

تُعدّ مسألة تحليل تعليقات وتغريدات الأشخاص على مواقع التواصل الاجتماعي من المسائل المهمة والتي لها الكثير من التطبيقات العملية. مثلًا: تهتم المتاجر الالكترونية كثيرًا بتحليل تعليقات الزبائن على منتجاتهم لاستكشاف توجهات الزبائن ومواطن الضعف والقوة في المتجر.
نعرض في هذه المقالة استخدام تقنيات التعلّم العميق deep learning في تحليل المشاعر لنصوص مكتوبة باللغة العربية وباللهجة السعودية بمعنى أن اللغة المستخدمة ليست بالضرورة اللغة العربية الفصحى، بل يُمكن أن تدخل فيها ألفاظ عامية يستخدمها المغردون عادةً.
بيانات التدريب
تحوي مجموعة البيانات المتوفرة dataset (التي تجدها أيضًا موضحةً بملف بنهاية المقال) حوالي 23500 تغريدة لتعليقات الأشخاص وملاحظاتهم حول مجموعة من الأماكن العامة في المملكة العربية السعودية. جُمّعت هذه التغريدات عن طريق مجموعة من الطلاب الجامعيين وذلك من مجموعة متنوعة من مواقع التواصل الاجتماعي.
نُعطي فيما يلي أمثلة عن هذه التغريدات (تعليقات حول حديقة حيوانات مثلًا):
- "أنصحكم والله بزيارته مكان جميل جدا مرتب ونظيف"
- "جميلة وكبيرة وتحتاج واحد عنده لياقه يمشي فيها"
- "حيوانات قليلة جدا ولا يوجد اهتمام مكثف"
- "كان يعيبها وقت الافتتاح والاغلاق وعدم وجود خريطه"
- "أول مرة أزور حديقة حيوانات"
- "أيام العوائل الخميس والجمعة والسبت"
يُمكننا، كبشر، تصنيف التغريدات السابقة وبشكل سريع إلى ثلاث فئات:
- التغريدات الموجبة (الأولى والثانية) أي التغريدات التي تحمل معاني إيجابية تُعّبر عن الرضا والارتياح.
- التغريدات السالبة (الثالثة والرابعة) أي التغريدات التي تحمل معاني سلبية تُعبّر عن الاستياء.
- التغريدات المحايدة (الخامسة والسادسة) أي التغريدات التي يُمكن أن تُعطي معلومات ولا تحمل أية مشاعر فيها سواء موجبة أم سالبة.
نعرض في هذه المسألة كيفية بناء مُصنّف حاسوبي آلي يُصنّف أي جملة عربية إلى موجبة أو سالبة أو محايدة.
تصنيف بيانات التدريب
يتطلب استخدام خوارزميات تعلّم الآلة (خوارزميات تصنيف النصوص في حالتنا) توفر بيانات للتدريب أي مجموعة من النصوص مُصنفّة مُسبقًا إلى: موجبة، سالبة، محايدة.
يُمكن، في بعض الأحيان، اللجوء إلى الطرق اليدوية: أي الطلب من مجموعة من الأشخاص قراءة النصوص وتصنيفها. وهو حل يصلح في حال كان عدد النصوص صغيرًا نسبيًا. يتميز هذا الحل بالدقة العالية لأن الأشخاص تُدرك، بشكل عام، معاني النصوص من خلال خبرتها اللغوية المُكتسبة وتُصنّف النصوص بشكل صحيح غالبًا.
نستخدم، في حالتنا، حلًا إحصائيًا بسيطًا لتصنيف نصوص التدريب إلى موجبة، سالبة، محايدة وذلك باستخدام قاموس للكلمات الموجبة وقاموس آخر للكلمات السالبة.
يحوي قاموس الكلمات الموجبة على مجموعة من الكلمات الموجبة الشائعة مع نقاط لكل كلمة (1 موجبة، 2 موجبة جدًا، 3 موجبة كثيرًا). مثلًا:
- روعة، 3
- جيد، 2
- معقول، 1
يحوي قاموس الكلمات السالبة على مجموعة من الكلمات السالبة الشائعة مع نقاط لكل كلمة (-1 سالبة، -2 سالبة جدًا، -3 سالبة كثيرًا). مثلًا:
- مقرف، -3
- سيء، -2
- زحمه، -1
اختيرت كلمات القواميس الموجبة والسالبة من قبل مجموعة من الطلاب بعد أنا طلبنا منهم استعراض التغريدات المُتاحة وانتقاء الكلمات التي تُعطي التغريدة معنى موجب أو معنى سالب، وإعطاء كل كلمة موجبة نقاط تدل على شدة الإيجابية لها (1,2,3) وكل كلمة سالبة نقاط تدل على شدة السلبية (-3،-2،-1)
نعدّ، فيما يلي، نصًا ما أنه موجبًا إذا كان مجموع نقاط الكلمات الموجبة الواردة ضمن النص أكبر من مجموع نقاط الكلمات السالبة الواردة ضمنه. وبالمقابل، نعدّ نصًا ما أنه سالبًا إذا كان مجموع نقاط الكلمات السالبة الواردة ضمن النص أكبر من مجموع نقاط الكلمات الموجبة الواردة ضمنه. يكون نصًا ما محايدًا إذا تساوى مجموع نقاط الكلمات الموجبة فيه مع مجموع نقاط الكلمات السالبة.
