

اتجه تطوير لغات الحاسوب سابقًا في اتجاهٍ من اتجاهين، إذ سلكت كوبول COBOL سلوكًا ركز على استخدام هياكل البيانات بعيدًا عن العمليات الحسابية والخوارزميات، بينما سلكت لغات مثل فورتران FORTRAN وألغول Algol سلوكًا معاكسًا. أراد العلماء وقتها إجراء العمليات الحسابية باستخدام بيانات غير مُهيكلة نسبيًا، إلا أنه سرعان ما لاحظ الجميع أن استخدام المصفوفات لا غنى عنه؛ بينما أراد المستخدمون الاعتياديون طريقةً لإجراء العمليات الحسابية البسيطة فقط، إلا أن طريقة هيكلة البيانات كانت عائقًا أمام تحقيق ذلك.
أثر كلا السلوكين في تصميم لغة سي، إذ أنها تحتوي تحكمًا هيكليًا لتدفق البرنامج مناسب للغة من هذا العمر، كما أنها جعلت من مفهوم هياكل البيانات شائعًا. ركزنا على جانب الخوارزميات من اللغة حتى اللحظة، ولم نولي الكثير من الانتباه بخصوص تخزين البيانات، ومع أننا تطرقنا إلى المصفوفات التي تُعدّ هيكل بيانات إلا أنها شائعة الاستخدام وبسيطة ولا تستحق فصلًا مخصصًا لها، واكتفينا إلى الآن بالنظر إلى اللغة انطلاقًا من بينة هيكلية شبيهة بلغة فورتران.
كان استخدام كلٍ من البيانات والخوارزميات هو التوجه الأكثر رواجًا في أواخر ثمانينيات وبداية تسعينيات القرن الماضي، وفق ما يُدعى بالبرمجة كائنية التوجه Object-Oriented Programming. لا يوجد أي دعم لهذه الطريقة في لغة سي، إلا أن لغة C++ قدمت دعمًا لها (وهي لغةٌ مبنيةٌ على لغة سي)، ولكن هذا النقاش خارج موضوعنا حاليًا.
تأخذ البيانات الانتباه الأكبر لمعظم مشاكل الحوسبة المتقدمة وليس الخوارزميات، فستكون مهمتك بسيطةً ببرمجة البرنامج إن استطعت تصميم هياكل بيانات صحيحة ومناسبة، إلا أنك تحتاج إلى دعمٍ من اللغة في هذه الحالة، فمهمتك ستصبح أقل سهولة ومعرضةً أكثر للأخطاء إن لم يكن هناك أي دعم لأنواع هياكل البيانات المختلفة عن المصفوفات. تقع هذه المهمة على كاهل لغة البرمجة، فليس كافيًا أن تسمح لك اللغة بفعل ما تريد، بل يجب أن تساعدك في فعل ما تريد.
تقدم لك لغة سي سعيًا منها بتقديم هياكل بيانات مناسبة كلًا من المصفوفات Arrays والهياكل Structures والاتحادات Unions، وقد برهنت على أنها كافيةٌ لمعظم المستخدمين الاعتياديين وبالتالي لم يُضِف المعيار أي جديد بشأنها.
الهياكل Structures
تسمح لك المصفوفات بتخزين مجموعة من الكائنات المتماثلة تحت اسم معين، وهذا مفيدٌ لعدد من المهام، ولكنه ليس مرن التعامل، إذ تحتوي معظم كائنات البيانات ذات التطبيقات الواقعية على هيكل معيّن معقد لا يمكن استخدامه مع طريقة تخزين المصفوفة للبيانات.
