

هذا المقال جزء من سلسلة «مدخل إلى الذكاء الاصطناعي»:
- الذكاء الاصطناعي: أهم الإنجازات والاختراعات وكيف أثرت في حياتنا اليومية
- الذكاء الاصطناعي: مراحل البدء والتطور والأسس التي نشأ عليها
- المفاهيم الأساسية لتعلم الآلة
- تعلم الآلة: التحديات الرئيسية وكيفية التوسع في المجال
- يمكنك قراءة السلسلة على شكل كتاب إلكتروني بالانتقال إلى صفحة الكتاب، مدخل إلى الذكاء الاصطناعي وتعلم الآلة.
إن سبق وحاولت قراءة أي مقالٍ على الإنترنت يتحدث عن تعلّم الآلة، فلا بدّ من أنك عثرت على نوعين من المقالات؛ فإما أن تكون سميكة وأكاديمية ومليئة بالنظريات (عن نفسي لم أستطع حتى تجاوز نصف مقال)، أو عن القصص الخيالية المريبة حول سيطرة الذكاء الصنعي على البشر، أو منهم من يتحدث عن البيانات وتأثيرها الساحر على مجالات العلوم الأخرى أو البعض الآخر من المقالات يتحدث عن كيفية تغيّر وظائف المستقبل. لم يكن هنالك أي كتاب يضعني على بداية الطريق لكي أتعلم أبسط الأساسيات لأنتقل بعدها إلى المفاهيم المعقدة واثق الخطى.
لذا كان لا بدّ لي من كتابة مقالٍ بسيط ومفهوم وواقعي لطالما تمنيت وجوده. سيكون هذا المقال مقدمة بسيطة لأولئك الّذين أرادوا دومًا فهم طريقة عمل مجال تعلّم الآلة. بتطبيق أفكاره على أمثلة من مشاكل العالم الحقيقي، والحلول العملية المطبقة، بلغة بسيطة ومفهومة، وتجنب النظريات الصعبة قدر الإمكان. ليستطيع الجميع فهم ماهيّة هذا العِلم سواءً أكانوا مبرمجين أو مدراء بل وحتى لأي شخص كان.
فهرس المحتويات
- لماذا نريد من الآلات أن تتعلم؟
- المكونات الرئيسية لتعلم الآلة
- الفرق بين التعلم (Learning) والذكاء (Intelligence)
- تعلم الآلة التقليدي
- التجميع (Clustering)
- التعلم المعزز (Reinforcement Learning)
- الشبكات العصبية (Neural Networks) والتعلم العميق (Deep Leaning)
- الخلاصة
- المراجع
وإليك المخطط الرئيسي للمواضيع التي سنتناولها في هذه المقالة ملخصة بالصورة التالية:

لماذا نريد من الآلات أن تتعلم؟
هذا صديقنا أحمد يريد شراء سيارة ويحاول حساب مقدار مبلغ المال الّذي سيحتاجُ لتوفيره شهريًا. واستعرض عشرات الإعلانات على الإنترنت وعلم بأن السيارات الجديدة يبلغ سعرها حوالي 20000 دولار، والسيارات المستعملة لعام واحد يبلغ سعرها 19000 دولار، والمستعملة لعامين يبلغ سعرها 18000 دولار وهكذا دواليك.
يبدأ أحمد -محللنا الرائع- بملاحظة نمط معين لسعر السيارات؛ إذ يعتمد سعر السيارة على مدة استخدامها، وينخفض سعرها بمقدار 1000 دولار مقابل كلّ عام من عمرها، لكن سعرها لن ينخفض أقل من 10000 دولار.

في هذه الحالة وطبقًا لمصطلحات تعلّم الآلة يكون أحمد قد ابتكر ما يُعرفُ بالانحدار (Regression): وهي طريقة لتوقع قيمة (أو سعر) معيّن على أساس بيانات قديمة معروفة. أغلب الناس تؤدي هذا الأمر طوال الوقت دون أن تشعر به، فمثلًا عند محاولتنا لتقدير السعر المعقول لجهاز أيفون مستعمل على موقع eBay، أو أثناء محاولتنا معرفة وزن اللحوم المناسب والكافي لبلوغ حدّ الشبع لكلّ شخص من المدعوين على عزومة الغداء. فعندها سنبدأ بتقدير الأمر ونسأل أنفسنا، هل 200 غرام كافي للشخص؟ أم 500 غرام أفضل؟ سواءً اعترفنا بذلك أم لا، أغلبنا يؤدي هذه المهمة لا شعوريًا.
سيكون من الجميل أن يكون لدينا صيغة بسيطة مثل هذه لحلّ كلّ مشكلة في العالم. وخاصة بالنسبة لعزومة الغداء. ولكن لسوء الحظ هذا مستحيل.
لنعود إلى مثال السيارات. المشكلة الحقيقية في هذا المثال هو وجود تواريخ تصنيع مختلفة، وعشرات الأنواع من السيارات، والحالة الفنية للسيارة، بالإضافة لارتفاع الطلب الموسمي على سيارة معينة، والكثير من العوامل المخفية الأخرى الّتي تؤثر بسعر السيارة. وبالتأكيد لن يستطيع صديقنا أحمد الاحتفاظ بكلّ هذه البيانات في رأسه أثناء حسابه للسعر.
معظم الناس كسالى بطبعهم ولذلك سنحتاج حتمًا لآلات لتأدية العمليات الرياضية. لذا لنجاري الوضع الحاصل ولِنتجه باتجاه توفير آلة تؤدي هذه المهمة الحسابية الّتي واجهناها. ولنُوفر لها بعض البيانات اللازمة وسنطلبُ منها العثور على جميع الأنماط المخفية المتعلقة بالسعر.
الجميل في الأمر أن هذه الآلة ستُؤدي هذه المهمة بطريقة أفضل بكثير مما سيُؤديه بعض الناس عند تحليلهم بعناية لجميع التبعيات المتعلقة بالسعر في أذهانهم. في الحقيقة كان هذا النوع من المشاكل المحفز الأساسي لولادة تعلّم الآلة.
المكونات الرئيسية لتعلم الآلة
لو أردنا اختصار جميع الأهداف الكامنة وراء مجال تعلّم الآلة فسيكون الهدف الوحيد هو توقع النتائج معينة بناءً على البيانات المدخلة (أي التعلّم من البيانات المدخلة). وهذا خلاصة الأمر. إذ يمكن تمثيل جميع مهام تعلّم الآلة بهذه الطريقة.
كلّما زاد تنوع البيانات (تسمى في بعض الأحيان بالعينات) المجمعة لديك، كلّما كان مهمة العثور على الأنماط ذات الصلة والتنبؤ بالنتيجة أسهل نسبيًا. لذلك، فإن أي نظام يستخدم تعلّم الآلة سيحتاجُ لثلاثة مكونات رئيسية وهي:
1. البيانات (Data)
هل تريد الكشف عن رسائل البريد الإلكتروني المزعجة؟ احصل على عينات من الرسائل هذه الرسائل المزعجة. هل تريد التنبؤ بالتغيرات الّتي تطرأ على أسعار الأسهم؟ ابحث عن سجلات أسعار الأسهم. هل تريد معرفة ما هي تفضيلات المستخدم؟ حللّ أنشطته على الفيسبوك، واعتقد بأن مارك زوكربيرج ماهرٌ جدًا في ذلك. كلما كانت البيانات أكثر تنوعًا، كانت النتيجة أفضل. في بعض الأحيان تكون عشرات الآلاف من سجلات البيانات هي الحد الأدنى لاستنتاج معلومة معينة. وفي البعض الآخر نحتاج إلى ملايين العينات.

هناك طريقتين رئيسيتين للحصول على البيانات:
- الطريقة اليدوية.
- الطريقة الآلية.
تتميز البيانات المجمّعة يدويًا باحتوائها على أخطاء أقل بكثير بالموازنة مع نظيرتها الآلية، ولكنها بالمقابل تستغرق وقتًا أطول في التجميع مما يجعلها أكثر تكلفة عمومًا. أما الطريقة الآلية فتكون أرخص إذ كلّ ما سنفعله هو جمع كلّ ما يمكننا العثور عليه على أمل أن تكون جودة هذه البيانات مقبولة.
تستخدم بعض الشركات مثل غوغل عملائها لتصنيف البيانات لهم مجانًا. هل تعلم لماذا طريقة التحقق البشري ReCaptcha (المستخدمة في أغلب المواقع) تجبرك على "تحديد جميع لافتات الشوارع الموجودة في صورة معينة"؟ في الحقيقة إن هذه الطريقة ما هي إلا وسيلة لتصنيف البيانات وتعظيم الاستفاد منها. إذ يستغلون حاجتك للتسجيل في الموقع معين ويسخّرونك مجبرًا للعمل لديهم وبالمجان. مدعين بأنهم بهذه الطريقة يختبرونك بأنك بشري! نعم هذا بالضبط ما يفعلونه! تبًا لهم الأشرار! أراهن لو أنك بمكانهم فستُظهر رمز التحقق البشري أكثر منهم بكثير. أليس كذلك؟
بيد أن من الصعوبة بمكان الحصول على مجموعة جيدة من البيانات -والتي تسمى عادةً مجموعة بيانات (Dataset). وهذه المجموعات مُهمّة للغاية بل إن مجموعة البيانات ذات الجودة العالية هي في الواقع كنز حقيقي لصاحبها لدرجة أن الشركات يمكن أن تكشف أحيانًا عن خوارزمياتها، إلا أنها نادرًا ما تكشف مجموعات البيانات الخاصة بها.
2. الميزات (Features)
تُعرف أيضًا باسم المعاملات (Parameters) أو المتغيّرات (Variables). والتي يمكن أن تعبر عن المسافة المقطوعة بالسيارات، أو جنس المستخدم، أو سعر السهم، أو تكرار كلمة معينة في النص. بعبارة أخرى، هذه هي الميزات الّتي يجب أن تنظرَ لها الآلة.
عندما تكون البيانات مخزنة في الجداول، يكون الأمر بسيطًا - فالميّزات هي أسماء الأعمدة. ولكن ماذا لو كان لديك 100 غيفابايت من صور القطط؟ بكلّ تأكيد لا يمكننا اعتبار كلّ بكسل ميزّة. هذا هو السبب بكون اختيار الميّزات الصحيحة يستغرق عادة وقتًا أطول من أي خطوة أخرى في بناء نظام يعتمد على تعلّم الآلة. وهذا أيضًا هو المصدر الرئيسي للأخطاء. ولذلك دائمًا ما تكون الاختيارات البشرية غير موضوعية. إذ يختارون فقط الميّزات الّتي يحبونها أو تلك الّتي يجدونها "أكثر أهمية". ولذا من فضلك تجنب أن تكون بشريًا!
3. الخوارزميات (Algorithms)
وهو الجزء الأسهل والأكثر وضوحًا. إذ يمكن حلّ أي مشكلة بطرق مختلفة. بيد أن الطريقة الّتي تختارها ستُؤثر على دقة النموذج النهائي وأدائه وحجمه. هناك فارق بسيط واحد مهم: إذا كانت البيانات سيئة فلن تساعدك حتى أفضل خوارزمية موجودة. في بعض الأحيان يشار إليها بمصطلح "الدخل السيئ سيؤدي إلى نتائج سيئة". لذلك لا تهتم كثيرًا لنسبة الدقة، وحاول الحصول على المزيد من البيانات كبداية.
من الجدير بالذكر أن مصطلح نموذج (Model) يشير إلى ما خلاصة ما تعلمته من البيانات، ويكمننا في بعض الأحيان استخدام نموذج جاهز وتمرير البيانات له أو تحسين نموذج حالي.
الفرق بين التعلم (Learning) والذكاء (Intelligence)
إن سبق ورأيت مقالًا بعنوان "هل ستحلّ الشبكات العصبية محل تعلم الآلة؟" أو على شاكلته من العناوين الّتي تنشرها بعض المواقع التابعة لوسائل إعلامية على الإنترنت. دائمًا ما يسمي رجال الإعلام هؤلاء أي انحدار خطي (Linear Regression) على أنه ذكاء اصطناعي، بل إن بعض وسائل الإعلام تضخم الأمور لدرجة يصعب تصديقها حتى أصبحنا نخاف من الذكاء الصنعي كما خاف أبطال فيلم Terminator من الروبوت SkyNet. وإليك صورة توضح المفاهيم وتفض الالتباس الموجود:
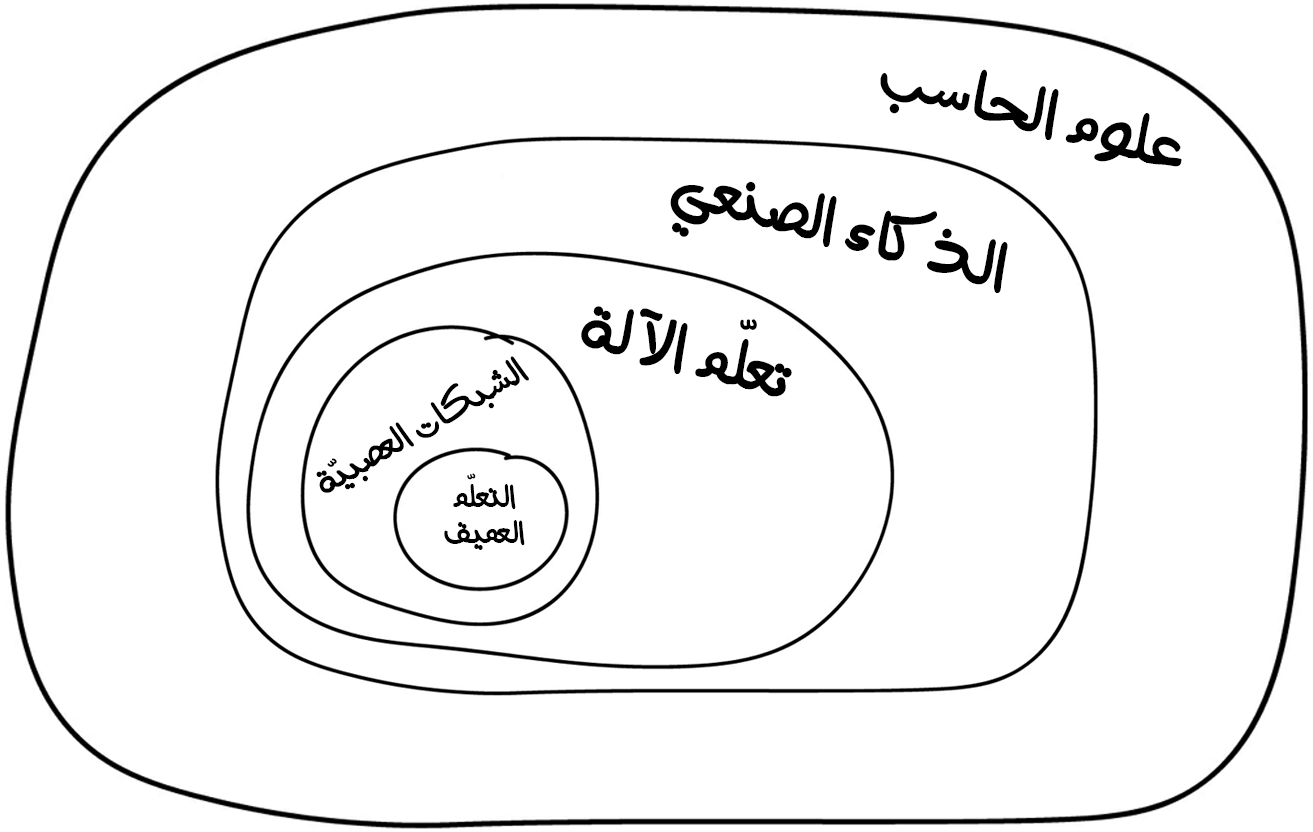
علوم الحاسب (Computer Science): عمومًا هو دراسة أجهزة الحاسب بما فيها من أسس نظرية و حسابية، كما تشتمل على دراسة الخوارزميات، وبُنى المعطيات وأساسيات تصميم الشبكات ونمذجة البيانات ..وغيرها.
الذكاء الصناعي (Artificial Intelligence): وهو فرع من فروع علوم الحاسب يهدف إلى تعزيز قدرة الآلات والحواسيب على أداء مهام مُعينة تُحاكي وتُشابه تلك الّتي تقوم بها الكائنات الذكيّة؛ كالقدرة على التفكير، أو التعلُم من التجارب السابقة، أو غيرها من العمليات الأُخرى الّتي تتطلب عمليات ذهنية.
تعلم الآلة (Machine Learning): وهو جزء مهم من الذكاء الاصطناعي، وهو أحد فروع الذكاء الاصطناعي الّذي يُعنى بجعل الحاسوب قادرًا على التعلُم من تلقاء نفسه من أيّ خبرات أو تجارب سابقة، مما يجعله قادرًا على التنبؤ واتخاذ القرار المُناسب بصورة أسرع، ولكن تعلم الآلة ليس الفرع الوحيد الّذي يؤدي هذه المهمة.
الشبكات العصبية الاصطناعية (Artificial Neural Networks): وهي من أحد أشهر الطرق الشعبية في مجال تعلّم الآلة، ولكن هناك طرق أخرى جيدة أيضًا.
التعلم العميق (Deep Learning): هو طريقة حديثة لبناء وتدريب واستخدام الشبكات العصبية. وهي بالأساس هيكلية جديدة للشبكات العصبية. وحاليًا لا أحد يفصل التعلم العميق عن "الشبكات العصبية العادية". حتى أننا نستخدم نفس المكتبات لهم. من الأفضل دومًا تسمية نوع الشبكة وتجنب استخدام الكلمات الرنانة.
من المهم دائمًا تذكر بأنه لا توجد طريقة واحدة أبدًا لحل مشكلة معينة في مجال تعلّم الآلة. بل هناك دائمًا العديد من الخوارزميات الّتي يمكنها حل نفس المشكلة، وتبقى مهمة اختيار الطريقة أو الخوارزمية الأنسب عائدة إليك. إذ يمكنك حلّ أيّ شيء باستخدام شبكة عصبية اصطناعية، ولكن من الّذي سيدفع لك ثمن استئجار (أو حتى شراء) بطاقة معالجة الرسوميات (GPU) من نوع GeForces؟
لنبدأ بنظرة عامة أساسية على الاتجاهات الأربعة السائدة حاليًا في مجال تعلّم الآلة.
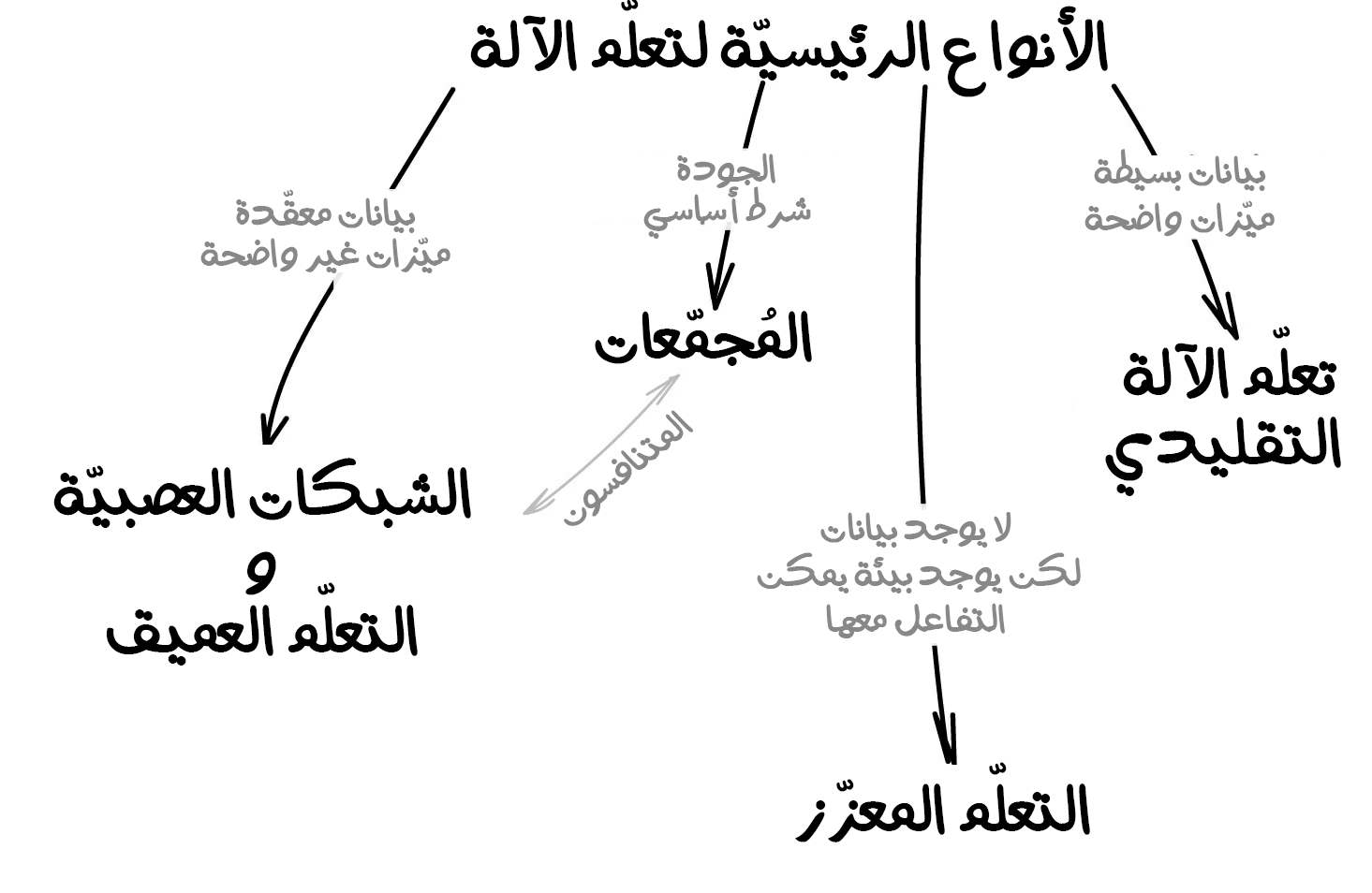
تعلم الآلة التقليدي
جاءت الطرق الأولى لتعلّم الآلة من مجال الإحصاء البحت في خمسينات القرن الماضي. إذ اعتمد العلماء على حلّ معظم المهام الرياضية الرسمية من خلال البحث عن الأنماط في الأرقام، وتقييم قرب نقاط البيانات، وحساب اتجاه المتجهات.
