

سنغطي في هذا المقال أسئلة واسعة حول تعلم الآلة Machine Learning، ومعالجة اللغات الطبيعية Natural Language Processing، والذكاء الاصطناعي Artificial Intelligence بهدف توسيع المهارات حول هذه التقنيات الحديثة، سنحاول الإجابة على مجموعة من الأسئلة المهمة بدءًا من أساسيات هذا المجال، والتقنيات الموصى بها، وصولًا إلى النماذج اللغوية المتقدمة مثل GPT 4، كما سنتناول التحديات التي تواجه المنتجات والأعمال المرتبطة بمعالجة اللغات الطبيعية ونناقش مستقبل هذا المجال.
أسئلة حول أساسيات معالجة اللغات الطبيعية
فيما يلي مجموعة أسئلة وإجابات حول أساسيات معالجة اللغات الطبيعية.
ما خطوات الانتقال من تطوير التطبيقات التقليدية لاحتراف مجال تعلم الآلة ML
في مجال تعلم الآلة، يحتاج المطور إلى استيعاب المفاهيم النظرية أولًا فهي تشكل الأساس الذي يبنى عليه كل شيء. ولكن من المهم أيضًا أن يتعرف على التقنيات واللغات الحديثة التي تدعم هذا المجال ويمكن تحقيق ذلك بحضور دورات تدريبية حول الذكاء الاصطناعي وتعلم الآلة وتنفيذ ما يتعلمه بشكل عملي.
أما بالنسبة للغات البرمجة، فلغة بايثون هي الخيار الأمثل للمطورين المبتدئين في تعلم الآلة فهي لغة برمجة عالية المستوى، وتحظى بشعبية واسعة، وتتميز بوجود مجتمع كبير يدعمها، كما تحتوي بايثون على مكتبات قوية في مجال تعلم الآلة مثل تنسرفلو TensorFlow وساي كت ليرن Scikit-learn التي تسهّل الوصول إلى الأدوات اللازمة لتطبيق مفاهيم تعلم الآلة.
هل تتطلب دراسة معالجة اللغة الطبيعية معرفة بمجال اللغويات Linguistics ونظرية المعلومات
تشكل نظرية المعلومات Information Theory الأساس الذي يعتمد عليه الكثيرون في فهم طريقة معالجة البيانات والمعلومات بطريقة منظمة وفعّالة، وهي تستخدم في مجالات متعددة، بما في ذلك معالجة اللغة الطبيعية NLP. فعلم البيانات ونظرية المعلومات يرتبطان ارتباطًا وثيقًا ببعضهما، وبالتالي فإن الفهم الجيد لمفاهيم مثل انتروبية المعلومات Information Entropy سيسهم في تعزيز قدرتنا على تطوير تطبيقات ذكاء اصطناعي احترافية، وسيساعدنا توظيف هذه المبادئ على التعمق في معالجة اللغات الطبيعية.
أما بالنسبة للغويات Linguistics وفهم بنية وقواعد اللغة فلا يتطلب الأمر بالضرورة الحصول على شهادة أكاديمية في هذا المجال. ويمكننا الاستفادة من الدورات التدريبية عبر الإنترنت التي توفر محتوى تطبيقي يساعد في تعزيز مهاراتنا، فمن خلال هذه الدورات سنتمكن من اكتساب الخبرة اللازمة لتطبيق تقنيات معالجة اللغات الطبيعية باحترافية.
ما هي نماذج BERT وGPT وما الأمثلة الواقعية عنها
نماذج BERT وGPT هما نوعان من النماذج اللغوية Language Models المدربة على كميات ضخمة من النصوص بهدف أداء مهام معينة مثل ملء المعلومات الناقصة في النصوص Text Infilling. إن هذه النماذج مهيأة بشكل خاص للاستخدام في التفاعل الحواري، حيث يمكنها فهم السياق اللغوي، والرد على الاستفسارات بطريقة طبيعية مشابهة لطريقة البشر.
