

سنتطرق في هذا المقال إلى برنامج عدّ الكلمات الذي كتبناه من قبل، وسننشئ برنامجًا يحاكي برنامج wc في يونكس، من حيث حساب عدد الأسطر والكلمات والمحارف التي في ملف ما، ثم نتعمق أكثر في هذا لنخرج عدد الجمل وأجزاء الجمل clauses والفقرات أيضًا، وسنتابع تطوير هذا البرنامج مرحلةً تلو الأخرى، وسنزيد من إمكانياته تدريجيًا، ثم ننقله إلى وحدة module ليكون قابلًا لإعادة الاستخدام بأن نجعله كائني التوجه object oriented لتحقيق أقصى حد ممكن من الإمكانيات، ثم نغلفه أخيرًا في واجهة رسومية لسهولة الاستخدام، ورغم أننا سنستخدم بايثون في هذا البرنامج إلا أنه يمكن كتابة نسخ منه باستخدام جافاسكربت أو VBScript بإجراء بعض التعديلات.
ويمكن إضافة مزايا أخرى لهذا البرنامج، لكننا سنتركها للقارئ للتدريب، من تلك المزايا:
- حساب فهرس FOG للنصوص، والذي يوضح مدى تعقيد النص، ويُعرَّف بأنه:
(متوسط عدد الكلمات للجملة الواحدة) + (نسبة الكلمات الأكثر من 5 أحرف) * 0.4
- حساب عدد الكلمات الفريدة المستخدمة، ومرات تكرارها.
- إنشاء نسخة جديدة تحلل ملفات RTF.
حساب عدد الأسطر والكلمات والحروف
إذا نظرنا إلى عداد الكلمات السابق:
import string def numwords(s): lst = string.split(s) return len(lst) with open("menu.txt","r") as inp: total = 0 # accumulate totals for each line for line in inp.readlines(): total += numwords(line) print( "File had %d words" % total )
فسنجد أننا بحاجة إلى إضافة عدد الأسطر والأحرف، وعدد الأسطر سهل لأننا نكرر على كل سطر، لذا سنحتاج إلى متغير يتزايد مع كل تكرار على الحلقة التكرارية، أما عدد الأحرف فسيكون أصعب قليلًا، لأننا نستطيع التكرار على قائمة الكلمات مضيفين أطوالها في متغير آخر.
كما ينبغي أن نجعل البرنامج عام الأغراض بقراءة اسم الملف من سطر الأوامر، أو نطلب من المستخدم أن يزودنا بالاسم إذا لم يكن متاحًا، كما يمكن قراءته من مجرى الدخل القياسي standard input، وهو ما يفعله برنامج wc.
سيبدو wc.py النهائي كما يلي:
import sys, string # احصل على اسم الملف من سطر الأوامر أو المستخدم if len(sys.argv) != 2: name = input("Enter the file name: ") else: name = sys.argv[1] # اضبط العدادات على الصفر. هذا ينشئ المتغيرات # words - lines - chars = 0, 0, 0 with open(name,"r") as inp: for line in inp: lines += 1 # Break into a list of words and count them lst = line.split() words += len(lst) chars += len(line) # Use original line which includes spaces etc. print( "%s has %d lines, %d words and %d characters" % (name, lines, words, chars) )
يستطيع من يستخدم برنامج wc في يونكس تمرير اسم ملف بمحارف بديلة wildcards؛ للحصول على إحصائيات لجميع الملفات المطابقة إضافةً إلى المجموع الكلي، أما برنامجنا فيتعامل مع اسم ملف واحد فقط، فإذا أردت توسيع ذلك إلى محارف البدل فألق نظرةً على الوحدة glob، وابن قائمةً من الأسماء، ثم كرر على قائمة الملفات، وستحتاج إلى عدادات مؤقتة لكل ملف، ثم عدادات تراكمية للمجموع الكلي، أو استخدم قاموسًا.
عد الجمل بدلًا من الأسطر
إذا أردنا توسيع هذا البرنامج ليشمل عد الجمل والكلمات بدلًا من "مجموعات المحارف"، فنكرر أولًا على الملف لاستخراج الأسطر إلى قائمة، ثم نكرر على كل سطر لنستخرج الكلمات إلى قائمة أخرى، ثم نعالج بعد ذلك كل "كلمة" لحذف المحارف الدخيلة عليها.
لكن توجد طريقة أبسط، بأن نجمع السطور ونحلل محارف الترقيم لعد الجمل وأجزاء الجمل وغيرها، من خلال تعريف الجملة أو جزء الجملة بحسب عناصر الترقيم، لنجرب ذلك في شيفرة وهمية:
لكل سطر في الملف: زِد عدد الأسطر بمقدار واحد إذا كان السطر فارغًا: زِد عدد الفقرات عد نهايات أجزاء الفقرات عد نهايات الجمل. أنشئ تقريرًا بالفقرات واأسطر والجمل وأجزاء الجمل والمجموعات والكلمات.
