

قبل أن تبدأ بكتابة البرامج عبر بايثون، هنا موضوع مهم يجب أن تعرفه إلى جانب ما تعرفت عليه بالمقالات السابقة من هذه السلسلة، وهو أنواع البيانات خصوصًا القوائم Lists والصفوف tuples.
يمكن أن تحتوي القوائم والصفوف على قيم متعددة، مما يجعل كتابة البرامج التي تعالج مقدرًا كبيرًا من البيانات أمرًا سهلًا. ولأن القوائم تستطيع احتواء قوائم أخرى فيها فيمكنك استخدامها لترتيب البيانات ترتيبًا هيكليًا.
سنناقش في هذا المقال أساسيات القوائم، وسنتحدث عن التوابع methods، وهي دوال مرتبطة بنوع بيانات معين تجري عمليات عليه. ثم سنتحدث باختصار عن أنواع البيانات المتسلسلة الأخرى مثل الصفوف tuples والسلاسل النصية strings، وكيف تقارن مع بعضها بعضًا. وسنغطي في المقال القادم نوعًا جديدًا من البيانات وهو القاموس dictionary.
نوع البيانات list
القائمة هي قيمة تحتوي على قيم أخرى متعددة داخلها بترتيب متسلسل. والمصطلح «قيمة القائمة» list value يشير إلى القائمة نفسها، والتي هي القيمة التي يمكن أن تخزن في متغير أو تمرر إلى دالة كغيرها من القيم، ولا تشير إلى القيم الموجودة داخل القائمة.
تبدو القائمة بالشكل الآتي: ['cat', 'bat', 'rat', 'elephant'] وكما كنّا نكتب السلاسل النصية محاطةً بعلامتَي اقتباس لتحديد متى تبدأ وتنتهي السلسلة النصية، فتبدأ القائمة بقوس مربع وتنتهي بقوس مربع آخر []. وتسمى القيم داخل القائمة بعناصر القائمة items، ويفصل بين عناصر القائمة بفاصلة. يمكنك إدخال ما يلي في الصدفة التفاعلية للتجربة:
>>> [1, 2, 3] [1, 2, 3] >>> ['cat', 'bat', 'rat', 'elephant'] ['cat', 'bat', 'rat', 'elephant'] >>> ['hello', 3.1415, True, None, 42] ['hello', 3.1415, True, None, 42] ➊ >>> spam = ['cat', 'bat', 'rat', 'elephant'] >>> spam ['cat', 'bat', 'rat', 'elephant']
المتغير spam ➊ له قيمة واحدة، وهي قيمة القائمة، ولكن القائمة نفسها تحتوي على عناصر أخرى. لاحظ أن القيمة [] تعني قائمة فارغة لا تحتوي على قيم مثلها كمثل السلسلة النصية الفارغة ''.
الوصول إلى عناصر القائمة عبر الفهرس
لنقل أن لديك القائمة ['cat', 'bat', 'rat', 'elephant'] مخزنةً في متغير باسم spam، حينها ستكون نتيجة التعبير spam[0] هي القيمة 'cat' ونتيجة التعبير spam[1] هي 'bat' وهلم جرًا للبقية.
العدد الصحيح الموجود داخل الأقواس المربعة يسمى فهرسًا index، والقيمة الأولى في القائمة يشار إليها بالفهرس 0، والقيمة الثانية بالفهرس 1، والثالثة بالفهرس 2 …إلخ.
يُظهر الشكل التالي قائمةً مسندةً إلى المتغير spam مع توضيح فهارس كل قيمة فيها. لاحظ أن فهرس العنصر الأول هو 0 ويكون فهرس آخر عنصر مساويًا لطول القائمة ناقص واحد. أي أن الفهرس 3 في قائمةٍ لها أربع قيم يشير إلى آخر عنصر.

الشكل 1: قائمة مخزنة في متغير مع فهارس كل عنصر فيها
على سبيل المثال، أدخل التعابير البرمجية الآتية في الصدفة التفاعلية وابدأ بضبط قيمة المتغير spam:
>>> spam = ['cat', 'bat', 'rat', 'elephant'] >>> spam[0] 'cat' >>> spam[1] 'bat' >>> spam[2] 'rat' >>> spam[3] 'elephant' >>> ['cat', 'bat', 'rat', 'elephant'][3] 'elephant' ➊ >>> 'Hello, ' + spam[0] ➋ 'Hello, cat' >>> 'The ' + spam[1] + ' ate the ' + spam[0] + '.' 'The bat ate the cat.'
لاحظ أن نتيجة التعبير 'Hello, ' + spam[0]➊ هي 'Hello, ' + 'cat' ذلك لأن نتيجة spam[0] هي 'cat', وبالنهاية ستكون نتيجة التعبير هي السلسلة النصية التالية: 'Hello, cat' ➋.
ستحصل على رسالة الخطأ IndexError إذا استخدمت فهرسًا يتجاوز عدد عناصر القائمة.
>>> spam = ['cat', 'bat', 'rat', 'elephant'] >>> spam[10000] Traceback (most recent call last): File "<pyshell#9>", line 1, in <module> spam[10000] IndexError: list index out of range
يجب أن تكون الفهارس أعدادًا صحيحةً فقط، ولا يقبل بالأعداد العشرية؛ فالمثال الآتي يتسبب بخطأ TypeError:
>>> spam = ['cat', 'bat', 'rat', 'elephant'] >>> spam[1] 'bat' >>> spam[1.0] Traceback (most recent call last): File "<pyshell#13>", line 1, in <module> spam[1.0] TypeError: list indices must be integers or slices, not float >>> spam[int(1.0)] 'bat'
يمكن أن تحتوي القائمة على قوائم أخرى عناصر لها، ويمكن الوصول إلى القيم بإدخال أكثر من فهرس:
>>> spam = [['cat', 'bat'], [10, 20, 30, 40, 50]] >>> spam[0] ['cat', 'bat'] >>> spam[0][1] 'bat' >>> spam[1][4] 50
يدل الفهرس الأول على أي عنصر من القائمة الأولى يجب استخدامه، والفهرس الثاني يدل على العنصر الموجود في القائمة الثانية، فمثلًا spam[0][1] يطبع 'bat'، وهي القيمة الثانية من القائمة الموجودة في الفهرس الأول. وإذا استخدمت فهرسًا واحدًا فسيطبع البرنامج القائمة الموجودة في ذلك الفهرس كاملةً.
الفهارس السالبة
صحيحٌ أن أرقام الفهارس تبدًا من 0، لكنك تستطيع استخدام الأعداد الصحيحة السالبة قيمًا للفهارس. فالقيمة -1 تشير إلى آخر عنصر في القائمة، والقيمة -2 تشير إلى العنصر ما قبل الأخير …إلخ. جرب ما يلي في الصدفة التفاعلية:
>>> spam = ['cat', 'bat', 'rat', 'elephant'] >>> spam[-1] 'elephant' >>> spam[-3] 'bat' >>> 'The ' + spam[-1] + ' is afraid of the ' + spam[-3] + '.' 'The elephant is afraid of the bat.'
الحصول على قائمة من قائمة أخرى عبر التقطيع slice
ستحصل على قيمة واحدة حين استخدام الفهارس، لكن التقطيع slice يعيد أكثر من قيمة من تلك القائمة على شكل قائمة جديدة؛ ونكتبه ضمن القوسين المربعين كما في الفهارس لكن سنضع عددين صحيحين يفصل بينهما بنقطتين رأسيتين :، لاحظ الاختلاف بينهما:
-
spam[2]ينتج عنصرًا واحدًا موجودًا في الفهرس المحدد. -
spam[1:4]
ينتج قائمة فيها أكثر من عنصر.