يعمل حاليًا نصف الإنترنت على هذه الخوارزميات. فعندما ترى قائمة بالمقالات المرشحة لك قراءتها في أحد المواقع، أو عندما يحظر البنك الّذي تتعامل معه بطاقتك عند تمريرك إياها على الآلة في محطة وقود عشوائية في مكان مجهول بعيدة عن سكنك، فعلى الأرجح هذه الأفعال ناتجة عن خوارزميات تعلّم الآلة.
تعد الشركات التكنولوجيا الكبرى من أكبر المعجبين بالشبكات العصبية، إذ أنها تستطيع الاستفادة منها بقدر أكبر من الشركات الناشئة. فمثلًا يمكن لدقة صغيرة ولتكن 2٪ لإحدى خوارزمياتها الحساسة أن تعود بالنفع على إيرادات الشركة بمبلغ مالي ضخم يبلغ 2 مليار دولار. ولكن عندما تكون شركتك صغيرة وناشئة، فهذه النسبة ليست ذات فائدة كبيرة.
فإذا أمضى المهندسين في فريقك البرمجي سنة كاملة يعملون على تطوير خوارزمية توصية جديدة لموقع التجارة الإلكترونية الخاص بك، مع معرفتهم بأن 99٪ من الزيارات تأتي من محركات البحث. عندها ستكون فائدة الخوارزمية قليل جدًا إذ لم عديمة الفائدة تمامًا وخصيصًا أن معظم المستخدمين لم يفتحوا الصفحة الرئيسية. فهذا سيكون أكبر هدر لطاقة فريقك البرمجي وبذلك سيكون أسوء استثمار لهذه العقول خلال هذه السنة.
بصرف النظر عن ما يقال عن هذه الطرق إلا أنها سهلة سهولة كبيرة. بل إنها مثل أساسيات الرياضيات وأغلبنا يستخدمها يوميًا بدون أن يفكر بها.
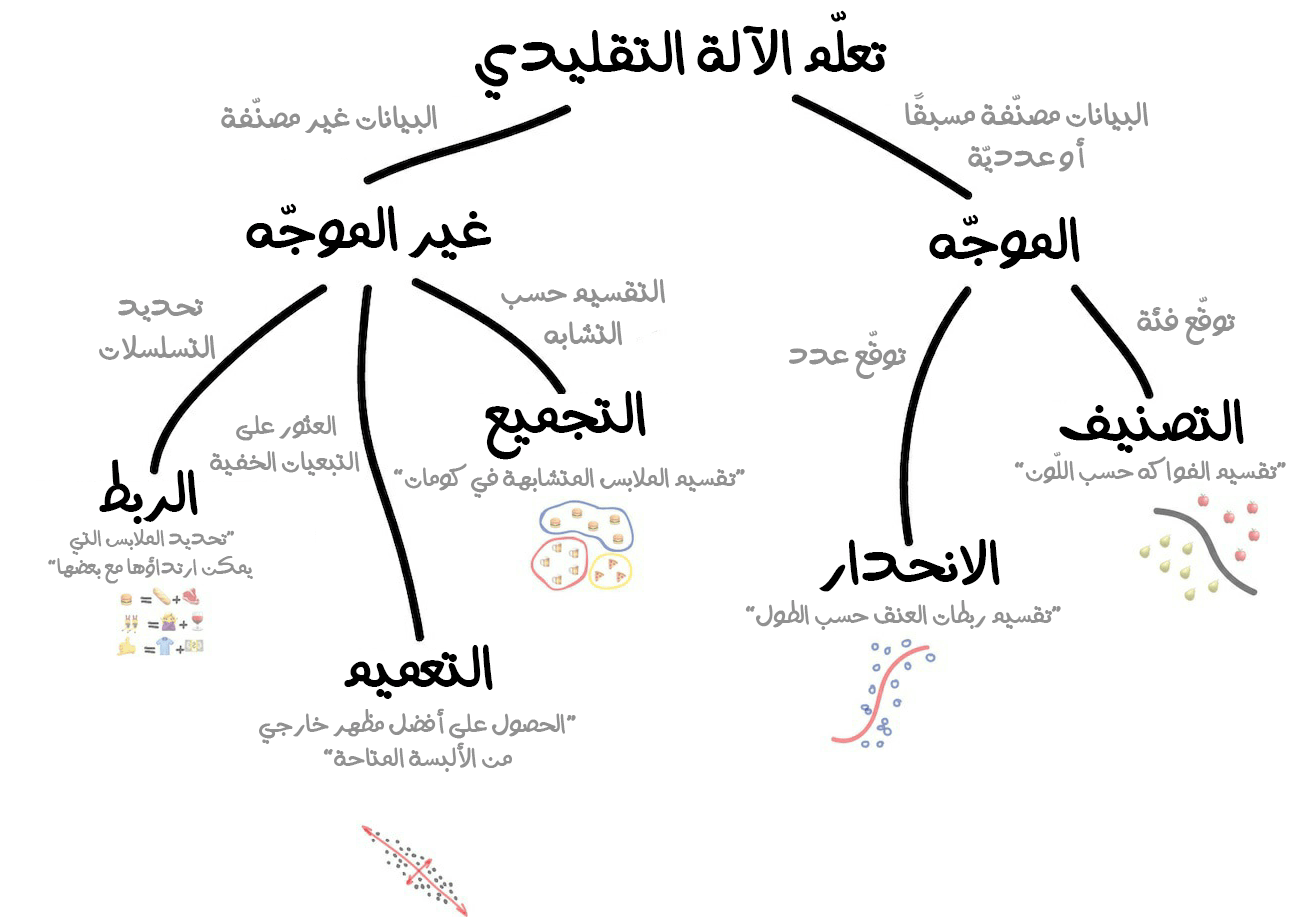
ينقسم تعلّم الآلة الكلاسيكي إلى فئتين وهما التعلّم الموجّه (ويسمى أيضًا التعلّم الخاضع للإشراف) و التعلّم غير الموجّه (ويسمى أيضًا التعلّم غير الخاضع للإشراف).
التعلم الموجه (Supervised Learning)
تحتوي الآلة على "مشرف" أو "مُعلّم" يزود الآلة بجميع الإجابات الصحيحة والدقيقة، مثل تحديد فيما إذا كان الشكل في الصورة لقطة أو كلب. قسّم (أو صنّف) المعلم بهذا الطريقة فعليًا البيانات إلى قطط وكلاب، ويستخدم الجهاز هذه الأمثلة الصحيحة للتعلم منها. واحدًا تلو الآخر.
أما التعلم غير الموجّه فأن سيترك الآلة بمفردها مع كومة كبيرة من صور الحيوانات ومهمتها ستكون تصنيف هذه الصور. وذلك لأن البيانات غير مصنفة، ولا يوجد معلّم يحدد لنا ما الشكل الموجود في هذه الصور، ولذلك ستحاول الآلة بمفردها العثور على أي أنماط في الصور لتحديد الفوارق ومعرفة ما الموجود في الصور. سنتحدث عن هذه الطرق في التعرف على الأنماط لاحقًا.
من الواضح أن الآلة ستتعلم أسرع بكثير مع معلّم، لذلك فالتعلّم الموجّه مستخدمٌ بكثرة في المهام الواقعية. هناك نوعين رئيسيين لطريقة التعلم الموجّه وهما:
- التصنيف (Classification): التنبؤ بصنف كائن معين.
- الانحدار (Regression): التنبؤ بنقطة معينة على محور رقمي.
التصنيف (Classification)
تقسيم الكائنات أو العناصر بناءً على إحدى السمات المعروفة مسبقًا. افصل الجوارب بحسب اللون، والمستندات بحسب اللغة، والموسيقى بحسب الأسلوب. وعمومًا يستخدم التصنيف من أجل:
- تصفية البريد الإلكتروني من الرسائل المزعجة.
- كشف عن اللغة المستخدمة.
- البحث عن وثائق مماثلة.
- تحليل المشاعر.
- التعرف على الحروف والأرقام المكتوبة بخط اليد.
- الكشف عن الغش.
ومن بعض الخوارزميات الشائعة المستخدمة للتصنيف:
- خوارزمية بايز أو المصنّف المعتمد على قانون بايز في الاحتمالات Naive Bayes.
- خوارزمية شجرة القرار Decision Tree.
- خوارزمية الانحدار اللوجستي Logistic Regression.
- خوارزمية الجار الأقرب K-Nearest Neighbours.
- خوارزمية الدعم الآلي للمتجه Support Vector Machine.
- ويوجد أيضًا العديد من الخوارزميات الأخرى.
غالبًا ما يعتمد مجال تعلّم الآلة على تصنيف الأشياء. إذ تكون الآلة في هذه الحالة مثل طفل يتعلم كيفية فرز الألعاب: فها هي الدمية، وهذه هي السيارة، وهذه هي الشاحنة …إلخ ولكن مهلًا. هل هذا الأمر صحيح؟ هل سيعرف الطفل المعنى الحقيقي للدمية أو للسيارة؟ ليستطيع بعدها تمييز أي دمية مهما اختلف شكلها ولونها وطريقة صنعها؟ أي بعبارة أخرى، هل سيستطيع أن يعمم ما تعلمه؟
في التصنيف سنحتاج دائمًا لمعلّم. ويجب تصنيف البيانات بميّزات (Features) حتى تتمكن الآلة من تعيين الأصناف المناسبة بناءً على هذه الميّزات. في الحقيقة يمكننا تصنيف كلّ شيئ تقريبًا ابتداءً من تصنيف المستخدمين بناءً على اهتماماتهم (كما تفعل خوارزمية فيسبوك)، والمقالات المستندة إلى اللغة أو الموضوع (وهذا أمر مهم لمحركات البحث)، والموسيقى المبنية على الأسلوب سواءً أكانت موسيقى جاز أو هيب هوب …إلخ (هذا الأمر نشاهده في قوائم تشغيل الخاصة بتطبيق Spotify)، وحتى تصنيف رسائل البريد الإلكتروني الخاصة بك.
في تصفية الرسائل المزعجة وغير المرغوب بها، تستخدم خوارزمية بايز Naive Bayes على نطاق واسع. إذ تحسبُ الآلة عدد الكلمات الجيدة في الرسالة وعدد الكلمات الاحتيالية أيضًا بناءً على تصنيف سابق للكلمات موجود في قاعدة بيانات أو مجموعة بيانات (Dataset)، ومن ثمّ تضرب الاحتمالات باستخدام معادلة بايز، وتجمعُ النتائج النهائية وبهذه البساطة أصبح لدينا جهاز يستفيد من طرق تعلّم الآلة من أجل أن يزيد ذكائه ومعرفته.
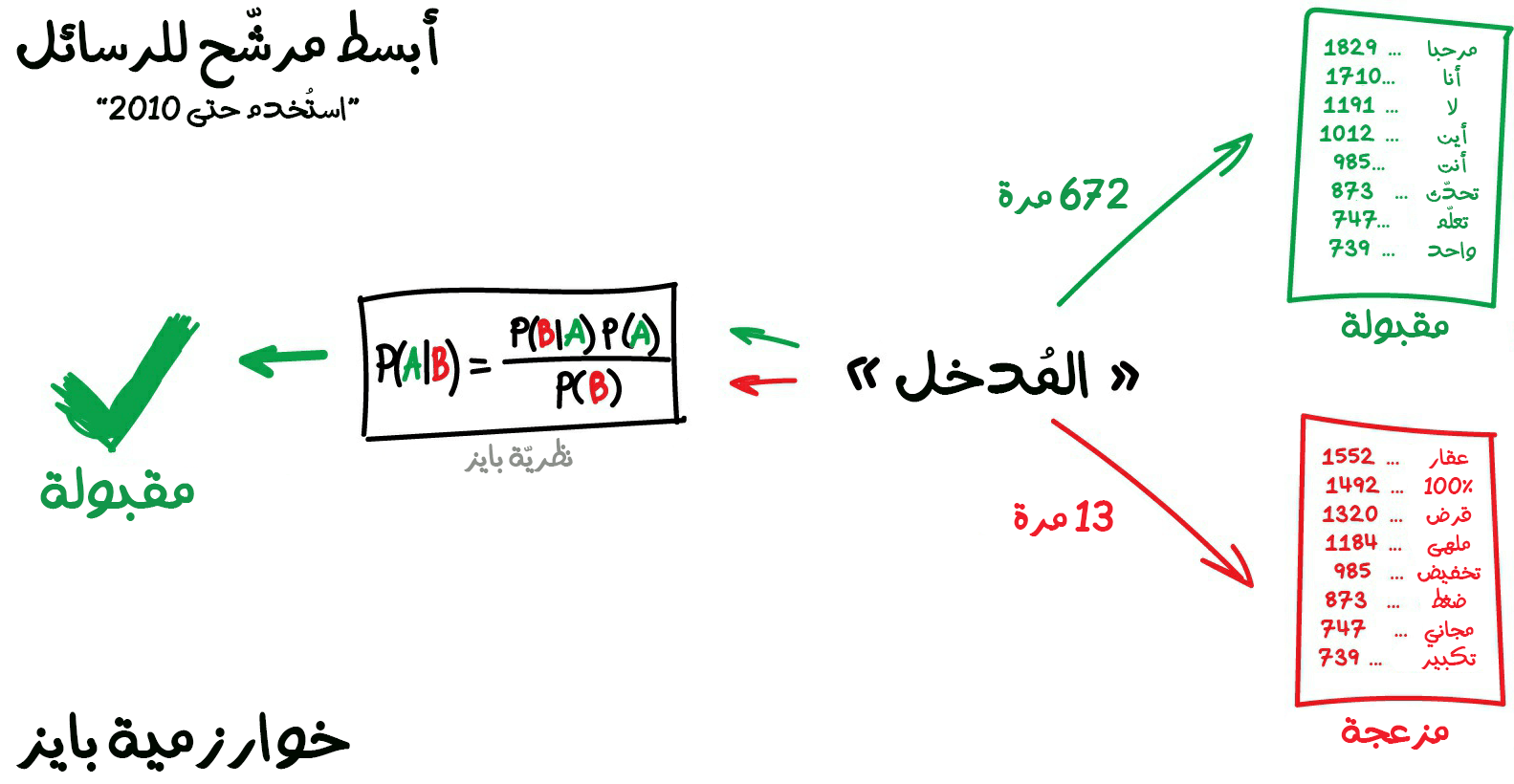
بعدها بفترة وجيزة تعلم مرسلو البريد العشوائي كيفية التعامل مع هذه المرشحات -إن صح التعبير- والّتي تعتمد على خوارزمية بايز فعكفوا على إضافة الكثير من الكلمات المصنّفة على أنها "جيدة" في نهاية البريد الإلكتروني لتُتضاف هذه الكلمات إلى العملية الحسابية الخاصة بحساب احتمالات كون الرسالة مزعجة أم لا. ومن المفارقة أن هذه الثغرة سمّيت لاحقًا بتسمم بايز. دخلت خوارزمية بايز التاريخ باعتبارها من أوائل الخوارزميات الأنيقة والمفيدة عمليًا في ترشيح رسائل البريد الإلكتروني، ولكن في وقتنا الحالي لا تستخدم هذه الخوارزمية وإنما تستخدم خوارزميات أكثر قوة وذكاءً معتمدًا على الشبكات العصبية الاصطناعية لتصفية رسائل البريد العشوائي المزعج.
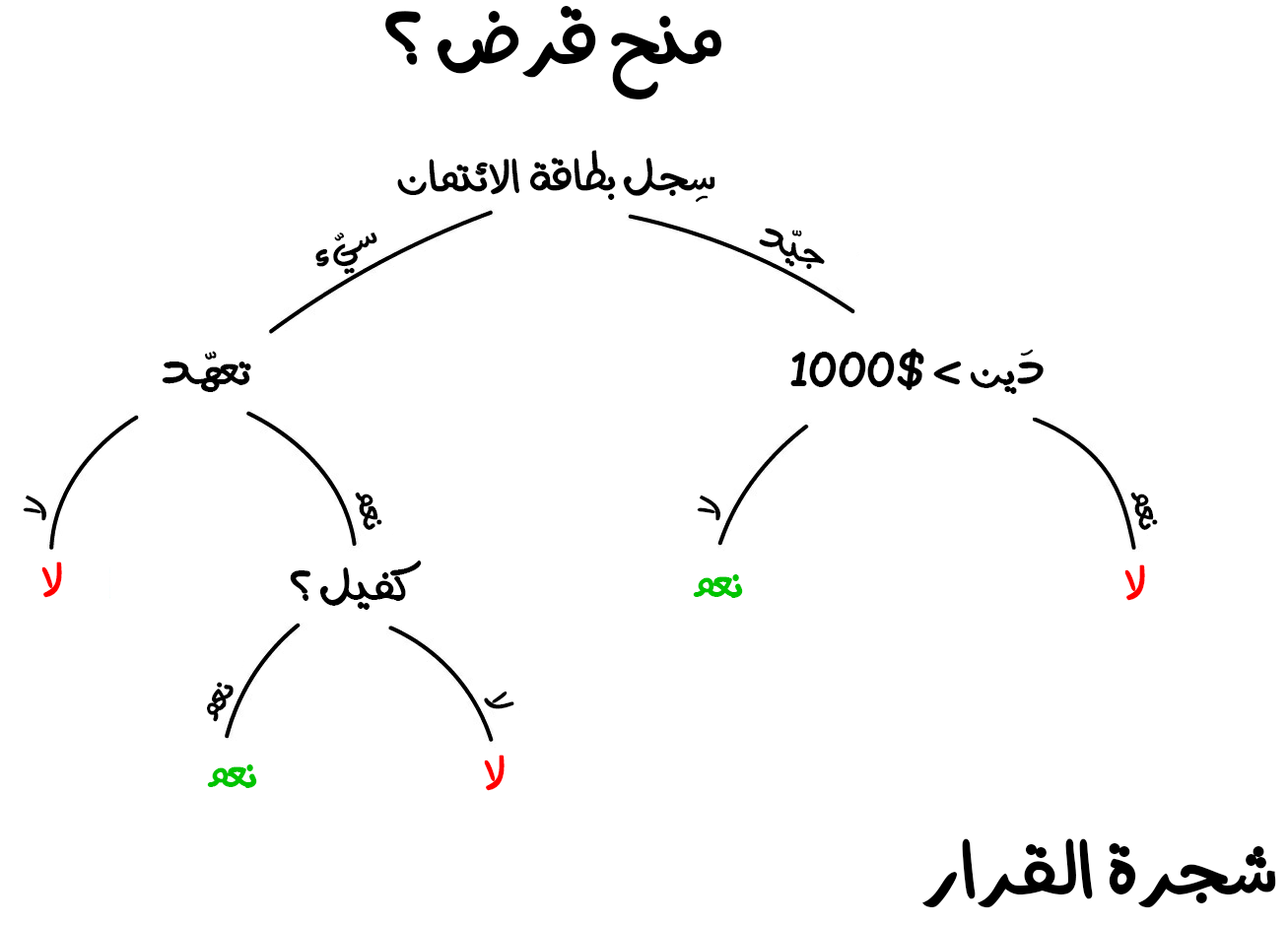
إليك مثال عملي آخر على تطبيقات خوارزميات التصنيف. لنفترض أنك بحاجة لاقتراض بعض المال عن طريق بطاقتك الائتمانية. كيف سيعرف البنك إذا كنت تريد فعلًا أن تسدد هذا القرض أم لا؟ وبالتأكيد لا توجد طريقة مباشرة لمعرفة ذلك، مثل أن يسألك مثلًا. ولكن لدى البنك الكثير من الملفات الشخصية لأشخاص اقترضوا مالًا في الماضي. في الواقع لدى البنك جميع البيانات المهمة حول أعمار الأشخاص المقترضين ومستوى تعليمهم ومهنهم ورواتبهم -والأهم من ذلك- حقيقة أن هل هؤلاء المقترضين سددوا القرض أم لا.