بالطبع، لا تُعدّ هذه الطريقة صحيحة دومًا إذ يُمكن أن تُخطئ في بعض الحالات إلا أنها على وجه العموم تُستخدم عوضًا عن الطريقة اليدوية.
المعالجة الأولية للنصوص
تهدف المعالجة الأولية إلى الحصول على الكلمات المهمة فقط من النصوص وذلك عن طريق تنفيذ بعض العمليات اللغوية عليها. تُنفذّ هذه العمليات على كل من التغريدات وكلمات القواميس.
لتكن لدينا مثلًا الجملة التالية: "أنا أحب الذهاب إلى الحديقة، كل يوم 9 صباحاً، مع رفاقي هؤلاء!"
سنقوم بتنفيذ العمليات التالية:
أولًا، حذف إشارات الترقيم المختلفة كالفواصل وإشارات الاستفهام وغيرها، ويكون ناتج الجملة السابقة:
اقتباس"أنا أحب الذهاب إلى الحديقة كل يوم 9 صباحاً مع رفاقي هؤلاء".
ثانيًا، حذف الأرقام الواردة في النص، فيكون ناتج الجملة السابقة:
اقتباس"أنا أحب الذهاب إلى الحديقة كل يوم صباحاً مع رفاقي هؤلاء"
ثالثًا، حذف كلمات التوقف stop words وهي الكلمات التي تتكرر كثيرًا في النصوص ولا تؤثر في معانيها كأحرف الجر (من، إلى، …) والضمائر (أنا، هو، …) وغيرها، فيكون ناتج الجملة السابقة:
اقتباس"أحب الذهاب الحديقة يوم صباحاً رفاقي"
رابعًا، تجذيع الكلمات stemming أي إرجاع الكلمات المتشابهة إلى كلمة واحدة (جذع أو جذر) مما يُساهم في إنقاص عدد الكلمات الكلية المختلفة في النصوص، ومطابقة الكلمات المتشابهة مع بعضها البعض. مثلًا: يكون للكلمات الأربع: (رائع، رايع، رائعون، رائعين) نفس الجذع المشترك: (رايع). فيكون ناتج الجملة السابقة:
اقتباس"احب ذهاب حديق يوم صباح رفاق "
ننتبه إلى أن الجذع يختلف عن الجذر اللغوي إذ الجذر هو عملية لغوية لرد الكلمة إلى أصلها وجذرها الأساسي لأغراض مختلفة أشهرها البحث في القاموس، أما الجذع فهو كلمة مشتركة بين مجموعة من الكلمات لا توجد بالضرورة في قاموس اللغة العربية وإنما إيجاد شكل موحد للكلمات.
إعداد المشروع
يُمكن تنزيل بيانات التدريب والقواميس والشيفرة البرمجية من الملف المرفق هنا.
يحتاج تنفذ شيفرات هذه المقالة بيئةً برمجيةً للغة بايثون الإصدار 3.8. ويجب أن تتضمن هذه البيئة البرمجية مدير الحِزم pip لتثبيت الحِزم، ومُنشئ البيئات الافتراضية venv لإنشاء بيئاتٍ افتراضيةٍ.
نستخدم محرر الشيفرات البرمجية Jupyter Notebooks، وهو مفيد جدًا لتجربة وتشغيل الأمثلة الخاصة بتَعَلّم الآلة بطريقةٍ تفاعليةٍ، حيث نستطيع من خلاله تشغيل كتلًا صغيرةً من الشيفرات البرمجية ورؤية النتائج بسرعة، مما يُسهّل علينا اختبار الشيفرات البرمجية وتصحيحها.
نحتاج أولًا لتثبيت بعض التبعيات، وذلك لإنشاء مساحة عملٍ للاحتفاظ بملفاتنا قبل أن نتمكن من تطوير برنامجنا.
نُنشئ مجلدًا جديدًا خاصًا بمشروعنا وندخل إليه هكذا:
mkdir sa
cd sa
نُنفذّ الأمر التالي لإنشاء البيئة الافتراضية:
python -m venv sa
ومن ثم الأمر التالي في Linux لتنشيط البيئة الافتراضية:
source sa/bin/activate
أما في Windows، فيكون أمر التنشيط:
"sa/Scripts/activate.bat"
نستخدم إصداراتٍ محددةٍ من المكتبات اللازمة، من خلال إنشاء ملف requirements.txt في مجلد المشروع، وسيُحدِّد هذا الملف المتطلبات والإصدارات التي سنحتاج إليها.
نفتح الملف requirements.txt في محرر النصوص، ونُضيف الأسطر التالية، وذلك لتحديد المكتبات التي نريدها وإصداراتها:
jupyter==1.0.0 keras==2.6.0 Keras-Preprocessing==1.1.2 matplotlib==3.5.1 nltk==3.6.5 numpy==1.19.5 pandas==1.3.5 scikit-learn==1.0.1 seaborn==0.11.2 sklearn==0.0 snowballstemmer==2.2.0 tensorflow==2.6.0 wordcloud==1.8.1 python-bidi==0.4.2 arabic-reshaper==2.1.3
نحفظ التغييرات التي طرأت على الملف ونخرج من محرر النصوص، ثم نُثَبت هذه المكتبات بالأمر التالي:
(sa) $ pip install -r requirements.txt
بعد تثبيتنا لهذه التبعيات، نُصبح جاهزين لبدء العمل على مشروعنا.
