

تُعدّ مسألة تصنيف الشخصيات بالاعتماد على تغريداتهم على وسائل التواصل الاجتماعي من المسائل المهمة مثلًا يُمكن أن يكون من المفيد تحديد الأشخاص الذين يكتبون تحليلات مهمة في مجالات الأعمال أو الاقتصاد أو الرياضة وغيرها مما يتيح للآخرين معرفة تقييمات أو آراء الأشخاص المغردين واتخاذ الإجراء المناسب.
نعرض في هذه المقالة استخدام تقنيات التعلم العميق في تصنيف الشخصيات المغردة بنصوص مكتوبة باللغة العربية وباللهجة السعودية بمعنى أن اللغة المستخدمة ليست بالضرورة اللغة العربية الفصحى بل يُمكن أن تدخل فيها ألفاظ عامية يستخدمها المغردون عادةً.
لتصنيف شخص ما، سنلجأ أولًا إلى تصنيف تغريداته (أي إسناد كل تغريده إلى صف معين)، ومن ثم تصنيفه بناًء على نتائج تصنيف تغريداته (الصفوف ذات التواتر الكبر).
بيانات التدريب
تحوي مجموعة البيانات المتوفرة حوالي 26500 تغريدة لمجموعة متنوعة من المغردين المشهورين في المملكة العربية السعودية. جُمّعت هذه التغريدات عن طريق مجموعة من الطلاب الجامعيين وذلك من موقع تويتر Twitter. بالطبع، لا يوجد تصنيف متوفر لهذه التغريدات على تويتر. تجدها موجودة هي وبقية ملفات هذا الفصل في الملف المضغوط المرفق.
تصنيف بيانات التدريب
يتطلب استخدام خوارزميات تعلم الآلة (خوارزميات تصنيف التغريدات في حالتنا) توفر بيانات للتدريب أي مجموعة من التغريدات مُصنفّة مُسبقًا إلى مجموعة من الصفوف، ويُمكن، كما في حالتنا، اللجوء إلى الطرق اليدوية أي الطلب من مجموعة من الأشخاص قراءة النصوص وتصنيفها وهو حل يصلح في حال كان عدد النصوص صغيرًا نسبيًا، ويتميز هذا الحل بالدقة العالية لأن الأشخاص تُدرك، بشكل عام، معاني النصوص من خلال خبرتها اللغوية المُكتسبة وتُصنّف النصوص بشكل صحيح غالبًا.
طلبنا من الطلاب المشاركين في مشروعنا تصنيف كل تغريدة إلى واحدة من المواضيع (الصفوف) التالية:
| الصف بالعربي | English |
|---|---|
| الرياضة | Sports |
| الأعمال | Business |
| التكنولوجيا | Technology |
| المجتمع | Social |
| السياسة | Politics |
| الأخبار | News |
| الاقتصاد | Economy |
نُعطي فيما يلي أمثلة عن هذه التغريدات (بعد تصنيفها):
- "الحمد لله مباراة الدوري وهدف غالي يشابه هدف القناص مباراة الفتح الرائد الهلال" (الرياضة).
- "قريبا جدا… تتابع السوق السعودي وشركاته والأمريكي وشركاته والعملات والكربتو النفط والذهب بمنصة واحدة مباشرة وتقدر ت…" (الأعمال).
- "فايروس خطير جدا يستهدف مستخدمي نظام الاندرويد قادر يسرق بيانات حساسه الصور وتسجيل صوت المستخدم والوصول لمعلوماتهم وسرقة…" (التكنولوجيا)
- "أالسلام عليكم ورحمة الله وبركاتة اللهم فرج يفرج همه ويبارك ماله ويفتح أبواب الخيروال…" (المجتمع)
- "مبادرون لأجل فلسطين.. تكريم كويتي لرافضي التطبيع في الفعاليات الرياضية والأدبية" (السياسة)
- "الخط العربي ومخاوف التقنية في الزمن الرقمي.. تجربة عالمية أم خروج عن تقاليد الفن العريق؟" (الأخبار)
- "معلومة فنية (٢)للشراء المضاربي ١- اقفال السوق ٥ دقايق اذا كانت شمعة ايجابية للحصول ربح مضاربي يوم ٢-عند…" (الاقتصاد).
نعرض في هذه المقالة كيفية بناء مُصنّف حاسوبي آلي يُصنّف أي تغريدة عربية إلى أحد الصفوف السبعة السابقة ومن ثم تصنيف الشخص المغرد لواحد أو أكثر من هذه الصفوف (الأكثر تواترًا).
المعالجة الأولية للنصوص
تتميز التغريدات، بشكل عام، باحتوائها على مجموعة من الأمور غير المهمة في مسألة التصنيف مثل الروابط Links والوسوم Hashtags والرموز التعبيرية Emojis وغيرها.
يُبين الشكل التالي مثالًا عن التغريدات المُجمّعة:
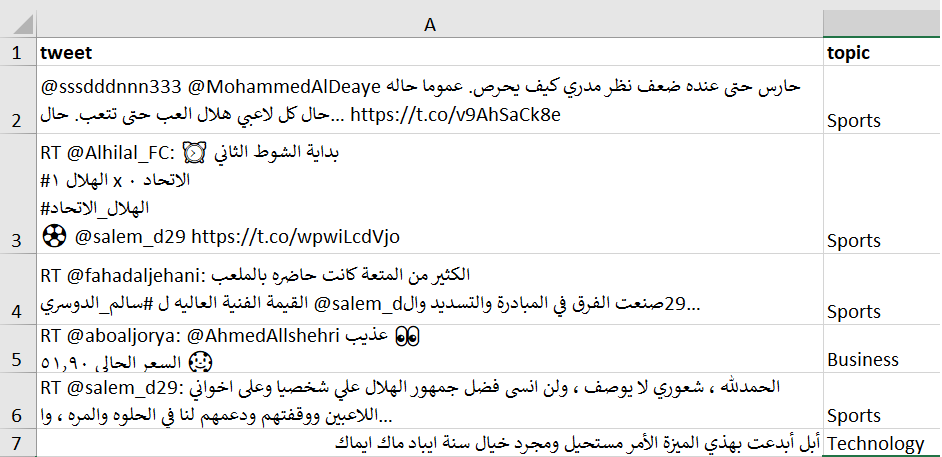
تهدف المعالجة الأولية إلى الحصول على الكلمات المهمة فقط من النصوص وذلك عن طريق تنفيذ بعض العمليات اللغوية عليها.
لتكن لدينا مثلًا الجملة التالية: "أنا أحب الذهاب إلى الحديقة ?، كل يوم 9 صباحاً، مع رفاقي هؤلاء! @toto "، سنقوم بتنفيذ العمليات التالية:
- حذف الروابط والوسوم والرموز التعبيرية: يكون ناتج الجملة السابقة: "أنا أحب الذهاب إلى الحديقة، كل يوم 9 صباحاً، مع رفاقي هؤلاء!"
