

سننظر في هذا المقال من سلسلة تعلم البرمجة في دور نظام التشغيل وكيفية الوصول إليه من بايثون، وسنشرح فيه:
- دور نظام التشغيل ووظيفته.
- وصول بايثون إلى نظام التشغيل.
- العمل مع الملفات والمجلدات.
- التعامل مع العمليات.
- معرفة البيانات الخاصة بالمستخدمين.
التعرف على نظام التشغيل
يدرك أغلب مستخدمي الحواسيب أن حواسيبهم تعمل بنظم تشغيل، سواء كانت ويندوز أو لينكس أو ماك أو غير ذلك، لكنهم قد يجهلون الدور الذي تقوم به تلك النظم على وجه الدقة، خاصةً أن أغلب نظم التشغيل التجارية تأتي مع برامج كثيرة ليست جزءًا من نظام التشغيل، مثل برامج عرض الصور، وتصفح الويب، ومحررات النصوص، لكن الجهة المصدرة للنظام تحزمها معه لأن المستخدم لن يستطيع الاستفادة من نظام التشغيل وحده.
مبدأ طبقات الكعكة
إذا أردنا معرفة حقيقة نظام التشغيل فيجب أن ننظر أولًا في الطريقة التي بُنيت بها الحواسيب، والتي يمكن النظر إليها على أنها كعكة متعددة الطبقات multi-layer cake، حيث يكون عتاد الحاسوب والقطع الإلكترونية المختلفة فيه الطبقة الدنيا، بما في ذلك وحدة المعالجة المركزية CPU، والقرص الصلب، والذاكرة، ونظام الإدخال والإخراج الذي يحوي مداخل USB، وفتحات بطاقات الذاكرة، ووصلات الشبكة وغيرها.
أما الطبقة التي فوقها فهي BIOS، أو نظام الإدخال والإخراج البسيط Basic Input Output System، وهي أول طبقة برمجية في تكوين الحاسوب، والمسؤولة عن إقلاع الحاسوب وتوفير أبسط واجهة ممكنة للعتاد، إذ تسمح بنقل رؤوس القرص الصلب من مسار لآخر، ومن قطاع لآخر داخل المسار الواحد، وبقراءة أو كتابة البايتات المنفردة في المخازن المؤقتة للبيانات data buffers المتصلة بكل منفذ، ومع هذا لا تعرف BIOS نفسها أي معلومات عن الملفات أو المجلدات أو أي من المفاهيم العليا الأخرى التي نتعامل معها نحن المستخدمون، وإنما تعرف كيفية التعامل مع الأجهزة الإلكترونية البسيطة التي يتكون منها الحاسوب، بل قد لا تتعامل معها مباشرةً، وإنما من خلال برمجيات يثبتها مزود العتاد نفسه في أماكن حساسة داخل BIOS، وهذا شائع في بطاقات الرسوم graphics cards على وجه الخصوص، إذ تثبت الشركات المصنعة لتلك البطاقات روابط إلى تعريفات الرسوم الخاصة بها في مكان معياري داخل شيفرة BIOS، لتستدعي BIOS واجهةً متفقًا عليها، مع توفير الشركة لبرنامجها الخاص بها، وتُخزَّن BIOS عادةً في نوع خاص من رقاقات الذاكرة ذات طبيعة شبه دائمة، أي أنها لا تحذَف عند قطع التيار الكهربي، لكن يمكن إعادة كتابتها عند الحاجة لتحديث BIOS.
أما الطبقة التالية لطبقة BIOS فهي طبقة نظام التشغيل، ويختلف هيكل هذه الطبقة كثيرًا وفقًا لكل نظام تشغيل، غير أنها تتكون في الغالب من نواة kernel، أو مجموعة أساسية من الخدمات مع تعريفات للعتاد device drivers، وقد توضع تعريفات العتاد داخل النواة، أو تكون وحدات تحمّلها النواة عند الحاجة، وهذا شبيه بتحميل البرامج لوحدات بايثون عند الحاجة، أما وظيفة هذه الطبقة فهي الترجمة من العتاد منخفض المستوى إلى البُنى المنطقية التي نستطيع فهمها واستخدامها، مثل الملفات والمجلدات، ومن المهم هنا ملاحظة أن نفس العتاد والـ BIOS يستطيعان تشغيل عدة نظم تشغيل مختلفة معًا، فمن السهل إعداد النظام والقرص الصلب بحيث يمكن تثبيت عدة نظم تشغيل على نفس الحاسوب، ويختار المستخدم بينها عند الإقلاع.
ننتقل إلى الطبقة قبل الأخيرة في هذه الكعكة، وهي الصدفة Shell أو بيئة المستخدم، وهي واجهة رسومية في أغلب أنظمة التشغيل الحديثة، رغم توفر واجهة سطرية لها بشكل أو بآخر.
أما الطبقة الأخيرة، فهي طبقة برمجيات المستخدم، التي تتكون من حزمة من البرامج التي يثبتها المستخدم أو تأتي مثبتةً مع النظام، وفيها متصفحات الويب، وبرامج البريد، ومعالجات النصوص وغيرها، كما تحتوي على أدوات برمجية مثل بايثون.
لندرس مثالًا نفهم من خلاله التفاعل بين هذه الطبقات، حيث سنرى ما الذي يحدث عند فتح ملف في بايثون وقراءته.
- نستخدم صدفة نظام التشغيل لبدء بايثون، وتحميل ملف سكربت أيضًا.
-
تستدعي شيفرة بايثون الدالة
open()الخاصة ببايثون. - تستدعي بايثون داخل هذه الدالة دالة نظام تشغيل لفتح نفس الملف.
- يبحث نظام التشغيل عن بعض البيانات الداخلية، ويترجم اسم الملف إلى مجموعة من المسارات والقطاعات على القرص الصلب. -ويكون قد عرف أي قرص يستخدم بداهةً!-، ويحدد ذلك الملف على أنه ملف مفتوح، ويمنع تعديلات المستخدمين الآخرين عليه إن دعت الحاجة إلى ذلك.
-
يستدعي برنامج بايثون
file.read(). - تستدعي بايثون دالة القراءة الخاصة بنظام التشغيل.
- يستدعي نظام التشغيل عدة دوال من BIOS لوضع رؤوس القراءة في القرص الصلب عند المواضع المناسبة.
- يخبر نظام التشغيل BIOS أن تقرأ أعداد البايتات المناسبة من ذلك الموضع.
- يكرر نظام التشغيل عملية الموضعة والقراءة تلك حتى الانتهاء من قراءة جميع البيانات المطلوبة للملف.
- تعيد دالة النظام البيانات إلى بايثون.
- تعالج بايثون البيانات، وتعرض النتائج للمستخدم من خلال دوال أخرى لنظام التشغيل والبيوس BIOS.
قد يبدو هذا معقدًا، ولن نقول إنه ليس كذلك، لكن هذا التعقيد نفسه هو سبب وجود نظم التشغيل، لتوفر على المستخدمين والمبرمجين تلك المهام، فما علينا نحن المبرمجون إلا استدعاء open() وread().
التحكم في العمليات
يوفر نظام التشغيل إمكانية بدء البرامج وتشغيلها، إضافةً إلى ما ذكرناه سابقًا من التحكم في الوصول إلى العتاد، كما يوفر الآليات اللازمة لإدارة تلك البرامج التي تعمل بالتوازي -أي في نفس الوقت– على الحاسوب، لأن عدد المعالجات الموجود على اللوحة الأم أقل بكثير من البرامج التي ستعمل على نظام التشغيل، لذا تنفذ نظم التشغيل عمليةً تسمى التقسيم الزمني time slicing، وهي إعطاء كل برنامج من البرامج العاملة حاليًا على الحاسوب حصةً صغيرةً من المعالج؛ ولفترة قصيرة من الزمن، قبل أن تنقل تلك الحصة بسرعة إلى عملية أخرى أو برنامج آخر، فتعطي ذلك الإحساس بأن جميع البرامج تعمل في نفس الوقت، وتختلف كفاءة نظم التشغيل في تنفيذ هذه العملية، فلم تكن الإصدارات الأولى من ويندوز وماك MacOS قادرةً على إجرائها وإدارتها إلا بمساعدة البرامج نفسها، فإذا فشل أحد البرامج في توفير نقطة توقف مناسبة فإن الحاسوب كله يتوقف عن الاستجابة، فيما يعرف بالتعليق Hanging.
وتستخدم أغلب نظم التشغيل الحديثة نظامًا يسمى تعدد المهام الوقائي pre-emptive multi-tasking، حيث يقاطع نظام التشغيل البرامج بغض النظر عما تفعله تلك البرامج عند المقاطعة، ويعطي البرنامج التالي الوصول إلى المعالج تلقائيًا، وتُستخدم عدة خوارزميات هنا لتحسين كفاءة تلك العملية وفقًا لنظام التشغيل نفسه، مثل التبديل الحلَقي round robin، أو الأحدث استخدامًا most recently used، أو الأقدم استخدامًا least recently used، ولا تهمنا هذه الخوارزميات نحن المبرمجون، ولا بأس إن افترضنا أن تلك البرامج المتعددة تعمل بالتوازي.
تأتي أغلب الحواسيب الحديثة بمعالجات متعددة قد تكون رقاقات متعددةً من السليكون، أو عدة نوى -عدة معالجات منفردة- على رقاقة واحدة، ووظيفة نظام التشغيل هنا أن يخصص العمليات الحالية إلى المعالجات والأنوية ليضمن الاستخدام الأمثل، ونعيد التذكير هنا أن ذلك لا يهمنا، ونترك هذه المهمة لنظام التشغيل نفسه.