لنحول الآن الشيفرة الوهمية إلى شيفرة حقيقية، وسنستخدم التعابير النمطية في حلنا، لذا ينبغي مراجعة مقال التعابير النمطية في البرمجة من نفس السلسلة، للاطلاع عليها ودراستها:
import re,sys # استخدم التعابير النمطية للعثور على الأجزاء sentenceStops = ".?!" clauseStops = sentenceStops + ",;:\-" # escape '-' to avoid range effect sentenceRE = re.compile("[%s]" % sentenceStops) clauseRE = re.compile("[%s]" % clauseStops) # احصل على اسم الملف من سطر الأوامر أو من المستخدم if len(sys.argv) != 2: name = input("Enter the file name: ") else: name = sys.argv[1] # اضبط العدادات الآن lines, words, chars = 0, 0, 0 sentences,clauses = 0, 0 paras = 1 # assume always at least 1 para # عالج الملف with open(name,"r") as inp: for line in inp: lines += 1 if line.strip() == "": # empty line paras += 1 words += len(line.split()) chars += len(line.strip()) sentences += len(sentenceRE.findall(line)) clauses += len(clauseRE.findall(line)) # اعرض النتائج output = ''' The file %s contains: %d\t characters %d\t words %d\t lines in %d\t paragraphs with %d\t sentences and %d\t clauses. ''' % (name, chars, words, lines, paras, sentences, clauses) print( output )
هناك عدة نقاط ينبغي الانتباه إليها في الشيفرة السابقة:
-
نستخدم التعابير النمطية هنا لتحسين كفاءة عمليات البحث، رغم إمكانية استخدام عمليات بحث بسيطة عن السلاسل النصية، لكن كنا سنحتاج حينئذ إلى البحث عن كل محرف ترقيم على حدة، وتزيد التعابير النمطية هنا من كفاءة البرنامج، من خلال إيجاد جميع العناصر التي نريدها في بحث واحد، لكن من ناحية أخرى يسهل حدوث الأخطاء فيها، فقد نسينا أثناء محاولتنا الأولى لكتابة الشيفرة أن نهرب المحرف
-، فرآه التعبير النمطي مجالًا range، لذا عومل أي عدد في الملف على أنه فاصل لجزء من جملة، واستغرق الأمر كثيرًا حتى عرضنا المشكلة على مجتمع بايثون للعثور على الخطأ، فلما أضفنا محرف"حٌلت المشكلة، كما صرَّفنا التعبيرات مسبقًا precompiled، مما حسّن من الأداء أكثر من استخدام نفس التعبير عدة مرات، كما نلاحظ استخدام التابعfindallللحصول على جميع التطابقات في سطر باستدعاء واحد. - تظهر كفاءة هذا البرنامج في أنه ينفذ ما نريده بالضبط، وإن كان أقل كفاءةً من منظور إمكانية إعادة الاستخدام، لعدم وجود دوال يمكن استدعاؤها من برامج أخرى.
- ليست اختبارات الجمل مثاليةً، لأن العناوين المختصرة -مثل "Mr."- ستُحسب جملةً، لأنها تحتوي على محرف النقطة، ونستطيع تحسين التعبير النمطي ليبحث عن النقطة متبوعةً بمسافة واحدة أو أكثر، ثم متبوعةً بحرف إنجليزي كبير، لكن ذلك لن يحل مشكلة "Mr." لأنها تُتبع عادةً بمسافة ثم كلمة بحرف كبير، وهذا يوضح مدى صعوبة معالجة اللغات الطبيعية بكفاءة، فإذا احتجنا حقًا إلى مثل هذا البحث في الممارسة العملية فهناك وحدات متاحة على الإنترنت مصممة خصيصًا لذلك.
سنتناول النقطة الثانية المتعلقة بإمكانية إعادة الاستخدام أثناء دراسة الحالة التي بين أيدينا، وننظر في المشاكل المتعلقة بتحليل النصوص بتفصيل أكثر، رغم أننا لن ننتج محلل نصوص مثاليًا في النهاية، حيث تحتاج هذه المهمة مهارات أكبر من التي نتوقعها من مبرمج مبتدئ.
تحويل البرنامج إلى وحدة
إذا أردنا تحويل البرنامج الذي كتبناه إلى وحدة فيجب أن نتبع بعض مبادئ التصميم الأساسية، فنضع الجزء الأكبر من الشيفرة في دوال ليستطيع مستخدمو الوحدة الوصول إليها، ثم ننقل شيفرة البدء التي تحصل على اسم الملف إلى جزء منفصل من الشيفرة؛ لا يُنفَّذ عند استيراد الوحدة، وأخيرًا سنترك التعريفات العامة global definitions متغيرات على مستوى الوحدة ليستطيع المستخدمون تغيير قيمها إذا أرادوا.