كتابة شيفرة برنامج تحليل المشاعر في النصوص العربي
نُشغّل محرر الشيفرات البرمجية Jupyter Notebook بمجرد اكتمال عملية التثبيت. هكذا:
(sa) $ jupyter notebook
ثم نُنشئ ملفًا جديدًا في داخل المحرر ونُسمّه باسم asa مثلًا.
يجب أولًا وضع كل من الملفات التالية في مجلد المشروع:
- ملف التغريدات: tweets.csv.
- القواميس: lexicon_positive.csv و lexicon_negative.csv.
- ملف الخط العربي: DroidSansMono.ttf.
تحميل البيانات
نبدأ أولًا بتحميل التغريدات من الملف tweets.csv ضمن إطار من البيانات DataFrame من مكتبة Pandas ومن ثم عرض بعضها:
import pandas as pd # قراءة التغريدات وتحميلها ضمن إطار من البيانات tweets_data = pd.read_csv('tweets.csv',encoding = "utf-8") tweets = tweets_data[['tweet']] # إظهار الجزء الأعلى من إطار البيانات tweets.head()
يظهر لنا أوائل التغريدات:

نُحمّل قاموس الكلمات الموجبة positive.csv وقاموس الكلمات السالبة negative.csv:
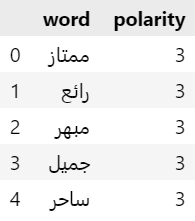
# قراءة قاموس الكلمات الموجبة positive_data = pd.read_csv('positive.csv' ,encoding = "utf-8") positive = positive_data[['word', 'polarity']] # قراءة قاموس الكلمات السالبة negative_data = pd.read_csv('negative.csv' ,encoding = "utf-8") negative = negative_data[['word', 'polarity']] positive.head()
نُظهر مثلًا أوائل الكلمات الموجبة ونقاطها:
المعالجة الأولية للنصوص
نستخدم فيما يلي بعض الخدمات التي توفرها المكتبة nltk لمعالجة اللغات الطبيعية كتوفير قائمة كلمات التوقف باللغة العربية (حوالي 700 كلمة) واستخراج الوحدات tokens من النصوص. كما نستخدم مجذع الكلمات العربية من مكتبة snowballstemmer.
# مكتبة السلاسل النصية import string # مكتبة التعابير النظامية import re # مكتبة معالجة اللغات الطبيعية import nltk nltk.download('punkt') nltk.download('stopwords') # مكتبة كلمات التوقف from nltk.corpus import stopwords # مكتبة استخراج الوحدات from nltk.tokenize import word_tokenize # مكتبة المجذع العربي from snowballstemmer import stemmer ar_stemmer = stemmer("arabic") # دالة حذف المحارف غير اللازمة def remove_chars(text, del_chars): translator = str.maketrans('', '', del_chars) return text.translate(translator) # دالة حذف المحارف المكررة def remove_repeating_char(text): return re.sub(r'(.)\1{2,}', r'\1', text) # دالة تنظيف النصوص def cleaningText(text): # حذف الأرقام text = re.sub(r'[0-9]+', '', text) # حذف المحارف غير اللازمة # علامات الترقيم العربية arabic_punctuations = '''`÷×؛<>_()*&^%][ـ،/:"؟.,'{}~¦+|!”…“–ـ''' # علامات الترقيم الانكليزية english_punctuations = string.punctuation # دمج علامات الترقيم العربية والانكليزية punctuations_list = arabic_punctuations + english_punctuations text = remove_chars(text, punctuations_list) # حذف المحارف المكررة text = remove_repeating_char(text) # استبدال الأسطر الجديدة بفراغات text = text.replace('\n', ' ') # حذف الفراغات الزائدة من اليمين واليسار text = text.strip(' ') return text # دالة تقسيم النص إلى مجموعة من الوحدات def tokenizingText(text): tokens_list = word_tokenize(text) return tokens_list # دالة حذف كلمات التوقف def filteringText(tokens_list): # قائمة كلمات التوقف العربية listStopwords = set(stopwords.words('arabic')) filtered = [] for txt in tokens_list: if txt not in listStopwords: filtered.append(txt) tokens_list = filtered return tokens_list # دالة التجذيع def stemmingText(tokens_list): tokens_list = [ar_stemmer.stemWord(word) for word in tokens_list] return tokens_list # دالة دمج قائمة من الكلمات في جملة def toSentence(words_list): sentence = ' '.join(word for word in words_list) return sentence
شرح الدوال التي كتبناها في الشيفرة:
-
cleaningText: تحذف الأرقام وعلامات الترقيم العربية والإنكليزية من النص. -
remove_repeating_char: تحذف المحارف المكررة والتي قد يستخدمها كاتب التغريدة. -
tokenizingText: تعمل على تجزئة النص إلى قائمة من الوحدات tokens. -
filteringText: تحذف كلمات التوقف من قائمة الوحدات. -
stemmingText: تعمل على تجذيع كلمات قائمة الوحدات المتبقية.