لنوضح ما سبق بالمثال التالي: لنفرض أننا نريد تمثيل سلسلةٍ نصية ذات خصائص معينة، بجانب محتواها. هناك نوع الخط وحجمه، وهما سمتان لا تؤثران في محتوى السلسلة، لكنهما تحددان الطريقة التي تُعرض فيها السلسلة على الشاشة سواءٌ كان النص مكتوبًا بخط غامق أو مائل، والأمر ذاته ينطبق على حجم الخط. كيف نستطيع تمثيل السلسلة النصية بكائن واحد ضمن مصفوفة إذا كان يحتوي على ثلاث سمات مختلفة؟
يمكننا تحقيق ذلك في لغة سي C بسهولة، حاول أولًا تمثيل السمات الثلاث باستخدام الأنواع الأساسية، فعلى فرض أنه يمكننا تخزين كل محرف باستخدام النوع char، يمكننا الإشارة إلى نوع الخط المستخدم باستخدام النوع short (نستخدم "1" للإشارة إلى الخط الاعتيادي و"2" للخط المائل و"3" للخط الغامق، وهكذا)، كما يمكننا تخزين حجم الخط باستخدام النوع short، وتُعد جميع الفرضيات السابقة معقولةً عمليًا، إذ تدعم معظم الأنظمة عددًا قليلًا من الخطوط مهما كانت هذه الأنظمة معقدة، ويتراوح حجم الخط بين 6 ومرتبة المئات القليلة، فأي خط أصغر من 6 هو صعب القراءة، والخط الأكبر من 50 هو خط أكبر من خطوط عناوين الجرائد. إذًا، لدينا الآن محرف وعددين صغيرين وتُعامل هذه البيانات معاملة كائن واحد، إليك كيف نصرّح عن ذلك في لغة سي:
struct wp_char{ char wp_cval; short wp_font; short wp_psize; };
يصرح ما سبق عن نوع جديد من الكائنات يمكنك استخدامه ضمن البرنامج، ويعتمد الأمر بصورةٍ رئيسية على ذكر الكلمة المفتاحية struct، المتبوعة بمعرّف identifier اختياري هو الوسم wp_char في هذه الحالة، ويسمح لنا هذا الوسم بتسمية النوع للإشارة إليه فيما بعد. يمكننا أيضًا استخدام الوسم بالطريقة التالية بعد التصريح عنه:
struct wp_char x, y;
يُعرّف ما سبق متغيرين باسم x و y، بالطريقة ذاتها للتعريف التالي:
int x, y;
لكن المتغيرات في المثال الأول من نوع struct wp_char عوضًا عن int في المثال الثاني، ويمثّل الوسم اسمًا للنوع الذي صرحنا عنه سابقًا.
نذّكر هنا أنه من الممكن استخدام اسم وسم الهيكل مثل أي معرّف اعتيادي بصورةٍ آمنة، ويدل الاسم على معنًى مختلف عندما يُسبق بالكلمة المفتاحية struct فقط، ومن الشائع أن يُعرّف كائن مُهيكل باسم مماثل لوسم الهيكل الخاص به.
struct wp_char wp_char;
يُعرّف السطر السابق متغيرًا باسم wp_char من النوع struct wp_char، ويمكننا فعل ذلك لأن لوسوم الهياكل "فضاء اسماء name space" خاصة بها ولا تتعارض مع الأسماء الأخرى، وسنتكلم أكثر عن الوسوم عندما نناقش "الأنواع غير المكتملة incomplete types".
يمكن التعريف عن المتغيرات على الفور عقب التصريح عن هيكل ما:
struct wp_char{ char wp_cval; short wp_font; short wp_psize; }v1; struct wp_char v2;
لدينا في هذه الحالة متغيرين، أحدهما باسم v1 والآخر باسم v2، وإذا استخدمنا الطريقة السابقة في التعريف عن v1، يصبح الوسم غير ضروري ويُتخلّى عنه غالبًا إلا في حال احتجنا إلى الوسم لاستخدامه مع عامل sizeof والتحويل بين الأنواع casts.
يُعد المتغيران السابقان كائنات مُهيكلة، ويحتوي كل منهما على ثلاثة أعضاء members مستقلين عن بعضهم باسم wp_cval و wp_font و wp_psize، ونستخدم عامل النقطة . للوصول إلى كلّ من الأعضاء السابقة على النحو التالي:
v1.wp_cval = 'x'; v1.wp_font = 1; v1.wp_psize = 10; v2 = v1;
تُضبط أعضاء المتغير v1 في المثال السابق إلى قيمها المناسبة، ومن ثم تُنسخ قيم v1 إلى v2 باستخدام عملية الإسناد.
في الحقيقة، العملية الوحيدة المسموحة في الهياكل بكاملها هي الإسناد؛ إذ يمكن إسناد الهياكل إلى بعضها بعضًا أو تمريرها مثل وسطاء للدوال أو قيمةٍ تُعيدها دالةٌ ما، إلا أن نسخ الهياكل عمليةٌ غير فعالة وتتفاداها معظم البرامج عن طريق التلاعب بالمؤشرات التي تشير إلى الهياكل عوضًا عن ذلك، إذ من الأسرع عمومًا نسخ المؤشرات عوضًا عن الهياكل. تسمح اللغة بمقارنة الهياكل بحثًا عن المساواة فيما بينها، وهي سهوة مفاجئة ولا يوجد سبب مقنع لسماحها بذلك كما سنذكر قريبًا.
