

التعابير النمطية Regular expressions هي أنماط تزودنا بأسلوب فعّال للبحث عن النصوص التي تطابق نمطًا محددًا واستبدالها في JavaScript، يتيح الكائن RegExp استخدام هذه التعابير، وتُدمج مع التوابع التي تتعامل مع النصوص.
مقدمة إلى التعابير النمطية
تتألف التعابير النمطية من نمط pattern، ورايات flags اختيارية، ولإنشاء كائن تعبير نمطي يمكن استخدام صيغتين، صيغة طويلة وصيغة قصيرة، أما الصيغة الطويلة فتكتب بالشكل:
regexp = new RegExp("pattern", "flags");
وأما الصيغة القصيرة فتكتب باستخدام المحرف "/" بالشكل:
regexp = /pattern/; // لا رايات regexp = /pattern/gmi; // g و m و i باستخدام الرايات
تخبر الخطوط المائلة JavaScript بأننا ننشئ تعبيرًا نمطيًا، فهي تلعب دورًا مماثلًا لعلامة الاقتباس في النصوص، وفي كلتا الصيغتين سيصبح الكائن regexp نسخةً عن الصنف المدمج RegExp.
لا يُسمح بإدخال متغيرات تمثل الأنماط ضمن صيغة الخطوط المائلة /.../ باستخدام القوالب {...}$ الديناميكية مثلًا كما نفعل في النصوص، فهي ثابتة بشكل كامل، وهذا هو الاختلاف الرئيسي بين الصيغتين، إذ نستخدم الخطوط المائلة عندما نريد استخدام تعابير نمطية محددة ومعروفة بالنسبة لنا عند كتابة الشيفرة، وهذه هي الحالة الأكثر شيوعًا، بينما نستخدم الصيغة new RegExp عادةً عندما نحتاج إلى إنشاء تعابير نمطية أثناء التنفيذ انطلاقًا من نص أُنشئ ديناميكيًا.
let tag = prompt("What tag do you want to find?", "h2"); let regexp = new RegExp(`<${tag}>`); // "h2" إن كان الجواب /<h2>/ نفس نتيجة
الرايات
للتعابير النمطية رايات تؤثر على نتيجة البحث، وتستخدم JavaScript ستةً منها، وهي:
-
i: سيكون البحث غير حساس لحالة الأحرف مع هذه الراية، أي لن يكون هناك فرق بين "a" و"A". -
g: سيعيد البحث جميع النتائج المتطابقة مع هذه الراية، وإلا فسيعيد النتيجة الأولى. -
m: سيعمل البحث في نمط الأسطر المتعددة، وسنغطي ذلك لاحقًا. -
s: ستمكّن نمط "dotall" الذي يسمح بأن نعدَّ النقطة.هي محرف نهاية السطرn\، وسنغطيه لاحقًا. -
u: سيمكّن الدعم الكامل لترميز Unicode، وبالتالي المعالجة الصحيحة لمحتويات الأقواس المعقوصة {..}، وسنغطيه لاحقًا. -
y: سيمكّن النمط اللاصق "Sticky"، حيث يبحث في المكان المحدد تمامًا من النص، وسنغطيه لاحقًا.
البحث باستخدام التابع str.match
تتكامل التعابير النمطية مع توابع النصوص، إذ يبحث التابع (str.match(regexp عن كل ما يطابق التعبير regexp في النص str، ويعمل وفق ثلاثة أنماط:
النمط الأول، التعبير النمطي مع الراية g، ويعيد مصفوفةً تضم النتائج المطابقة:
let str = "We will, we will rock you"; alert( str.match(/we/gi) ); // سيعيد مصفوفة من الحالتين المتطابقتين للبحث
وانتبه إلى أنّ البحث سيعيد النتيجتين "we" و"We" لأن راية حالة الأحرف i مفعّلة.
النمط الثاني، إذا لم نفعّل الراية g، فسيعيد البحث النتيجة الأولى فقط ضمن مصفوفة، مع وضع التطابق في الدليل 0، بالإضافة إلى تفاصيل أخرى في الخصائص:
let str = "We will, we will rock you"; let result = str.match(/we/i); // g دون الراية alert( result[0] ); // We (التطابق الأول) alert( result.length ); // 1 // Details: alert( result.index ); // 0 (موقع التطابق) alert( result.input ); // We will, we will rock you (النص الأصلي)
قد تحتوي المصفوفة على عناصر أخرى بالإضافة إلى العنصر ذي الدليل 0؛ إذا كان جزء من التعبير النمطي ضمن قوسين مغلقين وسنغطي ذلك في المقالات القادمة.