لننقل كتلة المعالجة الأساسية الآن إلى دالة نسميها analyze()، وسنمرر كائن ملف معامِلًا إليها، وستعيد الدالة قائمةً من قيم العد في صف tuple، وستبدو الشيفرة كما يلي:
############################# # Module: grammar # Created: A.J. Gauld, 2010/12/02 # Modified: A.J. Gauld, 2018/01/12 # # Function: ''' Provides facilities to count words, lines, characters, paragraphs, sentences and 'clauses' in text files. It assumes that sentences end with [.!?] and paragraphs have a blank line between them. A 'clause' is simply a segment of sentence separated by punctuation. The sentence and clause searches are regular expression based and the user can change the regex used. Can also be run as a program.''' ############################# import re, sys # اضبط المتغيرات العامة paras = 1 # We will assume at least 1 paragraph! lines, sentences, clauses, words, chars = 0,0,0,0,0 sentenceMarks = '.?!' clauseMarks = '&();:,/\-' + sentenceMarks sentenceRE = None # set via a function call clauseRE = None format = ''' The file %s contains: %d\t characters %d\t words %d\t lines in %d\t paragraphs with %d\t sentences and %d\t clauses. ''' ############################ # عرّف الدوال التي ستنفذ العمل # بإعادة تصريف التعبير النمطي إذا setCounterREs تسمح لنا # غيرنا قائمة الأجزاء def setCounterREs(): "compiles global regexs from global punctuation sets" global sentenceRE, clauseRE sentenceRE = re.compile('[%s]' % sentenceMarks) clauseRE = re.compile('[%s]' % clauseMarks) # تصفير العدادات analyze() تستدعي def resetCounters(): " reset global counter variables to initial values " chars, words, lines, sentences, clauses = 0,0,0,0,0 paras = 1 # لشيفرة التعريفات، إذ توفر تقريرًا نصيًا بسيطًا reportStats توجَّه def reportStats(theFile): " prints out results from global results " print( format % (theFile.name, chars, words, lines, paras, sentences, clauses) ) # هي الدالة الأساسية التي تعالج الملف analyze() def analyze(theFile): ''' analyze(aFile) -> None Analyzes the input file object putting results in global variables ''' global chars,words,lines,paras,sentences,clauses # مصرَّفًا بالفعل REs تحقق إن كان if not (sentenceRE and clauseRE): setCounterREs() resetCounters() for line in theFile: lines += 1 if line.strip() == "": # empty line paras += 1 words += len(line.split()) chars += len(line.strip()) sentences += len(sentenceRE.findall(line)) clauses += len(clauseRE.findall(line)) # اسمح بتشغيلها إذا استُدعيت من سطر الأوامر #'__main__' على '__name__' يُضبط متغير if __name__ == "__main__": if len(sys.argv) != 2: print( "Usage: python grammar.py <filename>" ) sys.exit() else: with open(sys.argv[1],"r") as aFile: analyze(aFile) reportStats(aFile)
إن أول ما نلاحظه هنا هو التعليقات التي في الأعلى، وهذا سلوك شائع لإعطاء فكرة عامة لمن يقرأ الملف عن محتوياته وكيفية استخدامه، كما أن معلومات الإصدار التي تشمل المؤلف والتاريخ مهمة عند موازنة النتائج مع شخص آخر قد يستخدم إصدارًا أحدث، ونلاحظ أن وصف الوحدة هو سلسلة نصية غير مخصصة لمتغير ما، وتذكر أن هذا ينشئ سلسلة توثيق documentation string في بايثون، يمكن الاطلاع عليها باستخدام الدالة help، كما لدينا سلاسل توثيق على كل تعريف دالة مستقلة، ولن نضيف تعليقات كثيرةً في الأمثلة الأخرى، رغم أننا سنعرض بعض الأنماط الأخرى من التعليقات والتوثيقات، لأن النص الأساسي يصف ما يحدث، فهذا المثال يوضح ما يمكن أن نوفره.
أما الجزء الأخير فهو خاصية في بايثون تستدعي أي وحدة محمَّلة في سطر الأوامر "__main__"، نستطيع تجريب المتغير الخاص والمضمَّن __name__، حيث نعرف أن الوحدة ستُستورد وتشغَّل، لذا ننفذ شيفرة التشغيل driver code داخل الكتلة if.
تتضمن شيفرة التعريف تلك إرشادًا حول كيفية تشغيل الملف إذا لم يتوفر اسم ملف، أو إذا توفرت أسماء ملفات كثيرة، فتسأل المستخدم عن اسم الملف باستخدام input()، ونلاحظ أن الدالة analyze() تستخدم دوال الضبط لضمان ضبط العدادات والتعابير العادية ضبطًا صحيحًا قبل أن تبدأ، مما يفيد المستخدم عند استدعاء analyze عدة مرات، خاصةً بعد تغيير التعابير النمطية المستخدمة في عد الجمل وأجزائها.
كما نلاحظ استخدام global لضمان ضبط المتغيرات على مستوى الوحدة بواسطة الدوال، ومن دونها كنا سننشئ متغيرات محليةً ليس لها تأثير على متغيرات الوحدة.
استخدام الوحدة grammar
بعد أن أنشأنا وحدةً نستطيع استخدامها مثل برنامج في سطر أوامر النظام، كما فعلنا من قبل عن طريق ما يلي:
C:\> python grammar.py spam.txt
إلا أننا نستطيع استيراد الوحدة إلى برنامج آخر أو في محث بايثون، شرط أن نكون قد حفظنا الوحدة في موقع تستطيع بايثون أن تراه.
لنجرِ الآن بعض الاختبارات على ملف اختبارات اسمه spam.txt، والذي يعطي الناتج التالي:
This is a file called spam. It has 3 lines, 2 sentences and, hopefully, 5 clauses.
أي هذا ملف اسمه spam، فيه 3 أسطر وجملتين وخمسة أجزاء جمل.
لنشغل بايثون الآن ونجرب:
>>> import grammar >>> grammar.setCounterREs() >>> txtFile = open("spam.txt") >>> grammar.analyze(txtFile) >>> grammar.reportStats(txtFile) The file spam.txt contains: 80 characters 16 words 3 lines in 1 paragraphs with 2 sentences and 5 clauses. >>> txtFile.close() >>> txtFile = open('spam.txt') >>> grammar.resetCounters() >>> # redefine sentences as ending in vowels! >>> grammar.sentenceMarks = 'aeiou' >>> grammar.setCounterREs() >>> grammar.analyze(txtFile) >>> print( grammar.sentences ) 21 >>> txtFile.close()
نلاحظ أنه يفضل استخدام open/cloSe على الملف عند استخدام المحث التفاعلي بدلًا من استخدام with، لأن with ستؤخر التنفيذ حتى نكتب جميع عمليات الملف التي ستكون داخل الكتلة with، أما استخدام open صراحةً فسيمكننا من تنفيذ كل أمر تنفيذًا منفصلًا.
