

يعد مفهوم دوال الخسارة Loss Functions أساسيًا في تدريب نماذج تعلم الآلة، فلا توجد طريقة لتحفيز النموذج على التخمين بشكل صحيح بدون استخدام دالة خسارة، ويمكن أن نعرّف دالة الخسارة على أنها دالة رياضية تستخدم لقياس أداء النموذج في تنفيذ مهمة على مجموعة بيانات محددة، ومن خلال معرفة أداء النموذج على مجموعة بيانات محددة سنحصل على نظرة عامة تمكننا من اتخاذ قرارات خلال عملية التدريب كاستخدام نموذج أقوى أو حتى تغير دالة الخسارة المستخدمة لنوع آخر.
سنستكشف في هذه المقالة دوال الخسارة المختلفة في باي تورش PyTorch. وكيف يتيح باي تورش للمستخدمين استخدام دوال الخسارة المطورة مسبقًا، أو بناء دالة خسارة مخصصة وأمثلة عملية توضح كيفية عملها.
متطلبات المقال
يتطلب فهم هذا المقال فهمًا جيدًا للشبكات العصبية الاصطناعية المكونة من طبقات متصلة تحتوي كل طبقة على عدد من العقد التي تسمى عصبون neuron. حيث تتعلم هذه الشبكات وتخمن القيم من خلال عملية التدريب training وتُضبط فيها الأوزان weights ومقدار الانحياز biases وهي معاملات تتحكم في درجة قوة التواصل بين العقد المختلفة، وهي تحاكي في طريقة عملها الخلايا العصبية الطبيعية.
ولفهم الشبكات العصبية بشكل متعمق نحتاج لمعرفة أنواع الطبقات المختلفة وهي: طبقة المدخلات input layer والطبقة المخفية hidden layer وطبقة المخرجات output layer، ومعرفة بدوال التنشيط activation functions وخوارزميات التحسين optimization algorithms مثل الانحدار المتدرج gradient descent ودوال الخسارة وغيرها.
كما يحتاج فهم المقال للإلمام بأساسيات لغة بايثون Python والتعامل مع إطار عمل باي تورش PyTorch لفهم الأكواد المكتوبة.
ما هي دوال الخسارة Loss Functions
تستخدم دوال الخسارة بشكل أساسي لتقييم أداء نموذج تعلم الآلة في تنفيذ مهمة على مجموعة بيانات محددة، فهي تحسب الفرق بين القيمة الحقيقية الصحيحة Y وبين القيمة المتوقعة ^Y، فعندما يخمن نموذج قيم قريبة جدًا من القيم الفعلية في كل من مجموعة بيانات التدريب ومجموعة بيانات الاختبار فهذا يعني أن النموذج موثوق ويُعتمد عليه.
فدوال الخسارة loss functions توفر لنا معلومات مفيدة عن أداء النموذج، ولكن هذا ليس الدور الوحيد لدالة الخسارة، فهناك طرق أخرى أكثر موثوقية لتقييم النماذج مثل الصحة accuracy أو F-scores. في حين تبرز أهمية دوال الخسارة loss functions بشكل أساسي خلال عملية التدريب، وتساعدنا على دفع أوزان ومعاملات النموذج في الاتجاه الذي يقلل من الخسارة. وتقليل الخسارة يعني بالضرورة زيادة احتمالية التخمين الصحيح للقيم بواسطة نموذج تعلم الآلة، وهذا التحسن في التخمين ليس ممكنًا بدون استخدام دالة خسارة.
تختلف أنواع دوال الخسارة loss functions باختلاف المشكلة التي نحاول حلها، حيث تصمم كل دالة بعناية لضمان تدفق التصحيح التدريجي gradient flow المناسب خلال عملية التدريب، ولكن من المهم معرفة دورها في عملية التدريب والتحسن المستمر.
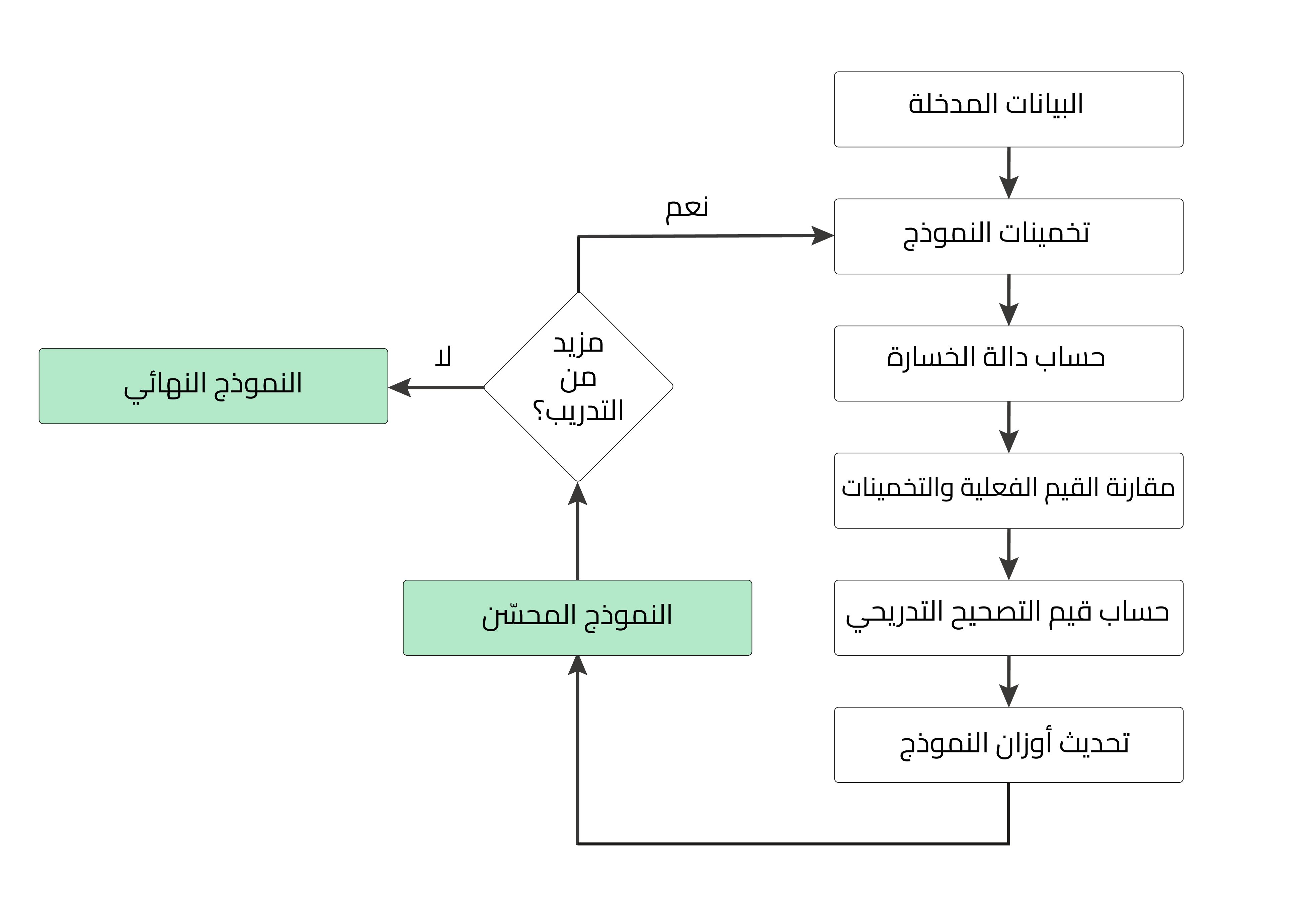
قد يصعب فهم الرموز الرياضية المعبرة عن معادلات الخسارة loss functions، حيث يتملص بعض المطورين من محاولة فهم هذه المعادلات الرياضية ويتعاملون معها على أنها صندوق أسود مجهول التفاصيل، ولكن فهم ما بداخل هذا الصندوق يعزز فهم دوال الخسارة ويساعدنا على تحديد الدالة الأفضل، سنشرح في الفقرات التالية أشهر دوال الخسارة في باي تورش، ولكن قبل هذا لنرى أين نضع هذا الصندوق، وكيف نستخدم دوال الخسارة في باي تورش؟
دوال الخسارة في باي تورش PyTorch
يأتي باي تورش PyTorch معززًا بالكثير من دوال الخسارة الأساسية سهلة الاستخدام، وتُجمع كافة دوال الخسارة في وحدة برمجية واحدة باسم nn module والتي تُعدّ الوحدة الأساسية لبناء الشبكات العصبية الاصطناعية ANNs في بايتورش.
