

سنتناول في هذه المقالة مقدمةً سريعةً عن تطبيق محرك البحث الذي ننوي بناءه، حيث سنَصِف مكوِّناته ونشرح أُولاها، وهي عبارة عن زاحف ويب crawler يُحمِّل صفحات موقع ويكيبيديا ويُحلِّلها. سنتناول أيضًا تنفيذًا تعاوديًا recursive لأسلوب البحث بالعمق أولًا depth-first وكذلك تنفيذًا تكراريًا للمُكدِّس stack (الداخل آخرًا، يخرج أولًا LIFO) باستخدام Deque.
محركات البحث
تستقبل محركات البحث -مثل محرك جوجل وبينغ- مجموعةً من كلمات البحث، وتعيد قائمةً بصفحات الإنترنت المرتبطة بتلك الكلمات (سنناقش ما تعنيه كلمة مرتبطة لاحقًا). يُمكِنك قراءة المزيد عن محركات البحث، ولكننا سنشرح هنا كل ما قد تحتاج إليه.
يتكوّن أي محرك بحث من عدة مكوناتٍ أساسيةٍ نستعرضها فيما يلي:
- الزحف crawling: برنامج بإمكانه تحميل صفحة إنترنت وتحليلها واستخراج النص وأي روابط إلى صفحات أخرى.
- الفهرسة indexing: هيكل بيانات data structure بإمكانه البحث عن كلمةٍ والعثور على الصفحات التي تحتوي على تلك الكلمة.
- الاسترجاع retrieval: طريقة لتجميع نتائج المُفهرِس واختيار الصفحات الأكثر صلةً بكلمات البحث.
سنبدأ بالزاحف، والذي تتلخص مهمته في اكتشاف مجموعة من صفحات الويب وتحميلها، في حين تهدف محركات البحث مثل جوجل وبينغ إلى العثور على جميع صفحات الإنترنت، لكن المعتاد أيضًا أن يكون الزاحف مقتصرًا على نطاق أصغر. وفي حالتنا هذه، سنقتصر على صفحات موقع ويكيبيديا فقط.
في البداية، سنبني زاحفًا يقرأ صفحةً من موقع ويكيبيديا، ويبحث عن أول رابطٍ ضمن الصفحة، وينتقل إلى الصفحة التي يشير إليها الرابط، ثم يكرر الأمر. سنَستخدِم ذلك الزاحف لاختبار صحة فرضيّة فرضيّة الطريق إلى الفلسفة، الموجودة في صفحات ويكيبيديا والتي تنصّ على ما يلي:
اقتباسإذا نقرت على أول رابطٍ مكتوبٍ بأحرفٍ صغيرةٍ في أي مقالةٍ في موقع ويكيبيديا، وكرَّرت ذلك على المقالات التالية، فسينتهي بك المطاف إلى مقالة الفلسفة في موقع ويكيبيديا.
سيسمح لنا اختبار تلك الفرضيّة ببناء القطع الأساسية للزاحف بدون الحاجة إلى الزحف عبر الإنترنت بأكمله أو حتى عبر كل صفحات موقع ويكيبيديا، كما أن هذا التمرين ممتعٌ نوعًا ما.
أمّا المُفهرس والمُسترجِع فسنبني كلًّا منهما في مقال مستقلّ لاحقًا.
تحليل مستند HTML
عندما تُحمِّل صفحة إنترنت، فإن محتوياتها تكون مكتوبةً بلغة ترميز النص الفائق HyperText Markup Language، التي تُختصَر عادةً إلى HTML. على سبيل المثال، انظر إلى مستند HTML التالي:
<!DOCTYPE html> <html> <head> <title>This is a title</title> </head> <body> <p>Hello world!</p> </body> </html>
تُمثِّل العبارات "This is a title" و"Hello world!" النصَّ الفعليَّ المعروض في الصفحة، أما بقية العناصر فهي عبارة عن وسوم tags تشير إلى الكيفية التي ستُعرَض بها تلك النصوص.
