

نشرح في هذا المقال التمثيل المرئي لمجموعة بيانات أزهار آيرس Iris dataset باستخدام مكتبة Scikit-Learn ومجموعة من المكتبات المفيدة الأخرى بهدف ملاحظة الأنماط وفهم العلاقات بين الخاصيات المختلفة لمجموعة بيانات الأزهار من خلال عرضها على شكل رسومات بيانية.
أهمية التمثيل المرئي للبيانات Data Visualization
سنوفر عدة تطبيقات عملية توضح مجموعة مهمة من أنواع الرسومات البيانية plots والتي لا غنى عنها في أي عملية تحليل للبيانات أو التمثيل المرئي للبيانات والنتائج التي تسهل فهم العلاقات واكتشاف الأنماط وعرض نتائج التحليل الإحصائي وتقييم أداء نماذج تعلم الآلة، ليس فقط للمختصين في البرمجة بل للعامة، فالجميع يمكن أن يفهم الرسومات البيانية والتوضيحية التي تسرع من توصيل المعلومات.
تمثيل مرئي عام للمعلومات الإحصائية
سنكتب برنامج بايثون لإنشاء رسم بياني للحصول على المعلومات الإحصائية العامة عن مجموعة بيانات آيرس.
import pandas as pd import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") iris.describe().plot(kind = "area",fontsize=16, figsize = (15,8), table = False, colormap="Accent") plt.xlabel('Statistics',) plt.ylabel('Value') plt.title("General Statistics of Iris Dataset") plt.show()
استوردنا في الكود السابق المكتبة pandas وهي مكتبة بايثون مفيدة لمعالجة البيانات وتحليلها، ومكتبة matplotlib والتي تتخصص في رسم الرسومات البيانية بمختلف أنواعها، وحمّلنا مجموعة البيانات في الكائن iris، ثم استخدمنا الدالةdescribe() الذي تطرقنا له في الدرس السابق لعرض الإحصائيات الهامة عن مجموعة البيانات، بعدها استدعيناplot() ومررنا له إعدادات الرسم مثل نوع الرسم البياني kind=area، وحجم الخط والألوان المستخدمة وأبعاد الرسم البياني وغيرها من الإعدادت، وأخيرًا عرضنا الرسم البياني باستخدام plt.show().
عند تنفيذ الكود السابق سنحصل على الرسم البياني التالي:
رسم بياني شريطي Bar Plot
سنكتب الآن برنامج بايثون لإنشاء رسم بياني شريطي لرسم توزيع ثلاث فصائل من الأزهار وبيان تكرار ها في مجموعة البيانات.
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") ax=plt.subplots(1,1,figsize=(10,8)) sns.countplot(data=iris) plt.title("Iris Species Count") plt.show()
أنشأنا باستخدام الدالةplt.subplots() شكلًا بيانيًا يمكنه احتواء عدد من الرسومات البيانية الجزئية، ومررنا للدالة عدد الصفوف والأعمدة التي نرغب أن يتكون منها الشكل البياني وهي في حالتنا صف واحد وعمود واحد، أي سيحتوي الشكل البياني على رسم بياني جزئي واحد فقط، ثم ضبطنا أبعاد الرسم البياني، بعدها استخدمنا الدالةsns.countplot() لإنشاء رسم شريطي Bar plot وهذه الدالة جزء من مكتبة seaborn التي تستخدم في الخلفية مكتبة matplotlib ولكنها تختصر العديد من الخطوات وتبسّطها حيث يمكن أن ننشئ العديد من الرسومات البيانية المعقدة بسطر برمجي واحد دون الدخول في تفاصيل معقدة.