يمكن إضافة دالة خسارة loss function للكود الخاص بنا بسهولة كتابة سطر برمجي واحد. لننظر معًا للمثال التالي لإضافة دالة خسارة متوسط مربع الخطأ Mean Squared Error loss function -أو MSE اختصارًا- في باي تورش PyTorch.
import torch.nn as nn MSE_loss_fn = nn.MSELoss()
تستخدم هذه الدالة في حساب الفرق بين قيم التخمينات والقيم الفعلية بالتنسيق التالي:
#predicted_value هو التخمين القادم من الشبكة العصبية #target القيم الفعلية الموجودة في مجموعة البيانات #loss_value الخسارة بين قيمة التخمين والقيمة الفعلية Loss_value = MSE_loss_fn(predicted_value, target)
بعد أن كونا فكرة أولية عن طريقة عمل دوال الخسارة في باي تورش PyTorch، لنتعمق أكثر في كواليس عمل عدد من هذه الدوال.
دوال الخسارة في باي تورش PyTorch
تقع معظم دوال الخسارة في باي تورش PyTorch تحت واحدة من التصنيفات الثلاثة التالية:
- دوال خسارة الانحدار regression loss functions
- دوال خسارة التصنيف classification loss functions
- دوال خسارة الترتيب ranking loss functions
تهتم دوال خسارة الانحدار regression loss functions بالقيم والمتغيرات المستمرة continuous وهي المتغيرات التي يمكنها أن تأخذ عددًا لا نهائيًا من القيم بين رقمين، وأحد الأمثلة على هذا النوع من المتغيرات هو الأسعار، فمثلًا هل يمكن إحصاء كل الأسعار الممكنة للمنازل في منطقتنا؟ بالطبع لا ولكن يمكننا حصرها في نطاق عددي.
تتعامل دوال خسارة التصنيف classification loss functions مع المتغيرات والقيم المتقطعة أو المنفصلة discrete، ومثال على هذا النوع من المهام عندما تحاول تميز كائن على أنه أحد التصنيفات المحددة ولتكن صندوق أو قلم أو زجاجة.
تتوقع دوال خسارة الترتيب ranking loss functions المسافة النسبية بين القيم، وأحد التطبيقات عليها سيكون التوثيق من خلال صورة الوجه حيث نريد أن نعرف هوية صاحب الوجه بمقارنة صورته بعدد من الصور المعلومة هويتها لدينا وترتيبها حسب درجة التشابه، فالصور التي تنتمي لهذا الشخص يفترض أن تتشابه معه بنسبة كبيرة أكثر من تلك التي لأشخاص آخرين.
دالة متوسط الخطأ المطلق Mean Absolute Error أو دالة الخسارة L1
تحسب دالة خسارة متوسط الخطأ المطلق MAE متوسط المجموع المطلق للفروق بين قيم التخمينات والقيم الفعلية. فتحسب أولًا الفرق بين قيمة التخمين والقيمة الفعلية عند كل عنصر في الموتر tensor، ونراكم المجموع المطلق لهذه الفروق التي حصلنا عليها في الخطوة السابقة، وفي النهاية نحسب متوسط هذا المجموع التراكمي بقسمته على العدد الكلي لتخمينات النموذج ونقارنها بالقيم الفعلية، للحصول على متوسط الخطأ المطلق MAE، وتعتبر دالة الخسارة هذه موثوقة للغاية في التعامل مع التشويش noise في البيانات. وتعرف هذه الدالة بمسمى آخر وهو دالة L1.
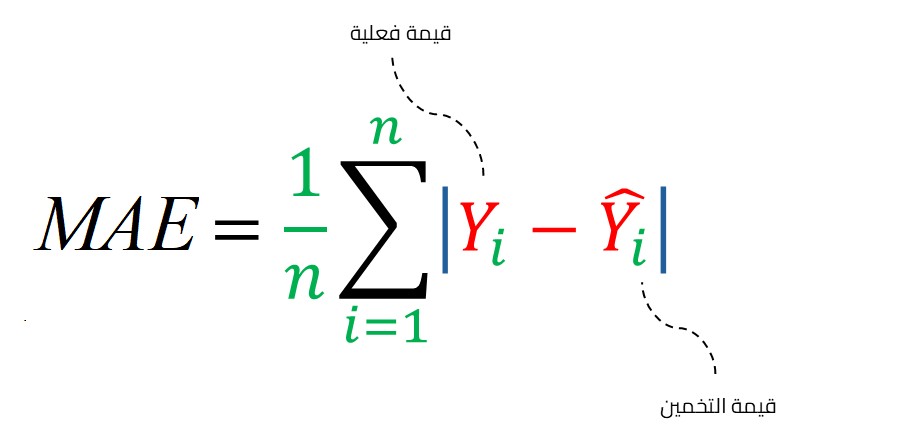
وفيما يلي كود برمجي يُعرّف ويستخدم دالة خسارة من نوع MAE أو L1:
import torch.nn as nn #size_average & reduce are deprecated # لا يوصى باستخدامهما فمن المحتمل تغيرهما في النسخ المستقبلية #reduction تحدد العملية التي ستحسب بعد حساب الفروق المطلقة لكل القيم ''' `none` tensor تعني أننا لن نقوم بأي عملية على الفروق المطلقة وسنخرجها كتنسور `sum` سنجمع جميع الفروق المطلقة لكل القيم دون أخذ المتوسط `mean` القيمة الافتراضية لهذا المعامل سنجمع جميع الفروق المطلقة ونأخذ متوسطها بقسمة المجموع على عدد العناصر في المخرجات ''' Loss_fn = nn.L1Loss(size_average=None, reduce=None, reduction='mean') input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) output = loss_fn(input, target) print(output) #tensor(0.7772, grad_fn=<L1LossBackward>)
متوسط مربع الخطأ Mean Squared Error
يتشابه متوسط مربع الخطأ MSE مع متوسط الخطأ المطلق MAE، لكن الفرق بينهما هو أن MSE يحسب مربع الفرق بين القيم المتوقعة والحقيقية، بينما يحسب MAE القيمة المطلقة للفرق. وبسبب وجود التربيع في MSE، تعطي هذه الدالة وزنًا أكبر للأخطاء الكبيرة، وهي أكثر حساسية للقيم الشاذة أو الضوضاء في البيانات مقارنة بالدالة MAE الأقل حساسية للقيم الشاذة لأنها لا تضخم الأخطاء الكبيرة بنفس الطريقة.