يكون أول عدد صحيح حين التقطيع هو مكان بدء القطع، والعدد الثاني هو مكان نهاية القطع، وستصل القائمة المقتطعة إلى فهرس العنصر الثاني دون تضمينه في الناتج، وستكون نتيجة القطع هي قائمة جديدة:
>>> spam = ['cat', 'bat', 'rat', 'elephant'] >>> spam[0:4] ['cat', 'bat', 'rat', 'elephant'] >>> spam[1:3] ['bat', 'rat'] >>> spam[0:-1] ['cat', 'bat', 'rat']
يمكنك اختصارًا أن تزيل أحد الفهرسين من عملية التقطيع مع الإبقاء على النقطتين الرأسيتين :، فإزالة الفهرس الأول تماثل استخدام الفهرس 0 وتشير إلى بداية القائمة، وإزالة الفهرس الثاني تماثل تمرير طول القائمة كاملًا وبالتالي ستنتهي عملية القطع عند نهاية القائمة:
>>> spam = ['cat', 'bat', 'rat', 'elephant'] >>> spam[:2] ['cat', 'bat'] >>> spam[1:] ['bat', 'rat', 'elephant'] >>> spam[:] ['cat', 'bat', 'rat', 'elephant']
الحصول على طول القائمة عبر الدالة len()
ستعيد الدالة len() عدد عناصر قائمة تُمرَّر إليها، وهي تشبه إحصاء عدد المحارف في سلسلة نصية:
>>> spam = ['cat', 'dog', 'moose'] >>> len(spam) 3
تغيير القيم في قائمة عبر الفهارس
تعودنا أن قيمة المتغير تكون على يسار عامل الإسناد، كما في spam = 42، ويمكننا فعل المثل مع القوائم بكتابة فهرس العنصر الذي نريد تغيير قيمته، مثلًا spam[1] = 'aardvark' يعني «أسند القيمة الموجودة في الفهرس 1 في القائمة spam إلى السلسلة النصية 'aardvark':
>>> spam = ['cat', 'bat', 'rat', 'elephant'] >>> spam[1] = 'aardvark' >>> spam ['cat', 'aardvark', 'rat', 'elephant'] >>> spam[2] = spam[1] >>> spam ['cat', 'aardvark', 'aardvark', 'elephant'] >>> spam[-1] = 12345 >>> spam ['cat', 'aardvark', 'aardvark', 12345]
جمع القوائم Concatenation وتكرارها Replication
يمكن أن تجمع القوائم وتكرر كما في السلاسل النصية، فالعامل + يجمع بين قائمتين لإنشاء قائمة جديدة، والعامل * يستخدم لتكرار سلسلة نصية عددًا من المرات:
>>> [1, 2, 3] + ['A', 'B', 'C'] [1, 2, 3, 'A', 'B', 'C'] >>> ['X', 'Y', 'Z'] * 3 ['X', 'Y', 'Z', 'X', 'Y', 'Z', 'X', 'Y', 'Z'] >>> spam = [1, 2, 3] >>> spam = spam + ['A', 'B', 'C'] >>> spam [1, 2, 3, 'A', 'B', 'C']
إزالة القيم من القوائم عبر عبارة del
تستخدم العبارة del لحذف قيم معينة من قائمة. جميع القيم الموجودة في القائمة بعد العنصر المحذوف سيتغير فهرسها ويصبح أقل بمقدار 1. مثلًا:
>>> spam = ['cat', 'bat', 'rat', 'elephant'] >>> del spam[2] >>> spam ['cat', 'bat', 'elephant'] >>> del spam[2] >>> spam ['cat', 'bat']
يمكن أن تستعمل العبارة del على المتغيرات العادية أيضًا، وإذا حاولت استخدام أحد المتغيرات بعد حذفه فستحصل على خطأ NameError لأن المتغير لم يعد موجودًا. لكن عمليًا من النادر جدًا أن تحذف قيمة أحد المتغيرات يدويًا وإنما تستعمل استعمالًا رئيسيًا لحذف أحد عناصر القوائم.
التعامل مع القوائم
حينما تبدأ بالبرمجة، قد يغيرك إنشاء متغيرات لكل قيمة من مجموعة قيم تنتمي إلى مجموعة محددة، فمثلًا لو أردت كتابة أسماء قططي فقد أفكر بكتابة شيفرة كالآتية:
catName1 = 'Zophie' catName2 = 'Pooka' catName3 = 'Simon' catName4 = 'Lady Macbeth' catName5 = 'Fat-tail' catName6 = 'Miss Cleo'
لكن هذه شيفرة تعيسة! فماذا يحصل لو كان عدد القطط في برنامج متغيرًا؟ فلن يستطيع برنامجك تخزين أسماء قصص لا تملك متغيرات لها. أفضل إلى ذلك أن هذه الأنواع من البرنامج فيها تكرار كثير للشيفرات نفسها، انظر إلى مقدار التكرار في المثال الآتي الذي أنصحك بكتابته باسم AllMyCats1.py وتجربته:
print('Enter the name of cat 1:') catName1 = input() print('Enter the name of cat 2:') catName2 = input() print('Enter the name of cat 3:') catName3 = input() print('Enter the name of cat 4:') catName4 = input() print('Enter the name of cat 5:') catName5 = input() print('Enter the name of cat 6:') catName6 = input() print('The cat names are:') print(catName1 + ' ' + catName2 + ' ' + catName3 + ' ' + catName4 + ' ' + catName5 + ' ' + catName6)
بدلًا من استخدام أسماء متغيرات متكررة، يمكنك إنشاء متغير واحد يحتوي على قائمة بكل القسم، فهذه نسخة محسنة من المثال السابق، التي نستخدم فيها قائمةً واحدةً يمكن أن تحتوي أي عدد من أسماء القطط التي يمكن أن يدخلها المستخدم. جرب المثال AllMyCats2.py:
catNames = [] while True: print('Enter the name of cat ' + str(len(catNames) + 1) + ' (Or enter nothing to stop.):') name = input() if name == '': break catNames = catNames + [name] # جمع القوائم print('The cat names are:') for name in catNames: print(' ' + name)
ناتج تجربة المثال السابق:
Enter the name of cat 1 (Or enter nothing to stop.): Zophie Enter the name of cat 2 (Or enter nothing to stop.): Pooka Enter the name of cat 3 (Or enter nothing to stop.): Simon Enter the name of cat 4 (Or enter nothing to stop.): Lady Macbeth Enter the name of cat 5 (Or enter nothing to stop.): Fat-tail Enter the name of cat 6 (Or enter nothing to stop.): Miss Cleo Enter the name of cat 7 (Or enter nothing to stop.): The cat names are: Zophie Pooka Simon Lady Macbeth Fat-tail Miss Cleo
الفائدة من استخدام القوائم هي أن بياناتك أصبحت مهيكلة هيكلةً أفضل، وسيكون برنامجك مرنًا في معالجة البيانات والتعامل مع مجموعة مشتركة من المتغيرات.
استخدام حلقات for مع القوائم
تعلمنا في المقال الثاني من هذه السلسلة عن حلقات التكرار for لتنفيذ كتلة من الشيفرات لعدد معين من المرات؛ لكن تقنيًا ما تفعله for هو تكرار الشيفرة داخلها مرةً واحدةً لكل عنصر من عناصر القائمة. فالشيفرة:
for i in range(4):
print(i)
ستخرج الناتج الآتي:
0 1 2 3
هذا لأن القيمة المعادة من تنفيذ range(4) هي قيمة متسلسلة sequence value التي تعاملها بايثون معاملةً شبيهة بالقائمة [0, 1, 2, 3] (سنشرح المتسلسلات Sequences لاحقًا في هذا المقال). سيكون ناتج البرنامج السابق مماثلًا تمامًا لما يلي:
for i in [0, 1, 2, 3]: print(i)
حلقة التكرار for السابقة تمر على جميع عناصر القائمة [0, 1, 2, 3] وتضبط قيمة المتغير i إلى قيمة كل عنصر منها.
من الشائع استخدام التعبير range(len(someList)) مع حلقة التكرار for في بايثون للمرور على جميع عناصر قائمة ما:
>>> supplies = ['pens', 'staplers', 'flamethrowers', 'binders'] >>> for i in range(len(supplies)): ... print('Index ' + str(i) + ' in supplies is: ' + supplies[i]) Index 0 in supplies is: pens Index 1 in supplies is: staplers Index 2 in supplies is: flamethrowers Index 3 in supplies is: binders
استخدام range(len(supplies)) في المثال السابق مناسب لأن الشيفرة داخل الحلقة تستطيع الوصول إلى الفهرس عبر المتغير i وإلى القيمة المرتبطة بذاك الفهرس عبر supplies[i]، والأفضل من ذلك كله أن range(len(supplies)) ستؤدي إلى المرور على جميع عناصر القائمة بغض النظر عن عددها.
العاملان in و not in
يمكنك معرفة إن كانت قيمةٌ ما موجودةً -أو غير موجودةٍ- في قائمة ما باستخدام العاملين in و not in. وكما في بقية العوامل، يستعمل العاملان in و not in في التعابير وتربطان قيمتين: قيمة نرغب بالبحث عنها في القائمة والقائمة التي نرغب بالبحث فيها؛ وتكون نتيجة هذه التعابير قيمة منطقية بوليانية:
>>> 'howdy' in ['hello', 'hi', 'howdy', 'heyas'] True >>> spam = ['hello', 'hi', 'howdy', 'heyas'] >>> 'cat' in spam False >>> 'howdy' not in spam False >>> 'cat' not in spam True
فمثلًا يسمح البرنامج الآتي للمستخدم بكتابة اسم قطته ليتأكد إن كان اسمها ضمن قائمة من أسماء القطط. احفظه باسم myPets.py وجربه:
myPets = ['Zophie', 'Pooka', 'Fat-tail'] print('Enter a pet name:') name = input() if name not in myPets: print('I do not have a pet named ' + name) else: print(name + ' is my pet.')
سيشبه الناتج ما يلي:
Enter a pet name: Footfoot I do not have a pet named Footfoot
خدعة للإسناد المتعدد
هنالك اختصار يسمى تقنيًا بنشر الصفوف tuple unpacking يسمح لنا بإسناد عدة قيمة لمتغيرات اعتمادًا على قائمة في سطر واحد. فبدلًا من كتابة:
>>> cat = ['fat', 'gray', 'loud'] >>> size = cat[0] >>> color = cat[1] >>> disposition = cat[2
نستطيع أن نكتب:
>>> cat = ['fat', 'gray', 'loud'] >>> size, color, disposition = cat
يجب أن يكون عدد المتغيرات وطول القائمة متساوٍ تمامًا، وإلا فستعطيك بايثون الخطأ ValueError:
>>> cat = ['fat', 'gray', 'loud'] >>> size, color, disposition, name = cat Traceback (most recent call last): File "<pyshell#84>", line 1, in <module> size, color, disposition, name = cat ValueError: not enough values to unpack (expected 4, got 3)
استخدام الدالة enumerate() مع القوائم
بدلًا من استخدام range(len(someList)) مع حلقة تكرار for للوصول إلى قيمة الفهرس لكل عنصر من عناصر القائمة، فيمكننا استدعاء الدالة enumerate() بدلًا منها.
