

رغم كون بايثون لغة البرمجة المفضلة لدى العديد من المبرمجين، إلا أنها لا تخلو من بعض العيوب؛ والتي تتفاوت بين لغة وأخرى، وهنا لا تعد بايثون استثناء، فعلى مبرمجي بايثون الجدد تعلم كيفية تجنّب بعض من البنى الشائعة التي تبدو صحيحة إلا أنها تؤدي بالنتيجة إلى حدوث أخطاء والتي ندعوها "gotchas". يكتسب عادةً المبرمجون هذه المعرفة عشوائيًا مع الخبرة، إلا أن هذا المقال يجمّع هذه البنى الشائعة لك في مكانٍ واحد، إذ ستتمكن من خلال معرفتك للتقاليد البرمجية الكائنة خلف هذه البنى من فهم سلوكيات بايثون الغريبة التي ستصادفك أحيانًا.
يوضّح هذا المقال أسباب السلوكيات غير المتوقعة للكائنات المتغيرة، مثل القوائم والقواميس، والتي تظهر لدى تغيير محتوياتها، كما ستتعلم أن تابع الفرز ()sort لا يفرز العناصر وفق ترتيب أبجدي تمامًا، وكيف يمكن لأخطاء التقريب أن تجد طريقها نحو الأعداد ذات الفاصلة العشرية، كما أن لعامل عدم التساوي =! سلوك غير طبيعي يظهر لدى استخدام سلسلة منه، ولابد أيضًا من استخدام فاصلة زائدة إضافية عند كتابة صف وحيد العنصر. باختصار: يوجهك هذا المقال إلى كيفية تجنُّب البنى الصحيحة المسببة للأخطاء gotchas.
لا تحذف أو تضيف عناصر إلى قائمة أثناء المرور على عناصرها
تؤدي غالبًا إضافة عناصر إلى قائمة أو حذفها منها أثناء المرور على عناصرها باستخدام حلقة for أو while إلى حدوث أخطاء. لنأخذ بالحسبان الحالة التالية مثالًا: نرغب بالمرور على قائمة من السلاسل النصية التي تصف عناصر من الملابس بغية التأكد من أن عدد عناصر الجوارب زوجي، وذلك بإدخال عنصر جوارب موافق جديد لكل مرة يوجد فيها عنصر جوارب في القائمة، وهنا تبدو المهمة بسيطة وواضحة؛ إذ أنها تتمثل بالمرور على السلاسل النصية في القائمة وعندما نجد عنصر جوارب 'sock' في إحدى السلاسل النصية مثل 'red sock' فإننا نُدخل سلسلة 'red sock' أخرى جديدة إلى القائمة.
لن تعمل شيفرة كهذه، لأنها ستدور في حلقة لا نهائية، ولن نستطيع إيقافها ما لم نضغط على مفتاحي "CTRL-C" لإيقافها قسريًا، على النحو التالي:
>>> clothes = ['skirt', 'red sock'] >>> for clothing in clothes: # Iterate over the list. ... if 'sock' in clothing: # Find strings with 'sock'. ... clothes.append(clothing) # Add the sock's pair. ... print('Added a sock:', clothing) # Inform the user. ... Added a sock: red sock Added a sock: red sock Added a sock: red sock --snip-- Added a sock: red sock Traceback (most recent call last): File "<stdin>", line 3, in <module> KeyboardInterrupt
وبإمكانك الاطلاع على تمثيل مرئي لتنفيذ الشيفرة السابقة بزيارة الرابط.
تكمن المشكلة في أنه عند إضافة العنصر 'red sock' إلى القائمة clothes، فسيصبح لدى هذه القائمة عنصر ثالث جديد، والذي يجب المرور عليه، وهو:
['skirt', 'red sock', 'red sock']
وبالتالي ستصل حلقة for إلى العنصر 'red sock' الثاني الجديد عند التكرار التالي مُضيفةً سلسلة 'red sock' أخرى إلى القائمة لتصبح على النحو:
['skirt', 'red sock', 'red sock', 'red sock']
مضيفةً سلسلةً نصيةً جديدةً إلى القائمة لتمر عليها بايثون. يستمر هذا الأمر بالحدوث كما هو موضح في الشكل 8-1 التالي، وهو سبب ظهور التدفق اللامتناهي من رسائل إضافة عنصر جوارب جديد 'Added a sock' إلى القائمة، وستستمر الحلقة بالتكرار حتى امتلاء ذاكرة الحاسب وبالتالي توقف برنامج بايثون عن العمل، أو حتى نضغط على مفتاحي "CTRL-C" في لوحة المفاتيح.

الشكل 8-1: يُضاف عنصر 'red sock' جديد إلى القائمة من أجل كل تكرار للحلقة for، إذ تشير قيمة المتغير clothing إلى قيمة التكرار التالي، وتتكرر هذه الحلقة لانهائيًا.

يكون الحل بعدم إضافة عناصر إلى القائمة الحالية أثناء المرور عليها، وبالتالي سنستخدم قائمة منفصلة لمحتويات القائمة الجديدة المعدلة مثل القائمة newClothes في المثال التالي لتكون بمثابة حل بديل:
>>> clothes = ['skirt', 'red sock', 'blue sock'] >>> newClothes = [] >>> for clothing in clothes: ... if 'sock' in clothing: ... print('Appending:', clothing) ... newClothes.append(clothing) # We change the newClothes list, not clothes. ... Appending: red sock Appending: blue sock >>> print(newClothes) ['red sock', 'blue sock'] >>> clothes.extend(newClothes) # Appends the items in newClothes to clothes. >>> print(clothes) ['skirt', 'red sock', 'blue sock', 'red sock', 'blue sock']
بإمكانك الاطلاع على تمثيل مرئي لتنفيذ الشيفرة السابقة بزيارة الرابط.
تمر الحلقة for في الشيفرة السابقة على عناصر القائمة clothes دون تعديلها، إذ تجري التعديلات ضمن قائمة مستقلة باسم newClothes، وبعد الانتهاء من المرور على عناصر القائمة clothes، نعدّلها بإضافة محتويات القائمة newClothes إليها، وبذلك نحصل على قائمة clothes تحتوي على عدد زوجي من أزواج الجوارب المتوافقة.
على نحوٍ مشابه، لا ينبغي حذف عناصر من قائمة أثناء المرور على عناصرها، مثل شيفرة تحذف أي سلسلة نصية ليست hello من قائمة ما. تتمثل المنهجية الأكثر سذاجة في هذه الحالة بالمرور على عناصر القائمة وحذف العناصر غير المساوية للقيمة hello، على النحو التالي:
>>> greetings = ['hello', 'hello', 'mello', 'yello', 'hello'] >>> for i, word in enumerate(greetings): ... if word != 'hello': # Remove everything that isn't 'hello'. ... del greetings[i] ... >>> print(greetings) ['hello', 'hello', 'yello', 'hello']
نلاحظ في نتيجة تنفيذ الشيفرة السابقة أن العنصر 'yello' بقي موجودًا في القائمة الناتجة، والسبب وراء ذلك هو أنه لدى وصول تكرار الحلقة for إلى العنصر ذو الفهرس (المؤشر) رقم 2، ستحذف العنصر المقابل وهو 'mello' من القائمة، ما سيؤدي إلى إزاحة فهرس كل من العناصر المتبقية بمقدار واحد نزولًا، وبالتالي يصبح فهرس العنصر 'yello' هو 2 بدلًا من 3. والتكرار التالي للحلقة سيختبر العنصر ذو الفهرس رقم 3، والذي أصبح الآن السلسلة النصية 'hello' الأخيرة، كما هو موضح في الشكل 8-2. إذ نلاحظ أن السلسلة النصية 'yello' لم تُختبر أصلًا، وبالتالي نؤكد مجددًا على ضرورة عدم حذف عناصر من قائمة أثناء المرور على عناصرها.