بعد أن يُحمِّل الزاحف صفحة إنترنت، يُحلِّل محتوياتها المكتوبة بلغة HTML ليتمكَّن من استخراج النص وإيجاد الروابط. سنَستخدِم مكتبة jsoup مفتوحة المصدر من لغة جافا لإجراء ذلك، حيث تستطيع تلك المكتبة تحميل صفحات HTML وتحليلها.
ينتج عن تحليل مستندات HTML شجرة نموذج كائن المستند Document Object Model التي تُختصرُ إلى DOM، حيث تحتوي تلك الشجرة على ما يتضمنه المستند من عناصر بما في ذلك النصوص والوسوم، تمثِّل هيكل بياناتٍ مترابطًا linked يتألف من عقد nodes تُمثِّلُ كلًا من النصوص والوسوم والعناصر الأخرى.
تُحدِّد بنية المستند العلاقات بين العقد. يُعدّ الوسم <html> -في المثال المُوضَّح في الأعلى مثلًا، العقدة الأولى التي يُطلَق عليها اسم الجذر root، وتحتوي تلك العقدة على روابط تشير إلى العقد التي تتضمنها وفي حالتنا هما العقدتان <head> و<body>، وتُعدّ كلٌّ منهما ابنًا للعقدة الجذر.
تملك العقدة <head> ابنًا واحدًا هو العقدة <title>، وبالمثل، تملك العقدة <body> ابنًا واحدًا هو العقدة <p> (اختصارًا لكلمة paragraph). تُوضِّح الصورة التالية تلك الشجرة بيانيًا.
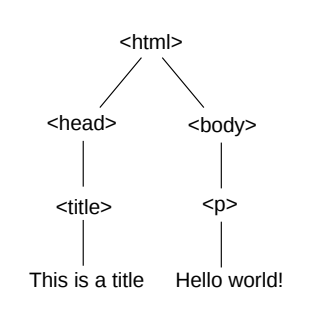
تحتوي كلّ عقدة على روابط إلى عقد الأبناء، كما تحتوي على رابط إلى عقدة الأب الخاصة بها، وبالتالي يُمكِننا أن نبدأ من أي عقدة في الشجرة، ثم نتنقّل إلى أعلاها أو أسفلها. عادةً ما تكون أشجار DOM المُمثِلة للصفحات الحقيقية أعقدَ بكثيرٍ من هذا المثال.
تُوفِّر غالبية متصفحات الإنترنت أدوات للتحقّق من نموذج DOM الخاص بالصفحة المعروضة. ففي متصفح كروم مثلًا، يُمكِنك النقر بزر الفأرة الأيمن على أي مكان من الصفحة، واختيار "Inspect" من القائمة؛ أما في متصفح فايرفوكس، فيُمكِنك أيضًا النقر بزر الفأرة الأيمن على أي مكان، واختيار "Inspect Element" من القائمة. يُمكِنك القراءة عن أداة Web Inspector التي يُوفِّرها متصفح سفاري أو قراءة التعليمات الخاصة بمتصفح إنترنت إكسبلورر.

تعرض الصورة السابقة لقطة شاشة لنموذج DOM الخاص بـمقالة ويكيبيديا عن لغة جافا، حيث يُمثِّلُ العنصر المظلل أول فقرة في النص الرئيسي من المقالة. لاحِظ أن الفقرة تقع داخل عنصر <div> الذي يملك السمة id="mw-content-text"، والتي سنَستخدِمها للعثور على النص الرئيسي في أي مقالةٍ نُحمِّلها.
استخدام مكتبة jsoup
تُسهِّل مكتبة jsoup من تحميل صفحات الإنترنت وتحليلها، وكذلك التنقُل عبر شجرة DOM. انظر إلى المثال التالي:
String url = "http://en.wikipedia.org/wiki/Java_(programming_language)"; // حمِّل المستند وحلّله Connection conn = Jsoup.connect(url); Document doc = conn.get(); // اختر المحتوى النصي واسترجع الفقرات Element content = doc.getElementById("mw-content-text"); Elements paragraphs = content.select("p");
يَستقبِل التابع Jsoup.connect مُحدِّد موارد موحدًا URL من النوع String، ويُنشِئ اتصالًا مع خادم الويب. بعد ذلك يُحمِّل التابع get مستند HTML ويُحلِّله، ويعيد كائنًا من النوع Document يُمثِل شجرة DOM.
