

كيف ينفذ البرنامج (How programs run)
يجب أن تفهم كيف تنفّذ الحواسيب البرامج لفهم عملية التخبئة (caching)، وينبغي عليك دراسة معمارية الحاسوب لفهم التخبئة بصورةٍ أعمق. تكون الشيفرة أو النص البرمجي ضمن القرص الصلب (hard disk) أو ضمن SSD عند بدء تشغيل البرنامج، وينشئ نظام التشغيل عمليةً جديدة لتشغيل البرنامج ثم ينسخ المحمِّل (loader) نص البرنامج من التخزين الدائم إلى الذاكرة الرئيسية ثم يبدأ البرنامج من خلال استدعاء الدالة main. تُخزَّن معظم بيانات البرنامج في الذاكرة الرئيسية أثناء تنفيذه، ولكن تكون بعض هذه البيانات موجودةً في مسجّلات (registers) والتي هي وحدات صغيرة من الذاكرة موجودة في المعالج (CPU) وتتضمن هذه المسجلات ما يلي:
- عداد البرنامج (The program counter) واختصاره PC الذي يتضمن عنوان التعليمة التالية من البرنامج (العنوان في الذاكرة).
- مسجّل التعليمة (The instruction register) ويختصر إلى IR ويتضمن شيفرة الآلة للتعليمة التي تنفّذ حاليًا.
- مؤشر المكدس (The stack pointer) واختصاره SP الذي يتضمن عنوان إطار المكدس (stack frame) للدالة الحالية ويحتوي إطار المكدس معاملات الدالة ومتغيراتها المحلية.
- مسجلات ذات أغراض عامة (General-purpose registers) التي تحتفظ بالبيانات التي يعمل عليها البرنامج حاليًا.
- مسجل الحالة (status register) أو مسجل الراية (flag register) الذي يتضمن معلومات عن العمليات الحسابية الحالية، حيث يتضمن مسجل الراية عادةً بتًا، ويُضبَط هذا البت إذا كانت نتيجة العملية السابقة صفرًا على سبيل المثال.
ينفّذ المعالج الخطوات التالية عند تشغيل البرنامج وتدعى هذه الخطوات بدورة التعليمة (instruction cycle):
- الجلب (Fetch): تُجلَب التعليمة التالية من الذاكرة ثم تُخزَّن في مسجّل التعليمة.
- فك التشفير (Decode): يَفك جزءُ المعالج الذي يدعى وحدة التحكم (control unit) تشفيرَ التعليمة ثم يرسل إشاراتٍ إلى الأجزاء الأخرى من المعالج.
- التنفيذ (Execute): تسبب إشارات وحدة التحكم ظهور العمليات الحسابية المناسبة.
تستطيع معظم الحواسيب تنفيذ بضع مئات من التعليمات المختلفة تدعى بمجموعة التعليمات (instruction set) ولكن تندرج معظم التعليمات ضمن فئات عامة هي:
- تعليمات التحميل (Load): تنقل قيمةً من الذاكرة إلى المسجل.
- التعليمات الحسابية أو المنطقية (Arithmetic/logic): تحمّل المعامَلات (operands) من المسجّلات ثم تجري عمليات رياضية ثم تخزّن النتيجة في مسجّل.
- تعليمات التخزين (Store): تنقل قيمةً من المسجّل إلى الذاكرة.
- تعليمات القفز وتعليمات الفرع (Jump/branch): تسبب تغييراتُ عداد البرنامج قفزَ تدفق التنفيذ (flow of execution) إلى موقعٍ آخر من البرنامج. تكون الفروع مشروطة عادةً وهذا يعني أن الفروع تتحقق من رايةٍ ما في مسجل الراية ثم تقفز إلى موقع آخر من البرنامج في حال ضُبطت هذه الراية فقط.
توفر بعضُ مجموعات التعليمات الموجودة ضمن معمارية نظام التشغيل واسعة الانتشار x86 تعليماتٍ تجمع بين عمليةٍ حسابيةٍ وعملية تحميل. تُقرَأ تعليمةٌ واحدةٌ من نص البرنامج خلال كل دورة تعليمة، ويُحمَّل حوالي نصف تعليمات البرنامج أو تخزن بياناتها، وتكمن هنا واحدة من المشاكل الأساسية في معمارية الحاسوب وهي مشكلة عنق زجاجة الذاكرة أو اختناق الذاكرة (memory bottleneck). نواة الحواسيب الحالية قادرةٌ على تنفيذ تعليمةٍ في أقل من 1 نانو ثانية، ولكن يُقدّر الوقت اللازم لنقل بيانات من وإلى الذاكرة بحوالي 100 نانو ثانية، وإذا توجّب على المعالج الانتظار 100 نانو ثانية لجلب التعليمة التالية و100 نانو ثانية أخرى لتحميل البيانات فسيكمل المعالج التعليمات بصورة أبطأ ب 200 مرة مما هو متوقع، لذلك تُعَد الذاكرة في العديد من العمليات الحسابية هي عامل تحديد السرعة ولا يُعَد المعالج كذلك.