- حذف إشارات الترقيم المختلفة كالفواصل وإشارات الاستفهام وغيرها: يكون ناتج الجملة السابقة: "أنا أحب الذهاب إلى الحديقة كل يوم 9 صباحاً مع رفاقي هؤلاء"
- حذف الأرقام الواردة في النص: يكون ناتج الجملة السابقة: "أنا أحب الذهاب إلى الحديقة كل يوم صباحاً مع رفاقي هؤلاء"
- حذف كلمات التوقف stop words وهي الكلمات التي تتكرر كثيرًا في النصوص ولا تؤثر في معانيها كأحرف الجر (من، إلى، …) والضمائر (أنا، هو، …) وغيرها فيكون ناتج الجملة السابقة: " أحب الذهاب الحديقة يوم صباحاً رفاقي"
- تجذيع الكلمات stemming أي إرجاع الكلمات المتشابهة إلى كلمة واحدة (جذع) مما يُساهم في إنقاص عدد الكلمات الكلية المختلفة في النصوص، ومطابقة الكلمات المتشابهة مع بعضها البعض. مثلًا: يكون للكلمات الأربع: (رائع، رايع، رائعون، رائعين) نفس الجذع المشترك: (رايع) فيكون ناتج الجملة السابقة: " احب ذهاب حديق يوم صباح رفاق"
إعداد المشروع
يحتاج تنفذ شيفرات هذه المقالة بيئةً برمجيةً للغة بايثون الإصدار 3.8. ويجب أن تتضمن هذه البيئة البرمجية مدير الحِزم pip لتثبيت الحِزم، ومُنشئ البيئات الافتراضية venv لإنشاء بيئاتٍ افتراضيةٍ.
نستخدم محرر الشيفرات البرمجية Jupyter Notebooks، وهو مفيد جدًا لتجربة وتشغيل الأمثلة الخاصة بتَعَلّم الآلة بطريقةٍ تفاعليةٍ، حيث نستطيع من خلاله تشغيل كتلًا صغيرةً من الشيفرات البرمجية ورؤية النتائج بسرعة، مما يُسهّل علينا اختبار الشيفرات البرمجية وتصحيحها.
نحتاج أولًا لتثبيت بعض التبعيات، وذلك لإنشاء مساحة عمل للاحتفاظ بملفاتنا قبل أن نتمكن من تطوير برنامجنا.
نُنشئ مجلدًا جديدًا خاصًا بمشروعنا وندخل إليه هكذا:
mkdir arc
cd arc
نُنفذّ الأمر التالي لإنشاء البيئة الافتراضية:
python -m venv arc
ومن ثم الأمر التالي في Linux لتنشيط البيئة الافتراضية:
source arc/bin/activate
أما في Windows، فيكون أمر التنشيط:
"arc/Scripts/activate.bat"
نستخدم إصداراتٍ محددةٍ من المكتبات اللازمة، من خلال إنشاء ملف requirements.txt في مجلد المشروع، وسيُحدِّد هذا الملف المتطلبات والإصدارات التي سنحتاج إليها.
نفتح الملف requirements.txt في محرر النصوص، ونُضيف الأسطر التالية، وذلك لتحديد المكتبات التي نريدها وإصداراتها:
absl-py==1.0.0 asttokens==2.0.5 astunparse==1.6.3 backcall==0.2.0 cachetools==5.1.0 certifi==2021.10.8 charset-normalizer==2.0.12 click==8.1.3 colorama==0.4.4 cycler==0.11.0 debugpy==1.6.0 decorator==5.1.1 entrypoints==0.4 executing==0.8.3 flatbuffers==1.12 fonttools==4.33.3 gast==0.4.0 google-auth==2.6.6 google-auth-oauthlib==0.4.6 google-pasta==0.2.0 grpcio==1.46.1 h5py==3.6.0 idna==3.3 imbalanced-learn==0.9.1 imblearn==0.0 importlib-metadata==4.11.3 ipykernel==6.13.0 ipython==8.3.0 jedi==0.18.1 joblib==1.1.0 jupyter-client==7.3.1 jupyter-core==4.10.0 keras==2.6.0 Keras-Applications==1.0.8 Keras-Preprocessing==1.1.2 kiwisolver==1.4.2 libclang==14.0.1 Markdown==3.3.7 matplotlib==3.5.2 matplotlib-inline==0.1.3 nest-asyncio==1.5.5 nltk==3.7 numpy==1.22.3 oauthlib==3.2.0 opt-einsum==3.3.0 packaging==21.3 pandas==1.4.2 parso==0.8.3 pickleshare==0.7.5 Pillow==9.1.1 prompt-toolkit==3.0.29 protobuf==3.20.1 psutil==5.9.0 pure-eval==0.2.2 PyArabic==0.6.14 pyasn1==0.4.8 pyasn1-modules==0.2.8 Pygments==2.12.0 pyparsing==3.0.9 python-dateutil==2.8.2 pytz==2022.1 #pywin32==304 pyzmq==22.3.0 regex==2022.4.24 requests==2.27.1 requests-oauthlib==1.3.1 rsa==4.8 scikit-learn==1.1.0 scipy==1.8.0 seaborn==0.11.2 six==1.16.0 sklearn==0.0 snowballstemmer==2.2.0 stack-data==0.2.0 tensorboard==2.9.0 tensorboard-data-server==0.6.1 tensorboard-plugin-wit==1.8.1 tensorflow==2.9.0 tensorflow-estimator==2.9.0 tensorflow-io-gcs-filesystem==0.26.0 termcolor==1.1.0 threadpoolctl==3.1.0 tornado==6.1 tqdm==4.64.0 traitlets==5.2.1.post0 typing-extensions==4.2.0 urllib3==1.26.9 wcwidth==0.2.5 Werkzeug==2.1.2 wrapt==1.14.1 zipp==3.8.0
نحفظ التغييرات التي طرأت على الملف ونخرج من محرر النصوص، ثم نُثَبت هذه المكتبات بالأمر التالي:
(arc) $ pip install -r requirements.txt
بعد تثبيتنا لهذه التبعيات، نُصبح جاهزين لبدء العمل على مشروعنا.
كتابة الشيفرة البرمجية
نُشغّل محرر الشيفرات البرمجية Jupyter Notebook بمجرد اكتمال عملية التثبيت هكذا:
(arc) $ jupyter notebook
ثم نُنشئ ملفًا جديدًا في داخل المحرر ونُسمّه باسم ac مثلًا.