النمط الثالث، إذا لم توجد أي تطابقات، فسيعيد التابع القيمة null، بوجود الراية g أو عدم وجودها، لذا انتبه أننا لن نحصل في هذه الحالة على مصفوفة فارغة، بل على القيمة null، وسيؤدي نسيان هذه الحقيقة إلى مشاكل عدة:
let matches = "JavaScript".match(/HTML/); // = null if (!matches.length) { //length خطأ لا يمكن قراءة الخاصية alert("Error in the line above"); }
إذا أردنا أن نحصل دائمًا على مصفوفة، فيمكننا أن ننفذ الأمر بالشكل التالي:
let matches = "JavaScript".match(/HTML/) || []; if (!matches.length) { alert("No matches"); // ستعمل الآن }
الاستبدال باستخدام التابع str.replace
يستبدل التابع (str.replace(regexp, replacement التطابقات الموافقة للكائن regexp في النص str بقيمة replacement، وستستبدل كل التطابقات عند استخدام الراية g، وإلا فسيستبدل أول تطابق فقط، وإليك مثالًا:
// g دون الراية alert( "We will, we will".replace(/we/i, "I") ); // I will, we will // مع الراية alert( "We will, we will".replace(/we/ig, "I") ); // I will, I will
يمكن استخدام محارف خاصة ضمن الوسيط الثاني replacement للبحث عن أجزاء من معيار التطابق:
| الرمز | ما يفعله ضمن النص replacment |
|---|---|
&$
|
يمثل نص التطابق |
`$
|
يمثل النص الواقع قبل نص التطابق. |
'$
|
يمثل النص الواقع بعد نص التطابق. |
n$
|
يمثل التطابق ذا الرقم n من مجموعة التطابق (الموجود ضمن قوسي تجميع"()" ) . |
$<name>
|
يمثل التطابق ذا الاسم name من مجموعة التطابق (الموجود ضمن قوسي تجميع"()" ). |
$$
|
يمثل المحرف $
|
مثال باستخدام &$:
alert( "I love HTML".replace(/HTML/, "$& and JavaScript") ); // I love HTML and JavaScript
الاختبار باستخدام التابع regexp.test
يبحث التابع (regexp.test(str عن تطابق واحد على الأقل -إن وُجد- ويعيد القيمة true، وإن لم يجد تطابقًا فسيعيد القيمة false.
let str = "I love JavaScript"; let regexp = /LOVE/i; alert( regexp.test(str) ); // true
سندرس لاحقًا في هذا القسم تعابير نمطيةً أكثر، وسنتعرف على توابع أخرى لاحقًا.
أصناف المحارف
لنتأمل مهمةً تتطلب تحويل رقم هاتف، مثل "67-45-123-(903)7+"، إلى رقم صرف، أي 79031234567، لتنفيذ ذلك يمكننا تتبع وحذف أي محرف لا يمثل رقمًا، وستساعدنا أصناف المحارف في ذلك، حيث تمثل إشارات خاصةً تطابق أي رمز ضمن مجموعة معينة، وسنتعرف بدايةً على الصنف "digit"، الذي يُعبَّر عنه بالشكل d\، ويرتبط بأي رقم مفرد، فمثلًا لنجد الرقم الأول في رقم الهاتف:
let str = "+7(903)-123-45-67"; let regexp = /\d/; alert( str.match(regexp) ); // 7
سيبحث التابع عن كل الأرقام التي سيجدها في النص بإضافة الراية g، وسيعيدها ضمن مصفوفة:
let str = "+7(903)-123-45-67"; let regexp = /\d/g; alert( str.match(regexp) ); // 7,9,0,3,1,2,3,4,5,6,7 // لنشكل عددًا من أرقام المصفوفة: alert( str.match(regexp).join('') ); // 79031234567
سنستعرض الآن بعض الأصناف الأكثر استعمالًا، وهي:
-
d\: من كلمة digit رقم، ويعيد أي رقم بين 0 و9. -
\s: من كلمة space فراغ، وتضم محارف الفراغ، مثل: مسافة الجدولةt\، والسطر الجديدn\، وغيرها من الرموز النادرة الاستخدام مثلr\وv\وf\. -
w\: من كلمة word كلمة، وتعيد محارف قد تشكل كلمةً، مثل الأحرف اللاتينية أو الأرقام أو الشرطة السفلية_، ولا تنتمي الأحرف غير اللاتينية، مثل العربية، إلى هذا الصنف، إذ تشير الرموزd\s\w\مثلًا إلى رقم متبوع بمحرف فراغ، ويليه محرف كلمة مثل1 a.