أداء الذاكرة المخبئية (Cache performance)
الذاكرة المخبئية هي الحل لمشكلة اختناق الذاكرة أو على الأقل حلٌ جزئي لها، حيث أن الذاكرة المخبئية (cache) ذاكرةٌ صغيرة الحجم وسريعة ومتواجدة قرب المعالج على نفس الشريحة عادةً. تحوي الحواسيب الحديثة مستويات متعددة من الذاكرة المخبئية هي: ذاكرة مخبئية ذات مستوى أول (Level 1 cache) وهي الأصغر حجمًا والأسرع حيث يتراوح حجمها بين 1 و 2 ميبي بايت مع وقت وصول 1 نانو ثانية تقريبًا، أما الذاكرة المخبئية ذات المستوى الثاني (Level 2 cache) التي تملك وقت وصول يساوي 4 نانو ثانية تقريبًا، وتملك الذاكرة المخبئية ذات المستوى الثالث وقت وصول يساوي 16 نانو ثانية. يخزّن المعالج نسخةً من القيمة التي يحمّلها من الذاكرة في الذاكرة المخبئية، وإذا حُمّلت تلك القيمة مرةً أخرى يجلب المعالج نسخة هذه القيمة من الذاكرة المخبئية وبالتالي لا يضطر المعالج إلى الانتظار لجلب القيمة من الذاكرة، ولكن من الممكن أن تمتلئ الذاكرة المخبئية وبالتالي يجب إخراج بعض القيم من الذاكرة المخبئية عند إحضار قيم أخرى، لذلك إذا حمّل المعالج قيمةً ثم عاد لتحميلها مرةً أخرى ولكن بعد وقت طويل فقد لا تكون هذه القيمة موجودةً ضمن الذاكرة المخبئية. إن أداء العديد من البرامج محدودٌ بمقدار فعالية الذاكرة المخبئية، فإذا كانت التعليمات والبيانات التي يحتاجها المعالج موجودةً في الذاكرة المخبئية فإن البرنامج يمكن أن ينفّذ بسرعةٍ قريبة من سرعة المعالج الكاملة، بينما إذا احتاج المعالج بياناتٍ غير موجودةٍ في الذاكرة المخبئية مرارًا فسيكون المعالج محدودًا بسرعة الذاكرة. معدّل الإصابة (hit rate) للذاكرة المخبئية الذي يرمز له h هو جزء عمليات الوصول للذاكرة التي تجد البيانات في الذاكرة المخبئية، أما معدل الإخفاق (miss rate) والذي يرمز له m هو جزء عمليات الوصول للذاكرة التي يجب أن تذهب إلى الذاكرة لأنها لم تجد البيانات التي تريدها ضمن الذاكرة المخبئية، فإذا كان وقت إصابة الذاكرة المخبئية هو Th ووقت إخفاق الذاكرة المخبئية هو Tm فإن متوسط وقت كل عملية وصولٍ للذاكرة هو: h Th + m Tm، ويمكن تعريف عقوبة الإخفاق (miss penalty) كوقتٍ إضافي لمعالجة إخفاق الذاكرة المخبئية والذي يساوي: Tp =Tm-Th وبالتالي متوسط وقت الوصول هو: Th+mTp، يساوي متوسط وقت الوصول تقريبًا Th عندما يكون معدل الإخفاق منخفضًا، وبالتالي يؤدي البرنامج عمله وكأن الذاكرة تعمل بسرعة الذاكرة المخبئية.
