

نَمت قوة الحوسبة بوتيرة سريعة دون ظهور أيّ علامات على التباطؤ كما توقّع قانون مور Moore، فليس مألوفًا أن تحتوي أيّ خوادم عالية الجودة على وحدة معالجة مركزية واحدة فقط مع إمكانية تحقيق ذلك باستخدام عدد من الأساليب المختلفة.
المعالجة المتعددة المتماثلة Symmetric Multi-Processing
تُعَدّ المعالجة المتعددة المتماثلة Symmetric Multi-Processing -أو SMP اختصارًا- الإعداد الأكثر شيوعًا حاليًا لتضمين وحدات المعالجة المركزية CPU المتعددة في نظام واحد، ويشير المصطلح متماثل Symmetric إلى حقيقة أنّ جميع وحدات المعالجة المركزية في النظام هي نفسها من حيث المعمارية وسرعة الساعة مثلًا، كما توجد في نظام SMP معالجات متعددة تشترك في جميع موارد النظام الأخرى مثل الذاكرة والقرص الصلب وغير ذلك.
ترابط الذواكر المخبئية Cache Coherency
تعمل وحدات المعالجة المركزية في النظام بصورة مستقلة عن بعضها بعضًا، فلكل منها مجموعته الخاصة من المسجلات وعدّاد البرنامج وغير ذلك، ولكن يوجد مكوِّن واحد يتطلب تزامنًا صارمًا بالرغم من تشغيل وحدات المعالجة المركزية بصورة منفصلة عن بعضها بعضًا، وهذا المكوِّن هو الذاكرة المخبئية Cache الخاصة بوحدة المعالجة المركزية.
تذكّر أنّ الذاكرة المخبئية هي مساحة صغيرة من الذاكرة يمكن الوصول إليها بسرعة وتعكس القيم المخزّنة في ذاكرة النظام الرئيسية، فإذا عدّلت إحدى وحدات المعالجة المركزية البيانات في الذاكرة الرئيسية وكان لدى وحدة معالجة مركزية أخرى نسخة قديمة من تلك الذاكرة في ذاكرتها المخبئية، فلن يكون النظام في حالة متناسقة، ولاحظ أنّ هذه المشكلة تحدث عندما تكتب المعالجات في الذاكرة فقط، إذ ستكون البيانات متناسقةً إذا كانت القيمة للقراءة فقط.
يستخدِم نظام SMP عملية التنصت Snooping لتنسيق الحفاظ على ترابط الذواكر المخبئية على جميع المعالجات، إذ يُعَدّ التنصت العمليةَ التي يستمع فيها المعالج إلى ناقل تتصل به جميع المعالجات لمعرفة أحداث الذاكرة المخبئية، ثم يحدّث الذاكرة المخبئية وفقًا لذلك.
يمكن تحقيق ذلك باستخدام بروتوكول واحد هو بروتوكول MOESI الذي يرمز إلى الكلمات مُعدَّل Modified ومالك Owner وحصري Exclusive ومشارَك Shared وغير صالح Invalid التي تمثّل الحالة التي يمكن أن يكون فيها خط الذاكرة المخبئية على معالج في النظام، كما توجد بروتوكولات أخرى لذلك، ولكن تشترك جميعها في مفاهيم متشابهة، وسنوضح فيما يلي بروتوكول MOESI.
إذا طلب المعالج قراءة خط ذاكرة مخبئية من الذاكرة الرئيسية، فيجب عليه أولًا التنصت على جميع المعالجات الأخرى في النظام لمعرفة ما إذا كانت تعرف حاليًا أيّ شيء عن تلك المنطقة من الذاكرة مثل تخزينها في الذاكرة المخبئية، فإذا لم تكن موجودةً في أيّ عملية أخرى، فيمكن للمعالج تحميل الذاكرة في الذاكرة المخبئية وتمييزها على أنها حصرية Exclusive، ويغير الحالة إلى معدَّلة Modified عند الكتابة في الذاكرة المخبئية.
تلعب هنا تفاصيل الذاكرة المخبئية دورًا أساسيًا، إذ ستعيد بعض الذواكر المخبئية مباشرةً كتابة الذاكرة المخبئية المعدَّلة إلى ذاكرة النظام المعروفة باسم الذاكرة المخبئية من النوع Write-through، لأن عمليات الكتابة تنتقل إلى الذاكرة الرئيسية، في حين لن تفعل ذلك الذواكر المخبئية الأخرى، بل ستترك القيمة المُعدَّلة في الذاكرة المخبئية فقط حتى التخلص منها عندما تمتلئ الذاكرة المخبئية مثلًا.
الحالة الأخرى هي المكان الذي يطبّق فيه المعالج عملية التنصت ويكتشف أن القيمة موجودة في ذاكرة مخبئية خاصة بمعالجات أخرى، فإذا كانت هذه القيمة مميَّزةً بوصفها مُعدَّلةً Modified، فسينسخ المعالج البيانات في ذاكرته المخبئية ويميّزها على أنها مشتركة Shared، كما سيرسل رسالةً إلى المعالج الآخر الذي حصلنا على البيانات منه لتمييز خط ذاكرته المخبئية بوصفه المالك Owner، لنفترض الآن أن معالجًا ثالثًا في النظام يريد استخدام تلك الذاكرة أيضًا، فسيتنصت ويبحث عن نسخة مشتركة ونسخة مالكة، وبالتالي سيأخذ قيمته من قيمة المالك.