ويعد متوسط مربع الخطأ المطلق المعيار الثاني Second norm أو L2 ويعرف أيضًا بالمعيار الإقليدي Euclidean norm أو المسافة الإقليدية، وهو نفس القانون المعروف لحساب المسافة بين نقطتين في الإحداثيات.
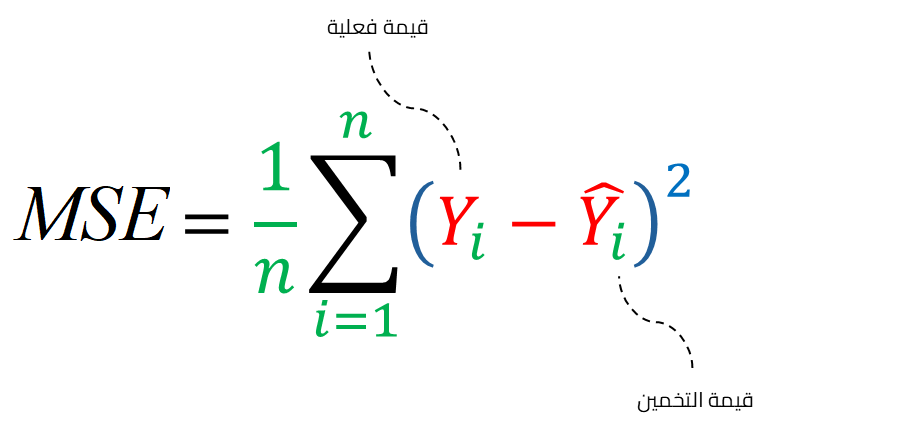
فيما يلي كود برمجي يُعرّف ويستخدم دالة خسارة من نوع MSE أو L2:
import torch.nn as nn loss = nn.MSELoss(size_average=None, reduce=None, reduction='mean') #ينطبق نفس الشرح السابق عن هذه المعاملات input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) output = loss(input, target) print(output) #tensor(0.9823, grad_fn=<MseLossBackward>)
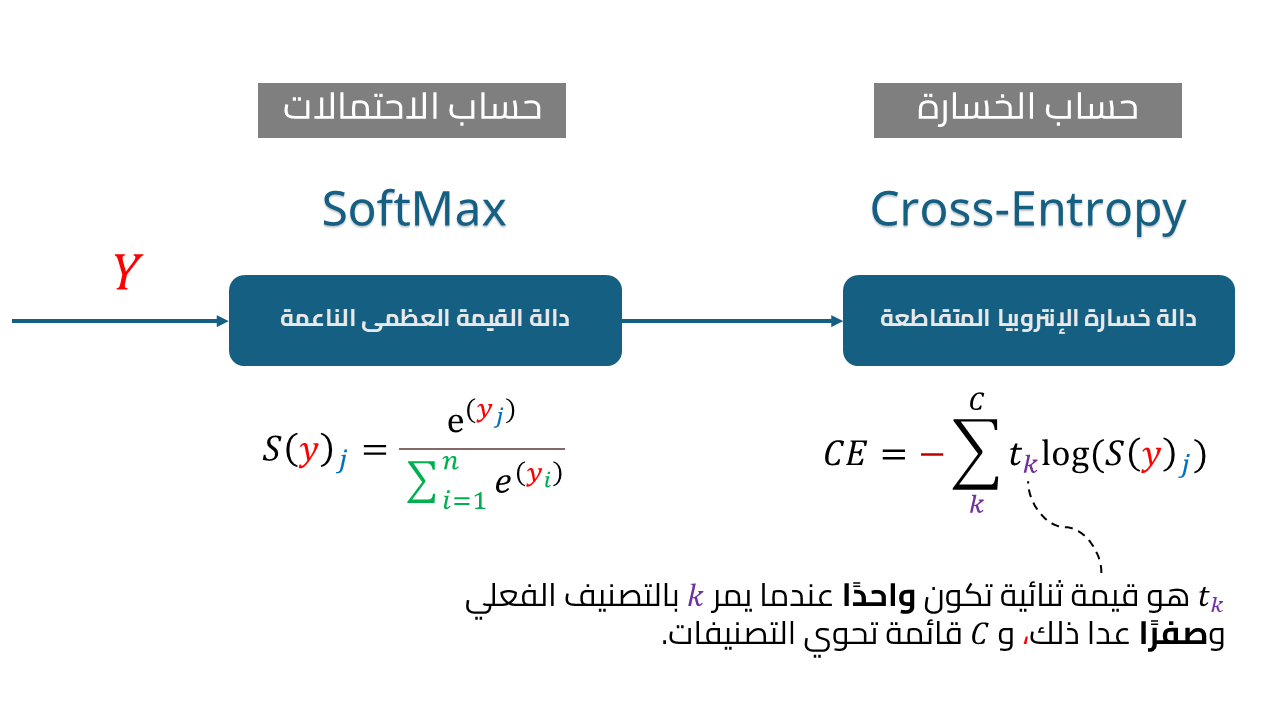
خسارة الإنتروبيا المتقاطعة Cross-Entropy Loss
تستخدم دالة خسارة الإنتروبيا المتقاطعة Cross Entropy في مسائل التصنيف classification والتي تتعامل مع تصنفيات محددة ومعدودة لقياس الفرق بين التوزيع الحقيقي للفئات والتوزيع الذي يتنبأ به النموذج. فتقيس الفرق بين توزيع الاحتماليات لكل مجموعة معطاة من المتغيرات العشوائية، ويغلب استخدام دالة softmax كطبقة المخرجات عند استخدم الإنتروبيا المتقاطعة كدالة خسارة، حيث تحوّل دالة softmax القيم الداخلة في المتجه أو التنسور tensor لتكون بين الصفر والواحد، ومجموع العناصر الخارجة ليساوي الواحد لتحقق شروط الاحتمالات، وتبقى القيمة العظمى في المتجه هي القيمة الأكبر بعد تطبيق الدالة.
وبالمقارنة مع دالة hardmax التي تستخرج القيمة العظمى من متجه وتُعيّنها إلى 1، بينما تتجاهل باقي العناصر وتحواها إلى 0 فإن دالة softmax تحافظ على المعلومات النسبية لجميع القيم، مما يجعلها مناسبة أكثر لترتيب الاحتمالات فهي تعطي قيمًا احتمالية لكل تصنيف. وتتكون دالة softmax من جزأين الأول هو عدد أويلر e مرفوعًا لأس قيمة التخمين لتصنيف معين في المتجه حيث يمثل كل عنصر أحد التصنيفات المحددة.
