشّخص المُسمّى مُحمّد أحمد). لماذا تعد الروابط مهمة؟ تُمكّن الروابط من الحصول على البيانات من عدّة جداول باستعلام (query) واحد. من المُستبعد بأنّك ستعمل مع جدول واحد فقط. استعمال جدول واحد فقط يعني بأنّك إمّا تحدّ نفسك في كميّة البيانات التي تحصل عليها أو أنّك تمتلك الكثير من البيانات التي قد تجعل من الجدول صعب المراس. تُنشئ الروابط علاقة بين جدول وآخر (ومنه جاء مُصطلح “قواعد البيانات العلائقيّة”). ما هي أنواع روابط SQL الموجودة؟ ما يلي عبارة عن قائمة من أنواع روابط SQL الأربعة الرّئيسية (إضافة إلى ثلاثة أشكال فرعيّة)، مُرتبة من أكثرها حصرا إلى أكثرها شمولا. أضفنا كذلك عينات SQL إلى الشروحات المكتوبة لتجربتها والنظر إلى نتيجة استعمال رابط مُعيّن في الاستعلام الخاص بك. الرابط الدّاخلي Inner Join رُبما يعتبر الرّابط الدّاخلي من أكثر أنواع روابط SQL استعمالا. ويُرجِع الرابط الداخلي جميع الصفوف التي تُحقّق شرط الرّبط (join condition) من جدولين أو أكثر. عينة SQL SELECT columns FROM TableA INNER JOIN TableB ON A.columnName = B.columnName; الربط اليساري (الخارجي) يُرجع الرّبط اليساري الخارجي (أحيانا يُختصر إلى الرّبط اليساري) جميع الصفوف من الجدول المُحدّد يسار الشّرط ON والصفوف التي تًحقّق شرط الرّبط فقط من الجدول في اليمين. عينة SQL SELECT columns FROM TableA LEFT OUTER JOIN TableB ON A.columnName = B.columnName الربط اليساري (الخارجي) دون تقاطع هذا الرّبط فرع من فروع الرّبط اليساري، ويُرجع جميع الصفوف من الجدول على يسار الشّرط ON والتي تُحقّق شرط الرّبط كذلك، دون الصفوف التي تُحقّق شرط الرّبط من الجدول على اليمين. عينة SQL SELECT columns FROM TableA LEFT OUTER JOIN TableB ON A.columnName = B.columnName WHERE B.columnName IS NULL الربط اليميني (الخارجي) يُرجع الرّبط اليميني الخارجي (أحيانا يُختصر إلى الرّبط اليميني) جميع الصّفوف من يمين شرط ON والصفوف التي تحقّق شرط الرّبط فقط من الجدول على اليسار. عيّنة SQL SELECT columns FROM TableA RIGHT OUTER JOIN TableB ON A.columnName = B.columnName الربط اليميني (الخارجي) دون تقاطع هذا الرّبط فرع من فروع الرّبط اليميني، ويُرجع جميع الصفوف من الجدول على يمين الشّرط ON والتي تُحقّق شرط الرّبط كذلك، دون الصفوف التي تُحقّق شرط الرّبط من الجدول على اليسار. عيّنة SQL SELECT columns FROM TableA RIGHT OUTER JOIN TableB ON A.columnName = B.columnName WHERE A.columnName IS NULL الربط التام (الخارجي) يُرجع الرّبط التّام الخارجي (يُختصر أحيانا إلى الرّبط التّام) جميع الصفوف من كلا الجدولين المُحددين في الشّرط ON في حالة لم يتحقق شرط الرّبط (ما يشمل القيم الفارغة NULL). عيّنة SQL SELECT columns FROM TableA FULL JOIN TableB ON A.columnName = B.columnName الربط التام (الخارجي) دون تقاطع هذا فرع من الرّوابط التّامة الخارجية يُرجع جميع الصفوف من كلا الجدولين المُحدّدين في الشّرط ON في حالة لم يتحقّق شرط الرّبط (باستثناء القيم الفارغة NULL). عيّنة SQL SELECT columns FROM TableA FULL JOIN TableB ON A.columnName = B.columnName WHERE A.columnName IS NULL OR B.columnName IS NULL ختاما غطّى هذا الدّرس الأنواع الأربعة الأساسيّة لروابط SQL وثلاثة روابط مُتفرّعة منها. الروابط هي التي تجعل من قواعد البيانات العلائقيّة علاقية، لذا إن لم تحترف أنواع روابط SQL المختلفة، فاستعمل TeamSQL الآن واستخدم عينات SQL الموفَّرة في هذا الدّرس لتُلقي نظرة على كيفيّة الحصول على أجزاء مختلفة من البيانات الخاصة بك. ترجمة -بتصرّف- للمقال The Seven Types of SQL Joins لصاحبه Eren Baydemir.- 1 تعليق
-
- 1
-

-
- روابط الجداول
- sql
- (و 2 أكثر)
-
.png.302ffa76bcfd440537f9c7c26450e5c6.png) سنتحدث في هذا المقال عن مفهوم العلاقات بين جداول قاعدة البيانات، وما أنواع هذه العلاقات وكيف تتمثل وما هو أثرها على العمل. ما هي العلاقات بين الجداول عند إنشاء جداول في قاعدة البيانات، فإن الظاهر لنا أننا نقوم ببناء جداول منفصلة وغير مترابطة، ولكننا في الواقع العملي نحتاج لربط هذه الكيانات المنفصلة بحيث تُبنَى علاقات تحكم البيانات الموجودة في هذه الجداول، وتحكم طريقة التعامل مع هذه البيانات. تنشَأ العلاقة بين جدوليْن عندما يُربط عمودان فيهما مع بعضهما عن طريق وجود قيود مطبقة على العمودين، بحيث يكون قيد المفتاح الرئيسي على عمود في الجدول “الأب” وقيد المفتاح الأجنبي على العمود في الجدول “الابن”، وعادة يكون اسم العمودين واحدًا في كلا الجدولين. مثلا، لحفظ عناوين الأشخاص نستطيع إنشاء جدول باسم Address ونربطه بجدول الأشخاص Persons بعلاقة تحكم البيانات الموجودة في الجدولين، بحيث يكون لكل شخص في الجدول Persons عنوان واحد مرتبط به في الجدول Address. يُربَط الجدولان عن طريق عمود باسم Person_Id في كلا الجدولين. مثال آخر، لو أردنا أن نتابع عملية استعارة الكتب في مكتبة، فإننا سننشئ جدولًا باسم Borrowed_Books (كُتُب مُعارة) ونربطها بالجدول Persons عن طريق العمود Person_Id. يستطيع الشخص الواحد - في هذا النوع من الربط - أن يستعير أكثر من كتاب. في هذا المثال، لو أننا حفظنا بيانات الأشخاص والكتب المستعارة في جدول واحد، ستظهر لنا مشكلة تكرار البيانات Data Redundancy لأننا سنكرّر بيانات الشخص لكل كتاب يستعيره. ماذا نستفيد من بناء العلاقات بين الجداول؟ التخلص من مشكلة تكرار البيانات عن طريق فصلها وحفظها في أكثر من جدول، فمشكلة تكرار البيانات هي عدو مستخدمي قواعد البيانات ومسؤوليها، لأنها تتسبب بزيادة حجم قاعدة البيانات بقدر كبير وبسرعة، وترفع السرعات المطلوبة لتنفيذ الاستعلامات، وتجعل من موضوع صيانة قاعدة البيانات كابوسا مقلقا. الحفاظ على دقة وسلامة البيانات في قاعدة البيانات، فمع وجود العلاقات بين الجداول، سوف تضمن مثلا عدم وجود كتاب مُعار ليس له شخص استعاره، أو عنوان وهمي ليس له صاحب، وقس على ذلك العديد من الأمثلة. استخراج البيانات من أكثر من جدول بكفاءة وسرعة عن طريق بناء جمل ربط استعلامية تطلب المعلومات من أعمدة مختلفة في جداول مختلفة، وإخراج النتيجة بطريقة مفيدة ومرتبة. أنواع العلاقات توجد أربعة أنواع من العلاقات بين الجداول كالتالي: علاقة واحد إلى واحد (One-to-One). علاقة واحد إلى كثير أو علاقة كثير إلى واحد (One-to-Many / Many-to-One). علاقة كثير إلى كثير (Many-to-Many). علاقة المرجعية الذاتية (Self Referencing). علاقة واحد إلى واحد لنفترض أن الجدول Persons لديه البنية والبيانات التالية: Person_ID First_Name Last_Name Age Address 101 Ibrahim Mohammed 31 12 Main St, Doha 102 Mohammed Khaled 25 Gaza, Middle Center نستطيع أن نضع بيانات العنوان في جدول منفصل ونسميه Address وتكون بنية الجدوليْن كالتالي. الجدول Persons: Person_ID First_Name Last_Name Age Address_Id 101 Ibrahim Mohammed 31 1 102 Mohammed Khaled 25 2 الجدول Address: Address_ID Address 1 12 Main St, Doha 2 Gaza, Middle Center لاحظ أنه أصبح لدينا عمود بنفس الاسم Address_Id في كلا الجدولين. لبناء العلاقة بين الجدولين، طبّقنا قيد المفتاح الأجنبي على العمود Address_Id في الجدول Persons بحيث يأخذ قيمه من العمود Address_Id في الجدول Address والمطبق عليه قيد المفتاح الرئيسي. أصبحت لدينا الآن علاقة بين الجدولين، وفي حال كان كل عنوان في الجدول Address يقترن فقط بشخص واحد في الجدول Persons فعندها نسمي هذه العلاقة واحدًا إلى واحد. يجب التنويه إلى أن هذا النوع من العلاقات غير مستخدم كثيرا، فالجدول الأول الذي يحتوي العنوان وبيانات الشخص يفي بالغرض في أغلب الأحيان. نستطيع تمثيل العلاقة بالشكل التالي: لاحظ أن وجود العلاقة اختياري، فمن الممكن أن يكون لدينا سجل في الجدول Persons دون عنوان له في الجدول Address وهذا مرتبط بعدم تطبيق قيد القيمة غير الفارغة على العمود Address_Id. في حال طُبِّق قيد غير القيمة غير الفارغة على العمود، فهنا تصبح العلاقة واجبة بين الجدولين، ولا يمكن أن نُنْشئ سجلًّا في الجدول Persons إلا بإدخال قيمة موجودة للعمود Address_Id وهو في مثالنا هذا غير منقطي نوعا ما. دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن علاقة واحد إلى كثير أو علاقة كثير إلى واحد هذا النوع من العلاقات هو الشائع بين أنواع العلاقات بين الجداول في قاعدة البيانات، لوجود تطبيقات كثيرة عليه، فمثلا: الطالب (واحد) يستطيع أن يدرس أكثر من مساق (كثير). الطبيب يعالج ويتابع حالة مريض واحد أو أكثر. طلبية الشراء تحتوي على أكثر من عنصر. الشخص يستعير أكثر من كتاب. وقس على ذلك العديد من الأمثلة. لنفترض وجود جدول للزبناء Customers بالهيكلية التالية: Customer_ID Customer_Name 1 Ibrahim Mohammed 2 Mohammed Ahmed نستطيع ربط جدول الزبناء السابق بجدولٍ للطلبيات Orders بعلاقة واحد إلى كثير، لتعبر العلاقة عن الطلبيات التي قام بها العملاء وقيمة كل طلبية وتاريخها. يمكن أن تكون هيكلية الجدول Orders كالتالي: Order_ID Customer_ID Order_Date Order_Value 997 101 1/5/2017 100 998 102 21/4/2016 150 999 101 21/4/2015 1500 تسمح هذه العلاقة للعميل بأن يطلُب طلبيةً أو أكثر، ويمكن ألا تكون له أية طلبية. ولكنّ كل طلبية في الجدول Orders ستكون تابعة لعميل واحد. ونستطيع تمثيل هذه العلاقة بالشكل التالي: علاقة كثير إلى كثير في علاقة كثير إلى واحد، تكون العلاقة مبنية على أن يكون أحد أطرافها “واحدًا”، مثل طالب واحد، عميل واحد، طلبية واحدة، وفي الطرف الثاني “كثير”. نحتاج أحيانا أن يكون طرفا العلاقة كثيرين. فمثلا، قد تكون لدينا طلبية تحتوي أكثر من عنصر، ونفس العنصر يكون متواجدًا في أكثر من طلبية. في هذه الحالة نحتاج لوجود جدول إضافي لبناء العلاقة، فمثلا تكون هيكلية جدول Orders كالتالي: Order_ID Customer_ID Order_Date Order_Value 997 101 1/5/2017 100 998 102 21/4/2016 150 999 101 21/4/2015 1500 وهيكلية جدول Items كالتالي: Item_Id Item_Name Item_Description 201 Hard Disk 1 1 Tera SSD Hard 202 Mouse Microsoft Optical Mouse 203 LCD 42 42” LCD نستطيع بناء علاقة كثير إلى كثير بين الجدولين السابقين بإضافة جدول ثالث يحلّ مكان الرابط وغرضه الوحيد هو بناء هذا النوع من العلاقات. نطلق عليه مثلا الاسم Orders_Items، ويكون بالهيكلية التالية: Order_Id Item_Id 997 201 997 202 999 201 999 202 999 203 998 203 يمثّل الشكل التالي علاقة كثير إلى كثير كما تظهر في الجدول Orders_Items: علاقة المرجعية الذاتية يُبنى هذا النوع من العلاقات عندما نريد أن نبني علاقة بين جدول ونفس الجدول، وأوضح مثال على هذا النوع من العلاقات هو جدول الموظفين الذي يحتوي على عمود رقم الموظف المسؤول، حيث يمكن ربط كل موظف بموظف آخر (مدير أو مسؤول) من نفس الجدول. فمثلا، لو كان لدينا جدول باسم Employees خاص بحفظ بيانات الموظفين، ستكون هيكليته على النحو التالي لتطبيق علاقة مرجعية ذاتية عليه: Employee_ID Employee_Name Manager_Id 100 Ibrahim Elbouhissi 101 Khaled Saber 100 102 Yasmeen Hadi 100 103 Duaa Yousef 101 104 Sami Saber بعلاقة المرجعية الذاتية، من الممكن أن يكون للموظف مسؤولًا أو لا يكون، ومن الممكن أن يكون الموظف مسؤولا عن موظف أو أكثر، ويمكن تمثيل العلاقة بالشكل التالي.
سنتحدث في هذا المقال عن مفهوم العلاقات بين جداول قاعدة البيانات، وما أنواع هذه العلاقات وكيف تتمثل وما هو أثرها على العمل. ما هي العلاقات بين الجداول عند إنشاء جداول في قاعدة البيانات، فإن الظاهر لنا أننا نقوم ببناء جداول منفصلة وغير مترابطة، ولكننا في الواقع العملي نحتاج لربط هذه الكيانات المنفصلة بحيث تُبنَى علاقات تحكم البيانات الموجودة في هذه الجداول، وتحكم طريقة التعامل مع هذه البيانات. تنشَأ العلاقة بين جدوليْن عندما يُربط عمودان فيهما مع بعضهما عن طريق وجود قيود مطبقة على العمودين، بحيث يكون قيد المفتاح الرئيسي على عمود في الجدول “الأب” وقيد المفتاح الأجنبي على العمود في الجدول “الابن”، وعادة يكون اسم العمودين واحدًا في كلا الجدولين. مثلا، لحفظ عناوين الأشخاص نستطيع إنشاء جدول باسم Address ونربطه بجدول الأشخاص Persons بعلاقة تحكم البيانات الموجودة في الجدولين، بحيث يكون لكل شخص في الجدول Persons عنوان واحد مرتبط به في الجدول Address. يُربَط الجدولان عن طريق عمود باسم Person_Id في كلا الجدولين. مثال آخر، لو أردنا أن نتابع عملية استعارة الكتب في مكتبة، فإننا سننشئ جدولًا باسم Borrowed_Books (كُتُب مُعارة) ونربطها بالجدول Persons عن طريق العمود Person_Id. يستطيع الشخص الواحد - في هذا النوع من الربط - أن يستعير أكثر من كتاب. في هذا المثال، لو أننا حفظنا بيانات الأشخاص والكتب المستعارة في جدول واحد، ستظهر لنا مشكلة تكرار البيانات Data Redundancy لأننا سنكرّر بيانات الشخص لكل كتاب يستعيره. ماذا نستفيد من بناء العلاقات بين الجداول؟ التخلص من مشكلة تكرار البيانات عن طريق فصلها وحفظها في أكثر من جدول، فمشكلة تكرار البيانات هي عدو مستخدمي قواعد البيانات ومسؤوليها، لأنها تتسبب بزيادة حجم قاعدة البيانات بقدر كبير وبسرعة، وترفع السرعات المطلوبة لتنفيذ الاستعلامات، وتجعل من موضوع صيانة قاعدة البيانات كابوسا مقلقا. الحفاظ على دقة وسلامة البيانات في قاعدة البيانات، فمع وجود العلاقات بين الجداول، سوف تضمن مثلا عدم وجود كتاب مُعار ليس له شخص استعاره، أو عنوان وهمي ليس له صاحب، وقس على ذلك العديد من الأمثلة. استخراج البيانات من أكثر من جدول بكفاءة وسرعة عن طريق بناء جمل ربط استعلامية تطلب المعلومات من أعمدة مختلفة في جداول مختلفة، وإخراج النتيجة بطريقة مفيدة ومرتبة. أنواع العلاقات توجد أربعة أنواع من العلاقات بين الجداول كالتالي: علاقة واحد إلى واحد (One-to-One). علاقة واحد إلى كثير أو علاقة كثير إلى واحد (One-to-Many / Many-to-One). علاقة كثير إلى كثير (Many-to-Many). علاقة المرجعية الذاتية (Self Referencing). علاقة واحد إلى واحد لنفترض أن الجدول Persons لديه البنية والبيانات التالية: Person_ID First_Name Last_Name Age Address 101 Ibrahim Mohammed 31 12 Main St, Doha 102 Mohammed Khaled 25 Gaza, Middle Center نستطيع أن نضع بيانات العنوان في جدول منفصل ونسميه Address وتكون بنية الجدوليْن كالتالي. الجدول Persons: Person_ID First_Name Last_Name Age Address_Id 101 Ibrahim Mohammed 31 1 102 Mohammed Khaled 25 2 الجدول Address: Address_ID Address 1 12 Main St, Doha 2 Gaza, Middle Center لاحظ أنه أصبح لدينا عمود بنفس الاسم Address_Id في كلا الجدولين. لبناء العلاقة بين الجدولين، طبّقنا قيد المفتاح الأجنبي على العمود Address_Id في الجدول Persons بحيث يأخذ قيمه من العمود Address_Id في الجدول Address والمطبق عليه قيد المفتاح الرئيسي. أصبحت لدينا الآن علاقة بين الجدولين، وفي حال كان كل عنوان في الجدول Address يقترن فقط بشخص واحد في الجدول Persons فعندها نسمي هذه العلاقة واحدًا إلى واحد. يجب التنويه إلى أن هذا النوع من العلاقات غير مستخدم كثيرا، فالجدول الأول الذي يحتوي العنوان وبيانات الشخص يفي بالغرض في أغلب الأحيان. نستطيع تمثيل العلاقة بالشكل التالي: لاحظ أن وجود العلاقة اختياري، فمن الممكن أن يكون لدينا سجل في الجدول Persons دون عنوان له في الجدول Address وهذا مرتبط بعدم تطبيق قيد القيمة غير الفارغة على العمود Address_Id. في حال طُبِّق قيد غير القيمة غير الفارغة على العمود، فهنا تصبح العلاقة واجبة بين الجدولين، ولا يمكن أن نُنْشئ سجلًّا في الجدول Persons إلا بإدخال قيمة موجودة للعمود Address_Id وهو في مثالنا هذا غير منقطي نوعا ما. دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن علاقة واحد إلى كثير أو علاقة كثير إلى واحد هذا النوع من العلاقات هو الشائع بين أنواع العلاقات بين الجداول في قاعدة البيانات، لوجود تطبيقات كثيرة عليه، فمثلا: الطالب (واحد) يستطيع أن يدرس أكثر من مساق (كثير). الطبيب يعالج ويتابع حالة مريض واحد أو أكثر. طلبية الشراء تحتوي على أكثر من عنصر. الشخص يستعير أكثر من كتاب. وقس على ذلك العديد من الأمثلة. لنفترض وجود جدول للزبناء Customers بالهيكلية التالية: Customer_ID Customer_Name 1 Ibrahim Mohammed 2 Mohammed Ahmed نستطيع ربط جدول الزبناء السابق بجدولٍ للطلبيات Orders بعلاقة واحد إلى كثير، لتعبر العلاقة عن الطلبيات التي قام بها العملاء وقيمة كل طلبية وتاريخها. يمكن أن تكون هيكلية الجدول Orders كالتالي: Order_ID Customer_ID Order_Date Order_Value 997 101 1/5/2017 100 998 102 21/4/2016 150 999 101 21/4/2015 1500 تسمح هذه العلاقة للعميل بأن يطلُب طلبيةً أو أكثر، ويمكن ألا تكون له أية طلبية. ولكنّ كل طلبية في الجدول Orders ستكون تابعة لعميل واحد. ونستطيع تمثيل هذه العلاقة بالشكل التالي: علاقة كثير إلى كثير في علاقة كثير إلى واحد، تكون العلاقة مبنية على أن يكون أحد أطرافها “واحدًا”، مثل طالب واحد، عميل واحد، طلبية واحدة، وفي الطرف الثاني “كثير”. نحتاج أحيانا أن يكون طرفا العلاقة كثيرين. فمثلا، قد تكون لدينا طلبية تحتوي أكثر من عنصر، ونفس العنصر يكون متواجدًا في أكثر من طلبية. في هذه الحالة نحتاج لوجود جدول إضافي لبناء العلاقة، فمثلا تكون هيكلية جدول Orders كالتالي: Order_ID Customer_ID Order_Date Order_Value 997 101 1/5/2017 100 998 102 21/4/2016 150 999 101 21/4/2015 1500 وهيكلية جدول Items كالتالي: Item_Id Item_Name Item_Description 201 Hard Disk 1 1 Tera SSD Hard 202 Mouse Microsoft Optical Mouse 203 LCD 42 42” LCD نستطيع بناء علاقة كثير إلى كثير بين الجدولين السابقين بإضافة جدول ثالث يحلّ مكان الرابط وغرضه الوحيد هو بناء هذا النوع من العلاقات. نطلق عليه مثلا الاسم Orders_Items، ويكون بالهيكلية التالية: Order_Id Item_Id 997 201 997 202 999 201 999 202 999 203 998 203 يمثّل الشكل التالي علاقة كثير إلى كثير كما تظهر في الجدول Orders_Items: علاقة المرجعية الذاتية يُبنى هذا النوع من العلاقات عندما نريد أن نبني علاقة بين جدول ونفس الجدول، وأوضح مثال على هذا النوع من العلاقات هو جدول الموظفين الذي يحتوي على عمود رقم الموظف المسؤول، حيث يمكن ربط كل موظف بموظف آخر (مدير أو مسؤول) من نفس الجدول. فمثلا، لو كان لدينا جدول باسم Employees خاص بحفظ بيانات الموظفين، ستكون هيكليته على النحو التالي لتطبيق علاقة مرجعية ذاتية عليه: Employee_ID Employee_Name Manager_Id 100 Ibrahim Elbouhissi 101 Khaled Saber 100 102 Yasmeen Hadi 100 103 Duaa Yousef 101 104 Sami Saber بعلاقة المرجعية الذاتية، من الممكن أن يكون للموظف مسؤولًا أو لا يكون، ومن الممكن أن يكون الموظف مسؤولا عن موظف أو أكثر، ويمكن تمثيل العلاقة بالشكل التالي. -
.png.e9d39a2148dc75b2524c5b5b57d4c13a.png) يتناول هذا المقال، الأول من سلسلة دروس عن لغة الاستعلام البنائية Structured Query language التي تعرف بالاختصار المشهور SQL، مفهوم قواعد البيانات، وماذا نقصد بأنظمة إدارة قواعد البيانات، وما هو الجدول، وما هي خصائص قواعد البيانات العلاقية. ما هي قاعدة البيانات؟ بطريقة بسيطة مجرّدة من مفاهيم التقنية، قاعدة البيانات هي مكان لحفظ بيانات معينة على نحو مستمر بهدف الرجوع إليها وقت الحاجة، فدفتر أرقام الهواتف الذي كنا نستعمله في الماضي يُعدّ قاعدة بيانات؛ والكم الهائل من الفواتير المحاسبية الورقية المحفوظة في خزانات الأقسام المالية في الشركات قديماً، أيضاً هو قاعدة بيانات. وقِس على ذلك العديد من الأمثلة الواقعية والملموسة. نستنبطُ من هذا التعريف البسيط وجود خاصية هامة لقاعدة البيانات، ألا وهي “الاستمرارية” أو “الدوام” في حفظ البيانات. في الجانب التقني والبرمجي، فإن قاعدة البيانات Database هي عبارة عن مستودع تُحفظ البيانات فيه داخل جهاز الحاسوب أو الخادوم، ويتمتع هذا المستودع بخاصية الاستمرارية في حفظ البيانات. ونعني بخاصية الاستمرارية هنا أنه في حال إطفاء جهاز الحاسوب أو إعادة تشغيله أو انقطاع التواصل معه، فإن قاعدة البيانات وما تحتويه من بيانات تبقى موجودة ومحفوظة دون أي خلل. أنظمة إدارة قواعد البيانات العلاقية تُسمى البرمجيات التي تنشئ وتدير قواعد البيانات بأنظمة إدارة قواعد البيانات (Databases Management Systems) وتكتب بالاختصار DBMS. ما هي أنواع أنظمة إدارة قواعد البيانات؟ تختلف وتتعدد تسميات أنواع أنظمة إدارة البيانات، وهذا الاختلاف نابع بالدرجة الأولى من تقدم الزمن وما صاحبه من تقدم في العلوم والتقنيات، ومن ثم بالدرجة الثانية، ينبع الاختلاف من التقنيات والخصائص المتعددة لهذه الأنظمة وما تقدمه من خدمات. تنقسم أنواع أنظمة قواعد البيانات إلى ثلاثة أنواع رئيسية. نظام قاعدة البيانات الملف والواحد Flat File Database: يعدّ هذا النوع من الأنظمة قديما ومن النادر أن تجد أحدا يعمل عليه إلى الآن، وهو ببساطة قاعدة بيانات من ملف واحد كبير يحتوي على كل البيانات، وهو يشبه جدول واحد به كل البيانات. نظام إدارة قاعدة البيانات غير العلاقية Non-Relational DBMS :ظهر هذا النوع من أنظمة قواعد البيانات في ظل عصر تضخم البيانات وزيادة حجمها، وخاصة مع انتشار ما يسمى بالمواقع الاجتماعية وتطبيقات الجوال وصفحات الوب الحديثة، فهذا النوع من الأنظمة يسمح بحفظ بيانات غير مرتبة وفق بنية معينة Unstructured Data، وليس من الشرط أن تترابط هذه البيانات Not relational، كما يطلق عليها No-SQL Databases. نظام إدارة قاعدة البيانات العلاقية Relational DBMS: وهو النوع الأشهر والأكثر استخداما منذ بداية ظهوره والذي سنعتمده في هذه السلسلة لشرح SQL، حيث تُجمَّع في هذا النوع من الأنظمة البيانات التي لها علاقة ببعضها البعض في مكان واحد يسمى الجدول، مع وجود الإمكانية لربط الجداول مع بعضها البعض بعلاقات ترابط. دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن ما هو الجدول؟ يُعدّ الجدول العنصر الأساسي في قواعد البيانات العلاقية، وعليه تعتمد أغلب مكونات قاعدة البيانات من مشاهد Views ودوال Functions وحِزم Packages وغيرها من العناصر الأخرى. يتكون الجدول من أعمدة Columns وصفوف Rows، حيث تمثل الأعمدة ما يسمى بالخصائص Features، والصفوف عبارة عن القيم التي تأخذها الأعمدة وتسمى بالسجلات Records. يوضح الشكل التالي مثالا لجدول يحتوي على بيانات تواريخ ميلاد وأسماء طلاب في مدرسة، وفي المثال نوضح مكونات الجدول في قاعدة البيانات. خصائص قواعد البيانات العلاقية ومميزاتها ظلت قواعد البيانات العلاقية مسيطرة منذ بدايات ظهور النموذج الأساسي لها عام 1970 على يد عالم الحاسوب Frank Codd أثناء عمله لصالح شركة IBM، ولم تكن هذه الأفضلية التي يتمتع بها نظام قواعد البيانات العلاقية تأتي من فراغ، بل من الخصائص التي تتمتع بها. البساطة تُرتَّب البيانات في أنظمة قواعد البيانات العلاقية وتُحفَظ بطريقة بعيدة عن التعقيد، حيث يعدّ الجدول الذي تُحفظ فيه البيانات مفهوما لأغلب المستخدمين وخاصة الذين مارسوا أعمالا في مجال البيانات المجدولة أو مراجعة السجلات. سهولة الاستعلام عن البيانات بعد عمليات الإضافة على قاعدة البيانات، وعند الحاجة للرجوع لها، فإن نظام قواعد البيانات العلائقية يوفر آلية سهلة للاستعلام عن هذه البيانات واستردادها، وذلك عن طريق لغة SQL، بالإضافة إلى وجود الإمكانية للمستخدم أن يستعلم عن البيانات من أكثر من جدول في نفس الوقت باستخدام جمل الربط Joins. كما أن خاصية ترشيح Filtering البيانات وتحديد شروط خاصة لظهور سجلات معينة هو أمر متاح بكل سهولة. سلامة البيانات تعدّ هذه الخاصية أساسية في أي نظام قواعد بيانات بغض النظر عن نوعه. ونعني بهذه الخاصية أن تتوفر جميع القدرات والإمكانات في نظام قواعد البيانات لضمان دقة وصحة المعلومات الموجودة فيه. ويندرج تحت هذه الخاصية ما يسمى بقيود التكامل Integrity constraints والتي هي عبارة عن مجموعة من القيود التي يجب الالتزام بها عند التعامل مع البيانات في الجدول، وسنتكلم عنها في مقال متقدم. المرونة تتمتع قواعد البيانات العلاقية بطبيعتها بالمرونة والقابلية للتطوير، مما يجعلها قابلة للتكيف مع طلبات التغيير والزيادة في كم البيانات. وهذا يعني مثلا أنك تستطيع التغيير على هيكلية جدول معين دون التأثير على البيانات الموجودة فيه أو على قاعدة البيانات ككل، كما أنك – مثلا - لن تحتاج إلى وقف قاعدة البيانات وإعادة تشغيلها مرة أخرى لتنفيذ بعض لتغييرات عليها. ما هي البرمجيات التي تقدم قواعد البيانات العلاقية؟ تَتَعدد الشركات والبرمجيات التي تُقدم أنظمة إدارة قواعد البيانات، وكل منها له سوقه ومجاله الذي يشتهر به. نُقدم لكم في الفقرات القادمة بعضًا من أشهر أنظمة إدارة قواعد البيانات العلاقية. قواعد بيانات MySQL أحد أشهر أنظمة قواعد البيانات العلاقية مفتوحة المصدر. تستطيع إنشاء العديد من قواعد البيانات بداخلها، وتستطيع الوصول لها عبر الوِب. تَعمل MySQL على هيئة خِدمة Service تُتيح لأكثر من مستخدم الوصول إلى أكثر من قاعدة بيانات، وتشتهر بين معشر مبرمجي تطبيقات الوِب لارتباطها الشائع مع لغة البرمجة PHP، ويمكن تنصيبها على أكثر من نظام تشغيل مثل وندوز أو لينكس أو ماك. تعدّ MySQL الخيار المفضل للشركات الناشئة أو المتوسطة وذلك لسهولة التعامل معها وانخفاض تكاليف تشغيلها مقارنة بخيارات أخرى. قواعد بيانات أوراكل Oracle تعدّ شركة أوراكل عملاق الشركات البرمجية التي تقدم أنظمة إدارة قواعد البيانات العلاقية، وتأتي قاعدة البيانات أوراكل بأكثر من إصدار (حسب البيئة والغرض) تبدأ من الإصدار الشخصي والخفيف، وتنتهي بالإصدار المتقدم Enterprise. تتميز قواعد بيانات أوراكل بكم كبير من الإمكانات التي تسهل عليك حل العديد من المشاكل والعقبات في التطبيقات التي تديرها وتنشئها، مع وجود دعم فني قوي عبر مجتمع أوراكل، لذلك فهي تعتبر الخيار الإستراتيجي (البعيد المدى) للعديد من الشركات الكبيرة والجامعات والحكومات. قواعد بيانات مايكروسوفت Microsoft SQL Server من قواعد البيانات الشهيرة، والذي تأتي أيضا بأكثر من إصدار، لتلبي احتياجات المستخدمين المختلفة وبيئات عملهم، ولكي تتعامل مع البيانات في هذا النوع تحتاج لاستخدام النسخة الخاصة من SQL والمسماة T-SQL اختصارا ل Transact SQL والتي هي عبارة عن نسخة SQL مضاف عليه ادوال خاصة وتعديلات على طريقة حذف وتعديل السجلات. قواعد بيانات PostgreSQL قواعد بينات PostgreSQL من قواعد البيانات العلاقية المفضلة لدى بعض مطوري تطبيقات الوِب وتطبيقات سطح المكتب، وهو نظام إدارة قواعد بيانات مفتوح المصدر. توجد الكثير من الشركات الكبيرة والعاملة في مجال نطاقات إنترنت تعتمد على هذا النوع من قواعد البيانات.
يتناول هذا المقال، الأول من سلسلة دروس عن لغة الاستعلام البنائية Structured Query language التي تعرف بالاختصار المشهور SQL، مفهوم قواعد البيانات، وماذا نقصد بأنظمة إدارة قواعد البيانات، وما هو الجدول، وما هي خصائص قواعد البيانات العلاقية. ما هي قاعدة البيانات؟ بطريقة بسيطة مجرّدة من مفاهيم التقنية، قاعدة البيانات هي مكان لحفظ بيانات معينة على نحو مستمر بهدف الرجوع إليها وقت الحاجة، فدفتر أرقام الهواتف الذي كنا نستعمله في الماضي يُعدّ قاعدة بيانات؛ والكم الهائل من الفواتير المحاسبية الورقية المحفوظة في خزانات الأقسام المالية في الشركات قديماً، أيضاً هو قاعدة بيانات. وقِس على ذلك العديد من الأمثلة الواقعية والملموسة. نستنبطُ من هذا التعريف البسيط وجود خاصية هامة لقاعدة البيانات، ألا وهي “الاستمرارية” أو “الدوام” في حفظ البيانات. في الجانب التقني والبرمجي، فإن قاعدة البيانات Database هي عبارة عن مستودع تُحفظ البيانات فيه داخل جهاز الحاسوب أو الخادوم، ويتمتع هذا المستودع بخاصية الاستمرارية في حفظ البيانات. ونعني بخاصية الاستمرارية هنا أنه في حال إطفاء جهاز الحاسوب أو إعادة تشغيله أو انقطاع التواصل معه، فإن قاعدة البيانات وما تحتويه من بيانات تبقى موجودة ومحفوظة دون أي خلل. أنظمة إدارة قواعد البيانات العلاقية تُسمى البرمجيات التي تنشئ وتدير قواعد البيانات بأنظمة إدارة قواعد البيانات (Databases Management Systems) وتكتب بالاختصار DBMS. ما هي أنواع أنظمة إدارة قواعد البيانات؟ تختلف وتتعدد تسميات أنواع أنظمة إدارة البيانات، وهذا الاختلاف نابع بالدرجة الأولى من تقدم الزمن وما صاحبه من تقدم في العلوم والتقنيات، ومن ثم بالدرجة الثانية، ينبع الاختلاف من التقنيات والخصائص المتعددة لهذه الأنظمة وما تقدمه من خدمات. تنقسم أنواع أنظمة قواعد البيانات إلى ثلاثة أنواع رئيسية. نظام قاعدة البيانات الملف والواحد Flat File Database: يعدّ هذا النوع من الأنظمة قديما ومن النادر أن تجد أحدا يعمل عليه إلى الآن، وهو ببساطة قاعدة بيانات من ملف واحد كبير يحتوي على كل البيانات، وهو يشبه جدول واحد به كل البيانات. نظام إدارة قاعدة البيانات غير العلاقية Non-Relational DBMS :ظهر هذا النوع من أنظمة قواعد البيانات في ظل عصر تضخم البيانات وزيادة حجمها، وخاصة مع انتشار ما يسمى بالمواقع الاجتماعية وتطبيقات الجوال وصفحات الوب الحديثة، فهذا النوع من الأنظمة يسمح بحفظ بيانات غير مرتبة وفق بنية معينة Unstructured Data، وليس من الشرط أن تترابط هذه البيانات Not relational، كما يطلق عليها No-SQL Databases. نظام إدارة قاعدة البيانات العلاقية Relational DBMS: وهو النوع الأشهر والأكثر استخداما منذ بداية ظهوره والذي سنعتمده في هذه السلسلة لشرح SQL، حيث تُجمَّع في هذا النوع من الأنظمة البيانات التي لها علاقة ببعضها البعض في مكان واحد يسمى الجدول، مع وجود الإمكانية لربط الجداول مع بعضها البعض بعلاقات ترابط. دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن ما هو الجدول؟ يُعدّ الجدول العنصر الأساسي في قواعد البيانات العلاقية، وعليه تعتمد أغلب مكونات قاعدة البيانات من مشاهد Views ودوال Functions وحِزم Packages وغيرها من العناصر الأخرى. يتكون الجدول من أعمدة Columns وصفوف Rows، حيث تمثل الأعمدة ما يسمى بالخصائص Features، والصفوف عبارة عن القيم التي تأخذها الأعمدة وتسمى بالسجلات Records. يوضح الشكل التالي مثالا لجدول يحتوي على بيانات تواريخ ميلاد وأسماء طلاب في مدرسة، وفي المثال نوضح مكونات الجدول في قاعدة البيانات. خصائص قواعد البيانات العلاقية ومميزاتها ظلت قواعد البيانات العلاقية مسيطرة منذ بدايات ظهور النموذج الأساسي لها عام 1970 على يد عالم الحاسوب Frank Codd أثناء عمله لصالح شركة IBM، ولم تكن هذه الأفضلية التي يتمتع بها نظام قواعد البيانات العلاقية تأتي من فراغ، بل من الخصائص التي تتمتع بها. البساطة تُرتَّب البيانات في أنظمة قواعد البيانات العلاقية وتُحفَظ بطريقة بعيدة عن التعقيد، حيث يعدّ الجدول الذي تُحفظ فيه البيانات مفهوما لأغلب المستخدمين وخاصة الذين مارسوا أعمالا في مجال البيانات المجدولة أو مراجعة السجلات. سهولة الاستعلام عن البيانات بعد عمليات الإضافة على قاعدة البيانات، وعند الحاجة للرجوع لها، فإن نظام قواعد البيانات العلائقية يوفر آلية سهلة للاستعلام عن هذه البيانات واستردادها، وذلك عن طريق لغة SQL، بالإضافة إلى وجود الإمكانية للمستخدم أن يستعلم عن البيانات من أكثر من جدول في نفس الوقت باستخدام جمل الربط Joins. كما أن خاصية ترشيح Filtering البيانات وتحديد شروط خاصة لظهور سجلات معينة هو أمر متاح بكل سهولة. سلامة البيانات تعدّ هذه الخاصية أساسية في أي نظام قواعد بيانات بغض النظر عن نوعه. ونعني بهذه الخاصية أن تتوفر جميع القدرات والإمكانات في نظام قواعد البيانات لضمان دقة وصحة المعلومات الموجودة فيه. ويندرج تحت هذه الخاصية ما يسمى بقيود التكامل Integrity constraints والتي هي عبارة عن مجموعة من القيود التي يجب الالتزام بها عند التعامل مع البيانات في الجدول، وسنتكلم عنها في مقال متقدم. المرونة تتمتع قواعد البيانات العلاقية بطبيعتها بالمرونة والقابلية للتطوير، مما يجعلها قابلة للتكيف مع طلبات التغيير والزيادة في كم البيانات. وهذا يعني مثلا أنك تستطيع التغيير على هيكلية جدول معين دون التأثير على البيانات الموجودة فيه أو على قاعدة البيانات ككل، كما أنك – مثلا - لن تحتاج إلى وقف قاعدة البيانات وإعادة تشغيلها مرة أخرى لتنفيذ بعض لتغييرات عليها. ما هي البرمجيات التي تقدم قواعد البيانات العلاقية؟ تَتَعدد الشركات والبرمجيات التي تُقدم أنظمة إدارة قواعد البيانات، وكل منها له سوقه ومجاله الذي يشتهر به. نُقدم لكم في الفقرات القادمة بعضًا من أشهر أنظمة إدارة قواعد البيانات العلاقية. قواعد بيانات MySQL أحد أشهر أنظمة قواعد البيانات العلاقية مفتوحة المصدر. تستطيع إنشاء العديد من قواعد البيانات بداخلها، وتستطيع الوصول لها عبر الوِب. تَعمل MySQL على هيئة خِدمة Service تُتيح لأكثر من مستخدم الوصول إلى أكثر من قاعدة بيانات، وتشتهر بين معشر مبرمجي تطبيقات الوِب لارتباطها الشائع مع لغة البرمجة PHP، ويمكن تنصيبها على أكثر من نظام تشغيل مثل وندوز أو لينكس أو ماك. تعدّ MySQL الخيار المفضل للشركات الناشئة أو المتوسطة وذلك لسهولة التعامل معها وانخفاض تكاليف تشغيلها مقارنة بخيارات أخرى. قواعد بيانات أوراكل Oracle تعدّ شركة أوراكل عملاق الشركات البرمجية التي تقدم أنظمة إدارة قواعد البيانات العلاقية، وتأتي قاعدة البيانات أوراكل بأكثر من إصدار (حسب البيئة والغرض) تبدأ من الإصدار الشخصي والخفيف، وتنتهي بالإصدار المتقدم Enterprise. تتميز قواعد بيانات أوراكل بكم كبير من الإمكانات التي تسهل عليك حل العديد من المشاكل والعقبات في التطبيقات التي تديرها وتنشئها، مع وجود دعم فني قوي عبر مجتمع أوراكل، لذلك فهي تعتبر الخيار الإستراتيجي (البعيد المدى) للعديد من الشركات الكبيرة والجامعات والحكومات. قواعد بيانات مايكروسوفت Microsoft SQL Server من قواعد البيانات الشهيرة، والذي تأتي أيضا بأكثر من إصدار، لتلبي احتياجات المستخدمين المختلفة وبيئات عملهم، ولكي تتعامل مع البيانات في هذا النوع تحتاج لاستخدام النسخة الخاصة من SQL والمسماة T-SQL اختصارا ل Transact SQL والتي هي عبارة عن نسخة SQL مضاف عليه ادوال خاصة وتعديلات على طريقة حذف وتعديل السجلات. قواعد بيانات PostgreSQL قواعد بينات PostgreSQL من قواعد البيانات العلاقية المفضلة لدى بعض مطوري تطبيقات الوِب وتطبيقات سطح المكتب، وهو نظام إدارة قواعد بيانات مفتوح المصدر. توجد الكثير من الشركات الكبيرة والعاملة في مجال نطاقات إنترنت تعتمد على هذا النوع من قواعد البيانات. -
.png.54d7e491c296bb38efdf2fb1f5ddb41a.png) تَعرفنا في المقال السابق على مفهوم قواعد البيانات وما هي أنواعها. سوف نبدأ في هذا المقال أُولى خطواتنا في شرح لغة الاستعلام البنائية SQL، حيث سنتكلم عن لغة SQL ونعطي لمحة عن دورها وعلاقتها بقاعدة البيانات، ومن ثم سوف نبدأ بشرح أساسيات وجمل بناء قاعدة البيانات والجداول الخاصة بها باستخدام لغة SQL. لغة SQL وماذا تقدم SQL هي اختصارٌ لـ Structured Query language وترجمتها هي “لغة الاستعلام البنائية” وتنطق بطريقتيْن؛ إما حرفًا حرفًا S Q L، أو تنطق كلمة واحدة “سيكيوال”. لغة SQL هي لغة ذات غرض متخصص هدفها إعطاء القدرة على إدارة البيانات الموجودة في قواعد البيانات العلاقية والتعامل معها، وتخضع هذه اللغة لمعايير دولية متفق عليها، ويقوم المعهد الوطني الأمريكي للمعايير (ANSI) بإدارة وإصدار المعايير الخاصة ب SQL. لا يعني ما سبق أن كل برمجيات إدارة قواعد البيانات التي ذكرناها في المقال السابق والتي لم نذكرها، لا يعني بأن SQL لديها موحدة، ولا يعني أنك تستطيع تماما أن تُنفذ نفس جملة SQL في جميع تلك البرمجيات بنجاح. فمن المهم أن نذكر هنا أن الشركات المسؤولة عن تلك البرمجيات الخاصة بإدارة قواعد البيانات، اعتمدت نسخًا مطورة من SQL المعيارية لتصبح خاصة بها وبأنظمتها مع اعتماد حد أدنى في التوافقية مع SQL المعيارية. تستطيع باستخدام لغة SQL أن تقوم بالتالي: الاستعلام عن البيانات وجلبها من قاعدة البيانات. إضافة، تعديل السجلات في قاعدة البيانات وحذفها منها. الحفاظ على سلامة ودقة البيانات في قاعدة البيانات. تحديد الصلاحيات والأذونات الخاصة بمستخدمي قاعدة البيانات. دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن أنواع أوامر SQL تنقسم جمل وأوامر SQL إلى ثلاث مجموعات، وذلك حسب الدور الذي يقوم به الأمر: لغة التعامل مع البيانات Data Manipulation Language: تحتوي هذه المجموعة على جمل غرضها إعطاء القدرة على التعامل مع البيانات دون التأثير على هيكليتها وشكلها العام، بحيث تستطيع الاستعلام عن البيانات، إضافة سجلّات، حذفها أو تعديلها. لغة تعريف البيانات Data Definition Language: تُقدم الأوامر التي تندرج تحت هذه المجموعة القدرة على تعريف البيانات وشكلها وطريقة ربطها ببعضها عبر استخدام أوامر لإنشاء الجداول وإنشاء قاعدة البيانات. لغة التحكم بالبيانات Data Control Language: تساعد هذه المجموعة من الأوامر في تحديد الصلاحيات التي يمكن منحها أو سلبها من المستخدمين الموجودين في قاعدة البيانات. يسرد الجدول التالي أهم الأوامر التي تُمَكّن المبرمج من إنشاء قاعدة البيانات الخاصة به وتنفيذ الجمل الخاصة بإدارتها وإدارة بياناتها. جملة إنشاء قاعدة البيانات في الواقع لا يوجد معيار لأمر إنشاء قاعدة البيانات في معيار SQL المقدم من معهد ANSI ولكن برمجيات قواعد البيانات العلاقية تقدم نسخة من هذا الأمر، وتختلف الصيغة من نظام إلى آخر. الصيغة العامة لأمر إنشاء قاعدة البيانات هي كالتالي: CREATE DATABASE database_name; ملاحظات هامة يُنشئ الأمر السابق قاعدة بيانات فارغة بالاسم المُمَرَّر (أي database_name في الجملة أعلاه). تتطلب أغلب نظم إدارة قواعد البيانات وجود صلاحيات المسؤول للمستخدم الذي ينشئ قاعدة البيانات. بمجرد إنشاء قاعدة البيانات، يستطيع المستخدم أو من له صلاحية، البدء بإضافة عناصر إلى قاعدة البيانات من جداول Tables، مشاهد Views، دوال وحزم، وإضافة سجلات وبيانات إلى الجداول المُنشأة. أثناء تنفيذ أمر إنشاء قاعدة البيانات وبعده، تُنشَأ ملفات خاصة بقاعدة البيانات الجديدة حسب النظام المستخدم، وتُدار هذه الملفات وتُسمَّى إما تلقائيًّا أو من قبل المستخدم. لأن أمر إنشاء قاعدة البيانات غير معياري، فإن خيارات هذا الأمر متعددة وكثيرة وتأتي حسب نوع النظام المستخدم، وحسب نوع نظام إدارة قواعد البيانات. يظهر أمر الإنشاء بأحرف كبيرة Upper case. ليس هذا ضروريّاً في أغلب برامج إدارة قواعد البيانات، إلا أنها عادة في التوثيقات Documentations لتمييز الكلمات المفتاحية التي تعدّ جزءًا من SQL. جملة إنشاء جدول يُعد إنشاء الجدول في قاعدة البيانات أول الخطوات في طريق بناء قاعدة البيانات وملئها بالسجلات، وهذا الأمر يقوم به مسؤول قواعد البيانات أو المبرمج على حد سواء. ستحتاج قبل أن تتمكّن من البدء في تنفيذ أوامر على القاعدة إلى تحديد قاعدة البيانات التي تريد العمل عليها، أي تلك التي ستُنشِئ الجداول فيها. تختلف طريقة تحديد قاعدة البيانات حسب طريقة الاتصال ببرنامج إدارة قواعد البيانات: في سطر أوامر MySQL يُنفَّذ الأمر بالطريقة التالية: USE database_name; في سطر أوامر PostgreSQL: \connect DBNAME الصيغة العامة لجملة إنشاء الجدول في SQL: CREATE TABLE table_name ( column1 datatype [constraint], column2 datatype [constraint], column3 datatype [constraint], .... ); شرح الصيغة: CREATE TABLE table_name ( CREATE تعني إنشاء العنصر (الجدول هنا) وهي بداية الأمر. TABLE لتحديد أن هذه الجملة لإنشاء جدول. table_name وهو الاسم الذي نريد إطلاقه على الجدول الجديد الذي نريد بناءه. القوس المفتوح باتجاه اليسار يعني البدء بكتابة هيكل الجدول والذي يتضمن الأعمدة ونوعها والقيود التي من الممكن أن نضيفها وبعض الإعدادات الأخرى. column1 datatype [constraint], column1: هو الاسم الذي سوف نعطيه للعمود الأول. Datatype:يعني نوع العمود (نصي, رقم, تاريخ. الخ). [Constraint]:تعني – اختيارياً - تستطيع تحديد قيود على مستوى هذا العمود (سنتكلم لاحقا بالتفصيل عن القيود). الفاصلة تعني وجود عمود آخر سوف نعرّفه بعد هذا العمود. عند كتابة العمود الأخير لا نضيف فاصلة، ومن ثم نضيف القوس المعاكس للقوس الذي فُتح عند بداية كتابة الأعمدة، ونختم الأمر بقاصلة منقوطة. ملاحظات هامة تبدأ أسماء الجداول والأعمدة عموما بحرف وليس برقم (بعض نظم إدارة قواعد البيانات تسمح بذلك)، ومن الممكن أن تُتبع بعد ذلك بالأرقام. يُفضَّل ألا يتجاوز طول اسم الجدول أو العمود30 محرفا Characters، حيث إن بعض النظم تمنع أن تتجاوز ذلك مثل نظام إدارة قواعد البيانات أوراكل. يجب ألا تُستخدَم كلمات محجوزة في تسمية الجدول أو العمود. جملة تعديل الجدول بعد أن تكلمنا عن جملة إنشاء الجدول، يجب علينا توضيح جملة تعديل الجدول بعد إنشائه، حيث إن إجراء عمليات التغيير على الجدول يُعد أمراً مهما للمبرمج ومسؤول قواعد البيانات إذ يُنفَّذ باستمرار أثناء وفي بداية بناء النظم البرمجية والبرامج نظرا لتغير المتطلبات وعدم اكتمالها. تُستخدَم جملة تعديل الجدول Alter Table عموما في الحالات التالية: إضافة عمود للجدول. حذف عمود من الجدول. تغيير نوع عمود في الجدول. إضافة قيد على العمود. حذف قيد عن العمود. نسرُد في ما يلي الصيغ العامة لجملة تعديل الجدول. إضافة عمود ALTER TABLE table_name ADD column_name datatype; حذف عمود ALTER TABLE table_name DROP COLUMN column_name; تعديل عمود ALTER TABLE table_name MODIFY | ALTER COLUMN column_name datatype; إنشاء جداول وتعديلها لإنشاء جدول باسم Persons يحتوي على 5 أعمدة تمثل معلومات أشخاص مثل رقم الشخص واسمه وعنوانه، نُنَفذ الجملة التالية (اختبرناها على MySQL 5.7 و Oracle XE 11.2): CREATE TABLE Persons ( PersonID int, Last_Name varchar(255), First_Name varchar(255), Address varchar(255), City varchar(255) ); يتكوّن الجدول السابق: من العمود PersonID الذي هو من النوع int، أي أن قيم هذا العموم يجب أن تكون أرقامًا؛ الأعمدة City، Last_Name، First_Name وAddressالتي هي من النوع varchar، أي سلسلة محارف، بطول 255 محرفا. بعد تنفيذ جملة إنشاء الجدول السابقة، ينتج لدينا جدول فارغ بالشكل التالي: +--------------+------------------+------------------+-------------+--------+ | PersonID | Last_Name | First_Name | Address | City | +--------------+------------------+------------------+-------------+--------+ نستطيع أن نملأ الجدول بالبيانات باستخدام جملة الإضافة والتي سوف نتكلم عنها في مقال قادم. لإنشاء نفس الجدول السابق بحيث يتضمن وجود قيود على مستوى الأعمدة، ننفذ الجملة التالية: CREATE TABLE Persons ( PersonID int PRIMARY KEY, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255) NOT NULL, City varchar(255) ); أضفنا في الجملة السابقة، قيودا على مستوى أعمدة الجدول، بحيث يُعرَّف العمود PersonID بأنه المفتاح الرئيسي للجدول، والأعمدة Last_Name و Address بأنها لا تستقبل القيم الفارغة. في حال أردنا أن نضيف عمودًا جديدًا للجدول باسم Age (العمر) ومن نوع البيانات رقم نستخدم جملة التعديل التالية: ALTER TABLE Persons ADD Age int; تمكن ترجمة الأمر على النحو التالي: “عدّل الجدول Persons بإضافة عمود اسمه Age ونوعه int“. في حال أردنا أن نحذف عمود City من الجدول نستخدم الجملة التالية: ALTER TABLE Persons DROP COLUMN City; أي: “عدّل الجدول Persons بحذف العمود City“. إذا أردنا تعديل نوع عمود Age إلى نص بدلا من رقم نستخدم الجملة التالية: ALTER TABLE Persons MODIFY Age varchar(10); ذكرنا خلال هذا المقال مصطلحي القيود ونوع البيانات في العمود. ولكن ما هي القيود؟ وماذا نستفيد منها في قواعد البيانات؟ وما هي أنواع البيانات التي من الممكن التعامل معها؟ يقدّم المقال القادم شرحا تفصيليا عن القيود وأنواعها، وكذلك سيشرح المقال الأنواع التي من الممكن أن نتعامل معها. اقرأ أيضًا دليلك الشامل إلى أنواع البيانات
تَعرفنا في المقال السابق على مفهوم قواعد البيانات وما هي أنواعها. سوف نبدأ في هذا المقال أُولى خطواتنا في شرح لغة الاستعلام البنائية SQL، حيث سنتكلم عن لغة SQL ونعطي لمحة عن دورها وعلاقتها بقاعدة البيانات، ومن ثم سوف نبدأ بشرح أساسيات وجمل بناء قاعدة البيانات والجداول الخاصة بها باستخدام لغة SQL. لغة SQL وماذا تقدم SQL هي اختصارٌ لـ Structured Query language وترجمتها هي “لغة الاستعلام البنائية” وتنطق بطريقتيْن؛ إما حرفًا حرفًا S Q L، أو تنطق كلمة واحدة “سيكيوال”. لغة SQL هي لغة ذات غرض متخصص هدفها إعطاء القدرة على إدارة البيانات الموجودة في قواعد البيانات العلاقية والتعامل معها، وتخضع هذه اللغة لمعايير دولية متفق عليها، ويقوم المعهد الوطني الأمريكي للمعايير (ANSI) بإدارة وإصدار المعايير الخاصة ب SQL. لا يعني ما سبق أن كل برمجيات إدارة قواعد البيانات التي ذكرناها في المقال السابق والتي لم نذكرها، لا يعني بأن SQL لديها موحدة، ولا يعني أنك تستطيع تماما أن تُنفذ نفس جملة SQL في جميع تلك البرمجيات بنجاح. فمن المهم أن نذكر هنا أن الشركات المسؤولة عن تلك البرمجيات الخاصة بإدارة قواعد البيانات، اعتمدت نسخًا مطورة من SQL المعيارية لتصبح خاصة بها وبأنظمتها مع اعتماد حد أدنى في التوافقية مع SQL المعيارية. تستطيع باستخدام لغة SQL أن تقوم بالتالي: الاستعلام عن البيانات وجلبها من قاعدة البيانات. إضافة، تعديل السجلات في قاعدة البيانات وحذفها منها. الحفاظ على سلامة ودقة البيانات في قاعدة البيانات. تحديد الصلاحيات والأذونات الخاصة بمستخدمي قاعدة البيانات. دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن أنواع أوامر SQL تنقسم جمل وأوامر SQL إلى ثلاث مجموعات، وذلك حسب الدور الذي يقوم به الأمر: لغة التعامل مع البيانات Data Manipulation Language: تحتوي هذه المجموعة على جمل غرضها إعطاء القدرة على التعامل مع البيانات دون التأثير على هيكليتها وشكلها العام، بحيث تستطيع الاستعلام عن البيانات، إضافة سجلّات، حذفها أو تعديلها. لغة تعريف البيانات Data Definition Language: تُقدم الأوامر التي تندرج تحت هذه المجموعة القدرة على تعريف البيانات وشكلها وطريقة ربطها ببعضها عبر استخدام أوامر لإنشاء الجداول وإنشاء قاعدة البيانات. لغة التحكم بالبيانات Data Control Language: تساعد هذه المجموعة من الأوامر في تحديد الصلاحيات التي يمكن منحها أو سلبها من المستخدمين الموجودين في قاعدة البيانات. يسرد الجدول التالي أهم الأوامر التي تُمَكّن المبرمج من إنشاء قاعدة البيانات الخاصة به وتنفيذ الجمل الخاصة بإدارتها وإدارة بياناتها. جملة إنشاء قاعدة البيانات في الواقع لا يوجد معيار لأمر إنشاء قاعدة البيانات في معيار SQL المقدم من معهد ANSI ولكن برمجيات قواعد البيانات العلاقية تقدم نسخة من هذا الأمر، وتختلف الصيغة من نظام إلى آخر. الصيغة العامة لأمر إنشاء قاعدة البيانات هي كالتالي: CREATE DATABASE database_name; ملاحظات هامة يُنشئ الأمر السابق قاعدة بيانات فارغة بالاسم المُمَرَّر (أي database_name في الجملة أعلاه). تتطلب أغلب نظم إدارة قواعد البيانات وجود صلاحيات المسؤول للمستخدم الذي ينشئ قاعدة البيانات. بمجرد إنشاء قاعدة البيانات، يستطيع المستخدم أو من له صلاحية، البدء بإضافة عناصر إلى قاعدة البيانات من جداول Tables، مشاهد Views، دوال وحزم، وإضافة سجلات وبيانات إلى الجداول المُنشأة. أثناء تنفيذ أمر إنشاء قاعدة البيانات وبعده، تُنشَأ ملفات خاصة بقاعدة البيانات الجديدة حسب النظام المستخدم، وتُدار هذه الملفات وتُسمَّى إما تلقائيًّا أو من قبل المستخدم. لأن أمر إنشاء قاعدة البيانات غير معياري، فإن خيارات هذا الأمر متعددة وكثيرة وتأتي حسب نوع النظام المستخدم، وحسب نوع نظام إدارة قواعد البيانات. يظهر أمر الإنشاء بأحرف كبيرة Upper case. ليس هذا ضروريّاً في أغلب برامج إدارة قواعد البيانات، إلا أنها عادة في التوثيقات Documentations لتمييز الكلمات المفتاحية التي تعدّ جزءًا من SQL. جملة إنشاء جدول يُعد إنشاء الجدول في قاعدة البيانات أول الخطوات في طريق بناء قاعدة البيانات وملئها بالسجلات، وهذا الأمر يقوم به مسؤول قواعد البيانات أو المبرمج على حد سواء. ستحتاج قبل أن تتمكّن من البدء في تنفيذ أوامر على القاعدة إلى تحديد قاعدة البيانات التي تريد العمل عليها، أي تلك التي ستُنشِئ الجداول فيها. تختلف طريقة تحديد قاعدة البيانات حسب طريقة الاتصال ببرنامج إدارة قواعد البيانات: في سطر أوامر MySQL يُنفَّذ الأمر بالطريقة التالية: USE database_name; في سطر أوامر PostgreSQL: \connect DBNAME الصيغة العامة لجملة إنشاء الجدول في SQL: CREATE TABLE table_name ( column1 datatype [constraint], column2 datatype [constraint], column3 datatype [constraint], .... ); شرح الصيغة: CREATE TABLE table_name ( CREATE تعني إنشاء العنصر (الجدول هنا) وهي بداية الأمر. TABLE لتحديد أن هذه الجملة لإنشاء جدول. table_name وهو الاسم الذي نريد إطلاقه على الجدول الجديد الذي نريد بناءه. القوس المفتوح باتجاه اليسار يعني البدء بكتابة هيكل الجدول والذي يتضمن الأعمدة ونوعها والقيود التي من الممكن أن نضيفها وبعض الإعدادات الأخرى. column1 datatype [constraint], column1: هو الاسم الذي سوف نعطيه للعمود الأول. Datatype:يعني نوع العمود (نصي, رقم, تاريخ. الخ). [Constraint]:تعني – اختيارياً - تستطيع تحديد قيود على مستوى هذا العمود (سنتكلم لاحقا بالتفصيل عن القيود). الفاصلة تعني وجود عمود آخر سوف نعرّفه بعد هذا العمود. عند كتابة العمود الأخير لا نضيف فاصلة، ومن ثم نضيف القوس المعاكس للقوس الذي فُتح عند بداية كتابة الأعمدة، ونختم الأمر بقاصلة منقوطة. ملاحظات هامة تبدأ أسماء الجداول والأعمدة عموما بحرف وليس برقم (بعض نظم إدارة قواعد البيانات تسمح بذلك)، ومن الممكن أن تُتبع بعد ذلك بالأرقام. يُفضَّل ألا يتجاوز طول اسم الجدول أو العمود30 محرفا Characters، حيث إن بعض النظم تمنع أن تتجاوز ذلك مثل نظام إدارة قواعد البيانات أوراكل. يجب ألا تُستخدَم كلمات محجوزة في تسمية الجدول أو العمود. جملة تعديل الجدول بعد أن تكلمنا عن جملة إنشاء الجدول، يجب علينا توضيح جملة تعديل الجدول بعد إنشائه، حيث إن إجراء عمليات التغيير على الجدول يُعد أمراً مهما للمبرمج ومسؤول قواعد البيانات إذ يُنفَّذ باستمرار أثناء وفي بداية بناء النظم البرمجية والبرامج نظرا لتغير المتطلبات وعدم اكتمالها. تُستخدَم جملة تعديل الجدول Alter Table عموما في الحالات التالية: إضافة عمود للجدول. حذف عمود من الجدول. تغيير نوع عمود في الجدول. إضافة قيد على العمود. حذف قيد عن العمود. نسرُد في ما يلي الصيغ العامة لجملة تعديل الجدول. إضافة عمود ALTER TABLE table_name ADD column_name datatype; حذف عمود ALTER TABLE table_name DROP COLUMN column_name; تعديل عمود ALTER TABLE table_name MODIFY | ALTER COLUMN column_name datatype; إنشاء جداول وتعديلها لإنشاء جدول باسم Persons يحتوي على 5 أعمدة تمثل معلومات أشخاص مثل رقم الشخص واسمه وعنوانه، نُنَفذ الجملة التالية (اختبرناها على MySQL 5.7 و Oracle XE 11.2): CREATE TABLE Persons ( PersonID int, Last_Name varchar(255), First_Name varchar(255), Address varchar(255), City varchar(255) ); يتكوّن الجدول السابق: من العمود PersonID الذي هو من النوع int، أي أن قيم هذا العموم يجب أن تكون أرقامًا؛ الأعمدة City، Last_Name، First_Name وAddressالتي هي من النوع varchar، أي سلسلة محارف، بطول 255 محرفا. بعد تنفيذ جملة إنشاء الجدول السابقة، ينتج لدينا جدول فارغ بالشكل التالي: +--------------+------------------+------------------+-------------+--------+ | PersonID | Last_Name | First_Name | Address | City | +--------------+------------------+------------------+-------------+--------+ نستطيع أن نملأ الجدول بالبيانات باستخدام جملة الإضافة والتي سوف نتكلم عنها في مقال قادم. لإنشاء نفس الجدول السابق بحيث يتضمن وجود قيود على مستوى الأعمدة، ننفذ الجملة التالية: CREATE TABLE Persons ( PersonID int PRIMARY KEY, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255) NOT NULL, City varchar(255) ); أضفنا في الجملة السابقة، قيودا على مستوى أعمدة الجدول، بحيث يُعرَّف العمود PersonID بأنه المفتاح الرئيسي للجدول، والأعمدة Last_Name و Address بأنها لا تستقبل القيم الفارغة. في حال أردنا أن نضيف عمودًا جديدًا للجدول باسم Age (العمر) ومن نوع البيانات رقم نستخدم جملة التعديل التالية: ALTER TABLE Persons ADD Age int; تمكن ترجمة الأمر على النحو التالي: “عدّل الجدول Persons بإضافة عمود اسمه Age ونوعه int“. في حال أردنا أن نحذف عمود City من الجدول نستخدم الجملة التالية: ALTER TABLE Persons DROP COLUMN City; أي: “عدّل الجدول Persons بحذف العمود City“. إذا أردنا تعديل نوع عمود Age إلى نص بدلا من رقم نستخدم الجملة التالية: ALTER TABLE Persons MODIFY Age varchar(10); ذكرنا خلال هذا المقال مصطلحي القيود ونوع البيانات في العمود. ولكن ما هي القيود؟ وماذا نستفيد منها في قواعد البيانات؟ وما هي أنواع البيانات التي من الممكن التعامل معها؟ يقدّم المقال القادم شرحا تفصيليا عن القيود وأنواعها، وكذلك سيشرح المقال الأنواع التي من الممكن أن نتعامل معها. اقرأ أيضًا دليلك الشامل إلى أنواع البيانات -
 تستغل هجمات حقن SQL البرمجة السيئة للشفرة الخاصّة بالبرمجيات. إنّها هجمات حيث يقوم المهاجمون بإرسال شفرة عبر واحدٍ من مربّعات الإدخال الموجودة على موقعك (أيّ مربّع)، عوضًا عن أن يرسل بياناتٍ عادية كنتَ تنوي استقبالها عبر مربّعات الإدخال تلك. تقوم تلك الشفرة المُدخلة بتنفيذ عمليات الاستعلام على قاعدة البيانات الخاصّة بموقعك بطريقةٍ لم تكن تتوقعها، أو تقوم بتحطيم تطبيق الويب الخاصّ بك وتقوم بتخريب خادومك السحابي. م السهل جدًا عمل هجمات حقن SQL ضدّ المواقع الغير مؤمّنة. وحراسة موقعك ضدّ هذه الهجمات قد يكون من أهمّ ما تقوم به منذ اليوم الأوّل. الخطوة الأولى: تعلم تمييز الشفرة المحتوية على ثغرات تأخذ هجمات SQL دومًا شكل سلسلة نصّية يتم إرسالها من طرف مستخدمٍ تتكون من قسمين. القسم الأول هو عبارة عن تخمين لكيفية تعطيل أمرٍ تحاول شفرتك المصدرية أن تقوم بتنفيذه بأمان; القسم الثاني هو الشفرة الخبيثة التي يريد المهاجم تنفيذها على خادومك. إليك مثالًا على سلسلة نصّية مصممة لاستغلال ثغرة ممكنة في الشفرة المصدرية لديك: x' AND user.email IS NULL; -- يبدو هذا كشيء قمتَ بكتابته بنفسك، وتلك هي النقطة. يأمل المستخدم المُخترِق أن تقوم بأخذ هذا السطر، وتقوم بتنفيذه بعملية استعلام SQL تبدو كالتالي: SELECT email, passwd FROM user WHERE email = 'x' AND user.email IS NULL; --'; لا يبدو أنّ هذا يقوم بالكثير حقًا، ولكن اعتمادًا على الطريقة التي سيستجيب بها تطبيقك إلى ما سبق، يمكن أن يوفّر هذا بعض المعلومات المهمّة للمُخترِق مثل اسم جدول قاعدة البيانات الذي تستعمله. بعد هذا، هناك المزيد من الهجمات التي يمكن للمهاجم أن يستخدمها لجلب المزيد من المعلومات، مثل أسماء المستخدمين وكلمات المرور. الفكرة الرئيسية التي يجب عليك فهمها هي أنّ الشفرة الخبيثة تحاول البحث عن ثغرة بعملية استعلام SQL التي يقوم بها تطبيقك لمحاولة استغلالها لجلب المعلومات أو إدراجها وتعديلها. لا تتطلب جميع هجمات حقن SQL إشارة الاقتباس المغلقة ('). إذا كانت شفرتك المصدرية تنفّذ عملية استعلامٍ متعلّقة برقم، فإنّك لن تقوم بالطبع بوضع تلك البيانات داخل إشارة اقتباس. وهذا يتركك عرضةً لهذا النوع من الهجمات: 2097 OR 1=1 يأمل المهاجم أن يقوم تطبيقك بعملية استعلام مشابهة للتالي: SELECT somedata FROM yourtable WHERE userid = 2097 OR 1=1; غالبًا ما تكون شفرتك البرمجية مصممة لتقوم بعملية الاستعلام السابقة لتعيد البيانات فقط في حال تطابق الـ userid مع المستخدم الصحيح. ولكنّ حقنة الـSQL تجعل عملية الاستعلام تقوم دومًا بإرجاع البيانات. النقطة ليست في سلوكٍ معيّن لأيّ حقنة SQL. الشيء الأكثر أهمّية من هذا كلّه هو القاعدة العامّة لجميع حقن SQL: محاولة لتخمين كيفية حذف جزء معيّن من عملية استعلام، وإضافة جزءٍ آخر إليها لم تكن تتوقعه. هذا هو توقيع جميع هجمات حقن SQL. وهذه هي طريقة محاربتها. الخطوة الثانية: اعثر على مدخلاتك أفضل طريقة لتعقّب جميع نقط إدخال حقن SQL الممكنة في شفرتك البرمجية ليس عبر النظر إلى حقول إدخال HTML. بالطبع يمكنك العثور على العديد من الثغرات الممكنة هناك، ولكن هناك طرقٌ أخرى يمكن من خلالها للمستخدم أن يقوم بإدخال البيانات، مثل عنوان الويب (URL)، أو عبر واحدةٍ من واجهات AJAX الخاصّة بك. أفضل مكان للبحث فيه عن الثغرات هو الشيء الذي يريد المخترقون اختراقه بنفسه; جملة استعلام SQL بنفسها. على الأغلب، فإنّك تقوم بتنفيذ جميع عمليات الاستعلام عن طريق الأمر الأساسي نفسه، وربّما أمران آخران أو أكثر قليلًا. فقط ابحث عن هذه الأوامر في شفرتك البرمجية وستجد جميع الثغرات الممكنة بشكلٍ سريع. كمثال، إذا كانت شفرتك البرمجية مكتوبة بـPerl، فإنّ جميع عمليات استعلام SQL الخاصّة بك ستبدو هكذا: $result = mysql_query($sql) في تلك الحالة، يمكنك العثور بسرعة على جميع الثغرات الممكنة بواسطة سطر الأوامر، عبر استخدام أمر شبيه بالتالي: $ grep -R mysql_query * الخطوة الثالثة: نظف مدخلاتك هناك العديد من التقنيات التي يستخدمها الناس لمنع هجمات حقن SQL، ولكن خطّ دفاعك الأمامي يجب أن يكون تنظيف جميع مُدخلات المستخدم من أيّ شفرة خبيثة مشبوهة. يجب ألّا تعتقد بتاتًا أنّ المستخدم سيقوم بإدخال البيانات بالطريقة التي تريدها. في الواقع، يجب عليك أن تفترض العكس - أنّهم سيقومون بإدخال الشفرات الخبيثة في كلّ مكانٍ ممكن في موقعك. تنظيف المُدخلات يعني أنّه يجب اختبار جميع مُدخلات المستخدم للتأكّد من أنّها تحتوي فقط مُدخلات آمنة، مُدخلات لا يمكن استخدامها بتاتًا في شنّ هجوم. المُدخلات التي سيتم إدخالها من طرف المستخدم إلى خادوم SQL الخاصّ بك ستكون على شكلَين: كرقم، مثل 2097. كسلسلة (string)، مثل اسم المستخدم، كلمة المرور أو البريد الإلكتروني. تتوقّع شفرتك البرمجية دومًا مُدخَلًا واحدًا من هذين الشكلين. في الأمثلة التي ذكرناها ببداية هذا المقال، كان المثال الأوّل عبارة عن سلسلة نصّية، وكان المثال الثاني عبارةً عن رقم. هناك أيضًا طريقتان لتنظيف البيانات: طريقة جيدة وطريقة سيئة. الطريقة السيئة هي التحقق من وجود حقن SQL الممكنة. السبب في كونها سيئة هو لأنّ عدد حقن SQL الممكن كبير جدًا، و"إبداع" المهاجمين واسع كذلك. الطريقة الجيّدة هي تنظيف البيانات للتعرّف على ما يبدو شكل الإدخال الصحيح عليه، وتجاهل كلّ شيء لا يتوافق مع شكل ذلك الإدخال الصحيح. البيانات الرقمية هي الأسهل للتنظيف، لذا سنقوم بتغطية هذا أوّلًا. يمكن للرقم أن يحتوي على إشارة سالبة على يساره، أو أن يكون متبوعا بأرقام أخرى، وربّما يحتوي على فاصلة عشرية. هذا كلّ ما يمكن للبيانات الرقمية أن تبدو عليه، في Perl، ستبدو الشفرة التي تتحقق من البيانات الرقمية كالتالي: if($numericaluserinput !~ /^-?[0-9.]+$/) { # البيانات المُدخلة ليست رقمًا } من الصعب تخيّل أيّ حقنة خبيثة يمكنها أن تتخطى ما سبق. تنظيف المُدخلات النصّية أكثر صعوبة، لأنّه هناك العديد من الطرق لمحاولة إدخالها. يمكن للمهاجم أن يستخدم إشارات الاقتباس وغيرها بطرق "إبداعية" للقيام بالهجمات. في الواقع، محاولة إنشاء قائمة سوداء للحروف المُدخلة هو أمرٌ سيّء، لأنّه من السهل نسيان شيء مهم مثلًا. هناك طريقة أفضل، كما قمنا مع البيانات الرقمية، وهي تقييد مُدخلات المستخدم إلى قائمة بيضاء من الحروف فقط. كمثال، عناوين البريد الإلكتروني لا يجب أن تحتوي على شيء سوى الأرقام والحروف العادية وبعض الإشارات مثل @ و _ وعدا ذلك، يجب منع كلّ الحروف الأخرى. في لغة Perl، ستبدو الشفرة كالتالي: if($useremail ~= /^[0-9a-zA-Z\-_+.\@]$/) { # the user's email address is unacceptable } يمكن العثور على قوائم بيضاء للأنواع الأخرى من المُدخلات كذلك مثل اسم المستخدم وكلمة المرور.. إلخ. قد تكون القوائم البيضاء مصدر إزعاج لبعض المستخدمين. فربّما يكون هناك رموز معيّنة في بعض مربّعات الإدخال تكون غير مقبولة من طرفها مثلًا، ولكنّك بالطبع حرّ لتقوم بتعديل القوائم البيضاء حسب حاجتك، ولكن لا تنسى أن تقوم ببحث عن الرموز والمحارف التي تريد تمكينها للتأكّد من أنّه لا يمكن استخدامها في حقن SQL، فعندما تختار بين حماية الموقع وراحة المستخدم، حماية الموقع تأتي أوّلًا. تنظيف المُدخلات بواسطة القوائم البيضاء جيّد لأنّه سهل. إذا كنتَ مُدركًا بشكل صحيح للرموز والمحارف التي تقوم بتمكينها، فحينها سيكون هذا الحلّ كافيًا للتخليص من هجمات حقن SQL. الخطوة الرابعة: قبول المدخلات الخطيرة لا تنخدع بالعنوان! سنتحدّث فقط عن أهمّية عدم قبول المُدخلات الخطيرة. صحيحٌ أنّ القوائم البيضاء شديدة التقييد جيّدة من أجل الحماية في حال ما إذا كان تطبيقك يستطيع أن يتوافق مع تلك التقييدات على المستخدمين. ولكن في بعض الحالات، قد يكون من المهمّ لنموذجك الربحي الخاصّ بالتطبيق ألّا تقوم بفرض أيّ تقييدات على مُدخلات المستخدمين. في هذه الحالة، غالبًا ما تكون لغة البرمجة التي تستعملها في تطبيقك تحوي على مكتباتٍ تساعدك في تنظيف مُدخلات المستخدمين من الشفرات الخبيثة. كمثال، مكتبة Perl DBI تحوي طُرقًا متعددة لمنع مُدخلات المستخدمين من التعامل مع استعلام SQL بخارج المنطقة المخصصة لها: my $sql = "INSERT INTO user (username, email) VALUES (?, ?)"; my $handle = $dbh->prepare( $sql ); $handle->execute( $untrustedusername, $untrustedemail); في المثال السابق، تمّ استخدام إشارة ؟ كعناصر نائبة (placeholders). تقوم مكتبة Perl DBI باستبدال هذه الإشارات بالمتغيّرات الغير موثوقة والتي تمّ إدخالها من طرف المستخدم. ولكن أثناء القيام بهذا، تقوم مكتبة DBI بتقييد هذه المتغيرات وتجعلها تتعامل فقط مع الحقول المخصصة لها بجدول قاعدة البيانات. هناك مكتبات مشابهة باللغات البرمجية الأخرى، إمّا لتقييد مُدخلات المستخدم، أو لتجاهل البيانات في حال حاولت التعامل مع خارج الحقل المخصص لها. ميّزة هذه التقنية هي أنّك قادرٌ على إعطاء ثقتك بالأشخاص المطورين لتلك المكتبات، حيث أنّهم سيقومون بتطويرها، والحفاظ عليها بعيدة عن الثغرات الأمنية والمشاكل الخطيرة. ولكن عيب هذه التقنية هي أنّها أقل قابلية للقراءة البشرية، وهكذا ربّما تنسى استخدام المكتبة الصحيحة لحماية بعض من عمليات استعلام SQL الخاصّة بك. الخطوة الخامسة: خفف ضرر الهجمات الناجحة اعتمادًا على ماهيّة نموذج الأعمال الذي تقوم به بموقعك، فربّما تودّ القيام بإنشاء خطٍّ أخير للدفاع، شيء مستقل تمامًا عن مطوري تطبيقك. فبعد كلّ شيء، ربّما يستخدم واحدٌ منهم القوائم البيضاء الخاطئة في مكان ما، أو فشل باستخدام المكتبة الصحيحة لتنظيف المُدخلات. ثغرة واحدة فقط من هذا النوع قد تسبب في تحويل موقعك بأكمله إلى موقع قابل للاختراق عبر هجمات SQL. أولًا، يجب عليك أن تفترض أنّ المهاجمين نجحوا باختراق دفاعاتك ضدّ حقن SQL، وأنّهم حصلوا على الصلاحيات الكاملة لإدارة خادومك. إنهم يملكون الآلة الآن بالكامل، على الرغم من أنّك من يهتم بصيانتها وتطويرها. لتجنّب ذلك السقوط المروع، يجب على الخادوم نفسه أن يكون مضبوطًا داخل بيئة معزولة عن الشبكة، حيث يكون مستخدم الجذر على النظام غير قادر على الرؤية أو الوصول إلى أيّ أجزاء أخرى موجودة على خادومك. هذا النوع من الدفاع يدعى DMZ، وهو رائع للغاية، وهو كذلك خارج نطاق هذا الدرس. مهما كانت الطريقة التي تستخدمها لتأمين خادومك ضدّ مستخدم مهاجم نجح بالدخول بالفعل، فإنّه يجب عليك أن تقوم بإعداد نظام تنبيهات يقوم بإخطار مدراء النظام في حال حصول نشاط معيّن على الخادوم. هذه التنبيهات ستخبرك ما إذا تمّ اختراق التطبيق، وأنّه عليك عمل مراجعة سريع للشفرة البرمجية وللخادوم نفسه. دون هذه التنبيهات، سيكون المهاجم قادرًا على قضاء وقتٍ ممتع في محاولة اختراق الـDMZ الخاصّ بك دون أن تشعر، وربّما لا تشعر بتاتًا بما يفعله إلى حين أن يسرق جميع البطاقات الائتمانية التي ظننت أنّها كانت معزولة تمامًا عن الخادوم، في بيئةً كنت تظن أنّها منفصلة عن خادومك الرئيسي. الخطوة السادسة: وظف محترف حماية إذا كنتَ تقوم بإدارة تطبيق ويب دون الاستعانة بخبير حماية، فحينها أنت تسبح بالمياه الخطيرة. وإذا كنت ولسبب ما غير قادر على توظيف خبير حماية وأمان، فإنّه يجب عليك الاستعانة بالقوائم البيضاء لتنظيف مُدخلات المستخدمين إلى حين. من السهل تضمين واستخدام القوائم البيضاء. لا بأس من تقييد تجرية المستخدمين قليلًا في سبيل حماية خادومك والبيانات الثمينة الموجودة عليه. وبمجرّد أن تقوم بتوظيف شخص يفهم في مجال الحماية والأمان، فستكون بعدها قادرًا بشكل أفضل على حماية موقعك من هجمات حقن SQL و XSS وغيرها من الهجمات الخطيرة التي قد تصيب موقعك. ترجمة -وبتصرف- للمقال: How To Secure a Cloud Server Against SQL Injection.