وهذه البيانات مهمة جدًا إذ يمكننا تمريرها للنظام الداخلي للبنك الّذي يعتمد على تعلّم الآلة للعثور على الأنماط المحددة الموجودة في الأشخاص الّذين يسددون القروض، وبذلك يمكننا الحصول على الإجابة المبنية على هذه البيانات السابقة. في الواقع لا توجد مشكلة حقيقية في الحصول على إجابة من هذه البيانات. وإنما تكمن المشكلة في أنه لا يستطيع البنك أن يثق في إجابة الآلة ثقةً عمياء. فماذا لو حدث فشل في النظام أو في جزء منه مثل تعطل أحد الاقراص الصلبة المخزن عليها قواعد البيانات المطلوبة، أو أن أحد قراصنة الإنترنت هجم على الخادم وتلاعب بالخوارزميات أو البيانات. فما الّذي سيحدث في هذه الحالة؟
للتعامل مع هذه الحالة لدينا خوارزمية شجرة القرار. والتي ستقسّم جميع البيانات تلقائيًا إلى أسئلة أجوبتها نعم أو لا. قد يبدو الأمر غريبًا بعض الشيئ من منظور بشري، فمثلًا ما المشكلة إذا كان الدائن يكسب أكثر من 128.12 دولارًا أمريكيًا؟ بالرغم من ذلك تضع الآلة مثل هذه الأسئلة لتقسيم البيانات بشكل أفضل في كلّ خطوة.
وهكذا تُصنعُ شجرة القرار. كلما كان الفرع أعلى كلما كان السؤال أعم. يمكن لأي محلل أن يأخذ ناتج الخوارزمية ويعلّم تمامًا ما هو القرار المناسب. يمكن ألا يشعر بأن كلّ تفاصيلها منطقية إلا أنه يستطيع أن يبني عليها قراره.
أشجار القرار (Decision Trees)
تستخدم خوارزمية شجرة القرار على نطاق واسع في المجالات ذات المسؤولية العالية مثل: التشخيص والطب وفي الأمور المالية.
من أكثر الخوارزمات شيوعًا لتشكيل الأشجار هما خوارزمية CART وخوارزمية C4.5.
ونادرًا ما تستخدم طريقة بناء أشجار القرار الأساسية الصرفة في وقتنا الحالي. إلا أنها غالبًا ما تضع حجر الأساس للأنظمة الكبيرة، بل إن المُجمّعات (Ensembles) المعتمدة على أشجار القرار تعمل بطريقة أفضل من المجمعات المعتمدة على الشبكات العصبية الاصطناعية (سنتحدث لاحقًا في هذا المقال عن كلّ جزء منهم بالتفصيل).
عندما تبحث عن شيء ما في غوغل، فما يحدث بالضبط هو أن مجموعة من الأشجار ستبحث عن إجابة أو مجموعة من الإجابات المناسبة لك. وهذه الأشجار سريعة جدًا، ولذلك تحبها محركات البحث.
تعدّ خوارزمية الدعم الآلي للمتجه (Support Vector Machines) والتي يشار إليها اختصارًا (SVM) هي الطريقة الأكثر شيوعًا للتصنيف الكلاسيكي. والمستخدمة لتصنيف كلّ شيئ موجود تقربيًا مثل: النباتات حسب مظهرها في الصور، والوثائق بحسب الفئات …إلخ. الفكرة وراء خوارزمية الدعم الآلي للمتجه بسيطة جدًا إذ تحاول رسم خطين بين نقاط البيانات الخاصة بك مع أكبر هامش بينهما.
هناك جانب مفيد جدًا من خوارزميات التصنيف وهو الكشف عن البيانات الشاذة. فعندما لا تتناسب الميزة مع أيّ من الفئات، فإننا نبرزها. وتستخدم هذه الطريقة حاليًا في الطب وتحديدًا في أجهزة التصوير بالرنين المغناطيسي، تبرز الحواسيب جميع المناطق المشبوهة أو انحرافات الاختبار. كما تستخدم أيضًا في أسواق الأسهم للكشف عن السلوك غير الطبيعي للتجار لمعرفة ما يحدث وراء الكواليس. الجميل في الأمر أنه عندما نعلّم الحاسب الأشياء الصحيحة فنكون علمناه تلقائيًا ما هي الأشياء الخاطئة.
القاعدة الأساسية هي كلّما زاد تعقيد البيانات، زاد تعقيد الخوارزمية. بالنسبة للنصوص والأرقام والجداول سنختار النهج الكلاسيكي. إذ النماذج الناتجة ستكون أصغر، وتتعلم أسرع وتعمل بوضوح أكبر. أما بالنسبة للصور ومقاطع الفيديو وجميع أنواع البيانات المعقدة الأخرى، سنتجه بالتأكيد نحو الشبكات العصبية.
منذ خمس سنوات فقط كان بإمكانك العثور على مصنف للوجه مبني على خوارزمية الدعم الآلي للمتجه (SVM). حاليًا أصبح من السهل الاختيار من بين مئات الخوارزميات المعتمدة على الشبكات العصبية المدربة مسبقًا. أما بالنسبة لمرشحات البريد العشوائي فلم يتغير شيئ. فلا تزال بعض الأنظمة مكتوبة بخوارزمية الدعم الآلي للمتجه (SVM).
الانحدار (Regression)
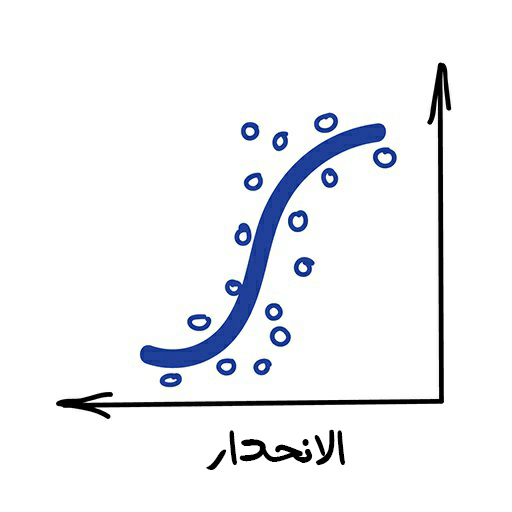
وهو طريقة لرسم خط بين مجموعة نقاط. نعم، هذا هو التعلّم الآلة!
يستخدم الانحدار حاليًا في تطبيقات متعددة، مثل:
- توقعات أسعار الأسهم.
- تحليل حجم الطلب والمبيعات.
- التشخيص الطبي.
- أي ارتباطات عددية.
ومن الخوارزميات الشائعة نذكر:
- خوارزمية الانحدار الخطي Linear.
- خوارزمية االانحدار متعدد الحواف Polynomial.
الانحدار هو في الأساس آلية للتصنيف ولكن هنا نتوقع رقمًا بدلًا من فئة. ومن الأمثلة على ذلك توقع سعر السيارة من خلال المسافة المقطوعة، وتوقع حركة المرور بحسب وقت محدد من اليوم، وتوقع حجم الطلب من خلال نمو الشركة، وما إلى ذلك. ويكون من الواجب استخدام الانحدار عندما تعتمد مشكلة معينة على الوقت.
كلّ من يعمل في مجالات التمويل والتحليل المالي يحب خوارزميات الانحدار. حتى أن معظمها مدمج في برنامج مايكروسوفت إكسل (Excel). وطريقة استخدامها سلسة جدًا من الداخل إذ تحاول الآلة ببساطة رسم خط يشير إلى متوسط الارتباط (Average Correlation). على عكس الشخص الّذي يحاول رسم شكل الانحدار يدويًا على السبورة، فإن الآلة ترسم الشكل بدقة رياضية عالية جدًا، بحساب متوسط الفاصل الزمني لكل نقطة.
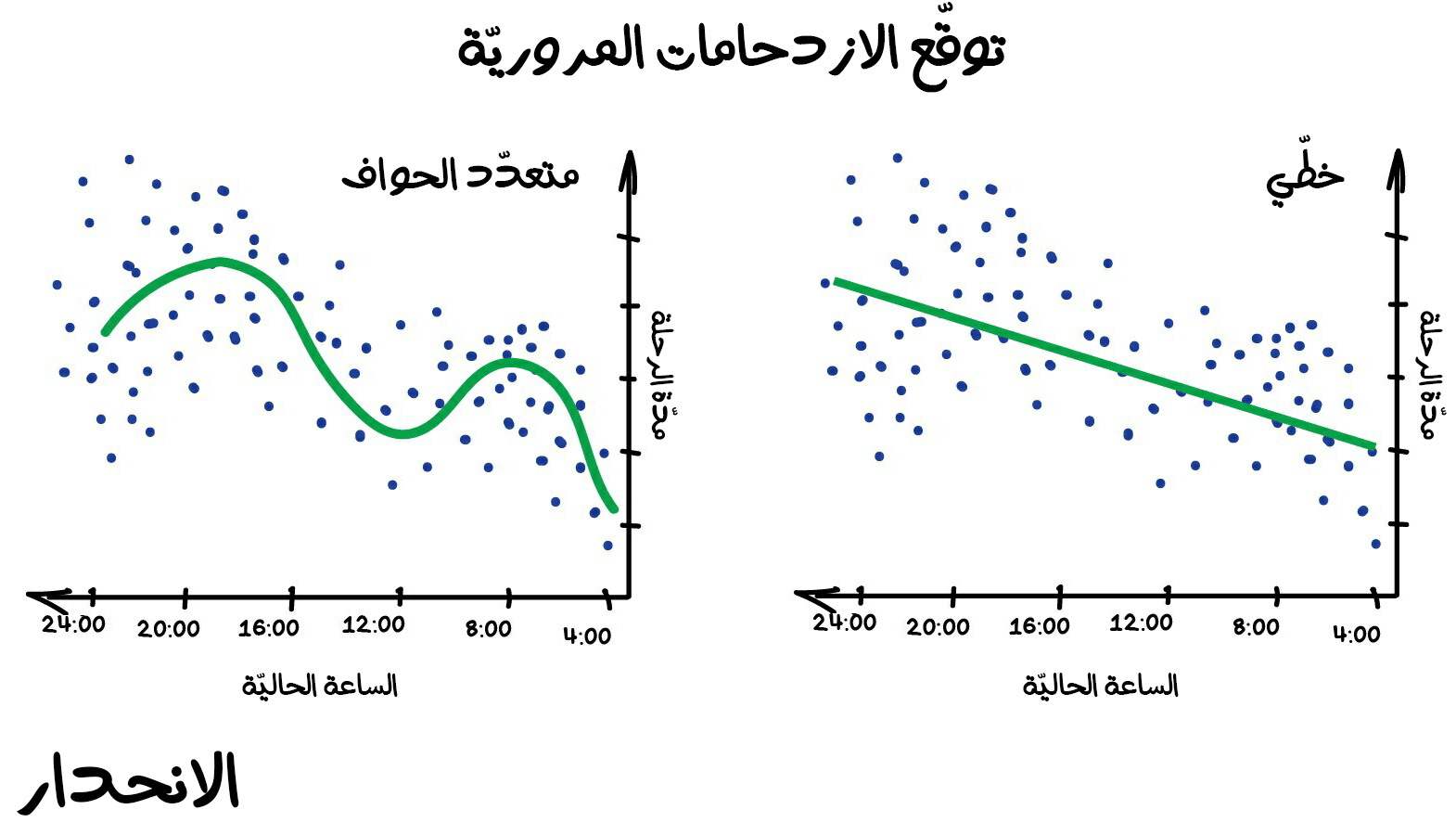
عندما يكون خط الانحدار مستقيمًا فيكون هذا الانحدار خطيًا، أما عندما يكون خط الانحدار منحنيًا فيكون الانحدار متعدد الحواف (Polynomial). وهذه الأنواع الرئيسية من الانحدار. والبعض الآخر أكثر غرابة مثل الانحدار اللوجستي (Logistic Regression) وسيكون شكله مميز كتميز الخروف الأسود في قطيع غنم. ولكن لا تدعه يخدعك، لأنه مجرد طريقة تصنيف وليس انحدارًا.
لا بأس في الخلط بين الانحدار والتصنيف. إذ يتحول العديد من المصنّفات لتنفيذ عملية انحدار بقليل من الضبط والإعداد. وعمومًا تستخدم طرق الانحدار عندما لا يمكننا تحديد فئة الكائن، وإنما يمكننا تحديد ومعرفة مدى قربه من هذه الفئة، وهنا بالضبط تأتي مهمته.
في حال أردت التعمق أكثر في التعلم الموجّه، فراجع هذه السلسلة: Machine Learning for Humans.
التعلم غير الموجه (Unsupervised learning)
ظهر التعلّم غير الموجّه بعد ظهور التعلّم الموجّه بقليل، وتحديدًا في التسعينيات. ويستخدم أقل من التعلّم الموجّه، ولكن في بعض الأحيان لن يكون لدينا خيار آخر سوى استخدامه.
تعدّ البيانات المصنّفة نوع فاخر من البيانات. ولكن ماذا لو كنت رغبت في إنشاء تصنيف مخصص للحافلات (الباصات)؟ هل يجب عليك التقاط صور يدويًا لمليون حافلة في الشوارع وتصنيف كلّ واحدةٍ منها؟ مستحيل، سيستغرق هذا الأمر عمرًا بأكمله.
في هذا النوع من التعلم من منظورنا نحن نعطيها أومر معينة للتجميع أو تقليل الأبعاد وهي تؤدي هذه المهمة من خلال تحليلها لقيم الميّزات (Features) ومحاولة الربط بينها ومعرفة العلاقات أو الارتباط بين هذه البيانات. كما يمكن أن تكون البيانات معقدة للغاية، ولذلك لا يمكن لهذه الخوارزميات التكهن بالنتيجة المطلوبة بصورة صحيحة. في تلك الحالات نحاول تنظيم بياناتنا أو إعادة هيكلتها في صيغة منطقية أكثر من السابق من أجل معرفة فيّما إذا استطاعت هذه الخوارزميات استنتاج شيئ ما، وبذلك الأمر له عدة جوانب للحلّ ومتعلّق بنوعية البيانات وطريقة تنظيمها وجودتها.
ولكن هناك بعض الأمل إذ لدينا الملايين من المنصات الّتي توفر خدمات رخيصة نسبيًا تبدأ من 5 دولار أمريكي، وغالبًا نعتمد عليها لمساعدتنا في تصنيف البيانات وهذه الطريقة المعتمدة الّتي تجري وفقها أمور تطوير البيانات في هذا المجال.
بعض الأنواع للتعلّم غير الموجّه:
- التجميع (Clustering).
- تقليل الأبعاد أو التعميم (Dimensionality Reduction).
- تعلم قواعد الربط (Association rule learning).
التجميع (Clustering)
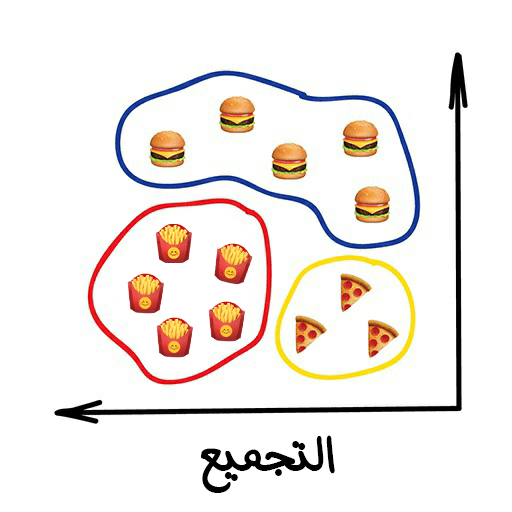
تُقسّم عملية التجميع الكائنات على أساس ميّزات غير معروفة. إذ تختار الآلة أفضل طريقة لفرز الميّزات الّتي تراها مناسبة.
هذه بعض التطبيقات لعملية التجميع في وقتنا الحالي:
- تقسيم السوق (أو تقسيم أنواع العملاء، أو طريقة ولائهم للعلامة التجارية).
- دمج نقاط قريبة على الخريطة.
- ضغط الصورة.
- تحليل وتسمية البيانات الجديدة.
- الكشف عن السلوك غير الطبيعي.
ومن بعض خوارزميات الشائعة للتجميع:
- خوارزمية K-mean_clustering.
- خوارزمية Mean-Shift.
- خوارزمية DBSCAN.
تعدّ عملية التجميع فعليًا عملية تصنيف ولكن المفارقة هنا أنها لا تحتوي على فئات محددة مسبقًا. مشابهة جدًا لعملية تقسيم الجوارب في الدرج بحسب ألوانهم، وذلك عندما لا تتذكر كلّ الألوان الّتي لديك فعندها ستجلب الجورب الأول ذو اللون الأسود وتضعه جانبًا وتأخذ الجورب الثاني ..وهكذا. تحاول خوارزميات التجميع العثور على كائنات متشابهة (بحسب بعض الميزات) ودمجها في مجموعة. تُجمّع الكائنات الّتي لديها الكثير من الميزات المماثلة في فئة واحدة. وتسمح لنا بعض الخوارزميات حتى تحديد العدد الدقيق للمجموعات الّتي نريدها.
من أحد أشهر الأمثلة على التجميع هي تجميع العلامات (أو المؤشرات) على خرائط الوِب. فمثلًا عندما تبحث عن جميع المطاعم النباتية المحيطة بك، سيجمّعُ محرك البحث الخاص بالخريطة جميع المطاعم على شكل أرقام. ولو أنه لم يجمّعها لك فحتمًا سيتجمد متصفحك بعد عملية البحث لأنه سيحاول رسم جميع المطاعم النباتية الموجودة على سطح الكرة الأرضية وعددهم سيكون كبير بكلّ تأكيد.
ومن بعض الاستخدامات الأخرى لخوارزميات التجميع تطبيقات الهواتف المحمولة مثل: Apple Photos وGoogle Photos إذ كِلاهما يستخدمان خوارزميات تجميع معقدة أكثر من المثال السابق، وذلك لإنهم يبحثان عن الوجوه المميزة في الصور بهدف إنشاء ألبومات خاصة لأصدقائك. لا يعرف التطبيق عدد أصدقاؤك ولا حتى كيف تبدوا أشكالهم، ولكنه مع ذلك يحاول العثور على ميزات صريحة في وجوههم، والموازنة بينها لمعرفة عددهم، وعرض الألبومات وفقًا لذلك.
ومن بعض الاستخدامات الأخرى هي ضغط الصورة فعند حفظ الصورة بلاحقة PNG، يمكنك ضبط مجموعة الألوان وليكن عددها 32 لونًا. هذا يعني أن آلية التجميع ستأخذ جميع البكسلات "المحمرة" وتحسب قيمة "المتوسط الأحمر" وتضبطه على جميع البكسلات الحمراء. وبذلك يكون لدينا ألوان أقل، مما يؤدي في نهاية المطاف إلى حجم ملف أقل، وبذلك تنخفضُ مصاريف التخزين المحلي أو السحابي.
ومع ذلك يمكن أن نواجه بعض مشاكل في الألوان مثل الألوان القريبة من لونين بنفس الوقت مثل لون الأزرق السمائي (Cyan). إذ لا يمكننا تصنيفه فيما إذا كان أخضرًا أم أزرق؟ هنا يأتي دور خوارزمية K-Means.