يمكن أن يضم الكائن محارف تعابير نمطية بالإضافة إلى الأصناف، فمثلًا سيبحث التعبير CSS\d عن الكلمة CSS متبوعةً برقم:
let str = "Is there CSS4?"; let regexp = /CSS\d/ alert( str.match(regexp) ); // CSS4
كما يمكن استخدام أصناف محارف عدة:
alert( "I love HTML5!".match(/\s\w\w\w\w\d/) ); // ' HTML5'

الأصناف المعكوسة
لكل صنف من أصناف المحارف صنف معكوس inverse class، يرمز له بالحرف نفسه لكن بحالة حرف كبير uppercase، ويعني ذلك الحصول على أي محرف عدا المحرف الذي يعيده الصنف عادةً، أي:
-
D\: لا يعيد رقمًا، وإنما يعيد أي محرف عدا المحارف التي يعيدهاd\، مثل الأحرف اللاتينية. -
S\: لا يعيد محرف فراغ، وإنما يعيد أي محرف عدا المحارف التي يعيدهاs\، مثل الأحرف اللاتينية. -
W\: لا يعيد محرف كلمة، وإنما يعيد أي محرف عدا المحارف التي يعيدهاw\، مثل الأحرف غير اللاتينية أو الفراغات.
لاحظ كيف سنستخدَم هذه الأصناف في تحويل رقم الهاتف في المثال السابق إلى رقم صرف وبطريقة أقصر، وذلك بإزالة المحارف التي لا تمثل أرقامًا D\:
let str = "+7(903)-123-45-67"; alert( str.replace(/\D/g, "") ); // 79031234567
يمثل المحرف نقطة أي محرف
يمثل المحرف . صنفًا مميزًا من المحارف، ويطابق أي محرف عدا محرف السطر الجديد، إليك مثالًا:
alert( "Z".match(/./) ); // Z
كما يمكن إدراجه وسط التعبير regexp:
let regexp = /CS.4/; alert( "CSS4".match(regexp) ); // CSS4 alert( "CS-4".match(regexp) ); // CS-4 alert( "CS 4".match(regexp) ); // CS 4 (الفراغ هو محرف أيضًا)
لاحظ أن النقطة تطابق أي محرف، لكنها لن تبحث عن محرف غير موجود، فلا بدّ من وجود محرف حتى يعيده هذا الصنف:
alert( "CS4".match(/CS.4/) ); // null, لن يعيد الصنف شيئًا لعدم وجود محرف
لاحظ أن محرف النقطة يمثل أي محرف بالفعل بوجود الراية "s"، فلا تعيد النقطة عادةً محرف السطر الجديد، إذ يعيد التعبير A.B الحرفين A وB وأي محارف بينهما عدا محرف السطر الجديد n\:
alert( "A\nB".match(/A.B/) ); // null (لا تطابقات)
لكننا في عدة حالات نريد للنقطة أن تعني أي محارف فعلًا، بما في ذلك السطر الجديد، لذلك سنستخدم الراية s وسنحصل على المطلوب:
alert( "A\nB".match(/A.B/s) ); // A\nB (match!)
انتبه إلى أن المتصفح IE لا يدعم الراية s، لكن يمكن استخدام التعبير النمطي [\s\S] الذي يعيد أي محرف في أي مكان، وسنغطي ذلك لاحقًا.
alert( "A\nB".match(/A[\s\S]B/) ); // A\nB (match!)
ويعني التعبير [\s\S] البحث عن (محرف فراغ أو محرف لا يمثل فراغًا)، وهذا يمثل عمليًا أي محارف، ويمكن استخدام أي أزواج من الأصناف وعكسها، مثل [\d\D]، كما يمكن استخدام التعبير [^] الذي يعني البحث عن أي محرف عدا "لا شيء"، ويمكن استخدام الحيلة ذاتها إن أردنا أن يؤدي المحرف "نقطة" . كلا الوظيفتين، أي مطابقة أي محارف عدا السطر الجديد . أو مع السطر الجديد [\s\S].
انتبه أيضًا إلى الفراغات، إذ لا نكترث عادةً لوجود فراغات زائدة، وسنعتبر النص 1-5 مماثلًا للنص 1 - 5، لكن قد يخفق التعبير النمطي regexp إن لم يأخذ هذه الفراغات في الحسبان.
لنحاول مثلًا أن نجد أرقامًا مفصولةً بشرطة صغيرة (-):
alert( "1 - 5".match(/\d-\d/) ); // null, لا تطابق
سنصلح ذلك بإضافة فراغات إلى التعبير النمطي d - \d\:
alert( "1 - 5".match(/\d - \d/) ); // 1 - 5, سنجد الآن تطابقًا // \s أو يمكن استخدام الصنف: alert( "1 - 5".match(/\d\s-\s\d/) ); // 1 - 5, سيعمل أيًا
فالفراغ هو محرف، ولا يمكننا إضافة أو إزالة الفراغات من تعبير نمطي، ثم نتوقع أن يعمل كما هو مطلوب، فكل المحارف التي ندخلها في التعبير النمطي ستُؤخذ في الحسبان عند البحث، بما فيها الفراغات.