تقرأ جميع المعالجات الأخرى القيمة فقط، ولكن يبقى خط الذاكرة المخبئية مشتركًا في النظام، فإذا احتاج معالج ما تحديث القيمة، فإنه يرسل رسالة إلغاء صلاحية Invalidate عبر النظام، كما يجب على أيّ معالج له هذا الخط الخاص بالذاكرة المخبئية تمييزه بوصفه غير صالح Invalid لأنه لم يَعُد يعكس القيمة الحقيقية، ويميز المعالج خط الذاكرة المخبئية بوصفه معدَّلًا في ذاكرته المخبئية عندما يرسل رسالة إلغاء الصلاحية وستميّزه المعالجات الأخرى على أنه غير صالح.
لاحظ أنه إذا كان خط الذاكرة المخبئية حصريًا، فسيعلم المعالج أنه لا يوجد معالج آخر يعتمد عليه، لذا يمكنه تجنّب إرسال رسالة إلغاء صلاحية، وتبدأ بعدها العملية من جديد، وبالتالي يتحمل أيُّ معالج له القيمة المعدّلة مسؤوليةَ كتابة القيمة الحقيقية مرةً أخرى إلى الذاكرة RAM عند التخلص منها من الذاكرة المخبئية، ولاحظ أنّ هذا البروتوكول يضمن تناسق خط الذاكرة المخبئية بين المعالجات.
هناك العديد من المشاكل في هذا النظام عند زيادة عدد المعالجات، إذ يمكن التحكم في تكلفة التحقق من وجود معالج آخر يحتوي على خط ذاكرة مخبئية (التنصت على عملية القراءة) أو إلغاء صلاحية البيانات في كل معالج آخر (إلغاء عملية التنصت) عند استخدام عدد قليل من المعالجات، ولكن تزداد حركة النواقل مع زيادة عدد المعالجات وهذا هو السبب في أن أنظمة SMP تصل إلى حوالي 8 معالجات فقط.
يعطي وجود جميع المعالجات في الناقل نفسه مشاكل فيزيائية أيضًا، إذ تسمح خصائص الأسلاك الفيزيائية بوضعها على مسافات معينة من بعضها بعضًا وتسمح بأن يكون لها أطوال معينة فقط، وتبدأ سرعة الضوء في أن تصبح أحد الجوانب التي يجب مراعاتها في المدة التي تستغرقها الرسائل للتنقل في النظام مع المعالجات التي تعمل بسرعة مقدَّرةً بالجيجاهيرتز.
لاحظ أنّ برمجيات النظام ليس لها أيّ جزء من هذه العملية، بالرغم من أنّ المبرمجين يجب أن يكونوا على دراية بما يطبّقه العتاد استجابةً للبرمجيات التي يصمّمونها لزيادة الأداء إلى الحد الأقصى.
حصرية الذاكرة المخبئية في أنظمة SMP
شرحنا في مقال سابق الذواكر المخبئية الشاملة Inclusive والحصرية Exclusive، إذ تكون الذواكر المخبئية L1 شاملةً، أي أن جميع البيانات الموجودة في الذاكرة المخبئية L1 موجودة في الذاكرة المخبئية L2، وتعني الذاكرة المخبئية L1 الشاملة أنّ الذاكرة المخبئية L2 يجب أن تتنصت حركة مرور الذاكرة للحفاظ على ترابطها في نظام متعدد المعالجات، إذ ستضمن L1 عكس أيّ تغييرات في الذاكرة L2، مما يقلل من تعقيد ذاكرة L1 ويفصله عن عملية التنصت، وبالتالي سيسمح لها بأن تكون أسرع.
تحتوي معظم المعالجات الحديثة المتطورة مثل المعالجات التي ليست مدمَجة على سياسة كتابة الذاكرة المخبئية L1 من النوع Write-through وسياسة الكتابة من النوع Write-back في الذواكر المخبئية ذات المستوى الأدنى، وهناك عدة أسباب لذلك، فبما أنّ ذواكر L2 المخبئية في هذا الصنف من المعالجات تكون حصريةً تقريبًا على الشريحة وسريعةً جدًا عمومًا، فليست العقوبات المفروضة على كتابة الذاكرة المخبئية L1 من النوع Write-through الأمر الرئيسي، كما يمكن أن تتسبّب مجمّعات البيانات المكتوبة التي لا يُحتمَل قراءتها في المستقبل في تلوث مورد L1 المحدود لأن أحجام L1 صغيرة.
ليس هناك داع للقلق بشأن الكتابة في L1 من النوع Write-through إذا احتوت على بيانات متسخة معلَّقة، وبالتالي يمكن أن تمرّر منطق الترابط الإضافي إلى ذاكرة L2 التي لديها دور أكبر تلعبه في ترابط الذاكرة المخبئية.