خوارزمية K-mean
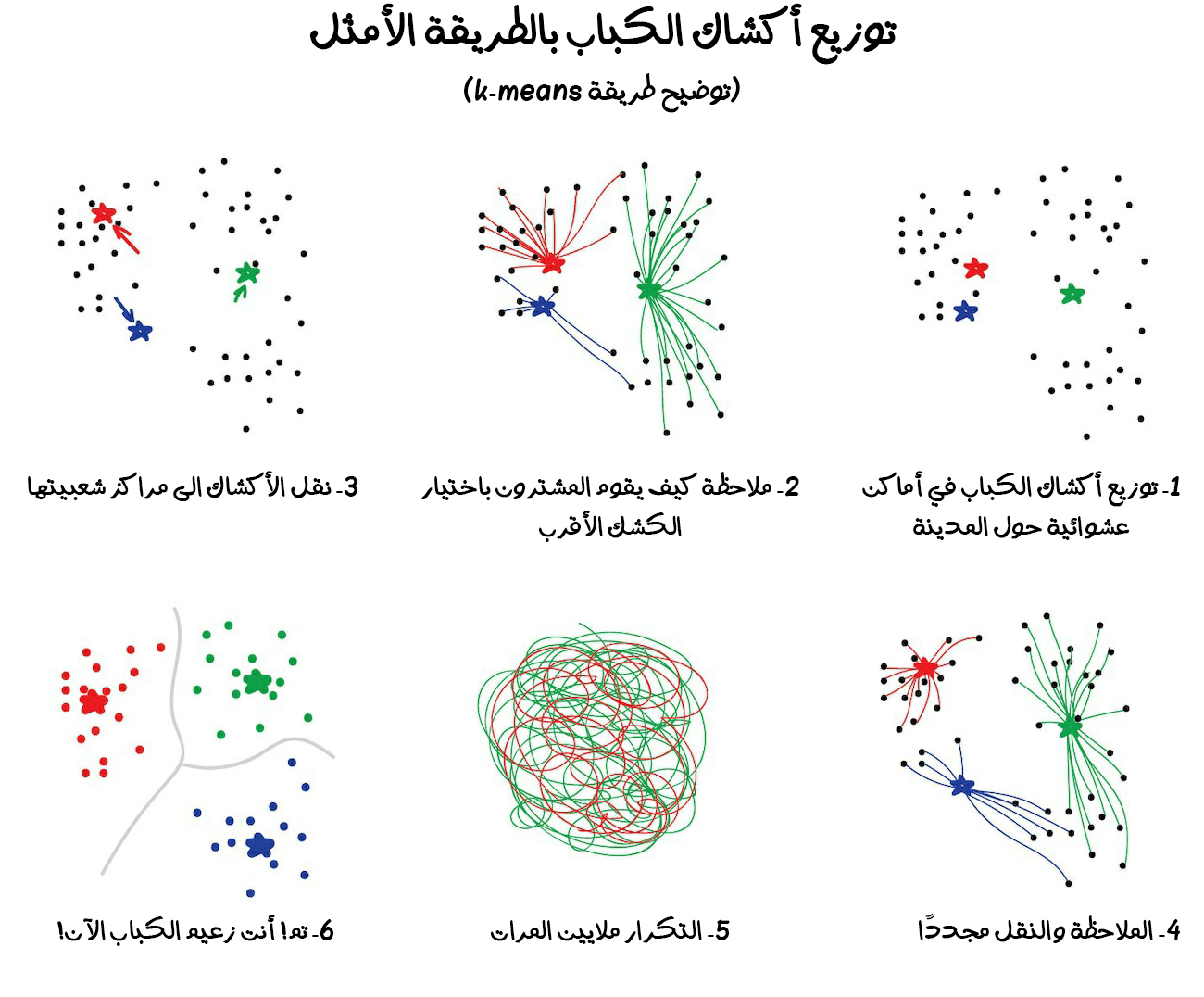
إذ تعيّن خوارزمية K-Means مجموعة من النقاط اللونية والبالغ عددها 32 نقطة لونية بطريقة عشوائية في مجموعة الألوان. وتسمى هذه النقاط (أو الألوان) بالنقاط المركزية (Centroids). وتُحدد النقاط المتبقية على أنها مخصصة لأقرب نقطة (لون) مركزي. وبعدها سنُلاحظ أننا حصلنا نوعًا ما على ما يشبه المجرات حول هذه الألوان 32. ثم ننقل النقطة المركزية إلى وسط مجرتنا، ونكرر ذلك حتى تتوقف النقطة المركزية عن التحرك.
نفذنا جميع المهام بنجاح. ولدينا 32 مجموعة محددة ومستقرة. وإليك شرحًا كرتونيًا وتفصيليًا لما جرى:
البحث عن الألوان المركزية مريح. إلا أن التجميعات في الحياة الواقعية ليست دائمًا على شكل دوائر. لنفترض أنك عالم جيولوجيا. وتحتاج للعثور على بعض المعادن المتماثلة على الخريطة. في هذه الحالة، يمكن تشكيل تجميعات بطريقة غريبة وحتى متشعبة. ولا يمكنك أيضًا أن تعرف عددهم فهل هم 10؟ أم 100؟ بكل تأكيد أن خوارزمية K-means لن تتناسب مع هذه الحالة، وإنما ستكون خوارزمية DBSCAN مفيدةً أكثر.
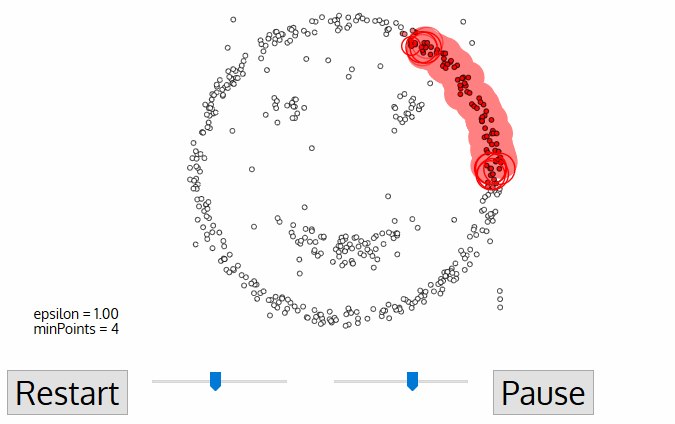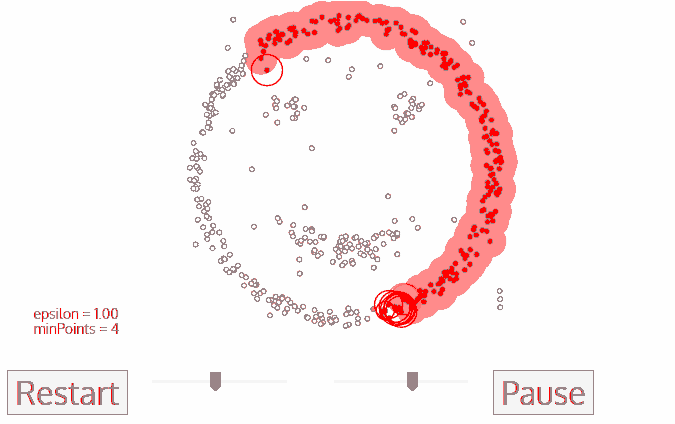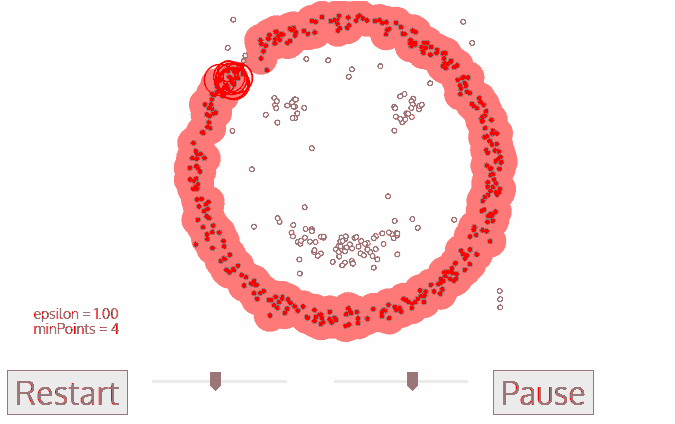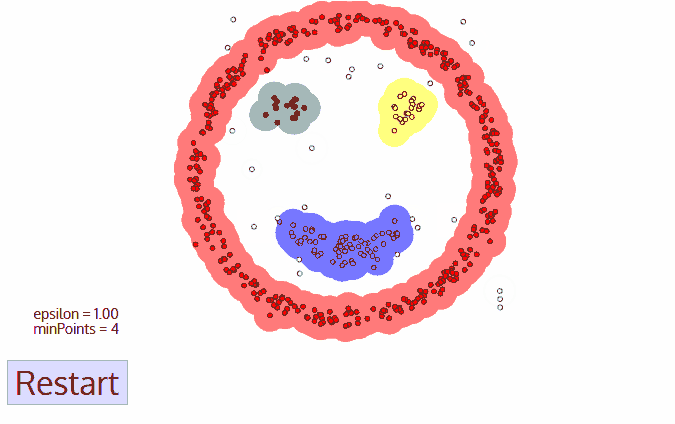
خوارزمية DBSCAN
لنفترض أن النقاط لدينا هم أناس في ساحة البلدة. اَبحث عن أي ثلاثة أشخاص يقفون بالقرب من بعضهم البعض واطلب منهم أن يمسكوا أيديهم. ثم اطلب منهم البدء في الإمساك بأولئك الجيران الّذين يمكنهم الوصول إليهم. وهكذا دواليك. إلى أن نصل لشخص لا يستطيع الامساك بأي شخص آخر. هذه هي مجموعتنا الأولى. كرر هذه العملية ليُجمعُ كلّ الناس بمجموعات.
ملاحظة: الشخص الّذي ليس لديه من يمسك يده - هو فعليًا مجرد بيانات شاذة.
إليك رسم توضيحي يبين لك كيف سيبدو الحل:
وإن كنت مهتم بخوارزميات التجميع؟ يمكنك الاطلاع على هذه المقالة The 5 Clustering Algorithms Data Scientists Need to Know.
نلاحظ أن التجميع مشابه تمامًا للتصنيف، إذ يمكن استخدام المجموعات للكشف عن الحالات الشاذة. هل لاحظت بأن المستخدم يتصرف بطريقة غير طبيعية بعد اشتراكه بموقعكK أو بخدمتك؟ دع الآلة تحجبه مؤقتًا، وتنشئ تذكرة للدعم الفني لفحص هذا النشاط المريب لاتخاذ القرار المناسب. فربما يكون روبوت آلي يحاول إشغال الخادم الّذي تحجزه لموقعك. في الحقيقة لن نحتاج حتى لمعرفة ماهيّة "السلوك الطبيعي" للمُستخدم وإنما سنأخذ جميع أفعال ونشاطات المستخدم ونحملها إلى نموذجنا ونترك الآلة تقرر ما إذا كان هذا المستخدم "نموذجيًا" أم لا.
يمكن أن لا يعمل هذا النهج بطريقة جيد بالموازنة مع التصنيف، ولكن القرار النهائي سيُبنى على المحاولة والتجربة.
تقليل الأبعاد (Dimensionality Reduction)
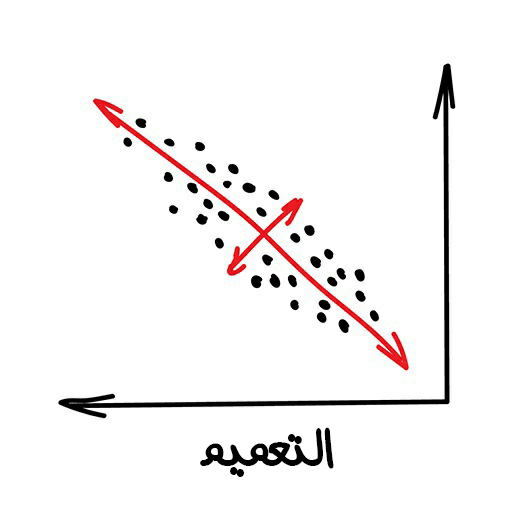
وتعرف أيضًا بالتعميم (Generalization) وهي عملية تجميع ميّزات محددة بداخل ميّزات ذات مستوى أعم وأعلى.
ومن بعض التطبيقات العملية لهذه الطريقة نجد:
- أنظمة التوصية.
- التصورات (المحاكاة) الجميلة.
- نمذجة الموضوعات والبحث عن وثائق مماثلة.
- تحليل الصور المزيفة.
- إدارة المخاطر.
ومن بعض الخوارزميات الشائعة لتطبيقها:
- خوارزمية تحليل المكونات الرئيسية Principal Component Analysis ويشار لها اختصارًا (PCA).
- خوارزمية تحليل القيمة المفردة Singular Value Decomposition ويشار لها اختصارًا (SVD).
- خوارزمية Latent Dirichlet allocation.
- خوارزمية التحليل الدلالي الكامن Latent Semantic Analysis ويشار إليها اختصارًا (LSA أو pLSA أو GLSA).
- خوارزمية t-SNE (التي تستخدم في مجال الرؤية الحاسوبية).
استخدم علماء البيانات المتعصبون سابقًا هذه الأساليب، وكان عليهم العثور على "شيئ مثير للاهتمام" في أكوام ضخمة من الأرقام. وعندما لم تساعدهم مخططات إكسل بهذه المهمة أجبروا الآلات على العثور على الأنماط. حتى حصلوا على طريقة تقليل الأبعاد أو ميّزة تعلّم كيفية تقليل البعد.

من الأفضل دائمًا استخدام التلخيص أو التجريد (Abstractions)، عوضًا عن مجموعة من الميزات المجزأة. فمثلًا، يمكننا دمج كلّ الكلاب ذات الآذان مثلثية الشكل والأنوف الطويلة والذيل الكبير ليصبح لدينا تلخيص لشكل كلب لطيف وهو كلب "شبيرد". نعم فقدنا بعض المعلومات حول الصفات المميزة الخاصة بالكلب شبيرد، إلا أن التلخيص الجديد يعدّ أكثر فائدة لتسمية الأغراض وتوضيحها. بالإضافة إلى ذلك، إن النماذج المُلخAصة تتعلّم بطريقة أسرع، ولا تظهر لديها مشكلة "فرض التخصيص" (Overfitting) -الّتي سنتحدث عنها بالتفصيل لاحقًا- بكثرة وهي تستخدم عددًا أقل من الميّزات.
أصبحت هذه الخوارزميات أداة مذهلة "لنمذجة المواضيع". إذ يمكننا تلخيص مواضيع من كلمات محددة لمعانيها. هذا ما تفعله خوارزمية التحليل الدلالي الكامن. تعتمد على عدد مرات تكرار كلمة معينة في موضوع محدد. مثل: استخدام كلمة "تقنية" بكثرة في المقالات التقنية، وبالتأكيد سنعثر على أسماء الأشخاص السياسيين بكثرة في الأخبار السياسية وهكذا.
كما يمكننا بكل تأكيد إنشاء مجموعات من جميع الكلمات في المقالات، ولكننا سنفقد جميع الروابط المهمة بين معاني الكلمات خصيصًا العلاقة بين الكلمات ذات المعنى نفسه مثل البطارية (Battery) والبطارية المقصود بها المدخرات الكهربائية - (Accumulator) الموجودة في مستندات مختلفة. إلا أن خوارزمية التحليل الدلالي الكامن ستتعامل معها بالطريقة الصحيحة، ولهذا السبب تحديدًا سمّيت "بخوارزمية التحليل الدلالي الكامن".
لذلك نحن بحاجة إلى ربط الكلمات والمستندات في ميزة واحدة للحفاظ على هذه الاتصالات الكامنة واتضح لنا بأن خوارزمية التفكيك المفرد (Singular decomposition) تؤدي هذه المهمة بقوة، مما يشفُ عن فائدة المجموعات المجمعة بحسب الموضوع الّتي تحدثنا عنها سابقًا.
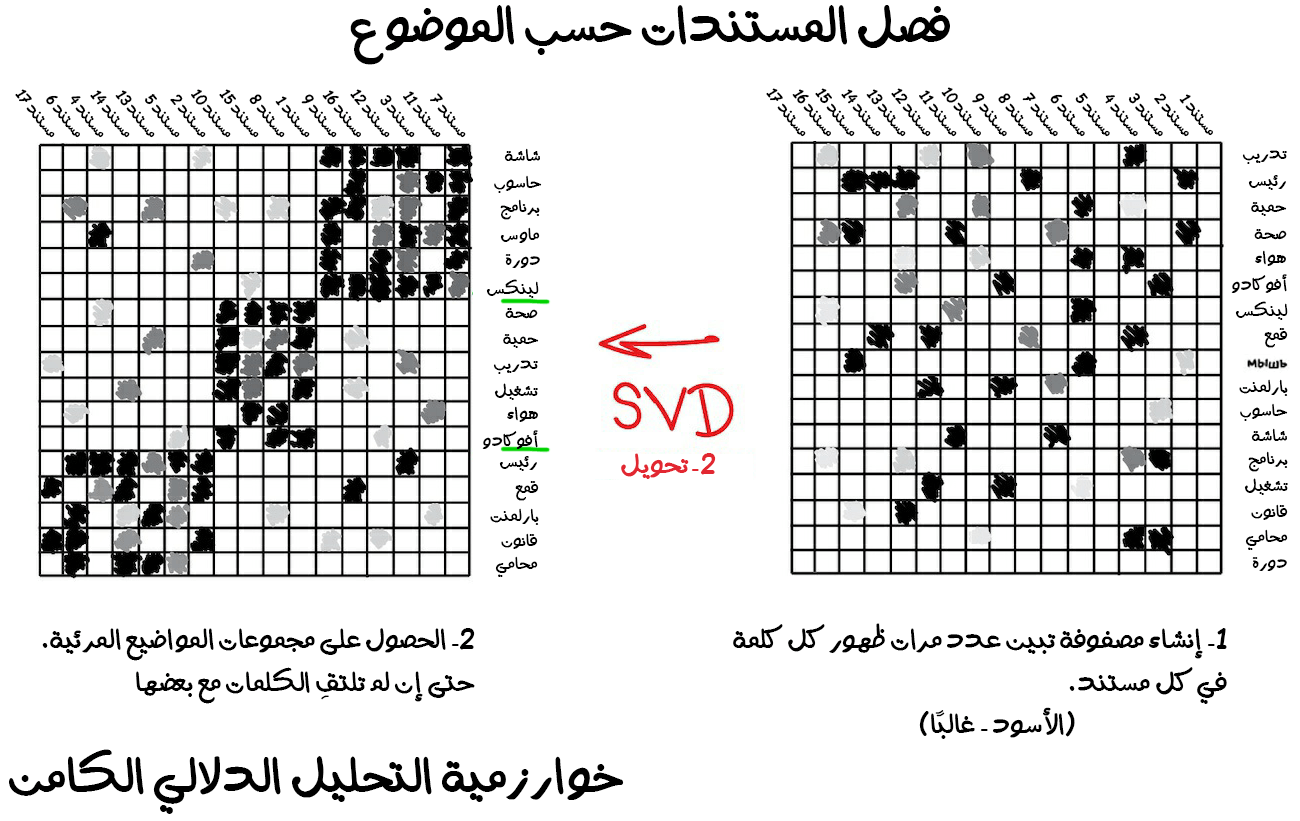
من الاستخدامات الشائعة الأخرى هي أنظمة التوصية (Recommender Systems) والتصفية التعاونية (Collaborative Filtering) من أجل تقليل الأبعاد. مما يبدو أنه إذا كنت تستخدمه في تلخيص تقييمات المستخدمين، فستحصل على نظام رائع للتوصية بالأفلام والموسيقى والألعاب بل وحتى أي شيئ تريده.
للمزيد من المعلومات حول هذا الموضوع نوصيك بالكتاب الرائع "برمجة الذكاء الجمعي" Programming Collective Intelligence.
بالكاد سنتمكن من فهم فهمًا كاملًا لفكرة التلخيص (أو التجريد) الآلي، ولكن من الممكن رؤية بعض الارتباطات عن قرب. إذ يرتبط بعضها بعمر المستخدم فمثلًا يلعب الأطفال لعبة ماين كرافت (Minecraft) ويشاهدون معها الرسوم المتحركة بكثرة، ويرتبط بعض المستخدمين الآخرين بنوعية فيلم معينة أو بهوايات مخصصة وهكذا.
تستطيع الآلات الحصول على هذه المفاهيم التجريدية عالية المستوى من دون حتى فهم ماهيتها، بناءً فقط على معرفة تقييمات المستخدم.
تعلم قواعد الربط (Association Rule Learning)

وهي طريقة للبحث عن الأنماط في تدفق الطلبات.