صلاحيات المستخدمين والأمان
تسمح أغلب نظم التشغيل الحديثة بوجود عدة مستخدمين على نفس الحاسوب، لكل واحد منهم ملفاته الخاصة وإعدادات سطح مكتبه وغير ذلك، وتزيد بعض نظم التشغيل على ذلك بأن تسمح بولوج عدة مستخدمين إلى نفس النظام في نفس الوقت، فيما يعرف باسم الجلسات المتعددة multi-session، لكن تعدد المستخدمين هذا تأتي معه مشكلة الأمان، فمن المهم ألا يستطيع سعيد رؤية بيانات محمد، وكذلك العكس، إلا إذا أعطى محمد صلاحية الوصول إلى ملفاته إلى سعيد، ويكون نظام التشغيل مسؤولًا عن ضمان حماية ملفات كل مستخدم، عن طريق منع الوصول إليها إلا من الأشخاص المصرح لهم فقط.
استخدام نظام التشغيل في البرامج
قد نتساءل عن جدوى هذا الحديث عن أنظمة التشغيل لنا نحن المبرمجون، بما أن وظيفة ذلك النظام أن يجنبنا كل تلك التفاصيل التي ذكرناها، من التعامل مع العتاد وتنظيم عمليات تشغيل البرامج.
والإجابة على ذلك أننا قد نحتاج أحيانًا إلى التعامل مع ذلك العتاد، ولا تستطيع الدوال البرمجية المعتادة تنفيذ ما نريده، أو ربما نحتاج إلى تشغيل برنامج آخر من داخل برنامجنا مثلًا، بل ربما نحتاج -من داخل برنامجنا- إلى التحكم في الحاسوب بنفس الطريقة التي يتحكم بها المستخدم فيه، وحل ذلك كله أن يكون لنا صلاحية الوصول إلى طبقة نظام التشغيل نفسه.
وتوفر بايثون عددًا من الوحدات التي يمكن استخدامها للتفاعل مع نظام التشغيل، لعل أهمها وحدة os، التي توفر واجهةً مشتركةً لأي نظام تشغيل، من خلال تحميل وحدات منخفضة المستوى lower level، وستتصرف أنظمة التشغيل تصرفًا مختلفًا وفقًا للطريقة التي تنفذ بها تلك الدوال داخليًا، ولا ينتج عن هذا السلوك مشاكل غالبًا، لكن إذا واجهنا سلوكًا غريبًا من وحدة os فنرجع إلى التوثيق لنرى إن كان ثمة قيود على نظام التشغيل الخاص الذي نستخدمه.
أما وحدات النظام الأخرى التي سندرسها فهي الوحدة shutil التي توفر للمبرمجين تحكمًا في الملفات والمجلدات على مستوى المستخدم، والوحدتان os.path وglob اللتان توفران أدوات للتنقل في نظام ملفات الحاسوب، وهذا هو الجزء الذي سننظر فيه أولًا.
اقتباسانتبه: ذكرنا أن نظم التشغيل مختلفة عن بعضها، لذا فإن الأمثلة التي سنذكرها أدناه لن تعمل على ويندوز في الغالب، وستحتاج إلى البحث عن أوامر CMD المكافئة لها وأماكنها، واستبدالها بأوامر يونكس التي سنكتبها هنا، أما مستخدمو لينكس أو MacOS X فلن تكون لديهم تلك المشكلة لأن كلا النظامين يونكس، مادامت البرامج المطلوبة موجودةً ومثبتةً، لأن بعض أنظمة يونكس لا تأتي بتلك البرامج افتراضيًا.
معالجة الملفات
شرحنا كيفية التعامل مع الملفات في مقال التعامل مع الملفات في البرمجة فما الذي نريده من نظام التشغيل طالما نستطيع التعامل معها؟
والجواب أن ما ذكرناه في مقال التعامل مع الملفات في البرمجة هو أننا نستطيع إنشاء الملفات وتعديلها، لكننا لم نذكر حذفها لأننا لم نكن نستطيع ذلك بتوابع الملفات العادية، أما هنا فنستطيع استخدام نظام التشغيل في حذف الملفات، كما أن open() ستكون كافيةً إذا علمنا مكان الملف، لكن كيف نجده إذا لم نعرف مكانه، بل ماذا لو أردنا معالجة مجموعات من الملفات؟ مثل ملفات الصور في مجلد ما، وكذلك التحكم الدقيق في القراءة من الملفات، حيث كانت التوابع القياسية التي شرحناها من قبل تقرأ سطرًا واحدًا فقط أو الملف كله، فماذا لو أردنا قراءة بضعة بايتات فقط؟ إن دوال نظام التشغيل هي الحل لتلك الحالات كلها.
إيجاد الملفات
أول وحدة سندرسها هي الوحدة glob التي نستخدمها للعثور على الملفات، والتي تجلب قوائم بأسماء الملفات، وتعود تسميتها إلى نظام يونكس، حيث استُخدم المصطلح لوصف عملية تحديد مجموعات من الملفات باستخدام محارف بدل wildcards، أما الاسم نفسه فيعود تاريخه إلى أمر قديم في نظم التشغيل استُخدم لإجراء عملية التوسع، وهو اختصار global، والوحدة سهلة الاستخدام، فبعد استيرادها نجد دالةً وحيدةً هي glob()، ونمرر إليها نمطًا pattern لتطابقه، فتعيد قائمةً بأسماء الملفات:
import glob files = glob.glob("*.txt") print( files )
سنحصل على قائمة من الملفات النصية في المجلد الحالي، وهذا يطرح سؤالًا حول كيفية معرفة المجلد الحالي الذي نحن فيه، وهل نستطيع تغييره أم لا؟ ولا شك أننا نستطيع معرفة المجلد وتغييره باستخدام وحدة os:
import os print( os.getcwd() ) #cwd=current working directory os.chdir("/usr/local") #chdir=change working directory print( os.getcwd() ) print( os.listdir('.') ) #عرض المجلدات الجديدة
تعلمنا البحث عن ملف في المجلد الحالي، وكيف ننتقل من ذلك المجلد إلى أي مجلد نريد، لكن لا زال البحث عن ملف ما عمليةً متعبةً، ولتسهيلها سنستخدم الدالة os.walk()، فللعثور على ملف في مكان ما من نقطة بداية نستخدام os.walk، كما سننشئ دالة findfile التي نستطيع استخدامها في برامجنا، لكن سننشئ أولًا بيئة اختبار تتكون من هرمية مجلدات تحت مجلد الجذر Root، وسنضع بعض الملفات في كل مجلد، وسيكون الملف الذي نبحث عنه في أحدها، وقد سميناه traget.txt، ويمكن رؤية هذه الهرمية في لقطة الشاشة التالية:
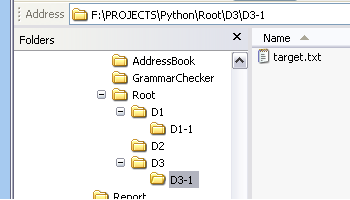
تأخذ دالة os.walk معاملاً هو نقطة البداية، وتعيد مولدًا generator هو أشبه بقائمة وهمية تبني نفسها عند الحاجة، ويتكون من صفوف tuples فيها ثلاثة عناصر، تسمى أحيانًا بالثلاثي triplet أو 3-tuple، وهذه العناصر هي: الجذر، قائمة المجلدات في الجذر الحالي، قائمة الملفات الحالية في مجلد الجذر.
فإذا نظرنا إلى الهرمية التي أنشأناها، فسنتوقع أن يبدو صف tuple الأول كما يلي:
( 'Root', ['D1','D2','D3'], ['FA.txt','FB.txt'] )
نتحقق بسهولة من ذلك بكتابة حلقة for في المحث التفاعلي:
>>> for t in os.walk('Root'): ... print( t ) ... ('Root', ['D1', 'D2', 'D3'], ['FA.txt', 'FB.txt']) ('Root/D1', ['D1-1'], ['FC.txt']) ('Root/D1/D1-1', [], ['FF.txt']) ('Root/D2', [], ['FD.txt']) ('Root/D3', ['D3-1'], ['FE.txt']) ('Root/D3/D3-1', [], ['target.txt']) >>>
يوضح هذا المسارَ الذي أخذته os.walk، كما يوضح كيف يمكن العثور على ملف، وإنشاء مساره الكامل بالبحث في عنصر files من الصفوف التي تعيدها os.walk، ودمج الاسم بمجرد العثور عليه مع قيمة root للصف الذي يحويه.
وإذا كتبنا دالتنا بحيث تستخدم التعابير النمطية وتعيد قائمةً، فنستطيع إنشاء دالة تكون أقوى من glob.glob البسيطة التي رأيناها من قبل، لكنها ستكون أبطأ أيضًا، لنجربها وننظر كيف تبدو:
# على دالة واحدة findfile.py تحتوي وحدة # os.walk() المبنية على استخدام دالة ،find_file() هي دالة import os,re def find_file(filepattern, base = '.'): regex = re.compile(filepattern) matches = [] for root,dirs,files in os.walk(base): for f in files: if regex.match(f): matches.append(root + '/' + f) return matches
احفظ ذلك في ملف اسمه findfile.py، ثم لنختبر المحث التفاعلي كما يلي:
>>> import findfile >>> findfile.find_file('t.*','Root') ['Root/D3/D3-1/target.txt'] >>> findfile.find_file('F.*','Root') ['Root/FA.txt', 'Root/FB.txt', 'Root/D1/FC.txt', 'Root/D1/D1-1/FF.txt', 'Root/D2 /FD.txt', 'Root/D3/FE.txt'] >>> findfile.find_file('.*\.txt','Root') ['Root/FA.txt', 'Root/FB.txt', 'Root/D1/FC.txt', 'Root/D1/D1-1/FF.txt', 'Root/D2 /FD.txt', 'Root/D3/FE.txt', 'Root/D3/D3-1/target.txt'] >>> findfile.find_file('D.*','Root') []
لاحظ أن الوسيط الأول في find_file() هو 't.*'، وتذكر أنه تعبير نمطي وليس محرف بدل لاسم ملف؛ مثل الذي استخدمناه مع glob، لذا فإنه يشير إلى t متبوعةً بعدد من المحارف يساوي صفرًا أو أكثر، وليس ملفًا فقط مثل t.txt.