يُبين المثال التالي تجذيع بعض الكلمات المتشابهة:
# مثال stem = ar_stemmer.stemWord(u"رايع") print (stem) stem = ar_stemmer.stemWord(u"رائع") print (stem) stem = ar_stemmer.stemWord(u"رائعون") print (stem) stem = ar_stemmer.stemWord(u"رائعين") print (stem)
يكون ناتج التنفيذ:
رايع رايع رايع رايع
يُبين المثال التالي نتيجة استدعاء كل دالة من الدوال السابقة:
# مثال text= "!أنا أحب الذهاب إلى الحديقة، كل يووووم 9 صباحاً، مع رفاقي هؤلاء " print(text) text=cleaningText(text) print(text) tokens_list=tokenizingText(text) print(tokens_list) tokens_list=filteringText(tokens_list) print(tokens_list) tokens_list=stemmingText(tokens_list) print(tokens_list)
يكون ناتج التنفيذ:
!أنا أحب الذهاب إلى الحديقة، كل يووووم 9 صباحاً، مع رفاقي هؤلاء أنا أحب الذهاب إلى الحديقة كل يوم صباحاً مع رفاقي هؤلاء ['أنا', 'أحب', 'الذهاب', 'إلى', 'الحديقة', 'كل', 'يوم', 'صباحاً', 'مع', 'رفاقي', 'هؤلاء'] ['أحب', 'الذهاب', 'الحديقة', 'يوم', 'صباحاً', 'رفاقي'] ['احب', 'ذهاب', 'حديق', 'يوم', 'صباح', 'رفاق']
تعرض الشيفرة التالية تنفيذ جميع دوال المعالجة الأولية على نصوص التغريدات ومن ثم حفظ النتائج في ملف جديد tweet_clean.csv. وبنفس الطريقة، نُنفذ دوال المعالجة الأولية على قاموس الكلمات الموجبة وقاموس الكلمات السالبة ونحفظ النتائج في ملفات جديدة لاستخدامها لاحقًا: positive_clean.csv و negative_clean.csv.
# المعالجة الأولية للتغريدات tweets['tweet_clean'] = tweets['tweet'].apply(cleaningText) tweets['tweet_preprocessed'] = tweets['tweet_clean'].apply(tokenizingText) tweets['tweet_preprocessed'] = tweets['tweet_preprocessed'].apply(filteringText) tweets['tweet_preprocessed'] = tweets['tweet_preprocessed'].apply(stemmingText) # حذف التغريدات المكررة tweets.drop_duplicates(subset = 'tweet_clean', inplace = True) # التصدير إلى ملف tweets.to_csv(r'tweet_clean.csv',encoding="utf-8", index = False, header = True,index_label=None) # معالجة القاموس الموجب positive['word_clean'] = positive['word'].apply(cleaningText) positive.drop(['word'], axis = 1, inplace = True) positive['word_preprocessed'] = positive['word_clean'].apply(tokenizingText) positive['word_preprocessed'] = positive['word_preprocessed'].apply(filteringText) positive['word_preprocessed'] = positive['word_preprocessed'].apply(stemmingText) # حذف التكرار والخطأ positive.drop_duplicates(subset = 'word_clean', inplace = True) nan_value = float("NaN") positive.replace("", nan_value, inplace=True) positive.dropna(subset= ['word_clean'], inplace=True) # التصدير إلى ملف positive.to_csv(r'positive_clean.csv',encoding="utf-8", index = False, header = True,index_label=None) # معالجة القاموس السالب negative['word_clean'] = negative['word'].apply(cleaningText) negative.drop(['word'], axis = 1, inplace = True) negative['word_preprocessed'] = negative['word_clean'].apply(tokenizingText) negative['word_preprocessed'] = negative['word_preprocessed'].apply(filteringText) negative['word_preprocessed'] = negative['word_preprocessed'].apply(stemmingText) # حذف التكرار والخطأ negative.drop_duplicates(subset = 'word_clean', inplace = True) negative.replace("", nan_value, inplace=True) negative.dropna(subset= ['word_clean'], inplace=True) # التصدير إلى ملف negative.to_csv(r'negative_clean.csv', encoding="utf-8", index = False, header = True,index_label=None)
تعرض الشيفرة التالية بناء قاموسين dict الأول للكلمات الموجبة والثاني للكلمات السالبة وبحيث يكون المفتاح key هو الكلمة والقيمة value هي نقاط الكلمة. يُعدّ استخدام بنية القاموس dict في بايثون مفيدًا جدًا للوصول المباشر إلى نقاط أي كلمة دون القيام بأي عملية بحث.
لاحظ أننا نقرأ الكلمات الموجبة والسالبة من الملفات الجديدة ناتج المعالجة الأولية لملفات الكلمات الأصلية.
# التصريح عن قاموس للكلمات الموجية dict_positive = dict() # بناء قاموس الكلمات الموجبة myfile = 'positive_clean.csv' positive_data = pd.read_csv(myfile, encoding='utf-8') positive = positive_data[['word_clean', 'polarity']] for i in range(len(positive)): dict_positive[positive_data['word_clean'][i].strip()] = int(positive_data['polarity'][i]) # التصريح عن قاموس للكلمات السالبة dict_negative = dict() # بناء قاموس الكلمات السالبة myfile = 'negative_clean.csv' negative_data = pd.read_csv(myfile, encoding='utf-8') negative = negative_data[['word_clean', 'polarity']] for i in range(len(negative)): dict_negative[negative_data['word_clean'][i].strip()] = int(negative_data['polarity'][i])
تقوم الدالة التالية sentiment_analysis_dict_arabic بحساب مجموع نقاط score قائمة من الكلمات وذلك بجمع نقاط الكلمات الواردة في قاموسي الكلمات الموجبة والسالبة. وفي النهاية تُعدّ قطبية polarity قائمة الكلمات موجبة positive إذا كان مجموع نقاطها أكبر من الصفر، وتُعدّ سالبة negative إذا كان مجموع نقاطها أصغر من الصفر، وإلا فإنها تكون محايدة neutral.