عند تنفيذ الكود سنحصل على الرسم البياني التالي:

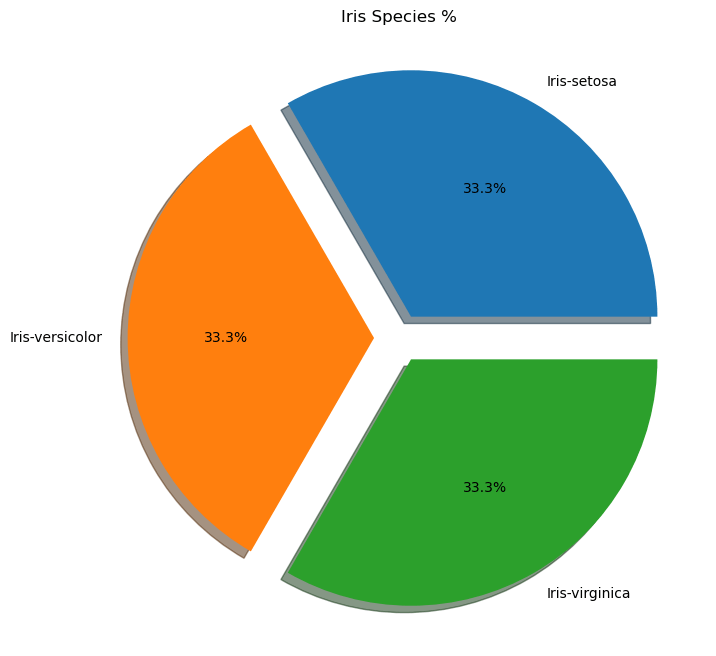
رسم بياني دائري Pie Plot
سنكتب الآن برنامج بايثون لإنشاء رسم بياني دائري يوضح توزيع فصائل الأزهار وتكرارها في مجموعة البيانات.
import pandas as pd import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") # ضبط أبعاد الرسم البياني plt.figure(figsize=(10,8)) labels = iris['Species'].value_counts().index # وسم كل شريحة # Index(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype='object', name='Species') values = iris['Species'].value_counts().values # تكرار كل فصيلة والتي يحسب منها نسبة كل شريحة # array([50, 50, 50], dtype=int64) plt.pie(x=values, labels=labels, autopct='%1.1f%%', shadow=True, explode=[0.1, 0.1, 0.1]) plt.title("Iris Species %") plt.show()
استخدمنا هنا الدالةplt.pie() لإنشاء الرسم البياني المطلوب ومررنا لها قائمة x=values تتضمن العدد في كل شريحة في الرسم البياني وقائمة أخرى labels=labels تتضمن وسم كل شريحة، وقد حصلنا على القيم ووسومها باستخدام iris['Species'].value_counts() فباستخدام التابع index نحصل على القيم الفهرسية أو المفتاحية وهي أسماء فصائل الأزهار وباستخدام التابع values نحصل على عدد كل فصيلة، بينما تحدد باقي العوامل بعض التأثيرات الجمالية مثل طريقة عرض الأرقام في الرسم البياني وإضافة ظل على الرسم، بينما القائمة الممررة للمعامل explode يعبر كل عنصر بها عن مقدار ابتعاد الشريحة عن المركز حيث تجعل القيمة 0.1 كل شريحة تبتعد عن المركز بمسافة قدرها 10% من طول نصف القطر ويمكنكم تجربة تغير هذه القيم وملاحظة التأثير الناتج.
عند تنفيذ الكود سنحصل على الرسم البياني التالي:
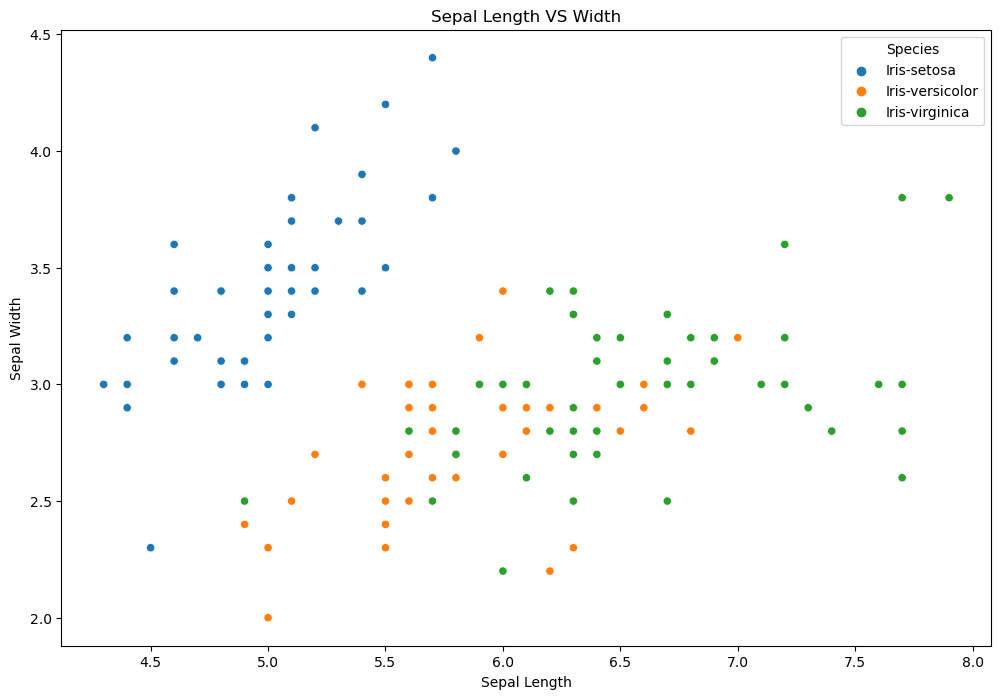
رسم بياني للنقاط المبعثرة Scatter plot لسبلات الأزهار
سنرسم في هذا التطبيق رسم نقطي مبعثر يوضح العلاقة بين أبعاد السبلات أي بين طولها وعرضها.