تستغل هجمات حقن SQL البرمجة السيئة للشفرة الخاصّة بالبرمجيات. إنّها هجمات حيث يقوم المهاجمون بإرسال شفرة عبر واحدٍ من مربّعات الإدخال الموجودة على موقعك (أيّ مربّع)، عوضًا عن أن يرسل بياناتٍ عادية كنتَ تنوي استقبالها عبر مربّعات الإدخال تلك. تقوم تلك الشفرة المُدخلة بتنفيذ عمليات الاستعلام على قاعدة البيانات الخاصّة بموقعك بطريقةٍ لم تكن تتوقعها، أو تقوم بتحطيم تطبيق الويب الخاصّ بك وتقوم بتخريب خادومك السحابي. م السهل جدًا عمل هجمات حقن SQL ضدّ المواقع الغير مؤمّنة. وحراسة موقعك ضدّ هذه الهجمات قد يكون من أهمّ ما تقوم به منذ اليوم الأوّل. الخطوة الأولى: تعلم تمييز الشفرة المحتوية على ثغرات تأخذ هجمات SQL دومًا شكل سلسلة نصّية يتم إرسالها من طرف مستخدمٍ تتكون من قسمين. القسم الأول هو عبارة عن تخمين لكيفية تعطيل أمرٍ تحاول شفرتك المصدرية أن تقوم بتنفيذه بأمان; القسم الثاني هو الشفرة الخبيثة التي يريد المهاجم تنفيذها على خادومك. إليك مثالًا على سلسلة نصّية مصممة لاستغلال ثغرة ممكنة في الشفرة المصدرية لديك: x' AND user.email IS NULL; -- يبدو هذا كشيء قمتَ بكتابته بنفسك، وتلك هي النقطة. يأمل المستخدم المُخترِق أن تقوم بأخذ هذا السطر، وتقوم بتنفيذه بعملية استعلام SQL تبدو كالتالي: SELECT email, passwd FROM user WHERE email = 'x' AND user.email IS NULL; --'; لا يبدو أنّ هذا يقوم بالكثير حقًا، ولكن اعتمادًا على الطريقة التي سيستجيب بها تطبيقك إلى ما سبق، يمكن أن يوفّر هذا بعض المعلومات المهمّة للمُخترِق مثل اسم جدول قاعدة البيانات الذي تستعمله. بعد هذا، هناك المزيد من الهجمات التي يمكن للمهاجم أن يستخدمها لجلب المزيد من المعلومات، مثل أسماء المستخدمين وكلمات المرور. الفكرة الرئيسية التي يجب عليك فهمها هي أنّ الشفرة الخبيثة تحاول البحث عن ثغرة بعملية استعلام SQL التي يقوم بها تطبيقك لمحاولة استغلالها لجلب المعلومات أو إدراجها وتعديلها. لا تتطلب جميع هجمات حقن SQL إشارة الاقتباس المغلقة ('). إذا كانت شفرتك المصدرية تنفّذ عملية استعلامٍ متعلّقة برقم، فإنّك لن تقوم بالطبع بوضع تلك البيانات داخل إشارة اقتباس. وهذا يتركك عرضةً لهذا النوع من الهجمات: 2097 OR 1=1 يأمل المهاجم أن يقوم تطبيقك بعملية استعلام مشابهة للتالي: SELECT somedata FROM yourtable WHERE userid = 2097 OR 1=1; غالبًا ما تكون شفرتك البرمجية مصممة لتقوم بعملية الاستعلام السابقة لتعيد البيانات فقط في حال تطابق الـ userid مع المستخدم الصحيح. ولكنّ حقنة الـSQL تجعل عملية الاستعلام تقوم دومًا بإرجاع البيانات. النقطة ليست في سلوكٍ معيّن لأيّ حقنة SQL. الشيء الأكثر أهمّية من هذا كلّه هو القاعدة العامّة لجميع حقن SQL: محاولة لتخمين كيفية حذف جزء معيّن من عملية استعلام، وإضافة جزءٍ آخر إليها لم تكن تتوقعه. هذا هو توقيع جميع هجمات حقن SQL. وهذه هي طريقة محاربتها. الخطوة الثانية: اعثر على مدخلاتك أفضل طريقة لتعقّب جميع نقط إدخال حقن SQL الممكنة في شفرتك البرمجية ليس عبر النظر إلى حقول إدخال HTML. بالطبع يمكنك العثور على العديد من الثغرات الممكنة هناك، ولكن هناك طرقٌ أخرى يمكن من خلالها للمستخدم أن يقوم بإدخال البيانات، مثل عنوان الويب (URL)، أو عبر واحدةٍ من واجهات AJAX الخاصّة بك. أفضل مكان للبحث فيه عن الثغرات هو الشيء الذي يريد المخترقون اختراقه بنفسه; جملة استعلام SQL بنفسها. على الأغلب، فإنّك تقوم بتنفيذ جميع عمليات الاستعلام عن طريق الأمر الأساسي نفسه، وربّما أمران آخران أو أكثر قليلًا. فقط ابحث عن هذه الأوامر في شفرتك البرمجية وستجد جميع الثغرات الممكنة بشكلٍ سريع. كمثال، إذا كانت شفرتك البرمجية مكتوبة بـPerl، فإنّ جميع عمليات استعلام SQL الخاصّة بك ستبدو هكذا: $result = mysql_query($sql) في تلك الحالة، يمكنك العثور بسرعة على جميع الثغرات الممكنة بواسطة سطر الأوامر، عبر استخدام أمر شبيه بالتالي: $ grep -R mysql_query * الخطوة الثالثة: نظف مدخلاتك هناك العديد من التقنيات التي يستخدمها الناس لمنع هجمات حقن SQL، ولكن خطّ دفاعك الأمامي يجب أن يكون تنظيف جميع مُدخلات المستخدم من أيّ شفرة خبيثة مشبوهة. يجب ألّا تعتقد بتاتًا أنّ المستخدم سيقوم بإدخال البيانات بالطريقة التي تريدها. في الواقع، يجب عليك أن تفترض العكس - أنّهم سيقومون بإدخال الشفرات الخبيثة في كلّ مكانٍ ممكن في موقعك. تنظيف المُدخلات يعني أنّه يجب اختبار جميع مُدخلات المستخدم للتأكّد من أنّها تحتوي فقط مُدخلات آمنة، مُدخلات لا يمكن استخدامها بتاتًا في شنّ هجوم. المُدخلات التي سيتم إدخالها من طرف المستخدم إلى خادوم SQL الخاصّ بك ستكون على شكلَين: كرقم، مثل 2097. كسلسلة (string)، مثل اسم المستخدم، كلمة المرور أو البريد الإلكتروني. تتوقّع شفرتك البرمجية دومًا مُدخَلًا واحدًا من هذين الشكلين. في الأمثلة التي ذكرناها ببداية هذا المقال، كان المثال الأوّل عبارة عن سلسلة نصّية، وكان المثال الثاني عبارةً عن رقم. هناك أيضًا طريقتان لتنظيف البيانات: طريقة جيدة وطريقة سيئة. الطريقة السيئة هي التحقق من وجود حقن SQL الممكنة. السبب في كونها سيئة هو لأنّ عدد حقن SQL الممكن كبير جدًا، و"إبداع" المهاجمين واسع كذلك. الطريقة الجيّدة هي تنظيف البيانات للتعرّف على ما يبدو شكل الإدخال الصحيح عليه، وتجاهل كلّ شيء لا يتوافق مع شكل ذلك الإدخال الصحيح. البيانات الرقمية هي الأسهل للتنظيف، لذا سنقوم بتغطية هذا أوّلًا. يمكن للرقم أن يحتوي على إشارة سالبة على يساره، أو أن يكون متبوعا بأرقام أخرى، وربّما يحتوي على فاصلة عشرية. هذا كلّ ما يمكن للبيانات الرقمية أن تبدو عليه، في Perl، ستبدو الشفرة التي تتحقق من البيانات الرقمية كالتالي: if($numericaluserinput !~ /^-?[0-9.]+$/) { # البيانات المُدخلة ليست رقمًا } من الصعب تخيّل أيّ حقنة خبيثة يمكنها أن تتخطى ما سبق. تنظيف المُدخلات النصّية أكثر صعوبة، لأنّه هناك العديد من الطرق لمحاولة إدخالها. يمكن للمهاجم أن يستخدم إشارات الاقتباس وغيرها بطرق "إبداعية" للقيام بالهجمات. في الواقع، محاولة إنشاء قائمة سوداء للحروف المُدخلة هو أمرٌ سيّء، لأنّه من السهل نسيان شيء مهم مثلًا. هناك طريقة أفضل، كما قمنا مع البيانات الرقمية، وهي تقييد مُدخلات المستخدم إلى قائمة بيضاء من الحروف فقط. كمثال، عناوين البريد الإلكتروني لا يجب أن تحتوي على شيء سوى الأرقام والحروف العادية وبعض الإشارات مثل @ و _ وعدا ذلك، يجب منع كلّ الحروف الأخرى. في لغة Perl، ستبدو الشفرة كالتالي: if($useremail ~= /^[0-9a-zA-Z\-_+.\@]$/) { # the user's email address is unacceptable } يمكن العثور على قوائم بيضاء للأنواع الأخرى من المُدخلات كذلك مثل اسم المستخدم وكلمة المرور.. إلخ. قد تكون القوائم البيضاء مصدر إزعاج لبعض المستخدمين. فربّما يكون هناك رموز معيّنة في بعض مربّعات الإدخال تكون غير مقبولة من طرفها مثلًا، ولكنّك بالطبع حرّ لتقوم بتعديل القوائم البيضاء حسب حاجتك، ولكن لا تنسى أن تقوم ببحث عن الرموز والمحارف التي تريد تمكينها للتأكّد من أنّه لا يمكن استخدامها في حقن SQL، فعندما تختار بين حماية الموقع وراحة المستخدم، حماية الموقع تأتي أوّلًا. تنظيف المُدخلات بواسطة القوائم البيضاء جيّد لأنّه سهل. إذا كنتَ مُدركًا بشكل صحيح للرموز والمحارف التي تقوم بتمكينها، فحينها سيكون هذا الحلّ كافيًا للتخليص من هجمات حقن SQL. الخطوة الرابعة: قبول المدخلات الخطيرة لا تنخدع بالعنوان! سنتحدّث فقط عن أهمّية عدم قبول المُدخلات الخطيرة. صحيحٌ أنّ القوائم البيضاء شديدة التقييد جيّدة من أجل الحماية في حال ما إذا كان تطبيقك يستطيع أن يتوافق مع تلك التقييدات على المستخدمين. ولكن في بعض الحالات، قد يكون من المهمّ لنموذجك الربحي الخاصّ بالتطبيق ألّا تقوم بفرض أيّ تقييدات على مُدخلات المستخدمين. في هذه الحالة، غالبًا ما تكون لغة البرمجة التي تستعملها في تطبيقك تحوي على مكتباتٍ تساعدك في تنظيف مُدخلات المستخدمين من الشفرات الخبيثة. كمثال، مكتبة Perl DBI تحوي طُرقًا متعددة لمنع مُدخلات المستخدمين من التعامل مع استعلام SQL بخارج المنطقة المخصصة لها: my $sql = "INSERT INTO user (username, email) VALUES (?, ?)"; my $handle = $dbh->prepare( $sql ); $handle->execute( $untrustedusername, $untrustedemail); في المثال السابق، تمّ استخدام إشارة ؟ كعناصر نائبة (placeholders). تقوم مكتبة Perl DBI باستبدال هذه الإشارات بالمتغيّرات الغير موثوقة والتي تمّ إدخالها من طرف المستخدم. ولكن أثناء القيام بهذا، تقوم مكتبة DBI بتقييد هذه المتغيرات وتجعلها تتعامل فقط مع الحقول المخصصة لها بجدول قاعدة البيانات. هناك مكتبات مشابهة باللغات البرمجية الأخرى، إمّا لتقييد مُدخلات المستخدم، أو لتجاهل البيانات في حال حاولت التعامل مع خارج الحقل المخصص لها. ميّزة هذه التقنية هي أنّك قادرٌ على إعطاء ثقتك بالأشخاص المطورين لتلك المكتبات، حيث أنّهم سيقومون بتطويرها، والحفاظ عليها بعيدة عن الثغرات الأمنية والمشاكل الخطيرة. ولكن عيب هذه التقنية هي أنّها أقل قابلية للقراءة البشرية، وهكذا ربّما تنسى استخدام المكتبة الصحيحة لحماية بعض من عمليات استعلام SQL الخاصّة بك. الخطوة الخامسة: خفف ضرر الهجمات الناجحة اعتمادًا على ماهيّة نموذج الأعمال الذي تقوم به بموقعك، فربّما تودّ القيام بإنشاء خطٍّ أخير للدفاع، شيء مستقل تمامًا عن مطوري تطبيقك. فبعد كلّ شيء، ربّما يستخدم واحدٌ منهم القوائم البيضاء الخاطئة في مكان ما، أو فشل باستخدام المكتبة الصحيحة لتنظيف المُدخلات. ثغرة واحدة فقط من هذا النوع قد تسبب في تحويل موقعك بأكمله إلى موقع قابل للاختراق عبر هجمات SQL. أولًا، يجب عليك أن تفترض أنّ المهاجمين نجحوا باختراق دفاعاتك ضدّ حقن SQL، وأنّهم حصلوا على الصلاحيات الكاملة لإدارة خادومك. إنهم يملكون الآلة الآن بالكامل، على الرغم من أنّك من يهتم بصيانتها وتطويرها. لتجنّب ذلك السقوط المروع، يجب على الخادوم نفسه أن يكون مضبوطًا داخل بيئة معزولة عن الشبكة، حيث يكون مستخدم الجذر على النظام غير قادر على الرؤية أو الوصول إلى أيّ أجزاء أخرى موجودة على خادومك. هذا النوع من الدفاع يدعى DMZ، وهو رائع للغاية، وهو كذلك خارج نطاق هذا الدرس. مهما كانت الطريقة التي تستخدمها لتأمين خادومك ضدّ مستخدم مهاجم نجح بالدخول بالفعل، فإنّه يجب عليك أن تقوم بإعداد نظام تنبيهات يقوم بإخطار مدراء النظام في حال حصول نشاط معيّن على الخادوم. هذه التنبيهات ستخبرك ما إذا تمّ اختراق التطبيق، وأنّه عليك عمل مراجعة سريع للشفرة البرمجية وللخادوم نفسه. دون هذه التنبيهات، سيكون المهاجم قادرًا على قضاء وقتٍ ممتع في محاولة اختراق الـDMZ الخاصّ بك دون أن تشعر، وربّما لا تشعر بتاتًا بما يفعله إلى حين أن يسرق جميع البطاقات الائتمانية التي ظننت أنّها كانت معزولة تمامًا عن الخادوم، في بيئةً كنت تظن أنّها منفصلة عن خادومك الرئيسي. الخطوة السادسة: وظف محترف حماية إذا كنتَ تقوم بإدارة تطبيق ويب دون الاستعانة بخبير حماية، فحينها أنت تسبح بالمياه الخطيرة. وإذا كنت ولسبب ما غير قادر على توظيف خبير حماية وأمان، فإنّه يجب عليك الاستعانة بالقوائم البيضاء لتنظيف مُدخلات المستخدمين إلى حين. من السهل تضمين واستخدام القوائم البيضاء. لا بأس من تقييد تجرية المستخدمين قليلًا في سبيل حماية خادومك والبيانات الثمينة الموجودة عليه. وبمجرّد أن تقوم بتوظيف شخص يفهم في مجال الحماية والأمان، فستكون بعدها قادرًا بشكل أفضل على حماية موقعك من هجمات حقن SQL و XSS وغيرها من الهجمات الخطيرة التي قد تصيب موقعك. ترجمة -وبتصرف- للمقال: How To Secure a Cloud Server Against SQL Injection. -
.png.4260f7b02f0c4027714bf3777be59fed.png) تعرّفنا في الدروس السابقة على إنشاء الجدول في قاعدة البيانات وإضافة البيانات إليه والتعامل معها من حيث التعديل والإضافة. سوف نبدأ في هذا المقال بالتعرف على أشهر جمل لغة الاستعلام البنائية، وهي جملة الاستعلام Select Statement، حيث سنتكلم عن كيفية كتابة جملة الاستعلام، وأشكالها، وكيفية ترشيح البيانات وتحديد الأعمدة التي نريدها وغيرها من المواضيع. جملة الاستعلام تجلب جملة الاستعلام SELECT بيانات جدول أو أكثر بعد الاستعلام عن وجود هذه الجداول في قاعدة البيانات، ونقصد بالاستعلام هنا ماذا نريد؟ ومن أين؟ ماذا نريد من أعمدة وسجلات، ومن أين، أي من أي الجداول نأتي بالمعلومات. البيانات الناتجة عن تنفيذ جملة الاستعلام تسمى مجموعة البيانات الناتجة Result Data-Set. الصيغة العامة لجملة الاستعلام SELECT column1, column2, ... FROM table_name [WHERE where_condition] [GROUP BY group_by_expression] [ORODER BY order_by_expression]; في بداية كل جملة استعلام نكتب كلمة SELECT (جمل SQL غير حساسة لحالة الأحرف) ومن ثم نُتبعها بأسماء الأعمدة التي نريد الاستعلام عنها، أو نستبدل أسماء الأعمدة برمز * والذي يعني كل الأعمدة، ثم نكتب كلمة From والتي يليها اسم الجدول أو أسماء الجداول التي تحتوي على البيانات التي نريدها. ما بين الأقواس المعكوفة هي جمل إضافية تقوم بمهام معينة في جملة الاستعلام وهي كالتالي: Where: هي جملة الشرط والتي ترشّح البيانات بناءً على الشرط الموجود بعدها. Group By: تجمّع البيانات الناتجة من تنفيذ جملة الاستعلام بناءً على جملة التجميع التي تليها. Order By: ترتّب البيانات تصاعديا أو تنازليا بناءً على جملة الترتيب التي تليها. سنتطرق لتفاصيل الجمل الإضافية في هذا المقال وفي مقالات قادمة. دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن مثال على جملة الاستعلام لو أردنا الاستعلام عن كافة البيانات الموجودة في جدول Persons والذي تكلمنا عنه في المقال السابق، ننفذ الجملة التالية: SELECT * FROM Persons; كما ذكرتُ سابقا، فإن * تعني عرض جميع البيانات، حيث ستُظهر كافة الأعمدة الموجودة في الجدول والسجلات التي يحتويها. وسيكون ناتج الجملة البيانات التالية: Person_ID First_Name Last_Name Age 101 Ibrahim Mohammed 21 102 Mohammed Khaled 25 103 Saleem Yaser 25 104 Aly Mohammed 25 105 Reem 25 لو أردنا أن نستعلم عن اسم الشخص الأول وعمره، نقوم بتنفيذ الجملة التالية: SELECT First_Name, Age FROM Persons; لاحظ أننا فصلنا بين الأعمدة التي نريد إظهاراها بفاصلة عادية ,، والعمود الأخير لا نكتب بعده فاصلة، بل كلمة From مباشر. وسيكون ناتج الجملة البيانات التالية: First_Name Age Ibrahim 21 Mohammed 25 Saleem 25 Aly 25 Reem 25 الاستعلام عن السجلات الفريدة في بيانات الجدول، ستجد في كثير من الأحيان أن هناك تكراراً للقيم في عمود ما، وقد تحتاج إلى الاستعلام عن القيم دون تكرار، فمثلا، في جدول الأشخاص Persons السابق، ستلاحظ أن عمود العمر Age يحتوي على 5 قيم، ولكن توجد 4 سجلات من نفس القيمة وهي 25، وهنا يأتي دور جملة الاستعلام الفريد DISTINCT Select. تُرجع جملة الاستعلام عن السجلّات الفريدة سجلات دون تكرار في القيم وصيغتها العامة: SELECT DISTINCT column1, column2, ... FROM table_name; لو نفذنا الجملة التالية: SELECT Age FROM Persons; سيكون الناتج: Age 21 25 25 25 25 ولكن لو استخدمنا جملة الاستعلام عن السجلّات الفريدة SELECT DISTINCT Age FROM Persons; ستكون النتيجة كالتالي: Age 21 25 ترشيح السجلات لإجراء عملية ترشيح السجلات، سنضيف إلى جملة الاستعلام جملة شرطية تبدأ بالكلمة Where ويتبعها الشرط (أو مجموعة الشروط) الذي نريد والذي سيُرشِّح السجلات بحيث تبقى السجلات التي تحقق الشرط في مجموعة البيانات الراجعة، وتُستبعد السجلات التي لا تحقق الشرط. الصيغة العامة لجملة الاستعلام والتي تحتوي على شرط لترشيح السجلات: SELECT column1, column2, ... FROM table_name WHERE condition; أمثلة على ترشيح البيانات في جدول Persons الحصول على البيانات الكاملة للشخص الذي له Person_ID يساوي 101: SELECT * FROM Persons WHERE Person_ID = 101; الاستعلام عن أسماء الأشخاص الذين تساوي أعمارهم 25 سنة أو تزيد عليها: SELECT First_Name, Last_Name FROM Persons WHERE Age >= 25; الاستعلام عن الاسم الأول والعمر للأشخاص الذين ليس لديهم قيمة للعمود Last_Name وأعمارهم فوق 22: SELECT First_Name, Age FROM Persons WHERE Age > 22 AND Last_Name IS Null; عمليات المقارنة في جملة Where يلخص الجدول التالي العمليات التي من الممكن استخدامها في بناء شرط جملة Where: العمليّة الوصف مثال = يساوي Age = 20 <> لا يساوي (في بعض النظم تكتب != ) Age <> 20 > أكبر من Age > 20 < أصغر من Age < 20 >= أكبر من أو يساوي Age >= 20 <= أصغر من أو يساوي Age <= 20 BETWEEN … AND بين قيمتين أو يساويهما Age BETWEEN 20 AND 25 LIKE مطابقة نمط First_Name LIKE “%Ibr%” IN يوجد ضمن قيم معينة Age in (20,23,25) ملاحظة هامة: نستطيع الجمع بين أكثر من شرط في جملة Where وذلك باستخدام العمليات المنطقية NOT (للنفي)، AND (وجوب تحقّق جميع الشروط) أو OR (يكفي تحقّق شرط واحد من الشروط). ترتيب السجلات نستطيع الحصول على البيانات الراجعة مرتبة تصاعديا أو تنازليا بعد تنفيذ جملة الاستعلام، وذلك باستخدام جملة Order By. ترتّب الجملةُ السجلات تصاعديًّا وهو الخيار المبدئي، ولترتيبها تنازليًّا نستخدم الكلمة المحجوزة DESC، كما أنه يمكن الترتيب باستخدام عمود واحد أو أكثر. الصيغة العامة لجملة الاستعلام مع جملة الترتيب هي: SELECT column1, column2, ... FROM table_name ORDER BY column1, column2, ... ASC|DESC; فمثلا لو أردنا أن نستعلم عن كل البيانات من جدول Persons بحيث تكون البيانات مرتبة ترتيبا تصاعديا حسب عمود First_Name، نستخدم الجملة التالية: SELECT * FROM Persons ORDER BY First_Name; وستكون النتيجة: Person_ID First_Name Last_Name Age 104 Aly Mohammed 25 101 Ibrahim Mohammed 21 102 Mohammed Khaled 25 105 Reem 25 103 Saleem Yaser 25 في حال أردنا أن نرتب نفس البيانات بطريقة تنازلية نستخدم الجملة التالية: SELECT * FROM Persons ORDER BY First_Name DESC; وتكون نتيجة الاستعلام كالتالي: Person_ID First_Name Last_Name Age 103 Saleem Yaser 25 105 Reem 25 102 Mohammed Khaled 25 101 Ibrahim Mohammed 21 104 Aly Mohammed 25 تجميع البيانات باستخدام Group By: تُستخدم جملة تجميع البيانات غالبا مع دوال التجميع Aggregate Functions بهدف تجميع وترتيب البيانات الناتجة عن الاستعلام حسب عمود أو أكثر. سوف نتكلم عن جملة تجميع البيانات في مقال متقدم لعلاقته بموضوع الدوال الموجودة في SQL.
تعرّفنا في الدروس السابقة على إنشاء الجدول في قاعدة البيانات وإضافة البيانات إليه والتعامل معها من حيث التعديل والإضافة. سوف نبدأ في هذا المقال بالتعرف على أشهر جمل لغة الاستعلام البنائية، وهي جملة الاستعلام Select Statement، حيث سنتكلم عن كيفية كتابة جملة الاستعلام، وأشكالها، وكيفية ترشيح البيانات وتحديد الأعمدة التي نريدها وغيرها من المواضيع. جملة الاستعلام تجلب جملة الاستعلام SELECT بيانات جدول أو أكثر بعد الاستعلام عن وجود هذه الجداول في قاعدة البيانات، ونقصد بالاستعلام هنا ماذا نريد؟ ومن أين؟ ماذا نريد من أعمدة وسجلات، ومن أين، أي من أي الجداول نأتي بالمعلومات. البيانات الناتجة عن تنفيذ جملة الاستعلام تسمى مجموعة البيانات الناتجة Result Data-Set. الصيغة العامة لجملة الاستعلام SELECT column1, column2, ... FROM table_name [WHERE where_condition] [GROUP BY group_by_expression] [ORODER BY order_by_expression]; في بداية كل جملة استعلام نكتب كلمة SELECT (جمل SQL غير حساسة لحالة الأحرف) ومن ثم نُتبعها بأسماء الأعمدة التي نريد الاستعلام عنها، أو نستبدل أسماء الأعمدة برمز * والذي يعني كل الأعمدة، ثم نكتب كلمة From والتي يليها اسم الجدول أو أسماء الجداول التي تحتوي على البيانات التي نريدها. ما بين الأقواس المعكوفة هي جمل إضافية تقوم بمهام معينة في جملة الاستعلام وهي كالتالي: Where: هي جملة الشرط والتي ترشّح البيانات بناءً على الشرط الموجود بعدها. Group By: تجمّع البيانات الناتجة من تنفيذ جملة الاستعلام بناءً على جملة التجميع التي تليها. Order By: ترتّب البيانات تصاعديا أو تنازليا بناءً على جملة الترتيب التي تليها. سنتطرق لتفاصيل الجمل الإضافية في هذا المقال وفي مقالات قادمة. دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن مثال على جملة الاستعلام لو أردنا الاستعلام عن كافة البيانات الموجودة في جدول Persons والذي تكلمنا عنه في المقال السابق، ننفذ الجملة التالية: SELECT * FROM Persons; كما ذكرتُ سابقا، فإن * تعني عرض جميع البيانات، حيث ستُظهر كافة الأعمدة الموجودة في الجدول والسجلات التي يحتويها. وسيكون ناتج الجملة البيانات التالية: Person_ID First_Name Last_Name Age 101 Ibrahim Mohammed 21 102 Mohammed Khaled 25 103 Saleem Yaser 25 104 Aly Mohammed 25 105 Reem 25 لو أردنا أن نستعلم عن اسم الشخص الأول وعمره، نقوم بتنفيذ الجملة التالية: SELECT First_Name, Age FROM Persons; لاحظ أننا فصلنا بين الأعمدة التي نريد إظهاراها بفاصلة عادية ,، والعمود الأخير لا نكتب بعده فاصلة، بل كلمة From مباشر. وسيكون ناتج الجملة البيانات التالية: First_Name Age Ibrahim 21 Mohammed 25 Saleem 25 Aly 25 Reem 25 الاستعلام عن السجلات الفريدة في بيانات الجدول، ستجد في كثير من الأحيان أن هناك تكراراً للقيم في عمود ما، وقد تحتاج إلى الاستعلام عن القيم دون تكرار، فمثلا، في جدول الأشخاص Persons السابق، ستلاحظ أن عمود العمر Age يحتوي على 5 قيم، ولكن توجد 4 سجلات من نفس القيمة وهي 25، وهنا يأتي دور جملة الاستعلام الفريد DISTINCT Select. تُرجع جملة الاستعلام عن السجلّات الفريدة سجلات دون تكرار في القيم وصيغتها العامة: SELECT DISTINCT column1, column2, ... FROM table_name; لو نفذنا الجملة التالية: SELECT Age FROM Persons; سيكون الناتج: Age 21 25 25 25 25 ولكن لو استخدمنا جملة الاستعلام عن السجلّات الفريدة SELECT DISTINCT Age FROM Persons; ستكون النتيجة كالتالي: Age 21 25 ترشيح السجلات لإجراء عملية ترشيح السجلات، سنضيف إلى جملة الاستعلام جملة شرطية تبدأ بالكلمة Where ويتبعها الشرط (أو مجموعة الشروط) الذي نريد والذي سيُرشِّح السجلات بحيث تبقى السجلات التي تحقق الشرط في مجموعة البيانات الراجعة، وتُستبعد السجلات التي لا تحقق الشرط. الصيغة العامة لجملة الاستعلام والتي تحتوي على شرط لترشيح السجلات: SELECT column1, column2, ... FROM table_name WHERE condition; أمثلة على ترشيح البيانات في جدول Persons الحصول على البيانات الكاملة للشخص الذي له Person_ID يساوي 101: SELECT * FROM Persons WHERE Person_ID = 101; الاستعلام عن أسماء الأشخاص الذين تساوي أعمارهم 25 سنة أو تزيد عليها: SELECT First_Name, Last_Name FROM Persons WHERE Age >= 25; الاستعلام عن الاسم الأول والعمر للأشخاص الذين ليس لديهم قيمة للعمود Last_Name وأعمارهم فوق 22: SELECT First_Name, Age FROM Persons WHERE Age > 22 AND Last_Name IS Null; عمليات المقارنة في جملة Where يلخص الجدول التالي العمليات التي من الممكن استخدامها في بناء شرط جملة Where: العمليّة الوصف مثال = يساوي Age = 20 <> لا يساوي (في بعض النظم تكتب != ) Age <> 20 > أكبر من Age > 20 < أصغر من Age < 20 >= أكبر من أو يساوي Age >= 20 <= أصغر من أو يساوي Age <= 20 BETWEEN … AND بين قيمتين أو يساويهما Age BETWEEN 20 AND 25 LIKE مطابقة نمط First_Name LIKE “%Ibr%” IN يوجد ضمن قيم معينة Age in (20,23,25) ملاحظة هامة: نستطيع الجمع بين أكثر من شرط في جملة Where وذلك باستخدام العمليات المنطقية NOT (للنفي)، AND (وجوب تحقّق جميع الشروط) أو OR (يكفي تحقّق شرط واحد من الشروط). ترتيب السجلات نستطيع الحصول على البيانات الراجعة مرتبة تصاعديا أو تنازليا بعد تنفيذ جملة الاستعلام، وذلك باستخدام جملة Order By. ترتّب الجملةُ السجلات تصاعديًّا وهو الخيار المبدئي، ولترتيبها تنازليًّا نستخدم الكلمة المحجوزة DESC، كما أنه يمكن الترتيب باستخدام عمود واحد أو أكثر. الصيغة العامة لجملة الاستعلام مع جملة الترتيب هي: SELECT column1, column2, ... FROM table_name ORDER BY column1, column2, ... ASC|DESC; فمثلا لو أردنا أن نستعلم عن كل البيانات من جدول Persons بحيث تكون البيانات مرتبة ترتيبا تصاعديا حسب عمود First_Name، نستخدم الجملة التالية: SELECT * FROM Persons ORDER BY First_Name; وستكون النتيجة: Person_ID First_Name Last_Name Age 104 Aly Mohammed 25 101 Ibrahim Mohammed 21 102 Mohammed Khaled 25 105 Reem 25 103 Saleem Yaser 25 في حال أردنا أن نرتب نفس البيانات بطريقة تنازلية نستخدم الجملة التالية: SELECT * FROM Persons ORDER BY First_Name DESC; وتكون نتيجة الاستعلام كالتالي: Person_ID First_Name Last_Name Age 103 Saleem Yaser 25 105 Reem 25 102 Mohammed Khaled 25 101 Ibrahim Mohammed 21 104 Aly Mohammed 25 تجميع البيانات باستخدام Group By: تُستخدم جملة تجميع البيانات غالبا مع دوال التجميع Aggregate Functions بهدف تجميع وترتيب البيانات الناتجة عن الاستعلام حسب عمود أو أكثر. سوف نتكلم عن جملة تجميع البيانات في مقال متقدم لعلاقته بموضوع الدوال الموجودة في SQL. -
.png.3f630543aead1e7dd2c224b754e4a0f1.png) بعد أن تعلمنا كيفية إنشاء الجدول في قواعد البيانات، وتعرفنا على أنواع البيانات المستخدمة غالبا، وكيفية إضافة القيود على الجدول، سوف نبدأ في هذا المقال التعرف على جمل التعامل مع البيانات Data Manipulation Language، بحيث ستكون لدينا في نهاية المقال المعرفة اللازمة لإضافة سجل بيانات على الجدول، تعديل سجل بيانات، وحذف سجل بيانات وذلك باستخدام جمل SQL اللازمة لذلك:UPDATE،INSERT وDELETE. تغيّر جمل التعامل مع البيانات على البيانات في الجدول، لذلك فإن مسؤول قواعد البيانات لا بدّ أن يدير الصلاحيّات اللازمة للتغيير على البيانات بطريقة مُثلى. لابد التنويه إلى أن جمل التعامل مع البيانات (UPDATE،INSERT وDELETE) لا تُرجع بيانات أو مُخرجات عند تنفيذها، ولكن أغلب أنظمة إدارة قواعد البيانات تطبع لك ملخص السجلات التي تأثرت بتنفيذ الجمل السابقة. هيكلية الجدول قبل البدء بشرح جمل التعامل مع البيانات ومعرفة كيفية تنفيذها، لابد أن تكون لدينا المعرفة الكاملة بهيكلية الجدول الذي نريد إضافة سجل إليه أو تعديله أو الحذف منه، والتعرف على هيكلية الجدول يتضمن: معرفة ترتيب الأعمدة الموجودة في الجدول، معرفة أسماء الأعمدة، معرفة نوع البيانات الخاصة بكل عمود، التعرف على الأعمدة المطبق عليها قيود ومعرفة هذه القيود وطبيعتها، معرفة القيم المبدئية إذا وجدت. تُقدم أغلب نظم إدارة قواعد البيانات الأمر اللازم لمعرفة هيكلية الجدول، والصيغة العامة لهذا الأمر تكون كالتالي: DESCRIBE table_name; أو تكون بالصيغة التالية: DESC table_name; دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن جُملة إضافة السجلات توجد طريقتان لإضافة سجلات البيانات على الجدول في قاعدة البيانات، الأولى تتضمن كتابة أسماء الأعمدة التي نريد إعطاءها قيمًا بالإضافة للقيم نفسها التي نريد حفظها، وتسمى هذه الطريقة الإضافة بأسماء الأعمدة، والطريقة الثانية، في حال أردنا أن نضيف بيانات لكل الأعمدة في الجدول بنفس الترتيب الموجود في الجدول، فهنا لا نكتب أسماء الأعمدة، وتسمى هذه الطريقة الإضافة بمواقع الأعمدة. الصيغة العامة للطريقة الأولى: INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...); الصيغة العامة للطريقة الثانية: INSERT INTO table_name VALUES (value1, value2, value3, ...); لنفترض وجود جدول Persons بالهيكلية والبيانات التالية: Person_ID First_Name Last_Name Age 101 Ibrahim Mohammed 31 102 Mohammed Khaled 25 لإضافة سجل إلى هذا الجدول نستخدم الجملة التالية: INSERT INTO Persons VALUES (103, 'Saleem', 'Yaser',20); ملاحظة: تُكتَب النصوص في بعض أنظمة قواعد البيانات بين علامتي التنصيص المزدوجة. فمثلا لكتابة اسم Ibrahim في جملة الإضافة نكتبها هكذا "Ibrahim"، بينما توجد أنظمة أخرى تعتمد التعامل مع النصوص بين علامتي تنصيص منفردة، هكذا 'Ibrahim'. في جملة إضافة السجل السابقة لم نذكر اسم أي من الأعمدة، لأننا أدخلنا قيمًا لكل الأعمدة. القيمة الأولى (103) هي للعمود الأول (Person_ID) والثانية ('Saleem') للعمود الثاني (First_Name) وهكذا. ولكن في بعض الحالات لا نضيف السجل بهذه الطريقة، ففي كثير من الأحيان نحتاج إلى إضافة قيم لأعمدة معينة. مثال على تحديد الأعمدة الأعمدة التي يكون عليها قيد مفتاح رئيسي غالبا لا تُدخَل قيم إليها في جمل الإضافة، ويُستخدم بدلاً لذلك طرق لتوليد قيم لها مثل طريقة جعل العمود (ذي النوع الرقمي) Auto Increment الذي يزيد آخر رقم في العمود بالعدد واحد ثم يستخدمه للعمود الذي يوجد عليه المفتاح الرئيسي. في هذه الحالة تكون جملة الإضافة بالصيغة التالية: INSERT INTO Persons (first_name, last_name, age) VALUES ('Aly',Mohammed',25); ويصبح الجدول بعد تنفيذ الجملتيْن السابقتيْن كالتالي: Person_ID First_Name Last_Name Age 101 Ibrahim Mohammed 31 102 Mohammed Khaled 25 103 Saleem Yaser 20 104 Aly Mohanmmed 25 نصيحة عملية: يُفضل أن تعتمد جمل الإضافة باستخدام أسماء الأعمدة وذلك لتجنب ظهور أخطاء عند تغيير هيكلية الجدول. القيم الفارغة لو افترضنا وجود قيد العمود غير الفارغ على الأعمدة First_Name وAge مع وجود قيد المفتاح الرئيسي على العمود Person_Id وخاصية Auto Increment عليه، فإن أي جملة إضافة لا تشتمل على قيم ل First_Name أو Age سوف تُظهِر خطأ عند تنفيذها، ولكن لأننا لم نضف قيد العمود غير الفارغ على عمود Last_Name، فإننا نستطيع تجاهل هذا العمود عند الإضافة كالتالي: INSERT INTO Persons (first_name, age) VALUES ('Reem', 20); تصبح البيانات في الجدول كالتالي عند تنفيذ الجملة السابقة: Person_ID First_Name Last_Name Age 101 Ibrahim Mohammed 31 102 Mohammed Khaled 25 103 Saleem Yaser 20 104 Aly Mohanmmed 25 105 Reem 20 من المهم فهم طبيعة القيم الفارغة Null في جداول قواعد البيانات، حيث إنها تختلف عن قيمة الصفر أو القيم النصية "". القيم الفارغة هي التي تُركت بدون اعتبار عند إضافة السجل أو تعديله، كما أن القيم الفارغة لا تخضع للفحص أو المقارنة باستخدام عمليات مثل = > < <>؛ ونستخدم بدلا منها عمليات IS NULL أو IS NOT NULL (هذه النقطة سوف نشرحها في درس جملة الاستعلام). جملة تعديل السجل نستخدم جملة تعديل السجل لإجراء عملية تغيير لقيم الأعمدة في سجل معين أو مجموعة سجلات أو على الجدول بأكمله. الصيغة العامة لجملة تعديل السجل كالتالي: UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition; ملاحظات هامة: في حالة تعديل أكثر من عمود، يجب وضع فاصلة بين القيم الجديدة للأعمدة. تُمثل column1وcolumn2 أسماء الأعمدة التي نريد تغيير قيمها، وتمثل value1 و value2 القيم الجديدة للأعمدة السابقة بالترتيب. نستطيع التعديل على أكثر من عمود في نفس جملة التعديل. لا بد من الحذر والانتباه الشديديْن عند تنفيذ جملة التعديل، حيث إن جملة الشرط (WHERE condition) تحدد السجلات التي سيُعدَّل عليها، وفي حالة عدم وجود جملة الشرط، فإن جميع السجلات في الجدول ستدخل في العملية. تعديل سجل واحد لتعديل سجل واحد، يجب أن نُحدد الشرط الذي يميز هذا السجل على نحو فريد في جملة الشرط، وغالبا يُستخدَم عمود قيد المفتاح الرئيسي في الجدول. فمثلا، إذا أردنا أن نُعدل قيمة العمر Age من 31 إلى 21 للشخص صاحب الرقم 101 في جدول Persons ننفذ الجملة التالية: UPDATE Persons SET Age = 21 WHERE Person_Id = 101; ويصبح السجل بالقيم التالية: Person_ID First_Name Last_Name Age 101 Ibrahim Mohammed 21 لاحظ أننا في جملة الشرط استخدمنا عملية المقارنة = لتحديد رقم Person_Id، وهنا يجب أن ننوه أننا نستطيع استخدام جميع عمليات المقارنة في جملة الشرط بشرط أن تكون منطقية ومكتوبة بطريقة صحيحة، فمثلا، لو أردنا أن نُعدل جميع أعمار الأشخاص الذين أعمارهم 20 أو أقل، لتصبح 25 ننفذ الجملة التالية: UPDATE Persons SET Age = 25 WHERE Age <= 20; السجلات التي لها القيمة 103 و105 في العمود Person_Id هي التي ستتأثر بالجملة السابقة عند تنفيذها، وتصبح البيانات في الجدول على النحو التالي: Person_ID First_Name Last_Name Age 101 Ibrahim Mohammed 21 102 Mohammed Khaled 25 103 Saleem Yaser 25 104 Aly Mohanmmed 25 105 Reem 25 جملة حذف السجل تُستخدَم جملة الحذف لإجراء عملية مسح بيانات موجودة في جدول معين وتتحكّم فيها جملة الشرط والتي تحدد السجل أو السجلات التي ستُحذَف. الصيغة العامة لجملة الحذف DELETE FROM table_name WHERE condition; لابد من الانتباه عند تنفيذ جملة الحذف، حيث إنه في حالة عدم تحديد جملة الشرط، فإن كل البيانات في الجدول ستُحذَف. حذف سجل واحد لحذف السجل الخاص بالشخص الذي رقمه 103 ننفذ الجملة التالية: DELETE FROM Persons WHERE Person_Id = 103; لحذف السجل الخاص بالشخص ذي القيمة الفارغة في الحقل Last_Name ننفذ الجملة التالية: DELETE FROM Persons WHERE Last_Name IS NULL; حذف بيانات الجدول لحذف البيانات بالكامل من الجدول Persons ننفذ إحدى الجملتيْن التاليّتيْن: DELETE FROM Persons; أو DELETE * FROM Persons; ملاحظة: العلامة * تعني جميع السجلات.
بعد أن تعلمنا كيفية إنشاء الجدول في قواعد البيانات، وتعرفنا على أنواع البيانات المستخدمة غالبا، وكيفية إضافة القيود على الجدول، سوف نبدأ في هذا المقال التعرف على جمل التعامل مع البيانات Data Manipulation Language، بحيث ستكون لدينا في نهاية المقال المعرفة اللازمة لإضافة سجل بيانات على الجدول، تعديل سجل بيانات، وحذف سجل بيانات وذلك باستخدام جمل SQL اللازمة لذلك:UPDATE،INSERT وDELETE. تغيّر جمل التعامل مع البيانات على البيانات في الجدول، لذلك فإن مسؤول قواعد البيانات لا بدّ أن يدير الصلاحيّات اللازمة للتغيير على البيانات بطريقة مُثلى. لابد التنويه إلى أن جمل التعامل مع البيانات (UPDATE،INSERT وDELETE) لا تُرجع بيانات أو مُخرجات عند تنفيذها، ولكن أغلب أنظمة إدارة قواعد البيانات تطبع لك ملخص السجلات التي تأثرت بتنفيذ الجمل السابقة. هيكلية الجدول قبل البدء بشرح جمل التعامل مع البيانات ومعرفة كيفية تنفيذها، لابد أن تكون لدينا المعرفة الكاملة بهيكلية الجدول الذي نريد إضافة سجل إليه أو تعديله أو الحذف منه، والتعرف على هيكلية الجدول يتضمن: معرفة ترتيب الأعمدة الموجودة في الجدول، معرفة أسماء الأعمدة، معرفة نوع البيانات الخاصة بكل عمود، التعرف على الأعمدة المطبق عليها قيود ومعرفة هذه القيود وطبيعتها، معرفة القيم المبدئية إذا وجدت. تُقدم أغلب نظم إدارة قواعد البيانات الأمر اللازم لمعرفة هيكلية الجدول، والصيغة العامة لهذا الأمر تكون كالتالي: DESCRIBE table_name; أو تكون بالصيغة التالية: DESC table_name; دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن جُملة إضافة السجلات توجد طريقتان لإضافة سجلات البيانات على الجدول في قاعدة البيانات، الأولى تتضمن كتابة أسماء الأعمدة التي نريد إعطاءها قيمًا بالإضافة للقيم نفسها التي نريد حفظها، وتسمى هذه الطريقة الإضافة بأسماء الأعمدة، والطريقة الثانية، في حال أردنا أن نضيف بيانات لكل الأعمدة في الجدول بنفس الترتيب الموجود في الجدول، فهنا لا نكتب أسماء الأعمدة، وتسمى هذه الطريقة الإضافة بمواقع الأعمدة. الصيغة العامة للطريقة الأولى: INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...); الصيغة العامة للطريقة الثانية: INSERT INTO table_name VALUES (value1, value2, value3, ...); لنفترض وجود جدول Persons بالهيكلية والبيانات التالية: Person_ID First_Name Last_Name Age 101 Ibrahim Mohammed 31 102 Mohammed Khaled 25 لإضافة سجل إلى هذا الجدول نستخدم الجملة التالية: INSERT INTO Persons VALUES (103, 'Saleem', 'Yaser',20); ملاحظة: تُكتَب النصوص في بعض أنظمة قواعد البيانات بين علامتي التنصيص المزدوجة. فمثلا لكتابة اسم Ibrahim في جملة الإضافة نكتبها هكذا "Ibrahim"، بينما توجد أنظمة أخرى تعتمد التعامل مع النصوص بين علامتي تنصيص منفردة، هكذا 'Ibrahim'. في جملة إضافة السجل السابقة لم نذكر اسم أي من الأعمدة، لأننا أدخلنا قيمًا لكل الأعمدة. القيمة الأولى (103) هي للعمود الأول (Person_ID) والثانية ('Saleem') للعمود الثاني (First_Name) وهكذا. ولكن في بعض الحالات لا نضيف السجل بهذه الطريقة، ففي كثير من الأحيان نحتاج إلى إضافة قيم لأعمدة معينة. مثال على تحديد الأعمدة الأعمدة التي يكون عليها قيد مفتاح رئيسي غالبا لا تُدخَل قيم إليها في جمل الإضافة، ويُستخدم بدلاً لذلك طرق لتوليد قيم لها مثل طريقة جعل العمود (ذي النوع الرقمي) Auto Increment الذي يزيد آخر رقم في العمود بالعدد واحد ثم يستخدمه للعمود الذي يوجد عليه المفتاح الرئيسي. في هذه الحالة تكون جملة الإضافة بالصيغة التالية: INSERT INTO Persons (first_name, last_name, age) VALUES ('Aly',Mohammed',25); ويصبح الجدول بعد تنفيذ الجملتيْن السابقتيْن كالتالي: Person_ID First_Name Last_Name Age 101 Ibrahim Mohammed 31 102 Mohammed Khaled 25 103 Saleem Yaser 20 104 Aly Mohanmmed 25 نصيحة عملية: يُفضل أن تعتمد جمل الإضافة باستخدام أسماء الأعمدة وذلك لتجنب ظهور أخطاء عند تغيير هيكلية الجدول. القيم الفارغة لو افترضنا وجود قيد العمود غير الفارغ على الأعمدة First_Name وAge مع وجود قيد المفتاح الرئيسي على العمود Person_Id وخاصية Auto Increment عليه، فإن أي جملة إضافة لا تشتمل على قيم ل First_Name أو Age سوف تُظهِر خطأ عند تنفيذها، ولكن لأننا لم نضف قيد العمود غير الفارغ على عمود Last_Name، فإننا نستطيع تجاهل هذا العمود عند الإضافة كالتالي: INSERT INTO Persons (first_name, age) VALUES ('Reem', 20); تصبح البيانات في الجدول كالتالي عند تنفيذ الجملة السابقة: Person_ID First_Name Last_Name Age 101 Ibrahim Mohammed 31 102 Mohammed Khaled 25 103 Saleem Yaser 20 104 Aly Mohanmmed 25 105 Reem 20 من المهم فهم طبيعة القيم الفارغة Null في جداول قواعد البيانات، حيث إنها تختلف عن قيمة الصفر أو القيم النصية "". القيم الفارغة هي التي تُركت بدون اعتبار عند إضافة السجل أو تعديله، كما أن القيم الفارغة لا تخضع للفحص أو المقارنة باستخدام عمليات مثل = > < <>؛ ونستخدم بدلا منها عمليات IS NULL أو IS NOT NULL (هذه النقطة سوف نشرحها في درس جملة الاستعلام). جملة تعديل السجل نستخدم جملة تعديل السجل لإجراء عملية تغيير لقيم الأعمدة في سجل معين أو مجموعة سجلات أو على الجدول بأكمله. الصيغة العامة لجملة تعديل السجل كالتالي: UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition; ملاحظات هامة: في حالة تعديل أكثر من عمود، يجب وضع فاصلة بين القيم الجديدة للأعمدة. تُمثل column1وcolumn2 أسماء الأعمدة التي نريد تغيير قيمها، وتمثل value1 و value2 القيم الجديدة للأعمدة السابقة بالترتيب. نستطيع التعديل على أكثر من عمود في نفس جملة التعديل. لا بد من الحذر والانتباه الشديديْن عند تنفيذ جملة التعديل، حيث إن جملة الشرط (WHERE condition) تحدد السجلات التي سيُعدَّل عليها، وفي حالة عدم وجود جملة الشرط، فإن جميع السجلات في الجدول ستدخل في العملية. تعديل سجل واحد لتعديل سجل واحد، يجب أن نُحدد الشرط الذي يميز هذا السجل على نحو فريد في جملة الشرط، وغالبا يُستخدَم عمود قيد المفتاح الرئيسي في الجدول. فمثلا، إذا أردنا أن نُعدل قيمة العمر Age من 31 إلى 21 للشخص صاحب الرقم 101 في جدول Persons ننفذ الجملة التالية: UPDATE Persons SET Age = 21 WHERE Person_Id = 101; ويصبح السجل بالقيم التالية: Person_ID First_Name Last_Name Age 101 Ibrahim Mohammed 21 لاحظ أننا في جملة الشرط استخدمنا عملية المقارنة = لتحديد رقم Person_Id، وهنا يجب أن ننوه أننا نستطيع استخدام جميع عمليات المقارنة في جملة الشرط بشرط أن تكون منطقية ومكتوبة بطريقة صحيحة، فمثلا، لو أردنا أن نُعدل جميع أعمار الأشخاص الذين أعمارهم 20 أو أقل، لتصبح 25 ننفذ الجملة التالية: UPDATE Persons SET Age = 25 WHERE Age <= 20; السجلات التي لها القيمة 103 و105 في العمود Person_Id هي التي ستتأثر بالجملة السابقة عند تنفيذها، وتصبح البيانات في الجدول على النحو التالي: Person_ID First_Name Last_Name Age 101 Ibrahim Mohammed 21 102 Mohammed Khaled 25 103 Saleem Yaser 25 104 Aly Mohanmmed 25 105 Reem 25 جملة حذف السجل تُستخدَم جملة الحذف لإجراء عملية مسح بيانات موجودة في جدول معين وتتحكّم فيها جملة الشرط والتي تحدد السجل أو السجلات التي ستُحذَف. الصيغة العامة لجملة الحذف DELETE FROM table_name WHERE condition; لابد من الانتباه عند تنفيذ جملة الحذف، حيث إنه في حالة عدم تحديد جملة الشرط، فإن كل البيانات في الجدول ستُحذَف. حذف سجل واحد لحذف السجل الخاص بالشخص الذي رقمه 103 ننفذ الجملة التالية: DELETE FROM Persons WHERE Person_Id = 103; لحذف السجل الخاص بالشخص ذي القيمة الفارغة في الحقل Last_Name ننفذ الجملة التالية: DELETE FROM Persons WHERE Last_Name IS NULL; حذف بيانات الجدول لحذف البيانات بالكامل من الجدول Persons ننفذ إحدى الجملتيْن التاليّتيْن: DELETE FROM Persons; أو DELETE * FROM Persons; ملاحظة: العلامة * تعني جميع السجلات. -
 إنَّ osquery عبارة عن أداة أمنية مفتوحة المصدر دورها تحويل نظام تشغيل بأكمله إلى قاعدة بيانات ضخمة، مع جداول يُمكنك استعلامها باستعمال جمل مُشابهة لجمل SQL. يُمكنك بهذه الاستعلامات مراقبة صلاحيّة الملفات، الاطلاع على حالة وإعدادات الجدار الناري، القيام بتدقيقات أمنية على الخادوم الهدف وغير ذلك. التطبيق عابر للمنصّات مع دعم للنسخ الجديدة من macOS، Windows 10، CentOS وUbuntu. تُوصف رسميا بأنّها "إطار عمل يحتوي على مجموعة من الأدوات المبنية على SQL لمراقبة نظام التّشغيل والحصول على الإحصائيات" وقد كانت بداية الإطار من شركة Facebook. يُمكنك باستخدام osquery تنفيذ أوامر مثل select * from logged_in_users ; على الخادوم الخاصّ بك لتحصل على نتيجة مُشابهة لما يلي: +-----------+----------+-------+------------------+------------+------+ | type | user | tty | host | time | pid | +-----------+----------+-------+------------------+------------+------+ | login | LOGIN | ttyS0 | | 1483580429 | 1546 | | login | LOGIN | tty1 | | 1483580429 | 1549 | | user | root | pts/0 | 24.27.68.82 | 1483580584 | 1752 | | user | sammy | pts/1 | 11.11.11.11 | 1483580770 | 4057 | | boot_time | reboot | ~ | 4.4.0-57-generic | 1483580419 | 0 | | runlevel | runlevel | ~ | 4.4.0-57-generic | 1483580426 | 53 | +-----------+----------+-------+------------------+------------+------+ إن سرَّك ما سبق، فسيُعجبك استعمال osquery كأداة أمنية لمُراقبة النظام واستكشاف الوصول غير المُصرّح له على خادومك الخاصّ. يُوفّر تنصيب osquery ما يلي من المكونات: osqueryi: صدفة osquery التفاعليّة، للقيام باستعلامات ظرفيّة. osqueryd: عفريت (daemon) لتوقيت وتشغيل الاستعلامات في الخلفيّة. osqueryctl: سكربت مُساعد لاختبار نشرِِ (deployment) أو إعدادِِ لـosquery. يُمكن أن يُستعمَل كذلك عوضا عن مُدير خدمات نظام التّشغيل لتشغيل/إيقاف/إعادة تشغيل osqueryd. أداتا osqueryi و osqueryd مُستقلّتان عن بعضهما. إذ لا يحتاجان إلى التواصل بينهما. ولا يتواصلان، ويُمكنك استعمال الواحدة دون الأخرى. معظم المعامِلات والخيارات المطلوبة لتشغيل كل واحدة هي نفسها بين الأداتين، ويُمكنك تشغيل osqueryi باستعمال ملفّ إعدادات osqueryd لتتمكّن من تشخيص البيئة دون الحاجة إلى انتقال دائم بين أسطر الأوامر. سنقوم في هذا الدّرس بما يلي: تثبيت osquery ضبط الأجزاء التي يحتاج إليها osquery في نظام التّشغيل (مثل Rsyslog)، وذلك لكي يعمل osquery بشكل صحيح. ضبط ملفّ إعدادات يُمكن أن يُستعمل من طرف كل من osqueryi و osqueryd. العمل مع حِزمات (packs) osquery، وهي عبارة عن مجموعات من الاستعلامات المسبوقَةِ التّعريف يُمكنك إضافتها إلى المُؤقّت (schedule). تنفيذ استعلامات ظرفيّة باستعمال osqueryi للبحث عن مشاكل أمنيّة. تشغيل العفريت لكي يقوم بتنفيذ الاستعلامات آليّا. السّجلات المُولَّدة من طرف العفريت osqueryd مُراد بها أن تُنقَل إلى نقاط نهاية (endpoints) خارجيّة تحتاج إلى خبرات إضافيّة لضبطها واستعمالها بشكل صحيح. لن يُغطيّ هذا الدّرس هذا الإعداد، لكنّك ستتعلّم كيفيّة ضبط وتشغيل العفريت وحفظ النتائج محليّا. المُتطلّبات لمُتابعة هذا الدّرس، ستحتاج إلى ما يلي: خادوم Ubuntu 16.04 معد بإتباع الخطوات المتواجدة في هذا الدّرس ومستخدم إداري بامتيازات sudo غير المستخدم الجذر وجدار ناري. يجب عليك كذلك أن تمتلك فهما بسيطا لأساسيّات SQL ومعرفة أوليّة حول تأمين نظام لينكس . الخطوة الأولى: تثبيت osquery على الخادوم يُمكنك تنصيب osquery عبر تجميعه من الشيفرة المصدرية، أو عبر استعمال مدير الحزم. وبما أنّ المستودع الرسمي لـUbuntu لا يحتوي على حزمة تنصيب، فسيتوجب عليك إضافة المستودع الرسمي لـosquery إلى النظام. أضف أولًا المفتاح العمومي للمُستودع: sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 1484120AC4E9F8A1A577AEEE97A80C63C9D8B80B ثمّ أضف المُستودع: sudo add-apt-repository "deb [arch=amd64] https://osquery-packages.s3.amazonaws.com/xenial xenial main" حدّث قاعدة بيانات الحزم: sudo apt-get update وأخيرا، نصّب osquery: sudo apt-get install osquery افتراضيّا، لا يُمكن اعتبار osquery مُفيدا للغاية، إذ لا يُعتبر تطبيقا يُمكنك تنصيبه والاستفادة من كامل مزاياه مُباشرة. سواء رغبت باستعمال الصدفة التفاعليّة (interactive shell) أو العفريت، سيتوجّب عليك تمرير بعض المُعاملات والخيارات، إما عبر سطر الأوامر أو عبر ملفّ إعدادات. لعرض المُعاملات والخيارات المتوفّرة للعفريت، اكتب ما يلي: osqueryd --help سيحتوي المُخرج على عشرات المعاملات لسطر الأوامر وخيارات الضّبط. ما يلي جزء من المُخرج عند تجربة الأمر في الخادوم التجريبي الذي استعمِل من أجل هذا المقال: osquery 2.1.2, your OS as a high-performance relational database Usage: osqueryd [OPTION]... osquery command line flags: --flagfile PATH Line-delimited file of additional flags --config_check Check the format of an osquery config and exit --config_dump Dump the contents of the configuration --config_path VALUE Path to JSON config file --config_plugin VALUE Config plugin name --config_tls_endpoint VALUE TLS/HTTPS endpoint for config retrieval --config_tls_max_attempts VALUE Number of attempts to retry a TLS config/enroll request --config_tls_refresh VALUE Optional interval in seconds to re-read configuration --daemonize Run as daemon (osqueryd only) ... ... osquery configuration options (set by config or CLI flags): --audit_allow_config Allow the audit publisher to change auditing configuration --audit_allow_sockets Allow the audit publisher to install socket-related rules --audit_persist Attempt to retain control of audit --aws_access_key_id VALUE AWS access key ID --aws_firehose_period VALUE Seconds between flushing logs to Firehose (default 10) --aws_firehose_stream VALUE Name of Firehose stream for logging --aws_kinesis_period VALUE Seconds between flushing logs to Kinesis (default 10) --aws_kinesis_random_partition_key Enable random kinesis partition keys --aws_kinesis_stream VALUE Name of Kinesis stream for logging --aws_profile_name VALUE AWS profile for authentication and region configuration --aws_region VALUE AWS region للاطلاع على المعاملات الإضافيّة المُتوفرة للصدفة التفاعلية فقط، نفّذ ما يلي: osqueryi --help تشغيل osqueryi أسهل طريقة لعرض واستعلام جداول osquery المتوفرة افتراضيّا. على سبيل المثال، شغّل الصّدفة باستعمال الأمر التّالي: osqueryi --verbose سيضعك هذا في صدفة تفاعليّة، وستُلاحظ مُخرجا مُشابها لما يلي: I0105 01:52:54.987584 4761 init.cpp:364] osquery initialized [version=2.1.2] I0105 01:52:54.987808 4761 extensions.cpp:351] Could not autoload extensions: Failed reading: /etc/osquery/extensions.load I0105 01:52:54.987944 4761 extensions.cpp:364] Could not autoload modules: Failed reading: /etc/osquery/modules.load I0105 01:52:54.988209 4761 init.cpp:606] Error reading config: config file does not exist: /etc/osquery/osquery.conf I0105 01:52:54.988334 4761 events.cpp:886] Error registering subscriber: socket_events: Subscriber disabled via configuration I0105 01:52:54.993973 4763 interface.cpp:307] Extension manager service starting: /home/sammy/.osquery/shell.em Using a virtual database. Need help, type '.help' osquery> من رسائل المعلومات والأخطاء أعلاه، من الواضح بأنّ بعضا من أجزاء osquery لا تعمل كما يجب . بعض الاستعلامات مثل select * from yara ; لن تُرجع أي شيء، ما يعني بأنّ الجدول لا يحتوي على أية بيانات. بعض الاستعلامات الأخرى مثل select time, severity, message from syslog ; تُرجع رسالة كما يلي، ما يُوضّح بأنّنا بحاجة إلى بعض من العمل الإضافي: W1202 15:44:48.600539 1720 virtual_table.cpp:492] Table syslog is event-based but events are disabled W1202 15:44:48.600587 1720 virtual_table.cpp:499] Please see the table documentation: https://osquery.io/docs/#syslog سنقوم بتعديل إعدادات الخادوم الخاصّ بنا لحل هذه المُشكلة. اخرج من سطر أوامر osquery عبر كتابة ما يلي: .exit سنقوم في الفقرة التّالية بتعديل الأجزاء من نظام التّشغيل التي يحتاج إليها osquery للعمل بشكل صحيح. الخطوة الثّانيّة: السّماح لـosquery بالوصول إلى سجلّ النّظام سنقوم في هذه الخطوة بتعديل تطبيق syslog الخاص بنظام التشغيل لتمكين osquery من الحصول على واستعلام سجّل النّظام. وفي Ubuntu 16.04، هذا يعني تعديل ملفّ إعدادات Rsyslog. والتعديل الوحيد الذي سيتوجب عليك القيام به هو إضافة بضعة أسطر من الشيفرة إلى ملفّ الإعدادات. كبداية، افتح الملفّ /etc/rsyslog.conf: sudo nano /etc/rsyslog.conf نحتاج إلى إضافة بضعة أسطر من الإعدادات التي ستُحدِّدُ لـRsyslog الأنبوب (pipe) الذي تجِبُ الكتابة إليه، وأيّا من مُعطيات (parameters) syslog يجب كتابتها للأنبوب. افتراضيّا، الأنبوب هو /var/osquery/syslog_pipe. سيقوم osquery بعد ذلك بملء جدول syslog الخاصّ به من المعلومات المكتوبة لهذا الأنبوب. ألحِق ما يلي من الأسطر إلى نهاية الملفّ: template( name="OsqueryCsvFormat" type="string" string="%timestamp:::date-rfc3339,csv%,%hostname:::csv%,%syslogseverity:::csv%,%syslogfacility-text:::csv%,%syslogtag:::csv%,%msg:::csv%\n" ) *.* action(type="ompipe" Pipe="/var/osquery/syslog_pipe" template="OsqueryCsvFormat") احفظ وأغلق الملفّ. لتطبيق التغييرات، أعد تشغيل عفريت syslog: sudo systemctl restart rsyslog لنُنشئ الآن ملفّ إعدادات يضبط بعض الخيارات الافتراضية ويُوقِّتُ بعض الاستعلامات. الخطوة الثّالثة: إنشاء ملفّ إعدادات osquery إنشاء ملفّ إعدادات يُسهِّلُ من عمليّة تشغيل osqueryi.فعوضا عن تمرير عدد كبير من خيارات سطر الأوامر، يُمكن لـosqueryi قراءة هذه الخيارات من ملفّ إعدادات مُتواجد في المسار /etc/osquery/osquery.conf. وبالطّبع، فملفّ الإعدادات سيكون مُتاحا للعفريت كذلك. يحتوي ملفّ الإعدادات على الاستعلامات التي تحتاج إلى تنفيذها حسب توقيت مُعيّن. لكنّ مُعظم الاستعلامات التي يُمكنك تشغيلها متوفّرة على شكل حزمات (packs). ملفّات الحزمات مُتوفرة في المُجلّد /usr/share/osquery/packs. لا يأتي osquery مُجهّزا بملفّ إعدادات مُسبق، لكنّ هناك نموذج ملفّ إعدادات يُمكنك نسخه إلى /etc/osquery وتعديله. لكنّ ملفّ الإعدادات هذا لا يحتوي على جميع الخيارات التي تحتاج إليها لتشغيله على توزيعة لينكس مثل Ubuntu، لذا سنقوم بإنشاء ملفّنا الخاصّ. هناك ثلاثة أقسام لملفّ الإعدادات: قائمة بخيارات العفريت وإعدادات المزايا. يُمكن لهذه الإعدادات أن تُقرأ كذلك من طرف osqueryi. قائمة استعلامات موقوتة لتُشغَّل متى ما وَجَبَ ذلك. قائمة حزمات لتُستعمل للتعامل مع استعلامات موقوتة أكثر تحديدا. ما يلي قائمة من الخيارات التي سنستعملها في ملفّ الإعدادات الخاصّ بنا، ما يعنيه كلّ خيار، والقيم التي سنعيِّنها لهذه الخيارات. تكفي هذه القائمة من الخيارات لتشغيل كل من osqueryi وosqueryd على Ubuntu 16.04 وتوزيعات لينكس الأخرى. config_plugin: من أين نُريد osquery أن يقرأ الإعدادات الخاصّة به. بما أنّ الإعدادات تُقرأ من ملفّ على القرص افتراضيّا، فستكون القيمة filesystem. logger_plugin: يُحدّد هذا الخيار مكان كتابة نتائج الاستعلامات الموقوتة. سنستعمل القيمة filesystem مُجدّدا. logger_path: هذا هو المسار الذي يُؤدّي إلى مُجلّد السّجلات الذي ستجد به ملفّات تحتوي على المعلومات، التنبيهات والأخطاء ونتائج الاستعلامات الموقوتة. القيمة الافتراضيّة هي /var/log/osquery. disable_logging: سنقوم بتفعيل التّسجيل عبر تحديد القيمة false لهذا الخيار. log_result_events: عبر تحديد القيمة true لهذا الخيار، سيُعبّر كل سطر من سجلات النّتائج عن تغيير في الحالة. schedule_splay_percent: في حالة تواجد عدد كبير من الاستعلامات الموقوتة في نفس المدة الزمنية، سيقوم هذا الخيار بتمديدها للحد من التأثيرات على أداء الخادوم. القيمة الافتراضيّة هي 10، وهي نسبة مئويّة. pidfile: المكان الذي سيُكتب فيه مُعرِّف العمليّة (process id) الخاصّ بعفريت osquery. القيمة الافتراضيّة هي /var/osquery/osquery.pidfile. events_expiry: المُدة الزمنية بالثواني التي سيتم فيها الاحتفاظ بنتائج المُشترك في مخزن osquery. القيمة الافتراضية هي 3600. database_path: مسار قاعدة بيانات osquery. سنستعمل القيمة الافتراضية /var/osquery/osquery.db. verbose: مع تفعيل التّسجيل، يُستعمل هذا الخيار لتفعيل أو تعطيل رسائل معلومات مُفصّلة. سنعيّن للخيار القيمة false. worker_threads: عدد السلاسل المُستعملة للتعامل مع الاستعلامات. سنترك القيمة الافتراضية 2. enable_monitor: تفعيل أو تعطيل مراقِب المُؤقّت. سنقوم بتفعيله، أي القيمة true. disable_events: يُستعمل هذا الخيار لضبط نظام osquery الخاصّ بالنّشر والاشتراك. نحتاج إلى تفعيله، أي القيمة false. disable_audit: يُستعمل لتعطيل استقبال الأحداث (events) من النظام الفرعي المسؤول عن التّدقيق في نظام التّشغيل. نحتاج إلى تفعيله، لذا فالقيمة التي سنستعملها هي false. audit_allow_config: السّماح لناشر التّدقيق بتغيير إعدادات التّدقيق. القيمة الافتراضية هي true. audit_allow_sockets: يقوم هذا الخيار بالسماح لناشر التّدقيق بتنصيب قواعد مُتعلّقة بالمقابس (socket). القيمة هي true. host_identifier: يُستعمَلُ لتعريف المُضيف الذي يُشغّل osquery. عند جمع نتائج من عدّة خوادم، فمن المُفيد التّمكن من التّعرف على الخادوم الذي جاء منه التّسجيل. القيمة تكون إمّا hostname أو uuid. القيمة الافتراضية التي سنعتمد عليها هي hostname. enable_syslog: يجب أن تكون قيمة هذا الخيار true ليتمكّن osquery من الحصول على معلومات syslog. schedule_default_interval: عند عدم توفير مُدّة لاستعلام موقوت، استعمِل هذه القيمة. سنُعيّن لهذا الخيار القيمَة 3600 ثانيّة. سبق لك وأن تعرّفت على كيفيّة عرض جميع مُعاملات سطر الأوامر وخيارات الضّبط المتوفّرة لكل من osqueryi و osqueryd، لكنّ الخيارات أعلاه كافيّة لتشغيل osquery على هذا الخادوم. أنشئ وافتح ملفّ الإعدادات باستخدام الأمر التّالي: sudo nano /etc/osquery/osquery.conf يعتمد ملفّ الإعدادات على صيغة JSON. انسخ ما يلي إلى الملفّ: { "options": { "config_plugin": "filesystem", "logger_plugin": "filesystem", "logger_path": "/var/log/osquery", "disable_logging": "false", "log_result_events": "true", "schedule_splay_percent": "10", "pidfile": "/var/osquery/osquery.pidfile", "events_expiry": "3600", "database_path": "/var/osquery/osquery.db", "verbose": "false", "worker_threads": "2", "enable_monitor": "true", "disable_events": "false", "disable_audit": "false", "audit_allow_config": "true", "host_identifier": "hostname", "enable_syslog": "true", "audit_allow_sockets": "true", "schedule_default_interval": "3600" }, القسم التّالي من ملفّ الإعدادات هو قسم التوقيت. يُعرَّف كل استعلام عبر مفتاح أو اسم يجب أن يكون فريدا في الملفّ، متبوعا بالاستعلام المُراد تنفيذه والمدّة الزمنية بالثواني. سنقوم بتوقيت استعلام لينظر إلى جدول crontab كلّ 300 ثانيّة. أضف ما يلي إلى ملفّ الإعدادات: "schedule": { "crontab": { "query": "SELECT * FROM crontab;", "interval": 300 } }, يُمكنك إضافة أي عدد من الاستعلامات تُريد، أبقِ فقط على الصّيغة الصحيحة لكي لا تحدث أخطاء في التدقيق. على سبيل المثال، لإضافة بضعة استعلامات أخرى، أضف ما يلي من الأسطر: "schedule": { "crontab": { "query": "SELECT * FROM crontab;", "interval": 300 }, "system_profile": { "query": "SELECT * FROM osquery_schedule;" }, "system_info": { "query": "SELECT hostname, cpu_brand, physical_memory FROM system_info;", "interval": 3600 } }, بعد الاستعلامات الموقوتة، يُمكنك إضافة استعلامات خاصّة تُدعى المُزخرفات (decorators)، وهي استعلامات تُضيف بيانات إلى بداية الاستعلامات الموقوتة الأخرى. الاستعلامات المُزخرفة التّالية ستقوم بإضافة المعرّف UUID الخاصّ بالمُضيف الذي يُشغّل osquery واسم المُستخدم في بداية كلّ استعلام موقوت. أضف ما يلي إلى نهاية الملفّ: "decorators": { "load": [ "SELECT uuid AS host_uuid FROM system_info;", "SELECT user AS username FROM logged_in_users ORDER BY time DESC LIMIT 1;" ] }, يُمكننا أخيرا توجيه osquery إلى قائمة من الحزمات التي تحتوي على استعلامات مُحدّدة. يوفّر osquery مجموعة افتراضيّة من الحزمات تجدها في المُجلّد /usr/share/osquery/packs. أحد هذه الحزمات مُخصّصة لنظام macOS وبقيّتها لأنظمة لينكس. يُمكنك استعمال الحزمات من مساراتها الافتراضية، ويُمكنك كذلك نسخها إلى المُجلّد /etc/osquery. أضف الأسطر التّالية إلى الملفّ لإنهاء الإعداد: "packs": { "osquery-monitoring": "/usr/share/osquery/packs/osquery-monitoring.conf", "incident-response": "/usr/share/osquery/packs/incident-response.conf", "it-compliance": "/usr/share/osquery/packs/it-compliance.conf", "vuln-management": "/usr/share/osquery/packs/vuln-management.conf" } } لاحظ معقوفة الإغلاق }في الأخير، هذه المعقوفة تُوافق معقوفة الفتح في السطر الأول من بداية الملفّ. يجب على ملفّ الإعدادات الكامل أن يبدو كما يلي: { "options": { "config_plugin": "filesystem", "logger_plugin": "filesystem", "logger_path": "/var/log/osquery", "disable_logging": "false", "log_result_events": "true", "schedule_splay_percent": "10", "pidfile": "/var/osquery/osquery.pidfile", "events_expiry": "3600", "database_path": "/var/osquery/osquery.db", "verbose": "false", "worker_threads": "2", "enable_monitor": "true", "disable_events": "false", "disable_audit": "false", "audit_allow_config": "true", "host_identifier": "hostname", "enable_syslog": "true", "audit_allow_sockets": "true", "schedule_default_interval": "3600" }, "schedule": { "crontab": { "query": "SELECT * FROM crontab;", "interval": 300 }, "system_profile": { "query": "SELECT * FROM osquery_schedule;" }, "system_info": { "query": "SELECT hostname, cpu_brand, physical_memory FROM system_info;", "interval": 3600 } }, "decorators": { "load": [ "SELECT uuid AS host_uuid FROM system_info;", "SELECT user AS username FROM logged_in_users ORDER BY time DESC LIMIT 1;" ] }, "packs": { "osquery-monitoring": "/usr/share/osquery/packs/osquery-monitoring.conf", "incident-response": "/usr/share/osquery/packs/incident-response.conf", "it-compliance": "/usr/share/osquery/packs/it-compliance.conf", "vuln-management": "/usr/share/osquery/packs/vuln-management.conf" } } احفظ وأغلق الملفّ ثمّ تحقّق من الإعدادات باستعمال الأمر التّالي: sudo osqueryctl config-check يجب على المُخرج أن يبدو كما يلي: I0104 11:11:46.022858 24501 rocksdb.cpp:187] Opening RocksDB handle: /var/osquery/osquery.db إن حدث خطأ ما، فسيحتوي المُخرج على موقع الخطأ لكي تتمكّن من إصلاحه. بعد إعداد ملفّ إعدادات سليم، يُمكنك الآن الانتقال إلى إعداد حزمة osquery المطلوبة لمُراقبة صلاحيّة الملفّات. الخطوة الرّابعة: إعداد حزمة osquery المطلوبة لمُراقبة صلاحيّة الملفّات مُراقبة صلاحيّة وسلامة الملفات على خادومك من الأجزاء المهمّة في مُراقبة أمن النّظام. ويُوفّر لنا osquery حلّا جاهزا في هذه المسألة. الحزمات التي أضفناها في ملفّ الإعدادات في القسم السّابق عبارة عن حزمات جاهزة. سنقوم في هذا الجزء من الدرس بإضافة حزمة واحدة إضافيّة إلى القائمة، والتي ستحتوي على الاستعلام والتّعليمات التي سيتم استعمالها لمُراقبة صلاحية الملفّات. سنقوم بتسمية الملفّ fim.conf. أنشئ الملفّ وافتحه باستعمال مُحرّر النّصوص الخاصّ بك: sudo nano /usr/share/osquery/packs/fim.conf سنقوم بإنشاء حزمة لمراقبة أحداث الملفّات في المُجلّدات /home، /etc و/tmp كلّ 300 ثانيّة. الضبط الكامل للحزمة متواجد أسفله، انسخه إلى الملفّ: { "queries": { "file_events": { "query": "select * from file_events;", "removed": false, "interval": 300 } }, "file_paths": { "homes": [ "/root/.ssh/%%", "/home/%/.ssh/%%" ], "etc": [ "/etc/%%" ], "home": [ "/home/%%" ], "tmp": [ "/tmp/%%" ] } } احفظ وأغلق الملفّ. لجعل الملفّ الجديد وقواعده مُتوفّرة لـosquery، أضفه إلى قائمة الحزمات في نهاية الملفّ /etc/osquery/osquery.conf، افتح الملفّ للتّعديل: sudo nano /etc/osquery/osquery.conf بعدها عدّل قسم الحزمات لتشمل الملفّ الجديد (الصّف الأول ممّا يلي): ... "packs": { "fim": "/usr/share/osquery/packs/fim.conf", "osquery-monitoring": "/usr/share/osquery/packs/osquery-monitoring.conf", "incident-response": "/usr/share/osquery/packs/incident-response.conf", "it-compliance": "/usr/share/osquery/packs/it-compliance.conf", "vuln-management": "/usr/share/osquery/packs/vuln-management.conf" } احفظ وأغلق الملفّ. ولتتأكد من أنّنا لم نرتكب أي خطأ في تعديل الملفّ، تحقّق مُجدّدا: sudo osqueryctl config-check لنبدأ الآن استعمال osqueryi لاستعلام النّظام. الخطوة الخامسة: استعمال osqueryi لتنفيذ تدقيقات أمنية ظرفيّة هناك العديد من الحالات التي يُفيد فيها osquery. سنقوم في هذا القسم بالقيام بمجموعة من التدقيقات الأمنية على النّظام باستعمال الصدفة التّفاعليّة osqueryi. وتذكّر بأنّنا لم نقم بتشغيل عفريت osquery بعد. وهذا من ميّزات osquery الجميلة، إذ تستطيع تنفيذ استعلامات باستعمال osqueryi حتى ولو لم يكن العفريت مُفعّلا، مع استعمال ملفّ الإعدادات الذي أعددناه لضبط البيئة أيضا. لتشغيل osqueryi مع ملفّ الإعدادات، نفّذ ما يلي: sudo osqueryi --config_path /etc/osquery/osquery.conf --verbose مُلاحظة: تمرير خيار --verbose إلى أمر تشغيل كلّ من osqueryi وosqueryd من أفضل الممارسات لأنّه يُظهر أية أخطاء أو تنبيهات يُمكن لها أن تُساعدك على استكشاف وحل مشاكل osquery. ويُمكن تشغيل osqueryi دون صلاحيات المُدير، لكنّك ستحتاج إلى تنفيذ الأمر بصلاحيات الجذر إن كنت ترغب في استعمال ملفّ الإعدادات الخاصّ بالعفريت. لنبدأ بتنفيذ تدقيقات أمنية بسيطة أولا ثمّ ننتقل إلى مُستويات أعلى خطوة بخطوة. على سبيل المثال، لنطّلع على من قد سجّل دخوله إلى النّظام في الوقت الحالي غيركَ أنت؟ يُمكن ذلك عبر الاستعلام التّالي: select * from logged_in_users ; يجب على المُخرج أن يبدو كالتّالي: +-----------+----------+-------+------------------+------------+------+ | type | user | tty | host | time | pid | +-----------+----------+-------+------------------+------------+------+ | boot_time | reboot | ~ | 4.4.0-57-generic | 1483580419 | 0 | | runlevel | runlevel | ~ | 4.4.0-57-generic | 1483580426 | 53 | | login | LOGIN | ttyS0 | | 1483580429 | 1546 | | login | LOGIN | tty1 | | 1483580429 | 1549 | | user | root | pts/0 | 11.11.11.11 | 1483580584 | 1752 | | user | sammy | pts/1 | 11.11.11.11 | 1483580770 | 4057 | +-----------+----------+-------+------------------+------------+------+ في المُخرج أعلاه حسابا مُستخدمين حقيقين قد سجّلا دخولهما إلى الجهاز، وكلاهما من نفس عنوان IP. يجب على عنوان IP هذا أن يكون معروفا. إن لم يكن كذلك، فسيتوجب عليك البحث عن مصدر تسجيل الدخول المثير للشبهات. يُخبرنا الاستعلام السّابق من قد سجّل دخوله في الوقت الحاليّ، لكن ماذا عن تسجيلات الدخول السّابقة؟ يُمكنك معرفة ذلك عبر استعلام الجدول last كما يلي: select * from last ; لا يُشير المُخرج إلى أي شيء غير اعتيادي، ما يعني بأنّه لم يُسجّل أي أحد غيرنا دخوله إلى الجهاز مُؤخّرا: +----------+-------+------+------+------------+------------------+ | username | tty | pid | type | time | host | +----------+-------+------+------+------------+------------------+ | reboot | ~ | 0 | 2 | 1483580419 | 4.4.0-57-generic | | runlevel | ~ | 53 | 1 | 1483580426 | 4.4.0-57-generic | | | ttyS0 | 1546 | 5 | 1483580429 | | | LOGIN | ttyS0 | 1546 | 6 | 1483580429 | | | | tty1 | 1549 | 5 | 1483580429 | | | LOGIN | tty1 | 1549 | 6 | 1483580429 | | | root | pts/0 | 1752 | 7 | 1483580584 | 11.11.11.11 | | sammy | pts/1 | 4057 | 7 | 1483580770 | 11.11.11.11 | +----------+-------+------+------+------------+------------------+ هل تم ضبط وتفعيل الجدار النّاري؟ هل لا يزال الجدار النّاري قيد التّشغيل؟ إن كنت في شك من أمرك، فنفّذ الاستعلام التّالي: select * from iptables ; إن لم تحصل على أي مُخرج، فهذا يعني بأنّ جدار IPTables النّاري لم يُضبَط. إن كان الخادوم مُتصلا بالأنترنت فهذا ليس جيّدا، لذا من المُفضّل أن تُعدّ الجدار النّاري الخاصّ بك. يُمكنك تعديل الاستعلام السّابق وتنفيذه لترشيح أعمدة مُحدّدة كما يلي: select chain, policy, src_ip, dst_ip from iptables ; يجب على الاستعلام أن يمنحك مُخرجا مُشابها لما يلي. ابحث عن أي مصدر مُثير للشبهات وعناوين IP الوجهة (destination IP addresses) التي لم تقم بضبطها: +---------+--------+---------+-----------+ | chain | policy | src_ip | dst_ip | +---------+--------+---------+-----------+ | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 127.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | FORWARD | ACCEPT | 0.0.0.0 | 0.0.0.0 | | FORWARD | ACCEPT | 0.0.0.0 | 0.0.0.0 | | OUTPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | OUTPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | +---------+--------+---------+-----------+ ما نوع العمليّات الموقوتة في crontab؟ هل قُمت بتوقيتها بنفسك؟ سيُساعدك الاستعلام التّالي على اكتشاف البرمجيات الخبيثة التي تمّ توقيتها لتعمل في فترات زمنية مُعيّنة: select command, path from crontab ; يجب على المُخرج أن يكون على الشّكل التّالي. إن بدت أية أوامر مُثيرة للشبهات، فهذا يعني بأنّها تحتاج إلى تحقيق إضافي: +----------------------------------------------------------------------------------------------------------------------------------------+--------------------------------+ | command | path | +----------------------------------------------------------------------------------------------------------------------------------------+--------------------------------+ | root cd / && run-parts --report /etc/cron.hourly | /etc/crontab | | root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily ) | /etc/crontab | | root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.weekly ) | /etc/crontab | | root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.monthly ) | /etc/crontab | | root if [ -x /usr/share/mdadm/checkarray ] && [ $(date +\%d) -le 7 ]; then /usr/share/mdadm/checkarray --cron --all --idle --quiet; fi | /etc/cron.d/mdadm | | root test -x /etc/cron.daily/popularity-contest && /etc/cron.daily/popularity-contest --crond | /etc/cron.d/popularity-contest | +----------------------------------------------------------------------------------------------------------------------------------------+--------------------------------+ هل هناك من ملفّات على النّظام مع خاصيّة setuid مُفعّلة؟ هناك بضعة من هذه الأنواع من الملفّات على أي خادوم يعمل بـUbuntu 16.04، لكن أي من هذه هي؟ وهل هناك من ملفات لا يجب عليها أن تتواجد في النظام؟ يُمكن لإجابات هذه الأسئلة أن تُساعدك على اكتشاف ثنائيّات بأبواب خلفيّة (backdoored binaries). نفّذ الاستعلام التّالي بين الفينة والأخرى وقارن النتائج مع نتائج أقدم لتتمكن من اكتشاف أية إضافات أو تغييرات غير مرغوب فيها: select * from suid_bin ; مقطع من المُخرج يبدو كما يلي: +-------------------------------+----------+-----------+-------------+ | path | username | groupname | permissions | +-------------------------------+----------+-----------+-------------+ | /bin/ping6 | root | root | S | | /bin/su | root | root | S | | /bin/mount | root | root | S | | /bin/umount | root | root | S | | /bin/fusermount | root | root | S | | /bin/ntfs-3g | root | root | S | | /bin/ping | root | root | S | | /sbin/mount.ntfs-3g | root | root | S | | /sbin/mount.ntfs | root | root | S | | /sbin/unix_chkpwd | root | shadow | G | | /sbin/pam_extrausers_chkpwd | root | shadow | G | | /usr/bin/chage | root | shadow | G | | /usr/bin/locate | root | mlocate | G | | /usr/bin/chfn | root | root | S | | /usr/bin/chsh | root | root | S | | /usr/bin/newuidmap | root | root | S | | /usr/bin/write | root | tty | G | | /usr/bin/mlocate | root | mlocate | G | | /usr/bin/at | daemon | daemon | SG | | /usr/bin/sg | root | root | S | لعرض قائمة بوحدات النواة المُحمَّلة (loaded kernel modules)، نفّذ الاستعلام التّالي: select name, used_by, status from kernel_modules where status="Live" ; هذا استعلام آخر يجب تنفيذه بين الحين والآخر لمُقارنة مُخرجه مع نتائج أقدم للتحقق ممّا إذا كان هناك تغيير ما أو لا. عرض قائمة بجميع المنافذ المُنصتة (listening ports) من أحد الطرق الأخرى التي يُمكنك بها إيجاد أبواب خلفيّة على الخادوم. للقيام بذلك، نفّذ الأمر التّالي: select * from listening_ports ; يجب على المُخرج أن يكون كالتّالي على خادوم جديد مع SSH وحدها تعمل على المنفذ 22: +-------+------+----------+--------+---------+ | pid | port | protocol | family | address | +-------+------+----------+--------+---------+ | 1686 | 22 | 6 | 2 | 0.0.0.0 | | 1686 | 22 | 6 | 10 | :: | | 25356 | 0 | 0 | 0 | | +-------+------+----------+--------+---------+ إن كان المُخرج يحتوي على منافذ تعلم بأنّ الخادوم يُنصت منها، فلا داعي للقلق، أمّا إن كانت هناك منافذ أخرى مفتوحة، فسيتوجّب عليك التّحقيق في ماهيّة هذه المنافذ. لعرض نشاطات الملفّات على الخادوم، نفّذ الاستعلام التّالي: select target_path, action, uid from file_events ; يعرض المُخرج جميع نشاطات الملفات الحديثة على الخادوم، إضافة إلى مُعرّف المُستخدم المسؤول عن النّشاط: +---------------------------+---------+------+ | target_path | action | uid | +---------------------------+---------+------+ | /home/sammy/..bashrc.swp | CREATED | 1000 | | /home/sammy/..bashrc.swp | UPDATED | 1000 | | /home/sammy/..bashrc.swp | UPDATED | 1000 | | /home/sammy/.bashrc | UPDATED | 1000 | | /home/sammy/..bashrc.swp | DELETED | 1000 | | /home/sammy/..bashrc.swp | CREATED | 1000 | | /home/sammy/..bashrc.swp | UPDATED | 1000 | | /home/sammy/..bashrc.swp | UPDATED | 1000 | | /home/sammy/.bashrc | UPDATED | 1000 | | /home/sammy/.bashrc | UPDATED | 1000 | | /home/sammy/.bashrc | UPDATED | 1000 | | /home/sammy/..bashrc.swp | DELETED | | | /etc/test_file.txt | DELETED | | | /home/sammy/.bash_history | UPDATED | 1000 | | /home/sammy/.bash_history | UPDATED | 1000 | | /etc/secret_file.md | CREATED | 0 | | /etc/secret_file.md | UPDATED | 0 | | /etc/secret_file.md | UPDATED | 0 | +---------------------------+---------+------+ هناك العديد من الاستعلامات مُشابهة لما سبق يُمكنك بها أن تحصل على فكرة حول مشاكل أمنية مُحتملة. إن لم تكن مُتأكدا من مُخطّط (schema) جدول ما، يُمكنك استعمال الأمر التّالي لمعرفة مُخطّط الجدول: .schema name-of-table مع إبدال name-of-table باسم الجدول. ويُمكنك كذلك عرض قائمة بالجداول المُتوفرة بالأمر: .tables هناك العديد من الأمثلة الأخرى في الحزمات التي تأتي مع osquery، وقد صُمِّم العديد منها ليعمل بشكل دوري من طرف osqueryd. سنتعرّف في القسم التّالي على كيفيّة تشغيل العفريت لتنفيذ هذه الاستعلامات. ##الخطوة السّادسة: تشغيل osqueryd يسمح العفريت osqueryd بتنفيذ الاستعلامات في فترات زمنيّة مُحدّدة. ما يشمل كلّا من الاستعلامات التي ضبطناها في الخطوة الرّابعة، الاستعلامات المتواجدة في الحزمات التي أعددناها في تلك الخطوة، وحزمة FIM التي أعددناها في الخطوة الخامسة كذلك. إن لم تطّلع على الحزمات بعد، فهذا وقت مُناسب لإلقاء نظرة على مُحتويات /usr/share/osquery/packs. تُكتَب النتائج المُولَّدة من طرف osqueryd إلى ملفّ باسم osqueryd.results.log في مُجلّد /var/log/osquery. هذا الملفّ غير موجود افتراضيّا. ولا يتم إنشاؤه إلا بعد تشغيل العفريت وبدء توليد النّتائج من طرفه. يُمكنك تشغيل osqueryd إما بأداة systemctl أو osqueryctl. كلاهما يؤدي نفس المُهمّة، لذا لا يهم أيّ واحد منهما تستعمل. سيتحقّق osqueryd من تواجد ملفّ إعدادات عند تشغيله، وسيُنبّهك إن لم يجد واحدا. سيبقى مُشتغلا دون ملفّ إعدادات، إلا أن ذلك لن يكون ذا فائدة تُذكر. وبما أنّه قد سبق وأن أعددنا ملفّ إعدادات، فكل ما تحتاج إليه هو تشغيل العفريت: sudo systemctl start osqueryd أو يُمكن كتابة ما يلي: sudo osqueryctl start بعد بضعة دقائق من تشغيل العفريت، من المُفترض أن يزداد حجم الملفّ /var/log/osquery/osqueryd.results.log. يُمكنك أن ترى ذلك بنفسك عبر تنفيذ الأمر التّالي مرارا وتكرارا: ls -lh /var/log/osquery/osqueryd.results.log ازدياد حجم الملفّ يدل على أن نتائج الاستعلامات الموقوتة تُكتَب على القرص. لا يمتلك osquery للأسف نظام تنبيهات مثل OSSEC، ما يعني بأنّك لن تستطيع رؤية نتائج الاستعلامات الموقوتة إلا عبر عرض ملفّ النتائج. ويُمكنك القيام بذلك عبر الأمر tail الذي سيقوم بعرض آخر 10 أسطر من الملفّ على الشّاشة بشكل مُستمر: sudo tail -f /var/log/osquery/osqueryd.results.log اضغط على CTRL+C لإيقاف العرض المُستمرّ للسّجل. قد ترغب على المدى البعيد بنقل نتائج الاستعلامات إلى منصّة تحليل خارجيّة يُمكنك العمل معها. بعض الخيارات مفتوحة المصدر تشمل كلّا من Doorman، Zentral و ElasticSearch. ختاما يعد osquery أداة قويّة مُفيدة لتشغيل استعلامات ظرفية وموقوتة باستعمال جمل SQL المألوفة. osqueryi هو المكون الذي يُمكّنك من تشغيل استعلامات سريعة، أما osqueryd فهو للاستعلامات الموقوتة. لتحليل نتائج الاستعلامات الموقوتة، سيتوجب عليك نقلها إلى منصّة خارجية لتحليل السّجلات. يُمكنك الحصول على المزيد من المعلومات حول osquery على osquery.io. ترجمة -بتصرّف- للمقال How To Monitor Your System Security with osquery on Ubuntu 16.04 لصاحبه finid.