حاليا تستخدم في عدد من المجالات مثل:
- التنبؤ بالمبيعات والخصومات.
- تحليل البضائع المشتراة معًا.
- معرفة كيفية وضع المنتجات على الرفوف.
- تحليل أنماط تصفح الإنترنت.
الخوارزميات الشائعة لها هي:
- خوارزمية Apriori.
- خوارزمية Eclat.
- خوارزمية FP-growth.
وتستخدم هذه الطريقة لتحليل عربات (سلّات) التسوق الإلكترونية أو الواقعية، كما تستخدم أيضًا لأتمتة استراتيجية التسويق، والمهام الأخرى المتعلقة بمثل هذه الأحداث. وتحديدًا عندما يكون لديك تسلسل لشيئ معين وترغب في إيجاد أنماط فيه - جرب هذه الأشياء.
لنفترض أن العميل سيأخذ ستة عبوات من العصائر ويذهب إلى طاولة المحاسبة ثم إلى باب الخروج. هل يجب أن نضع الفول السوداني بجانب الطريق المؤدي إلى طاولة المحاسبة؟ وفي حال وضعناها، كم مرة سيشتريها الناس بالمجمل؟ لربما تتماشى العصائر مع الفول السوداني، ولكن ما هي التسلسلات الأخرى الّتي يمكننا التنبؤ بها اعتمادًا على البيانات؟ هل يمكن لتغييرات بسيطة في ترتيب البضائع أن تؤدي إلى زيادة كبيرة في الأرباح؟
وينطبق نفس الشيء على التجارة الإلكترونية. إذ المهمة هنا أكثر حماسية وإثارة للاهتمام، فما الّذي سيشتريه العميل في المرة القادمة؟ هل سيشتري المنتجات النباتية؟ أم الحيوانية؟

تعتمد الأساليب الكلاسيكية لتعلم الآلة على نظرة مباشرة على جميع السلع المشتراة باستخدام الأشجار أو المجموعات. يمكن للخوارزميات البحث عن الأنماط فقط، ولكن لا يمكنها تعميمها أو إعادة إنتاجها بما يتوافق مع الأمثلة الجديدة.
أما في العالم الحقيقي فإن كلّ متجر تجزئة كبير يبني حلًا خاصًا ومناسبًا له، لذلك لا نرى تطورات كبيرة في هذا المجال. وعلى المستوى التقني فإن أعلى مستوى من التقنيات المستخدمة هي أنظمة التوصية (أو تسمى أحيانًا الأنظمة الناصحة).
التعلم المعزز (Reinforcement Learning)
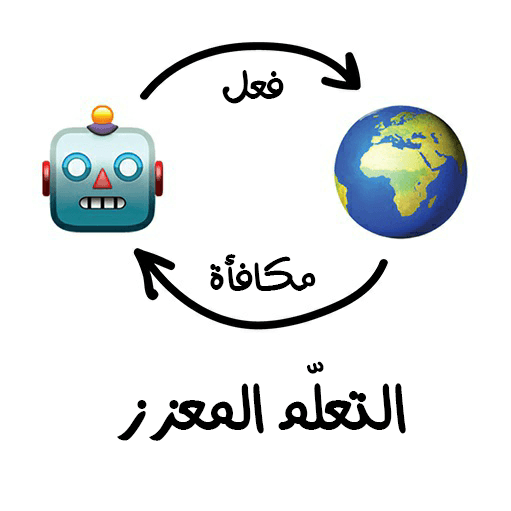
وهو عملية رمي روبوت في متاهة وتركه بمفرده ليجد طريق الخروج بنفسه.
من بعض التطبيقات العملية المستخدمة حاليًا:
- السيارات ذاتية القيادة.
- روبوت تنظيف الأرضية.
- الألعاب.
- أتمتة التداول.
- إدارة موارد المؤسسة.
من أبرز الخوارزميات الشائعة لها:
- خوارزمية التعلم المعزز وفق النموذج الحر Q-Learning.
- خوارزمية خطة ماركوف للتعلّم المعزز لاتخاذ القرار SARSA.
- خوارزمية التعلم المعزز العميق وفق النموذج الحر DQN.
- خوارزمية الناقد المميز غير المتزامن A3C.
- الخوارزمية الجينية Genetic algorithm.
أخيرًا وليس آخرًا، نصل إلى شيئ يشبه الذكاء الحقيقي. في كثير من المقالات نرى خطأ شائعًا بأن يصنف التعلّم المعزز تحت قسم التعلّم الموجّه أو أحيانًا في قسم التعلّم غير الموجّه. لذا وجب التنويه إلى كونه طريقة تعلّم منفصلة.
يستخدم التعلّم المعزز في الحالات الّتي لا تتعلق فيها مشكلتك بالبيانات على الإطلاق، وإنما لديك بيئة افتراضية تتعامل معها. مثل عالم ألعاب الفيديو أو مدينة افتراضية للسيارات ذاتية القيادة.
إن معرفة جميع قواعد الطرقات الجوية في العالم لن تعلّم الطيار الآلي كيفية القيادة على بأحد الطرق الجوية. بغض النظر عن مقدار البيانات الّتي نجمعها، لا يزال يتعذر علينا توقع جميع المواقف المحتملة. وهذا هو السبب الأساسي لهدف التعلم المعزز وهو ** تقليل الخطأ، وليس التنبؤ بجميع التحركات المحتملة**.
إن البقاء على قيد الحياة في البيئة الافتراضية هي الفكرة الأساسية للتعلم المعزز. إذ سنعتمد على ترك الروبوت الصغير الفقير يتجول في الحياة الافتراضية ونُعاقبه على الأخطاء ونُكافؤه على الأفعال الصحيحة. بنفس الطريقة الّتي نعلم بها أطفالنا، أليس كذلك؟
الطريقة أكثر فعالية لتدريب الروبوت هي بناء مدينة افتراضية والسماح للسيارة ذاتية القيادة بتعلم كلّ طرق القيادة وحيلها فيها أولًا. في الحقيقة هذه هي الطريقة المعتمدة في تدريب الروبوت الموجودة في السيارات ذاتية القيادة. إذ ننشئ في البداية مدينة افتراضية استنادًا لخريطة المدينة الحقيقية، ونضيف إليها أناس افتراضيين يمشون في الشوارع (لمحاكاة الواقع) ونترك السيارة تتعلم بمفردها وذلك بوضع هدف نصب أعيننا وهو "تقليل العدد الّذي تقتله من الناس بأقل ما يمكن" وهكذا يستمر الروبوت في التدرب إلى أن يصل لمرحلة لا يقتل بها أحد. عندما يؤدي الروبوت أداءً جيدًا في لعبة GTA عندها سنُحرره ونختبره في الشوارع الحقيقية.
قد يكون هناك نهجان مختلفان للتعلم المعزز وهما:
- نهج قائم على نموذج (Model-Based).
- نهج غير قائم على نموذج أو النهج الحر (Model-Free).
إن النهج القائم على نموذج يعني أن السيارة بحاجة لحفظ كامل الخريطة أو أجزائها. هذا نهج قديم جدًا لأنه من المستحيل بالنسبة للسيارة الفقيرة ذاتية القيادة أن تحفظ الكوكب بأكمله.
أما في النهج غير القائم على نموذج فلا تحفظ السيارة كلّ حركة ولكنها تحاول تعميم المواقف، ومحاولة التصرف بعقلانية إلى جانب محاولتها الحصول على أقصى مكافأة.

هل تذكر الأخبار المتداولة حول خسار بطل العالم بلعبة Go أمام الذكاء الصنعي؟ هل تعلم بأن عدد التركيبات القانونية المحتملة للعبِ بهذه اللعبة أكبر من عدد الذرات الموجودة في الكون كلّه؟ حتى أن العلماء أثبتوا ذلك لاحقًا. ولكن هل سنطلب من هذا الروبوت المسكين حفظ كلّ ذلك؟
في الواقع أن الآلة لم تتذكر جميع التركيبات المحتملة للعب ومع ذلك فازت بلعبة Go، إذ حاولت تطبيق أفضل حركة في كلّ دور على حدة (تمامًا كما فعلت في لعبة الشطرنج عندما هزمت غاري كاسباروف في المباراة الشهيرة سنة 1997 والّتي سميت بمباراة القرن). هي فعليًا اختارت ببساطة أفضل حركة (من ناحية المكسب) لكلّ حالة، وقد فعلت ما يكفي للتغلب على البشر.
يعد هذا النهج مفهومًا أساسيًا أدى لظهور التعلّم المعزز وفق النموذج الحرّ (Q-learning) وهو فرع من فروع التعلّم المعزز بل وظهور الخوارزميات مثل خوارزمية خطة ماركوف للتعلّم المعزز لاتخاذ القرار (SARSA) وخوارزمية التعلّم المعزز العميق وفق النموذج الحرّ (DQN). ومن الجدير بالذكر أن حرف "Q" يشير إلى "الجودة" (Quality) إذ يتعلم الروبوت أداء الفعل الأكثر "نوعية" في كلّ حالة ويحفظ جميع المواقف على أنها سلسلة ماركوفية بسيطة.
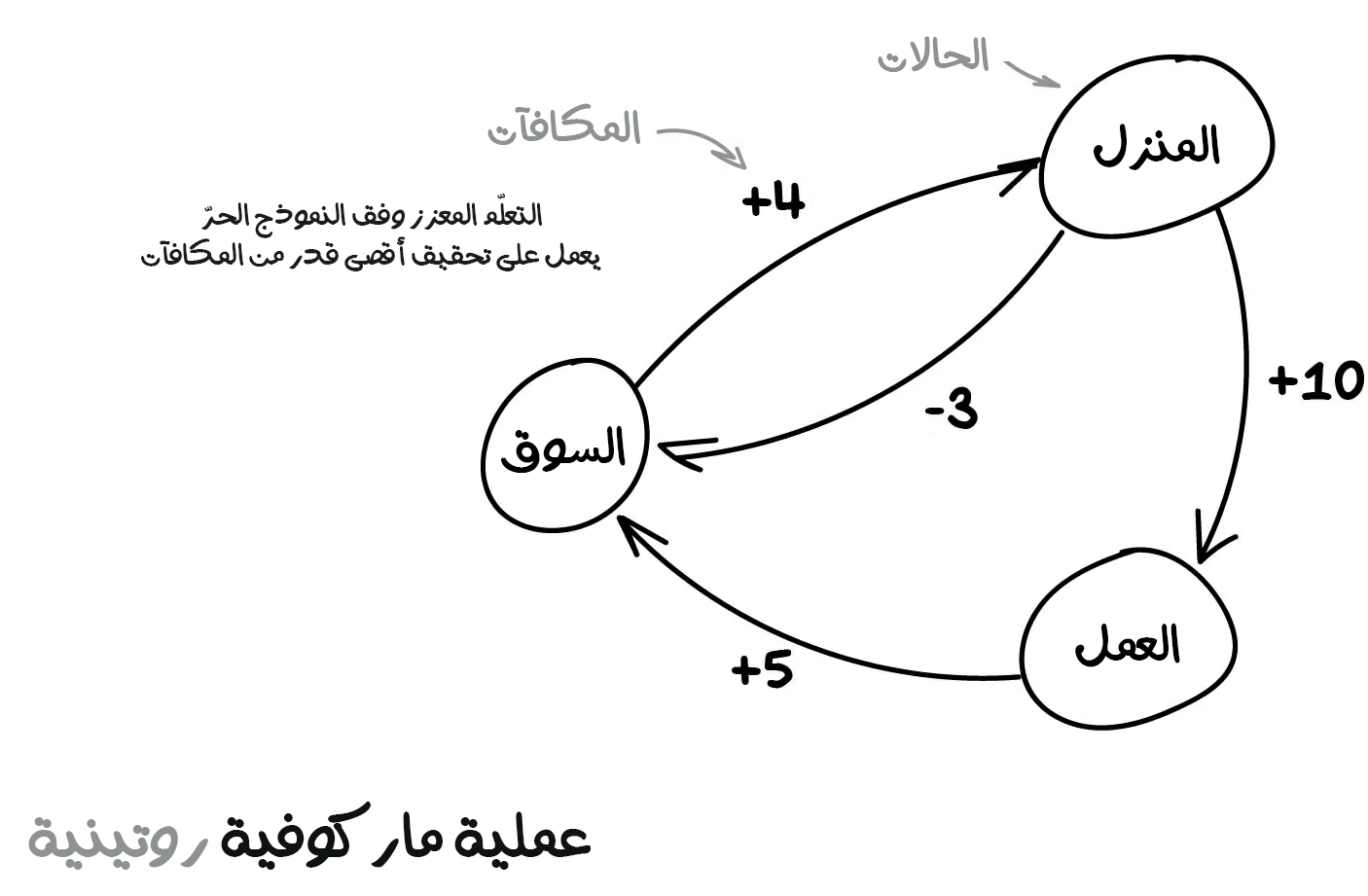
يمكن للآلة اختبار مليارات المواقف والحالات في البيئة افتراضية، ويمكنها تذكر جميع الحلول الّتي أدت لمكافأة أكبر. ولكن كيف يمكنها أن تميز المواقف الّتي رأتها مسبقًا عن المواقف الجديدة كليًا؟ فمثلًا إذا كانت السيارة ذاتية القيادة في إحدى التقاطعات بين الشوارع وكانت إشارة المرور حمراء وتحولت فجأة الإشارة الخضراء فهل هذا يعني أنها يمكن أن تسير مباشرة؟ ماذا لو كانت هناك سيارة إسعاف تسير في شارع قريب وتطلب من السيارات الأخرى إفساح الطريق لها؟
الإجابة الحالية على هذا السؤال وفق المعطيات المتاحة إلى يومنا هذا هو "لا أحد يعرف ما الّذي ستفعله هذه السيارة ذاتية القيادة". فعليًا لا توجد إجابة سهلة. لطالما استمر الباحثون في المحاولة للعثور على إجابة، ولكن في الوقت نفسه لا يجدون سوى الحلول المؤقتة لبعض الحالات. إذ يعتمد البعض على محاكاة جميع المواقف يدويًا الّتي تنتج حلًا للحالات الاستثنائية، مثل: مشكلة العربة. والبعض الآخر يتعمق أكثر من ذلك ويترك للشبكات العصبية مهمة اكتشافها. وهذا قادنا لتطور التعلم المعزز وفق النموذج الحر (Q-learning) إلى شبكات التعلم المعزز العميق (Deep Q-Network). لكنها ليست بالحل المثالي أيضًا.
طريقة المجموعات
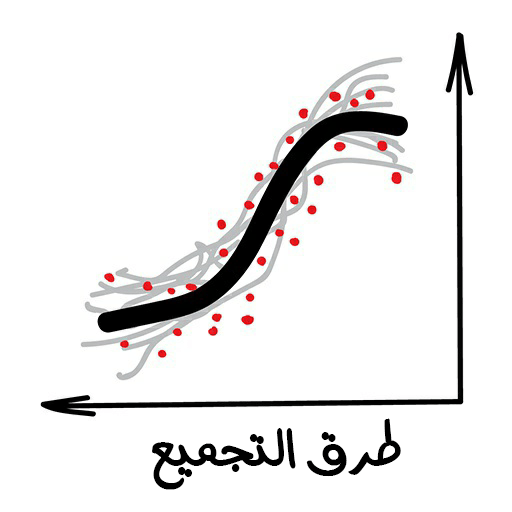
وهو مجموعة أشجار غبية تتعلّم تصحيح أخطاء بعضها البعض.
من بعض تطبيقاتها العملية في وقتنا الحالي:
- جميع التطبيقات الّتي تعمل على الخوارزميات الكلاسيكية (الفارق هنا أنها تقدم أداء أفضل).
- أنظمة البحث.
- الرؤية الحاسوبية.
- الكشف عن الأغراض.
من أبرز الخوارزميات الشائعة لها:
- خوارزمية الغابات العشوائية (Random Forest).
- خوارزمية التدرج المعزز (Gradient Boosting).
حان الوقت للأساليب الحديثة والكبيرة. تعدّ المجمعات والشبكات العصبية مقاتلان رئيسيان يمهدان طريقنا نحو التفرد في عملية التعلّم. واليوم ينتجون أكثر النتائج دقة ويستخدمون على نطاق واسع في جميع الأحداث.
على الرغم من فعاليتها العالية إلا أن الفكرة الكامنة وراءها بسيطة للغاية. إذ تعتمد على أخذ مجموعة من الخوارزميات ذات الفعالية العادية، وتجبرها على تصحيح أخطاء بعضها بعضًا، فستكون الجودة الإجمالية للنظام أفضل من أفضل خوارزميات تعمل بطريقة منفردة.
ستحصل على نتائج أفضل إذا أخذت أكثر الخوارزميات تقلبًا في النتائج، والّتي تتوقع نتائج مختلفة تمامًا في حالة حدوث ضوضاء صغيرة على بيانات الدخل. مثل خوارزميات أشجار القرار وأشجار الانحدار. هذه الخوارزميات حساسة للغاية، حتى أنه يمكن لقيمة شاذة واحدة خارجية مطبقة على بيانات الدخل أن تجعل النماذج يجن جنونها. في الحقيقة هذا بالضبط ما نحتاجه.
هنالك ثلاث طرق لبناء المجمعات:
- طريقة التكديس (Stacking).
- طريقة التعبئة (Bagging).
- طريقة التعزيز (Boosting).
سنشرح كلّ واحدٍ منهم على حدة:
1. طريقة التكديس (Stacking)
تُمرر مجموعة من النماذج المتوازية كمدخلات للنموذج الأخير والّذي سيتخذ القرار النهائي.
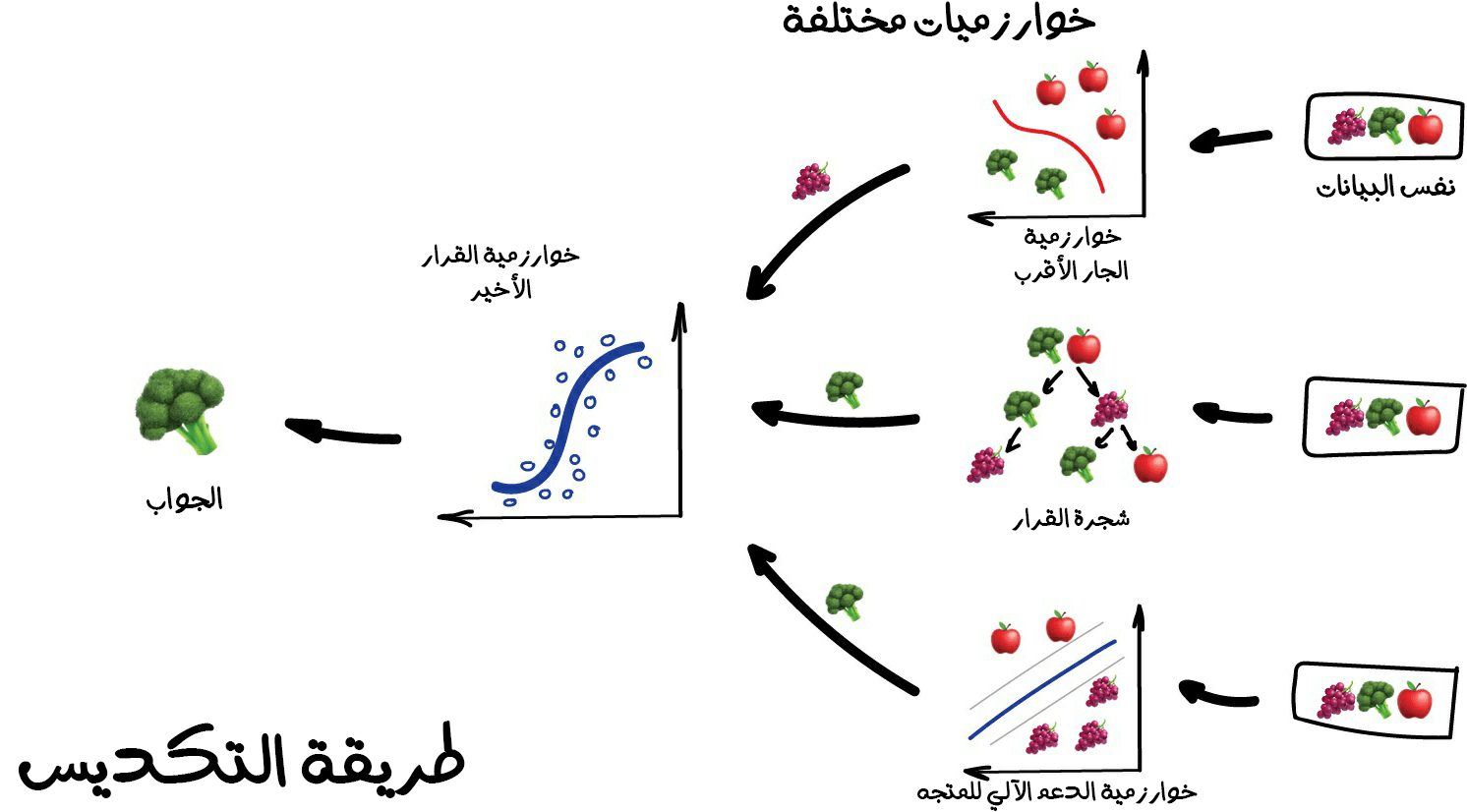
تَنتجُ هذه النماذج من تطبيق خوارزميات مختلفة وكلمة "مختلفة" تعني أي أن خلط تكديس نفس الخوارزميات على نفس البيانات لن يكون له أي معنى أو أهمية. وإن عملية اختيار الخوارزميات أمر متروك لك مطلق الحرية في اختباره. إلا أنه بالنسبة للنموذج المعني باتخاذ القرار النهائي، عادة ما يكون الانحدار خيارًا جيدًا لخوارزميته.
