

اقتباسيبادر البعض إذا قابلَته مشكلة إلى استخدام التعابير النمطية، ولا يدرك المرء أنه بهذا قد جعل المشكلة اثنتين. ـــ جيمي زاوينيسكي Jamie Zawiniski
إذا قطعت الخشب في عكس اتجاه أليافه فستحتاج إلى قوة أكبر، كذلك إذا سار البرنامج عكس اتجاه المشكلة، إذ ستحتاج شيفرات أكثر لحلها. ـــ يوان-ما Yuan-Ma، كتاب البرمجة The Book of Programming.
إذا نظرنا إلى التقنيات والأدوات البرمجية المنتشرة، فسنرى أنّ التقنية أو الأداة المشهورة هي التي تُثبت كفاءتها العملية في مجالها، أو التي تتكامل تكاملًا ممتازًا مع تقنية أخرى مستخدَمة بكثرة، وليس لأنها الأجمل أو الأذكى.إرشادات للحل
سنناقش هنا إحدى تلك الأدوات التي تدعى بالتعابير النمطية Regular Expressions، وهي طريقة لوصف الأنماط patterns في بيانات السلاسل النصية، إذ تُكوِّن هذه التعابير لغةً صغيرةً مستقلةً بذاتها، لكنها رغم ذلك تدخل في لغات برمجية أخرى مثل جافاسكربت، كما تدخل في العديد من الأنظمة.
قد تكون صيغة التعابير النمطية غريبةً للناظر إليها، كما أنّ الواجهة التي توفرها جافاسكربت للتعامل معها ليست بالمثلى، لكن رغم هذا، فتلك التعابير تُعَد أداةً قويةً لفحص ومعالجة السلاسل النصية، كما سيعينك فهمها على كتابة حلول أكفأ للمشاكل التي تواجهك.
إنشاء تعبير نمطي
التعبير النمطي هو نوع من أنواع الكائنات؛ فإما يُنشأ باستخدام الباني RegExp، أو يُكتب على أساس قيمة مصنَّفة النوع literal value بتغليف النمط بشرطتين مائلتين أماميتين من النوع /.
let re1 = new RegExp("abc"); let re2 = /abc/;
يُمثِّل كائنا التعبيرات النمطية في المثال السابق النمط نفسه أي محرف a يتبعه b ثم c، ويُكتب النمط على أساس سلسلة نصية عادية عند استخدام الباني RegExp، لذا تطبَّق القواعد المعتادة للشرطات المائلة الخلفية \، على عكس الحالة الثانية التي نرى فيها النمط بين شرطتين مائلتين، إذ تعامَل الشرطات هنا تعاملًا مختلفًا.
نحتاج إلى وضع شرطة خلفية قبل أي شرطة أمامية نريدها جزءًا من النمط نفسه، وذلك لأن الشرطة الأمامية تنهي النمط إذا وُجدت. كذلك فإن الشرطات الخلفية التي لا تكون جزءًا من ترميز خاص لمحرف -مثل \n- لن تُتَجاهل كما نفعل في السلاسل النصية، وعليه ستتسبب في تغيير معنى النمط.
تملك بعض المحارف مثل علامات الاستفهام وإشارات الجمع مَعاني خاصة في التعابير النمطية، حيث سنحتاج إلى وضع شرطة مائلة خلفية قبلها إذا أردنا لها تمثيل المحرف نفسه وليس معناه في التعابير النمطية.
let eighteenPlus = /eighteen\+/;
التحقق من المطابقات
تملك كائنات التعابير النمطية توابع عديدة، وأبسط تلك التوابع هو التابع test الذي إن مرَّرنا سلسلةً نصيةً إليه، فسيُعيد قيمةً بوليانيةً تخبرنا هل تحتوي السلسلة على تطابق للنمط الذي في التعبير أم لا.
console.log(/abc/.test("abcde")); // → true console.log(/abc/.test("abxde")); // → false
يتكون التعبير النمطي من محارف عادية غير خاصة تمثِّل -ببساطة- ذلك التسلسل من المحارف، فإذا وُجد abc في أيّ مكان في السلسلة النصية التي نختبرها -ولا يُشترط وجودها في بدايتها-، فسيُعيد test القيمة true.
مجموعات المحارف
يمكن التحقق من وجود abc في سلسلة نصية باستدعاء التابع indexof.
تسمح لنا التعابير النمطية بالتعبير عن أنماط أكثر تعقيدًا، فمثلًا كل ما علينا فعله لمطابقة عدد ما هو وضع مجموعة من المحارف بين قوسين مربعين لجعل ذلك الجزء من التعبير يطابق أيًا من المحارف الموجودة بين الأقواس.
لننظر المثال التالي حيث يطابق التعبيران جميع السلاسل النصية التي تحتوي على رقم ما:
console.log(/[0123456789]/.test("in 1992")); // → true console.log(/[0-9]/.test("in 1992")); // → true
يمكن الإشارة إلى مجال من المحارف داخل القوسين المربعين باستخدام الشرطة - بين أول محرف فيه وآخر محرف، ويُحدَّد الترتيب في تلك المحارف برمز اليونيكود لكل محرف -كما ترى من المثال أعلاه الذي يشير إلى مجال الأرقام من 0 إلى 9-، وهذه الأرقام تحمل رمز 48 حتى 57 بالترتيب في اليونيكود، وعليه فإنّ المجال [0-9] يشملها جميعًا، ويطابق أي رقم.
تمتلك مجموعة محارف الأعداد اختصارات خاصة بها كما هو شأن العديد من مجموعات المحارف الشائعة، فإذا أردنا الإشارة إلى المجال من 0 حتى 9، فسنستخدِم الاختصار \d.
| الاختصار | الدلالة |
|---|---|
\d
|
أيّ محرف رقمي |
\w
|
محرف أبجدي أو رقمي، أي محرف الكلمة |
\s
|
أيّ محرف مسافة بيضاء، مثل المسافات الفارغة والجداول والأسطر الجديدة وما شابهها |
\D
|
محرف غير رقمي |
\W
|
محرف غير أبجدي وغير رقمي |
\S
|
محرف مغاير للمسافة البيضاء |
.
|
أيّ محرف عدا السطر الجديد |
نستطيع مطابقة تنسيق التاريخ والوقت -كما في 01-30-2003 15:20- باستخدام التعبير التالي:
let dateTime = /\d\d-\d\d-\d\d\d\d \d\d:\d\d/; console.log(dateTime.test("01-30-2003 15:20")); // → true console.log(dateTime.test("30-jan-2003 15:20")); // → false
تعيق الشرطات المائلة الموجودة في المثال أعلاه قراءة النمط الذي نعبر عنه، وسنرى لاحقًا نسخةً أفضل في هذا المقال.