المحلية (Locality)
تحمّل الذاكرة المخبئية عادةً كتلةً أو سطرًا من البيانات الذي يتضمن البايت المطلوب وبعضًا من البايتات المجاورة له وذلك عندما يقرأ البرنامج بايتًا للمرة الأولى، وبالتالي إذا حاول البرنامج قراءة إحدى تلك البايتات المجاورة للبايت المطلوب لاحقًا فستكون موجودةً في الذاكرة المخبئية مسبقًا. افترض أن حجم الكتلة هو 64 بايتًا مثل قراءة سلسلة طولها 64 بايتًا، حيث يمكن أن يقع أول بايت من السلسلة في بداية الكتلة، فستتحمّل عقوبة إخفاق (miss penalty) إذا حمّلت أول بايت ولكن ستوجد بقية السلسلة في الذاكرة المخبئية بعد ذلك، أي يساوي معدل الإصابة 63/64 بعد قراءة كامل السلسلة أي ما يعادل 98%، أما إذا كان حجم السلسلة يعادل كتلتين فستتحمّل عقوبتي إخفاق ويكون معدل الإصابة مساويًا 62/64 أو 97%، ويصبح معدل الإصابة 100% إذا قرأت السلسلة ذاتها مرة أخرى، ولكن سيصبح أداء الذاكرة المخبئية سيئًا إذا قفز البرنامج بصورة غير متوقعة محاولًا قراءة بيانات من مواقع متفرقة في الذاكرة أو إذا كان الوصول إلى نفس الموقع مرتين نادرًا. يدعى ميل البرنامج لاستخدام البيانات ذاتها أكثر من مرة بالمحلية الزمانية (temporal locality)، ويدعى ميل البرنامج لاستخدام البيانات المتواجدة في مواقع قريبة من بعضها بعضًا بالمحلية المكانية (spatial locality)، حيث تقدّم البرامج نوعي المحلية كما يلي:
- تحوي معظم البرامج كتلًا من الشيفرة بدون تعليمات قفزٍ أو فروع، حيث تنفّذ التعليمات في هذه الكتل تسلسليًا، وبالتالي يملك نموذج الوصول (access pattern) محليةً مكانية (spatial locality).
- تنفّذ البرامج نفس التعليمات مرات متعددة في الحلقات التكرارية (loop)، وبالتالي يملك نموذج الوصول (access pattern) محليةً زمانية (temporal locality).
- تُستخدم نتيجة تعليمةٍ ما كمُعامَل (operand) للتعليمة التالية مباشرةً، وبالتالي يملك نموذج وصول البيانات محليةً زمانية (temporal locality).
- تُخزَّن معامِلات دالةٍ ومتغيراتها المحلية معًا في جزء المكدس عندما ينفّذ البرنامج هذه الدالة، أي يملك الوصول إلى هذه القيم محليةً مكانية (spatial locality).
- أحد أكثر نماذج المعالجة شيوعًا هو قراءة أو كتابة عناصر مصفوفةٍ تسلسليًا وبالتالي تملك هذه النماذج محليةً مكانية (spatial locality).
قياس أداء الذاكرة المخبئية (Measuring cache performance)
أحد برامجي المفضلة، يقول الكاتب، هو البرنامج الذي يتكرر خلال مصفوفة ويقيس متوسط وقت قراءة وكتابة عنصر، ويمكن استنتاج حجم الذاكرة المخبئية وحجم الكتلة وبعض الخصائص الأخرى من خلال تغيير حجم تلك المصفوفة، والجزء الأهم من هذا البرنامج هو الحلقة التكرارية (loop) التالية:
iters = 0; do { sec0 = get_seconds(); for (index = 0; index < limit; index += stride) array[index] = array[index] + 1; iters = iters + 1; sec = sec + (get_seconds() - sec0); } while (sec < 0.1);
حيث تعبُر (traverses) حلقة for الداخلية المصفوفة، ويحدد المتغير limit مقدار قيم المصفوفة التي تريد عبورها، ويحدد المتغير stride الخطوة أو عدد العناصر التي يجب تجاوزها في كل تكرار، فمثلًا إذا كانت قيمة المتغيرlimit هي 16 وقيمة المتغير stride هي 4 فإن الحلقة ستصل إلى القيم التالية: 0 و 4 و 8 و 12. يتتبّع المتغير sec وقت المعالج الذي تستخدمه حلقة for الداخلية، وتنفّذ الحلقة الخارجية حتى يتخطى المتغير sec حاجز 0.1 ثانية والذي هو وقتٌ كافٍ لحساب الوقت الوسطي بدقةٍ كافية. تستخدم الدالة get_seconds استدعاء النظام clock_gettime وتحوّل الوقت إلى ثوانٍ ثم تعيد النتيجة كعدد عشري مضاعف double:
double get_seconds() { struct timespec ts; clock_gettime(CLOCK_PROCESS_CPUTIME_ID, &ts); return ts.tv_sec + ts.tv_nsec / 1e9; }