2. طريقة التعبئة (Bagging)
وهي معروفة أيضًا باسم Bootstrap Aggregating. في هذه الطريقة نستخدم نفس الخوارزمية، ولكن ندربها على مجموعات فرعية مختلفة من البيانات الأصلية. في النهاية نحسب متوسط الإجابات فقط.
يمكن أن تتكرر البيانات في مجموعات فرعية عشوائية. فمثلًا، يمكننا الحصول على مجموعات فرعية من المجموعة "1-2-3" مثل: "2-2-3" و"1-2-2" و"3-1-2" وما إلى ذلك. نستخدم مجموعات البيانات الجديدة هذه لتعليم الخوارزمية نفسها عدة مرات، ثمّ نتوقع الإجابة النهائية عن طريق خوارزمية البسيطة التصويت بالأغلبية.
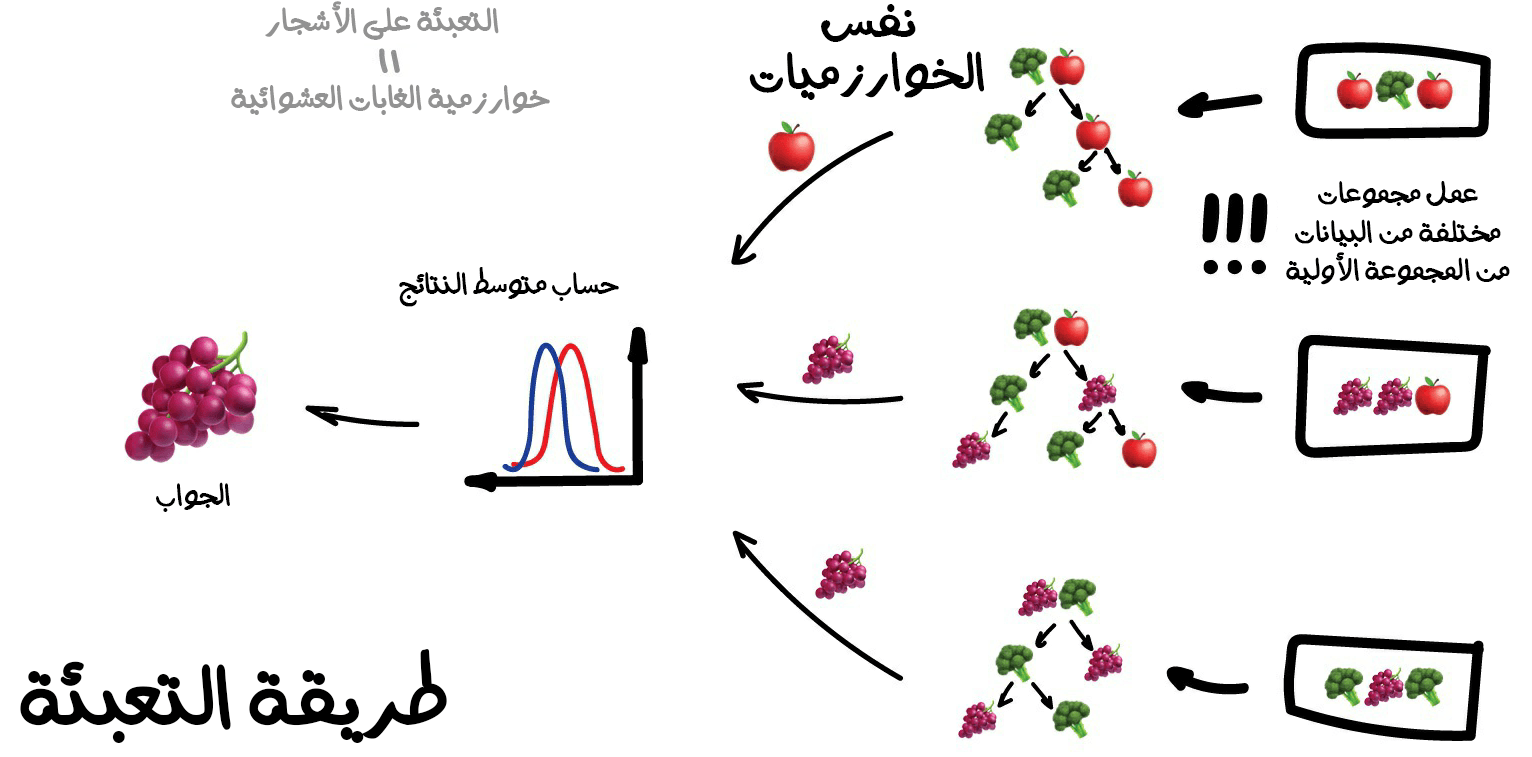
أشهر مثال على استخدام طريقة التعبئة هي خوارزمية الغابات العشوائية (Random Forest) والتي ببساطة تعبأ باستخدام أشجار القرار (الّتي سبق وأن وتحدثنا عنها في الفقرات السابقة). فمثلًا عند فتحك لتطبيق الكاميرا الخاص بهاتفك ورؤيتك لمربعات مرسومة حول وجوه الأشخاص فيجب أن تسأل نفسك، كيف حدث ذلك؟
في الحقيقة من المحتمل أن تكون هذه النتيجة بفضل خوارزمية الغابات العشوائية. وذلك لأن الشبكات العصبية بطيئة جدًا عند تشغيلها في الزمن الحقيقي (Real-time)، وبالمقابل تكون طريقة التعبئة مثالية بهذه الحالات لأنه يمكنها أن تبني أشجار القرار على جميع البطاقات الرسومية الضعيفة والقوية بل وحتى على المعالجات الجديدة الفاخرة الخاصة بتعلّم الآلة!
في بعض المهام، تكون الاستراتيجية المتبعة هي التركيز على قدرة الغابة العشوائية على العمل بالتوازي مثلما يحدث عند استخدام الشبكات العصبية الاصطناعية أما طريقة التجميع لا تستطيع العمل بالتوازي، والبعض الآخر من التطبيقات تتطلب السرعة الّتي تستطيع تحققها طرق المجموعات بغض النظر عن أسلوب تطبيقها وتحديدًا في المهام الّتي تتطلب معالجة بالزمن الحقيقي. ولكنها في النهاية مسألة مفاضلة بين خياري الدقة أو السرعة وذلك بحسب كلّ مهمة.

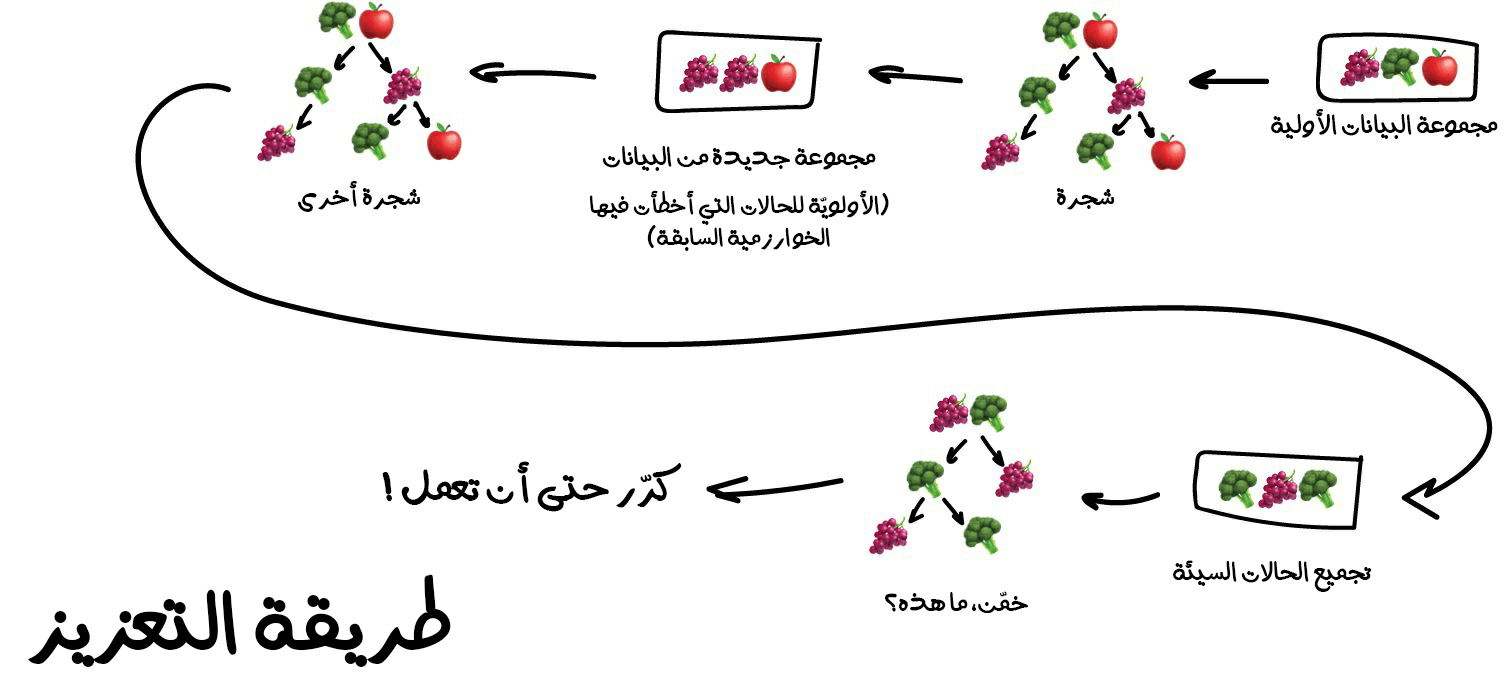
3. طريقة التعزيز (Boosting)
وهي الطريقة الّتي تعتمد على تدريب الخوارزميات واحدةً تلو الآخرى. وكلّ خوارزمية لاحقة تولي معظم اهتمامها لنقاط البيانات الّتي أخطأت الخوارزمية السابقة في تفسيرها. وتكرر هذه العملية إلى أن تصبح النتيجة مرضية.
كما هو الحال في طريقة التعبئة، تستخدم الخوارزمية مجموعات فرعية متنوعة من بياناتنا ولكن هذه المرة لن نُنشئها بطريقة عشوائية. وإنما في كلّ عينة فرعية، نأخذ جزءًا من البيانات الّتي فشلت الخوارزمية السابقة في معالجتها. وبذلك نُنشئ خوارزمية جديدة لتتعلم كيفية إصلاح الأخطاء الموجودة في الخوارزمية السابقة.
الميزة الرئيسية في طرق التجميع هي الدقة الممتازة بالموازنة مع الوقت المأخوذ، وتعد أسرع بكثير من الشبكات العصبية. تقريبًا الأمر أشبه ما يمكن بسباق بين سيارة وشاحنة على المضمار. يمكن للشاحنة أن تؤدي المزيد من الأفعال، ولكن في حال أردت أن تسير بسرعة فحتمًا ستأخذ السيارة. لالقاء نظرة على مثال حقيقي لاستخدام طرق التجميع (وتحديدًا طريقة التعزيز) افتح موقع فيسبوك أو موقع غوغل واكتب أي استعلام في مربع البحث. هل يمكنك سماع جيوش من الأشجار تزأر وتتحطم معًا لفرز النتائج حسب الصلة؟ ذلك بسبب أن هذه الشركات يستخدمون طريقة التجميع باستخدام التعزيز. حاليًا هناك ثلاث أدوات شائعة لتطبيق طريقة التعزيز، يمكنك قراءة هذا التقرير المفصل الّذي يوازن بينها CatBoost مقابل LightGBM مقابل XGBoost.
الشبكات العصبية (Neural Networks) والتعلم العميق (Deep Leaning)
الشبكات العصبية (Neural Networks)
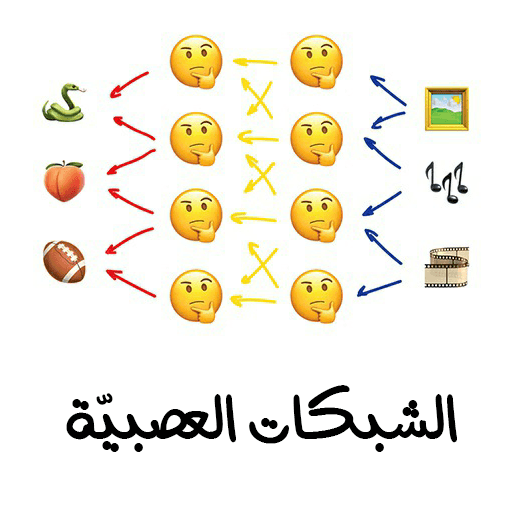
الشبكات العصبية: وهي عبارة عن مجموعة من الخلايا العصبية الاصطناعية الموجودة في طبقاتٍ متوضعةٍ فوق بعضها بعضًا، ولها طبقة أولية، وطبقة النهائية، تتلقى الطبقة الأولية المعلومات الخام، وتعالجها لتُمررها لاحقًا للطبقة الّتي تليها وهكذا إلى أن نحصل على الخرج من الطبقة النهائية.
بعض أشهر تطبيقاتها العملية المستخدمة في وقتنا الحالي:
- تحديد الكائن في الصور ومقاطع الفيديو.
- التعرف على الكلام والتراكيب اللغوية.
- معالجة الصور وتحويل التنسيق.
- الترجمة الآلية.
- بالإضافة إلى أنه يمكنها أن تعمل عوضًا عن جميع تطبيقات طرق تعلّم الآلة السابقة.
من بعض الهيكليات الشائعة للشبكات العصبية:
- الشبكات العصبية بيرسيبترون (Perceptron).
- الشبكات العصبية التلافيفية (CNN).
- الشبكات العصبية المتكررة (RNN).
- الشبكات العصبية ذات الترميز التلقائي (Autoencoders).
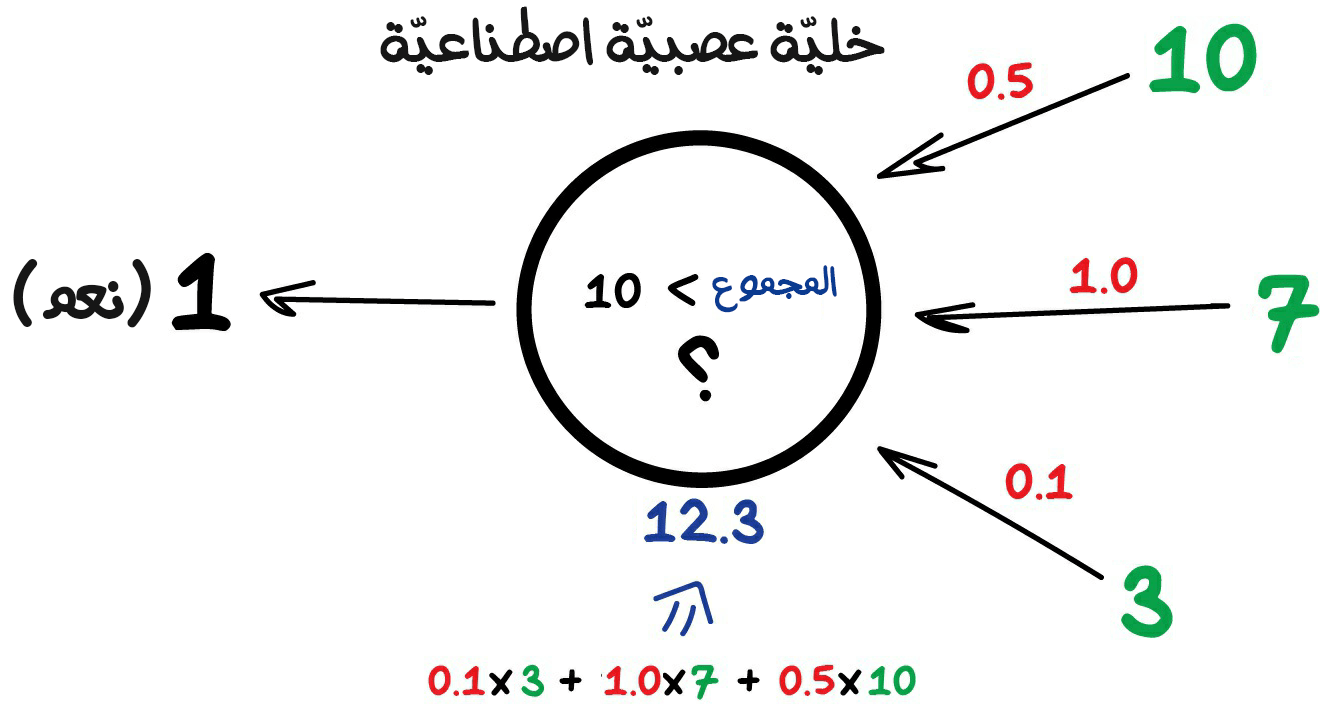
إن أي شبكة عصبية اصطناعية هي في الأساس مجموعة من الخلايا العصبية الاصطناعية (Neurons) و الاتصالات (Connections) الّتي بينهم. وإن الخلية العصبية الاصطناعية: هي مجرد تابع لديه مجموعة من المدخلات وخرج وحيد. وتتمثل مهمة الخلية العصبية الاصطناعية في أخذ جميع الأرقام من مدخلاتها، وأداء الوظيفة المنوطة إليها وإرسال النتيجة للخرج.
الاتصالات تشبه إلى حدٍ ما القنوات بين الخلايا العصبية الحقيقية. إذ تربط مخرجات خلية عصبية معينة لمدخل خلية عصبية أخرى حتى يتمكنوا من إرسال الأرقام والنتائج لبعضهم بعضًا. وكلّ اتصال له وسيط واحد فقط وهو الوزن (Weight). وهو مشابه لقوة الاتصال للإشارة. فعندما يمر الرقم 10 من خلال اتصال بوزن 0.5 يتحول إلى 5.
هذه الأوزان تطلب من الخلية العصبية الاصطناعية أن تستجيب أكثر للدخل ذو الوزن الأكبر، وأقل للدخل ذو الوزن الأقل. تُعدل هذه الأوزان عند التدريب وهكذا تتعلّم الشبكة العصبية الاصطناعية.
فيما يلي مثال لخلايا عصبية اصطناعية بسيطة ولكنها مفيدة في الحياة الواقعية: ستجمع جميع الأرقام من مدخلاتها وإذا كان هذا العدد أكبر من N فستُعطي النتيجة 1 وإلا ستعطي النتيجة 0.