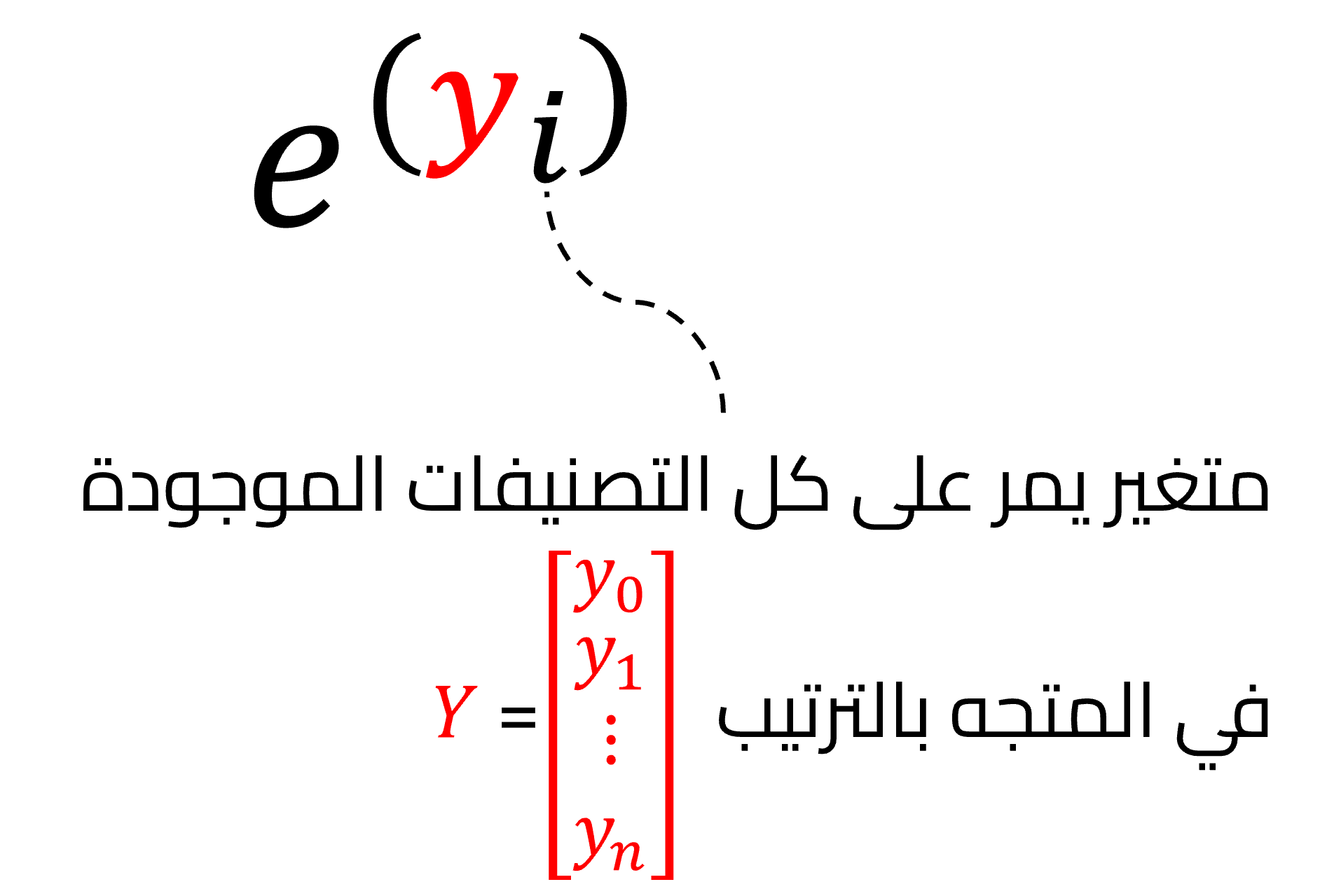
حيث أن y_i هي خرج من الشبكة العصبية الاصطناعية لتصنيف معين، وتعطينا هذه الدالة رقمًا قريبًا من الصفر ولكنه لا يكون أبدًا مساويًا للصفر، وتقترب قيمة الدالة من الواحد عندما تكون y_i قيمة كبيرة سالبة، وعندما تكون قيمة كبيرة موجبة تعطي الدالة رقمًا موجبًا كبيرًا، كما نلاحظ في المثال التالي:
import numpy as np np.exp(34) #583461742527454.9 np.exp(-34) #1.713908431542013e-15
أما الجزء الثاني من الدالة فهو عملية توحيد normalization حيث تضمن هذه الخطوة أن دالة softmax تعطي دائمًا قيمة احتمالات بين الصفر والواحد. توضح الصورة التالية الخطوات التي قمنا بها:
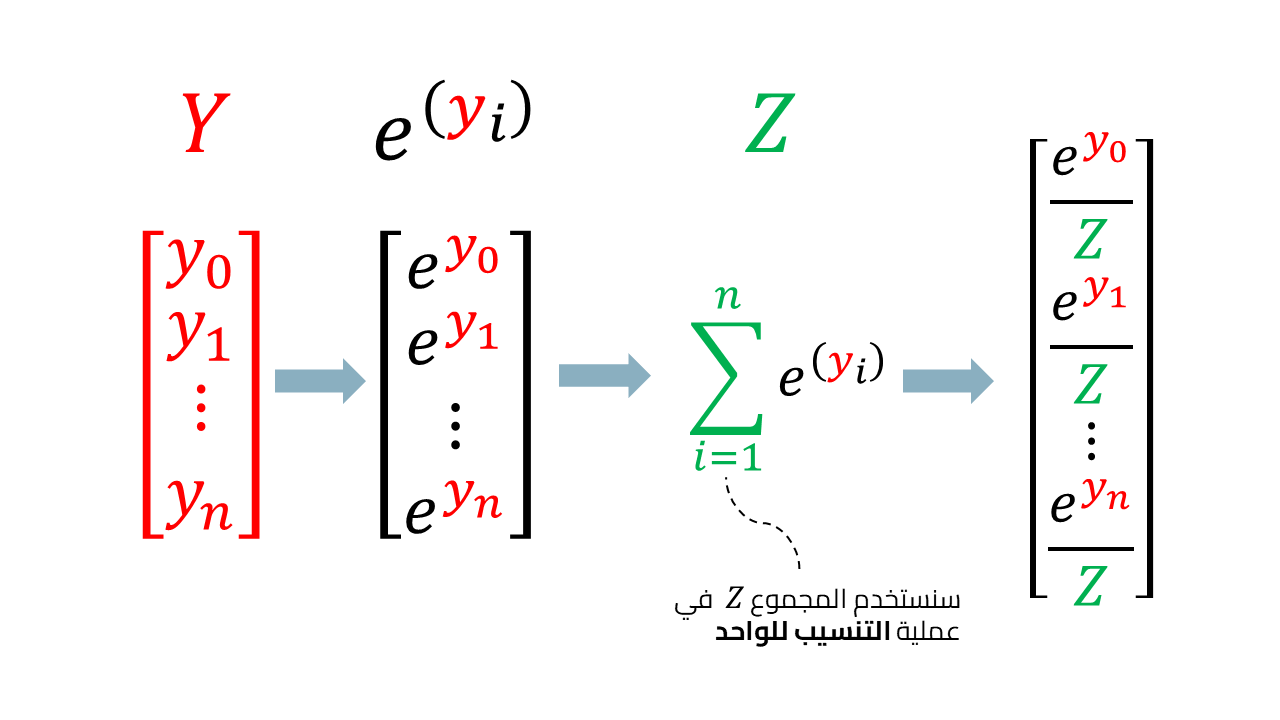
ويمكننا جمع الخطوات في معادلة واحدة تعبر عن استخدامنا لدالة softmax لتحول متجه المخرجات لاحتمالات كل تصنيف، مثلًا في مهمة التمييز بين صور القطط والكلاب قد يكون احتمال كون الصورة المدخلة للشبكة العصبية قطة هو 0.80 بينما احتمال أن تكون الصورة لكلب 0.20 مما يسهل علينا فهم التصنيفات بشكل احتمالات قابلة للترتيب.