يُوفِّر الصنف Document توابعًا للتنقل عبر الشجرة واختيار العقد. في الواقع، إنه يُوفِّر توابع كثيرةً جدًا لدرجة تُصيبَك بالحيرة. وسيَعرِض المثال التالي طريقتين لاختيار العقد:
-
getElementById: يستقبِل سلسلةً نصيةً من النوعString، ويبحث ضمن الشجرة عن عنصرٍ يملك نفس قيمة حقل id المُمرَّرة. يختار التابع في هذا المثال العقدة<div id="mw-content-text" lang="en" dir="ltr" class="mw-content-ltr">التي تَظهَر في أيّ مقالةٍ من موقع ويكيبيديا لكي تُميّز عنصر<div>المُتضمِّن للنص الرئيسي للصفحة، عن شريط التنقل الجانبي والعناصر الأخرى. يعيد التابعgetElementByIdكائنًا من النوعElementيُمثِل عنصر<div>ذاك، ويحتوي على العناصر الموجودة داخله بهيئة أبناءٍ وأحفادٍ وغيرها. -
select: يستقبل سلسلةً نصيّةً من النوعString، ويتنقّل عبر الشجرة، ثم يُعيد جميع العناصر التي يتوافق الوسم tag الخاص بها مع تلك السلسلة النصية. يعيد التابع في هذا المثال جميع وسوم الفقرات الموجودة في الكائنcontent. تكون القيمة المعادة عبارة عن كائن من النوعElements.
قبل أن تُكمِل القراءة، يُفضَّل أن تلقي نظرةً على توثيق كلٍّ من الأصناف المذكورة لكي تتعرف على إمكانيات كلٍّ منها. تجدر الإشارة إلى أنّ الأصناف Element و Elements و Node هي الأصناف الأهمّ.
يُمثِل الصنف Node عقدةً في شجرة DOM. وتمتد منه أصنافٌ فرعيةٌ subclasses كثيرةٌ مثل Element وTextNode وDataNode وComment. يُعدّ الصنف Elements تجميعةً من النوع Collection التي تحتوي على كائناتٍ من النوع Element.
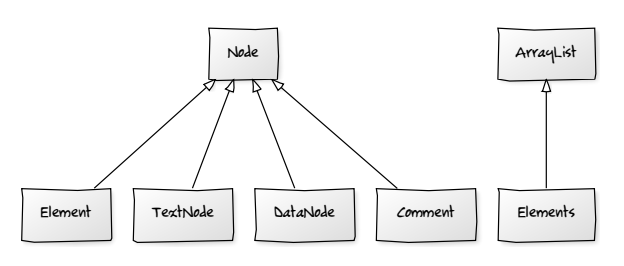
تحتوي الصورة السابقة على مخطط UML يُوضّح العلاقة بين تلك الأصناف. يشير الخط ذو الرأس الأجوف إلى أن هناك صنفًا يمتد من صنفٍ آخر، إذ يمتد الصنف Elements مثلًا، من الصنف ArrayList. وسنعود لاحقًا للحديث عن مخططات UML.
اجتياز شجرة DOM
يَسمَح لك الصنف WikiNodeIterable -الذي كتبه المؤلف- بالمرور عبر عقد شجرة DOM. انظر إلى المثال التالي الذي يبين طريقة استخدامه:
Elements paragraphs = content.select("p"); Element firstPara = paragraphs.get(0); Iterable<Node> iter = new WikiNodeIterable(firstPara); for (Node node: iter) { if (node instanceof TextNode) { System.out.print(node); } }
يُكمِل هذا المثال ما وصلنا إليه في المثال السابق، فهو يختار الفقرة الأولى في الكائن paragraphs أولًا، ثم يُنشِئ كائنًا من النوع WikiNodeIterable ليُنفِّذ الواجهة Iterable<Node>. يُجرِي WikiNodeIterable بحثًا بتقنية العمق أولًا depth-first، ويُولِّد العقد بنفس ترتيب ظهورها بالصفحة.