كما تُظهر نماذج BERT وGPT أداء مذهلًا وتتفوق في العديد من التطبيقات الأخرى غير الحوارية، مثل حل المسائل الرياضية أو ترجمة النصوص. ويُظهِر كل من نموذج BERT الذي يعتمد على المعالجة ثنائية الاتجاه للنصوص Bidirectional Processing ونموذج GPT الذي يعتمد على النماذج اللغوية التوليدية Generative Language Models قدرة فائقة على فهم وتوليد اللغة في العديد من السياقات. وأحد الأمثلة الواقعية على استخدام GPT هو روبوت الدردشة ChatGPT، أما نموذج BERT فيستخدم بشكل رئيسي في تحسين محركات البحث SEO وأنظمة التوصية.
ما أبرز الأدوات المفيدة في مجال معالجة اللغات الطبيعية
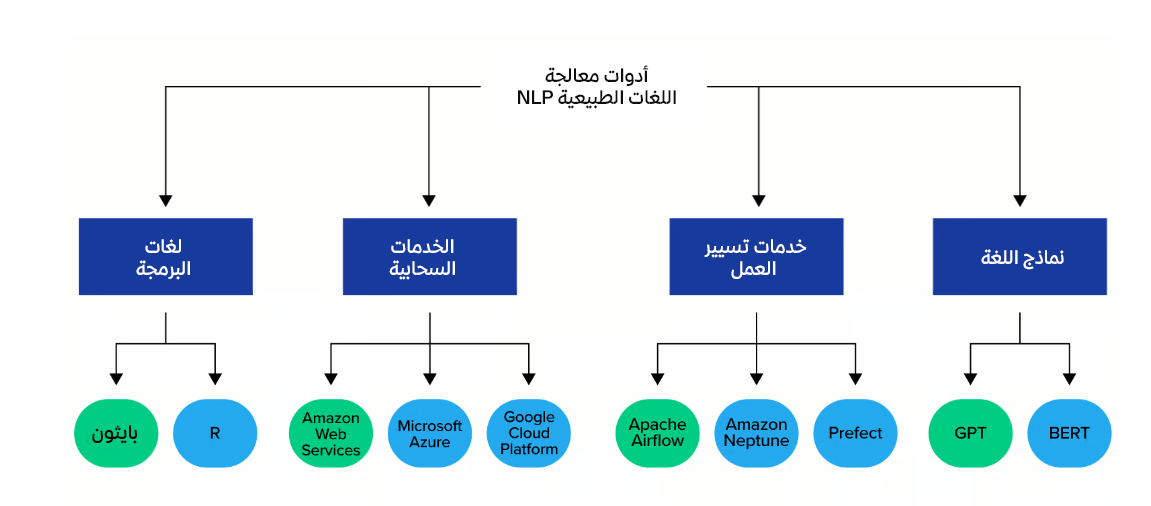
من أبرز أدوات معالجة اللغة الطبيعية NLP نذكر:
- لغات البرمجة مثل بايثون Python و R
- الخدمات السحابية مثل Amazon Web Services و Microsoft Azure
- خدمات تسيير العمل مثل Apache Airflow و Amazon Neptune
- النماذج اللغوية مثل GPT و BERT
أي لغة أفضل في تحليل النصوص لغة بايثون أم R
يُفضِّل كثيرون استخدام لغة بايثون في كل شيء، وليس في علم البيانات فقط، فلهذه اللغة مميزات عديدة من أبرزها سهولتها ووجود مجتمع كبير داعم لها، وتوفر العديد من مكتبات تحليل النصوص واستخراج المعلومات مثل NLTK و spaCy و TextBlob. أما لغة R، فهي مختلفة عن لغات البرمجة الأخرى وقد يكون استخدامها صعبًا ومعقدًا في بيئة الإنتاج. لكن قدراتها في مجال الإحصاء الرياضي يعطيها ميزة كبيرة مقارنة بلغة بايثون.
ما هي الخدمة السحابية الأفضل لبناء النماذج ونشرها
هناك العديد من الخدمات السحابية المتاحة لبناء النماذج Models ونشرها مثل خدمات AWS و Azure و Google، يمكن اختيار الخدمة التي تناسبنا وينصح الكاتب باستخدام منصة AWS لأنها تجنبنا مشكلة احتكار البائع Vendor Lock-in التي قد نواجهها عندما نعتمد على مزود سحابي معين، والتي قد تعيق انتقالنا إلى مزود آخر بسهولة وتكبدنا تكاليف ضخمة وتحديات كبيرة في نقل بيئة العمل.