تقنية خيوط المعالجة الفائقة Hyperthreading
يمكن أن يقضي المعالج الحديث كثيرًا من وقته في انتظار أجهزة أبطأ بكثير في تسلسل الذواكر الهرمي لتقديم البيانات للمعالجة، وبالتالي فإن إستراتيجيات الحفاظ على خط أنابيب المعالج ممتلئًا لها أهمية قصوى، وتتمثل إحدى الإستراتيجيات في تضمين عدد كاف من المسجلات ومنطق الحالة بحيث يمكن معالجة مجريين من التعليمات في الوقت نفسه، مما يجعل وحدة معالجة مركزية واحدة تبحث عن جميع النوايا والأهداف المطلوبة كأنها وحدتان CPU.
تحتوي كل وحدة معالجة مركزية على مسجلاتها الخاصة، ولكن يجب عليها مشاركة منطق المعالج الأساسي والذاكرة المخبئية وحيز النطاق التراسلي للإدخال والإخراج من وحدة المعالجة المركزية إلى الذاكرة، لذا يمكن أن يحافظ مجريان من التعليمات على المنطق الأساسي للمعالج أكثر انشغالًا، ولكن لن تكون زيادة الأداء كبيرةً بسبب وجود وحدتَي CPU منفصلتين فيزيائيًا، ويكون تحسين الأداء أقل من 20%، ولكن يمكن أن يكون أفضل أو أسوأ كثيرًا اعتمادًا على الحِمل.
الأنوية المتعددة Multi Core
أصبح وضع معالِجَين أو أكثر في الحزمة الفيزيائية نفسها ممكنًا مع زيادة القدرة على احتواء مزيد من الترانزستورات على شريحة واحدة، ولكن المعالجات الأكثر شيوعًا هي المعالجات ثنائية النواة، إذ توجد نواتان للمعالج على الشريحة نفسها، وتُعَدّ هذه الأنوية -على عكس تقنية خيوط المعالجة الفائقة Hyperthreading- معالجات كاملةً، وبالتالي تبدو على أنها معالجات منفصلة فيزيائيًا مثل نظام SMP.
تحتوي المعالجات على ذاكرة L1 المخبئية الخاصة بها، ولكن يجب عليها مشاركة الناقل المتصل بالذاكرة الرئيسية وأجهزة أخرى، وبالتالي لن يكون الأداء جيدًا مثل نظام SMP الكامل، ولكنه أفضل بكثير من نظام خيوط المعالجة الفائقة، ويمكن لكل نواة تطبيق تقنية خيوط المعالجة الفائقة لتحسين إضافي.
تتمتع المعالجات متعددة الأنوية ببعض المزايا التي لا تتعلق بالأداء، كما أنّ للناقلات الفيزيائية الخارجية بين المعالجات حدود فيزيائية، ولكن يمكن حل بعض هذه المشاكل من خلال احتواء المعالجات على قطعة السيليكون نفسها بحيث تكون قريبةً جدًا من بعضها بعضًا.
تُعَدّ متطلبات الطاقة للمعالجات متعددة الأنوية أقل بكثير من المعالجات المنفصلة عن بعضها بعضًا، وهذا يعني أن هناك حاجة أقل لتبريد الحرارة والتي يمكن أن تكون ميزةً كبيرةً في تطبيقات مراكز البيانات حيث تُجمَّع الحواسيب مع وجود حاجة كبيرة للتبريد، كما يجعل وجود الأنوية في الحزمة الفيزيائية نفسها المعالجةَ المتعددة عمليةً في التطبيقات التي لن تكون فيها كذلك مثل الحواسيب المحمولة، كما يُعَدّ إنتاج شريحة واحدة بدلًا من شريحتين أرخص بكثير.
العناقيد Clusters
تتطلب العديد من التطبيقات أنظمةً أكبر بكثير من عدد المعالجات التي يمكن لنظام SMP التوسع إليها، وتُعَدّ العناقيد Clusters إحدى الطرق لتوسيع النظام أكثر، وهي عدد من الحواسيب التي لديها بعض القدرة على التواصل مع بعضها بعضًا، كما لا تعرف الأنظمة بعضها بعضًا على مستوى العتاد، إذ تُترَك مهمة ربط هذه الحواسيب للبرمجيات.
تسمح البرمجيات مثل MPI للمبرمجين بكتابة برامجهم ثم وضع أجزاء منها على حواسيب أخرى في النظام مثل تمثيل حلقة تُنفَّذ عدة آلاف من المرات وتطبّق إجراءً مستقلًا، أي لا يوجد تكرار للحلقة يؤثر على أيّ تكرار آخر، ويمكن للبرمجيات جعل كل حاسوب يشغّل 250 حلقة لكل منها مع وجود أربعة حواسيب في العنقود.