الشكل 8-2: بعد مرور الحلقة على العنصر 'mello' واختباره وحذفه، تُزاح فهارس العناصر المتبقية نزولًا بمقدار واحد، ما يجعل المؤشر i يتجاوز العنصر 'yello'.
يمكن بدلًا من ذلك إنشاء قائمة جديدة لننسخ فيها كافّة العناصر من القائمة الأصلية عدا تلك التي نريد حذفها، لنستبدل القائمة الأصلية بها كنتيجة. سنكتب الشيفرة التالية في الصدفة التفاعلية لتكون مكافئةً للمثال السابق لكن دون أخطاء:
>>> greetings = ['hello', 'hello', 'mello', 'yello', 'hello'] >>> newGreetings = [] >>> for word in greetings: ... if word == 'hello': # Copy everything that is 'hello'. ... newGreetings.append(word) ... >>> greetings = newGreetings # Replace the original list. >>> print(greetings) ['hello', 'hello', 'hello']
يمكنك الاطلاع على تمثيل مرئي لتنفيذ الشيفرة السابقة بزيارة الرابط.
تجدر الملاحظة أنه وبما أن الشيفرة السابقة مجرد حلقة بسيطة تُنشِئ قائمة، فمن الممكن استبدالها ببنية اشتمال قوائم list comprehensions وحدها. لن تعمل هذه القوائم أسرع ولن تستخدم مساحةً أقل من الذاكرة، إلا أنها أسهل للكتابة وتجعل من مقروئية الشيفرة أفضل. لنكتب الشيفرة التالية ضمن الصدفة التفاعلية لتكون مكافئة للشيفرة السابقة:
>>> greetings = ['hello', 'hello', 'mello', 'yello', 'hello'] >>> greetings = [word for word in greetings if word == 'hello'] >>> print(greetings) ['hello', 'hello', 'hello']
لا يُعد استخدام بنية اشتمال قوائم أكثر إيجازًا فحسب، بل ويجنبنا وقوع أخطاء من شيفرات تبدو صحيحة gotcha، والتي تحدث لدى تغيير عناصر قائمة أثناء المرور عليها.
المراجع واستخدام الذاكرة والدالة ()sys.getsizeof
قد يبدو إنشاء قائمة جديدة بدلًا من تعديل الأصلية نفسها هدرًا للذاكرة، لكن علينا تذكر أنه كما أن المتغيرات تحتوي من الناحية التقنية على مراجع للقيم وليس على القيم نفسها، كذلك الأمر بالنسبة للقوائم، إذ تحتوي على مراجع للقيم؛ فالسطر البرمجي (newGreetings.append(word المُستخدَم سابقًا لا يُنشئ نسخةً عن السلسلة النصية الموجودة في المتغير word، وإنما ينسخ فقط مرجع هذه السلسلة النصية وهو أصغر بكثير منها حجمًا.
يمكن التأكد من ذلك باستخدام الدالة ()sys.getsizeof التي تعيد عدد البايتات التي يحجزها الكائن في الذاكرة. نلاحظ في مثالنا التالي في الصدفة التفاعلية أن السلسلة النصية القصيرة 'cat' تحجز 52 بايتًا، في حين أن سلسلة نصية أطول تحجز 85 بايتًا، على النحو التالي:
>>> import sys >>> sys.getsizeof('cat') 52 >>> sys.getsizeof('a much longer string than just "cat"') 85
في إصدار بايثون الذي نستخدم، يُحجَز 49 بايتًا لحمل overhead كائن السلسلة النصية، في حين يُحجَز بايت واحد لكل محرف، أما القائمة وبغض النظر عن السلاسل النصية التي تتضمنها فإنها تحجز 72 بايت، مهما كان طول هذه السلاسل النصية، كما يلي:
>>> sys.getsizeof(['cat']) 72 >>> sys.getsizeof(['a much longer string than just "cat"']) 72
السبب وراء ذلك هو أن القوائم من الناحية التقنية لا تحتوي على السلاسل النصية نفسها وإنما عناوينها فقط، وللمرجع الحجم نفسه بغض النظر عن البيانات التي يشير إليها؛ فتعليمة مثل (newGreetings.append(word لا تنسخ السلسلة النصية الموجودة في المتغير word وإنما تنسخ مرجعها فقط. إذا كنت ترغب بمعرفة الحجم الذي يحجزه كائن ما مع كل الكائنات التي يشير إليها، يمكنك استخدام الدالة التي أنشأها مطور نواة بايثون "ريمون هيتينجر Raymond Hettinger" لهذا الغرض والمتوفرة على الرابط.
ينبغي ألا تعتقد بأنك تهدر ذاكرة بإنشائك لقائمة جديدة بدلًا من التعديل في نفس القائمة أثناء المرور على عناصرها، وحتى وإن بدت شيفرتك تعمل ظاهريًا، فقد تكون هي مصدر لأخطاء دقيقة تتطلب وقتًا طويلًا لاكتشافها وإصلاحها؛ فوقت المبرمج أثمن من الذاكرة، وهدره مكلف أكثر بكثير من هدرها.
بالعودة الآن إلى موضوعنا، ورغم أنه لا يجب إضافة أو حذف عناصر من قائمة أو أي كائن تكراري آخر أثناء المرور على عناصرها، لكن من الممكن تعديل عناصر القائمة أثناء ذلك؛ فعلى سبيل المثال، ليكن لدينا قائمة من الأعداد في صورة سلاسل نصية بالشكل:
['5', '4', '3', '2', '1']
من الممكن تحويل قائمة السلاسل النصية هذه إلى قائمة من الأعداد الصحيحة [5, 4, 3, 2, 1] أثناء المرور على عناصرها، على النحو التالي:
>>> numbers = ['1', '2', '3', '4', '5'] >>> for i, number in enumerate(numbers): ... numbers[i] = int(number) ... >>> numbers [1, 2, 3, 4, 5]
يمكنك الاطلاع على تمثيل مرئي لتنفيذ الشيفرة السابقة بزيارة الرابط، فتعديل العناصر في القائمة مقبول، لا سيما أنه قد يقلل عدد العناصر المعرضة للأخطاء فيها.