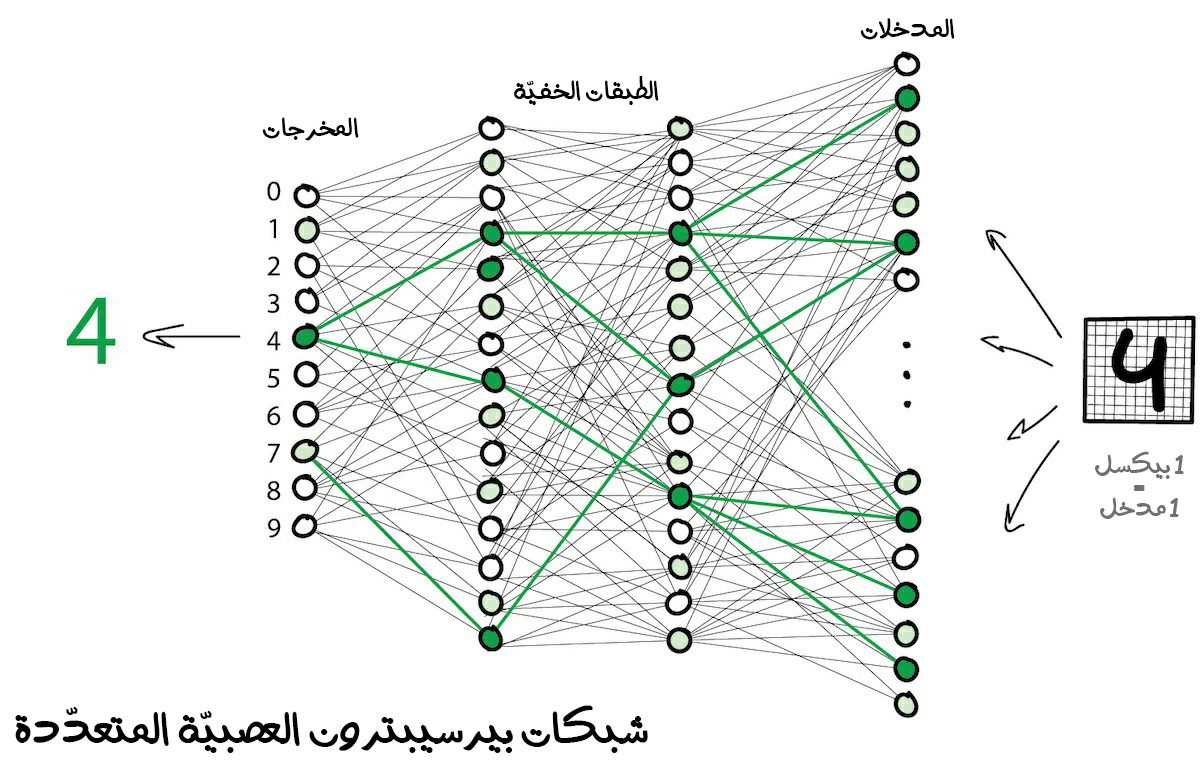
لمنع حدوث فوضى في الشبكة، ترتبط الخلايا العصبية بطبقات، وليس بطريقة عشوائية. لا ترتبط الخلايا العصبية داخل الطبقة الواحدة، وإنما تتصل بالخلايا العصبية للطبقات التالية والسابقة (الأعلى والأسفل). تتحرك البيانات في الشبكة العصبية الاصطناعية تحركًا صارمًا باتجاه واحد من مدخلات الطبقة الأولى إلى مخرجات الطبقة الأخيرة.
إذا وضعت عددًا كافيًا من الطبقات ووضعت الأوزان بطريقة صحيحة، فستحصل على النتيجة المرجوة وإليك مثلًا يوضح الأمر، تريد أن تكتشف ما هو الرقم المكتوب بخط اليد في الصورة الممررة، ستمرر الصورة إلى الشبكة عن طريق مدخلات الطبقة الأولى، وبعدها فإن البكسلات السوداء ستُنشّط الخلايا العصبية المرتبطة بها، وهي بدورها ستُنشّط الطبقات التالية المرتبطة بها، وهكذا حتى يضيء أخيرًا المخرج المسؤول عن الرقم أربعة. إذا هكذا وصلنا للنتيجة المرجوة (سنأخذ هذا المثال بوضوح أكبر وبكلّ تفاصيله الدقيقة في الجزء الثاني من هذه السلسلة).
في الواقع عند برمجة الخلايا العصبية على الحاسب لا نكتب عمليًا الخلايا العصبية والوصلات المرتبطة بها. وإنما يمثل كلّ شيء كمصفوفات وتحسب النتيجة بناءً على ضرب المصفوفات ببعضها بعضًا للحصول على أداء أفضل. يبسط هذا الفيديو كيف تحدث عملية التعلّم في الخلايا العصبية الاصطناعية، وكيف تحدد عملية الضرب دقة الشبكة العصبية الّتي لدي (لا تنس أن تغعّل خيار التعليقات التوضيحية لأن الفيديو مترجم إلى اللغة العربية).
تحتوي الشبكة على طبقات متعددة لها روابط بين كلّ خلية عصبية تسمى الشبكات العصبية بيرسيبترون المتعددة (Multilayer Perceptron) وتسمى اختصارًا (MLP) وتعد أبسط بنية مناسبة للمبتدئين.
بعد إنشاء الشبكة، ستكون مهمتنا هي تعيين الطرق المناسبة لتتفاعل الخلايا العصبية مع الإشارات الواردة بطريقة صحيحة. وسنُعطي الشبكة بيانات الدخل أو "مدخلات الشبكة العصبية" صورة الرقم المكتوب بخط اليد وبيانات الخرج أو "مخرجات الشبكة العصبية" ستكون الرقم الموافق للصورة المُمررة عبر مدخلات الشبكة. أي سنقول للشبكة "عدلي أوزانك بالطريقة الصحيحة حتى تستطيعين معرفة الصورة الممررة لك على أنها صورة للرقم 4".
في البداية تُسند جميع الأوزان بطريقة عشوائية. بعد أن نعرض لها رقمًا معينًا، إذ تنبعث منها إجابة عشوائية لأن الأوزان ليست صحيحة حتى الآن، ونوازن مدى اختلاف هذه النتيجة عن النتيجة الصحيحة. ثم نبدأ في بالرجوع للخلف عبر الشبكة من المخرجات إلى المدخلات ونخبر كلّ خلية عصبية، لقد تنشطت هنا وأديت عملًا رهيبًا وهكذا.
بعد مئات الآلاف من هذه الدورات "الاستدلال ثمّ التحقق ثمّ التغيير" المتتالية هناك أمل في أن تُصحح الشبكة العصبية أوزانها وتجعلها تعمل على النحو المنشود. الاسم العلمي لهذه المنهجية هي "منهجية الانتشار العكسي" (Backpropagation).
يبسط هذا الفيديو كيف تَحدثُ عملية التعلّم بالتفاصيل الدقيقة في الطبقات المخفية وكيف تتعلم من أخطائها (مرة أخرى لا تنسَ أن تغعّل خيار التعليقات التوضيحية لأن الفيديو مترجم إلى اللغة العربية).
يمكن للشبكة العصبية المدربة تدريبًا جيدًا أن تنوب عن عمل أي من الخوارزميات الموضحة في هذا الفصل (بل وغالبًا ما يمكنها أن تعمل بدقة أكثر منهم). وهذا ما جعلها شائعة الاستخدام على نطاق واسع.
اتضح لاحقًا أن الشبكات الّتي تحتوي على عدد كبير من الطبقات تتطلب قوة حسابية لا يمكن تصورها آنذاك (عند بداية ظهور الشبكات العصبية). أما حاليًا فأي حاسوب مُخصص للألعاب يتفوق بالأداء على أداء مراكز البيانات الضخمة آنذاك. لذلك لم يكُ لدى الناس أي أمل في أن تصبح هذه القدرة الحسابية متوفرة ذلك الحين، وكانت فكرة الشبكات العصبية مزعجة بضخامتها.
سنتاول في شرحنا أهم الهياكل المشهورة للشبكات العصبية في الوقت الحاضر.
الشبكات العصبية التلافيفية (Convolutional Neural Networks)
أحدثت بنية الشبكات العصبية التلافيفية والتي تدعى اختصارًا (CNN) ثورة في عالم الشبكات العصبية حاليًا. إذ تستخدم للبحث عن الكائنات في الصور وفي مقاطع الفيديو، كما تستخدم أيضًا للتعرف على الوجوه، وتحويل التنسيق، وتوليد وتحسين الصور، وإنشاء تأثيرات مثل التصوير البطيء وتحسين جودة الصورة. باختصار تستخدم بنية الشبكات العصبية التلافيفية في جميع الحالات الّتي تتضمن صورًا ومقاطع فيديو.
يمكنك ملاحظة كيف استطاعت تقنيات تعلم الآلة الّتي طورتها شركة فيسبوك من تحديد الكائنات الموجودة في الصورة بدقة ممتازة.

من أبرز المشاكل الرئيسية الّتي تواجهنا عند التعامل مع الصور هي صعوبة استخراج الميزات منها. على عكس سهولة الّتي نجدها عند التعامل مع النصوص، إذ في النصوص يمكنك ببساطة تقسيم النص بحسب الجمل، والبحث عن الكلمات ذات سمات معينة، وما إلى ذلك. ولكن في الصور الأمر أعقد من ذلك بكثير إذ يجب تصنيف الصور تصنيفًا يدويًا لكي تتمكن برامج تعلّم الآلة من معرفة مكان آذان القطط أو ذيولها في هذه الصورة المحددة والمنصفة. سميت هذه المنهجية لاحقًا باسم "صناعة الميزات يدويًا" وكان يستخدمها الجميع تقريبًا.

ولكن الأمر لم يتوقف إلى هذا الحد فحسب وإنما ظهرت العديد من المشاكل مع منهجية صناعة الميزات يدويًا.فمثلًا في البداية إذا كانت تعرفت الشبكة العصبية على أذني القطة وأبعدت هذه القطة عن الكاميرا فنحن في مشكلة لأن الشبكة لن ترى شيئًا (بسبب تغيّر حجم أذن القطة).
ثانيًا لنحاول تسمية 10 ميزات مختلفة تميّز القطط عن بقية الحيوانات الأخرى (في الحقيقة أنا أول من فشل في هذه المهمة)، ولكن مع ذلك عندما أرى نقطة سوداء تُسرعُ من جانبي أثناء تجولي في الشارع عند منتصف الليل - حتى لو لمحتها فقط في زاوية عيني - سأستطيع أن أحدد بأنها قطة وليست فأر. والسبب بسيط جدًا إذ لا شعوريًا يصنف دماغنا العديد من الميزات الخاصة بالقطط ولا ينظر إلى شكل الأذن أو عدد الأرجل فقط وذلك بدون أي جهد مني ولا حتى تفكير. وبناءً على ذلك سيصعب الأمر جدًا عند محاولتي لنقل هذه المعرفة إلى الآلة.
لذا فهذا يعني أن الآلة ستحتاج إلى تعلّم هذه الميزات بمفردها، وإنشاء هذه الميزات اعتمادًا على الخطوط الأساسية للصورة. سننفذ ما يلي:
- سنقسم الصورة بأكملها إلى كتل ذات حجم 8×8 بكسل.
- سنخصص لكل نوع من أنواع الخطوط على الصورة رمزًا معينًا - سواء أكان الخط أفقيًا سيكون الرمز [-] أو رأسيًا سيكون الرمز [|] أو قطريًا سيكون الرمز [/]. يمكن أيضًا أن يكون العديد منها مرئيًا للغاية - وهذا يحدث ولذلك لسنا دائمًا على ثقة تامة.
سيكون الناتج عدة جداول من الخطوط الّتي هي في الواقع أبسط الميزات الّتي تمثل حواف الكائنات على الصورة. إنها صور بمفردها ولكنها مبنية من الخطوط. وهكذا نستمر في أخذ كتلة ذات حجم 8×8 ونرى كيف تتطابق معًا. ونعيدها مرارًا وتكرارًا.
تسمى هذه العملية بعملية الإلتفاف أو الطيّ (Convolution)، مستمدة هذا الاسم من تابع الطيّ المطبق فيها. يمكن تمثيل عملية الطيّ كطبقة من الشبكة العصبية، لأنه في نهاية الأمر يمكن لكلّ خلية عصبية أن تكون بمثابة تابع يؤدي أي وظيفة أريدها.
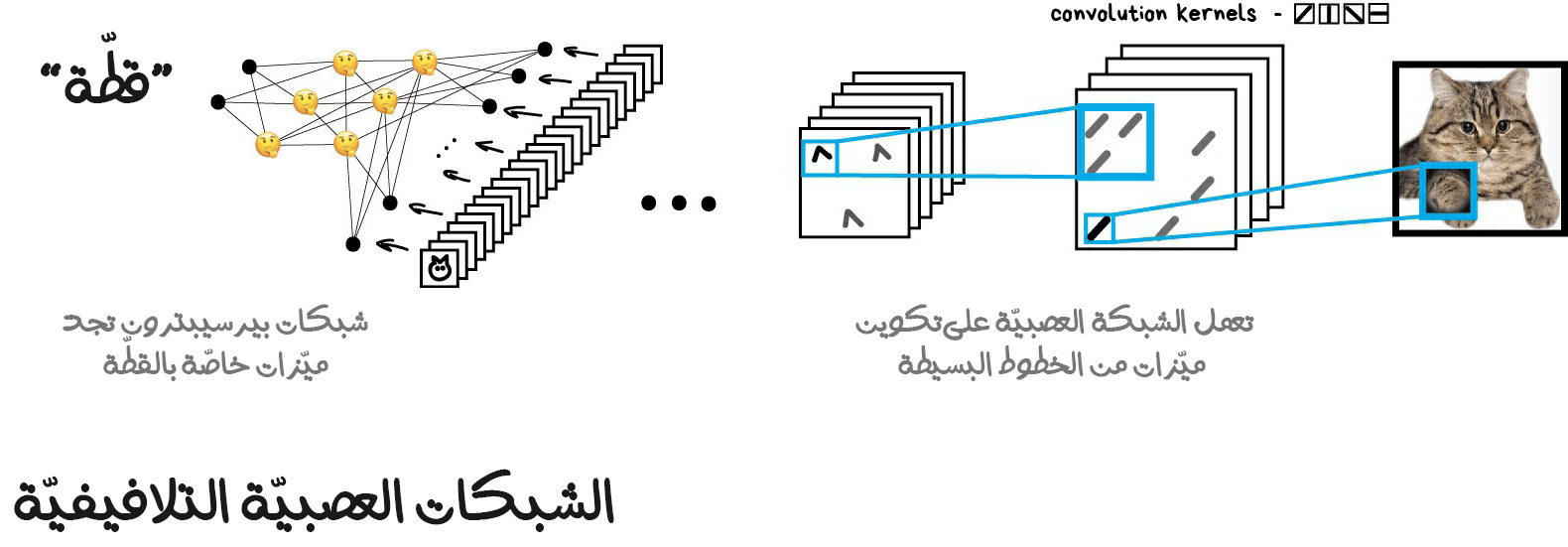
عندما نغذي ونزود شبكتنا العصبية بالكثير من صور القطط، فإنها ستعيّن تلقائيًا أوزانًا أكبر لمجموعات الخطوط الّتي تتكرر كثيرًا في هذه النوع من الصور. لا تهتم الآلة ما إذا كان ظهر القطة خطًا مستقيمًا أو جسمًا هندسيًا معقدًا مثل وجه القطة، وبالمجمل ستكون بعض مجموعات الخطوط ستكون نشطة دائمًا.
كمخرجات ستنظر هذه الشبكة العصبية الاصطناعية ذات البنية التلافيفية لأكثر المجموعات نشاطًا في هذه الصور وستبني عليها قرارها فيما إذا كانت الصور لقطة أو لكلب.

يكمن جمال هذه الفكرة في أن الشبكة العصبية ستبحث عن الميزات الأكثر تميزًا للكائنات بمفردها. لسنا بحاجة لاختيارها يدويًا. يمكننا تزويد الشبكة بكمية كبيرة من الصور لأي كائن فقط من خلال البحث في غوغل عن مليارات من الصور المشابهة وهكذا سوف تنشئ شبكتنا خرائط مميزة من الخطوط وتتعلم كيفية تمييز أي كائن بمفردها.
الشبكات العصبية المتكررة (Recurrent Neural Networks)
تعدّ الشبكات العصبية المتكررة والتي يشار لها اختصارًا (RNN) من أكثر البُنى الهيكلية للشبكات العصبية الاصطناعية شيوعًا في وقتنا الحاضر. وذلك لفوائدها الجمّة إذ أعطتنا الكثير من الأشياء المفيدة مثل: الترجمة الآلية، والتعرف على الكلام، وتركيب صوت مميز للمساعد الشخصي مثل المساعد سيري (Siri). وعمومًا تعدّ هذه البنية من أفضل الخيارات الموجودة للبيانات التسلسلية مثل: الصوت أو النص أو الموسيقى.
هل تذكر القارئ الصوتي الخاص الموجود في نظام التشغيل ويندوز إكس بي (Windows XP)؟ هذا الرجل المضحك يبني الكلمات حرفًا بحرف، محاولًا لصقها معًا. الآن وازن بين صوته وصوت المساعد الشخصي أليكسا الخاص بشركة أمازون، أو المساعد الشخصي الخاص بغوغل، فرق كبير بينهم، أليس كذلك؟ إنهم لا ينطقون الكلمات بوضوح فقط وإنما يضيفون لكنة خاصة مناسبة لهم! إليك هذا الفيديو اللطيف لشبكة عصبية تحاول أن تتحدث.
كلّ ذلك لأن المساعدين الصوتيين الحديثين مدربون على التحدث على عبارات كاملة دفعة واحدة وليس حرفًا بحرف، يمكننا أخذ مجموعة من النصوص الصوتية وتدريب شبكة عصبية لإنشاء تسلسل صوتي أقرب إلى الكلام الأصلي. بمعنى آخر، سنستخدم النص كمدخل للشبكة العصبية الاصطناعية وصوت الشخص المجرّد كخرج لهذه الشبكة. نطلب من الشبكة العصبية إنشاء بعض الأصوات لنص محدد، ثم موازنته بالصوت الأصلي ومحاولة تصحيح الأخطاء للاقتراب قدر الإمكان من الصوت الأصلي المثالي.
تبدو عملية التعلم بسيطة وكلاسيكية أليس كذلك؟ حتى الشبكات العصبية ذات التغذية المُسبقة تستطيع فعل ذلك. ولكن كيف يجب تعريف مخرجات هذه الشبكة؟ هل سيكون بلفظ كلّ عبارة ممكنة موجودة في اللغة الإنكليزية؟ بالتأكيد هذا ليس خيارًا جيدًا.
هنا ستساعدنا حقيقة أن النص أو الكلام أو حتى الموسيقى؛ ما هي إلا تسلسلات من المعلومات. تتكون من وحدات متتالية (مثل المقاطع اللفظية للكلمات الإنكليزية). تبدو جميعها فريدة من نوعها ولكنها تعتمد على مقاطع سابقة. ألغِ هذا الاتصال بين هذه المقاطع وستحصل على مقطع موسيقي من نوع دبستيب (Dubstep).
يمكننا تدريب الشبكة العصبية بيرسيبترون لتوليد هذه الأصوات الفريدة، ولكن كيف ستتذكر الإجابات السابقة؟ لذا تكمن الفكرة في إضافة ذاكرة خاصة لكلّ خلية عصبية اصطناعية، واستخدامها كمدخل إضافي عند تشغيل المقطع التالي. يمكن للخلايا العصبية أن تدون ملاحظات لنفسها مثل اكتشافها لحرفٍ متحرك، ولذلك يتوجب عليها أن تُظهر المقطع الصوتي التالي بنبرة أعلى (في الحقيقة إنها مجرد مقاربة بسطية للغاية). بهذه الطريقة ظهرت الشبكات المتكررة.