يمكن استخدام رموز الشرطات المائلة تلك داخل أقواس مربعة، إذ تعني [\d.] مثلًا أيّ رقم أو محرف النقطة .، لكن تفقِد النقطة نفسها معناها المميز لها إذا كانت داخل أقواس مربعة، وبالمثل في حالة إشارة الجمع +؛ أما إذا أردنا عكس مجموعة محارف، أي إذا أردنا التعبير عن رغبتنا في مطابقة أيّ محرف عدا تلك المحارف التي في المجموعة، فنستخدم رمز الإقحام ^ بعد قوس الافتتاح.
let notBinary = /[^01]/; console.log(notBinary.test("1100100010100110")); // → false console.log(notBinary.test("1100100010200110")); // → true
تكرار أجزاء من النمط
لقد بتنا الآن نعلم كيف نطابق رقمًا واحدًا، لكن كيف سنفعل ذلك إذا أردنا مطابقة عدد يحتوي على أكثر من رقم؟ إذا وضعنا إشارة الجمع + بعد شيء ما في تعبير نمطي، فستشير إلى أنّ هذا العنصر قد يكرَّر أكثر من مرة، بالتالي تعني /\d+/ مطابقة محرف رقم أو أكثر.
console.log(/'\d+'/.test("'123'")); // → true console.log(/'\d+'/.test("''")); // → false console.log(/'\d*'/.test("'123'")); // → true console.log(/'\d*'/.test("''")); // → true
تحمل إشارة النجمة * معنى قريبًا من ذلك، حيث تسمح للنمط بالمطابقة على أي حال، فإذا لحقت إشارة النجمة بشيء ما، فلن تمنع النمط من مطابقته، إذ ستطابق نُسخًا صفرية zero instances حتى لو لم تجد نصًا مناسبًا لمطابقته؛ أما إذا جاءت علامة الاستفهام بعد محرف في نمط، فستجعل ذلك المحرف اختياريًا optional، أي قد يحدث مرةً واحدةً أو لا يحدث.
يُسمح للمحرف u في المثال التالي بالحدوث، ويحقق النمط المطابقة حتى لو لم يكن u موجودًا أيضًا.
let neighbor = /neighbou?r/; console.log(neighbor.test("neighbour")); // → true console.log(neighbor.test("neighbor")); // → true
نستخدم الأقواس المعقوصة إذا أردنا حدوث النمط عددًا معينًا من المرات، فإذا وضعنا {4} بعد عنصر ما مثلًا، فسيجبره بالحدوث 4 مرات حصرًا، ومن الممكن تحديد المجال الذي يمكن للعنصر حدوثه فيه بكتابة {2,4} التي تشير إلى وجوب ظهور العنصر مرتين على الأقل، وأربع مرات على الأكثر.
لدينا نسخة أخرى من نمط التاريخ والوقت، حيث تسمح بذكر الأيام برقم واحد -أو رقمين-، والأشهر، والساعات، إذ تُعَدّ أسهل قليلًا في قراءتها، وهي المثال الذي قلنا أننا سنعود إليه بنسخة أفضل.
let dateTime = /\d{1,2}-\d{1,2}-\d{4} \d{1,2}:\d{2}/; console.log(dateTime.test("1-30-2003 8:45")); // → true
نستطيع تحديد مجالات مفتوحة عند استخدام الأقواس بإهمال الرقم الموجود بعد الفاصلة، وبالتالي، تعني {5,} خمس مرات على الأقل.
جمع التعبيرات الفرعية
إذا أردنا استخدام عامل مثل *، أو + على أكثر من عنصر في المرة الواحدة، فيجب استخدام الأقواس، وسترى العوامل الجزء الذي داخل الأقواس من التعبير النمطي عنصرًا واحدًا.
let cartoonCrying = /boo+(hoo+)+/i; console.log(cartoonCrying.test("Boohoooohoohooo")); // → true
تطبَّق إشارتا الجمع الأولى والثانية على o الثانية فقط في boo، وhoo على الترتيب؛ أما علامة الجمع الثالثة فتطبَّق على المجموعة كلها (hoo+) مطابِقةً تسلسلًا واحدًا أو أكثر بهذا.
يجعل محرف i -الذي في نهاية التعبير- هذا التعبير النمطي غير حساس لحالة المحارف، إذ يسمح بمطابقة المحرف B في سلسلة الدخل النصية رغم تكوّن النمط من محارف صغيرة.
التطابقات والمجموعات
يُعَدّ التابع test أبسط طريقة لمطابقة تعبير نمطي، إذ لا يخبرك إلا بمطابقة التعبير النمطي من عدمها وفقط، كذلك تملك التعبيرات النمطية تابعًا اسمه exec، حيث يُعيد القيمة null إذا لم يجد مطابقة، كما يُعيد كائنًا مع معلومات عن المطابقة إذا وجد تطابق.
let match = /\d+/.exec("one two 100"); console.log(match); // → ["100"] console.log(match.index); // → 8
تكون للكائن المعاد من exec خاصية تدعى index، إذ تخبرنا أين تبدأ المطابقة الناجحة للسلسلة النصية؛ أما خلاف هذا فيبدو الكائن أشبه بمصفوفة من السلاسل النصية -وهو كذلك حقًا-، ويكون أول عنصر في تلك المصفوفة هو السلسلة المطابَقة، كما يكون ذلك هو تسلسل الأرقام الذي كنا نبحث عنه في المثال السابق.
تحتوي قيم السلاسل النصية على التابع match الذي له سلوك مشابه:
console.log("one two 100".match(/\d+/)); // → ["100"]
حين يحتوي التعبير النمطي على تعبيرات فرعية مجمَّعة داخل أقواس، فسيظهر النص الذي يطابق تلك المجموعات في مصفوفة، ويكون العنصر الأول هو التطابق كله دومًا، في حين يكون العنصر التالي هو الجزء المطابَق بواسطة المجموعة الأولى التي يأتي قوس افتتاحها أولًا في التعبير، ثم المجموعة الثانية، وهكذا.
let quotedText = /'([^']*)'/; console.log(quotedText.exec("she said 'hello'")); // → ["'hello'", "hello"]
إذا لم تطابَق مجموعة ما مطلقًا -كأن تُتبَع بعلامة استفهام-، فسيكون موضعها في مصفوفة الخرج غير معرَّفًا undefined، وبالمثل، فإذا طابقت مجموعةً ما أكثر من مرة، فستكون المطابقة الأخيرة هي التي في المصفوفة فقط.
console.log(/bad(ly)?/.exec("bad")); // → ["bad", undefined] console.log(/(\d)+/.exec("123")); // → ["123", "3"]
تفيدنا المجموعات في استخراج أجزاء من سلسلة نصية، فإذا أردنا التحقق من احتواء السلسلة النصية على تاريخ، ومن ثم استخراج ذلك التاريخ وبناء كائن يمثله؛ فيمكننا إحاطة الأنماط الرقمية بأقواس، وأخذ التاريخ مباشرةً من نتيجة exec، لكن نحتاج قبل ذلك إلى النظر سريعًا على الطريقة المضمَّنة لتمثيل قيم التاريخ والوقت في جافاسكربت.
صنف التاريخ
تحتوي جافاسكربت على صنف قياسي لتمثيل البيانات -أو النقاط- في الزمن، ويسمى ذلك الصنف Date، فإذا أنشأنا كائن تاريخ باستخدام new، فسنحصل على التاريخ والوقت الحاليين.
console.log(new Date()); // → Mon Nov 13 2017 16:19:11 GMT+0100 (CET)
من الممكن إنشاء كائن لوقت محدد:
console.log(new Date(2009, 11, 9)); // → Wed Dec 09 2009 00:00:00 GMT+0100 (CET) console.log(new Date(2009, 11, 9, 12, 59, 59, 999)); // → Wed Dec 09 2009 12:59:59 GMT+0100 (CET)
تستخدِم جافاسكربت تقليدًا تبدأ فيه أعداد الشهور بالصفر -وعليه يكون شهر ديسمبر هو عدد 11-، بينما تبدأ أرقام الأيام بالواحد، وذلك أمر محيِّر وسخيف كذلك لكنه واقع، وإنما ذكرناه للتنبيه.
تُعَدّ آخر أربعة وسائط arguments -أي الساعات والدقائق والثواني والميلي ثانية- وسائط اختيارية، وإذا لم تحدد قيمة أيّ منهم فتكون صفرًا افتراضيًا.