إحدى الطرق الأخرى الممكنة لإضافة أو حذف عناصر من قائمة بأمان هي بالمرور على العناصر عكسًا من نهاية القائمة إلى بدايتها، ويمكن بهذه الطريقة حذف عناصر من القائمة أثناء المرور عليها، أو حتى إضافة عناصر جديدة إليها دون أن يكون لها أثرًا طالما أننا نضيفها إلى نهاية القائمة، فعلى سبيل المثال، لنكتب الشيفرة التالية التي تحذف الأعداد الزوجية من القائمة المسماة someInts:
>>> someInts = [1, 7, 4, 5] >>> for i in range(len(someInts)): ... ... if someInts[i] % 2 == 0: ... del someInts[i] ... Traceback (most recent call last): File "<stdin>", line 2, in <module> IndexError: list index out of range >>> someInts = [1, 7, 4, 5] >>> for i in range(len(someInts) - 1, -1, -1): ... if someInts[i] % 2 == 0: ... del someInts[i] ... >>> someInts [1, 7, 5]
ستعمل الشيفرة السابقة على نحوٍ سليم، لأن فهرس أي من العناصر التي ستمر عليها الحلقة لاحقًا لن يتغير أبدًا، إلا أن الإزاحة المتكررة للقيم الواقعة بعد تلك المحذوفة تجعل من هذه التقنية غير فعّالة لا سيما للقوائم الطويلة. يمكنك الاطلاع على تمثيل مرئي لتنفيذ الشيفرة السابقة عبر الرابط. يوضح الشكل 8-3 التالي الفرق ما بين المرور المباشر (الأمامي) والعكسي على عناصر القائمة.
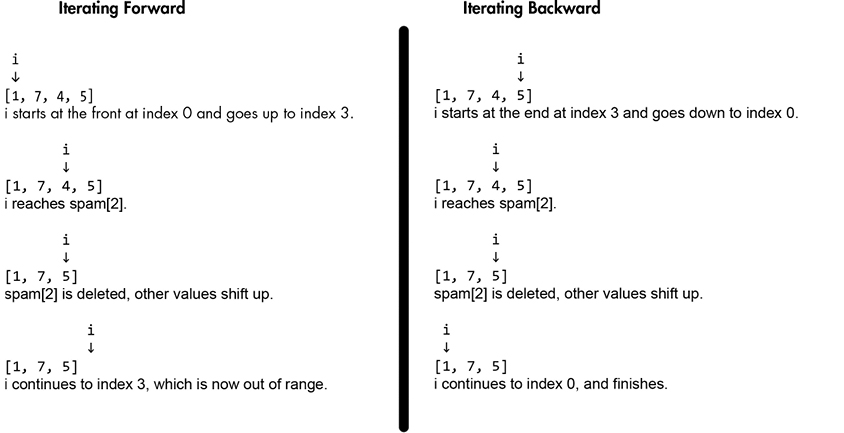
الشكل 8-3: حذف الأعداد الزوجية من قائمة أثناء المرور على عناصرها عكسيًا (على اليسار) وأماميًا (على اليمين).
يمكن بصورةٍ مشابهة للحالة السابقة إضافة عناصر إلى نهاية القائمة أثناء المرور عليها عكسيًا. لنكتب الشيفرة التالية في الصدفة التفاعلية، والتي تضيف نسخةً من أي عدد زوجي تصادفه إلى نهاية القائمة somwInts على النحو التالي:
>>> someInts = [1, 7, 4, 5] >>> for i in range(len(someInts) - 1, -1, -1): ... if someInts[i] % 2 == 0: ... someInts.append(someInts[i]) ... >>> someInts [1, 7, 4, 5, 4]
بإمكانك الاطلاع على تمثيل مرئي لتنفيذ الشيفرة السابقة بزيارة الرابط.
إذًا، يمكن بالمرور عكسًا على عناصر القائمة إضافة عناصر إلى القائمة أو حذفها منها، وقد يكون تنفيذ هذه التقنية على النحو الصحيح صعبًا، إذ قد يؤدي أدنى تغيير فيها بالنتيجة إلى وقوع الأخطاء، وبالتالي يبقى من الأسهل والأبسط إنشاء قائمة جديدة بدلًا من التعديل على القائمة الأصلية. وصّف مطور نواة بايثون ريمون هيتينجر:
اقتباسالسؤال: ما هي أفضل آلية لتعديل القوائم أثناء المرور على عناصرها؟
الإجابة: ألا تفعل ذلك أصلًا.
لا تنسخ القيم المتغيرة Mutable Values دون استخدام الدالتين ()copy.copy و ()copy.deepcopy
لعله من الأفضل فهم المتغيرات على أنها لافتات أو أسماء وسوم تشير إلى الكائنات بدلًا من فهمها على أنها صناديق تحتوي على الكائنات نفسها، ويؤتي هذا الفهم ثماره لدى تعديل الكائنات المتغيرة، وهي كائنات مثل القوائم والقواميس والمجموعات، والتي قيمها قابلة للتغيير mutable؛ فإذا كان لدينا متغير يشير إلى كائن ما متغيّر، وأردنا نسخ هذا المتغير إلى متغير آخر، فإن اعتقادنا بأن الكائن نفسه سيُنسخ يمثل مصدرًا شائعًا لأخطاء gotcha. إذ أن تعليمات الإسناد في بايثون لا تنسخ الكائنات، وإنما تنسخ فقط المراجع المشيرة إليها.
لنكتب مثلًا الشيفرة التالية في الصدفة التفاعلية، ونلاحظ منها أنه رغم تغيير المتغير spam وحده، فإن المتغير cheese قد تغير أيضًا:
>>> spam = ['cat', 'dog', 'eel'] >>> cheese = spam >>> spam ['cat', 'dog', 'eel'] >>> cheese ['cat', 'dog', 'eel'] >>> spam[2] = 'MOOSE' >>> spam ['cat', 'dog', 'MOOSE'] >>> cheese ['cat', 'dog', 'MOOSE'] >>> id(cheese), id(spam) 2356896337288, 2356896337288
يمكنك الاطلاع على تمثيل مرئي لتنفيذ الشيفرة السابقة على الرابط.
إذا كنت تعتقد بأن التعليمة cheese=spam تنسخ كائن القائمة نفسه، ستتفاجأ بأن المتغير cheese قد تغير رغم أننا عدلنا على المتغير spam وحده، ما يؤكّد أن تعليمة الإسناد في بايثون لا تنسخ الكائن نفسه وإنما المرجع إلى هذا الكائن؛ فتعليمة الإسناد cheese=spam تجعل من المتغير cheese يشير إلى نفس كائن القائمة الذي يشير إليه المتغير spam في ذاكرة الحاسب، وبالتالي لا تُستنسخ القائمة مرتين، وهذا ما يفسّر أن التعديل على المتغير spam سيطرأ أيضًا على المتغير cheese، إذ يشير كلاهما إلى نفس كائن القائمة.
ينطبق المبدأ ذاته على الكائنات المتغيرة المُمررة إلى استدعاءات الدوال. لنكتب الشيفرة التالية في الصدفة التفاعلية ملاحظين أن كلًا من المتغير العام spam والمعامل المحلي theList يشيران إلى الكائن ذاته. تذكّر أن المعاملات parameters ما هي إلا متغيرات مُعرّفة ضمن تعليمة التصريح عن الدالة.
