

يتساءل العديد من مستخدمي منصة تيكتوك عن كيف يمكن لهذه المنصة أن تقدم لنا محتوى يبدو وكأنه مصمم خصيصًا لنا، حتى قبل أن نبحث عنه؟ لا بد أن هذا السؤال قد تبادر إلى ذهن الكثيرين ممن لاحظوا الدقة اللافتة في الاقتراحات التي تظهر لهم، والتي أثبتت أنها تعتمد بقوة على الخوارزميات في جذب انتباه المستخدمين.
في مجال علوم الحاسوب، تُعرف هذه الآليات بخوارزميات أنظمة التوصية، وهي تعتمد على تحليل مستمر لسلوك المستخدمين. ويتم بناء هذه الأنظمة على جمع وتحليل كميات هائلة من البيانات المتعلقة بالتفاعلات اليومية، مثل ما يشاهده المستخدم، وما يضغط عليه، أو ما يتجاهله. وبطبيعة الحال، تكوّن هذه البيانات نموذجا شخصيًا يتيح للمنصة تيكتوك وغيرها إمكانية تقديم محتوى مخصص يواكب اهتمامات المستخدم واحتياجاته.
سنتعمق في آلية عمل هذه الخوارزميات عمليًا بهذا المقال، وسنقدم شرحًا تطبيقيًا مبسطًا يوضح كيف تعمل أنظمة التوصية في تيكتوك، مما يسهم في تسهيل فهم هذه التكنولوجيا واستكشاف تطبيقاتها المتنوعة.
سنستخدم للعمل بهذا المقال قاعدة بيانات التي تحتوي على مجموعة من بيانات الفيديوهات التي تتمثل في أسماء الفيديوهات والوسوم المرتبطة بها والعديد من البيانات المختلفة. هذه البيانات ستساعدنا في تطبيق الخوارزميات وقياس التشابه بين الفيديوهات المختلفة، مما يتيح لنا بناء نظام توصية عملي.
آلية عمل خوارزمية التوصية في منصة تيكتوك
تقوم خوارزميات التوصية التي تعتمدها منصة تيكتوك باقتراح محتوى مخصص يتحسن بمرور الوقت مع استمرار المستخدم في قضاء الوقت على المنصة، ولأجل ذلك يتم العمل على:
- جمع البيانات: وتشمل أنواع التفاعلات المتمثلة في الاعجابات والتعليقات ومدة المشاهدة وتخطي المحتوى
- تصنيف المحتوى حسب النوع: بتحديد موضوع الفيديو وجودته وملاءمته لاهتمامات المستخدمين، يتم استخدام تقنيات مثل تحليل ميزات الفيديو وتتبع أداء الفيديو
- تصنيف المحتوى حسب مبدأ التصفية التعاونية: تستخدم لتوليد التوقعات بناءً على سلوك المستخدم السابق لاعتماد اقتراحه من عدمه على أصحاب السلوكيات والاهتمامات المتشابهة
تهيئة بيئة العمل لبناء نظام توصية شبيه بنظام توصية تيكتوك
تعتمد خوارزميات تيكتوك كثيرًا على لغة البرمجة بايثون Python، خاصةً في تقنيات الذكاء الاصطناعي والتعلم الآلي لتطوير خوارزمياتها، بالإضافة إلى لغات برمجية أخرى مثل ++C و Java و Go.
لكن نظرًا لأننا سنركز في هذا المقال على خوارزميات التوصية، فسنبني نظام توصية مشابه قائم على لغة بايثون، وسنحتاج لأجل ذلك إلى كل من:
- مكتبة pandas: لقراءة ومعالجة البيانات
- إطار العمل scikit-learn: لتحويل البيانات النصية إلى شكل يمكن لنموذج التوصية التعامل معه.