إليك مثالًا يستخدم مصفوفةً من الهياكل، وهو الهيكل ذاته الذي تكلمنا عنه سابقًا، إذ تُستخدم دالةٌ لقراءة المحارف من دخل البرنامج القياسي وتُعيد هيكلًا مهيّأً بقيمٍ مناسبة مقابله، ومن ثم تُرتّب الهياكل بحسب قيمة كل محرف وتُطبع وذلك عندما يُقرأ محرف سطر جديد، أو عندما تمتلئ المصفوفة.
#include <stdio.h> #include <stdlib.h> #define ARSIZE 10 struct wp_char{ char wp_cval; short wp_font; short wp_psize; }ar[ARSIZE]; /* نوع دخل الدالة الذي كان من الممكن التصريح عنه سابقًا، وتعيد الدالة هيكلًا ولا تأخذ أي وسطاء */ struct wp_char infun(void); main(){ int icount, lo_indx, hi_indx; for(icount = 0; icount < ARSIZE; icount++){ ar[icount] = infun(); if(ar[icount].wp_cval == '\n'){ /* * غادر الحلقة التكرارية * دون زيادة قيمة icount * مع تجاهل \n */ break; } } /* نجري الآن عملية الترتيب */ for(lo_indx = 0; lo_indx <= icount-2; lo_indx++) for(hi_indx = lo_indx+1; hi_indx <= icount-1; hi_indx++){ if(ar[lo_indx].wp_cval > ar[hi_indx].wp_cval){ /* * التبديل بين الهيكلين */ struct wp_char wp_tmp = ar[lo_indx]; ar[lo_indx] = ar[hi_indx]; ar[hi_indx] = wp_tmp; } } /* طباعة القيم */ for(lo_indx = 0; lo_indx < icount; lo_indx++){ printf("%c %d %d\n", ar[lo_indx].wp_cval, ar[lo_indx].wp_font, ar[lo_indx].wp_psize); } exit(EXIT_SUCCESS); } struct wp_char infun(void){ struct wp_char wp_char; wp_char.wp_cval = getchar(); wp_char.wp_font = 2; wp_char.wp_psize = 10; return(wp_char); }
مثال 1
من الطبيعي أن نلجأ إلى التصريح عن مصفوفات من الهياكل حالما نستطيع ونتعلم كيفية التصريح عنها، وأن نستخدم هذه الهياكل عناصرًا لهياكل أخرى وما إلى ذلك، والقيد الوحيد هنا هو أنه لا يمكن للهيكل أن يحتوي مثالًا لنفسه على أنه عضو داخله (يصبح حينها حجمها موضع جدل مثير للفلاسفة، ولكنه غير مفيد لأي مبرمج سي C).
المؤشرات والهياكل
ذكرنا سابقًا أنه من الشائع استخدام المؤشرات في الهياكل بدلًا من استخدام الهياكل مباشرةً، لنتعلم كيفية تحقيق ذلك إذَا. يُعد التصريح عن المؤشرات سهلًا، ونعتقد أنك أتقنته:
struct wp_char *wp_p;
يمنحنا التصريح السابق مؤشرًا مباشرةً، ولكن كيف يمكننا الوصول إلى أعضاء الهيكل؟ تتمثل إحدى الطرق باستخدام المؤشر الذي يشير إلى الهيكل، ثم اختيار العضو على النحو التالي:
/* نحصل على الهيكل ومن ثم نحدد العضو*/ (*wp_p).wp_cval
نستخدم الأقواس لأن أسبقية عامل النقطة . أعلى من *، إلا أن الطريقة السابقة غير سهلة التعامل وقدمت لغة سي نتيجة لذلك عاملًا جديدًا لجعل التعليمة أنيقة ويُعرف باسم العامل "المُشير إلى pointing-to"، إليك مثالًا عن استخدامه:
// العضو الذي يشير إليه المؤشر wp_p في الهيكل wp_cval wp_p->wp_cval = 'x';
ومع أن مظهره غير مثالي، إلا أنه مفيد جدًا في حال احتواء هيكل ما على المؤشرات، مثل القوائم المترابطة Linked list، إذ أن استخدام الطريقة السابقة أسهل بكثير إن أردت تتبع مرحلة أو مرحلتين من الروابط ضمن قائمة مترابطة. إذا لم تصادف القوائم المترابطة بعد، فلا تقلق، إذ سنتطرق إليها لاحقًا.