تُخزَّن العلامات الزمنية Timestamps بعدد من الميلي ثانية منذ العام 1970 في منطقة UTC الزمنية -أي التوقيت العالمي-، ويتبع هذا اصطلاحًا ضُبِط بواسطة توقيت يونكس Unix time الذي اختُرع في تلك الفترة أيضًا، كما يمكن استخدام الأرقام السالبة للتعبير عن الأعوام التي سبقت 1970.
إذا استُخدم التابع getTime على كائن تاريخ، فسيُعيد ذلك العدد، وهو عدد كبير كما هو متوقع.
console.log(new Date(2013, 11, 19).getTime()); // → 1387407600000 console.log(new Date(1387407600000)); // → Thu Dec 19 2013 00:00:00 GMT+0100 (CET)
إذا أعطينا الباني Date وسيطًا واحدًا، فسيعامَل الوسيط على أنه تعداد الميلي ثانية، ويمكن الحصول على القيمة الحالية لتعداد المللي ثانية بإنشاء كائن Date جديد، واستدعاء getTime عليه، أو استدعاء الدالة Date.now.
توفِّر كائنات التاريخ توابعًا، مثل getFullYear وgetMonth وgetDate وgetHours وgetMinutes وgetSeconds، من أجل استخراج مكوناتها، كما يعطينا التابع getYear السنة بعد طرح 1900 منها -98، أو 119-، لكن لن نستخدِمه كثيرًا لعدم وجود فائدة حقيقية منه.
نستطيع الآن إنشاء كائن تاريخ من سلسلة نصية بما أننا وضعنا أقواسًا حول أجزاء التعبير التي تهمنا، أي كما يلي:
function getDate(string) { let [_, month, day, year] = /(\d{1,2})-(\d{1,2})-(\d{4})/.exec(string); return new Date(year, month - 1, day); } console.log(getDate("1-30-2003")); // → Thu Jan 30 2003 00:00:00 GMT+0100 (CET)
تُهمَل رابطة الشرطة السفلية _، ولا تُستخدَم إلا لتجاوز عنصر المطابَقة التامة في المصفوفة التي يُعيدها التابع exec.
حدود الكلمة والسلسلة النصية
يستخرِج التابع getDate التاريخ 00-1-3000 من السلسلة النصية "100-1-30000"، وهو تاريخ غير منطقي لا شك، حيث تحدث المطابقة في أي موقع في السلسلة النصية، لذا تبدأ في حالتنا عند المحرف الثاني، وتنتهي عند المحرف الثاني من النهاية.
نضيف العلامتين ^ و$ لإجبار المطابقة على النظر في السلسلة كلها، إذ تطابِق علامة الإقحام بداية سلسلة الدخل، بينما تطابِق علامة الدولار نهايتها، إذ تطابق /^\d+$/ مثلًا سلسلةً مكونةً من رقم واحد أو أكثر، وتطابق /^!/ أي سلسلة تبدأ بعلامة تعجب، بينما لا تطابق /x^/ أي سلسلة نصية، إذ لا يمكن وجود x قبل بداية السلسلة.
نستخدم العلامة \b للتأكد من أنّ التاريخ يبدأ وينتهي عند حدود كلمة، وقد يكون حد الكلمة بداية السلسلة، أو نهايتها، أو أي نقطة فيها تملك محرف كلمة -كما في \w على أحد الجانبين، و محرف غير كلمي على الجانب الآخر.
console.log(/cat/.test("concatenate")); // → true console.log(/\bcat\b/.test("concatenate")); // → false
لاحظ أنّ علامة الحد لا تطابق محرفًا حقيقيًا، بل تضمن عدم مطابقة التعبير النمطي إلا عند حدوث حالة معينة في الموضع الذي يظهر فيه في النمط.
أنماط الاختيار
لنقل أننا نريد معرفة هل يحتوي جزء ما من النص على عدد متبوع بإحدى الكلمات التالية: horse، أو cow، أو chicken، أو أي صورة من صور الجمع لها، قد نكتب ثلاثة تعابير نمطية ونختبرها لكن ثَم طريقة أفضل، وذلك بوضع محرف الأنبوب | الذي يشير إلى خيار بين النمط الذي عن يمينه والنمط الذي عن يساره، وعليه نستطيع القول كما يلي:
let animalCount = /\b\d+ (horse|cow|chicken)s?\b/; console.log(animalCount.test("15 horses")); // → true console.log(animalCount.test("15 horsechickens")); // → false
يمكن استخدام الأقواس لتقييد جزء النمط الذي يطبَّق عليه عامل الأنبوب، ويمكن وضع عدة عوامل مثل هذا بجانب بعضها البعض للتعبير عن اختيار بين أكثر من بديلين اثنين.
آلية المطابقة
يبحث محرك التعبير نظريًا عند استخدام exec أو test عن تطابق في سلسلتنا النصية، وذلك بمحاولة مطابقة التعبير من بداية السلسلة أولًا، ثم من المحرف الثاني، وهكذا حتى يجد تطابقًا أو يصل إلى نهاية السلسلة، وعندئذ يُعيد أول تطابق وجده، أو يكون قد فشل في إيجاد تطابق أصلًا؛ أما في عملية المطابقة الفعلية، فيعامِل المحرك التعبير النمطي مثل مخطط تدفق flow diagram، وإذا استخدمنا مثالنا السابق عن الحيوانات، فسيبدو مخطط التعبير الخاص بها كما يلي:
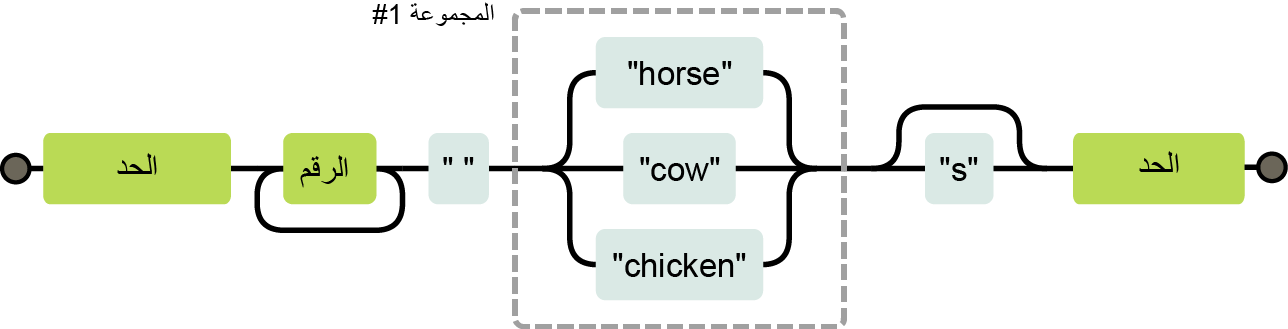
يكون تعبيرنا مطابقًا إذا استطعنا إيجاد مسار من جانب المخطط الأيسر إلى جانبه الأيمن، حيث نحفظ الموضع الحالي في السلسلة النصية، ونتأكد في كل حركة نتحركها خلال صندوق من أنّ جزء السلسلة التالي لموضعنا الحالي يطابق ذلك الصندوق.
إذا كنا نحاول مطابقة "the 3 horses" من الموضع 4، فسيبدو مسار تقدمنا داخل المخطط كما يلي:
- يمكننا تجاوز الصندوق الأول لوجود حد كلمي word boundary عند الموضع 4.
- لا زلنا في الموضع 4 ووجدنا رقمًا، لذا نستطيع تجاوز الصندوق الثاني.
- يتكرر أحد المسارات إلى ما قبل الصندوق الثاني (الرقم) عند الموضع 5، بينما يتحرك الآخر للأمام خلال الصندوق، ويحمل محرف مسافة واحد؛ لذا يجب أخذ المسار الثاني لوجود مسافة وليس رقمًا.