>>> def printIdOfParam(theList): ... print(id(theList)) ... >>> eggs = ['cat', 'dog', 'eel'] >>> print(id(eggs)) 2356893256136 >>> printIdOfParam(eggs) 2356893256136
يمكنك الاطلاع على تمثيل مرئي لتنفيذ الشيفرة السابقة على الرابط. نلاحظ أن الهويتين identities المُعادتين من التابع ()id متساويتان لكل من eggs و theList، ما يعني أن هذان المتغيران يشيران إلى كائن القائمة ذاته، أي أن كائن القائمة الخاص بالمتغير eggs لم يُنسخ إلى المتغير theList، وإنما المرجع إلى هذا الكائن هو الذي نُسخ، وهذا ما يفسر كون كلا المتغيرين يشيران إلى القائمة ذاتها، فلا يشغل المرجع سوى بضعة بايتات في الذاكرة، ولكن ماذا لو كانت بايثون تنسخ القائمة كاملةً بدلًا من نسخ المرجع فقط، فلو كان المتغير يتضمّن مليار عنصر بدلًا من ثلاثة فقط‘ فإن تمريره إلى الدالة ()printIdOfParam سيتطلب نسخ هذه القائمة الضخمة كاملةً، ما سيستهلك حتى عدة جيجا بايت من الذاكرة من أجل هذا الاستدعاء البسيط للدالة، وهذا ما يفسر سبب أن تعليمة الإسناد في بايثون تنسخ المراجع فقط ولا تنسخ الكائنات.
إحدى طرق تجنب خطأ gotcha هذا تكون بأخذ نسخة عن كائن القائمة -وليس مرجعه فقط- باستخدام الدالة ()copy.copy. لنكتب ما يلي في الصدفة التفاعلية:
>>> import copy >>> fish = [2, 4, 8, 16] >>> chicken = copy.copy(fish) >>> id(fish), id(chicken) (2356896337352, 2356896337480) >>> fish[0] = 'CHANGED' >>> fish ['CHANGED', 4, 8, 16] >>> chicken [2, 4, 8, 16] >>> id(fish), id(chicken) (2356896337352, 2356896337480)
يمكنك الاطلاع على تمثيل مرئي لتنفيذ الشيفرة السابقة على الرابط، وفيها يشير المتغير chicken إلى كائن قائمة مستقل منسوخ وليس على كائن القائمة الأصلي المشار إليه بالمتغير fish، وبذلك لن يحدث خطأ gotcha آنف الذكر.
لكن وكما أن المتغيرات تمثّل عناوين أو أسماء وسوم تدل على الكائنات وليست صناديق محتوية على هذه الكائنات، فالقوائم تشابهها من حيث أنها تتضمن عناوين وأسماء وسوم دالة على الكائنات ولا تحتوي على الكائنات نفسها، فلو كان لدينا قائمة تحتوي على قوائم أخرى، فإن الدالة ()copy.copy تنسخ فقط مراجع تلك القوائم الداخلية. لنكتب الشيفرة التالية في الصدفة التفاعلية بغية الاطلاع على هذه المشكلة:
>>> import copy >>> fish = [[1, 2], [3, 4]] >>> chicken = copy.copy(fish) >>> id(fish), id(chicken) (2356896466248, 2356896375368) >>> fish.append('APPENDED') >>> fish [[1, 2], [3, 4], 'APPENDED'] >>> chicken [[1, 2], [3, 4]] >>> fish[0][0] = 'CHANGED' >>> fish [['CHANGED', 2], [3, 4], 'APPENDED'] >>> chicken [['CHANGED', 2], [3, 4]] >>> id(fish[0]), id(chicken[0]) (2356896337480, 2356896337480)
يمكنك الاطلاع على تمثيل مرئي لتنفيذ الشيفرة السابقة على الرابط.
بالرغم من كون كل من fish و chicken كائنا قوائم مختلفين، إلا أنهما يشيران إلى ذات القائمتين الداخليتين [1,2] و [3,4]، وبالتالي فإن تغيير أي منهما سيؤثّر على كلا المتغيرين، رغم استخدامنا للدالة ()copy.copy. يكمن الحل باستخدام الدالة ()copy.deepcopy، التي ستنسخ أي كائنات قوائم موجودة ضمن كائن القائمة الأصلي المنسوخ، وأي كائنات قوائم فرعية ضمن كائنات القوائم الداخلية في كائن القائمة الأصلي، وهكذا. لنكتب ما يلي في الصدفة التفاعلية:
>>> import copy >>> fish = [[1, 2], [3, 4]] >>> chicken = copy.deepcopy(fish) >>> id(fish[0]), id(chicken[0]) (2356896337352, 2356896466184) >>> fish[0][0] = 'CHANGED' >>> fish [['CHANGED', 2], [3, 4]] >>> chicken [[1, 2], [3, 4]]
يمكنك الاطلاع على تمثيل مرئي لتنفيذ الشيفرة السابقة على الرابط.
بالرغم من كون الدالة ()copy.deepcopy أبطأ قليلًا من الدالة ()copy.copy إلا أنها أأمن للاستخدام لحالات كونك غير متأكد من احتواء القائمة المنسوخة على قوائم داخلية أخرى، أو غيرها من الكائنات المتغيرة مثل القواميس والمجموعات. نصيحتنا العامة لك هي أن تستخدم الدالة ()copy.deepcopy دومًا، إذ أنها قد تجنبك وقوع أخطاء دقيقة، وغالبًا لن تلاحظ أصلًا البطء في تنفيذ الشيفرة الناتج عن استخدامها.
لا تستخدم القيم المتغيرة من أجل وسطاء افتراضية
تسمح بايثون بتعيين وسطاء افتراضية default arguments للمعاملات parameters لدى التصريح عن الدوال، فإذا لم يعين المستخدم معاملًا لدى استدعاء الدالة صراحةً، ستُنفّذ الدالة مُستخدمةً الوسيط الافتراضي مثل معامل، وهذا أمر مفيد خاصةُ لحالات كون معظم استدعاءات الدالة ستكون من أجل نفس الوسيط، إذ أن وجود الوسيط الافتراضي يجعل من تمرير معامل لدى استدعاء الدالة أمرًا اختياريًا؛ فعلى سبيل المثال، تمرير القيمة None إلى التابع ()split سيجعله يقتطع محارف المسافات البيضاء، ولكن ونظرًا لكون None هي أصلًا الوسيط الافتراضي لهذا التابع، إذ سيؤدي الاستدعاء ()cat dog'.split نفس الوظيفة كما لو كان بالشكل (cat dog'.split(None'، إذ تستخدم الدالة الوسيط الافتراضي معاملًا ما لم يُمرِّر المستخدم وسيطًا آخر.