يشغّل البرنامج حلقة أخرى لعزل وقت الوصول لعناصر المصفوفة، وهذه الحلقة مطابقة للحلقة في المثال السابق باستثناء أن الحلقة الداخلية لا تمس المصفوفة وإنما تزيد نفس المتغير كما يلي:
iters2 = 0; do { sec0 = get_seconds(); for (index = 0; index < limit; index += stride) temp = temp + index; iters2 = iters2 + 1; sec = sec - (get_seconds() - sec0); } while (iters2 < iters);
حيث تلاحظ أن الحلقة الثانية تنفّذ نفس عدد تكرارات الحلقة الأولى، وتطرح الوقت المستغرق بعد كل تكرار من المتغير sec، يتضمن المتغير sec عند اكتمال الحلقة الوقت الكلي لكل عمليات الوصول إلى المصفوفة مطروحًا منه الوقت الإجمالي لازدياد المتغير temp، وتتحمّل كل عمليات الوصول هذا الاختلاف الذي يمثّل عقوبة الإخفاق الكلية، ثم تُقسَم عقوبة الإخفاق الكلية على عدد عمليات الوصول للحصول على متوسط عقوبات الإخفاق في كل وصول مقدّرًا بالنانو ثانية كما يلي:
sec * 1e9 / iters / limit * stride
إذا صرّفت البرنامج السابق ثم شغّلته سيظهر الخرج التالي:
Size: 4096 Stride: 8 read+write: 0.8633 ns Size: 4096 Stride: 16 read+write: 0.7023 ns Size: 4096 Stride: 32 read+write: 0.7105 ns Size: 4096 Stride: 64 read+write: 0.7058 ns
إذا كان لديك Python و matplotlib على جهازك فيمكنك استخدام graph_data.py لتحصل على رسمٍ بياني للنتائج كما في الشكل التالي الذي يظهر نتائج البرنامج عندما أشغّله، يقول الكاتب، على Dell Optiplex 7010:
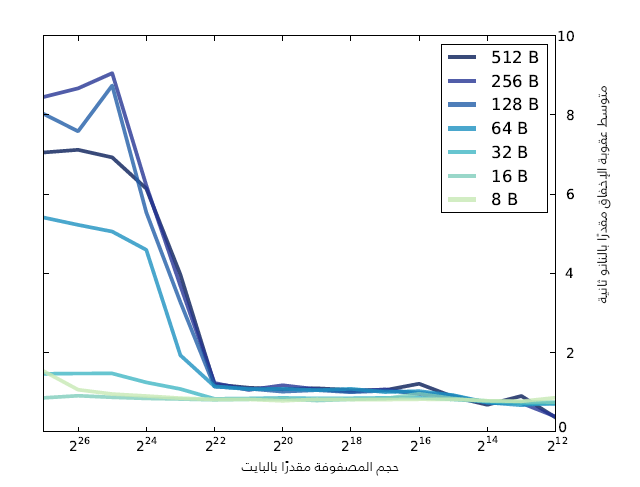
لاحظ أن حجم المصفوفة والخطوة (stride) مقدران بالبايت وليس بأعداد عناصر المصفوفة. إذا تمعنت النظر في الرسم البياني السابق سيمكنك استنتاج بعض الأشياء عن الذاكرة المخبئية والتي هي:
- يقرأ البرنامج من المصفوفة مراتٍ متعددة لذلك يكون لديه كثيرٌ من المحلية الزمانية (temporal locality)، فإذا كانت المصفوفة بكاملها في الذاكرة المخبئية فهذا يعني أن متوسط عقوبة الإخفاق (miss penalty) تساوي 0 تقريبًا.
- يمكنك قراءة كل عناصر المصفوفة إذا كانت قيمة الخطوة (stride) هي 4 بايتات أي يكون لدى البرنامج كثيرٌ من المحلية المكانية (spatial locality)، وإذا كان حجم الكتلة مناسبًا لتضمين 64 عنصرًا على سبيل المثال فإن معدل الإصابة (hit rate) يساوي 63/64 على الرغم من عدم وجود المصفوفة في الذاكرة المخبئية.
- إذا كانت الخطوة الواحدة مساويةً لحجم الكتلة أو أكبر منها فإن قيمة المحلية المكانية صفر عمليًا، لأنك تصل إلى عنصرٍ واحد فقط في كل مرة تقرأ فيها كتلةً، أي من المتوقع أن تشاهد الحد الأعلى من عقوبة الإخفاق (miss penalty) في هذه الحالة.
من المتوقع الحصول على أداء جيد للذاكرة المخبئية إذا كانت المصفوفة أصغر من حجم الذاكرة المخبئية أو إذا كانت الخطوة أصغر من حجم الكتلة، بينما يقل الأداء فقط إذا كانت المصفوفة أكبر من الذاكرة المخبئية والخطوة كبيرة. أداء الذاكرة المخبئية في الرسم البياني السابق جيد بالنسبة لجميع الخطوات طالما أن المصفوفة أصغر من 222 بايتًا، وبالتالي يمكنك استنتاج أن حجم الذاكرة المخبئية يقارب 4 ميبي بايت ولكن اعتمادًا على المواصفات فإن حجمها هو 3 ميبي بايت. يكون أداء الذاكرة المخبئية جيدًا مع قيم الخطوة 8 و 16 و 32 بايتًا، ولكن يبدأ الأداء بالانخفاض عندما تصبح قيمة الخطوة 64 بايتًا، ويصبح متوسط عقوبة الإخفاق 9 نانو ثانية تقريبًا عندما تصبح الخطوة أكبر، وبالتالي يمكنك استنتاج أن حجم الكتلة يقارب 128 بايتًا. تستخدم العديد من المعالجات الذواكر المخبئية ذات المستويات المتعددة (multi-level caches) والتي تتضمن ذواكر مخبئية صغيرة وسريعة وذواكر مخبئية كبيرة وبطيئة، ويُلاحَظ أن عقوبة الإخفاق تزيد قليلًا عندما يصبح حجم المصفوفة أكبر من 214 بايتًا، لذلك من المحتمل أن يكون للمعالج ذاكرةٌ مخبئية حجمها 16 كيلو بايت وبوقت وصول أقل من 1 نانو ثانية.