تعامل التعابير النمطية مع ترميز يونيكود Unicode
تستخدم JavaScript ترميز يونيكود Unicode لتمثيل النصوص، حيث تُرمّز معظم المحارف باستخدام 2 بايت، وهذا ما يسمح بترميز 65536 محرف كحد أقصى، ولا يعتبر العدد السابق كافيًا لترميز كل المحارف الممكنة، لذلك ستجد أن بعض المحارف الخاصة رمِّزت باستخدام 4 بايت، مثل المحرف ? -التمثيل الرياضي للمحرف X- أو ? -الابتسامة- وبعض المحارف الهيروغليفية وغيرها، وإليك قيم Unicode لبعض المحارف الخاصة:
| المحرف | ترميز Unicode | عدد البايتات المستخدمة |
|---|---|---|
| a |
0x0061
|
2 |
| ≈ |
0x2248
|
2 |
| ? |
0x1d4b3
|
4 |
| ? |
0x1d4b4
|
4 |
| ? |
0x1f604
|
4 |
تشغل محارف -مثل a- بايتين اثنين، ومحارف -مثل ? و?- أربعة بايتات.
كان ترميز Unicode في الأيام الأولى لظهور JavaScript أكثر بساطةً، حيث لم توجد محارف من أربعة بايتات، لذلك ستجد أن بعض ميزات اللغة ستتعامل معها بشكل غير صحيح، فتعتقد الخاصية length مثلًا أنها عبارة عن محرفين:
alert('?'.length); // 2 alert('?'.length); // 2
والسبب في ذلك أنّ هذه الخاصية ستعامل المحرف ذا البايتات الأربعة على أنه محرفان لكل منهما بايتان فقط، وهذا أمر خاطئ، حيث ينبغي اعتبارها محرفًا واحدًا، وتُدعى "الزوج البديل" surrogate pair، وسنرى ذلك لاحقًا.
تعامل التعابير النمطية regular expression المحارف الطويلة ذات البايتات الأربع مثل زوج من البايتات الثنائية، وقد يقود ذلك إلى أخطاء كما هو الحال في النصوص، لكن -وعلى خلاف النصوص- للتعابير النمطية الراية u التي تعالج هذه المشكلة، إذ يعالج التعبير المحارف ذات البايتات الأربع بشكل صحيح عند وجود هذه الراية، وسيصبح البحث متاحًا ضمن خصائص الترميز Unicode كما سنرى تاليًا.
خصائص ترميز Unicode باستعمال {…}p\
لمحارف Unicode العديد من الخصائص التي تصف الفئة التي ينتمي إليها المحرف، كما تقدم معلومات متنوعةً عنها، فلو كان للمحرف الخاصية Letter فسيعني ذلك أنه ينتمي إلى أبجدية ما، كما يعني امتلاكه الخاصية Number أنه رقم، وقد يكون رقمًا عربيًا أو صينيًا وهكذا، ويمكن البحث عن محرف يمتلك خاصيةً معينةً باستخدام الصنف {...}p\، ولاستخدام هذا الصنف لا بد أن نفعّل الراية u في التعبير النمطي.
يبحث التعبير {p{Letter\مثلًا عن حرف في أي لغة، كما يمكن كتابته بالشكل {p{L\، وهو اسم مستعار للخاصية Letter، ولمعظم الخصائص أسماء مستعارة قصيرة.
سيجد البحث في المثال التالي ثلاثة أنواع من الأحرف: انكليزي وجورجي وكوري.
let str = "A ბ ㄱ"; alert( str.match(/\p{L}/gu) ); // A,ბ,ㄱ alert( str.match(/\p{L}/g) ); // null (no matches, \p doesn't work without the flag "u")
إليك الفئات الأساسية للمحارف، وفئاتها الفرعية:
-
الحرف Letter: واسمها المستعار
L. -
Ll: حرف صغير. -
Lm: حرف معدِّل modifier. -
Lt: عنوان. -
Lu: حرف كبير. -
Lo: غير ذلك. -
العدد Number: واسمها المستعار
N. -
Nd: رقم بالصيغة العشرية. -
Nl: رقم حرف. -
No: غير ذلك. -
علامات الترقيم Punctuation: واسمها المستعار
P. -
Pc: واصلة. -
Pd: خط فاصل dash. -
Pi: علامة اقتباس فاتحة. -
Pf: علامة اقتباس غالقة. -
Ps: مفتوح. -
Pe: مغلق. -
Po: غير ذلك. -
العلامة أو الحركة Mark: واسمها المستعار
M، مثل العلامات أو الحركات فوق الأحرف وغيرها. -
Mc: علامة ضم مع فراغ spacing combining، وعلامة الضم هي محرف يعدّل محرفًا آخر بإضافة علامة أو حركة فوقه أو تحته وهكذا. -
Me: علامة ضم محيطة enclosing. -
Mn: علامة ضم دون فراغ non-spacing. -
الرمز Symbol: واسمه المستعار
S. -
Sc: رموز عملة. -
Sk: رمز مُعدِّل. -
Sm: رمز رياضي. -
So: رمز آخر. -
الفواصل Separator: واسمها المستعار
Z. -
Zl: خط. -
Zp: مقطع. -
Zs: فراغ. -
فئات أخرى: واسمها المستعار
C. -
Cc: تحكم. -
Cf: تنسيق. -
Cn: لم يحدد بعد. -
Co: استخدام خاص. -
Cs: بديل.