إنَّ osquery عبارة عن أداة أمنية مفتوحة المصدر دورها تحويل نظام تشغيل بأكمله إلى قاعدة بيانات ضخمة، مع جداول يُمكنك استعلامها باستعمال جمل مُشابهة لجمل SQL. يُمكنك بهذه الاستعلامات مراقبة صلاحيّة الملفات، الاطلاع على حالة وإعدادات الجدار الناري، القيام بتدقيقات أمنية على الخادوم الهدف وغير ذلك. التطبيق عابر للمنصّات مع دعم للنسخ الجديدة من macOS، Windows 10، CentOS وUbuntu. تُوصف رسميا بأنّها "إطار عمل يحتوي على مجموعة من الأدوات المبنية على SQL لمراقبة نظام التّشغيل والحصول على الإحصائيات" وقد كانت بداية الإطار من شركة Facebook. يُمكنك باستخدام osquery تنفيذ أوامر مثل select * from logged_in_users ; على الخادوم الخاصّ بك لتحصل على نتيجة مُشابهة لما يلي: +-----------+----------+-------+------------------+------------+------+ | type | user | tty | host | time | pid | +-----------+----------+-------+------------------+------------+------+ | login | LOGIN | ttyS0 | | 1483580429 | 1546 | | login | LOGIN | tty1 | | 1483580429 | 1549 | | user | root | pts/0 | 24.27.68.82 | 1483580584 | 1752 | | user | sammy | pts/1 | 11.11.11.11 | 1483580770 | 4057 | | boot_time | reboot | ~ | 4.4.0-57-generic | 1483580419 | 0 | | runlevel | runlevel | ~ | 4.4.0-57-generic | 1483580426 | 53 | +-----------+----------+-------+------------------+------------+------+ إن سرَّك ما سبق، فسيُعجبك استعمال osquery كأداة أمنية لمُراقبة النظام واستكشاف الوصول غير المُصرّح له على خادومك الخاصّ. يُوفّر تنصيب osquery ما يلي من المكونات: osqueryi: صدفة osquery التفاعليّة، للقيام باستعلامات ظرفيّة. osqueryd: عفريت (daemon) لتوقيت وتشغيل الاستعلامات في الخلفيّة. osqueryctl: سكربت مُساعد لاختبار نشرِِ (deployment) أو إعدادِِ لـosquery. يُمكن أن يُستعمَل كذلك عوضا عن مُدير خدمات نظام التّشغيل لتشغيل/إيقاف/إعادة تشغيل osqueryd. أداتا osqueryi و osqueryd مُستقلّتان عن بعضهما. إذ لا يحتاجان إلى التواصل بينهما. ولا يتواصلان، ويُمكنك استعمال الواحدة دون الأخرى. معظم المعامِلات والخيارات المطلوبة لتشغيل كل واحدة هي نفسها بين الأداتين، ويُمكنك تشغيل osqueryi باستعمال ملفّ إعدادات osqueryd لتتمكّن من تشخيص البيئة دون الحاجة إلى انتقال دائم بين أسطر الأوامر. سنقوم في هذا الدّرس بما يلي: تثبيت osquery ضبط الأجزاء التي يحتاج إليها osquery في نظام التّشغيل (مثل Rsyslog)، وذلك لكي يعمل osquery بشكل صحيح. ضبط ملفّ إعدادات يُمكن أن يُستعمل من طرف كل من osqueryi و osqueryd. العمل مع حِزمات (packs) osquery، وهي عبارة عن مجموعات من الاستعلامات المسبوقَةِ التّعريف يُمكنك إضافتها إلى المُؤقّت (schedule). تنفيذ استعلامات ظرفيّة باستعمال osqueryi للبحث عن مشاكل أمنيّة. تشغيل العفريت لكي يقوم بتنفيذ الاستعلامات آليّا. السّجلات المُولَّدة من طرف العفريت osqueryd مُراد بها أن تُنقَل إلى نقاط نهاية (endpoints) خارجيّة تحتاج إلى خبرات إضافيّة لضبطها واستعمالها بشكل صحيح. لن يُغطيّ هذا الدّرس هذا الإعداد، لكنّك ستتعلّم كيفيّة ضبط وتشغيل العفريت وحفظ النتائج محليّا. المُتطلّبات لمُتابعة هذا الدّرس، ستحتاج إلى ما يلي: خادوم Ubuntu 16.04 معد بإتباع الخطوات المتواجدة في هذا الدّرس ومستخدم إداري بامتيازات sudo غير المستخدم الجذر وجدار ناري. يجب عليك كذلك أن تمتلك فهما بسيطا لأساسيّات SQL ومعرفة أوليّة حول تأمين نظام لينكس . الخطوة الأولى: تثبيت osquery على الخادوم يُمكنك تنصيب osquery عبر تجميعه من الشيفرة المصدرية، أو عبر استعمال مدير الحزم. وبما أنّ المستودع الرسمي لـUbuntu لا يحتوي على حزمة تنصيب، فسيتوجب عليك إضافة المستودع الرسمي لـosquery إلى النظام. أضف أولًا المفتاح العمومي للمُستودع: sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 1484120AC4E9F8A1A577AEEE97A80C63C9D8B80B ثمّ أضف المُستودع: sudo add-apt-repository "deb [arch=amd64] https://osquery-packages.s3.amazonaws.com/xenial xenial main" حدّث قاعدة بيانات الحزم: sudo apt-get update وأخيرا، نصّب osquery: sudo apt-get install osquery افتراضيّا، لا يُمكن اعتبار osquery مُفيدا للغاية، إذ لا يُعتبر تطبيقا يُمكنك تنصيبه والاستفادة من كامل مزاياه مُباشرة. سواء رغبت باستعمال الصدفة التفاعليّة (interactive shell) أو العفريت، سيتوجّب عليك تمرير بعض المُعاملات والخيارات، إما عبر سطر الأوامر أو عبر ملفّ إعدادات. لعرض المُعاملات والخيارات المتوفّرة للعفريت، اكتب ما يلي: osqueryd --help سيحتوي المُخرج على عشرات المعاملات لسطر الأوامر وخيارات الضّبط. ما يلي جزء من المُخرج عند تجربة الأمر في الخادوم التجريبي الذي استعمِل من أجل هذا المقال: osquery 2.1.2, your OS as a high-performance relational database Usage: osqueryd [OPTION]... osquery command line flags: --flagfile PATH Line-delimited file of additional flags --config_check Check the format of an osquery config and exit --config_dump Dump the contents of the configuration --config_path VALUE Path to JSON config file --config_plugin VALUE Config plugin name --config_tls_endpoint VALUE TLS/HTTPS endpoint for config retrieval --config_tls_max_attempts VALUE Number of attempts to retry a TLS config/enroll request --config_tls_refresh VALUE Optional interval in seconds to re-read configuration --daemonize Run as daemon (osqueryd only) ... ... osquery configuration options (set by config or CLI flags): --audit_allow_config Allow the audit publisher to change auditing configuration --audit_allow_sockets Allow the audit publisher to install socket-related rules --audit_persist Attempt to retain control of audit --aws_access_key_id VALUE AWS access key ID --aws_firehose_period VALUE Seconds between flushing logs to Firehose (default 10) --aws_firehose_stream VALUE Name of Firehose stream for logging --aws_kinesis_period VALUE Seconds between flushing logs to Kinesis (default 10) --aws_kinesis_random_partition_key Enable random kinesis partition keys --aws_kinesis_stream VALUE Name of Kinesis stream for logging --aws_profile_name VALUE AWS profile for authentication and region configuration --aws_region VALUE AWS region للاطلاع على المعاملات الإضافيّة المُتوفرة للصدفة التفاعلية فقط، نفّذ ما يلي: osqueryi --help تشغيل osqueryi أسهل طريقة لعرض واستعلام جداول osquery المتوفرة افتراضيّا. على سبيل المثال، شغّل الصّدفة باستعمال الأمر التّالي: osqueryi --verbose سيضعك هذا في صدفة تفاعليّة، وستُلاحظ مُخرجا مُشابها لما يلي: I0105 01:52:54.987584 4761 init.cpp:364] osquery initialized [version=2.1.2] I0105 01:52:54.987808 4761 extensions.cpp:351] Could not autoload extensions: Failed reading: /etc/osquery/extensions.load I0105 01:52:54.987944 4761 extensions.cpp:364] Could not autoload modules: Failed reading: /etc/osquery/modules.load I0105 01:52:54.988209 4761 init.cpp:606] Error reading config: config file does not exist: /etc/osquery/osquery.conf I0105 01:52:54.988334 4761 events.cpp:886] Error registering subscriber: socket_events: Subscriber disabled via configuration I0105 01:52:54.993973 4763 interface.cpp:307] Extension manager service starting: /home/sammy/.osquery/shell.em Using a virtual database. Need help, type '.help' osquery> من رسائل المعلومات والأخطاء أعلاه، من الواضح بأنّ بعضا من أجزاء osquery لا تعمل كما يجب . بعض الاستعلامات مثل select * from yara ; لن تُرجع أي شيء، ما يعني بأنّ الجدول لا يحتوي على أية بيانات. بعض الاستعلامات الأخرى مثل select time, severity, message from syslog ; تُرجع رسالة كما يلي، ما يُوضّح بأنّنا بحاجة إلى بعض من العمل الإضافي: W1202 15:44:48.600539 1720 virtual_table.cpp:492] Table syslog is event-based but events are disabled W1202 15:44:48.600587 1720 virtual_table.cpp:499] Please see the table documentation: https://osquery.io/docs/#syslog سنقوم بتعديل إعدادات الخادوم الخاصّ بنا لحل هذه المُشكلة. اخرج من سطر أوامر osquery عبر كتابة ما يلي: .exit سنقوم في الفقرة التّالية بتعديل الأجزاء من نظام التّشغيل التي يحتاج إليها osquery للعمل بشكل صحيح. الخطوة الثّانيّة: السّماح لـosquery بالوصول إلى سجلّ النّظام سنقوم في هذه الخطوة بتعديل تطبيق syslog الخاص بنظام التشغيل لتمكين osquery من الحصول على واستعلام سجّل النّظام. وفي Ubuntu 16.04، هذا يعني تعديل ملفّ إعدادات Rsyslog. والتعديل الوحيد الذي سيتوجب عليك القيام به هو إضافة بضعة أسطر من الشيفرة إلى ملفّ الإعدادات. كبداية، افتح الملفّ /etc/rsyslog.conf: sudo nano /etc/rsyslog.conf نحتاج إلى إضافة بضعة أسطر من الإعدادات التي ستُحدِّدُ لـRsyslog الأنبوب (pipe) الذي تجِبُ الكتابة إليه، وأيّا من مُعطيات (parameters) syslog يجب كتابتها للأنبوب. افتراضيّا، الأنبوب هو /var/osquery/syslog_pipe. سيقوم osquery بعد ذلك بملء جدول syslog الخاصّ به من المعلومات المكتوبة لهذا الأنبوب. ألحِق ما يلي من الأسطر إلى نهاية الملفّ: template( name="OsqueryCsvFormat" type="string" string="%timestamp:::date-rfc3339,csv%,%hostname:::csv%,%syslogseverity:::csv%,%syslogfacility-text:::csv%,%syslogtag:::csv%,%msg:::csv%\n" ) *.* action(type="ompipe" Pipe="/var/osquery/syslog_pipe" template="OsqueryCsvFormat") احفظ وأغلق الملفّ. لتطبيق التغييرات، أعد تشغيل عفريت syslog: sudo systemctl restart rsyslog لنُنشئ الآن ملفّ إعدادات يضبط بعض الخيارات الافتراضية ويُوقِّتُ بعض الاستعلامات. الخطوة الثّالثة: إنشاء ملفّ إعدادات osquery إنشاء ملفّ إعدادات يُسهِّلُ من عمليّة تشغيل osqueryi.فعوضا عن تمرير عدد كبير من خيارات سطر الأوامر، يُمكن لـosqueryi قراءة هذه الخيارات من ملفّ إعدادات مُتواجد في المسار /etc/osquery/osquery.conf. وبالطّبع، فملفّ الإعدادات سيكون مُتاحا للعفريت كذلك. يحتوي ملفّ الإعدادات على الاستعلامات التي تحتاج إلى تنفيذها حسب توقيت مُعيّن. لكنّ مُعظم الاستعلامات التي يُمكنك تشغيلها متوفّرة على شكل حزمات (packs). ملفّات الحزمات مُتوفرة في المُجلّد /usr/share/osquery/packs. لا يأتي osquery مُجهّزا بملفّ إعدادات مُسبق، لكنّ هناك نموذج ملفّ إعدادات يُمكنك نسخه إلى /etc/osquery وتعديله. لكنّ ملفّ الإعدادات هذا لا يحتوي على جميع الخيارات التي تحتاج إليها لتشغيله على توزيعة لينكس مثل Ubuntu، لذا سنقوم بإنشاء ملفّنا الخاصّ. هناك ثلاثة أقسام لملفّ الإعدادات: قائمة بخيارات العفريت وإعدادات المزايا. يُمكن لهذه الإعدادات أن تُقرأ كذلك من طرف osqueryi. قائمة استعلامات موقوتة لتُشغَّل متى ما وَجَبَ ذلك. قائمة حزمات لتُستعمل للتعامل مع استعلامات موقوتة أكثر تحديدا. ما يلي قائمة من الخيارات التي سنستعملها في ملفّ الإعدادات الخاصّ بنا، ما يعنيه كلّ خيار، والقيم التي سنعيِّنها لهذه الخيارات. تكفي هذه القائمة من الخيارات لتشغيل كل من osqueryi وosqueryd على Ubuntu 16.04 وتوزيعات لينكس الأخرى. config_plugin: من أين نُريد osquery أن يقرأ الإعدادات الخاصّة به. بما أنّ الإعدادات تُقرأ من ملفّ على القرص افتراضيّا، فستكون القيمة filesystem. logger_plugin: يُحدّد هذا الخيار مكان كتابة نتائج الاستعلامات الموقوتة. سنستعمل القيمة filesystem مُجدّدا. logger_path: هذا هو المسار الذي يُؤدّي إلى مُجلّد السّجلات الذي ستجد به ملفّات تحتوي على المعلومات، التنبيهات والأخطاء ونتائج الاستعلامات الموقوتة. القيمة الافتراضيّة هي /var/log/osquery. disable_logging: سنقوم بتفعيل التّسجيل عبر تحديد القيمة false لهذا الخيار. log_result_events: عبر تحديد القيمة true لهذا الخيار، سيُعبّر كل سطر من سجلات النّتائج عن تغيير في الحالة. schedule_splay_percent: في حالة تواجد عدد كبير من الاستعلامات الموقوتة في نفس المدة الزمنية، سيقوم هذا الخيار بتمديدها للحد من التأثيرات على أداء الخادوم. القيمة الافتراضيّة هي 10، وهي نسبة مئويّة. pidfile: المكان الذي سيُكتب فيه مُعرِّف العمليّة (process id) الخاصّ بعفريت osquery. القيمة الافتراضيّة هي /var/osquery/osquery.pidfile. events_expiry: المُدة الزمنية بالثواني التي سيتم فيها الاحتفاظ بنتائج المُشترك في مخزن osquery. القيمة الافتراضية هي 3600. database_path: مسار قاعدة بيانات osquery. سنستعمل القيمة الافتراضية /var/osquery/osquery.db. verbose: مع تفعيل التّسجيل، يُستعمل هذا الخيار لتفعيل أو تعطيل رسائل معلومات مُفصّلة. سنعيّن للخيار القيمة false. worker_threads: عدد السلاسل المُستعملة للتعامل مع الاستعلامات. سنترك القيمة الافتراضية 2. enable_monitor: تفعيل أو تعطيل مراقِب المُؤقّت. سنقوم بتفعيله، أي القيمة true. disable_events: يُستعمل هذا الخيار لضبط نظام osquery الخاصّ بالنّشر والاشتراك. نحتاج إلى تفعيله، أي القيمة false. disable_audit: يُستعمل لتعطيل استقبال الأحداث (events) من النظام الفرعي المسؤول عن التّدقيق في نظام التّشغيل. نحتاج إلى تفعيله، لذا فالقيمة التي سنستعملها هي false. audit_allow_config: السّماح لناشر التّدقيق بتغيير إعدادات التّدقيق. القيمة الافتراضية هي true. audit_allow_sockets: يقوم هذا الخيار بالسماح لناشر التّدقيق بتنصيب قواعد مُتعلّقة بالمقابس (socket). القيمة هي true. host_identifier: يُستعمَلُ لتعريف المُضيف الذي يُشغّل osquery. عند جمع نتائج من عدّة خوادم، فمن المُفيد التّمكن من التّعرف على الخادوم الذي جاء منه التّسجيل. القيمة تكون إمّا hostname أو uuid. القيمة الافتراضية التي سنعتمد عليها هي hostname. enable_syslog: يجب أن تكون قيمة هذا الخيار true ليتمكّن osquery من الحصول على معلومات syslog. schedule_default_interval: عند عدم توفير مُدّة لاستعلام موقوت، استعمِل هذه القيمة. سنُعيّن لهذا الخيار القيمَة 3600 ثانيّة. سبق لك وأن تعرّفت على كيفيّة عرض جميع مُعاملات سطر الأوامر وخيارات الضّبط المتوفّرة لكل من osqueryi و osqueryd، لكنّ الخيارات أعلاه كافيّة لتشغيل osquery على هذا الخادوم. أنشئ وافتح ملفّ الإعدادات باستخدام الأمر التّالي: sudo nano /etc/osquery/osquery.conf يعتمد ملفّ الإعدادات على صيغة JSON. انسخ ما يلي إلى الملفّ: { "options": { "config_plugin": "filesystem", "logger_plugin": "filesystem", "logger_path": "/var/log/osquery", "disable_logging": "false", "log_result_events": "true", "schedule_splay_percent": "10", "pidfile": "/var/osquery/osquery.pidfile", "events_expiry": "3600", "database_path": "/var/osquery/osquery.db", "verbose": "false", "worker_threads": "2", "enable_monitor": "true", "disable_events": "false", "disable_audit": "false", "audit_allow_config": "true", "host_identifier": "hostname", "enable_syslog": "true", "audit_allow_sockets": "true", "schedule_default_interval": "3600" }, القسم التّالي من ملفّ الإعدادات هو قسم التوقيت. يُعرَّف كل استعلام عبر مفتاح أو اسم يجب أن يكون فريدا في الملفّ، متبوعا بالاستعلام المُراد تنفيذه والمدّة الزمنية بالثواني. سنقوم بتوقيت استعلام لينظر إلى جدول crontab كلّ 300 ثانيّة. أضف ما يلي إلى ملفّ الإعدادات: "schedule": { "crontab": { "query": "SELECT * FROM crontab;", "interval": 300 } }, يُمكنك إضافة أي عدد من الاستعلامات تُريد، أبقِ فقط على الصّيغة الصحيحة لكي لا تحدث أخطاء في التدقيق. على سبيل المثال، لإضافة بضعة استعلامات أخرى، أضف ما يلي من الأسطر: "schedule": { "crontab": { "query": "SELECT * FROM crontab;", "interval": 300 }, "system_profile": { "query": "SELECT * FROM osquery_schedule;" }, "system_info": { "query": "SELECT hostname, cpu_brand, physical_memory FROM system_info;", "interval": 3600 } }, بعد الاستعلامات الموقوتة، يُمكنك إضافة استعلامات خاصّة تُدعى المُزخرفات (decorators)، وهي استعلامات تُضيف بيانات إلى بداية الاستعلامات الموقوتة الأخرى. الاستعلامات المُزخرفة التّالية ستقوم بإضافة المعرّف UUID الخاصّ بالمُضيف الذي يُشغّل osquery واسم المُستخدم في بداية كلّ استعلام موقوت. أضف ما يلي إلى نهاية الملفّ: "decorators": { "load": [ "SELECT uuid AS host_uuid FROM system_info;", "SELECT user AS username FROM logged_in_users ORDER BY time DESC LIMIT 1;" ] }, يُمكننا أخيرا توجيه osquery إلى قائمة من الحزمات التي تحتوي على استعلامات مُحدّدة. يوفّر osquery مجموعة افتراضيّة من الحزمات تجدها في المُجلّد /usr/share/osquery/packs. أحد هذه الحزمات مُخصّصة لنظام macOS وبقيّتها لأنظمة لينكس. يُمكنك استعمال الحزمات من مساراتها الافتراضية، ويُمكنك كذلك نسخها إلى المُجلّد /etc/osquery. أضف الأسطر التّالية إلى الملفّ لإنهاء الإعداد: "packs": { "osquery-monitoring": "/usr/share/osquery/packs/osquery-monitoring.conf", "incident-response": "/usr/share/osquery/packs/incident-response.conf", "it-compliance": "/usr/share/osquery/packs/it-compliance.conf", "vuln-management": "/usr/share/osquery/packs/vuln-management.conf" } } لاحظ معقوفة الإغلاق }في الأخير، هذه المعقوفة تُوافق معقوفة الفتح في السطر الأول من بداية الملفّ. يجب على ملفّ الإعدادات الكامل أن يبدو كما يلي: { "options": { "config_plugin": "filesystem", "logger_plugin": "filesystem", "logger_path": "/var/log/osquery", "disable_logging": "false", "log_result_events": "true", "schedule_splay_percent": "10", "pidfile": "/var/osquery/osquery.pidfile", "events_expiry": "3600", "database_path": "/var/osquery/osquery.db", "verbose": "false", "worker_threads": "2", "enable_monitor": "true", "disable_events": "false", "disable_audit": "false", "audit_allow_config": "true", "host_identifier": "hostname", "enable_syslog": "true", "audit_allow_sockets": "true", "schedule_default_interval": "3600" }, "schedule": { "crontab": { "query": "SELECT * FROM crontab;", "interval": 300 }, "system_profile": { "query": "SELECT * FROM osquery_schedule;" }, "system_info": { "query": "SELECT hostname, cpu_brand, physical_memory FROM system_info;", "interval": 3600 } }, "decorators": { "load": [ "SELECT uuid AS host_uuid FROM system_info;", "SELECT user AS username FROM logged_in_users ORDER BY time DESC LIMIT 1;" ] }, "packs": { "osquery-monitoring": "/usr/share/osquery/packs/osquery-monitoring.conf", "incident-response": "/usr/share/osquery/packs/incident-response.conf", "it-compliance": "/usr/share/osquery/packs/it-compliance.conf", "vuln-management": "/usr/share/osquery/packs/vuln-management.conf" } } احفظ وأغلق الملفّ ثمّ تحقّق من الإعدادات باستعمال الأمر التّالي: sudo osqueryctl config-check يجب على المُخرج أن يبدو كما يلي: I0104 11:11:46.022858 24501 rocksdb.cpp:187] Opening RocksDB handle: /var/osquery/osquery.db إن حدث خطأ ما، فسيحتوي المُخرج على موقع الخطأ لكي تتمكّن من إصلاحه. بعد إعداد ملفّ إعدادات سليم، يُمكنك الآن الانتقال إلى إعداد حزمة osquery المطلوبة لمُراقبة صلاحيّة الملفّات. الخطوة الرّابعة: إعداد حزمة osquery المطلوبة لمُراقبة صلاحيّة الملفّات مُراقبة صلاحيّة وسلامة الملفات على خادومك من الأجزاء المهمّة في مُراقبة أمن النّظام. ويُوفّر لنا osquery حلّا جاهزا في هذه المسألة. الحزمات التي أضفناها في ملفّ الإعدادات في القسم السّابق عبارة عن حزمات جاهزة. سنقوم في هذا الجزء من الدرس بإضافة حزمة واحدة إضافيّة إلى القائمة، والتي ستحتوي على الاستعلام والتّعليمات التي سيتم استعمالها لمُراقبة صلاحية الملفّات. سنقوم بتسمية الملفّ fim.conf. أنشئ الملفّ وافتحه باستعمال مُحرّر النّصوص الخاصّ بك: sudo nano /usr/share/osquery/packs/fim.conf سنقوم بإنشاء حزمة لمراقبة أحداث الملفّات في المُجلّدات /home، /etc و/tmp كلّ 300 ثانيّة. الضبط الكامل للحزمة متواجد أسفله، انسخه إلى الملفّ: { "queries": { "file_events": { "query": "select * from file_events;", "removed": false, "interval": 300 } }, "file_paths": { "homes": [ "/root/.ssh/%%", "/home/%/.ssh/%%" ], "etc": [ "/etc/%%" ], "home": [ "/home/%%" ], "tmp": [ "/tmp/%%" ] } } احفظ وأغلق الملفّ. لجعل الملفّ الجديد وقواعده مُتوفّرة لـosquery، أضفه إلى قائمة الحزمات في نهاية الملفّ /etc/osquery/osquery.conf، افتح الملفّ للتّعديل: sudo nano /etc/osquery/osquery.conf بعدها عدّل قسم الحزمات لتشمل الملفّ الجديد (الصّف الأول ممّا يلي): ... "packs": { "fim": "/usr/share/osquery/packs/fim.conf", "osquery-monitoring": "/usr/share/osquery/packs/osquery-monitoring.conf", "incident-response": "/usr/share/osquery/packs/incident-response.conf", "it-compliance": "/usr/share/osquery/packs/it-compliance.conf", "vuln-management": "/usr/share/osquery/packs/vuln-management.conf" } احفظ وأغلق الملفّ. ولتتأكد من أنّنا لم نرتكب أي خطأ في تعديل الملفّ، تحقّق مُجدّدا: sudo osqueryctl config-check لنبدأ الآن استعمال osqueryi لاستعلام النّظام. الخطوة الخامسة: استعمال osqueryi لتنفيذ تدقيقات أمنية ظرفيّة هناك العديد من الحالات التي يُفيد فيها osquery. سنقوم في هذا القسم بالقيام بمجموعة من التدقيقات الأمنية على النّظام باستعمال الصدفة التّفاعليّة osqueryi. وتذكّر بأنّنا لم نقم بتشغيل عفريت osquery بعد. وهذا من ميّزات osquery الجميلة، إذ تستطيع تنفيذ استعلامات باستعمال osqueryi حتى ولو لم يكن العفريت مُفعّلا، مع استعمال ملفّ الإعدادات الذي أعددناه لضبط البيئة أيضا. لتشغيل osqueryi مع ملفّ الإعدادات، نفّذ ما يلي: sudo osqueryi --config_path /etc/osquery/osquery.conf --verbose مُلاحظة: تمرير خيار --verbose إلى أمر تشغيل كلّ من osqueryi وosqueryd من أفضل الممارسات لأنّه يُظهر أية أخطاء أو تنبيهات يُمكن لها أن تُساعدك على استكشاف وحل مشاكل osquery. ويُمكن تشغيل osqueryi دون صلاحيات المُدير، لكنّك ستحتاج إلى تنفيذ الأمر بصلاحيات الجذر إن كنت ترغب في استعمال ملفّ الإعدادات الخاصّ بالعفريت. لنبدأ بتنفيذ تدقيقات أمنية بسيطة أولا ثمّ ننتقل إلى مُستويات أعلى خطوة بخطوة. على سبيل المثال، لنطّلع على من قد سجّل دخوله إلى النّظام في الوقت الحالي غيركَ أنت؟ يُمكن ذلك عبر الاستعلام التّالي: select * from logged_in_users ; يجب على المُخرج أن يبدو كالتّالي: +-----------+----------+-------+------------------+------------+------+ | type | user | tty | host | time | pid | +-----------+----------+-------+------------------+------------+------+ | boot_time | reboot | ~ | 4.4.0-57-generic | 1483580419 | 0 | | runlevel | runlevel | ~ | 4.4.0-57-generic | 1483580426 | 53 | | login | LOGIN | ttyS0 | | 1483580429 | 1546 | | login | LOGIN | tty1 | | 1483580429 | 1549 | | user | root | pts/0 | 11.11.11.11 | 1483580584 | 1752 | | user | sammy | pts/1 | 11.11.11.11 | 1483580770 | 4057 | +-----------+----------+-------+------------------+------------+------+ في المُخرج أعلاه حسابا مُستخدمين حقيقين قد سجّلا دخولهما إلى الجهاز، وكلاهما من نفس عنوان IP. يجب على عنوان IP هذا أن يكون معروفا. إن لم يكن كذلك، فسيتوجب عليك البحث عن مصدر تسجيل الدخول المثير للشبهات. يُخبرنا الاستعلام السّابق من قد سجّل دخوله في الوقت الحاليّ، لكن ماذا عن تسجيلات الدخول السّابقة؟ يُمكنك معرفة ذلك عبر استعلام الجدول last كما يلي: select * from last ; لا يُشير المُخرج إلى أي شيء غير اعتيادي، ما يعني بأنّه لم يُسجّل أي أحد غيرنا دخوله إلى الجهاز مُؤخّرا: +----------+-------+------+------+------------+------------------+ | username | tty | pid | type | time | host | +----------+-------+------+------+------------+------------------+ | reboot | ~ | 0 | 2 | 1483580419 | 4.4.0-57-generic | | runlevel | ~ | 53 | 1 | 1483580426 | 4.4.0-57-generic | | | ttyS0 | 1546 | 5 | 1483580429 | | | LOGIN | ttyS0 | 1546 | 6 | 1483580429 | | | | tty1 | 1549 | 5 | 1483580429 | | | LOGIN | tty1 | 1549 | 6 | 1483580429 | | | root | pts/0 | 1752 | 7 | 1483580584 | 11.11.11.11 | | sammy | pts/1 | 4057 | 7 | 1483580770 | 11.11.11.11 | +----------+-------+------+------+------------+------------------+ هل تم ضبط وتفعيل الجدار النّاري؟ هل لا يزال الجدار النّاري قيد التّشغيل؟ إن كنت في شك من أمرك، فنفّذ الاستعلام التّالي: select * from iptables ; إن لم تحصل على أي مُخرج، فهذا يعني بأنّ جدار IPTables النّاري لم يُضبَط. إن كان الخادوم مُتصلا بالأنترنت فهذا ليس جيّدا، لذا من المُفضّل أن تُعدّ الجدار النّاري الخاصّ بك. يُمكنك تعديل الاستعلام السّابق وتنفيذه لترشيح أعمدة مُحدّدة كما يلي: select chain, policy, src_ip, dst_ip from iptables ; يجب على الاستعلام أن يمنحك مُخرجا مُشابها لما يلي. ابحث عن أي مصدر مُثير للشبهات وعناوين IP الوجهة (destination IP addresses) التي لم تقم بضبطها: +---------+--------+---------+-----------+ | chain | policy | src_ip | dst_ip | +---------+--------+---------+-----------+ | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 127.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | INPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | FORWARD | ACCEPT | 0.0.0.0 | 0.0.0.0 | | FORWARD | ACCEPT | 0.0.0.0 | 0.0.0.0 | | OUTPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | | OUTPUT | ACCEPT | 0.0.0.0 | 0.0.0.0 | +---------+--------+---------+-----------+ ما نوع العمليّات الموقوتة في crontab؟ هل قُمت بتوقيتها بنفسك؟ سيُساعدك الاستعلام التّالي على اكتشاف البرمجيات الخبيثة التي تمّ توقيتها لتعمل في فترات زمنية مُعيّنة: select command, path from crontab ; يجب على المُخرج أن يكون على الشّكل التّالي. إن بدت أية أوامر مُثيرة للشبهات، فهذا يعني بأنّها تحتاج إلى تحقيق إضافي: +----------------------------------------------------------------------------------------------------------------------------------------+--------------------------------+ | command | path | +----------------------------------------------------------------------------------------------------------------------------------------+--------------------------------+ | root cd / && run-parts --report /etc/cron.hourly | /etc/crontab | | root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily ) | /etc/crontab | | root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.weekly ) | /etc/crontab | | root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.monthly ) | /etc/crontab | | root if [ -x /usr/share/mdadm/checkarray ] && [ $(date +\%d) -le 7 ]; then /usr/share/mdadm/checkarray --cron --all --idle --quiet; fi | /etc/cron.d/mdadm | | root test -x /etc/cron.daily/popularity-contest && /etc/cron.daily/popularity-contest --crond | /etc/cron.d/popularity-contest | +----------------------------------------------------------------------------------------------------------------------------------------+--------------------------------+ هل هناك من ملفّات على النّظام مع خاصيّة setuid مُفعّلة؟ هناك بضعة من هذه الأنواع من الملفّات على أي خادوم يعمل بـUbuntu 16.04، لكن أي من هذه هي؟ وهل هناك من ملفات لا يجب عليها أن تتواجد في النظام؟ يُمكن لإجابات هذه الأسئلة أن تُساعدك على اكتشاف ثنائيّات بأبواب خلفيّة (backdoored binaries). نفّذ الاستعلام التّالي بين الفينة والأخرى وقارن النتائج مع نتائج أقدم لتتمكن من اكتشاف أية إضافات أو تغييرات غير مرغوب فيها: select * from suid_bin ; مقطع من المُخرج يبدو كما يلي: +-------------------------------+----------+-----------+-------------+ | path | username | groupname | permissions | +-------------------------------+----------+-----------+-------------+ | /bin/ping6 | root | root | S | | /bin/su | root | root | S | | /bin/mount | root | root | S | | /bin/umount | root | root | S | | /bin/fusermount | root | root | S | | /bin/ntfs-3g | root | root | S | | /bin/ping | root | root | S | | /sbin/mount.ntfs-3g | root | root | S | | /sbin/mount.ntfs | root | root | S | | /sbin/unix_chkpwd | root | shadow | G | | /sbin/pam_extrausers_chkpwd | root | shadow | G | | /usr/bin/chage | root | shadow | G | | /usr/bin/locate | root | mlocate | G | | /usr/bin/chfn | root | root | S | | /usr/bin/chsh | root | root | S | | /usr/bin/newuidmap | root | root | S | | /usr/bin/write | root | tty | G | | /usr/bin/mlocate | root | mlocate | G | | /usr/bin/at | daemon | daemon | SG | | /usr/bin/sg | root | root | S | لعرض قائمة بوحدات النواة المُحمَّلة (loaded kernel modules)، نفّذ الاستعلام التّالي: select name, used_by, status from kernel_modules where status="Live" ; هذا استعلام آخر يجب تنفيذه بين الحين والآخر لمُقارنة مُخرجه مع نتائج أقدم للتحقق ممّا إذا كان هناك تغيير ما أو لا. عرض قائمة بجميع المنافذ المُنصتة (listening ports) من أحد الطرق الأخرى التي يُمكنك بها إيجاد أبواب خلفيّة على الخادوم. للقيام بذلك، نفّذ الأمر التّالي: select * from listening_ports ; يجب على المُخرج أن يكون كالتّالي على خادوم جديد مع SSH وحدها تعمل على المنفذ 22: +-------+------+----------+--------+---------+ | pid | port | protocol | family | address | +-------+------+----------+--------+---------+ | 1686 | 22 | 6 | 2 | 0.0.0.0 | | 1686 | 22 | 6 | 10 | :: | | 25356 | 0 | 0 | 0 | | +-------+------+----------+--------+---------+ إن كان المُخرج يحتوي على منافذ تعلم بأنّ الخادوم يُنصت منها، فلا داعي للقلق، أمّا إن كانت هناك منافذ أخرى مفتوحة، فسيتوجّب عليك التّحقيق في ماهيّة هذه المنافذ. لعرض نشاطات الملفّات على الخادوم، نفّذ الاستعلام التّالي: select target_path, action, uid from file_events ; يعرض المُخرج جميع نشاطات الملفات الحديثة على الخادوم، إضافة إلى مُعرّف المُستخدم المسؤول عن النّشاط: +---------------------------+---------+------+ | target_path | action | uid | +---------------------------+---------+------+ | /home/sammy/..bashrc.swp | CREATED | 1000 | | /home/sammy/..bashrc.swp | UPDATED | 1000 | | /home/sammy/..bashrc.swp | UPDATED | 1000 | | /home/sammy/.bashrc | UPDATED | 1000 | | /home/sammy/..bashrc.swp | DELETED | 1000 | | /home/sammy/..bashrc.swp | CREATED | 1000 | | /home/sammy/..bashrc.swp | UPDATED | 1000 | | /home/sammy/..bashrc.swp | UPDATED | 1000 | | /home/sammy/.bashrc | UPDATED | 1000 | | /home/sammy/.bashrc | UPDATED | 1000 | | /home/sammy/.bashrc | UPDATED | 1000 | | /home/sammy/..bashrc.swp | DELETED | | | /etc/test_file.txt | DELETED | | | /home/sammy/.bash_history | UPDATED | 1000 | | /home/sammy/.bash_history | UPDATED | 1000 | | /etc/secret_file.md | CREATED | 0 | | /etc/secret_file.md | UPDATED | 0 | | /etc/secret_file.md | UPDATED | 0 | +---------------------------+---------+------+ هناك العديد من الاستعلامات مُشابهة لما سبق يُمكنك بها أن تحصل على فكرة حول مشاكل أمنية مُحتملة. إن لم تكن مُتأكدا من مُخطّط (schema) جدول ما، يُمكنك استعمال الأمر التّالي لمعرفة مُخطّط الجدول: .schema name-of-table مع إبدال name-of-table باسم الجدول. ويُمكنك كذلك عرض قائمة بالجداول المُتوفرة بالأمر: .tables هناك العديد من الأمثلة الأخرى في الحزمات التي تأتي مع osquery، وقد صُمِّم العديد منها ليعمل بشكل دوري من طرف osqueryd. سنتعرّف في القسم التّالي على كيفيّة تشغيل العفريت لتنفيذ هذه الاستعلامات. ##الخطوة السّادسة: تشغيل osqueryd يسمح العفريت osqueryd بتنفيذ الاستعلامات في فترات زمنيّة مُحدّدة. ما يشمل كلّا من الاستعلامات التي ضبطناها في الخطوة الرّابعة، الاستعلامات المتواجدة في الحزمات التي أعددناها في تلك الخطوة، وحزمة FIM التي أعددناها في الخطوة الخامسة كذلك. إن لم تطّلع على الحزمات بعد، فهذا وقت مُناسب لإلقاء نظرة على مُحتويات /usr/share/osquery/packs. تُكتَب النتائج المُولَّدة من طرف osqueryd إلى ملفّ باسم osqueryd.results.log في مُجلّد /var/log/osquery. هذا الملفّ غير موجود افتراضيّا. ولا يتم إنشاؤه إلا بعد تشغيل العفريت وبدء توليد النّتائج من طرفه. يُمكنك تشغيل osqueryd إما بأداة systemctl أو osqueryctl. كلاهما يؤدي نفس المُهمّة، لذا لا يهم أيّ واحد منهما تستعمل. سيتحقّق osqueryd من تواجد ملفّ إعدادات عند تشغيله، وسيُنبّهك إن لم يجد واحدا. سيبقى مُشتغلا دون ملفّ إعدادات، إلا أن ذلك لن يكون ذا فائدة تُذكر. وبما أنّه قد سبق وأن أعددنا ملفّ إعدادات، فكل ما تحتاج إليه هو تشغيل العفريت: sudo systemctl start osqueryd أو يُمكن كتابة ما يلي: sudo osqueryctl start بعد بضعة دقائق من تشغيل العفريت، من المُفترض أن يزداد حجم الملفّ /var/log/osquery/osqueryd.results.log. يُمكنك أن ترى ذلك بنفسك عبر تنفيذ الأمر التّالي مرارا وتكرارا: ls -lh /var/log/osquery/osqueryd.results.log ازدياد حجم الملفّ يدل على أن نتائج الاستعلامات الموقوتة تُكتَب على القرص. لا يمتلك osquery للأسف نظام تنبيهات مثل OSSEC، ما يعني بأنّك لن تستطيع رؤية نتائج الاستعلامات الموقوتة إلا عبر عرض ملفّ النتائج. ويُمكنك القيام بذلك عبر الأمر tail الذي سيقوم بعرض آخر 10 أسطر من الملفّ على الشّاشة بشكل مُستمر: sudo tail -f /var/log/osquery/osqueryd.results.log اضغط على CTRL+C لإيقاف العرض المُستمرّ للسّجل. قد ترغب على المدى البعيد بنقل نتائج الاستعلامات إلى منصّة تحليل خارجيّة يُمكنك العمل معها. بعض الخيارات مفتوحة المصدر تشمل كلّا من Doorman، Zentral و ElasticSearch. ختاما يعد osquery أداة قويّة مُفيدة لتشغيل استعلامات ظرفية وموقوتة باستعمال جمل SQL المألوفة. osqueryi هو المكون الذي يُمكّنك من تشغيل استعلامات سريعة، أما osqueryd فهو للاستعلامات الموقوتة. لتحليل نتائج الاستعلامات الموقوتة، سيتوجب عليك نقلها إلى منصّة خارجية لتحليل السّجلات. يُمكنك الحصول على المزيد من المعلومات حول osquery على osquery.io. ترجمة -بتصرّف- للمقال How To Monitor Your System Security with osquery on Ubuntu 16.04 لصاحبه finid.-
- 1
-
-
- أمن النظام
- osquery
- (و 3 أكثر)
-
 منذ زمن سحيق، كانت الذاكرةُ أكثر وظيفة نحتاجها ونعتمد عليها في الحاسوب. ورغم اختلاف التقنيات وأساليب التنفيذ الكامنة وراءها، إلّا أنّ معظم الحواسيب تأتي بالعتاد الضروريّ لمعالجة المعلومات وحفظها بأمان لاستخدامها في المستقبل متى احتجنا لها. لقد صار من المستحيل في عالمنا الحديث تخيل أيّ عمل لا يستفيد من هذه القدرة في الأجهزة، سواء كانت خواديم أو حواسيب شخصية أو كفّيّة. تُعالَج البيانات وتُسجَّل وتُسترجَع مع كل عملية، وفي كل مكان من الألعاب إلى الأدوات المتعلقة بالأعمال، بما فيها المواقع. أنظمة إدارة قواعد البيانات (DataBase Management Systems – DBMS) هي برمجيات عالية المستوى تعمل مع واجهات برمجة تطبيقات (APIs) أدنى منها في المستوى، وتلك الواجهات بدورها تهتم بهذه العمليات. لقد تم تطوير العديد من أنظمة إدارة قواعد البيانات (كقواعد البيانات العلائقيّة relational databases، وnoSQL، وغيرها) لعقود من الزمن للمساعدة على حلّ المشكلات المختلفة، إضافة إلى برامج لها (مثل MySQL ,PostgreSQL ,MongoDB ,Redis، إلخ). سنقوم في هذا المقال بالمرور على أساسيّات قواعد البيانات وأنظمة إدارة قواعد البيانات. وسنتعرف من خلالها على المنطق الذي تعمل به قواعد البيانات المختلفة، وكيفية التفرقة بينها. أنظمة إدارة قواعد البياناتإن مفهوم نظام إدارة قاعدة البيانات مظلّةٌ تندرج تحتها كلّ الأدوات المختلفة أنواعها (كبرامج الحاسوب والمكتبات المضمّنة)، والتي غالبًا تعمل بطرق مختلفة وفريدة جدًّا. تتعامل هذه التطبيقات مع مجموعات من المعلومات، أو تساعد بكثرة في التعامل معها. وحيث أن المعلومات (أو البيانات) يُمكِن إن تأتي بأشكال وأحجام مختلفة، فقد تم تطوير العشرات من أنظمة قواعد البيانات، ومعها أعداد هائلة من تطبيقات قواعد البيانات منذ بداية النصف الثاني من القرن الحادي والعشرين، وذلك من أجل تلبية الاحتياجات الحوسبيّة والبرمجية المختلفة. تُبنى أنظمة إدارة قواعد البيانات على نماذج لقواعد البيانات: وهي بُنى محدّدة للتعامل مع البيانات. وكل تطبيق ونظام إدارة محتوى جديد أنشئ لتطبيق أساليبها يعمل بطريقة مختلفة فيما يتعلق بالتعريفات وعمليات التخزين والاسترجاع للمعلومات المُعطاة. ورغم أنّ هناك عددًا كبيرًا من الحلول التي تُنشئ أنظمة إدارة قواعد بيانات مختلفة، إلّا أنّ كلّ مدة زمنية تضمّنت خيارات محدودة صارت شائعة جدًّا وبقيت قيد الاستخدام لمدة أطول، والغالب أنّ أكثرها هيمنة على هذه الساحة خلال العقدين الأخيرين (وربما أكثر من ذلك) هي أنظمة إدارة قواعد البيانات العلائقيّة (Relational Database Management Systems – RDBMS). أنواع قواعد البياناتيستخدم كلُّ نظام إدارة بياناتٍ نموذجًا لقواعد البيانات لترتيب البيانات التي يديرها منطقيًّا. هذه النماذج (أو الأنواع) هي الخطوة الأولى والمحدّد الأهم لكيفية عمل تطبيق قواعد البيانات وكيفية تعامله مع المعلومات وتصرفه بها. هناك بعض الأنواع المختلفة لنماذج لقواعد البيانات التي تعرض بوضوع ودقّة معنى هيكلة البيانات، والغالب أن أكثر هذه الأنواع شهرةً قواعدُ البيانات العلائقيّة. ورغم أنّ النموذج العلائقيّ وقواعد البيانات العلائقيّة (relational databases) مرنة وقويّة للغاية –عندما يعلم المبرمج كيف يستخدمها–، إلّا أنّ هناك بعض المشكلات التي واجهات عديدين، وبعض المزايا التي لم تقدمها هذه الحلول. لقد بدأت حديثًا مجموعة من التطبيقات والأنظمة المختلفة المدعوّة بقواعد بيانات NoSQL بالاشتهار بسرعة كبيرة، والتي قدمت وعودًا لحل هذه المشكلات وتقديم بعض الوظائف المثيرة للاهتمام بشدّة. بالتخلص من البيانات المهيكلة بطريقة متصلّبة (بإبقاء النمط المعرّف في النموذج العلائقيّ (relational model))، تعمل هذه الأنظمة بتقديم طريقة حرّة أكثر في التعامل مع المعلومات، وبهذا توفّر سهولة ومرونة عاليتين جدًّا؛ رغم أنّها تأتي بمشاكل خاصة بها –والتي تكون بعضها جدّيّة– فيما يتعلق بطبيعة البيانات الهامّة والتي لا غنى عنها. النموذج العلائقيّيقدّم النظام العلائقيّ الذي ظهر في تسعينات القرن الماضي طريقة مناسبة للرياضيات في هيكلة وحفظ واستخدام البيانات. توسّع هذه الطريقة من التصاميم القديمة، كالنموذج المسطّح (flat)، والشبكيّ، وغيرها، وذلك بتقديمها مفهوم "العلاقات". تقدّم العلاقات فوائد تتعلق بتجميع البيانات كمجموعات مقيّدة، تربط فيها جداول البيانات –المحتوية على معلومات بطريقة منظمة (كاسم شخص وعنوانه مثلاً)– كل المدخلات بإعطاء قيم للصفات (كرقم هوية الشخص مثلًا). وبفضل عقود من البحث والتطوير، تعمل أنظمة قواعد البيانات التي تستخدم النموذج العلائقيّ بكفاءة وموثوقيّة عاليتين جدًّا. أضف إلى ذلك الخبرة الطويلة للمبرمجين ومديري قواعد البيانات في التعامل مع هذه الأدوات؛ لقد أدّى هذا إلى أن يصبح استخدام تطبيقات قواعد البيانات العلائقيّة الخيار الأمثل للتطبيقات ذات المهام الحرجة، والتي لا يمكنها احتمال فقدان أيّة بيانات تحت أيّ ظرف، وخاصة كنتيجة لخلل ما أو لطبيعة التطبيق نفسه الذي قد يكون أكثر عرضة للأخطاء. ورغم طبيعتها الصارمة المتعلقة بتشكيل والتعامل مع البيانات، يمكن لقواعد البيانات العلائقيّة أن تكون مرنة للغاية وأن تقدم الكثير، وذلك بتقديم قدر ضئيل من المجهود. التوجّه عديم النموذج (Model-less) أو NoSQLتعتمد طريقة NoSQL في هيكلة البيانات على التخلص من هذه القيود، حيث تحرر أساليب حفظ، واستعلام، واستخدام المعلومات. تسعى قواعد بيانات NoSQL إلى التخلص من العلائقات المعقدة، وتقدم أنواع عديدة من الطرق للحفاظ على البيانات والعمل عليها لحالات استخدام معينة بكفاءة (كتخزين مستندات كاملة النصوص)، وذلك من خلال استخدامها توجّها غير منظم (أو الهيكلة على الطريق / أثناء العمل). أنظمة إدارة قواعد بيانات شائعةهدفنا في هذا المقال هو أن نقدم لك نماذج عن بعض أشهر حلول قواعد البيانات وأكثرها استخدامًا. ورغم صعوبة الوصول إلى نتيجة بخصوص نسبة الاستخدام، يمكننا بوضوح افتراض أنّه بالنسبة لغالب الناس، تقع الاختيارات بين محرّكات قواعد البيانات العلائقيّة، أو محرك NoSQL أحدث. لكن قبل البدء بشرح الفروقات بين التطبيقات المختلفة لكل منهما، دعنا نرى ما يجري خلف الستار. أنظمة إدارة قواعد البيانات العلائقيّةلقد حصلت أنظمة إدارة قواعد البيانات العلائقيّة على اسمها من النموذج الذي تعتمد عليه، وهو النموذج العلائقيّ الذي ناقشناه أعلاه. إنّ هذه الأنظمة –الآن، وستبقى لمدة من الزمن في المستقبل– الخيار المفضّل للحفاظ على البيانات موثوقة وآمنة؛ وهي كذلك كفؤة. تتطلب أنظمة إدارة قواعد البيانات العلائقيّة مخططات معرفة ومحددة جيدًا –ولا يجب أن يختلط الأمر مع تعريف PostgreSQL الخاص بهذه الأنظمة– لقبول هذه البيانات. تشكّل هذه الهيئات التي يحددها المستخدم كيفية حفظ واستخدام البيانات. إنّ هذه المخططات شبيهة جدًّا بالجداول، وفيها أعمدة تمثّل عدد ونوع المعلومات التي تنتمي لكل سجل، والصفوف التي تمثّل المدخلات. من أنظمة إدارة قواعد البيانات الشائعة نذكر: SQLite: نظام إدارة قواعد بيانات علائقيّة مضمّن قويّ جدًّا.MySQL: نظام إدارة قواعد بيانات علائقيّة الأكثر شهرة والشائع استخدامه.PostgreSQL: أكثر نظام إدارة قواعد بيانات علائقيّة كيانيّ (objective-RDBMS) متقدم وهو متوافق مع SQL ومفتوح المصدر.ملاحظة: لمعرفة المزيد عن أنظمة إدارة قواعد بيانات NoSQL، راجع المقالة التالية عن الموضوع: A Comparison Of NoSQL Database Management Systems. أنظمة قواعد بيانات NoSQL (أو NewSQL)لا تأتي أنظمة قواعد بيانات NoSQL بنموذج كالمستخدم في (أو الذي تحتاجه) الحلول العلائقيّة المهيكلة. هناك العديد من التطبيقات، وكلّ منها تعمل بطريقة مختلفة كليًّا، وتخدم احتياجات محدّدة. هذه الحلول عديمة المخططات (schema-less) إمّا تسمح تشكيلات غير محدودة للمدخلات، أو –على العكس– بسيطة جدًّا ولكنها كفؤة للغاية كمخازن قيم معتمد على المفاتيح (key based value stores) مفيدة. على خلاف قواعد البيانات العلائقيّة التقليديّة، يمكن تجميع مجموعات من البينات معًا باستخدام قواعد بيانات NoSQL، كـ MongoDB مثلًا. تُبقي مخازن المستندات هذه كل قطعة من البيانات مع بعضها كمجموعة واحدة (أي كملف) في قاعدة البيانات. يمكن تمثيل هذه المستندات ككيانات بيانات منفردة، مثلها في ذلك كمثل JSON، ومع ذلك تبقى كراسات، وذلك يعتمد على خصائصها. ليس لقواعد بيانات NoSQL طريقة موحدة للاستعلام عن البيانات (مثل SQL لقواعد البيانات العلائقيّة) ويقدم كلّ من الحلول طريقته الخاصّة للاستعلام. ملاحظة: لمعرفة المزيد عن أنظمة إدارة قواعد البيانات العلائقيّة، ألق نظرة على هذه المقالة المتعلقة بالموضوع: A Comparison Of Relational Database Management Systems. مقارنة بين أنظمة إدارة قواعد بيانات SQL و NoSQLمن أجل الوصول إلى نتيجة بسيطة ومفهومة، لنحلّل أولًا الاختلافات بين أنظمة إدارة قواعد البيانات: هيكلية ونوع البيانات المحتفظ بها:تتطلب قواعد البيانات العلائقيّة SQL هيكلة ذات خصائص محدّدة للحفاظ على البيانات، على خلاف قواعد بيانات NoSQL التي تسمح بعمليات انسياب حُرّ (free-flow operations). الاستعلام: وبغضّ النظر عن تراخيصها، تستخدم كلّ قواعد البيانات العلائقيّة معيار SQL إلى حدّ ما، ولهذا يمكن الاستعلام فيها بلغة SQL (أي Structured Query Language). أما قواعد بيانات NoSQL فلا تستخدم طريقة محدّدة للعمل على البيانات التي تديرها. التحجيم: يمكن تحجيم كلي الحلين عموديًّا (أي بزيادة موارد النظام). لكن لكون حلول NoSQL تطبيقات أحدث (وأبسط)، فهذا يجعلها تقدّم وسائل أسهل بكثير لتحجيمها أفقيًّا (أي بإنشاء شبكة عنقودية cluster من أجهزة متعدّدة). المتانة Reliability: عندما يتعلق الأمر بالمتانة والثقة الآمنة بالقَيد المنفّذ، تبقى قواعد بيانات SQL الخيار الأفضل. الدعم: لأنظمة إدارة قواعد البيانات العلائقيّة تاريخ طويل استمر لعقود من الزمن. إنها شائعة جدًّا، ومن السهل إيجاد دعم سواء مجانيّ أو مدفوع. إذا حدثت مشكلة، فمن الأسهل حلّها عليها من قواعد بيانات NoSQL التي شاعت حديثًا، وخاصة إذا كان الحلّ موضع السؤال ذا طبيعة معقّدة (مثل MongoDB). احتياجات حفظ واستعلام البيانات المعقدة: إنّ قواعد البيانات العلائقيّة بطبيعتها الخيار الأمثل لاحتياجات حفظ البيانات والاستعلامات المعقّدة. إنها أكثر كفاءة وتتفوق في هذا المجال. ترجمة -وبتصرّف- للمقال Understanding SQL And NoSQL Databases And Different Database Models لصاحبه O.S. Tezer.