نستطيع الآن أن نرى أن إعادة تعريف أجزاء الجمل قد غيرت عدد الجمل تغييرًا جذريًا، ولا شك أن التعريف الجديد غريب لكنه يظهر أن الوحدة قابلة للاستخدام والتخصيص، ونلاحظ أننا كنا نستطيع طباعة عدد الجمل مباشرةً، دون الحاجة إلى استخدام الدالة reportStats()، وهذا يظهر قيمة مبدأ مهم في التصميم، وهو فصل البيانات عن العرض display، فلما فصلنا عرض البيانات عن حسابها صارت وحدتنا أكثر مرونةً للمستخدمين.
ولننهي مشروعنا نعيد صياغة وحدة القواعد grammar لتستخدم تقنيات كائنية التوجه، ثم نضيف واجهةً رسوميةً بسيطةً، وسنرى خلال ذلك كيف يعطينا المنظور الكائني وحدات أكثر مرونةً للمستخدم، وقابلةً للتوسيع أيضًا.
الأصناف والكائنات
من أكبر المشاكل التي يواجهها من يستخدم وحدتنا الاعتماد على المتغيرات العامة، مما يعني أنها تستطيع تحليل ملف واحد في كل مرة، وسيؤدي تحليل أكثر من ملف إلى تغيير القيم العامة، فإذا نقلنا هذه المتغيرات العامة إلى صنف class، فسنستطيع إنشاء عدة نسخ من الصنف -واحد لكل ملف-، وستحصل كل نسخة على مجموعتها الخاصة من المتغيرات، وإذا جعلنا التوابع دقيقةً بما يكفي فيمكن إنشاء بنية يسهل من خلالها -على منشئ نوع جديد من كائن المستند- تعديل معايير البحث ليوافق احتياجات النوع الجديد، فإذا رفضنا جميع وسوم HTML من قائمة الكلمات مثلًا فيمكن معالجة ملفات HTML إضافةً إلى ملفات آسكي ASCII الخالصة.
أدت محاولتنا الأولى في هذا إلى إنشاء الصنف Document لتمثيل الملف الذي نعالجه:
#! /usr/local/bin/python ################################ # Module: document.py # Author: A.J. Gauld # Date: 2010/12/10 # Version: 3.1 ################################ ''' Provides 2 classes for parsing text/files. A Generic Document class for plain ASCII text, and an HTMLDocument for HTML files. Primary services available include - analyze(), - reportStats(). ''' import sys,re class Document: sentenceMarks = '?!.' clauseMarks = '&()/\-;:,' + sentenceMarks def __init__(self, filename): self.filename = filename self.setREs() self.resetCounters() def resetCounters(self): self.paras = 1 self.lines = self.getLines() self.sentences, self.clauses, self.words, self.chars = 0,0,0,0 def setREs(self): self.sentenceRE = re.compile('[%s]' % Document.sentenceMarks) self.clauseRE = re.compile('[%s]' % Document.clauseMarks) def getLines(self): with open(self.filename)as infile: lines = infile.readlines() return lines def analyze(self): self.resetCounters() for line in self.lines: self.sentences += len(self.sentenceRE.findall(line)) self.clauses += len(self.clauseRE.findall(line)) self.words += len(line.split()) self.chars += len(line.strip()) if line.strip() == "": self.paras += 1 def formatResults(self): format = ''' The file %s contains: %d\t characters %d\t words %d\t lines in %d\t paragraphs with %d\t sentences and %d\t clauses. ''' return format % (self.filename, self.chars, self.words, len(self.lines), self.paras, self.sentences, self.clauses) class TextDocument(Document): pass class HTMLDocument(Document): pass if __name__ == "__main__": if len(sys.argv) == 2: doc = Document(sys.argv[1]) doc.analyze() print( doc.formatResults() ) else: print( "Usage: python document3.py <file>" ) print( "Failed to analyze file" )
نلاحظ استخدام متغيرات الصنف في بداية تعريفه، لتخزين محددات الجمل وأجزائها، حيث تُشارَك متغيرات الصنف بين جميع نسخه، لذا فهي مكان ممتاز لتخزين المعلومات المشتركة، ويمكن الوصول إليها باستخدام اسم الصنف كما فعلنا هنا، أو باستخدام self، ونفضل استخدام اسم الصنف لأنه يبرز حقيقة أن هذه المتغيرات لصنف.
لا زلنا بحاجة إلى resetCounters() للمرونة في التعامل مع أنواع المستندات الأخرى، رغم أننا نخزن المتغيرات الآن داخل الصنف، فعلى الأرجح أننا سنستخدم مجموعة عدادات أخرى عند تحليل ملفات HTML -مثل عدد الوسوم-، ونستطيع التعامل مع أي نوع من المستندات تقريبًا إذا جمعنا resetCounters() مع formatResults()، ووفرنا تابع analyze() جديد، أما التوابع الأخرى فهي أكثر استقرارًا، لأن قراءة أسطر الملف أمر قياسي بغض النظر عن نوعه، وضبط التعبيرين النمطيين فرصة جيدة للتدرب، فإذا لم نكن بحاجة إلى ذلك فلا نفعله.
لدينا الآن وظائف مماثلة لنسخة وحدتنا الخاصة لكننا عبرنا عنها في صنف، ونريد أن نستغل الأسلوب الكائني من خلال فك أجزاء من صنفنا كي لا يحتوي المستوى الأساسي أو Document المجرد إلا على أجزاء عامة، وسننقل الأجزاء الخاصة بمعالجة النصوص إلى الصنف TextDocument أكثر تحديدًا، وتُعرف هذه العملية بإعادة التصميم (Refactoring) في أوساط البرمجة الاحترافية، وسنرى كيفية تنفيذ ذلك فيما يلي.