تحميل البيانات
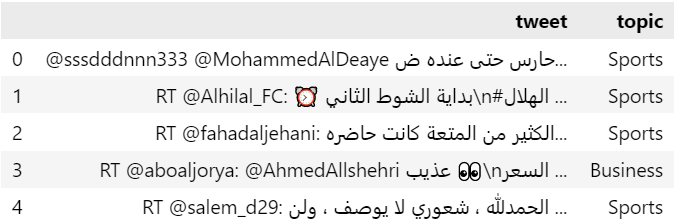
نبدأ أولًا بتحميل التغريدات من الملف tweets.csv ضمن إطار من البيانات DataFrame من مكتبة Pandas ومن ثم عرض بعضها:
import pandas as pd # قراءة التغريدات وتحميلها ضمن إطار من البيانات tweets = pd.read_csv('tweets.csv',encoding = "utf-8") # إظهار الجزء الأعلى من إطار البيانات tweets.head()
يظهر لنا أوائل التغريدات:
يُمكن استخدام خاصية الشكل shape لمعرفة عدد الصفوف والأعمدة للبيانات المُحمّلة:
print('Data size:', tweets.shape)
يكون الناتج:
Data size: (26748, 2)
المعالجة الأولية للنصوص
نستخدم فيما يلي بعض الخدمات التي توفرها المكتبة nltk لمعالجة اللغات الطبيعية كتوفير قائمة كلمات التوقف باللغة العربية (حوالي 700 كلمة) واستخراج الوحدات tokens من النصوص. كما نستخدم مجذع الكلمات العربية من مكتبة snowballstemmer.
كما نستخدم التعابير النمطية regular expressions للتعرف على الرموز التعبيرية والوسوم والروابط وحذفها.
# مكتبة السلاسل النصية import string # مكتبة التعابير النظامية import re # مكتبة معالجة اللغات الطبيعية import nltk #nltk.download('punkt') #nltk.download('stopwords') # مكتبة كلمات التوقف from nltk.corpus import stopwords # مكتبة استخراج الوحدات from nltk.tokenize import word_tokenize # مكتبة المجذع العربي from snowballstemmer import stemmer ar_stemmer = stemmer("arabic") # دالة حذف المحارف غير اللازمة def remove_chars(text, del_chars): translator = str.maketrans('', '', del_chars) return text.translate(translator) # دالة حذف المحارف المكررة def remove_repeating_char(text): return re.sub(r'(.)\1{2,}', r'\1', text) # دالة تنظيف التغريدات def clean_tweet(tweet): stop_words = stopwords.words('arabic') # محارف الرموز التعبيرية emoj = re.compile("[" u"\U0001F600-\U0001F64F" u"\U0001F300-\U0001F5FF" u"\U0001F680-\U0001F6FF" u"\U0001F1E0-\U0001F1FF" u"\U00002500-\U00002BEF" u"\U00002702-\U000027B0" u"\U00002702-\U000027B0" u"\U000024C2-\U0001F251" u"\U0001f926-\U0001f937" u"\U00010000-\U0010ffff" u"\u2640-\u2642" u"\u2600-\u2B55" u"\u200d" u"\u23cf" u"\u23e9" u"\u231a" u"\ufe0f" u"\u3030" "]+", re.UNICODE) tweet = str(tweet) # حذف @ وما يتبعها tweet = re.sub("@[^\s]+","",tweet) tweet = re.sub("RT","",tweet) # حذف الروابط tweet = re.sub(r"(?:\@|http?\://|https?\://|www)\S+", "", tweet) # حذف الرموز التعبيرية tweet = re.sub(emoj, '', tweet) # حذف كلمات التوقف tweet = ' '.join(word for word in tweet.split() if word not in stop_words) # حذف الإشارات # tweet = tweet.replace("#", "").replace("_", " ") # حذف الأرقام tweet = re.sub(r'[0-9]+', '', tweet) # حذف المحارف غير اللازمة # علامات الترقيم العربية arabic_punctuations = '''`÷×؛<>_()*&^%][ـ،/:"؟.,'{}~¦+|!”…“–ـ''' # علامات الترقيم الإنجليزية english_punctuations = string.punctuation # دمج علامات الترقيم العربية والانكليزية punctuations_list = arabic_punctuations + english_punctuations tweet = remove_chars(tweet, punctuations_list) # حذف المحارف المكررة tweet = remove_repeating_char(tweet) # استبدال الأسطر الجديدة بفراغات tweet = tweet.replace('\n', ' ') # حذف الفراغات الزائدة من اليمين واليسار tweet = tweet.strip(' ') return tweet # دالة تقسيم النص إلى مجموعة من الوحدات def tokenizingText(text): tokens_list = word_tokenize(text) return tokens_list # دالة حذف كلمات التوقف def filteringText(tokens_list): # قائمة كلمات التوقف العربية listStopwords = set(stopwords.words('arabic')) filtered = [] for txt in tokens_list: if txt not in listStopwords: filtered.append(txt) tokens_list = filtered return tokens_list # دالة التجذيع def stemmingText(tokens_list): tokens_list = [ar_stemmer.stemWord(word) for word in tokens_list] return tokens_list # دالة دمج قائمة من الكلمات في جملة def toSentence(words_list): sentence = ' '.join(word for word in words_list) return sentence
شرح الدوال السابقة:
-
الدالة
clean_tweetتحذف الرموز التعبيرية والروابط والوسوم والأرقام وعلامات الترقيم العربية والإنكليزية من النص وذلك باستخدام التعابير النظامية الموافقة. -
الدالة
remove_repeating_charتحذف المحارف المكررة والتي قد يستخدمها كاتب التغريدة. -
الدالة
tokenizingTextتعمل على تجزئة النص إلى قائمة من الوحدات tokens. -
الدالة
filteringTextتحذف كلمات التوقف من قائمة الوحدات. -
الدالة
stemmingTextتعمل على تجذيع كلمات قائمة الوحدات المتبقية.
يُبين المثال التالي نتيجة استدعاء كل دالة من الدوال السابقة:
# مثال text= "أنا أحب الذهاب إلى الحديقة ?، كل يوم 9 صباحاً، مع رفاقي هؤلاء! @toto " print(text) text=clean_tweet(text) print(text) tokens_list=tokenizingText(text) print(tokens_list) tokens_list=filteringText(tokens_list) print(tokens_list) tokens_list=stemmingText(tokens_list) print(tokens_list)
يكون ناتج التنفيذ:
اقتباسأنا أحب الذهاب إلى الحديقة ?، كل يوم 9 صباحاً، مع رفاقي هؤلاء! @toto
أحب الذهاب الحديقة يوم صباحاً رفاقي هؤلاء
['أحب', 'الذهاب', 'الحديقة', 'يوم', 'صباحاً', 'رفاقي', 'هؤلاء']
['أحب', 'الذهاب', 'الحديقة', 'يوم', 'صباحاً', 'رفاقي']
['احب', 'ذهاب', 'حديق', 'يوم', 'صباح', 'رفاق']
تعرض الشيفرة التالية التصريح عن الدالة process_tweet والتي تقوم أولًا بتنظيف التغريدات وذلك باستدعاء الدالة clean_tweet، ومن ثم تحويل التغريدات إلى وحدات وذلك باستدعاء الدالة tokenizingText، وأخيرًا تجذيع الوحدات عن طريق الدالة stemmingText.