منذ زمن سحيق، كانت الذاكرةُ أكثر وظيفة نحتاجها ونعتمد عليها في الحاسوب. ورغم اختلاف التقنيات وأساليب التنفيذ الكامنة وراءها، إلّا أنّ معظم الحواسيب تأتي بالعتاد الضروريّ لمعالجة المعلومات وحفظها بأمان لاستخدامها في المستقبل متى احتجنا لها. لقد صار من المستحيل في عالمنا الحديث تخيل أيّ عمل لا يستفيد من هذه القدرة في الأجهزة، سواء كانت خواديم أو حواسيب شخصية أو كفّيّة. تُعالَج البيانات وتُسجَّل وتُسترجَع مع كل عملية، وفي كل مكان من الألعاب إلى الأدوات المتعلقة بالأعمال، بما فيها المواقع. أنظمة إدارة قواعد البيانات (DataBase Management Systems – DBMS) هي برمجيات عالية المستوى تعمل مع واجهات برمجة تطبيقات (APIs) أدنى منها في المستوى، وتلك الواجهات بدورها تهتم بهذه العمليات. لقد تم تطوير العديد من أنظمة إدارة قواعد البيانات (كقواعد البيانات العلائقيّة relational databases، وnoSQL، وغيرها) لعقود من الزمن للمساعدة على حلّ المشكلات المختلفة، إضافة إلى برامج لها (مثل MySQL ,PostgreSQL ,MongoDB ,Redis، إلخ). سنقوم في هذا المقال بالمرور على أساسيّات قواعد البيانات وأنظمة إدارة قواعد البيانات. وسنتعرف من خلالها على المنطق الذي تعمل به قواعد البيانات المختلفة، وكيفية التفرقة بينها. أنظمة إدارة قواعد البياناتإن مفهوم نظام إدارة قاعدة البيانات مظلّةٌ تندرج تحتها كلّ الأدوات المختلفة أنواعها (كبرامج الحاسوب والمكتبات المضمّنة)، والتي غالبًا تعمل بطرق مختلفة وفريدة جدًّا. تتعامل هذه التطبيقات مع مجموعات من المعلومات، أو تساعد بكثرة في التعامل معها. وحيث أن المعلومات (أو البيانات) يُمكِن إن تأتي بأشكال وأحجام مختلفة، فقد تم تطوير العشرات من أنظمة قواعد البيانات، ومعها أعداد هائلة من تطبيقات قواعد البيانات منذ بداية النصف الثاني من القرن الحادي والعشرين، وذلك من أجل تلبية الاحتياجات الحوسبيّة والبرمجية المختلفة. تُبنى أنظمة إدارة قواعد البيانات على نماذج لقواعد البيانات: وهي بُنى محدّدة للتعامل مع البيانات. وكل تطبيق ونظام إدارة محتوى جديد أنشئ لتطبيق أساليبها يعمل بطريقة مختلفة فيما يتعلق بالتعريفات وعمليات التخزين والاسترجاع للمعلومات المُعطاة. ورغم أنّ هناك عددًا كبيرًا من الحلول التي تُنشئ أنظمة إدارة قواعد بيانات مختلفة، إلّا أنّ كلّ مدة زمنية تضمّنت خيارات محدودة صارت شائعة جدًّا وبقيت قيد الاستخدام لمدة أطول، والغالب أنّ أكثرها هيمنة على هذه الساحة خلال العقدين الأخيرين (وربما أكثر من ذلك) هي أنظمة إدارة قواعد البيانات العلائقيّة (Relational Database Management Systems – RDBMS). أنواع قواعد البياناتيستخدم كلُّ نظام إدارة بياناتٍ نموذجًا لقواعد البيانات لترتيب البيانات التي يديرها منطقيًّا. هذه النماذج (أو الأنواع) هي الخطوة الأولى والمحدّد الأهم لكيفية عمل تطبيق قواعد البيانات وكيفية تعامله مع المعلومات وتصرفه بها. هناك بعض الأنواع المختلفة لنماذج لقواعد البيانات التي تعرض بوضوع ودقّة معنى هيكلة البيانات، والغالب أن أكثر هذه الأنواع شهرةً قواعدُ البيانات العلائقيّة. ورغم أنّ النموذج العلائقيّ وقواعد البيانات العلائقيّة (relational databases) مرنة وقويّة للغاية –عندما يعلم المبرمج كيف يستخدمها–، إلّا أنّ هناك بعض المشكلات التي واجهات عديدين، وبعض المزايا التي لم تقدمها هذه الحلول. لقد بدأت حديثًا مجموعة من التطبيقات والأنظمة المختلفة المدعوّة بقواعد بيانات NoSQL بالاشتهار بسرعة كبيرة، والتي قدمت وعودًا لحل هذه المشكلات وتقديم بعض الوظائف المثيرة للاهتمام بشدّة. بالتخلص من البيانات المهيكلة بطريقة متصلّبة (بإبقاء النمط المعرّف في النموذج العلائقيّ (relational model))، تعمل هذه الأنظمة بتقديم طريقة حرّة أكثر في التعامل مع المعلومات، وبهذا توفّر سهولة ومرونة عاليتين جدًّا؛ رغم أنّها تأتي بمشاكل خاصة بها –والتي تكون بعضها جدّيّة– فيما يتعلق بطبيعة البيانات الهامّة والتي لا غنى عنها. النموذج العلائقيّيقدّم النظام العلائقيّ الذي ظهر في تسعينات القرن الماضي طريقة مناسبة للرياضيات في هيكلة وحفظ واستخدام البيانات. توسّع هذه الطريقة من التصاميم القديمة، كالنموذج المسطّح (flat)، والشبكيّ، وغيرها، وذلك بتقديمها مفهوم "العلاقات". تقدّم العلاقات فوائد تتعلق بتجميع البيانات كمجموعات مقيّدة، تربط فيها جداول البيانات –المحتوية على معلومات بطريقة منظمة (كاسم شخص وعنوانه مثلاً)– كل المدخلات بإعطاء قيم للصفات (كرقم هوية الشخص مثلًا). وبفضل عقود من البحث والتطوير، تعمل أنظمة قواعد البيانات التي تستخدم النموذج العلائقيّ بكفاءة وموثوقيّة عاليتين جدًّا. أضف إلى ذلك الخبرة الطويلة للمبرمجين ومديري قواعد البيانات في التعامل مع هذه الأدوات؛ لقد أدّى هذا إلى أن يصبح استخدام تطبيقات قواعد البيانات العلائقيّة الخيار الأمثل للتطبيقات ذات المهام الحرجة، والتي لا يمكنها احتمال فقدان أيّة بيانات تحت أيّ ظرف، وخاصة كنتيجة لخلل ما أو لطبيعة التطبيق نفسه الذي قد يكون أكثر عرضة للأخطاء. ورغم طبيعتها الصارمة المتعلقة بتشكيل والتعامل مع البيانات، يمكن لقواعد البيانات العلائقيّة أن تكون مرنة للغاية وأن تقدم الكثير، وذلك بتقديم قدر ضئيل من المجهود. التوجّه عديم النموذج (Model-less) أو NoSQLتعتمد طريقة NoSQL في هيكلة البيانات على التخلص من هذه القيود، حيث تحرر أساليب حفظ، واستعلام، واستخدام المعلومات. تسعى قواعد بيانات NoSQL إلى التخلص من العلائقات المعقدة، وتقدم أنواع عديدة من الطرق للحفاظ على البيانات والعمل عليها لحالات استخدام معينة بكفاءة (كتخزين مستندات كاملة النصوص)، وذلك من خلال استخدامها توجّها غير منظم (أو الهيكلة على الطريق / أثناء العمل). أنظمة إدارة قواعد بيانات شائعةهدفنا في هذا المقال هو أن نقدم لك نماذج عن بعض أشهر حلول قواعد البيانات وأكثرها استخدامًا. ورغم صعوبة الوصول إلى نتيجة بخصوص نسبة الاستخدام، يمكننا بوضوح افتراض أنّه بالنسبة لغالب الناس، تقع الاختيارات بين محرّكات قواعد البيانات العلائقيّة، أو محرك NoSQL أحدث. لكن قبل البدء بشرح الفروقات بين التطبيقات المختلفة لكل منهما، دعنا نرى ما يجري خلف الستار. أنظمة إدارة قواعد البيانات العلائقيّةلقد حصلت أنظمة إدارة قواعد البيانات العلائقيّة على اسمها من النموذج الذي تعتمد عليه، وهو النموذج العلائقيّ الذي ناقشناه أعلاه. إنّ هذه الأنظمة –الآن، وستبقى لمدة من الزمن في المستقبل– الخيار المفضّل للحفاظ على البيانات موثوقة وآمنة؛ وهي كذلك كفؤة. تتطلب أنظمة إدارة قواعد البيانات العلائقيّة مخططات معرفة ومحددة جيدًا –ولا يجب أن يختلط الأمر مع تعريف PostgreSQL الخاص بهذه الأنظمة– لقبول هذه البيانات. تشكّل هذه الهيئات التي يحددها المستخدم كيفية حفظ واستخدام البيانات. إنّ هذه المخططات شبيهة جدًّا بالجداول، وفيها أعمدة تمثّل عدد ونوع المعلومات التي تنتمي لكل سجل، والصفوف التي تمثّل المدخلات. من أنظمة إدارة قواعد البيانات الشائعة نذكر: SQLite: نظام إدارة قواعد بيانات علائقيّة مضمّن قويّ جدًّا.MySQL: نظام إدارة قواعد بيانات علائقيّة الأكثر شهرة والشائع استخدامه.PostgreSQL: أكثر نظام إدارة قواعد بيانات علائقيّة كيانيّ (objective-RDBMS) متقدم وهو متوافق مع SQL ومفتوح المصدر.ملاحظة: لمعرفة المزيد عن أنظمة إدارة قواعد بيانات NoSQL، راجع المقالة التالية عن الموضوع: A Comparison Of NoSQL Database Management Systems. أنظمة قواعد بيانات NoSQL (أو NewSQL)لا تأتي أنظمة قواعد بيانات NoSQL بنموذج كالمستخدم في (أو الذي تحتاجه) الحلول العلائقيّة المهيكلة. هناك العديد من التطبيقات، وكلّ منها تعمل بطريقة مختلفة كليًّا، وتخدم احتياجات محدّدة. هذه الحلول عديمة المخططات (schema-less) إمّا تسمح تشكيلات غير محدودة للمدخلات، أو –على العكس– بسيطة جدًّا ولكنها كفؤة للغاية كمخازن قيم معتمد على المفاتيح (key based value stores) مفيدة. على خلاف قواعد البيانات العلائقيّة التقليديّة، يمكن تجميع مجموعات من البينات معًا باستخدام قواعد بيانات NoSQL، كـ MongoDB مثلًا. تُبقي مخازن المستندات هذه كل قطعة من البيانات مع بعضها كمجموعة واحدة (أي كملف) في قاعدة البيانات. يمكن تمثيل هذه المستندات ككيانات بيانات منفردة، مثلها في ذلك كمثل JSON، ومع ذلك تبقى كراسات، وذلك يعتمد على خصائصها. ليس لقواعد بيانات NoSQL طريقة موحدة للاستعلام عن البيانات (مثل SQL لقواعد البيانات العلائقيّة) ويقدم كلّ من الحلول طريقته الخاصّة للاستعلام. ملاحظة: لمعرفة المزيد عن أنظمة إدارة قواعد البيانات العلائقيّة، ألق نظرة على هذه المقالة المتعلقة بالموضوع: A Comparison Of Relational Database Management Systems. مقارنة بين أنظمة إدارة قواعد بيانات SQL و NoSQLمن أجل الوصول إلى نتيجة بسيطة ومفهومة، لنحلّل أولًا الاختلافات بين أنظمة إدارة قواعد البيانات: هيكلية ونوع البيانات المحتفظ بها:تتطلب قواعد البيانات العلائقيّة SQL هيكلة ذات خصائص محدّدة للحفاظ على البيانات، على خلاف قواعد بيانات NoSQL التي تسمح بعمليات انسياب حُرّ (free-flow operations). الاستعلام: وبغضّ النظر عن تراخيصها، تستخدم كلّ قواعد البيانات العلائقيّة معيار SQL إلى حدّ ما، ولهذا يمكن الاستعلام فيها بلغة SQL (أي Structured Query Language). أما قواعد بيانات NoSQL فلا تستخدم طريقة محدّدة للعمل على البيانات التي تديرها. التحجيم: يمكن تحجيم كلي الحلين عموديًّا (أي بزيادة موارد النظام). لكن لكون حلول NoSQL تطبيقات أحدث (وأبسط)، فهذا يجعلها تقدّم وسائل أسهل بكثير لتحجيمها أفقيًّا (أي بإنشاء شبكة عنقودية cluster من أجهزة متعدّدة). المتانة Reliability: عندما يتعلق الأمر بالمتانة والثقة الآمنة بالقَيد المنفّذ، تبقى قواعد بيانات SQL الخيار الأفضل. الدعم: لأنظمة إدارة قواعد البيانات العلائقيّة تاريخ طويل استمر لعقود من الزمن. إنها شائعة جدًّا، ومن السهل إيجاد دعم سواء مجانيّ أو مدفوع. إذا حدثت مشكلة، فمن الأسهل حلّها عليها من قواعد بيانات NoSQL التي شاعت حديثًا، وخاصة إذا كان الحلّ موضع السؤال ذا طبيعة معقّدة (مثل MongoDB). احتياجات حفظ واستعلام البيانات المعقدة: إنّ قواعد البيانات العلائقيّة بطبيعتها الخيار الأمثل لاحتياجات حفظ البيانات والاستعلامات المعقّدة. إنها أكثر كفاءة وتتفوق في هذا المجال. ترجمة -وبتصرّف- للمقال Understanding SQL And NoSQL Databases And Different Database Models لصاحبه O.S. Tezer. -
.png.f6bfb4790803ae169ff43eed67960d0c.png) تعرفنا في المقالات السابقة على مفهوم قواعد البيانات، وعرضنا مقدمة عن لغة الاستعلام البنائية SQL وأنواع الجمل فيها، وتعرفنا أيضا على كيفية بناء الجدول في قاعدة البيانات والتعديل على هيكله. سنتطرق في هذا المقال إلى مفهوم القيود الموجودة في قواعد البيانات، وسنتكلم عن أنواع البيانات التي يمكن استخدامها. أنواع البيانات Data Types في قاعدة البيانات يُحدّد نوع البيانات طبيعة وشكل القيمة التي من الممكن أن يأخذها العمود في الجدول، ويجب علينا أن نحدد اسم العمود ونوع بياناته عند إنشاء هذا الجدول وذلك في جملة إنشائه. توجد أنواع بيانات معيارية حدّدتها مؤسسة ANSI، ولكن ليس كل أنظمة إدارة قواعد البيانات توفر هذه المعايير وتطبقها على نحو كامل. يلخص الجدول التالي أهم وأشهر الأنواع المستخدمة هناك أنواع معيارية أخرى مثل XML، ARRAY، MULTISET ولكنها غير متداولة على نطاق واسع، ويجب الانتباه إلى أن نظم إدارة قواعد البيانات تختلف في تسمية وتعريف بعض أنواع البيانات، فمثلاً، نوع البيانات الرقم يسمى في قواعد بيانات أوراكل بـ Number ولكن في قواعد البيانات MySQL وPostgreSQL يسمى Int أو Integer. دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن القيود يعدّ موضوع القيود من المواضيع الهامة جدا في قواعد البيانات، ويجب على المبرمج ومسؤول قواعد البيانات الإلمام بأنواع القيود وكيفية تعريفها والتعامل معها. الهدف العام من القيود هو الحفاظ على سلامة البيانات Data integrity ودقتها. نستطيع أن نُعرّف القيد على أنه شرط يحكم العمود أو الجدول ويُتأكد من الالتزام بهذا الشرطعند إجراء عمليات مثل الإضافة والتعديل والحذف (على سبيل الذكر لا الحصر)، وفي حال لم يُحترَم الشرط فإن العملية مصدر الأمر تُرفَض ويوقَف تنفيذها ويُتراجع عن أي أثر أحدثته. مجال القيود تُطبَّق القيود على مستويين: مستوى العمود: يُعَرَّف القيد ضمن تعريف العمود ويطبق القيد على مستوى هذا العمود فقط. مستوى الجدول: يُعَرَّف القيد منفصلا عن أي عمود (عادة في نهاية تعريف الجدول)، ويمكن أن يطبق القيد على واحد أو أكثر من الأعمدة. أنواع القيود قيد “العمود غير الفارغ” Not Null Constraint: نستطيع إعطاء قيمة فارغة لعمود ما لم نُعرف هذا القيد عليه، والذي نقصد به منع إدخال أو إعطاء العمود قيمة فارغة Null عند إجراء عمليات مثل الإضافة أو التعديل على السجلات. يعرف المثال التالي جدولًا Persons مع تطبيق قيد العمود غير الفارغ على أول ثلاث أعمدة (طبقنا المثال على MySQL 5.7 وOracle XE): CREATE TABLE Persons ( ID int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255) NOT NULL, Age int ); قيد القيمة الفريدة UNIQUE Constraint: مهمة هذا القيد هي ضمان عدم تكرار قيمة عمود في أي من سجلات الجدول، بحيث تكون هذه القيمة فريدة ومختلفة. نستطيع تعريف أكثر من قيد فريد في الجدول على أكثر من عمود، كما أن قيد المفتاح الرئيسي (انظر بالأسفل) يقدم ضمان القيمة الفريدة للعمود بجانب القيد الفريد. يُعرَّف القيد الفريد بالطريقة التالية: CREATE TABLE Persons ( ID int NOT NULL UNIQUE, LastName varchar(255) NOT NULL, FirstName varchar(255) NOT NULL, Age int ); أو CREATE TABLE Persons ( ID int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Age int, UNIQUE (ID) ); وفي حال أردنا أن نعرف القيد على مستوى أكثر من عمود: CREATE TABLE Persons ( ID int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Age int, CONSTRAINT UC_Person UNIQUE (ID,LastName) ); قيد المفتاح الرئيسي Primary Key Constraint: يُطبَّق هذا القيد على عمود أو أكثر بحيث تكون قيمة العمود أو قيمة الأعمدة مجتمعة تُعَرِّف كل سجل على نحو فريد عن السجلات الأخرى في الجدول. يُعدّ قيد المفتاح الرئيسي قيدًا فريدًا أضيف إليه قيد غير فارغ. خصائص قيد المفتاح الرئيسي: يمكن تعريف قيد مفتاح رئيسي واحد على مستوى الجدول. لا يمكن تعريف قيد المفتاح الرئيسي على أعمدة من نوع BLOB،CLOB،NCLOB،ARRAY. قيم العمود المطبق عليه قيد المفتاح الرئيسي لابد أن تكون فريدة لكل سجل وألا تأخذ قيمة فارغة. تُعَرف قيود المفتاح الأجنبي بأخذها مَرجِعاً من مفتاح قيد رئيسي في جدول آخر، وذلك لبناء علاقة بين جدولين. يُعرَّف قيد المفتاح الرئيسي كالتالي: CREATE TABLE Persons ( ID int PRIMARY KEY, LastName varchar(255) NOT NULL, FirstName varchar(255), Age int ); أو CREATE TABLE Persons ( ID int , LastName varchar(255) NOT NULL, FirstName varchar(255), Age int, PRIMARY KEY (ID) ); نعرّف في ما يلي قيد مفتاح رئيسي على أكثر من عمود ونعطيه الاسم PK_Person: CREATE TABLE Persons ( ID int , LastName varchar(255) NOT NULL, FirstName varchar(255), Age int, CONSTRAINT PK_Person PRIMARY KEY (ID,LastName) ); قيد المفتاح الأجنبي Foreign Key Constraint: يعرّف قيد المفتاح الأجنبي عمودًا - أو أكثر - في الجدول على أنه مرجع من عمود يوجد في جدول آخر، بحيث تكون قيمة العمود مأخوذة من هذا العمود المرجعي بشرط أن يُعرَّف عليه قيد فريد أو قيد مفتاح رئيسي (في الجدول الآخر). يعدّ هذا القيد وسيلة لربط جداول قاعدة البيانات وبناء علاقات بينها، ومن الممكن تعريف أكثر من قيد أجنبي في الجدول الواحد. نستطيع أن نعرف القيد الأجنبي في الجدول كالتالي: CREATE TABLE Orders ( OrderID int NOT NULL, OrderNumber int NOT NULL, PersonID int, PRIMARY KEY (OrderID), FOREIGN KEY (PersonID) REFERENCES Persons(ID) ); لإعطاء القيد الأجنبي اسما مخصَّصا نستخدم الطريقة التالية: CREATE TABLE Orders ( OrderID int NOT NULL, OrderNumber int NOT NULL, PersonID int, PRIMARY KEY (OrderID), CONSTRAINT FK_PersonOrder FOREIGN KEY (PersonID) REFERENCES Persons(ID) ); إن أردت الاستزادة، فارجع إلى توثيق أنواع البيانات في لغة SQL من موسوعة حسوب.
تعرفنا في المقالات السابقة على مفهوم قواعد البيانات، وعرضنا مقدمة عن لغة الاستعلام البنائية SQL وأنواع الجمل فيها، وتعرفنا أيضا على كيفية بناء الجدول في قاعدة البيانات والتعديل على هيكله. سنتطرق في هذا المقال إلى مفهوم القيود الموجودة في قواعد البيانات، وسنتكلم عن أنواع البيانات التي يمكن استخدامها. أنواع البيانات Data Types في قاعدة البيانات يُحدّد نوع البيانات طبيعة وشكل القيمة التي من الممكن أن يأخذها العمود في الجدول، ويجب علينا أن نحدد اسم العمود ونوع بياناته عند إنشاء هذا الجدول وذلك في جملة إنشائه. توجد أنواع بيانات معيارية حدّدتها مؤسسة ANSI، ولكن ليس كل أنظمة إدارة قواعد البيانات توفر هذه المعايير وتطبقها على نحو كامل. يلخص الجدول التالي أهم وأشهر الأنواع المستخدمة هناك أنواع معيارية أخرى مثل XML، ARRAY، MULTISET ولكنها غير متداولة على نطاق واسع، ويجب الانتباه إلى أن نظم إدارة قواعد البيانات تختلف في تسمية وتعريف بعض أنواع البيانات، فمثلاً، نوع البيانات الرقم يسمى في قواعد بيانات أوراكل بـ Number ولكن في قواعد البيانات MySQL وPostgreSQL يسمى Int أو Integer. دورة علوم الحاسوب دورة تدريبية متكاملة تضعك على بوابة الاحتراف في تعلم أساسيات البرمجة وعلوم الحاسوب اشترك الآن القيود يعدّ موضوع القيود من المواضيع الهامة جدا في قواعد البيانات، ويجب على المبرمج ومسؤول قواعد البيانات الإلمام بأنواع القيود وكيفية تعريفها والتعامل معها. الهدف العام من القيود هو الحفاظ على سلامة البيانات Data integrity ودقتها. نستطيع أن نُعرّف القيد على أنه شرط يحكم العمود أو الجدول ويُتأكد من الالتزام بهذا الشرطعند إجراء عمليات مثل الإضافة والتعديل والحذف (على سبيل الذكر لا الحصر)، وفي حال لم يُحترَم الشرط فإن العملية مصدر الأمر تُرفَض ويوقَف تنفيذها ويُتراجع عن أي أثر أحدثته. مجال القيود تُطبَّق القيود على مستويين: مستوى العمود: يُعَرَّف القيد ضمن تعريف العمود ويطبق القيد على مستوى هذا العمود فقط. مستوى الجدول: يُعَرَّف القيد منفصلا عن أي عمود (عادة في نهاية تعريف الجدول)، ويمكن أن يطبق القيد على واحد أو أكثر من الأعمدة. أنواع القيود قيد “العمود غير الفارغ” Not Null Constraint: نستطيع إعطاء قيمة فارغة لعمود ما لم نُعرف هذا القيد عليه، والذي نقصد به منع إدخال أو إعطاء العمود قيمة فارغة Null عند إجراء عمليات مثل الإضافة أو التعديل على السجلات. يعرف المثال التالي جدولًا Persons مع تطبيق قيد العمود غير الفارغ على أول ثلاث أعمدة (طبقنا المثال على MySQL 5.7 وOracle XE): CREATE TABLE Persons ( ID int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255) NOT NULL, Age int ); قيد القيمة الفريدة UNIQUE Constraint: مهمة هذا القيد هي ضمان عدم تكرار قيمة عمود في أي من سجلات الجدول، بحيث تكون هذه القيمة فريدة ومختلفة. نستطيع تعريف أكثر من قيد فريد في الجدول على أكثر من عمود، كما أن قيد المفتاح الرئيسي (انظر بالأسفل) يقدم ضمان القيمة الفريدة للعمود بجانب القيد الفريد. يُعرَّف القيد الفريد بالطريقة التالية: CREATE TABLE Persons ( ID int NOT NULL UNIQUE, LastName varchar(255) NOT NULL, FirstName varchar(255) NOT NULL, Age int ); أو CREATE TABLE Persons ( ID int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Age int, UNIQUE (ID) ); وفي حال أردنا أن نعرف القيد على مستوى أكثر من عمود: CREATE TABLE Persons ( ID int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Age int, CONSTRAINT UC_Person UNIQUE (ID,LastName) ); قيد المفتاح الرئيسي Primary Key Constraint: يُطبَّق هذا القيد على عمود أو أكثر بحيث تكون قيمة العمود أو قيمة الأعمدة مجتمعة تُعَرِّف كل سجل على نحو فريد عن السجلات الأخرى في الجدول. يُعدّ قيد المفتاح الرئيسي قيدًا فريدًا أضيف إليه قيد غير فارغ. خصائص قيد المفتاح الرئيسي: يمكن تعريف قيد مفتاح رئيسي واحد على مستوى الجدول. لا يمكن تعريف قيد المفتاح الرئيسي على أعمدة من نوع BLOB،CLOB،NCLOB،ARRAY. قيم العمود المطبق عليه قيد المفتاح الرئيسي لابد أن تكون فريدة لكل سجل وألا تأخذ قيمة فارغة. تُعَرف قيود المفتاح الأجنبي بأخذها مَرجِعاً من مفتاح قيد رئيسي في جدول آخر، وذلك لبناء علاقة بين جدولين. يُعرَّف قيد المفتاح الرئيسي كالتالي: CREATE TABLE Persons ( ID int PRIMARY KEY, LastName varchar(255) NOT NULL, FirstName varchar(255), Age int ); أو CREATE TABLE Persons ( ID int , LastName varchar(255) NOT NULL, FirstName varchar(255), Age int, PRIMARY KEY (ID) ); نعرّف في ما يلي قيد مفتاح رئيسي على أكثر من عمود ونعطيه الاسم PK_Person: CREATE TABLE Persons ( ID int , LastName varchar(255) NOT NULL, FirstName varchar(255), Age int, CONSTRAINT PK_Person PRIMARY KEY (ID,LastName) ); قيد المفتاح الأجنبي Foreign Key Constraint: يعرّف قيد المفتاح الأجنبي عمودًا - أو أكثر - في الجدول على أنه مرجع من عمود يوجد في جدول آخر، بحيث تكون قيمة العمود مأخوذة من هذا العمود المرجعي بشرط أن يُعرَّف عليه قيد فريد أو قيد مفتاح رئيسي (في الجدول الآخر). يعدّ هذا القيد وسيلة لربط جداول قاعدة البيانات وبناء علاقات بينها، ومن الممكن تعريف أكثر من قيد أجنبي في الجدول الواحد. نستطيع أن نعرف القيد الأجنبي في الجدول كالتالي: CREATE TABLE Orders ( OrderID int NOT NULL, OrderNumber int NOT NULL, PersonID int, PRIMARY KEY (OrderID), FOREIGN KEY (PersonID) REFERENCES Persons(ID) ); لإعطاء القيد الأجنبي اسما مخصَّصا نستخدم الطريقة التالية: CREATE TABLE Orders ( OrderID int NOT NULL, OrderNumber int NOT NULL, PersonID int, PRIMARY KEY (OrderID), CONSTRAINT FK_PersonOrder FOREIGN KEY (PersonID) REFERENCES Persons(ID) ); إن أردت الاستزادة، فارجع إلى توثيق أنواع البيانات في لغة SQL من موسوعة حسوب.- 7 تعليقات
-
- 6
-
-
- sql
- نوع بيانات
- (و 1 أكثر)
-
.png.5c3adf073ec67e4fd3f7cc92cfbd782d.png) بعد أن تكلمنا في المقال السابق عن موضوع جملة الاستعلام في SQL وكيفية الاستعلام عن البيانات في جدول معين وترشيحها وفق الشروط التي نرغب بها، سنتناول في هذا المقال موضوع الفهارس Indexes وما تمثله في قاعدة البيانات، وما هي الفائدة منها. فهرس الجدول لو افترضنا وجود 1000 ملف ورقيّ غير مميزة عن بعضها وتحتوي على بيانات خاصة بطلاب جامعة، وهذه الملفات محفوظة في خزانتين منفصلتين، وأردنا الحصول على بيانات الطلاب الذين يسكنون منطقة معينة، ففي هذه الحالة سنضطر إلى فتح كل الملفات الموجودة في الخزانتيْن والبحث عن فئة الطلاب المستهدفة، وفرزهم والحصول على البيانات المطلوبة. ماذا لو كان لدينا عدد ملفات أكبر؟ سيزداد الوقت والجهد للحصول على البيانات، لذلك، فإن فكرة فهرسة الملفات في هذه الحالة ستكون أمرا جيدا بالتأكيد. سنُفهرِس مثلا الملفات حسب المكان ثم نحفظها في الخزانتين، بحيث تحتوي كل خزانة على بيانات الطلاب لمنطقة أو مناطق معينة. ثم داخل كل خزانة، نستطيع فرز الملفات وحفظها حسب الاسم مثلا. بتطبيق مفهوم الفهرسة، سنوفر على أنفسنا عناء البحث في الخزانتين، وسنقلل الوقت والجهد اللازمين لذلك. الفكرة الرئيسة للفهارس في قاعدة البيانات تدور حول المثال السابق، ففي ظل عصر تضخم البيانات، فإنه أصبح من الملح والضّروريّ وجود تقنيات لتسهيل الوصول السريع للمعلومة. ما هو الفهرس؟ لو أردنا مثلا أن نبحث عن اسم شخص في جدول الأشخاص Persons عبر استخدام الجملة التالية: SELECT * FROM Persons WHERE First_Name = "Ibrahim"; فإن نظام إدارة قاعدة البيانات سيمرّ على كل السجلات الموجودة في الجدول لترشيح السجلات وإرجاع تلك التي توافق الشرط في جملة where. ستظهر لنا مشكلة الوقت اللازم لتنفيذ جملة الاستعلام – وتزداد -كلما زاد عدد السجلات في الجدول، فلو كان لدينا مثلا مليون سجل في الجدول Persons، ولنفترض جدلاً أن النظام باستطاعته المرور على 10 آلاف سجل في الثانية، فإننا بحاجة إلى 100 ثانية لتنفيذ جملة الاستعلام السابقة. لحل المشكلة السابقة، فإن نُظم إدارة قواعد البيانات تقدم خاصية الفَهْرَسة. الفَهْرَسة هي ببساطة عبارة عن مؤشر يحتوي على نسخة من جزء من البيانات في الجدول، بحيث تقوم هذه النسخة من البيانات بمهمة “الدليل” أو “المُؤَشّر” الذي يسرع الوصول إلى البيانات الأصلية الكاملة الموجودة في الجدول، بحيث لا تحتاج المرور الكامل على كل الجدول (No Full Table Scan) عند البحث عن البيانات. يعدّ الفهرس عمليا طريقةً من طُرُق تراكيب البيانات، وهو عنصر مرتبط بوجود جدول في قاعدة البيانات، ولكن نستطيع تعريفه وحذفه منفصلا عن تعريف الجدول، ولا يكون له أي تأثير على نفس البيانات، فعند حذف الفهرس، فإن البيانات الموجودة في الجدول لا تتأثر. يكون الفهرس في أغلب أنظمة إدارة قواعد البيانات من نوع “B-Tree” ويأتي هذا الاسم من بنية البيانات Data structure التي تحمل نفس الاسم، وهو المفضل لأن تُطبقه على العمود الذي يحتوي قيمًا متنوعة وكثيرة مثل الرقم القومي للشخص، وليس من المفضل أن تطبق فهرس “B-Tree” على العمود الذي يحتوي عددًا قليلًا من القيم. توجد أنواع أخرى من الفهارس تُقدمها أنظمة إدارة قواعد البيانات مثل “Bitmap Index” و “Denes Index” ولكننا لن نتكلم عنها هنا لأنها خارج إطار موضوع المقال ولأنها تحتاج إلى مقالة منفصلة لشرحها. كيف تُعرَّف الفهارس؟ يُعرَّف الفهرس بطريقتيْن: تعريفه ضمنيًّا: تُبنَى الفهارس ضمنيا على الأعمدة التي يُطَبَّق عليها القيد الفريد وقيد المفتاح الرئيسي، فعند تعريف أحد القيود السابقة، يُبنى فهرس تلقائيًّا على العمود أو الأعمدة المُقيَّدة. تعريفه صراحةً: يُبنَى الفهرس بطريقة مباشرة على العمود أو الأعمدة الذي نرغب وذلك باستخدام جملة Create Index. على الرغم من أنه لا يوجد تعريف للفهرس في معايير SQL، إلا أن أغلب أنظمة إدارة قواعد البيانات تقدم الإمكانية لتعريف الفهرس ويتفق أغلبها على الصيغة العامة لذلك. الصيغة العامة لتعريف الفهرس: CREATE INDEX index_name ON table_name (column1, column2, ...); عند تعريف الفهرس، لابد أن يكون اسمه متوافقا مع القيود الخاصة بنظام إدارة قاعدة البيانات المستخدم، كما أنه يجب ألا يكون مُكررا، فأسماء الفهارس في قواعد البيانات يجب أن تكون فريدة ولا تتكرر. لإضافة فهرس باسم First_Name_idx على عمود First_Name في الجدول Persons ننفذ الجملة التالية: CREATE INDEX First_Name_idx ON Persons (First_Name); نستطيع تعريف فهرس فريد UNIQUE Index على عمود ممّا يجعل نظام قواعد البيانات يفحص التكرار داخل هذا النوع من الفهارس، حيث يتأكد النظام - في حالة إضافة أو تعديل قيمة لعمود عليه فهرس فريد - من أن هذه القيمة فريدة وغير مكررة؛ وفي حال كانت مكررة، يُرفَض هذا التغيير ويُظهَر خطأ في العملية. مثلا، لو أردنا أن نضيف فهرسًا فريدًا على عمود Age في الجدول Persons ننفذ الجملة التالية: CREATE UNIQUE INDEX Age_idx ON Persons (Age); نستطيع أيضا تعريف الفهرس على أكثر من عمود، كما في المثال التالي: CREATE UNIQUE INDEX Multiple_Columns_idx ON Persons (First_Name ,Age); عرّفنا في المثال السابق فهرسًا على عمودين، وفي هذه الحالة، فإن الفهرس سيفيد في تنفيذ جملة الترتيب Order by التي تحتوي العمود First_Name ثم عمود Age بنفس الترتيب. لن نستفيد من الفهرس السابق في حالة تنفيذ جملة الترتيب بترتيب مختلف للعمودين، ولن نستفيد أيضا منه في حالة تنفيذ جملة الاستعلام المشروطة بالبحث في هذين العمودين، حيث نحتاج لتعريف فهارس أخرى لكل عمود على حدة لتسريع عملية الاستعلام مع جملة Where. حذف الفهارس الصيغة العامة لحذف الفهرس كالتالي: DROP INDEX Index_Name ; فلحذف فهرس باسم Age_idx ننفذ الأمر التالي: DROP INDEX Age_idx ; متى نستخدم الفهارس؟ يفضل أن يتم بناء الفهارس على الأعمدة التي: يُبحث عنها في جملة Where. تُكتَب في جملة الترتيب Order By. تُكتَب في جملة التجميع Group By. تُستخدَم في جمل الربط Joins. تُستخدَم في الدوال الإحصائية مثل min وmax وmedian. متى نتجنب استخدام الفهارس؟ لا تعدّ الفهارس مناسبة على الأعمدة التي: - تحتوي على قيم فريدة قليلة مثل عمود الجنس (قيمتان فقط)، أو الحالة الاجتماعية. - نادرة الاستخدام في جمل الاستعلام SELECT. - التي تكون جزءًا من جدول ذي سجلات قليلة. ملاحظات هامة: لأن الفهرس عنصر مستقل في قواعد البيانات، وبناؤه وتعريفه يعدّ إضافة عليها، فلابد أن يدير مسؤول قاعدة البيانات الصلاحيات اللازمة لهذا الأمر بحيث لا يؤثر سلبا على أداء قاعدة البيانات. لا يعدّ الفهرس أساسيا في بناء الجدول في قاعدة البيانات، وعليه قد لا يحتوي الجدول على فهرس، وقد يحتوي على فهرس أو أكثر. نستطيع أن نُعرّف الفهرس عند بناء الجدول (في نفس جملة بناء الجدول)، ولكن من ناحية عملية، فإن إدارة الفهارس والتعامل معها تعدّ عملية مستمرة ومتكررة. تُبنَى الفهارس وتُحذَف حسب الحاجة للوصول إلى الكفاءة المطلوبة في قاعدة البيانات، لذلك تُقدم نُظم قواعد البيانات الأدوات اللازمة لقياس كفاءة جمل الاستعلام وقياس الحاجة لبناء الفهارس من عدمه. لا تُعَرِّف فهارس أكثر من حاجتك وخاصة في الجداول التي تحتوي سجلات كثيرة، فكما أن الفهارس تُسرع من عملية الوصول للبيانات، فإنها تؤثر سلبا على عمليات الإضافة والتعديل، فعند كل إضافة أو تعديل لابد من تعديل الفهرس ليتلاءم مع التغييرات الجديدة. عند تعريف الفهرس، فإن نظام قاعدة البيانات هو الذي يحافظ على الفهرس ويستخدمه تلقائيا، وعليه لا يُطلب من مسؤول قاعدة البيانات أو المبرمج أو حتى المستخدم أي إجراء آخر بعد تعريف وبناء الفهرس. يُسمى الفهرس الذي يُعرَّف على عمود واحد “فهرسا بسيطا”، والفهرس الذي يُعرَّف على أكثر من عمود يسمى “فهرسا مركبا”.
بعد أن تكلمنا في المقال السابق عن موضوع جملة الاستعلام في SQL وكيفية الاستعلام عن البيانات في جدول معين وترشيحها وفق الشروط التي نرغب بها، سنتناول في هذا المقال موضوع الفهارس Indexes وما تمثله في قاعدة البيانات، وما هي الفائدة منها. فهرس الجدول لو افترضنا وجود 1000 ملف ورقيّ غير مميزة عن بعضها وتحتوي على بيانات خاصة بطلاب جامعة، وهذه الملفات محفوظة في خزانتين منفصلتين، وأردنا الحصول على بيانات الطلاب الذين يسكنون منطقة معينة، ففي هذه الحالة سنضطر إلى فتح كل الملفات الموجودة في الخزانتيْن والبحث عن فئة الطلاب المستهدفة، وفرزهم والحصول على البيانات المطلوبة. ماذا لو كان لدينا عدد ملفات أكبر؟ سيزداد الوقت والجهد للحصول على البيانات، لذلك، فإن فكرة فهرسة الملفات في هذه الحالة ستكون أمرا جيدا بالتأكيد. سنُفهرِس مثلا الملفات حسب المكان ثم نحفظها في الخزانتين، بحيث تحتوي كل خزانة على بيانات الطلاب لمنطقة أو مناطق معينة. ثم داخل كل خزانة، نستطيع فرز الملفات وحفظها حسب الاسم مثلا. بتطبيق مفهوم الفهرسة، سنوفر على أنفسنا عناء البحث في الخزانتين، وسنقلل الوقت والجهد اللازمين لذلك. الفكرة الرئيسة للفهارس في قاعدة البيانات تدور حول المثال السابق، ففي ظل عصر تضخم البيانات، فإنه أصبح من الملح والضّروريّ وجود تقنيات لتسهيل الوصول السريع للمعلومة. ما هو الفهرس؟ لو أردنا مثلا أن نبحث عن اسم شخص في جدول الأشخاص Persons عبر استخدام الجملة التالية: SELECT * FROM Persons WHERE First_Name = "Ibrahim"; فإن نظام إدارة قاعدة البيانات سيمرّ على كل السجلات الموجودة في الجدول لترشيح السجلات وإرجاع تلك التي توافق الشرط في جملة where. ستظهر لنا مشكلة الوقت اللازم لتنفيذ جملة الاستعلام – وتزداد -كلما زاد عدد السجلات في الجدول، فلو كان لدينا مثلا مليون سجل في الجدول Persons، ولنفترض جدلاً أن النظام باستطاعته المرور على 10 آلاف سجل في الثانية، فإننا بحاجة إلى 100 ثانية لتنفيذ جملة الاستعلام السابقة. لحل المشكلة السابقة، فإن نُظم إدارة قواعد البيانات تقدم خاصية الفَهْرَسة. الفَهْرَسة هي ببساطة عبارة عن مؤشر يحتوي على نسخة من جزء من البيانات في الجدول، بحيث تقوم هذه النسخة من البيانات بمهمة “الدليل” أو “المُؤَشّر” الذي يسرع الوصول إلى البيانات الأصلية الكاملة الموجودة في الجدول، بحيث لا تحتاج المرور الكامل على كل الجدول (No Full Table Scan) عند البحث عن البيانات. يعدّ الفهرس عمليا طريقةً من طُرُق تراكيب البيانات، وهو عنصر مرتبط بوجود جدول في قاعدة البيانات، ولكن نستطيع تعريفه وحذفه منفصلا عن تعريف الجدول، ولا يكون له أي تأثير على نفس البيانات، فعند حذف الفهرس، فإن البيانات الموجودة في الجدول لا تتأثر. يكون الفهرس في أغلب أنظمة إدارة قواعد البيانات من نوع “B-Tree” ويأتي هذا الاسم من بنية البيانات Data structure التي تحمل نفس الاسم، وهو المفضل لأن تُطبقه على العمود الذي يحتوي قيمًا متنوعة وكثيرة مثل الرقم القومي للشخص، وليس من المفضل أن تطبق فهرس “B-Tree” على العمود الذي يحتوي عددًا قليلًا من القيم. توجد أنواع أخرى من الفهارس تُقدمها أنظمة إدارة قواعد البيانات مثل “Bitmap Index” و “Denes Index” ولكننا لن نتكلم عنها هنا لأنها خارج إطار موضوع المقال ولأنها تحتاج إلى مقالة منفصلة لشرحها. كيف تُعرَّف الفهارس؟ يُعرَّف الفهرس بطريقتيْن: تعريفه ضمنيًّا: تُبنَى الفهارس ضمنيا على الأعمدة التي يُطَبَّق عليها القيد الفريد وقيد المفتاح الرئيسي، فعند تعريف أحد القيود السابقة، يُبنى فهرس تلقائيًّا على العمود أو الأعمدة المُقيَّدة. تعريفه صراحةً: يُبنَى الفهرس بطريقة مباشرة على العمود أو الأعمدة الذي نرغب وذلك باستخدام جملة Create Index. على الرغم من أنه لا يوجد تعريف للفهرس في معايير SQL، إلا أن أغلب أنظمة إدارة قواعد البيانات تقدم الإمكانية لتعريف الفهرس ويتفق أغلبها على الصيغة العامة لذلك. الصيغة العامة لتعريف الفهرس: CREATE INDEX index_name ON table_name (column1, column2, ...); عند تعريف الفهرس، لابد أن يكون اسمه متوافقا مع القيود الخاصة بنظام إدارة قاعدة البيانات المستخدم، كما أنه يجب ألا يكون مُكررا، فأسماء الفهارس في قواعد البيانات يجب أن تكون فريدة ولا تتكرر. لإضافة فهرس باسم First_Name_idx على عمود First_Name في الجدول Persons ننفذ الجملة التالية: CREATE INDEX First_Name_idx ON Persons (First_Name); نستطيع تعريف فهرس فريد UNIQUE Index على عمود ممّا يجعل نظام قواعد البيانات يفحص التكرار داخل هذا النوع من الفهارس، حيث يتأكد النظام - في حالة إضافة أو تعديل قيمة لعمود عليه فهرس فريد - من أن هذه القيمة فريدة وغير مكررة؛ وفي حال كانت مكررة، يُرفَض هذا التغيير ويُظهَر خطأ في العملية. مثلا، لو أردنا أن نضيف فهرسًا فريدًا على عمود Age في الجدول Persons ننفذ الجملة التالية: CREATE UNIQUE INDEX Age_idx ON Persons (Age); نستطيع أيضا تعريف الفهرس على أكثر من عمود، كما في المثال التالي: CREATE UNIQUE INDEX Multiple_Columns_idx ON Persons (First_Name ,Age); عرّفنا في المثال السابق فهرسًا على عمودين، وفي هذه الحالة، فإن الفهرس سيفيد في تنفيذ جملة الترتيب Order by التي تحتوي العمود First_Name ثم عمود Age بنفس الترتيب. لن نستفيد من الفهرس السابق في حالة تنفيذ جملة الترتيب بترتيب مختلف للعمودين، ولن نستفيد أيضا منه في حالة تنفيذ جملة الاستعلام المشروطة بالبحث في هذين العمودين، حيث نحتاج لتعريف فهارس أخرى لكل عمود على حدة لتسريع عملية الاستعلام مع جملة Where. حذف الفهارس الصيغة العامة لحذف الفهرس كالتالي: DROP INDEX Index_Name ; فلحذف فهرس باسم Age_idx ننفذ الأمر التالي: DROP INDEX Age_idx ; متى نستخدم الفهارس؟ يفضل أن يتم بناء الفهارس على الأعمدة التي: يُبحث عنها في جملة Where. تُكتَب في جملة الترتيب Order By. تُكتَب في جملة التجميع Group By. تُستخدَم في جمل الربط Joins. تُستخدَم في الدوال الإحصائية مثل min وmax وmedian. متى نتجنب استخدام الفهارس؟ لا تعدّ الفهارس مناسبة على الأعمدة التي: - تحتوي على قيم فريدة قليلة مثل عمود الجنس (قيمتان فقط)، أو الحالة الاجتماعية. - نادرة الاستخدام في جمل الاستعلام SELECT. - التي تكون جزءًا من جدول ذي سجلات قليلة. ملاحظات هامة: لأن الفهرس عنصر مستقل في قواعد البيانات، وبناؤه وتعريفه يعدّ إضافة عليها، فلابد أن يدير مسؤول قاعدة البيانات الصلاحيات اللازمة لهذا الأمر بحيث لا يؤثر سلبا على أداء قاعدة البيانات. لا يعدّ الفهرس أساسيا في بناء الجدول في قاعدة البيانات، وعليه قد لا يحتوي الجدول على فهرس، وقد يحتوي على فهرس أو أكثر. نستطيع أن نُعرّف الفهرس عند بناء الجدول (في نفس جملة بناء الجدول)، ولكن من ناحية عملية، فإن إدارة الفهارس والتعامل معها تعدّ عملية مستمرة ومتكررة. تُبنَى الفهارس وتُحذَف حسب الحاجة للوصول إلى الكفاءة المطلوبة في قاعدة البيانات، لذلك تُقدم نُظم قواعد البيانات الأدوات اللازمة لقياس كفاءة جمل الاستعلام وقياس الحاجة لبناء الفهارس من عدمه. لا تُعَرِّف فهارس أكثر من حاجتك وخاصة في الجداول التي تحتوي سجلات كثيرة، فكما أن الفهارس تُسرع من عملية الوصول للبيانات، فإنها تؤثر سلبا على عمليات الإضافة والتعديل، فعند كل إضافة أو تعديل لابد من تعديل الفهرس ليتلاءم مع التغييرات الجديدة. عند تعريف الفهرس، فإن نظام قاعدة البيانات هو الذي يحافظ على الفهرس ويستخدمه تلقائيا، وعليه لا يُطلب من مسؤول قاعدة البيانات أو المبرمج أو حتى المستخدم أي إجراء آخر بعد تعريف وبناء الفهرس. يُسمى الفهرس الذي يُعرَّف على عمود واحد “فهرسا بسيطا”، والفهرس الذي يُعرَّف على أكثر من عمود يسمى “فهرسا مركبا”. -
![مزيد من المعلومات حول "[فيديو] تثبيت وإعداد قاعدة بيانات PostgreSQL"](https://academy.hsoub.com/uploads/monthly_2019_03/PostgreSQL.png.9093b6cae4c4e4e9f39e6cb61aaac614.png) نشرح طريقة تثبيت وإعداد خادم PostgreSQL على نظام أوبنتو 18.04. مع إعداد كلمة مرور للمستخدم root؛ وإنشاء قاعدة بيانات جديدة ومستخدم جديد لديه الصلاحيات الكاملة عليها. قسم PostgreSQL في أكاديمية حسوب غني بالمقالات المفيدة للتعامل معها: https://academy.hsoub.com/devops/servers/databases/postgresql/ نوفر توثيقًا كاملًا لجميع تعليمات SQL على موسوعة حسوب: https://wiki.hsoub.com/SQL
نشرح طريقة تثبيت وإعداد خادم PostgreSQL على نظام أوبنتو 18.04. مع إعداد كلمة مرور للمستخدم root؛ وإنشاء قاعدة بيانات جديدة ومستخدم جديد لديه الصلاحيات الكاملة عليها. قسم PostgreSQL في أكاديمية حسوب غني بالمقالات المفيدة للتعامل معها: https://academy.hsoub.com/devops/servers/databases/postgresql/ نوفر توثيقًا كاملًا لجميع تعليمات SQL على موسوعة حسوب: https://wiki.hsoub.com/SQL -
![مزيد من المعلومات حول "[فيديو] تثبيت وإعداد قاعدة بيانات MySQL"](https://academy.hsoub.com/uploads/monthly_2019_03/mysql.png.94e6e25b52d79b71f687b15797317eee.png) نشرح طريقة تنصيب وإعداد خادم MySQL على نظام أوبنتو 18.04. مع إعداد كلمة مرور للمستخدم root؛ وإنشاء قاعدة بيانات جديدة ومستخدم جديد لديه الصلاحيات الكاملة عليها. نوفر توثيقًا كاملًا لجميع تعليمات SQL على موسوعة حسوب: https://wiki.hsoub.com/SQL
نشرح طريقة تنصيب وإعداد خادم MySQL على نظام أوبنتو 18.04. مع إعداد كلمة مرور للمستخدم root؛ وإنشاء قاعدة بيانات جديدة ومستخدم جديد لديه الصلاحيات الكاملة عليها. نوفر توثيقًا كاملًا لجميع تعليمات SQL على موسوعة حسوب: https://wiki.hsoub.com/SQL -
.png.eae0d9a0ff09780f6eca35a28749217a.png) من الممكن أن تكون المعايرة مهمّة صعبة جدًا، وخاصّة عند العمل مع بيانات ضخمة، حيث أنّ أصغر تغيير من الممكن أن يتسبب بتغيرات غير متوقعه ( إيجابية أو سلبية) على الأداء ككل. تتم معظم عمليات معايرة SQl database في الشركات المتوسطة والصغيرة من قبل مدير قاعدة البيانات (Database Administrator (DBA، لكن صدقني، يوجد العديد من المطوّرين بحاجة للقيام بعمليات متعلقة بالإدارة، وأكثر من ذلك أنا شاهدت أنّهم يقومون فعليًّا بعمليات الإدارة في كثير من الشركات التي تتطلع للعمل مع المطوّرين، حين يتطلب الوضع ببساطة تقنيات مختلفة لحل المشاكل، والتي يمكن أن تؤدي إلى خلاف بين زملاء العمل. عند التعامل مع بيانات ضخمة، فإنّ التغيير الصغير قد يؤدي إلى تغيرات غير متوقعة على الأداء. وبناء على ذلك، فإنّ هيكلية الشبكة أيضًا لها تأثير، افترض أن فريق الإدارة DBA team مع قواعد البيانات التي يديرونها يتوضع في الطابق العاشر، بينما يتوضع المطوّرين في الطابق الخامس عشر، أو حتى في بناء مختلف تحت هيكلية منفصلة تمامًا، وبالتالي من الصعب العمل المشترك بينهم بمرونة تحت هذه الظروف، سأقوم بإتمام شيئين هامين في هذه المقالة: تزويد المطوّرين بتقنيات معايرة لقواعد بيانات خاصة بالمطوّرين. شرح كيف يمكن لمطوّري ومديري قواعد البيانات العمل معًا بكفاءة. تحسين قاعدة البيانات (في Codebase) الفهارس إذا كنت حديثًا في مجال قواعد البيانات أو حتى تسأل نفسك، “ماهي معايرة SQL”، فيجب أن تعلم أنّ الفهرسة هي طريقة فعّالة لمعايرة قاعدة البيانات database SQL الخاصة بك، والتي غالبًا ما يتم إهمالها خلال عملية التطوير، كمصطلح أولي: الفهرس index هو هيكلة للبيانات تسمح بتسريع عملية استخلاص هذه البيانات من جدول قاعدة البيانات، عن طريق تأمين عمليات بحث عشوائية سريعة، وطريقة فعّالة للوصول إلى السجلات المرتبة، هذا يعني أنّه حالما تقوم بإنشاء فهرس يمكنك القيام بعمليات الاستعلام والترتيب بشكل أسرع. تستخدم الفهارس أيضًا لتعريف المفتاح الرئيسي أو فهرس فريد يضمن أنّ أي عمود آخر لن يحتوي نفس القيمة. بالطبع إنّ موضوع الفهرسة متنوع وهام ولا يمكنني إعطاءه حقه في هذا الوصف الموجز. إذا كنت حديثًا على موضوع الفهرسة فأنا أفضل أن تستخدم هذا المخطط لهيكلة استعلاماتك. بشكل أولي، الهدف هو فهرسة أعمدة البحث والترتيب. لاحظ أنه إذا كانت تجري بشكل مستمر عمليات إدخال INSERT أو تعديل UPDATE أو حذف DELETE، فيجب عليك الحذر من القيام بعمليات الفهرسة، حيث يمكن أن يؤدي إلى هبوط في الأداء، إذ أنّه يتطلب تعديل جميع الفهارس بعد هذه العمليات. كذلك مديري قواعد البيانات يقومون بحذف الفهارس قبل القيام مثلًا بإدخال أكثر من مليون سجل دفعة واحدة، وذلك لتسريع عملية الإدخال، ثم يقومون بإعادة إنشاء الفهارس بعد انتهاء الإدخال، تذكر على أية حال أن حذف الفهارس يؤثر على كافة الاستعلامات على الجداول، لذلك هذه الطريقة محبذة فقط عند عملية إدخال واحدة ضخمة للبيانات. معايرة أداء SQL Server: خطط التنفيذ بالمناسبة، أداة خطة التنفيذ في SQL Server مفيدة لإنشاء الفهارس. مهمتها الأساسية تتمثل في الإظهار المرئي لطرق تحصيل البيانات المختارة من قبل منسق استعلام SQL Server. للحصول على خطة التنفيذ (في برنامج الإدارة SQL Server Management Studio)، قم فقط بالنقر على Include Actual Execution Plan" CTRL + M" قبل بدء تشغيل الاستعلام. بعدئذ ،سوف يظهر إطار ثالث اسمه “Execution Plan”، حيث يمكن أن تشاهد اكتشاف فهرس مفقود، ولإنشائه قم بالنقر بالزر اليميني على execution plan وقم باختيار Missing Index Details، بكل بساطة. معايرة استعلام SQL عن طريق تجنب حلقات الشفرة تخيّل سيناريو يقوم فيه 1000 استعلام بإضافة بيانات على قاعدة بياناتك بشكل تسلسلي، كالتالي: for (int i = 0; i < 1000; i++) { SqlCommand cmd = new SqlCommand("INSERT INTO TBL (A,B,C) VALUES..."); cmd.ExecuteNonQuery(); } يجب عليك تجنب مثل هذه الحلقات في شفرتك، وكمثال سنقوم بتحويل باستخدام العبارات الفريدة INSERT UPDATE مع أسطر وقيم عدّة. INSERT INTO TableName (A,B,C) VALUES (1,2,3),(4,5,6),(7,8,9) -- SQL SERVER 2008 INSERT INTO TableName (A,B,C) SELECT 1,2,3 UNION ALL SELECT 4,5,6 -- SQL SERVER 2005 UPDATE TableName SET A = CASE B WHEN 1 THEN 'NEW VALUE' WHEN 2 THEN 'NEW VALUE 2' WHEN 3 THEN 'NEW VALUE 3' END WHERE B in (1,2,3) تأكد من أن عبارة تتجنب تحديث القيم المخزنة إذا كانت تتطابق مع القيمة الموجودة. مثل هذه يمكن أن تحسّن أداء الاستعلام بشكل كبير عن طريق تعديل مئات السجلات بدل الآلاف وكمثال: UPDATE TableName SET A = @VALUE WHERE B = 'YOUR CONDITION' AND A <> @VALUE -- VALIDATION تجنّب الاستعلامات الفرعيّة المرتبطة Correlated Subqueries الاستعلامات المرتبطة هي الاستعلامات التي تستخدم قيم من الاستعلام الأب، هذه النوع من الاستعلامات ينحو إلى العمل سجل بعد سجل row-by-row، مرة لكل سجل معاد من الاستعلام الخارجي الأب، ولذلك فإنه ينقص أداء استعلام SQl. المطوّرين الحديثين غالبًا ما يبنون استعلاماتهم على هذه الشاكلة لأنها عادة الطريقة الأسهل. هنا تجد مثال عن الاستعلامات المرتبطة: SELECT c.Name, c.City, (SELECT CompanyName FROM Company WHERE ID = c.CompanyID) AS CompanyName FROM Customer c بشكل خاص، المشكلة تكون بأن الاستعلام الداخلي(...SELECT CompanyName) ينفذ لكل سجل مسترجع من الاستعلام الخارجي (...SELECT c.Name)، لكن لماذا العودة إلى مرّة ثم أخرى في كل مرة يعالج فيها سجل من الاستعلام الخارجي؟ التقنية الافضل لمعايرة الأداء تكون بمعاملة الاستعلام الفرعي كعملية ربط join SELECT c.Name, c.City, co.CompanyName FROM Customer c LEFT JOIN Company co ON c.CompanyID = co.CompanyID وبهذه الحالة نقوم بالمرور على جدول Company مرة واحدة ، نربطه بجدول Customer، وعندها يمكننا الحصول على القيم التي نريدها (co.CompanyName) بشكل أفضل. الاختيار باعتدال Select Sparingly واحدة من أهم نصائح المعايرة هو تجنب استخدام تعليمة SELECT * . وبدلًا من ذلك يجب تحديد الأعمدة التي تحتاجها فقط مره ثانية. هذا الأمر بسيط، لكن هذا الخطأ منتشر، افترض جدولًا بمئات الأعمدة وملايين السجلات فإذا كان تطبيقك يحتاج إلى عدد محدّد من الأعمدة فقط، فلا حاجة لاستجلاب جميع البيانات، لأن ذلك تضييع للمصادر كمثال: SELECT * FROM Employees مقابل SELECT FirstName, City, Country FROM Employees إذا كنت بالفعل تحتاج إلى كل الأعمدة ، قم بتسميتهم ضمن الاستعلام، هذه ليست قاعدة، لكنها طريقة للمعايرة و لتجنب الأخطاء المستقبلية. كمثال إذا كنت تستخدم التعليمة INSERT... ...SELECT وتم تغيير الجدول عن طريق إضافة عمود جديد، عندها ربما تقع في مشكلة إذا كان هذا العمود غير مطلوبًا في الجدول الهدف وكمثال: INSERT INTO Employees SELECT * FROM OldEmployees Msg 213, Level 16, State 1, Line 1 Insert Error: Column name or number of supplied values does not match table definition ولتجنب هذا الخطأ عليك تسمية كل عمود بشكل مستقل. INSERT INTO Employees (FirstName, City, Country) SELECT Name, CityName, CountryName FROM OldEmployees ملاحظة: على أية حال، هنالك بعض الحالات يكون فيها استخدام SELECT مناسبًا، كمثال من أجل الجداول المؤقتة، وهذا يقودنا الى الفقرة التالية. استخدام الجداول المؤقتة Temporary Tables الجداول المؤقتة عادة ما تزيد تعقيد الاستعلام، فإذا كان بالإمكان كتابة شيفرتك بطريقة بسيطة ومباشرة، فأنا أنصحك بتجنب الجداول المؤقتة. لكن إذا كنت تمتلك إجرائية مخزّنة stored procedure مع عمليات تعديل على البيانات لا يمكن إتمامها باستعلام واحد ، يمكنك استخدام الجداول المؤقتة كوسيط لمساعدتك في تحصيل النتائج النهائية. عندما تودّ أن تقوم بعملية ضم جدول ضخم وهنالك قيود على الجدول المذكور، يمكنك تحسين أداء قاعدة البيانات عن طريق ترحيل البيانات الى جدول مؤقت، والقيام بعملية ضم ذلك الجدول، حيث ان الجدول المؤقت يحتوي على سجلات أقل من الجدول الأساسي الضخم، ولذلك ستتم عملية الضم بشكل أسرع. القرار ليس واضح بشكل دائم، ولكن هذا المثال سوف ينبهك للحالات التي يمكنك فيها استخدام الجداول المؤقتة. تخيّل جدول الزبائن بملايين من السجلات، وعليك أن تقوم بعملية الضم لمنطقة محدّدة، يمكنك القيام بذلك عن طريق استخدام SELECT INTO ،والقيام بعملية الضم مع الجدول المؤقت. SELECT * INTO #Temp FROM Customer WHERE RegionID = 5 SELECT r.RegionName, t.Name FROM Region r JOIN #Temp t ON t.RegionID = r.RegionID لاحظ : مطوري SQl أيضًا يتجنبون استخدام SELECT INTO لإنشاء الجداول المؤقتة، لأن هذا الأمر يؤدي إلى قفل قاعدة بيانات tempdb database مما يمنع باقي المستخدمين من إنشاء جداول مؤقتة ، ولحسن الحظ تم التصحيح في النسخة السابعة وما بعدها. وكحل بديل عن استخدام الجداول المؤقتة يمكن استخدام الاستعلام الفرعي كجدول. SELECT r.RegionName, t.Name FROM Region r JOIN (SELECT * FROM Customer WHERE RegionID = 5) AS t ON t.RegionID = r.RegionID لكن انتظر، هنالك مشكلة في الاستعلام الثاني، كما تم شرحه أعلاه، يجب تضمين الأعمدة التي نحتاجها فقط (عدم استخدام * SELECT )، يجب أخذ هذا الأمر بالحسبان SELECT r.RegionName, t.Name FROM Region r JOIN (SELECT Name, RegionID FROM Customer WHERE RegionID = 5) AS t ON t.RegionID = r.RegionID كل هذه الطرق ستعيد نفس البيانات، لكن باستخدام الجداول المؤقتة، وكمثال يمكننا انشاء فهرس في جدول مؤقت لتحسين الأداء. وأخيرًا، عندما تنهي عملك بالجدول المؤقت، قم بحذفه لتنظيف مصادر tempdb بدل أن تنتظر عملية الحذف الاوتوماتيكي (عندما يتم إنهاء اتصالك مع قاعدة البيانات) DROP TABLE #temp هل يتواجد السجل الخاص بي؟ تقنية المعايرة هذه الخاصة ب SQl متعلقة باستخدام التعليمة ()EXISTS إذا كنت تنوي تفحص فيما إذا كان السجل موجودًا استخدم ()EXISTS بدل من ()COUNT. حيث أن ()COUNT يقوم بفحص كامل الجدول، معتبرًا جميع القيم التي تطابق شروطك، بينما ()EXISTS ستوقف الفحص حالما تجد قيمة مطابقة لما تحتاجه. وهذا يفضي إلى أداء أفضل و شفرة أوضح IF (SELECT COUNT(1) FROM EMPLOYEES WHERE FIRSTNAME LIKE '%JOHN%') > 0 PRINT 'YES' مقابل IF EXISTS(SELECT FIRSTNAME FROM EMPLOYEES WHERE FIRSTNAME LIKE '%JOHN%') PRINT 'YES' معايرة قاعدة البيانات (في المكتب) مديري ومطوري قاعدة البيانات غالبًا ما يتجادلون فيما إذا كانت القضايا التي يواجهونها متعلقة أو غير متعلقة بالبيانات. ومن خبرتي الشخصية أقدم هنا مجموعة من النصائح لكليهما كي يتمكنا من العمل بشكل أكثر فاعلية. للمطوّرين: إذا توقف تطبيقك عن العمل فجأة، فقد لايكون الأمر متعلقًا بقاعدة البيانات، كمثال ربما هنالك مشكلة بالشبكة، قم بالتحقق قليلًا قبل أن ترجع السبب إلى مدير قاعدة البيانات. حتى ولو كنت بارعًا في نمذجة بيانات SQl، قم بطلب المساعدة من مدير قاعدة البيانات في المخطط العلائقي relational diagram فلديه الكثير ليقدمه لك. مديري قاعدة البيانات لا يحبون التغيرات السريعة، هذا طبيعي، عليهم تحليل قاعدة البيانات بشكل كامل واكتشاف مدى تأثير أي تغيير من كافة الزوايا. تغيير بسيط في عمود يمكن أن يستغرق اسبوعًا للإنجاز هذا بسبب أن الخطأ قد يعتبر خسارة ضخمة للشركة. كن صبورًا! لا تقم بالطلب من مدير قاعدة بيانات SQL بإجراء تغييرات على البيانات في بيئة العمل وقت التشغيل. إذا كنت تود الوصول الى قاعدة البيانات النشطة، يجب عليك تحمل المسؤولية عن كافة التغيرات. لمديري قاعدة بيانات SQl: إذا كنت لا تحب أن يسألك النّاس بشأن قاعدة البيانات، قم بتزويدهم بلوحة تبيّن الحالة وقت التشغيل. فالمطوّرين عادة لديهم شك بحالة قاعدة البيانات، وهذه اللوحة تساعد في توفير الوقت والجهد للجميع. ساعد المطوّرين في اختبارات ضمان الجودة للبيئة. قم بتسهيل عملية محاكاة عمل المخدّم مع اختبار بسيط على بيانات حقيقية. مما يوفر الوقت بشكل كبير عليك وعليهم. يقضي المطوّرين كل اليوم متعاملين مع أنظمة بمفاهيم عمل تتغير بشكل مستمر. تفهمك لذلك يجعل الأمر أكثر مرونة، ويمكنك من تجاوز بعض القواعد في اللحظات الحرجة. قواعد البيانات تتطور، سيأتي اليوم الذي تحتاج فيه إلى نقل بياناتك الى إصدار جديد، حيث يعتمد المطوّرين على خصائص جديدة في كل إصدار جديد، لذلك خطط و تحسب لعملية النقل بدلًا من أن تقوم برفض هذه التغيرات. ترجمة -وبتصرّف- للمقال SQL-Database-Performance-Tuning-for-Developers لصاحبه Rodrigo Koch حقوق خلفية الصورة البارزة Gradient clouds background محفوظة لـ Vexels
من الممكن أن تكون المعايرة مهمّة صعبة جدًا، وخاصّة عند العمل مع بيانات ضخمة، حيث أنّ أصغر تغيير من الممكن أن يتسبب بتغيرات غير متوقعه ( إيجابية أو سلبية) على الأداء ككل. تتم معظم عمليات معايرة SQl database في الشركات المتوسطة والصغيرة من قبل مدير قاعدة البيانات (Database Administrator (DBA، لكن صدقني، يوجد العديد من المطوّرين بحاجة للقيام بعمليات متعلقة بالإدارة، وأكثر من ذلك أنا شاهدت أنّهم يقومون فعليًّا بعمليات الإدارة في كثير من الشركات التي تتطلع للعمل مع المطوّرين، حين يتطلب الوضع ببساطة تقنيات مختلفة لحل المشاكل، والتي يمكن أن تؤدي إلى خلاف بين زملاء العمل. عند التعامل مع بيانات ضخمة، فإنّ التغيير الصغير قد يؤدي إلى تغيرات غير متوقعة على الأداء. وبناء على ذلك، فإنّ هيكلية الشبكة أيضًا لها تأثير، افترض أن فريق الإدارة DBA team مع قواعد البيانات التي يديرونها يتوضع في الطابق العاشر، بينما يتوضع المطوّرين في الطابق الخامس عشر، أو حتى في بناء مختلف تحت هيكلية منفصلة تمامًا، وبالتالي من الصعب العمل المشترك بينهم بمرونة تحت هذه الظروف، سأقوم بإتمام شيئين هامين في هذه المقالة: تزويد المطوّرين بتقنيات معايرة لقواعد بيانات خاصة بالمطوّرين. شرح كيف يمكن لمطوّري ومديري قواعد البيانات العمل معًا بكفاءة. تحسين قاعدة البيانات (في Codebase) الفهارس إذا كنت حديثًا في مجال قواعد البيانات أو حتى تسأل نفسك، “ماهي معايرة SQL”، فيجب أن تعلم أنّ الفهرسة هي طريقة فعّالة لمعايرة قاعدة البيانات database SQL الخاصة بك، والتي غالبًا ما يتم إهمالها خلال عملية التطوير، كمصطلح أولي: الفهرس index هو هيكلة للبيانات تسمح بتسريع عملية استخلاص هذه البيانات من جدول قاعدة البيانات، عن طريق تأمين عمليات بحث عشوائية سريعة، وطريقة فعّالة للوصول إلى السجلات المرتبة، هذا يعني أنّه حالما تقوم بإنشاء فهرس يمكنك القيام بعمليات الاستعلام والترتيب بشكل أسرع. تستخدم الفهارس أيضًا لتعريف المفتاح الرئيسي أو فهرس فريد يضمن أنّ أي عمود آخر لن يحتوي نفس القيمة. بالطبع إنّ موضوع الفهرسة متنوع وهام ولا يمكنني إعطاءه حقه في هذا الوصف الموجز. إذا كنت حديثًا على موضوع الفهرسة فأنا أفضل أن تستخدم هذا المخطط لهيكلة استعلاماتك. بشكل أولي، الهدف هو فهرسة أعمدة البحث والترتيب. لاحظ أنه إذا كانت تجري بشكل مستمر عمليات إدخال INSERT أو تعديل UPDATE أو حذف DELETE، فيجب عليك الحذر من القيام بعمليات الفهرسة، حيث يمكن أن يؤدي إلى هبوط في الأداء، إذ أنّه يتطلب تعديل جميع الفهارس بعد هذه العمليات. كذلك مديري قواعد البيانات يقومون بحذف الفهارس قبل القيام مثلًا بإدخال أكثر من مليون سجل دفعة واحدة، وذلك لتسريع عملية الإدخال، ثم يقومون بإعادة إنشاء الفهارس بعد انتهاء الإدخال، تذكر على أية حال أن حذف الفهارس يؤثر على كافة الاستعلامات على الجداول، لذلك هذه الطريقة محبذة فقط عند عملية إدخال واحدة ضخمة للبيانات. معايرة أداء SQL Server: خطط التنفيذ بالمناسبة، أداة خطة التنفيذ في SQL Server مفيدة لإنشاء الفهارس. مهمتها الأساسية تتمثل في الإظهار المرئي لطرق تحصيل البيانات المختارة من قبل منسق استعلام SQL Server. للحصول على خطة التنفيذ (في برنامج الإدارة SQL Server Management Studio)، قم فقط بالنقر على Include Actual Execution Plan" CTRL + M" قبل بدء تشغيل الاستعلام. بعدئذ ،سوف يظهر إطار ثالث اسمه “Execution Plan”، حيث يمكن أن تشاهد اكتشاف فهرس مفقود، ولإنشائه قم بالنقر بالزر اليميني على execution plan وقم باختيار Missing Index Details، بكل بساطة. معايرة استعلام SQL عن طريق تجنب حلقات الشفرة تخيّل سيناريو يقوم فيه 1000 استعلام بإضافة بيانات على قاعدة بياناتك بشكل تسلسلي، كالتالي: for (int i = 0; i < 1000; i++) { SqlCommand cmd = new SqlCommand("INSERT INTO TBL (A,B,C) VALUES..."); cmd.ExecuteNonQuery(); } يجب عليك تجنب مثل هذه الحلقات في شفرتك، وكمثال سنقوم بتحويل باستخدام العبارات الفريدة INSERT UPDATE مع أسطر وقيم عدّة. INSERT INTO TableName (A,B,C) VALUES (1,2,3),(4,5,6),(7,8,9) -- SQL SERVER 2008 INSERT INTO TableName (A,B,C) SELECT 1,2,3 UNION ALL SELECT 4,5,6 -- SQL SERVER 2005 UPDATE TableName SET A = CASE B WHEN 1 THEN 'NEW VALUE' WHEN 2 THEN 'NEW VALUE 2' WHEN 3 THEN 'NEW VALUE 3' END WHERE B in (1,2,3) تأكد من أن عبارة تتجنب تحديث القيم المخزنة إذا كانت تتطابق مع القيمة الموجودة. مثل هذه يمكن أن تحسّن أداء الاستعلام بشكل كبير عن طريق تعديل مئات السجلات بدل الآلاف وكمثال: UPDATE TableName SET A = @VALUE WHERE B = 'YOUR CONDITION' AND A <> @VALUE -- VALIDATION تجنّب الاستعلامات الفرعيّة المرتبطة Correlated Subqueries الاستعلامات المرتبطة هي الاستعلامات التي تستخدم قيم من الاستعلام الأب، هذه النوع من الاستعلامات ينحو إلى العمل سجل بعد سجل row-by-row، مرة لكل سجل معاد من الاستعلام الخارجي الأب، ولذلك فإنه ينقص أداء استعلام SQl. المطوّرين الحديثين غالبًا ما يبنون استعلاماتهم على هذه الشاكلة لأنها عادة الطريقة الأسهل. هنا تجد مثال عن الاستعلامات المرتبطة: SELECT c.Name, c.City, (SELECT CompanyName FROM Company WHERE ID = c.CompanyID) AS CompanyName FROM Customer c بشكل خاص، المشكلة تكون بأن الاستعلام الداخلي(...SELECT CompanyName) ينفذ لكل سجل مسترجع من الاستعلام الخارجي (...SELECT c.Name)، لكن لماذا العودة إلى مرّة ثم أخرى في كل مرة يعالج فيها سجل من الاستعلام الخارجي؟ التقنية الافضل لمعايرة الأداء تكون بمعاملة الاستعلام الفرعي كعملية ربط join SELECT c.Name, c.City, co.CompanyName FROM Customer c LEFT JOIN Company co ON c.CompanyID = co.CompanyID وبهذه الحالة نقوم بالمرور على جدول Company مرة واحدة ، نربطه بجدول Customer، وعندها يمكننا الحصول على القيم التي نريدها (co.CompanyName) بشكل أفضل. الاختيار باعتدال Select Sparingly واحدة من أهم نصائح المعايرة هو تجنب استخدام تعليمة SELECT * . وبدلًا من ذلك يجب تحديد الأعمدة التي تحتاجها فقط مره ثانية. هذا الأمر بسيط، لكن هذا الخطأ منتشر، افترض جدولًا بمئات الأعمدة وملايين السجلات فإذا كان تطبيقك يحتاج إلى عدد محدّد من الأعمدة فقط، فلا حاجة لاستجلاب جميع البيانات، لأن ذلك تضييع للمصادر كمثال: SELECT * FROM Employees مقابل SELECT FirstName, City, Country FROM Employees إذا كنت بالفعل تحتاج إلى كل الأعمدة ، قم بتسميتهم ضمن الاستعلام، هذه ليست قاعدة، لكنها طريقة للمعايرة و لتجنب الأخطاء المستقبلية. كمثال إذا كنت تستخدم التعليمة INSERT... ...SELECT وتم تغيير الجدول عن طريق إضافة عمود جديد، عندها ربما تقع في مشكلة إذا كان هذا العمود غير مطلوبًا في الجدول الهدف وكمثال: INSERT INTO Employees SELECT * FROM OldEmployees Msg 213, Level 16, State 1, Line 1 Insert Error: Column name or number of supplied values does not match table definition ولتجنب هذا الخطأ عليك تسمية كل عمود بشكل مستقل. INSERT INTO Employees (FirstName, City, Country) SELECT Name, CityName, CountryName FROM OldEmployees ملاحظة: على أية حال، هنالك بعض الحالات يكون فيها استخدام SELECT مناسبًا، كمثال من أجل الجداول المؤقتة، وهذا يقودنا الى الفقرة التالية. استخدام الجداول المؤقتة Temporary Tables الجداول المؤقتة عادة ما تزيد تعقيد الاستعلام، فإذا كان بالإمكان كتابة شيفرتك بطريقة بسيطة ومباشرة، فأنا أنصحك بتجنب الجداول المؤقتة. لكن إذا كنت تمتلك إجرائية مخزّنة stored procedure مع عمليات تعديل على البيانات لا يمكن إتمامها باستعلام واحد ، يمكنك استخدام الجداول المؤقتة كوسيط لمساعدتك في تحصيل النتائج النهائية. عندما تودّ أن تقوم بعملية ضم جدول ضخم وهنالك قيود على الجدول المذكور، يمكنك تحسين أداء قاعدة البيانات عن طريق ترحيل البيانات الى جدول مؤقت، والقيام بعملية ضم ذلك الجدول، حيث ان الجدول المؤقت يحتوي على سجلات أقل من الجدول الأساسي الضخم، ولذلك ستتم عملية الضم بشكل أسرع. القرار ليس واضح بشكل دائم، ولكن هذا المثال سوف ينبهك للحالات التي يمكنك فيها استخدام الجداول المؤقتة. تخيّل جدول الزبائن بملايين من السجلات، وعليك أن تقوم بعملية الضم لمنطقة محدّدة، يمكنك القيام بذلك عن طريق استخدام SELECT INTO ،والقيام بعملية الضم مع الجدول المؤقت. SELECT * INTO #Temp FROM Customer WHERE RegionID = 5 SELECT r.RegionName, t.Name FROM Region r JOIN #Temp t ON t.RegionID = r.RegionID لاحظ : مطوري SQl أيضًا يتجنبون استخدام SELECT INTO لإنشاء الجداول المؤقتة، لأن هذا الأمر يؤدي إلى قفل قاعدة بيانات tempdb database مما يمنع باقي المستخدمين من إنشاء جداول مؤقتة ، ولحسن الحظ تم التصحيح في النسخة السابعة وما بعدها. وكحل بديل عن استخدام الجداول المؤقتة يمكن استخدام الاستعلام الفرعي كجدول. SELECT r.RegionName, t.Name FROM Region r JOIN (SELECT * FROM Customer WHERE RegionID = 5) AS t ON t.RegionID = r.RegionID لكن انتظر، هنالك مشكلة في الاستعلام الثاني، كما تم شرحه أعلاه، يجب تضمين الأعمدة التي نحتاجها فقط (عدم استخدام * SELECT )، يجب أخذ هذا الأمر بالحسبان SELECT r.RegionName, t.Name FROM Region r JOIN (SELECT Name, RegionID FROM Customer WHERE RegionID = 5) AS t ON t.RegionID = r.RegionID كل هذه الطرق ستعيد نفس البيانات، لكن باستخدام الجداول المؤقتة، وكمثال يمكننا انشاء فهرس في جدول مؤقت لتحسين الأداء. وأخيرًا، عندما تنهي عملك بالجدول المؤقت، قم بحذفه لتنظيف مصادر tempdb بدل أن تنتظر عملية الحذف الاوتوماتيكي (عندما يتم إنهاء اتصالك مع قاعدة البيانات) DROP TABLE #temp هل يتواجد السجل الخاص بي؟ تقنية المعايرة هذه الخاصة ب SQl متعلقة باستخدام التعليمة ()EXISTS إذا كنت تنوي تفحص فيما إذا كان السجل موجودًا استخدم ()EXISTS بدل من ()COUNT. حيث أن ()COUNT يقوم بفحص كامل الجدول، معتبرًا جميع القيم التي تطابق شروطك، بينما ()EXISTS ستوقف الفحص حالما تجد قيمة مطابقة لما تحتاجه. وهذا يفضي إلى أداء أفضل و شفرة أوضح IF (SELECT COUNT(1) FROM EMPLOYEES WHERE FIRSTNAME LIKE '%JOHN%') > 0 PRINT 'YES' مقابل IF EXISTS(SELECT FIRSTNAME FROM EMPLOYEES WHERE FIRSTNAME LIKE '%JOHN%') PRINT 'YES' معايرة قاعدة البيانات (في المكتب) مديري ومطوري قاعدة البيانات غالبًا ما يتجادلون فيما إذا كانت القضايا التي يواجهونها متعلقة أو غير متعلقة بالبيانات. ومن خبرتي الشخصية أقدم هنا مجموعة من النصائح لكليهما كي يتمكنا من العمل بشكل أكثر فاعلية. للمطوّرين: إذا توقف تطبيقك عن العمل فجأة، فقد لايكون الأمر متعلقًا بقاعدة البيانات، كمثال ربما هنالك مشكلة بالشبكة، قم بالتحقق قليلًا قبل أن ترجع السبب إلى مدير قاعدة البيانات. حتى ولو كنت بارعًا في نمذجة بيانات SQl، قم بطلب المساعدة من مدير قاعدة البيانات في المخطط العلائقي relational diagram فلديه الكثير ليقدمه لك. مديري قاعدة البيانات لا يحبون التغيرات السريعة، هذا طبيعي، عليهم تحليل قاعدة البيانات بشكل كامل واكتشاف مدى تأثير أي تغيير من كافة الزوايا. تغيير بسيط في عمود يمكن أن يستغرق اسبوعًا للإنجاز هذا بسبب أن الخطأ قد يعتبر خسارة ضخمة للشركة. كن صبورًا! لا تقم بالطلب من مدير قاعدة بيانات SQL بإجراء تغييرات على البيانات في بيئة العمل وقت التشغيل. إذا كنت تود الوصول الى قاعدة البيانات النشطة، يجب عليك تحمل المسؤولية عن كافة التغيرات. لمديري قاعدة بيانات SQl: إذا كنت لا تحب أن يسألك النّاس بشأن قاعدة البيانات، قم بتزويدهم بلوحة تبيّن الحالة وقت التشغيل. فالمطوّرين عادة لديهم شك بحالة قاعدة البيانات، وهذه اللوحة تساعد في توفير الوقت والجهد للجميع. ساعد المطوّرين في اختبارات ضمان الجودة للبيئة. قم بتسهيل عملية محاكاة عمل المخدّم مع اختبار بسيط على بيانات حقيقية. مما يوفر الوقت بشكل كبير عليك وعليهم. يقضي المطوّرين كل اليوم متعاملين مع أنظمة بمفاهيم عمل تتغير بشكل مستمر. تفهمك لذلك يجعل الأمر أكثر مرونة، ويمكنك من تجاوز بعض القواعد في اللحظات الحرجة. قواعد البيانات تتطور، سيأتي اليوم الذي تحتاج فيه إلى نقل بياناتك الى إصدار جديد، حيث يعتمد المطوّرين على خصائص جديدة في كل إصدار جديد، لذلك خطط و تحسب لعملية النقل بدلًا من أن تقوم برفض هذه التغيرات. ترجمة -وبتصرّف- للمقال SQL-Database-Performance-Tuning-for-Developers لصاحبه Rodrigo Koch حقوق خلفية الصورة البارزة Gradient clouds background محفوظة لـ Vexels -