ينبغي عليك عدم تعيين أي من الكائنات المتغيرة مثل القائمة أو القاموس وسيطًا افتراضيًا. إذ سيؤدي ذلك إلى وقوع أخطاء كما هو موضح في المثال التالي، وفيه نصرح عن دالة باسم ()addIngredient تضيف سلسلةً نصيةً تمثّل مكونًا ما لقائمة تمثل شطيرة، وبما المكون الأول والأخير في الشطائر عادةً هو الخبز bread، استخدمنا القائمة المتغيرة ['bread', 'bread'] وسيطًا افتراضيًا:
>>> def addIngredient(ingredient, sandwich=['bread', 'bread']): ... sandwich.insert(1, ingredient) ... return sandwich ... >>> mySandwich = addIngredient('avocado') >>> mySandwich ['bread', 'avocado', 'bread']
إلا أن استخدام كائنًا متغيّر مثل قائمة ['bread', 'bread'] وسيطًا افتراضيًا ينطوي على إشكال دقيق ألا وهو أن القائمة تُنشأ ولمرة واحدة لحظة تنفيذ التعليمة def المسؤولة عن التصريح عن الدالة، ولا تُنشأ من أجل كل استدعاء جديد للدالة، ما يعني أن كائن قائمة ['bread', 'bread'] وحيد سيُنشأ، كوننا لا نصرّح عن الدالة ()addIngredient سوى لمرة واحدة، إلا أن كل استدعاء جديد لهذه الدالة سيستخدم نفس القائمة، ما سيؤدي إلى سلوك خاطئ غير متوقع، كما يلي:
>>> mySandwich = addIngredient('avocado') >>> mySandwich ['bread', 'avocado', 'bread'] >>> anotherSandwich = addIngredient('lettuce') >>> anotherSandwich ['bread', 'lettuce', 'avocado', 'bread']
في الشيفرة السابقة وبما أن الاستدعاء ('addIngredient('lettuce سيستخدم نفس القائمة المُعيّنة وسيطًا افتراضيًا كما هو الحال في الاستدعاءات السابقة، التي أُضيفت إليها هذه القائمة أصلًا على العنصر avocado، لذا وبدلًا من الحصول على قائمة بالشكل: ['bread', 'lettuce', 'bread']، ستعيد الدالة القائمة: ['bread', 'lettuce', 'avocado', 'bread']؛ إذ تظهر السلسلة النصية avocado مجددًا لأن القائمة الخاصة بالمعامل sandwich هي نفسها من الاستدعاء السابق للدالة، فلا تُنشأ سوى قائمة ['bread', 'bread'] واحدة، نظرًا لأن تعليمة def الخاصة بالتصريح عن الدالة لا تُنفّذ سوى مرة واحدة، ولا تُنفّذ من أجل كل استدعاء جديد للدالة. يمكنك الاطلاع على تمثيل مرئي لتنفيذ الشيفرة السابقة على الرابط.
يكمن الحل البايثوني لدى حاجتك لتعيين قائمة أو قاموس وسيطًا افتراضيًا، في تعيين قيمة هذا الوسيط إلى None، ثم جعل شيفرتك تتحقق من إعادة هذه القيمة لتُنشئ عندها قائمة أو قاموس جديد من أجل كل استدعاء جديد للدالة، وهذا يضمن إنشاء الدالة لكائن مُتغير جديد من أجل كل استدعاء للدالة بدلًا من إنشائه لمرة واحدة عند التصريح عن الدالة، كما في المثال التالي:
>>> def addIngredient(ingredient, sandwich=None): ... if sandwich is None: ... sandwich = ['bread', 'bread'] ... sandwich.insert(1, ingredient) ... return sandwich ... >>> firstSandwich = addIngredient('cranberries') >>> firstSandwich ['bread', 'cranberries', 'bread'] >>> secondSandwich = addIngredient('lettuce') >>> secondSandwich ['bread', 'lettuce', 'bread'] >>> id(firstSandwich) == id(secondSandwich) 1 False
نلاحظ أن المعاملين firstSandwich وsecondSandwich لا يتشاركان مرجع القائمة ذاتها كما هو موضح في السطر رقم 1 من الشيفرة السابقة، ذلك لأن التعليمة ['sandwich = ['bread', 'bread تُنشئ كائن قائمة جديد في كل مرة تُستدعى فيها الدالة ()addIngredient، بدلًا من إنشائها لمرة واحدة لحظة التصريح عن الدالة.
تتضمن أنماط البيانات المتغيرة كلًا من القوائم والقواميس والمجموعات وجميع الكائنات المُصرّح عنها باستخدام التعليمة class، فلا تستخدم كائنات من هذه الأنماط وسطاء افتراضية ضمن تعليمة def الخاصة بالتصريح عن الدوال.
لا تبن السلاسل النصية باستخدام عمليات ربط السلاسل النصية String Concatenation
تعد السلاسل النصية في بايثون كائناتٍ ثابتة immutable، ما يعني أنه لا يمكن تغيير قيم السلاسل النصية، وأي شيفرة تبدو وكأنها تُعدّل على سلسلة نصية، فإنها في الواقع تُنشئ كائن سلسلة نصية جديد؛ فعلى سبيل المثال، كل من العمليات التالية تُغير من محتوى المتغير spam، الأمر الذي يحدث باستبدال محتواه بسلسلة نصية جديدة ذات هوية جديدة وليس بالتعديل على قيمة السلسلة الموجودة أصلًا:
>>> spam = 'Hello' >>> id(spam), spam (38330864, 'Hello') >>> spam = spam + ' world!' >>> id(spam), spam (38329712, 'Hello world!') >>> spam = spam.upper() >>> id(spam), spam (38329648, 'HELLO WORLD!') >>> spam = 'Hi' >>> id(spam), spam (38395568, 'Hi') >>> spam = f'{spam} world!' >>> id(spam), spam (38330864, 'Hi world!')
من الجدير بالملاحظة أن كل استدعاء للدالة (id(spam يعيد هويةً جديدةً، والسبب وراء ذلك هو أن كائن السلسلة النصية الموجود في المتغير spam لا يُعدَّل، وإنما يُستبدل كاملًا بكائن سلسلة نصية جديد بهوية مختلفة، كما أن إنشاء سلاسل نصية جديدة باستخدام أي من بناء السلاسل النصية f-strings أو التابع ()format أو المحدد s% يُنشئ كائنات سلاسل نصية جديدة، كما هو الحال لدى ربط السلاسل النصية. قد لا تهمنا هذه التفاصيل التقنية في الأحوال العادية، إذ أن بايثون لغة برمجة عالية المستوى والتي تأخذ على عاتقها إنجاز العديد من التفاصيل المشابهة بدلًا عنك، سانحةً لك المجال لتصب تركيزك فقط على إنشاء برنامجك، إلا أن بناء سلسلة نصية باستخدام عدد كبير من عمليات ربط السلاسل النصية قد يتسبب بإبطاء برنامجك، فمع كل تكرار للحلقة سيُنشَئ كائن سلسلة نصية جديد ليُحذف سابقه، أي لدى استخدام عملية ربط سلاسل نصية ضمن حلقة for أو while كما في المثال التالي:
>>> finalString = '' >>> for i in range(100000): ... finalString += 'spam ' ... >>> finalString spam spam spam spam spam spam spam spam spam spam spam spam --snip–
بما أن العملية ' finalString += 'spam ستُنفّذ 100000 مرة ضمن الحلقة، ستجري بايثون 100000 عملية ربط سلاسل محرفية، إذ ستُنشئ وحدة المعالجة المركزية CPU قيم السلاسل النصية الوسيطة بربط القيمة الحالية للمتغير finalString عند كل تكرار مع السلسلة 'spam'، لتخزّن السلسلة الناتجة في الذاكرة، لتعود وتحذفها من الذاكرة مجددًا عند التكرار الجديد للحلقة، ما يمثل مقدارًا كبيرًا من الجهد الضائع، فكل ما يهمنا هو الحصول على السلسلة النصية النهائية بالنتيجة.