تَطبَع الشيفرةُ العقدَ إذا كانت من النوع TextNode وتتجاهلها إذا كانت من أي نوع آخر، والتي تُمثِل وسومًا من الصنف Element في هذا المثال. ينتج عن ذلك طباعة نص الفقرة بدون أيّ ترميزات. وقد كان الخرج في هذا المثال كما يلي:
اقتباسJava is a general-purpose computer programming language that is concurrent, class-based, object-oriented,[13] and specifically designed …
البحث بالعمق أولا Depth-first search
تتوفَّر العديد من الطرائق لاجتياز الأشجار، ويتلاءم كلٌّ منها مع أنواعٍ مختلفةٍ من التطبيقات. سنبدأ بطريقة البحث بالعمق أولًا DFS. تبدأ تلك الطريقة من جذر الشجرة، ثم تختار الابن الأول للجذر. إذا كان لديه أبناء، فإنها ستختار الابن الأول، وتستمر في ذلك حتى تصل إلى عقدةٍ ليس لها أبناء، أين تبدأ بالتراجع عندها والتحرك لأعلى إلى عقدة الأب، لتختار منها الابن التالي إن كان موجودًا، وفي حالة عدم وجوده، فإنها تتراجع للوراء مجددًا. عندما تنتهي من البحث في الابن الأخير لعقدة الجذر، فإنها تكون قد انتهت.
هناك طريقتان شائعتان لتنفيذ DFS، وذلك إما بالتعاود recursion، أو بالتكرار. يُعدّ التنفيذ بالتعاود هو الطريقة الأبسط:
private static void recursiveDFS(Node node) { if (node instanceof TextNode) { System.out.print(node); } for (Node child: node.childNodes()) { recursiveDFS(child); } }
يُستدعَى التابع السابق من أجل كل عقدةٍ ضمن الشجرة بدايةً من الجذر. إذا كانت العقدة المُمرَّرة من النوع TextNode، ويطبع التابع محتوياتِها، ثم يفحص إذا كان للعقدة أي أبناء. فإذا كان لها أبناء، فإنه سيَستدعِي recursiveDFS -أي ذاته- لجميع عقد الأبناء على التوالي.
في هذا المثال، طَبَعَنا محتويات العقد التي تنتمي إلى النوع TextNode قبل أن ننتقل إلى الأبناء، وهو ما يُعدّ مثالًا على الاجتياز ذي الترتيب السابق. يُمكِنك القراءة عن الاجتيازات ذات الترتيب السابق pre-order والترتيب اللاحق post-order وفي الترتيب in-order. لا يُشكّل ترتيب الاجتياز في تطبيقنا هذا أي فارق.
نظرًا لأن التابع recursiveDFS يَستدعِي ذاته تعاوديًا، فقد كان بإمكانه استخدام مُكدِّس الاستدعاءات للاحتفاظ بالعقد الأبناء، ومعالجتها بالترتيب المناسب، لكننا بدلًا من ذلك يُمكِننا أن نَستخدِم مُكدِّسًا صريحًا للاحتفاظ بالعقد، وفي تلك الحالة لن نحتاج إلى التعاود، حيث سنتمكَّن من اجتياز الشجرة عبر حلقة تكراريّة.
المكدسات Stacks في جافا
قبل أن نشرح التنفيذ التكراري لتقنية DFS، سنناقش أولًا هيكل بياناتٍ يُعرَف باسم المُكدّس. سنبدأ بالفكرة العامة للمُكدِّس، ثم سنتحدث عن واجهتين interfaces بلغة جافا تُعرِّفان توابع المُكدِّس، وهما Stack وDeque.