import matplotlib.pyplot as plt import seaborn as sns iris = pd.read_csv("iris.csv") plt.figure(figsize=(10,8)) # Plotting sns.scatterplot(data=iris, x="SepalLengthCm", y="SepalWidthCm", hue="Species") # Titles plt.xlabel("Sepal Length") plt.ylabel("Sepal Width") plt.title("Sepal Length VS Width") plt.show()
استخدمنا الدالةsns.scatterplot() لإنشاء رسم بياني للنقاط المبعثرة بين طول السبلة SepalLengthCm وعرض السبلة SepalWidthCm مع تلوين الفصائل المختلفة للأزهار وفقًا لتصنيفها باستخدام المعامل hue وضبطنا قيمته ليلون النقاط المبعثرة اعتمادًا على الوسوم Species، ثم استخدمنا مكتبة matplotlib لضبط إعدادات الرسم والعناوين.
عند تنفيذ الكود سنحصل على الرسم البياني التالي:
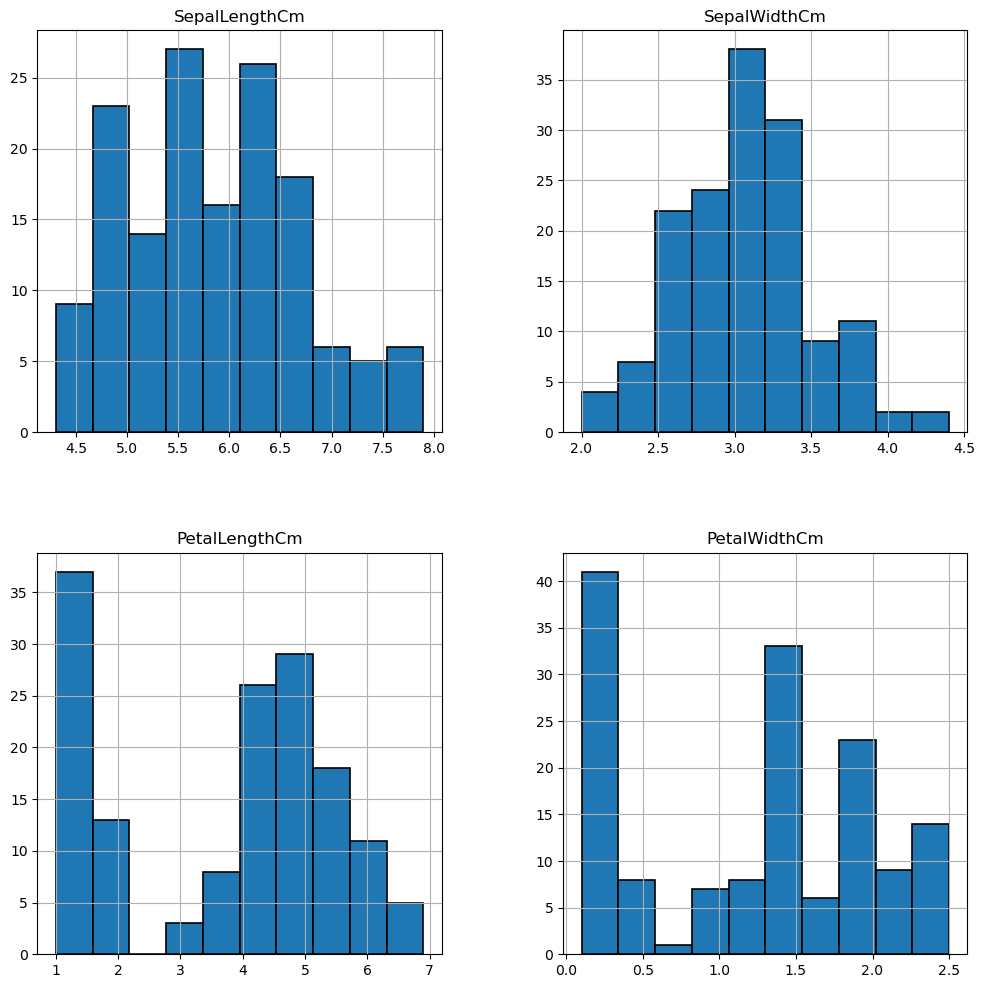
رسم بياني للمدرّج التكراري Histogram Plot
سننشئ تطبيق يعرض رسم بياني من نوع Histogram ويوضح التوزيع لأبعاد كل من البتلات Petals والسبلات Sepals.