تكمن الطريقة البايثونية في بناء السلاسل النصية بإضافة السلاسل الفرعية الأقصر إلى قائمة ومن ثم دمجها معًا وصولًا إلى سلسلة نصية واحدة. رغم كون هذه الطريقة تُنشئ أيضًا 100000 كائن سلسلة نصية، إلا أنها لا تجري سوى عملية ربط سلاسل نصية واحدة وذلك عند استدعاء الدالة ()join؛ فعلى سبيل المثال، تُنشئ الشيفرة التالية سلسلة نهائية في المتغير finalString مكافئة لتلك في المثال السابق ولكن دون استخدام عمليات ربط وسيطة للسلاسل النصية، على النحو التالي:
>>> finalString = [] >>> for i in range(100000): ... finalString.append('spam ') ... >>> finalString = ''.join(finalString) >>> finalString spam spam spam spam spam spam spam spam spam spam spam spam --snip–
لدى قياس زمن التنفيذ لكلا الشيفرتين السابقتين وعلى الحاسب نفسه، وجدنا أن المنهجية الثانية المتمثلة باستخدام قائمة لإضافة السلاسل النصية المراد ربطها إليها أسرع بعشر مرات من منهجية ربط السلاسل المحرفية بالعوامل، وسيغدو الفرق في السرعة هذا أكبر وأوضح مع زيادة عدد التكرارات المطلوبة، ولكن حتى لحالة التكرار 100 مرة عوضًا عن 100000، ورغم كون منهجية ربط السلاسل الأولى تبقى أبطأ من منهجية الإضافة إلى قائمة، إلا أن الفرق في هذه الحالة ضئيل ويمكن إهماله؛ ما يعني أنه لا يجب إلغاء استخدام ربط السلاسل النصية تمامًا سواء باستخدام f-strings أو التابع ()format أو المعرف s% لكل الحالات، فالسرعة تتحسن بصورة ملحوظة فقط من أجل عدد ضخم من عمليات الربط.
تخفف عنك بايثون عبء التفكير والاهتمام بالكثير من التفاصيل التي تجري في الخلفية، سامحةً للمبرمجين بكتابة برامجهم بسرعة، وكما ذكرنا سابقًا فإن وقت المبرمج أثمن من وقت وحدة المعالجة المركزية، ومع ذلك من الجيد فهم التفاصيل في بعض الحالات، مثل الفرق ما بين السلاسل النصية الثابتة والقوائم المتغيرة، ما يجنبنا الوقوع في فخ أخطاء gotcha، كما في حالة بناء السلاسل النصية عبر ربطها.
لا تتوقع من التابع ()sort أن يرتب القيم أبجديا
لعل فهم خوارزميات الترتيب -الخوارزميات المسؤولة عن ترتيب القيم بطريقة ممنهجة وفقًا لترتيب أو فرز محدد- أمر أساسي ومهم في دراسة علم الحاسوب، إلا أن ما بين يديك الآن هو ليس كتاب في علم الحاسوب، ما قد يوحي بعدم أهمية معرفتك لهذه الخوارزميات، طالما أنه من الممكن استدعاء تابع الترتيب في بايثون ()sort ببساطة، ولكن ستلاحظ أن لهذا التابع بعض السلوكيات الغريبة أحيانًا في ترتيب البيانات، كأن يضع ترتيب حرف Z (الأخير في الأبجدية الإنجليزية) وهو في حالته الكبيرة قبل حرف a (الأول في الأبجدية الإنجليزية) وهو في حالته الصغيرة، كما في المثال:
>>> letters = ['z', 'A', 'a', 'Z'] >>> letters.sort() >>> letters ['A', 'Z', 'a', 'z']
الترميز الأمريكي المعياري لتبادل المعلومات American Standard Code for Information Interchange -أو اختصارًا ASCII- ويُقرأ أسكي هو جدول يربط ما بين الترميزات الرقمية numeric codes (وتسمى بنقاط الترميز code points أو الأعداد الترتيبية ordinals) والمحارف النصية، ويرتب التابع ()sort القيم وفقًا لترتيب ترميز أسكي (ASCII-betical وهو مصطلح شائع ويعني الفرز وفق ترتيب عددي موافق لقيم ترميز الأسكي) وليس وفق ترتيب أبجدي. فوفقًا لترميز الأسكي نقطة الترميز الموافقة للحرف A هي 65، وللحرف B هي 66 وهكذا حتى الحرف Z الموافق لنقطة الترميز 90، أما الحرف a (الحرف A في حالته الصغيرة) فيوافق 97 والحرف b يوافق 98 وهكذا حتى الحرف z الموافق لنقطة الترميز 122، وبالتالي ولدى الفرز وفقًا لترميز الأسكي سيأتي الحرف Z (ذو نقطة الترميز 90) قبل الحرف a (ذو نقطة الترميز 97).
رغم كون ترميز الأسكي هو الأشيع في مجال الحوسبة عند الغرب ما قبل وخلال التسعينيات، ولكن يبقى هذا الترميز أمريكيًا فقط، إذ يوجد نقطة ترميز لعلامة الدولار $ وهي 36، ولكن لا يوجد نقطة ترميز لعلامة الجنيه البريطاني £، وبالتالي استُبدل ترميز الأسكي على نطاقٍ واسع بترميز Unicode، إذ يتضمّن كافة نقاط ترميز الأسكي إضافةً إلى ما يزيد عن 100000 نقطة ترميز أخرى.
يمكن معرفة نقطة الترميز الموافقة لمحرف ما بتمريره إلى الدالة ()ord. كما يمكن معرفة المحرف الموافق لنقطة ترميز ما بتمريره العدد الصحيح الموافق لنقطة الترميز إلى الدالة ()chr، التي تعيد سلسلةً نصيةً تتضمن المحرف الموافق، فعلى سبيل المثال، لنكتب الشيفرة التالية في الصدفة التفاعلية:
>>> ord('a') 97 >>> chr(97) 'a'
أما في حال الرغبة بالفرز وفق ترتيب أبجدي، نمرر التابع str.lower إلى المعامل key من التابع ()sort، وبالتالي تُفرز القيم كما لو أنها مُررت إلى الدالة ()lower قبل فرزها وترتيبها:
>>> letters = ['z', 'A', 'a', 'Z'] >>> letters.sort(key=str.lower) >>> letters ['A', 'a', 'z', 'Z']
نلاحظ في الشيفرة السابقة أن السلاسل النصية ضمن القائمة لم تحوّل إلى حالة الأحرف الصغيرة، وإنما فقط فُرزت كما لو أنها كانت كذلك. يؤمن نيد باتشيلدرNed Batchelder مزيدًا من المعلومات حول يونيكود Unicode ونقاط الشيفرة في حديثه عن يونيكود البراغماتي أو كيف يمكنني إيقاف الألم من خلال الرابط.