المستند النصي
المستندات النصية مألوفة، لكننا يجب أن نتريث لنوضح الغرض من موازنة المستند النصي بالمفهوم العام للمستندات، تتكون المستندات النصية من محارف مرتبة في سطور، تحتوي مجموعات من الأحرف مرتبةً في كلمات تفصل بينها مسافات وعلامات ترقيم أخرى، وإذا جمعنا تلك الأسطر في مجموعات فسيتكون لدينا فقرات يُفصل بينها بأسطر فارغة.
والمستند الافتراضي -يُطلق عليه vanilla document أو مستند الفانيليا أحيانًا في إشارة إلى نكهة المثلجات الافتراضية- يتكون من أسطر من المحارف التي لا نعرف عن صياغتها إلا القليل، لذا يجب أن يكون صنفنا Document الأساسي قادرًا على فتح الملف وقراءة محتوياته إلى قائمة من الأسطر، وربما يعيد عدد المحارف والأسطر مثلًا، كما يوفر توابع خطافيةً hook methods فارغةً للأصناف الفرعية الخاصة بالمستند لاستخدامها، لاحظ أن نص آسكي هو أحد أقدم وأبسط الطرق للتعبير عن النصوص، إلا أن الأبجديات التي أضيفت إليه وإضافة اليونيكود قد جعلته معقدًا.
وفقًا لما شرحناه في الفقرات السابقة يجب أن يبدو الصنف Document كما يلي:
############################# # Module: document # Created: A.J. Gauld, 2010/12/15 # Version 3 # Function: ''' Provides abstract Document class to count lines, characters and provide hook methods for subclasses to use to process more specific document types''' ############################# import sys,re class Document: def __init__(self,filename): self.filename = filename self.lines = self.getLines() self.chars = sum( [len(L) for L in self.lines] ) self._initSeparators() def getLines(self): f = open(self.filename,'r') lines = f.readlines() f.close() return lines # قائمة بالتوابع الخطافية التي يجب تغييرها def formatResults(self): return "%s contains $d lines and %d characters" % (len(self.lines), self.chars) def _initSeparators(self): pass def analyze(self): pass
نلاحظ أن التابع _initSeparators يحوي شرطةً سفليةً قبل اسمه، حيث يستخدم هذا الاصطلاح مبرمجو بايثون للإشارة أن هذا التابع لا يُستدعى إلا من داخل توابع الصنف، وليس مخصصًا ليصل إليه مستخدمو الكائن، ويسمى مثل هذا التابع أحيانًا في بعض اللغات الأخرى بالتابع المحمي protected أو الخاص private.
كما نلاحظ أننا استخدمنا الدالة sum() لحساب عدد المحارف، وهي تعيد مجموع قائمة من الأعداد، والقائمة في حالتنا هي قائمة أطوال الأسطر في الملف المنتج بواسطة list comprehension.
لم نوفر خيارًا قابلًا للتشغيل باستخدام if __name__ == etc لأن هذا الصنف مجرد abstract.
يجب أن يبدو المستند النصي الآن كما يلي:
class TextDocument(Document): def __init__(self,filename): super().__init__(filename) self.paras = 1 self.words, self.sentences, self.clauses = 0,0,0 # غيّر الخطاطيف الآن def formatResults(self): format = ''' The file %s contains: %d\t characters %d\t words %d\t lines in %d\t paragraphs with %d\t sentences and %d\t clauses. ''' return format % (self.filename, self.chars, self.words, len(self.lines), self.paras, self.sentences, self.clauses) def _initSeparators(self): sentenceMarks = "[.!?]" clauseMarks = "[.!?,&:;-]" self.sentenceRE = re.compile(sentenceMarks) self.clauseRE = re.compile(clauseMarks) def analyze(self): for line in self.lines: self.sentences += len(self.sentenceRE.findall(line)) self.clauses += len(self.clauseRE.findall(line)) self.words += len(line.split()) self.chars += len(line.strip()) if line.strip() == "": self.paras += 1 if __name__ == "__main__": if len(sys.argv) == 2: doc = TextDocument(sys.argv[1]) doc.analyze() print( doc.formatResults() ) else: print( "Usage: python <document> " ) print( "Failed to analyze file" )
يحقق دمج الأصناف هذا نفس ما يحققه الإصدار غير الكائني الأول، وإذا وازنّا بين طول هذه النسخة وطول الملف الأصلي فسندرك أن بناء كائنات قابلة لإعادة الاستخدام ليس سهلًا، لذا ينبغي أن نكتب إصدارات غير كائنية دومًا؛ ما لم نكن بحاجة إلى إعادة استخدام الكائنات، كأن نخطط لتوسيع التصميم مستقبلًا، كما سنفعل بعد قليل.
ومن المهم أن نراعي الموقع الفعلي للشيفرة، فقد كان بإمكاننا عرض إنشاء ملفين، واحد لكل صنف، وهو سلوك شائع في البرمجة الكائنية، ويحافظ على النظام العام، رغم أنه يكون على حساب كثير من الملفات الصغيرة، وكثير من تعليمات الاستيراد في الشيفرة عند استخدام تلك الملفات أو الأصناف.
ونفضل أن نعامل الأصناف المرتبطة ببعضها بشدة مثل مجموعة، ونضعها جميعًا في ملف واحد، بما يكفي على الأقل لإنشاء برنامج صغير عامل، لذا جمعنا الصنفين Document وTextDocument في وحدة واحدة، وميزة ذلك أن الصنف العامل يوفر قالبًا للمستخدمين ليقرؤوه مثالًا على توسيع الصنف المجرد، لكن عيبه أن أي تعديل في TextDocument سيؤثر على صنف المستند، وبالتالي سيعطل أجزاءً من الشيفرة، فلا يوجد حل صالح هنا، وتوجد أمثلة على كلا النمطين في مكتبة بايثون، فاختر أحدهما والتزم به.