ففي كل دورة لحلقة التكرار ستعيد الدالة enumerate() قيمتين: فهرس العنصر الموجود في القائمة والعنصر نفسه على شكل قائمة. فالشيفرة الآتية مماثلة في الوظيفة للمثال الموجود في قسم «استخدام حلقات for مع القوائم»:
>>> supplies = ['pens', 'staplers', 'flamethrowers', 'binders'] >>> for index, item in enumerate(supplies): ... print('Index ' + str(index) + ' in supplies is: ' + item) Index 0 in supplies is: pens Index 1 in supplies is: staplers Index 2 in supplies is: flamethrowers Index 3 in supplies is: binders
الدالة enumerate() مفيدة إن كنت تريد الوصول إلى العنصر وفهرسه ضمن حلقة التكرار.
استخدام الدالتين random.choice() و random.shuffle() مع القوائم
الوحدة random فيها عدة دوال تقبل القوائم كمعاملات لها. الدالة random.choice() تعيد عنصرًا مختارًا عشوائيًا من القائمة:
>>> import random >>> pets = ['Dog', 'Cat', 'Moose'] >>> random.choice(pets) 'Dog' >>> random.choice(pets) 'Cat' >>> random.choice(pets) 'Cat'
يمكنك أن تقول أن random.choice(someList) هي نسخة مختصرة من someList[random.randint(0, len(someList) – 1]. الدالة random.shuffle() تعيد ترتيب العناصر ضمن القائمة عشوائيًا، وتعدل القائمة مباشرة دون إعادة قائمة جديدة:
>>> import random >>> people = ['Alice', 'Bob', 'Carol', 'David'] >>> random.shuffle(people) >>> people ['Carol', 'David', 'Alice', 'Bob'] >>> random.shuffle(people) >>> people ['Alice', 'David', 'Bob', 'Carol']
عوامل الإسناد المحسنة
من الشائع حين إسناد قيمة ما إلى متغير أن تستعمل قيمة المتغير الابتدائية أساسًا للقيمة الجديدة. فمثلًا بعد إسنادك القيمة 42 للمتغير spam وأردت زيادة قيمة المتغير بمقدار واحد:
>>> spam = 42 >>> spam = spam + 1 >>> spam 43
يمكنك بدلًا من ذلك استخدام عامل الإسناد المحسن += لنفس النتيجة:
>>> spam = 42 >>> spam += 1 >>> spam 43
هنالك عوامل إسناد محسنة للعوامل + و - و * و/ و % موضحة في الجدول التالي:
| عامل الإسناد المحسن | التعبير البرمجي المكافئ |
|---|---|
| spam += 1 | spam = spam + 1 |
| spam -= 1 | spam = spam - 1 |
spam *= 1
|
spam = spam * 1
|
| spam /= 1 | spam = spam / 1 |
| spam %= 1 | spam = spam % 1 |
الجدول 1: عوامل الأسناد المحسنة
يمكن استخدام عامل الإسناد المحسن += لدمج قائمتين، والمعامل *= لتكرار قائمة:
>>> spam = 'Hello,' >>> spam += ' world!' >>> spam 'Hello world!' >>> olive = ['Zophie'] >>> olive *= 3 >>> olive ['Zophie', 'Zophie', 'Zophie']
التوابع Methods
يمكننا القول مجازًا أن التابع method يكافئ الدوال لكنها «تستدعى على» قيمة ما. فمثلًا إذا استدعيت دالة القوائم index() -التي سنشرحها بعد قليل- على قائمة فستكتب: list.index('hello')؛ أي أن التابع يأتي بعد القيمة ويفصل عنها بنقطة.
لكل نوع من أنواع البيانات مجموعة توابع خاصة به، ولنوع بيانات القوائم عدد من التوابع المفيدة للبحث والإضافة والحذف ومختلف عمليات التعديل الأخرى.
العثور على قيمة في قائمة عبر التابع index()
تمتلك القوائم التابع index() الذي تقبل معاملًا وهو القيمة التي سيجري البحث عنها في القائمة، وإذا كان العنصر موجودًا فسيعاد فهرس ذاك العنصر، وإذا لم يكن موجودًا فستطلق بايثون الخطأ ValueError:
>>> spam = ['hello', 'hi', 'howdy', 'heyas'] >>> spam.index('hello') 0 >>> spam.index('heyas') 3 >>> spam.index('howdy howdy howdy') Traceback (most recent call last): File "<pyshell#31>", line 1, in <module> spam.index('howdy howdy howdy') ValueError: 'howdy howdy howdy' is not in list
وعند وجود قيم مكررة في القائمة فسيعاد الفهرس لأول قيمة يُعثَر عليها، لاحظ أن التابع index() قد أعاد 1 وليس 3 في هذا المثال:
>>> spam = ['Zophie', 'Pooka', 'Fat-tail', 'Pooka'] >>> spam.index('Pooka') 1
إضافة قيم إلى القوائم عبر append() و insert()
استخدم التابعين append() و insert() لإضافة قيم جديدة إلى قائمة:
>>> spam = ['cat', 'dog', 'bat'] >>> spam.append('moose') >>> spam ['cat', 'dog', 'bat', 'moose']
أدى استدعاء التابع append() إلى إضافة قيمة المعامل الممرر إليه إلى نهاية القائمة.
التابع insert() يضيف قيمةً جديدةً إلى أي فهرس في القائمة، ويكون الوسيط الأول الممرر إلى التابع insert() هو فهرس القيمة الجديدة، والوسيط الثاني هو القيمة التي نريد إضافتها:
>>> spam = ['cat', 'dog', 'bat'] >>> spam.insert(1, 'chicken') >>> spam ['cat', 'chicken', 'dog', 'bat']
لاحظ أن الشيفرة التي كتبناها هي spam.append('moose') و spam.insert(1, 'chicken') وليست spam = spam.append('moose') أو spam = spam.insert(1, 'chicken')، إذ لا يعيد التابع append() أو insert() القيمة الجديدة للقائمة spam (وفي الواقع تكون نتيجة استدعائها هي None، فلا حاجة إلى تخزين قيمة استدعاء تلك التوابع في متغير، بل تعدل تلك التوابع القائمةَ مباشرةً. سنتحدث بالتفصيل عن القوائم القابلة للتغيير وغير القابلة للتغيير لاحقًا في هذا المقال.
التوابع التي ترتبط بنوع بيانات محدد -مثل append() و insert()- هي خاصة بذاك النوع، فلا يمكن استخدامها على قيم أخرى مثل السلاسل النصية أو الأعداد الصحيحة. لاحظ ظهور رسالة الخطأ AttributeError في المثال الآتي:
>>> eggs = 'hello' >>> eggs.append('world') Traceback (most recent call last): File "<pyshell#19>", line 1, in <module> eggs.append('world') AttributeError: 'str' object has no attribute 'append' >>> olive = 42 >>> olive.insert(1, 'world') Traceback (most recent call last): File "<pyshell#22>", line 1, in <module> olive.insert(1, 'world') AttributeError: 'int' object has no attribute 'insert'
إزالة القيم من القوائم عبر التابع remove()
نمرر إلى التابع remove() القيمة التي نريد حذفها من القائمة التي يستدعى التابع عليها:
>>> spam = ['cat', 'bat', 'rat', 'elephant'] >>> spam.remove('bat') >>> spam ['cat', 'rat', 'elephant']
إذا حاولنا حذف قيمة غير موجودة في القائمة فسيظهر الخطأ ValueError:
>>> spam = ['cat', 'bat', 'rat', 'elephant'] >>> spam.remove('chicken') Traceback (most recent call last): File "<pyshell#11>", line 1, in <module> spam.remove('chicken') ValueError: list.remove(x): x not in list
إذا تكررت القيمة التي نريد حذفها أكثر من مرة في القائمة فستزال أول نسخة من تلك القيمة:
>>> spam = ['cat', 'bat', 'rat', 'cat', 'hat', 'cat'] >>> spam.remove('cat') >>> spam ['bat', 'rat', 'cat', 'hat', 'cat']
لاحظ أن العبارة del مفيدة حينما تعرف فهرس العنصر الذي تريد حذفه من القائمة، بينما يفيد التابع remove() إذا كنت تعرف قيمة العنصر الذي تريد حذفه.
ترتيب عناصر قائمة عبر التابع sort()
يمكن ترتيب القوائم التي تحتوي على أعداد أو على سلاسل نصية باستخدام التابع sort():
>>> spam = [2, 5, 3.14, 1, -7] >>> spam.sort() >>> spam [-7, 1, 2, 3.14, 5] >>> spam = ['ants', 'cats', 'dogs', 'badgers', 'elephants'] >>> spam.sort() >>> spam ['ants', 'badgers', 'cats', 'dogs', 'elephants']
يمكنك تمرير القيمة True قيمةً للوسيط المسمى reverse لجعل التابعsort() يرتب النتائج ترتيبًا عكسيًا:
>>> spam.sort(reverse=True) >>> spam ['elephants', 'dogs', 'cats', 'badgers', 'ants']
هنالك ثلاثة أمور أساسية يجب عليك معرفتها حول التابع sort(): بدايةً يرتب التابع sort() عناصر القائمة مباشرةً دون إعادة قائمة جديدة، أي ليس هنالك فائدة من كتابة شيء يشبه spam = spam.sort().