هل يفيدنا استخدام أدوات تسيير العمل في خطوط عمل معالجة اللغة الطبيعية
نعم، تفيد أدوات تسيير العمل مثل Prefect أو Airflow أو Luigi أو Neptune بشكل فعّال في خطوط عمل معالجة اللغة الطبيعية NLP pipelines، لاسيما عندما يتطلب الأمر تنسيق عدة عمليات مع الحاجة لإضافة أو تعديل خطوط العمل في المستقبل.
فهذه الأدوات ضرورية في حالات معالجة البيانات الضخمة التي تتطلب عمليات استخراج البيانات Extract، وتحويلها Transform، وتحميلها Load، والمعروفة اختصارًا بعمليات ETL، وهي تساهم في إدارة العمليات بثقة ومرونة وتنظم تنفيذ العمليات المعقدة، وتُسهّل التعامل مع تدفقات البيانات وتحسن الكفاءة في مشاريع معالجة اللغة الطبيعية.
ما الأدوات التي يُوصى بها في مجال تعلم الآلة ومعالجة اللغات الطبيعية
ينصح الكاتب باستخدام التابع style من مكتبة Pandas لعرض البيانات وإجراء مقارنات سريعة بينها. كما ينصح باستخدام MLflow عند الحاجة لمشاركة نتائج تجربة معينة مع فريق من المبرمجين أو علماء البيانات، واستخدام مكتبة ploty بدلًا من matplotlib للحصول على تقارير تفاعلية، ويمكن استخدام منصة Weights & Biases في مجال التعلم العميق Deep Learning، لأن مراقبة الموترات أو التنسورات tensors -وهي البنية الأساسية للبيانات التي تعالجها الشبكة العصبية- أصعب بكثير من مراقبة المقاييس metrics بسبب طبيعة البيانات التي تعمل بها التنسورات، حيث تحتوي على معلومات متعددة الأبعاد قد تكون ضخمة ومعقدة، في حين أن المقاييس، مثل دقة النموذج accuracy و خسارة النموذج Loss فهي قيم واحدة مفردة يجري تحديثها باستمرار وعرضها خلال تدريب النموذج ومن السهل تتبعها وتحليلها.
نصائح وأسئلة حول العمل في مجال معالجة اللغة الطبيعية
فيما يلي مجموعة أسئلة وإجابات مرتبطة بالعمل في مجال معالجة اللغات الطبيعية.
كيف يمكن تقسيم المهام اليومية في تنظيف البيانات وبناء نماذج التطبيقات
يعد تنظيف البيانات Data Cleaning وهندسة الميزات Feature Engineering من المهام التي تتطلب وقتًا كبيرًا عند تطوير تطبيقات فعلية، نظرًا لأن جودة البيانات هي الأساس الذي يعتمد عليه تعلم الآلة في تقديم حلول فعّالة. لذا، يُنصح بتخصيص أكبر قدر ممكن من الوقت لبناء النماذج Models، خصوصًا عندما تكون متطلبات التطبيق بسيطة ومحدودة، ولا تحتاج إلى استخدام تقنيات معقدة أو حلول مبتكرة للوصول إلى النتائج المطلوبة.
كيف يمكن تحليل جدوى لنموذج تعلم آلة لا يحقق الأداء المطلوب
لو طُلب منا العمل على نموذج تعلم آلة لا يحقق الأداء المطلوب مهما درّبناه، وأردنا إجراء تحليل جدوى لتوفير الوقت وتقديم دليل على أن من الأفضل الانتقال إلى طرق أخر فيمكننا استخدام أسلوب التطوير المرن Lean الذي يهدف إلى تحقيق أفضل النتائج بأقل جهد ووقت، يجري ذلك من خلال معالجة بسيطة مسبقة للبيانات Data Preprocessing، واستخدام مجموعة نماذج بسيطة سهلة التنفيذ، واتباع ممارسات من شأنها ضمان عمل النموذ بشكل صحيح مثل فصل مجموعات التدريب، والتحقق من الصحة validation، واستخدام الاختبار والتقويم المتقاطع cross-validation عند الإمكان. فباستخدام هذه الخطوات البسيطة، يمكننا تقييم فيما إذا كان النموذج الحالي قابل للتحسين أو من الأفضل استخدام نماذج أخرى لتحقيق الأداء المطلوب.