من مصادر المعلومات المفيدة في مثل هذا النوع من التعديل على الملفات النصية كتاب "معالجة النصوص في بايثون" أو Text Processing in Python لـ David Mertz، لكن لاحظ أن هذا الكتاب متقدم وموجه إلى المبرمجين المحترفين، لذا قد تجد صعوبةً في استيعاب مادته إذا كنت مبتدئًا في البرمجة، لكنك ستجد فيه دروسًا مفيدةً للغاية بالمثابرة والتعلم.
مستند HTML
الخطوة التالية في تطوير تطبيقنا هي توسيع إمكانياته لنستطيع تحليل مستندات HTML، وسنفعل ذلك بإنشاء صنف جديد، وبما أن مستند HTML ما هو إلا مستند نصي يحتوي على الكثير من وسوم HTML وقسم للترويسة في الأعلى؛ فكل ما نحتاج إليه هو حذف هذه العناصر الإضافية ومعاملته بعدها على أنه نص عادي، لذا سننشئ صنفًا جديدًا نسميه HTMLDocument مشتقًا من TextDocument، وسنغير التابع getLines() الذي ورثناه من Document بحيث يحذف الترويسة ووسوم HTML.
سيبدو الصنف HTMLDocument الآن كما يلي:
class HTMLDocument(TextDocument): def getLines(self): lines = super().getLines() lines = self._stripHeader(lines) lines = self._stripTags(lines) return lines def _stripHeader(self,lines): ''' remove all lines up until start of body ''' bodyMark = '<body>' bodyRE = re.compile(bodyMark,re.IGNORECASE) while bodyRE.findall(lines[0]) == []: del lines[0] return lines def _stripTags(self,lines): ''' remove anything between < and >, not perfect but ok for now''' tagMark = '<.+>' tagRE = re.compile(tagMark) lines2 = [] for line in lines: line = tagRE.sub('',line).strip() if line: lines2.append(line) return lines2
استخدمنا التابع الموروث داخل getLines، وهذا سلوك شائع عند توسيع تابع موروث،حيث ننفذ ذلك بمعالجة أولية، أو نستدعي الشيفرة الموروثة ثم نكمل باقي العمل في الصنف الجديد كما فعلنا هنا، وينفّضذ هذا في التابع __init__ الخاص بالصنف TextDocument أعلاه.
وصلنا إلى التابع الموروث getLines من خلال super()، رغم أن التابع معرَّف فعليًا في الصنف Document المجرد في الأعلى، ويرث TextDocument جميع مزايا Document، وبالتالي يحتوي على getLines أيضًا، وهكذا نرى أن بايثون وsuper تجدان التابع المناسب دومًا.
أما التابعان الآخران فهما محميان نظريًا -كما هو واضح من الشرطة السفلية قبل اسميهما-، وهما هنا لإبقاء المنطق مستقلًا، ولتسهيل توسيع هذا الصنف في المستقبل إلى مستند XHTML أو XML مثلًا، فتدرب على بناء أحدهما.
من الصعب أن نحذف جميع وسوم HTML باستخدام التعابير النمطية بسبب إمكانية تشعب الوسوم، وبسبب احتمال حدوث خطأ في احتساب محرفي < و> غير المهرَّبيْن على أنهما وسوم في حين أنهما ليسا كذلك، كما أن الوسوم قد تأتي على أكثر من سطر، وغير ذلك من احتمالات الخطأ الواردة، فالأسلم هنا استخدام محلل HTML -مثل الموجود في وحدة html.parser القياسية- لتحويل ملفات HTML إلى نص عادي، لذا أعد كتابة الصنف HTMLDocument لتستخدم وحدة المحلل هنا لتوليد الأسطر النصية.
نحتاج الآن إلى تعديل شيفرة التعريف في نهاية الملف لتكون على الصورة التالية من أجل اختبار HTMLDocument:
if __name__ == "__main__":
if len(sys.argv) == 2:
doc = HTMLDocument(sys.argv[1])
doc.analyze()
print( doc.formatResults() )
else:
print( "Usage: python <document> " )
print( "Failed to analyze file" )
وإذا كنت على دراية ببعض أنواع الملفات الأخرى مثل ملفات PDF و LaTeX و RTF و Postscript وغيرها، فهل تستطيع إنشاء أصناف تحقق وفحص لها؟
إضافة واجهة رسومية
سنستخدم Tkinter الذي شرحناه باختصار في مقال البرمجة الحدَثية، ثم توسعنا فيه بتفصيل أكثر في مقال برمجة الواجهات الرسومية المشار إليه بالأعلى، أما هنا فستكون الواجهة الرسومية أكثر تعقيدًا وتستخدم مزيدًا من الودجات widgets التي يوفرها Tk، ومن العوامل التي ستعيننا على إنشاء النسخة الرسومية تجنبنا لوضع أي تعليمات طباعة في أصنافنا، ووضعنا لطباعة الخرج في شيفرة التعريف بدلًا من ذلك، وهذا سيفيدنا حين نستخدم الواجهة الرسومية، حيث سنستطيع استخدام سلسلة الخرج نفسها وعرضها في ودجت، بدلًا من طباعتها على مجرى الخرج القياسي stdout، ويُعد تغليف التطبيق في واجهة رسومية بسهولة من أهم الأسباب التي نتجنب استخدام تعليمات الطباعة في الدوال أو التوابع الخاصة بمعالجة البيانات لأجلها.