يظهِر الخرج أن برنامجنا يعمل، ونلاحظ في المثال الأخير أنه يعمل فقط في حالة الملفات لأن أسماء المجلدات تكون في قوائم dirs التي لا نستطيع التحقق منها. جرب إضافة دالة جديدة إلى وحدة findfile سمِّها find_dir()، للبحث عن المجلدات التي تطابق تعبيرًا نمطيًا ما، ثم ادمجهما معًا لإنشاء دالة ثالثة هي find_all() تبحث في كل من الملفات والمجلدات.
نقل الملفات ونسخها وحذفها
تحدثنا في مقال التعامل مع الملفات عن كيفية نسخ ملف من خلال قراءته ثم كتابته إلى موقع جديد، إلا أنه يمكن استخدام نظام التشغيل لينفذ هذا العمل بدلًا منا بتعليمة واحدة، ونستخدم في بايثون وحدة shutil لمثل هذه المهام، وهي تحتوي على عدة دوال مفيدة، سندرس منها ما يلي:
الدالة copy(src, dst)
تنسخ هذه الدالة الملف المصدر src إلى الملف أو المجلد الوجهة dst، فإذا كانت الوجهة مجلدًا فسيُنشأ ملف له نفس اسم الملف المصدر، أو يكتب فوقه overwritten في المجلد المحدد، وتُنسخ بتات الصلاحية permission bits كذلك، وتعطى أسماء المصدر src والوجهة dst في صورة سلاسل نصية.
الدالة move(src, dst)
تنقل هذه الدالة الملف أو المجلد تعاوديًا recursively إلى موقع جديد، فإذا كانت الوجهة على نظام الملفات الحالي فستعاد تسمية الملف المصدر src، وإلا فستنسخ الدالة الملف src إلى الوجهة dst، ثم تحذف المصدر src.
كما سندرس أيضًا الدوال التالية من وحدة os:
الدالة remove(path)
تحذف هذه الدالة مسار الملف، فإذا كان المسار path مجلدًا فيُرفع OSError، ولحذف المجلد انظر في rmdir().
rename(src, dst)
تعيد هذه الدالة تسمية الملف أو المجلد المصدر src ليكون اسم الملف الوجهة dst، فإذا كانت الوجهة مجلدًا dst فسيُرفع خطأ OSError.
وأبسط طريقة لنرى بها هذه الدوال عمليًا هي تجربتها في المحث التفاعلي باستخدام بنية المجلد/الملف التي أنشأناها لمثال os.walk السابق:
>>> import os >>> import shutil as sh >>> import glob as g >>> os.chdir('Root') >>> os.listdir('.') ['D1', 'D2', 'D3', 'FA.txt', 'FB.txt'] >>> sh.copy('FA.txt', 'CA.txt') >>> os.listdir('.') ['CA.txt', 'D1', 'D2', 'D3', 'FA.txt', 'FB.txt'] >>> sh.move('FB.txt','CB.txt') >>> os.listdir('.') ['CA.txt', 'CB.txt', 'D1', 'D2', 'D3', 'FA.txt'] >>> os.remove('FA.txt') >>> os.listdir('.') ['CA.txt', 'CB.txt', 'D1', 'D2', 'D3'] >>> for f in g.glob('*.txt'): ... newname = f.replace('C','F') ... os.rename(f,newname) ... >>> os.listdir('.') ['D1', 'D2', 'D3', 'FA.txt', 'FB.txt'] >>> >>>
في الأمثلة السابقة نقلنا الملفات ونسخناها وحذفنا الملف الأصلي، ثم أعدنا التسمية لاستعادة المجلد إلى حالته الأولى، ويستطيع المستخدم تنفيذ كل تلك عمليات في سطر الأوامر أو في مدير الملفات، لكننا نفذناها هنا باستخدام بايثون.
لاحظ استخدام حلقة for لتنفيذ التغييرات المتعددة، وقد كان باستطاعتنا إضافة جميع أشكال التحققات والقواعد داخل الحلقة، للسماح بإنشاء بعض الأدوات القوية للتعديل في الملفات، وبكتابة تلك الشيفرة في سكربت يمكننا تنفيذ تلك التغييرات بالقدر الذي نشاء بمجرد تشغيل السكربت.
اختبار خصائص الملفات
نحتاج عند التعامل مع الملفات إلى معرفة خصائصها، فمثلًا عندما نقرأ قائمة مجلد من glob، سنرغب في معرفة هل ما نريده ملف أم مجلد، وكذلك معرفة آخر مرة عدِّل عليه فيها، أو مراقبة ذلك لنرى إن كان يُعدَّل بانتظام، مما يدل على أن مستخدمًا غيرنا -أو حتى برنامجًا آخر- له وصول إلى الملف، أو ربما نريد مراقبة حجم الملف، لنرى إن كان يزيد مثلًا، ونستطيع فعل كل تلك الأمور من برامجنا باستغلال مزايا نظام التشغيل، ولكن يجب أن نرى أولًا كيف نتحقق من نوع الملف الذي نتعامل معه:
import os.path as p import glob for item in glob.glob('*') if p.isfile(item): print( item, ' is a file' ) elif p.isdir(item): print( item, ' is a directory' ) else: print( item, ' is of unknown type' )
لاحظ أن دوال الاختبار توجد في وحدة os.path، وأن هناك عدة اختبارات أخرى متاحة، ويمكن الرجوع إليها والقراءة عنها في توثيق وحدة os.path.
سننظر الآن في ميزة عمر الملف، إذ توجد عدة تواريخ مهمة في حياة كل الملف، أولها تاريخ إنشائه، ثم تاريخ آخر تعديل عليه، وأخيرًا تاريخ آخر وصول إليه، وقد لا توفر بعض أنظمة التشغيل جميع تلك التواريخ، لكن أغلبها توفر تواريخ الإنشاء والتعديل، ويمكن الوصول إليهما في بايثون من خلال وحدة os.path باستخدام الدالتين ctime() وmtime() على الترتيب، وسننظر في بعض الملفات الموجودة في بنية Root لدينا، وقد أنشئت جميعها بنفس الوقت تقريبًا، مع اختلاف طفيف لملفات المستوى الأعلى، لأننا أجرينا تعديلات عليها في مثالنا السابق باستخدام rename().
>>> import time as t >>> os.listdir('.') >>> for r,d,files in os.walk('.'): ... for f in files: ... print( f,' created: %s:%s:%s' % t.localtime(p.getctime(r+'/'+f))[3:6] ) ... print( f,' modified: %s:%s:%s' % t.localtime(p.getmtime(r+'/'+f))[3:6]) ... FA.txt created: 13:42:11 FA.txt modified: 13:36:27 FB.txt created: 13:42:11 FB.txt modified: 17:32:5 FC.txt created: 17:32:46 FC.txt modified: 17:32:5 FF.txt created: 17:34:3 FF.txt modified: 17:32:5 FD.txt created: 17:33:12 FD.txt modified: 17:32:5 FE.txt created: 17:33:53 FE.txt modified: 17:32:5 target.txt created: 17:34:28 target.txt modified: 17:32:5 >>>
لاحظ النتيجة الغريبة لملف FA حيث يظهر أنه عُدّل قبل إنشائه! لأننا أنشأناه نسخةً من الملف الأصلي ثم حذفنا الأصل، وأعدنا تسمية النسخة بنفس اسم الملف الأصلي، فرأى نظام التشغيل أن إعادة التسمية لم تغير شيئًا من المحتوى فلم يغير تاريخ التعديل -وهو وقت عملية النسخ- لكنه رأى عملية إعادة التسمية على أنها توقيت إنشاء اسم الملف الحالي، فلابد أن هذا ملف FA.txt جديد بما أننا حذفنا الملف الأصلي!
يختلف أمر الملف FB.txt قليلًا، إذ لم يتغير المحتوى لأننا نقلنا الملف بدلًا من نسخه، لذا تاريخ آخر تعديل هو نفسه تاريخ الإنشاء الأصلي -انظر الملفات الأخرى-، لكن مرةً أخرى يرى نظام التشغيل عملية إعادة التسمية على أنها إنتاج لملف FB.txt جديد، فتظهر هنا قيمة الوقت الأخرى.
في نظام التشغيل دالة تستطيع إعادة أغلب المعلومات التي نحتاجها عن ملف في صف tuple واحد، وهي دالة stat()، ولها عدة صور، إلا أننا لن ندرس إلا النسخة الموجودة في وحدة os، حيث تعيد os.stat() صف tuple يحتوي على ما يلي:
- st_mode: بتات الحماية.
- st_ino: رقم مؤشر الفهرسة inode.
- st_dev: جهاز.
- st_nlink: عدد الروابط الصلبة hard links.
- st_uid: معرِّف المستخدم المالك.
- st_gid: معرِّف المجموعة للمالك.
- st_size: حجم الملف بالبايت.
- st_atime: وقت آخر وصول للملف.
- st_mtime: وقت آخر تعديل للمحتوى.
- st_ctime: وقت الإنشاء، لكن وفقًا للمنصة.
لاحظ أنه قد توجد بعض الحقول الإضافية أحيانًا وفقًا لما يدعمه نظام التشغيل نفسه، فتحقق من توثيق المنصة لديك. لننظر المثال التالي المطبق على ملف المستوى الأعلى FA.txt:
>>> fmtString = "protection: %s\nsize: %s\naccessed: %s\ncreated: %s" >>> stats = os.stat('FA.txt') >>> print( fmtString % stats[0],stats[6],stats[7],stats[9] ) protection: 33279 size: 0 access: 1132407387 created: 1132407731
نحتاج لفك ترميز جميع القيم لنفهمها، باستثناء الحجم الذي ما هو إلا عدد البايتات في الملف، وسنرى كيفية العمل مع كل منها لاحقًا، أما العلامات الزمنية timestamps فهي سهلة لأن الأرقام فيها تمثل عدد الثواني لكل دورة، وقد شرحنا ذلك من قبل، ونستطيع استخدام دوال وحدة time، مثلما فعلنا في localtime() أعلاه لتحويلها إلى بنية بيانات ذات فائدة لنا أو إلى سلسلة نصية.