إذا كان الكائن على يسار العامل . أو <- نوعًا مؤهّلًا qualified type (باستخدام الكلمة المفتاحية const أو volatile)، فستكون النتيجة أيضًا معرفةً حسب هذه المؤهلات qualifiers. إليك مثالًا عن ذلك باستخدام المؤشرات؛ فعندما يشير المؤشر إلى نوع مؤهل، تكون النتيجة من نوع مؤهل أيضًا.
#include <stdio.h> #include <stdlib.h> struct somestruct{ int i; }; main(){ struct somestruct *ssp, s_item; const struct somestruct *cssp; s_item.i = 1; /* مسموح */ ssp = &s_item; ssp->i += 2; /* مسموح */ cssp = &s_item; cssp->i = 0; /*يشير إلى كائن ثابت cssp غير مسموح لأن المؤشر */ exit(EXIT_SUCCESS); }
يبدو أن بعض مبرمجي المصرّفات نسوا هذا المتطلب، إذ استخدمنا مصرفًا لتجربة المثال السابق ولم يحذرنا بخصوص الإسناد الأخير الذي خرق القيد.
إليك المثال 1 مكتوبًا باستخدام المؤشرات، وبتغيير دالة الدخل infun بحيث تقبل مؤشرًا يشير إلى هيكل بدلًا من إعادة مؤشر، وهذا ما ستراه على الأغلب عندما تنظر إلى بعض البرامج العملية.
نتخلى عن نسخ الهياكل في البرامج إن أردنا زيادة فاعلية تنفيذها ونستخدم بدلًا من ذلك مصفوفات تحتوي على مؤشرات؛ إذ تُستخدم هذه المؤشرات للحصول على البيانات المخزنة، إلا أن هذه الطريقة ستزيد من تعقيد الأمور، ولا تستحق العناء في التطبيقات البسيطة.
#include <stdio.h> #include <stdlib.h> #define ARSIZE 10 struct wp_char{ char wp_cval; short wp_font; short wp_psize; }ar[ARSIZE]; void infun(struct wp_char *); main(){ struct wp_char wp_tmp, *lo_indx, *hi_indx, *in_p; for(in_p = ar; in_p < &ar[ARSIZE]; in_p++){ infun(in_p); if(in_p->wp_cval == '\n'){ /* * غادر الحلقة التكرارية * دون زيادة قيمة in_p * مع تجاهل \n */ break; } } /* * نبدأ بترتيب القيم * علينا الحرص هنا وتجنب حالة طفحان * لذا نتفقد دائمًا وجود قيمتين لترتيبهما */ if(in_p-ar > 1) for(lo_indx = ar; lo_indx <= in_p-2; lo_indx++){ for(hi_indx = lo_indx+1; hi_indx <= in_p-1; hi_indx++){ if(lo_indx->wp_cval > hi_indx->wp_cval){ /* * التبديل بين الهيكلين */ struct wp_char wp_tmp = *lo_indx; *lo_indx = *hi_indx; *hi_indx = wp_tmp; } } } /* طباعة القيم */ for(lo_indx = ar; lo_indx < in_p; lo_indx++){ printf("%c %d %d\n", lo_indx->wp_cval, lo_indx->wp_font, lo_indx->wp_psize); } exit(EXIT_SUCCESS); } void infun( struct wp_char *inp){ inp->wp_cval = getchar(); inp->wp_font = 2; inp->wp_psize = 10; return; }
مثال 2
هناك مشكلةٌ أخرى يجب النظر إليها، ألا وهي كيف سيبدو الهيكل عند تخزينه في الذاكرة؟ إلا أننا لن نقلق بهذا الخصوص كثيرًا في الوقت الحالي، ولكن من المفيد أن تستخدم في بعض الأحيان هياكل لغة سي C مكتوبة بواسطة برامج أخرى. تُحجز المساحة للهيكل wp_char كما هو موضح على النحو التالي:

شكل 1 مخطط تخزين الهيكل
يفترض الشكل بعض الأشياء مسبقًا: يأخذ المتغير من نوع char بايتًا واحدًا من الذاكرة، بينما يأخذ short 2 بايت من الذاكرة، وأن لجميع المتغيرات من نوع short عنوانًا زوجيًا على هذه المعمارية، ونتيجةً لما سبق يبقى عضو واحد بحجم 1 بايت ضمن الهيكل دون تسمية مُدخل من المصرف وذلك لأغراض تتعلق بمعمارية الذاكرة. القيود السابقة شائعة الوجود وتتسبب غالبًا بما يسمى هياكل ذات "ثقوب holes".