يختلف الترابط بين الحواسيب، إذ يمكن أن يكون بطيئًا مثل روابط شبكة الإنترنت أو سريعًا مثل الناقلات المخصَّصة والخاصة مثل روابط إنفيني باند Infiniband، ومهما كان هذا الترابط، فسيبقى في المستوى الأخفض من تسلسل الذواكر الهرمي وسيكون أبطأ بكثير من الذاكرة RAM، وبالتالي لن يقدّم العنقود أداءً جيدًا في الموقف الذي تتطلب فيه كل وحدة معالجة مركزية الوصول إلى البيانات المُخزَّنة في الذاكرة RAM الخاصة بحاسوب آخر، إذ ستحتاج البرمجيات في كل مرة أن تطلب نسخةً من البيانات من الحاسوب الآخر، وتنسخها عبر الرابط البطيء إلى الذاكرة RAM المحلية قبل أن يتمكن المعالج من إنجاز أيّ عمل.
لا تتطلب العديد من التطبيقات هذا النسخ المستمر بين الحواسيب، وأحد الأمثلة الشائعة عن ذلك هو SETI@Home، إذ تُحلَّل البيانات التي جرى جمعها من هوائي راديو بحثًا عن علامات على وجود كائن فضائي، ويمكن توزيع كل حاسوب لبضع دقائق للحصول على البيانات لتحليلها ويعطي تقريرًا ملخصًا لما وجده، إذ يُعَدّ SETI@Home عنقودًا مخصَّصًا وكبيرًا جدًا.
يوجد تطبيق آخر هو تطبيق تصيير الصور Rendering of Images الذي يُستخدَم خاصةً للتأثيرات الخاصة في الأفلام، إذ يُسلَّم كل حاسوب إطارًا واحدًا من الفيلم يحتوي على نماذج إطارات شبكية وخامات Textures ومصادر إضاءة يجب دمجها أو تصييرها في التأثيرات الخاصة المذهلة التي نحصل عليها، كما يُعَدّ كل إطار ساكنًا، لذلك لا يحتاج الحاسوب بمجرد حصوله على الدخل الأولي لمزيد من الاتصال حتى يصبح الإطار النهائي جاهزًا لإرساله ودمجه في الحركة، فقد كان لفيلم سيد الخواتم مثلًا تأثيرات خاصة مصيَّرة على عنقود ضخم يعمل بنظام لينكس.
الوصول غير الموحد للذاكرة Non-Uniform Memory Access
يُعَدّ الوصول غير الموحد للذاكرة Non-Uniform Memory Access -أو NUMA اختصارًا- عكس نظام العناقيد السابق تقريبًا، ولكنه -كما هو الحال في نظام العنقود- يتكون من عقد فردية مرتبطة ببعضها بعضًا، إلا أنّ الارتباط بين العقد شديد التخصص ومكلف، ولا يمتلك العتاد أيّ معرفة بالربط بين العقد في نظام العنقود، في حين لا تمتلك البرمجيات في نظام NUMA معرفةً جيدةً أو تمتلك معرقةً أقل حول تخطيط النظام، إذ يطبّق العتاد كل العمل لربط العقد مع بعضها بعضًا.
يأتي مصطلح الوصول غير الموحّد إلى الذاكرة من حقيقة أن الذاكرة RAM ليست محلية بالنسبة لوحدة المعالجة المركزية، وبالتالي يمكن أن هناك حاجة لأن تصل عقدة على بعد مسافة ما إلى البيانات، إذ يستغرق ذلك وقتًا أطول على النقيض من معالج واحد أو نظام SMP حيث يمكن الوصول إلى الذاكرة RAM مباشرةً، ويستغرق ذلك دائمًا وقتًا ثابتًا أو موحّدًا.
تخطيط نظام NUMA
يُعَدّ تقليل المسافة بين العقد أمرًا بالغ الأهمية مع وجود العديد من العقد التي تتواصل مع بعضها في النظام، إذ يُفضَّل أن يكون لكل عقدة رابط مباشر بكل عقدة أخرى لأنه يقلّل المسافة التي تحتاجها أيّة عقدة للعثور على البيانات، لكن لا يُعَدّ ذلك موقفًا عمليًا عندما ينمو عدد العقد إلى المئات والآلاف كما هو الحال مع الحواسيب العملاقة الكبيرة، فالأساس في هذا النمو هو مجموعة مؤلفة من عقدتين تتواصلان مع بعضهما بعضًا ثم ستنمو إلى n!/2*(n-2)!.
تُستخدَم التخطيطات البديلة لمقايضة المسافة بين العقد مع الوصلات المطلوبة بهدف التقليل من هذا النمو الأسي، فأحد هذه التخطيطات الشائعة في معماريات NUMA الحديثة هو المكعب الفائق Hypercube الذي يحتوي على تعريف رياضي صارم، ويكون المكعب الفائق هو نظير رباعي الأبعاد للمكعب الذي هو نظير ثلاثي الأبعاد للمربع.