يُعدّ المُكدِّس هيكل بياناتٍ مشابهًا للقائمة، فهو عبارة عن تجميعة تتذكر ترتيب العناصر. ويتمثل الفرق بين المكدّس والقائمة في أن المُكدِّس يوفِّر توابعَ أقل، وأنه عادةً ما يُوفِّر المُكدِّس التوابع التالية:
-
push: يضيف عنصرًا إلى أعلى المُكدِّس. -
pop: يحذِف العنصر الموجود أعلى المُكدِّس ويعيده. -
peek: يعيد العنصر الموجود أعلى المُكدِّس دون حذفه. -
isEmpty: يشير إلى ما إذا كان المُكدِّس فارغًا.
نظرًا لأن التابع pop يسترجع العنصر الموجود في أعلى المكدّسِ دائمًا، يُشار إلى المكدّساتِ باستخدام كلمة LIFO، والتي تُعدّ اختصارًا لعبارة "الداخل آخرًا، يخرج أولًا". في المقابل، تُعدّ الأرتال queue بديلًا للمكدّساتِ، ولكنها تُعيد العناصر بنفس ترتيب إضافتها، ولذلك، يُشار إليها عادةً باستخدام كلمة FIFO أي "الداخل أولًا، يخرج أولًا".
قد لا تكون أهمية المُكدِّسات والأرتال واضحةً بالنسبة لك، فهما لا يوفران أي إمكانياتٍ إضافيةً عن تلك الموجودة في القوائم lists. بل يوفران إمكانيات أقل، لذلك قد تتساءل لم لا نكتفي باستخدام القوائم؟ والإجابة هي أن هناك سببان:
- إذا ألزمت نفسك بعدد أقل من التوابع، أي بواجهة تطوير تطبيقات API أصغر، فعادةً ما تصبح الشيفرة مقروءةً أكثر، كما تقل احتمالية احتوائها على أخطاء. على سبيل المثال، إذا استخدمت قائمةً لتمثيل مُكدِّس، فقد تَحذِف -عن طريق الخطأ- عنصرًا بترتيب خاطئ. في المقابل، إذا استخدمت واجهة تطوير التطبيقات المُخصَّصة للمُكدِّس، فسيستحيل أن تقع في مثل هذا الخطأ، ولهذا فالطريقة الأفضل لتجنُّب الأخطاء هي بأن تجعلها مستحيلة.
- إذا كانت واجهة تطوير التطبيقات التي يُوفِّرها هيكل البيانات صغيرةً، فسيكون تنفيذها بكفاءةٍ أسهل. على سبيل المثال، يُمكِننا أن نَستخدِم قائمةً مترابطةً linked list أحادية الترابط لتنفيذ المُكدِّس بسهولة، وعندما نضع عنصرًا في المُكدِّس، فعلينا أن نضيفه إلى بداية القائمة؛ أما عندما نسحب عنصرًا منها، فعلينا أن نَحذفه من بدايتها. ونظرًا لأن عمليتي إضافة العناصر وحذفها من بداية القوائم المترابطة تستغرق زمنًا ثابتًا، فإننا نكون قد حصلنا على تنفيذٍ ذي كفاءةٍ عالية. في المقابل، يَصعُب تنفيذ واجهات التطوير الكبيرة بكفاءة.
لديك ثلاثة خيارات لتنفيذ مُكدِّسٍ بلغة جافا:
-
اِستخدِم الصنف
ArrayListأو الصنفLinkedList. إذا اِستخدَمت الصنفArrayList، تأكَّد من إجراء عمليتي الإضافة والحذف من نهاية القائمة لأنهما بذلك سيستغرِقان زمنًا ثابتًا، وانتبه من إضافة العناصر في مكانٍ خاطئٍ أو تحذفها بترتيبٍ خاطئ. -
تُوفِّر جافا الصنف
Stackالذي يحتوي على التوابع الأساسية للمُكدِّسات، ولكنه يُعدّ جزءًا قديمًا من لغة جافا، فهو غير متوافق مع إطار عمل جافا للتجميعات Java Collections Framework الذي أُضيفَ لاحقًا. -
ربما الخيار الأفضل هو استخدام إحدى تنفيذات الواجهة
Dequeمثل الصنفArrayDeque.