الأمر الثاني هو أنك لا تستطيع ترتيب القوائم التي تحتوي على قيم عددية ونصية في آن واحد، لأن بايثون لا تعرف كيف تقارن هذه القيم مع بعضها بعضًا. لاحظ الخطأ TypeError في المثال الآتي:
>>> spam = [1, 3, 2, 4, 'Alice', 'Bob'] >>> spam.sort() Traceback (most recent call last): File "<pyshell#70>", line 1, in <module> spam.sort() TypeError: '<' not supported between instances of 'str' and 'int'
وأخيرًا، يستعمل التابع sort() ترتيب ASCII للسلاسل النصية بدلًا من الترتيب الهجائي، هذا يعني أن الأحرف الكبيرة في الإنكليزية تأتي قبل الأحرف الصغيرة أي أن a سيكون بعد Z مباشرةً:
>>> spam = ['Alice', 'ants', 'Bob', 'badgers', 'Carol', 'cats'] >>> spam.sort() >>> spam ['Alice', 'Bob', 'Carol', 'ants', 'badgers', 'cats']
إذا أردت ترتيب القيم ترتيبًا هجائيًا، فمرر القيمة str.lower للوسيط المسمى key في التابع sort():
>>> spam = ['a', 'z', 'A', 'Z'] >>> spam.sort(key=str.lower) >>> spam ['a', 'A', 'z', 'Z']
هذا سيجعل التابع sort() يتعامل مع جميع عناصر القائمة كما لو أنها في حالة الأحرف الصغيرة دون تعديل القيم نفسها.
قلب ترتيب عناصر قائمة عبر التابع reverse()
إذا احتجت إلى قلب ترتيب عناصر إحدى القوائم سريعًا فاستعمل التابع reverse():
>>> spam = ['cat', 'dog', 'moose'] >>> spam.reverse() >>> spam ['moose', 'dog', 'cat']
وكما في التابع sort()، لا يعيد التابع reverse() قائمةً بل يعدلها مباشرةً، ولهذا نكتب spam.reverse() وليس spam = spam.reverse().
استثناءات من قواعد المسافات البادئة في بايثون
في أغلبية الحالات، يكون عدد المسافات البادئة قبل كل سطر برمجي دليلًا يقول لمفسر لغة بايثون في أي كتلة ينتمي ذاك السطر. لكن هنالك بعض الاستثناءات لهذه القائمة، فمثلًا يمكن أن تمتد كتابة القائمة على أكثر من سطر في الشيفرة المصدرية، ولا تهم المسافة البادئة هنا، لأن مفسر بايثون يفهم أن تعريف القائمة لا ينتهي إلا بوجود قوس الإغلاق [. فيمكن أن يكون لدينا شيفرة كما يلي:
spam = ['apples', 'oranges', 'bananas', 'cats'] print(spam)
لكن عمليًا يستعمل أغلبية المبرمجين المسافات البادئة استعمالًا صحيحًا لتسهل عملية قراءة شيفرتهم.
يمكنك أن تقسم تعليمة برمجية واحدة على أكثر من سطر باستخدام محرف إكمال السطر \ في نهاية السطر، يمكنك أن تقول أن محرف إكمال السطر \ يقول «سنكمل هذه التعليمة في السطر القادم»، ولن تكون المسافة البادئة في السطر الذي يلي محرف إكمال السطر \ مهمةً، فالشيفرة الآتية صحيحة:
print('Four score and seven ' + \ 'years ago...')
ستستفيد من هذه الأمور حينما تحتاج إلى تقسيم الأسطر الطويلة إلى أسطر أقصر لتسهيل قابلية قراءتها.
مثال عملي: إعادة كتابة برنامج الكرة السحرية باستخدام القوائم
يمكننا كتابة نسخة أفضل من مثال الكرة السحرية الذي كتبناه عبر عبارات elif سابقًا، إذ يمكننا إنشاء قائمة واحدة وسنجعل البرنامج يتعامل معها مباشرةً. احفظ ما يلي في ملف باسم magic8ball2.py:
import random messages = ['It is certain', 'It is decidedly so', 'Yes definitely', 'Reply hazy try again', 'Ask again later', 'Concentrate and ask again', 'My reply is no', 'Outlook not so good', 'Very doubtful'] print(messages[random.randint(0, len(messages) - 1)])
حينما تجرب هذا البرنامج فسيبدو ناتجه كما في المثال magic8ball.py الأصلي.
لاحظ التعبير الذي استخدمناه كفهرس للقائمة messages: random.randint (0, len(messages) - 1). وهو يولد عدد عشوائيًا نستعمله كفهرس بغض النظر عن عدد العناصر الموجودة في القائمة messages.
ذاك التعبير يولد قيمةً عشوائيًا بين 0 وقيمة len(messages) - 1، والقائدة من هذه الطريقة أننا نستطيع إضافة وإزالة العناصر من القائمة messages دون الحاجة إلى تغيير أي شيفرات أخرى، فعندما تحدث شيفرة البرنامج مستقبلًا لإضافة عناصر جديدة إلى القائمة، فلا تضطر إلى تعديلات إضافية، وكلما قللت من الأمور التي تغيرها قلَّت احتمالية استحداث علل برمجية جديدة.
أنواع البيانات المتسلسلة Sequence Data Types
القوائم هي إحدى أنواع البيانات التي تمثل قائمةً من القيم، لكنها ليست الوحيدة. فمثلًا السلاسل النصية strings والقوائم lists متشابهة جدًا إذا تخيلنا أن السلسلة النصية هي «قائمة» من المحارف.
أنواع البيانات المتسلسلة في بايثون تتضمن القوائم lists، والسلاسل النصية strings، وكائنات المجالات range objects المعادة من الدالة range()، والصفوف tuples.
أغلبية الأمور التي تستطيع فعلها مع القوائم يمكنك فعلها مع بقية أنواع البيانات المتسلسلة، بما في ذلك: الفهرسة، والتقطيع، واستخدامها مع حلقات for، واستخدام len()، واستخدام العوامل in و not in.
جرب المثال الآتي لترى ذلك عمليًا:
>>> name = 'Zophie' >>> name[0] 'Z' >>> name[-2] 'i' >>> name[0:4] 'Zoph' >>> 'Zo' in name True >>> 'z' in name False >>> 'p' not in name False >>> for i in name: ... print('* * * ' + i + ' * * *') * * * Z * * * * * * o * * * * * * p * * * * * * h * * * * * * i * * * * * * e * * *
أنواع البيانات القابلة وغير القابلة للتعديل
تختلف القوائم والسلاسل النصية عن بعضها اختلافًا جوهريًا، فالقوائم هي من أنواع البيانات القابلة للتعديل mutable data type، فيمكن أن تضاف أو تحذف أو تعدل عناصرها؛ بينما السلاسل النصية غير قابلة للتعديل immutable، فإذا حاولت ضبط قيمة أحد محارف السلسلة النصية يدويًا فسيحدث الخطأ TypeError كما في المثال الآتي:
>>> name = 'Zophie a cat' >>> name[7] = 'the' Traceback (most recent call last): File "<pyshell#50>", line 1, in <module> name[7] = 'the' TypeError: 'str' object does not support item assignment
الطريقة المعتمدة «لتعديل» سلسلة نصية هي استخدام التقطيع والجمع لبناء سلسلة نصية جديدة اعتمادًا على أجزاء من السلسلة النصية القديمة:
>>> name = 'Zophie a cat' >>> newName = name[0:7] + 'the' + name[8:12] >>> name 'Zophie a cat' >>> newName 'Zophie the cat'
استعملنا [0:7] و [8:12] للإشارة إلى المحارف التي لا نريد تعديلها، لاحظ أن السلسلة النصية الأصلية 'Zophie a cat' لم تعدل، بل أنشأنا سلسلة نصية جديدة.
وصحيحٌ أن القوائم قابلة للتعديل، لكن السطر الثاني في المثال الآتي لن يعدل القائمة eggs:
>>> eggs = [1, 2, 3] >>> eggs = [4, 5, 6] >>> eggs [4, 5, 6]
لم تبدل القيم في القائمة eggs هنا؛ بل أُنشِئت قائمة جديدة [4, 5, 6] وكتبت فوق القائمة القديمة [1, 2, 3] كما في الشكل الآتي:
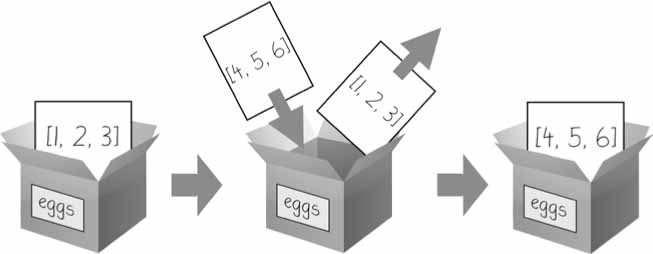
الشكل 2: ما يحدث عند إسناد قائمة جديدة إلى متغير
إذا أردت فعليًا تعديل القائمة الأصلية المخزنة في eggs لتحتوي على [4, 5, 6]، فعليك فعل شيء يشبه ما يلي:
>>> eggs = [1, 2, 3] >>> del eggs[2] >>> del eggs[1] >>> del eggs[0] >>> eggs.append(4) >>> eggs.append(5) >>> eggs.append(6) >>> eggs [4, 5, 6]
يوضح الشكل الموالي التعديلات السبع التي جرت على القائمة eggs لتصل إلى النتيجة النهائية.