ومن ثم تنفيذ دالة المعالجة الأولية على جميع التغريدات:
# دالة معالجة التغريدات def process_tweet(tweet): # تنظيف التغريدة tweet=clean_tweet(tweet) # التحويل إلى وحدات tweet=tokenizingText(tweet) # التجذيع tweet=stemmingText(tweet) return tweet # المعالجة الأولية للتغريدات tweets['tweet'] = tweets['tweet'].apply(process_tweet)
موازنة الصفوف
تتطلب معظم خوارزميات التصنيف توفر بيانات للتدريب وبصفوف متوازنة، بمعنى أن يكون عدد أسطر البيانات من كل صف متساوية تقريبًا تجنبًا لانحياز المُصنف إلى الصف ذي العدد الأكبر من الأسطر في بيانات التدريب.
من المفيد إذًا أولًا معاينة توزع أعداد الصفوف.
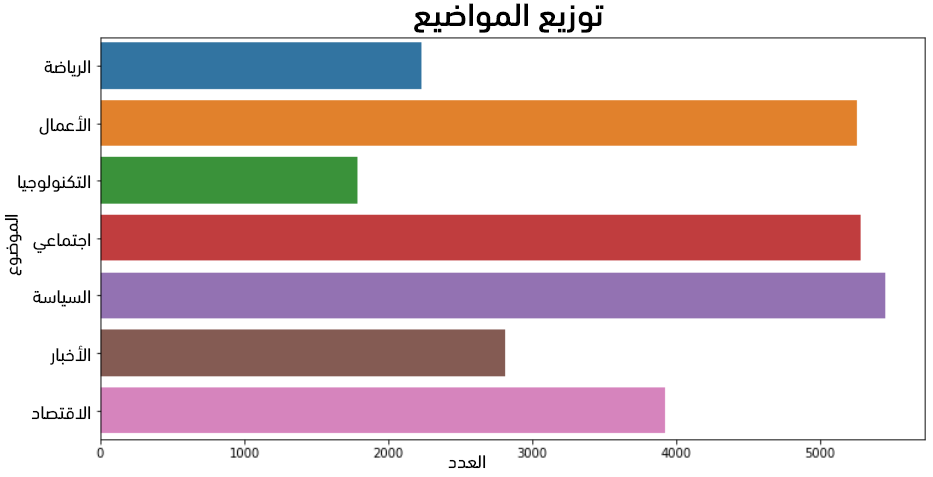
نستخدم في الشيفرة البرمجية التالية مكتبات الرسم اللازمة لرسم أشرطة تُمثّل أعداد الصفوف:
# مكتبات الرسم import matplotlib.pyplot as plt import seaborn as sns # حجم الرسم plt.figure(figsize=(12, 6)) # رسم عدد كل صف sns.countplot(data=tweets, y='topic'); plt.title('Topics Distribution', fontsize=18) plt.show()
يُبين الشكل الناتج عدم توازن الصفوف على الإطلاق:
نستخدم في الشيفرة التالية الصنف RandomOverSampler من المكتبة imblearn.over_sampling والذي يقوم باختيار أسطر عشوائية من الصفوف القليلة العدد ويُكررها في مجموعة البيانات.
# استيراد مكتبة الموازنة from imblearn.over_sampling import RandomOverSampler # إنشاء كائن من الصنف oversample = RandomOverSampler() # توليد سطر عشوائي tweets = tweets.sample(frac=1) # توليد الأسطر الجديدة tweets, Y = oversample.fit_resample(tweets, tweets.topic)
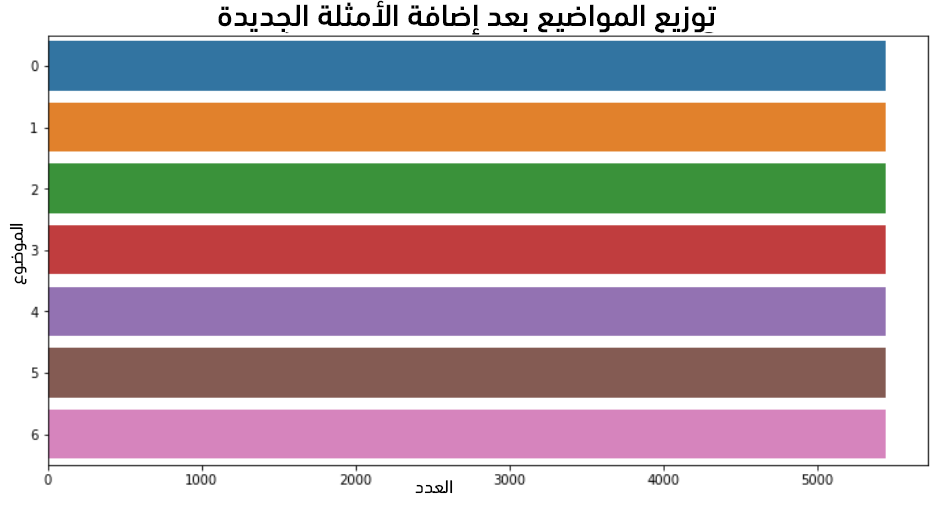
نعيد رسم أعداد الصفوف بعد الموازنة:
# إعادة رسم أعداد الصفوف # بعد الموازنة plt.figure(figsize=(12, 6)) sns.countplot(data=tweets, y='topic'); plt.title('Topics Distribution After OverSampling', fontsize=18) plt.show()
يُبين الشكل الناتج توازن الصفوف بشكل كامل:
ترميز الصفوف
لا تقبل بنى تعلم الآلة النصوص كمدخلات لها، تقوم الشيفرة التالية باستخدام الصنف LabelEncoder من المكتبة sklearn.preprocessing لترميز الصفوف باستخدام الأرقام.
نطبع في النهاية أسماء الصفوف والترميز المقابل لها:
from sklearn.preprocessing import LabelEncoder # ترميز الصفوف le_topics = LabelEncoder() tweets['topic'] = tweets[['topic']].apply(le_topics.fit_transform) classes = le_topics.classes_ # الصفوف n_classes = len(classes) # عدد الصفوف print("No. of classes:", n_classes) print("Classes:", classes) print("Coding: ", le_topics.transform(classes))
يكون الإظهار:
No. of classes: 7 Classes: ['Business' 'Economy' 'News' 'Politics' 'Social' 'Sports' 'Technology'] Coding: [0 1 2 3 4 5 6]
تحويل النصوص إلى أشعة رقمية
لا تقبل بنى تعلم الآلة النصوص كمدخلات لها، بل تحتاج إلى أشعة رقمية كمدخلات.