 مقدمة تأتي قواعد بيانات SQL مُثبّتة مع جميع الأوامر التي تحتاجها للإضافة، والتعديل، والحذف والاستعلام عن بياناتك. يوفّر هذا الدليل لنمط الورقة المرجعية cheat sheet مرجعًا سريعًا لبعضٍ من أوامر SQL الأكثر شيوعًا. كيفية استخدام هذا الدليل: هذا الدليل على شكل ورقة مرجعيّة فيها أمثلة منفصلة قابلة للاستخدام فرادى. انتقل إلى أي مقطع ذي صلة بالمهمة التي تحاول إكمالها. عندما ترى نصًّا مميّزًا في أوامر هذا الدليل، فضع بالحسبان أن هذا النص يشير إلى الأعمدة، والجداول، والبيانات في قاعدة البيانات الخاصة بك. ضُمّنت قيم البيانات في هذا الدليل في الأمثلة المُعطاة بعلامة ('). من الضروري في SQL تضمين أي قيم بيانات تحتوي على سلاسل نصية في علامات اقتباس أحادية. هذا التضمين غير مطلوب من أجل البيانات الرقمية، ولكنه لن يتسبب بأيّة مشاكل أيضًا. يرجى ملاحظة أنّه على الرغم من كون SQL معياريّة، إلاّ أنّ معظم برامج قواعد بيانات SQL لها إضافاتها الخاصّة. يستخدم هذا الدليل MySQL كنموذج لنظام إدارة قواعد البيانات العلائقية (RDBMS)، ولكن الأوامر المقدّمة ستعمل مع برامج قواعد البيانات العلائقية الأخرى، بما في ذلك PostgreSQL و MariaDB وSQLite. سنُضمّن الأوامر البديلة عند وجود فروق مهمّة بين أنظمة إدارة قواعد البيانات العلائقية RDBMSs. بدء مِحث أوامر قاعدة البيانات (باستخدام استيثاق Socket/Trust) يمكن لمستخدم MySQL الجذر root الاستيثاق بدون كلمة مرور بشكل افتراضي في نظام التشغيل أبونتو Ubuntu 18.04 باستخدام الأمر التالي: $ sudo mysql استخدم الأمر التالي لفتح مِحث أوامر PostgreSQL. سيُسجلك هذا المثال كمستخدم postgres، والذي يتضمن صلاحيات دور المستخدم المميّز superuser role، ولكن يمكنك استبداله بأي دور مُنشئ مُسبقًا: $ sudo -u postgres psql بدء مِحث أوامر قاعدة البيانات (باستخدام استيثاق كلمة المرور) إذا ُضبط مستخدم MySQL الجذر root للاستيثاق باستخدام كلمة مرور، فبإمكانك استخدام الأمر التالي: $ mysql -u root -p إذا أعددت مُسبقًا حساب مستخدم عادي non-root لقاعدة بياناتك، فيمكنك أيضًا استخدام هذه الطريقة لتسجيل الدخول باسم هذا المستخدم: $ mysql -u user -p سيُقاطعك الأمر السابق بعد تشغيله للمطالبة بكلمة المرور الخاصّة بك. إذا كنت ترغب في جعل كلمة المرور كجزء من الأمر، فأَتبعْ الخيار p- مباشرة بكلمة مرورك، بدون ترك فراغ بينهما: $ mysql -u root -ppassword إنشاء قاعدة بيانات يُنشئ الأمر التالي قاعدة بيانات بإعداداتٍ افتراضيّة: mysql> CREATE DATABASE database_name; يمكنك إذا أردت لقاعدة بياناتك أن تستخدم مجموعة محارف وتصنيف مختلفة عن الإعدادات الافتراضيّة تحديد ذلك باستخدام الصياغة التالية: mysql> CREATE DATABASE database_name CHARACTER SET character_set COLLATE collation; إظهار قائمة قواعد البيانات شغّل الأمر التالي لرؤية قواعد البيانات الموجودة في نظام MySQL أو MariaDB: mysql> SHOW DATABASES; يمكنك في PostgreSQL مشاهدة قواعد البيانات المُنشأة باستخدام الأمر التالي: postgres=# \list حذف قاعدة البيانات شغّل الأمر التالي لحذف قاعدة بيانات بما في ذلك ضمنًا أي جداول وبيانات موجودة فيها: mysql> DROP DATABASE IF EXISTS database; إنشاء مستخدم نفّذ الأمر التالي لإنشاء معرّف مستخدِم لقاعدةِ بياناتك من دون تحديد أيّ امتيازاتٍ له: mysql> CREATE USER username IDENTIFIED BY 'password'; تَستخدم PostgreSQL بنية مشابهة، ولكنها مختلفة قليلاً، إليك الصياغة: postgres=# CREATE USER user WITH PASSWORD 'password'; يمكنك إذا أردتَ إنشاء مستخدم جديد ومنحه امتيازات باستخدام أمر واحد عن طريق إصدار عبارة GRANT. ينشئ الأمر التالي مستخدمًا جديدًا ويمنحه امتيازات كاملة لكامل قاعدة البيانات والجداول في نظام إدارة قواعد البيانات العلائقية RDBMS: mysql> GRANT ALL PRIVILEGES ON *.* TO 'username'@'localhost' IDENTIFIED BY 'password'; لاحظ الكلمة المفتاحيّة PRIVILEGES في تعليمة GRANT السابقة. إن هذه الكلمة اختيارية في معظم أنظمة إدارة قواعد البيانات العلائقية، ويمكن كتابة هذه التعليمة بشكل مكافئ على النحو التالي: mysql> GRANT ALL ON *.* TO 'username'@'localhost' IDENTIFIED BY 'password'; كن منتبهًا مع ذلك، أنّ الكلمة المفتاحيّة PRIVILEGES مطلوبة لمنح امتيازات كهذه عندما يكون وضع Strict SQL مُشغّلًا. حذف مستخدم استخدم الصياغة التالية لحذف اسم مستخدم قاعدة البيانات: mysql> DROP USER IF EXISTS username; لاحظ أن هذا الأمر لا يحذف افتراضيًا أيّة جداول أُنشأت بواسطة المستخدم المحذوف، وقد تؤدي محاولات الوصول إلى جداول كهذه إلى حدوث أخطاء. اختيار قاعدة البيانات يجب أولًا إخبار RDBMS بقاعدة البيانات التي ترغب في إنشائها في MySQL و MariaDB قبل أن تتمكن من إنشاء جدول. استخدم الصياغة التالية للقيام بذلك: mysql> USE database; يجب عليك استخدام الأمر التالي في PostgreSQL لاختيار قاعدة بياناتك المرغوبة: postgres=# \connect database إنشاء جدول تنشئ بنية الأمر التالية جدولًا جديدًا باسم table يحوي عمودين لكل منهما نوع بياناته الخاص: mysql> CREATE TABLE table ( column_1 column_1_data_type, column_2 column_2_data_taype ); حذف جدول نفّذ ما يلي لحذف جدول بالكامل، بما في ذلك جميع البيانات الخاصّة به: mysql> DROP TABLE IF EXISTS table إدخال البيانات في جدول استخدم الصياغة التالية لملء جدول بصف واحد من البيانات (row): mysql> INSERT INTO table ( column_A, column_B, column_C ) VALUES ( 'data_A', 'data_B', 'data_C' ); يمكنك أيضًا ملء جدول بعدة صفوف من البيانات باستخدام أمر واحد، على النحو التالي: mysql> INSERT INTO table ( column_A, column_B, column_C ) VALUES ( 'data_1A', 'data_1B', 'data_1C' ), ( 'data_2A', 'data_2B', 'data_2C' ), ( 'data_3A', 'data_3B', 'data_3C' ); حذف بيانات من جدول استخدم بنية الأوامر التالية لحذف صف من البيانات من جدول. لاحظ أن value يجب أن تكون القيمة الموجودة في العمود المحدد column في الصف الذي تريد حذفه: mysql> DELETE FROM table WHERE column='value'; ملاحظة: إذا لم تُضمّن عبارة WHERE في تعليمة DELETE، كما هو موضّح في المثال التالي، فستُحذف جميع البيانات الموجودة في الجدول، ولكن لن تُحذف الأعمدة أو الجدول نفسه: mysql> DELETE FROM table; تغيير البيانات في جدول استخدم الصياغة التالية لتحديث البيانات الموجودة في الصف المُعطى. لاحظ أنّ عبارة WHERE في نهاية الأمر تُخبر SQL بالصف المطلوب تحديثه. إنّ value هي القيمة الموجودة في column_A المحاذية للصفِ الذي تريد تغييره. ملاحظة: إذا أهملتَ تضمين عبارة WHERE في تعليمة UPDATE، فسيَستبدِل الأمر البيانات الموجودة في كل صف من الجدول. mysql> UPDATE table SET column_1 = value_1, column_2 = value_2 WHERE column_A=value; إضافة عمود ستضيف صياغة الأمر التالية عمودًا جديدًا إلى جدول: mysql> ALTER TABLE table ADD COLUMN column data_type; حذف عمود سيؤدي هذا الأمر إلى حذف عمود من جدول: mysql> ALTER TABLE table DROP COLUMN column; تنفيذ الاستعلامات الأساسيّة استخدم الصياغة التالية لعرض جميع البيانات من عمود واحد من جدول: mysql> SELECT column FROM table; افصلْ بين أسماء الأعمدة بفاصلة للاستعلام عن أعمدة متعددة من نفس الجدول: mysql> SELECT column_1, column_2 FROM table; يمكنك أيضًا الاستعلام عن كل الأعمدة في جدول عن طريق استبدال أسماء الأعمدة بعلامة النجمة (*). تعمل علامات النجمة في SQL كبدائل لتمثيل "الكل": mysql> SELECT * FROM table; استخدام عبارات WHERE يمكنك تضييق نطاق نتائج استعلام عن طريق إلحاق تعليمة SELECT بعبارة WHERE، كما يلي: mysql> SELECT column FROM table WHERE conditions_that_apply; يمكنك على سبيل المثال الاستعلام عن جميع البيانات من صف واحد من خلال صياغة مشابهة لما يلي. لاحظ أن value يجب أن تكون قيمة محفوظة في كل من column المحدّد والصف الذي تريد الاستعلام عنه: mysql> SELECT * FROM table WHERE column = value; العمل مع مُعاملات المقارنة يحدّد مُعامل المقارنة في جملة WHERE كيفيّة مقارنة العمود المحدّد بقيمة ما. فيما يلي بعض معاملات المقارنة الشائعة لـ SQL: = : اختبار المساواة != : اختبار عدم المساواة < : اختبار أقل من > : اختبار أكبر من <= : اختبار أقل من أو يساوي >= : اختبار أكبر من أو يساوي BETWEEN : اختبار فيما إذا كانت القيمة ضمن مجال مُعطى IN : اختبار ما إذا كانت قيمة الصّف مُتضَمّنة في مجموعة من القيم المحدّدة EXISTS : اختبار ما إذا كانت صفوف موجودة، تبعاً للشروط المحدّدة LIKE : اختبار فيما إذا كانت قيمة تتطابق مع سلسلة نصيّة محدّدة IS NULL : اختبار القيم الفارغة IS NOT NULL : اختبار كافّة القيم غير الفارغة "NULL" العمل مع محارف البدل Wildcards يسمح SQL باستخدام محارف البدل wildcard. وهي مفيدة عندما تحاول العثور على مُدخل محدّد في جدول، ولكنك لا تكون متأكدًا تماماً من هذا المُدخل. تعتبر علامات النجمة (*) عناصر بديلة لتمثيل "الكل"، حيث تقوم بالاستعلام كل الأعمدة في جدول: mysql> SELECT * FROM table; تمثل علامات النسبة المئوية (٪) صفراً أو أكثر من محارف غير معروفة. mysql> SELECT * FROM table WHERE column LIKE val%; يُستخدم التسطير السفلي (_) لتمثيل محرف واحد غير معروف: mysql> SELECT * FROM table WHERE column LIKE v_lue; حساب المُدخلات في عمود تُستخدم الدّالة COUNT لإيجاد عدد الإدخالات في عمود محدّد. ستُرجع الصياغة التالية إجمالي عدد القيم الموجودة في column: mysql> SELECT COUNT(column) FROM table; يمكنك تضييق نتائج دالة COUNT من خلال إضافة عبارة WHERE، كما يلي: mysql> SELECT COUNT(column) FROM table WHERE column=value; إيجاد قيمة المعدل في عمود تُستخدم الدّالة AVG لإيجاد المعدل بين القيم الموجودة في عمود محدّد. لاحظ أن دالة AVG ستعمل فقط مع الأعمدة التي تحتوي على قيم رقميّة. وقد تُعيد خطأ أو 0 عند استخدامها على عمود يحمل قيم نصيّة: mysql> SELECT AVG(column) FROM table; إيجاد مجموع القيم في عمود تُستخدم الدّالة SUM لإجمالي مجموع القيم الرقميّة الموجودة في عمود: mysql> SELECT SUM(column) FROM table; كما هو الحال مع دالة AVG، إذا نَفّذتَ الدالة SUM على عمود يحوي قيم نصيّة، فقد تُعيد خطأ أو فقط 0، وذلك اعتمادًا على نظام إدارة قواعد البيانات العلائقية خاصتك. إيجاد القيمة الكبرى في عمود استخدم دالة MAX للعثور على أكبر قيمة رقميّة في عمود أو القيمة الأخيرة أبجديًا : mysql> SELECT MAX(column) FROM table; إيجاد القيمة الصغرى في عمود استخدم الدّالة MIN للعثور على أصغر قيمة رقميّة في عمود أو القيمة الأولى أبجديًا: mysql> SELECT MIN(column) FROM table; فرز النتائج باستخدام عبارات ORDER BY تُستخدم عبارة ORDER BY لفرز نتائج الاستعلام. تُعيد الصياغة التالية للاستعلام القيم من column_1 و column_2 وتُرتّب النتائج حسب القيم الموجودة في column_1 بترتيب تصاعدي، أو بترتيب أبجدي بالنسبة لقيم السلاسل النصيّة: mysql> SELECT column_1, column_2 FROM table ORDER BY column_1; أتبع الاستعلام بـ DESC لتنفيذ نفس الإجراء، ولكن مع ترتيب النتائج بترتيب أبجدي تنازلي: mysql> SELECT column_1, column_2 FROM table ORDER BY column_1 DESC; فرز النتائج باستخدام عبارات GROUP BY تشبه عبارة GROUP BY عبارة ORDER BY، ولكنها تُستخدم لفرز نتائج استعلام يتضمن دالة مُجمِّعة مثل COUNT أو MAX أو MIN أو SUM. ستؤدي الدوال التجميعيّة الموضّحة في القسم السابق بمفردها إلى إرجاع قيمة واحدة فقط. ويمكنك مع ذلك عرض نتائج دالة التجميع المنفّذة على كل قيمة مطابقة في العمود من خلال تضمين عبارة GROUP BY. ستَحسب الصياغة التالية عدد القيم المطابقة في column_2 وتُجمّعها بترتيب تصاعدي أو أبجدي: mysql> SELECT COUNT(column_1), column_2 FROM table GROUP BY column_2; أتبِعْ الاستعلام بـ DESC لتنفيذ نفس الإجراء، ولكن بتجميع النتائج بالترتيب الأبجدي التنازلي: mysql> SELECT COUNT(column_1), column_2 FROM table GROUP BY column_2 DESC; الاستعلام عن جداول متعددة مع عبارات JOIN تستخدم عبارات JOIN لإنشاء مجموعات نتائج تجمع بين صفوف من جدولين أو أكثر. لن تعمل عبارات JOIN إلا إذا كان لكل من الجدولين عمود له اسم ونوع بيانات متطابقان، كما في هذا المثال: mysql> SELECT table_1.column_1, table_2.column_2 FROM table_1 JOIN table_2 ON table_1.common_column=table_2.common_column; هذا مثال على عبارة INNER JOIN. ستقوم INNER JOIN بإرجاع جميع السجلات التي تحتوي على قيم متطابقة في كلا الجدولين، ولكنها لن تعرض أي سجلات لا تحتوي على قيم متطابقة. من الممكن إرجاع كافة السجلات من أحد الجدولين، بما في ذلك القيم التي لا تحتوي على مطابق في الجدول الآخر، وذلك باستخدام عبارة JOIN خارجيّة. تُكتب عبارات JOIN الخارجية إما كـ LEFT JOIN أو RIGHT JOIN. تُرجع عبارة LEFT JOIN كافة السجلات من الجدول "الأيسر" والسجلات المطابقة فقط من الجدول "اليمين". في سياق عبارة JOIN الخارجيّة، يكون الجدول الأيسر هو المشار إليه في جملة FROM، والجدول الأيمن هو أي جدول آخر مشار إليه بعد عبارة JOIN. سيَعرض الاستعلام التالي كل سجل من table_1 وفقط القيم المطابقة من table_2. ستظهر القيم غير المطابقة في table2 كـ NULL في مجموعة النتائج: mysql> SELECT table_1.column_1, table_2.column_2 FROM table_1 LEFT JOIN table_2 ON table_1.common_column=table_2.common_column; إن وظيفة عبارة RIGHT JOIN مماثلة لـ LEFT JOIN، ولكنها تُرجع جميع النتائج من الجدول الأيمن، والقيم المطابقة فقط من الجدول الأيسر: mysql> SELECT table_1.column_1, table_2.column_2 FROM table_1 RIGHT JOIN table_2 ON table_1.common_column=table_2.common_column; دمج تعليمات SELECT متعددة باستخدام عبارات UNION يفيد مُعامل UNION في دمج نتائج تعليمتي SELECT (أو أكثر) في مجموعة نتائج واحدة: mysql> SELECT column_1 FROM table UNION SELECT column_2 FROM table; يمكن بالإضافة إلى ذلك أن تجمع عبارة UNION بين تعليمتي SELECT (أو أكثر) والتي تستعلم عن جداول مختلفة في نفس مجموعة النتائج: mysql> SELECT column FROM table_1 UNION SELECT column FROM table_2; الخلاصة يغطي هذا الدليل بعضًا من الأوامر الأكثر شيوعًا في SQL المُستخدمة لإدارة قواعد البيانات، والمستخدمين، والجداول، والاستعلام عن المحتويات الموجودة في هذه الجداول. ومع ذلك، هناك العديد من تجميعات العبارات والمعاملات والتي تنتج جميعها مجموعات فريدة من النتائج. إذا كنت تبحث عن دليل أكثر شموليّة للعمل مع SQL، فإنّنا نُشجعك على مراجعة Oracle's Database SQL Reference بالإضافة إلى ذلك، إذا كانت هناك أوامر SQL شائعة ترغب في رؤيتها في هذا الدليل، فيرجى طرحها أو تقديم اقتراحات في التعليقات أدناه. ترجمة بتصرّف للمقال How To Manage an SQL Database لصاحبه Mark Drake
مقدمة تأتي قواعد بيانات SQL مُثبّتة مع جميع الأوامر التي تحتاجها للإضافة، والتعديل، والحذف والاستعلام عن بياناتك. يوفّر هذا الدليل لنمط الورقة المرجعية cheat sheet مرجعًا سريعًا لبعضٍ من أوامر SQL الأكثر شيوعًا. كيفية استخدام هذا الدليل: هذا الدليل على شكل ورقة مرجعيّة فيها أمثلة منفصلة قابلة للاستخدام فرادى. انتقل إلى أي مقطع ذي صلة بالمهمة التي تحاول إكمالها. عندما ترى نصًّا مميّزًا في أوامر هذا الدليل، فضع بالحسبان أن هذا النص يشير إلى الأعمدة، والجداول، والبيانات في قاعدة البيانات الخاصة بك. ضُمّنت قيم البيانات في هذا الدليل في الأمثلة المُعطاة بعلامة ('). من الضروري في SQL تضمين أي قيم بيانات تحتوي على سلاسل نصية في علامات اقتباس أحادية. هذا التضمين غير مطلوب من أجل البيانات الرقمية، ولكنه لن يتسبب بأيّة مشاكل أيضًا. يرجى ملاحظة أنّه على الرغم من كون SQL معياريّة، إلاّ أنّ معظم برامج قواعد بيانات SQL لها إضافاتها الخاصّة. يستخدم هذا الدليل MySQL كنموذج لنظام إدارة قواعد البيانات العلائقية (RDBMS)، ولكن الأوامر المقدّمة ستعمل مع برامج قواعد البيانات العلائقية الأخرى، بما في ذلك PostgreSQL و MariaDB وSQLite. سنُضمّن الأوامر البديلة عند وجود فروق مهمّة بين أنظمة إدارة قواعد البيانات العلائقية RDBMSs. بدء مِحث أوامر قاعدة البيانات (باستخدام استيثاق Socket/Trust) يمكن لمستخدم MySQL الجذر root الاستيثاق بدون كلمة مرور بشكل افتراضي في نظام التشغيل أبونتو Ubuntu 18.04 باستخدام الأمر التالي: $ sudo mysql استخدم الأمر التالي لفتح مِحث أوامر PostgreSQL. سيُسجلك هذا المثال كمستخدم postgres، والذي يتضمن صلاحيات دور المستخدم المميّز superuser role، ولكن يمكنك استبداله بأي دور مُنشئ مُسبقًا: $ sudo -u postgres psql بدء مِحث أوامر قاعدة البيانات (باستخدام استيثاق كلمة المرور) إذا ُضبط مستخدم MySQL الجذر root للاستيثاق باستخدام كلمة مرور، فبإمكانك استخدام الأمر التالي: $ mysql -u root -p إذا أعددت مُسبقًا حساب مستخدم عادي non-root لقاعدة بياناتك، فيمكنك أيضًا استخدام هذه الطريقة لتسجيل الدخول باسم هذا المستخدم: $ mysql -u user -p سيُقاطعك الأمر السابق بعد تشغيله للمطالبة بكلمة المرور الخاصّة بك. إذا كنت ترغب في جعل كلمة المرور كجزء من الأمر، فأَتبعْ الخيار p- مباشرة بكلمة مرورك، بدون ترك فراغ بينهما: $ mysql -u root -ppassword إنشاء قاعدة بيانات يُنشئ الأمر التالي قاعدة بيانات بإعداداتٍ افتراضيّة: mysql> CREATE DATABASE database_name; يمكنك إذا أردت لقاعدة بياناتك أن تستخدم مجموعة محارف وتصنيف مختلفة عن الإعدادات الافتراضيّة تحديد ذلك باستخدام الصياغة التالية: mysql> CREATE DATABASE database_name CHARACTER SET character_set COLLATE collation; إظهار قائمة قواعد البيانات شغّل الأمر التالي لرؤية قواعد البيانات الموجودة في نظام MySQL أو MariaDB: mysql> SHOW DATABASES; يمكنك في PostgreSQL مشاهدة قواعد البيانات المُنشأة باستخدام الأمر التالي: postgres=# \list حذف قاعدة البيانات شغّل الأمر التالي لحذف قاعدة بيانات بما في ذلك ضمنًا أي جداول وبيانات موجودة فيها: mysql> DROP DATABASE IF EXISTS database; إنشاء مستخدم نفّذ الأمر التالي لإنشاء معرّف مستخدِم لقاعدةِ بياناتك من دون تحديد أيّ امتيازاتٍ له: mysql> CREATE USER username IDENTIFIED BY 'password'; تَستخدم PostgreSQL بنية مشابهة، ولكنها مختلفة قليلاً، إليك الصياغة: postgres=# CREATE USER user WITH PASSWORD 'password'; يمكنك إذا أردتَ إنشاء مستخدم جديد ومنحه امتيازات باستخدام أمر واحد عن طريق إصدار عبارة GRANT. ينشئ الأمر التالي مستخدمًا جديدًا ويمنحه امتيازات كاملة لكامل قاعدة البيانات والجداول في نظام إدارة قواعد البيانات العلائقية RDBMS: mysql> GRANT ALL PRIVILEGES ON *.* TO 'username'@'localhost' IDENTIFIED BY 'password'; لاحظ الكلمة المفتاحيّة PRIVILEGES في تعليمة GRANT السابقة. إن هذه الكلمة اختيارية في معظم أنظمة إدارة قواعد البيانات العلائقية، ويمكن كتابة هذه التعليمة بشكل مكافئ على النحو التالي: mysql> GRANT ALL ON *.* TO 'username'@'localhost' IDENTIFIED BY 'password'; كن منتبهًا مع ذلك، أنّ الكلمة المفتاحيّة PRIVILEGES مطلوبة لمنح امتيازات كهذه عندما يكون وضع Strict SQL مُشغّلًا. حذف مستخدم استخدم الصياغة التالية لحذف اسم مستخدم قاعدة البيانات: mysql> DROP USER IF EXISTS username; لاحظ أن هذا الأمر لا يحذف افتراضيًا أيّة جداول أُنشأت بواسطة المستخدم المحذوف، وقد تؤدي محاولات الوصول إلى جداول كهذه إلى حدوث أخطاء. اختيار قاعدة البيانات يجب أولًا إخبار RDBMS بقاعدة البيانات التي ترغب في إنشائها في MySQL و MariaDB قبل أن تتمكن من إنشاء جدول. استخدم الصياغة التالية للقيام بذلك: mysql> USE database; يجب عليك استخدام الأمر التالي في PostgreSQL لاختيار قاعدة بياناتك المرغوبة: postgres=# \connect database إنشاء جدول تنشئ بنية الأمر التالية جدولًا جديدًا باسم table يحوي عمودين لكل منهما نوع بياناته الخاص: mysql> CREATE TABLE table ( column_1 column_1_data_type, column_2 column_2_data_taype ); حذف جدول نفّذ ما يلي لحذف جدول بالكامل، بما في ذلك جميع البيانات الخاصّة به: mysql> DROP TABLE IF EXISTS table إدخال البيانات في جدول استخدم الصياغة التالية لملء جدول بصف واحد من البيانات (row): mysql> INSERT INTO table ( column_A, column_B, column_C ) VALUES ( 'data_A', 'data_B', 'data_C' ); يمكنك أيضًا ملء جدول بعدة صفوف من البيانات باستخدام أمر واحد، على النحو التالي: mysql> INSERT INTO table ( column_A, column_B, column_C ) VALUES ( 'data_1A', 'data_1B', 'data_1C' ), ( 'data_2A', 'data_2B', 'data_2C' ), ( 'data_3A', 'data_3B', 'data_3C' ); حذف بيانات من جدول استخدم بنية الأوامر التالية لحذف صف من البيانات من جدول. لاحظ أن value يجب أن تكون القيمة الموجودة في العمود المحدد column في الصف الذي تريد حذفه: mysql> DELETE FROM table WHERE column='value'; ملاحظة: إذا لم تُضمّن عبارة WHERE في تعليمة DELETE، كما هو موضّح في المثال التالي، فستُحذف جميع البيانات الموجودة في الجدول، ولكن لن تُحذف الأعمدة أو الجدول نفسه: mysql> DELETE FROM table; تغيير البيانات في جدول استخدم الصياغة التالية لتحديث البيانات الموجودة في الصف المُعطى. لاحظ أنّ عبارة WHERE في نهاية الأمر تُخبر SQL بالصف المطلوب تحديثه. إنّ value هي القيمة الموجودة في column_A المحاذية للصفِ الذي تريد تغييره. ملاحظة: إذا أهملتَ تضمين عبارة WHERE في تعليمة UPDATE، فسيَستبدِل الأمر البيانات الموجودة في كل صف من الجدول. mysql> UPDATE table SET column_1 = value_1, column_2 = value_2 WHERE column_A=value; إضافة عمود ستضيف صياغة الأمر التالية عمودًا جديدًا إلى جدول: mysql> ALTER TABLE table ADD COLUMN column data_type; حذف عمود سيؤدي هذا الأمر إلى حذف عمود من جدول: mysql> ALTER TABLE table DROP COLUMN column; تنفيذ الاستعلامات الأساسيّة استخدم الصياغة التالية لعرض جميع البيانات من عمود واحد من جدول: mysql> SELECT column FROM table; افصلْ بين أسماء الأعمدة بفاصلة للاستعلام عن أعمدة متعددة من نفس الجدول: mysql> SELECT column_1, column_2 FROM table; يمكنك أيضًا الاستعلام عن كل الأعمدة في جدول عن طريق استبدال أسماء الأعمدة بعلامة النجمة (*). تعمل علامات النجمة في SQL كبدائل لتمثيل "الكل": mysql> SELECT * FROM table; استخدام عبارات WHERE يمكنك تضييق نطاق نتائج استعلام عن طريق إلحاق تعليمة SELECT بعبارة WHERE، كما يلي: mysql> SELECT column FROM table WHERE conditions_that_apply; يمكنك على سبيل المثال الاستعلام عن جميع البيانات من صف واحد من خلال صياغة مشابهة لما يلي. لاحظ أن value يجب أن تكون قيمة محفوظة في كل من column المحدّد والصف الذي تريد الاستعلام عنه: mysql> SELECT * FROM table WHERE column = value; العمل مع مُعاملات المقارنة يحدّد مُعامل المقارنة في جملة WHERE كيفيّة مقارنة العمود المحدّد بقيمة ما. فيما يلي بعض معاملات المقارنة الشائعة لـ SQL: = : اختبار المساواة != : اختبار عدم المساواة < : اختبار أقل من > : اختبار أكبر من <= : اختبار أقل من أو يساوي >= : اختبار أكبر من أو يساوي BETWEEN : اختبار فيما إذا كانت القيمة ضمن مجال مُعطى IN : اختبار ما إذا كانت قيمة الصّف مُتضَمّنة في مجموعة من القيم المحدّدة EXISTS : اختبار ما إذا كانت صفوف موجودة، تبعاً للشروط المحدّدة LIKE : اختبار فيما إذا كانت قيمة تتطابق مع سلسلة نصيّة محدّدة IS NULL : اختبار القيم الفارغة IS NOT NULL : اختبار كافّة القيم غير الفارغة "NULL" العمل مع محارف البدل Wildcards يسمح SQL باستخدام محارف البدل wildcard. وهي مفيدة عندما تحاول العثور على مُدخل محدّد في جدول، ولكنك لا تكون متأكدًا تماماً من هذا المُدخل. تعتبر علامات النجمة (*) عناصر بديلة لتمثيل "الكل"، حيث تقوم بالاستعلام كل الأعمدة في جدول: mysql> SELECT * FROM table; تمثل علامات النسبة المئوية (٪) صفراً أو أكثر من محارف غير معروفة. mysql> SELECT * FROM table WHERE column LIKE val%; يُستخدم التسطير السفلي (_) لتمثيل محرف واحد غير معروف: mysql> SELECT * FROM table WHERE column LIKE v_lue; حساب المُدخلات في عمود تُستخدم الدّالة COUNT لإيجاد عدد الإدخالات في عمود محدّد. ستُرجع الصياغة التالية إجمالي عدد القيم الموجودة في column: mysql> SELECT COUNT(column) FROM table; يمكنك تضييق نتائج دالة COUNT من خلال إضافة عبارة WHERE، كما يلي: mysql> SELECT COUNT(column) FROM table WHERE column=value; إيجاد قيمة المعدل في عمود تُستخدم الدّالة AVG لإيجاد المعدل بين القيم الموجودة في عمود محدّد. لاحظ أن دالة AVG ستعمل فقط مع الأعمدة التي تحتوي على قيم رقميّة. وقد تُعيد خطأ أو 0 عند استخدامها على عمود يحمل قيم نصيّة: mysql> SELECT AVG(column) FROM table; إيجاد مجموع القيم في عمود تُستخدم الدّالة SUM لإجمالي مجموع القيم الرقميّة الموجودة في عمود: mysql> SELECT SUM(column) FROM table; كما هو الحال مع دالة AVG، إذا نَفّذتَ الدالة SUM على عمود يحوي قيم نصيّة، فقد تُعيد خطأ أو فقط 0، وذلك اعتمادًا على نظام إدارة قواعد البيانات العلائقية خاصتك. إيجاد القيمة الكبرى في عمود استخدم دالة MAX للعثور على أكبر قيمة رقميّة في عمود أو القيمة الأخيرة أبجديًا : mysql> SELECT MAX(column) FROM table; إيجاد القيمة الصغرى في عمود استخدم الدّالة MIN للعثور على أصغر قيمة رقميّة في عمود أو القيمة الأولى أبجديًا: mysql> SELECT MIN(column) FROM table; فرز النتائج باستخدام عبارات ORDER BY تُستخدم عبارة ORDER BY لفرز نتائج الاستعلام. تُعيد الصياغة التالية للاستعلام القيم من column_1 و column_2 وتُرتّب النتائج حسب القيم الموجودة في column_1 بترتيب تصاعدي، أو بترتيب أبجدي بالنسبة لقيم السلاسل النصيّة: mysql> SELECT column_1, column_2 FROM table ORDER BY column_1; أتبع الاستعلام بـ DESC لتنفيذ نفس الإجراء، ولكن مع ترتيب النتائج بترتيب أبجدي تنازلي: mysql> SELECT column_1, column_2 FROM table ORDER BY column_1 DESC; فرز النتائج باستخدام عبارات GROUP BY تشبه عبارة GROUP BY عبارة ORDER BY، ولكنها تُستخدم لفرز نتائج استعلام يتضمن دالة مُجمِّعة مثل COUNT أو MAX أو MIN أو SUM. ستؤدي الدوال التجميعيّة الموضّحة في القسم السابق بمفردها إلى إرجاع قيمة واحدة فقط. ويمكنك مع ذلك عرض نتائج دالة التجميع المنفّذة على كل قيمة مطابقة في العمود من خلال تضمين عبارة GROUP BY. ستَحسب الصياغة التالية عدد القيم المطابقة في column_2 وتُجمّعها بترتيب تصاعدي أو أبجدي: mysql> SELECT COUNT(column_1), column_2 FROM table GROUP BY column_2; أتبِعْ الاستعلام بـ DESC لتنفيذ نفس الإجراء، ولكن بتجميع النتائج بالترتيب الأبجدي التنازلي: mysql> SELECT COUNT(column_1), column_2 FROM table GROUP BY column_2 DESC; الاستعلام عن جداول متعددة مع عبارات JOIN تستخدم عبارات JOIN لإنشاء مجموعات نتائج تجمع بين صفوف من جدولين أو أكثر. لن تعمل عبارات JOIN إلا إذا كان لكل من الجدولين عمود له اسم ونوع بيانات متطابقان، كما في هذا المثال: mysql> SELECT table_1.column_1, table_2.column_2 FROM table_1 JOIN table_2 ON table_1.common_column=table_2.common_column; هذا مثال على عبارة INNER JOIN. ستقوم INNER JOIN بإرجاع جميع السجلات التي تحتوي على قيم متطابقة في كلا الجدولين، ولكنها لن تعرض أي سجلات لا تحتوي على قيم متطابقة. من الممكن إرجاع كافة السجلات من أحد الجدولين، بما في ذلك القيم التي لا تحتوي على مطابق في الجدول الآخر، وذلك باستخدام عبارة JOIN خارجيّة. تُكتب عبارات JOIN الخارجية إما كـ LEFT JOIN أو RIGHT JOIN. تُرجع عبارة LEFT JOIN كافة السجلات من الجدول "الأيسر" والسجلات المطابقة فقط من الجدول "اليمين". في سياق عبارة JOIN الخارجيّة، يكون الجدول الأيسر هو المشار إليه في جملة FROM، والجدول الأيمن هو أي جدول آخر مشار إليه بعد عبارة JOIN. سيَعرض الاستعلام التالي كل سجل من table_1 وفقط القيم المطابقة من table_2. ستظهر القيم غير المطابقة في table2 كـ NULL في مجموعة النتائج: mysql> SELECT table_1.column_1, table_2.column_2 FROM table_1 LEFT JOIN table_2 ON table_1.common_column=table_2.common_column; إن وظيفة عبارة RIGHT JOIN مماثلة لـ LEFT JOIN، ولكنها تُرجع جميع النتائج من الجدول الأيمن، والقيم المطابقة فقط من الجدول الأيسر: mysql> SELECT table_1.column_1, table_2.column_2 FROM table_1 RIGHT JOIN table_2 ON table_1.common_column=table_2.common_column; دمج تعليمات SELECT متعددة باستخدام عبارات UNION يفيد مُعامل UNION في دمج نتائج تعليمتي SELECT (أو أكثر) في مجموعة نتائج واحدة: mysql> SELECT column_1 FROM table UNION SELECT column_2 FROM table; يمكن بالإضافة إلى ذلك أن تجمع عبارة UNION بين تعليمتي SELECT (أو أكثر) والتي تستعلم عن جداول مختلفة في نفس مجموعة النتائج: mysql> SELECT column FROM table_1 UNION SELECT column FROM table_2; الخلاصة يغطي هذا الدليل بعضًا من الأوامر الأكثر شيوعًا في SQL المُستخدمة لإدارة قواعد البيانات، والمستخدمين، والجداول، والاستعلام عن المحتويات الموجودة في هذه الجداول. ومع ذلك، هناك العديد من تجميعات العبارات والمعاملات والتي تنتج جميعها مجموعات فريدة من النتائج. إذا كنت تبحث عن دليل أكثر شموليّة للعمل مع SQL، فإنّنا نُشجعك على مراجعة Oracle's Database SQL Reference بالإضافة إلى ذلك، إذا كانت هناك أوامر SQL شائعة ترغب في رؤيتها في هذا الدليل، فيرجى طرحها أو تقديم اقتراحات في التعليقات أدناه. ترجمة بتصرّف للمقال How To Manage an SQL Database لصاحبه Mark Drake -
 Sqlite هي عبارة عن محرك SQL مفتوح المصدر سريع وبسيط جدا، يشرح هذا الدرس متى يكون من الأمثل استخدام Sqlite كبديل لأنظمة إدارة قواعد البيانات الارتباطية RDBMS مثل MySQL أو Postgres، بالإضافة إلى كيفية تثبيتها وأمثلة عن استخداماتها الأساسية، تُغطي عمليات CRUD: الإنشاء Create، القراءة Read، التحديث Update، والحذف Delete. مفاهيم خاطئةلا يجب أن ننخدع بالاعتقاد أن Sqlite تستَخدم فقط للاختبار والتطوير، فعلى سبيل المثال تعمل Sqlite بشكل جيد لمواقع الإنترنت التي تتلقى 100,000 زائر يوميا، وهذا هو الحد المُحافظ. إن الحد الأقصى لحجم قاعدة بيانات Sqlite هو 140 تيرابايت (والذي من المفترض أن يكون كافيًا، أليس كذلك؟)، وبإمكانها أن تكون أسرع بكثير من RDBMS، يتم تخزين قاعدة البيانات كاملةمع كافة البيانات الضرورية في ملف عادي في نظام ملفات المضيف Host، ولذلك لا توجد حاجة لعملية خادوم Server منفصلة (الاستغناء عن الحاجة إلى الاتصالات البطيئة بين العمليّات). الاستخدام الأمثل على VPS الخاص بناتركز Sqlite على البساطة، وبما أنها تعمل داخليا internal بشكلٍ تام، فهي غالبًا ما تكون أسرع بكثير من البدائل الأخرى، إن كنا نبحث عن قابلية النقل portability (فيما يتعلق باللغات والمنصّات معًا)، البساطة، السرعة، والاستهلاك القليل للذاكرة فإن Sqlite مثاليّة لهذا، فعيوبها تكون واضحة فقط عند الحاجة لتزامن عال بالقراءة أو الكتابة. حيث تستطيع Sqlite أن تدعم كاتب writer واحد فقط في نفس الوقت، وقد يكون زمن الوصول latency لنظام الملفات المرتَفِع عادة غير مُلائِم إن كانت هناك حاجة لنفاذ access العديد من العملاء إلى قاعدة بيانات Sqlite في نفس الوقت. العيب الأخير المُحتَمل وجوده في Sqlite هو صياغتها syntax الفريدة، بالرغم من تشابهها مع أنظمة SQL الأخرى، ومن البديهي عند الانتقال إلى نظام آخر -إن قمنا باستخدام Sqlite والتي تتطوّر بسرعة- أن نجد بعض العقبات في المرحلة الانتقاليّة. تثبيت Sqlite على VPS الخاص بناإن وحدة sqlite3 module هي جزء من مكتبة بايثون المعيارية، لذلك لا نحتاج لأي تثبيت آخر على توزيعة Ubuntu المعيارية أو على أي نظام آخر مُثبّت عليه بايثون، ولتثبيت واجهة سطر الأوامر لـ Sqlite على Ubuntu نستخدم هذه الأوامر: sudo apt-get update sudo apt-get install sqlite3 libsqlite3-devإن كُنّا نريد تصريفه Compile من المصدر Source يجب علينا الحصول على آخر إصدار من autoconf من الرّابط sqlite.org/download.html، وهو الإصدار المتوفّر وقت كتابة هذا الدّرس: wget http://sqlite.org/2013/sqlite-autoconf-3080100.tar.gz tar xvfz sqlite-autoconf-3080100.tar.gz cd sqlite-autoconf-3080100 ./configure make make installملاحظات من أجل البناء من المصدر: لا يجب أن نقوم بفعل هذا على توزيعة Ubuntu معياريّة لأنّه من المُحتمل أن نتلقّى خطأ عن عدم التّوافق في إصدار التّرويسة Header والمصدر "header and source version mismatch" بسبب التّعارض بين الإصدار المُثبّت حاليًّا والإصدار الجّديد الذي نريد تثبيته.إن كان يبدو أنّ الأمر make ينتظر المزيد من المُدخلات منك فكُن صبورًا فقط، حيث أنّ تصريف Compile المصدر قد يستغرق بعض الوقت.الاستخدامات الأساسية لواجهة سطر الأوامرلإنشاء قاعدة بيانات نقوم بتنفيذ الأمر التالي: sqlite3 database.dbحيث يكون database هو اسم قاعدة البيانات لدينا، وإن كان الملف database.db موجودًا مُسبقًا ستقوم Sqlite بإنشاء اتصال معه، وإن لم يكن موجودًا سيتمّ إنشاؤه، يجب أن يكون الخرج Output مُشابهًا لما يلي: SQLite version 3.8.1 2013-10-17 12:57:35 Enter ".help" for instructions Enter SQL statements terminated with a ";" sqlite>فلنقم الآن بإنشاء جدول Table وإدخال بعض البيانات إليه، يملك هذا الجدول المُسمَّى الأندية clubs أربعة أعمدة columns، من أجل id، اسم النادي name، مدرّبه coach، وبلد النّادي country، سنقوم بإدخال بيانات ثلاثة أندية كرة قدم إلى قاعدة بياناتنا: CREATE TABLE clubs (id integer, name varchar(30), coach varchar(20), country varchar(20)); INSERT INTO clubs VALUES (1, "Real Madrid", "Benitez", "Spain"); INSERT INTO clubs VALUES (2, "Barcelona", "Enrique", "Spain"); INSERT INTO clubs VALUES (3, "Chelsea", "Mourinho", "England");لقد أنشأنا قاعدة بيانات، جدول، وبعض الإدخالات، نضغط الآن Ctrl+D للخروج من Sqlite ونكتب ما يلي (يجب هنا أيضًا أن نضع اسم قاعدة بياناتنا بدلًا من 'database') والذي سيقوم بإعادة الاتصال إلى قاعدة البيانات التي أنشأناها للتو: sqlite3 database.dbالآن نكتب: SELECT * FROM clubs;يجب أن نرى هنا الإدخالات التي قُمنا بها: 1|Real Madrid|Benitez|Spain 2|Barcelona|Enrique|Spain 3|Chelsea|Mourinho|Englandرائع، هذا هو كلّ شيء فيما يتعلّق بالإنشاء Creating والقراءة Reading، فلنقم الآن بالتّحديث Update والحذف Delete: UPDATE clubs SET country="Spain" WHERE country="England";سيقوم هذا الأمر بتحديث قاعدة البيانات بحيث يجعل الأندية المُدرَجة على أنّها من إنكلترا يتم إدراجها وكأنّها أندية من إسبانيا، فلنتأكّد من النتائج باستخدام الأمر: SELECT * FROM clubs;يجب أن نرى: 1|Real Madrid|Benitez|Spain 2|Barcelona|Enrique|Spain 3|Chelsea|Mourinho|Spainأصبحت لدينا الآن كل الأندية من إسبانيا، فلنقم بحذف Chelsea من قاعدة بياناتنا كونه النادي الوحيد الذي في الحقيقة ليس من إسبانيا: DELETE FROM clubs WHERE id=3; SELECT * FROM clubs;ينبغي أن نجد الآن عدد الأندية لدينا أقل بواحد من السّابق: 1|Real Madrid|Benitez|Spain 2|Barcelona|Enrique|Spainيُغطِّي هذا جميع العمليّات الأساسيّة لقواعد البيانات، وقبل أن ننتهي دعونا نجرّب مثالًا آخر أقل بديهيّة بقليل، والذي يستخدم جدولين وانضمام join أساسي بينهما. فلنخرج الآن من Sqlite باستخدام الأمر Ctrl+D ونعيد الاتصال إلى قاعدة بيانات جديدة باستخدام: sqlite3 database2.dbسنقوم بإنشاء جدول مشابه جدًّا لجدول الأندية clubs ولكنّنا سننشئ أيضًا جدول للدول countries، والذي يقوم بتخزين اسم الدّولة ورئيسها الحالي، فلنقم أولًا بإنشاء جدول الدّول countries وإدخال إسبانيا وفرنسا إليه باستخدام ما يلي (لاحظ أنّنا نستطيع نسخ ولصق عدّة أسطر من شيفرة sqlite دفعة واحدة): CREATE TABLE countries (id integer, name varchar(30), president varchar(30)); INSERT INTO countries VALUES (1, "Spain", "Rajoy Brey"); INSERT INTO countries VALUES(2, "France", "Francois Hollande");ونستطيع بعدها إعادة إنشاء الجدول clubs باستخدام ما يلي: CREATE TABLE clubs (id integer, name varchar(30), country_id integer); INSERT INTO clubs VALUES (1, "Real Madrid", 1); INSERT INTO clubs VALUES (2, "Barcelona", 1); INSERT INTO clubs VALUES (3, "Chelsea", 2);دعونا الآن نرى ما هي الأندية الموجودة في إسبانيا باستخدام: SELECT name FROM clubs JOIN countries ON country_id=countries.id WHERE countries.name="Spain";ينبغي أن نشاهد ما يلي: Real Madrid Barcelonaيُغطّي هذا موضوع الانضمام الأساسي basic join، فلنلاحظ أنّ sqlite تفعل الكثير من أجلنا، ففي التّعبير السّابق يرمز الانضمام Join افتراضيًّا إلى INNER JOIN بالرغم من أنّنا استخدمنا فقط الكلمة المفتاحيّة JOIN، ولا يجب علينا أيضًا تحديد clubs.country_id لأنّها واضحة لا لبس فيها، من ناحية أخرى إن جرّبنا هذا الأمر: SELECT name FROM clubs JOIN countries ON country_id=id WHERE country_id=1;سنتلقّى رسالة خطأ: "Error: ambiguous column name: id" وهو خطأ معقول بما فيه الكفاية لأنّ الجدولين لدينا كلاهما يملكان عمود id، ولكن بشكلٍ عام sqlite متسامحة مع الأخطاء إلى حد ما، فرسائل الأخطاء فيها تميل إلى أن تجعل تحديد مكان أيّ مشاكل وإصلاحها شيئًا بديهيا إلى حد ما، وهذا يُساعد على تسريع عمليّة التّطوير. للمزيد من المساعدة في موضوع الصّياغة Syntax فإنّ الوثائق الرّسميّة لها مليئة بالمخطّطات البيانيّة diagrams مثل هذا sqlite.org/langdelete.html، والتي من الممكن أن تكون مفيدة. وفي الختام، تملك sqlite أغلفة wrappers وتعريفات في جميع اللغات الرئيسيّة، ويُمكن تشغيلها على معظم الأنظمة، نستطيع إيجاد قائمة بالعديد من هذه اللغات هنا، حظًّا سعيدًا واستمتع بوقتك. ترجمة -وبتصرّف- للمقال How and When to Use Sqlite لصاحبه Gareth Dwyer.
Sqlite هي عبارة عن محرك SQL مفتوح المصدر سريع وبسيط جدا، يشرح هذا الدرس متى يكون من الأمثل استخدام Sqlite كبديل لأنظمة إدارة قواعد البيانات الارتباطية RDBMS مثل MySQL أو Postgres، بالإضافة إلى كيفية تثبيتها وأمثلة عن استخداماتها الأساسية، تُغطي عمليات CRUD: الإنشاء Create، القراءة Read، التحديث Update، والحذف Delete. مفاهيم خاطئةلا يجب أن ننخدع بالاعتقاد أن Sqlite تستَخدم فقط للاختبار والتطوير، فعلى سبيل المثال تعمل Sqlite بشكل جيد لمواقع الإنترنت التي تتلقى 100,000 زائر يوميا، وهذا هو الحد المُحافظ. إن الحد الأقصى لحجم قاعدة بيانات Sqlite هو 140 تيرابايت (والذي من المفترض أن يكون كافيًا، أليس كذلك؟)، وبإمكانها أن تكون أسرع بكثير من RDBMS، يتم تخزين قاعدة البيانات كاملةمع كافة البيانات الضرورية في ملف عادي في نظام ملفات المضيف Host، ولذلك لا توجد حاجة لعملية خادوم Server منفصلة (الاستغناء عن الحاجة إلى الاتصالات البطيئة بين العمليّات). الاستخدام الأمثل على VPS الخاص بناتركز Sqlite على البساطة، وبما أنها تعمل داخليا internal بشكلٍ تام، فهي غالبًا ما تكون أسرع بكثير من البدائل الأخرى، إن كنا نبحث عن قابلية النقل portability (فيما يتعلق باللغات والمنصّات معًا)، البساطة، السرعة، والاستهلاك القليل للذاكرة فإن Sqlite مثاليّة لهذا، فعيوبها تكون واضحة فقط عند الحاجة لتزامن عال بالقراءة أو الكتابة. حيث تستطيع Sqlite أن تدعم كاتب writer واحد فقط في نفس الوقت، وقد يكون زمن الوصول latency لنظام الملفات المرتَفِع عادة غير مُلائِم إن كانت هناك حاجة لنفاذ access العديد من العملاء إلى قاعدة بيانات Sqlite في نفس الوقت. العيب الأخير المُحتَمل وجوده في Sqlite هو صياغتها syntax الفريدة، بالرغم من تشابهها مع أنظمة SQL الأخرى، ومن البديهي عند الانتقال إلى نظام آخر -إن قمنا باستخدام Sqlite والتي تتطوّر بسرعة- أن نجد بعض العقبات في المرحلة الانتقاليّة. تثبيت Sqlite على VPS الخاص بناإن وحدة sqlite3 module هي جزء من مكتبة بايثون المعيارية، لذلك لا نحتاج لأي تثبيت آخر على توزيعة Ubuntu المعيارية أو على أي نظام آخر مُثبّت عليه بايثون، ولتثبيت واجهة سطر الأوامر لـ Sqlite على Ubuntu نستخدم هذه الأوامر: sudo apt-get update sudo apt-get install sqlite3 libsqlite3-devإن كُنّا نريد تصريفه Compile من المصدر Source يجب علينا الحصول على آخر إصدار من autoconf من الرّابط sqlite.org/download.html، وهو الإصدار المتوفّر وقت كتابة هذا الدّرس: wget http://sqlite.org/2013/sqlite-autoconf-3080100.tar.gz tar xvfz sqlite-autoconf-3080100.tar.gz cd sqlite-autoconf-3080100 ./configure make make installملاحظات من أجل البناء من المصدر: لا يجب أن نقوم بفعل هذا على توزيعة Ubuntu معياريّة لأنّه من المُحتمل أن نتلقّى خطأ عن عدم التّوافق في إصدار التّرويسة Header والمصدر "header and source version mismatch" بسبب التّعارض بين الإصدار المُثبّت حاليًّا والإصدار الجّديد الذي نريد تثبيته.إن كان يبدو أنّ الأمر make ينتظر المزيد من المُدخلات منك فكُن صبورًا فقط، حيث أنّ تصريف Compile المصدر قد يستغرق بعض الوقت.الاستخدامات الأساسية لواجهة سطر الأوامرلإنشاء قاعدة بيانات نقوم بتنفيذ الأمر التالي: sqlite3 database.dbحيث يكون database هو اسم قاعدة البيانات لدينا، وإن كان الملف database.db موجودًا مُسبقًا ستقوم Sqlite بإنشاء اتصال معه، وإن لم يكن موجودًا سيتمّ إنشاؤه، يجب أن يكون الخرج Output مُشابهًا لما يلي: SQLite version 3.8.1 2013-10-17 12:57:35 Enter ".help" for instructions Enter SQL statements terminated with a ";" sqlite>فلنقم الآن بإنشاء جدول Table وإدخال بعض البيانات إليه، يملك هذا الجدول المُسمَّى الأندية clubs أربعة أعمدة columns، من أجل id، اسم النادي name، مدرّبه coach، وبلد النّادي country، سنقوم بإدخال بيانات ثلاثة أندية كرة قدم إلى قاعدة بياناتنا: CREATE TABLE clubs (id integer, name varchar(30), coach varchar(20), country varchar(20)); INSERT INTO clubs VALUES (1, "Real Madrid", "Benitez", "Spain"); INSERT INTO clubs VALUES (2, "Barcelona", "Enrique", "Spain"); INSERT INTO clubs VALUES (3, "Chelsea", "Mourinho", "England");لقد أنشأنا قاعدة بيانات، جدول، وبعض الإدخالات، نضغط الآن Ctrl+D للخروج من Sqlite ونكتب ما يلي (يجب هنا أيضًا أن نضع اسم قاعدة بياناتنا بدلًا من 'database') والذي سيقوم بإعادة الاتصال إلى قاعدة البيانات التي أنشأناها للتو: sqlite3 database.dbالآن نكتب: SELECT * FROM clubs;يجب أن نرى هنا الإدخالات التي قُمنا بها: 1|Real Madrid|Benitez|Spain 2|Barcelona|Enrique|Spain 3|Chelsea|Mourinho|Englandرائع، هذا هو كلّ شيء فيما يتعلّق بالإنشاء Creating والقراءة Reading، فلنقم الآن بالتّحديث Update والحذف Delete: UPDATE clubs SET country="Spain" WHERE country="England";سيقوم هذا الأمر بتحديث قاعدة البيانات بحيث يجعل الأندية المُدرَجة على أنّها من إنكلترا يتم إدراجها وكأنّها أندية من إسبانيا، فلنتأكّد من النتائج باستخدام الأمر: SELECT * FROM clubs;يجب أن نرى: 1|Real Madrid|Benitez|Spain 2|Barcelona|Enrique|Spain 3|Chelsea|Mourinho|Spainأصبحت لدينا الآن كل الأندية من إسبانيا، فلنقم بحذف Chelsea من قاعدة بياناتنا كونه النادي الوحيد الذي في الحقيقة ليس من إسبانيا: DELETE FROM clubs WHERE id=3; SELECT * FROM clubs;ينبغي أن نجد الآن عدد الأندية لدينا أقل بواحد من السّابق: 1|Real Madrid|Benitez|Spain 2|Barcelona|Enrique|Spainيُغطِّي هذا جميع العمليّات الأساسيّة لقواعد البيانات، وقبل أن ننتهي دعونا نجرّب مثالًا آخر أقل بديهيّة بقليل، والذي يستخدم جدولين وانضمام join أساسي بينهما. فلنخرج الآن من Sqlite باستخدام الأمر Ctrl+D ونعيد الاتصال إلى قاعدة بيانات جديدة باستخدام: sqlite3 database2.dbسنقوم بإنشاء جدول مشابه جدًّا لجدول الأندية clubs ولكنّنا سننشئ أيضًا جدول للدول countries، والذي يقوم بتخزين اسم الدّولة ورئيسها الحالي، فلنقم أولًا بإنشاء جدول الدّول countries وإدخال إسبانيا وفرنسا إليه باستخدام ما يلي (لاحظ أنّنا نستطيع نسخ ولصق عدّة أسطر من شيفرة sqlite دفعة واحدة): CREATE TABLE countries (id integer, name varchar(30), president varchar(30)); INSERT INTO countries VALUES (1, "Spain", "Rajoy Brey"); INSERT INTO countries VALUES(2, "France", "Francois Hollande");ونستطيع بعدها إعادة إنشاء الجدول clubs باستخدام ما يلي: CREATE TABLE clubs (id integer, name varchar(30), country_id integer); INSERT INTO clubs VALUES (1, "Real Madrid", 1); INSERT INTO clubs VALUES (2, "Barcelona", 1); INSERT INTO clubs VALUES (3, "Chelsea", 2);دعونا الآن نرى ما هي الأندية الموجودة في إسبانيا باستخدام: SELECT name FROM clubs JOIN countries ON country_id=countries.id WHERE countries.name="Spain";ينبغي أن نشاهد ما يلي: Real Madrid Barcelonaيُغطّي هذا موضوع الانضمام الأساسي basic join، فلنلاحظ أنّ sqlite تفعل الكثير من أجلنا، ففي التّعبير السّابق يرمز الانضمام Join افتراضيًّا إلى INNER JOIN بالرغم من أنّنا استخدمنا فقط الكلمة المفتاحيّة JOIN، ولا يجب علينا أيضًا تحديد clubs.country_id لأنّها واضحة لا لبس فيها، من ناحية أخرى إن جرّبنا هذا الأمر: SELECT name FROM clubs JOIN countries ON country_id=id WHERE country_id=1;سنتلقّى رسالة خطأ: "Error: ambiguous column name: id" وهو خطأ معقول بما فيه الكفاية لأنّ الجدولين لدينا كلاهما يملكان عمود id، ولكن بشكلٍ عام sqlite متسامحة مع الأخطاء إلى حد ما، فرسائل الأخطاء فيها تميل إلى أن تجعل تحديد مكان أيّ مشاكل وإصلاحها شيئًا بديهيا إلى حد ما، وهذا يُساعد على تسريع عمليّة التّطوير. للمزيد من المساعدة في موضوع الصّياغة Syntax فإنّ الوثائق الرّسميّة لها مليئة بالمخطّطات البيانيّة diagrams مثل هذا sqlite.org/langdelete.html، والتي من الممكن أن تكون مفيدة. وفي الختام، تملك sqlite أغلفة wrappers وتعريفات في جميع اللغات الرئيسيّة، ويُمكن تشغيلها على معظم الأنظمة، نستطيع إيجاد قائمة بالعديد من هذه اللغات هنا، حظًّا سعيدًا واستمتع بوقتك. ترجمة -وبتصرّف- للمقال How and When to Use Sqlite لصاحبه Gareth Dwyer. -
 بعد أن تعرّفنا على طريقة تمرير قيم المُتغيّرات من بايثون إلى ملفّات HTML أصبح بإمكاننا أن نستعمل قاعدة بيانات تحتوي على جدول للمقالات عوضا عن استعمال قائمة أو قاموس. ما هي قاعدة البيانات قاعدة البيانات ببساطة مخزَن للبيانات المُختلفة كأسماء المستخدمين، كلمات المرور، وباقي القيم التي يُمكن أن تحصل عليها ممن يستخدم تطبيقك، ويُمكن كذلك جلب، تعديل وحذف البيانات منها بسهولة. يُمكن أن تكون قاعدة البيانات عبارة عن ملفّ نصي بسيط، بحيث يمثل كل سطر منه قيمة مُستقلّة، ويُمكن أن تكون عبارة عن جدول، بحيث يكون لهذا الجدول أعمدة وخانات، في كلّ عمود نوع محدد من القيم، وفي كلّ خانة القيمة الخاصّة بهذا النوع. سنستخدم في هذا الدّرس نظام SQL لقواعد البيانات، وهو نظام يعتمد على الجداول، وسنستخدم في هذا الدّرس جدولا لتخزين المقالات كالتّالي: رقم المُعرّف عنوان المقال مُحتوى المقال 1 عنوان المقال الأول مُحتوى المقال الأول 2 عنوان المقال الثّاني مُحتوى المقال الثّاني بنية تطبيق "مدونتي" سنعمل في هذا الدّرس على بناء تطبيق مُتكامل يُمكن أن يعمل كنظام إدارة مُحتوى بسيط، ستكون بنية التّطبيق كالآتي: الصّفحة الرّئيسيّة: هنا تُعرض عناوين ومحتويات المقالات المُتواجدة في قاعدة البيانات، بالإضافة إلى زر لحذف كل مقال. صفحة المقال: هنا ستتمكن من قراءة المقال مع رابط تحت المقال لحذفه. إضافة مقال جديد: ستتمكّن من إضافة مقال جديد إلى قاعدة البيانات في الصّفحة الرّئيسيّة مباشرة بعد عرض المقالات الموجودة. وهذه صور للتّطبيق النّهائي: الصفحة الرئيسية صفحة المقال إنشاء قاعدة البيانات وإنشاء جدول المقالات سنستعمل في الدّرس قواعد البيانات Sqlite لإدارة قاعدة البيانات، وذلك لسهولة التّعامل معها وسهولة نقل ملفّات قاعدة البيانات إلى أجهزة أخرى، كما أنّها لا تعمل على خادوم كما هو الحال مع MySQL أو Postgresql. تنويه: من المُفضّل عدم استخدام Sqlite في التّطبيقات التي ستنشرها على الأنترنت أو المشاريع الرّسميّة، ومن المُفضّل استخدام Postgresql أو MySQL في هذه الحالة. سننشئ قاعدة بيانات باسم database. في قاعدة البيانات هذه سنضيف جدولا للمقالات باسم posts. سيتكون جدول المقالات من ثلاثة أعمدة: رقم المقال/المعرّف (ID) عنوان المقال (Title) مُحتوى المقال (Content) لإنشاء قاعدة البيانات وجدول المقالات يُمكنك تنفيذ الشيفرة التّالية، ضعها داخل ملفّ باسم create_db.py وقم بتنفيذه: # -*- coding: utf-8 -*- import sqlite3 # الاتّصال بقاعدة البيانات db = sqlite3.connect('database.db') # إنشاء مُؤشّر في قاعدة البيانات لنتمكّن من تنفيذ استعلامات SQL cursor = db.cursor() # إنشاء الجدول cursor.execute(""" CREATE TABLE posts( id INTEGER PRIMARY KEY, title CHAR(200), content TEXT )""") # إدخال القيم إلى الجدول cursor.execute('''INSERT INTO posts(title, content) VALUES(?,?)''', (u'عنوان المقال الأول', u'محتوى المقال الأول')) cursor.execute('''INSERT INTO posts(title, content) VALUES (?,?)''', (u'عنوان المقال الثّاني', u'مُحتوى المقال الثّاني')) # تطبيق التغييرات db.commit() لاحظ بأنّنا نستدعي الوحدة sqite3 في البداية، وذلك لتنفيذ شيفرة لغة SQL، والشيفرة الممرّرة كمُعاملات للدّالة execute هي شيفرة SQL خاصّة بقاعدة البيانات Sqlite. بعد تنفيذ الشيفرة سنحصل على ملف database.db وهو الذي سيكون قاعدة بيانات التّطبيق، يوجد داخل قاعدة البيانات جدول مقالات باسم posts يحتوي بدوره على 3 أعمدة (رقم مُعرّف المقال، عنوان المقال ومحتواه)، مُعرّف المقال سيزيد بواحد تلقائيّا في كلّ مرّة نُضيف فيها عنوانا ومحتوى جديدين وهذا لأنّه من النّوع PRIMARY KEY، ما يعني بأنّنا نستطيع توفير قيمتين فقط دون الاهتمام بخانة رقم المعرّف. نضيف بعد ذلك مقالين: المقال الأول: عنوانه "عنوان المقال الأول"، مُحتواه "محتوى المقال الأول" المقال الثاني: عنوانه "عنوان المقال الثاني"، مُحتواه "محتوى المقال الثّاني" بعد الانتهاء من إضافة القيم، نقوم باستدعاء الدّالة commit لحفظ التّغييرات إلى قاعدة البيانات. الحصول على المقالات للحصول على رقم مُعرّف وعنوان ومحتوى المقالات يُمكننا تنفيذ الاستعلام التّالي: SELECT * FROM posts; النّجمة عبارة تعني all أو الكل. يُمكننا كذلك الحصول على قيم عمود واحد فقط: SELECT title FROM posts; ويُمكن الحصول على أكثر قيم أكثر من عمود: SELECT title, content FROM posts; لوضع القيم في مُتغيّر وإرجاعه في دالة في بايثون يُمكنك كتابة دالة كالتّالي: import sqlite3 BASE_DIR = path.dirname(path.realpath(__file__)) DB_PATH = path.join(BASE_DIR, 'database.db') def get_posts(): db = sqlite3.connect(DB_PATH) cursor = db.cursor() query = cursor.execute('''SELECT * FROM posts''') posts = query.fetchall() return posts السّطر الأول يستورد مكتبة sqlite3. السّطر الثّاني مسؤول عن الحصول على مسار المُجلّد الحالي، بعدها نقوم بإيصال مسار المُجلّد الحالي مع ملفّ قاعدة البيانات لنحصل على المسار الكامل للملفّ كقيمة للمُتغيّر DB_PATH، وهذا لتفادي بعض الأخطاء التّي قد تحدث عند نقل ملفّات التّطبيق إلى مكان آخر كاستضافة ما أو نظام تشغيل مُختلف. أما الدالة فتقوم أولا بالاتصال بقاعدة البيانات بالدّالة connect ومعامل DB_PATH الذي يُمثّل مسار ملف قاعدة البيانات database.db، بعدها نُنشئ مؤشّرا بالدّالة cursor، ثمّ ننفّذ الاستعلام كمُعامل مُمرّر للدّالة execute، بعدها نُطبّق الدالّة fetchall على نتيجة الاستعلام للحصول على القيم في قائمة من المجموعات، بحيث تحتوي القائمة على مجموعة بثلاثة عناصر العنصر الأول هو رقم المعرّف والعنصر الثّاني يمثّل عنوان المقال والعنصر الثّالث يمثّل محتوى المقال. وبالتّالي فإنّنا سنتمكن من الوصول إلى محتويات المقال كعناصر في مجموعة داخل قائمة، والقائمة تحتوي على العديد من المجموعات. قائمة المقالات ستكون كالتّالي: posts = [(1, u'عنوان المقال الأول', u'محتوى المقال الأول'), (2, u'عنوان المقال الثّاني', u'محتوى المقال الثّاني') ] ما يعني بأنّنا نستطيع الوصول إلى مُعرّف كل مقال، عنوانه ومحتواه بحلقة For بسيطة: posts = get_posts() for post in posts: post[0] # رقم المعرّف post[1] # عنوان المقال post[2] # محتوى المقال احفظ الدّالة get_posts في ملفّ باسم manage_db.py لنستعملها لاحقا كوحدة مع تطبيقنا (انظر درس الوحدات والحزم في لغة بايثون). الحصول على مقال حسب معرفه/رقمه للحصول على مقال حسب رقم مُعرّفه يكفي أن نُضيف جملة WHERE إلى استعلام SQL: SELECT title, content FROM posts WHERE id=1 ستُمكّننا الجملة أعلاه من الحصول على عنوان ومحتوى المقال الذي يمتلك رقم المُعرّف 1. لاستغلال الأمر في لغة بايثون بمُساعدة وحدة sqlite يُمكننا أن نكتب دالة باسم get_post_by_id لنحصل على مقال حسب رقم مُعرّفه، وبالطّبع سيكون للدّالة مُعامل واحد باسم post_id ليحمل قيمة رقم المُعرّف. def get_post_by_id(post_id): db = sqlite3.connect(DB_PATH) cursor = db.cursor() post_id = int(post_id) query = cursor.execute('''SELECT title, content FROM posts WHERE id=?''',(post_id,)) post = query.fetchone() return post بعد الاتّصال بقاعدة البيانات وإنشاء مؤشّر، نقوم أولا بتحويل قيمة رقم المُعرّف إلى عدد صحيح لأن الدّالة رقم المعرّف في قاعدة البيانات عبارة عن عدد صحيح. بعدها نُنفّذ الاستعلام الذي سبق وأن ذكرناه، لكن هذه المرّة قُمنا بتمرير مجموعة من عنصر واحد، وهذا العنصر هو مُعامل الدّالة، بعدها عرّفنا مُتغيّرا باسم post ليحمل بيانات المقال التي حصلنا عليها بتنفيذ الدّالة fetchone على الاستعلام، بعدها نُرجع المُتغيّر post. إذا استدعيت الدّالة مع تمرير قيمة بالعدد 1 فسيكون المُخرج كالتّالي: (u'عنوان المقال الأول', u'محتوى المقال الأول') أضف الدالة get_post_by_id إلى ملفّ manage_db.py واحفظه. حذف مقال حسب رقم المقال طريقة حذف المقال مُشابهة لطريقة الحصول عليه، فقط استبدل SELECT بالأمر DELETE. DELETE FROM posts WHERE id=? ما يعني بأنّنا نستطيع كتابة دالة في لغة بايثون لحذف مقال حسب رقم مُعرّفه: def delete(post_id): db = sqlite3.connect(DB_PATH) cursor = db.cursor() cursor.execute('''DELETE FROM posts WHERE id=?''', (post_id,)) db.commit() الاختلاف هنا هو أنّنا سنحتاج إلى تنفيذ الدّالة commit لتأكيد العمليّة. وكما العادة، أضف دالة الحذف إلى ملفّ manage_db.py. إضافة مقال تعرّفنا في بداية هذا الدّرس على طريقة إضافة مقال إلى قاعدة البيانات. INSERT INTO posts(title, content) VALUES('Title 1','Content 1') يُمكننا في بايثون إدخال قيم المُتغيّرات إلى قاعدة البيانات بالطّريقة التّالية: import sqlite3 db = sqlite3.connect('database.db') cursor = db.cursor() title_variable = 'Title 3' content_variable = 'Content 3' cursor.execute('''INSERT INTO posts(title, content) VALUES(?,?)''', (title_variable, content_variable)) db.commit() لا تنس أن تقوم باستدعاء الدّالة commit لتأكيد العمليّة. إذا قُمت بتنفيذ الشّيفرة أعلاه، وقُمت بعدها بتنفيذ الدّالة get_posts التي أنشأناها سابقا، ستتمكّن من رؤية القيمتين Title 3 و Content 3 كعنصرين من قائمة المقالات. لنضع هذه الشّيفرة في دالة باسم create لإضافتها إلى الوحدة manage_db، ستقبل الدّالة مُعاملين، مُعامل للعنوان، ومُعامل آخر لمُحتوى المقال. def create(title, content): db = sqlite3.connect('DB_PATH') cursor = db.cursor() cursor.execute('''INSERT INTO posts(title, content) VALUES(?,?)''', (title, content)) db.commit() الحصول على القيم وتمريرها إلى القالب بعد أن أنشأنا وحدة تحتوي على أربعة دوال تؤدّي أربعة أوامر أساسيّة: get_posts: الحصول على المقالات على شكل قائمة من المجموعات يُمكن الدّوران حولها get_post_by_id: الحصول على عنوان ومُحتوى مقال حسب رقم مُعرّفه delete: حذف مقال create: إنشاء مقال جديد إذا اطّلعت على الدّرسين السّابقين، ستعرف كيفيّة الحصول على قائمة المقالات وكيفيّة تقديمها في ملفّ HTML دون قراءة الجزء الموالي، لذا فمن الأفضل أن تُحاول ذلك الآن، وعد إلى هنا إذا واجهتك أية مشاكل. مبدأ التطبيق سيحتوي التّطبيق على 4 موجّهات: موجّه الصّفحة الرّئيسية / موجّه إضافة المقال create/ موجّه صفحة المقال الواحد <post/<post_id/ موجّه حذف المقال <delete/<post_id/ موجها إضافة المقال وحذفه لن يقدّما صفحة HTML بل سيُنفّذان دالّة وبعدها سيعيدان التّوجيه إلى الصّفحة الرّئيسيّة مباشرة. الصفحة الرئيسية ستحتوي الصّفحة الرّئيسية على عناوين ومحتويات المقالات لذا سنستخدم الدّالة get_posts من الوحدة manage_db في المُوجّه الرّئيسي ما يعني بأنّنا يجب علينا استدعاء الوحدة، كما سنُقدّم المقالات في ملفّ HTML باسم index.html. في ملّف app.py ضع ما يلي: # -*- coding:utf8 -*- from flask import Flask, render_template import manage_db app = Flask(__name__) # Home Page @app.route("/") def home(): posts = manage_db.get_posts() return render_template('index.html', posts = posts) if __name__ == "__main__": app.run(debug=True) لاحظ بأنّنا استدعينا الدّالة get_posts وأسندنا قيمتها إلى المُتغيّر posts وبعدها نُقدّم الملفّ index.html مع تمرير المُتغيّر posts. بما أنّ المُتغيّر الذي مرّرناه عبارة عن قائمة سنقوم بالدوران حول هذه القائمة والوصول إلى كل عنصر في المجموعة على حدة. الجزء المسؤول عن عرض المقالات في ملفّ index.html: {% for post in posts %} <a href="post/{{ post[0] }}"> <h2> {{ post[1] }} </h2> </a> <a href="delete/{{ post[0] }}"><span class="delete">حذف</span></a> <p> {{ post[2] }} </p> {% endfor %} الشّيفرة أعلاه هي الجزء المسؤول عن عرض المقالات فقط، وقد تجاهلت العناصر الأخرى التي لا تهمّنا مثل الشّعار والتّنسيق وغير ذلك. يُمكنك الحصول على ملفّ index.html كاملا من على Github بعد حلقة For سنحصل على مجموعة بثلاثة عناصر، العنصر الأول عبارة عن رقم مُعرّف المقال، وسنستخدمه لوضع رابطين للمقال، رابط عرض المقال ورابط حذفه، ما يعني بأنّنا نستطيع الوصول مثلا إلى المقال الأول كالتّالي: post/{{ post[0] }} => http://127.0.0.1:5000/post/1 ويُمكن حذفه بالرّابط التّالي: delete/{{ post[0] }} => http://127.0.0.1:5000/delete/1 الرّوابط لن تعمل حاليّا لأنّنا لم ننشئ المُوجّهات بعد. سيُعرض عنوان المقال داخل وسم h2 بالسّطر التّالي: <h2> {{ post[1] }} </h2> سيُعرض مُحتوى المقال داخل وسم p بالسّطر التّالي: <p> {{ post[2] }} </p> صفحة عرض المقال لعرض المقال الواحد، سنستخدم ملفّ HTML آخر وسنسمّيه post.html، أمّا الموجّه المسؤول عن تقديم هذا المقال فسيكون كالتّالي: موجّه post في ملفّ app.py: # Single Post Page @app.route("/post/<post_id>") def post(post_id): post = manage_db.get_post_by_id(post_id) return render_template('post.html', post = post) الشّيفرة أعلاه عبارة عن مُوجّه باسم post يقبل مُعاملا post_id لنتمكّن من تمريره كمُعرّف للمقال للدّالة get_post_by_id من الوحدة manage_db. بعدها نقوم باستدعاء الدّالة للحصول على بيانات المقال على شكل مجموعة يُمكننا أن نصل إلى عناصرها كالتّالي: post[0] # عنوان المقال post[1] # المحتوى صفحة post.html: <div class="main"> <h2> {{ post[0] }} </h2> <p> {{ post[1] }} </p> </div> <a href="{{ url_for('home') }}" class="back_to_home">عُد إلى الصّفحة الرّئيسيّة</a> في الشّيفرة أعلاه، نقوم بعرض عنوان المقال داخل وسم h2 ونقوم بعرض المُحتوى داخل وسم p. السّطر الأخير عبارة عن رابط لتمكين الزّائر من العودة إلى الصّفحة الرّئيسيّة و home اسم الدّالة المسؤولة عن تقديم الصّفحة الرّئيسية (الموجودة مُباشرة بعد الموجّه /). # Home Page @app.route("/") def home(): ... ملحوظة: نستطيع استخدام الدّالة url_for لتوليد روابط الموجّهات، وذلك بوضع اسم الدّالة كمعامل. مثال: لنفرض بأنّ لدينا مُوجّها باسم hello ودالة باسم hello_page، سنتمكّن من إنشاء رابط إلى الموجّه hello كالتّالي: <a href="{{ url_for('hello_page') }}">Link to Hello Page</a> يُمكن كذلك وضع عنوان المقال كعنوان للصّفحة داخل وسم title: <title>{{ post[0] }}</title> حذف مقال طريقة حذف المقال شبيهة بطريقة عرضه، الاختلاف هنا هو أنّنا سنستخدم الدّالة redirect لإعادة توجيه المُستخدم إلى الصّفحة الرّئيسية مُباشرة بعد حذف المقال. لاستخدام الدّالة redirect سيتوجّب علينا استيرادها من وحدة Flask في بداية الملفّ app.py. سنحتاج كذلك إلى الدّالة url_for للتوجيه إلى الرّابط الصّحيح. from flask import Flask, render_template, redirect, url_for موجّه delete سيقبل معاملا باسم post_id لتمريره إلى الدّالة delete من الوحدة manage_db لحذف المقال الذي يحمل رقم المعرّف المُمرّر. # Delete Post @app.route("/delete/<post_id>") def delete(post_id): manage_db.delete(post_id) return redirect(url_for('home')) لاحظ استخدام الدّالة redirect مُباشرة بعد حذف المقال، تقبل الدّالة مُعاملا بقيمة رّابط الصّفحة الرّئيسية والذي حصلنا عليه بالدّالة url_for، ما يعني بأنّنا نقوم بحذف المقال ثمّ توجيه المُستخدم مُباشرة إلى الصّفحة الرّئيسية. إنشاء مقال جديد تعرّفنا مُسبقا على طريقة الحصول على القيم من المستخدم بطريقة طلبات GET من عنوان URL كالآتي: /create?title=post1&content=content1 يُمكننا استخدام request للحصول على القيم كالتّالي: title = request.args.get('title') content = request.args.get('content') يُمكن استخدام هذه الطّريقة لإضافة مقال إلى قاعدة البيانات لكنّها ليست مُجديّة في هذه الحالة، لأنّنا نرغب بأن نُتيح للمُستخدم إرسال بيانات دون تعديل عنوان URL كما يجب علينا أن نُسهّل المأموريّة على المُستخدم العادي. لكي نحصل على العنوان والمُحتوى بطريقة أفضل، سنستخدم نماذج HTML أو HTML Forms، وسنستخدم طريقة POST عوضا عن GET. سنضع النّماذج في ملفّ index.html مُباشرة تحت الجزء المسؤول عن عرض المقالات. <h4>أضف مقالا</h4> <form action="{{ url_for('create') }}" method="POST"> <input class="input" type="text" name="title" placeholder="عنوان المقال"/> <br> <textarea name="content" class="input" rows="10" placeholder="مُحتوى المقال"></textarea> <br> <input type="submit" value="أضف" /> </form> في الوسم form نضع رابط الموجّه create داخل الصّفة action لنُخبر المُتصفّح بأنّ البيانات التّي سيُرسلها المُستخدم يجب أن تذهب إلى موجّه إضافة مقال جديد create. بعدها نُخصّص طريقة إرسال البيانات بوضع كلمة POST داخل الصّفة method. بعد ذلك ننشئ حقلا لعنوان المقال باسم title وحقل نصّ باسم content وبعدها نضيف زرّا لتأكيد الإرسال. بعد أن تملأ النموذج وتضغط على زر "أضف" سيُرسل المُتصفّح البيانات إلى الخادوم وسنتمكّن من الحصول عليها في المُوجّه create عبر الوحدة request، ما يعني بأنّنا سنحتاج إلى استدعاءها في بداية الملف. from flask import Flask, render_template, redirect, url_for, request سننشئ المُوجّه create مع تمرير مُعامل آخر باسم methods يحتوي على قائمة بعنصرين يُمثّلان الطريقتين GET وPOST لأنّ الإعداد الافتراضي هو GET فقط، نضع هذا العامل لكي نتمكّن من استقبال البيانات. @app.route("/create", methods=['GET', 'POST']) بعدها سنتمكّن من الحصول على البيانات وإدخالها إلى قاعدة البيانات كالتّالي: if request.method == 'POST': title = request.form['title'] # الحصول على عنوان المقال content = request.form['content'] # الحصول على مُحتوى المقال manage_db.create(title, content) # إدخال القيم إلى قاعدة البيانات لاحظ بأنّنا نضع شرطا للتأكّد من أن الطلب الذي يرسله المُتصفح من نوع POST. بعدها نحصل على القيم التي أدخلها المُستخدم في النّموذج الموجود بملفّ index.html عبر القاموس form المُتواجد داخل الوحدة request. وكما فعلنا مع الموجّه delete سنقوم بإعادة توجيه المُستخدم إلى الصّفحة الرّئيسية. return redirect(url_for('home')) الموجّه create كاملا: # Create Post Page @app.route("/create", methods=['GET', 'POST']) def create(): if request.method == 'POST': title = request.form['title'] content = request.form['content'] manage_db.create(title, content) return redirect(url_for('home')) أصبح التّطبيق كاملا الآن ويُمكنك مُشاركته مع العالم. يُمكنك إضافة تنسيق css خاصّ بك أو تحميل الملفّات الكاملة للتّطبيق من Github وإضافة ملفّ style.css إلى التّطبيق الذي أنشأته (يُمكنك كذلك تعديله). إذا كان لديك سؤال حول هذا الدّرس، يُمكنك وضعه في قسم الأسئلة والأجوبة. ختاما تعرّفنا على طريقة بناء تطبيق يتفاعل مع المُستخدم ويترك له حريّة الوصول إلى قاعدة البيانات، لكنك تُلاحظ بأنّ الحماية معدومة في التّطبيق، إذ يُمكن لأي شخص أن يحذف جميع المقالات دون أي حاجز (ككلمة مرور مثلا). سنتعلّم في الدّرس القادم على كيفيّة حماية التّطبيق وإتاحة الوصول إلى قاعدة البيانات لمُستخدم واحد فقط، بحيث يُسجّل دخوله إذا أراد حذف أو إضافة مقال، أمّا بقيّة المُستخدمين فلهم إمكانيّة القراءة فقط.