- نحن الآن في الموضع 6، أي بداية horses وعند التفرع الثلاثي في المخطط، إذ لا نرى cow، ولا chicken هنا، لكن نرى horse، لذا سنأخذ ذلك الفرع.
- يتخطى أحد المسارات صندوق s عند الموضع 9 بعد التفرع الثلاثي، ويذهب مباشرةً إلى حد الكلمة الأخير، بينما يطابق المسار الآخر s، كما سنمر خلال صندوق s لوجود المحرف s وليس حدًا لكلمة.
- نحن الآن عند الموضع 10 وهو نهاية السلسلة النصية، ونستطيع مطابقة حد الكلمة فقط، وتُحسب نهاية السلسلة النصية على أنها حد كلمي، لذا سنمر خلال الصندوق الأخير ونكون قد طابقنا تلك السلسلة النصية بنجاح.
التعقب الخلفي
يطابق التعبير النمطي /\b([01]+b|[\da-f]+h|\d+)\b/ عددًا ثنائيًا متبوعًا بـ b، أو عددًا ست عشريًا hexadecimal -وهو نظام رقمي تمثل فيه الأعداد من 10 إلى 15 بالأحرف a حتى f- متبوعًا بـ h، أو عددًا عشريًا عاديًا ليس له محرف لاحق، وفيما يلي المخطط الذي يصف ذلك:

سيدخل الفرع العلوي الثنائي عند مطابقة ذلك التعبير حتى لو لم يحوي الدخل على عدد ثنائي، حيث سيصبح من الواضح عند المحرف 3 مثلًا أننا في الفرع الخاطئ عند مطابقة السلسلة "103"، فعلى الرغم تطابق السلسلة للتعبير، إلا أنها لا تطابق الفرع الذي نحن فيه.
يبدأ هنا المطابِق matcher بالتعقب الخلفي، فيتذكر موضعه الحالي عند دخول فرع ما -وهو بداية السلسلة في هذه الحالة، بعد صندوق "حد الكلمة" الأول في المخطط-، وذلك ليستطيع العودة والنظر في فرع آخر إذا لم ينجح الفرع الحالي.
سيجرب الفرع الخاص بالأرقام الست عشرية في حالة السلسلة النصية "103" إذا وصل إلى المحرف 3، لكنه سيفشل مجددًا لعدم وجود h بعد العدد، وهنا سيحاول في الفرع الخاص بالأعداد العشرية، وتنجح المطابقة، ويُبلَّغ بها.
يتوقف المطابِق عندما يجد مطابقةً تامةً، وهذا يعني أنه حتى لو كان لدينا فروع متعددة يمكنها مطابقة سلسلة نصية ما، فهو لن يُستخدَم إلا الفرع الأول الذي ظهر وفقًا لترتيبه في التعبير النمطي.
ويحدث التعقب الخلفي أيضًا لعوامل التكرار، مثل + و*، فإذا طابقنا /^.*x/ مع "abcxe"، فسيحاول الجزء .* أخذ السلسلة كلها أولًا، لكن سيدرك المحرك أنه يحتاج إلى x كي يطابق النمط، وبما أنه لا توجد x بعد نهاية السلسلة، فسيحاول عامل النجمة المطابقة من غير المحرف الأخير، لكن لا يعثر المطابِق على x بعد abcx، فيعود أدراجه بالتعقب الخلفي ليطابق عامل النجمة مع abc فقط، وهنا يجد x حيث يحتاجها، ويبلِّغ بمطابقة ناجحة من الموضع 0 حتى 4.
قد يحدث ونكتب تعبيرًا نمطيًا ينفذ الكثير من عمليات التعقب الخلفي، وهنا تحدث مشكلة حين يستطيع النمط مطابقة جزء من الدخل بطرق عديدة مختلفة، فإذا لم ننتبه عند كتابة تعبير نمطي لعدد ثنائي، فقد نكتب شيئًا مثل /([01]+)+b/.
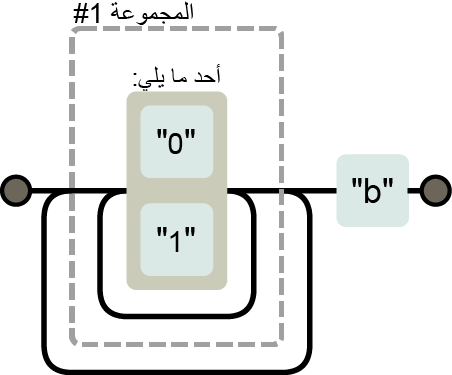
عندما يحاول التعبير مطابقة سلسلة طويلة من الأصفار والآحاد التي ليس لها لاحقة b، فسيمر المطابِق على الحلقة الداخلية حتى تنتهي الأرقام، ثم يلاحظ عدم وجود المحرف b، فينفِّذ تعقبًا خلفيًا لموضع واحد فقط، ثم يمر على الحلقة الخارجية مرةً واحدةً قبل أن يستسلم ويعود أدراجه ليتعقب الحلقة الداخلية مرةً أخرى، كما سيظل يحاول جميع الطرق الممكنة عبر هاتين الحلقتين، وهذا يعني مضاعفة مقدار العمل مع كل محرف إضافي، فلو أضفنا بعض العشرات من المحارف، لاستغرقت عملية المطابقة إلى ما لا نهاية.
التابع replace
تحتوي قيم السلاسل النصية على التابع replace الذي يمكن استخدامه لاستبدال سلسلة نصية بجزء من سلسلة أخرى.
console.log("papa".replace("p", "m")); // → mapa
يمكن أن يكون الوسيط الأول تعبيرًا نمطيًا، وعندئذ يُستبدل التطابق الأول للتعبير النمطي؛ أما إذا أضيف الخيار g -اختصارًا لـ global- إلى التعبير النمطي، فتُستبدل جميع التطابقات.
console.log("Borobudur".replace(/[ou]/, "a")); // → Barobudur console.log("Borobudur".replace(/[ou]/g, "a")); // → Barabadar
لو كان لدينا وسيط إضافي للتابع replace بحيث نختار منه استبدال تطابق واحد أو جميع التطابقات، لكان أفضل من الاعتماد على خاصية للتعبير النمطي، بل لو كان من خلال توفير تابع مختلف باسم replaceAll لكان أفضل.
ملاحظة: أضيف دعم حديث للغة جافاسكربت يحل النقطة السابقة وأصبحت تدعم التابع replaceAll لتبديل كل التطابقات في النص.
يأتي مكمن القوة في استخدام التعابير النمطية مع التابع replace من حقيقة استطاعتنا الإشارة إلى المجموعات المطابَقة في السلسلة النصية البديلة، فمثلًا، لدينا سلسلة كبيرة تحتوي على أسماء أشخاص، بحيث يحتوي كل سطر على اسم واحد، ويبدأ بالاسم الأخير، ثم الاسم الأول، أي بالصورة:
Lastname, Firstname
إذا أردنا التبديل بين تلك الأسماء وحذف الفاصلة الأجنبية التي بين كل منها لنحصل على الصورة Firstname Lastname، فنستطيع استخدام الشيفرة التالية:
console.log( "Mohsin, Samira\nFady, Eslam\nSahl, Hasan" .replace(/(\w+), (\w+)/g, "$2 $1")); // → Samira Mohsin // Eslam Fady // Hasan Sahl
يشير كل من $1، و$2 في السلسلة البديلة إلى المجموعات المحاطة بأقواس في النمط، ويحل النص الذي يطابق المجموعة الأولى محل $1، كما يحل النص الذي يطابق المجموعة الثانية محل $2، وهكذا حتى نصل إلى $9؛ أما التطابق كله فيمكن الإشارة إليه باستخدام $&.