من الجدير بالذكر أن خوارزمية الفرز التي يستخدمها التابع ()sort هي Timsort،المصممة من قبل تيم بيترز Tim Peters مطوّر نواة بايثون ومؤلف مبادئ بايثون التوجيهية العشرون (Zen of Python)، وهي خوارزمية هجينة من الفرز بالدمج والفرز بالإدراج insertion.
لا تفترض أن الأعداد ذات الفاصلة العشرية دقيقة تماما
لا تستطيع الحواسيب تخزين الأعداد سوى في نظام العد الثنائي، المكون من الخانتين 1 و0 فقط. ولعرض الأرقام ذات الفاصلة العشرية بالشكل المألوف بالنسبة لنا، لا بد من ترجمة رقم مثل 3.14 إلى سلسلة من الأصفار والواحدات، وتجري الحواسيب عملية التحويل هذه وفقًا للمعيار IEEE 754، المنشور من قبل معهد مهندسي الكهرباء والإلكترونيات (IEEE والتي تُقرأ آي تربل إي). لتبسيط الأمور فإن هذه التفاصيل مخفية على المبرمجين، سامحةً لنا بكتابة الأعداد مع الفاصلة العشرية دون التفكير بعملية التحويل من النظام العشري إلى الثنائي:
>>> 0.3 0.3
ورغم كون تفاصيل بعض الحالات هي خارج اهتمامات كتابنا هذا، لن يطابق تمثيل IEEE 754 للأعداد ذات الفاصلة العشرية تمامًا القيمة الموافقة في النظام العشري دومًا. أحد أشهر الأمثلة هو العدد 0.1، على النحو التالي:
>>> 0.1 + 0.1 + 0.1 0.30000000000000004 >>> 0.3 == (0.1 + 0.1 + 0.1) False
وهذا المجموع الغريب غير الدقيق ناتج عن أخطاء تقريب الناتجة عن كيفية تمثيل الحواسيب ومعالجتها للأعداد ذات الفاصلة العشرية، وهذا ليس خطأ gotcha خاص ببايثون، إذ أن المعيار IEEE 754 مطبق مباشرةً على دارات احتساب الفاصلة العشرية في وحدة المعالجة المركزية، وبالتالي سنحصل على نتيجة مشابهة لو استخدمنا لغات برمجة أخرى مثل ++C أو جافا سكريبت JavaScript أو أي لغة برمجة عاملة على وحدة معالجة مركزية تستخدم المعيار IEEE 754، وفي الواقع هو المعيار المطبق على كل وحدات المعالجة المركزية حول العالم، كما أن المعيار IEEE 754 ولأسبابٍ خارج اهتمامات كتابنا هذا غير قادر أيضًا على تمثيل كافة الأعداد الصحيحة التي تزيد عن 253. فمثلًا كلا القيمتين 253 و 253+1 مثل أعداد حقيقية (من النوع float) تقربان إلى القيمة 9007199254740992.0 ذاتها:
>>> float(2**53) == float(2**53) + 1 True
طالما أنك تستخدم نمط بيانات الفاصلة العشرية، فما من مفر من أخطاء التقريب هذه، ولكن لا تقلق، فطالما أنك لا تكتب برنامجًا لأحد المصارف أو لمفاعل نووي أو لمفاعل نووي خاص بأحد البنوك فإن أخطاء التقريب هذه ستكون صغيرة بما يكفي بحيث أنها لن تتسبب بمشاكل جوهرية في برامجك، ومن الممكن غالبًأ تجاوز هذه المشكلة بالاعتماد على الأعداد الصحيحة مع وحدات أصغر، كأن نستخدم 133 سنتًا بدلًا من 1.33 دولارًا، أو 200 ميللي ثانية بدلًا من 0.2 ثانية، وعلى هذا النحو تُجمع القيم 10+10+10 لتعطي 30 سنتًا أو ميللي ثانية بدلًا من جمع 0.1+0.1+0.1 لتعطي 0.30000000000000004 دولارًا أو ثانية.
أما في حال الحاجة لدقة متناهية، مثلًا لحسابات علمية أو مالية، فمن الممكن استخدام وحدة decimal المبنية مُسبقًا في بايثون، ورغم كون كائنات هذه الوحدة أبطأ، إلا أنها بديل دقيق للقيم الحقيقية العشرية، فعلى سبيل المثال، التعليمة ('decimal.Decimal('0.1 تُنشئ كائنًا يمثل العدد 0.1 تمامًا بعيدًا عن خطأ التقريب الذي ينطوي عليه العدد ذاته كقيمة عشرية من النوع float.
سيُنشئ تمرير القيمة الحقيقية 0.1 إلى ()decimal.Decimal كائن Decimal بنفس خطأ التقريب كما لو كان قيمة حقيقية عادية، وهذا ما يفسر كون القيمة الناتجة لا تساوي تمامًا القيمة ('Decimal('0.1. لذا يجب تمرير القيم الحقيقية مثل سلاسل نصية إلى ()decimal.Decimal، ولتوضيح هذه النقطة، لنكتب التالي في الصدفة التفاعلية:
>>> import decimal >>> d = decimal.Decimal(0.1) >>> d Decimal('0.1000000000000000055511151231257827021181583404541015625') >>> d = decimal.Decimal('0.1') >>> d Decimal('0.1') >>> d + d + d Decimal('0.3')
ليس لدى الأعداد الصحيحة أخطاء تقريب، لذا من الآمن تمريرها كما هي إلى ()decimal.Decimal. والآن لنكتب التالي في الصدفة التفاعلية:
>>> 10 + d Decimal('10.1') >>> d * 3 Decimal('0.3') >>> 1 - d Decimal('0.9') >>> d + 0.1 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unsupported operand type(s) for +: 'decimal.Decimal' and 'float'
ولكن كائنات Decimal لا تمتلك دقة غير متناهية، إذ أنها ببساطة تمتلك مستوى دقة محدد ومعرّف. لنأخذ العمليات التالية كمثال:
>>> import decimal >>> d = decimal.Decimal(1) / 3 >>> d Decimal('0.3333333333333333333333333333') >>> d * 3 Decimal('0.9999999999999999999999999999') >>> (d * 3) == 1 # d is not exactly 1/3 False
يُقيّم في الشيفرة السابقة التعبير البرمجي decimal.Decimal(1) / 3 إلى قيمة لا تساوي تمامًا الثلث. وافتراضيًا يكون بمستوى 28 رقمًا بارزًا significant، ومن الممكن الاطلاع على عدد الأرقام البارزة التي تستخدمها الوحدة decimal باستخدام السمة decimal.getcontext().prec (إذ أن prec تقنيًا هي سمة للكائن المعاد من التابع ()getcontext، ولكن من المناسب استخدامها في نفس السطر مع التابع). يمكنك تغيير هذه السمة وبالتالي مستوى الدقة بتغيير عدد الأرقام البارزة إلى ذلك المحدد من قبلك، ففي المثال التالي في الصدفة التفاعلية، سنقلل عدد الأرقام البارزة من 28 إلى 2 على النحو التالي:
>>> import decimal >>> decimal.getcontext().prec 28 >>> decimal.getcontext().prec = 2 >>> decimal.Decimal(1) / 3 Decimal('0.33')
إذ توفر الوحدة decimal لنا القدرة على التحكم بكيفية تعاطي الأرقام مع بعضها بعضًا.