بعد أن تعرّفنا على طريقة تمرير قيم المُتغيّرات من بايثون إلى ملفّات HTML أصبح بإمكاننا أن نستعمل قاعدة بيانات تحتوي على جدول للمقالات عوضا عن استعمال قائمة أو قاموس. ما هي قاعدة البيانات قاعدة البيانات ببساطة مخزَن للبيانات المُختلفة كأسماء المستخدمين، كلمات المرور، وباقي القيم التي يُمكن أن تحصل عليها ممن يستخدم تطبيقك، ويُمكن كذلك جلب، تعديل وحذف البيانات منها بسهولة. يُمكن أن تكون قاعدة البيانات عبارة عن ملفّ نصي بسيط، بحيث يمثل كل سطر منه قيمة مُستقلّة، ويُمكن أن تكون عبارة عن جدول، بحيث يكون لهذا الجدول أعمدة وخانات، في كلّ عمود نوع محدد من القيم، وفي كلّ خانة القيمة الخاصّة بهذا النوع. سنستخدم في هذا الدّرس نظام SQL لقواعد البيانات، وهو نظام يعتمد على الجداول، وسنستخدم في هذا الدّرس جدولا لتخزين المقالات كالتّالي: رقم المُعرّف عنوان المقال مُحتوى المقال 1 عنوان المقال الأول مُحتوى المقال الأول 2 عنوان المقال الثّاني مُحتوى المقال الثّاني بنية تطبيق "مدونتي" سنعمل في هذا الدّرس على بناء تطبيق مُتكامل يُمكن أن يعمل كنظام إدارة مُحتوى بسيط، ستكون بنية التّطبيق كالآتي: الصّفحة الرّئيسيّة: هنا تُعرض عناوين ومحتويات المقالات المُتواجدة في قاعدة البيانات، بالإضافة إلى زر لحذف كل مقال. صفحة المقال: هنا ستتمكن من قراءة المقال مع رابط تحت المقال لحذفه. إضافة مقال جديد: ستتمكّن من إضافة مقال جديد إلى قاعدة البيانات في الصّفحة الرّئيسيّة مباشرة بعد عرض المقالات الموجودة. وهذه صور للتّطبيق النّهائي: الصفحة الرئيسية صفحة المقال إنشاء قاعدة البيانات وإنشاء جدول المقالات سنستعمل في الدّرس قواعد البيانات Sqlite لإدارة قاعدة البيانات، وذلك لسهولة التّعامل معها وسهولة نقل ملفّات قاعدة البيانات إلى أجهزة أخرى، كما أنّها لا تعمل على خادوم كما هو الحال مع MySQL أو Postgresql. تنويه: من المُفضّل عدم استخدام Sqlite في التّطبيقات التي ستنشرها على الأنترنت أو المشاريع الرّسميّة، ومن المُفضّل استخدام Postgresql أو MySQL في هذه الحالة. سننشئ قاعدة بيانات باسم database. في قاعدة البيانات هذه سنضيف جدولا للمقالات باسم posts. سيتكون جدول المقالات من ثلاثة أعمدة: رقم المقال/المعرّف (ID) عنوان المقال (Title) مُحتوى المقال (Content) لإنشاء قاعدة البيانات وجدول المقالات يُمكنك تنفيذ الشيفرة التّالية، ضعها داخل ملفّ باسم create_db.py وقم بتنفيذه: # -*- coding: utf-8 -*- import sqlite3 # الاتّصال بقاعدة البيانات db = sqlite3.connect('database.db') # إنشاء مُؤشّر في قاعدة البيانات لنتمكّن من تنفيذ استعلامات SQL cursor = db.cursor() # إنشاء الجدول cursor.execute(""" CREATE TABLE posts( id INTEGER PRIMARY KEY, title CHAR(200), content TEXT )""") # إدخال القيم إلى الجدول cursor.execute('''INSERT INTO posts(title, content) VALUES(?,?)''', (u'عنوان المقال الأول', u'محتوى المقال الأول')) cursor.execute('''INSERT INTO posts(title, content) VALUES (?,?)''', (u'عنوان المقال الثّاني', u'مُحتوى المقال الثّاني')) # تطبيق التغييرات db.commit() لاحظ بأنّنا نستدعي الوحدة sqite3 في البداية، وذلك لتنفيذ شيفرة لغة SQL، والشيفرة الممرّرة كمُعاملات للدّالة execute هي شيفرة SQL خاصّة بقاعدة البيانات Sqlite. بعد تنفيذ الشيفرة سنحصل على ملف database.db وهو الذي سيكون قاعدة بيانات التّطبيق، يوجد داخل قاعدة البيانات جدول مقالات باسم posts يحتوي بدوره على 3 أعمدة (رقم مُعرّف المقال، عنوان المقال ومحتواه)، مُعرّف المقال سيزيد بواحد تلقائيّا في كلّ مرّة نُضيف فيها عنوانا ومحتوى جديدين وهذا لأنّه من النّوع PRIMARY KEY، ما يعني بأنّنا نستطيع توفير قيمتين فقط دون الاهتمام بخانة رقم المعرّف. نضيف بعد ذلك مقالين: المقال الأول: عنوانه "عنوان المقال الأول"، مُحتواه "محتوى المقال الأول" المقال الثاني: عنوانه "عنوان المقال الثاني"، مُحتواه "محتوى المقال الثّاني" بعد الانتهاء من إضافة القيم، نقوم باستدعاء الدّالة commit لحفظ التّغييرات إلى قاعدة البيانات. الحصول على المقالات للحصول على رقم مُعرّف وعنوان ومحتوى المقالات يُمكننا تنفيذ الاستعلام التّالي: SELECT * FROM posts; النّجمة عبارة تعني all أو الكل. يُمكننا كذلك الحصول على قيم عمود واحد فقط: SELECT title FROM posts; ويُمكن الحصول على أكثر قيم أكثر من عمود: SELECT title, content FROM posts; لوضع القيم في مُتغيّر وإرجاعه في دالة في بايثون يُمكنك كتابة دالة كالتّالي: import sqlite3 BASE_DIR = path.dirname(path.realpath(__file__)) DB_PATH = path.join(BASE_DIR, 'database.db') def get_posts(): db = sqlite3.connect(DB_PATH) cursor = db.cursor() query = cursor.execute('''SELECT * FROM posts''') posts = query.fetchall() return posts السّطر الأول يستورد مكتبة sqlite3. السّطر الثّاني مسؤول عن الحصول على مسار المُجلّد الحالي، بعدها نقوم بإيصال مسار المُجلّد الحالي مع ملفّ قاعدة البيانات لنحصل على المسار الكامل للملفّ كقيمة للمُتغيّر DB_PATH، وهذا لتفادي بعض الأخطاء التّي قد تحدث عند نقل ملفّات التّطبيق إلى مكان آخر كاستضافة ما أو نظام تشغيل مُختلف. أما الدالة فتقوم أولا بالاتصال بقاعدة البيانات بالدّالة connect ومعامل DB_PATH الذي يُمثّل مسار ملف قاعدة البيانات database.db، بعدها نُنشئ مؤشّرا بالدّالة cursor، ثمّ ننفّذ الاستعلام كمُعامل مُمرّر للدّالة execute، بعدها نُطبّق الدالّة fetchall على نتيجة الاستعلام للحصول على القيم في قائمة من المجموعات، بحيث تحتوي القائمة على مجموعة بثلاثة عناصر العنصر الأول هو رقم المعرّف والعنصر الثّاني يمثّل عنوان المقال والعنصر الثّالث يمثّل محتوى المقال. وبالتّالي فإنّنا سنتمكن من الوصول إلى محتويات المقال كعناصر في مجموعة داخل قائمة، والقائمة تحتوي على العديد من المجموعات. قائمة المقالات ستكون كالتّالي: posts = [(1, u'عنوان المقال الأول', u'محتوى المقال الأول'), (2, u'عنوان المقال الثّاني', u'محتوى المقال الثّاني') ] ما يعني بأنّنا نستطيع الوصول إلى مُعرّف كل مقال، عنوانه ومحتواه بحلقة For بسيطة: posts = get_posts() for post in posts: post[0] # رقم المعرّف post[1] # عنوان المقال post[2] # محتوى المقال احفظ الدّالة get_posts في ملفّ باسم manage_db.py لنستعملها لاحقا كوحدة مع تطبيقنا (انظر درس الوحدات والحزم في لغة بايثون). الحصول على مقال حسب معرفه/رقمه للحصول على مقال حسب رقم مُعرّفه يكفي أن نُضيف جملة WHERE إلى استعلام SQL: SELECT title, content FROM posts WHERE id=1 ستُمكّننا الجملة أعلاه من الحصول على عنوان ومحتوى المقال الذي يمتلك رقم المُعرّف 1. لاستغلال الأمر في لغة بايثون بمُساعدة وحدة sqlite يُمكننا أن نكتب دالة باسم get_post_by_id لنحصل على مقال حسب رقم مُعرّفه، وبالطّبع سيكون للدّالة مُعامل واحد باسم post_id ليحمل قيمة رقم المُعرّف. def get_post_by_id(post_id): db = sqlite3.connect(DB_PATH) cursor = db.cursor() post_id = int(post_id) query = cursor.execute('''SELECT title, content FROM posts WHERE id=?''',(post_id,)) post = query.fetchone() return post بعد الاتّصال بقاعدة البيانات وإنشاء مؤشّر، نقوم أولا بتحويل قيمة رقم المُعرّف إلى عدد صحيح لأن الدّالة رقم المعرّف في قاعدة البيانات عبارة عن عدد صحيح. بعدها نُنفّذ الاستعلام الذي سبق وأن ذكرناه، لكن هذه المرّة قُمنا بتمرير مجموعة من عنصر واحد، وهذا العنصر هو مُعامل الدّالة، بعدها عرّفنا مُتغيّرا باسم post ليحمل بيانات المقال التي حصلنا عليها بتنفيذ الدّالة fetchone على الاستعلام، بعدها نُرجع المُتغيّر post. إذا استدعيت الدّالة مع تمرير قيمة بالعدد 1 فسيكون المُخرج كالتّالي: (u'عنوان المقال الأول', u'محتوى المقال الأول') أضف الدالة get_post_by_id إلى ملفّ manage_db.py واحفظه. حذف مقال حسب رقم المقال طريقة حذف المقال مُشابهة لطريقة الحصول عليه، فقط استبدل SELECT بالأمر DELETE. DELETE FROM posts WHERE id=? ما يعني بأنّنا نستطيع كتابة دالة في لغة بايثون لحذف مقال حسب رقم مُعرّفه: def delete(post_id): db = sqlite3.connect(DB_PATH) cursor = db.cursor() cursor.execute('''DELETE FROM posts WHERE id=?''', (post_id,)) db.commit() الاختلاف هنا هو أنّنا سنحتاج إلى تنفيذ الدّالة commit لتأكيد العمليّة. وكما العادة، أضف دالة الحذف إلى ملفّ manage_db.py. إضافة مقال تعرّفنا في بداية هذا الدّرس على طريقة إضافة مقال إلى قاعدة البيانات. INSERT INTO posts(title, content) VALUES('Title 1','Content 1') يُمكننا في بايثون إدخال قيم المُتغيّرات إلى قاعدة البيانات بالطّريقة التّالية: import sqlite3 db = sqlite3.connect('database.db') cursor = db.cursor() title_variable = 'Title 3' content_variable = 'Content 3' cursor.execute('''INSERT INTO posts(title, content) VALUES(?,?)''', (title_variable, content_variable)) db.commit() لا تنس أن تقوم باستدعاء الدّالة commit لتأكيد العمليّة. إذا قُمت بتنفيذ الشّيفرة أعلاه، وقُمت بعدها بتنفيذ الدّالة get_posts التي أنشأناها سابقا، ستتمكّن من رؤية القيمتين Title 3 و Content 3 كعنصرين من قائمة المقالات. لنضع هذه الشّيفرة في دالة باسم create لإضافتها إلى الوحدة manage_db، ستقبل الدّالة مُعاملين، مُعامل للعنوان، ومُعامل آخر لمُحتوى المقال. def create(title, content): db = sqlite3.connect('DB_PATH') cursor = db.cursor() cursor.execute('''INSERT INTO posts(title, content) VALUES(?,?)''', (title, content)) db.commit() الحصول على القيم وتمريرها إلى القالب بعد أن أنشأنا وحدة تحتوي على أربعة دوال تؤدّي أربعة أوامر أساسيّة: get_posts: الحصول على المقالات على شكل قائمة من المجموعات يُمكن الدّوران حولها get_post_by_id: الحصول على عنوان ومُحتوى مقال حسب رقم مُعرّفه delete: حذف مقال create: إنشاء مقال جديد إذا اطّلعت على الدّرسين السّابقين، ستعرف كيفيّة الحصول على قائمة المقالات وكيفيّة تقديمها في ملفّ HTML دون قراءة الجزء الموالي، لذا فمن الأفضل أن تُحاول ذلك الآن، وعد إلى هنا إذا واجهتك أية مشاكل. مبدأ التطبيق سيحتوي التّطبيق على 4 موجّهات: موجّه الصّفحة الرّئيسية / موجّه إضافة المقال create/ موجّه صفحة المقال الواحد <post/<post_id/ موجّه حذف المقال <delete/<post_id/ موجها إضافة المقال وحذفه لن يقدّما صفحة HTML بل سيُنفّذان دالّة وبعدها سيعيدان التّوجيه إلى الصّفحة الرّئيسيّة مباشرة. الصفحة الرئيسية ستحتوي الصّفحة الرّئيسية على عناوين ومحتويات المقالات لذا سنستخدم الدّالة get_posts من الوحدة manage_db في المُوجّه الرّئيسي ما يعني بأنّنا يجب علينا استدعاء الوحدة، كما سنُقدّم المقالات في ملفّ HTML باسم index.html. في ملّف app.py ضع ما يلي: # -*- coding:utf8 -*- from flask import Flask, render_template import manage_db app = Flask(__name__) # Home Page @app.route("/") def home(): posts = manage_db.get_posts() return render_template('index.html', posts = posts) if __name__ == "__main__": app.run(debug=True) لاحظ بأنّنا استدعينا الدّالة get_posts وأسندنا قيمتها إلى المُتغيّر posts وبعدها نُقدّم الملفّ index.html مع تمرير المُتغيّر posts. بما أنّ المُتغيّر الذي مرّرناه عبارة عن قائمة سنقوم بالدوران حول هذه القائمة والوصول إلى كل عنصر في المجموعة على حدة. الجزء المسؤول عن عرض المقالات في ملفّ index.html: {% for post in posts %} <a href="post/{{ post[0] }}"> <h2> {{ post[1] }} </h2> </a> <a href="delete/{{ post[0] }}"><span class="delete">حذف</span></a> <p> {{ post[2] }} </p> {% endfor %} الشّيفرة أعلاه هي الجزء المسؤول عن عرض المقالات فقط، وقد تجاهلت العناصر الأخرى التي لا تهمّنا مثل الشّعار والتّنسيق وغير ذلك. يُمكنك الحصول على ملفّ index.html كاملا من على Github بعد حلقة For سنحصل على مجموعة بثلاثة عناصر، العنصر الأول عبارة عن رقم مُعرّف المقال، وسنستخدمه لوضع رابطين للمقال، رابط عرض المقال ورابط حذفه، ما يعني بأنّنا نستطيع الوصول مثلا إلى المقال الأول كالتّالي: post/{{ post[0] }} => http://127.0.0.1:5000/post/1 ويُمكن حذفه بالرّابط التّالي: delete/{{ post[0] }} => http://127.0.0.1:5000/delete/1 الرّوابط لن تعمل حاليّا لأنّنا لم ننشئ المُوجّهات بعد. سيُعرض عنوان المقال داخل وسم h2 بالسّطر التّالي: <h2> {{ post[1] }} </h2> سيُعرض مُحتوى المقال داخل وسم p بالسّطر التّالي: <p> {{ post[2] }} </p> صفحة عرض المقال لعرض المقال الواحد، سنستخدم ملفّ HTML آخر وسنسمّيه post.html، أمّا الموجّه المسؤول عن تقديم هذا المقال فسيكون كالتّالي: موجّه post في ملفّ app.py: # Single Post Page @app.route("/post/<post_id>") def post(post_id): post = manage_db.get_post_by_id(post_id) return render_template('post.html', post = post) الشّيفرة أعلاه عبارة عن مُوجّه باسم post يقبل مُعاملا post_id لنتمكّن من تمريره كمُعرّف للمقال للدّالة get_post_by_id من الوحدة manage_db. بعدها نقوم باستدعاء الدّالة للحصول على بيانات المقال على شكل مجموعة يُمكننا أن نصل إلى عناصرها كالتّالي: post[0] # عنوان المقال post[1] # المحتوى صفحة post.html: <div class="main"> <h2> {{ post[0] }} </h2> <p> {{ post[1] }} </p> </div> <a href="{{ url_for('home') }}" class="back_to_home">عُد إلى الصّفحة الرّئيسيّة</a> في الشّيفرة أعلاه، نقوم بعرض عنوان المقال داخل وسم h2 ونقوم بعرض المُحتوى داخل وسم p. السّطر الأخير عبارة عن رابط لتمكين الزّائر من العودة إلى الصّفحة الرّئيسيّة و home اسم الدّالة المسؤولة عن تقديم الصّفحة الرّئيسية (الموجودة مُباشرة بعد الموجّه /). # Home Page @app.route("/") def home(): ... ملحوظة: نستطيع استخدام الدّالة url_for لتوليد روابط الموجّهات، وذلك بوضع اسم الدّالة كمعامل. مثال: لنفرض بأنّ لدينا مُوجّها باسم hello ودالة باسم hello_page، سنتمكّن من إنشاء رابط إلى الموجّه hello كالتّالي: <a href="{{ url_for('hello_page') }}">Link to Hello Page</a> يُمكن كذلك وضع عنوان المقال كعنوان للصّفحة داخل وسم title: <title>{{ post[0] }}</title> حذف مقال طريقة حذف المقال شبيهة بطريقة عرضه، الاختلاف هنا هو أنّنا سنستخدم الدّالة redirect لإعادة توجيه المُستخدم إلى الصّفحة الرّئيسية مُباشرة بعد حذف المقال. لاستخدام الدّالة redirect سيتوجّب علينا استيرادها من وحدة Flask في بداية الملفّ app.py. سنحتاج كذلك إلى الدّالة url_for للتوجيه إلى الرّابط الصّحيح. from flask import Flask, render_template, redirect, url_for موجّه delete سيقبل معاملا باسم post_id لتمريره إلى الدّالة delete من الوحدة manage_db لحذف المقال الذي يحمل رقم المعرّف المُمرّر. # Delete Post @app.route("/delete/<post_id>") def delete(post_id): manage_db.delete(post_id) return redirect(url_for('home')) لاحظ استخدام الدّالة redirect مُباشرة بعد حذف المقال، تقبل الدّالة مُعاملا بقيمة رّابط الصّفحة الرّئيسية والذي حصلنا عليه بالدّالة url_for، ما يعني بأنّنا نقوم بحذف المقال ثمّ توجيه المُستخدم مُباشرة إلى الصّفحة الرّئيسية. إنشاء مقال جديد تعرّفنا مُسبقا على طريقة الحصول على القيم من المستخدم بطريقة طلبات GET من عنوان URL كالآتي: /create?title=post1&content=content1 يُمكننا استخدام request للحصول على القيم كالتّالي: title = request.args.get('title') content = request.args.get('content') يُمكن استخدام هذه الطّريقة لإضافة مقال إلى قاعدة البيانات لكنّها ليست مُجديّة في هذه الحالة، لأنّنا نرغب بأن نُتيح للمُستخدم إرسال بيانات دون تعديل عنوان URL كما يجب علينا أن نُسهّل المأموريّة على المُستخدم العادي. لكي نحصل على العنوان والمُحتوى بطريقة أفضل، سنستخدم نماذج HTML أو HTML Forms، وسنستخدم طريقة POST عوضا عن GET. سنضع النّماذج في ملفّ index.html مُباشرة تحت الجزء المسؤول عن عرض المقالات. <h4>أضف مقالا</h4> <form action="{{ url_for('create') }}" method="POST"> <input class="input" type="text" name="title" placeholder="عنوان المقال"/> <br> <textarea name="content" class="input" rows="10" placeholder="مُحتوى المقال"></textarea> <br> <input type="submit" value="أضف" /> </form> في الوسم form نضع رابط الموجّه create داخل الصّفة action لنُخبر المُتصفّح بأنّ البيانات التّي سيُرسلها المُستخدم يجب أن تذهب إلى موجّه إضافة مقال جديد create. بعدها نُخصّص طريقة إرسال البيانات بوضع كلمة POST داخل الصّفة method. بعد ذلك ننشئ حقلا لعنوان المقال باسم title وحقل نصّ باسم content وبعدها نضيف زرّا لتأكيد الإرسال. بعد أن تملأ النموذج وتضغط على زر "أضف" سيُرسل المُتصفّح البيانات إلى الخادوم وسنتمكّن من الحصول عليها في المُوجّه create عبر الوحدة request، ما يعني بأنّنا سنحتاج إلى استدعاءها في بداية الملف. from flask import Flask, render_template, redirect, url_for, request سننشئ المُوجّه create مع تمرير مُعامل آخر باسم methods يحتوي على قائمة بعنصرين يُمثّلان الطريقتين GET وPOST لأنّ الإعداد الافتراضي هو GET فقط، نضع هذا العامل لكي نتمكّن من استقبال البيانات. @app.route("/create", methods=['GET', 'POST']) بعدها سنتمكّن من الحصول على البيانات وإدخالها إلى قاعدة البيانات كالتّالي: if request.method == 'POST': title = request.form['title'] # الحصول على عنوان المقال content = request.form['content'] # الحصول على مُحتوى المقال manage_db.create(title, content) # إدخال القيم إلى قاعدة البيانات لاحظ بأنّنا نضع شرطا للتأكّد من أن الطلب الذي يرسله المُتصفح من نوع POST. بعدها نحصل على القيم التي أدخلها المُستخدم في النّموذج الموجود بملفّ index.html عبر القاموس form المُتواجد داخل الوحدة request. وكما فعلنا مع الموجّه delete سنقوم بإعادة توجيه المُستخدم إلى الصّفحة الرّئيسية. return redirect(url_for('home')) الموجّه create كاملا: # Create Post Page @app.route("/create", methods=['GET', 'POST']) def create(): if request.method == 'POST': title = request.form['title'] content = request.form['content'] manage_db.create(title, content) return redirect(url_for('home')) أصبح التّطبيق كاملا الآن ويُمكنك مُشاركته مع العالم. يُمكنك إضافة تنسيق css خاصّ بك أو تحميل الملفّات الكاملة للتّطبيق من Github وإضافة ملفّ style.css إلى التّطبيق الذي أنشأته (يُمكنك كذلك تعديله). إذا كان لديك سؤال حول هذا الدّرس، يُمكنك وضعه في قسم الأسئلة والأجوبة. ختاما تعرّفنا على طريقة بناء تطبيق يتفاعل مع المُستخدم ويترك له حريّة الوصول إلى قاعدة البيانات، لكنك تُلاحظ بأنّ الحماية معدومة في التّطبيق، إذ يُمكن لأي شخص أن يحذف جميع المقالات دون أي حاجز (ككلمة مرور مثلا). سنتعلّم في الدّرس القادم على كيفيّة حماية التّطبيق وإتاحة الوصول إلى قاعدة البيانات لمُستخدم واحد فقط، بحيث يُسجّل دخوله إذا أراد حذف أو إضافة مقال، أمّا بقيّة المُستخدمين فلهم إمكانيّة القراءة فقط. -

 PostgreSQL، هو نظام متطور مفتوح المصدر، كائنيّ الارتباط-Object Relational ﻹدارة قواعد البيانات، وهو نظام قابل للتوسع، بمعنى أنه يستطيع معالجة اﻷحمال المختلفة بدءًا من تطبيقات جهاز واحد إلى خدمات الويب التجارية التي تتعامل مع مستخدمين كثر في نفس الوقت. وهذا النظام Transactional أي يعامل النقل المتسلسل للبيانات -مثل تحديث قاعدة البيانات- كوحدة واحدة لضمان سلامتها، ويحقق خصائص ACID (Atomicity – Consistency – Isolation – Durability). وكذلك يدعم قسمًا كبيرًا من معايير SQL. فائدة: خصائص ACID هي أربعة خصائص يجب توافرها في تعاملات قواعد البيانات، وهي الذرية-Atomicity -أن تُنفَّذ العملية كوحدة واحدة-، والتناسق-Consistency، والعزل-Isolation، والثبات-Durability. ويوفر PostgreSQL العديد من المزايا مثل: الاستعلامات المعقدة-Complex Queries المفاتيح الأجنبية-Foreign Keys المشاهدات القابلة للتحديث-Updatable Views سلامة عمليات نقل البيانات-Transactional Integrity التحكم في التزامن متعدد الإصدارات-Multiversion Concurrency Control وذكرنا قبل قليل أنه قابل للتمدد والتوسع بواسطة مستخدميه عبر إضافة دوال-Functions جديدة، ومشغّلات-operators، وأنواع بيانات، وطرق فهرسة، ولغات إجرائية-Procedural Languages. ويقدّم PostgreSQL طرقًا عديدة لتكرار قاعدة بيانات، وسنتعلم في هذا الدليل كيفية إعداد تكرار من نوع (الرئيسي-Master/الثانوي-Slave)، وهي عملية مزامنة بين قاعدتي بيانات من خلال النسخ من قاعدة بيانات على خادم (الرئيسي) إلى قاعدة بيانات أخرى في خادم آخر (الثانوي)، وسننفذ هذه العملية على خادم يعمل بتوزيعة أوبنتو 16.04. المتطلبات أن يكون PostgreSQL 9.6 مثبتًا على خادم أوبنتو 16.04 إعداد UFW ثبّت جدار الحماية الناري غير المعقّد-Uncomplicated Firewall على خوادم أوبنتو، وهو أداة ﻹدارة جدار الحماية المعتمِد على iptables. استخدم الأمر التالي في الطرفية: # apt-get install -y ufw واﻵن، أضف PostgreSQL وخدمة SSH إلى جدار الحماية، عبر تنفيذ اﻷمر التالي: # ufw allow ssh # ufw allow postgresql فعّل جدار الحماية: # ufw enable إعداد خادم PostgreSQL الرئيسي سيمتلك الخادم الرئيسي صلاحيات القراءة والكتابة لقاعدة البيانات، وسيكون هو القادر على نقل البيانات إلى الخادم الثانوي. • افتح محررًا نصيًا وعدّل إعدادات PostgreSQL الرئيسية كما يلي: (ملاحظة: استبدل EDITOR$ بالمحرر النصي الذي تفضّله) # $EDITOR /etc/postgresql/9.6/main/postgresql.conf أزل التعليق (#) من سطر listen_addresses وأضف عنوان IP للخادم الرئيسي: listen_addresses = 'master_server_IP_address' واﻵن، أزل التعليق من سطر wal_level لتغيير قيمته: wal_level = hot_standby وأزل التعليق من السطر التالي كي تستخدم المزامنة المحلية-Local Syncing لمستوى المزامنة "Synchronization Level" synchronous_commit = local ثم أزل التعليق من السطرين التاليين، وعدلهما كما يلي، بما أننا نستخدم خادمين: max_wal_senders = 2 wal_keep_segments = 10 واﻵن احفظ الملف وأغلقه. عدّل ملف pg_hba.conf من أجل إعدادات التوثيق-Authentication، كما يلي: افتح الملف عبر هذا الأمر: # $EDITOR /etc/postgresql/9.6/main/pg_hba.conf الصق الإعدادات التالية: # Localhost host replication replica 127.0.0.1/32 md5 # PostgreSQL Master IP address host replication replica master_IP_address/32 md5 # PostgreSQL SLave IP address host replication replica slave_IP_address/32 md5 احفظ الملف وأغلقه، ثم أعد تشغيل PostgreSQL باستخدام systemctl # systemctl restart postgresql إنشاء مستخدم من أجل التكرار سننشئ مستخدم PostgreSQL من أجل عملية التكرار، فسجّل الدخول أولًا إلى حساب المستخدم المسمّىpostgres وافتح صدفة PostgreSQL، من خلال الأوامر التالية: # su - postgres $ psql أنشئ مستخدمًا جديدًا: postgres=# CREATE USER replica REPLICATION LOGIN ENCRYPTED PASSWORD 'usr_strong_pwd'; أغلق الصَّدَفة، وهكذا تنتهي إعدادات الخادم الرئيسي. إعداد الخادم الثانوي لن تكون للخادم الثانوي صلاحيات الكتابة في قاعدة البيانات، وستكون وظيفته الوحيدة هي استقبال البيانات من الخادم الرئيسي، أي ستكون له صلاحية القراءة فقط. • سنوقف أولًا خدمة PostgreSQL: # systemctl stop postgresql افتح ملف الإعدادات الرئيسية لـ PostgreSQL: # $EDITOR /etc/postgresql/9.6/main/postgresql.conf أزل التعليق من سطر listen_addresses وغيّر قيمته: listen_addresses = 'slave_IP_address' أزل التعليق من سطر wal_level وغيّره كما يلي: wal_level = hot_standby وأزل التعليق أيضًا من سطر synchronous_commit كما في الخادم الرئيسي للاستفادة من المزامنة المحلية-local syncing: synchronous_commit = local ثم أزل التعليق من السطرين التاليين وغيّر قيمهما كما يلي: max_wal_senders = 2 wal_keep_segments = 10 أزل التعليق من السطر التالي وغيّر قيمته كما يلي من أجل تفعيل hot_standby للخادم الثانوي: hot_standby = on احفظ الملف وأغلقه. نسخ البيانات من الخادم الرئيسي إلى الثانوي لكي نزامن بيانات الخادم الرئيسي مع الثانوي، فيجب أن يحل المجلد الأساسي “main” في الخادم الرئيسي محل المجلد الرئيسي في الخادم الثانوي، ونفعل هذا كما يلي: • سجل الدخول إلى مستخدم postgres: # su – postgres خذ نسخة احتياطية من مجلد البيانات الفعلي: $ cd/var/lib/postgresql/9.6/ $ mv main main_bak أنشئ مجلد أساسيًا جديدًا: $ mkdir main/ غيّر صلاحياته: $ chmod 700 main وهنا، انسخ المجلد الأساسي من الخادم الرئيسي إلى الخادم الثانوي باستخدام pg_basebackup: # pg_basebackup -h master_IP_address -U replica -D /var/lib/postgresql/9.6/main /-P –xlog وحين ينتهي النسخ، أنشئ ملف recovery.conf داخل المجلد الأساسي "main” وانسخ المحتوى التالي فيه: standby_mode = 'on' primary_conninfo = 'host=10.0.15.10 port=5432 user=replica password=usr_strong_pwd' trigger_file = '/tmp/postgresql.trigger.5432' واﻵن، احفظ الملف وأغلقه، ثم غير صلاحياته كما يلي: # chmod 600 recovery.conf شغّل خدمة PostgreSQL: # systemctl start postgresql وهنا تنتهي إعدادات الخادم الثانوي. الخلاصة لقد رأينا في هذا الدليل المبسّط كيفية ضبط تكرار Master/Slave في PostgreSQL عبر استخدام خادمين يعملان بأوبنتو. وهذه الطريقة في التكرار ما هي إﻻ إحدى طرق عديدة يوفرها نظام PostgreSQL لإدارة قواعد البيانات. ترجمة -بتصرف- لمقال PostgreSQL Replication on Ubuntu Tutorial لصاحبه Giuseppe Molica
PostgreSQL، هو نظام متطور مفتوح المصدر، كائنيّ الارتباط-Object Relational ﻹدارة قواعد البيانات، وهو نظام قابل للتوسع، بمعنى أنه يستطيع معالجة اﻷحمال المختلفة بدءًا من تطبيقات جهاز واحد إلى خدمات الويب التجارية التي تتعامل مع مستخدمين كثر في نفس الوقت. وهذا النظام Transactional أي يعامل النقل المتسلسل للبيانات -مثل تحديث قاعدة البيانات- كوحدة واحدة لضمان سلامتها، ويحقق خصائص ACID (Atomicity – Consistency – Isolation – Durability). وكذلك يدعم قسمًا كبيرًا من معايير SQL. فائدة: خصائص ACID هي أربعة خصائص يجب توافرها في تعاملات قواعد البيانات، وهي الذرية-Atomicity -أن تُنفَّذ العملية كوحدة واحدة-، والتناسق-Consistency، والعزل-Isolation، والثبات-Durability. ويوفر PostgreSQL العديد من المزايا مثل: الاستعلامات المعقدة-Complex Queries المفاتيح الأجنبية-Foreign Keys المشاهدات القابلة للتحديث-Updatable Views سلامة عمليات نقل البيانات-Transactional Integrity التحكم في التزامن متعدد الإصدارات-Multiversion Concurrency Control وذكرنا قبل قليل أنه قابل للتمدد والتوسع بواسطة مستخدميه عبر إضافة دوال-Functions جديدة، ومشغّلات-operators، وأنواع بيانات، وطرق فهرسة، ولغات إجرائية-Procedural Languages. ويقدّم PostgreSQL طرقًا عديدة لتكرار قاعدة بيانات، وسنتعلم في هذا الدليل كيفية إعداد تكرار من نوع (الرئيسي-Master/الثانوي-Slave)، وهي عملية مزامنة بين قاعدتي بيانات من خلال النسخ من قاعدة بيانات على خادم (الرئيسي) إلى قاعدة بيانات أخرى في خادم آخر (الثانوي)، وسننفذ هذه العملية على خادم يعمل بتوزيعة أوبنتو 16.04. المتطلبات أن يكون PostgreSQL 9.6 مثبتًا على خادم أوبنتو 16.04 إعداد UFW ثبّت جدار الحماية الناري غير المعقّد-Uncomplicated Firewall على خوادم أوبنتو، وهو أداة ﻹدارة جدار الحماية المعتمِد على iptables. استخدم الأمر التالي في الطرفية: # apt-get install -y ufw واﻵن، أضف PostgreSQL وخدمة SSH إلى جدار الحماية، عبر تنفيذ اﻷمر التالي: # ufw allow ssh # ufw allow postgresql فعّل جدار الحماية: # ufw enable إعداد خادم PostgreSQL الرئيسي سيمتلك الخادم الرئيسي صلاحيات القراءة والكتابة لقاعدة البيانات، وسيكون هو القادر على نقل البيانات إلى الخادم الثانوي. • افتح محررًا نصيًا وعدّل إعدادات PostgreSQL الرئيسية كما يلي: (ملاحظة: استبدل EDITOR$ بالمحرر النصي الذي تفضّله) # $EDITOR /etc/postgresql/9.6/main/postgresql.conf أزل التعليق (#) من سطر listen_addresses وأضف عنوان IP للخادم الرئيسي: listen_addresses = 'master_server_IP_address' واﻵن، أزل التعليق من سطر wal_level لتغيير قيمته: wal_level = hot_standby وأزل التعليق من السطر التالي كي تستخدم المزامنة المحلية-Local Syncing لمستوى المزامنة "Synchronization Level" synchronous_commit = local ثم أزل التعليق من السطرين التاليين، وعدلهما كما يلي، بما أننا نستخدم خادمين: max_wal_senders = 2 wal_keep_segments = 10 واﻵن احفظ الملف وأغلقه. عدّل ملف pg_hba.conf من أجل إعدادات التوثيق-Authentication، كما يلي: افتح الملف عبر هذا الأمر: # $EDITOR /etc/postgresql/9.6/main/pg_hba.conf الصق الإعدادات التالية: # Localhost host replication replica 127.0.0.1/32 md5 # PostgreSQL Master IP address host replication replica master_IP_address/32 md5 # PostgreSQL SLave IP address host replication replica slave_IP_address/32 md5 احفظ الملف وأغلقه، ثم أعد تشغيل PostgreSQL باستخدام systemctl # systemctl restart postgresql إنشاء مستخدم من أجل التكرار سننشئ مستخدم PostgreSQL من أجل عملية التكرار، فسجّل الدخول أولًا إلى حساب المستخدم المسمّىpostgres وافتح صدفة PostgreSQL، من خلال الأوامر التالية: # su - postgres $ psql أنشئ مستخدمًا جديدًا: postgres=# CREATE USER replica REPLICATION LOGIN ENCRYPTED PASSWORD 'usr_strong_pwd'; أغلق الصَّدَفة، وهكذا تنتهي إعدادات الخادم الرئيسي. إعداد الخادم الثانوي لن تكون للخادم الثانوي صلاحيات الكتابة في قاعدة البيانات، وستكون وظيفته الوحيدة هي استقبال البيانات من الخادم الرئيسي، أي ستكون له صلاحية القراءة فقط. • سنوقف أولًا خدمة PostgreSQL: # systemctl stop postgresql افتح ملف الإعدادات الرئيسية لـ PostgreSQL: # $EDITOR /etc/postgresql/9.6/main/postgresql.conf أزل التعليق من سطر listen_addresses وغيّر قيمته: listen_addresses = 'slave_IP_address' أزل التعليق من سطر wal_level وغيّره كما يلي: wal_level = hot_standby وأزل التعليق أيضًا من سطر synchronous_commit كما في الخادم الرئيسي للاستفادة من المزامنة المحلية-local syncing: synchronous_commit = local ثم أزل التعليق من السطرين التاليين وغيّر قيمهما كما يلي: max_wal_senders = 2 wal_keep_segments = 10 أزل التعليق من السطر التالي وغيّر قيمته كما يلي من أجل تفعيل hot_standby للخادم الثانوي: hot_standby = on احفظ الملف وأغلقه. نسخ البيانات من الخادم الرئيسي إلى الثانوي لكي نزامن بيانات الخادم الرئيسي مع الثانوي، فيجب أن يحل المجلد الأساسي “main” في الخادم الرئيسي محل المجلد الرئيسي في الخادم الثانوي، ونفعل هذا كما يلي: • سجل الدخول إلى مستخدم postgres: # su – postgres خذ نسخة احتياطية من مجلد البيانات الفعلي: $ cd/var/lib/postgresql/9.6/ $ mv main main_bak أنشئ مجلد أساسيًا جديدًا: $ mkdir main/ غيّر صلاحياته: $ chmod 700 main وهنا، انسخ المجلد الأساسي من الخادم الرئيسي إلى الخادم الثانوي باستخدام pg_basebackup: # pg_basebackup -h master_IP_address -U replica -D /var/lib/postgresql/9.6/main /-P –xlog وحين ينتهي النسخ، أنشئ ملف recovery.conf داخل المجلد الأساسي "main” وانسخ المحتوى التالي فيه: standby_mode = 'on' primary_conninfo = 'host=10.0.15.10 port=5432 user=replica password=usr_strong_pwd' trigger_file = '/tmp/postgresql.trigger.5432' واﻵن، احفظ الملف وأغلقه، ثم غير صلاحياته كما يلي: # chmod 600 recovery.conf شغّل خدمة PostgreSQL: # systemctl start postgresql وهنا تنتهي إعدادات الخادم الثانوي. الخلاصة لقد رأينا في هذا الدليل المبسّط كيفية ضبط تكرار Master/Slave في PostgreSQL عبر استخدام خادمين يعملان بأوبنتو. وهذه الطريقة في التكرار ما هي إﻻ إحدى طرق عديدة يوفرها نظام PostgreSQL لإدارة قواعد البيانات. ترجمة -بتصرف- لمقال PostgreSQL Replication on Ubuntu Tutorial لصاحبه Giuseppe Molica -
 يأتي Laravel بإطار العمل Eloquent مضمّنا مبدئيا؛ وهو ما يتيح بناء نماذج تُعالّج فيها البيانات وتُطبّق عليها القواعد التي تحكُم سير التطبيق. يُيسّر Eloquent كثيرا من الأمور على المطوِّر؛ إلا أنّه يمكن أن يكون أحيانا غير مناسب لتعقيد المشروع الذي تعمل عليه. يوفّر Laravel آلية للتعامل مع قواعد البيانات مباشرة دون الحاجة لربط كائنات التطبيق بجداول قاعدة البيانات. تُسمى هذه الآلية منشئ الاستعلامات Query builder. كانت الاستعلامات المعدّة بمنشئ الاستعلامات ترجع النتائج، في الإصدارات السابقة (قبل الإصدار 5.3) من Laravel، على هيئة مصفوفة Array؛ إلا أن الأمر تغيّر في الإصدار 5.3 وأصبحت أغلب دوالّ بناء الاستعلامات ترجع نتيجة من نوع Collection (مجموعة). سنرى في هذا المقال أمثلة تفصيلية حول هذا التغيير، ولكن قبل ذلك سنعرّج على مقارنة بين Eloquent ومنشئ الاستعلامات ومتى يكون استخدام أحدهما أنسب. أيهما أستخدم.. Eloquent أم منشئ الاستعلامات؟ يخضع تطوير البرمجيّات لإكراهات كثيرة، وهو ما يعني أن عليك أحيانا كتابة استعلامات SQL للتخاطب مع قاعدة البيانات مباشرة. يتيح Eloquent آلية أنيقة للتعامل مع قاعدة البيانات بربطها بأصناف التطبيق ممّا يقلّل كثيرا من الحاجة لتدخّل المطوّر في تفاصيل تنفيذ العمليّات. تشمل التسهيلات التي يتيحها Eloquent: التحقق المُستَتِر Dirty check: تحديث الحقول التي تغيّرت قيمتها فقط دون غيرها، عند تنفيذ استعلامات UPDATE. ربط النماذج بأحداث Events؛ مثلا لإشعار المستخدمين أو تحديث إحصائيات عند إنشاء مستخدم جديد. إدارة الحذف اللطيف Soft delete: تعليم تسجيلة على أنها محذوفة بدلا من حذفها فعلا. تنفيذ آليات التحميل الحثيث Lazy loading (طلب البيانات عند الحاجة إليها). يمكن - بالطبع - تطبيق هذه الآليات بنفسك دون الاعتماد على Eloquent؛ إلا أن ذلك سيأخذ وقتا. من الجيد أن يكون لديك سبب مقنع للوقت الذي ستمضيه في هذه المهمة بدلا من التركيز على أمور *قد* تكون أهم. سيكون مثاليّا جدا الحصولُ على كلّ هذه التسجيلات بدون دفع ثمن، إلا أن الأمور في الواقع ليست مثالية. الثمن الذي تدفعه مقابل التسهيلات التي يتضمّنها Eloquent - وأطر عمل ORM الأخرى، بغضّ النظر عن لغة البرمجة - هو سرعة تنفيذ الاستعلامات. على الجهة الأخرى، تمكّن كتابة الاستعلامات من الوصول إلى أقصى سرعة ممكنة في التنفيذ، مقابل التضحية بالجهد والوقت أثناء التطوير. لا يوجد مانع من مزج جميع الوسائل المتاحة أمامك؛ بل إن الأمر محبّذ. مثلا؛ استخدم Eloquent عندما تتعامل مع كيانات منفردة (استمارة تسجيل على موقع مثلا)، الجأ لمنشئ الاستعلامات في المهامّ التي تتطلب وقتا للتنفيذ (كيانات بالجملة Batch processing أو إعداد تقارير على سبيل المثال) واكتب استعلامات SQL مباشرة عندما تكون أمام استعلام شديد التعقيد. الجديد في Laravel 5.3 نستخدم منشئ الاستعلامات في المثال التالي للحصول على كافة المستخدمين (جدول users في قاعدة البيانات): DB::table('users')->get(); تكافئ التعليمة السابقة في نتيجتها تنفيذ الاستعلام التالي: SELECT * FROM users; كانت النتيجة، في الإصدارات السابقة من Laravel، من نوع Array (مصفوفة)؛ إلا أن هذا الأمر تغيّر في الإصدار 5.3 لتصبح النتيجة من نوع Collection (مجموعة). يعني هذا أنه للوصول إلى العنصر الأول في مجموعة المستخدمين السابقة فإننا يمكن أن نكتب: DB::table('users')->get()->first(); بدلا من: DB::table('users')->get()[0]; يجعل هذا التغيير من منشئ الاستعلامات متناسقا في نوع النتيجة مع Eloquent الذي يرجع مجموعة كائنات؛ كما أنه يمكّن من استخدام الدوال الموجودة مبدئيا للتعامل مع المجموعات؛ ومن بينها الدالة all التي ترجع مصفوفة مكافئة للمجموعة؛ مثلا ترجع التعليمة التالية مصفوفة بالمستخدمين: DB::table('users')->get()->all(); إن كان لديك تطبيق مبني على اعتبار أن منشئ الاستعلامات يُرجع النتائج على هيئة مصفوفات، فأسهل طريقة لتعديل الشفرة المصدرية للتوافق مع تغيير نوع النتيجة إلى مجموعة بدلا من مصفوفة؛ هي استخدام الدالة all. ملحوظة 1: لا ينطبق التغيير المذكور أعلاه (إرجاع مجموعة بدلا من مصفوفة) على دوال الصنف DB التي تتعامل مع استعلامات SQL مباشرة. مثلا؛ ترجع التعليمة التالية مصفوفة: DB::select('SELECT name FROM users WHERE id = ?', [1]); ملحوظة 2: انتبه عند استخدام استعلامات SQL مباشرة من ثغرات الحَقن SQL injection. استخدم ربط المتغيّرات Binding (كما في الملحوظة 1) بدلا من تمرير المتغيّر مباشرة كما في الاستعلام التالي: DB::select("SELECT name FROM users WHERE id = '$id' "]); قد يمثل الاستعلام الأخير خطرا إن لم يُتحقّق من المتغيّرid$ قبل استخدامه في الاستعلام. يتحقّق Laravel تلقائيا من المُدخلات عند ربط المتغيّرات كما في استعلام الملحوظة 1. راجع مقال استخدام Eloquent ORM للتعامل مع قاعدة البيانات في Laravel 5.
يأتي Laravel بإطار العمل Eloquent مضمّنا مبدئيا؛ وهو ما يتيح بناء نماذج تُعالّج فيها البيانات وتُطبّق عليها القواعد التي تحكُم سير التطبيق. يُيسّر Eloquent كثيرا من الأمور على المطوِّر؛ إلا أنّه يمكن أن يكون أحيانا غير مناسب لتعقيد المشروع الذي تعمل عليه. يوفّر Laravel آلية للتعامل مع قواعد البيانات مباشرة دون الحاجة لربط كائنات التطبيق بجداول قاعدة البيانات. تُسمى هذه الآلية منشئ الاستعلامات Query builder. كانت الاستعلامات المعدّة بمنشئ الاستعلامات ترجع النتائج، في الإصدارات السابقة (قبل الإصدار 5.3) من Laravel، على هيئة مصفوفة Array؛ إلا أن الأمر تغيّر في الإصدار 5.3 وأصبحت أغلب دوالّ بناء الاستعلامات ترجع نتيجة من نوع Collection (مجموعة). سنرى في هذا المقال أمثلة تفصيلية حول هذا التغيير، ولكن قبل ذلك سنعرّج على مقارنة بين Eloquent ومنشئ الاستعلامات ومتى يكون استخدام أحدهما أنسب. أيهما أستخدم.. Eloquent أم منشئ الاستعلامات؟ يخضع تطوير البرمجيّات لإكراهات كثيرة، وهو ما يعني أن عليك أحيانا كتابة استعلامات SQL للتخاطب مع قاعدة البيانات مباشرة. يتيح Eloquent آلية أنيقة للتعامل مع قاعدة البيانات بربطها بأصناف التطبيق ممّا يقلّل كثيرا من الحاجة لتدخّل المطوّر في تفاصيل تنفيذ العمليّات. تشمل التسهيلات التي يتيحها Eloquent: التحقق المُستَتِر Dirty check: تحديث الحقول التي تغيّرت قيمتها فقط دون غيرها، عند تنفيذ استعلامات UPDATE. ربط النماذج بأحداث Events؛ مثلا لإشعار المستخدمين أو تحديث إحصائيات عند إنشاء مستخدم جديد. إدارة الحذف اللطيف Soft delete: تعليم تسجيلة على أنها محذوفة بدلا من حذفها فعلا. تنفيذ آليات التحميل الحثيث Lazy loading (طلب البيانات عند الحاجة إليها). يمكن - بالطبع - تطبيق هذه الآليات بنفسك دون الاعتماد على Eloquent؛ إلا أن ذلك سيأخذ وقتا. من الجيد أن يكون لديك سبب مقنع للوقت الذي ستمضيه في هذه المهمة بدلا من التركيز على أمور *قد* تكون أهم. سيكون مثاليّا جدا الحصولُ على كلّ هذه التسجيلات بدون دفع ثمن، إلا أن الأمور في الواقع ليست مثالية. الثمن الذي تدفعه مقابل التسهيلات التي يتضمّنها Eloquent - وأطر عمل ORM الأخرى، بغضّ النظر عن لغة البرمجة - هو سرعة تنفيذ الاستعلامات. على الجهة الأخرى، تمكّن كتابة الاستعلامات من الوصول إلى أقصى سرعة ممكنة في التنفيذ، مقابل التضحية بالجهد والوقت أثناء التطوير. لا يوجد مانع من مزج جميع الوسائل المتاحة أمامك؛ بل إن الأمر محبّذ. مثلا؛ استخدم Eloquent عندما تتعامل مع كيانات منفردة (استمارة تسجيل على موقع مثلا)، الجأ لمنشئ الاستعلامات في المهامّ التي تتطلب وقتا للتنفيذ (كيانات بالجملة Batch processing أو إعداد تقارير على سبيل المثال) واكتب استعلامات SQL مباشرة عندما تكون أمام استعلام شديد التعقيد. الجديد في Laravel 5.3 نستخدم منشئ الاستعلامات في المثال التالي للحصول على كافة المستخدمين (جدول users في قاعدة البيانات): DB::table('users')->get(); تكافئ التعليمة السابقة في نتيجتها تنفيذ الاستعلام التالي: SELECT * FROM users; كانت النتيجة، في الإصدارات السابقة من Laravel، من نوع Array (مصفوفة)؛ إلا أن هذا الأمر تغيّر في الإصدار 5.3 لتصبح النتيجة من نوع Collection (مجموعة). يعني هذا أنه للوصول إلى العنصر الأول في مجموعة المستخدمين السابقة فإننا يمكن أن نكتب: DB::table('users')->get()->first(); بدلا من: DB::table('users')->get()[0]; يجعل هذا التغيير من منشئ الاستعلامات متناسقا في نوع النتيجة مع Eloquent الذي يرجع مجموعة كائنات؛ كما أنه يمكّن من استخدام الدوال الموجودة مبدئيا للتعامل مع المجموعات؛ ومن بينها الدالة all التي ترجع مصفوفة مكافئة للمجموعة؛ مثلا ترجع التعليمة التالية مصفوفة بالمستخدمين: DB::table('users')->get()->all(); إن كان لديك تطبيق مبني على اعتبار أن منشئ الاستعلامات يُرجع النتائج على هيئة مصفوفات، فأسهل طريقة لتعديل الشفرة المصدرية للتوافق مع تغيير نوع النتيجة إلى مجموعة بدلا من مصفوفة؛ هي استخدام الدالة all. ملحوظة 1: لا ينطبق التغيير المذكور أعلاه (إرجاع مجموعة بدلا من مصفوفة) على دوال الصنف DB التي تتعامل مع استعلامات SQL مباشرة. مثلا؛ ترجع التعليمة التالية مصفوفة: DB::select('SELECT name FROM users WHERE id = ?', [1]); ملحوظة 2: انتبه عند استخدام استعلامات SQL مباشرة من ثغرات الحَقن SQL injection. استخدم ربط المتغيّرات Binding (كما في الملحوظة 1) بدلا من تمرير المتغيّر مباشرة كما في الاستعلام التالي: DB::select("SELECT name FROM users WHERE id = '$id' "]); قد يمثل الاستعلام الأخير خطرا إن لم يُتحقّق من المتغيّرid$ قبل استخدامه في الاستعلام. يتحقّق Laravel تلقائيا من المُدخلات عند ربط المتغيّرات كما في استعلام الملحوظة 1. راجع مقال استخدام Eloquent ORM للتعامل مع قاعدة البيانات في Laravel 5. -
 مُقدّمة: بعد أن عرّفنا كلّا من جدول المقالات وجدول المُستخدمين، بقيت لنا خطوة الرّبط بينهما ليُشير كلّ مقال إلى كاتبه ونستطيع الوصول إلى مقالات كلّ مُستخدم، وسنقوم بهذا الأمر باستغلال خصائص قواعد بيانات SQL العلائقيّة لإنشاء علاقة واحد للعديد، بحيث يُمكن لكلّ مُستخدم أن يمتلك العديد من المقالات ويكون لكلّ مقال كاتب واحد فقط. المُشكلة عند تصفّحك لتطبيقات الوب في وقتنا الحالي، ستُلاحظ بأنّ المُستخدمين يمتلكون بياناتهم الخاصّة، مثلا يُمكن للمُستخدم الواحد أن يمتلك عدّة مقالات وتدرج تحت اسمه، ويُمكن أن يمتلك كذلك عدّة تعليقات باسمه، إذن كيف يُمكن أن نُدرج مقالات من جدول المقالات الخاصّ بنا إلى المُستخدم الذي يقوم بإضافتها؟ بمعنى آخر، كيف يُمكن للمُستخدم الواحد أن يمتلك عدّة مقالات مُندرجة باسمه؟ الحل الخاطئ الطّريقة التّي يُمكن أن تُفكّر فيها هي بإدراج رقم مُعرّف كل مقال يُضيفه المُستخدم إلى عمود خاص به مع الفصل بينها بمسافة أو شيء من هذا القبيل، بعدها تحصل عليها وتقوم باستخراج مقالات كل مُستخدم. الجدول سيكون كما يلي: id | name | posts 1 | Ali | 1, 3, 5 ... أهملت هنا عمودي البريد الإلكتروني وكلمة المرور لأنّها غير مُهمّة في مثالنا. الآن إن نظرت إلى العمود posts فستجد بأنّ المقالات ذات المُعرّفات 1 و 3 و 5 قد أضافها المُستخدم Ali. هذه الطّريقة فكرة سيّئة جدّا، فلو أردنا حذف مقال فحذف علاقته بالمُستخدم أمر مُعقّد، وهناك العديد من المشاكل مع استخدام هذه الطّريقة، وقد أشرت إليها لأنّها شائعة جدّا ويجب أن تحذفها من ذهنك قبل أن تحدث أمور أسوأ، فإن أردت أن تكون مُطوّر وب جيّدا فعليك تعلّم الطّرق الصّحيحة وعليك كذلك الإلمام بالطّرق الخاطئة في التّطوير. الطّريقة الصّحيحة لربط سجلّ واحد بالعديد من السّجلّات في جدولين مُختلفين علاقة الواحد-للعديد أو One-to-Many Relationship هي طريقة لربط جدولين أو أكثر بحيث يمتلك كلّ فرد في جدول العديد من السّجلّات في جدول آخر. في مثالنا، سيمتلك المُستخدم الواحد عدّة مقالات باسمه. للقيام بهذا الأمر، نقوم بوضع عمود آخر في الجدول الذي سيمتلك العديد من السّجلّات الخاصّة بفرد واحد من جدول آخر ليحمل قيمة رقم مُعرّف هذا الفرد، أي أننا سنُضيف عمودا آخر في جدول المقالات ليحمل رقم مُعرّف المُستخدم الذي أضاف المقال ليكون جدول المقالات كما يلي: | id | title | user_id | 1 | Post 1 | 1 | 2 | Post 2 | 2 | 3 | Post 3 | 1 | 4 | Post 4 | 3 لنفترض بأنّ لدينا ثلاثة مُستخدمين في جدول المُستخدمين كما يلي: | id | name | 1 | Ali | 2 | Abdelhadi | 3 | Hassan مُجدّدا، قمت بإهمال الأعمدة الأخرى لأنّها لا تهمّنا في هذا المثال، وكما تُلاحظ لكل مقال قيمة في عمود user_id لتُشير إلى المُستخدم الذي أنشأ هذا المقال، وعند النّظر إلى جدولي المقالات والمُستخدمين والسّجلّات المتواجدة فيها حاليّا، يتبيّن لنا بأنّ المستخدم Ali قد أضاف مقالين، المقال ذو رقم المُعرّف 1 و المقال ذو رقم المُعرّف 3، أمّا Abdelhadi فهو صاحب المقال ذي المُعرّف 2 أمّا المقال الأخير فمن الواضح بأنّ المُستخدم Hassan هو من أضافه. هذه هي علاقة الواحد للعديد ببساطة، عندما يمتلك سجلّ واحد من جدول العديد من السّجلّات في جدول آخر، فإنّنا نُضيف عمودا إلى الجدول الذي يحمل العديد من السّجلات ليحمل كل سجلّ منه قيمة المفتاح الأولي Primary Key للسّجل الواحد في الجدول الآخر والذي يُسمّى فيه مفتاحا أجنبيا Foreign Key، أي أنّ العمود user_id عبارة عن مفتاح أجنبي لأنّه يحمل قيمة المفتاح الأولي الخاصّ بالمُستخدم، وعندما نقوم بتحديد عمود على أنّه مفتاح أجنبي، فالعلاقة بين الجدولين تكون مفهومة بالنّسبة لقاعدة البيانات لدينا، كما يُساعدنا ذلك على تخطّي بعض المشاكل في حالة ما أضيفت قيمة خاطئة إلى العمود عوضا عن قيمة صحيحة. في SQLAlchemy يُمكننا إنشاء علاقة واحد للعديد بسهولة وبساطة بإضافة سطرين فقط إلى الشفرة التّي حدّدناها سابقا، سطر في صنف (جدول) المقالات لإضافة عمود باسم author_id والذي سيكون عبارة عن مفتاح أجنبي يُشير إلى قيمة المفتاح الأولي للمُستخدم، وسطر في صنف المُستخدم لنتمكّن من الوصول إلى مقالات كل مُستخدم ببساطة. أضف هذا السّطر في آخر الصّنف Post: # project/models.py author_id = db.Column(db.Integer, db.ForeignKey('users.id'), nullable=False) لتعريف مفتاح أجنبي، نستعمل الدّالة db.ForeignKey مع تمرير اسم الجدول واسم المفتاح الأولي مفصولين بنُقطة (في هذا المثال users.id) ونقوم كذلك بإضافة المُعامل nullable وإسناد القيمة المنطقيّة False له للتأكّد من أنّ الحقل الذي يربط بين المُستخدم والمقال الذي أضافه لا يحمل قيمة فارغة. بعد إضافة المفتاح الأجنبي، حان الوقت لإخبار SQLAlchemy بأنّنا نريد الحصول على مقالات كلّ مُستخدم، والمُستخدم الذي أضاف كلّ مقال انطلاقا من العلاقة بين الجدولين، لذا أضف السّطر التّالي في آخر الصّنف User: # project/models.py posts = db.relationship("Post", backref="author", lazy="dynamic") في هذا السّطر، نقوم بتعريف العلاقة بين المُستخدم والمقال عن طريق الدّالّة db.relationship مع تمرير ثلاثة مُعاملات، الأول عبارة عن اسم الصّنف الذي يشير لجدول المقالات، والمُعامل backref يُمكّننا من الوصول إلى المُستخدم الذي كتب المقال عن طريق الاسم author أمّا المعامل الأخير فهو لتحديد نوعيّة النّتيجة التّي سنحصل عليها عند طلب جميع المقالات التّي كتبها أحد المُستخدمين، وقد وضعنا القيمة dynamic لتكون النّتيجة عبارة عن استعلام ديناميكي لجميع المقالات التّي كتبها المُستخدم، وهكذا سنحصل على مرونة أكثر عند طلب المقالات وسنتمكّن من التّعامل معها على أنّها كائنات يُمكننا استغلالها بجميع ما توفّره مكتبة SQLAlchemy من طرق ودوال مُساعدة، وسنرى تطبيقا لهذا الكلام فيما بعد. سنُضيف كذلك عمود author_id إلى التّابع __init__ الخاصّة بالصّنف Post وبالتّالي سيُصبح التّابع كما يلي: def __init__(self, title, content, author_id, created_date = None): self.title = title self.content = content self.author_id = author_id self.created_date = datetime.utcnow() بعد تحديد العلاقة بين الجدولين، سنستطيع إضافة مقال وإسناد رقم مُعرّف المُستخدم أو المُستخدم ككاتب للمقال الذي أضافه لنتمكّن فيما بعد من الحصول على كاتب كل مقال بجميع معلوماته (بريده الإلكتروني، اسمه …)، وكذا المقالات التّي كتبها كلّ مُستخدم مع مرونة في التّعامل معها عبر ما تُوفّره لنا مكتبة SQLAlchemy من مُساعدة. خاتمة بعد أن تعرّفنا على طريقة ربط المُستخدم ومقالاته والمقالات وكاتبها، أصبحنا نستطيع تطبيق التّغييرات إلى قاعدة بياناتنا والتّعامل مع السّجلّات بعمليّات قواعد البيانات المعروفة اختصارا بـCRUD أو Create, Read, Update, Delete، أي الإضافة/الإنشاء، القراءة/العرض، التّعديل والحذف.
مُقدّمة: بعد أن عرّفنا كلّا من جدول المقالات وجدول المُستخدمين، بقيت لنا خطوة الرّبط بينهما ليُشير كلّ مقال إلى كاتبه ونستطيع الوصول إلى مقالات كلّ مُستخدم، وسنقوم بهذا الأمر باستغلال خصائص قواعد بيانات SQL العلائقيّة لإنشاء علاقة واحد للعديد، بحيث يُمكن لكلّ مُستخدم أن يمتلك العديد من المقالات ويكون لكلّ مقال كاتب واحد فقط. المُشكلة عند تصفّحك لتطبيقات الوب في وقتنا الحالي، ستُلاحظ بأنّ المُستخدمين يمتلكون بياناتهم الخاصّة، مثلا يُمكن للمُستخدم الواحد أن يمتلك عدّة مقالات وتدرج تحت اسمه، ويُمكن أن يمتلك كذلك عدّة تعليقات باسمه، إذن كيف يُمكن أن نُدرج مقالات من جدول المقالات الخاصّ بنا إلى المُستخدم الذي يقوم بإضافتها؟ بمعنى آخر، كيف يُمكن للمُستخدم الواحد أن يمتلك عدّة مقالات مُندرجة باسمه؟ الحل الخاطئ الطّريقة التّي يُمكن أن تُفكّر فيها هي بإدراج رقم مُعرّف كل مقال يُضيفه المُستخدم إلى عمود خاص به مع الفصل بينها بمسافة أو شيء من هذا القبيل، بعدها تحصل عليها وتقوم باستخراج مقالات كل مُستخدم. الجدول سيكون كما يلي: id | name | posts 1 | Ali | 1, 3, 5 ... أهملت هنا عمودي البريد الإلكتروني وكلمة المرور لأنّها غير مُهمّة في مثالنا. الآن إن نظرت إلى العمود posts فستجد بأنّ المقالات ذات المُعرّفات 1 و 3 و 5 قد أضافها المُستخدم Ali. هذه الطّريقة فكرة سيّئة جدّا، فلو أردنا حذف مقال فحذف علاقته بالمُستخدم أمر مُعقّد، وهناك العديد من المشاكل مع استخدام هذه الطّريقة، وقد أشرت إليها لأنّها شائعة جدّا ويجب أن تحذفها من ذهنك قبل أن تحدث أمور أسوأ، فإن أردت أن تكون مُطوّر وب جيّدا فعليك تعلّم الطّرق الصّحيحة وعليك كذلك الإلمام بالطّرق الخاطئة في التّطوير. الطّريقة الصّحيحة لربط سجلّ واحد بالعديد من السّجلّات في جدولين مُختلفين علاقة الواحد-للعديد أو One-to-Many Relationship هي طريقة لربط جدولين أو أكثر بحيث يمتلك كلّ فرد في جدول العديد من السّجلّات في جدول آخر. في مثالنا، سيمتلك المُستخدم الواحد عدّة مقالات باسمه. للقيام بهذا الأمر، نقوم بوضع عمود آخر في الجدول الذي سيمتلك العديد من السّجلّات الخاصّة بفرد واحد من جدول آخر ليحمل قيمة رقم مُعرّف هذا الفرد، أي أننا سنُضيف عمودا آخر في جدول المقالات ليحمل رقم مُعرّف المُستخدم الذي أضاف المقال ليكون جدول المقالات كما يلي: | id | title | user_id | 1 | Post 1 | 1 | 2 | Post 2 | 2 | 3 | Post 3 | 1 | 4 | Post 4 | 3 لنفترض بأنّ لدينا ثلاثة مُستخدمين في جدول المُستخدمين كما يلي: | id | name | 1 | Ali | 2 | Abdelhadi | 3 | Hassan مُجدّدا، قمت بإهمال الأعمدة الأخرى لأنّها لا تهمّنا في هذا المثال، وكما تُلاحظ لكل مقال قيمة في عمود user_id لتُشير إلى المُستخدم الذي أنشأ هذا المقال، وعند النّظر إلى جدولي المقالات والمُستخدمين والسّجلّات المتواجدة فيها حاليّا، يتبيّن لنا بأنّ المستخدم Ali قد أضاف مقالين، المقال ذو رقم المُعرّف 1 و المقال ذو رقم المُعرّف 3، أمّا Abdelhadi فهو صاحب المقال ذي المُعرّف 2 أمّا المقال الأخير فمن الواضح بأنّ المُستخدم Hassan هو من أضافه. هذه هي علاقة الواحد للعديد ببساطة، عندما يمتلك سجلّ واحد من جدول العديد من السّجلّات في جدول آخر، فإنّنا نُضيف عمودا إلى الجدول الذي يحمل العديد من السّجلات ليحمل كل سجلّ منه قيمة المفتاح الأولي Primary Key للسّجل الواحد في الجدول الآخر والذي يُسمّى فيه مفتاحا أجنبيا Foreign Key، أي أنّ العمود user_id عبارة عن مفتاح أجنبي لأنّه يحمل قيمة المفتاح الأولي الخاصّ بالمُستخدم، وعندما نقوم بتحديد عمود على أنّه مفتاح أجنبي، فالعلاقة بين الجدولين تكون مفهومة بالنّسبة لقاعدة البيانات لدينا، كما يُساعدنا ذلك على تخطّي بعض المشاكل في حالة ما أضيفت قيمة خاطئة إلى العمود عوضا عن قيمة صحيحة. في SQLAlchemy يُمكننا إنشاء علاقة واحد للعديد بسهولة وبساطة بإضافة سطرين فقط إلى الشفرة التّي حدّدناها سابقا، سطر في صنف (جدول) المقالات لإضافة عمود باسم author_id والذي سيكون عبارة عن مفتاح أجنبي يُشير إلى قيمة المفتاح الأولي للمُستخدم، وسطر في صنف المُستخدم لنتمكّن من الوصول إلى مقالات كل مُستخدم ببساطة. أضف هذا السّطر في آخر الصّنف Post: # project/models.py author_id = db.Column(db.Integer, db.ForeignKey('users.id'), nullable=False) لتعريف مفتاح أجنبي، نستعمل الدّالة db.ForeignKey مع تمرير اسم الجدول واسم المفتاح الأولي مفصولين بنُقطة (في هذا المثال users.id) ونقوم كذلك بإضافة المُعامل nullable وإسناد القيمة المنطقيّة False له للتأكّد من أنّ الحقل الذي يربط بين المُستخدم والمقال الذي أضافه لا يحمل قيمة فارغة. بعد إضافة المفتاح الأجنبي، حان الوقت لإخبار SQLAlchemy بأنّنا نريد الحصول على مقالات كلّ مُستخدم، والمُستخدم الذي أضاف كلّ مقال انطلاقا من العلاقة بين الجدولين، لذا أضف السّطر التّالي في آخر الصّنف User: # project/models.py posts = db.relationship("Post", backref="author", lazy="dynamic") في هذا السّطر، نقوم بتعريف العلاقة بين المُستخدم والمقال عن طريق الدّالّة db.relationship مع تمرير ثلاثة مُعاملات، الأول عبارة عن اسم الصّنف الذي يشير لجدول المقالات، والمُعامل backref يُمكّننا من الوصول إلى المُستخدم الذي كتب المقال عن طريق الاسم author أمّا المعامل الأخير فهو لتحديد نوعيّة النّتيجة التّي سنحصل عليها عند طلب جميع المقالات التّي كتبها أحد المُستخدمين، وقد وضعنا القيمة dynamic لتكون النّتيجة عبارة عن استعلام ديناميكي لجميع المقالات التّي كتبها المُستخدم، وهكذا سنحصل على مرونة أكثر عند طلب المقالات وسنتمكّن من التّعامل معها على أنّها كائنات يُمكننا استغلالها بجميع ما توفّره مكتبة SQLAlchemy من طرق ودوال مُساعدة، وسنرى تطبيقا لهذا الكلام فيما بعد. سنُضيف كذلك عمود author_id إلى التّابع __init__ الخاصّة بالصّنف Post وبالتّالي سيُصبح التّابع كما يلي: def __init__(self, title, content, author_id, created_date = None): self.title = title self.content = content self.author_id = author_id self.created_date = datetime.utcnow() بعد تحديد العلاقة بين الجدولين، سنستطيع إضافة مقال وإسناد رقم مُعرّف المُستخدم أو المُستخدم ككاتب للمقال الذي أضافه لنتمكّن فيما بعد من الحصول على كاتب كل مقال بجميع معلوماته (بريده الإلكتروني، اسمه …)، وكذا المقالات التّي كتبها كلّ مُستخدم مع مرونة في التّعامل معها عبر ما تُوفّره لنا مكتبة SQLAlchemy من مُساعدة. خاتمة بعد أن تعرّفنا على طريقة ربط المُستخدم ومقالاته والمقالات وكاتبها، أصبحنا نستطيع تطبيق التّغييرات إلى قاعدة بياناتنا والتّعامل مع السّجلّات بعمليّات قواعد البيانات المعروفة اختصارا بـCRUD أو Create, Read, Update, Delete، أي الإضافة/الإنشاء، القراءة/العرض، التّعديل والحذف. -
 مُقدّمة بعد تجهيز قاعدة بيانات PostgreSQL التي سنستعملها في تطبيقنا، وبعد أن تعرّفنا في الدرس السابق على كيفيّة تنصيب وتجهيز كل من مكتبة SQLAlchemy و إضافة Flask-SQLAlchemy، حان الوقت لتجهيز جدولين من أهم جداول تطبيقات إدارة المحتوى، ألا وهي جدول المقالات الذي يمثل المحتوى بعينه وجدول المُستخدمين الذين سيُدِيرُون المحتوى، وبالتالي فسنقوم في هذا الدرس بوضع أساس لتطبيق “إدارة المحتوى” عبر تجهيز الطرف الذي سيقوم بالإدارة والطرف الذي يُمثل المحتوى. تذكير نعلم بأنّ قاعدة البيانات تحتوي على عدة جداول، كل جدول يمثل نوعا من المحتوى، وكل جدول يشمل عدة أعمدة، فمثلا جدول المُستخدمين سيحتوي على عمود لأسماء المستخدمين، وعمود لكلمات المرور، بحيث تكون قيمة كل عمود مربطة بمستخدم واحد فقط. تعرّفنا في الدرس السابق على الشكل العام لجداول قاعدة البيانات عند استعمال إضافة Flask-SQLAlchemy وقلنا بأنّ جدولا باسم table_name سيكون كالتّالي: from project import db class TableName(db.Model): __tablename__ = 'table_name' column_name = db.Column(db.Type, args) الجدول به عمود واحد باسم column_name ونقوم بإخبار SQLAlchemy بأنّ هذا عمود في الجدول عبر استخدام التّابع db.Column الذي يقبل عدّة معاملات لتحديد نوعية العمود وما يمكن له أن يقبل من قيم. نقوم بتحديد نوع البيانات التي يجب أن يقبلها العمود عبر استخدام المعامل db.Type مع استبدال Type بأحد الأنواع التي يدعمها SQLAlchemy. ما يلي أكثر أنواع القيم استخداما والتي يدعمها SQLAlchemy: Integer الأعداد الصّحيحة String(size) سلسلة نصيّة، size مُعامل يشير إلى أقصى قيمة لعدد المحارف في السّلسلة النّصيّة، مثلاString(25) يشير إلى أنّ العمود يُمكن أن يحمل سلسلة نصيّة بحدود خمسة وعشرين محرفا فقط ولا يُمكن تجاوز هذا الحد. Text نوع للإشارة إلى أنّ هذا العمود يُمكن أن يحتوي على النّصوص الطّويلة. DateTime نوع يُشير إلى أنّ العمود سيحمل تواريخ مُعبّر عنها بالكائن datetime في لغة بايثون، وسنستخدم هذا النّوع لوضع تاريخ نشر للمقال وتاريخ لانضمام مُستخدم معيّن. يُساعد تحديد نوع القيم في العمود على تجنّب الكثير من الأخطاء، ومن المُفضّل أن تختار دائما النّوع الذي يُناسبك أكثر لتحفظ المساحة وتتجنّب بعض الهجمات المُمكنة، فمثلا لو كان نوع القيمة Text في حقل اسم المُستخدم لتمكّن أحدهم من وضع نص كاسم مُستخدم له، وإن عرضناه في صفحة لكانت تلك الصّفحة بشعة لوجود نص عوضا عن كلمة أو كلمتين، هذا بالإضافة إلى أنّ المساحة في الخادوم ستُستهلك بشكل غير معقول. أعلم بأنّ الكلام النّظري مُمل بعض الشّيء، لكنّه مهم جدّا لتفهم ما سنقوم به تاليّا، وسنرى تطبيقا لهذا الكلام عند إنشاء جدولي المقالات والمُستخدمين في ما بعد وأتمنّى أن تُساعد هذه المُقدّمة على تقليص الصّداع الذي يحدث عندما تتعلّم شيئا لأول مرّة. تجهيز جدول المقالات بعد أن وضّحنا المفاهيم الأساسيّة، حان الوقت لتطبيق هذه المفاهيم وإنشاء الجداول التّي سنتعامل معها في تطبيقنا، تذكر بأنّ هذه الجداول عبارة عن أصناف بايثون عادية، ويجب عليك وضعها داخل ملفّ models.py المتواجد بمُجلّد project. سنبدأ بجدول المقالات الذي سيكون كالآتي: # project/models.py from datetime import datetime from project import db class Post(db.Model): __tablename__ = "posts" id = db.Column(db.Integer, primary_key=True) title = db.Column(db.String(255), nullable=False) content = db.Column(db.Text, nullable=False) created_date = db.Column(db.DateTime) def __init__(self, title, content, created_date = None): self.title = title self.content = content self.created_date = datetime.utcnow() def __repr__(self): return '<title {} | {} >'.format(self.title, self.content) مُلاحظة: تذكّر بأنّ جميع الجداول التّي نعرّفها عبارة عن أصناف في ملفّ project/models.py. أولا، نقوم باستيراد الكائن datetime لنستعمله في تأريخ إضافة المقال، بعدها نستدعي الكائن db الذي عرّفناه سابقا، بعد ذلك نقوم بتطبيق مفهوم الصّنف كجدول لإنشاء جدول المقالات باسم Post الذي يرث من db.Model، بعدها نقوم بتحديد اسم الجدول posts ثمّ نعرّف عمود رقم المُعرّف كمفتاح أولي، ثمّ العنوان كسلسلة نصيّة بحدود 255 حرفا، محتوى المقال كنصّ، تاريخ إضافة المقال من نوع db.DateTime. بعد تعريف جميع الأعمدة، نعرّف الأعمدة التّي يُمكننا إدارتها عبر الدّالة __init__، وتشمل هذه الأعمدة حاليا العنوان والمحتوى وتاريخ الإضافة فقط، وإدارة تاريخ الإضافة اختياري لأنّنا سبق وأن وضعنا له قيمة افتراضيّة عبارة عن تاريخ إضافة السّجل إلى قاعدة البيانات والذي نصل إليه من الدّالة datetime.utcnow، الآن إن أردنا إضافة قيم إلى الجدول فسنحتاج إلى توفير عنوان المقال ومحتواه فقط، أمّا العمودان الآخران فيهتمّ بهما SQLAlchemy. بعد الانتهاء من التّابع الخاص __init__ نعرّف التّابع الخاص __repr__ ليُساعدنا على عرض عنوان المقال ومحتواه بعد استعلامه بـSQLAlchemy ككائن، وقد سبق وأن شرحت وظيفة هذه الدّالة الخاصّة في درس البرمجة كائنيّة التوجّه ضمن سلسلة تعلّم بايثون، وسنرى في ما بعد نتيجة هذه الدّالة وبماذا ستُفيدنا. تجهيز جدول المُستخدمين سنقوم بإنشاء جدول المُستخدمين بنفس الطريقة، صنف باسم User، جدول باسم users، رقم مُعرّف كقيمة أوليّة، اسم مُستخدم، بريد إلكتروني، كلمة المرور، وتاريخ الانضمام. class User(db.Model): __tablename__ = "users" id = db.Column(db.Integer, primary_key=True) name = db.Column(db.String(25), nullable=False) email = db.Column(db.String(25), nullable=False) password = db.Column(db.String(25), nullable=False) created_date = db.Column(db.DateTime) def __init__(self, name, email, password, created_date = None): self.name = name self.email = email self.password = password self.created_date = datetime.utcnow() def __repr__(self): return '<username: {} | email: {} >'.format(self.name, self.email) هذه المرّة سيتوجّب علينا تحديد كلّ من اسم المُستخدم، كلمة المرور وبريده الإلكتروني إذا أردنا إضافة سجل مُستخدم إلى قاعدة البيانات، أمّا الدّالّة __repr__ فستعرض كلّا من اسم المُستخدم وبريده الإلكتروني. مُلاحظة: حاليّا نقوم بتخزين كلمات المرور على شكل نصوص واضحة، ويُمكن لأي شخص أن يحصل عليها ببساطة إن استطاع الوصول إلى قاعدة بيانات التّطبيق، وهذا أمر خطير جدّا، إذ أنّ حماية بيانات مُستخدمي التّطبيق أمر مهم جدّا، ولابد من تشفير كلمات المرور قبل إدخالها إلى قاعدة البيانات، وسنقوم بذلك فيما بعد، فالهدف الرّئيسي من هذا الدّرس هو إعطاؤك مقدّمة لكيفيّة تجهيز الجداول في قاعدة البيانات أمّا الحماية فسنتطرّق إليها لاحقا، لذا لا تحاول القيام بتخزين كلمات المرور بهذه الطّريقة، وتابع السّلسلة إلى نهايتها لتتعلّم كيفيّة تطوير تطبيقاتك بإطار العمل Flask بشكل آمن. خاتمة بعد أن تعرّفنا على كيفيّة تجهيز جداول قاعدة البيانات التّي سنتعامل معها في تطبيقنا باستعمال مكتبة SQLAlchemy وإضافة Flask-SQLAlchemy وتعرّفنا على بعض المفاهيم المُهمّة في التّعامل مع قواعد البيانات بهذه المكتبة، بقيت نقطة مهمّة يجب الإشارة إليها قبل إنشاء الجداول في قاعدة البيانات وجلب، إضافة وتعديل وحذف السّجلات منها، ألا وهي علاقة الواحد للعديد One-to-Many Relationship، وهي العلاقة التّي سنستكشفها وسنستعملها لربط كلّ مقال بالمُستخدم الذي أضافه وربط المقالات بكاتبها في الدّرس القادم.