نستخدم الشيفرة التالية لتحويل الشعاع النصي لكل تغريدة tweet_preprocessed إلى شعاع رقمي:
from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences # نركيب جمل التغريدات من المفردات المعالجة sentences = tweets['tweet'].apply(toSentence) print(sentences[6]) # عدد الكلمات الأعظمي ذات التواتر الأكبر # التي ستُستخدم max_words = 5000 # الطول الأعظمي لشعاع الأرقام max_len = 50 # التصريح عن المجزئ # مع تحديد عدد الكلمات التي ستبقى # بالاعتماد على تواترها tokenizer = Tokenizer(num_words=max_words ) # ملائمة المجزئ لنصوص التغريدات tokenizer.fit_on_texts(sentences) # تحويل النص إلى قائمة من الأرقام S = tokenizer.texts_to_sequences(sentences) print(S[0]) # توحيد أطوال الأشعة X = pad_sequences(S, maxlen=max_len) print(X[0]) X.shape
نجد من الشيفرة أن المتغير max_words يُحدّد عدد الكلمات الأعظمي التي سيتم الاحتفاظ بها حيث يُحسب تواتر كل كلمة في كل النصوص ومن ثم تُرتب حسب تواترها (المرتبة الأولى للكلمة ذات التواتر الأكبر). ستُهمل الكلمات ذات المرتبة أكبر من max_words، و يُحدّد المتغير max_len طول الشعاع الرقمي النهائي فإذا كان موافقًا لنص أقل من max_len تُضاف أصفار للشعاع حتى يُصبح طوله مساويًا إلى max_len. أما إذا كان طوله أكبر يُقتطع جزءًا منه ليُصبح طوله مساويًا إلى max_len.
بينما تقوم الدالة fit_on_texts بملائمة المُجزء tokenizer لنصوص جمل التغريدات sentences.values أي حساب تواتر الكلمات والاحتفاظ بالكلمات ذات التواتر أكبر أو يساوي max_words.
نطبع في الشيفرة السابقة، بهدف التوضيح، ناتج كل مرحلة.
اخترنا مثلًا شعاع التغريدة 6 بعد المعالجة:
اقتباسدخل يوم يوافق يوم نوم عالم وفي يتم تذكير اهم نوم فوايد عظيم لجسم انس تبخل نفس
تكون نتيجة تحويل الشعاع السابق النصي إلى شعاع من الأرقام:
[1839, 1375, 2751, 315, 975, 1420, 1839, 3945, 436, 794, 919, 445, 1290, 312, 258]
وبعد عملية توحيد الطول يكون الشعاع الرقمي النهائي الناتج:
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1839 1375 2751 315 975 1420 1839 3945 436 794 919 445 1290 312 258]
تجهيز دخل وخرج الشبكة العصبية
تعرض الشيفرة التالية حساب شعاع الخرج أولًا وذلك بإسناد العمود topic من إطار البيانات، والذي يحوي الترميز الرقمي للصفوف إلى المتغير y.
نستخدم الدالة train_test_split لتقسيم البيانات المتاحة إلى 80% منها لعملية التدريب و20% لعملية الاختبار وحساب مقاييس الأداء:
# توليد شعاع الخرج y = tweets['topic'] # مكنبة تقسيم البيانات إلى تدريب واختبار from sklearn.model_selection import train_test_split # تقسيم البيانات إلى تدريب واختبار X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0) print(X_train.shape, y_train.shape) print(X_test.shape, y_test.shape)
نطبع في الشيفرة السابقة حجوم أشعة الدخل والخرج للتدريب وللاختبار:
(30520, 50) (30520,) (7630, 50) (7630,)
نموذج الشبكة العصبية المتعلم
تُعدّ المكتبة Keras من أهم مكتبات بايثون التي توفر بناء شبكات عصبية لمسائل التعلم الآلي.
تعرض الشيفرة التالية التصريح عن دالة بناء نموذج التعلّم create_model مع إعطاء جميع المعاملات المترفعة قيمًا ابتدائية:
# تضمين النموذج التسلسلي from keras.models import Sequential # تضمين الطبقات اللازمة from keras.layers import Embedding, Dense, LSTM # دوال التحسين from tensorflow.keras.optimizers import Adam, RMSprop # التصريح عن دالة إنشاء نموذج التعلم # مع إعطاء قيم أولية للمعاملات المترفعة def create_model(embed_dim = 32, hidden_unit = 16, dropout_rate = 0.2, optimizers = RMSprop, learning_rate = 0.001): # التصريح عن نموذج تسلسلي model = Sequential() # طبقة التضمين model.add(Embedding(input_dim = max_words, output_dim = embed_dim, input_length = MAX_LENGTH)) # LSTM model.add(LSTM(units = hidden_unit ,dropout=dropout_rate)) # الطبقة الأخيرة model.add(Dense(units = len(classes), activation = 'softmax')) # يناء النموذج model.compile(loss = 'sparse_categorical_crossentropy', optimizer = optimizers(learning_rate = learning_rate), metrics = ['accuracy']) # طباعة ملخص النموذج print(model.summary()) return model
نستخدم من أجل مسألتنا نموذج شبكة عصبية تسلسلي يتألف من ثلاث طبقات هي: طبقة التضمين Embedding وطبقة LSTM (شبكة ذات ذاكرة طويلة المدى) والطبقة الكثيفة Dense.
الطبقة الأولى: طبقة التضمين Embedding
نستخدم هذه الطبقة لتوليد ترميز مكثف للكلمات dense word encoding مما يُساهم في تحسين عملية التعلم. نطلب تحويل الشعاع الذي طوله input_length (في حالتنا 50) والذي يحوي قيم ضمن المجال input_dim (من 1 إلى 5000 في مثالنا) إلى شعاع من القيم ضمن المجال output_dim (مثلًا 32 قيمة).
الطبقة الثانية: شبكة ذات ذاكرة طويلة المدى Long Short-Term Memory
يُحدّد المعامل المترفع units عدد الوحدات المخفية لهذه الطبقة. يُساهم المعامل dropout في معايرة الشبكة خلال التدريب حيث يقوم بإيقاف تشغيل الوحدات المخفية بشكل عشوائي أثناء التدريب، وبهذه الطريقة لا تعتمد الشبكة بنسبة 100٪ على جميع الخلايا العصبية الخاصة بها. وبدلاً من ذلك، تُجبر نفسها على العثور على أنماط أكثر أهمية في البيانات من أجل زيادة المقياس الذي تحاول تحسينه (الدقة مثلًا).