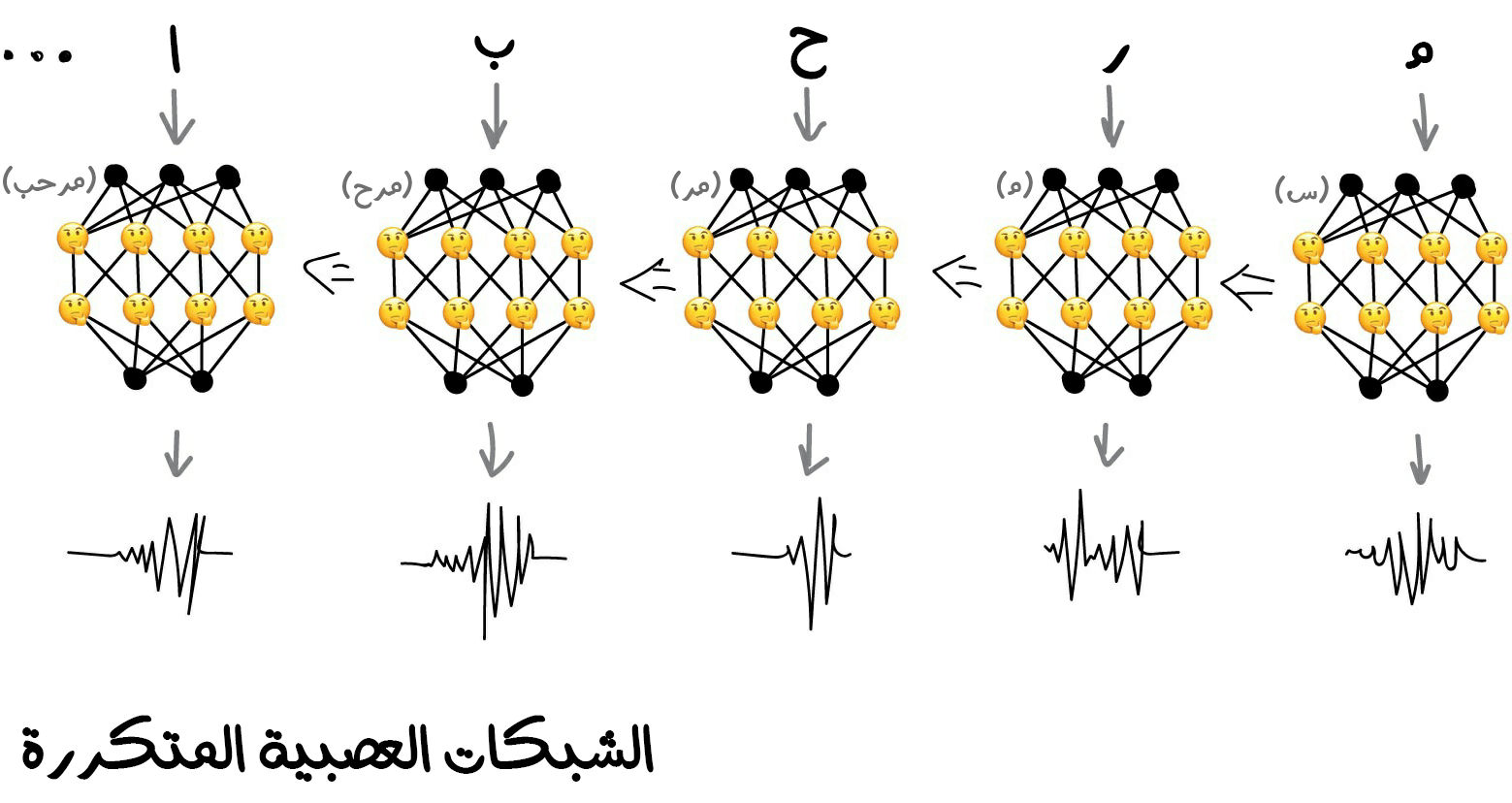
كان لهذا النهج مشكلة كبيرة وهي عندما تتذكر جميع الخلايا العصبية نتائجها السابقة، يصبح عدد الاتصالات في الشبكة ضخمًا جدًا لدرجة أنه من المستحيل -من الناحية الفنية- ضبط جميع الأوزان.
لذلك عندما لا تستطع الشبكة العصبية نسيان بعض الأشياء غير الهامّة فلن تتمكن من تعلّم الأشياء الجديدة (حتى نحن البشر لدينا نفس المشكلة نسيان بعض المعلومات غير الهامة، أو لعلّها ميزة؟ وخصيصًا إذا كانت هذه الأشياء هي ذكريات مؤلمة!).
كان التحسين الأول بسيطًا جدًا وذلك بتحديد حجم معين لذاكرة الخلية العصبية الاصطناعية. لنقل بأن الشبكة ستحفظ آخر 5 نتائج فقط. ولكن أليست هذه الفكرة مناقضة للفكرة الأساسية الّتي انطلقنا منها (وهي تذكر ما تعلمته الشبكة بالكامل)؟
بعد تحديثاتٍ وتطويرات كثيرة جاء لاحقًا نهج أفضل بكثير، والّذي سيستخدم خلايا خاصة، تشبه إلى حدٍ ما ذاكرة الحاسوب. يمكن لكلّ خلية إمكانية تسجيل رقم معين أو قراءته أو إعادة تعيينه. وسميت هذه الخلايا بخلايا الذاكرة طويلة وقصيرة الأجل (LSTM).
والآن عندما تحتاج الخلية العصبية إلى تعيين منبه لتذكر هذا المقطع، فإنها ستضع راية (Flag) في تلك الخلية. مثل "كان الحرف ساكنًا في الكلمة، استخدم المرة التالية قواعد نطق مختلفة". عندما لا تستدعي الحاجة لاستخدام الرايات، سيُعاد ضبط الخلية تاركة فقط الاتصالات "طويلة الأجل" للشبكة العصبية. وبعبارة أخرى، ستُتدربُ الشبكة العصبية ليس فقط لكي تتعلّم كيفية ضبط الأوزان وإنما لتتعلّم أيضًا كيفية ضبط الرايات (وهي أشبه ما يمكن بالمنبهات) في الخلايا العصبية.
قد يبدو الحل بسيط جدًا ومع ذلك يعمل بكفاءة عالية. لكن ماذا لو دمجنا إمكانية تعديل مقاطع الفيديو باستخدام الشبكات العصبية التلافيفية (CNN) مع إمكانية تعديل الصوت باستخدام الشبكات العصبية المتكررة (RNN) على ماذا سنحصل؟ هل حقًا سنحصل على الرئيس السابق للولايات المتحدة الأمريكية؟ إليك هذا الفيديو لتكتشف الأمر.
التعلم العميق (Deep Learning)
إذا أردنا أن نختصر التعلم العميق بجملة واحدة وواحدة فقط ستكون حتمًا: "التعلّم العميق هو شبكة عصبية اصطناعية كبيرة".
من بعض التطبيقات العملية للتعلم العميق:
- التعرف على الصور والأصوات.
- تحليل بيانات الأرصاد الجوية.
- تحليل بيانات الأبحاث البيولوجية.
- مجال التسويق واختيار الجمهور المستهدف من الإعلانات.
من بعض الهيكليات الشبكة العصبية الاصطناعية المستخدمة بكثرة في التعلّم العميق نجد:
- شبكات بيرسيبترون متعددة الطبقات (Multilayer Perceptron Networks).
- الشبكات العصبية التلافيفية (Convolutional Neural Networks).
- الشبكات العصبية المتكررة ذات الذاكرة قصيرة وطويلة الأمد (Long Short-Term Memory Recurrent Neural Networks).
- والعديد من البنى الأخرى للشبكة.
بعد بناء العلماء والباحثين للعديد من البُنى (المعماريات) الخاصة بالشبكات العصبية في محاولة منهم للعثور على البنية الأنسب لاكتشاف الأنماط في البيانات، ومن بين أبرز هذه البُنى (المعماريات) كانت البنية الخاصة بالشبكة التعلم العميق، ويذكر أن أول مرة ظهر فيها مفهوم التعلم العميق كان في عام 2006، وعرفت في ذلك الوقت على أنها مجال فرعي من مجالات تعلّم الآلة (مع أنها تندرج تحت نفس فئة الشبكات العصبية)، إلا أنها لاقت الاهتمام الواسع عندما طبق جيفري هينتون وزملائه بنية الشبكة الخاصة بالتعلّم العميق في مسابقة ImgNet وحققوا آنذاك نتائج مبهرة، إذ استطاعوا تحقيق دقة أفضل بـ10% من البُنى القديمة في التعرف على الصور.
بعد هذا النجاح المدوّي استطاعت بجدارة لفت الأنظار حولها وبدأت بالظهور العديد من التطبيقات والأبحاث الجديدة الخاصة بالتعلم العميق، مما أدى إلى تطورها تطورًا كبيرًا، كما أنها أثببت جودتها بتحقيقها نتائج مذهلة في العديد من التطبيقات، وبذلك أوجدت لنفسها مكانة لا يستهان بها في مجال الذكاء الصنعي عمومًا ومجال تعلم الآلة خصوصًا.
يعتمدُ مفهوم التعلم العميق في أساسه على طريقة تعلّم مؤلفة من عدّة طبقات من التمثيلات المقابلة لبنيةٍ هرمية من السمات، ويتم تعريفُ السِّمات والمفاهيم عالية المستوى نزولًا إلى المفاهيم ذات المستوى الأدنى، وهي تعمل أيضًا نمط التعلم الموجه وغير الموجه إلا أنها تعمل عملًا ممتازً مع البيانات المصنفة (أي مع التعلّم الموجّه).
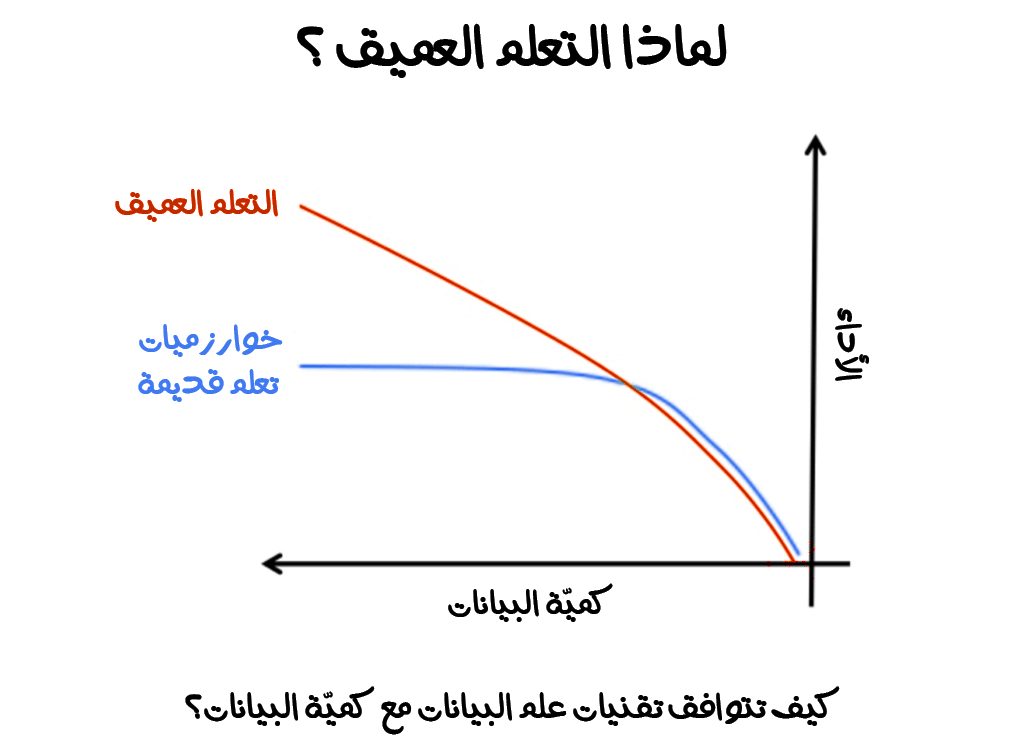
إن للتعلم العميق علاقة وطيدة مع البيانات إذ لا بدّ من الحصول على كميات كبيرة من البيانات إذا أردنا استخدام هذا النوع من التعلّم. ومع ازدياد البيانات سوف تتحسن الدقة تحسنًا كبيرًا مما سيؤدي لنتائج أفضل في نهاية المطاف.
الفرق بين الشبكات العصبية والتعلم العميق
في الحقيقة إن التعلم العميق ما هو إلا بنية مخصصة من الشبكات العصبية، ولكنها سميت بالتعلم العميق نسبة إلى عدد الطبقات الّتي تحتويها هذه البنية الشبكية، وبما أنها أكبر من عدد الطبقات الخاصة بالشبكات العادية آنذاك فلذلك سُميت بهذا الإسم.
تكمن قوة التعلم العميق في إمكانيته في تعلّم الميزات (Features) بطريقة هرمية، أي تتعلّم التسلسل الهرمي للميزات انطلاقًا من ميزات من مستوى عالٍ مرورًا بميزات بمستوى أخفض وهكذا إلى أن نصل لآخر الميزات ذات المستوى الأدنى، مما يعطي لأسلوب التعلم هذا مستوًى جديدًا من التجريد للنظام وخصوصًا مع الوظائف والمفاهيم المعقدة من خلال بنائها من المفاهيم الأبسط فالأبسط.
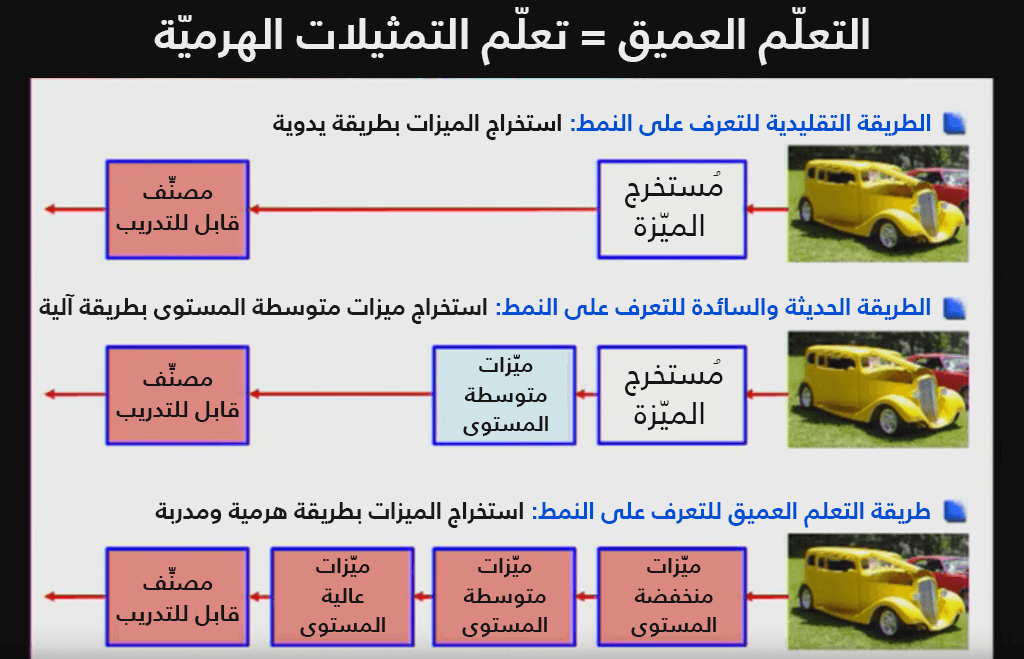
من الشكل السابق نلاحظ كيف أن التعلم العميق يستطيع تعلم التمثيلات الهرمية للبيانات. الّتي تربط المدخلات مع المخرجات مباشرة من البيانات دون الاعتماد على الميزات الّتي حددها الإنسان. أي تستطيع استنتاج كميات كبيرة من الميزات ومحاولة تحليلها وبطها بالصورة الكاملة للمشكلة. يطلق على هذا النوع من طريقة تعلّم الميزات الخاصة بالبيانات بتعلم الميزات (Feature learning).
ومن بين أبرز الطفرات العلمية الّتي شهدها التعلم العميق كان على يد شركة ديب مايند (والتي استحوذت عليها شركة ألفابت)، إذ استطاعت شركة ديب مايند أن تدمج بين التعلم العميق مع التعلم المعزز من أجل حلّ المشاكل المعقدة مثل لعب الألعاب.
أطلقوا لاحقًا على طريقتهم هذه اسم شبكات التعلم المعزز العميق (Deep Q-Network)، بعدها اصبح التعلّم العميق في أغلب البنى الخاصة بالشبكات العصبية. ومن الملاحظ مما سبق أن طريقة التعلم العميق تتطلب أجهزة حاسب قوية جدًا، وذلك لأنها تتعامل مع كميات كبيرة من البيانات.
هنالك العديد من البنى الخاصة بالشبكات العصبية لدرجة أننا نحتاج لكتاب كامل لتغطية كافة أنواعها ومميزاتها وسلبياتها وطرق عملها ..إلخ، إلا أنه وبما أنك استطعت تعلم الأساسيات فحتمًا ستستطيع تعلم أصعب البنى الشبكية، ولإعطاء نظرة دقيقة للأمر إليك الصورة التالية:
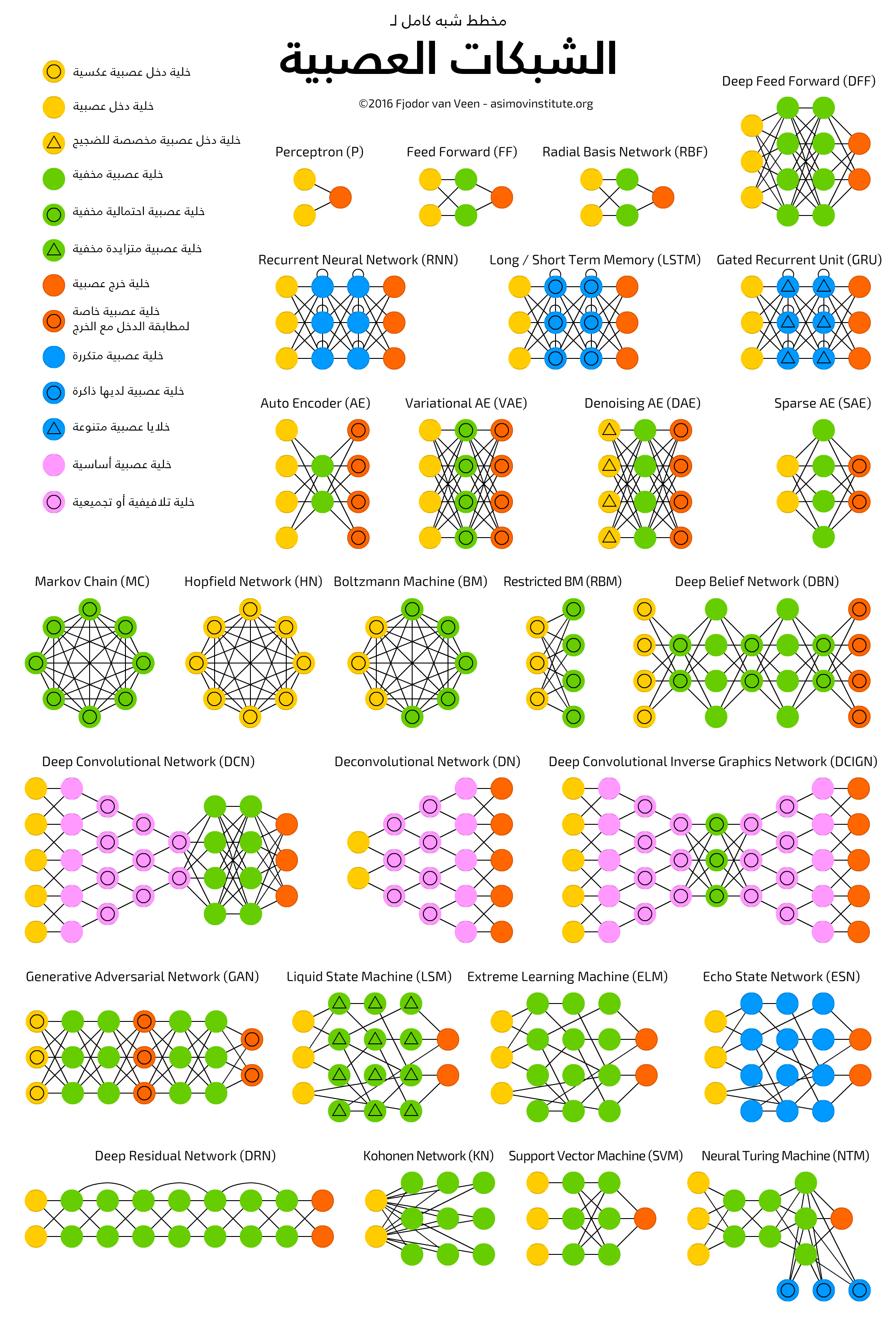
كما يمكنك ايضًا الرجوع إلى هذا المقال لمزيد من المعلومات.

الخلاصة
بعد تعرفنا على أهم الأساسيات الخاصة بتعلّم الآلة، وكيف تختلف عن بعضها بعضًا، وما هي النقاط الّتي يجب علينا التركيز عليها عند اختيارنا لطريقة ما على حساب الأخرى، وتعرفنا أخيرًا على الشبكات العصبية والتعلم العميق، لا بدّ لنا من أن نسأل أنفسنا، ما هي المشاكل الّتي يُواجهنا هذا المجال؟ ما نوع هذه المشاكل؟ وكيف نستطيع تجاوزها؟
في مقالنا القادم سنحاول الإجابة على هذه الأسئلة ونتعلم أيضًا بعض الأمور المهمة والّتي ستساعدنا في المضي قدمًا في هذا المجال.
المراجع
- مقال Machine Learning for Everyone.
- كتاب Hands on Machine Learning with Scikit Learn Keras and TensorFlow الطبعة الثانية.
- مقال What is Deep Learning?.
اقرأ أيضًا
- المقال التالي: تعلم الآلة: التحديات الرئيسية وكيفية التوسع في المجال
- المقال السابق: الذكاء الاصطناعي: مراحل البدء والتطور والأسس التي نشأ عليها
- النسخة الكاملة من كتاب مدخل إلى الذكاء الاصطناعي وتعلم الآلة












أفضل التعليقات
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.