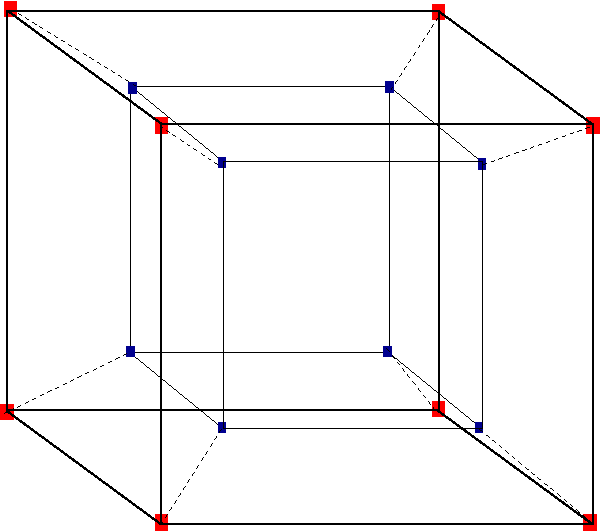
مثال عن المكعب الفائق Hypercube الذي يوفر مقايضةً جيدةً بين المسافة بين العقد وعدد الوصلات المطلوب.
يمكننا أن نرى في الشكل السابق أن المكعب الخارجي يحتوي على 8 عقد، والحد الأقصى لعدد المسارات المطلوبة لأي عقدة للتواصل مع عقدة أخرى هو 3، فإذا وضعنا مكعبًا آخر داخل هذا المكعب، فسيكون لدينا ضعف عدد المعالجات ولكن زادت التكلفة القصوى للمسار إلى 4، مما يعني نمو تكلفة المسار القصوى خطيًا فقط عند نمو عدد المعالجات بمقدار 2n.
ترابط الذاكرة المخبئية Cache Coherency
لا يزال الحفاظ على ترابط الذاكرة المخبئية في نظام NUMA ممكنًا، إذ يشار إلى ذلك باسم نظام NUMA مع ترابط الذاكرة المخبئية Cache Coherent NUMA System أو ccNUMA اختصارًا، ولا يتوسّع المخطط القائم على البث الإذاعي المُستخدَم للحفاظ على ترابط ذاكرة المعالج المخبئية في نظام SMP إلى مئات أو حتى آلاف المعالجات في نظام NUMA كبير.
يشار إلى أحد المخططات الشائعة لترابط الذاكرة المخبئية في نظام NUMA باسم النموذج المستند إلى الدليل Directory Based Model الذي تتصل فيه المعالجات الموجودة في النظام بعتاد دليل الذاكرة المخبئية، إذ يحافظ عتاد الدليل على صورة متناسقة لكل معالج، كما يخفي هذا التجريد عمل نظام NUMA عن المعالج.
يحتفظ المخطط المستند إلى الدليل لصاحبيه Censier و Feautrier بدليل مركزي، إذ تحتوي كل كتلة ذاكرة على بِت راية يُعرَف بالبِت الصالح Valid Bit لكل معالج وبِت واحد يُسمَّى بالبِت المتسخ Dirty Bit، ويضبط الدليل البِت الصالح للمعالج الذي يقرأ الذاكرة إلى ذاكرته المخبئية.
إذا أراد المعالج الكتابة إلى خط الذاكرة المخبئية، فيجب أن يضبِط الدليل البِتَّ المتسخ لكتلة الذاكرة من خلال إرسال رسالة إلغاء صلاحية إلى تلك المعالجات التي تستخدِم خط الذاكرة المخبئية والمعالجات التي جرى ضبط رايتها فقط بهدف تجنب حركة مرور البث broadcast traffic.
يجب بعد ذلك أن يحاول أيّ معالج آخر قراءة كتلة الذاكرة، وسيجد الدليل ضبط البِت المتسخ، كما يجب أن يحصل الدليل على خط الذاكرة المخبئية المُحدَّث من المعالج مع البِت الصالح المضبوط حاليًا، ويعيد كتابة البيانات المتسخة إلى الذاكرة الرئيسية ثم إعادة هذه البيانات إلى المعالج المطلوب، مما يؤدي إلى ضبط البِت الصالح للمعالج الطالب في هذه العملية، ولاحظ أنّ هذا الأمر واضح للمعالج الطالب ويمكن أن يحتاج الدليل الحصول على تلك البيانات من مكان قريب جدًا أو من مكان بعيد جدًا.
لا يمكن أن يتوسع المخطط المؤلَّف من آلاف المعالجات التي تتصل بدليل واحد بصورة جيدة، إذ تتضمن توسّعات المخطط وجود تسلسل هرمي من الدلائل التي تتواصل فيما بينها باستخدام بروتوكول منفصل، كما يمكن أن تستخدِم الدلائل شبكة اتصالات ذات أغراض أعم للتواصل فيما بينها بدلًا من ناقل وحدة المعالجة المركزية، مما يسمح بالتوسع إلى أنظمة أكبر بكثير.
تطبيقات NUMA
تُعَدّ أنظمة NUMA الأنسب لأنواع المشاكل التي تتطلب قدرًا كبيرًا من التفاعل بين المعالج والذاكرة، فمن المصطلحات الشائعة في محاكاة الطقس مثلًا هو تقسيم البيئة إلى صناديق صغيرة تستجيب بطرق مختلفة، بحيث تعكس المحيطات والأرض أو تخزن كميات مختلفة من الحرارة مثلًا، ويجب تغذية الاختلافات الصغيرة لمعرفة النتيجة الإجمالية أثناء تشغيل عمليات المحاكاة.