# دالة حساب قطبية قائمة من الكلمات def sentiment_analysis_dict_arabic(words_list): score = 0 for word in words_list: if (word in dict_positive): score = score + dict_positive[word] for word in words_list: if (word in dict_negative): score = score + dict_negative[word] polarity='' if (score > 0): polarity = 'positive' elif (score < 0): polarity = 'negative' else: polarity = 'neutral' return score, polarity
نستخدم الدالة السابقة في حساب قطبية كل تغريدة وذلك بتنفيذ الدالة على قائمة الكلمات التي حصلنا عليها بعد المعالجة الأولية لنص التغريدة tweet_preprocessed. أي أنه سيكون لكل تغريدة في نهاية المطاف قطبية polarity موجبة أو سالبة أو محايدة وفق مجموع النقاط الحاصلة عليها polarity_score. نحفظ نتائج الحساب في ملف جديد tweets_clean_polarity.csv.
# حساب قطبية التغريدات results = tweets['tweet_preprocessed'].apply(sentiment_analysis_dict_arabic) results = list(zip(*results)) tweets['polarity_score'] = results[0] tweets['polarity'] = results[1] # كتابة النتائج في ملف tweets.to_csv(r'tweets_clean_polarity.csv', encoding='utf-8', index = False, header = True,index_label=None)
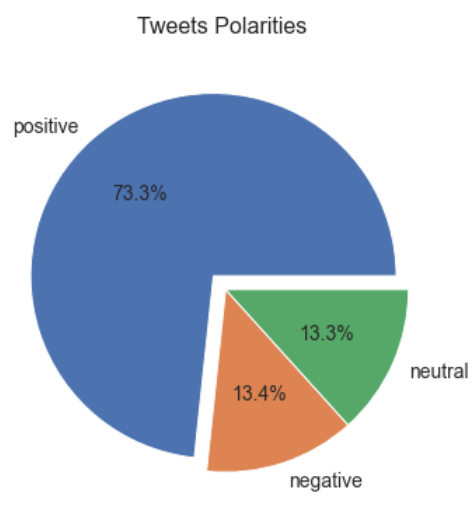
تعرض الشيفرة التالية حساب عدد التغريدات من كل قطبية (موجبة، سالبة، محايدة) ومن ثم استخدام المكتبة matplotlib لرسم مخطط بياني من النوع pie يعرض نسب قطبية التغريدات:
# رسم نسب قطبية التغريدات import matplotlib.pyplot as plt fig, ax = plt.subplots(figsize = (6, 6)) # حساب عدد التغريدات من كل قطبية x = [count for count in tweets['polarity'].value_counts()] # تسميات الرسم labels = list(tweets['polarity'].value_counts().index) explode = (0.1, 0, 0) # تنفيذ الرسم ax.pie(x = x, labels = labels, autopct = '%1.1f%%', explode = explode, textprops={'fontsize': 14}) # عنوان الرسم ax.set_title('Tweets Polarities ', fontsize = 16, pad = 20) # الإظهار plt.show()
يكون الإظهار:
يُمكن الآن إظهار التغريدات الأكثر إيجابيًة باستخدام الشيفرة التالية:
# طباعة أكثر التغريدات إيجابية pd.set_option('display.max_colwidth', 3000) positive_tweets = tweets[tweets['polarity'] == 'positive'] positive_tweets = positive_tweets[['tweet_clean', 'polarity_score', 'polarity']].sort_values(by = 'polarity_score', ascending=False).reset_index(drop = True) positive_tweets.index += 1 positive_tweets[0:10]
يكون الإظهار:

كما يُمكن إظهار التغريدات الأكثر سلبيًة:
# طباعة أكثر التغريدات سلبية pd.set_option('display.max_colwidth', 3000) negative_tweets = tweets[tweets['polarity'] == 'negative'] negative_tweets = negative_tweets[['tweet_clean', 'polarity_score', 'polarity']].sort_values(by = 'polarity_score', ascending=True)[0:10].reset_index(drop = True) negative_tweets.index += 1 negative_tweets[0:10]
يكون الإظهار:

يُمكن استخدام مكتبة سحابة الكلمات WordCloud لرسم مجموعة من الكلمات بشكل فني كما تُبين الشيفرة التالية:
# سحابة الكلمات from wordcloud import WordCloud # مكتبة للغة العربية import arabic_reshaper from bidi.algorithm import get_display # انتقاء بعض الكلمات المعالجة list_words='' i=0 for tweet in tweets['tweet_preprocessed']: for word in tweet: i=i+1 if i>100: break list_words += ' '+(word) # ضبط اللغة العربية reshaped_text = arabic_reshaper.reshape(list_words) artext = get_display(reshaped_text) # إعدادات سحابة الكلمات wordcloud = WordCloud(font_path='DroidSansMono.ttf', width = 600, height = 400, background_color = 'black', min_font_size = 10).generate(artext) fig, ax = plt.subplots(figsize = (8, 6)) # عنوان السحابة ax.set_title('Word Cloud of Tweets', fontsize = 18) ax.grid(False) ax.imshow((wordcloud)) fig.tight_layout(pad=0) ax.axis('off') plt.show()
يكون الإظهار:

تُجمّع الدالة التالية words_with_sentiment الكلمات الموجبة والكلمات السالبة المستخرجة من قائمة الكلمات المُمررة للدالة list_words في قائمتين منفصلتين الأولى للكلمات الموجبة والثانية للكلمات السالبة. تستخدم الدالة قاموسي الكلمات الموجبة والسالبة السابقين.