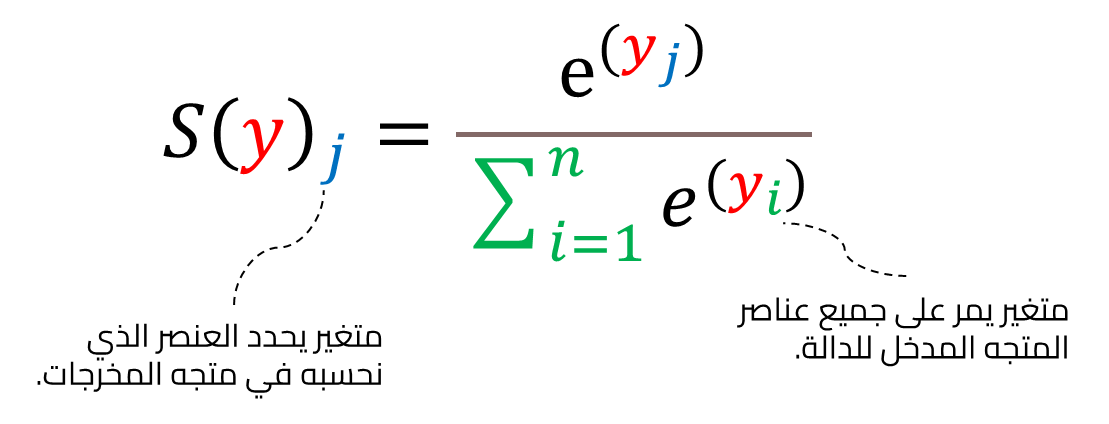
يجمع باي تورش في الوحدة nn كلًا من الإنتروبيا المتقاطعة Cross-entropy و احتمالية اللوغاريتم السالب Negative Log-Likelihood لدالة softmax في دالة خسارة واحدة.
دالة خسارة احتمالية اللوغاريتم السالب
تعمل دالة خسارة احتمالية اللوغاريتم السالب Negative Log-Likelihood loss -أو NLL اختصارًا- بشكل مشابه لدالة خسارة الإنتروبيا المتقاطعة Cross-Entropy، وكما ذكرنا سابقًا تجمع دالة الإنتروبيا المتقاطعة CE طبقة لوغاريتم الدالة العظمى الناعمة log-softmax مع احتمالية اللوغاريتم السالب NLL من أجل حساب قيمة خسارة الإنتوربية المتقاطعة. ويعني هذا أنه يمكننا الحصول على قيمة خسارة الإنتروبيا المتقاطعة CE باستخدام احتمالية اللوغاريتم السالب NLL بجعل الطبقة الأخيرة من الشبكة العصبية طبقة log-softmax بدلًا من دالة softmax التقليدية.

وفيما يلي كود برمجي ينجز تصنيف متعدد الفئات Multi-class Classification باستخدام الدالة softmax و NLL:
m = nn.LogSoftmax(dim=1) loss = nn.NLLLoss() # أبعاد المدخلات # N x C = 3 x 5 input = torch.randn(3, 5, requires_grad=True) # يجب أن تكون قيمة كل عنصر في تنسور الهدف أو القيم الفعلية أحد التصنيفات المحددة بالفعل # 0 <= value < C # C ---> يعبر عن آخر تصنيف اعتبارًا أن أول تصنيف سنرمز له بالصفر target = torch.tensor([1, 0, 4]) # المخرجات وهنا نطبق دالة لوغاريتم دالة القيمة العظمي على المدخلات # ثم نحسب مقدار الخسارة بين بينها وبين متجه الهدف أو القيم الفعلية output = loss(m(input), target) output.backward() # حساب الخسارة لتنسورات ثنائية الأبعاد يمكن على سبيل المثال أن تستخدم مع الصور N, C = 5, 4 loss = nn.NLLLoss() # أبعاد المدخلات # N x C x height x width data = torch.randn(N, 16, 10, 10) conv = nn.Conv2d(16, C, (3, 3)) m = nn.LogSoftmax(dim=1) target = torch.empty(N, 8, 8, dtype=torch.long).random_(0, C) output = loss(m(conv(data)), target) print(output) #tensor(1.4892, grad_fn=<NllLoss2DBackward>) #credit NLLLoss — PyTorch 1.9.0 documentation
دالة خسارة الإنتروبيا المتقاطعة للتصنيفات الثنائية Binary Cross-Entropy Loss
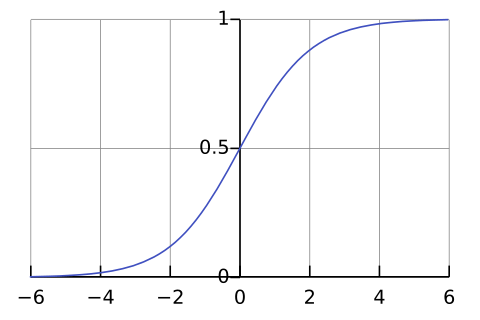
دالة خسارة الإنتروبيا المتقاطعة الثنائية Binary CE هي حالة خاصة من الإنتروبيا المتقاطعة CE وتستخدم عند تصنيف البيانات لأحد تصنيفين، ولذلك تسمى ثنائية حيث نرمز لأحد التصنيفين بصفر وللآخر بواحد، ونهدف عند استخدامها لجعل النموذج يخمّن رقمًا قريبًا من الصفر عندما يكون التصنيف الفعلي هو الصفر ورقمًا قريبًا للواحد إن كان التصنيف الفعلي واحد، وتكون في الغالب الطبقة الأخيرة في الشبكة العصبية عند استخدام هذه النوع من دوال حساب الخسارة طبقة تستخدم دالة سينية Sigmoid وبالتحديد الدالة اللوجستية logistic function وهي نوع خاص من الدوال السينية sigmoid functions والتي تضمن أن المخرجات رقمًا قريبًا من الواحد أو الصفر ليحقق شروط الاحتمالات.
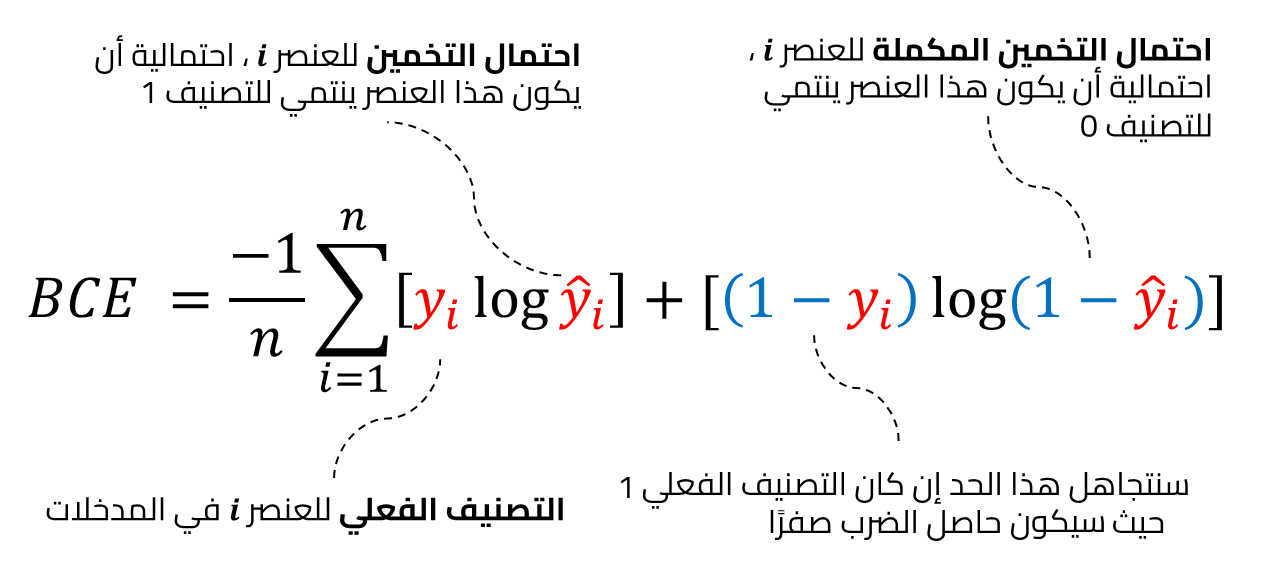
وفيما يلي كود يحسب دالة الخسارة للانحدار اللوجستي باستخدام الدالة BCE:
import torch.nn as nn m = nn.Sigmoid() loss = nn.BCELoss() input = torch.randn(3, requires_grad=True) target = torch.empty(3).random_(2) output = loss(m(input), target) print(output) #tensor(0.4198, grad_fn=<BinaryCrossEntropyBackward>)
دالة خسارة الإنتروبيا المتقاطعة للتصنيفات الثنائية مع لوغاريتم الفرص Binary Cross-Entropy Loss with Logits
لو سألنا أحدهم ما هي فرص فوز فريقك المفضل في المباراة؟ يمكن أن يجيب باحتمال مباشر مثل 40%، ويمكن يعبر عن فرص فوز الفريق فيقول يفوز الفريق مرتين من كل خمس مرات، فهذه نفس النسبة ولكن بطريقة مختلفة. حيث يعبر الاحتمال Probability عن فرصة وقوع الحدث من إجمالي جميع الحالات الممكنة، وتعبر الفرص odds عن نسبة احتمال وقوع الحدث إلى احتمال عدم وقوعه، ويستخدم لوغاريتم الفرص Logits أو log(odds) لتحويل الاحتمالات لقيم يمكن استخدامها بسهولة في الحسابات الرياضية، ويضمن أن النتائج تتبع توزيعًا خطيًا بدلاً من أن تكون مقيدة بين الصفر والواحد.