- قاعدة البيانات التي سنعمل على أساسها بهذا المقال
نثبت المكتبات وأطر العمل التي نحتاجها على النحو الآتي:
pip install pandas scikit-learn
قراءة و تحليل البيانات الضخمة لفهم سلوك المستخدمين
سنطلب الآن قراءة البيانات وتحميلها من قاعدة البيانات المستخدمة وطباعة أول خمس صفوف منها باستخدام مكتبة Pandas.
import pandas as pd #DataFrames للتعامل مع البيانات وتحليلها باستخدام رابط ملف البيانات لتيكتوك بصيغة خام (raw) من GitHub # ratings_url = "https://raw.githubusercontent.com/Peter-Lankton/tik-tok-data/main/tik_tok_analytics.csv" ratings = pd.read_csv(ratings_url) عرض أول خمس صفوف من البيانات للتحقق من التحميل بنجاح # print(ratings.head())
وكما نلاحظ تتم قراءة خمس صفوف من قاعدة البيانات على النحو الآتي:
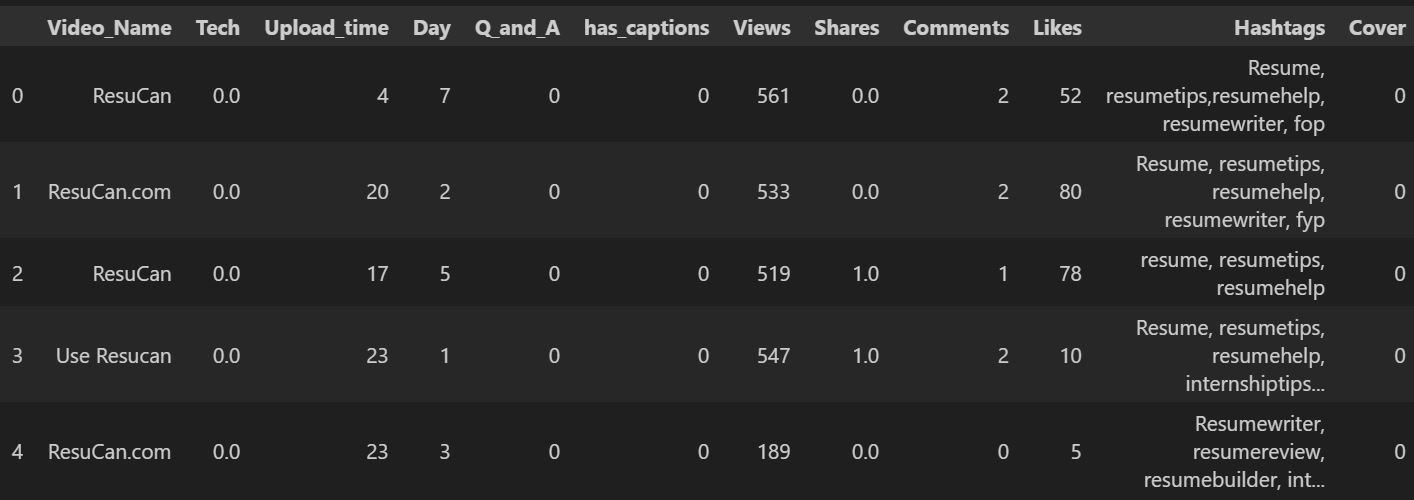
تحتوي البيانات تحتوي على معلومات حول مقاطع فيديو مختلفة مثل اسم الفيديو، التكنولوجيا المستخدمة في الفيديو، ووقت التحميل، اليوم الذي تم فيه رفع الفيديو، وأسئلة وأجوبة، ووجود الترجمة، والمشاهدات، والمشاركات، والتعليقات، والإعجابات، والوسوم؛ وسنستفيد منها لبناء نظام توصيات يقترح ما يجب على المستخدم مشاهدته بعد ذلك، بناءً على تفضيلاته الحالية للفيديو.
ستظهر لنا التعليمة التالية عدد الأعمدة و عدد الصفوف، بالاضافة الى نوع كل عمود و عدد القيم غير الفارغة:
ratings.info()
وستكون النتتيجة على النحو التالي:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 102 entries, 0 to 101 Data columns (total 17 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Video_Name 102 non-null object 1 Tech 101 non-null float64 2 Upload_time 102 non-null int64 3 Day 102 non-null int64 4 Q_and_A 102 non-null int64 5 has_captions 102 non-null int64 6 Views 102 non-null int64 7 Shares 101 non-null float64 8 Comments 102 non-null int64 9 Likes 102 non-null int64 10 Hashtags 83 non-null object 11 Cover 102 non-null int64 12 Length 102 non-null int64 13 avg_watch 102 non-null int64 14 Location 101 non-null float64 15 Humor 101 non-null float64 16 Hat 100 non-null float64 dtypes: float64(5), int64(10), object(2) memory usage: 13.7+ KB
معالجة البيانات
سنضيف بهذه المرحلة معالجةً جيدةً لنظام توصيتنا ليكون أقرب إلى نظام التوصية المستخدم على تيكتوك. ونلاحظ كيفية معالجة البيانات وإدخالها بسهولة في النموذج.