# تجميع الكلمات الموجبة والكلمات السالبة def words_with_sentiment(list_words): positive_words=[] negative_words=[] for word in list_words: score_pos = 0 score_neg = 0 if (word in dict_positive): score_pos = dict_positive[word] if (word in dict_negative): score_neg = dict_negative[word] if (score_pos + score_neg > 0): positive_words.append(word) elif (score_pos + score_neg < 0): negative_words.append(word) return positive_words, negative_words
نستخدم الدالة السابقة في الشيفرة التالية لاستخراج قائمة الكلمات الموجبة وقائمة الكلمات السالبة من التغريدات، ومن ثم إنشاء سحابتي كلمات لكل منهما لعرض الكلمات الموجبة والكلمات السالبة بشكل فني:
# سحابة الكلمات الموجبة والسالبة # فرز الكلمات الموجبة والسالبة sentiment_words = tweets['tweet_preprocessed'].apply(words_with_sentiment) sentiment_words = list(zip(*sentiment_words)) # قائمة الكلمات الموجبة positive_words = sentiment_words[0] # قائمة الكلمات السالبة negative_words = sentiment_words[1] # سحابة الكلمات الموجبة fig, ax = plt.subplots(1, 2,figsize = (12, 10)) list_words_postive='' for row_word in positive_words: for word in row_word: list_words_postive += ' '+(word) reshaped_text = arabic_reshaper.reshape(list_words_postive) artext = get_display(reshaped_text) wordcloud_positive = WordCloud(font_path='DroidSansMono.ttf',width = 800, height = 600, background_color = 'black', colormap = 'Greens' , min_font_size = 10).generate(artext) ax[0].set_title(' Positive Words', fontsize = 14) ax[0].grid(False) ax[0].imshow((wordcloud_positive)) fig.tight_layout(pad=0) ax[0].axis('off') # سحابة الكلمات السالبة list_words_negative='' for row_word in negative_words: for word in row_word: list_words_negative += ' '+(word) reshaped_text = arabic_reshaper.reshape(list_words_negative) artext = get_display(reshaped_text) wordcloud_negative = WordCloud(font_path='DroidSansMono.ttf',width = 800, height = 600, background_color = 'black', colormap = 'Reds' , min_font_size = 10).generate(artext) ax[1].set_title('Negative Words', fontsize = 14) ax[1].grid(False) ax[1].imshow((wordcloud_negative)) fig.tight_layout(pad=0) ax[1].axis('off') plt.show()
يكون الإظهار:

تحويل النصوص إلى أشعة رقمية
لا تقبل بنى تعلم الآلة النصوص كمدخلات لها، بل تحتاج إلى أشعة رقمية كمدخلات، لذا نستخدم الشيفرة التالية لتحويل الشعاع النصي لكل تغريده tweet_preprocessed إلى شعاع رقمي:
# تحويل التغريدات إلى أشعة رقمية from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences # تركيب جمل التغريدات من المفردات المعالجة sentences = tweets['tweet_preprocessed'].apply(toSentence) print(sentences.values[25]) max_words = 5000 max_len = 50 # التصريح عن المجزئ # مع تحديد عدد الكلمات التي ستبقى # بالاعتماد على تواترها tokenizer = Tokenizer(num_words=max_words ) # ملائمة المجزئ لنصوص التغريدات tokenizer.fit_on_texts(sentences.values) # تحويل النص إلى قائمة من الأرقام S = tokenizer.texts_to_sequences(sentences.values) print(S[0]) # توحيد أطوال الأشعة X = pad_sequences(S, maxlen=max_len) print(X[0]) X.shape
نقاط في الشيفرة السابقة لشرحها:
-
يُحدّد المتغير
max_wordsعدد الكلمات الأعظمي التي سيتم الاحتفاظ بها حيث يُحسب تواتر كل كلمة في كل النصوص ومن ثم تُرتب حسب تواترها (المرتبة الأولى للكلمة ذات التواتر الأكبر). ستُهمل الكلمات ذات المرتبة أكبر منmax_words. -
يُحدّد المتغير
max_lenطول الشعاع الرقمي النهائي. إذا كان طول الشعاع الرقمي الموافق لنص أقل منmax_lenتُضاف أصفار للشعاع حتى يُصبح طوله مساويًا إلىmax_len. أما إذا كان طوله أكبر يُقتطع جزءًا منه ليُصبح طوله مساويًا إلىmax_len. -
تقوم الدالة
fit_on_texts(sentences.values)بملائمة المُجزء tokenizer لنصوص جمل التغريدات أي حساب تواتر الكلمات والاحتفاظ بالكلمات ذات التواتر أكبر أو يساويmax_words.