وتحتاج صيغة الحماية protection لفك ترميزها أولًا، باستخدام بعض القيم الخاصة الموجودة في وحدة stat، إلا أننا نحتاج إلى استخدام بعض العوامل operators الأخرى، والتي تعرف بالعوامل الثنائية bitwise operators.
العوامل الثنائية والرايات
تحتوي وحدة stat على مجموعة من الثوابت مسبقة التعريف، مثل المتغيرات ذات القيم التي لا تتغير، وتسمح تلك الثوابت بفك ترميز بيانات الصلاحيات باستخدام العوامل الثنائية، وهذه العوامل هي نفسها العوامل البوليانية المنطقية التي استخدمناها من قبل مثل and وor وnot، إضافةً إلى عامل جديد هو xor، لكن الفرق أن هذه تعمل على البتات الثنائية المنفردة من البيانات، بدلًا من القيمة الكلية.
يمكن العثور على القيم الموجودة في stat بالنظر إلى المتغيرات المعرَّفة مثل قيم ثنائية، وتوفر بايثون خيار صيغة ثنائية مضمنة فيها هي bin، والتي تبدو كما يلي:
>>> bin(22) '0b10110'
يمثل الجزء 0b في بداية السلسلة النصية أسلوب بايثون في إخبارنا أن هذا عدد ثنائي، ونستطيع تحويل السلسلة النصية الثنائية إلى عدد عشري باستخدام دالة int، من خلال توفير وسيط ثانٍ قيمته 2، لأن قاعدة العدد الثنائي هي 2 في الاصطلاح الرياضي:
>>> int('0b10110',2) 22 >>> int('10110',2) 22
لاحظ أن 0b في بداية السلسلة النصية اختيارية، لأن الوسيط الثاني 2 يخبر بايثون بوجوب معاملة السلسلة النصية على أنها ثنائية، وهذا مفيد إذا كنا نقرأ السلسلة من المستخدم مثلًا بدلًا من استخدام خرج bin.
العوامل الثنائية Bitwise Operators
سننظر الآن في كيفية عمل العوامل الثنائية باستخدام دالة bin لعرض قيم الدخل والخرج، ولننظر أولًا في تأثير and الثنائية التي رمزها &:
>>> print( bin(5) ) '0b101' >>> print( bin(1) ) '0b001' >>> print( bin(2) ) '0b010' >>> print( bin(5 & 1) ) '0b001' >>> print( bin(5 & 2) ) '0b000'
سنراجع تلك النتائج لنرى ما يحدث، تذكر أن and المنطقية تتحقق -أي تكون true- إذا وفقط إذا تحققت كلا القيمتين، أي كانتا true، وبالمثل فإن & الثنائية تكون true -قيمتها 1- إذا تحقق البتّان الموافقان -كان لهما القيمة 1-، وإذا نظرنا إلى 5 & 1 فسنجد أن البت الذي في أقصى اليمين يتحقق في كل من 5 و1، أي تكون قيمتها 1، وبناءً عليه فإن البت الذي في أقصى اليمين لـ 5 & 1 سيكون 1 أيضًا، أما في حالة 5 & 2 فلا توجد حالة تكون فيها لبتين اثنين القيمة 1 في كل من 5 و2، وعليه تكون النتيجة كلها أصفارًا بالنسبة لـ 5 & 2.
يقود هذا السلوك إلى ميزة خاصة لعمليات & الثنائية، فمن خلال "جمع" قيمة ثنائية مع عدد يحتوي على رقم ثنائي وحيد مضبوط على القيمة 1، نستطيع معرفة إن كانت قيمة البت الموافقة في القيمة التي نختبرها هي 1 أيضًا أم لا، فإن كانت كذلك فسنحصل على نتيجة غير صفرية، وهي الموافقة للقيمة True في الاصطلاح البولياني، لنستعرض الآن مثالًا نفترض فيه أننا نريد التحقق من كون البت الثاني في عدد معيَّنًا أم لا، ونحن نعلم مما سبق أن القيمة التي فيها بت واحد في الموضع الثاني -إذا بدأنا العد من اليمين- هي 2:
BIT2 = 2 for n in range(10): if n & BIT2: print( n,' = ',bin(n) )
ستكون النتيجة أن البت الثانية معينة -أي set- في كل من 2 و3 و6 و7.
نستطيع تنفيذ أمور مشابهة لذلك باستخدام or الثنائية، والتي نستخدم لها الرمز |، وكذلك not الثنائية التي لها الرمز ~، رغم أن هذه الأخيرة قد يكون لها بعض النتائج الغريبة المتعلقة بكيفية تخزين الحواسيب للأعداد السالبة، جرب استخدام دالة bin() مع هذه العوامل لعرض دخل وخرج البتّات لترى سلوكها، وتذكر أن توازن بين القيم بتًا بتًا.
أما العامل الثنائي الأخير فهو or الحصرية أو xor، التي لها الرمز ^، وتتحقق -أي تكون true- إن تحققت قيمة واحدة فقط من قيمتي الاختبار، لكنها لا تتحقق عند تحقق كلا القيمتين، وسنحصل على نتائج مثيرة للاهتمام وفقًا لهذه القاعدة، فمثلًا إذا طبقنا هذا العامل على أي عدد مع نفسه فسنحصل على صفر، أما إذا طبقناه على أي عدد مع مفتاح فسنحصل على نتيجة، وإذا طبقنا هذا العامل مرةً ثانيةً على النتيجة والمفتاح فسنحصل على القيمة الأصلية، وهذا السلوك مفيد جدًا في علم التشفير. لننظر في بعض الأمثلة قبل أن نعود إلى وحدة stat ونبحث في قيم الصلاحيات.
>>> print( bin(5 ^ 2) ) '0b111' >>> print( bin(5^5) ) '0b000' >>> print( bin((5^2)^2) ) '0b101'
لاحظ أن النتيجة في الحالة الأخيرة هي سلسلة ثنائية للعدد 5، أي أننا إذا طبقنا العامل xor مرتين فسنحصل على القيمة الأصلية.
الرايات Flags
يسمى المتغير المستخدَم لتخزين قيمة بوليانية رايةً flag، لأن الراية يمكن رفعها أو خفضها، وعندما يكون لدينا قيم رايات كثيرة تتعلق بوحدة واحدة؛ فمن الشائع استخدام عدد واحد لتخزين الفئة المجمَّعة للرايات، باستخدام بتات بيانات منفردة لتمثيل كل راية منفردة، ويمكن جلب قيم الرايات فيما بعد باستخدام العوامل الثنائية التي شرحناها أعلاه، مدمجةً مع قيمة فك ترميز تعرف باسم القناع mask، مما يسمح لنا باستخراج البتات التي نريدها تحديدًا، فعلى سبيل المثال، كانت القيمة BIT2 أعلاه قناعًا لاستخراج البت الثاني، وتشكل وحدة stat مجموعةً من الأقنعة مسبقة التعريف لاختبار رايات الصلاحيات التي تعيدها الدالة os.stat().
استخدام ثوابت stat مع العوامل الثنائية
سننظر الآن إلى بعض قيم stat مثل أعداد ثنائية، ونرى إن كنا نستطيع معرفة كيفية استخدامها:
>>> import stat >>> dir(stat) ['ST_ATIME', 'ST_CTIME', 'ST_DEV', 'ST_GID', 'ST_INO', 'ST_MODE', 'ST_MTIME', 'ST_NLINK', 'ST_SIZE', 'ST_UID', 'S_ENFMT', 'S_IEXEC', 'S_IFBLK', 'S_IFCHR', 'S_IFDIR', 'S_IFIFO', 'S_IFLNK', 'S_IFMT', 'S_IFREG', 'S_IFSOCK', 'S_IMODE', 'S_IREAD', 'S_IRGRP', 'S_IROTH', 'S_IRUSR', 'S_IRWXG', 'S_IRWXO', 'S_IRWXU', 'S_ISBLK','S_ISCHR', 'S_ISDIR', 'S_ISFIFO', 'S_ISGID', 'S_ISLNK', 'S_ISREG', 'S_ISSOCK', 'S_ISUID', 'S_ISVTX', 'S_IWGRP', 'S_IWOTH', 'S_IWRITE', 'S_IWUSR', 'S_IXGRP', 'S_IXOTH', 'S_IXUSR', '__builtins__', '__doc__', '__file__', '__name__'] >>> print( bin(stat.S_IREAD) ) '0b100000000' >>> print( bin(stat.S_IWRITE) ) '0b010000000' >>> print( bin(stat.S_IEXEC) ) '0b001000000'
الملاحظة الأولى هنا هي تعريفنا للكثير من الثوابت، والثانية أن القيم الثلاثة التي طبعناها هي القيم التي تحدد إمكانية قراءة الملف أو كتابته أو تنفيذه على الترتيب، ولاحظ أن لكل قيمة مجموعة بتات واحدة، كما في قيمة BIT2 في الأمثلة السابقة، لذا نستطيع استخدام عامل and الثنائي لإيجاد صلاحيات ملفنا، بعد استدعاء الدالة os.stat()، كما يلي:
import os, stat permission = os.stat('FA.txt')[0] if permission & stat.S_IREAD: print( 'The file is readable' ) if permission & stat.S_IWRITE: print( 'The file is writeable' ) if permission & stat.S_IEXEC: print( 'The file is executable' )
هذه هي الصلاحيات التي نريدها غالبًا، ويمكنك الرجوع إلى توثيق وحدة stat للمزيد من الصلاحيات، والتحقق من فهمها بتجربتها في محث بايثون.