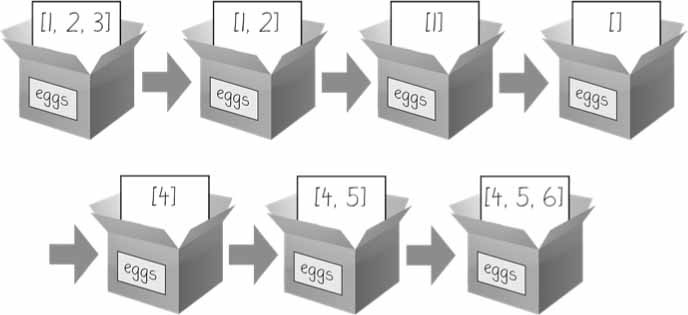
الشكل 3: تُغيِّر العبارة del والتابع append() قيمة القائمة مباشرة
تغيير قيمة نوع بيانات قابل للتعديل (مثل استخدام العبارة del والتابع append() كما في الثالث السابق) سيؤدي إلى تغيير القيمة في مكانها، وذلك لأن قيمة المتغير لا تبدل إلى قائمة جديدة.
قد يبدو لك الآن أن الفرق بين أنواع البيانات القابلة وغير القابلة للتعديل تافه ولا يهم، لكن قسم «تمرير المرجعيات» سيشرح لك الفرق في السلوك حين استدعاء الدوال مع وسائط قابلة للتعديل ووسائط غير قابلة للتعديل. لكن قبل ذلك دعنا نتعلم عن نوع بيانات جديد وهو الصفوف tuples، وهو يشبه القوائم لكنه غير قابل للتعديل.
الصفوف Tuples
يكاد يماثل نوع البيانات tuple القوائم تمامًا، مع استثناء أمرين اثنين: الأول أننا نعرف الصفوف عبر قوسين هلاليين () بدلًا من القوسين المربعين []:
>>> eggs = ('hello', 42, 0.5) >>> eggs[0] 'hello' >>> eggs[1:3] (42, 0.5) >>> len(eggs) 3
والثاني -وهو المهم- أن الصفوف هي نوع بيانات غير قابل للتعديل كما في السلاسل النصية، أي لا يمكننا تعديل قيم عناصر الصف أو إضافتها أو حذفها. لاحظ رسالة الخطأ TypeError حين تنفيذ المثال الآتي:
>>> eggs = ('hello', 42, 0.5) >>> eggs[1] = 99 Traceback (most recent call last): File "<pyshell#5>", line 1, in <module> eggs[1] = 99 TypeError: 'tuple' object does not support item assignment
إذا كانت لديك قيمة واحدة في الصف، فيمكنك أن تطلب من بايثون تعريف ذاك الصف بوضع فاصلة بعد تلك القيمة، وإلا فستظن بايثون أنك كتبت قيمةً عاديةً ضمن قوسين، فالفاصلة هنا هي ما سيخبر بايثون أن ما تريده هو نوع البيانات tuple.
لاحظ أن من الطبيعي في بايثون وجود فاصلة بعد آخر عنصر في صف أو قائمة على عكس بعض لغات البرمجة الأخرى.
جرب الدالة type() في المثال الآتي لترى الفرق الذي يحدثه استخدام الفاصلة بعد القيمة عمليًا:
>>> type(('hello',)) <class 'tuple'> >>> type(('hello')) <class 'str'>
يمكنك استخدام الصفوف في برنامجك لتقول لمن يقرأه من المبرمجين أنك لا تنوي لهذه السلسلة من القيم أن تتغير؛ أي لو أردت قيمًا متسلسلة مرتبة لا تتغير فاستخدم الصفوف.
ميزة أخرى من مزايا الصفوف بدلًا من القوائم هي أن بايثون تستطيع تطبيق بعض التحسينات الداخلية لمعالجة الصفوف معالجةً أسرع من القوائم، وذلك لعلمها أنها قيم متسلسلة غير قابلة للتعديل.
تبديل أنواع التسلسلات باستخدام الدوال list() و tuple()
كما تعيد الدالة str(42) القيمة '42' وهو التمثيل النصي للرقم 42؛ تعيد الدالتان list() و tuple() نسخة القائمة والصف من القيم الممررة إليها.
جرب المثال الآتي ولاحظ كيف أن نوع القيمة المعادة مختلف عن نوع القيمة الممررة:
>>> tuple(['cat', 'dog', 5]) ('cat', 'dog', 5) >>> list(('cat', 'dog', 5)) ['cat', 'dog', 5] >>> list('hello') ['h', 'e', 'l', 'l', 'o']
قد يفيدك تحويل صف إلى قائمة إن احتجت إلى نسخة قابلة للتعديل من قيمة ذاك الصف.
المرجعيات References
كما رأيت سابقًا، «تُخزِّن» المتغيرات قيم السلاسل النصية والأعداد، لكن هذا تبسيط لما تقوم به بايثون فعلًا. فتقنيًا تخزن المتغيرات مرجعيةً أو إشارةً إلى مكان تخزين قيمة المتغير في ذاكرة الحاسوب:
>>> spam = 42 >>> cheese = spam >>> spam = 100 >>> spam 100 >>> cheese 42
فعندما تسند القيمة 42 إلى المتغير spam فأنت تنشِئ القيمة 42 في ذاكرة الحاسوب ثم تخزِّن مرجعيةً reference إليها في المتغير spam، وعندما تنسخ القيمة في spam وتسندها إلى المتغير cheese فأنت فعليًا تنسخ المرجعية إلى القيمة 42 في ذاكرة الحاسوب وليس القيمة نفسها، أي أن كلا المتغيرين spam و cheese يشيران إلى القيمة 42 نفسها في ذاكرة الحاسوب.
ثم حينما تغيّر قيمة المتغير spam إلى 100 فأنت تنشِئ قيمةً جديدةً وهي 100 ثم تخزن مرجعيةً إليها في المتغير spam، وهذا لا يؤثر على القيمة الموجودة في المتغير cheese.
تذكر أن القيم العددية من أنواع البيانات غير القابلة للتعديل، أي أن تغيير قيمة spam سيؤدي إلى تغيير المرجعية التي تشير إليها في الذاكرة. لكن لا تعمل القوائم بهذه الطريقة، وذلك لأن القوائم من أنواع البيانات القابلة للتعديل. هذا المثال يسهِّل فهم الآلية السابقة والفروق بين القوائم وغيرها من أنواع البيانات:
➊ >>> spam = [0, 1, 2, 3, 4, 5] ➋ >>> cheese = spam # ستنسخ المرجعية وليست القائمة ➌ >>> cheese[1] = 'Hello!' # وهذا ما يغير قيمة عنصر القائمة >>> spam [0, 'Hello!', 2, 3, 4, 5] >>> cheese # يشير المتغير إلى القائمة نفسها [0, 'Hello!', 2, 3, 4, 5]
قد يبدو الناتج السابق غريبًا بالنسبة إليك، فأنت تعدل فيه على القائمة cheese لكن التغييرات حدثت على المتغير cheese و spam معًا! عند إنشائك للقائمة ➊ فأنت تخزن مرجعيةً إليها في المتغير spam، وفي السطر التالي ➋ نسخت المرجعية الموجودة في spam إلى cheese وليس القائمة نفسها. وهذا يعني أن القيم المخزنة في المتغيرين spam و cheese تشير إلى القائمة نفسها. لاحظ أن هنالك قائمة واحدة لأن القائمة لم تنسَخ بحد ذاتها بل نُسِخَت المرجعية إليها؛ لذا حينما تعدل أحد عناصر القائمة cheese ➌ فأنت تعدل نفس القائمة التي يُشار إليها عبر المتغير spam.
تذكر أن المتغيرات تشبه الصناديق التي تحتوي على قيم، والرسومات التوضيحية التي رأيتها في هذا الفصل لحد الآن ليست دقيقة تمامًا لأن من غير الممكن احتواء قائمة داخل صندوق، بل تحتوي الصناديق على إشارات لتلك القوائم، وتلك الإشارات تملك معرفات ID تستعملها بايثون داخليًا، ولتصحيح تخيلنا للمتغيرات والقوائم فانظر إلى الشكل الآتي:
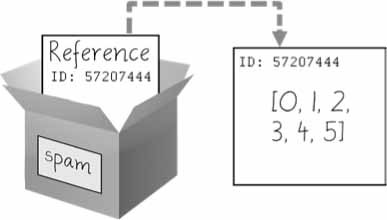
الشكل 4: تخزن مرجعية إلى قائمة في المتغيرات، وليست القائمة نفسها
في الشكل الآتي 5 سننسخ المرجعية الموجودة في spam إلى cheese، لاحظ تخزين قيمة المرجعية في cheese وليس القائمة. لاحظ كيف يشير كلا المتغيرين إلى القائمة نفسها:
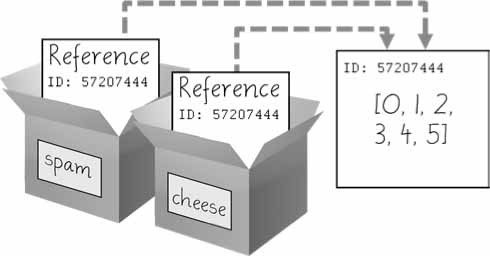
الشكل 5: إسناد قيمة متغير إلى آخر ينسخ المرجعية وليس القائمة
وحينما تعدل القائمة التي يشير إليها المتغير cheese فأنت تعدل القائمة التي يشير إليها spam أيضًا، لأنهما يشيران إلى القائمة نفسها، يمكنك ملاحظة ذلك في الشكل الموالي:
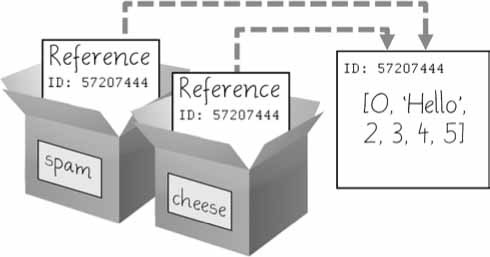
الشكل 6: تغيير عنصر في قائمة يشار إليها من متغيرين مختلفين
صحيحٌ أن بايثون تخزن مرجعيات في المتغيرات، لكن من الشائع أن يقول المطورون أن «المتغيرات تحتوي على قيم» وليس «المتغيرات تحتوي على مرجعيات تشير إلى قيم».