نطبع في الشيفرة السابقة، بهدف التوضيح، ناتج كل مرحلة. اخترنا مثلًا شعاع التغريدة 25 بعد المعالجة:
[مكان جميل انصح زيار رسوم دخول]
تكون نتيجة تحويل الشعاع السابق النصي إلى شعاع من الأرقام:
[246, 1401, 467, 19, 87, 17, 74, 515, 2602, 330, 218, 579, 507, 465, 270, 45, 54, 343, 587, 7, 33, 58, 434, 30, 74, 144, 233, 451, 468]
وبعد عملية توحيد الطول يكون الشعاع الرقمي النهائي الناتج:
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 246 1401 467 19 87 17 74 515 2602 330 218 579 507 465 270 45 54 343 587 7 33 58 434 30 74 144 233 451 468]
تجهيز دخل وخرج الشبكة العصبية
تعرض الشيفرة التالية حساب شعاع الخرج أولًا، حيث نقوم بترميز القطبيات الثلاث إلى 0 للسالبة و1 للمحايدة و2 للموجبة. نستخدم الدالة train_test_split لتقسيم البيانات المتاحة إلى 80% منها لعملية التدريب و20% لعملية الاختبار وحساب مقاييس الأداء:
# ترميز الخرج polarity_encode = {'negative' : 0, 'neutral' : 1, 'positive' : 2} # توليد شعاع الخرج y = tweets['polarity'].map(polarity_encode).values # مكنبة تقسيم البيانات إلى تدريب واختبار from sklearn.model_selection import train_test_split # تقسيم البيانات إلى تدريب واختبار X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0) print(X_train.shape, y_train.shape) print(X_test.shape, y_test.shape)
نطبع في الشيفرة السابقة حجوم أشعة الدخل والخرج للتدريب وللاختبار:
(16428, 50) (16428,) (4107, 50) (4107,)
نموذج الشبكة العصبية المتعلم
تُعدّ المكتبة Keras من أهم مكتبات بايثون التي توفر بناء شبكات عصبية لمسائل التعلم الآلي.
تعرض الشيفرة التالية التصريح عن دالة بناء نموذج التعلّم create_model مع إعطاء جميع المعاملات المترفعة قيمًا ابتدائية:
# تضمين النموذج التسلسلي from keras.models import Sequential # تضمين الطبقات اللازمة from keras.layers import Embedding, Dense, LSTM # دوال التحسين from tensorflow.keras.optimizers import Adam, RMSprop # التصريح عن دالة إنشاء نموذج التعلم # مع إعطاء قيم أولية للمعاملات المترفعة def create_model(embed_dim = 32, hidden_unit = 16, dropout_rate = 0.2, optimizers = RMSprop, learning_rate = 0.001): # التصريح عن نموذج تسلسلي model = Sequential() # طبقة التضمين model.add(Embedding(input_dim = max_words, output_dim = embed_dim, input_length = max_len)) # LSTM model.add(LSTM(units = hidden_unit ,dropout=dropout_rate)) # الطبقة الأخيرة model.add(Dense(units = 3, activation = 'softmax')) # بناء النموذج model.compile(loss = 'sparse_categorical_crossentropy', optimizer = optimizers(learning_rate = learning_rate), metrics = ['accuracy']) # طباعة ملخص النموذج print(model.summary()) return model
نستخدم من أجل مسألتنا نموذج شبكة عصبية تسلسلي يتألف من ثلاث طبقات:
الطبقة الأولى: طبقة التضمين Embedding
نستخدم هذه الطبقة لتوليد ترميز مكثف للكلمات dense word encoding مما يُساهم في تحسين عملية التعلم. نطلب تحويل الشعاع الذي طوله input_length (في حالتنا 50) والذي يحوي قيم ضمن المجال input_dim (من 1 إلى 5000 في مثالنا) إلى شعاع من القيم ضمن المجال output_dim (مثلًا 32 قيمة).
الطبقة الثانية LSTM
يُحدّد المعامل المترفع units عدد الوحدات المخفية لهذه الطبقة. يُساهم المعامل dropout في معايرة الشبكة خلال التدريب حيث يقوم بإيقاف تشغيل الوحدات المخفية بشكل عشوائي أثناء التدريب، وبهذه الطريقة لا تعتمد الشبكة بنسبة 100٪ على جميع الخلايا العصبية الخاصة بها، وبدلاً من ذلك، تُجبر نفسها على العثور على أنماط أكثر أهمية في البيانات من أجل زيادة المقياس الذي تحاول تحسينه (الدقة مثلًا).
الطبقة الثالثة Dense
يُحدّد المعامل units حجم الخرج لهذه الطبقة (3 في حالتنا: 0 سالبة، 1 محايدة، 2 موجبة) ويُبين الشكل التالي ملخص النموذج:

معايرة المعاملات الفائقة وصولا لنموذج أمثلي
يُمكن الوصول لنموذج تعلم أمثلي بمعايرة معاملاته الفائقة وفق معطيات المشروع. لنُبين أولًا الفرق بين المعاملات الفائقة لنموذج والمعاملات الأخرى له:
- المعاملات الفائقة hyperparameters: هي إعدادات خوارزمية التعلّم قبل التدريب (والتي وضعها مصممو الخوارزمية) .
- المعاملات parameters: هي المعاملات التي يتعلّمها النموذج أثناء التدريب مثل أوزان الشبكة العصبية.
تؤثر عملية معايرة المعاملات الفائقة على أداء النموذج لاسيما لجهة التوزان المطلوب بين مشكلة قلة التخصيص underfitting ومشكلة فرط التخصيص overfitting واللتان تؤديان إلى نموذج غير قادر على تعميم أمثلة التدريب وبالتالي لن يتمكن من التصنيف مع معطيات جديدة (يُمكن العودة للرابط من أكاديمية حسوب للمزيد من التفصيل حول هاتين المشكلتين).