وفي أول خطوة من عملية المعالجة سنعمل على إزالة التكرارات، من خلال التحقق مما إذا كانت هناك أي أسماء مكررة للفيديوهات، فهي زائدة عن الحاجة بالنسبة للخوارزمية ويجب إزالتها.
# حساب عدد القيم المكررة في العمود ratings.duplicated(subset='Video_Name').sum() # 11 # إزالة التكرار df = ratings.drop_duplicates(subset='Video_Name') # التأكد من إزالة التكرار df.duplicated(subset='Video_Name').sum() # 0
أخذ عينات عشوائية
بعد التأكد من إزالة التكرارات، سنعمل على حل المشاكل التي قد تقع بها الذاكرة، وسنعمل على أخذ عينات عشوائية على النحو التالي:
sample_size = 91 # عدد البيانات في الصفوف # أخذ العينة df = df.sample(n=sample_size, replace=False, random_state=80) # إعادة ضبط الفهرس df = df.reset_index() # إزالة عمود 'index' الناتج من reset_index() df = df.drop('index', axis=1)
تنظيف البيانات
ستحتاج البيانات الموجودة بقاعدة البيانات المستخدمة في هذه المرحلة الى التنظيف، ويكون ذلك من خلال ازالة المسافات البيضاء من عمود Video_Name لتجنب حدوث الأخطاء، إذ لو اعتمدنا التسمية العادية دون تنظيف، فقد يتسبب هذا بالحصول على نظام أقل دقة وصحة؛ فقد يعد الفيديو ?strong math for ml مثلًا و الفيديو strong opinion متشابهين.
توضح الصورة التوضيحية التالية مثالًا عن ازالة المسافات البيضاء من أسماء الفيديوهات:

وسنتتبع هنا كل مرحلة من مراحل تنظيف قاعدة البيانات، لتشمل كل أسماء الفيديوهات كما هو موضح في الكود كالتالي:
def clean_Video_Name(Video_Name): result = str(Video_Name).lower() # تحويل النص إلى حروف صغيرة (lowercase) return(result.replace(' ','')) # إزالة المسافات من النص df['Video_Name'] = df['Video_Name'].apply(clean_Video_Name) # يتم تطبيق التنظيف على كل قيمة في العمود باستخدام الدالة "clean_Video_Name" df.head()
وستكون النتيجة على النحو:

نحوّل الآن بيانات اسم الفيديو والوسوم إلى أحرف صغيرة:
# تحويل جميع القيم في عمود "Video_Name" إلى حروف صغيرة (lowercase) df['Video_Name'] = df['Video_Name'].str.lower() # تحويل جميع القيم في عمود "Hashtags" إلى حروف صغيرة (lowercase) df['Hashtags'] = df['Hashtags'].str.lower() # عرض أول خمس صفوف من DataFrame للتحقق من التغييرات df.head()
بعد ذلك ندمج الأعمدة المستخدمة في نظام التوصية، بحيث يتم تكوين نص واحد لكل صف يتكون من جميع القيم النصية التي كانت موجودة في الأعمدة.