كما توجد دالة access() المساعِدة والموجودة في وحدة os، والتي تسمح لنا بالتحقق من أغلب صلاحيات الوصول الشائعة، غير أن منظور القناع البِتي bitmask الموصوف أعلاه يغطي خيارات أكثر، لذا يمكن استخدامه في المواضع التي لا يصلح استخدام access() فيها.
تغيير صلاحيات الملفات
بعد أن عرفنا صلاحيات ملف ما، نستطيع استخدام وحدة os لتغييرها إلى ما يناسبنا، وتستخدم بايثون اصطلاحات يونكس لتغييرها، حيث يكون لكل ملف مجموعة من ثلاث رايات هي (قراءة read، كتابة write، تنفيذ execute)، لكل تصنيف من تصنيفات المستخدمين الثلاثة (المالك owner، المجموعة المالكة group، العالم world أي بقية المستخدمين)، لذا سيكون لدينا 9 رايات لكل ملف، وتمثَّل تلك الرايات بتسعة بتّات، تشكل البتات اليمنى في راية الصلاحيات التي تعيدها os.stat.
تمثَّل مجموعات الصلاحيات تلك في التوثيق بسلسلة من تسعة محارف، تتكون من ثلاث مجموعات من المحارف rwx، مع شرطةٍ بدل المحرف إذا لم تكن الصلاحية مضبوطةً أو معيَّنةً set، وبناءً على ذلك ستعني السلسلة النصية "rwxr-xr--" أن للمستخدم صلاحية القراءة والكتابة والتنفيذ rwx، وللمجموعة صلاحية القراءة والتنفيذ r-x، وللنوع الثالث الذي هو العالم صلاحية القراءة فقط r--، وإذا أردنا تغيير الصلاحيات فسنعين البتات وفقًا لما نريد التغيير إليه، لذلك سنستخدم الدالة chmod() في وحدة os، حيث تأخذ وسيطًا هو الرقم المكون من 9 بتات، فعلى سبيل المثال يمثل الرقم 0b111101100 الصلاحيات rwxr-xr--، ونستخدم ذلك لضبط الوصول لملف ما كما يلي:
>>> os.chmod('FA.txt',0b111101100)
وإذا كانت لديك خبرة سابقة بالأعداد الثُمانية octal فستعرف أن كل رقم ثُماني يمثل ثلاثة بتات ثنائية، وعلى ذلك نستطيع التعبير عن الصلاحيات بسهولة في ثلاثة أرقام ثُمانية، ويربط الجدول التالي القيم الثُمانية بنظائرها المكافئة لها من الأرقام الثنائية وصلاحيات rwx:
| الثُماني | الثنائي | "rwx" |
|---|---|---|
| 0 | 0b000 | "---" |
| 1 | 0b001 | "--x" |
| 2 | 0b010 | "-w-" |
| 3 | 0b011 | "-wx" |
| 4 | 0b100 | "r--" |
| 5 | 0b101 | "r-x" |
| 6 | 0b110 | "rw-" |
| 7 | 0b111 | "rwx" |
لن يجد مستخدمو يونكس مشكلةً في التعبير عن الصلاحيات بهذه الطريقة، ويمكن استخدام ذلك في بايثون أيضًا لجعل استدعاء chmod يبدو كما يلي:
>>> # يجب استخدام صفر في البداية ليُعامل على أنه ثُماني >>> os.chmod('FA.txt',0754)
ينفذ المثالان أعلاه نفس الأمر، حيث يعيّنان صلاحيات المالكين لتكون قراءةً وكتابةً وتنفيذًا، ويعيّنان صلاحيات المجموعة لتكون قراءةً وتنفيذًا فقط، وصلاحيات العالم لتكون قراءةً فقط، وتجدر الإشارة إلى أن النسخة الثُمانية أسهل في الكتابة إذا أردت التعود على التحويلات بين الثُمانية والثنائية.
المسارات والملفات والمجلدات
من الشائع عند تطوير برنامج ما أن تكون ملفات البيانات في نفس المجلد الذي فيه ملفات البرنامج، ليسهل العثور على الملفات عند الحاجة، أما إذا كان استخدام البرنامج عامًا فلا يمكن افتراض أن الملفات ستكون في مواضع معروفة، لذا قد نحتاج إلى البحث عنها باستخدام glob أو os.walk اللتين شرحناهما أعلاه، فإذا وجدنا الملف الذي نريده وأردنا فتحه أو فحص خصائصه؛ فسنحتاج إلى تعيين المسار الكامل له، أما إذا كان لدينا اسم المسار الكامل فقد نفككه لاستخراج اسم الملف أو المجلد فقط، لوضعه في متغير مثلًا، وتوفر os.path إمكانية تنفيذ مثل تلك المهام.
يُنظر إلى أسماء الملفات في بايثون على أنها تتكون من عدة أجزاء، فهناك حرف اختياري يمثل القرص الذي يوجد عليه الملف، رغم أن هذا قد لا يكون في جميع أنظمة التشغيل، إذ ليس لأنظمة التشغيل غير ويندوز هذا المفهوم الذي يضع اسم القرص الصلب جزءًا من اسم الملف، ثم يأتي تسلسل من أسماء المجلدات تفصل بينها بعض المحارف المحددة، ففي بايثون مثلًا نستخدم /، لكن قد يكون لبعض أنظمة التشغيل محارفها الخاصة، وأخيرًا لدينا اسم الملف أو الاسم القاعدي basename، والذي يحوي صورةً من صور امتدادات الملفات extension:
F:/PROJECTS/PYTHON/Root/FA.txt
يخبرنا المسار أعلاه أن الملف المسمى FA.txt موجود في مجلد الجذر Root، الذي يوجد بدوره في مجلد PYTHON تحت مجلد PROJECTS، في مجلد المستوى الأعلى للقرص F:، ويحمل الملف امتداد الملفات النصية .txt.
نستطيع الآن استخراج الاسم القاعدي base name، والامتداد extension، وتسلسل المجلدات من المسار الكامل، باستخدام الدوال الموجودة في وحدة os.path، كما يلي:
>>> pth = F:/PROJECTS/PYTHON/Root/FA.txt >>> stem, aFile = os.path.split(pth) >>> print( 'stem : ',stem, '\nfile : ',aFile ) stem : F:/PROJECTS/PYTHON/Root file : FA.txt >>> # this only works on OS with drive concept, like Windows >>> print( os.path.splitdrive(pth) ) ('F:', '/PROJECTS/PYTHON/Root/FA.txt') >>> print( os.path.dirname(pth) ) F:/PROJECTS/PYTHON/Root >>> print( os.path.basename(pth) ) FA.txt >>> print( os.path.splitext(aFile) ) ('FA', '.txt')
وندمجها معًا بالشكل:
>>> print( os.path.join(stem,aFile) ) F:/PROJECTS/PYTHON/Root\\FA.txt
يجب ملاحظة أن os.path.join تستخدم محرف الفصل الرسمي للنظام، فإذا أردنا بناء مسار يصلح للعمل على نظم تشغيل مختلفة فيجب استخدام os.path.join بدلًا من كتابة المسار في برنامجنا، كما يمكن تحديد أي عدد نرغب فيه من عناصر المسار في قائمة الوسطاء، فيمكن كتابة المثال أعلاه بالشكل:
>>> print( os.path.join("F:\\", "PROJECTS", "PYTHON", "Root", "FA.txt")) F:\\PROJECTS\\PYTHON\\Root\\FA.txt
واصفات الملفات وكائنات الملفات
تستخدم بعض الوحدات من عائلة os آليةً مختلفةً قليلًا للوصول إلى الملفات، وهو ما يُعرف باسم واصف الملفات file descriptor، وهو مرتبط بشدة بمفهوم الملف في نظم التشغيل بدلًا من كائن الملف file object الذي استخدمناه حتى الآن، ومزيته أننا نستطيع الوصول إلى حزمة من عمليات الملفات منخفضة المستوى low-level operations، والتي تمكننا من الحصول على تحكم أكبر في الملفات وبياناتها، ويمكن إنشاء واصف ملف من كائن ملف والعكس، لكن من الأفضل ألا نخلط بين وضعي العمليات داخل دالة واحدة أو برنامج واحد، فإما أن نستخدم واصفات الملفات أو كائنات الملفات.
تشمل دوال واصفات الملفات جميع عمليات الملفات المعتادة، مثل فتح open وقراءة read وكتابة write وإغلاق close، أما البرامج منخفضة المستوى فتكون صعبة الاستخدام، إضافةً إلى احتمال حدوث أخطاء عند استخدامها، لهذا يجب استخدام الوصول منخفض المستوى عند الضرورة فقط، أما في أغلب الحالات فيكفي استخدام كائنات الملف القياسية.