تضمن لغة سي المعيارية بعض الأمور بخصوص تنسيق الهياكل والاتحادات:
- تُحجز الذاكرة لكلٍ من أعضاء الهياكل بحسب الترتيب التي ظهرت بها هذه الأعضاء ضمن التصريح عن الهيكل وبترتيبٍ تصاعدي للعناوين.
- لا يجب أن يكون هناك أي حشو padding في الذاكرة أمام العضو الأول.
-
يماثل عنوان الهيكل عنوان العضو الأول له، وذلك بفرض استخدام تحويل الأنواع casting المناسب، وبالنظر إلى التصريح السابق للهيكل
wp_charفإن التالي محقق:(char *)item == &item.wp_cval. - ليس لحقول البتات bit fields (سنذكرها لاحقًا) أي عناوين، فهي محزّمةٌ تقنيًا إلى وحدات units وتنطبق عليها القوانين السابقة.
القوائم المترابطة وهياكل أخرى
يفتح استخدام الهياكل مع المؤشرات الباب لكثيرٍ من الإمكانات. لسنا بصدد تقديم شرح مفصل ومعقد عن هياكل البيانات المترابطة هنا، ولكننا سنشرح مثالين شائعين جدًا من هذه الطبيعة، ألا وهما القوائم المترابطة Linked lists والأشجار Trees، ويجمع بين الهيكلين السابقين استخدام المؤشرات بداخلهما تشير إلى هياكل أخرى، وتكون الهياكل الأخرى عادةً من النوع ذاته. يوضح الشكل 2 طبيعة القائمة المترابطة.
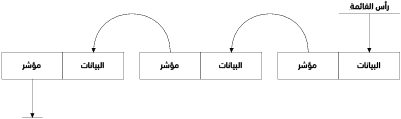
شكل 2 قائمة مترابطة باستخدام المؤشرات
نحتاج للحصول على ما سبق إلى لتصريح عنه بما يوافق التالي:
struct list_ele{ int data; /* تستطيع تسمية العضو بأي اسم*/ struct list_ele *ele_p; };
يبدو للوهلة الأولى أن الهيكل يحتوي نفسه (وهو ممنوع) ولكن يحتوي الهيكل في حقيقة الأمر مؤشرًا يشير إلى نفسه فقط، لكن لمَ يُعد التصريح عن المؤشر بالشكل السابق مسموحًا؟ يعلم المصرف بحلول وصوله إلى تلك النقطة بوجود struct list_ele، ولهذا السبب يكون التصريح مسموح، ومن الممكن أيضًا كتابة تصريح غير مكتمل للهيكل على النحو التالي قبل التصريح الكامل:
struct list_ele;
يصرح التصريح السابق عن نوع غير مكتمل incomplete type، سيسمح بالتصريح عن المؤشرات قبل التصريح الكامل، يفيد ذلك أيضًا في حال وجود حالة للإشارة إلى هياكل فيما بينها التي يجب أن تحتوي مؤشرًا لكل منها كما هو موضح في المثال.
struct s_1; /* نوع غير مكتمل */ struct s_2{ int something; struct s_1 *sp; }; struct s_1{ /* التصريح الكامل */ float something; struct s_2 *sp; };
مثال 3
يوضح المثال السابق حاجتنا للأنواع غير المكتملة، كما يوضح خاصيةً مهمةً لأسماء أعضاء الهيكل إذ يشكّل كل هيكل فضاء أسماء name space خاصٍ به، ويمكن بذلك أن تتماثل أسماء عناصر من هياكل مختلفة دون أي مشاكل.
تُستخدم الأنواع غير المكتملة فقط في حال لم نكن بحاجة استخدام حجم الهيكل، وإلا فيجب التصريح كاملًا عن الهيكل قبل استخدام حجمه، ولا يجب أن يكون هذا التصريح بداخل كتلة برمجية داخلية وإلا سيصبح تصريحًا جديدًا لهيكل مختلف.