import pandas as pd import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") # Drop id column new_data = iris.drop('Id',axis=1) new_data.hist(edgecolor='black', linewidth=1.2) # gcf() -> get current figure fig=plt.gcf() fig.set_size_inches(12,12) plt.show()
استخدمنا التابع new_data.hist لإنشاء رسم بياني للمدرّج التكراري، حيث يوضح هذا النوع تكرار القيم في كل متغير، وضبطنا لون الحواف لكل شريط في الرسم البياني ليكون باللون الأسود باستخدام edgecolor، وعرض الحواف باستخدام linewidth، واستخدامنا الدالة plt.gcf للحصول على الشكل البياني الحالي وتخزينه في الكائن fig حتى نتمكن من تعديله بحريّة. مثلًا يمكننا إعادة ضبط أبعاد الشكل البياني باستخدام الدالة fig.set_size_inches(12,12) وهي دالة تابعة للكائن fig، ثم عرضنا الرسم البياني على النحو التالي:
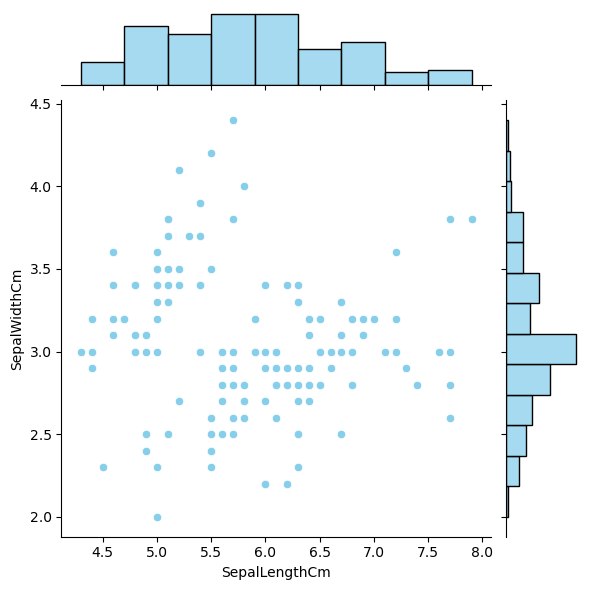
رسم بياني مشترك Join Plot
سنكتب برنامج لإنشاء رسم بياني مشترك يصف توزيع كل متغير من متغيرات الأزهار بشكل منفرد ثم بشكل مشترك في نفس الرسمة البيانية.
اقتباسملاحظة : الرسم البياني المشترك join plot هو رسم بياني يوضح علاقة متغيرين من خلال رسم توزيع كل منهما بشكل منفرد على المحور الذي يمثل ذلك المتغير، ومن ثم رسم العلاقة بينهما.