من الممكن تمرير دالة بدلًا من سلسلة نصية على أساس وسيط ثاني إلى التابع replace، حيث تُستدعى الدالة لكل استبدال مع المجموعات المطابَقة والتطابق كله على أساس وسائط arguments، وتُدخَل قيمتها المعادة في السلسلة الجديدة، أي كما في المثال التالي:
let s = "the cia and fbi"; console.log(s.replace(/\b(fbi|cia)\b/g, str => str.toUpperCase())); // → the CIA and FBI
وهذا مثال آخر:
let stock = "1 lemon, 2 cabbages, and 101 eggs"; function minusOne(match, amount, unit) { amount = Number(amount) - 1; if (amount == 1) { // only one left, remove the 's' unit = unit.slice(0, unit.length - 1); } else if (amount == 0) { amount = "no"; } return amount + " " + unit; } console.log(stock.replace(/(\d+) (\w+)/g, minusOne)); // → no lemon, 1 cabbage, and 100 eggs
يأخذ المثال أعلاه سلسلةً نصيةً، ويبحث عن حالات حدوث عدد متبوع بكلمة أبجدية رقمية، ويُعيد سلسلةً نصيةً، إذ تكون في كل حالة من تلك الحالات أُنقصت بمقدار 1.
ستكون المجموعة (\d+) هي الوسيط amount للدالة، وتقيَّد المجموعة (\w+) بالوسيط unit، وتحوِّل الدالة الوسيط amount إلى عدد، وينجح ذلك بما أنه طابَق \d+، كما تُجري بعض التعديلات في حالة إذا كان المتبقي صفر أو واحد فقط.
الجشع Greed
من الممكن استخدام replace لكتابة دالة تحذف جميع التعليقات من شيفرة جافاسكربت، لننظر في محاولة أولية لها:
function stripComments(code) { return code.replace(/\/\/.*|\/\*[^]*\*\//g, ""); } console.log(stripComments("1 + /* 2 */3")); // → 1 + 3 console.log(stripComments("x = 10;// ten!")); // → x = 10; console.log(stripComments("1 /* a */+/* b */ 1")); // → 1 1
يطابق الجزء الذي يسبق العامل or محرفي شرطة مائلة متبوعتين بعدد من محارف لا تكون محارف سطر جديد؛ أما الجزء المتعلِّق بالتعليقات متعددة الأسطر فيملك بعض التفصيل، إذ نستخدم [^] -أيّ محرف ليس ضمن مجموعة المحارف الفارغة- على أساس طريقة لمطابقة أي محرف، غير أننا لا نستطيع استخدام محرف النقطة هنا لاحتواء التعليقات الكتلية على عدة أسطر، ولا يطابق محرف النقطة محارف السطر الجديد.
لكن إذا نظرنا إلى خرج السطر الأخير فسنرى أنه خطأ نوعًا ما، وذلك أنّ الجزء [^]* من التعبير سيطابِق كل ما يستطيع مطابقته كما وضحنا في القسم الخاص بالتعقب الخلفي، فإذا تسبب ذلك في فشل الجزء التالي من التعبير، فسيعود المطابِق محرفًا واحدًا إلى الوراء، ثم يحاول مرةً أخرى من هناك، وهو في هذا المثال يحاول مطابقة بقية السلسلة، ثم يعود إلى الوراء من هناك.
سيجد الحدث */ بعد العودة أربعة محارف إلى الوراء ويطابقها، وليس هذا ما أردنا، إذ كنا نريد مطابقة تعليق واحد، وليس العودة إلى نهاية الشيفرة لنجد نهاية آخر تعليق كتلي.
نقول بسبب هذا السلوك أنّ عوامل التكرار مثل + و* و? و{} هي عوامل جشعة greedy، أي تطابق كل ما تستطيع مطابقته وتتعقب خلفيًا من هناك، لكن إذا وضعنا علامة استفهام بعد تلك العوامل لتصير هكذا ?+ و?* و?? و?{}، فسننفي عنها صفة الجشع لتطابق أقل ما يمكن، ولا تطابِق أكثر إلا كان النمط الباقي لا يناسب تطابقًا أصغر.
هذا هو عين ما نريده في هذه الحالة، فبجعل عامل النجمة يطابق أصغر امتداد من المحارف التي تقودنا إلى */، فسنستهلك تعليقًا كتليًا واحدًا فقط.
function stripComments(code) { return code.replace(/\/\/.*|\/\*[^]*?\*\//g, ""); } console.log(stripComments("1 /* a */+/* b */ 1")); // → 1 + 1
نستطيع على ذلك نسْب الكثير من الزلات البرمجية bugs في برامج التعابير النمطية إلى استخدام عامل جشِع من غير قصد، في حين أنّ استخدام عامل غير جشِع أفضل، لهذا يجب النظر في استخدام النسخة الغير جشعة من العامل أولًا عند استخدام أحد عوامل التكرار.
إنشاء كائنات RegExp ديناميكيا
ستكون لدينا حالات لا نعرف فيها النمط الذي يجب مطابقته عند كتابة الشيفرة، فمثلًا، نريد البحث عن اسم المستخدِم في جزء من النص، وإحاطته بمحرفي شرطة سفلية لإبرازه عما حوله، إذ لن نستطيع استخدام الترميز المبني على الشرطة المائلة لأننا لن نعرف الاسم إلا عند تشغيل البرنامج فعليًا، لكن نستطيع رغم ذلك بناء سلسلة نصية، واستخدام باني RegExp عليها، كما في المثال التالي:
let name = "Saad"; let text = "Saad is a suspicious character."; let regexp = new RegExp("\\b(" + name + ")\\b", "gi"); console.log(text.replace(regexp, "_$1_")); // → _Saad_ is a suspicious character.
يجب استخدام شرطتين خلفيتين مائلتين عند إنشاء علامات الحدود \b، وذلك لعدم كتابتها في تعبير نمطي محاط بشرطات مائلة، وإنما في سلسلة نصية عادية، كذلك يحتوي الوسيط الثاني للباني RegExp على خيارات للتعبير النمطي، وهي "gi" في هذه الحالة لتشير إلى عمومها global وعدم حساسيتها لحالة المحارف case insensitive.
إذا احتوى اسم المستخدِم على محارف غريبة مثل "dea+hl[]rd"، فسيتسبب هذا في تعبير نمطي غير منطقي، وسنحصل على اسم مستخدِم لا يطابق اسم المستخدِم الفعلي.
سنضيف شرطات مائلة خلفية قبل أي محرف يملك معنىً خاص به لحل هذه المشكلة.
let name = "dea+hl[]rd"; let text = "This dea+hl[]rd guy is super annoying."; let escaped = name.replace(/[\\[.+*?(){|^$]/g, "\\$&"); let regexp = new RegExp("\\b" + escaped + "\\b", "gi"); console.log(text.replace(regexp, "_$&_")); // → This _dea+hl[]rd_ guy is super annoying.
التابع search
لا يمكن استخدام تعبير نمطي لاستدعاء التابع indexOf على سلسلة نصية، والحل هو استخدام التابع search الذي يتوقع تعبيرًا نمطيًا، حيث يُعيد أول فهرس يجده التعبير كما يفعل indexOf، أو يُعيد -1 إذا لم يجده.
console.log(" word".search(/\S/)); // → 2 console.log(" ".search(/\S/)); // → -1
لا توجد طريقة في التابع search لاختيار بدء المطابقة عند إزاحة offset بعينها، على عكس indexOf الذي يملكها في الوسيط الثاني، إذ تُعَدّ مفيدةً في بعض الأحيان.