المعرفات والدالة id()
قد تتساءل لماذا يطبق السلوك السابق الغريب الذي ناقشناه في القسم السابق على القوائم القابلة للتعديل ولا يحدث على القيم غير القابلة للتعديل كالأعداد أو السلاسل النصية.
يمكننا استخدام الدالة ()id لفهم ذلك، فكل القيم في بايثون لها معرف خاص بها يمكن الحصول عليه باستخدام الدالة id():
>>> id('Howdy') # ستختلف القيمة المعادة في حاسوبك 44491136
عندما تشغل بايثون العبارة البرمجية id('Howdy') فهي تنشِئ السلسلة النصية 'Howdy' في ذاكرة حاسوبك، ويعاد عنوان الذاكرة الرقمي الذي خُزِّنَت السلسلة النصية فيه عبر الدالة id()، وتختار بايثون العنوان اعتمادًا على أي بايتات تتوافر في ذاكرة حاسوبك في وقت التنفيذ، لذا ستختلف القيمة في كل مرة تشغل فيها الشيفرة.
وككل السلاسل النصية، السلسلة 'Howdy' غير قابلة للتعديل، وإذا حاولت «تعديل» قيمة السلسلة النصية الموجودة في متغير، فستُنشَأ سلسلة نصية جديدة في مكان آخر في الذاكرة ثم سيشير المتغير إلى السلسلة النصية الجديدة. جرب المثال الآتي ولاحظ تغيير المعرف الذي يشير إليه المتغير olive:
>>> olive = 'Hello' >>> id(olive) 44491136 >>> olive += ' world!' # سلسلة نصية جديدة >>> id(olive) # يشير المتغير إلى سلسلة نصية مختلفة 44609712
لكن يمكن تعديل القوائم لأنها من أنواع البيانات القابلة للتعديل. فالتابع append() لا ينشِئ قائمة جديدة حين تنفيذه، بل يعدل القائمة الموجودة، ونسمي هذا السلوك «بالتعديل في المكان» in-place:
>>> eggs = ['cat', 'dog'] # إنشاء قائمة جديدة >>> id(eggs) 35152584 >>> eggs.append('moose') # يضيف التابع القيم مباشرة >>> id(eggs) # يشير المتغير إلى نفس القائمة السابقة 35152584 >>> eggs = ['bat', 'rat', 'cow'] # إنشاء قائمة جديدة لها معرف مختلف >>> id(eggs) # يشير المتغير إلى قائمة مختلفة كليًا 44409800
إذا أشار متغيران أو أكثر إلى القائمة نفسها (كما في المثال في القسم السابق) ثم تغيرت قيمة القائمة، فستحدث التغييرات على كلا المتغيرات لأنهما يشيران إلى القائمة نفسها.
التوابع append() و extend() و remove() و sort() و reverse() وغيرها من توابع القوائم ستعمل القوائم في مكانها. جامع القمامة التلقائي في Python (أي Garbage Collector) يحذف أي قيم لا يشار إليها من المتغيرات لكي يُفرِّغ الذاكرة، وهذا رائع لأن الإدارة اليدوية للذاكرة في لغات البرمجة الأخرى هي سبب رئيسي للعلل البرمجية.
تمرير المرجعيات
من المهم فهم المرجعيات لاستيعاب كيف تمرر الوسائط إلى الدوال.
حين استدعاء دالة ما، فإن القيم الممررة كوسائط arguments تنسخ إلى المعاملات parameters، وبالنسبة إلى القوائم (والقواميس التي سنتعرف عليها في المقال القادم) هذا يعني أن المرجعية التي تشير إلى القائمة ستنسخ من الوسيط إلى المعامل، ولكي تعي آثار ذلك جرب المثال الآتي باسم passingReference.py:
def eggs(someParameter): someParameter.append('Hello') spam = [1, 2, 3] eggs(spam) print(spam)
لاحظ أنه حين استدعاء eggs() فلن تستعمل القيمة المعادة من الدالة لإسناد قيمة جديدة إلى المتغير spam، بل ستعدل المتغير spam في مكانه مباشرةً؛ وسيخرج الناتج الآتي:
[1, 2, 3, 'Hello']
وصحيحٌ أن قيمة spam نسخت إلى someParameter لكن ما نسخ فعليًا هو المرجعية إلى نفس القائمة، ولهذا سيؤدي استدعاء التابع append('Hello') إلى تعديل القائمة خارج الدالة.
أبقِ هذا السلوك في ذهنك أثناء كتابة الشيفرات، فلو نسيت كيف تتعامل بايثون مع القوائم والقواميس فستقع في أخطاء وعلل كان من السهل تفاديها.
الدالة copy() و deepcopy() في الوحدة copy
صحيحٌ أن تمرير المرجعيات للإشارة إلى القوائم والقواميس يسهل التعامل معها، لكن إن كانت لدينا دالة تغير القائمة أو القاموس الممرر إليها وكنّا لا نريد إجراء تلك التعديلات على القائمة أو القاموس الأصليين، فحينها يمكننا الاستفادة من الوحدة التي توفرها بايثون باسم copy التي توفر الدالتين copy() و deepcopy(). أول دالة منهما copy.copy() تنشِئ نسخةً طبق الأصل من قيمة قابلة للتعديل كقوائم أو القواميس:
>>> import copy >>> spam = ['A', 'B', 'C', 'D'] >>> id(spam) 44684232 >>> cheese = copy.copy(spam) >>> id(cheese) # قائمة مختلفة بمعرف مختلف 44685832 >>> cheese[1] = 42 >>> spam ['A', 'B', 'C', 'D'] >>> cheese ['A', 42, 'C', 'D']
يشير المتغيران spam و cheese إلى قوائم مختلفة، ولهذا السبب سنجد أن القائمة المشار إليها عبر المتغير cheese هي من تغيرت حينما ضبطنا العنصر ذا الفهرس 1 إلى القيمة 42.
لاحظ في الشكل التالي أن أرقام المعرفات ID مختلفة لكلا المتغيرين، لأن كل واحد منهما يشير إلى قائمة مختلفة.
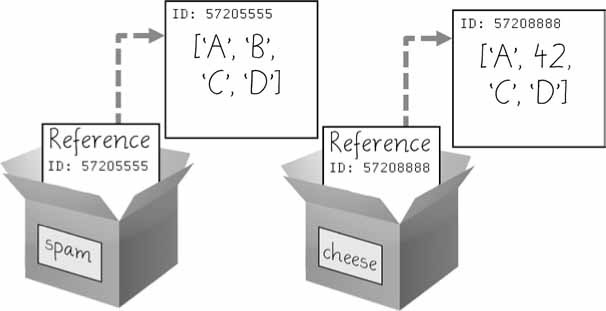
الشكل 7: نسخ القائمة عبر copy() ينشِئ قائمة جديدة يمكن تعديلها بشكل مستقل عن القائمة الأصلية
إذا كانت لديك قائمة ترغب بنسخ محتوياتها أيضًا فاستعمال الدالة copy.deepcopy() بدلًا من copy.copy(). ستنسخ الدالة deepcopy() القوائم الداخلية أيضًا.
برنامج قصير: لعبة الحياة
لعبة الحياة لكونواي Conway’s Game of Life هي مثال عن خلايا ذاتية السلوك cellular automata: مجموعة من القوائم التي تحكم سلوك حقل مؤلف من خلايا منفصلة. عمليًا هذه طريقة لإنشاء أشكال متحركة جميلة، يمكنك أن ترسل كل خطوة على ورقة رسم بياني، وتمثل المربعات في ورقة الرسم الخلايا.
- المربع الممتلئ هو خلية «حية»، بينما المربع الفارغ هو خلية «ميتة».
- تموت أي خلية حية لها أقل من اثنتين من الجيران الأحياء.
- أي خلية حية لها اثنتين أو ثلاثة جيران من الخلايا الحية تعيش إلى الجيل القادم.
- تموت أي خلية حية لها أكثر من ثلاثة جيران من الخلايا الحية.
- أي خلية ميتة تصبح حية عندما يصبح حولها بالضبط ثلاثة من الخلايا الأحياء.
- تموت أي خلية أخرى أو تبقى ميتة في الجيل القادم.