تصميم الواجهة الرسومية
إن الخطوة الأولى في بناء أي برنامج رسومي هي محاولة تصور شكله النهائي، فمثلًا سنحتاج إلى تحديد اسم ملف، لذا سنضيف متحكمًا للتعديل أو الإدخال النصي، كما سنحدد إذا كنا نريد تحليل ملف نصي أم ملف HTML، فنمثل هذا الاختيار من متعدد بمجموعة من متحكمات أزرار الانتقاء radiobuttons، ويجب أن تُجمع هذه الأزرار معًا لإظهار ارتباطها ببعضها.
أما الشرط الثاني فهو أسلوب عرض النتائج، ورغم أنه يمكن اعتماد عدة متحكمات للعناوين؛ بحيث يكون لدينا عنوان لكل عداد، إلا أننا سنستخدم متحكمًا نصيًا بسيطًا نستطيع إدخال سلاسل نصية فيه، وهو بهذا أقرب إلى خرج سطر الأوامر، مع أن هذا يرجع بالنهاية لمصمم البرنامج، لكن هذا التصميم الذي سنعتمده لن يكون الأجمل مظهرًا.
وأخيرًا نحتاج إلى وسيلة لبدء التحليل والخروج من التطبيق، وبما أننا نستخدم متحكمًا نصيًا لعرض النتائج؛ فقد يكون من الأفضل أن يكون لدينا وسيلة لإعادة ضبط الشاشة، ويمكن تمثيل جميع خيارات الأوامر بمتحكمات أزرار.
إذا رسمنا هذه الأفكار أعلاه فقد نحصل على شكل قريب مما يلي:
+-------------------------+-----------+ | FILENAME | O TEXT | | | O HTML | +-------------------------+-----------+ | | | | | | | | | | +-------------------------------------+ | | | ANALYZE RESET QUIT | | | +-------------------------------------+
يشبه هذا التصميم ثلاثة إطارات بالعرض الكامل فوق بعضها، وفي الإطار العلوي إطاران جنبًا إلى جنب، ويحتوي الإطار الأيمن العلوي على زري انتقاء مرتبين رأسيًا، أما الإطار السفلي فيحتوي على ثلاثة أزرار مرتبة أفقيًا، ونستطيع استخدام تخطيط المحزِّم pack لكل ما سبق، وبهذا نعلم الودجات التي نحتاج إليها، ومدير التخطيط المطلوب لكل إطار، ويتبقى لدينا مزية واحدة جديدة، وهي أزرار الانتقاء، وسننظر فيها لاحقًا.
لنحول ما سبق إلى شيفرة:
import tkinter as tk import document ################### CLASS DEFINITIONS ###################### class GrammarApp(Frame): def __init__(self, parent=0): super().__init__(parent) self.type = 1 # create variable with default value self.master.title('Grammar counter') self.buildUI()
استوردنا وحدتي tkinter وdocument، وجعلنا كل أسماء Tkinter مرئيةً داخل الوحدة الحالية، أما بالنسبة للوحدة الثانية فسنحتاج إلى سبق الأسماء بـ document..
كما عرَّفنا التطبيق على أنه صنف فرعي للصنف Frame، ويستدعي التابع __init__ تابع الصنف الرئيسي Frame.__init__ لضمان إعداد Tk بالطريقة الصحيحة داخليًا، ثم ننشئ سمةً تخزن قيمة نوع المستند، ونستدعي التابع buildUI الذي ينشئ جميع الودجات لنا، وسننظر الآن فيه:
def buildUI(self): # إطار الخيارات أولًا # - اسم الملف ونوعه fOpts = tk.Frame(self) fFile = tk.Frame(fOpts) tk.Label(fFile, text="Filename: ").pack(side="left") self.eName = tk.Entry(fFile) self.eName.insert(tk.INSERT,"test.htm") self.eName.pack(side='left', padx=5) fFile.pack(side='left', padx=3) # والآن أزرار الانتقاء fType = Frame(fFile, borderwidth=1, relief=tk.SUNKEN) self.rText = Radiobutton(fType, text="TEXT", variable = self.type, value=1, command=self.doText) self.rText.pack(side=tk.TOP, anchor=tk.W) self.rHTML = Radiobutton(fType, text="HTML", variable=self.type, value=2, command=self.doHTML) self.rHTML.pack(side=tk.TOP, anchor=tk.W) # هو الخيار الافتراضي TEXT اجعل self.rText.select() fType.pack(side=tk.RIGHT, padx=3) fOpts.pack(side=tk.TOP, fill=tk.X) # يحتوي الصندوق النصي على الخرج، فأضف له حشوة # (self أي) لإضافة حد إليه، واجعل الأب هو إطار التطبيق self.txtBox = Text(self, width=60, height=10) self.txtBox.pack(side=tk.TOP, padx=3, pady=3) # ضع بعض أزرار التحكم fButts = Frame(self) self.bAnal = Button(fButts, text="Analyze", command=self.doAnalyze) self.bAnal.pack(side=tk.LEFT, anchor=tk.W, padx=50, pady=2) self.bReset = Button(fButts, text="Reset", command=self.doReset) self.bReset.pack(side=tk.LEFT, padx=10) self.bQuit = Button(fButts, text="Quit", command=self.quit) self.bQuit.pack(side=tk.RIGHT, anchor=tk.E, padx=50, pady=2) fButts.pack(side=tk.BOTTOM, fill=tk.X) self.pack()
لن نشرح كل هذا إذ يجب أن يكون مفهومًا لمن قرأ الفصل التاسع عشر: برمجة الواجهات الرسومية، أما لمن أراد الاستزادة فعليه فيمكنه الرجوع إلى مراجع وتوثيقات أخرى خارجية، والقاعدة العامة هي أن ننشئ ودجات من أصنافها الموافقة لها، ونوفر الخيارات مثل معاملات ذوات أسماء، ثم نحزّم الودجت في إطارها الحاوي لها.