يؤثر كل صندوق على الصناديق المحيطة، إذ يعني وجود الشمس أكثر قليلًا مثلًا أنّ صندوقًا معينًا ينشر مزيدًا من الحرارة مما يؤثر على الصناديق المجاورة له، ولكن سيكون هناك الكثير من الاتصالات على عكس إطارات الصور الفردية في عملية التصيير Rendering التي لا تؤثر على بعضها، كما يمكن أن تحدث عمليةً مماثلةً إذا أردت تصميم نموذج لحادث سيارة، حيث سيُطوى كل صندوق صغير من السيارة التي تحاكيها بطريقة ما وسيمتص قدرًا من الطاقة.
ليس للبرمجيات معرفة مباشرة بأن النظام الأساسي هو نظام NUMA، ولكن يجب أن يتوخّى المبرمجون الحذر عند البرمجة لهذا النظام للحصول على أفضل أداء، وسيؤدي الاحتفاظ بالذاكرة بالقرب من المعالج الذي سيستخدِمها إلى أفضل أداء، ولكن يجب أن يستخدِم المبرمجون تقنيات مثل التشخيص Profiling لتحليل مسارات الشيفرة البرمجية المتّبَعة والعواقب التي تسببها الشيفرة البرمجية للنظام لاستخراج أفضل أداء.
ترتيب الذاكرة وقفلها
تجلب الذاكرة المخبئية متعددة المستويات والمعمارية متعددة المعالجات الفائقة بعض المشاكل المتعلقة بكيفية رؤية المبرمج لشيفرة المعالج البرمجية التي تكون قيد التشغيل.
لنفترض أنّ شيفرة البرنامج البرمجية تعمل على معالجَين في الوقت نفسه، وأنّ كلا المعالجين يشتركان بفعالية في منطقة واحدة كبيرة من الذاكرة، فإذا أصدر أحد المعالجَين تعليمات تخزين لوضع قيمة مسجّل في الذاكرة، فلا بد أنك تتساءل عن الوقت الذي يمكن فيه التأكد من أن المعالج الآخر يحمّل تلك الذاكرة التي سيرى قيمتها الصحيحة.
يمكن للنظام في أبسط الحالات أن يضمن أنه في حالة تنفيذ أحد البرامج لتعليمات التخزين، وبالتالي سترى أيّ تعليمات تحميل لاحقة هذه القيمة، إذ يُشار إلى ذلك باسم ترتيب الذاكرة الصارم Strict Memory Ordering، لأن القواعد لا تسمح بأيّ مجال للحركة، كما يجب أن تدرك أنّ هذا النوع من الأشياء يُعَدّ عائقًا خطيرًا أمام أداء النظام.
لا يُطلَب من ترتيب الذاكرة أن يكون صارمًا جدًا في كثير من الأحيان، إذ يمكن للمبرمج تحديد النقاط التي يحتاجها للتأكد من رؤية جميع العمليات المُعلَّقة بطريقة عامة، ولكن يمكن أن يكون هناك العديد من التعليمات من بين هذه النقاط حيث لا تكون الدلالات Semantics مهمة، ولنفترض الموقف التالي مثلًا الذي يمثل ترتيب الذاكرة:
typedef struct { int a; int b; } a_struct; /* * مرّر مؤشرًا لتخصيصه بوصفه بنيةً جديدةً */ void get_struct(a_struct *new_struct) { void *p = malloc(sizeof(a_struct)); /* لا نهتم بترتيب التعليمتين التاليتين * اللتين ستُنفَّذان في النهاية */ p->a = 100; p->b = 150; /* .لكن يجب أن تُنفَّذا قبل التعليمة التالية * p وإلّا فسيتمكن معالج آخر ينظر إلى قيمة * .من أن يجدها تؤشّر إلى بنية قيمها غير مملوءة */ new_struct = p; }
لدينا في هذا المثال عمليتَي تخزين يمكن تطبيقهما بأيّ ترتيب معيّن بما يناسب المعالج، ولكن يجب في الحالة الأخيرة تحديث المؤشر فقط بمجرد التأكد من اكتمال عمليتَي التخزين السابقتين، وإلّا فيمكن أن ينظر معالج آخر إلى قيمة p ويتبع المؤشر إلى الذاكرة ويحمّلها ويحصل على قيمة غير صحيحة تمامًا، لذا يجب أن تحتوي عمليات التحميل والتخزين على دلالات تصف سلوكها.
توصَف دلالات الذاكرة من حيث الأسوار Fences التي تحدّد كيفية إعادة ترتيب عمليات التحميل والتخزين، كما يمكن افتراضيًا إعادة طلب عملية التحميل أو التخزين في أيّ مكان، ويشبه اكتساب الدلالات Acquire Semantics السورَ الذي يسمح فقط لعمليات التحميل والتخزين بالتحرك للأسفل عبره، أي يمكنك ضمان أنّ أيّ عملية تحميل أو تخزين لاحقة سترى القيمة -لأنه لا يمكن نقلها فوقها- عند اكتمال هذا التحميل أو التخزين.