الطبقة الثالثة: الكثيفة Dense
يُحدّد المعامل units حجم الخرج لهذه الطبقة (7 في حالتنا: عدد الصفوف) ويُبين الشكل التالي ملخص النموذج:
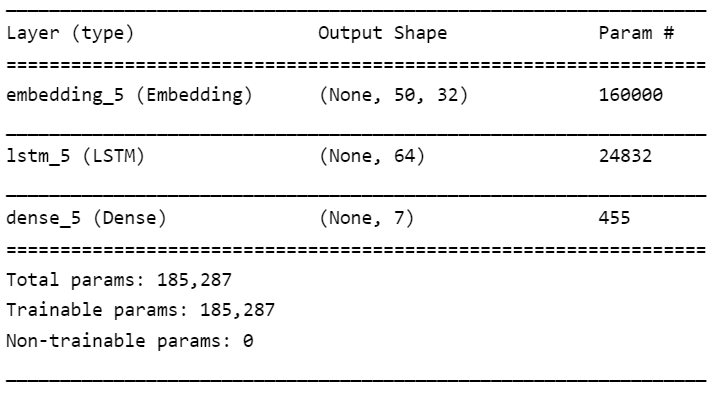
معايرة المعاملات الفائقة للوصول لنموذج أمثلي
يمكن الوصول لنموذج تعلم أمثلي بمعايرة معاملاته الفائقة وفق معطيات المشروع. لنُبين أولًا الفرق بين المعاملات الفائقة لنموذج والمعاملات الأخرى له:
- المعاملات الفائقة hyperparameters: هي إعدادات خوارزمية التعلّم قبل التدريب (والتي وضعها مصممو الخوارزمية).
- المعاملات parameters: هي المعاملات التي يتعلّمها النموذج أثناء التدريب مثل أوزان الشبكة العصبية.
تؤثر عملية معايرة المعاملات الفائقة على أداء النموذج لاسيما لجهة التوزان المطلوب بين مشكلة قلة التخصيص underfitting ومشكلة فرط التخصيص overfitting واللتان تؤديان إلى نموذج غير قادر على تعميم أمثلة التدريب وبالتالي لن يتمكن من التصنيف مع معطيات جديدة (يُمكن العودة لمقال تعلم الآلة: التحديات الرئيسية وكيفية التوسع في المجال من أكاديمية حسوب للمزيد من التفصيل حول هاتين المشكلتين).
تظهر مشكلة قلة التخصيص عندما لا يكون للنموذج درجات حرية كافية ليتعلّم الربط بين الميزات والهدف، وبالتالي يكون له انحياز كبير Bias–variance tradeoff نحو قيم معينة للهدف. يُمكن تصحيح قلة التخصيص بجعل النموذج أكثر تعقيدًا. أما مشكلة فرط التخصيص فتظهر عندما يقوم النموذج بتخزين بيانات التدريب فيكون له بالتالي تباين كبير والذي يُمكن تصحيحه بالحد من تعقيد النموذج باستخدام التسوية regularization.
تكمن المشكلة في معايرة المعاملات الفائقة بأن قيمها المثلى تختلف من مسألة لأخرى! وبالتالي، فإن الطريقة الوحيدة للوصول لهذه القيم المثلى هي تجريب قيم مختلفة مع كل مجموعة بيانات تدريب جديدة.
يوفر Scikit-Learn العديد من الطرق لتقويم المعاملات الفائقة وبالتالي سنعتمد في مشروعنا عليها دون أن نُعقّد الأمور أكثر.
يُمكن العودة إلى مقال تحليل المشاعر في اللغة العربية باستخدام التعلم العميق فقرة "البحث الشبكي مع التقييم المتقاطع" لشرح طريقة حسابنا لأفضل القيم للمعاملات المترفعة.
بناء نموذج التعلم النهائي
نستخدم الدالة KerasClassifier من scikit لبناء المُصنف مع الدالة السابقة create_model:
# مكتبة التصنيف from keras.wrappers.scikit_learn import KerasClassifier # إنشاء النموذج مع قيم المعاملات المترفعة الأمثلية model = KerasClassifier(build_fn = create_model, # معاملات النموذج dropout_rate = 0.2, embed_dim = 32, hidden_unit = 64, optimizers = Adam, learning_rate = 0.001, # معاملات التدريب epochs=10, batch_size=256, # نسبة بيانات التقييم validation_split = 0.1) # ملائمة النموذج مع بيانات التدريب model_prediction = model.fit(X_train, y_train)
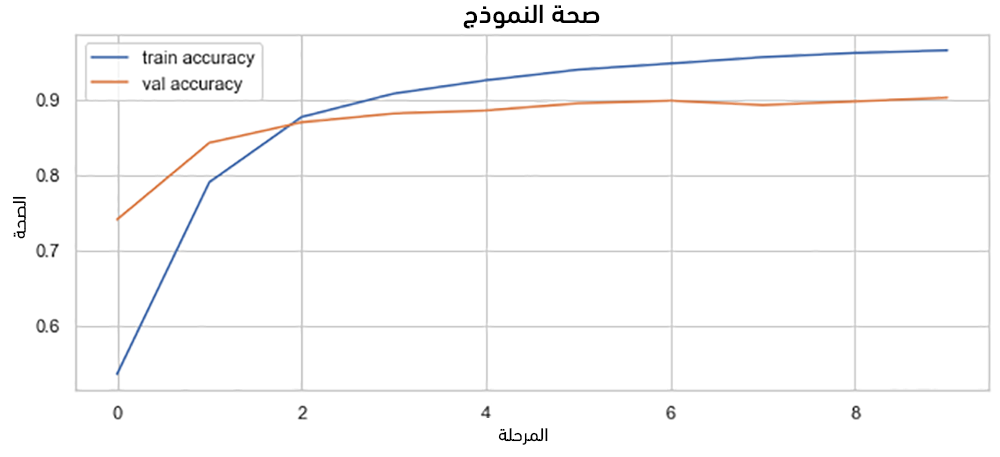
يُمكن الآن رسم منحني الدقة accuracy لكل من بيانات التدريب والتقييم (لاحظ أننا في الشيفرة السابقة احتفاظنا بـ 10% من بيانات التدريب للتقييم):
# معاينة دقة النموذج # التدريب والتقييم fig, ax = plt.subplots(figsize = (10, 4)) ax.plot(model_prediction.history['accuracy'], label = 'train accuracy') ax.plot(model_prediction.history['val_accuracy'], label = 'val accuracy') ax.set_title('Model Accuracy') ax.set_xlabel('Epoch') ax.set_ylabel('Accuracy') ax.legend(loc = 'upper left') plt.show()
يكون للمنحي الشكل التالي:
حساب مقاييس الأداء
يُمكن الآن حساب مقاييس الأداء المعروفة في مسائل التصنيف (الصحة Accuracy، الدقة Precision، الاستذكار Recall، المقياس F1) للنموذج المتعلم باستخدام الشيفرة التالية:
# مقاييس الأداء # مقياس الصحة from sklearn.metrics import accuracy_score # مقياس الدقة from sklearn.metrics import precision_score # مقياس الاستذكار from sklearn.metrics import recall_score # f1 from sklearn.metrics import f1_score # مصفوفة الارتباك from sklearn.metrics import confusion_matrix # تصنيف بيانات الاختبار y_pred = model.predict(X_test) # حساب مقاييس الأداء accuracy = accuracy_score(y_test, y_pred) precision=precision_score(y_test, y_pred , average='weighted') recall= recall_score(y_test, y_pred, zero_division=1, average='weighted') f1= f1_score(y_test, y_pred, zero_division=1, average='weighted') print('Model Accuracy on Test Data:', accuracy*100) print('Model Precision on Test Data:', precision*100) print('Model Recall on Test Data:', recall*100) print('Model F1 on Test Data:', f1*100) confusion_matrix(y_test, y_pred)
تكون النتائج:
Model Accuracy on Test Data: 90.90 Model Precision on Test Data: 90.88 Model Recall on Test Data: 90.90 Model F1 on Test Data: 90.86 array([[ 964, 22, 24, 57, 16, 12, 19], [ 18, 1029, 26, 20, 15, 9, 8], [ 13, 18, 1033, 19, 5, 8, 3], [ 45, 19, 52, 871, 59, 12, 10], [ 11, 25, 18, 38, 990, 11, 3], [ 3, 10, 13, 3, 15, 986, 3], [ 4, 10, 8, 2, 0, 8, 1063]], dtype=int64)
لاحظ ارتفاع قيم جميع المقاييس مما يعني جودة المُصنف.