هل يمكن بناء نماذج تعلم آلة تستخدم موارد أقل وبجودة النماذج الأكبر حجمًا
نعم، يمكن بناء نماذج أصغر باستخدام تقنيات مثل التقليم Pruning. والتقليم هو عملية تقليص حجم النموذج عن طريق إزالة العناصر غير المهمة التي لا تؤثر بشكل كبير على أداء النموذج. تساعدنا هذه التقنية في تقليل حجم النموذج وتحسين كفاءته الحسابية وتمكننا من تشغيله على أجهزة أقل قوة مع الحفاظ على نفس مستوى الأداء.
من الأمثلة الحديثة على ذلك نموذج Chinchilla من DeepMind، فعلى الرغم من أن هذا النموذج أصغر بكثير من النماذج القوية مثل GPT-3 من حيث الحجم الحسابي، إلا أنه يقدم أداء أفضل. وهذا يثبت أن تقنيات مثل التقليم يمكن أن تساعدنا في تحسين الكفاءة الحسابية وتحقيق نتائج عالية الأداء بنماذج أصغر.
أسئلة حول منتجات الذكاء الاصطناعي ورؤى الأعمال
فيما يلي مجموعة أمثلة وإجابات حول منتجات الذكاء الاصطناعي ورؤى الأعمال
ما هي الخطوات المتبعة في دورة تطوير منتجات تعلم الآلة
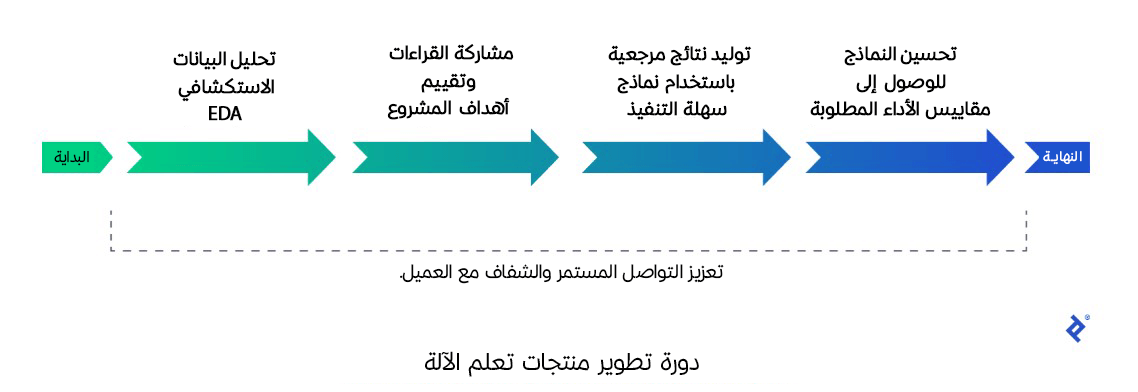
تتكون دورة تطوير منتجات تعلم الآلة من عدة خطوات أساسية: تبدأ الدورة بتحليل البيانات الاستكشافي Exploratory Data Analysis أو اختصارًا EDA من خلال فحص البيانات بعناية لتحديد ما هو ضروري للعمل على منتج تعلم الآلة، بعدها تُناقش نتائج التحليل مع الفريق وتقيّم أهداف المشروع لضمان وضوح التوجهات بعد تحديد الأهداف، ثم تُستَخدم نماذج بسيطة لتوليد نتائج مرجعية تساعد في تحديد أفضل الحلول، وأخيرًا يجري تحسين النماذج وتعديلها لتحقيق النتائج المثلى وفقًا لمقاييس الأداء. وخلال جميع الخطوات يجب أن يكون هناك تواصل مستمر مع العميل لضمان تطابق الحلول مع احتياجاته.
