

السلاسل النصية في بايثون هي مجموعةٌ مُنشأةٌ من المحارف المنفصلة والتي تُمثِّل الأحرف والأرقام والفراغات والرموز. ولأنَّ السلسلة النصية هي «سلسلة»، فيمكن الوصول إليها كغيرها من أنواع البيانات المتسلسلة، عبر الفهارس والتقسيم.
سيشرح لك هذا الدرس كيفية الوصول إلى السلاسل النصية بفهارسها، وتقسيمها إلى مجموعات من المحارف، وسيُغطي طرائق إحصاء المحارف وتحديد مواضعها.

آلية فهرسة السلاسل النصية
وكما في نوع البيانات list الذي فيه عناصر مرتبطة بأرقام، فإنَّ كل محرف في السلسلة النصية يرتبط بفهرس معيّن، بدءًا من الفهرس 0.
فللسلسلة النصية Sammy Shark! ستكون الفهارس والمحارف المرتبطة بها كالآتي:
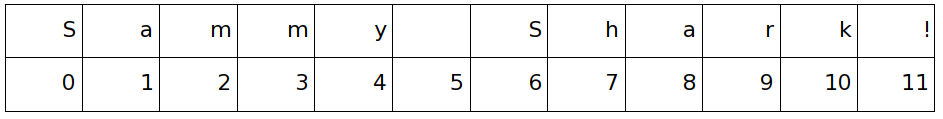
وكما لاحظت، سيرتبط المحرف S بالفهرس 0، وستنتهي السلسلة النصية بالفهرس 11 مع الرمز !.
لاحظ أيضًا أنَّ الفراغ بين كلمتَي Sammy و Shark له فهرسٌ خاصٌ به، وفي مثالنا سيكون له الفهرس 5.
علامة التعجب (!) لها فهرسٌ خاصٌ بها أيضًا، وأيّة رموز أو علامات ترقيم أخرى مثل *#$&.;? سترتبط بفهرسٍ مخصصٍ لها.
وحقيقة أنَّ المحارف في بايثون لها فهرسٌ خاصٌ بها ستعني أنَّ بإمكاننا الوصول إلى السلاسل النصية وتعديلها كما نفعل مع أنواع البيانات المتسلسلة الأخرى.
الوصول إلى المحارف عبر أرقام الفهارس الموجبة
يمكننا الحصول على محرف من سلسلة نصية بالإشارة إليه عبر فهرسه. يمكننا فعل ذلك بوضع رقم الفهرس بين قوسين مربعين. سنُعرِّف في المثال الآتي سلسلةً نصيةً ونطبع المحرف المرتبط بالفهرس المذكور بين قوسين مربعين:
ss = "Sammy Shark!" print(ss[4])
الناتج:
y
عندما نُشير إلى فهرسٍ معيّنٍ في سلسلةٍ نصيةٍ، فستُعيد بايثون المحرف الموجود في ذاك الموضع، ولمّا كان المحرف y موجودًا في الفهرس الرابع في السلسلة النصية ss = "Sammy Shark!" فعندما طبعنا ss[4] فظهر الحرف y.
الخلاصة: أرقام الفهارس ستسمح لنا بالوصول إلى محارف معيّنة ضمن سلسلة نصية.
الوصول إلى المحارف عبر أرقام الفهارس السالبة
إذا كانت لديك سلسلةٌ طويلةٌ وأردنا تحديد أحد محارفها لكن انطلاقًا من نهايتها، فعندئذٍ نستطيع استخدام الأرقام السالبة للفهارس، بدءًا من الفهرس -1.
لو أردنا أن نستخدم الفهارس السالبة مع السلسلة النصية Sammy Shark!، فستبدو كما يلي:

يمكننا أن نطبع المحرف r في السلسلة السابقة في حال استخدمنا الفهارس السالبة بالإشارة إلى المحرف الموجود في الفهرس -3 كما يلي:
print(ss[-3])
الخلاصة: يمكننا الاستفادة من الفهارس السالبة لو أردنا الوصول إلى محرف في آخر سلسلة نصية طويلة.