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt iris = pd.read_csv("iris.csv") fig=sns.jointplot(x='SepalLengthCm', y='SepalWidthCm', data=iris, color='skyblue') plt.show()
عند تنفيذ الكود سنحصل على الرسم البياني التالي:
ويمكننا إظهار مزيد من المعلومات باستخدام خاصية hue والتي تعطى لونًا مختلفًا لكل تصنيف.
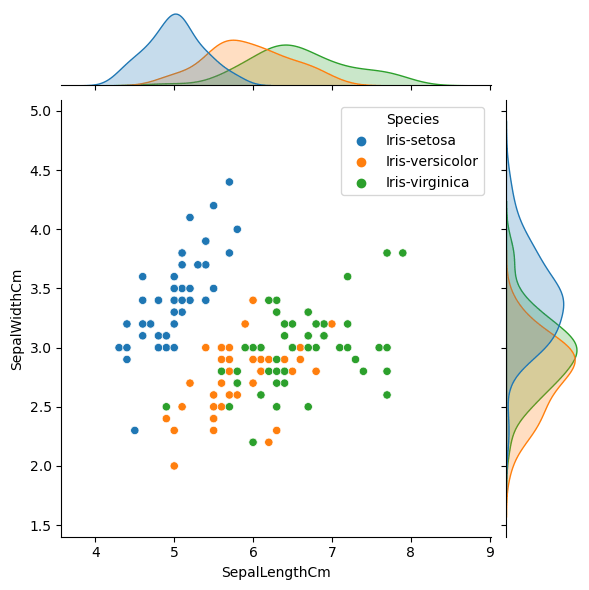
fig=sns.jointplot(x='SepalLengthCm', y='SepalWidthCm', data=iris, color='skyblue', hue="Species")
عند تنفيذ الكود سنحصل على الرسم البياني التالي:
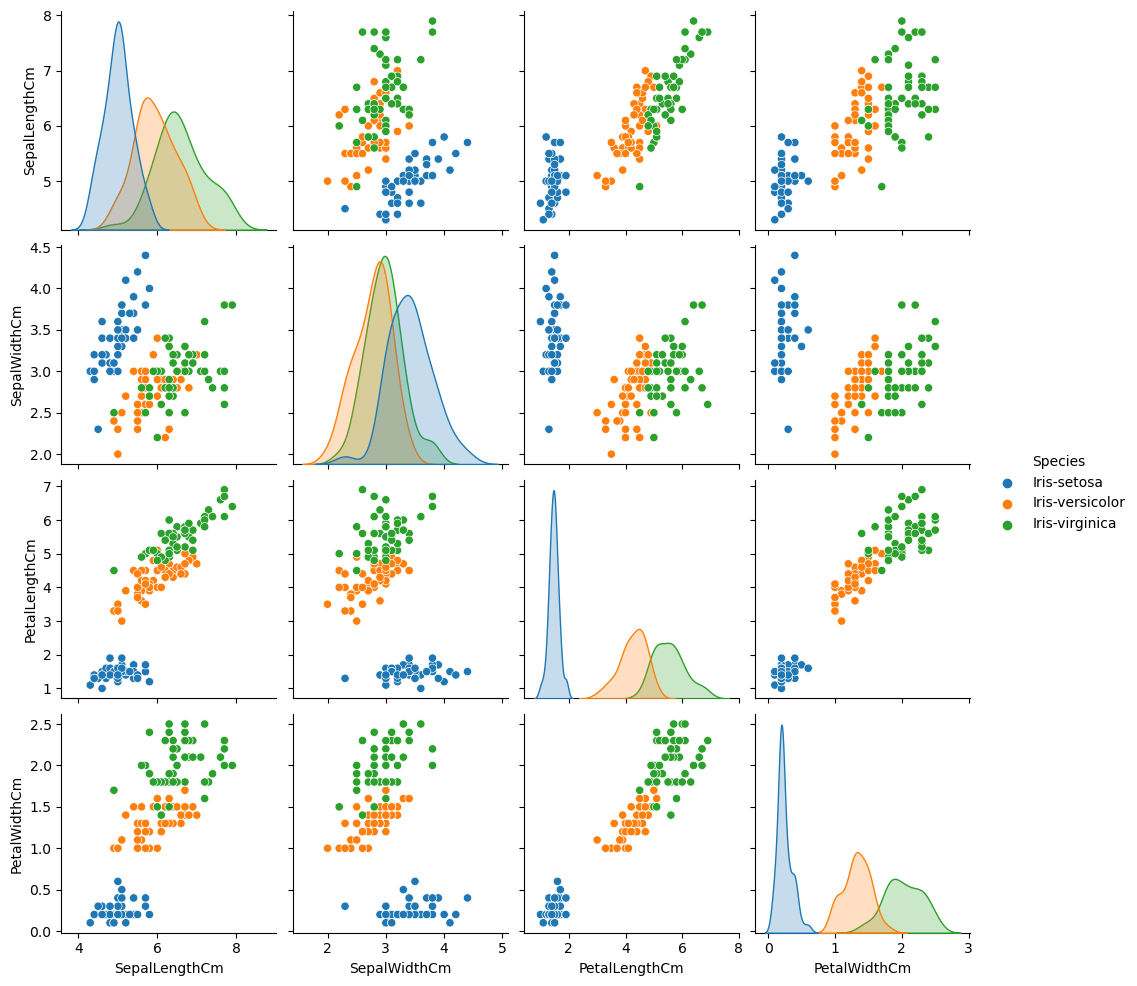
شبكة رسومات بيانية لأزواج من المتغيرات
سنكتب برنامج بايثون لإنشاء رسم بياني يوضح العلاقة بين أزواج مختلفة من المتغيرات pairplot، وتحديد أي الفصائل يسهل تميزها عن الأخرى وفصلها.
# Import necessary modules import pandas as pd import seaborn as sns iris = pd.read_csv("iris.csv") #Drop id column iris = iris.drop('Id',axis=1) sns.pairplot(iris,hue='Species')