برمجة أداء الذاكرة المخبئية (Programming for cache performance)
تُطبَّق تخبئة الذاكرة في العتاد لذلك لا يتوجّب على المبرمجين معرفة الكثير عنها ولكن إذا عرفت كيفية عمل الذواكر المخبئية فيمكّنك ذلك من كتابة برامجٍ تستخدم الذاكرة المخبئية بفعاليةٍ أكثر، وإذا عملت مع مصفوفة كبيرة على سبيل المثال فمن الممكن أن تعبُر المصفوفة بسرعةٍ مرة واحدة ثم إجراء عملياتٍ متعددة على كل عنصر من المصفوفة وذلك أفضل من عبور المصفوفة مراتٍ متعددة، وإذا تعاملت مع مصفوفة ثنائية الأبعاد (2D array) فيمكن أن تُخزّن هذه المصفوفة كمصفوفة من الصفوف (rows)، وإذا عبرت خلال عناصر المصفوفة فسيكون عبور عناصر هذه المصفوفة من خلال الصفوف (row-wise) أسرع وذلك مع خطوةٍ مساويةٍ لحجم العنصر وهذا أفضل من عبورها من خلال الأعمدة (column-wise) مع خطوة مساوية لطول الصف (row) الواحد. لا تقدّم بنى البيانات المترابطة (Linked data structures) محليةً مكانية وذلك لأنه ليس ضروريًا أن تكون عقد هذه البنى المترابطة متجاورةً في الذاكرة، ولكن إذا خصصت عدة عقد في نفس الوقت فستكون موجودة في مواقع مشتركة من الكومة، وإذا خصصت مصفوفة العقد كلها مرةً واحدةً فستكون في مواقع متجاورة حتمًا. تملك الاستراتيجيات التعاودية (Recursive strategies) مثل خوارزمية الفرز بالدمج (mergesort) سلوك ذاكرةٍ مخبئية جيدًا لأنها تقسّم المصفوفات الكبيرة إلى أجزاء صغيرة ثم تعمل على هذه الأجزاء الصغيرة، وتُضبَط هذه الخوارزميات في بعض الأحيان للاستفادة من سلوك الذاكرة المخبئية. يمكن تصميم خوارزمياتٍ في التطبيقات التي يكون الأداء فيها مهمًا جدًا بحيث تكون هذه الخوارزميات مضبوطة من حيث حجم الذاكرة المخبئية وحجم الكتلة وخصائص عتاد أخرى، ويدعى هذا النوع من من الخوارزميات بالخوارزميات ذات الإدراك حسب الذاكرة المخبئية (cache-aware)، ولكن العائق الأهم لهذا النوع من الخوارزميات هو أنها خاصة بالعتاد (hardware-specific).