تقسيم السلاسل النصية
يمكننا أن نحصل على مجال من المحارف من سلسلة نصية، فلنقل مثلًا أننا نريد أن نطبع الكلمة Shark فقط، يمكننا فعل ذلك بإنشائنا «لقسم» من السلسلة النصية، والذي هو سلسلةٌ من المحارف الموجودة ضمن السلسلة الأصلية. فالأقسام تسمح لنا بالوصول إلى عدِّة محارف دفعةً واحدة باستعمال مجال من أرقام الفهارس مفصولة فيما بينها بنقطتين رأسيتين [x:y]:
print(ss[6:11])
الناتج:
Shark
عند إنشائنا لقسم مثل [6:11] فسيُمثِّل أوّل رقم مكان بدء القسم (متضمنًا المحرف الموجود عند ذاك الفهرس)، والرقم الثاني هو مكان نهاية القسم (دون تضمين ذاك المحرف)، وهذا هو السبب وراء استخدمنا لرقم فهرس يقع بعد نهاية القسم الذي نريد اقتطاعه في المثال السابق.
نحن نُنشِئ «سلسلةً نصيةً فرعيةً» (substring) عندما نُقسِّم السلاسل النصية، والتي هي سلسلةٌ موجودةٌ ضمن سلسلةٍ أخرى. وعندما نستخدم التعبير ss[6:11] فنحن نستدعي السلسلة النصية Shark التي تتواجد ضمن السلسلة النصية Sammy Shark!.
إذا أردت تضمين نهاية السلسلة (أو بدايتها) في القسم الذي ستُنشِئه، فيمكننا ألّا نضع أحد أرقام الفهارس في string[n:n]. فمثلًا، نستطيع أن نطبع أوّل كلمة من السلسلة ss –أي Sammy– بكتابة ما يلي:
print(ss[:5])
فعلنا ذلك بحذف رقم الفهرس قبل النقطتين الرأسيتين، ووضعنا رقم فهرس النهاية فقط، الذي يُشير إلى مكان إيقاف اقتطاع السلسلة النصية الفرعية.
لطباعة منتصف السلسلة النصية إلى آخرها، فسنضع فهرس البداية فقط قبل النقطتين الرأسيتين، كما يلي:
print(ss[7:])
الناتج:
hark!
بكتابة فهرس البداية فقط قبل النقطتين الرأسيتين وترك تحديد الفهرس الثاني، فإنَّ السلسلة الفرعية ستبدأ من الفهرس الأول إلى نهاية السلسلة النصية كلها.
يمكنك أيضًا استخدام الفهارس السالبة في تقسيم سلسلة نصية، فكما ذكرنا سابقًا، تبدأ أرقام الفهارس السلبية من الرقم -1، ويستمر العد إلى أن نصل إلى بداية السلسلة النصية. وعند استخدام الفهارس السالبة فسنبدأ من الرقم الأصغر لأنه يقع أولًا في السلسلة.
لنستخدم فهرسين ذوي رقمين سالبين لاقتطاع جزء من السلسلة النصية ss:
print(ss[-4:-1])
الناتج:
ark
السلسلة النصية «ark» مأخوذة من السلسلة النصية «Sammy Shark!» لأنَّ الحرف «a» يقع في الموضع -4 والمحرف k يقع قبل الفهرس -1 مباشرةً.
تحديد الخطوة عند تقسيم السلاسل النصية
يمكن تمرير معامل ثالث عند تقسيم السلاسل النصية إضافةً إلى فهرسَي البداية والنهاية، وهو الخطوة، التي تُشير إلى عدد المحارف التي يجب تجاوزها بعد الحصول على المحرف من السلسلة النصية.
لم نُحدِّد إلى الآن الخطوة في أمثلتنا، إلا أنَّ قيمته الافتراضية هي 1، لذا سنحصل على كل محرف يقع بين الفهرسين.