تسمح لنا الدالةsns.pairplot() برسم العلاقة بين كل المتغيرات في مجموعة البيانات، حيث تقارن كل زوج من المتغيرات برسم بياني لتشكل مصفوفة متكاملة، يمكنك من خلالها ملاحظة العلاقة بين أي زوج من المتغيرات أو الخاصيات في مجموعة البيانات، ونمرر لهذه الدالة بشكل أساسي مجموعة البيانات iris وهذا كافٍ للحصول على نتيجة ولكن يمكننا إضافة المزيد من الألوان والأبعاد في مصفوفة الرسومات البيانية باستخدام معامل hue الذي يميز بين كل تصنيف في مجموعة البيانات بلون مميز في الرسم البياني، مما يسهّل علينا اكتشاف الأنماط المتعلقة بتصنيف محدد، حيث سنلاحظ أن أغلب النقاط التي تنتمي لتصنيف واحد أي لصنف واحد من الأزهار ستتجمع حول بعضها في بعض الأماكن في الرسم البياني.
عند تنفيذ الكود سنحصل على الرسم البياني التالي:
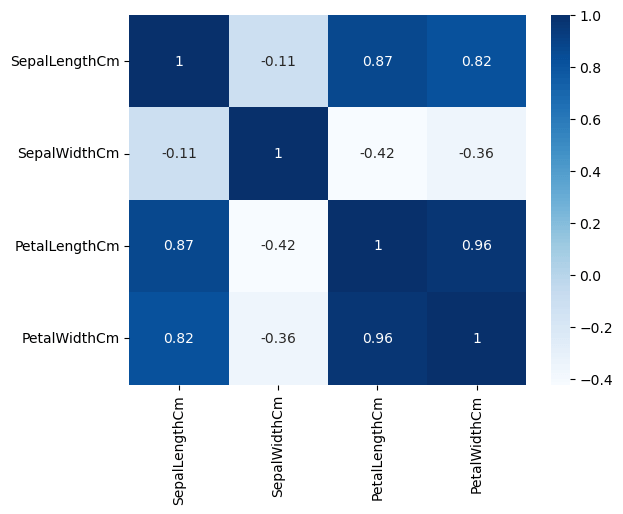
الخريطة الحرارية Heat map
سنكتب برنامج بايثون لإيجاد الترابط Correlation بين المتغيرات في مجموعة بيانات آيرس، باستخدام خريطة حرارية Heatmap.