هرمية الذاكرة (The memory hierarchy)
لا بدّ أنه خطر على بالك السؤال التالي: لماذا لم تُصنّع ذاكرة مخبئية كبيرة وبالتالي تُلغى الذاكرة الرئيسية نهائيًا بما أن الذاكرة المخبئية أسرع بكثير من الذاكرة الرئيسية؟ وجواب هذا السؤال هو وجود سببين أساسيين هما: سبب متعلق بالالكترونيات والآخر سبب اقتصادي، فإن الذواكر المخبئية سريعة لأنها صغيرة وقريبة من المعالج وهذا يقلل التأخير بسبب سعة وانتشار الإشارة، وبالتالي إذا صنعت ذاكرة مخبئية كبيرة فستكون بطيئة حتمًا، وتشغَل الذواكر المخبئية حيّزًا على شريحة المعالج وكلما كانت الشريحة أكبر فسيصبح سعرها أكبر. أما الذاكرة الرئيسية فهي ذاكرة عشوائية ديناميكية (dynamic random-access memory واختصارها DRAM) والتي تستخدم ترانزستورًا ومكثفًا واحدًا لكل بت، وبالتالي يمكن ضغط مزيد من الذاكرة في نفس الحيّز، ولكن هذا التطبيق يجعل الذاكرة أبطأ من الطريقة التي تُطبَّق فيها الذواكر المخبئية. تُحزَم الذاكرة الرئيسية عادةً ضمن وحدة الذاكرة ثنائية الخط (dual in-line memory module) واختصارها DIMM والتي تتضمن 16 شريحة أو أكثر، فشرائح صغيرة متعددة أرخص من شريحة واحدة كبيرة الحجم. وجود تقايض بين السرعة والحجم والكلفة هو السبب الأساسي لصنع الذواكر المخبئية، فإذا وجدت تقنية سريعة وكبيرة ورخيصة للذاكرة فلسنا بحاجة أي شيء آخر. يطبّق نفس المبدأ بالنسبة للتخزين الدائم كما في الذاكرة الرئيسية، فالأقراص من النوع SSD سريعة ولكنها أغلى من الأقراص الصلبة HDD وبالتالي يجب أن تكون أصغر من أجل التوفير في الكلفة، ومحركات الأشرطة (Tape drives) أبطأ من الأقراص الصلبة ولكنها تخزّن كميات كبيرة من البيانات وبسعر رخيص نسبيًا. يظهر الجدول التالي وقت الوصول والحجم والكلفة لكل من هذه التقنيات:
| الجهاز (Device) | وقت الوصول (Access time) | الحجم (Typical size) | الكلفة (Cost) |
|---|---|---|---|
| المسجل (Register) | يقدر ب 0.5 نانو ثانية | 256 بايت | ؟ |
| الذاكرة المخبئية (Cache) | يقدر ب 1 نانو ثانية | 2 ميبي بايت | ؟ |
| الذاكرة العشوائية الديناميكية (DRAM) | يقدر ب 100 نانو ثانية | 4 جيبي بايت | 10 دولار / جيبي بايت |
| قرص التخزين ذو الحالة الثابتة (SDD) | يقدر ب 10 ميكرو ثانية | 100 جيبي بايت | 1 دولار / جيبي بايت |
| القرص الصلب (HDD) | يقدر ب 5 ميلي ثانية | 500 جيبي بايت | 0.25 دولار / جيبي بايت |
| محرك الأشرطة (Tape) | دقائق | من 1 إلى 2 تيبي بايت | 0.02 دولار / جيبي بايت |
يعتمد عدد وحجم المسجلات على تفاصيل معمارية الحواسيب حيث تملك الحواسيب الحالية 32 مسجلًا ذو أغراضٍ عامة (general-purpose registers) ويخزن كل مسجل منها كلمة (word) واحدة حيث تساوي الكلمة 32 بتًا أو 4 بايتات في حواسيب 32 بت وتساوي 64 بتًا أو 8 بايتات في حواسيب 64 بت، وبالتالي يتراوح الحجم الإجمالي لملف المسجلات بين 100 إلى 300 بايت. من الصعب تحديد كلفة المسجلات والذواكر المخبئية لأنه تُجمَل كلفتهم مع كلفة الشرائح الموجودين عليها، وبالتالي لا يرى المستهلك كلفتهم بطريقة مباشرة، وبالنسبة للأرقام الأخرى الموجودة في الجدول فقد ألقيت النظر، يقول الكاتب، على العتاد النموذجي الموجود في المتاجر الالكترونية لعتاد الحاسوب، وربما ستكون هذه الأرقام غير مستعملة في الوقت الذي ستقرأ فيه هذا المقال ولكنها ستعطيك فكرةً عن الفجوة التي كانت موجودة بين الأداء والكلفة في وقتٍ ما. تشكل التقنيات الموجودة في الجدول السابق هرمية الذاكرة (memory hierarchy) -والذي يتضمن التخزين الدائم (storage) أيضًا- حيث يكون كل مستوى من هذه الهرمية أكبر وأبطأ من المستوى الذي فوقه، وبمعنىً آخر يمكن عدّ كل مستوى هو ذاكرة مخبئية للمستوى الذي تحته، فيمكنك عدّ الذاكرة الرئيسية كذاكرة مخبئية للبرامج والبيانات التي تُخزَّن على أقراص SSD و HHD بصورة دائمة، وإذا عملت مع مجموعات بيانات كبيرة جدًا ومخزنة على محرك أشرطة (tape) فيمكنك استخدام القرص الصلب كذاكرة مخبئية لمجموعة بيانات فرعية واحدة في كل مرة.