لننظر مرةً أخرى إلى المثال السابق الذي يطبع السلسلة النصية الفرعية «Shark»:
print(ss[6:11]) Shark
سنحصل على نفس النتائج بتضمين معامل ثالث هو الخطوة وقيمته 1:
print(ss[6:11:1]) Shark
إذًا، إذا كانت الخطوة 1 فهذا يعني أنَّ بايثون ستُضمِّن جميع المحارف بين فهرسين، وإذا حذفتَ الخطوة فستعتبرها بايثون مساويةً للواحد.
أما لو زدنا الخطوة، فسنرى أنَّ بعض المحارف ستهمل:
print(ss[0:12:2]) SmySak
تحديد الخطوة بقيمة 2 كما في ss[0:12:2] سيؤدي إلى تجاوز حرف بين كل حرفين، ألقِ نظرةً على المحارف المكتوبة بخطٍ عريضٍ:
Sammy Shark!
لاحظ أنَّ الفراغ الموجود في الفهرس 5 قد أُهمِل أيضًا عندما كانت الخطوة 2.
إذا وضعنا قيمةً أكبر للخطوة، فسنحصل على سلسلةٍ نصيةٍ فرعيةٍ أصغر بكثير:
print(ss[0:12:4]) Sya
حذف الفهرسين وترك النقطتين الرأسيتين سيؤدي إلى إبقاء كامل السلسلة ضمن المجال، لكن إضافة معامل ثالث وهو الخطوة سيُحدِّد عدد المحارف التي سيتم تخطيها.
إضافةً إلى ذلك، يمكنك تحديد رقم سالب كخطوة، مما يمكِّنك من كتابة السلسلة النصية بترتيبٍ معكوس إذا استعملتَ القيمة -1:
print(ss[::-1])
الناتج:
!krahS ymmaS
لنجرِّب ذلك مرةً أخرى لكن إذا كانت الخطوة -2:
print(ss[::-2])
الناتج:
!rh ma
في المثال السابق (ss[::-2])، سنتعامل مع كامل السلسلة النصية لعدم وجود أرقام لفهارس البداية والنهاية، وسيتم قلب اتجاه السلسلة النصية لاستخدامنا لخطوةٍ سالبة. بالإضافة إلى أنَّ الخطوة -2 ستؤدي إلى تخطي حرف بين كل حرفين بترتيبٍ معكوس:
!krahS[whitespace]ymmaS
سيُطبَع الفراغ في المثال السابق.
الخلاصة: تحديد المعامل الثالث عند تقسيم السلاسل النصية سيؤدي إلى تحديد الخطوة التي تُمثِّل عدد المحارف التي سيتم تخطيها عند الحصول على السلسلة الفرعية من السلسلة الأصلية.
دوال الإحصاء
بعد أن تعرفنا على آلية فهرسة المحارف في السلاسل النصية، حان الوقت لمعاينة بعض الدوال التي تُحصي السلاسل النصية أو تعيد أرقام الفهارس. يمكننا أن نستفيد من ذلك بتحديد عدد المحارف التي نريد استقبالها من مدخلات المستخدم، أو لمقارنة السلاسل النصية. ولدى السلاسل النصية –كغيرها من أنواع البيانات– عدِّة دوال تُستخدم للإحصاء.
لننظر أولًا إلى الدالة len() التي تُعيد طول أيّ نوع متسلسل من البيانات، بما في ذلك string و lists و tuples و dictionaries.
لنطبع طول السلسلة النصية ss:
print(len(ss)) 12
طول السلسلة النصية «Sammy Shark!» هو 12 محرفًا، بما في ذلك الفراغ وعلامة التعجب.
بدلًا من استخدام متغير، فلنحاول مباشرةً تمرير سلسلة نصية إلى الدالة len():
print(len("Let's print the length of this string.")) 38
الدالة len() تُحصي العدد الإجمالي من المحارف في سلسلة نصية.