لكن ما هي الحالات التي قد نحتاج فيها إلى وصول منخفض المستوى إلى الملفات؟
تستخدم العمليات القياسية مبدأً يعرف باسم التخزين المؤقت للدخل/الخرج أو buffered IO، حيث تُحفظ البيانات في مناطق تخزين تسمى بالمخازن المؤقتة buffers أثناء عمليات القراءة والكتابة، وقد تتسبب تلك المخازن في مشاكل عند الوصول إلى عتاد غريب أو إجراء عمليات ذات توقيت حرج time critical، ففي مثل تلك الحالات يكون الحل هو العمليات منخفضة المستوى، لكن إذا لم تكن متأكدًا من سبب استخدامها فلا تفعل، لكن مع هذا العيب الكبير في العمليات منخفضة المستوى، فإننا نقول إن استخدامها ليس بتلك الصعوبة التي تظهر من سياق الحديث، وإنما قصدنا أن هناك بعض المشاكل التي يجب تجنبها، لنبدأ بإجراء مهمة بسيطة، مثل فتح ملف نصي، وكتابة بعض البيانات فيه، ثم إغلاقه:
fname = 'F:/PROJECTS/PYTHON/Root/FL.txt' mode = os.O_CREAT | os.O_WRONLY # create and write access = 0777 # read/write/execute for all data = 'Test text to check that it worked' fd = os.open(fname, mode, access) # NB. os version not the builtin! length = os.write(fd, data) if length != len(data): print( 'Amount of data written doesn't match the data!' ) os.close(fd)
بالمثل نستطيع قراءة البيانات من الملف:
mode = os.O_RDONLY # read only fd = os.open(fname,mode) # no access needed this time result = os.read(fd, length) print( result ) os.close(fd)
نلاحظ عدة أمور هي:
-
الطريقة التي نعين بها نوع وصول الملف أعقد هنا، ويجب أن نستخدم عامل
orالثنائي لدمج جميع الرايات المطلوبة كما وفرتها وحدةos. - نستطيع توفير مستوى وصول غير المستوى الافتراضي، وهذا أمر تمتاز به عن توابع كائن الملف القياسية.
- العدد الثُماني -لأنه يبدأ بصفر- هو نفسه العدد المذكور في قسم "تغيير صلاحيات الملفات" السابق.
-
عند قراءة البيانات يجب أن نمرر طول البيانات المقروءة، باستخدام
readالقياسية، لكن هذا إجباري بالنسبة للعمليات منخفضة المستوى.
أما البيانات المقروءة والمكتوبة فعلًا فهي من النوع سلسلة بايتات bytestring، وهذا لن يكون مشكلةً عند التعامل مع سلاسل المحارف، لأننا نستطيع استخدام تابع decode الخاص باليونيكود لتحويل البايتات إلى محارف، لكن تظهر المشكلة عند التعامل مع أنواع بيانات أخرى، إذ يجب استخدام وحدة struct كما شرحنا في مقال التعامل مع الملفات.
معالجة العمليات
يُعد تنفيذ البرامج أو تشغيلها من أكثر المهام التي ننفذها عن استخدام نظام التشغيل، ونفعل ذلك غالبًا من خلال واجهة رسومية أو صدفة سطر أوامر، كما يمكن أيضًا أن نبدأ البرامج من داخل برامج أخرى، فقد لا نحتاج أحيانًا إلى أكثر من بدء برنامج والسماح له بالعمل حتى نهايته، أما في أحيان أخرى فقد نحتاج إلى توفير بيانات الدخل أو قراءة الخرج إلى برنامجنا، ويُعرف هذا اصطلاحًا باسم التواصل البيني للعمليات أو التواصل بين العمليات inter-proces communication، أو IPC اختصارًا، وسنشرح هذا المفهوم بالتفصيل في المقال التالي.
تعريف العملية
العملية Process في الاصطلاح الحاسوبي هي ما يطلق عليه المستخدمون "تشغيل البرنامج"، فإذا كان لدينا ملف تنفيذي على الحاسوب ونريد تنفيذه؛ فسيبدأ التشغيل داخل مساحة الذاكرة الخاصة به، وقد يكون من الممكن بدء أكثر من نسخة من نفس الملف التنفيذي، ويشغل كل منها مساحةً خاصةً به من الذاكرة، ويدير بياناته الخاصة به، ويطلَق اسم العملية على كل واحد من تلك البرامج التنفيذية مع بيئة التشغيل الخاصة به.
نستطيع أن نرى العمليات الحالية على الحاسوب باستخدام الأدوات التي يوفرها نظام التشغيل، فإذا كنت على ويندوز فاضغط على Ctrl+Alt+Del لتشغيل برنامج Task Manager، وانظر في التبويب المسمى Processes، وسترى قوائم طويلةً من العمليات الحالية التي قد تتعرف على بعضها من البرامج الخاصة بك، أما بقية العمليات فتكون خدمات بدأها نظام ويندوز نفسه، كما قد تلاحظ أن بعض التطبيقات تبدأ عدة عمليات، مثل قواعد البيانات العلائقية relational databases وخوادم الويب، وتوضح الصورة التالية مثالًا لبرنامج Task Manager:
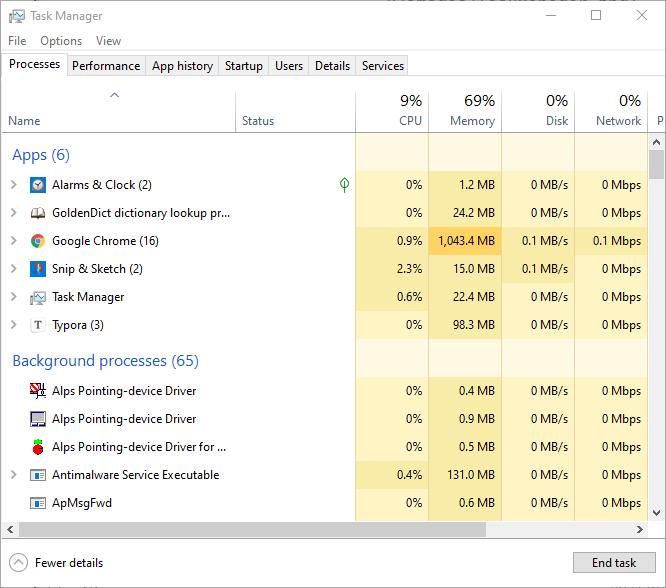
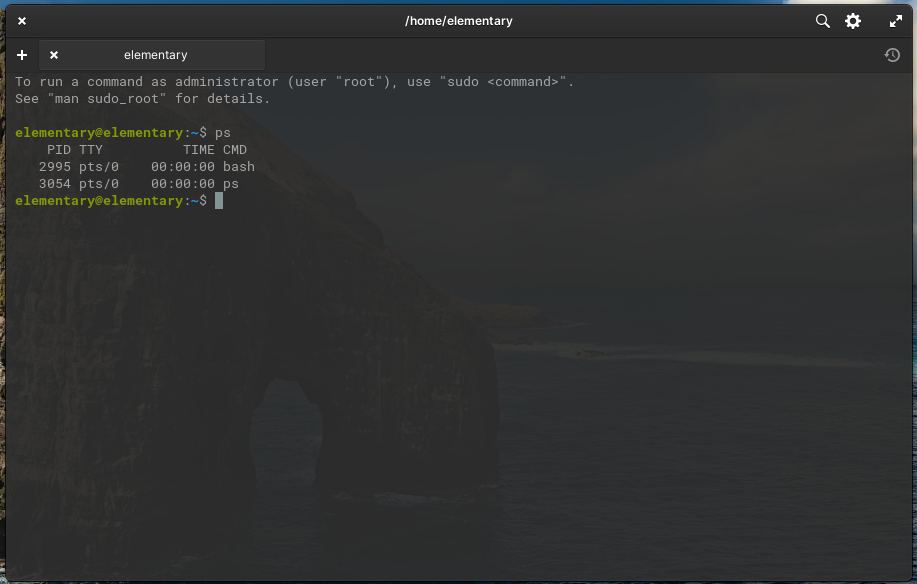
أما على لينكس أو نظام MacOS فيُستخدم الأمر ps لعرض العمليات أو المهام الحالية، أو top الذي يعطي عرضًا حيًا لتلك العمليات، وسيبدو أمر ps كما يلي:
تشغيل برنامج خارجي: الدالة os.system()
نعلم الآن الفرق بين البرنامج والعملية، وسننظر في كيفية تنفيذ برنامج من بايثون، وتوجد الكثير من الطرق لذلك -لأسباب تاريخية-، لكننا سنكتفي باثنتين فقط، والأولى منهما بسيطة الاستخدام للغاية، لكنها محدودة الإمكانيات، أما الثانية فهي المنظور الذي يُنصح به هذه الأيام، وهي أكثر قوةً ومرونةً.
الطريقة الأولى السهلة والقديمة هي استخدام دالة system() من وحدة os، وهذا ينفذ سلسلة أمر command string، ويعيد شيفرة خطأ تعكس انتهاء الأمر على النحو الصحيح أو لا، ولا توجد طريقة للوصول إلى الخرج الفعلي للبرنامج المستدعى ولا لتزويد العملية الحالية بالدخل المناسب، لذا تناسب system() تنفيذ البرامج التي لا تحتاج إلى متابعة، مثل إخلاء شاشة الطرفية، حيث لا نحتاج أن نعرف هل نُفّذ الأمر بنجاح أم لا، ولا أن نتفاعل مع الأمر بمجرد بدئه، ويمكن رؤية مثال على ذلك في يونكس:
>>> import os >>> errorcode = os.system("clear") >>> print( errorcode ) 0
ويختلف الأمر قليلًا في أنظمة التشغيل المبنية على ويندوز:
>>> errorcode = os.system("CLS") >>> print( errorcode ) 0
غير أن النتيجة في الحالتين يجب أن تكون إخلاء النافذة الطرفية، ويجب أن يكون رمز الخطأ errorcode هو الصفر إشارةً إلى نجاح التنفيذ، وقد لا يكون هذا مفيدًا؛ لكننا نستطيع استخدام system في سكربتاتنا حين نرغب في عرض الخرج الطبيعي للأمر، أو عندما لا يهمنا إلا نجاح الأمر أو فشله، فمثلًا نستطيع أن نطلب من المستخدم أن يعدل إعدادات ملف من خلال بدء جلسة محرر editor، ثم يغلق جلسة التحرير عند انتهائه، ويعود التحكم إلى برنامجنا الذي يستطيع عندئذ أن يقرأ الملف المعدَّل.
>>> filename = 'xxyyzz.config' >>> errorcode = os.system('nano %s' % filename) >>> if not errorcode: ... with open(filename) as config: ... # للعملية config هنا ملف
يُظهر المثال بعض التقنيات المفيدة، حيث يُظهر طريقةً لوصف استدعاءات النظام باستخدام تنسيق السلاسل النصية، كما يُظهر تفسير رمز الخطأ لتحديد نتيجة العملية.