لا تستخدم سلسلة من عوامل عدم التساوي =!
يمثّل استخدام سلسلة من عوامل المقارنة مثل 18 < age < 35 أو سلسلة من عوامل الإسناد مثل six = halfDozen = 6 اختصارًا مفيدًا للتعابير:
( age > 18 ) and (age < 35) six = 6; halfDozen = 6
على التوالي، ولكن لا ينبغي استخدام سلسلة من عوامل عدم التساوي =!، فقد تظن أن الشيفرة التالية تتحقق من كون المتغيرات الثلاث تمتلك قيمًا مختلفة عن بعضها بعضًا، نظرًا لأن التعبير قد قُيّم على أنه صحيح True:
>>> a = 'cat' >>> b = 'dog' >>> c = 'moose' >>> a != b != c True
إلا أن السلسلة السابقة في الواقع تكافئ (a != b) and (b != c)، ما يعني أنه من الممكن كون المتغير a مساويًا للمتغير c وسيُقيم التعبير a != b != c أيضًا على أنه صحيح True، على النحو التالي:
>>> a = 'cat' >>> b = 'dog' >>> c = 'cat' >>> a != b != c True
وهو خطأ دقيق ومعه ستكون الشيفرة مُضلِلة، لذا من الأفضل تجنب استخدام سلسلة من عوامل عدم المساواة =! معًا.
لا تنس استخدام الفاصلة في الصفوف وحيدة العنصر
لدى استخدام الصفوف في الشيفرات، يجب أن نأخذ بالحسبان وضع فاصلة لاحقة زائدة حتى وإن كان الصف يحتوي على عنصر وحيد. ففي حين أن القيمة ( ,42) تُمثّل صفًا يحتوي على العدد الصحيح 42، فإن القيمة (42) تمثّل العدد الصحيح 42 نفسه؛ فالأقواس في (42) مشابهة لتلك في التعبير (20+1)*2 والذي يُقيّم إلى القيمة 42. فنسيان الفاصلة في الصف قد يؤدي لما يلي:
>>> spam = ('cat', 'dog', 'moose') >>> spam[0] 'cat' >>> spam = ('cat') 1 >>> spam[0] 'c' 2 >>> spam = ('cat', ) >>> spam[0] 'cat'
فبدون الفاصلة سيُقيّم ('cat') إلى قيمة سلسلة محارف، ما يفسر أن التعبير [spam[0 المشار إليه في السطر رقم 1 يُقيّم إلى المحرف الأول من السلسلة وهو c؛ فالفاصلة الزائدة مطلوبة ضمن القوسين حتى يجري التعرف عليها مثل صف كما في السطر رقم 2 من الشيفرة السابقة. يميز استخدام الفاصلة في بايثون الصف عن الأقواس المجردة.
الخلاصة
قد يحدث سوء التواصل في أي لغة بما في ذلك في لغات البرمجة، ولدى بايثون بضعة صيغ تبدو صحيحة إلا أنها قد تتسبب بحدوث أخطاء نسميها gotchas والتي يمكن أن يقع في فخها المبرمج غير المحترف، ورغم ندرتها إلا أنه من الضروري معرفتها بما يسمح بملاحظتها والتعرف عليها عند وقوعها وتنقيح المشاكل الناجمة عنها.
بالرغم أنه من الممكن تقنيًا إضافة العناصر أو حذفها من قائمة ما أثناء المرور عليها، إلا أن هذه الآلية تُشكّل مصدرًا محتملًا للأخطاء، والحل الآمن هنا يكون بالتكرار على نسخة من القائمة، ثم إجراء التغييرات على القائمة الأصلية. من الجدير بالذكر أنه عند إنشاء نسخة عن قائمة (أو عن أي كائن قابل للتغيير)، فإن تعليمة الإسناد تنسخ فقط المرجع إلى هذا الكائن، وليس الكائن نفسه، وفي حال رغبتك بنسخ الكائن (مع أي كائنات فرعية يشير إليها) فيمكنك استخدام الدالة ()copy.deepcopy.
ينبغي عليك عدم استخدام الكائنات المتغيرة مثل وسطاء افتراضية ضمن عبارة def الخاصة بالتصريح عن الدوال، إذ بذلك لن يُنشأ هذا الوسيط سوى مرة واحدة لحظة تنفيذ التعليمة def وليس في كل مرة تُستدعى فيها الدالة، والحل الأفضل يكون بتعيين الوسيط الافتراضي ليكون None، مع إضافة شيفرة لتتحقق من تمرير None بالفعل مثل وسيط لتُنشئ عندها الكائن المتغير المطلوب عند استدعاء الدالة.
ينتج أحد أخطاء gotcha عن بناء سلسلة نصية عبر ربط العديد من السلاسل النصية الأصغر باستخدام العامل + ضمن حلقة. فمن أجل عدد صغير من التكرارات تعد الصياغة السابقة مقبولة. ولكن خلف الكواليس وباستخدام هذه الطريقة تضطر بايثون لإنشاء كائنات سلاسل نصية وإعادة حذفها على التوالي من أجل كل تكرار. الحل الأفضل يكون بإضافة السلاسل النصية الأصغر إلى قائمة ومن ثم المعامل ()join لإنشاء السلسلة النهائية المطلوبة.
يفرز التابع ()sort القيم اعتمادًا على نقاط الترميز المختلفة عن الترتيب الأبجدي، إذ يُرتّب الحرف Z في حالته الكبيرة قبل الحرف a في حالته الصغيرة، ويمكن حل هذه المشكلة باستخدام الاستدعاء على النحو (sort(key=str.lower.
تمتلك الأعداد العشرية خطأ تقريب بسيط ناتج عن طريقة تمثيل الأعداد، وهذا الأمر عديم الأهمية في معظم البرامج، وإذا كان الأمر ذو تأثير على برنامجك، فمن الممكن استخدام وحدة بايثون decimal.
نهايةً، تجنّب تمامًا ربط عوامل عدم التساوي =!، لأن التعبير 'cat' != 'dog' != 'cat' سيُقيّم على نحوٍ غريب على أنه صحيح True.
رغم أن هذا المقال يوصف أخطاء gotcha في بايثون التي قد تواجهها، إلا أن هذا النوع من الأخطاء قليل الحدوث في معظم الشيفرات الواقعية، وقد بذلت بايثون مجهودًا كبيرًا في تقليل المفاجآت التي قد تصادفك في برامجك. سنغطي في المقال التالي بعضًا من أخطاء gotcha الأندر والأغرب، ويكاد يكون من المستحيل أن تواجه هذه السلوكيات الغريبة ما لم تبحث عنها متعمدًا، ومع ذلك يبقى من الممتع الاطلاع عليها ومعرفة أسباب حدوثها.
ترجمة -وبتصرف- للفصل الثامن "البنى الصحيحة المؤدية إلى الأخطاء Gotchas الشائعة في بايثون" من كتاب Beyond the Basic Stuff with Python لصاحبه Al Sweigart.








أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.