كذلك قد ترغب في تجربة إضافة زر "browse" الذي يفتح صندوق FileOpen الحواري، ويمكن تنفيذ ذلك باستخدام صناديق Tk الافتراضية، انظر الدليل أعلاه لمزيد من الشرح.
أما النقاط الأخرى التي يجب ملاحظتها فهي استخدام ودجات Frame الفرعية لتحوي أزرار الانتقاء Radiobuttons وأزرار الأوامر Button، كما تأخذ أزرار الانتقاء زوجًا من الخيارات هما variable وvalue، ويربط الأول أزرار الانتقاء معًا، من خلال تحديد نفس المتغير الخارجي self.type، ويعطي الخيار الثاني قيمةً فريدةً لكل زر منها.
لاحظ أيضًا الخيارات command=xxx الممررة إلى المتحكمات، فهي توابع سيستدعيها Tk عند الضغط على الزر.
الشيفرة الممثلة لما سبق هي كما يلي:
################# EVENT HANDLING METHODS #################### # استعد الإعدادات الافتراضية def doReset(self): self.txtBox.delete(1.0, tk.END) self.rText.select() # اضبط قيم الانتقاء def doText(self): self.type = 1 def doHTML(self): self.type = 2
اقتباستأتي أزرار الانتقاء مع القليل من سحر Tk الذي يسمح لها أن تُربط مع أنواع خاصة من متغيرات بايثون، بحيث إذا ضُغط على الزر فستُسند قيمته تلقائيًا إلى المتغير المرتبط به، ولم نستخدم هذه التقنية لأنها خاصة بصندوق Tk وحده، واستخدمنا الآلية المعتادة لمعالجة الأحداث بدلًا منها ليكون الشرح واضحًا، وليكون صريحًا في الدالة.
للاطلاع على المزيد حول الخيار المؤتمت فانظر
IntVarوStringVarفي توثيق Tkinter، حيث يمكن استخدام هذه الأنواع الخاصة من المتغيرات مع العديد من ودجات ضبط القيم في Tk، لكنها خارج نطاق شرحنا.
يتبقى لدينا آخر معالج أحداث، وهو الذي ينفذ التحليل:
# أنشئ نوع المستند المناسب وحلله. # ثم اعرض النتائج في الاستمارة def doAnalyze(self): filename = self.eName.get() if filename == "": self.txtBox.insert(tk.END,"\nNo filename provided!\n") return if self.type == 1: doc = document.TextDocument(filename) else: doc = document.HTMLDocument(filename) self.txtBox.insert(tk.END, "\nAnalyzing...\n") doc.analyze() resultStr = doc.formatResults() self.txtBox.insert(tk.END, resultStr)
تتحقق هذه الشيفرة من وجود اسم ملف صالح قبل إنشاء كائن المستند، رغم أنها قد لا تتحقق من صلاحية الاسم.
تستخدم قيمة self.type المحددة بواسطة أزرار الانتقاء لتحديد نوع المستند الذي يجب إنشاؤه.
تلحَق النتائج بالحقل النصي -الوسيط tk.END في insert- مما يعني أننا نستطيع التحليل عدة مرات وموازنة النتائج، وهذه ميزة الصندوق النصي هنا عن أسلوب خرج العناوين المتعددة multiple label output.
وكل ما نحتاج إليه الآن هو إنشاء نسخة لصنف التطبيق GrammarApp وتشغيل حلقة الحدث:
if __name__ == "__main__": myApp = GrammarApp() myApp.mainloop()
لننظر الآن إلى النتيجة النهائية في نظام ويندوز، والتي تعرض نتائج تحليل ملف HTML:
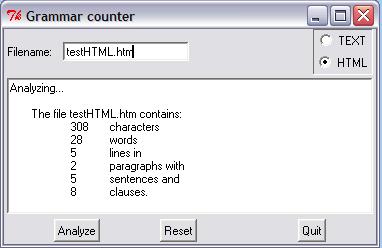
من الممكن جعل معالجة ملف HTML أكثر تعقيدًا إذا أردنا، حيث نتحقق أكثر من الأخطاء -مثل التحقق من عدم وجود الملف-، وننشئ وحدات لأنواع المستندات الجديدة، ونستبدل عدة عناوين مجموعة في إطار واحد بالصندوق النصي، كما يمكن استخدام قائمة منسدلة لأنواع المستندات، خاصةً إذا أضفنا أنواعًا جديدة.
خاتمة
ينظر المقال التالي في الجانب العملي من بايثون في مشاريع حقيقية، وستكون الأمثلة أطول ولن نكثر من التفاصيل في الشرح، إذ يجب أن تكون الآن قادرًا على متابعة الأمثلة بسهولة.
ترجمة -بتصرف- للفصل الثاني والعشرين: A Case Study من كتاب Learn To Program لصاحبه Alan Gauld.
اقرأ أيضًا
- المقال التالي: التعامل مع قواعد البيانات
- المقال السابق: مقدمة إلى البرمجة الوظيفية Functional Programming
- تعلم البرمجة
- بداية رحلة تعلم البرمجة










أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.