يمكنك النظر إلى تمثيل لتقدم أجيل لعبة الحياة في الشكل الآتي:
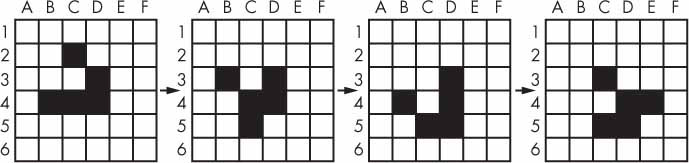
الشكل 8: أربع خطوات أو أجيال في لعبة الحياة
صحيح أن القواعد بسيطة نسبيًا، لكن قد تحدث بعض السلوكيات المثيرة، فيمكن أن تتحرك الأنماط في لعبة الحياة أو أن تتكاثر، أو حتى تحاكي عمل المعالجات المركزية CPUs. لكن في أساس كل هذه الأنماط المعقدة برنامج بسيط.
يمكننا استخدام قائمة تحتوي على قوائم داخلها لتمثيل الحقل ثنائي الأبعاد، وتمثل القوائم الداخلية عمودًا من المربعات، وتخزن القيمة '#' للخلايا الحية، والقيمة ' ' للخلايا الميتة.
اكتب المثال الآتي في ملف باسم conway.py، ولا مشكلة إن لم تفهم كل ما هو مذكور فيه، كل ما عليك هو إدخاله ومحاولة فهم التعليقات والشروحات:
# لعبة الحياة import random, time, copy WIDTH = 60 HEIGHT = 20 # إنشاء قوائم الخلايا nextCells = [] for x in range(WIDTH): column = [] # إنشاء عمود جديد for y in range(HEIGHT): if random.randint(0, 1) == 0: column.append('#') # إضافة خلية حية else: column.append(' ') # إضافة خلية ميتة nextCells.append(column) # nextCells هي قائمة تتألف من قوائم للأعمدة while True: # حلقة البرنامج الرئيسية print('\n\n\n\n\n') # فصل الخطوة أو الجيل القادم بأسطر فارغة currentCells = copy.deepcopy(nextCells) # طباعة الخلايا الحالية على الشاشة for y in range(HEIGHT): for x in range(WIDTH): print(currentCells[x][y], end='') # طباعة # أو فراغ print() # طباعة سطر جديد في نهاية السطر # حساب الخطوة أو الجيل القادم اعتمادًا على القيم الحالية للخلايا for x in range(WIDTH): for y in range(HEIGHT): # الوصول إلى إحداثيات الخلايا المجاورة # `% WIDTH` يضمن أن leftCoord سيكون بين 0 و WIDTH - 1 leftCoord = (x - 1) % WIDTH rightCoord = (x + 1) % WIDTH aboveCoord = (y - 1) % HEIGHT belowCoord = (y + 1) % HEIGHT # إحصاء عدد الخلايا المجاورة numNeighbors = 0 if currentCells[leftCoord][aboveCoord] == '#': numNeighbors += 1 # الخلية في الركن العلوي الأيسر حية if currentCells[x][aboveCoord] == '#': numNeighbors += 1 # الخلية في الأعلى حية if currentCells[rightCoord][aboveCoord] == '#': numNeighbors += 1 # الخلية في الركن العلوي الأيمن حية if currentCells[leftCoord][y] == '#': numNeighbors += 1 # الخلية على اليسار حية if currentCells[rightCoord][y] == '#': numNeighbors += 1 #الخلية على اليمين حية if currentCells[leftCoord][belowCoord] == '#': numNeighbors += 1 # الخلية في الركن السفلي الأيسر حية if currentCells[x][belowCoord] == '#': numNeighbors += 1 # الخلية في الأسفل حية if currentCells[rightCoord][belowCoord] == '#': numNeighbors += 1 # الخلية في الركن السفلي الأيمن حية # ضبط قيمة القيمة اعتمادًا على قواعد لعبة الحياة if currentCells[x][y] == '#' and (numNeighbors == 2 or numNeighbors == 3): # الخلايا التي لها خلايا جارة حية عددها 2 أو 3 nextCells[x][y] = '#' elif currentCells[x][y] == ' ' and numNeighbors == 3: # الخلايا الميتة التي لها 3 خلايا جارة حية nextCells[x][y] = '#' else: # كل ما بقي يكون ميتًا أو سيمين nextCells[x][y] = ' ' time.sleep(1) # التوقف لمدة ثانية لتجنب تأثير الوموض المزعج
لنلقي نظرةً على الشيفرة سطرًا بسطر بدءًا من الأعلى:
# لعبة الحياة import random, time, copy WIDTH = 60 HEIGHT = 20
استوردنا بدايةً الوحدات التي تحتوي على الدوال التي سنحتاج إليها، تحديدًا الدوال random.randint() و time.sleep() و copy.deepcopy().
# إنشاء قوائم الخلايا nextCells = [] for x in range(WIDTH): column = [] # إنشاء عمود جديد for y in range(HEIGHT): if random.randint(0, 1) == 0: column.append('#') # إضافة خلية حية else: column.append(' ') # إضافة خلية ميتة nextCells.append(column) # nextCells هي قائمة تتألف من قوائم للأعمدة
أول خطوة من إنشاء خلايا ذاتية السلوك هي خطوة (أو «جيل») عشوائية تمامًا. سنحتاج إلى إنشاء قائمة تضم قوائم لتخزين السلاسل النصية '#' و ' ' التي تمثل الخلايا الحية والميتة، وسيدل مكانها في قائمة القوائم على مكانها في الشاشة، فكل قائمة داخلية تمثل عمودًا من الخلايا، واستدعاؤنا للدالة random.randint(0, 1) سيعطي الخلية احتمال 50% أن تكون حية و 50% أن تكون ميتة.
سنضع قائمة القوائم في متغير اسمه nextCells، لأن أول خطوة ستجريها في حلقة البرنامج الرئيسية هي نسخ nextCells إلى currentCells.
ستبدأ إحداثيات محور السينات X من 0 في الأعلى وستزداد نحو اليمين، بينما ستبدأ إحداثيات محور العينات Y من 0 أيضًا في الأعلى وستزداد نحو الأسفل، أي أن nextCells[0][0] ستمثل الخلية في الركن العلوي الأيسر من الشاشة، بينما nextCells[1][0] ستمثل الخلية التي على يمينها، و nextCells[0][1] ستمثل الخلية التي تدنوها.
while True: # حلقة البرنامج الرئيسية print('\n\n\n\n\n') # فصل الخطوة أو الجيل القادم بأسطر فارغة currentCells = copy.deepcopy(nextCells)
كل دورة من حلقة تكرار البرنامج الرئيسية ستمثل خطوة أو جيلًا من الخلايا ذاتية السلوك التي لدينا. وفي كل دورة سننسخ قيمة nextCells إلى currentCells ثم نطبع currentCells على الشاشة، ثم سنستخدم الخلايا الموجودة في currentCells لحساب الخلايا التي ستكون في nextCells.
# طباعة الخلايا الحالية على الشاشة for y in range(HEIGHT): for x in range(WIDTH): print(currentCells[x][y], end='') # طباعة # أو فراغ print() # طباعة سطر جديد في نهاية السطر
حلقات for المتشعبة تعني أننا سنطبع سطرًا كاملًا من الخلايا على الشاشة، ثم يكون متبوعًا بسطر فارغ، ثم نكرر العملية لكل سطر في nextCells.
# حساب الخطوة أو الجيل القادم اعتمادًا على القيم الحالية للخلايا for x in range(WIDTH): for y in range(HEIGHT): # الوصول إلى إحداثيات الخلايا المجاورة # `% WIDTH` يضمن أن leftCoord سيكون بين 0 و WIDTH - 1 leftCoord = (x - 1) % WIDTH rightCoord = (x + 1) % WIDTH aboveCoord = (y - 1) % HEIGHT belowCoord = (y + 1) % HEIGHT
ثم سنسنعمل حلقتي for متشعبتين لحساب كل خلية للخطوة أو الجيل القادم، ولمّا كانت حالة الخلية إن كانت ستحيى أم ستموت في الجيل القادم معتمدةً على جاراتها من الخلايا، فعلينا أولًا حساب فهرس الخلايا التي على يسارها ويمينها وأعلاها وأدناها.
عامل باقي القسمة % يجري عملية «التفاف للسطر»، فالجار الأيسر لخلية موجودة في العمود الأيسر سيكون 0 - 1 أو -1، والالتفاف العمود إلى فهرس العمود الأيمن 59 فسنحسب (0 - 1) % WIDTH، ولأن قيمة WIDTH هي 60 فستكون نتيجة التعبير هي 59. يمكن فعل المثل بالنسبة إلى الخلايا الجارة التي تعلو وتدنو وعلى يمين الخلية الحالية.
# إحصاء عدد الخلايا المجاورة numNeighbors = 0 if currentCells[leftCoord][aboveCoord] == '#': numNeighbors += 1 # الخلية في الركن العلوي الأيسر حية if currentCells[x][aboveCoord] == '#': numNeighbors += 1 # الخلية في الأعلى حية if currentCells[rightCoord][aboveCoord] == '#': numNeighbors += 1 # الخلية في الركن العلوي الأيمن حية if currentCells[leftCoord][y] == '#': numNeighbors += 1 # الخلية على اليسار حية if currentCells[rightCoord][y] == '#': numNeighbors += 1 #الخلية على اليمين حية if currentCells[leftCoord][belowCoord] == '#': numNeighbors += 1 # الخلية في الركن السفلي الأيسر حية if currentCells[x][belowCoord] == '#': numNeighbors += 1 # الخلية في الأسفل حية if currentCells[rightCoord][belowCoord] == '#': numNeighbors += 1 # الخلية في الركن السفلي الأيمن حية
لتقرير إن كانت الخلية الموجودة في nextCells[x][y] ستكون حيةً أو ميتةً فنحتاج إلى إحصاء عدد الخلايا الحية المجاورة للخلية currentCells[x][y]، والسلسلة السابقة من تعابير if الشرطية تتحقق من الجارات الثمانية المجاورة للخلية، وتضيف القيمة 1 للمتغير numNeighbors لكل خلية حية.