يُعَدّ تحرير الدلالات Release Semantics عكس ذلك، أي يسمح السور بأي عملية تحميل أو تخزين أن تكتمل قبله -أي التحرك للأعلى-، ولكن لا يوجد شيء قبلها للتحرك للأسفل. وبالتالي يمكنك تخزين أيّ عملية تحميل أو تخزين سابقة مكتملة عند معالجة التحميل أو التخزين باستخدام تحرير الدلالات.
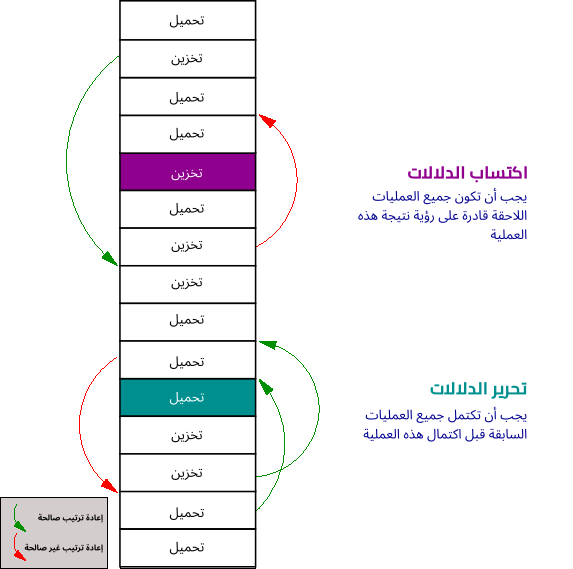
رسم توضيحي يمثّل عمليات إعادة الترتيب الصالحة للعمليات باستخدام اكتساب الدلالات وتحريرها
سور الذاكرة الكامل full memory fence هو مزيج من اكتساب الدلالات وتحريرها، حيث لا يمكن إعادة ترتيب عمليات التحميل أو التخزين في أيّ اتجاه حول عملية التحميل أو التخزين الحالية، كما يستخدِم نموذج الذاكرة الأكثر صرامة سور ذاكرة كامل لكل عملية، في حين سيترك النموذج الأضعف كل عملية تحميل وتخزين على أساس تعليمات عادية قابلة لإعادة الترتيب.
المعالجات ونماذج الذاكرة
تطبّق المعالجات المختلفة نماذج ذاكرة مختلفة، إذ يحتوي معالج x86 ومعالج AMD64 على نموذج ذاكرة صارم تمامًا، حيث تحتوي جميع عمليات التخزين على تحرير دلالات، أي يجب أن ترى أيّة عملية تحميل أو تخزين لاحقة نتيجةَ عملية التخزين، ولكن جميع عمليات التحميل لها دلالات عادية، كما تعطي بادئة القفل سورًا للذاكرة، في حين يسمح المعالج إيتانيوم Itanium لجميع عمليات التحميل والتخزين بأن تكون عاديةً ما لم يُجرَى إخباره صراحةً بغير ذلك.
القفل
ليست معرفة متطلبات ترتيب الذاكرة لكل معمارية عمليةً ومناسبةً لجميع المبرمجين وسيجعل ذلك نقل البرامج وتنقيحها عبر أنواع المعالجات المختلفة أمرًا صعبًا، إذ يستخدِم المبرمجون مستوًى أعلى من التجريد يسمى القفل Locking للسماح بالتشغيل المتزامن للبرامج عندما يكون هناك وحدات معالجة مركزية متعددة، كما لا يمكن لأيّ معالج آخر الحصول على القفل حتى يُحرَّر عندما يحصل برنامج ما عليه لجزء من شيفرة برمجية، كما يجب أن يحاول المعالج أخذ القفل قبل أيّ أجزاء مهمة من الشيفرة البرمجية، فإذا لم يستطع الحصول عليه، فلن يستمر في عمله.
يمكنك رؤية كيف أنّ ذلك مقيَّد بتسمية دلالات ترتيب الذاكرة الموضَّحة سابقًا، كما نريد التأكد من أنه لن يُعاد طلب أيّ عمليات يجب أن يحميها القفل قبل الحصول عليه، وهذه هي الطريقة التي تعمل بها عملية اكتساب الدلالات، في حين يجب التأكد من أنّ كل عملية طبّقناها أثناء احتفاظنا بالقفل مكتملة عندما نحرره مثل مثال تحديث المؤشر الموضَّح سابقًا، وهذا ما يسمى بتحرير الدلالات.
هناك العديد من المكتبات البرمجية المتاحة التي تسمح للمبرمجين بعدم القلق بشأن تفاصيل دلالات الذاكرة واستخدام المستوى الأعلى من تجريد القفل lock() وإلغاء القفل unlock().