سياسة التخبئة (Caching policy)
تقدّم هرمية الذاكرة إطار عملٍ للتخبئة (caching) من خلال الإجابة على أربعة أسئلة أساسية عن التخبئة في كل مستوٍ من هذه الهرمية وهي:
- من ينقل البيانات إلى الأعلى والأسفل ضمن هذه الهرمية؟ يخصص المصرّفُ (compiler) المسجّلَ في قمة هذه الهرمية، ويكون العتاد الموجود على المعالج مسؤولًا عن الذاكرة المخبئية، ينقل المستخدمون البيانات من التخزين الدائم إلى الذاكرة ضمنيًا عندما ينفّذون برامجًا وعندما يفتحون ملفات، ولكن ينقل نظام التشغيل البيانات أيضًا ذهابًا وإيابًا بين الذاكرة والتخزين الدائم، وينقل مسؤولو نظام التشغيل البيانات بين القرص الصلب ومحرك الأشرطة بوضوح وليس ضمنيًا في أسفل هذه الهرمية.
- ماذا يُنقَل؟ تكون أحجام الكتل صغيرةً في قمة الهرمية وكبيرة في أسفلها، فحجم الكتلة في الذاكرة المخبئية هو 128 بايتًا ويقدّر حجم الصفحات في الذاكرة ب 4 كيبي بايت، ولكن عندما يقرأ نظام التشغيل ملفًا من القرص الصلب فهو بذلك يقرأ عشرات أو مئات الكتل في كل مرة.
- متى تُنقَل البيانات؟ تُنقَل البيانات إلى الذاكرة المخبئية عندما تُستخدَم للمرة الأولى في معظم أنواع الذواكر المخبئية، ولكن تستخدم العديد من الذواكر المخبئية ما يسمّى بالجلب المسبق (prefetching) والذي يعني تحميل البيانات قبل أن تُطلَب صراحةً. وقد رأيت مسبقًا نموذجًا من الجلب المسبق هو تحميل الكتلة بأكملها عندما يُطلب جزء منها فقط.
- أين تذهب البيانات في الذاكرة المخبئية؟ لا تستطيع جلب أي شيء آخر إلى الذاكرة المخبئية عندما تمتلئ إلا إذا أخرجت شيئًا ما منها، لذلك يجب أن تبقي البيانات التي ستُستخدم مرة أخرى قريبًا وتستبدل البيانات التي لن تُستخدم قريبًا.
تشكّل أجوبة الأسئلة الأربعة السابقة ما يدعى بسياسة الذاكرة المخبئية (cache policy)، فيجب أن تكون سياسات الذاكرة المخبئية بسيطة في قمة هرمية الذاكرة لأنها يجب أن تكون سريعة وتُطبّق ضمن العتاد، أما في أسفل الهرمية فيوجد وقتٌ أكثر لاتخاذ القرارات حيث تصنع السياسات المصمَّمة جيدًا اختلافًا كبيرًا. معظم سياسات الذاكرة المخبئية قائمةٌ على المبدأ الذي يقول أن التاريخ يعيد نفسه، فإذا ملكت معلومات عن الماضي القريب فيمكنك استخدامها لتنبؤ المستقبل القريب أيضًا، أي إذا اُستخدمت كتلة بيانات مؤخرًا فيمكنك توقع أنها ستُستخدم مرة أخرى قريبًا، وبالتالي يقدّم هذا المبدأ سياسة بديلة تدعى الأقل استخدامًا مؤخرًا (least recently used) واختصارها LRU والتي تحذف كتلة بيانات من الذاكرة المخبئية التي لم تُستخدم مؤخرًا (تعرف على خوارزميات الذاكرة المخبئية).
تبديل الصفحات (Paging)
يستطيع نظام التشغيل الذي يملك ذاكرة وهمية أن ينقل الصفحات ذهابًا وإيابًا بين الذاكرة والتخزين الدائم وتدعى هذه الآلية بتبديل الصفحات (paging) أو بالتبديل (swapping) أحيانًا، وتجري هذه الآلية كما يلي:
-
افترض أن العملية A تستدعي الدالة
mallocلتخصيص قطعةٍ من الذاكرة، فإذا لم يوجد حيّز حر في الكومة بنفس الحجم المطلوب فإن الدالةmallocتستدعي الدالةsbrkمن أجل طلب المزيد من الذاكرة من نظام التشغيل. - يضيف نظام التشغيل صفحةً إلى جدول الصفحات الخاص بالعملية A عند وجود صفحةٍ حرّة في الذاكرة الحقيقية منشئًا بذلك مجالًا جديدًا من العناوين الوهمية الصالحة.
- يختار نظام الصفحات صفحةً ضحية (victim page) تابعة للعملية B وذلك عند عدم وجود صفحات حرة، ثم ينسخ محتوى هذه الصفحة الضحية من الذاكرة إلى القرص الصلب ثم يعدّل جدول الصفحات الخاص بالعملية B ليشير إلى أن هذه الصفحة بُدِّلت (swapped out).