ذكرنا سابقًا أن دالة خسارة الإنتروبيا المتقاطعة الثنائية BCE تُسبق بطبقة بها الدالة السينية اللوجيستية logistic sigmoid لضمان أن المخرجات بين الواحد والصفر. وتُجمَع دالة خسارة الإنتروبيا المتقاطعة للتصنيفات الثنائية Binary Cross-Entropy Loss مع لوغاريتم الفرص Logits الطبقتين في طبقة واحدة، ووفقًا لتوثيق باي تورش PyTorch فهذا يجعلها أكثر استقرارًا عند إجراء العمليات الحسابية حيث يمكنها الاستفادة من تحويل الضرب إلى جمع بفضل اللوغاريتم.
import torch import torch.nn as nn # 64 تصنيفًا # حجم الدفعة الواحدة 10 target = torch.ones([10, 64], dtype=torch.float32) # 64 classes, batch size = 10 # المخرجات التي سنجرب عليها # هذا مثال افتراضي # ولكن عندما تكون هذه المخرجات من الشبكة العصبية # قبل مرورها في الدالة اللوجستية تسمي # logit / prediction output = torch.full([10, 64], 1.5) # جميع الأوزان هنا متساوية بواحد pos_weight = torch.ones([64]) criterion = torch.nn.BCEWithLogitsLoss(pos_weight=pos_weight) loss = criterion(output, target) # -log(sigmoid(1.5)) print(loss) #tensor(0.2014)
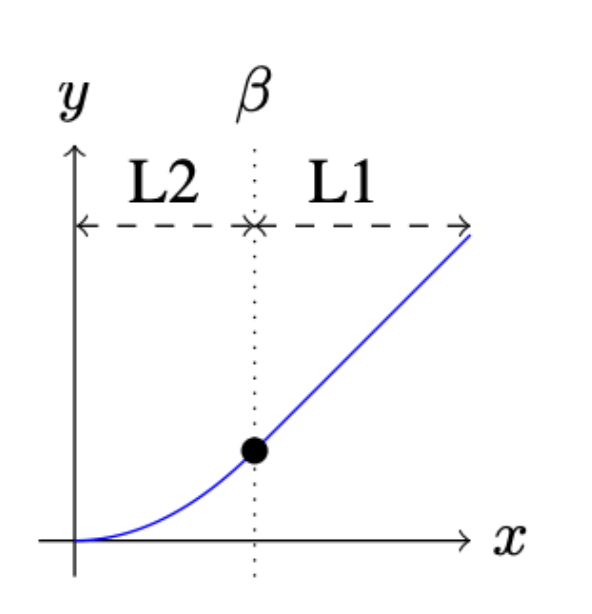
دالة خسارة المعيار الأول المرنة Smooth L1 loss
تستفيد دالة خسارة المعيار الأول Smooth L1 loss من مزايا كل من متوسط مربع الخطأ MSE ومتوسط الخطأ المطلق MAE من خلال معامل تحكم بيتا beta، وقُدم المعيار لأول مرة في الورقة البحثية Fast R-CNN . ويستخدم المعيار مربع الفرق عندما يكون الفرق المطلق بين القيم الفعلية والقيم المتوقعة أقل من بيتا beta فيصبح المعيار المستخدم MSE، ويرسم معدل الخسارة لمتوسط مربع الخطأ بشكل منحني متصل ومستمر، مما يجعل الدالة قابلة للاشتقاق عند كل القيم مما يمكننا من حساب معدل التدرج التصحيحي gradients لكل هذه القيم، ولكن عندما تصبح قيمة الخطأ عالية تظهر مشكلة تزايد التدرج بشكل خارج عن السيطرة يوصف بالإنفجاري gradient explosion حيث تصبح قيم التدرج gradients عالية وعند ضربها في الأوزان بشكل مستمر نحصل على أرقام ضخمة تؤدي في النهاية إلى عدم استيعاب المتغيرات لحجم الأرقام وعدم قدرة النظام على التعلم فيما يعرف بالفوران overflow، ولذلك عندما تبدأ هذه الظاهرة في الحدوث نستخدم معيار قيمة الخطأ المطلق MAE والذي يجعل الزيادة في قيم التدرج شبه ثابتة أي خطية عند كل القيم، ونحدد وقت التغيير بناءً على معامل التحكم بيتا beta.
import torch.nn as nn loss = nn.SmoothL1Loss() input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) output = loss(input, target) print(output) #tensor(0.7838, grad_fn=<SmoothL1LossBackward>)
دالة الخسارة المفصلية التضمينية Hinge Embedding loss
تستخدم هذه الدالة في الغالب مع مهام التعلم غير الخاضع للإشراف unsupervised learning لقياس درجة التشابه بين مُدخلين كل منهما عبارة عن تنسور tensor، يمثًل هو تنسور المدخلات input tensor والآخر تنسور الوسم labels tensor وتكون الوسوم في هذه الحالة أحد قيمتين 1 أو 1-، وتٌحلّ من خلالها المسائل التي تحتوي على تضمين غير خطي non-linear embeddings ومهام التعلم غير الخاضع للإشراف.