خاصية lastIndex
لا يوفر التابع exec طريقةً سهلةً لبدء البحث من موضع بعينه في السلسلة النصية، شأنه في ذلك شأن التابع search، والطريقة التي يوفرها لذلك موجودة، لكنها ليست سهلة.
تحتوي كائنات التعبير النمطي على خصائص إحداها هي source التي تحتوي على السلسلة التي أُنشئ منها التعبير، وثمة خاصية أخرى هي lastIndex التي تتحكم في موضع بدء التطابق التالي، وإن كان في حالات محدودة، وحتى حينئذ يجب أن يكون كل من الخيار العام g وخيار y اللزج sticky مفعَّلين في التعبير النمطي، كما يجب وقوع التطابق من خلال التابع exec. كان من الممكن هنا السماح بتمرير وسيط إضافي إلى exec.
let pattern = /y/g; pattern.lastIndex = 3; let match = pattern.exec("xyzzy"); console.log(match.index); // → 4 console.log(pattern.lastIndex); // → 5
إذا نجح التطابق، فسيحدِّث الاستدعاء إلى exec خاصية lastIndex إلى النقطة التي تلي التطابق تلقائيًا؛ أما إذا لم يُعثر على تطابق، فستُضبِط خاصية lastIndex على الصفر، حيث يكون هو القيمة في كائن التعبير النمطي الذي سيُبنى تاليًا.
يكون الفرق بين الخيارين العام واللزج هو عدم نجاح التطابق حالة الخيار اللزج إلا عندما يبدأ من lastIndex مباشرةً؛ أما في حالة الخيار العام، فسيبحث عن موضع يمكن بدء التطابق عنده.
let global = /abc/g; console.log(global.exec("xyz abc")); // → ["abc"] let sticky = /abc/y; console.log(sticky.exec("xyz abc")); // → null
تتسبب تلك التحديثات التلقائية لخاصية lastIndex في مشاكل عند استخدام قيمة تعبير نمطي مشتركة لاستدعاءات exec متعددة، فقد يبدأ تعبيرنا النمطي عند فهرس من مخلَّفات استدعاء سابق.
let digit = /\d/g; console.log(digit.exec("here it is: 1")); // → ["1"] console.log(digit.exec("and now: 1")); // → null
كذلك من الآثار اللافتة للخيار العام أنه يغيِّر الطريقة التي يعمل بها التابع match على السلاسل النصية، إذ يبحث عن جميع تطابقات النمط في السلسلة النصية، ويُعيد مصفوفةً تحتوي على السلاسل المطابَقة عندما يُستدعى مع الخيار العام، بدلًا من إعادة مصفوفة تشبه التي يُعيدها exec.
console.log("Banana".match(/an/g)); // → ["an", "an"]
لهذا يجب الحذر عند التعامل مع التعابير النمطية العامة، واستخدامها في الحالات الضرورية فقط،، مثل الاستدعاءات إلى replace والأماكن التي تريد استخدام lastIndex فيها صراحةً.
التكرار على التطابقات
يُعَدّ البحث في جميع مرات حدوث النمط في سلسلة نصية بطريقة تعطينا وصولًا إلى كائن المطابقة في متن الحلقة loop body أمرًا شائعًا، ويمكن فعل ذلك باستخدام lastIndex، وexec.
let input = "A string with 3 numbers in it... 42 and 88."; let number = /\b\d+\b/g; let match; while (match = number.exec(input)) { console.log("Found", match[0], "at", match.index); } // → Found 3 at 14 // Found 42 at 33 // Found 88 at 40
يستفيد هذا من كون قيمة تعبير الإسناد = هي القيمة المسندَة، لذا ننفذ التطابق عند بداية كل تكرار باستخدام match = number.exec(input) على أساس شرط في تعليمة while، ثم نحفظ النتيجة في رابطة binding، ونوقف التكرار إذا لم نجد تطابقات أخرى.
تحليل ملف INI
لنقل أننا نكتب برنامجًا يجمع بيانات عن أعدائنا على الإنترنت، رغم أننا لن نكتبه حقًا وإنما يهمنا الجزء الذي يقرأ ملف التهيئة، على أساس مثال على مشكلة تحتاج إلى التعابير النمطية، إذ سيبدو ملف التهيئة كما يلي:
searchengine=https://duckduckgo.com/?q=$1 spitefulness=9.7 ; تُسبق التعليقات بفاصلة منقوطة... ; يختص كل قسم بعدو منفصل [larry] fullname=Larry Doe type=kindergarten bully website=http://www.geocities.com/CapeCanaveral/11451 [davaeorn] fullname=Davaeorn type=evil wizard outputdir=/home/marijn/enemies/davaeorn
تكون القواعد الحاكمة لهذه الصيغة -وهي صيغة مستخدمة بكثرة، ويطلق عليها اسم INI- كما يلي:
- تُتجاهل الأسطر الفارغة والأسطر البادئة بفاصلة منقوطة.
-
تبدأ الأسطر المغلَّفة بالقوسين المعقوفين
[ ]قسمًا جديدًا. -
تضيف الأسطر التي تحتوي على معرِّف أبجدي-رقمي متبوع بمحرف
=إعدادًا setting إلى القسم الحالي. - لا يُسمح بأي شيء غير ما سبق، ويُعَدّ ما سواه غير صالح.
مهمتنا هنا هي تحويل سلسلة نصية مثل هذه إلى كائن تحمل خصائصه سلاسل نصية للإعدادات المكتوبة قبل ترويسة القسم الأول، وكائنات فرعية للأقسام، بحيث يحمل كل كائن فرعي إعدادات القسم الخاص به، وبما أنه يجب معالجة الصيغة سطرًا سطرًا، فمن الجيد تقسيم الملف إلى أسطر منفصلة، مستفيدين من التابع split الذي تعرضنا له في هياكل البيانات: الكائنات والمصفوفات في جافاسكريبت.
لا تقتصر بعض أنظمة التشغيل على محرف السطر الجديد لفصل الأسطر، وإنما تستخدِم محرف الإرجاع carriage return متبوعًا بسطر جديد "\r\n"، وبما أنّ التابع split يسمح بالتعبير النمطي على أساس وسيط، فنستطيع استخدام تعبير نمطي مثل /\r?\n/ للتقسيم بطريقة تسمح بوجود كل من "\n" و"\r\n" بين الأسطر.
function parseINI(string) { // ابدأ بكائن ليحمل حقول المستوى العلوي let result = {}; let section = result; string.split(/\r?\n/).forEach(line => { let match; if (match = line.match(/^(\w+)=(.*)$/)) { section[match[1]] = match[2]; } else if (match = line.match(/^\[(.*)\]$/)) { section = result[match[1]] = {}; } else if (!/^\s*(;.*)?$/.test(line)) { throw new Error("Line '" + line + "' is not valid."); } }); return result; } console.log(parseINI(` name=Vasilis [address] city=Tessaloniki`)); // → {name: "Vasilis", address: {city: "Tessaloniki"}}
تمر الشيفرة على أسطر الملف وتبني الكائن، كما تخزَّن الخصائص التي في القمة داخل الكائن مباشرةً، بينما تخزن الخصائص الموجودة في الأقسام داخل كائن قسم مستقل، كما تشير الرابطة section إلى كائن القسم الحالي.
لدينا نوعان من الأسطر المميزة، وهما ترويسة الأقسام، أو أسطر الخصائص، فإذا كان السطر خاصيةً عاديةً، فسيخزَّن في الموضع الحالي؛ أما إذا كان ترويسةً لقسم، فسيُنشأ كائن قسم جديد وتُضبط section لتشير إليه.