- يمكن إعادة تخصيص صفحة العملية B للعملية A وذلك بعد نقل بيانات العملية B، حيث يجب أن تصفّر الصفحة قبل إعادة تخصيصها لمنع العملية A من قراءة بيانات العملية B.
-
عندها يستطيع استدعاء الدالة
sbrkإرجاع نتيجة وهي إعطاء الدالةmallocحيّزًا إضافيًا في الكومة، ثم تخصص الدالةmallocقطعة الذاكرة المطلوبة وتستأنف العملية A عملها. - قد يسمح مجدول نظام التشغيل (scheduler) استئناف العملية B عند اكتمال العملية A أو عند مقاطعتها. تلاحظ وحدة إدارة الذاكرة أن الصفحة التي بُدّلت والتي تحاول العملية B الوصول إليها غير صالحة (invalid) ثم تسبب حدوث مقاطعة.
- يرى نظام التشغيل أن الصفحة بُدّلت عند استلامه للمقاطعة فيقوم بنقل الصفحة من القرص الصلب إلى الذاكرة.
- ثم تستطيع العملية B استئناف عملها عندما تُبدَّل الصفحة.
يحسّن تبديل الصفحات من استخدامية (utilization) الذاكرة الحقيقية كثيرًا عندما يعمل جيدًا وبذلك يسمح لعمليات أكثر أن تُشغَّل في حيّز أصغر والسبب هو:
- لا تستخدم معظم العمليات كامل ذاكرتها المخصصة ولا تنفَّذ أقسامٌ كثيرة من جزء نص البرنامج أبدًا أو قد تنفَّذ مرة واحدة ولا تنفَّذ مرة أخرى، ولكن يمكن تبديل هذه الصفحات بدون أن تسبب مشاكلًا.
- إذا سرّب البرنامج ذاكرةً فقد يترك حيّزًا مخصصًا وراءه ولا يصل إليه أبدًا مرةً أخرى ولكن يستطيع نظام التشغيل إيقاف هذا التسرب بفعالية عن طريق تبديل هذه الصفحات.
- يوجد على معظم أنظمة التشغيل عملياتٍ تشبه العفاريت (daemons) التي تبقى خاملة معظم الوقت وتتنبّه أحيانًا لتستجيب للأحداث ويمكن تبديل هذه العمليات عندما تكون خاملة.
- قد يفتح المستخدم نوافذ متعددة ولكن يكون عدد قليل منها فاعلًا في نفس الوقت وبالتالي يمكن تبديل هذه العمليات غير الفاعلة.
- يمكن وجود عدة عملياتٍ مشغِّلةٍ لنفس البرنامج بحيث تتشارك هذه العمليات في جزء نص البرنامج والجزء الساكن لتجنب الحاجة إلى إبقاء نسخ متعددة في الذاكرة الحقيقية.
إذا أضفت مجمل الذاكرة المخصصة إلى كل العمليات فهذا سيزيد من حجم الذاكرة الحقيقة بصورة كبيرة ومع ذلك لا يزال بإمكان النظام العمل جيدًا. يجب على العملية التي تحاول الوصول إلى صفحة مبدَّلة أن تعيد البيانات من القرص الصلب والذي يستغرق عدة ميلي ثواني، ويكون هذا التأخير ملحوظًا غالبًا، فإذا تركت نافذةً خاملة لمدة طويلة ثم عدت إليها فستكون بطيئةً في البداية وقد تسمع القرص الصلب يعمل ريثما تُبدّل الصفحات. إن مثل هذه التأخيرات العرضية مقبولة ولكن إذا كان لديك عدة عمليات تستخدم حيّزًا كبيرًا فستتواجه هذه العمليات مع بعضها بعضًا، حيث تطرد العملية A عند تشغيلها الصفحات التي تحتاجها العملية B، ثم تطرد العملية B عند تشغيلها الصفحات التي تحتاجها العملية A، وبالتالي تصبح كلا العمليتين بطيئتين إلى حدٍ كبير ويصبح النظام غير مستجيب، يدعى هذا السيناريو بالتأزّم (thrashing). يمكن أن يتجنّب نظام التشغيل هذا التأزُّم من خلال اكتشاف زيادة في تبديل الصفحات (paging) ثم ينهي أو يوقف عملياتٍ حتى يستجيب النظام مرة أخرى، ولكن يمكن القول أن نظام التشغيل لا يقوم بذلك أو لا يقوم بذلك بصورة جيدة وإنما يترك الأمر أحيانًا للمستخدمين من خلال الحد من استخدامهم للذاكرة الحقيقية أو محاولة استرجاع النظام عند ظهور التأزّم.
ترجمة -وبتصرّف- للفصل Caching من كتاب Think OS A Brief Introduction to Operating Systems










أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.