import torch import torch.nn as nn input = torch.randn(3, 5, requires_grad=True) target = torch.randn(3, 5) hinge_loss = nn.HingeEmbeddingLoss() output = hinge_loss(input, target) output.backward() print('input: ', input) print('target: ', target) print('output: ', output) #input: tensor([[ 1.4668e+00, 2.9302e-01, -3.5806e-01, 1.8045e-01, #1.1793e+00], # [-6.9471e-05, 9.4336e-01, 8.8339e-01, -1.1010e+00, #1.5904e+00], # [-4.7971e-02, -2.7016e-01, 1.5292e+00, -6.0295e-01, #2.3883e+00]], # requires_grad=True) #target: tensor([[-0.2386, -1.2860, -0.7707, 1.2827, -0.8612], # [ 0.6747, 0.1610, 0.5223, -0.8986, 0.8069], # [ 1.0354, 0.0253, 1.0896, -1.0791, -0.0834]]) #output: tensor(1.2103, grad_fn=<MeanBackward0>)
دالة خسارة الترتيب الهامشية Margin Ranking Loss
تنتمي دالة الترتيب الهامشية إلى دوال خسارة الترتيب التي تهدف لقياس المسافة النسبية بين مجموعة من المدخلات في مجموعة بيانات. ويُدخل للدالة مدخلان ووسم إما 1 أو 1-، فإذا كان الوسم 1 سنفترض أن المُدخل الأول يملك ترتيبًا أعلى من المُدخل الثاني، والعكس صحيح فإذا كان الوسم 1- يكون ترتيب المٌدخل الثاني أعلى، ويمكن أن نرى هذه العلاقة في المعادلة التالية:
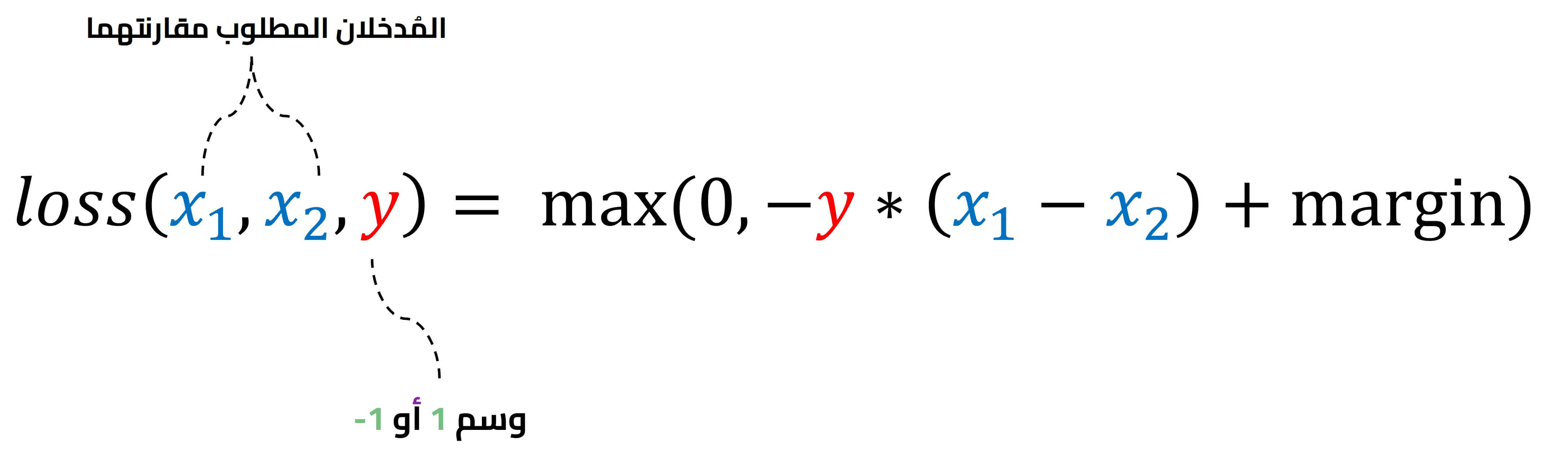
يوضح الكود التالي حساب الخسارة بين مُدخلين input1 و input2 باستخدام الدالة MarginRankingLoss:
import torch.nn as nn loss = nn.MarginRankingLoss() input1 = torch.randn(3, requires_grad=True) input2 = torch.randn(3, requires_grad=True) target = torch.randn(3).sign() output = loss(input1, input2, target) print('input1: ', input1) print('input2: ', input2) print('output: ', output) #input1: tensor([-1.1109, 0.1187, 0.9441], requires_grad=True) #input2: tensor([ 0.9284, -0.3707, -0.7504], requires_grad=True) #output: tensor(0.5648, grad_fn=<MeanBackward0>)
دالة الخسارة الثلاثية الهامشية Triplet Margin loss
تقيس هذه الدالة التشابه بين المُدخلات باستخدام ثلاث عينات من البيانات. فتستخدم الدالة عينة المرساة anchor sample، وعينة سالبة لا تنتمي لنفس التصنيف، وعينة إيجابية تنتمي لنفس تصنيف عينة المرساة، ونهدف إلى تعظيم المسافة بين عينة المرساة والعينة الموجبة وتقليص المسافة بين عينة المرساة والعينة السالبة بحيث لا تقل عن قيمة هامشية محددة، وباستخدام هذه الدالة الثلاثية الهامشية triplet margin نريد تخمين درجة عالية من التشابه بين المرساة anchor والعينة الموجبة، وتشابه ضعيف منخفض بين عينة المرساة anchor والعينة السالبة.

يوضح الكود التالي استخدام دالة الخسارة TripletMarginLoss:
import torch.nn as nn triplet_loss = nn.TripletMarginLoss(margin=1.0, p=2) anchor = torch.randn(100, 128, requires_grad=True) positive = torch.randn(100, 128, requires_grad=True) negative = torch.randn(100, 128, requires_grad=True) output = triplet_loss(anchor, positive, negative) print(output) #tensor(1.1151, grad_fn=<MeanBackward0>)
دالة خسارة تضمين جيب التمام اCosine Embedding Loss
تقيس دالة خسارة تضمين جيب التمام Cosine Embedding Loss الخسارة بين اثنين من المدخلات وتنسور من الوسوم قيم عناصره إما 1 أو 1-، وتستخدم عندما نريد قياس درجة التشابه أو القرب بين مُدخلين.
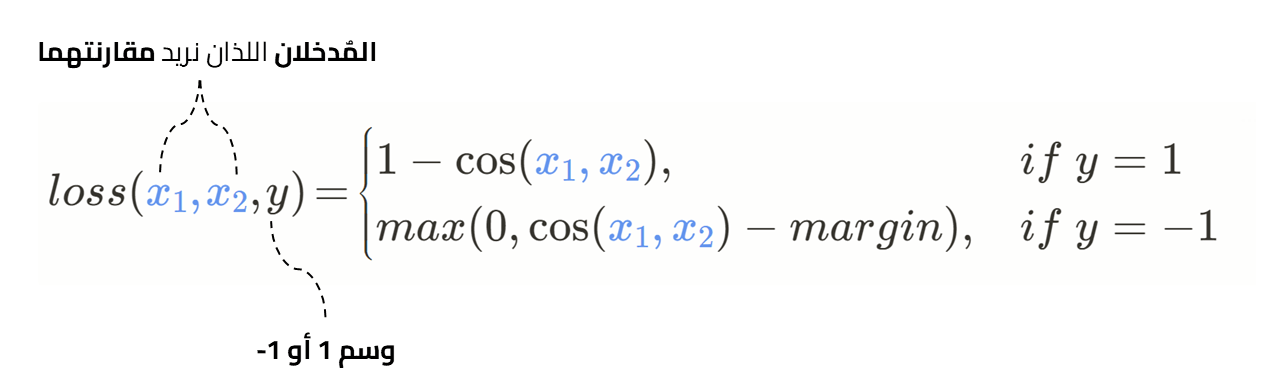
وتحسب الدالة درجة التشابه بحساب مسافة جيب تمام الزاوية Cosine distance بين نقطتين أو متجهين في الفضاء. حيث تتناسب مسافة جيب التمام Cosine distance مع الزاوية بين المتجهين، فكلما قلت الزاوية قلت المسافة بين المتجهين وكلما كان المتجهان أقرب كلما كانت الكائنات التي يصفانها متشابهة.