نضمن بالاستخدام المتكرر لمحرفي ^ و$، مطابقة التعبير للسطر كاملًا وليس جزءًا منه فقط، كما ستعمل الشيفرة عند إهمالهما، لكنها ستتصرف مع بعض المدخلات بغرابة، وهو الأمر الذي سيكون زلةً bug يصعب تعقبها وإصلاحها.
يُعَدّ النمط if (match = string.match(...)) شبيهًا بما سبق في شأن استخدام الإسناد على أساس شرط لتعليمة while، فلن نكون على يقين من نجاح استدعاء match، لذا لا نستطيع الوصول إلى الكائن الناتج إلا داخل تعليمة if تختبر ذلك، ولكي لا نقطع سلسلة الصيغ else if، فسنسند نتيجة التطابق إلى رابطة، وسنستخدم هذا التعيين على أساس اختبار لتعليمة if مباشرةً.
تتحقق الدالة من السطر باستخدام التعبير /^\s*(;.*)?$/ إذا لم يكن ترويسةً لقسم أو خاصيةً ما، إذ تتحقق من أنه تعليق أو سطر فارغ، حيث يطابق الجزء الذي بين الأقواس التعليقات، ثم تتأكد ? أنه يطابق الأسطر التي تحتوي على مسافة بيضاء فقط، وإذا وُجد سطر لا يطابق أي صيغة من الصيغ المتوقعة، فسترفع الدالة اعتراضًا exception.
المحارف الدولية
كان اتجاه تصميم جافاسكربت في البداية نحو سهولة الاستخدام، وقد ترسخ ذلك الاتجاه مع الوقت إلى أن صار هو السمة الأساسية للغة ومعيارًا لتحديثاتها، لكن أتت هذه السهولة بعواقب لم تكن في الحسبان وقتها، إذ تُعَدّ تعابير جافاسكربت النمطية غبيةً لغويًا، فالمحرف الكلمي بالنسبة لها هو واحد من 26 محرفًا فقط، وهي المحارف الموجودة في الأبجدية اللاتينية بحالتيها الصغرى والكبرى، أو أرقامًا عشريةً، أو محرف الشرطة السفلية _؛ أما بالنسبة لأيّ شيء غير ذلك، مثل é أو β، فلن تطابق \w رغم أنها محارف كلمية، لكنها ستطابق الحالة الكبرى منها \W التي تشير إلى التصنيف غير الكلمي nonword category.
تجدر الإشارة إلى ملاحظة غريبة في شأن محرف المسافة البيضاء العادية \s، إذ لا تعاني من هذه المشكلة، وتطابق جميع المحارف التي يَعُدّها معيار اليونيكود محارف مسافة بيضاء، بما في ذلك المسافة غير الفاصلة nonbreaking space، والفاصلة المتحركة المنغولية Mongolian vowel separator.
أيضًا، من المشاكل التي سنواجهها مع التعابير النمطية في جافاسكربت أنها لا تعمل على المحارف الحقيقية وإنما تعمل على الأعداد البِتّية للمحارف code units كما ذكرنا في الدوال العليا في جافاسكريبت، وبالتالي سيكون سلوك المحارف المكونة من عددين بِتّيين غريبًا، وعلى خلاف ما نريد.
console.log(/?{3}/.test("???")); // → false console.log(/<.>/.test("<?>")); // → false console.log(/<.>/u.test("<?>")); // → true
المشكلة أنّ ? التي في السطر الأول تعامَل على أنها عددين بِتّيين، ولا يطبَّق الجزء {3} إلا على العدد الثاني. وبالمثل، تطابق النقطة عددًا بِتَيًا واحدًا، وليس العددين اللذَين يكونان الرمز التعبيري للوردة، كما يجب إضافة خيار اليونيكود u للتعبير النمطي كي يعامَل مثل تلك المحارف على الوجه الذي ينبغي.
سيظل السلوك الخاطئ للتعبير النمطي هو الافتراضي للأسف، لأنّ التغيير قد يتسبب في مشاكل للشيفرة الموجودة والتي تعتمد عليه، ومن الممكن استخدام \p في تعبير نمطي مفعّل فيه خيار اليونيكود لمطابقة جميع المحارف التي يسند اليونيكود إليها خاصية معطاة، رغم أنّ هذه الطريقة معتمدة حديثًا ولم تُستخدم كثيرًا بعد.
console.log(/\p{Script=Greek}/u.test("α")); // → true console.log(/\p{Script=Arabic}/u.test("α")); // → false console.log(/\p{Alphabetic}/u.test("α")); // → true console.log(/\p{Alphabetic}/u.test("!")); // → false
يعرِّف اليونيكود عددًا من الخصائص المفيدة رغم أنّ إيجاد الخاصية التي نحتاجها قد لا يكون أمرًا سهلًا في كل مرة، حيث يمكن استخدام الصيغة \p{Property=Value} لمطابقة أيّ محرف له قيمة معطاة لتلك الخاصية، وإذا أُهمل اسم الخاصية كما في \p{Name}، فسيُفترض الاسم إما خاصيةً بِتّيةً مثل Alphabetic، أو فئةً مثل Number.
خاتمة
التعبيرات النمطية هي كائنات تمثل أنماطًا في السلاسل النصية، وتستخدم لغتها الخاصة للتعبير عن تلك الأنماط.
| التعبير النمطي | دلالته |
|---|---|
/abc/
|
تسلسل من المحارف |
/[abc]/
|
أيّ محرف في مجموعة محارف |
/[^abc]/
|
أيّ محرف ليس في مجموعة ما من المحارف |
/[0-9]/
|
أيّ محرف من مجال ما من المحارف |
/x+/
|
مرة حدوث واحدة أو أكثر للنمط x
|
/x+?/
|
مرة حدوث أو أكثر غير جشعة |
/x*/
|
حدوث صفري أو أكثر. |
/x?/
|
حدوث صفري أو حدوث لمرة واحدة |
/x{2,4}/
|
حدوث لمرتَين إلى أربعة مرات |
/(abc)/
|
مجموعة |
| `/a | b |
| c/` | أيّ نمط من بين أنماط متعددة |
/\d/
|
أيّ محرف رقمي |
/\w/
|
محرف أبجدي رقمي alphanumeric، أي محرف كلمة |
/\s/
|
أيّ محرف مسافة بيضاء |
/./
|
أيّ محرف عدا الأسطر الجديدة |
/\b/
|
حد كلِمي word boundary |
/^/
|
بداية الدخل |
/$/
|
نهاية الدخل |
يملك التعبير النمطي التابع test للتحقق هل السلسلة المعطاة مطابقة أم لا، كما يملك التابع exec الذي يُعيد مصفوفةً تحتوي على جميع المجموعات المطابِقة إذا وُجدت مطابقات، ويكون لتلك المصفوفة خاصية index التي توضِّح أين بدأت المطابقة.
تملك السلاسل النصية التابع match الذي يطابقها مع تعبير نمطي، وتابع search الذي يبحث عن التعابير النمطية ثم يُعيد موضع بداية التطابق فقط، كما تملك السلاسل النصية تابعًا اسمه replace، حيث يستبدِل سلسلةً نصيةً أو دالةً بتطابقات النمط.
يمكن امتلاك التعابير النمطية خيارات تُكتب بعد شرطة الإغلاق المائلة، إذ يجعل الخيار i التطابق حساسًا لحالة الأحرف، كما يجعل الخيار g التعبير عامًا global، ويمكِّن التابع replace من استبدال جميع النسخ بدلًا من النسخة الأولى فقط؛ أما الخيار y فيجعله لزجًا، أي لن يتجاوز جزءًا من السلسلة أثناء البحث عن تطابق، كذلك يفعِّل الخيار u وضع اليونيكود الذي يصلح لنا عددًا من المشاكل المتعلقة بمعالجة المحارف التي تأخذ أكثر من عددين بتيين.