فلو أردنا مثلًا أحرفًا كبيرة فسنستخدم {p{Ll\، بينما نستخدم {p{p\ لعلامات الترقيم وهكذا.
ستجد أيضًا بعض الفئات المشتقة، مثل:
-
Alphabetic: واسمها المستعارAlpha، وتضم الأحرفL، والأرقام على شكل أحرفNl، مثل Ⅻ وهو 12 بالرومانية. -
Hex_Digit: وتضم الأرقام الست عشرية:0-9وa-f.
يدعم الترميز Unicode خصائص عديدةً، وسيزيد ذكرها من حجم المقالة بشكل كبير، لكن يمكنك الاطلاع على المراجع التالية:
- قائمة بكل الخصائص وفقًا للمحرف.
- قائمة بكل المحارف وفقًا للخاصية.
- قائمة بالاسماء المستعارة القصيرة للخصائص.
- قاعدة كاملة بمحارف Unicode بتنسيق نصي مع كامل خصائصها.
مثال: الأعداد الست عشرية
لننظر مثلًا إلى الأعداد الست عشرية المكتوبة بالشكل xFF، حيث F هو رقم ست عشري (0-1 أو A-F)، ويمكن الإشارة إلى الرقم الست عشري بالشكل {p{Hex_Digit\:
let regexp = /x\p{Hex_Digit}\p{Hex_Digit}/u; alert("number: xAF".match(regexp)); // xAF
مثال: الكتابة التصويرية الصينية
في ترميز Unicode خاصية تحدد نظام الكتابة، ويمكن أن تأخذ قيمًا مثل: Cyrillic وGreek وArabic وHan (الصينية) وغيرها من القيم المشابهة، وللبحث عن محرف في نظام كتابة محدد علينا استخدام الخاصية <Script=<value، فللعربية مثلًا نستخدم {p{sc=Arabic\، وللصينية نستخدم {p{sc=Han\ وهكذا.
let regexpHan = /\p{sc=Han}/gu; // يعيد التصويرية الصينية let regexpArab = /\p{sc=Arabic}/gu; // يعيد العربية let str = `Hello Привет 你好 جميل 123_456`; alert( str.match(regexpHan) ); // 你,好 alert( str.match(regexpArab) ); // ج,م,ي,ل
مثال: رموز العملة
للمحارف التي ترمز إلى العملات -مثل $ و€ و¥- خاصية في ترميز Unicode، هي {p{Currency_Symbol\، واسمها المختصر {p{Sc\، لنستخدم هذه الخاصية في الحصول على سعر منتج ضمن تنسيق يحوي رمز عملة يليه رقم:
let regexp = /\p{Sc}\d/gu; let str = `Prices: $2, €1, ¥9`; alert( str.match(regexp) ); // $2,€1,¥9
وسنتعرف لاحقًا في مقالات قادمة على آلية البحث عن أعداد تحتوي عدة أرقام.
محارف الارتكاز: محرفا بداية النص ^ ونهايته $
يحمل المحرفان ^ و$ معانٍ خاصةً في التعابير النمطية regular expression، وتسمى بالمرتكزات أو المرابط Anchors، حيث تبحث العلامة ^ عن تطابق في بداية النص، بينما تبحث $ عن تطابق في نهايته، لنر مثلًا إن بدأ نص ما بالكلمة "Mary":
let str1 = "Mary had a little lamb"; alert( /^Mary/.test(str1) ); // true
يعني النمط أن نبحث عن الكلمة "Mary" في بداية السطر حصرًا، وبشكل مشابه يمكن أن نستخدم $ للتحقق من وجود الكلمة "snow" مثلًا في نهاية نص:
let str1 = "it's fleece was white as snow"; alert( /snow$/.test(str1) ); // true
يمكن استخدام توابع التعامل مع النصوص startsWith/endsWith في هذه الحالات بالتحديد، لكن ينبغي استخدام التعابير النمطية في الحالات الأكثر تعقيدًا.