إذا نجحت عملية التعديل فسيكون رمز الخطأ صفرًا، حتى لو لم يحدث أي تعديل على الملف، لكن إذا فشلت -كما في حالة عدم العثور على المحرر مثلًا- فسنحصل على رمز خطأ قيمته غير الصفر.
ومع أن system سهلة الاستخدام إلا أنها ليست مرنةً، ولا توجد طريقة مباشرة لتوصيل أي بيانات إلى برامجنا، ونستطيع محاكاة ذلك بالتقاط الخرج إلى ملف نصي مؤقت، ثم فتح ذلك الملف ومعالجته مثلما اعتدنا، لكن ثمة طريقة أفضل لتحقيق نفس النتيجة وهي استخدام وحدة subprocess.
إدارة العمليات باستخدام الوحدة subprocess
بعد العديد من المحاولات الفاشلة لتحسين التحكم في العمليات، حدث تطور كبير عند إدخال الوحدة subprocess إلى الإصدار 2.4 من بايثون، وقد جاءت تلك الوحدة خصيصًا لاستبدال جميع الآليات القديمة، ويمكن رؤية العديد من الأمثلة على كيفية استخدامها في توثيقها، أما هنا فسنغطي أغلب استخدامها العام، وتوجد دوال سهلة ومريحة إذا رغبت في محاكاة وظيفة os.system أو ما شابهها.
بُنت الوحدة subprocess على صنف يسمى Popen، لاحظ الحرف الأول بالحرف الكبير، ويمكن استخدامه لإنشاء نسخة من أمر ما، لكن توثيق هذا الصنف قد يسبب الرهبة للبعض لأن باني Popen يحتوي على الكثير من المعامِلات الرائعة، لكن الجيد في الأمر أن لجميعها تقريبًا قيمًا افتراضية، ويمكن تجاهلها في الحالات بالغة البساطة، وبناءً على ذلك لتشغيل أمر من أوامر نظام التشغيل من داخل سكربت ما، لا نحتاج إلا إلى فعل ما يلي:
import subprocess ps = subprocess.Popen(['ps', '-ef'], shell=False)
الوسيط الأول قائمة من السلاسل النصية، التي تمثل الأمرَ وجميع وسطائه، ففي المثال أعلاه ننفذ أمر ps -ef.
يمنع الوسيط الثاني shell=False تمرير الأمر من خلال برامج الصدفة الخاصة بالمستخدمين -مثل Bash-، مما قد ينتج عنه مشاكل أمنية، بسبب الأسماء البديلة aliases المخصصة للأوامر مثلًا، فيجب أن نستخدم shell=False كلما أمكن ذلك، لكن من الضروري أحيانًا أن نفسر الأمر بواسطة الصدفة، كما في حالة تمرير محارف بدل wild-cards مثل "*.jpg" إلى تطبيق معالجة للصور، فالصدفة هي التي توسع محرف البدل إلى قائمة من أسماء الملفات فعلًا.
خزّنا نسخة Popen الناتجة في متغير سميناه باسم الأمر الذي ننفذه، وهذا ليس ضروريًا لكنه سلوك حسن إذا كنا نشغّل عدة عمليات مساعِدة في نفس الوقت.
توجد دالة أخرى اسمها call يمكن استخدامها بدلًا من os.sytem في المثال أعلاه:
subprocess.call(['ps', '-ef'], shell=False)
تكاد دالة call أن تطابق استخدام صنف Popen الذي شرحناه من قبل، غير أنه ليس لها تلك الخيارات المتاحة في Popen، ولا تنشئ نسخًا، لذا فهي أوفر في استهلاك موارد النظام، لكن لها نفس عيوب os.system.
لوحدة subprocess التي نستخدمها هنا مزية عن الدوال القديمة، وهي أنها ترفع استثناءً OSError إذا لم يوجد الأمر المطلوب، أما الدوال الأخرى فكانت ستتركنا دون أي إشارة على وجود أخطاء.
التواصل مع العمليات باستخدام Popen
من الممكن تنفيذ كل ما فعلناه بوحدة subprocess باستخدام os.system، لكن هذا على وشك التغير الآن حيث سنتعرف على كيفية تبادل البيانات مع عملية جارية بدأناها باستخدام subprocess.Popen، فإذا عدنا قليلًا إلى أمر ps الذي نفذناه من قبل فسنجد أننا شغلنا البرنامج، لكننا لم نستطع الوصول إلى خرجه، ونحتاج إلى إجراء تعديل بسيط لنتمكن من الوصول إلى ذلك الخرج:
import subprocess as sub ps = sub.Popen(['ps', '-ef'], shell=False, stdout=sub.PIPE) print( ps.stdout.read().decode('utf8') )
لقد أضفنا وسيطًا هنا يخبر Popen أن يرسل خرجه القياسي stdout إلى أنبوب عملية فرعية subprocess Pipe وقد شرحنا مجرى الخرج والدخل القياسيين stdin وstdout في مقال قراءة البيانات من المستخدم، ونستطيع الآن أن نصل إلى بيانات الخرج باستخدام الخاصية stdout لنسخة Popen التي نقرؤها مثل أي ملف عادي، وتُحوَّل سلسلة البايتات bytestring الناتجة إلى محارف يونيكود باستخدام decode ثم تُطبع، لكن من الممكن أن نسندها إلى متغير ونعالجها بأي طريقة نشاء.
انتبه، توجد بعض المشاكل في الوصول إلى مجرى الخرج القياسي بهذه الطريقة، تدور أغلبها حول إدارة عدة عمليات متزامنة معًا، لذا نشجع استخدام التابع Popen.communicating الذي يعيد قائمةً من مجاري البيانات data streams يكون مجرى الخرج القياسي stdout هو الأول فيها، ثم مجرى الدخل القياسي stdin، ثم مجرى الخطأ القياسي stderr.
فإن مثّل ذلك مشكلةً فيمكن إعادة كتابة المثال السابق كما يلي:
import subprocess as sub ps = sub.Popen(['ps', '-ef'], shell=False, stdout=sub.PIPE) print( ps.communicate()[0].decode('utf8') )
نستخدم Popen.communicate([0]) هنا للوصول إلى أنبوب الخرج القياسي بطريقة آمنة.
ويمكن إرسال بيانات إلى عملية ما بطريقة مشابهة، إذ نخبر الصنف Popen أن يستخدم أنبوبًا لمجرى الدخل القياسي، ثم يكتب البيانات إلى مجرى البيانات ذاك مثل الملف العادي، رغم أن البيانات هنا يجب أن تكون سلسلة بايتات وليست سلسلة محارف.
في المثال التالي، نفتح محرر أسطر يونكس ex، ونرسل إليه بعض البيانات لينشئ ملفًا نصيًا، ثم نغلق المحرر قبل التحقق من وجود ذلك الملف الجديد:
import subprocess as sub import os ex = sub.Popen(['ex', '/tmp/testex.txt'],stdin=sub.PIPE) ex.stdin.write(b'i\nthis is some text\n.\n') ex.stdin.write(b'wq\n') ex.stdin.close() print( os.listdir('/tmp') )
لاحظ أن المدخلات كلها سلاسل بايتات، وأننا نحتاج إلى إدراج محارف الإرجاع carriage return على أنها محددات أسطر جديدة في السلاسل، كما أن النقطة الموجودة في أول سطر من ex.stdin.write هي التي تخبر ex بانتهاء تسلسل الدخل، ويؤكد استدعاء os.listdir أن الملف الجديد موجود في مجلد tmp، أو يمكن أن نتحقق من ذلك بواسطة مدير الملفات.
وبهذا استطعنا الكتابة في عملية جارية، رغم أنها أقل شيوعًا من القراءة من العمليات.
مسألة الأمان
توفر نظم التشغيل هذه الأيام أغلب الأدوات التي تضمن أمان بيئة التشغيل التي يستخدمها المستخدم على الحاسوب، يمكن الوصول إليها -مثل باقي أدوات نظم التشغيل- من خلال واجهة برمجة التطبيقات API الخاصة بنظام التشغيل نفسه، لكن مع شرط تنظيم نظام التشغيل وصولنا إلى مزايا معينة؛ وفقًا للصلاحيات الممنوحة للمستخدم الذي يشغل البرنامج، فإذا أردنا الوصول إلى ملفات أحد المستخدمين فلا بد أن نملك صلاحية الوصول إلى ملفاته أولًا، وهذا لا يعني ترك مزايا الأمان المضمنة في نظام التشغيل.
سندرس بعض الدوال المتعلقة بالأمان، مثل تحديد معرِّف المستخدم، وتغيير ملكية الملفات، واستخدام متغيرات البيئة للحصول على بيانات حول بيئة المستخدم الحالي.
المستخدمون وملكية الملفات
يمكن الحصول على معرِّفات المستخدمين باستخدام دالة os.getuid، والتي تعيد معرّف المستخدم في صورة رقم، ولا نحتاج إلى تحويله إلى اسم المستخدم نفسه إلا نادرًا،لأننا نستطيع الحصول على ذلك الاسم باستخدام دالة getpass.getuser() التي تنظر في متغيرات البيئة التي قد تحمل تلك المعلومة.
>>> import getpass >>> print( getpass.getuser() )
أما معرف المستخدم فيكون القيمة التي يحتاج البرنامج إليها لتغيير إعدادات الأمان، ونحصل عليه كما يلي:
>>> import os >>> print( os.getuid() )
لعل أشهر استخدام لذلك هو تغيير ملكية ملف -أنشأناه سابقًا في جزء من برنامجنا- برمجيًا، فمثلًا سنستخدم أحد الملفات التي أنشأناها سابقًا في هذا المقال:
import os os.chdir('src/Python/Root') os.system('ls -l *.txt') id = os.getuid() os.chown('FA.txt',id,-1) os.system('ls -l *.txt')
نستخدم os.chdir لضبط مجلد العمل ليكون المكان الذي فيه الملفات، ثم نستخدم system() لعرض قائمة المجلدات بما فيها صلاحيات الملفات قبل وبعد استدعاء chown()، لنستطيع أن نرى التغيرات إن وجدت.