نوجد أولاً مصفوفة الترابط Correlation Matrix
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns iris = pd.read_csv("iris.csv") corr_matrix = iris.drop(columns=["Id", "Species"]).corr() print(corr_matrix)
عند تنفيذ الكود سنحصل على الخرج التالي:
SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm SepalLengthCm 1.000000 -0.109369 0.871754 0.817954 SepalWidthCm -0.109369 1.000000 -0.420516 -0.356544 PetalLengthCm 0.871754 -0.420516 1.000000 0.962757 PetalWidthCm 0.817954 -0.356544 0.962757 1.000000
بعدها، نرسم الخريطة الحرارية Heat Map المعبرة عن مصفوفة الترابط Correlation Matrix
sns.heatmap(corr_matrix, annot=True, cmap="Blues") plt.show()
عند تنفيذ الكود سنحصل على الرسم البياني التالي:
الرسومات البيانية باللغة العربية
إذا حاولنا إنشاء رسم بياني للحصول على المعلومات الإحصائية العامة عن مجموعة بيانات آيرس، كما فعلنا في التطبيق الأول مع جعل العناوين باللغة العربية، سنلاحظ أن مكتبة Matplotlib لا توفر دعمًا جيدًا للغة العربية وتعرض الأحرف مبعثرة، وكذلك ستظهر كل كلمة معكوسة الاتجاه من اليسار إلى اليمين.
لنلاحظ نتيجة تنفيذ الكود التالي عند محاولة عرض العناوين العربية قبل استخدام المكتبات الخارجية:
iris.describe().plot(kind = "area",fontsize=15, figsize = (15,8), table = False, colormap="Accent") plt.xlabel('الاحصائيات',) plt.ylabel('القيمة') plt.title("معلومات احصائية عامة لمجموعة بيانات آيرس") plt.show()
لتصحيح هذا الخطأ سنستخدم مكتبتين خارجيتين:
- مكتبة arabic_reshaper لحل مشكلة عدم اتصال الحروف ببعضها
- مكتبة python-bidi لحل مشكلة اتجاه الحروف المعكوس والسماح بدمج مناسب لنصوص عربية مع نصوص أجنبية
نستخدم الأوامر التالية لتثبيت المكتبات:
pip install arabic-reshaper pip install python-bidi
الآن إذا حاولنا عرض العناوين العربية بعد استخدام المكتبات الخارجية كما يلي:
import pandas as pd import matplotlib.pyplot as plt from bidi.algorithm import get_display import arabic_reshaper def arabic(txt): return get_display(arabic_reshaper.reshape(txt)) iris = pd.read_csv("iris.csv") iris.describe().plot(kind = "area",fontsize=16, figsize = (15,8), table = False, colormap="Accent") plt.xlabel(arabic('الاحصائيات')) plt.ylabel(arabic('القيمة')) plt.title(arabic("معلومات احصائية عامة لمجموعة بيانات آيرس")) plt.show()

الخاتمة
تعرفنا في هذا المقال على كيفية تمثيل البيانات بشكل مرئي من خلال أمثلة عملية متنوعة بمكتبة Scikit-Learn والمكتبات المساعدة، وقد اكتفينا بعرض بعض أنواع فقط ونترك لكم استكشاف أنواع الرسومات المختلفة الأخرى والاستفادة منها في تمثيل البيانات وملاحظة الأنماط والعلاقات الموجودة بينها بسرعة وسهولة.
ترجمة -وبتصرف- للجزء الثاني من مقال Python: Machine learning - Scikit-learn Exercises, Practice, Solution
اقرأ أيضًا
- المقال السابق: أساسيات تحليل البيانات باستخدام Scikit-Learn مع Pandas
- تعرف على مكتبة Scikit learn وأهم خوارزمياتها
- الدليل الشامل إلى تحليل البيانات Data Analysis
- بناء مصنف بالاعتماد على طرق تعلم الآلة بلغة البايثون باستخدام مكتبة Scikit-Learn
- أفضل أدوات الذكاء الاصطناعي وتعلم الآلة للمطورين المبتدئين








أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.