اختبار التطابق الكامل
يستخدم المرتكزان السابقان معًا $...^ لاختبار تطابق نص بشكل كامل مع النمط، مثل التحقق من مطابقة ما يدخله المستخدم للتنسيق المطلوب، لنتحقق مثلًا أن نصًا له التنسيق الزمني التالي 12:34، وهو عدد من رقمين، تليه نقطتان ":"، ثم عدد من رقمين، لذا سنستخدم التعبير d\d:\d\d\ في عالم التعابير النمطية:
let goodInput = "12:34"; let badInput = "12:345"; let regexp = /^\d\d:\d\d$/; alert( regexp.test(goodInput) ); // true alert( regexp.test(badInput) ); // false
يجب أن يبدأ التطابق مباشرة ًعند بداية النص ^، وينتهي بنهايته $، ويجب أن يطابق تنسيق النص تنسيق التعبير النمطي، فإذا وجدَت أي اختلافات أو محارف زائدة فستكون النتيجة "false"، وتسلك المرتكزات سلوكًا مختلفًا بوجود الراية m، وسنطلع على ذلك لاحقًا.
انتبه إلى أن ليس للمرتكزات عرض، فالمرتكزات محارف اختبار، وليس لها عرض، فهي لا تطابق محارف محددةً، بل تجبر محرك التعبير النمطي للتحقق من الشرط (بداية ونهاية نص).
نمط الأسطر المتعددة: تأثير الراية "m" على المرتكزان ^ و $
يُفعّل نمط الأسطر المتعددة باستخدام الراية m، التي تؤثر على سلوك المرتكزين $ و^ فقط، فلا تطابق المرتكزات في نمط الأسطر المتعددة بداية ونهاية النص فقط، بل بداية ونهاية السطر.
البحث عند بداية سطر ^
يحتوي النص في المثال التالي على عدة أسطر، وسيأخذ النمط d/gm\^/ رقمًا من بداية كل سطر:
let str = `1st place: Winnie 2nd place: Piglet 3rd place: Eeyore`; alert( str.match(/^\d/gm) ); // 1, 2, 3
سنحصل دون الراية m على الرقم الموجود في أول سطر فقط يطابق النمط:
let str = `1st place: Winnie 2nd place: Piglet 3rd place: Eeyore`; alert( str.match(/^\d/g) ); // 1
والسبب أنّ العلامة ^ ستطابق افتراضيًا بداية النص فقط، بينما ستطابق في نمط الأسطر المتعددة بداية أي سطر.
انتبه، فتعني بداية السطر رسميًا المحرف الذي يأتي بعد محرف السطر الجديد، وهكذا ستطابق العلامة ^ في نمط الأسطر المتعددة كل المحارف التي يسبقها محرف السطر الجديد n\.
البحث عند نهاية سطر $
يسلك المرتكز $ السلوك السابق نفسه، إذ يجد التعبير النمطي $d\ مثلًا آخر رقم في كل سطر:
let str = `Winnie: 1 Piglet: 2 Eeyore: 3`; alert( str.match(/\d$/gm) ); // 1,2,3
سيطابق المرتكز $ نهاية النص ككل دون استخدام الراية m، وبالتالي سنحصل فقط على آخر رقم.
انتبه، فتعني نهاية السطر رسميًا المحرف الذي يأتي قبل محرف السطر الجديد، وهكذا ستطابق العلامة $ في نمط الأسطر المتعددة كل المحارف التي تسبق محرف السطر الجديد n\ مباشرةً.
البحث عن محرف السطر الجديد n\ بدل المرتكز $
يمكن البحث عن سطر جديد باستخدام المحرف n\ بدلًا من البحث عن المرتكزين ^ و$، لكن ما الفرق؟
سنبحث في المثال التالي عن d\n\بدلًا من $d\:
let str = `Winnie: 1 Piglet: 2 Eeyore: 3`; alert( str.match(/\d\n/gm) ); // 1\n,2\n
ستجد الشيفرة تطابقين بدلًا من ثلاث، وذلك لعدم وجود سطر جديد بعد الرقم 3، على الرغم من وجود مرتكز نهاية النص الذي يطابق $، أما الاختلاف الآخر فهو أنّ n\محرف، وسيظهر ضمن النتيجة، وليس مثل المرتكزين ^ و$ اللذين يحددان شرط البحث في بداية ونهاية النص، وبالتالي سنستخدم n\ إذا أردنا ظهور محرف السطر الجديد في النتيجة، وإلا استخدمنا ^ و$.
حدود الكلمة: b\
حدود الكلمة اختبار، مثل ^ و$، حيث يشير وجود العلامة b\ بأنّ الموقع الذي وصل إليه محرك بحث التعابير النمطية هو حد لكلمة، وتوجد ثلاثة مواقع مختلفة يمكن اعتبارها حدودًا لكلمة، وهي:
-
في بداية نص، إذا كان أول محرف نصي فيه هو محرف كلمة
w\. -
بين محرفين في نص، إذا كان أحدهما محرف كلمة
w\والآخر ليس كذلك. -
في نهاية نص، إذا كان آخر محرف فيه هو محرف الكلمة
w\.