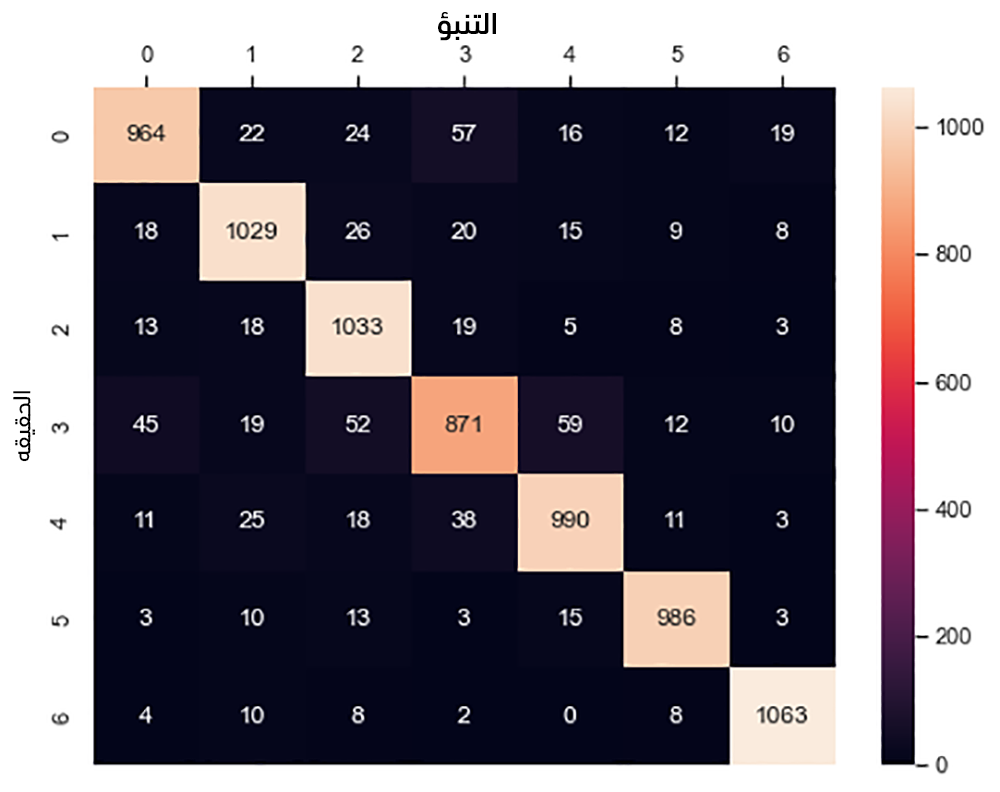
يُمكن رسم مصفوفة الارتباك confusion matrix بشكل أوضح باستخدام المكتبة seaborn:
# رسم مصفوفة الارتباك import seaborn as sns sns.set(style = 'whitegrid') fig, ax = plt.subplots(figsize = (8,6)) sns.heatmap(confusion_matrix(y_true = y_test, y_pred = y_pred), fmt = 'g', annot = True) ax.xaxis.set_label_position('top') ax.xaxis.set_ticks_position('top') ax.set_xlabel('Prediction', fontsize = 14) ax.set_ylabel('Actual', fontsize = 14) plt.show()
مما يُظهر المخطط التالي:
يُمكن حساب بعض مقاييس الأداء الأخرى المُستخدمة في حالة وجود أكثر من صف في المسألة (Micro, Macro, Weighted):
# مقاييس الأداء في حالة أكثر من صفين print('\nAccuracy: {:.2f}\n'.format(accuracy_score(y_test, y_pred))) print('Micro Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='micro'))) print('Micro Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='micro'))) print('Micro F1-score: {:.2f}\n'.format(f1_score(y_test, y_pred, average='micro'))) print('Macro Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='macro'))) print('Macro Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='macro'))) print('Macro F1-score: {:.2f}\n'.format(f1_score(y_test, y_pred, average='macro'))) print('Weighted Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='weighted'))) print('Weighted Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='weighted'))) print('Weighted F1-score: {:.2f}'.format(f1_score(y_test, y_pred, average='weighted'))) # تقرير التصنيف from sklearn.metrics import classification_report print('\nClassification Report\n') print(classification_report(y_test, y_pred, target_names=classes))
مما يُعطي الناتج التالي:
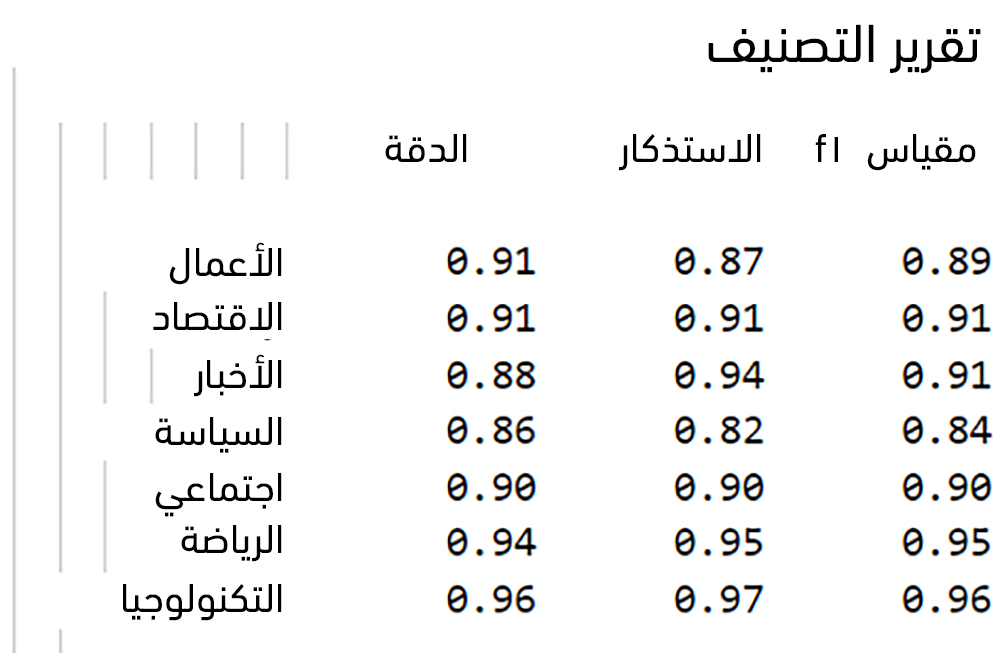
لاحظ ارتفاع جميع المقاييس مما يعني جودة المُصنف.