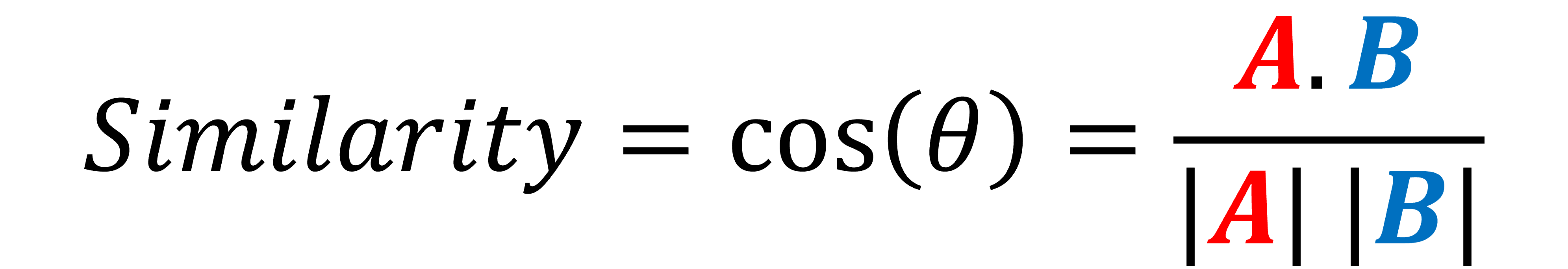
يوضح الكود التالي استخدام دالة الخسارة CosineEmbeddingLoss:
import torch.nn as nn loss = nn.CosineEmbeddingLoss() input1 = torch.randn(3, 6, requires_grad=True) input2 = torch.randn(3, 6, requires_grad=True) target = torch.randn(3).sign() output = loss(input1, input2, target) print('input1: ', input1) print('input2: ', input2) print('output: ', output) #input1: tensor([[ 1.2969e-01, 1.9397e+00, -1.7762e+00, -1.2793e-01, #-4.7004e-01, # -1.1736e+00], # [-3.7807e-02, 4.6385e-03, -9.5373e-01, 8.4614e-01, -1.1113e+00, # 4.0305e-01], # [-1.7561e-01, 8.8705e-01, -5.9533e-02, 1.3153e-03, -6.0306e-01, # 7.9162e-01]], requires_grad=True) #input2: tensor([[-0.6177, -0.0625, -0.7188, 0.0824, 0.3192, 1.0410], # [-0.5767, 0.0298, -0.0826, 0.5866, 1.1008, 1.6463], # [-0.9608, -0.6449, 1.4022, 1.2211, 0.8248, -1.9933]], # requires_grad=True) #output: tensor(0.0033, grad_fn=<MeanBackward0>)
دالة خسارة تباعد كولباك ليبلر Kullback Leibler Divergence
تستخدم هذه الدالة في تقدير الخسارة لنماذج تعلم الآلة التي تحاول تعلم توزيع احتمالات probability distribution عن طريق حساب كمية المعلومات المفقودة في عملية التقريب، ونرمز للتوزيع الفعلي الذي نحاول تعليمه للآلة بالرمز P وللتوزيع التقريبي بالرمز Q ، وتعمل هذه الدالة على قياس التشابه بين التوزيع الفعلي P والتقريبي Q وبالتالي دفع خوارزمية تعلم الآلة نحو إنتاج توزيع قريب من التوزيع الفعلي قدر الإمكان. ويلاحظ أن مقدار الخسارة في المعلومات عند استخدام التوزيع التقريبي Q لتقدير التوزيع الفعلي P ليس مساويًا للعملية العكسية التي تستخدم التوزيع الفعلي P لتقدير التوزيع التقريبي Q ولذلك يعد تباعد كولباك ليبلر KL divergence غير متماثل Not symmetric.

يوضح الكود التالي استخدام الدالة KLDivLoss:
import torch.nn as nn loss = nn.KLDivLoss(size_average=None, reduce=None, reduction='mean', log_target=False) input1 = torch.randn(3, 6, requires_grad=True) input2 = torch.randn(3, 6, requires_grad=True) output = loss(input1, input2) print('output: ', output) #tensor(-0.0284, grad_fn=<KlDivBackward>)
بناء دالة خسارة مخصصة
توجد طريقتان لبناء دالة خسارة خاصة بنا تتناسب مع المشكلة التي نحاول حلها، الأولى عن طريق تحقيقها داخل صنف class والثانية عن طريق تحقيقها كدالة مستقلة، وسنستعرض كلا الطريقتين.
تُعدّ طريقة الدالة المستقلة أسهل لبناء دالة خسارة مخصصة، حيث تُمرّر المُدخلات المطلوبة للدالة وتجري بعض العمليات عليها في جسم الدالة باستخدام العوامل والدوال البرمجية الأخرى المتاحة في باي تورش PyTorch أو من أي مصدر آخر، ومن ثم تعيد قيمة تمثّل الخسارة.
يوضح المثال التالي تعريف دالة مخصصة لحساب متوسط مربع الخطأ MSE:
def custom_mean_square_error(y_predictions, target): square_difference = torch.square(y_predictions - target) loss_value = torch.mean(square_difference) return loss_value
نمرر لهذه الدالة الخاصة تنسور التخمينات predictions tensor وتنسور الوسوم labels tensor ونستخدم بعض الدوال لحساب مربع الفرق بين التنسورين tensors ومن ثم نأخذ المتوسط ونعيده كقيمة الخسارة.
y_predictions = torch.randn(3, 5, requires_grad=True); target = torch.randn(3, 5) pytorch_loss = nn.MSELoss(); p_loss = pytorch_loss(y_predictions, target) loss = custom_mean_square_error(y_predictions, target) print('custom loss: ', loss) print('pytorch loss: ', p_loss) #custom loss: tensor(2.3134, grad_fn=<MeanBackward0>) #pytorch loss: tensor(2.3134, grad_fn=<MseLossBackward>)
ونقارن في هذا المقطع البرمجي بين دالتنا المخصصة والدالة المدمجة بإطار عمل باي تورش PyTorch framework ويمكنك أن تلاحظ اتفاق الدالتين في القيم النهائية مما يعني أن الدالة مبنية بشكل صحيح.
بناء صنف برمجي مخصص لحساب الخسارة
يوصى بهذه الطريقة لكونها الطريقة التي يستخدمها باي تورش PyTorch في الكود المصدري، ففي هذه الطريقة نعرّف دالة الخسارة داخل صنف يرث من الصنف الأساسي nn.Module وهذا يسمح لدالة الخسارة المخصصة بالعمل بطريقة مشابهة للطبقات التقليدية في باي تورش، مما يسهّل دمجها واستخدامها ضمن الشبكات العصبية الاصطناعية ANN بنفس الطريقة التي تُستخدم بها الطبقات الأخرى.
class Custom_MSE(nn.Module): def __init__(self): super(Custom_MSE, self).__init__(); def forward(self, predictions, target): square_difference = torch.square(predictions - target) loss_value = torch.mean(square_difference) return loss_value def __call__(self, predictions, target): square_difference = torch.square(y_predictions - target) loss_value = torch.mean(square_difference) return loss_value
الخاتمة
ناقشنا في هذا المقال العديد من دوال الخسارة loss functions المتوفرة في باي تورش PyTorch وتعمقنا في آلية عمل هذه الدوال والعلاقات الرياضية المعبرة عنها، قد يكون اختيار الدالة المناسبة مهمة صعبة، ولكن بفهمك الجيد لمحتوى هذه المقالة والرجوع للتوثيق الخاص بإطار عمل باي تورش PyTorch ستتمكن من اختيار دالة الخسارة المناسبة لمشكلتك بدقة.
ترجمة وبتصرف لمقالة PyTorch Loss Functions لصاحبها Henry Ansah Fordjour.











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.