وهكذا فإنّ التعابير النمطية أشبه بسكين حاد لها مقبض غريب الشكل، فهي تيسِّر المهام التي ننفذها كثيرًا، لكن قد تصبح صعبة الإدارة حين نستخدمها في مشاكل معقدة، ومن الحكمة تجنب حشر الأشياء التي لا تستطيع التعبيرات النمطية التعبير عنها بسهولة.
تدريبات
ستجد نفسك لا محالةً أثناء العمل على هذه التدريبات أمام سلوكيات محيِّرة للتعابير النمطية، فمن المفيد عندئذ إدخال تعبيراتك النمطية في أداة مثل https://debuggex.com لترى إن كان تصورها المرئي يوافق السلوك الذي أردت أم لا، ولترى كيف تستجيب لسلاسل الدخل المختلفة.
Regexp golf
Code golf هو مصطلح مستخدم للعبة تحاول التعبير عن برنامج معيَّن بأقل عدد ممكن من المحارف، وبالمثل، يكون regexp golf عملية كتابة تعابير نمطية، بحيث تكون أصغر ما يمكن، وتطابق النمط المعطى فقط.
اكتب تعبيرًا نمطيًا لكل عنصر مما يلي، بحيث يتحقق من حدوث أيّ سلسلة نصية فرعية داخل السلسلة النصية الأم، ويجب على التعبير النمطي مطابقة السلاسل المحتوية على إحدى السلاسل الفرعية التي ذكرناها.
لا تشغل بالك بحدود الكلمات إلا إذا ذُكر ذلك صراحةً، وإذا نجح تعبيرك النمطي فانظر إن كنت تستطيع جعله أصغر.
- Car وcat.
- Pop وprop.
- Ferret وferry وferrari.
- أيّ كلمة تنتهي بـ ious.
- محرف مسافة بيضاء متبوع بنقطة، أو فاصلة أجنبية، أو نقطتين رأسيتين، أو فاصلة منقوطة.
- كلمة أكبر من ستة أحرف.
- كلمة ليس فيها الحرف e أو E.
استرشد بالجدول الذي في خاتمة المقال أعلاه، واختبر كل حل ببعض السلاسل النصية.
تستطيع تعديل شيفرة التدريب لكتابة الحل وتشغيلها في طرفية المتصفح إن كنت تقرأ من متصفح، أو بنسخها إلى codepen.
// املأ التعابير النمطية التالية verify(/.../, ["my car", "bad cats"], ["camper", "high art"]); verify(/.../, ["pop culture", "mad props"], ["plop", "prrrop"]); verify(/.../, ["ferret", "ferry", "ferrari"], ["ferrum", "transfer A"]); verify(/.../, ["how delicious", "spacious room"], ["ruinous", "consciousness"]); verify(/.../, ["bad punctuation ."], ["escape the period"]); verify(/.../, ["Siebentausenddreihundertzweiundzwanzig"], ["no", "three small words"]); verify(/.../, ["red platypus", "wobbling nest"], ["earth bed", "learning ape", "BEET"]); function verify(regexp, yes, no) { // تجاهل التدريبات غير المكتملة if (regexp.source == "...") return; for (let str of yes) if (!regexp.test(str)) { console.log(`Failure to match '${str}'`); } for (let str of no) if (regexp.test(str)) { console.log(`Unexpected match for '${str}'`); } }
أسلوب الاقتباس
تخيَّل أنك كتبت قصةً، واستخدمت علامات الاقتباس المفردة فيها لتحديد النصوص التي قالتها الشخصيات فيها، وتريد الآن استبدال علامات الاقتباس المزدوجة بكل تلك العلامات المفردة، لكن مع استثناء الكلمات التي تكون فيها العلامة المفردة لغرض مختلف مثل كلمة aren't.
فكر في نمط يميز هذين النوعين من استخدامات الاقتباس، وصمم استدعاءً إلى التابع replace الذي ينفذ عملية الاستبدال المناسبة.
تستطيع تعديل شيفرة التدريب لكتابة الحل وتشغيلها في طرفية المتصفح إن كنت تقرأ من متصفح، أو بنسخها إلى codepen.
let text = "'أنا الطاهي،' he said, 'إنها وظيفتي.' "; // غيِّر هذا الاستدعاء. console.log(text.replace(/A/g, "B")); // → "أنا الطاهي،" he said, "إنها وظيفتي."
إرشادات للحل
يكون الحل البديهي هنا هو استبدال محرف غير كلمي nonword بعلامات الاقتباس على الأقل من جانب واحد، كما في /\W'|'\W/، لكن سيكون عليك أخذ بداية السطر ونهايته في حسابك.
كذلك يجب ضمان أنّ الاستبدال سيشمل المحارف التي طابقها نمط \W كي لا تُنسى، ويمكن فعل ذلك بتغليفها في أقواس، ثم تضمين مجموعاتها في السلسلة النصية البديلة (1$ و2$)، كما لا يُستبدل شيء بالمجموعات التي لم تطابَق.
الأعداد مرة أخرى
اكتب تعبيرًا لا يطابق إلا الأعداد التي لها نسق جافاسكربت، ويجب عليه دعم علامة + أو - قبل العدد، والعلامة العشرية، والصيغة الأسية -أي 5e-3، أو 1E10-، مع علامتي موجب أو سالب قبل الأس.
لاحظ عدم اشتراط وجود أرقام قبل العلامة العشرية أو بعدها، لكن لا يمكن أن يكون العدد مكونًا من العلامة العشرية وحدها، أي يسمح بكل من .5 و5. في جافاسكربت، لكن لا يُسمح بـ ..
تستطيع تعديل شيفرة التدريب لكتابة الحل وتشغيلها في طرفية المتصفح إن كنت تقرأ من متصفح، أو بنسخها إلى codepen.
// املأ التعبير النمطي التالي. let number = /^...$/; // الاختبارات: for (let str of ["1", "-1", "+15", "1.55", ".5", "5.", "1.3e2", "1E-4", "1e+12"]) { if (!number.test(str)) { console.log(`Failed to match '${str}'`); } } for (let str of ["1a", "+-1", "1.2.3", "1+1", "1e4.5", ".5.", "1f5", "."]) { if (number.test(str)) { console.log(`Incorrectly accepted '${str}'`); } }
إرشادات للحل
- يجب عدم نسيان الشرطة المائلة الخلفية التي قبل النقطة.
-
يمكن مطابقة العلامة الاختيارية التي قبل العدد وقبل الأس بواسطة
[+\-]?، أو(\+|-|)، والتي تعني موجب، أو سالب، أو لا شيء. -
يبقى الجزء الأصعب من هذا التدريب مطابقة كل من
"5."و".5"دون مطابقة"."، وأحد الحلول الممتازة هنا هو استخدام العامل|لفصل الحالتين؛ فإما رقم واحد أو أكثر متبوع اختياريًا بنقطة وصفر، أو أرقام أخرى، أو نقطة متبوعة برقم واحد أو أكثر. -
وأخيرًا، نريد جعل e حساسة لحالتها؛ فإما نضيف الخيار
iللتعبير النمطي أو نستخدم[eE].
ترجمة -بتصرف- للفصل التاسع من كتاب Elequent Javascript لصاحبه Marijn Haverbeke.












أفضل التعليقات
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.