struct x; /* نوع غير مكتمل */ /* استخدام مسموح للوسوم */ struct x *p, func(void); void f1(void){ struct x{int i;}; /* إعادة تصريح */ } /* التصريح الكامل */ struct x{ float f; }s_x; void f2(void){ /* تعليمات صالحة */ p = &s_x; *p = func(); s_x = func(); } struct x func(void){ struct x tmp; tmp.f = 0; return (tmp); }
مثال 4
يجدر الانتباه إلى أنك تحصل على هيكل من نوع غير مكتمل فقط عن طريق ذكر اسمه، وبناءً على ما سبق، تعمل الشيفرة التالية دون مشاكل:
struct abc{ struct xyz *p;}; /* struct xyz تصريح النوع غير المكتمل */ struct xyz{ struct abc *p;}; /* أصبح النوع غير المكتمل مكتملًا */
هناك خطرٌ كبير في المثال السابق، كما هو موضح هنا:
struct xyz{float x;} var1; main(){ struct abc{ struct xyz *p;} var2; /* struct xyz إعادة تصريح للهيكل */ struct xyz{ struct abc *p;} var3; }
نتيجةً لما سبق، يمكن للمتغير var2.p أن يخزن عنوان var1، وليس عنوان var3 قطعًا الذي هو من نوع مختلف. يمكن تصحيح ما سبق (بفرض أنك لم تتعمد فعله) على النحو التالي:
struct xyz{float x;} var1; main(){ struct xyz; /* نوع جديد غير مكتمل */ struct abc{ struct xyz *p;} var2; struct xyz{ struct abc *p;} var3; }
يُستكمل نوع الهيكل أو الاتحاد عند الوصول إلى قوس الإغلاق {، ويجب أن يحتوي عضوًا واحدًا على الأقل أو نحصل على سلوك غير محدد.
نستطيع الحصول على أنواع غير مكتملة عن طريق تصريح مصفوفة دون تحديد حجمها، ويصنف النوع على أنه غير مكتمل حتى يقدم تصريحًا آخرًا حجمها:
int ar[]; /* نوع غير مكتمل */ int ar[5]; /* نكمل النوع هنا */
سيعمل المثال السابق إن جربته فقط في حال كانت التصريحات خارج أي كتلة برمجية (تصريحات خارجية)، إلا أن السبب في ذلك ليس متعلقًا بموضوعنا.
بالعودة إلى مثال القوائم المترابطة، كان لدينا ثلاث عناصر مترابطة في القائمة، التي يمكن بناؤها على النحو التالي:
struct list_ele{ int data; struct list_ele *pointer; }ar[3]; main(){ ar[0].data = 5; ar[0].pointer = &ar[1]; ar[1].data = 99; ar[1].pointer = &ar[2]; ar[2].data = -7; ar[2].pointer = 0; /* ترميز نهاية المصفوفة */ return(0); }
مثال 5
يمكننا طباعة محتويات القائمة بطريقتين، إما بالمرور على المصفوفة بحسب دليلها index، أو باستخدام المؤشرات كما سنوضح في المثال التالي:
#include <stdio.h> #include <stdlib.h> struct list_ele{ int data; struct list_ele *pointer; }ar[3]; main(){ struct list_ele *lp; ar[0].data = 5; ar[0].pointer = &ar[1]; ar[1].data = 99; ar[1].pointer = &ar[2]; ar[2].data = -7; ar[2].pointer = 0; /* ترميز نهاية المصفوفة */ /* اتباع المؤشرات */ lp = ar; while(lp){ printf("contents %d\n", lp->data); lp = lp->pointer; } exit(EXIT_SUCCESS); }
مثال 6
الطريقة التي تُستخدم فيها المؤشرات في المثال السابق مثيرةٌ للاهتمام، لاحظ كيف أن المؤشر الذي يشير إلى عنصر ما يُستخدم للإشارة إلى العنصر الذي يليه حتى إيجاد المؤشر ذو القيمة 0، مما يتسبب بتوقف حلقة while التكرارية. يمكن ترتيب المؤشرات بأي طريقة وهذا ما يجعل القائمة هيكلًا مرن التعامل. إليك دالةً يمكن تضمينها مثل جزء من برنامجنا السابق بهدف ترتيب القائمة المترابطة بحسب قيمة بياناتها العددية، وذلك عن طريق إعادة ترتيب المؤشرات حتى الوصول إلى عناصر القائمة عند المرور عليها بالترتيب. من المهم أن نشير هنا إلى أن البيانات لا تُنسخ، إذ تعيد الدالة مؤشرًا إلى بداية القائمة لأن بدايتها لا تساوي إلى التعبير ar[0] بالضرورة.