ما تحديات تطبيق الذكاء الاصطناعي وتعلم الآلة في تطوير المنتجات
في الوقت الحالي، هناك تحديان رئيسيان في مجال الذكاء الاصطناعي وتعلم الآلة: الأول هو الذكاء الاصطناعي العام Artificial General Intelligence أو AGI اختصارًا، والذي أصبح محور اهتمام كبير فهو نوع من الذكاء الاصطناعي يُفترض أن يكون قادرًا على أداء أي مهمة يمكن أن يؤديها الإنسان. لكن رغم الاهتمام الكبير به، لا زال تحقيقه غير ممكن في الوقت الحالي، وما زال أمامنا وقت طويل للوصول إلى تحقيق مستوى عالي من الكفاءة في أداء مهام متنوعة، ولا زال الذكاء الاصطناعي يواجه صعوبة في التعامل مع مشكلات لم يتعلم كيفية حلها مسبقًا.
الحد الثاني في الذكاء الاصطناعي هو التعلم المعزز Reinforcement Learning حيث يعتمد هذا النوع من التعلم على تحسين الأنظمة من خلال المحاولة والتجربة والتفاعل مع البيئة بدلاً من الاعتماد على البيانات الضخمة Big data. ورغم أنه يعد بديلاً للتعلم التقليدي القائم على البيانات الضخمة والتعلم الخاضع للإشراف Supervised learning، إلا أن جمع البيانات اللازمة لتعلم جميع المهام البشرية أمر يستغرق وقتًا طويلاً، وحتى إذا جمعنا البيانات المطلوبة، قد لا تكون كافية لإنشاء نموذج ذكي يعمل بنفس مستوى الكفاءة التي يعمل بها البشر، خاصة عندما تتغير الظروف والبيئات في المستقبل. فهذه التغيرات قد تؤثر على قدرة النموذج على التكيف مع التحديات الجديدة. لذا من غير المحتمل أن يتمكن مجتمع الذكاء الاصطناعي من حل هذه المشكلات قريبًا، وإذا تمكن من ذلك، ستتحول التحديات إلى أمور تتعلق بالكفاءة الحسابية.
ما حالات استخدام عمليات تعلم الآلة
تعد عمليات تعلم الآلة Machine Learning Operations أو MLOps اختصارًا، ممتازة لعديد من المنتجات والأهداف مثل الحلول المصممة بدون خادم Serverless والتي تُحَصَّل الرسوم فيها مقابل ما نستخدمه والتي لا نحتاج فيها إلى إدارة الخوادم أو القلق بشأن صيانتها، وكذلك تستخدم في واجهات برمجة تطبيقات تعلم الآلة التجارية مثل التنبؤ بالطلب على المنتجات أو تحسين تجربة العملاء، كما تُستخدم خدمات مجانية مثل MLflow لمتابعة ومراقبة التجارب أثناء تطوير النماذج في مراحلها الأولى، ومراقبة الأداء بعد نشر التطبيقات.
كيف نقنع العميل أو المدير باستخدام تعلم الآلة في التطبيقات
تتمتع عمليات تعلم الآلة بفوائد كبيرة في التطبيقات على مستوى المؤسسات، حيث تساهم في تحسين كفاءة عملية التطوير وتقليل التكاليف التقنية. ومع ذلك، من المهم تقييم مدى ملاءمة الحل المقترح للهدف المطلوب. على سبيل المثال، إذا كان لدينا خادم في مكتبنا ويمكن ضمان تلبية متطلبات اتفاقية مستوى الخدمة Service-level agreement أو اختصارًا SLA، ومعرفة عدد الطلبات المتوقعة، فلن نحتاج لاستخدام خدمات عمليات تعلم الآلة المُدارة managed MLOps service. تحدث المشكلات الشائعة عندما نفترض أن الخدمة المُدارة ستلبي جميع متطلبات المشروع، مثل أداء النموذج، ومتطلبات اتفاقية مستوى الخدمة SLA، وقابلية التوسع، وغيرها.