صعوبات الأقفال
تجعل أنظمة القفل البرمجة أكثر تعقيدًا، إذ يمكنها أن تؤدي إلى تعطيل البرامج، ولنفترض أنّ معالجًا ما يحتفظ بقفل على بعض البيانات، وينتظر قفلًا على بيانات أخرى حاليًا، فإذا انتظر معالج آخر البيانات التي يحتفظ بها المعالج الأول وكان قبل ذلك وقبل دخوله في حالة قفل يحتفظ ببيانات يريدها المعالج الأول ذاك لفك قفله، فسنواجه حالة تعطل تام، بحيث ينتظر كل معالج المعالج الآخر ولا يمكن لأيّ منهما الاستمرار بدون قفل المعالج الآخر.
ينشأ هذا الموقف بسبب حالة التسابق Race Condition في أغلب الأحيان التي تُعَدّ إحدى أصعب الأخطاء التي يمكن تعقّبها، فإذا كان هناك معالِجان يعتمدان على عمليات تحدث بترتيب معيّن في الوقت، فهناك دائمًا احتمال حدوث حالة تسابق، كما يمكن أن تصطدم أشعة جاما المنبعثة من نجم متفجر في مجرة أخرى بأحد المعالجات، مما يؤدي إلى الخروج عن ترتيب العمليات، ثم ستحدث حالة تعطل تام كما رأينا سابقًا، لذا يجب ضمان ترتيب البرامج باستخدام الدلالات وليس عبر الاعتماد على سلوكيات محددة لمرة واحدة.
يوجد وضع مماثل يسمى المنع Livelock وهو عكس التعطل Deadlock، إذ يمكن أن تكون إحدى الاستراتيجيات لتجنب التعطل أن يكون لديك قفل مؤدب Polite يرفض إعطاء القفل لكل مَن يطلبه، وقد يتسبب هذا القفل المؤدّب في جعل خيطين Threads يمنحان بعضهما القفل باستمرار دون الحاجة إلى أخذ القفل لفترة كافية لإنجاز العمل المهم والانتهاء من القفل، إذ يمكن أن يكون هناك وضع مشابه في الحياة الواقعية لشخصين يلتقيان عند الباب في الوقت نفسه، ويقول كلاهما: "لا، أنت أولًا، أنا أصر على ذلك" دون المرور عبر الباب نهائيًا.
استراتيجيات القفل
هناك العديد من الاستراتيجيات المختلفة لتطبيق سلوك الأقفال، إذ يُشار إلى القفل البسيط الذي يحتوي ببساطة على حالتين -مقفل Locked أو غير مقفل Unlocked- على أنه كائن مزامنة Mutex، وهو اختصار للاستبعاد المتبادل Mutual Exclusion الذي يعني أنه إذا كان لدى شخص ما قفلًا، فلا يمكن لشخص آخر الحصول عليه، وهناك عدد من الطرق لتطبيق قفل كائن المزامنة، إذ لدينا في أبسط الحالات ما يسمى بالقفل الدوار Spinlock إذ يبقى المعالج ضمن حلقة في انتظار أخذ القفل مثل طفل صغير يطلب من والديه شيئًا ويقول "هل يمكنني الحصول عليه الآن؟" باستمرار.
تكمن مشكلة هذه الاستراتيجية في أنها تضيع الوقت، إذ لا ينفّذ المعالج أيّ عملٍ مفيد بينما يكون متوقفًا ويطلب القفل باستمرار، وقد يكون ذلك مناسبًا للأقفال التي يُحتمَل أن تُقفَل لفترة قصيرة جدًا من الوقت فقط، ولكن يمكن أن يكون مقدار الوقت الذي يستغرقه القفل أطول بكثير في كثير من الحالات.
الاستراتيجية الأخرى هي السكون Sleep، حيث إذا لم يتمكن المعالج من الحصول على القفل، فسينفّذ بعض الأعمال الأخرى في انتظار إشعار بأن القفل متاح للاستخدام، وسنرى في المقالات القادمة كيف يمكن لنظام التشغيل تبديل العمليات وإعطاء المعالج مزيدًا من العمل لتنفيذه.
يُعَدّ كائن المزامنة حالةً خاصةً من متغير تقييد الوصول Semaphore الذي اخترعه عالم الحاسوب الهولندي ديكسترا Dijkstra، إذ يمكن ضبط متغير تقييد الوصول Semaphore لحساب عدد مرات الوصول إلى الموارد في حالة توفر العديد منها، في حين يكون لديك كائن المزامنة Mutex في الحالة التي يكون فيها عدد الموارد يساوي واحدًا فقط.
لكن لا تزال أنظمة القفل هذه تواجه بعض المشاكل، إذ يرغب معظم الأشخاص في قراءة البيانات التي تُحدَّث في حالات نادرة فقط. يمكن أن يؤدي وجود جميع المعالجات التي ترغب في قراءة البيانات فقط التي تتطلب قفلًا إلى تنازع القفل حيث يُنجَز القليل من العمل لأن الجميع ينتظر الحصول على القفل نفسه لبعض البيانات.
ترجمة -وبتصرُّف- للقسم Small to big systems من الفصل Computer Architecture من كتاب Computer Science from the Bottom Up لصاحبه Ian Wienand.








أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.