# ضبط قيمة القيمة اعتمادًا على قواعد لعبة الحياة if currentCells[x][y] == '#' and (numNeighbors == 2 or numNeighbors == 3): # الخلايا التي لها خلايا جارة حية عددها 2 أو 3 nextCells[x][y] = '#' elif currentCells[x][y] == ' ' and numNeighbors == 3: # الخلايا الميتة التي لها 3 خلايا جارة حية nextCells[x][y] = '#' else: # كل ما بقي يكون ميتًا أو سيمين nextCells[x][y] = ' ' time.sleep(1) # التوقف لمدة ثانية لتجنب تأثير الوموض المزعج
ثم بمعرفتنا لعدد الخلايا الجارة الحية للخلية currentCells[x][y]، فيمكننا ضبط قيمة nextCells[x][y] إلى '#' أو ' '. وبعد المرور على جميع إحداثيات x و y فسيتوقف التنفيذ لبرهة باستدعاء time.sleep(1) ثم سيكمل تنفيذ البرنامج في بداية حلقة التكرار مجددًا.
هنالك عدد من الأنماط للخلايا لها أسماء مثل «الطائرة الشراعية» أو «الطائرة ذات المروحة» أو «سفينة الفضاء الثقيلة». نمط «الطائرة الشراعية» هو النمط الذي رأيته في الشكل 8 وهو «يتحرك» قطريًا كل أربع خطوات. يمكنك إنشاء «طائرة شراعية» بتبديل السطر الآتي في برنامج conway.py:
if random.randint(0, 1) == 0:
إلى هذا السطر:
if (x, y) in ((1, 0), (2, 1), (0, 2), (1, 2), (2, 2)):
الخلاصة
القوائم هي نوع بيانات مفيد يسمح لك بكتابة شيفرات تتعامل مع قيم متعددة مخزنة في متغير واحد. سنرى برامج في مقالات هذه السلسلة كان من المستحيل برمجتها دون الاعتماد على القوائم.
القوائم هي نوع من أنواع البيانات المتسلسلة القابلة للتعديل. أي أن محتوياتها قد تتعدل برمجيًا. بينما تكون الصفوف tuple والسلاسل النصية من أنواع البيانات المتسلسلة لكنها غير قابلة للتعديل.
يمكن إعادة كتابة قيمة متغير يحتوي على سلسلة نصية أو صف بقيمة أخرى، لكن هذا لا يكافئ تعديل قيمة السلسلة النصية أو الصف في مكانها، مثلما تفعل التوابع append() أو remove() على القوائم.
لا تخزن المتغيرات قيم القوائم مباشرةً فيها، بل هي تشير إلى تلك القوائم، ومن المهم استيعاب هذه النقطة حين نسخ المتغيرات أو تمرير القوائم كوسائط إلى الدوال. ولأن القيمة التي ستنسخ هي مرجعية إلى القائمة وليست القائمة نفسها، فأي تعديل يجرى على القائمة سيؤثر عليها في كامل البرنامج؛ لكننا نستطيع استخدام الدالة copy() أو deepcopy() لنسخ القوائم ثم إجراء تعديلات عليها لا تؤثر على القائمة الأصلية.
مشاريع تدريبية
لكي تتدرب، اكتب برامج لتنفيذ المهام الآتية.
افصل بفاصلة
لنقل لدينا القائمة الآتية:
spam = ['apples', 'bananas', 'tofu', 'cats']
اكتب دالة تأخذ قائمةً كمعامل وتعيد سلسلةً نصيةً فيها كل عناصر تلك القائمة مفصولٌ بينها بفاصلة ثم فراغ، وأضف الكلمة and قبل آخر عنصر. فلو كانت لدينا القائمة السابقة فستعيد الدالة القيمة 'apples, bananas, tofu, and cats'؛ لكن يجب أن تعمل دالتك مع جميع القيم. تذكر أن تجرب الدالة على قائمة فارغة [].
سلسلة رمي القطع النقدية
سنجري تجربة بسيطة. إذا رمينا قطعة نقدية مئة مرة، وكتبنا الحرف H لكل رأس والحرف T لكل نقش، فسيكون لدينا قائمة تشبه T T T T H H H H T T.
إذا طلبنا من كائن بشري (أهلًا بك أخي البشري ? ) أن يكتب عشوائيًا نتائج مئة رمية لقطعة نقد، فستحصل على شيء يشبه H T H T H H T H T T والذي يبدو عشوائيًا إذا نظر كائن بشري إليه، لكنه لا يمثل سلسلة عشوائية رياضيًا. فلن يكتب الكائن البشري سلسلة من ستة رؤوس أو ستة نقوش متتالية، مع أن ذلك ممكن رياضيًا لو كانت عملية رمي القطع النقدية عشوائيًا فعليًا. فمن المتوقع أن تكون التوقعات العشوائية للكائنات البشرية تعيسةً (آسف أخي البشري، لكنها الحقيقة ? ).
اكتب برنامجًا يعرف كم مرة ظهرت سلسلة من ستة رؤوس أو ستة نقوش في قائمة مولدة عشوائيًا.
سيقسم برنامجك هذه التجربة إلى قسمين: القسم الأول سيولد قائمة عشوائية من الرؤوس والنقوش، والقسم الثاني سيتحقق من سلسلةً متتاليةً من الروؤس أو النقوش موجودة في تلك القائمة.
أجرِ هذه التجربة 10,000 مرة لكي يكون تعرف النسبة التي تحتوي فيها قائمة الرؤوس والنقوش على ستة رؤوس متتالية أو ستة نقوش متتالية. أذكرك أن الدالة random.randint(0, 1) ستعيد القيمة 0 بنسبة 50% والقيمة 1 بنسبة 50%.
يمكنك أن تستفيد من القالب الآتي:
import random numberOfStreaks = 0 for experimentNumber in range(10000): # الشيفرة التي ستولد قائمة من 100 قيمة عشوائية لعملية رمي القطعة النقدية # الشيفرة التي ستتحقق من ظهور 6 رؤوس أو 6 نقوش متتالية print('Chance of streak: %s%%' % (numberOfStreaks / 100))
تذكر أن الرقم الناتج تقريبي عملي، لكن حجم العينة (عشرة آلاف) مناسب؛ لكن إذا كنت تعرف بعض المبادئ الأساسية في الاحتمالات والإحصاء الرياضي فستعرف الإجابة الدقيقة دون الحاجة إلى كتابة البرنامج السابق، لكن من الشائع أن تكون معرفة المبرمجين بالرياضيات تعيسة (على عكس المتوقع).
صورة حرفية
لنقل أن لدينا قائمة تضم قوائم أخرى، وكل قيمة في القوائم الداخلية هي حرف واحد كما يلي:
grid = [['.', '.', '.', '.', '.', '.'], ['.', 'O', 'O', '.', '.', '.'], ['O', 'O', 'O', 'O', '.', '.'], ['O', 'O', 'O', 'O', 'O', '.'], ['.', 'O', 'O', 'O', 'O', 'O'], ['O', 'O', 'O', 'O', 'O', '.'], ['O', 'O', 'O', 'O', '.', '.'], ['.', 'O', 'O', '.', '.', '.'], ['.', '.', '.', '.', '.', '.']]
تخيل أن العنصر grid[x][y] هو المحرف الموجود في الإحداثيات x و y «للصورة» التي سنرسمها عبر الأحرف. مبدأ الإحداثيات (0, 0) هو الركن العلوي الأيسر، وستزداد إحداثيات x بالذهاب نحو اليمين، وإحداثيات y نحو الأسفل.
انسخ الشبكة السابقة واكتب شيفرة لطباعة الشكل الآتي منها:
..OO.OO.. .OOOOOOO. .OOOOOOO. ..OOOOO.. ...OOO... ....O....
تلميحة: ستحتاج إلى حلقة تكرار داخل حلقة تكرار، لكي تطبع grid[0][0] ثم grid[1][0] ثم grid[2][0] وهلم جرًا إلى أن تصل إلى grid[8][0]؛ ثم ستنتهي من أول صف وتطبع سطرًا جديدًا، ثم تطبع grid[0][1] ثم grid[1][1] ثم grid[2][1] …إلخ. وآخر عنصر سيطبعه برنامجك هو grid[8][5].
تذكر أن تمرر الوسيط المسمى end إلى الدالة print() إذا لم تكن تريد طباعة سطر جديد بعد كل استدعاء للدالة print().
ترجمة -بتصرف- للفصل LISTS من كتاب Automate the Boring Stuff with Python.
اقرأ أيضًا
- المقال السابق: الدوال في لغة بايثون Python
- المقال السابق: بنى التحكم في لغة بايثون Python
- أنواع البيانات والعمليات الأساسية في لغة بايثون
- تعلم لغة بايثون
- النسخة العربية الكاملة لكتاب البرمجة بلغة بايثون







أفضل التعليقات
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.