تصنيف الأشخاص
يُمكن الآن تصنيف الأشخاص وذلك وفق تصنيفات تغريداتهم.
تقوم الشيفرة التالية بتصنيف تغريدة واحدة، فيكون دخل الدالة classify_tweet سلسلة نصية نضعها أولًا في متجهة تحوي النص. نستدعي دالة تحويل النص إلى أرقام tokenizer.texts_to_sequences ومن ثم توحيد طول المتجهة الرقمية الناتجة وذلك باستدعاء الدالة pad_sequences.
# دالة تصنيف تغريدة def classify_tweet(tweet): # تحويل شعاع الكلمات إلى جملة tweet = toSentence(tweet) # وضع الجملة في شعاع ar=[] ar.append(tweet) # تحويل النص إلى قائمة من الأرقام seq = tokenizer.texts_to_sequences(ar) # توحيد طول المتجهة الرقمية pseq = pad_sequences(seq, maxlen=max_len) # استدعاء دالة التنبؤ للنموذج pred = model.predict(pseq) return pred
تقوم الدالة classify_person بتصنيف شخص، ويكون معامل الدالة اسم الشخص (بفرض أن ملف تغريداته يحمل نفس الاسم مع اللاحقة csv)، إذ تعمل الدالة أولًا على تحميل تغريدات الشخص في إطار بيانات df.
وأخيرًا تكون دالة تصنيف الشخص classify_person هي:
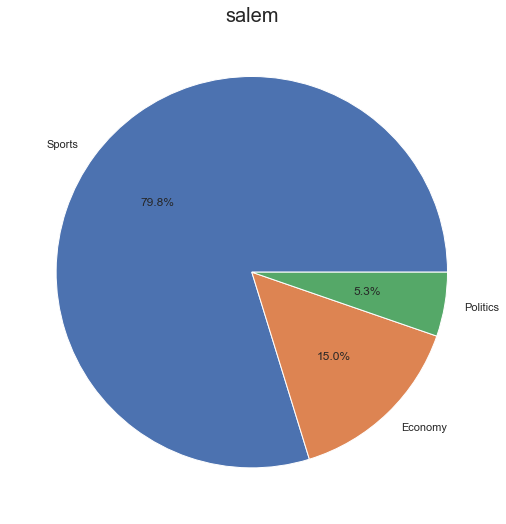
# دالة تصنيف الشخص def classify_person(person_name): # تحميل تغريدات الشخص # في إطار بيانات path = person_name + '.csv' df = pd.read_csv(path) # إنشاء قاموس لعد # التغريدات من كل صف classes_count=dict() # إعطاء قيم ابتدائيه 0 for i in range(len(classes)): key=classes[i] classes_count[key]=0 # الحد الأدنى لطول التغريدة min_tweet_len=5 total=0 for _, row in df.iterrows(): tweet=row['tweet'] # تنظيف التغريدة processed_tweet=process_tweet(tweet) if len(processed_tweet)>min_tweet_len: # تصنيف التغريدة c= classify_tweet(processed_tweet) # إيجاد اسم الصف من رمزه topic=le_topics.inverse_transform(c)[0] # إضافة 1 للصف الموافق classes_count[topic]=classes_count[topic]+1 total=total+1 # ترتيب الصفوف وفق العدد # تنازلياً sorted_classes = sorted(classes_count, key=classes_count.get,reverse=True) # القاموس النهائي sorted_classes_cleaned = {} min_display=total/25 # إهمال الصفوف ذات العدد الصغير for w in sorted_classes: if classes_count[w]>min_display: sorted_classes_cleaned[w] = classes_count[w] # طباعة النتائج print(sorted_classes_cleaned) n=0 for key, value in sorted_classes_cleaned.items(): n=n+value print(person_name, "is classified as :") for key, value in sorted_classes_cleaned.items(): print(key, "(", "{:.2f}".format((value/n)*100) , "%)") # رسم فطيرة أعداد الصفوف x = sorted_classes_cleaned.keys() y = sorted_classes_cleaned.values() import matplotlib.pyplot as plt # pie plt.figure(figsize=(9,9)); plt.title(person_name, fontdict = {'fontsize':20}) plt.pie(y, labels = x,autopct='%1.1f%%') plt.show() # مثال classify_person("salem")
نجد من الشيفرة السابقة، تُنشئ الدالة القاموس classes_count والذي يكون مفتاحه اسم الصف وقيمته ستكون عدد التغريدات من هذا الصف (تُعطي أولًا قيمة ابتدائية 0 لكل قيم القاموس).
يُحدّد المتغير min_tweet_len الطول الأدنى للتغريدة لتؤخذ بعين الاعتبار (لا تحمل التغريدات الصغيرة جدًا معاني بل تكون على الأغلب عبارات مجاملة وترحيب).
تدور الدالة على تغريدات الشخص وتستدعي من أجل كل تغريدة دالة المعالجة الأولية للتغريدة process_tweet ثم دالة التصنيف السابقة classify_tweet.
يكون ناتج التصنيف رقم (ترميز الصف) ولذا تستدعي الدالة inverse_transform للحصول على اسم الصف ثم نزيد عدد الصف الموافق في القاموس بـ 1.
يحسب المتغير total العدد الكلي للتغريدات التي تم أخذها بعين الاعتبار، وتُستخدم الدالة المتغير sorted لترتيب القاموس تنازليا (المعامل reverse=True) وفق العدد.
نضع في المتغير min_display مثلًا القيمة total/25 وذلك بهدف عدم إظهار صفوف الشخص قليلة التواتر في تغريداته، ونضع أخيرًا في القاموس sorted_classes_cleaned الصفوف الأكثر تواترًا ونطبع النتائج ونرسم فطيرة تُمثل النسب المئوية لتغريدات الشخص.
تكون النتائج مثلًا:
الخلاصة
عرضنا في هذه المقالة خطوات بناء نموذج تعلّم لتصنيف الأشخاص وفق تغريداتهم.
يُمكن تجربة المثال كاملًا من موقع Google Colab من الرابط أو من الملف المرفق data.zip.
اقرأ أيضًا
- تحليل المشاعر في النصوص العربية باستخدام التعلم العميق
- دليل المبتدئين لفهم أساسيات التعلم العميق
- خطوات تنفيذ مشروع عن تعلم الآلة في بايثون: الجزء الأول







أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.