مُقدّمة بعد تجهيز قاعدة بيانات PostgreSQL التي سنستعملها في تطبيقنا، وبعد أن تعرّفنا في الدرس السابق على كيفيّة تنصيب وتجهيز كل من مكتبة SQLAlchemy و إضافة Flask-SQLAlchemy، حان الوقت لتجهيز جدولين من أهم جداول تطبيقات إدارة المحتوى، ألا وهي جدول المقالات الذي يمثل المحتوى بعينه وجدول المُستخدمين الذين سيُدِيرُون المحتوى، وبالتالي فسنقوم في هذا الدرس بوضع أساس لتطبيق “إدارة المحتوى” عبر تجهيز الطرف الذي سيقوم بالإدارة والطرف الذي يُمثل المحتوى. تذكير نعلم بأنّ قاعدة البيانات تحتوي على عدة جداول، كل جدول يمثل نوعا من المحتوى، وكل جدول يشمل عدة أعمدة، فمثلا جدول المُستخدمين سيحتوي على عمود لأسماء المستخدمين، وعمود لكلمات المرور، بحيث تكون قيمة كل عمود مربطة بمستخدم واحد فقط. تعرّفنا في الدرس السابق على الشكل العام لجداول قاعدة البيانات عند استعمال إضافة Flask-SQLAlchemy وقلنا بأنّ جدولا باسم table_name سيكون كالتّالي: from project import db class TableName(db.Model): __tablename__ = 'table_name' column_name = db.Column(db.Type, args) الجدول به عمود واحد باسم column_name ونقوم بإخبار SQLAlchemy بأنّ هذا عمود في الجدول عبر استخدام التّابع db.Column الذي يقبل عدّة معاملات لتحديد نوعية العمود وما يمكن له أن يقبل من قيم. نقوم بتحديد نوع البيانات التي يجب أن يقبلها العمود عبر استخدام المعامل db.Type مع استبدال Type بأحد الأنواع التي يدعمها SQLAlchemy. ما يلي أكثر أنواع القيم استخداما والتي يدعمها SQLAlchemy: Integer الأعداد الصّحيحة String(size) سلسلة نصيّة، size مُعامل يشير إلى أقصى قيمة لعدد المحارف في السّلسلة النّصيّة، مثلاString(25) يشير إلى أنّ العمود يُمكن أن يحمل سلسلة نصيّة بحدود خمسة وعشرين محرفا فقط ولا يُمكن تجاوز هذا الحد. Text نوع للإشارة إلى أنّ هذا العمود يُمكن أن يحتوي على النّصوص الطّويلة. DateTime نوع يُشير إلى أنّ العمود سيحمل تواريخ مُعبّر عنها بالكائن datetime في لغة بايثون، وسنستخدم هذا النّوع لوضع تاريخ نشر للمقال وتاريخ لانضمام مُستخدم معيّن. يُساعد تحديد نوع القيم في العمود على تجنّب الكثير من الأخطاء، ومن المُفضّل أن تختار دائما النّوع الذي يُناسبك أكثر لتحفظ المساحة وتتجنّب بعض الهجمات المُمكنة، فمثلا لو كان نوع القيمة Text في حقل اسم المُستخدم لتمكّن أحدهم من وضع نص كاسم مُستخدم له، وإن عرضناه في صفحة لكانت تلك الصّفحة بشعة لوجود نص عوضا عن كلمة أو كلمتين، هذا بالإضافة إلى أنّ المساحة في الخادوم ستُستهلك بشكل غير معقول. أعلم بأنّ الكلام النّظري مُمل بعض الشّيء، لكنّه مهم جدّا لتفهم ما سنقوم به تاليّا، وسنرى تطبيقا لهذا الكلام عند إنشاء جدولي المقالات والمُستخدمين في ما بعد وأتمنّى أن تُساعد هذه المُقدّمة على تقليص الصّداع الذي يحدث عندما تتعلّم شيئا لأول مرّة. تجهيز جدول المقالات بعد أن وضّحنا المفاهيم الأساسيّة، حان الوقت لتطبيق هذه المفاهيم وإنشاء الجداول التّي سنتعامل معها في تطبيقنا، تذكر بأنّ هذه الجداول عبارة عن أصناف بايثون عادية، ويجب عليك وضعها داخل ملفّ models.py المتواجد بمُجلّد project. سنبدأ بجدول المقالات الذي سيكون كالآتي: # project/models.py from datetime import datetime from project import db class Post(db.Model): __tablename__ = "posts" id = db.Column(db.Integer, primary_key=True) title = db.Column(db.String(255), nullable=False) content = db.Column(db.Text, nullable=False) created_date = db.Column(db.DateTime) def __init__(self, title, content, created_date = None): self.title = title self.content = content self.created_date = datetime.utcnow() def __repr__(self): return '<title {} | {} >'.format(self.title, self.content) مُلاحظة: تذكّر بأنّ جميع الجداول التّي نعرّفها عبارة عن أصناف في ملفّ project/models.py. أولا، نقوم باستيراد الكائن datetime لنستعمله في تأريخ إضافة المقال، بعدها نستدعي الكائن db الذي عرّفناه سابقا، بعد ذلك نقوم بتطبيق مفهوم الصّنف كجدول لإنشاء جدول المقالات باسم Post الذي يرث من db.Model، بعدها نقوم بتحديد اسم الجدول posts ثمّ نعرّف عمود رقم المُعرّف كمفتاح أولي، ثمّ العنوان كسلسلة نصيّة بحدود 255 حرفا، محتوى المقال كنصّ، تاريخ إضافة المقال من نوع db.DateTime. بعد تعريف جميع الأعمدة، نعرّف الأعمدة التّي يُمكننا إدارتها عبر الدّالة __init__، وتشمل هذه الأعمدة حاليا العنوان والمحتوى وتاريخ الإضافة فقط، وإدارة تاريخ الإضافة اختياري لأنّنا سبق وأن وضعنا له قيمة افتراضيّة عبارة عن تاريخ إضافة السّجل إلى قاعدة البيانات والذي نصل إليه من الدّالة datetime.utcnow، الآن إن أردنا إضافة قيم إلى الجدول فسنحتاج إلى توفير عنوان المقال ومحتواه فقط، أمّا العمودان الآخران فيهتمّ بهما SQLAlchemy. بعد الانتهاء من التّابع الخاص __init__ نعرّف التّابع الخاص __repr__ ليُساعدنا على عرض عنوان المقال ومحتواه بعد استعلامه بـSQLAlchemy ككائن، وقد سبق وأن شرحت وظيفة هذه الدّالة الخاصّة في درس البرمجة كائنيّة التوجّه ضمن سلسلة تعلّم بايثون، وسنرى في ما بعد نتيجة هذه الدّالة وبماذا ستُفيدنا. تجهيز جدول المُستخدمين سنقوم بإنشاء جدول المُستخدمين بنفس الطريقة، صنف باسم User، جدول باسم users، رقم مُعرّف كقيمة أوليّة، اسم مُستخدم، بريد إلكتروني، كلمة المرور، وتاريخ الانضمام. class User(db.Model): __tablename__ = "users" id = db.Column(db.Integer, primary_key=True) name = db.Column(db.String(25), nullable=False) email = db.Column(db.String(25), nullable=False) password = db.Column(db.String(25), nullable=False) created_date = db.Column(db.DateTime) def __init__(self, name, email, password, created_date = None): self.name = name self.email = email self.password = password self.created_date = datetime.utcnow() def __repr__(self): return '<username: {} | email: {} >'.format(self.name, self.email) هذه المرّة سيتوجّب علينا تحديد كلّ من اسم المُستخدم، كلمة المرور وبريده الإلكتروني إذا أردنا إضافة سجل مُستخدم إلى قاعدة البيانات، أمّا الدّالّة __repr__ فستعرض كلّا من اسم المُستخدم وبريده الإلكتروني. مُلاحظة: حاليّا نقوم بتخزين كلمات المرور على شكل نصوص واضحة، ويُمكن لأي شخص أن يحصل عليها ببساطة إن استطاع الوصول إلى قاعدة بيانات التّطبيق، وهذا أمر خطير جدّا، إذ أنّ حماية بيانات مُستخدمي التّطبيق أمر مهم جدّا، ولابد من تشفير كلمات المرور قبل إدخالها إلى قاعدة البيانات، وسنقوم بذلك فيما بعد، فالهدف الرّئيسي من هذا الدّرس هو إعطاؤك مقدّمة لكيفيّة تجهيز الجداول في قاعدة البيانات أمّا الحماية فسنتطرّق إليها لاحقا، لذا لا تحاول القيام بتخزين كلمات المرور بهذه الطّريقة، وتابع السّلسلة إلى نهايتها لتتعلّم كيفيّة تطوير تطبيقاتك بإطار العمل Flask بشكل آمن. خاتمة بعد أن تعرّفنا على كيفيّة تجهيز جداول قاعدة البيانات التّي سنتعامل معها في تطبيقنا باستعمال مكتبة SQLAlchemy وإضافة Flask-SQLAlchemy وتعرّفنا على بعض المفاهيم المُهمّة في التّعامل مع قواعد البيانات بهذه المكتبة، بقيت نقطة مهمّة يجب الإشارة إليها قبل إنشاء الجداول في قاعدة البيانات وجلب، إضافة وتعديل وحذف السّجلات منها، ألا وهي علاقة الواحد للعديد One-to-Many Relationship، وهي العلاقة التّي سنستكشفها وسنستعملها لربط كلّ مقال بالمُستخدم الذي أضافه وربط المقالات بكاتبها في الدّرس القادم. -
 مُقدّمة لا شك بأنّ معظم تطبيقات اليوم تعتمد على نوع من أنواع البيانات، لذا لا بدّ من حفظها في مكان مُناسب، وتعتبر قواعد البيانات التّي يُمكن التّعامل معها بلغة SQL أحد أفضل الطّرق لحفظ بيانات تطبيقات الويب، وبما أنّنا أنشأنا قاعدة بيانات خاصّة بنا، فقد حان الوقت للتعرف على كيفية استعمال مكتبة SQLAlchemy لإدارة قاعدة بيانات تطبيقنا. في هذا الدرس، سنتعرف على كيفية تجهيز إضافة Flask-SQLAlchemy لتسهيل العمل مع مكتبة SQLAlchemy. تنصيب إضافة Flask-SQLAlchemy تأكّد أولا من أنّ البيئة الوهميّة مفعّلة عندك وأنّك في مُجلّد kalima، وبعدها نفّذ الأمر التّالي لتنصيب الإضافة مع مكتبة psycopg2: pip install Flask-SQLAlchemy psycopg2 لكي نتمكّن من التّعامل مع قاعدة بيانات PostgreSQL باستعمال SQLAlchemy يجب تنصيب مكتبة psycopg2 التّي تُمكنّنا من ذلك. مُلاحظة: تعتمد الإضافة أساسا على مكتبة SQLAlchemy لذا ستُنصّب كذلك، هذا يعني بأنّك تستطيع الوصول إلى جميع الدّوال والكائنات المُتواجدة في المكتبة إن أردت ذلك. لاختبار نجاح التّنصيب، افتح مفسّر بايثون وقم باستيراد الحزم التّاليّة: import flask_sqlalchemy import sqlalchemy إن لم يحدث أي خطأ فالحزمة مُنصّبة بنجاح، وإن واجهت أي خطأ فحاول التّأكد من أنّك اتّبعت ما ذكرته في الدّروس الأولى من السّلسلة بشكل صحيح. تذكير قواعد البيانات من نوع SQL تعتمد بشكل رئيسيّ على الجداول Tables، كلّ جدول يحمل أعمدة مُختلفة، وكلّ عمود يحمل قيما معيّنة، وهناك عمود خاصّ يسمى برقم المُعرّف وعادة ما يُشار إليه بـid ولأنّ كل مُدخل من المُدخلات يحمل رقم مُعرّف فريدا، فسيُمكّننا من تمييز المُستخدمين والمقالات وبقيّة الأجزاء المُهمّة في تطبيقاتنا، وقد سبق وأن شرحت هذا في درس ربط تطبيق Flask مع قاعدة بيانات SQLite، لذا عد إلى ذلك الدّرس لتفهم أكثر. ربط التّطبيق بإضافة Flask-SQLAlchemy لربط التّطبيق مع إضافة Flask-SQLAlchemy نقوم أولا باستيراد SQLAlchemy من حزمة الإضافة بالسّطر التّالي: # project/__init__.py from flask_sqalchemy import SQLAlchemy وبعدها نقوم بتمرير كائن التّطبيق app إلى ما قمنا باستيراده وإسناد النّاتج إلى مُتغيّر باسم db كما يلي: # project/__init__.py db = SQLAlchemy(app) سنقوم كذلك بإضافة سطرين لإعدادات التّطبيق app.config، السّطر الأول سيكون عبارة عن رابط قاعد البيانات، كما يلي: app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql://username:password@127.0.0.1/kalima' استبدل username بالمُستخدم الذي أنشأت به قاعدة البيانات وكلمة المرور بكلمة المرور التّي سبق أن حدّدتها، إن كنت على أحد أنظمة لينكس فالمُستخدم المبدئي هو postgres والعنوان 127.0.0.1 يُشير إلى أنّنا سنعتمد على قاعدة بياناتنا المحليّة، أمّا kalima فهو اسم قاعدة البيانات التّي أنشأناها سابقا. السّطر الثّاني غير مُهم وقد لا تحتاج إليه في قادم النّسخ من إضافة Flask-SQLAlchemy، وقد قمت بإضافته لإخفاء تنبيه يظهر بعد تشغيل الخادوم. app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True مُلاحظة: من المعروف بأنّ التّطبيق يمر عبر عدّة مراحل، مرحلة التّطوير، الاختبار ثمّ مرحلة الإنتاج (النّشر إلى العالم الخارجي)، وعادة ما تُعزل كلّ مرحلة عن الأخرى فيما يُسمّى بالبيئة، ولذا تسمع مُصطلحات كبيئة التّطوير Development Environment، بيئة الاختبار Testing Environment، بيئة الإنتاج Production Environment، وإعدادات كلّ بيئة تكون مختلفة عن البيئات الأخرى، ولهذا يعدّ تخزين الإعدادات في الملفّ الرّئيسي للمشروع أمر سيئا لأنّك ستضطر إلى تغيير الإعدادات في كل مرّة تنتقل فيها من بيئة إلى أخرى، وقد يُشكل إعداد خاطئ واحد خطرا كبيرا على تطبيقك، خاصّة إن كان التّطبيق ذا وظائف مُتعدّدة، والحل الأمثل هو تخزين هذه الإعدادات في ملفّ مُستقل وهذا الأمر مهم جدا وقد سبق وأن شرحت طريقة بسيطة للقيام بذلك، وسنتطرّق إليه بالتّفصيل في ما بعد، المهم الآن أن تُدرك بأنّ كل ما يقع تحت قاموس app.config عبارة عن إعداد من إعدادات التّطبيق. بعد ربط كائن التّطبيق بإضافة Flask-SQLAlchemy سنتمكّن من استغلال الكائن db للاستفادة من كل ما تمنحه لنا الإضافة من تسهيلات للعمل مع مكتبة SQLAlchemy. ومع التّغييرات التّي قُمنا بها سيُصبح الجزء العلوي من ملفّ project/__init__.py كالآتي: # project/__init__.py from flask import Flask, render_template app = Flask(__name__) app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql://username:password@127.0.0.1/kalima' app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True from flask_sqlalchemy import SQLAlchemy db = SQLAlchemy(app) from project.posts.views import posts from project.users.views import users app.register_blueprint(posts) app.register_blueprint(users) تأكّد فقط من أنّ الإعدادين يقعان مُباشرة بعد تعريف الكائن app وأنّ استيراد الطّبعات الزّرقاء Blueprints وتسجيلها يقع بعد تعريف المُتغيّر db لتجنّب بعض المشاكل التّي قد تحدث عندما تعتمد كل حزمة على الأخرى أثناء الاستيراد أو ما يُسمى بـ circular imports أو الاستيرادات الدّائريّة. الجداول في Flask-SQLAlchemy لتجهيز الجداول في التّطبيق، سنفتح أولا ملفّا جديدا باسم models.py في مجلّد project، وسنضع فيه كل ما يتعلّق بالجداول وطريقة تسجيلها والبيانات المبدئية. وطريقة إنشاء الجداول في Flask-SQLAlchemy هي كالآتي: from project import db class TableName(db.Model): __tablename__ = 'table_name' column_name = db.Column(db.Type, args) كما ترى، نقوم أولا باستيراد الكائن db من حزمة المشروع ثمّ نقوم بإنشاء صنف باسم الجدول، ولابد لهذا الصّنف أن يرث من الصّنف db.Model الذي تُوفّره لنا إضافة Flask-SQLAlchemy، بعدها نقوم بتسميّة الجدول عبر وضع اسمه على شكل سلسلة نصيّة وإسنادها للمُتغيّر الخاصّ __tablename__، ثمّ بعد ذلك نقوم بتعريف مُختلف أسماء الأعمدة وإسنادها قيمة عن طريق التّابع db.Column، ثمّ نُخصّص نوع قيم العمود وبعض المُعاملات الإضافيّة، وأحد أشهر المُعاملات هو مُعامل primary_key الذي يجعل من العمود مفتاحا أوليا إن أسندت له القيمة المنطقيّة True وعادة ما يُستخدم مع عمود رقم المُعرّف id، والمُعامل الآخر الذي ستصادفه كثيرا هو مُعامل nullable ويقبل كذلك القيمتين المنطقيّتين True و False فإن كانت قيمة المُعامل False فهذا يعني بأنّ العمود لا يمكن أن يحمل قيمة فارغة، ويُستعمل في الأعمدة المُهمّة كالبريد الإلكتروني وكلمة المرور، ويُمكن أن تسمح بأن تكون قيم العمود فارغة إن لم يكن توفير المعلومة ضروريا مثل نبذة عن المُستخدم وصورته الشّخصيّة أو اسمه الحقيقي وهذه الأمور تختلف حسب نوعيّة التّطبيق بكل تأكيد. المفتاح الأولي Primary Key عبارة عن عمود يحمل قيما فريدة في الجدول بأكمله، ولا يُمكن أن تكون قيمته فارغة ولكنّنا لا نحتاج إلى إضافة المُعامل nullable عند تعريف العمود، ويُستعمل لتعريف كل سجلّ من سجلّات الجدول على حدة، ومن المُفضّل أن يكون نوعه عددا صحيحا لحفظ بعض المساحة، ولإبقاء القيم فريدة ومُختلفة عن بعضها البعض، يضاف واحد إلى القيمة السّابقة عند كل إضافة إلى قاعدة البيانات، وكما قُلت سابقا، الطّريقة الشّائعة لاستخدامه هو بوضع عمود باسم id في الجدول ليحمل القيم الفريدة على شكل أعداد صحيحة، فمثلا لو كان لدينا قاعدة بيانات بأسماء ما كما يلي: id | name 1 | أحمد 2 | مُحمّد 3 | أحمد للوهلة الأولى يبدو بأنّ سجلّ أحمد قد كرّر مرّتين، لكن لاحظ رقم المُعرّف الخاص بكل سجلّ، أحمد الأول رقم مُعرّفه 1 والآخر 3، هذا يعني بأنّهما شخصان مُختلفان بنفس الاسم، لا بد أنّك أدركت الآن مدى أهميّة المفتاح الأولي، فلو كان تطبيقنا يسمح بتسجيل المُستخدمين بأسمائهم لوجدنا مُشكلة مع أحمد هذا، لكنّ رقم المُعرّف يقوم بحل المُشكلة. أمّا عن db.Type فهو لتحديد نوع القيم التي سيحملها العمود، وهي مُشابهة لأنواع القيم المُتاحة في لغة SQL، مثل العدد الصّحيح Integer والسّلسلة النّصيّة String (VARCHAR في لغة SQL) والتّاريخ وغير ذلك من أنواع القيم. خاتمة قمنا في هذا الدرس بتجهيز أداة SQLAlchemy وتعرّفنا على كيفيّة استخدام إضافة Flask-SQLAlchemy للتعامل معها وألقينا نظرة بسيطة إلى الصورة العامة لجدول SQL مكتوب بلغة بايثون. في الدرس القادم، سنقوم بإنشاء جدولي المقالات والمُستخدمين في قاعدة بياناتنا.
مُقدّمة لا شك بأنّ معظم تطبيقات اليوم تعتمد على نوع من أنواع البيانات، لذا لا بدّ من حفظها في مكان مُناسب، وتعتبر قواعد البيانات التّي يُمكن التّعامل معها بلغة SQL أحد أفضل الطّرق لحفظ بيانات تطبيقات الويب، وبما أنّنا أنشأنا قاعدة بيانات خاصّة بنا، فقد حان الوقت للتعرف على كيفية استعمال مكتبة SQLAlchemy لإدارة قاعدة بيانات تطبيقنا. في هذا الدرس، سنتعرف على كيفية تجهيز إضافة Flask-SQLAlchemy لتسهيل العمل مع مكتبة SQLAlchemy. تنصيب إضافة Flask-SQLAlchemy تأكّد أولا من أنّ البيئة الوهميّة مفعّلة عندك وأنّك في مُجلّد kalima، وبعدها نفّذ الأمر التّالي لتنصيب الإضافة مع مكتبة psycopg2: pip install Flask-SQLAlchemy psycopg2 لكي نتمكّن من التّعامل مع قاعدة بيانات PostgreSQL باستعمال SQLAlchemy يجب تنصيب مكتبة psycopg2 التّي تُمكنّنا من ذلك. مُلاحظة: تعتمد الإضافة أساسا على مكتبة SQLAlchemy لذا ستُنصّب كذلك، هذا يعني بأنّك تستطيع الوصول إلى جميع الدّوال والكائنات المُتواجدة في المكتبة إن أردت ذلك. لاختبار نجاح التّنصيب، افتح مفسّر بايثون وقم باستيراد الحزم التّاليّة: import flask_sqlalchemy import sqlalchemy إن لم يحدث أي خطأ فالحزمة مُنصّبة بنجاح، وإن واجهت أي خطأ فحاول التّأكد من أنّك اتّبعت ما ذكرته في الدّروس الأولى من السّلسلة بشكل صحيح. تذكير قواعد البيانات من نوع SQL تعتمد بشكل رئيسيّ على الجداول Tables، كلّ جدول يحمل أعمدة مُختلفة، وكلّ عمود يحمل قيما معيّنة، وهناك عمود خاصّ يسمى برقم المُعرّف وعادة ما يُشار إليه بـid ولأنّ كل مُدخل من المُدخلات يحمل رقم مُعرّف فريدا، فسيُمكّننا من تمييز المُستخدمين والمقالات وبقيّة الأجزاء المُهمّة في تطبيقاتنا، وقد سبق وأن شرحت هذا في درس ربط تطبيق Flask مع قاعدة بيانات SQLite، لذا عد إلى ذلك الدّرس لتفهم أكثر. ربط التّطبيق بإضافة Flask-SQLAlchemy لربط التّطبيق مع إضافة Flask-SQLAlchemy نقوم أولا باستيراد SQLAlchemy من حزمة الإضافة بالسّطر التّالي: # project/__init__.py from flask_sqalchemy import SQLAlchemy وبعدها نقوم بتمرير كائن التّطبيق app إلى ما قمنا باستيراده وإسناد النّاتج إلى مُتغيّر باسم db كما يلي: # project/__init__.py db = SQLAlchemy(app) سنقوم كذلك بإضافة سطرين لإعدادات التّطبيق app.config، السّطر الأول سيكون عبارة عن رابط قاعد البيانات، كما يلي: app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql://username:password@127.0.0.1/kalima' استبدل username بالمُستخدم الذي أنشأت به قاعدة البيانات وكلمة المرور بكلمة المرور التّي سبق أن حدّدتها، إن كنت على أحد أنظمة لينكس فالمُستخدم المبدئي هو postgres والعنوان 127.0.0.1 يُشير إلى أنّنا سنعتمد على قاعدة بياناتنا المحليّة، أمّا kalima فهو اسم قاعدة البيانات التّي أنشأناها سابقا. السّطر الثّاني غير مُهم وقد لا تحتاج إليه في قادم النّسخ من إضافة Flask-SQLAlchemy، وقد قمت بإضافته لإخفاء تنبيه يظهر بعد تشغيل الخادوم. app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True مُلاحظة: من المعروف بأنّ التّطبيق يمر عبر عدّة مراحل، مرحلة التّطوير، الاختبار ثمّ مرحلة الإنتاج (النّشر إلى العالم الخارجي)، وعادة ما تُعزل كلّ مرحلة عن الأخرى فيما يُسمّى بالبيئة، ولذا تسمع مُصطلحات كبيئة التّطوير Development Environment، بيئة الاختبار Testing Environment، بيئة الإنتاج Production Environment، وإعدادات كلّ بيئة تكون مختلفة عن البيئات الأخرى، ولهذا يعدّ تخزين الإعدادات في الملفّ الرّئيسي للمشروع أمر سيئا لأنّك ستضطر إلى تغيير الإعدادات في كل مرّة تنتقل فيها من بيئة إلى أخرى، وقد يُشكل إعداد خاطئ واحد خطرا كبيرا على تطبيقك، خاصّة إن كان التّطبيق ذا وظائف مُتعدّدة، والحل الأمثل هو تخزين هذه الإعدادات في ملفّ مُستقل وهذا الأمر مهم جدا وقد سبق وأن شرحت طريقة بسيطة للقيام بذلك، وسنتطرّق إليه بالتّفصيل في ما بعد، المهم الآن أن تُدرك بأنّ كل ما يقع تحت قاموس app.config عبارة عن إعداد من إعدادات التّطبيق. بعد ربط كائن التّطبيق بإضافة Flask-SQLAlchemy سنتمكّن من استغلال الكائن db للاستفادة من كل ما تمنحه لنا الإضافة من تسهيلات للعمل مع مكتبة SQLAlchemy. ومع التّغييرات التّي قُمنا بها سيُصبح الجزء العلوي من ملفّ project/__init__.py كالآتي: # project/__init__.py from flask import Flask, render_template app = Flask(__name__) app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql://username:password@127.0.0.1/kalima' app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True from flask_sqlalchemy import SQLAlchemy db = SQLAlchemy(app) from project.posts.views import posts from project.users.views import users app.register_blueprint(posts) app.register_blueprint(users) تأكّد فقط من أنّ الإعدادين يقعان مُباشرة بعد تعريف الكائن app وأنّ استيراد الطّبعات الزّرقاء Blueprints وتسجيلها يقع بعد تعريف المُتغيّر db لتجنّب بعض المشاكل التّي قد تحدث عندما تعتمد كل حزمة على الأخرى أثناء الاستيراد أو ما يُسمى بـ circular imports أو الاستيرادات الدّائريّة. الجداول في Flask-SQLAlchemy لتجهيز الجداول في التّطبيق، سنفتح أولا ملفّا جديدا باسم models.py في مجلّد project، وسنضع فيه كل ما يتعلّق بالجداول وطريقة تسجيلها والبيانات المبدئية. وطريقة إنشاء الجداول في Flask-SQLAlchemy هي كالآتي: from project import db class TableName(db.Model): __tablename__ = 'table_name' column_name = db.Column(db.Type, args) كما ترى، نقوم أولا باستيراد الكائن db من حزمة المشروع ثمّ نقوم بإنشاء صنف باسم الجدول، ولابد لهذا الصّنف أن يرث من الصّنف db.Model الذي تُوفّره لنا إضافة Flask-SQLAlchemy، بعدها نقوم بتسميّة الجدول عبر وضع اسمه على شكل سلسلة نصيّة وإسنادها للمُتغيّر الخاصّ __tablename__، ثمّ بعد ذلك نقوم بتعريف مُختلف أسماء الأعمدة وإسنادها قيمة عن طريق التّابع db.Column، ثمّ نُخصّص نوع قيم العمود وبعض المُعاملات الإضافيّة، وأحد أشهر المُعاملات هو مُعامل primary_key الذي يجعل من العمود مفتاحا أوليا إن أسندت له القيمة المنطقيّة True وعادة ما يُستخدم مع عمود رقم المُعرّف id، والمُعامل الآخر الذي ستصادفه كثيرا هو مُعامل nullable ويقبل كذلك القيمتين المنطقيّتين True و False فإن كانت قيمة المُعامل False فهذا يعني بأنّ العمود لا يمكن أن يحمل قيمة فارغة، ويُستعمل في الأعمدة المُهمّة كالبريد الإلكتروني وكلمة المرور، ويُمكن أن تسمح بأن تكون قيم العمود فارغة إن لم يكن توفير المعلومة ضروريا مثل نبذة عن المُستخدم وصورته الشّخصيّة أو اسمه الحقيقي وهذه الأمور تختلف حسب نوعيّة التّطبيق بكل تأكيد. المفتاح الأولي Primary Key عبارة عن عمود يحمل قيما فريدة في الجدول بأكمله، ولا يُمكن أن تكون قيمته فارغة ولكنّنا لا نحتاج إلى إضافة المُعامل nullable عند تعريف العمود، ويُستعمل لتعريف كل سجلّ من سجلّات الجدول على حدة، ومن المُفضّل أن يكون نوعه عددا صحيحا لحفظ بعض المساحة، ولإبقاء القيم فريدة ومُختلفة عن بعضها البعض، يضاف واحد إلى القيمة السّابقة عند كل إضافة إلى قاعدة البيانات، وكما قُلت سابقا، الطّريقة الشّائعة لاستخدامه هو بوضع عمود باسم id في الجدول ليحمل القيم الفريدة على شكل أعداد صحيحة، فمثلا لو كان لدينا قاعدة بيانات بأسماء ما كما يلي: id | name 1 | أحمد 2 | مُحمّد 3 | أحمد للوهلة الأولى يبدو بأنّ سجلّ أحمد قد كرّر مرّتين، لكن لاحظ رقم المُعرّف الخاص بكل سجلّ، أحمد الأول رقم مُعرّفه 1 والآخر 3، هذا يعني بأنّهما شخصان مُختلفان بنفس الاسم، لا بد أنّك أدركت الآن مدى أهميّة المفتاح الأولي، فلو كان تطبيقنا يسمح بتسجيل المُستخدمين بأسمائهم لوجدنا مُشكلة مع أحمد هذا، لكنّ رقم المُعرّف يقوم بحل المُشكلة. أمّا عن db.Type فهو لتحديد نوع القيم التي سيحملها العمود، وهي مُشابهة لأنواع القيم المُتاحة في لغة SQL، مثل العدد الصّحيح Integer والسّلسلة النّصيّة String (VARCHAR في لغة SQL) والتّاريخ وغير ذلك من أنواع القيم. خاتمة قمنا في هذا الدرس بتجهيز أداة SQLAlchemy وتعرّفنا على كيفيّة استخدام إضافة Flask-SQLAlchemy للتعامل معها وألقينا نظرة بسيطة إلى الصورة العامة لجدول SQL مكتوب بلغة بايثون. في الدرس القادم، سنقوم بإنشاء جدولي المقالات والمُستخدمين في قاعدة بياناتنا. -
 تجهيز قاعدة البيانات بما أنّنا سنستخدم قاعدة البيانات PostgreSQL لهذا التّطبيق، عليك أولا أن تقوم بتنصيبها، إن كنت تستخدم Ubuntu فيُمكنك مُراجعة درس كيفيّة تنصيب PostgreSQL على Ubuntu، أمّا إن كنت على نظام Windows أو نظام Mac OS فتستطيع تحميلها من الموقع الرّسمي وتنصيبها، يُمكنك كذلك استخدام برنامج pgAdmin لإدارة قواعد بياناتك عن طريق برنامج رسومي. يُمكنك استعمال البرنامج الرّسومي لإنشاء قاعدة البيانات إن أردت ذلك، لكنّنا سنستعمل أداة psql لتنفيذ أوامر PostgreSQL واستعمال لغة SQL مباشرة من سطر الأوامر، لذا تأكّد من أنّك تستطيع الوصول إلى أداة psql. إنشاء قاعدة البيانات لإنشاء قاعدة البيانات، يكفي أن ننفّذ الأمر التّالي على سطر أوامر psql : CREATE DATABASE kalima; بعد تنفيذ الأمر، سيكون المُخرج كما يلي: CREATE DATABASE كلمة المرور للاتّصال بقاعدة البيانات، سنحتاج إلى كلمة مرور، إن سبق لك وأن خصّصت كلمة مرور أثناء التّنصيب، تستطيع تخطي هذه الخطوة، أمّا إن لم تمتلك كلمة مرور أو أنّك نسيتها، فيُمكنك ببساطة تغييرها في سطر أوامر psql بالأمر التّالي: \password بعد تنفيذ الأمر سيُطلب منك كتابة كلمة مرور جديدة وإعادة كتابتها للتّأكد من أنّك لم تُخطئ. كلمة المرور هذه مُهمّة جدا للاتّصال بقاعدة البيانات من تطبيق فلاسك باستخدام أداة SQLAlchemy لذا تأكّد من أنّها مُتاحة. ما معنى ORM؟ ORM اختصار Object-Relational Mapper أي رابط الكائنات بالعلاقات (الجداول)، الهدف منه ببساطة التّعامل مع قواعد بيانات SQL باستعمال الكائنات Objects والأصناف Classes عوضا عن تعليمات SQL، فعوضا عن إنشاء البيانات وجلبها وتعديلها وحذفها عن طريق تعليمات SQL التّي ستتكرّر كثيرا في الشّفرة يُمكن ببساطة استخدام لغة بايثون للوصول إلى نفس الهدف، كما أنّ استعمالها مع لغة برمجة يخلق شيئا من عدم التّناسق. لو تابعت سلسلة دروس Flask للمُبتدئين، للاحظت بأنّنا استعملنا ملفّا باسم manage_db للتّعامل مع قواعد البيانات عن طريق الدّوال عوضا عن كتابة تعليمات SQL عند الرّغبة في إجراء كل عمليّة، ولو استعملنا SQL الخام لكان تكرار الشّفرة كثيرا. بالإضافة إلى ميّزة تعريف الأصناف التّي تُمثّل الجداول والتّعامل معها عن طريق التّوابع (الدوال) لتجنّب تكرار الشّفرة، يقوم الـORM بالكثير من الأشياء المُملّة خلف الكواليس، فعوضا عن الاهتمام بالتّفاصيل الصّغيرة بأنفسنا، يقوم الـORM بالاهتمام بها من أجلنا لنهتمّ بالأمور الأكثر أهميّة، وفي النّهاية، مُعظمنا لا يتقن لغة SQL كثيرا لذا من المُفضّل استعمال مكتبة للتّعامل مع قواعد البيانات باللغة التّي نُجيدها. وبما أنّ استعمال الـORM يُتيح لنا عزل الشّفرة المسؤولة عن التّعامل مع قاعدة البيانات في معزل عن التّطبيق فهذا يُتيح لنا تعديل الخصائص وإضافة الميّزات للتّطبيقات دون التّأثير على تطبيق معيّن بحد ذاته، ومن الشّائع جمع الشّفرة المسؤولة عن التّعامل مع قاعدة البيانات في ملف باسم models.py في مجلّد المشروع. يُساعدنا الـORM كذلك على تحقيق مبدأ MVC أو Model-View-Controller أي “نموذج، عرض، مُتحكّم ” وهو مبدأ يقوم على عزل جزء العرض، المُتحكّمات، والنّماذج في تطوير التّطبيقات لمرونة أكثر في التّطوير، أي أنّ كلّا من العرض (الذي يُمثّل القوالب في تطبيقنا) والمُتحكّم (الذي يُمثّل دوال الموجّهات في ملفّات views.py) والنّموذج (أي الجزء الذي يتعامل مع البيانات) أجزاء منفصلة حسب الوظيفة متّصلة في التّطبيق ويُمكن أن تنتقل البيانات بينها ببساطة، ورغم أنّ إطار Flask يمنحك الحريّة الكاملة في طريقة تسميّة أجزاء تطبيقك، إلّا أن أطر عمل أخرى مثل Django و Rails تفرض عليك تسميّات محدّدة. ما هو SQLAlchemy؟ بعد أن عرّفنا معنى الـORM بقي تعريف مكتبة SQLAlchemy، وهي مكتبة تُسهّل علينا التّعامل مع قواعد البيانات المُختلفة، كما أنّها تحتوي على ORM قوي ومُعتمد عليه من طرف المشاريع الكبيرة. تحتوي SQLAlchemy على الكثير من الدّوال المُساعدة والكائنات التّي تُسهّل عليك كتابة SQL بلغة بايثون، والORM المبني فيه يُستعمل لربط الكائنات بالبيانات في قاعدة البيانات. سنستعمل في غالب هذا المشروع الـORM الخاص بـSQLAlchemy ولن نتطرّق إلى بقيّة ميّزات المكتبة، لذا إن أردت معرفة المزيد عن المكتبة فعليك بالتّوثيق الرّسمي. إضافات Flask Flask Extensions أو إضافات فلاسك عبارة عن مكتبات وأطر عمل Frameworks مبنيّة لتُسهّل على المُطوّر القيام بالأشياء المُفصّلة وتجنّب التّعامل مع كل شيء بأنفسنا، فمثلا، يُمكننا أن نستعمل مكتبة SQLAlchemy مع تطبيق Flask مُباشرة، إلّا أن في هذه الطّريقة الكثير من الأمور غير المُهمّة والكثير من الإعدادات، وبما أنّنا في مسيرة تعلّم إطار فلاسك لا كيفيّة استعمال SQLAlchemy، ولتسهيل استعمال SQLAlchemy مع المشاريع المبنيّة بإطار العمل فلاسك، قام كاتب الإطار Armin Ronacher بتطوير إضافة للإطار باسم Flask-SQLAlchemy التّي أصبحت أحد أشهر الإضافات على موقع Github. بالإضافة إلى Flask-SQLAlchemy هناك الكثير من الإضافات التّي يُمكننا استعمالها لتطوير تطبيقات فلاسك، وإليك بعضا من هذه الإضافات: Flask-Login إضافة لتسهيل التّعامل مع جلسات المُستخدمين Sessions، تُتيح إمكانيّة تسجيل دخول مُستخدم وتسجيل خروجه، لكنّها لا تقوم بالتّحقق من صحّة البيانات (اسم المُستخدم وكلمة المرور مثالا) وتترك المُطوّر للاهتمام بالأمر. Flask-Bcrypt إضافة لتشفير كلمات المرور باستعمال خوارزميّة Bcrypt قبل حفظها بقاعدة البيانات لحماية أكثر، هذا لمنع المُخترق من سرقة كلمات المرور حتى بعد وصوله إلى قاعدة البيانات، وكلّما كانت خوارزميّة التّشفير أعقد كلّما كان من الصّعب فك التّشفير عن كلمة المرور ما يُوفّر حماية أكثر. Flask-WTF بما أنّ مُعظم التّطبيقات تعتمد على نماذج HTML (حقول النّصوص، كلمات المرور و مساحة النّص TextArea) وبما أنّها تُسبّب الكثير من الثّغرات الأمنيّة في التّطبيقات والتّي يُمكن أن يُساء استغلالها، فلا بد من توفير طريقة آمنة وبسيطة للتأكّد من أنّ ما يُدخله المُستخدم في هذه الحقول آمن. يُمكنك بالطّبع التّأكد من مُدخلات المُستخدم بنفسك، لكنّ الأمر يأخذ وقتا، كما أنّه ممل في الحقيقة، إذ عليك تكرار نفس الشّيء كلّ مرّة. عوضا عن الاعتماد على مهاراتك البرمجيّة للتأكّد من سلامة المُدخلات، يُمكنك أن تترك إضافة Flask-WTF للاهتمام بالأمر في تطبيقاتك المبنيّة بإطار فلاسك، الإضافة مبنيّة على مكتبة WTForms التّي يُمكنك استعمالها مع أطر عمل أخرى، وأنصحك بالاطلاع على توثيق المكتبة الرّسمي للمزيد من المعلومات عن كيفيّة مُعالجة النّماذج. Flask-Migrate ببساطة، Flask-Migrate إضافة تُتيح لك تهجير البيانات Migrations عند تطوير تطبيقك. هذه الإضافة مهمّة جدّا إن كنت تطوّر تطبيقا سبق وأن نشرته على نحو مُتواصل، إذ تُتيح لك تهجير البيانات في كل مرّة تُضيف جدولا جديدا أو علاقة بين الجداول إلى قاعدة البيانات. تخيّل أنّك تمتلك تطبيقا يحتوي جدول المُستخدمين فيه على أكثر من ألف مُدخل، إن أردت إتاحة إمكانيّة إضافة تاريخ ازدياد للمُستخدمين فستضطر إلى حذف كلّ شيء في هذا الجدول وإضافة العمود الجديد ثمّ إعادة البيانات من جديد، الأمر مُعقّد بعض الشّيء وفقدان البيانات أمر غير مرغوب فيه بتاتا. مُجدّدا عوضا عن القيام بكل شيء بنفسك، دع إضافة Flask-Migrate لتهتمّ بكل هذا التّعقيد من أجلك، فبسطر أو سطرين تستطيع تطبيق الميّزة الجديدة لتطبيقك وتهجير البيانات القديمة بكل بساطة. Flask-Testing إضافة لتسهيل إجراء اختبارات وحدة Unit tests لتطبيقك، إذ أنّ اختبار التّطبيق مُهمّ جدّا للتأكّد من أنّ كلّ شيء بخير وأنّ المُستخدمين لا يواجهون أية مشاكل، خاصّة إذا كان مشروعك كبيرا، فاختبار كل وظيفة يدويّا قد يأخذ منك وقتا طويلا، وإن لم تختبره آليا فنسبة الخطأ كبيرة جدّا. إذا أضفت خاصيّة جديدة لتطبيقك فأنت بذلك تُعرّض أجزاء أخرى من التّطبيق إلى الخطأ، وستُسهّل عليك الاختبارات معرفة ما إذا كان التّطبيق لا يزال يعمل كما ينبغي له أو لا، وبما أنّ اختبارات الوحدة تختبر كلّ وظيفة على نحو مُستقل، فسيسهل عليك معرفة أي جزء يجب عليك الاهتمام به لإصلاح التّطبيق. Flask-Gravatar هذه الإضافة تُسهّل لنا استعمال خدمة Gravatar لتمكين المُستخدمين من إضافة صورة شخصيّة لهم، إذ تكون الصّورة الشّخصيّة مُرتبطة بالبريد الإلكتروني للمُستخدم وتُستعمل هذه الخدمة في الكثير من التّطبيقات في وقتنا الحالي. هناك مئات الإضافات الخاصّة بإطار Flask لذا لا يُمكنني ذكرها كلّها، إن أردت الاطّلاع على إضافات أخرى، تستطيع البحث عنها عن طريق أداة pip كما يلي: pip search flask سنتعرّف على معظم هذه الإضافات في قادم الدّروس مع التّقدم في المشروع، وهذا الهدف الأساسي من هذه الإضافات، كلّما تقدّمت أكثر وكبر المشروع كلّما احتجت إلى التّعامل مع الكثير من المهام المُملّة كالتّأكد من أنّ ما يرسله المُستخدم إلى قاعدة بياناتك آمن، وكالتّعامل مع الجلسات لتوفير نظام تسجيل دخول آمن دون الاضطرار للقيام بكل التّفاصيل؛ كما أنّ الإضافات تُقلّل من حجم الخطأ في التّطوير، فالاعتماد على إضافة لتسجيل دخول المُستخدمين بشكل آمن أفضل من مُحاولة إنشاء طريقة خاصّة بك قد تكون مليئة بالثّغرات الأمنيّة. وبما أنّ فلاسك إطار عمل مُصغّر، فبإضافاته يُمكنك أن تستخدمه كما تُستخدم أطر العمل الضّخمة كـDjango و Rails و Laravel وغيرها من الأطر المشهورة. خاتمة بعد أن أنشأنا قاعدة البيانات وتعرّفنا على بعض المفاهيم المُهمّة في تطوير تطبيقات الويب مع إطار فلاسك، حان الوقت لإنشاء الجداول الأساسيّة في قاعدة البيانات لنتمكّن من التّعامل معها عن طريق إضافة Flask-SQLAlchemy وهذا بالضّبط ما سنقوم به في الدّرس القادم.
تجهيز قاعدة البيانات بما أنّنا سنستخدم قاعدة البيانات PostgreSQL لهذا التّطبيق، عليك أولا أن تقوم بتنصيبها، إن كنت تستخدم Ubuntu فيُمكنك مُراجعة درس كيفيّة تنصيب PostgreSQL على Ubuntu، أمّا إن كنت على نظام Windows أو نظام Mac OS فتستطيع تحميلها من الموقع الرّسمي وتنصيبها، يُمكنك كذلك استخدام برنامج pgAdmin لإدارة قواعد بياناتك عن طريق برنامج رسومي. يُمكنك استعمال البرنامج الرّسومي لإنشاء قاعدة البيانات إن أردت ذلك، لكنّنا سنستعمل أداة psql لتنفيذ أوامر PostgreSQL واستعمال لغة SQL مباشرة من سطر الأوامر، لذا تأكّد من أنّك تستطيع الوصول إلى أداة psql. إنشاء قاعدة البيانات لإنشاء قاعدة البيانات، يكفي أن ننفّذ الأمر التّالي على سطر أوامر psql : CREATE DATABASE kalima; بعد تنفيذ الأمر، سيكون المُخرج كما يلي: CREATE DATABASE كلمة المرور للاتّصال بقاعدة البيانات، سنحتاج إلى كلمة مرور، إن سبق لك وأن خصّصت كلمة مرور أثناء التّنصيب، تستطيع تخطي هذه الخطوة، أمّا إن لم تمتلك كلمة مرور أو أنّك نسيتها، فيُمكنك ببساطة تغييرها في سطر أوامر psql بالأمر التّالي: \password بعد تنفيذ الأمر سيُطلب منك كتابة كلمة مرور جديدة وإعادة كتابتها للتّأكد من أنّك لم تُخطئ. كلمة المرور هذه مُهمّة جدا للاتّصال بقاعدة البيانات من تطبيق فلاسك باستخدام أداة SQLAlchemy لذا تأكّد من أنّها مُتاحة. ما معنى ORM؟ ORM اختصار Object-Relational Mapper أي رابط الكائنات بالعلاقات (الجداول)، الهدف منه ببساطة التّعامل مع قواعد بيانات SQL باستعمال الكائنات Objects والأصناف Classes عوضا عن تعليمات SQL، فعوضا عن إنشاء البيانات وجلبها وتعديلها وحذفها عن طريق تعليمات SQL التّي ستتكرّر كثيرا في الشّفرة يُمكن ببساطة استخدام لغة بايثون للوصول إلى نفس الهدف، كما أنّ استعمالها مع لغة برمجة يخلق شيئا من عدم التّناسق. لو تابعت سلسلة دروس Flask للمُبتدئين، للاحظت بأنّنا استعملنا ملفّا باسم manage_db للتّعامل مع قواعد البيانات عن طريق الدّوال عوضا عن كتابة تعليمات SQL عند الرّغبة في إجراء كل عمليّة، ولو استعملنا SQL الخام لكان تكرار الشّفرة كثيرا. بالإضافة إلى ميّزة تعريف الأصناف التّي تُمثّل الجداول والتّعامل معها عن طريق التّوابع (الدوال) لتجنّب تكرار الشّفرة، يقوم الـORM بالكثير من الأشياء المُملّة خلف الكواليس، فعوضا عن الاهتمام بالتّفاصيل الصّغيرة بأنفسنا، يقوم الـORM بالاهتمام بها من أجلنا لنهتمّ بالأمور الأكثر أهميّة، وفي النّهاية، مُعظمنا لا يتقن لغة SQL كثيرا لذا من المُفضّل استعمال مكتبة للتّعامل مع قواعد البيانات باللغة التّي نُجيدها. وبما أنّ استعمال الـORM يُتيح لنا عزل الشّفرة المسؤولة عن التّعامل مع قاعدة البيانات في معزل عن التّطبيق فهذا يُتيح لنا تعديل الخصائص وإضافة الميّزات للتّطبيقات دون التّأثير على تطبيق معيّن بحد ذاته، ومن الشّائع جمع الشّفرة المسؤولة عن التّعامل مع قاعدة البيانات في ملف باسم models.py في مجلّد المشروع. يُساعدنا الـORM كذلك على تحقيق مبدأ MVC أو Model-View-Controller أي “نموذج، عرض، مُتحكّم ” وهو مبدأ يقوم على عزل جزء العرض، المُتحكّمات، والنّماذج في تطوير التّطبيقات لمرونة أكثر في التّطوير، أي أنّ كلّا من العرض (الذي يُمثّل القوالب في تطبيقنا) والمُتحكّم (الذي يُمثّل دوال الموجّهات في ملفّات views.py) والنّموذج (أي الجزء الذي يتعامل مع البيانات) أجزاء منفصلة حسب الوظيفة متّصلة في التّطبيق ويُمكن أن تنتقل البيانات بينها ببساطة، ورغم أنّ إطار Flask يمنحك الحريّة الكاملة في طريقة تسميّة أجزاء تطبيقك، إلّا أن أطر عمل أخرى مثل Django و Rails تفرض عليك تسميّات محدّدة. ما هو SQLAlchemy؟ بعد أن عرّفنا معنى الـORM بقي تعريف مكتبة SQLAlchemy، وهي مكتبة تُسهّل علينا التّعامل مع قواعد البيانات المُختلفة، كما أنّها تحتوي على ORM قوي ومُعتمد عليه من طرف المشاريع الكبيرة. تحتوي SQLAlchemy على الكثير من الدّوال المُساعدة والكائنات التّي تُسهّل عليك كتابة SQL بلغة بايثون، والORM المبني فيه يُستعمل لربط الكائنات بالبيانات في قاعدة البيانات. سنستعمل في غالب هذا المشروع الـORM الخاص بـSQLAlchemy ولن نتطرّق إلى بقيّة ميّزات المكتبة، لذا إن أردت معرفة المزيد عن المكتبة فعليك بالتّوثيق الرّسمي. إضافات Flask Flask Extensions أو إضافات فلاسك عبارة عن مكتبات وأطر عمل Frameworks مبنيّة لتُسهّل على المُطوّر القيام بالأشياء المُفصّلة وتجنّب التّعامل مع كل شيء بأنفسنا، فمثلا، يُمكننا أن نستعمل مكتبة SQLAlchemy مع تطبيق Flask مُباشرة، إلّا أن في هذه الطّريقة الكثير من الأمور غير المُهمّة والكثير من الإعدادات، وبما أنّنا في مسيرة تعلّم إطار فلاسك لا كيفيّة استعمال SQLAlchemy، ولتسهيل استعمال SQLAlchemy مع المشاريع المبنيّة بإطار العمل فلاسك، قام كاتب الإطار Armin Ronacher بتطوير إضافة للإطار باسم Flask-SQLAlchemy التّي أصبحت أحد أشهر الإضافات على موقع Github. بالإضافة إلى Flask-SQLAlchemy هناك الكثير من الإضافات التّي يُمكننا استعمالها لتطوير تطبيقات فلاسك، وإليك بعضا من هذه الإضافات: Flask-Login إضافة لتسهيل التّعامل مع جلسات المُستخدمين Sessions، تُتيح إمكانيّة تسجيل دخول مُستخدم وتسجيل خروجه، لكنّها لا تقوم بالتّحقق من صحّة البيانات (اسم المُستخدم وكلمة المرور مثالا) وتترك المُطوّر للاهتمام بالأمر. Flask-Bcrypt إضافة لتشفير كلمات المرور باستعمال خوارزميّة Bcrypt قبل حفظها بقاعدة البيانات لحماية أكثر، هذا لمنع المُخترق من سرقة كلمات المرور حتى بعد وصوله إلى قاعدة البيانات، وكلّما كانت خوارزميّة التّشفير أعقد كلّما كان من الصّعب فك التّشفير عن كلمة المرور ما يُوفّر حماية أكثر. Flask-WTF بما أنّ مُعظم التّطبيقات تعتمد على نماذج HTML (حقول النّصوص، كلمات المرور و مساحة النّص TextArea) وبما أنّها تُسبّب الكثير من الثّغرات الأمنيّة في التّطبيقات والتّي يُمكن أن يُساء استغلالها، فلا بد من توفير طريقة آمنة وبسيطة للتأكّد من أنّ ما يُدخله المُستخدم في هذه الحقول آمن. يُمكنك بالطّبع التّأكد من مُدخلات المُستخدم بنفسك، لكنّ الأمر يأخذ وقتا، كما أنّه ممل في الحقيقة، إذ عليك تكرار نفس الشّيء كلّ مرّة. عوضا عن الاعتماد على مهاراتك البرمجيّة للتأكّد من سلامة المُدخلات، يُمكنك أن تترك إضافة Flask-WTF للاهتمام بالأمر في تطبيقاتك المبنيّة بإطار فلاسك، الإضافة مبنيّة على مكتبة WTForms التّي يُمكنك استعمالها مع أطر عمل أخرى، وأنصحك بالاطلاع على توثيق المكتبة الرّسمي للمزيد من المعلومات عن كيفيّة مُعالجة النّماذج. Flask-Migrate ببساطة، Flask-Migrate إضافة تُتيح لك تهجير البيانات Migrations عند تطوير تطبيقك. هذه الإضافة مهمّة جدّا إن كنت تطوّر تطبيقا سبق وأن نشرته على نحو مُتواصل، إذ تُتيح لك تهجير البيانات في كل مرّة تُضيف جدولا جديدا أو علاقة بين الجداول إلى قاعدة البيانات. تخيّل أنّك تمتلك تطبيقا يحتوي جدول المُستخدمين فيه على أكثر من ألف مُدخل، إن أردت إتاحة إمكانيّة إضافة تاريخ ازدياد للمُستخدمين فستضطر إلى حذف كلّ شيء في هذا الجدول وإضافة العمود الجديد ثمّ إعادة البيانات من جديد، الأمر مُعقّد بعض الشّيء وفقدان البيانات أمر غير مرغوب فيه بتاتا. مُجدّدا عوضا عن القيام بكل شيء بنفسك، دع إضافة Flask-Migrate لتهتمّ بكل هذا التّعقيد من أجلك، فبسطر أو سطرين تستطيع تطبيق الميّزة الجديدة لتطبيقك وتهجير البيانات القديمة بكل بساطة. Flask-Testing إضافة لتسهيل إجراء اختبارات وحدة Unit tests لتطبيقك، إذ أنّ اختبار التّطبيق مُهمّ جدّا للتأكّد من أنّ كلّ شيء بخير وأنّ المُستخدمين لا يواجهون أية مشاكل، خاصّة إذا كان مشروعك كبيرا، فاختبار كل وظيفة يدويّا قد يأخذ منك وقتا طويلا، وإن لم تختبره آليا فنسبة الخطأ كبيرة جدّا. إذا أضفت خاصيّة جديدة لتطبيقك فأنت بذلك تُعرّض أجزاء أخرى من التّطبيق إلى الخطأ، وستُسهّل عليك الاختبارات معرفة ما إذا كان التّطبيق لا يزال يعمل كما ينبغي له أو لا، وبما أنّ اختبارات الوحدة تختبر كلّ وظيفة على نحو مُستقل، فسيسهل عليك معرفة أي جزء يجب عليك الاهتمام به لإصلاح التّطبيق. Flask-Gravatar هذه الإضافة تُسهّل لنا استعمال خدمة Gravatar لتمكين المُستخدمين من إضافة صورة شخصيّة لهم، إذ تكون الصّورة الشّخصيّة مُرتبطة بالبريد الإلكتروني للمُستخدم وتُستعمل هذه الخدمة في الكثير من التّطبيقات في وقتنا الحالي. هناك مئات الإضافات الخاصّة بإطار Flask لذا لا يُمكنني ذكرها كلّها، إن أردت الاطّلاع على إضافات أخرى، تستطيع البحث عنها عن طريق أداة pip كما يلي: pip search flask سنتعرّف على معظم هذه الإضافات في قادم الدّروس مع التّقدم في المشروع، وهذا الهدف الأساسي من هذه الإضافات، كلّما تقدّمت أكثر وكبر المشروع كلّما احتجت إلى التّعامل مع الكثير من المهام المُملّة كالتّأكد من أنّ ما يرسله المُستخدم إلى قاعدة بياناتك آمن، وكالتّعامل مع الجلسات لتوفير نظام تسجيل دخول آمن دون الاضطرار للقيام بكل التّفاصيل؛ كما أنّ الإضافات تُقلّل من حجم الخطأ في التّطوير، فالاعتماد على إضافة لتسجيل دخول المُستخدمين بشكل آمن أفضل من مُحاولة إنشاء طريقة خاصّة بك قد تكون مليئة بالثّغرات الأمنيّة. وبما أنّ فلاسك إطار عمل مُصغّر، فبإضافاته يُمكنك أن تستخدمه كما تُستخدم أطر العمل الضّخمة كـDjango و Rails و Laravel وغيرها من الأطر المشهورة. خاتمة بعد أن أنشأنا قاعدة البيانات وتعرّفنا على بعض المفاهيم المُهمّة في تطوير تطبيقات الويب مع إطار فلاسك، حان الوقت لإنشاء الجداول الأساسيّة في قاعدة البيانات لنتمكّن من التّعامل معها عن طريق إضافة Flask-SQLAlchemy وهذا بالضّبط ما سنقوم به في الدّرس القادم. -

 إن كان قد مضى على استخدامك لووردبريس فترة من الزمن فمن الوارد أن الوقت قد حان لتقوم بعملية تنظيف شاملة لقاعدة بيانات موقعك التي يمكن أن تكون مليئة ببعض الجداول (tables) غير الضرورية والمتسببة في بطئه وتشنجه. يعمل تنظيف قواعد بيانات موقعك بوتيرة منتظمة على خفض حجمها ما يعني صغر حجم ملفات النسخة الاحتياطية وبالتالي سرعة إنشائها واسترجاعها على حد سواء. سنتطرق في موضوع اليوم إلى مجموعة من الطرق التي يمكن اتباعها للحفاظ على قاعدة بيانات نظيفة سواء من خلال استعلامات SQL بسيطة أو من خلال بعض الملحقات، كما سنعمل على الإشارة إلى بعض النصائح سواء بالنسبة لمواقع ووردبريس المنفردة أو شبكات المواقع. أساسيات تنظيف قواعد البيانات قبل أن تنهمك في عملية التنظيف عليك بالتأكد من إنشاء نسخة احتياطية لكل من قاعدة بيانات وملفات موقعك لتكون على أتم استعداد لاسترجاعه بسرعة في حال حدوث مشكل ما غير متوقع. حذف الملحقات غير المستخدمة يعتبر حذف الملحقات غير المستخدمة من بين أبسط الطرق وأكثرها نجاعة في التخفيف من الفوضى التي تعرفها قاعدة بيانات موقعك، خصوصا إن كنت من محبي تجربة الملحقات كما هو الحال بالنسبة لي، فقد يحدث في بعض الأحيان أن تغفل عن حذف الملحقات التي لن تستخدمها أو التي لم تنل إعجابك بعد تجربتها. إن كنت مثلي تملك العديد من الملحقات الغير المنشطة على صفحة الملحقات الخاصة بك عليك أن تأخذ حذفها بعين الاعتبار لا أعتقد أني الوحيد الذي يقوم بهذا الأمر. عدا ذلك، قد يحدث في بعض الأحيان الأخرى أن تقوم بتنصيب ملحق ما ناسيا أنك تمتلك ملحقا مشابها يقوم بنفس الدور. بغض النظر عن أي هذه الوضعيات تواجه، يعتبر فحص قائمة الملحقات المنصبة على موقعك بشكل دوري لتحدد تلك التي تحتاجها من تلك التي يمكن التخلي عنها أمرا مفيدا للغاية. تأخذ الملحقات قسطا مهما من حجم قاعدة بيانات موقعك، لذى فإن حذف تلك غير الضرورية منها يعتبر خطوة أساسية نحو تنظيفها. كيفية تنفيذ تعليمات SQL على قاعدة بيانات موقعك حتى تقوم بالعديد من الخيارات التي سنتطرق لها، سيكون عليك أن تلج إلى قاعدة بيانات موقعك. إن لم تكن تذكر اسم المستخدم وكلمة المرور الخاصتين بك يمكنك أن تجدهما محفوظتين في ملف wp-config.php. يبدو الكود الذي يجب عليك أن تبحث عنه كالتالي: // ** MySQL settings - You can get this info from your web host ** // /** The name of the database for WordPress */ define('DB_NAME', 'your_db'); /** MySQL database username */ define('DB_USER', 'yourusername'); /** MySQL database password */ define('DB_PASSWORD', 'this-is-your-password'); /** MySQL hostname */ define('DB_HOST', 'localhost'); /** Database Charset to use in creating database tables. */ define('DB_CHARSET', 'utf8'); عوض yourusername الواردة في هذا المثال ستجد كلمة المستخدم الخاصة بقاعدة بيانات موقعك وعوض this-is-your-password ستجد كلمة السر. بمجرد ولوجك إلى لوحة التحكم phpMyAdmin اضغط على قاعدة البيانات التي تود تنظيفها ثم اضغط على تبويب SQL. يمكنك أن تكون مبدعا بعض الشيء وتقوم بإنشاء استعلاماتك الخاصة من خلال الضغط على تبويب Query وملء الخانات المطلوبة يمكنك على هذه الصفحة أن تدخل الاستعلامات التي تريد في الأسفل ثم تقوم بالضغط على زر Go لتشغيلها. إن ظهرت لك رسالة مفادها أنه لم يتم التأثير على أي جدول فهنيئا لك، فجداول قاعدة بيانات موقعك كانت في أحسن حالة من تلك الناحية بالتحديد. بعد تطرقنا لهذه التحضيرات الأولية لنمر الآن إلى تنفيذ بعض الاستعلامات. حذف مخلفات الملحقات ومعطيات المنشورات بعد حذف الملحقات التي لا تستخدمها عليك بالتفكير أيضا في حذف البقايا التي تتركها هذه الملحقات، تتواجد هذه العوالق في نفس مكان تواجد معطيات منشوراتك، أي في جدول wp_postmeta. يسمح لك تنفيذ الاستعلام التالي بالتخلص من بعض الفوضى في قاعدة بياناتك، فقط تذكر وضع القيمة التي تود حذفها مكان your-meta-key. DELETE FROM wp_postmeta WHERE meta_key = 'your-meta-key'; إن كنت تستخدم ووردبريس متعدد المواقع عليك بتنفيذ الاستعلام التالي: DELETE from wp_#_postmeta WHERE meta_key = 'your-meta-key'; عليك أن تغير في هذا الاستعلام # برقم تعريف (ID) موقعك الذي تود تنظيفه، وكما في الاستعلام السابق، يجب أن تعمل على تعويض your-meta-key بالقيمة التي تود حذفها. حذف كل تعليقات السبام المزعجة عرف ووردبريس تواجد تعليقات السبام المزعجة منذ بداياته ولا يبدوا أن لها زوالا في الأمد المنظور، إن كنت تجد كما كبيرا من هذه التعليقات في موقعك، عليك باستخدام هذا الاستعلام الذي سيعمل على حذفها كاملة. DELETE FROM wp_comments WHERE comment_approved = 'spam'; أما بالنسبة لشبكة مواقع ووردبريس، عليك بتنفيذ الاستعلام التالي: DELETE FROM wp_#_comments WHERE comment_approved = 'spam'; قم بتغيير # برقم الموقع الذي تود العمل عليه. تخلص من كل التعليقات التي تنتظر معاينتك لتصنيفها إن كنت تتوفر على الكثير من التعليقات التي لم تسنح لك الفرصة بمعاينتها، يمكنك استخدام الاستعلام في هذه الفقرة للتخلص منها كلها دفعة واحدة. لا تنس تصفح التعليقات والموافقة على نشر تلك الأصلية منها حتى لا يتم حذفها أيضا بعد استخدام هذا الاستعلام. DELETE FROM wp_comments WHERE comment_approved = '0'; بالنسبة لووردبريس متعدد المواقع عليك بتنفيذ الاستعلام التالي: DELETE FROM wp_#_comments WHERE comment_approved = '0'; لا تنس تغيير # بالرقم التعريفي (ID) للموقع الذي تود تنظيفه. الوسوم المنسية وغير المستخدمة إن كنت تمتلك العديد من الوسوم غير المستخدمة لأنك غيرت رأيك حولها أو كنت تقوم بالتعديل على الوسوم بضع مرات كل منشور، عليك بتنفيذ الاستعلام التالي الذي سيعمل على حذف كل الوسوم غير المرتبطة بأي منشور. DELETE FROM wp_terms wt INNER JOIN wp_term_taxonomy wtt ON wt.term_id = wtt.term_id WHERE wtt.taxonomy = 'post_tag' AND wtt.count = 0; أما بالنسبة لشبكة مواقع ووردبريس، عليك بتنفيذ الاستعلام التالي: DELETE FROM wp_#_terms wt INNER JOIN wp_#_term_taxonomy wtt ON wt.term_id = wtt.term_id WHERE wtt.taxonomy = 'post_tag' AND wtt.count = 0; قم بتغيير # برقم الموقع الذي تود العمل عليه. قل وداعا للتنبيهات الداخلة (Pingbacks) إن كنت قد قمت بتعطيل خاصية السماح بالتنبيهات الداخلة (pingbacks) فمن الجيد أن تفكر في حذفها كلها من قاعدة بيانات موقعك، عليك بتنفيذ الاستعلام التالي: DELETE FROM wp_comments WHERE comment_type = 'pingback'; إن كنت تستخدم شبكة مواقع ووردبريس وتريد حذف التنبيهات الداخلة في موقع آخر غير الموقع الرئيسي استخدم الاستعلام التالي: DELETE FROM wp_#_comments WHERE comment_type = 'pingback'; لا تنس تغيير # بالرقم التعريفي (ID) للموقع الذي تود تنظيفه. تخلص من روابط التتبع (Trackbacks) كما قمنا في الفقرة السابقة بحذف التنبيهات الداخلة لنتطرق الآن لكيفية حذف روابط التتبع، عليك بتنفيذ الاستعلام التالي بعد التأكد من تعطيل كل من التنبيهات الداخلة وروابط التتبع. DELETE FROM wp_comments WHERE comment_type = 'trackback'; أما بالنسبة لشبكة مواقع ووردبريس، عليك بتنفيذ الاستعلام التالي، لا تنس تغيير # بالرقم التعريفي (ID) للموقع الذي تود تنظيفه: DELETE FROM wp_#_comments WHERE comment_type = 'trackback'; قل وداعا لمراجعات المنشورات يمكن لمراجعات المنشورات أن تتراكم بسرعة كبيرة خصوصا في المواقع القديمة والتي تتوفر على الكثير من الصفحات والمنشورات، يمكنك استخدام الاستعلام التالي للعمل على حذفها كلها. يرجع الفضل في هذا الكود الذي يسمح بحذف كل المراجعات دون ضياع غير مقصود لأي بيانات للمبرمج Joseph Michael Ambrosio حيث أورده في مقاله: تنظيف مراجعات ووردبريس باستخدام حذف الجداول المتعددة على MySQL DELETE a,b,c FROM wp_posts a LEFT JOIN wp_term_relationships b ON ( a.ID = b.object_id) LEFT JOIN wp_postmeta c ON ( a.ID = c.post_id ) LEFT JOIN wp_term_taxonomy d ON ( b.term_taxonomy_id = d.term_taxonomy_id) WHERE a.post_type = 'revision' AND d.taxonomy != 'link_category'; أما بالنسبة لشبكة مواقع ووردبريس يمكنك استخدام الكود التالي لحذف المراجعات على أحد المواقع غير الموقع الرئيسي: DELETE a,b,c FROM wp_#_posts a LEFT JOIN wp_#_term_relationships b ON ( a.ID = b.object_id) LEFT JOIN wp_#_postmeta c ON ( a.ID = c.post_id ) LEFT JOIN wp_#_term_taxonomy d ON ( b.term_taxonomy_id = d.term_taxonomy_id) WHERE a.post_type = 'revision' AND d.taxonomy != 'link_category'; لا تنس تغيير # بالرقم التعريفي (ID) للموقع الذي تود تنظيفه. التخلص من كل الشيفرات المختصرة (Shortcodes) إن سبق لك تنصيب العديد من الملحقات بغرض تجريبها دون القيام بحذفها فمن الوارد أن يتسبب ذلك في تواجد العديد من الشيفرات المختصرة التي لم يعد لها أي دور يذكر، نفس الأمر يحدث عند التوقف عن استخدام أحد القوالب التي تحتوي على بعض هذه الشيفرات. عليك بتنفيذ الاستعلام التالي بغرض حذفها كلها: UPDATE wp_post SET post_content = replace(post_content, '[your-shortcode]', '' ) ; أما بالنسبة لشبكة مواقع ووردبريس، عليك بتنفيذ الاستعلام التالي، لا تنس تغيير # بالرقم التعريفي (ID) للموقع الذي تود حذف الشيفرات المختصرة منه: UPDATE wp_#_post SET post_content = replace(post_content, '[your-shortcode]', '' ); احذف كل مواضيعك القديمة قد توجد لديك العديد من المواضيع التي تحبذ أن يتم حذفها من موقعك خصوصا إن كنت تملكه منذ عدة سنوات. يمكنك القيام بذلك بكل بساطة باستخدام هذا الاستعلام. عليك بتغيير #-of-days بعدد الأيام التي تريد أن تبدأ عملية الحذف انطلاقا منها، إن أردت على سبيل المثال أن يتم حذف كل المنشورات الأقدم من 5 سنوات عليك بإدخال العدد: 1825. DELETE FROM `wp_posts` WHERE `post_type` = 'post' AND DATEDIFF(NOW(), `post_date`) > #-of-days أما بالنسبة لشبكة مواقع ووردبريس، عليك بتنفيذ الاستعلام التالي: DELETE FROM `wp_#_posts` WHERE `post_type` = 'post' AND DATEDIFF(NOW(), `post_date`) > #-of-days لا تنس تغيير #-of-days بعدد الأيام كما في الكود السابق و# بالرقم التعريفي (ID) للموقع الذي تود تنظيفه. حذف كل بقايا التعليقات قد يحدث أن يمتلئ جدول wp_commentsmeta بالتعليقات غير المخزنة في جدول wp_comments. من المحتمل ألا يناسب هذا الاستعلام كل المستخدمين إلا أنه قد يساعد كثيرا في تنظيف قاعدة البيانات خصوصا إن قمت بحذف أحد الملحقات التي تستخدم جدول wp_commentsmeta. SELECT * FROM wp_commentmeta WHERE comment_id NOT IN ( SELECT comment_id FROM wp_comments ); إن أردت أن تقوم بنفس العملية بالنسبة لأحد مواقع شبكتك عليك بتنفيذ الاستعلام التالي: SELECT * FROM wp_#_commentmeta WHERE comment_id NOT IN ( SELECT comment_id FROM wp_#_comments ); لا تنس تغيير # بالرقم التعريفي (ID) للموقع الذي تود تنظيفه. تحسين جداول قاعدة البيانات يمكنك تحسين جداولك في بضع ضغطات زر دون الحاجة إلى استخدام ملحق ما. بعد الولوج إلى phpMyAdmin، اضغط على قاعدة البيانات الخاصة بك ثم اذهب إلى أسفل الصفحة التي تم تحميلها في اليمين. اضغط على Check All checkbox في الأسفل ثم حدد Optimize table من القائمة المنسدلة. إن كنت تملك عدة صفحات جداول سيكون عليك أن تكرر هذه العملية لها كلها. يكفي أن تحدد الجداول كبيرة الحجم التي تجدها في خانة Size، لا داع لتحديد كل الجداول ستبدأ عملية التحسين بشكل أوتوماتيكي دون الحاجة إلى ضغط زر Go، لا تقلق إن استغرق الأمر بعض الوقت خصوصا إن كان موقعك كبيرا فهذا أمر عادي. عند الانتهاء، ستظهر رسالة تفيد بنجاح العملية. على الصفحة التي يتم تحميلها، من المحتمل أن تظهر رسالة تفيد بنجاح العملية مشيرة إلى أن الجداول لا تقبل عملية التحسين وأنه قد تم إعادة إنشائها، لا عليك فلا ضرر في ذلك. بعد أن تطرقنا لبعض النصائح حول كيفية القيام بتنظيف قاعدة البيانات بشكل يدوي، لنلق الآن نظرة على بعض الملحقات التي من شأنها أن تجعل هذه العملية أكثر بساطة. ملحقات تحسين قاعدة البيانات تتميز هذه الملحقات بتحديثها بشكل مستمر فضلا عن توافقها مع مواقع ووردبريس المنفردة (single installations of WordPress). بعد تجريبها على استضافة ووردبريس متعددة المواقع (Multisite)، لاحظت أن أدائها لم يضعف بل قامت بالعمل على أتم وجه. WP-Optimize يعتبر WP-Optimize من بين أفضل ملحقات تحسين قواعد البيانات المتواجدة على الساحة منذ فترة من الزمن، كما أنه يتوفر على العديد من الإعدادات والخيارات لحذف الجداول غير الضرورية فضلا عن إمكانية برمجة عمليات التحسين بشكل دوري للمساعدة على الحفاظ على موقعك في أحسن حالة. يتميز الملحق أيضا بسهولة التنصيب والإعداد. إن كنت مهتما بهذا الملحق عليك بزيارة الرابط التالي: WP-Optimize Revision Control يمكنك من خلال هذا الملحق أن تحد من عدد المراجعات التي يتم تخزينها في قاعدة البيانات عوض حذفها بشكل كلي كما هو الشأن بالنسبة لاستخدام استعلام SQL الذي أسلفنا الذكر، يتميز Revision Control أيضا بسهولة التنصيب والاستخدام. إن كنت مهتما بهذا الملحق عليك بزيارة الرابط التالي: Revision Control خاتمة يمكنك الآن أن تقوم بتنظيف قاعدة بياناتك سواء بالنسبة لموقع ووردبريس الخاص بك أو شبكة مواقع ووردبريس. ما هي أفضل الاستراتيجيات التي تستخدمها للحفاظ على قاعدة بيانات نظيفة ومنظمة؟ هل أغفلت بعض النقاط؟ شاركنا رأيك في التعليقات أسفله. ترجمة بتصرف للمقال: 10 Tips for Keeping a Squeaky Clean WordPress (and Multisite!) Database لكاتبه: Jenni McKinnon