# حذف الأعمدة غير المطلوبة df2 = df.drop(['Tech', 'Upload_time', 'Day', 'Q_and_A', 'has_captions', 'Views', 'Shares', 'Comments', 'Likes', 'Cover', 'Length', 'avg_watch', 'Location', 'Humor', 'Hat'], axis=1) # تحقق من الأعمدة المتبقية print(df2.columns) print(df2.head()) # دمج النصوص في الأعمدة المتبقية df2['Data'] = df2[df2.columns[1:]].apply( lambda x: ' '.join(x.dropna().astype(str)), axis=1 ) # عرض النتيجة print(df2['Data'].head())
وستكون النتيجة كالتالي:
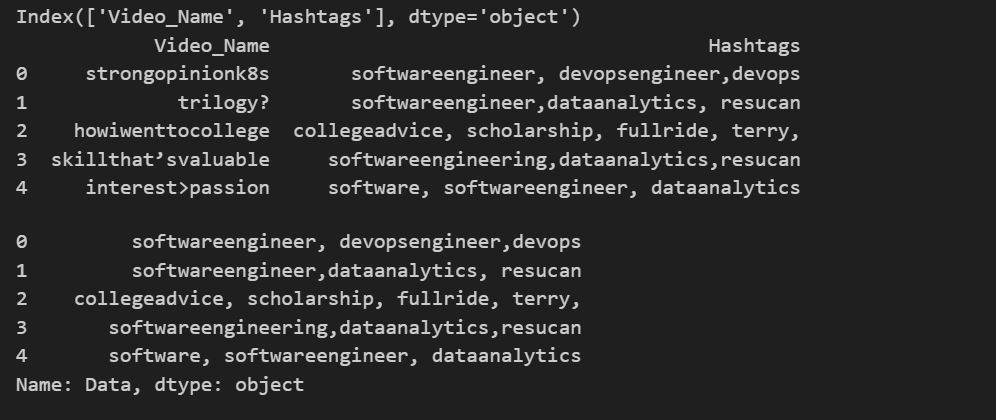
تحويل أطر البيانات Dataframe إلى تمثيلات عددية
من أجل تحويل النصوص إلى تمثيلات عددية تعبر عن تكرار الكلمات في مجموعة النصوص من أجل تسهيل فهم النصوص وتحليلها بدقة من طرف النموذج، سوف نستخدم دالة ()CountVectorizer من مكتبة Scikit-Learn كالتالي:
# استيراد CountVectorizer من مكتبة sklearn لتحويل النصوص إلى تمثيل عددي from sklearn.feature_extraction.text import CountVectorizer # إنشاء كائن CountVectorizer لتحويل النصوص إلى متجهات تمثل تكرار الكلمات vectorizer = CountVectorizer() # تطبيق fit_transform على عمود 'Data' في DataFrame df2 لتحويل النصوص إلى تمثيل عددي # fit_transform تقوم بتدريب CountVectorizer على البيانات وتحويل النصوص إلى مصفوفة من التكرارات vectorized = vectorizer.fit_transform(df2['Data'])
حساب تشابه الفيديوهات لبناء نظام التوصية
في أنظمة التوصية، الهدف الأساسي هو اقتراح محتوى يتناسب مع اهتمامات المستخدم. يعتمد ذلك على إيجاد تشابه بين المحتوى المعروض والمحتوى الذي سبق أن تفاعل معه المستخدم؛ إذ لو اعتمدنا فقط على التطابق الحرفي بين أسماء الفيديوهات أو الوسوم، فقد نفقد العديد من العلاقات المهمة بين المحتوى، فقد يحدث تشابه بالكلمات أحيانًا رغم وجود اختلاف تام بالمحتوى، بالتالي اقتراح الفيديو بناءً على الكلمات المستخدمة وحدها، لن يكون كافي، ولهذا السبب سنحول أسماء الفيديوهات والوسوم إلى متجهات عددية باستخدام دالة ()CountVectorizer، ثم نحسب درجة التشابه بين هذه المتجهات باستخدام دالة cosine_similarity من مكتبة sklearn.
بمعنى آخر، يمكننا استخدام تشابه جيب التمام لقياس مدى تشابه الفيديوهات من خلال مقارنة تمثيل البيانات. اسم الفيديو والوسم.
# استيراد cosine_similarity من مكتبة sklearn لحساب التشابه بين المتجهات باستخدام مقياس جيب التمام from sklearn.metrics.pairwise import cosine_similarity # حساب التشابه بين المتجهات التي تم إنشاؤها باستخدام CountVectorizer # سيتم حساب تشابه جيب التمام بين كل زوج من المتجهات similarities = cosine_similarity(vectorized) # طباعة مصفوفة التشابه بين الفيديوهات أو النصوص print(similarities)
نلاحظ النتيجة كالتالي :
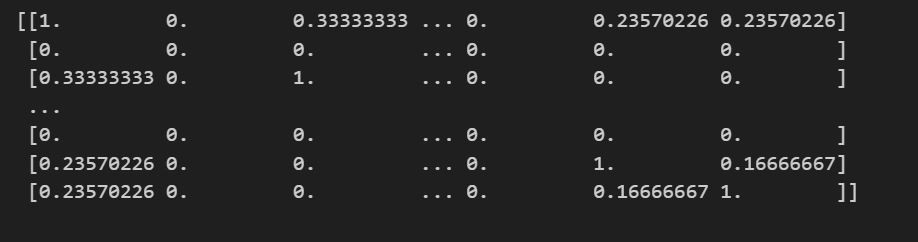
وكما هو واضح، تتراوح نتائج نسبة التشابه بين 0 و1، و يمثل كل متجه تشابه فيديو بالنسبة إلى فيديو آخر؛ لكن نظرًا لعدم ذكر عناوين الفيديوهات هنا، سنحتاج مجددًا لتعيين هذا المتجه إلى إطار البيانات السابق.