يمكن أن تجد التعبير bJava\b\ مثلًا في النص !Hello, Java عندما تكون الكلمة Java منفصلةً عن غيرها، لكنك لن تحصل على نفس النتيجة في النص !Hello, JavaScript
alert( "Hello, Java!".match(/\bJava\b/) ); // Java alert( "Hello, JavaScript!".match(/\bJava\b/) ); // null
في الشكل التالي ستمثل المواقع المشار إليها العلامة b\ في النص !Hello, Java:
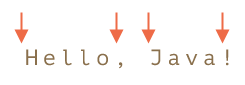
لذلك فهي تطابق النمط bHello\b\ لأن:
-
بداية النص تتطابق مع العلامة
b\. -
ثم تتطابق مع الكلمة
Hello. -
ثم تتطابق مع العلامة
b\مرةً أخرى، كما لو أنها بين المحرفoوالفاصلة.
إذًا سنعثر على النمط bHello\b\، لكن ليس النمط bHell\b\، لعدم وجود علامة حد الكلمة b\ بعد المحرف l، كما لن نحصل على النمط Java!\b لأن علامة التعجب ليست محرف كلمة w\، وبالتالي لا وجود لعلامة حد الكلمة b\ بعده.
alert( "Hello, Java!".match(/\bHello\b/) ); // Hello alert( "Hello, Java!".match(/\bJava\b/) ); // Java alert( "Hello, Java!".match(/\bHell\b/) ); // null (no match) alert( "Hello, Java!".match(/\bJava!\b/) ); // null (no match)
يمكن استخدام b\ مع الأرقام أيضًا، إذ يبحث النمط b\d\d\b\ مثلًا عن عدد من رقمين -عدد بخانتين- منفصل عن غيره، أي يبحث عن عدد بخانتين غير محاط بمحارف الكلمة w\، مثل محارف الفراغات أو علامات الترقيم أو مرتكزات بداية ونهاية نص.
alert( "1 23 456 78".match(/\b\d\d\b/g) ); // 23,78 alert( "12,34,56".match(/\b\d\d\b/g) ); // 12,34,56
انتبه، لا تعمل العلامة b\ مع الأبجديات غير اللاتينية، إذ تتحقق العلامة b\ من وجود محرف كلمة w\ في طرف نص وعدم وجوده في الطرف الآخر، وبما أنّ محرف الكلمة w\ سيدل على الأحرف اللاتينية a-z أو الأرقام أو الشرطة السفلية فقط، فلن يعمل مع محارف اللغات الأخرى، مثل العربية أو الصينية.
المحارف الخاصة وطريقة تجاوزها
يُستخدم المحرف \ كما رأينا للإشارة إلى أصناف المحارف -مثل d\- فهو إذًا محرف خاص، وستجد محارف خاصةً أخرى تحمل معنىً خاصًا في التعابير النمطية، وتستخدم لتنفيذ عمليات بحث أكثر قدرةً، وهذه المحارف هي: [ ]\ ^ $ . | ? * + ( )، ولا حاجة طبعًا لتذكر هذه القائمة، فسنتعامل مع كل محرف منها بشكل منفصل وستحفظها تلقائيًا.
التجاوز
لنفترض أننا نريد البحث عن محرف النقطة بذاته، وليس أي محرف، في هذه الحالة -وبقية الحالات التي نريد فيها البحث عن محرف خاص بحد ذاته كما لو أنه محرف عادي- سنضع المحرف \ قبله، أي .\ في حالة النقطة، وتُدعى هذه العملية بالتجاوز أو تهريب محرف escaping a character، إليك مثالًا:
alert( "Chapter 5.1".match(/\d\.\d/) ); // 5.1 (تطابق!) alert( "Chapter 511".match(/\d\.\d/) ); // null
تعتبر الأقواس محارف خاصةً أيضًا، فلا بد من البحث عنها وفق النمط )\، ويبحث المثال التالي عن النص "()g":
alert( "function g()".match(/g\(\)/) ); // "g()"
إذا أردنا البحث عن المحرف الخاص \ فلا بدّ من مضاعفته \\:
alert( "1\\2".match(/\\/) ); // '\'
الشرطة المائلة "/"
لا تعتبر الشرطة المائلة '/' من المحارف الخاصة، لكنها تستخدم في JavaScript لفتح وإغلاق التعابير النمطية /...pattern.../ فلا بد من تجاوزها أيضًا، إليك الطريقة التي نبحث فيها عن الشرطة المائلة:
alert( "/".match(/\//) ); // '/'
لا داعي لتجاوز الشرطة المائلة في الحالة التي لا نستخدم فيها النمط /.../، بل ننشئ كائن تعبير نمطي باستخدام new RegExp:
alert( "/".match(new RegExp("/")) ); // / يجد
الإنشاء باستخدام new RegExp
عندما ننشئ تعبيرًا نمطيًا باستخدام new RegExp، فلا حاجة لتجاوز المحرف / لكن يتحتم علينا تجاوز غيره.