إذا أردنا إحصاء عدد مرات تكرار محرف أو مجموعة من المحارف في سلسلة نصية، فيمكننا استخدام الدالة str.count()، لنحاول إحصاء الحرف «a» في السلسلة النصية ss = "Sammy Shark!":
print(ss.count("a")) 2
يمكننا البحث عن محرفٍ آخر:
print(ss.count("s")) 0
صحيحٌ أنَّ الحرف «S» قد ورد في السلسلة النصية، إلا أنَّه من الضروري أن تبقي بذهنك أنَّ بايثون حساسةٌ لحالة الأحرف، فلو أردنا البحث عن حروفٍ معيّنة بغض النظر عن حالتها، فعلينا حينها استخدام الدالة str.lower() لتحويل حروف السلسلة النصية إلى حروفٍ صغيرة أولًا. يمكنك قراءة المزيد من المعلومات عن دالة str.lower() في درس «مقدمة إلى دوال التعامل مع السلاسل النصية في بايثون 3»
لنحاول استخدام الدالة str.count() مع سلسلة من المحارف:
likes = "Sammy likes to swim in the ocean, likes to spin up servers, and likes to smile." print(likes.count("likes"))
الناتج هو 3، حيث تتواجد مجموعة المحارف «likes» ثلاث مرات في السلسلة النصية الأصلية.
يمكننا أيضًا معرفة موقع الحرف أو مجموعة الحروف في السلسلة النصية، وذلك عبر الدالة str.find()، وسيُعاد موضع المحرف بناءً على رقم فهرسه.
يمكننا أن نعرف متى يقع أوّل حرف «m» في السلسلة النصية ss كالآتي:
print(ss.find("m")) 2
أوّل مرة يقع فيها الحرف «m» في الفهرس 2 من السلسلة «Sammy Shark!»، يمكنك أن تراجع بداية هذا الدرس لرؤية جدول يبيّن ارتباطات المحارف مع فهارسها في السلسلة السابقة.
لنرى الآن مكان أوّل ظهور لمجموعة المحارف «likes» في السلسلة likes:
print(likes.find("likes")) 6
أوّل مرة تظهر فيها السلسلة «likes» هي في الفهرس 6، أي مكان وجود الحرف l من likes.
ماذا لو أردنا أن نعرف موضع ثاني تكرار للكلمة «likes»؟ نستطيع فعل ذلك بتمرير معاملٍ ثانٍ إلى الدالة str.find() الذي سيجعلها تبدأ بحثها من ذاك الفهرس، فبدلًا من البحث من أوّل السلسلة النصية سنبحث انطلاقًا من الفهرس 9:
print(likes.find("likes", 9)) 34
بدأ البحث في هذا المثال من الفهرس 9، وكانت أوّل مطابقة للسلسلة النصية «likes» عند الفهرس 34.
إضافةً إلى ذلك، يمكننا تحديد نهاية إلى مجال البحث بتمرير معامل ثالث. وكما عند تقسيم السلاسل النصية، يمكننا استخدام أرقام الفهارس السالبة للعد عكسيًا:
print(likes.find("likes", 40, -6)) 64
يبحث آخر مثال عن موضع السلسلة النصية «likes» بين الفهرس 40 و -6، ولمّا كان المعامل الأخير هو رقم سالب، فسيبدأ العد من نهاية السلسلة الأصلية.
دوال الإحصاء مثل len() و str.count() و str.find() مفيدةٌ في تحديد طول السلسلة النصية وعدد حروفها وفهارس ورود محارف معيّنة فيها.
الخلاصة
ستمنحنا القدرة على تحديد محارف بفهارسها أو تقسيم سلسلة نصية أو البحث فيها مرونةً عاليةً عند التعامل مع السلاسل النصية. ولأنَّ السلاسل النصية هي نوعٌ من أنواع البيانات المتسلسلة (كنوع البيانات list)، فيمكننا الوصول إلى عناصرها عبر فهارس خاصة.
هذه المقالة جزء من سلسة مقالات حول تعلم البرمجة في بايثون 3.
ترجمة -وبتصرّف- للمقال How To Index and Slice Strings in Python 3 لصاحبته Lisa Tagliaferri.
اقرأ أيضًا
- المقال التالي: كيفية التحويل بين أنواع البيانات
- المقال السابق: مقدمة إلى دوال التعامل مع السلاسل النصية
- المرجع الشامل إلى تعلم لغة بايثون
- كتاب البرمجة بلغة بايثون











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.