إن كان قد مضى على استخدامك لووردبريس فترة من الزمن فمن الوارد أن الوقت قد حان لتقوم بعملية تنظيف شاملة لقاعدة بيانات موقعك التي يمكن أن تكون مليئة ببعض الجداول (tables) غير الضرورية والمتسببة في بطئه وتشنجه. يعمل تنظيف قواعد بيانات موقعك بوتيرة منتظمة على خفض حجمها ما يعني صغر حجم ملفات النسخة الاحتياطية وبالتالي سرعة إنشائها واسترجاعها على حد سواء. سنتطرق في موضوع اليوم إلى مجموعة من الطرق التي يمكن اتباعها للحفاظ على قاعدة بيانات نظيفة سواء من خلال استعلامات SQL بسيطة أو من خلال بعض الملحقات، كما سنعمل على الإشارة إلى بعض النصائح سواء بالنسبة لمواقع ووردبريس المنفردة أو شبكات المواقع. أساسيات تنظيف قواعد البيانات قبل أن تنهمك في عملية التنظيف عليك بالتأكد من إنشاء نسخة احتياطية لكل من قاعدة بيانات وملفات موقعك لتكون على أتم استعداد لاسترجاعه بسرعة في حال حدوث مشكل ما غير متوقع. حذف الملحقات غير المستخدمة يعتبر حذف الملحقات غير المستخدمة من بين أبسط الطرق وأكثرها نجاعة في التخفيف من الفوضى التي تعرفها قاعدة بيانات موقعك، خصوصا إن كنت من محبي تجربة الملحقات كما هو الحال بالنسبة لي، فقد يحدث في بعض الأحيان أن تغفل عن حذف الملحقات التي لن تستخدمها أو التي لم تنل إعجابك بعد تجربتها. إن كنت مثلي تملك العديد من الملحقات الغير المنشطة على صفحة الملحقات الخاصة بك عليك أن تأخذ حذفها بعين الاعتبار لا أعتقد أني الوحيد الذي يقوم بهذا الأمر. عدا ذلك، قد يحدث في بعض الأحيان الأخرى أن تقوم بتنصيب ملحق ما ناسيا أنك تمتلك ملحقا مشابها يقوم بنفس الدور. بغض النظر عن أي هذه الوضعيات تواجه، يعتبر فحص قائمة الملحقات المنصبة على موقعك بشكل دوري لتحدد تلك التي تحتاجها من تلك التي يمكن التخلي عنها أمرا مفيدا للغاية. تأخذ الملحقات قسطا مهما من حجم قاعدة بيانات موقعك، لذى فإن حذف تلك غير الضرورية منها يعتبر خطوة أساسية نحو تنظيفها. كيفية تنفيذ تعليمات SQL على قاعدة بيانات موقعك حتى تقوم بالعديد من الخيارات التي سنتطرق لها، سيكون عليك أن تلج إلى قاعدة بيانات موقعك. إن لم تكن تذكر اسم المستخدم وكلمة المرور الخاصتين بك يمكنك أن تجدهما محفوظتين في ملف wp-config.php. يبدو الكود الذي يجب عليك أن تبحث عنه كالتالي: // ** MySQL settings - You can get this info from your web host ** // /** The name of the database for WordPress */ define('DB_NAME', 'your_db'); /** MySQL database username */ define('DB_USER', 'yourusername'); /** MySQL database password */ define('DB_PASSWORD', 'this-is-your-password'); /** MySQL hostname */ define('DB_HOST', 'localhost'); /** Database Charset to use in creating database tables. */ define('DB_CHARSET', 'utf8'); عوض yourusername الواردة في هذا المثال ستجد كلمة المستخدم الخاصة بقاعدة بيانات موقعك وعوض this-is-your-password ستجد كلمة السر. بمجرد ولوجك إلى لوحة التحكم phpMyAdmin اضغط على قاعدة البيانات التي تود تنظيفها ثم اضغط على تبويب SQL. يمكنك أن تكون مبدعا بعض الشيء وتقوم بإنشاء استعلاماتك الخاصة من خلال الضغط على تبويب Query وملء الخانات المطلوبة يمكنك على هذه الصفحة أن تدخل الاستعلامات التي تريد في الأسفل ثم تقوم بالضغط على زر Go لتشغيلها. إن ظهرت لك رسالة مفادها أنه لم يتم التأثير على أي جدول فهنيئا لك، فجداول قاعدة بيانات موقعك كانت في أحسن حالة من تلك الناحية بالتحديد. بعد تطرقنا لهذه التحضيرات الأولية لنمر الآن إلى تنفيذ بعض الاستعلامات. حذف مخلفات الملحقات ومعطيات المنشورات بعد حذف الملحقات التي لا تستخدمها عليك بالتفكير أيضا في حذف البقايا التي تتركها هذه الملحقات، تتواجد هذه العوالق في نفس مكان تواجد معطيات منشوراتك، أي في جدول wp_postmeta. يسمح لك تنفيذ الاستعلام التالي بالتخلص من بعض الفوضى في قاعدة بياناتك، فقط تذكر وضع القيمة التي تود حذفها مكان your-meta-key. DELETE FROM wp_postmeta WHERE meta_key = 'your-meta-key'; إن كنت تستخدم ووردبريس متعدد المواقع عليك بتنفيذ الاستعلام التالي: DELETE from wp_#_postmeta WHERE meta_key = 'your-meta-key'; عليك أن تغير في هذا الاستعلام # برقم تعريف (ID) موقعك الذي تود تنظيفه، وكما في الاستعلام السابق، يجب أن تعمل على تعويض your-meta-key بالقيمة التي تود حذفها. حذف كل تعليقات السبام المزعجة عرف ووردبريس تواجد تعليقات السبام المزعجة منذ بداياته ولا يبدوا أن لها زوالا في الأمد المنظور، إن كنت تجد كما كبيرا من هذه التعليقات في موقعك، عليك باستخدام هذا الاستعلام الذي سيعمل على حذفها كاملة. DELETE FROM wp_comments WHERE comment_approved = 'spam'; أما بالنسبة لشبكة مواقع ووردبريس، عليك بتنفيذ الاستعلام التالي: DELETE FROM wp_#_comments WHERE comment_approved = 'spam'; قم بتغيير # برقم الموقع الذي تود العمل عليه. تخلص من كل التعليقات التي تنتظر معاينتك لتصنيفها إن كنت تتوفر على الكثير من التعليقات التي لم تسنح لك الفرصة بمعاينتها، يمكنك استخدام الاستعلام في هذه الفقرة للتخلص منها كلها دفعة واحدة. لا تنس تصفح التعليقات والموافقة على نشر تلك الأصلية منها حتى لا يتم حذفها أيضا بعد استخدام هذا الاستعلام. DELETE FROM wp_comments WHERE comment_approved = '0'; بالنسبة لووردبريس متعدد المواقع عليك بتنفيذ الاستعلام التالي: DELETE FROM wp_#_comments WHERE comment_approved = '0'; لا تنس تغيير # بالرقم التعريفي (ID) للموقع الذي تود تنظيفه. الوسوم المنسية وغير المستخدمة إن كنت تمتلك العديد من الوسوم غير المستخدمة لأنك غيرت رأيك حولها أو كنت تقوم بالتعديل على الوسوم بضع مرات كل منشور، عليك بتنفيذ الاستعلام التالي الذي سيعمل على حذف كل الوسوم غير المرتبطة بأي منشور. DELETE FROM wp_terms wt INNER JOIN wp_term_taxonomy wtt ON wt.term_id = wtt.term_id WHERE wtt.taxonomy = 'post_tag' AND wtt.count = 0; أما بالنسبة لشبكة مواقع ووردبريس، عليك بتنفيذ الاستعلام التالي: DELETE FROM wp_#_terms wt INNER JOIN wp_#_term_taxonomy wtt ON wt.term_id = wtt.term_id WHERE wtt.taxonomy = 'post_tag' AND wtt.count = 0; قم بتغيير # برقم الموقع الذي تود العمل عليه. قل وداعا للتنبيهات الداخلة (Pingbacks) إن كنت قد قمت بتعطيل خاصية السماح بالتنبيهات الداخلة (pingbacks) فمن الجيد أن تفكر في حذفها كلها من قاعدة بيانات موقعك، عليك بتنفيذ الاستعلام التالي: DELETE FROM wp_comments WHERE comment_type = 'pingback'; إن كنت تستخدم شبكة مواقع ووردبريس وتريد حذف التنبيهات الداخلة في موقع آخر غير الموقع الرئيسي استخدم الاستعلام التالي: DELETE FROM wp_#_comments WHERE comment_type = 'pingback'; لا تنس تغيير # بالرقم التعريفي (ID) للموقع الذي تود تنظيفه. تخلص من روابط التتبع (Trackbacks) كما قمنا في الفقرة السابقة بحذف التنبيهات الداخلة لنتطرق الآن لكيفية حذف روابط التتبع، عليك بتنفيذ الاستعلام التالي بعد التأكد من تعطيل كل من التنبيهات الداخلة وروابط التتبع. DELETE FROM wp_comments WHERE comment_type = 'trackback'; أما بالنسبة لشبكة مواقع ووردبريس، عليك بتنفيذ الاستعلام التالي، لا تنس تغيير # بالرقم التعريفي (ID) للموقع الذي تود تنظيفه: DELETE FROM wp_#_comments WHERE comment_type = 'trackback'; قل وداعا لمراجعات المنشورات يمكن لمراجعات المنشورات أن تتراكم بسرعة كبيرة خصوصا في المواقع القديمة والتي تتوفر على الكثير من الصفحات والمنشورات، يمكنك استخدام الاستعلام التالي للعمل على حذفها كلها. يرجع الفضل في هذا الكود الذي يسمح بحذف كل المراجعات دون ضياع غير مقصود لأي بيانات للمبرمج Joseph Michael Ambrosio حيث أورده في مقاله: تنظيف مراجعات ووردبريس باستخدام حذف الجداول المتعددة على MySQL DELETE a,b,c FROM wp_posts a LEFT JOIN wp_term_relationships b ON ( a.ID = b.object_id) LEFT JOIN wp_postmeta c ON ( a.ID = c.post_id ) LEFT JOIN wp_term_taxonomy d ON ( b.term_taxonomy_id = d.term_taxonomy_id) WHERE a.post_type = 'revision' AND d.taxonomy != 'link_category'; أما بالنسبة لشبكة مواقع ووردبريس يمكنك استخدام الكود التالي لحذف المراجعات على أحد المواقع غير الموقع الرئيسي: DELETE a,b,c FROM wp_#_posts a LEFT JOIN wp_#_term_relationships b ON ( a.ID = b.object_id) LEFT JOIN wp_#_postmeta c ON ( a.ID = c.post_id ) LEFT JOIN wp_#_term_taxonomy d ON ( b.term_taxonomy_id = d.term_taxonomy_id) WHERE a.post_type = 'revision' AND d.taxonomy != 'link_category'; لا تنس تغيير # بالرقم التعريفي (ID) للموقع الذي تود تنظيفه. التخلص من كل الشيفرات المختصرة (Shortcodes) إن سبق لك تنصيب العديد من الملحقات بغرض تجريبها دون القيام بحذفها فمن الوارد أن يتسبب ذلك في تواجد العديد من الشيفرات المختصرة التي لم يعد لها أي دور يذكر، نفس الأمر يحدث عند التوقف عن استخدام أحد القوالب التي تحتوي على بعض هذه الشيفرات. عليك بتنفيذ الاستعلام التالي بغرض حذفها كلها: UPDATE wp_post SET post_content = replace(post_content, '[your-shortcode]', '' ) ; أما بالنسبة لشبكة مواقع ووردبريس، عليك بتنفيذ الاستعلام التالي، لا تنس تغيير # بالرقم التعريفي (ID) للموقع الذي تود حذف الشيفرات المختصرة منه: UPDATE wp_#_post SET post_content = replace(post_content, '[your-shortcode]', '' ); احذف كل مواضيعك القديمة قد توجد لديك العديد من المواضيع التي تحبذ أن يتم حذفها من موقعك خصوصا إن كنت تملكه منذ عدة سنوات. يمكنك القيام بذلك بكل بساطة باستخدام هذا الاستعلام. عليك بتغيير #-of-days بعدد الأيام التي تريد أن تبدأ عملية الحذف انطلاقا منها، إن أردت على سبيل المثال أن يتم حذف كل المنشورات الأقدم من 5 سنوات عليك بإدخال العدد: 1825. DELETE FROM `wp_posts` WHERE `post_type` = 'post' AND DATEDIFF(NOW(), `post_date`) > #-of-days أما بالنسبة لشبكة مواقع ووردبريس، عليك بتنفيذ الاستعلام التالي: DELETE FROM `wp_#_posts` WHERE `post_type` = 'post' AND DATEDIFF(NOW(), `post_date`) > #-of-days لا تنس تغيير #-of-days بعدد الأيام كما في الكود السابق و# بالرقم التعريفي (ID) للموقع الذي تود تنظيفه. حذف كل بقايا التعليقات قد يحدث أن يمتلئ جدول wp_commentsmeta بالتعليقات غير المخزنة في جدول wp_comments. من المحتمل ألا يناسب هذا الاستعلام كل المستخدمين إلا أنه قد يساعد كثيرا في تنظيف قاعدة البيانات خصوصا إن قمت بحذف أحد الملحقات التي تستخدم جدول wp_commentsmeta. SELECT * FROM wp_commentmeta WHERE comment_id NOT IN ( SELECT comment_id FROM wp_comments ); إن أردت أن تقوم بنفس العملية بالنسبة لأحد مواقع شبكتك عليك بتنفيذ الاستعلام التالي: SELECT * FROM wp_#_commentmeta WHERE comment_id NOT IN ( SELECT comment_id FROM wp_#_comments ); لا تنس تغيير # بالرقم التعريفي (ID) للموقع الذي تود تنظيفه. تحسين جداول قاعدة البيانات يمكنك تحسين جداولك في بضع ضغطات زر دون الحاجة إلى استخدام ملحق ما. بعد الولوج إلى phpMyAdmin، اضغط على قاعدة البيانات الخاصة بك ثم اذهب إلى أسفل الصفحة التي تم تحميلها في اليمين. اضغط على Check All checkbox في الأسفل ثم حدد Optimize table من القائمة المنسدلة. إن كنت تملك عدة صفحات جداول سيكون عليك أن تكرر هذه العملية لها كلها. يكفي أن تحدد الجداول كبيرة الحجم التي تجدها في خانة Size، لا داع لتحديد كل الجداول ستبدأ عملية التحسين بشكل أوتوماتيكي دون الحاجة إلى ضغط زر Go، لا تقلق إن استغرق الأمر بعض الوقت خصوصا إن كان موقعك كبيرا فهذا أمر عادي. عند الانتهاء، ستظهر رسالة تفيد بنجاح العملية. على الصفحة التي يتم تحميلها، من المحتمل أن تظهر رسالة تفيد بنجاح العملية مشيرة إلى أن الجداول لا تقبل عملية التحسين وأنه قد تم إعادة إنشائها، لا عليك فلا ضرر في ذلك. بعد أن تطرقنا لبعض النصائح حول كيفية القيام بتنظيف قاعدة البيانات بشكل يدوي، لنلق الآن نظرة على بعض الملحقات التي من شأنها أن تجعل هذه العملية أكثر بساطة. ملحقات تحسين قاعدة البيانات تتميز هذه الملحقات بتحديثها بشكل مستمر فضلا عن توافقها مع مواقع ووردبريس المنفردة (single installations of WordPress). بعد تجريبها على استضافة ووردبريس متعددة المواقع (Multisite)، لاحظت أن أدائها لم يضعف بل قامت بالعمل على أتم وجه. WP-Optimize يعتبر WP-Optimize من بين أفضل ملحقات تحسين قواعد البيانات المتواجدة على الساحة منذ فترة من الزمن، كما أنه يتوفر على العديد من الإعدادات والخيارات لحذف الجداول غير الضرورية فضلا عن إمكانية برمجة عمليات التحسين بشكل دوري للمساعدة على الحفاظ على موقعك في أحسن حالة. يتميز الملحق أيضا بسهولة التنصيب والإعداد. إن كنت مهتما بهذا الملحق عليك بزيارة الرابط التالي: WP-Optimize Revision Control يمكنك من خلال هذا الملحق أن تحد من عدد المراجعات التي يتم تخزينها في قاعدة البيانات عوض حذفها بشكل كلي كما هو الشأن بالنسبة لاستخدام استعلام SQL الذي أسلفنا الذكر، يتميز Revision Control أيضا بسهولة التنصيب والاستخدام. إن كنت مهتما بهذا الملحق عليك بزيارة الرابط التالي: Revision Control خاتمة يمكنك الآن أن تقوم بتنظيف قاعدة بياناتك سواء بالنسبة لموقع ووردبريس الخاص بك أو شبكة مواقع ووردبريس. ما هي أفضل الاستراتيجيات التي تستخدمها للحفاظ على قاعدة بيانات نظيفة ومنظمة؟ هل أغفلت بعض النقاط؟ شاركنا رأيك في التعليقات أسفله. ترجمة بتصرف للمقال: 10 Tips for Keeping a Squeaky Clean WordPress (and Multisite!) Database لكاتبه: Jenni McKinnon -
 يُنفّذ ووردبريس استعلامًا في كل صفحة من صفحات الموقع، ليجلب البيانات من قواعد بيانات (databases) الموقع ومن ثُمّ يعرضها بالطريقة الّتي يحدّدها القالب (theme) المُستخدَم وذلك باستخدام حلقة التكرار (loop)، ويُشار إلى هذا الاستعلام بالاستعلام الرئيسي main query. سيَستخدم ووردبريس ملفّ القالب (template) المُلائم وذلك اعتمادًا على نوع الصّفحة الّتي يتمّ عرضها، بمعنى أنّ حلقة (loop) قد تتغيّر بناءً على المُحتوى، ولكنّه سيُنفّذ استعلامًا دائمًا لجلب البيانات من قاعدة البيانات. يُرغب أحيانًا في تغيير طريقة عمل الاستعلام، فعلى سبيل المثال في الصّفحة الرئيسيّة للمدوّنة قد يُرغب في استثناء منشورات من فئة (category) مُعيّنة، أو قد يُرغب في عرض قائمة بالمنشورات على حسب الصنف بدلًا من الترتيب على حسب التاريخ في صفحة الأرشيف (archive page)، كما من المُحتمل جدًا أنّ يُرغب في إضافة استعلامات إضافيّة إلى صفحات (pages) الموقع، أو إضافة قائمة بالمنشورات الأخيرة (recent posts) أو المنشورات ذات الصِلة بمنشورات أخرى، أو قد يُرغب في إنشاء ملفّ قالب (template) يستبدل الاستعلام الرئيسي (main query) باستعلام مُخصّص وجديد كليًّا. يجعل سكريبت إدارة المُحتوى ووردبريس من هذه التخصيصات أمرًا ميسّرًا للغاية، وذلك بطرقٍ عدّة، وذلك إما بالتعديل على الاستعلام الرئيسي أو بإنشاء استعلام جديد. سيتطرّق هذا الدليل إلى الأمور التّالية: متى يُستخدم الاستعلام المُخصّص، ومتى يُخصّص الاستعلام الرئيسي ومتى يتمّ إنشاء استعلام جديد. الطرق الخمس لإنشاء استعلامات مُخصّصة، بما في ذلك الطريقة الّتي لا يجب أنّ تُستخدم ولماذا. فهم الأساسيات يجب الإلمام ببعض المصطلحات قبل الدخول في التفاصيل وهي ضروريّة لمن لم يُنشئ استعلامات مُخصّصة من قَبل. الاستعلام (query) وهو طريقة يَستعين بها ووردبريس لجب البيانات من قاعدة بيانات الموقع، وتتضمّن هذه البيانات المنشورات posts، المرفقات attachments، التعليقات comments، والصّفحات pages، أو أي مُحتوى تمّت إضافته إلى الموقع. الحلقة (loop) وهي شيفرة/كود يستخدمها القالب (theme) (أو أحيانًا الإضافة plugin) لتحديد كيفيّة عرض نتائج الاستعلام على الصّفحة، فعلى سبيل المثال قد تُضمِّن الحلقة في الصّفحة الرئيسيّة عنوان كل صفحة (title)، مُلخص كل تدوينة (extract)، ربّما صورة مُميّزة/بارزة، ورابط صفحة المنشور (والّذي يُدعى permalink أو الرابط الثابت). ملفّات القالب (template files): وتُستخدم من قِبل القالب (theme) لعرض الصفحات لكل نوع من أنواع المُحتوى، مع العلم أنّ كل قالب (theme) يملك ملفّات قالب (template) تختلف عن الآخر، ولكن يجب على القالب (theme) أنّ يتضمّن ملفّ index.php رئيسي، وغالبًا على الملفّ page.php للصفحات الثابتة static pages، والملفّ single.php للمنشورات المُنفردة single posts، والملفّ archive.php لصفحات الأرشيف، وربّما الملفّ category.php للتصنيفات، والملفّ tag.php للوسوم، وغيره من الملفّات وللمزيد من التفاصيل يُمكن العودة إلى الصّفحة التّالية في التوثيق الرسمي. الوسوم/الدّوال الشرطيّة: والّتي من المُمكن أنّ تُستخدم في ملفّات القالب (template) أو من قِبل الإضافات plugins لتحديد نوع الصّفحة الّتي يتمّ عرضها، فعلى سبيل المثال الدّالّة/الوسم ()is_page تُحدّد فيما إذا كانت الصّفحة الّتي يتمّ عرضها ثابتة (static) أم لا، والدّالّة/الوسم ()is_home تُحدّد فيما إذا كانت الصّفحة هي صفحة البداية home page، ويوجد العديد من هذه الوسوم/الدّوال الشرطيّة منها ما يُحدّد فيما إذا كان المُستخدم مُسجّلًا دخوله logged in أم لا، وغيره من هذه الدوال. متى يجب استخدام الاستعلام المخصص في ووردبريس يوجد نوعان من الاستعلامات المُخصّصة: الاستعلام الرئيسي بعد تعديله. استعلامات جديدة كليًّا لجلب مُحتوى مُختلف/مُحدّد أو محتوى إضافي. التعديل على الاستعلام الرئيسي Main Query في ووردبريس يُمكن استخدام نسخة مُعدّلة من الاستعلام الرئيسي عند الرغبة في أنّ تَعرض الصّفحة نتائج الاستعلام الرئيسي لذات المحتوى ولكن مع بعض التحسين والتعديل، وفي هذا النوع من الاستعلام ليس الهدف هو إظهار محتوى مُختلف كليًّا، وليس من المُفترض إضافة حلقة تكراريّة (loop) إضافيّة. أمثلة للحالات الّتي من المُمكن بها استخدام استعلام مُعدّل: في الصّفحة الرئيسيّة للمدوّنة، عرض أنواع منشورات مُخصّصة بالإضافة إلى المنشورات. في صفحة أرشيف التصنيفات category، عرض منشورات من نوع مُحدّد فقط. في صفحة أرشيف التصنيفات، ترتيب المنشورات ترتيبًا أبجديًا بدلًا من الترتيب الافتراضي. يوجد العديد من الحالات الأُخرى، ولكن كما هو واضح فالتعديلات مقتصرة على التعديلات البسيطة للاستعلام. كتابة استعلام جديد في ووردبريس قد لا يكون التعديل على الاستعلامات كافيًا في بعض الحالات، فعندها يُمكن إنشاء استعلام جديد، ويتمّ بهذا الحصول على مرونة أكبر في بناء الاستعلام، ولكن لا يُحبّذ إنشاء استعلام جديد عندما يكون التعديل على الاستعلام الرئيسي أمرًا كافيًا، حيث يُمكن إنشاء استعلامًا جديدًا عند الحاجة إلى استخدام أكثر من حلقة loop واحدة في الصّفحة أو عند الرغبة في استبدال الاستعلام الرئيسي باستعلام جديد كليًّا. أمثلة للحالات الّتي من المُمكن بها إنشاء استعلام جديد عديدة ومُختلفة، ولكن أبرزها: عند تنفيذ حلقتين two loops في صفحة الأرشيف: إحداهما للمنشور الأوّل والأخرى للمنشورات اللاحقة، بهدف عرض مُحتوى مُختلف للمنشور الأوّل، مثلًا عندما يكون المطلوب أنّ يتضمّن المنشور الأوّل مُلخّص أو صورة مميّزة فقط بدون بقيّة المنشورات، ولكن إن كان المطلوب هو تنسيق المنشور الأوّل بشكل مُختلف فقط، فمن غير المُستحسن استخدام حلقات (loops) متعدّدة في ذلك، بل من المُفترض استخدام CSS لاستهداف المنشور الأوّل في التنسيق دون بقيّة المنشورات. في صفحة المنشور المنفردة (single post)، وذلك عند تنفيذ حلقة (loop) إضافيّة لعرض المنشورات الأخيرة (أو المنشورات المُميّزة) وذلك أسفل محتوى المنشور، بغرض تشجيع القارئ لقراءة المزيد. عند إضافة لافتة (banner) مربوطة مع منشور مُميّز منفرد single featured post (أو لجميع المنشورات المُميّزة) في أعلى كل صفحة من صفحات الموقع، كما هو الأمر عند إضافة منشور يُروّج إلى مُنتج جديد، وهذه الطريقة هي أكثر مرونة من إضافة لافتة ثابتة (static banner) بما أنّه من المُمكن تعديل المنشور المُستخدَم بسهولة. عند إنشاء قائمة من الصفحات في نفس القسم (section) من الموقع، وذلك عندما يَملك الموقع بُنية مُعتمدة على صفحات هرميّة/شجريّة، فمن المُستحسن وضعها في الشريط الجانبي sidebar. إنشاء قالب صفحة page template باستعلام مخصّص كليًّا لعرض المنشورات على حسب التصنيف (taxonomy) أو نوع المنشور (أو ربّما حسب المعيارين). في صفحة أرشيف نوع المنشور (post type archive page)، وذلك لعرض المنشورات حسب التصنيف (category) بدلًا من التاريخ. إنشاء لافتة (banner) في الشريط الجانبي sidebar للربط إلى المنشور الأخير مع صورته الرئيسيّة. إنشاء صفحة لعرض المنشورات المُرتبطة فيما بينها وبأكثر من تصنيف، مثلًا عرض المقالات البرمجيّة وللغة روبي (Ruby) مثلًا ولكاتب مُحدّد. إنشاء نوع منشور لمحتوى الشريط الجانبي واستعلام منشورات هذا النوع في الشريط الجانبي، الأمر الّذي يُساعد أصحاب الخلفيّة غير البرمجيّة في إضافة مُحتوى إلى الشريط الجانبي بمرونة أكثر فيما لو تمّ استخدام ودجت (widget). يوجد العديد من السيناريوهات الأخرى، ولكن القائمة السابقة تعطي فكرة عامّة، ولن يتمّ التفصيل في كيفيّة تنفيذ كلٍ منها بل سيتمّ تغطية بعض الأمثلة. طرق إنشاء استعلام مخصص Custom Query يتوفّر خمس طرق لإنشاء استعلامات مُخصّصة custom queries، ويُمكن أنّ تُقسّم هذه الطرق تبعًا فيما إذا كان سيتمّ التعديل على الاستعلام الرئيسي أو سيتمّ إنشاء استعلام جديد. الطرق لتعديل الاستعلام الرئيسي هي: استعمال الخطّاف الإجرائي pre_get_posts، والّذي يسمح للمطوّر في التعديل على الاستعلام الرئيسي عن طريق إضافة دالّة إلى ملفّ الدّوال الخاصّ بالقالب (theme) أو بواسطة إضافة (وليس في ملفّات القالب template) ويُمكن دمجه مع تصريح شرطي conditional statement لتأكّد من أنّه يُنفّذ فقط على الصفحات الّتي تعرض أنواع مُحدّدة من المُحتوى. استعمال ()query_posts، مع العلم أنّ وجود هذه الدّالّة ضمن القائمة لتوضيح لماذا لا يجب استخدامها، فالدّالّة ()query_posts هي دالّة غير عمليّة ولا يُمكن الاعتماد عليها في تعديل وتحسين الاستعلام الرئيسي، فبدلًا من تحسين وتعديل الاستعلام الرئيسي فهي تجلب الاستعلام الرئيسي ومن ثُمّ توقفه وتبدأ مرّة أخرى بإعادة تنفيذه مع التغيرات المُدخلة، الأمر الّذي سيؤثّر على أداء الموقع، ومن المُمكن جدًا أنّ لا تعمل كما يجب لدى استخدامها مع التّصفيح pagination. تسمح الطرق المتبقية في إنشاء استعلام جديد: باستخدام الصنف WP_Query، وهي طريقة مرنة جدًا في إنشاء استعلام جديد، ويُستخدم هذا الصنف (class) عند إنشاء حلقة (loop) ثانية في ملفّ القالب (template file) أو عند إنشاء ملفّ قالب باستعلام مُخصّص كليًّا لاستبدال الحلقة الرئيسية (main loop)، ولكن يجب الحذر في استخدامه، وتأتي الخطورة في عدم تصفير (reset) الاستعلام بعد تنفيذ الحلقة (loop)، والّذي يعني أنّ ووردبريس لن يكون قادرًا على التعرّف بشكلٍ صحيح ما نوع الصّفحة الّتي يتمّ عرضها، ولكن من المُمكن حل هذه المشكلة بسهولة. دالّة/وسم القالب ()get_posts، وتُستخدم في ملفّ القالب (template) (بما في ذلك الشريط الجانبي sidebar وذيل الصّفحة على سبيل المثال) لجلب قائمة المنشورات، ويَستخدم الصنف WP_Query لعمل ذلك، ويُمكن استخدام مُعامِلات (parameters) معه لتحديد المنشورات المطلوبة. دالّة/وسم القالب ()get_pages، والّتي تعمل بنفس طريقة عمل ()get_posts، ولكن في جلب الصفحات بدلًا من المنشورات. سيتم التطرّق إلى أهم هذه الطرق بمزيد من التفصيل بعد أنّ تمّ عرضهم بشكل سريع. الخطاف الإجرائي pregetposts إن الدّالّة pre_get_posts هي خطّاف إجرائي (action hook)، وبالتالي يُمكن ربط دالّة معها لجعل شيء ما يحدث في الوقت الذي يُنفّذ ووردبريس الإجراء pre_get_posts، وكما هو واضح، يُنفّذ ووردبريس هذا الإجراء (action) مباشرةً قبل جلب المنشورات من قاعدة البيانات، ولذلك فإن أي دالّة يتمّ ربطّها معها ستؤثّر في كيفيّة جلب ووردبريس لتلك المنشورات. إن استخدام الدّالّة pre_get_posts يتطلّب إنشاء دالّة ومن ثُمّ ربطّها مع الإجراء، كما في التّالي: <?php function my_function() { // contents of function go here } add_action( 'pre_get_posts', 'my_function'); ?> أوّلًا، تمّ إنشاء الدّالّة وبالاسم my_function وما ستفعله هذه الدّالّة سيكون داخل الحاصرتين (braces). ثانيًا، تمّ ربط تلك الدّالّة مع الخطّاف pre_get_posts باستخدام الدّالّة ()add_action، وبدون ذلك لن تعمل الدّالّة. سيتمّ الحاجة غالبًا بالإضافة إلى ما سبق، إلى تضمين وسم/دالّة شرطيّة داخل الدّالّة المنشأة، فبدونها لن يقوم ووردبريس بتنفيذ الدالة المُنشأة كل مرّة يتمّ فيها جلب المنشورات، بما في ذلك عند التعامل مع المنشورات في الصفحات الإداريّة (admin)، وعليه ستكون الدالة المُنشأة بالشكل التّالي: <?php function my_function() { if ( !is_admin() && $query_>is_main_query() ) { // contents of function go here } } add_action( 'pre_get_posts', 'my_function'); ?> تمّ في الشيفرة السابقة، التأكّد من أنّ الصّفحة ليس صفحة إداريّة (admin) وأيضًا أنّ الاستعلام الّذي يتمّ تنفيذه هو الاستعلام الرئيسي (main query)، ومن المهم التأكّد من أن ووردبريس يُنفّذ الاستعلام الرئيسي تجنبًا للمشاكل المحتملة عند تنفيذ الدّالّة من أجل استعلامات إضافية قد تم إنشاؤها، كما يُمكن إضافة وسوم/دوال شرطيّة إضافيّة هنا كما سيتمّ لاحقًا. إدراج أنواع منشورات مخصصة في صفحة المدونة الرئيسية يَعرض ووردبريس بشكلٍ افتراضي قائمة بالمنشورات فقط في صفحة البداية (homepage) فإن تمّ إنشاء نوع منشورات مخصصة، فسيفترض ووردبريس أنّ المُراد هو عرضها في مكان آخر وعدم تضمينهم هنا، ولكن أحيانًا قد يُرغب في عرض أكثر من نوع منشور واحد في صفحة البداية (home page) وفي هذه الحالة يجب استخدام الخطّاف pre_get_posts. ويتم ذلك عبر إضافة الشيفرة التّالية إلى الملفّ functions.php الخاصّ بالقالب (theme) أو الإضافة المُنشأة. <?php function my_function() { if ( is_home() && $query->is_main_query() ) { $query->set( 'post_type', array( 'post', 'custom_post_type') ); return $query; } } add_action( 'pre_get_posts', 'my_function'); ?> تتأكّد الشيفرة السابقة من أمرين اثنين، أوّلًا فيما إذا كان الاستعلام هو الاستعلام الرئيسي وثانيًا فيما إذا كانت الصّفحة هي صفحة البداية (باستخدام الدالة ()is_home) بعد ذلك يتمّ تعيين (set) الاستعلام ليتضمّن نوعين من المنشورات: هما 'post' و 'customposttype'، ليكونا نوع المنشور المُخصّص، مع مُلاحظة وجوب تضمين 'post' هنا إن كان المرغوب من صفحة البداية أن تَعرض المنشورات أيضًا بالإضافة إلى نوع المنشور المخصّص، وفي حال إضافة custom_post_type فقط، سيتمّ استبدال السلوك الافتراضي وعرض المنشورات من نوع المنشور المخصّص، وقد يكون هذا المرغوب في بعض الحالات ولكن ليس في المثال الحالي. عرض منشورات من نوع المنشور المخصص في صفحة أرشيف التصنيف يَفترض هذا المثال أنه عندما تمّ تسجيل نوع المنشورات المُخصّصة، فقد تمّ منحها دعمًا للتصنيفات (categories) وتم إسناد التصنيفات إلى منشورات نوع المنشور المُخصّص، ولتعديل أرشيفات التصنيفات لكي تَعرض منشورات نوع المنشور المُخصّص يُستخدم التّالي: <?php function my_function() { if ( is_category() && $query->is_main_query() ) { $query->set( 'post_type', 'custom_post_type' ); return $query; } } add_action( 'pre_get_posts', 'my_function'); ?> تتأكّد الشيفرة السابقة من أنّ الاستعلام المُنفّذ هو الاستعلام الرئيسي والصفحة هي أرشيف التصنيفات وذلك باستخدام الدالة ()is_category، ومن ثُمّ تمّ التعديل على الاستعلام ليجلب منشورات نوع المنشور المُخصّص، وبما أنّه لم يتمّ تضمين 'post' هنا، فإن المنشورات الاعتياديّة لن يتمّ عرضها في أيٍ من أرشيفات التصنيفات، بالإضافة إلى أنّه لن يتمّ الحاجة إلى استخدام مصفوفة بما أنّه تمّ تحديد نوع منشور واحد. إنّ كان المطلوب هو التحديد بدقة أكبر فيُمكن تحديد نوع مُعيّن من التصنيفات كما في التّالي: <?php function my_function() { if ( is_category( 'category-slug' ) && $query->is_main_query() ) { $query->set( 'post_type', 'custom_post_type' ); return $query; } } add_action( 'pre_get_posts', 'my_function'); ?> سيتمّ في الشيفرة السابقة التعديل الاستعلام الرئيسي في صفحة الأرشيف category-slug فقط، حيثُ أنّ category-slug هو الاسم اللطيف (slug) للتصنيف (category). تغيير طريقة ترتيب المنشورات لن يتعامل المثال الأخير مع ما هي البيانات الّتي يتمّ استعلامُها بل مع كيف يتمّ عرضها/خَرْجُها (output)، فمثلًا في صفحات أرشيف التصنيفات (category archive) وعند عدم الرغبة في ترتيب المنشورات بواسطة التاريخ ولكن بالترتيب الأبجدي، يُمكن استخدام pre_get_posts كما في التّالي: <?php function my_function() { if ( is_category() && $query->is_main_query() ) { $query->set( 'orderby', 'title'); $query->set( 'order', 'ASC' ); return $query; } } add_action( 'pre_get_posts', 'my_function'); ?> تمّ في الشيفرة السابقة استعمال المُعامِل orderby والمُعامِل order لتحديد بناءً على ماذا ستُرتّب المنشورات وكيف ستُرتّب وذلك عند عرضها، وللمزيد من المُعامِلات (parameters) الّتي يُمكن استخدامها مع pre_get_posts يُمكن الرجوع إلى التوثيق الرسميّ للصنف WP_Query والّذي يستخدم نفس المُعامِلات. الصنف WP_Query يُعتبر الصنف WP_Query الطريقة الأفضل لكتابة استعلام مُخصّص، ويُستخدم عند الرغبة في استبدال الاستعلام الرئيسي (main query) باستعلام جديد أو عند الرغبة في إضافة استعلام جديد بالإضافة إلى الاستعلام الرئيسي. أجزاء الصنف WP_Query: المُعطيات (arguments) للاستعلام، وذلك باستخدام المُعامِلات (parameters) بشكل مُشابه إلى الّتي قد تُستخدم مع أجل pre_get_posts. الاستعلام نفسه. الحلقة (loop). الإنهاء: وذلك بإغلاق وسوم if و while، وتصفير (reset) بيانات المنشور. ستكون الشيفرة على النحو التّالي: <?php $args = array( // arguments for your query ); // the query $query = new WP_Query( $args ); // The Loop if ( $query->have_posts() ) : while ( $query->have_posts() ) : $query->the_post() : // contents of the Loop go here endwhile : endif; /* Restore original Post Data */ wp_reset_postdata(); ?> كما هو واضح إن الأمر أكثر تعقيدًا من استخدام pre_get_posts وهو أحد الأسباب لتجنّب استخدام الطريقة السابقة عندما يكون المطلوب هو التعديل على الاستعلام الرئيسي، ولكن السبب الرئيسي لتجنّب استخدامها هو أنها ستُجهد سكريبت ووردبريس نفسه، الأمر الّذي قد يؤثّر على أداء الموقع بالمُجمل. سيتمّ إلقاء نظرة على مثال للتوضيح أكثر، حيثُ سيتمّ إضافة حلقة (loop) ثانية بعد محتوى المنشور في ملفّ القالب (template) المُسمّى single.php، لعرض قائمة بالمنشورات المُميّزة، حيثُ تمّ تعريف هذه المنشورات المُميّزة باستخدام التصنيف "featured" (مُميّز)، ولكل واحدة من هذه المنشورات سيتمّ عرض الصورة المُميّزة والعنوان (title) مع الروابط الّتي تُحيل إلى المنشور: <?php $args = array( 'post_type' => 'post', 'posts_per_page' => '4', 'post__not_in' => array( $post->ID ) ); // the query $query = new WP_Query( $args ); // The Loop if ( $query->have_posts() ) { ?> <section class="recent-posts clear"> <?php while ( $query->have_posts() ) : $query->the_post() ; ?> <article id="post-<?php the_ID(); ?>" <?php post_class( 'left' ); ?>> <a href="<?php the_permalink(); ?>" title="<?php the_title_attribute(); ?>"> <?php post_thumbnail( 'thumbnail' );?> </a> <a href="<?php the_permalink(); ?>" title="<?php the_title_attribute(); ?>"> <?php the_title(); ?> </a> </article> <?php endwhile; ?> </section> <?php } /* Restore original Post Data */ wp_reset_postdata(); ?> تَستخدم الشيفرة السابقة ثلاثة مُعطيات (arguments) لاستعلام البيانات: 'post_type' => 'post' لجلب المنشورات فقط. 'posts_per_page' => '4' لجلب أربعة منشورات فقط. (post__not_in' => array($post->ID' للتأكيد على أنّ المنشور الّذي يُعرض حاليًا غير مُضمّن. ستُخرج (output) الشيفرة بعدها أربعة منشورات في حلقة (loop) والّتي تَعرض الصورة المُميّزة والعنوان (title) كلٍ محتوى داخل رابط يُحيل إلى صفحة المنشور، ومن المُمكن استخدام CSS للتنسيق، أو توضيعهم جنبًا إلى جنب أو في عرض شبكي (grid) أو حتّى جعل العنوان يتداخل مع الصورة. وسم/دالة القالب ()get_posts يُمكن اللجوء إلى get_posts عند عدم الحاجة إلى تلك المرونة الّتي يُقدمها الصنف WP_Query، وعليه فمن المُمكن الاستفادة منها في تطبيق المثال الأخير، مع العلم أنّ الوسم/الدالة get_posts ما هي إلا وسم قالب (template tag) يَستخدم الصنف WP_Query ويُمكن استخدامه بطريقة مُشابهة إلى WP_Query. يُمكن إنشاء قائمة بالمنشورات الأربعة الأخيرة باستخدام ()get_posts كما تمّ مع WP_Query على النحو التّالي: <?php $args = array( 'posts_per_page' => '4', 'exclude' => array( $post->ID ) ); // get posts $posts = get_posts( $args ); // check if any posts are returned if ( $posts ) { ?> <section class="recent-posts clear"> <?php foreach ($posts as $post ) { ?> <?php setup_postdata( $post ); ?> <article id="post-<?php the_ID(); ?>" <?php post_class( 'left' ); ?>> <a href="<?php the_permalink(); ?>" title="<?php the_title_attribute(); ?>"> <?php post_thumbnail( 'thumbnail' );?> </a> <a href="<?php the_permalink(); ?>" title="<?php the_title_attribute(); ?>"> <?php the_title(); ?> </a> </article> <?php } ?> </section> <?php } /* Restore original Post Data */ wp_reset_postdata(); ?> تُشبه الشيفرة السابقة إلى حدٍ كبير جدًا شيفرة مثال الصنف WP_Query السابقة، ولكن مع اختلاف طفيف: لا يجب على المُعطيات (arguments) أنّ تُضمّن نوع المنشور. تمّ استخدام المُتغيّر posts$ لتخزين خَرْج (output) المصفوفة باستخدام ()get_posts. بدلًا من التأكّد فيما إذا كان الاستعلام يملك منشورات، تمّ استخدام (if($posts في ذلك. بدلًا من استخدام حلقة (loop) معياريّة (standard)، تمّ استخدام (foreach ($posts as $post، والّتي ستُكرّر لكل صفّ (row) في المصفوفة. للوصول إلى جميع بيانات المنشور المطلوبة تمّ تضمين (setup_postdat($post. بما أنّ الدّالّة ()get_posts تستخدم الصنف WP_Query، فلا فرق يُذكر بين الاثنين عامّةً، ولذلك يميل بعض المُطوّرين إلى استخدام الصنف WP_Query بما أنّه يُقدّم مرونةً أكبر، مع ذلك يُمكن أنّ تكون الدّالّة ()get_posts أكثر نفعًا عند الرغبة من التأكّد إن كان يوجد أي منشورات مع المُعطيات (arguments)، عندها يُمكن خَرْج (output) الشيفرة اعتمادًا على وجود أية منشورات، من دون الضرورة إلى استخدام حلقة (loop). دالة/وسم القالب ()get_pages تُشبه الدّالّة ()get_pages إلى حدٍ كبيرٍ الدّالّة ()get_posts وهي تستخدم الصنف WP_Query ولكن في جلب الصفحات الثابتة (static pages) بدلًا من المنشورات، ومن الأمثلة الّتي تُستخدم بها: إن كان الموقع يملك مجموعة من الصفحات الهامّة ومن النوع top level، وكان الطلوب إضافة قائمة لها في الشريط الجانبي (sidebar) لكي يتمّ تنسيق روابطها وتشجيع الزوار إلى الذهاب إلى هذه الصفحات، فعندها وفي الملفّ sidebr.php يُمكن إضافة الشيفرة التّالية: <?php $args = array( 'parent' => 0, 'sort_order' => 'ASC', 'sort_column' => 'post_title', ); // get posts $pages = get_pages( $args ); // check if any posts are returned if ( $pages ) { ?> <ul class="sidebar-pages"> <?php foreach ( $pages as $page ) { ?> <li> <a href="<?php echo get_page_link( $page->ID ); ?>"> <?php echo $page->post_title; ?> </a> </li> <?php } ?> </ul> <?php } ?> تفاصيل الشيفرة السابقة هي كالتّالي: أوّلًا تمّ تعريف المُعطيات حيثُ أنّ parent' => 0' ستُعيد الصفحات الّتي هي بدون صفحة بداية، بينما بقيّة المُعطيات ستُحدّد كيف ستُرتّب هذه الصفحات. تمّ بعد ذلك استخدام ()get_pages وتمرير مصفوفة المُعطيات وتخزينها في المُتغيّر pages$. بعد ذلك تمّ التأكّد فيما إذا كان المُتغيّر pages$ يحتوي على أية بيانات وذلك باستخدام (if($pages. وفي حال توفّر الصفحات سيتمّ عرضها من خلال عناصر قائمة (list item). وبدلًا من استخدام ()setup_postdata كما تمّ مع ()get_pages، فقد تمّ استخدام المُتغيّر post$ مُباشرةً وبوسوم قالب (template) مُختلفة والّتي ستُخرج (output) الرابط والعنوان (title)، ومن الضروري استخدامها هنا بسبب عدم استخدام ()setup_postdata. وبسبب عدم استخدام ()setup_postdata فلا داعي لاستخدام ()wp_reset_postdata. إن طريقة الشيفرة السابقة هي طريقة أكثر عمليّة في خَرْج (output) قائمة من الصفحات من طريقة استخدام الصنف WP_Query وبكل ما يملكنه من إمكانيات. الختام إن التعديل على الاستعلام الرئيسي أو كتابة استعلامات جديدة هي مهارة ليجب الاهتمام بها وتطويرها خاصّة إن كان المطلوب هو إنشاء قوالب (themes) مُخصّصة أو إضافات (plugins) أو تطوير مواقع مُعقّدة للعُملاء. تمّ التطرّق إلى الطرق الخمس في إنشاء استعلامات مُخصّصة، ولكن أربعة منها فقط يُمكن استخدامها: pre_get_posts للتعديل على الاستعلام الرئيسي. WP_Query لإنشاء استعلامات مُخصّصة ومُعقّدة. ()get_posts و ()get_pages وذلك للاستعلامات المُخصّصة والبسيطة في جلب المنشورات والصفحات. يُمكن الخلط والمزج بين الطرق السابقة وذلك لإنشاء مواقع ووردبريس مُتقدّمة ولعرض البيانات بالكيفيّة المطلوبة. ترجمة -وبتصرّف- للمقال 5Simple Methods for Creating Custom Queries in WordPress لصاحبته Rachel McCollin.
يُنفّذ ووردبريس استعلامًا في كل صفحة من صفحات الموقع، ليجلب البيانات من قواعد بيانات (databases) الموقع ومن ثُمّ يعرضها بالطريقة الّتي يحدّدها القالب (theme) المُستخدَم وذلك باستخدام حلقة التكرار (loop)، ويُشار إلى هذا الاستعلام بالاستعلام الرئيسي main query. سيَستخدم ووردبريس ملفّ القالب (template) المُلائم وذلك اعتمادًا على نوع الصّفحة الّتي يتمّ عرضها، بمعنى أنّ حلقة (loop) قد تتغيّر بناءً على المُحتوى، ولكنّه سيُنفّذ استعلامًا دائمًا لجلب البيانات من قاعدة البيانات. يُرغب أحيانًا في تغيير طريقة عمل الاستعلام، فعلى سبيل المثال في الصّفحة الرئيسيّة للمدوّنة قد يُرغب في استثناء منشورات من فئة (category) مُعيّنة، أو قد يُرغب في عرض قائمة بالمنشورات على حسب الصنف بدلًا من الترتيب على حسب التاريخ في صفحة الأرشيف (archive page)، كما من المُحتمل جدًا أنّ يُرغب في إضافة استعلامات إضافيّة إلى صفحات (pages) الموقع، أو إضافة قائمة بالمنشورات الأخيرة (recent posts) أو المنشورات ذات الصِلة بمنشورات أخرى، أو قد يُرغب في إنشاء ملفّ قالب (template) يستبدل الاستعلام الرئيسي (main query) باستعلام مُخصّص وجديد كليًّا. يجعل سكريبت إدارة المُحتوى ووردبريس من هذه التخصيصات أمرًا ميسّرًا للغاية، وذلك بطرقٍ عدّة، وذلك إما بالتعديل على الاستعلام الرئيسي أو بإنشاء استعلام جديد. سيتطرّق هذا الدليل إلى الأمور التّالية: متى يُستخدم الاستعلام المُخصّص، ومتى يُخصّص الاستعلام الرئيسي ومتى يتمّ إنشاء استعلام جديد. الطرق الخمس لإنشاء استعلامات مُخصّصة، بما في ذلك الطريقة الّتي لا يجب أنّ تُستخدم ولماذا. فهم الأساسيات يجب الإلمام ببعض المصطلحات قبل الدخول في التفاصيل وهي ضروريّة لمن لم يُنشئ استعلامات مُخصّصة من قَبل. الاستعلام (query) وهو طريقة يَستعين بها ووردبريس لجب البيانات من قاعدة بيانات الموقع، وتتضمّن هذه البيانات المنشورات posts، المرفقات attachments، التعليقات comments، والصّفحات pages، أو أي مُحتوى تمّت إضافته إلى الموقع. الحلقة (loop) وهي شيفرة/كود يستخدمها القالب (theme) (أو أحيانًا الإضافة plugin) لتحديد كيفيّة عرض نتائج الاستعلام على الصّفحة، فعلى سبيل المثال قد تُضمِّن الحلقة في الصّفحة الرئيسيّة عنوان كل صفحة (title)، مُلخص كل تدوينة (extract)، ربّما صورة مُميّزة/بارزة، ورابط صفحة المنشور (والّذي يُدعى permalink أو الرابط الثابت). ملفّات القالب (template files): وتُستخدم من قِبل القالب (theme) لعرض الصفحات لكل نوع من أنواع المُحتوى، مع العلم أنّ كل قالب (theme) يملك ملفّات قالب (template) تختلف عن الآخر، ولكن يجب على القالب (theme) أنّ يتضمّن ملفّ index.php رئيسي، وغالبًا على الملفّ page.php للصفحات الثابتة static pages، والملفّ single.php للمنشورات المُنفردة single posts، والملفّ archive.php لصفحات الأرشيف، وربّما الملفّ category.php للتصنيفات، والملفّ tag.php للوسوم، وغيره من الملفّات وللمزيد من التفاصيل يُمكن العودة إلى الصّفحة التّالية في التوثيق الرسمي. الوسوم/الدّوال الشرطيّة: والّتي من المُمكن أنّ تُستخدم في ملفّات القالب (template) أو من قِبل الإضافات plugins لتحديد نوع الصّفحة الّتي يتمّ عرضها، فعلى سبيل المثال الدّالّة/الوسم ()is_page تُحدّد فيما إذا كانت الصّفحة الّتي يتمّ عرضها ثابتة (static) أم لا، والدّالّة/الوسم ()is_home تُحدّد فيما إذا كانت الصّفحة هي صفحة البداية home page، ويوجد العديد من هذه الوسوم/الدّوال الشرطيّة منها ما يُحدّد فيما إذا كان المُستخدم مُسجّلًا دخوله logged in أم لا، وغيره من هذه الدوال. متى يجب استخدام الاستعلام المخصص في ووردبريس يوجد نوعان من الاستعلامات المُخصّصة: الاستعلام الرئيسي بعد تعديله. استعلامات جديدة كليًّا لجلب مُحتوى مُختلف/مُحدّد أو محتوى إضافي. التعديل على الاستعلام الرئيسي Main Query في ووردبريس يُمكن استخدام نسخة مُعدّلة من الاستعلام الرئيسي عند الرغبة في أنّ تَعرض الصّفحة نتائج الاستعلام الرئيسي لذات المحتوى ولكن مع بعض التحسين والتعديل، وفي هذا النوع من الاستعلام ليس الهدف هو إظهار محتوى مُختلف كليًّا، وليس من المُفترض إضافة حلقة تكراريّة (loop) إضافيّة. أمثلة للحالات الّتي من المُمكن بها استخدام استعلام مُعدّل: في الصّفحة الرئيسيّة للمدوّنة، عرض أنواع منشورات مُخصّصة بالإضافة إلى المنشورات. في صفحة أرشيف التصنيفات category، عرض منشورات من نوع مُحدّد فقط. في صفحة أرشيف التصنيفات، ترتيب المنشورات ترتيبًا أبجديًا بدلًا من الترتيب الافتراضي. يوجد العديد من الحالات الأُخرى، ولكن كما هو واضح فالتعديلات مقتصرة على التعديلات البسيطة للاستعلام. كتابة استعلام جديد في ووردبريس قد لا يكون التعديل على الاستعلامات كافيًا في بعض الحالات، فعندها يُمكن إنشاء استعلام جديد، ويتمّ بهذا الحصول على مرونة أكبر في بناء الاستعلام، ولكن لا يُحبّذ إنشاء استعلام جديد عندما يكون التعديل على الاستعلام الرئيسي أمرًا كافيًا، حيث يُمكن إنشاء استعلامًا جديدًا عند الحاجة إلى استخدام أكثر من حلقة loop واحدة في الصّفحة أو عند الرغبة في استبدال الاستعلام الرئيسي باستعلام جديد كليًّا. أمثلة للحالات الّتي من المُمكن بها إنشاء استعلام جديد عديدة ومُختلفة، ولكن أبرزها: عند تنفيذ حلقتين two loops في صفحة الأرشيف: إحداهما للمنشور الأوّل والأخرى للمنشورات اللاحقة، بهدف عرض مُحتوى مُختلف للمنشور الأوّل، مثلًا عندما يكون المطلوب أنّ يتضمّن المنشور الأوّل مُلخّص أو صورة مميّزة فقط بدون بقيّة المنشورات، ولكن إن كان المطلوب هو تنسيق المنشور الأوّل بشكل مُختلف فقط، فمن غير المُستحسن استخدام حلقات (loops) متعدّدة في ذلك، بل من المُفترض استخدام CSS لاستهداف المنشور الأوّل في التنسيق دون بقيّة المنشورات. في صفحة المنشور المنفردة (single post)، وذلك عند تنفيذ حلقة (loop) إضافيّة لعرض المنشورات الأخيرة (أو المنشورات المُميّزة) وذلك أسفل محتوى المنشور، بغرض تشجيع القارئ لقراءة المزيد. عند إضافة لافتة (banner) مربوطة مع منشور مُميّز منفرد single featured post (أو لجميع المنشورات المُميّزة) في أعلى كل صفحة من صفحات الموقع، كما هو الأمر عند إضافة منشور يُروّج إلى مُنتج جديد، وهذه الطريقة هي أكثر مرونة من إضافة لافتة ثابتة (static banner) بما أنّه من المُمكن تعديل المنشور المُستخدَم بسهولة. عند إنشاء قائمة من الصفحات في نفس القسم (section) من الموقع، وذلك عندما يَملك الموقع بُنية مُعتمدة على صفحات هرميّة/شجريّة، فمن المُستحسن وضعها في الشريط الجانبي sidebar. إنشاء قالب صفحة page template باستعلام مخصّص كليًّا لعرض المنشورات على حسب التصنيف (taxonomy) أو نوع المنشور (أو ربّما حسب المعيارين). في صفحة أرشيف نوع المنشور (post type archive page)، وذلك لعرض المنشورات حسب التصنيف (category) بدلًا من التاريخ. إنشاء لافتة (banner) في الشريط الجانبي sidebar للربط إلى المنشور الأخير مع صورته الرئيسيّة. إنشاء صفحة لعرض المنشورات المُرتبطة فيما بينها وبأكثر من تصنيف، مثلًا عرض المقالات البرمجيّة وللغة روبي (Ruby) مثلًا ولكاتب مُحدّد. إنشاء نوع منشور لمحتوى الشريط الجانبي واستعلام منشورات هذا النوع في الشريط الجانبي، الأمر الّذي يُساعد أصحاب الخلفيّة غير البرمجيّة في إضافة مُحتوى إلى الشريط الجانبي بمرونة أكثر فيما لو تمّ استخدام ودجت (widget). يوجد العديد من السيناريوهات الأخرى، ولكن القائمة السابقة تعطي فكرة عامّة، ولن يتمّ التفصيل في كيفيّة تنفيذ كلٍ منها بل سيتمّ تغطية بعض الأمثلة. طرق إنشاء استعلام مخصص Custom Query يتوفّر خمس طرق لإنشاء استعلامات مُخصّصة custom queries، ويُمكن أنّ تُقسّم هذه الطرق تبعًا فيما إذا كان سيتمّ التعديل على الاستعلام الرئيسي أو سيتمّ إنشاء استعلام جديد. الطرق لتعديل الاستعلام الرئيسي هي: استعمال الخطّاف الإجرائي pre_get_posts، والّذي يسمح للمطوّر في التعديل على الاستعلام الرئيسي عن طريق إضافة دالّة إلى ملفّ الدّوال الخاصّ بالقالب (theme) أو بواسطة إضافة (وليس في ملفّات القالب template) ويُمكن دمجه مع تصريح شرطي conditional statement لتأكّد من أنّه يُنفّذ فقط على الصفحات الّتي تعرض أنواع مُحدّدة من المُحتوى. استعمال ()query_posts، مع العلم أنّ وجود هذه الدّالّة ضمن القائمة لتوضيح لماذا لا يجب استخدامها، فالدّالّة ()query_posts هي دالّة غير عمليّة ولا يُمكن الاعتماد عليها في تعديل وتحسين الاستعلام الرئيسي، فبدلًا من تحسين وتعديل الاستعلام الرئيسي فهي تجلب الاستعلام الرئيسي ومن ثُمّ توقفه وتبدأ مرّة أخرى بإعادة تنفيذه مع التغيرات المُدخلة، الأمر الّذي سيؤثّر على أداء الموقع، ومن المُمكن جدًا أنّ لا تعمل كما يجب لدى استخدامها مع التّصفيح pagination. تسمح الطرق المتبقية في إنشاء استعلام جديد: باستخدام الصنف WP_Query، وهي طريقة مرنة جدًا في إنشاء استعلام جديد، ويُستخدم هذا الصنف (class) عند إنشاء حلقة (loop) ثانية في ملفّ القالب (template file) أو عند إنشاء ملفّ قالب باستعلام مُخصّص كليًّا لاستبدال الحلقة الرئيسية (main loop)، ولكن يجب الحذر في استخدامه، وتأتي الخطورة في عدم تصفير (reset) الاستعلام بعد تنفيذ الحلقة (loop)، والّذي يعني أنّ ووردبريس لن يكون قادرًا على التعرّف بشكلٍ صحيح ما نوع الصّفحة الّتي يتمّ عرضها، ولكن من المُمكن حل هذه المشكلة بسهولة. دالّة/وسم القالب ()get_posts، وتُستخدم في ملفّ القالب (template) (بما في ذلك الشريط الجانبي sidebar وذيل الصّفحة على سبيل المثال) لجلب قائمة المنشورات، ويَستخدم الصنف WP_Query لعمل ذلك، ويُمكن استخدام مُعامِلات (parameters) معه لتحديد المنشورات المطلوبة. دالّة/وسم القالب ()get_pages، والّتي تعمل بنفس طريقة عمل ()get_posts، ولكن في جلب الصفحات بدلًا من المنشورات. سيتم التطرّق إلى أهم هذه الطرق بمزيد من التفصيل بعد أنّ تمّ عرضهم بشكل سريع. الخطاف الإجرائي pregetposts إن الدّالّة pre_get_posts هي خطّاف إجرائي (action hook)، وبالتالي يُمكن ربط دالّة معها لجعل شيء ما يحدث في الوقت الذي يُنفّذ ووردبريس الإجراء pre_get_posts، وكما هو واضح، يُنفّذ ووردبريس هذا الإجراء (action) مباشرةً قبل جلب المنشورات من قاعدة البيانات، ولذلك فإن أي دالّة يتمّ ربطّها معها ستؤثّر في كيفيّة جلب ووردبريس لتلك المنشورات. إن استخدام الدّالّة pre_get_posts يتطلّب إنشاء دالّة ومن ثُمّ ربطّها مع الإجراء، كما في التّالي: <?php function my_function() { // contents of function go here } add_action( 'pre_get_posts', 'my_function'); ?> أوّلًا، تمّ إنشاء الدّالّة وبالاسم my_function وما ستفعله هذه الدّالّة سيكون داخل الحاصرتين (braces). ثانيًا، تمّ ربط تلك الدّالّة مع الخطّاف pre_get_posts باستخدام الدّالّة ()add_action، وبدون ذلك لن تعمل الدّالّة. سيتمّ الحاجة غالبًا بالإضافة إلى ما سبق، إلى تضمين وسم/دالّة شرطيّة داخل الدّالّة المنشأة، فبدونها لن يقوم ووردبريس بتنفيذ الدالة المُنشأة كل مرّة يتمّ فيها جلب المنشورات، بما في ذلك عند التعامل مع المنشورات في الصفحات الإداريّة (admin)، وعليه ستكون الدالة المُنشأة بالشكل التّالي: <?php function my_function() { if ( !is_admin() && $query_>is_main_query() ) { // contents of function go here } } add_action( 'pre_get_posts', 'my_function'); ?> تمّ في الشيفرة السابقة، التأكّد من أنّ الصّفحة ليس صفحة إداريّة (admin) وأيضًا أنّ الاستعلام الّذي يتمّ تنفيذه هو الاستعلام الرئيسي (main query)، ومن المهم التأكّد من أن ووردبريس يُنفّذ الاستعلام الرئيسي تجنبًا للمشاكل المحتملة عند تنفيذ الدّالّة من أجل استعلامات إضافية قد تم إنشاؤها، كما يُمكن إضافة وسوم/دوال شرطيّة إضافيّة هنا كما سيتمّ لاحقًا. إدراج أنواع منشورات مخصصة في صفحة المدونة الرئيسية يَعرض ووردبريس بشكلٍ افتراضي قائمة بالمنشورات فقط في صفحة البداية (homepage) فإن تمّ إنشاء نوع منشورات مخصصة، فسيفترض ووردبريس أنّ المُراد هو عرضها في مكان آخر وعدم تضمينهم هنا، ولكن أحيانًا قد يُرغب في عرض أكثر من نوع منشور واحد في صفحة البداية (home page) وفي هذه الحالة يجب استخدام الخطّاف pre_get_posts. ويتم ذلك عبر إضافة الشيفرة التّالية إلى الملفّ functions.php الخاصّ بالقالب (theme) أو الإضافة المُنشأة. <?php function my_function() { if ( is_home() && $query->is_main_query() ) { $query->set( 'post_type', array( 'post', 'custom_post_type') ); return $query; } } add_action( 'pre_get_posts', 'my_function'); ?> تتأكّد الشيفرة السابقة من أمرين اثنين، أوّلًا فيما إذا كان الاستعلام هو الاستعلام الرئيسي وثانيًا فيما إذا كانت الصّفحة هي صفحة البداية (باستخدام الدالة ()is_home) بعد ذلك يتمّ تعيين (set) الاستعلام ليتضمّن نوعين من المنشورات: هما 'post' و 'customposttype'، ليكونا نوع المنشور المُخصّص، مع مُلاحظة وجوب تضمين 'post' هنا إن كان المرغوب من صفحة البداية أن تَعرض المنشورات أيضًا بالإضافة إلى نوع المنشور المخصّص، وفي حال إضافة custom_post_type فقط، سيتمّ استبدال السلوك الافتراضي وعرض المنشورات من نوع المنشور المخصّص، وقد يكون هذا المرغوب في بعض الحالات ولكن ليس في المثال الحالي. عرض منشورات من نوع المنشور المخصص في صفحة أرشيف التصنيف يَفترض هذا المثال أنه عندما تمّ تسجيل نوع المنشورات المُخصّصة، فقد تمّ منحها دعمًا للتصنيفات (categories) وتم إسناد التصنيفات إلى منشورات نوع المنشور المُخصّص، ولتعديل أرشيفات التصنيفات لكي تَعرض منشورات نوع المنشور المُخصّص يُستخدم التّالي: <?php function my_function() { if ( is_category() && $query->is_main_query() ) { $query->set( 'post_type', 'custom_post_type' ); return $query; } } add_action( 'pre_get_posts', 'my_function'); ?> تتأكّد الشيفرة السابقة من أنّ الاستعلام المُنفّذ هو الاستعلام الرئيسي والصفحة هي أرشيف التصنيفات وذلك باستخدام الدالة ()is_category، ومن ثُمّ تمّ التعديل على الاستعلام ليجلب منشورات نوع المنشور المُخصّص، وبما أنّه لم يتمّ تضمين 'post' هنا، فإن المنشورات الاعتياديّة لن يتمّ عرضها في أيٍ من أرشيفات التصنيفات، بالإضافة إلى أنّه لن يتمّ الحاجة إلى استخدام مصفوفة بما أنّه تمّ تحديد نوع منشور واحد. إنّ كان المطلوب هو التحديد بدقة أكبر فيُمكن تحديد نوع مُعيّن من التصنيفات كما في التّالي: <?php function my_function() { if ( is_category( 'category-slug' ) && $query->is_main_query() ) { $query->set( 'post_type', 'custom_post_type' ); return $query; } } add_action( 'pre_get_posts', 'my_function'); ?> سيتمّ في الشيفرة السابقة التعديل الاستعلام الرئيسي في صفحة الأرشيف category-slug فقط، حيثُ أنّ category-slug هو الاسم اللطيف (slug) للتصنيف (category). تغيير طريقة ترتيب المنشورات لن يتعامل المثال الأخير مع ما هي البيانات الّتي يتمّ استعلامُها بل مع كيف يتمّ عرضها/خَرْجُها (output)، فمثلًا في صفحات أرشيف التصنيفات (category archive) وعند عدم الرغبة في ترتيب المنشورات بواسطة التاريخ ولكن بالترتيب الأبجدي، يُمكن استخدام pre_get_posts كما في التّالي: <?php function my_function() { if ( is_category() && $query->is_main_query() ) { $query->set( 'orderby', 'title'); $query->set( 'order', 'ASC' ); return $query; } } add_action( 'pre_get_posts', 'my_function'); ?> تمّ في الشيفرة السابقة استعمال المُعامِل orderby والمُعامِل order لتحديد بناءً على ماذا ستُرتّب المنشورات وكيف ستُرتّب وذلك عند عرضها، وللمزيد من المُعامِلات (parameters) الّتي يُمكن استخدامها مع pre_get_posts يُمكن الرجوع إلى التوثيق الرسميّ للصنف WP_Query والّذي يستخدم نفس المُعامِلات. الصنف WP_Query يُعتبر الصنف WP_Query الطريقة الأفضل لكتابة استعلام مُخصّص، ويُستخدم عند الرغبة في استبدال الاستعلام الرئيسي (main query) باستعلام جديد أو عند الرغبة في إضافة استعلام جديد بالإضافة إلى الاستعلام الرئيسي. أجزاء الصنف WP_Query: المُعطيات (arguments) للاستعلام، وذلك باستخدام المُعامِلات (parameters) بشكل مُشابه إلى الّتي قد تُستخدم مع أجل pre_get_posts. الاستعلام نفسه. الحلقة (loop). الإنهاء: وذلك بإغلاق وسوم if و while، وتصفير (reset) بيانات المنشور. ستكون الشيفرة على النحو التّالي: <?php $args = array( // arguments for your query ); // the query $query = new WP_Query( $args ); // The Loop if ( $query->have_posts() ) : while ( $query->have_posts() ) : $query->the_post() : // contents of the Loop go here endwhile : endif; /* Restore original Post Data */ wp_reset_postdata(); ?> كما هو واضح إن الأمر أكثر تعقيدًا من استخدام pre_get_posts وهو أحد الأسباب لتجنّب استخدام الطريقة السابقة عندما يكون المطلوب هو التعديل على الاستعلام الرئيسي، ولكن السبب الرئيسي لتجنّب استخدامها هو أنها ستُجهد سكريبت ووردبريس نفسه، الأمر الّذي قد يؤثّر على أداء الموقع بالمُجمل. سيتمّ إلقاء نظرة على مثال للتوضيح أكثر، حيثُ سيتمّ إضافة حلقة (loop) ثانية بعد محتوى المنشور في ملفّ القالب (template) المُسمّى single.php، لعرض قائمة بالمنشورات المُميّزة، حيثُ تمّ تعريف هذه المنشورات المُميّزة باستخدام التصنيف "featured" (مُميّز)، ولكل واحدة من هذه المنشورات سيتمّ عرض الصورة المُميّزة والعنوان (title) مع الروابط الّتي تُحيل إلى المنشور: <?php $args = array( 'post_type' => 'post', 'posts_per_page' => '4', 'post__not_in' => array( $post->ID ) ); // the query $query = new WP_Query( $args ); // The Loop if ( $query->have_posts() ) { ?> <section class="recent-posts clear"> <?php while ( $query->have_posts() ) : $query->the_post() ; ?> <article id="post-<?php the_ID(); ?>" <?php post_class( 'left' ); ?>> <a href="<?php the_permalink(); ?>" title="<?php the_title_attribute(); ?>"> <?php post_thumbnail( 'thumbnail' );?> </a> <a href="<?php the_permalink(); ?>" title="<?php the_title_attribute(); ?>"> <?php the_title(); ?> </a> </article> <?php endwhile; ?> </section> <?php } /* Restore original Post Data */ wp_reset_postdata(); ?> تَستخدم الشيفرة السابقة ثلاثة مُعطيات (arguments) لاستعلام البيانات: 'post_type' => 'post' لجلب المنشورات فقط. 'posts_per_page' => '4' لجلب أربعة منشورات فقط. (post__not_in' => array($post->ID' للتأكيد على أنّ المنشور الّذي يُعرض حاليًا غير مُضمّن. ستُخرج (output) الشيفرة بعدها أربعة منشورات في حلقة (loop) والّتي تَعرض الصورة المُميّزة والعنوان (title) كلٍ محتوى داخل رابط يُحيل إلى صفحة المنشور، ومن المُمكن استخدام CSS للتنسيق، أو توضيعهم جنبًا إلى جنب أو في عرض شبكي (grid) أو حتّى جعل العنوان يتداخل مع الصورة. وسم/دالة القالب ()get_posts يُمكن اللجوء إلى get_posts عند عدم الحاجة إلى تلك المرونة الّتي يُقدمها الصنف WP_Query، وعليه فمن المُمكن الاستفادة منها في تطبيق المثال الأخير، مع العلم أنّ الوسم/الدالة get_posts ما هي إلا وسم قالب (template tag) يَستخدم الصنف WP_Query ويُمكن استخدامه بطريقة مُشابهة إلى WP_Query. يُمكن إنشاء قائمة بالمنشورات الأربعة الأخيرة باستخدام ()get_posts كما تمّ مع WP_Query على النحو التّالي: <?php $args = array( 'posts_per_page' => '4', 'exclude' => array( $post->ID ) ); // get posts $posts = get_posts( $args ); // check if any posts are returned if ( $posts ) { ?> <section class="recent-posts clear"> <?php foreach ($posts as $post ) { ?> <?php setup_postdata( $post ); ?> <article id="post-<?php the_ID(); ?>" <?php post_class( 'left' ); ?>> <a href="<?php the_permalink(); ?>" title="<?php the_title_attribute(); ?>"> <?php post_thumbnail( 'thumbnail' );?> </a> <a href="<?php the_permalink(); ?>" title="<?php the_title_attribute(); ?>"> <?php the_title(); ?> </a> </article> <?php } ?> </section> <?php } /* Restore original Post Data */ wp_reset_postdata(); ?> تُشبه الشيفرة السابقة إلى حدٍ كبير جدًا شيفرة مثال الصنف WP_Query السابقة، ولكن مع اختلاف طفيف: لا يجب على المُعطيات (arguments) أنّ تُضمّن نوع المنشور. تمّ استخدام المُتغيّر posts$ لتخزين خَرْج (output) المصفوفة باستخدام ()get_posts. بدلًا من التأكّد فيما إذا كان الاستعلام يملك منشورات، تمّ استخدام (if($posts في ذلك. بدلًا من استخدام حلقة (loop) معياريّة (standard)، تمّ استخدام (foreach ($posts as $post، والّتي ستُكرّر لكل صفّ (row) في المصفوفة. للوصول إلى جميع بيانات المنشور المطلوبة تمّ تضمين (setup_postdat($post. بما أنّ الدّالّة ()get_posts تستخدم الصنف WP_Query، فلا فرق يُذكر بين الاثنين عامّةً، ولذلك يميل بعض المُطوّرين إلى استخدام الصنف WP_Query بما أنّه يُقدّم مرونةً أكبر، مع ذلك يُمكن أنّ تكون الدّالّة ()get_posts أكثر نفعًا عند الرغبة من التأكّد إن كان يوجد أي منشورات مع المُعطيات (arguments)، عندها يُمكن خَرْج (output) الشيفرة اعتمادًا على وجود أية منشورات، من دون الضرورة إلى استخدام حلقة (loop). دالة/وسم القالب ()get_pages تُشبه الدّالّة ()get_pages إلى حدٍ كبيرٍ الدّالّة ()get_posts وهي تستخدم الصنف WP_Query ولكن في جلب الصفحات الثابتة (static pages) بدلًا من المنشورات، ومن الأمثلة الّتي تُستخدم بها: إن كان الموقع يملك مجموعة من الصفحات الهامّة ومن النوع top level، وكان الطلوب إضافة قائمة لها في الشريط الجانبي (sidebar) لكي يتمّ تنسيق روابطها وتشجيع الزوار إلى الذهاب إلى هذه الصفحات، فعندها وفي الملفّ sidebr.php يُمكن إضافة الشيفرة التّالية: <?php $args = array( 'parent' => 0, 'sort_order' => 'ASC', 'sort_column' => 'post_title', ); // get posts $pages = get_pages( $args ); // check if any posts are returned if ( $pages ) { ?> <ul class="sidebar-pages"> <?php foreach ( $pages as $page ) { ?> <li> <a href="<?php echo get_page_link( $page->ID ); ?>"> <?php echo $page->post_title; ?> </a> </li> <?php } ?> </ul> <?php } ?> تفاصيل الشيفرة السابقة هي كالتّالي: أوّلًا تمّ تعريف المُعطيات حيثُ أنّ parent' => 0' ستُعيد الصفحات الّتي هي بدون صفحة بداية، بينما بقيّة المُعطيات ستُحدّد كيف ستُرتّب هذه الصفحات. تمّ بعد ذلك استخدام ()get_pages وتمرير مصفوفة المُعطيات وتخزينها في المُتغيّر pages$. بعد ذلك تمّ التأكّد فيما إذا كان المُتغيّر pages$ يحتوي على أية بيانات وذلك باستخدام (if($pages. وفي حال توفّر الصفحات سيتمّ عرضها من خلال عناصر قائمة (list item). وبدلًا من استخدام ()setup_postdata كما تمّ مع ()get_pages، فقد تمّ استخدام المُتغيّر post$ مُباشرةً وبوسوم قالب (template) مُختلفة والّتي ستُخرج (output) الرابط والعنوان (title)، ومن الضروري استخدامها هنا بسبب عدم استخدام ()setup_postdata. وبسبب عدم استخدام ()setup_postdata فلا داعي لاستخدام ()wp_reset_postdata. إن طريقة الشيفرة السابقة هي طريقة أكثر عمليّة في خَرْج (output) قائمة من الصفحات من طريقة استخدام الصنف WP_Query وبكل ما يملكنه من إمكانيات. الختام إن التعديل على الاستعلام الرئيسي أو كتابة استعلامات جديدة هي مهارة ليجب الاهتمام بها وتطويرها خاصّة إن كان المطلوب هو إنشاء قوالب (themes) مُخصّصة أو إضافات (plugins) أو تطوير مواقع مُعقّدة للعُملاء. تمّ التطرّق إلى الطرق الخمس في إنشاء استعلامات مُخصّصة، ولكن أربعة منها فقط يُمكن استخدامها: pre_get_posts للتعديل على الاستعلام الرئيسي. WP_Query لإنشاء استعلامات مُخصّصة ومُعقّدة. ()get_posts و ()get_pages وذلك للاستعلامات المُخصّصة والبسيطة في جلب المنشورات والصفحات. يُمكن الخلط والمزج بين الطرق السابقة وذلك لإنشاء مواقع ووردبريس مُتقدّمة ولعرض البيانات بالكيفيّة المطلوبة. ترجمة -وبتصرّف- للمقال 5Simple Methods for Creating Custom Queries in WordPress لصاحبته Rachel McCollin.