نستدعي chown() مع معرف المستخدم الذي حصلنا عليه من getuid()، ونستخدم -1 للمعامل الثالث الخاص بالدالة chown()، للإشارة إلى أننا لا نريد تغيير ملكية المجموعة، لكن إذا أردنا ذلك فسنستخدم الدالة os.getid() التي تجلب معرف المجموعة.
لاحظ أنه لن يكون للسكربت تأثير إلا إذا شغلناه من مستخدم مختلف عن الحالي، ويجب أن يكون للمستخدم صلاحيات تلك التغييرات، لذا ننصح أن تسجل الدخول بالمستخدم المدير administrator أو الجذر root.
لا تخبرنا chown() أي معلومات عن الخرج، لذا إذا أردنا التحقق من النتيجة فيجب أن نستخدم شيئًا مثل os.stat للتحقق من قيمة معرف المستخدم قبل استدعائها وبعده، وبهذا نتحقق من حدوث التغييرات التي نتوقعها.
بيئة المستخدم
يرث البرنامج عند بداية تشغيله سياق الذاكرة من البرنامج الذي شغّله، حيث يكون البرنامج المشغِّل غالبًا صدفة سطر الأوامر الخاصة بالمستخدم، CMD في ويندوز أو Bash أو غيرها في يونكس، وتشمل بيئة المستخدم تلك معلومات كثيرةً عن النظام، مثل اسم المستخدم، ومجلد home، والمجلد الحالي، والمجلد المؤقت، ومسارات البحث، وهذا يعني أن إعداد متغيرات البيئة المختلفة يمكّن كل مستخدم من تخصيص كيفية عمل نظام التشغيل وبرامجه إلى حد ما، فمثلًا تراقب بايثون متغير البيئة PYTHONPATH عند البحث عن الوحدات، لذلك قد يكون لكل مستخدم على نفس الحاسوب مسارات بحث مستقلة للوحدات، بما أن كل واحد منها يضبط قيمةً مختلفةً للمتغير PYTHONPATH، ويستفيد المبرمجون من ذلك بتعريف بعض متغيرات البيئة لبرنامج ما بحيث يستطيع المستخدم تغيير قيم البرنامج الافتراضية، ويجب أن نتمكن من قراءة البيئة الحالية للعثور على تلك القيم، بأن نقرأ متغيرًا واحدًا باستخدام دالة os.getenv()، أو نقرأ جميع المتغيرات المضبوطة حاليًا بالنظر في متغير os.environ الذي يحتوي قاموسًا بأزواج الاسم/القيمة.
سنطبع قائمةً بجميع متغيرات البيئة، حيث تحتوي تلك القائمة على معلومات كثيرة:
>>> import os >>> print( os.environ )
لا شك أننا نستطيع استخدام عمليات القاموس والسلاسل النصية المعتادة، لكن يُفضل في أغلب الحالات أن نحصل على قيم المتغيرات قيمةً قيمةً، كما يلي:
>>> os.getenv('PYTHONPATH')
أو:
>>> os.environ['PYTHONPATH']
يبين لنا هذا هل ضبطنا المتغير PYTHONPATH أم لا؟ وعلى أي قيمة أيضًا.
تتيح getenv() إمكانية ضبط نتيجة افتراضية إذا لم يكن المتغير معرَّفًا، نظرًا لخطورة عدم تعريفه، ويمكن استخدام تابع القاموس القياسي get() لتنفيذ نفس الشيء في قاموس environ، ويستخدَم هذا عادةً أثناء تهيئة البرامج، حين نضبط الإعدادات، مثل المجلد الذي ستوجد فيه ملفات البيانات، ففي المثال التالي سننظر أين يجب تخزين دليل جهات الاتصال الخاص بنا، باستخدام الإعداد الافتراضي للمجلد الحالي إن لم يكن ثمة متغير:
# ... خطوات تهيئة هنا. folder = os.getenv('PY_ADDRESSES', os.getcwd()) # ... بقية البرنامج
تعيد getenv() وسيطها الثاني عند عدم وجود قيمة افتراضية للمتغير PY_ADDRESSES، وهو الموقع الافتراضي لنا.
ينشئ المستخدم متغيرات البيئة تلك ويضبطها يدويًا باستخدام نظام التشغيل، ففي ويندوز مثلًا ينفّذ ذلك بتسلسل الإعدادات التالي:
MyComputer->Properties->Advanced->Environment Variables
أما في لينكس وماك فيُنفذ في سطر الأوامر باستخدام الأمرين export وsetenv وفقًا للصدفة المستخدمة.
يمكن تغيير قيم متغير البيئة الحالي في بعض أنظمة التشغيل، لكن يجب استخدام ذلك بحذر، إذ قد يؤدي إلى الكتابة فوق قيم أخرى، كما قد تعكس بعض أنظمة التشغيل تلك التغييرات على بيئات المستخدمين، غير أن هذا لا ينطبق إلا في سياق عملية الكتابة غالبًا، فإذا كان نظام التشغيل يدعم تلك العملية فنستطيع كتابة قيمة المجلد الافتراضي الخاصة بنا إلى بيئة المستخدمين لضمان استخدام نسخ برنامجنا الأخرى لنفس الموقع، إلا أننا لا ننصح بذلك لهشاشة تلك الآلية، وإنما ننصح باستخدام ملف config لأنه أكثر موثوقيةً لمثل هذه الإعدادات.
# شيفرة أخرى كما سبق putenv('PY_ADDRESSES', folder) # ... بقية البرنامج
تُستخدم بعض متغيرات البيئة في يونكس من قبل برامج عديدة، منها على سبيل المثال:
-
EDITOR: يحدد هذا المتغير برنامج التحرير الذي يفضله المستخدم، ويكون ed أو vi أو ViM أو Emacs، فتشغّل البرامج الأخرى هذا المحرر إذا احتاج المستخدم إلى تعديل ملف نصي في جزء من البرنامج، فمثلًا يمكننا استخدام
getenv ('EDITOR')لإطلاق المحرر الخاص بالمستخدم في مثالos.systemأعلاه، بدلًا من ضبط المحرر nano ليكون هو الافتراضي. - PRINTER: يحدد هذا المتغير إعدادات المستخدم المفضلة لطباعة الملفات.
- PAGER: يحدد هذا المتغير برنامج عرض الملفات الذي يفضله المستخدم، ويُضبط غالبًا على more أو less أو view.
سنكتفي بهذا الشرح عن البيئات، وسنعود إليها في مقال لاحق، لكن نذكر أنه عند الحاجة إلى الحصول على بيانات تخص المستخدم فيجب التحقق من وجود متغير بيئة بالفعل أم لا، أو نتيح للمستخدم إمكانية ضبط ذلك من خلال متغير بيئة خاص ببرنامجنا.
مزيد من المعلومات حول نظم التشغيل
تحتوي وحدة os ومثيلاتها على إمكانيات أكثر مما يمكن أن نشرحه هنا، بل إن توثيق بايثون يحتاج إلى عدة صفحات HTML لشرح وحدة os وحدها، وصفحة لكل وحدة أخرى، ويمكن الرجوع إلى تلك التوثيقات لتصفح وظائف تلك الوحدات، وستجد فيها أسماءً غريبةً، تأتي أغلبها من يونكس وواجهة برمجة تطبيقاته.
توفر os وظائف مكافئةً على أي نظام تشغيل، لكن إذا أردت معرفة المزيد عن وظائف تلك الدوال فيجب الرجوع إلى توثيق يونكس نفسه، فإن لم يكن لديك أحد أنظمة يونكس فيمكن الرجوع إلى كتاب Unix Systems Programming for SVR4، وإذا أعجبك ما شرحناه عن نظم التشغيل فربما تود قراءة كتاب Fundamentals of Operating Systems لصاحبه ليستر A. M. Lister، فهو كتاب قصير ويسهل فهم شرحه المدعوم بمخططات توضيحية، أما إذا رغبت في إلقاء نظرة فاحصة على نظم التشغيل فانظر كتاب أندرو تانينباوم Andrew Tanenbaum الشهير Operating Systems: Design and Implementation، الذي شجع لينوس تورفالدز Linus Torvalds على كتابة نواة لينكس.
خاتمة
نرجو في نهاية هذا المقال أن تتذكر ما يلي:
- يوفر نظام التشغيل بيئةً يمكن تشغيل العمليات فيها.
- كما يوفر وصولًا إلى عتاد الحاسوب.
- يمكن الوصول إلى نظام التشغيل من خلال واجهة برمجة التطبيقات، التي تكتَب عادةً بلغة C.
-
توفر وحدة
osالخاصة ببايثون مغلِّفًا لواجهة برمجة التطبيقات الخاصة بنظام التشغيل. -
تسهل الوحدتان
os.pathوglobالوصول إلى الملفات. -
توفر كل من
os.system()وsubprocess.Popenمستويات مختلفةً من التحكم في العمليات والتواصل بينها IPC. -
تسمح
getuid()وgetenv()والمزايا الشبيهة بهما بالتعرف على المستخدم وإعداداته المفضلة.
ترجمة -بتصرف- للفصل الخامس والعشرين: Working with the Operating System من كتاب Learning To Program لصاحبه Alan Gauld.
اقرأ أيضًا
- المقال التالي: التواصل بين العمليات في البرمجة
- المقال السابق: التعامل مع قواعد البيانات
- أهم 20 أمرا في نظام التشغيل لينكس لجميع المستخدمين
- النسخة الكاملة لكتاب: البرمجة بلغة بايثون











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.