struct list_ele * sortfun( struct list_ele *list ) { int exchange; struct list_ele *nextp, *thisp, dummy; /* * الخوارزمية على النحو التالي: * البحث عبر القائمة بصورةٍ متكررة * إذا وجد عنصرين خارج الترتيب * اِربطهما بصورةٍ معاكسة * توقف عند المرور بجميع عناصر القائمة * دون أي تبديل مطلوب * يحدث الخلط عند العمل على العنصر خلف العنصر الأول المثير للاهتمام * وهذا بسبب الآليات البسيطة المتعلقة بربط العناصر وإلغاء ربطها */ dummy.pointer = list; do{ exchange = 0; thisp = &dummy; while( (nextp = thisp->pointer) && nextp->pointer){ if(nextp->data < nextp->pointer->data){ /* exchange */ exchange = 1; thisp->pointer = nextp->pointer; nextp->pointer = thisp->pointer->pointer; thisp->pointer->pointer = nextp; } thisp = thisp->pointer; } }while(exchange); return(dummy.pointer); }
مثال 7
ستلاحظ استخدام تعابير مشابهة للتعبير thisp->pointer->pointer عند التعامل مع القوائم، وبالتالي يجب أن تفهم هذه التعابير، وهي بسيطة إذ يدل شكلها على الروابط المتبعة.
الأشجار
تُعد الأشجار هيكل بيانات شائع أيضًا، وهي في حقيقة الأمر قائمةٌ مترابطةٌ ذات فروع، والنوع الأكثر شيوعًا هو الشجرة الثنائية binary tree، التي تحتوي على عناصر تُدعى العقد "nodes" كما يلي:
struct tree_node{ int data; struct tree_node *left_p, *right_p; };
تعمل الأشجار في علوم الحاسوب من الأعلى إلى الأسفل (لأسباب تاريخية لن نناقشها)، إذ توجد عقدة الجذر root أعلى الشجرة وتتفرع فروع هذه الشجرة في الأسفل. تُستبدل بيانات أعضاء الهيكل الخاصة بالعقد بقيمها في الشكل التالي والتي سنستخدمها لاحقًا.
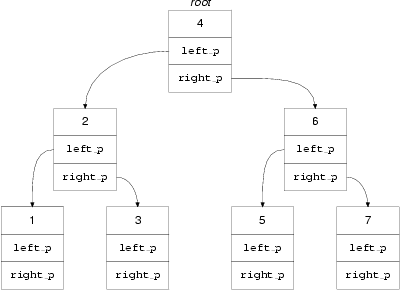
شكل 3 شجرة
لن تجذب الأشجار انتباهك إذا كان اهتمامك الرئيس هو التعامل مع المحارف والتلاعب بها، ولكنها مهمة جدًا بالنسبة لمصمّمي كل من قواعد البيانات والمصرّفات والأدوات المعقدة الأخرى.
تتميز الأشجار بميزة خاصة جدًا ألا وهي أنها مرتبة، فيمكن أن تدعم بكل سهولة خوارزميات البحث الثنائي، ومن الممكن دائمًا إضافة مزيدٍ من العقد الجديدة إلى الشجرة في الأماكن المناسبة، فالشجرة هيكل بيانات مفيدٌ ومرن.
بالنظر إلى الشكل السابق، نلاحظ أن الشجرة مبنيّةٌ بحرص حتى تكون مهمة البحث عن قيمة ما في حقول البيانات من العقد مهمةً سهلةً، وإن فرضنا أننا نريد أن نعرف فيما إذا كانت القيمة x موجودةً في الشجرة عبر البحث عنها، نتبع الخوارزمية التالية:
- نبدأ بعقدة جذر الشجرة:
-
إذا كانت الشجرة فارغة (لا تحتوي على عقد)
- إعادة القيمة "فشل البحث"
-
إذا كانت القيمة التي نبحث عنها مساويةً إلى قيمة العقدة الحالية
- إعادة القيمة "نجاح البحث"
-
إذا كانت القيمة في العقدة الحالية أكبر من القيمة التي نبحث عنها
- ابحث عن القيمة في الشجرة المُشار إليها بواسطة المؤشر الأيسر
- فيما عدا ذلك، ابحث عن القيمة في الشجرة المُشار إليها بواسطة المؤشر الأيمن
إليك الخوارزمية بلغة سي:
#include <stdio.h> #include <stdlib.h> struct tree_node{ int data; struct tree_node *left_p, *right_p; }tree[7]; /* * خوارزمية البحث ضمن الشجرة * تبحث عن القيمةفي الشجرة v * تُعيد مؤشر يشير إلى أول عقدة تحوي النتيجة * أو تُعيد القيمة 0 */ struct tree_node * t_search(struct tree_node *root, int v){ while(root){ if(root->data == v) return(root); if(root->data > v) root = root->left_p; else root = root->right_p; } /* لا يوجد أي شجرة متبقية ولم يُعثر على القيمة */ return(0); } main(){ /* بناء الشجرة يدويًا */ struct tree_node *tp, *root_p; int i; for(i = 0; i < 7; i++){ int j; j = i+1; tree[i].data = j; if(j == 2 || j == 6){ tree[i].left_p = &tree[i-1]; tree[i].right_p = &tree[i+1]; } } /* الجذر */ root_p = &tree[3]; root_p->left_p = &tree[1]; root_p->right_p = &tree[5]; /* حاول أن تبحث */ tp = t_search(root_p, 9); if(tp) printf("found at position %d\n", tp-tree); else printf("value not found\n"); exit(EXIT_SUCCESS); }
مثال 8
يعمل المثال السابق بنجاح دون أخطاء، ومن الجدير بالذكر أنه يمكننا استخدام ذلك في جعل أي قيمة مدخلة إلى الشجرة تُخزن في مكانها الصحيح باستخدام خوارزمية البحث ذاتها، أي بإضافة شيفرة برمجية إضافية تحجز مساحة لقيمة جديدة باستخدام دالة malloc عندما لا تجد الخوارزمية القيمة، وتُضاف العقدة الجديدة في مكان مؤشر الفراغ null pointer الأول. من المعقد تحقيق ما سبق، وذلك بسبب مشكلة التعامل مع مؤشر العقدة الجذر، ونلجأ في هذه الحالة إلى مؤشر يشير إلى مؤشر آخر. اقرأ المثال التالي بانتباه، إذ أنه أحد أكثر الأمثلة تعقيدًا حتى اللحظة، وإذا استطعت فهمه فهذا يعني أنك تستطيع فهم الأغلبية الساحقة من برامج سي.
#include <stdio.h> #include <stdlib.h> struct tree_node{ int data; struct tree_node *left_p, *right_p; }; /* * خوارزمية البحث ضمن شجرة * ابحث عن القيمة v ضمن الشجرة * أعد مؤشرًا إلى أول عقدة تحتوي على القيمة هذه * أعد القيمة 0 إن لم تجد نتيجة */ struct tree_node * t_search(struct tree_node *root, int v){ while(root){ printf("looking for %d, looking at %d\n", v, root->data); if(root->data == v) return(root); if(root->data > v) root = root->left_p; else root = root->right_p; } /* value not found, no tree left */ return(0); } /* * أدخل عقدة ضمن شجرة * أعد 0 عند نجاح العملية أو * أعد 1 إن كانت القيمة موجودة في الشجرة * أعد 2 إن حصل خطأ في عملية حجز الذاكرة malloc error */ int t_insert(struct tree_node **root, int v){ while(*root){ if((*root)->data == v) return(1); if((*root)->data > v) root = &((*root)->left_p); else root = &((*root)->right_p); } /* value not found, no tree left */ if((*root = (struct tree_node *) malloc(sizeof (struct tree_node))) == 0) return(2); (*root)->data = v; (*root)->left_p = 0; (*root)->right_p = 0; return(0); } main(){ /* construct tree by hand */ struct tree_node *tp, *root_p = 0; int i; /* we ingore the return value of t_insert */ t_insert(&root_p, 4); t_insert(&root_p, 2); t_insert(&root_p, 6); t_insert(&root_p, 1); t_insert(&root_p, 3); t_insert(&root_p, 5); t_insert(&root_p, 7); /* try the search */ for(i = 1; i < 9; i++){ tp = t_search(root_p, i); if(tp) printf("%d found\n", i); else printf("%d not found\n", i); } exit(EXIT_SUCCESS); }
مثال 9
تسمح لك الخوارزمية التالية بالمرور على الشجرة وزيارة جميع العُقد بالترتيب باستخدام التعاودية recursion، وهي أحد أكثر الأمثلة أناقةً، انظر إليها وحاول فهمها.
void t_walk(struct tree_node *root_p){ if(root_p == 0) return; t_walk(root_p->left_p); printf("%d\n", root_p->data); t_walk(root_p->right_p); }
مثال 10
ترجمة -وبتصرف- لقسم من الفصل Structured Data Types من كتاب The C Book.









أفضل التعليقات
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.