إن كلمة Deque هي اختصار للتسمية رتل ذو نهايتين double-ended queue، والتي يُفترَض أن تُلفَظ deck، ولكنها تُلفَظ أحيانًا deek. تُوفِّر واجهة Deque بلغة جافا التوابع push وpop وpeek وisEmpty، لذلك يُمكِنك أن تَستخدِم كائنًا من النوع Deque كمُكدِّس، كما أنها تُوفِّر توابع أخرى ولكننا لن نَستخدِمها حاليًا.
التنفيذ التكراري لتقنية البحث بالعمق أولا
انظر إلى التنفيذ التكراري لأسلوب "البحث بالعمق أولًا". يَستخدِم ذلك التنفيذ كائنًا من النوع ArrayDeque ليُمثِل مُكدِّسًا يحتوي على كائنات تنتمي إلى النوع Node:
private static void iterativeDFS(Node root) { Deque<Node> stack = new ArrayDeque<Node>(); stack.push(root); while (!stack.isEmpty()) { Node node = stack.pop(); if (node instanceof TextNode) { System.out.print(node); } List<Node> nodes = new ArrayList<Node>(node.childNodes()); Collections.reverse(nodes); for (Node child: nodes) { stack.push(child); } } }
يُمثِل المعامل root جذر الشجرة التي نريد أن نجتازها، حيث سنُنشِئ المُكدِّس ونضيف الجذر إليه.
تستمر الحلقة loop بالعمل إلى أن يُصبِح المُكدِّس فارغًا. يَسحَب كل تكرار ضمن الحلقة عقدةً من المُكدِّس، فإذا كانت العقدة من النوع TextNode، فإنه يَطبَعُ محتوياتِها ثم يضيف أبناءها إلى المُكدِّس. ينبغي أن نضيف الأبناء إلى المُكدِّس بترتيبٍ معاكسٍ لكي نتمكَّن من معالجتها بالترتيب الصحيح، ولذلك سنَنَسخ الأبناء أولًا إلى قائمة من النوع ArrayList، ثم نعكس ترتيب العناصر فيها، وفي النهاية سنمرّ عبر القائمة المعكوسة.
من السهل كتابة التنفيذ التكراري لتقنيةِ البحث بالعمق أولًا باستخدام كائن من النوع Iterator، وسترى ذلك في المقالة التالية.
في ملاحظة أخيرة عن الواجهة Deque، بالإضافة إلى الصنف ArrayDeque، تُوفِّر جافا تنفيذًا آخرًا لتلك الواجهة، هو الصنف LinkedList الذي يُنفِّذ الواجهتين List وDeque، وتعتمد الواجهة التي تحصل عليها على الطريقة التي تَستخدِمه بها. على سبيل المثال، إذا أسندت كائنًا من النوع LinkedList إلى متغيرٍ من النوع Deque كالتالي:
Deqeue<Node> deque = new LinkedList<Node>();
فسيكون في إمكانك استخدام التوابع المُعرَّفة بالواجهة Deque، لا توابع الواجهةِ List. وفي المقابل، إذا أسندته إلى متغيرٍ من النوع List، كالتالي:
List<Node> deque = new LinkedList<Node>();
فسيكون في إمكانك استخدام التوابع المُعرَّفة بالواجهة List لا توابع الواجهة Deque؛ أما إذا أسندته على النحو التالي:
LinkedList<Node> deque = new LinkedList<Node>();
فسيكون بإمكانك استخدام جميع التوابع، ولكن الذي يحدث عند دمج توابع من واجهاتٍ مختلفةٍ، هو أن الشيفرة ستصبح أصعب قراءةً وأكثر عرضةً لاحتواء الأخطاء.
ترجمة -بتصرّف- للفصل Chapter 6: Tree traversal من كتاب Think Data Structures: Algorithms and Information Retrieval in Java.






أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.