ملاحظة : متجه التشابه هو تمثيل عددي يعبّر عن مدى التشابه بين كل فيديو وآخر. يتم حسابه باستخدام دالة Cosine Similarity، بحيث تكون كل قيمة في المتجه مؤشرًا على درجة القرب بين الفيديوهات بناءً على اسم الفيديو والوسم.
# تحويل مصفوفة التشابه إلى DataFrame باستخدام pandas # نقوم بتحديد الأعمدة على أنها أسماء الفيديوهات (من العمود 'Video_Name')، والصفوف على أنها الوسوم (من العمود #'Hashtags') df = pd.DataFrame(similarities, columns=df['Video_Name'], index=df['Hashtags']).reset_index() # عرض أول 5 صفوف من DataFrame لتفقد النتيجة df.head()

في هذه المرحلة حولنا متجه التشابه إلى إطار بيانات يحتوي على أسماء الفيديوهات المدرجة رأسيًا وأفقيًا. تمثل قيم إطار البيانات تشابه جيب التمام بين الفيديوهات المختلفة.
نلاحظ أيضًا أن الخط القطري يساوي دائمًا 1.000، وهو يعرض تشابه كل فيديو مع نفسه.
عرض التوصية للمستخدم
سنستخدم إطار البيانات السابق لعرض توصيات الفيديوهات للمستخدم، بحيث يتم ارجاع أفضل 5 فيديوهات مشابهة في حال إدخال فيديو واحد. كما يلي:
# إذا كانت لديك مصفوفة التشابه 'similarities' وبيانات الفيديو 'df2' similarities_df = pd.DataFrame( similarities, index=df2['Video_Name'], columns=df2['Video_Name'] ) # دالة للحصول على التوصيات بناءً على الفيديو المدخل def get_recommendations(video_name, top_n=5): if video_name in similarities_df.columns: recommendations = ( similarities_df[video_name] .nlargest(top_n + 1) # الحصول على أفضل N+1 (بما في ذلك الفيديو نفسه) .iloc[1:] # إرجاع أسماء الفيديوهات الموصى بها ) return recommendations.index.tolist() else: return f"'{video_name}' not found in the video list." # مثال للاستخدام input_video = 'strongopinionk8s' # نستبدله بالفيديو الذي نرغب في الحصول على التوصيات بناءً عليه recommended_videos = get_recommendations(input_video, top_n=5) print("Recommended videos:") print(recommended_videos)
وهنا سنلاحظ النتيجة المتمثلة في أحسن خمس فيديوهات مقترحة:
Recommended videos: ['housefoundation', 'showinghowresucanworks', 'recommendeddatacourses', 'softwareengineering?', 'firstdataanalyticshw']
الخاتمة
يمكن القول أن خوارزميات أنظمة التوصية هي جوهر التجربة الرقمية المخصصة التي تقدمها منصات التواصل الاجتماعي؛ فمن خلال تحليل سلوك المستخدمين وتفاعلهم مع المحتوى، يمكن لهذه الخوارزميات أن تقدم توصيات دقيقة تتناسب مع اهتماماتهم الشخصية.
باستخدام تقنيات مثل التعلم الآلي وتحليل البيانات الضخمة، تستمر هذه الأنظمة في تحسين دقة التوصيات مع مرور الوقت، مما يعزز تجربة المستخدم بشكل كبير.
المصادر
- tik-tok-data
- TikTok Algorithm with Machine Learning
- Recommendation System in Python
- Understanding Social Media Recommendation Algorithms
- TikTokData








أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.