تأمل الشيفرة التالية:
let regexp = new RegExp("\d\.\d"); alert( "Chapter 5.1".match(regexp) ); // null
لقد نجح البحث المشابه في أمثلة سابقة عندما استخدمنا /\d\.\d/، لكن لن يعمل البحث باستخدام ("new RegExp("\d\.\d فما السبب؟
السبب أن الشرطة المائلة ستُستهلك من قبل النص، وكما نتذكر فللنصوص العادية محارفها الخاصة -مثل n\- وقد استخدمت الشرطة المعكوسة backslash للتهريب.
إليك مثالًا:
alert("\d\.\d"); // d.d
تستهلك إشارتا التنصيص الشرطة المعكوسة وتفسرها بطريقتها، فمثلًا:
-
تتحول
n\إلى محرف السطر الجديد. -
تتحول
u1234\إلى محرف Unicode بهذا الرمز. -
وفي حال لم يوجد معنىً لوجود الشرطة المعكوسة -مثل
d\أوz\- فستُزال هذه الشرطة ببساطة.
يحصل new RegExp على نص بلا شرطات معكوسة، لهذا لن يفلح البحث، ولحل المشكلة لا بدّ من مضاعفة الشرطة المعكوسة، لأن إشارتي التنصيص تحولان \\ إلى \.
let regStr = "\\d\\.\\d"; alert(regStr); // \d\.\d (عملية صحيحة) let regexp = new RegExp(regStr); alert( "Chapter 5.1".match(regexp) ); // 5.1
خلاصة
-
يتألف التعبير النمطي من نمط pattern، ورايات flags اختيارية هي:
gوiوmوuوsوy. - لا تختلف عملية البحث دون استخدام الرايات والرموز الخاصة عن أي عملية بحث اعتيادية ضمن نص.
-
يبحث التابع
(str.match(regexpعن كل حالات التطابق التي يحددها التعبيرregexpبوجود الرايةg، وإلا فسيبحث عن أول تطابق فقط. -
يستبدل التابع
(str.replace(regexp, replacementالتطابقات التي يحددها التعبيرregexpبالنصreplacement، حيث يستبدل التطابقات كلها عند وجود الرايةg، وإلا فسيستبدل أولها فقط. -
يعيد التابع
(regexp.test(strالقيمةtrueإن وجد تطابقًا على الأقل مع التعبير المستخدم، وإلا فسيعيدfalse.
هنالك أصناف محارف متعددة، هي:
-
d\: للأرقام. -
D\: لغير الأرقام. -
s\: لمحارف الفراغات والجدولة والسطر الجديد. -
S\: لكل المحارف عدا محارف الفراغات والجدولة والسطر الجديد. -
w\: كل الأرقام والأحرف اللاتينية والشرطة السفلية (_). -
W\: كل المحارف عدا ما ذكرناه في السطر السابق. -
.: أي محرف عدا محرف السطر الجديد، وأي محرف تمامًا عند استخدام الراية"s".
تؤمن مجموعة المحارف Unicode التي تستخدمها JavaScript العديد من الميزات المتعلقة بالمحارف، مثل تحديد اللغة التي ينتمي إليها محرف معين، وهل يمثل المحرف علامة ترقيم وغيرها، ويتطلب ذلك استخدام الراية u.
تدعم الراية u استخدام رموز Unicode في التعابير النمطية، ويعني ذلك أمرين اثنين:
- ستتعامل الميزات والخصائص مع المحارف المكونة من أربع بايتات بشكل صحيح ومثل محرف واحد، وليس مثل محرفين يتكون كل منهما من بايتين.
-
يمكن استخدام خصائص Unicode في عمليات البحث من خلال
{...}\p.
يمكن البحث عن كلمات في لغة محددة باستخدام خصائص Unicode، بالإضافة إلى البحث عن محارف خاصة مثل إشارات التنصيص، العملات،….
-
للبحث عن المحارف الخاصة
[ \ ^ $ . | ? * + ( )بذاتها، لا بدّ من وضع الشرطة المائلة\قبلها لتجاوز الوظيفة الخاصة للمحرف. -
ينبغي تجاوز الشرطة المعكوسة
\أيضًا في النمط/.../، لكن ليس ضمنnew RegExp. -
عند تمرير نص إلى
new RegExpفلا بدّ من مضاعفة الشرطة المعكوسة، لأن إشارة التنصيص\\تستهلك إحداهما.
ترجمة -وبتصرف- للفصول:
- Patterns and flags
- character classes
- Unicode: flag "u" and class \p{…}
- Anchors: string start ^ and end $
- Multiline mode of anchors ^ $, flag "m"
- Word boundary: \b
- Escaping special characters
من سلسلة The Modern JavaScript Tutorial.












أفضل التعليقات
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.