على سبيل المثال، يتطلب إنشاء واجهة برمجة تطبيقات للتعرف الضوئي على الحروف Optical Character Recognition أو OCR اختصارًا إجراء ختبارات دقيقة لتقييم نقاط الفشل وكيفية حدوثها. ويجب استخدام هذه الاختبارات لتحديد العوائق التي قد تعيق الوصول إلى الأداء المطلوب.
كيف تحدد المؤسسات احتياجات العميل بدقة وتنشئ نماذج تساعد في اتخاذ القرارات
تُضيف أدوات علم البيانات مزيدًا من الغموض للعميل مقارنة بحلول البرمجة التقليدية، لأنها تعتمد غالبًا على التعامل مع حالات عدم اليقين بدلاً من تجنبها. لهذا، من الضروري أن يظل العميل على اطلاع دائم بسير العمل فالعميل هو الأكثر دراية باحتياجات المشروع وهو من يوافق على النتيجة النهائية.
أسئلة حول مستقبل معالجة اللغات الطبيعية
فيما يلي مجموعة أمثلة وإجابات حول مستقبل معالجة اللغات الطبيعية وتحديات تطبيقها.
ما مبرر ارتفاع استهلاك الطاقة الناتج عن الشبكات العصبية التلافيفية الكبيرة CNNs
قد يعتقد البعض أن نماذج مثل LLaMA من شركة Meta غير مفيدة وتهدر الموارد. ومع ذلك، بما أن هذه النماذج ستكون متاحة مجانًا للجمهور في المستقبل، فإن الاستثمارات التي تُنفق على تدريب هذه النماذج ستعود بالفائدة على المدى البعيد وستساهم في تقدم الأبحاث والتقنيات، فبتقديم هذه النماذج، نفتح الفرصة للباحثين والمطورين للاستفادة منها في مجالات متنوعة، ونسرع من الابتكار ونعزز من تقدم الذكاء الاصطناعي بشكل عام.
هل استطاعت نماذج الذكاء الاصطناعي اكتساب وعي يماثل الوعي البشري
إن الوعي في الذكاء الاصطناعي هو مفهوم نظري للغاية، والحديث عن وعي الذكاء الاصطناعي قد يكون غير دقيق في الغالب، ويؤثر سلبًا على فهم معالجة اللغات الطبيعية. بالعموم، تظل مشاريع الذكاء الاصطناعي اصطناعية ولا تمتلك وعيًا مشابهًا للوعي البشري.
هل يجب أن نقلق بشأن القضايا الأخلاقية المتعلقة بالذكاء الاصطناعي وتعلم الآلة
يجب أن نكون حذرين بشأن ذلك خاصة مع التقدم السريع في أنظمة الذكاء الاصطناعي مثل ChatGPT. ولكن، من المهم أن يكون لدينا تعليم وخبرة كافية لفهم هذه التقنية بشكل جيد. ومن المفترض أن تكون الحكومات هي المسؤولة عن تنظيم الأمور، ما زلنا بحاجة إلى وقت إضافي لتحقيق ذلك، ولعل إحدى القضايا الأخلاقية المهمة هي كيفية تقليل تحيز الذكاء الاصطناعي وتجنبه ومسؤولية ذلك تقع على عاتق المهندسين والشركات، وكذلك على العملاء. لذا يجب بذل جهد كبير لضمان عدم التمييز أو المعاملة غير العادلة لأي شخص، بغض النظر عن تكاليف تحقيق ذلك.
الخاتمة
ختامًا، لنتذكر أن تعلم الآلة هو المحرك الرئيسي الذي يمكن أن يقود البشرية إلى ثورتها الصناعية القادمة. فقد اختفت وظائف عدة أثناء الثورة الصناعية، ولكن ظهرت وظائف جديدةً أكثر إبداعًا ويمكنها تأدية عمل ينجزه عدد كبير من العمال. وبإمكاننا فعل الشيء نفسه الآن والتكيف مع تعلم الآلة والذكاء الاصطناعي بشكل إيجابي وفعال.
ترجمة، وبتصرّف، للمقال Ask an NLP Engineer: From GPT Models to the Ethics of AI، لكاتبه Daniel Pérez Rubio.








أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.