تظهر مشكلة قلة التخصيص عندما لا يكون للنموذج درجات حرية كافية ليتعلّم الربط بين الميزات والهدف، وبالتالي يكون له انحياز كبير نحو قيم معينة للهدف. يُمكن تصحيح قلة التخصيص بجعل النموذج أكثر تعقيدًا. أما مشكلة فرط التخصيص فتظهر عندما يقوم النموذج بتخزين بيانات التدريب فيكون له بالتالي تباين كبير والذي يُمكن تصحيحه بالحد من تعقيد النموذج باستخدام التسوية regularization.
تكمن المشكلة في معايرة المعاملات الفائقة بأن قيمها المثلى تختلف من مسألة لأخرى! وبالتالي، فإن الطريقة الوحيدة للوصول لهذه القيم المثلى هي تجريب قيم مختلفة مع كل مجموعة بيانات تدريب جديدة.
يوفر Scikit-Learn العديد من الطرق لتقويم المعاملات الفائقة وبالتالي سنعتمد في مشروعنا عليها دون أن نُعقّد الأمور أكثر.
البحث الشبكي مع التقييم المتقاطع
تُدعى الطريقة التي سنستخدمها في إيجاد القيم المثلى بالبحث الشبكي مع التقويم المتقاطع grid search with cross validation:
- البحث الشبكي grid search: نُعرّف شبكة grid من بعض القيم المُمكنة ومن ثم نولد كل التركيبات المُمكنة بينها.
- التقييم المتقاطع cross validation: وهو الطريقة المستخدمة لتقييم مجموعة قيم مُحدّدة للمعاملات الفائقة. عوضًا عن تقسيم البيانات إلى بيانات للتدريب وبيانات للتقييم مما يُخفّض من البيانات التي يُمكن لنا استخدامها للتدريب، نستخدم التقييم المتقاطع مع عدد محدّد من الحاويات K-Fold. تُقسم بيانات التدريب إلى عدد K من الحاويات ومن ثم نقوم بتكرار ما يلي K مرة: في كل مرة نقوم بتدريب النموذج مع بيانات K-1 حاوية ومن ثم تقويمه مع بيانات الحاوية K. في النهاية، يكون مقياس الأداء النهائي هو متوسط الخطأ لكل التكرارات.
يُمكن تلخيص خطوات البحث الشبكي مع التقييم المتقاطع كما يلي:
- إعداد شبكة من المعاملات الفائقة.
- توليد كل تركيبات قيم المعاملات الفائقة.
- إنشاء نموذج لكل تركيب من القيم.
- تقييم النموذج باستخدام التقويم المتقاطع.
- اختيار تركيب قيم المعاملات ذو الأداء الأفضل.
بالطبع، لن نقوم ببرمجة هذه الخطوات لأن الكائن GridSearchCV في Scikit-Learn يقوم بكل ذلك (يجب ملاحظة أن تنفيذ الشيفرة قد يستغرق بعض الوقت: حوالي الساعة على حاسوب ذو مواصفات عالية):
from sklearn.model_selection import GridSearchCV from keras.wrappers.scikit_learn import KerasClassifier # حساب القيم الأمثلية للمعاملات المترفعة model = KerasClassifier(build_fn = create_model, epochs = 25, batch_size=128) # بعض القيم الممكنة للمعاملات المترفعة embed_dim = [32, 64] hidden_unit = [16, 32, 64] dropout_rate = [0.2] optimizers = [Adam, RMSprop] learning_rate = [0.01, 0.001, 0.0001] epochs = [10, 15, 25 ] batch_size = [128, 256] param_grid = dict(embed_dim = embed_dim, hidden_unit = hidden_unit, dropout_rate = dropout_rate, learning_rate = learning_rate, optimizers = optimizers, epochs = epochs, batch_size = batch_size) # تقويم النموذج لاختيار أفضل القيم grid = GridSearchCV(estimator = model, param_grid = param_grid, cv = 3) grid_result = grid.fit(X_train, y_train) results = pd.DataFrame() results['means'] = grid_result.cv_results_['mean_test_score'] results['stds'] = grid_result.cv_results_['std_test_score'] results['params'] = grid_result.cv_results_['params'] print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_)) # حفظ النتائج results.to_csv(r'gridsearchcv_results.csv', index = False, header = True) results.sort_values(by='means', ascending = False).reset_index(drop=True)
يُبين خرج الشيفرة السابقة أفضل القيم للمعاملات المترفعة:
Best: 0.898588 using {'batch_size': 256, 'dropout_rate': 0.2, 'embed_dim': 32, 'epochs': 10, 'hidden_unit': 64, 'learning_rate': 0.001, 'optimizers': <class 'keras.optimizer_v2.adam.Adam'>}
نحفظ نتائج حساب المعاملات الأمثلية في الملف gridsearchcv_results.csv.
يُمكن معاينة هذه القيم:
# قراءة نتائج معايرة المعاملات المترفعة results = pd.read_csv('gridsearchcv_results.csv') results.sort_values(by='means', ascending = False).reset_index(drop=True) print (results)
يكون الخرج:

حساب أوزان الصفوف
يُمكن أن نلاحظ أن عدد التغريدات ذات القطبية الموجبة (73% من التغريدات) تطغى على عدد التغريدات السلبية (13%) والتغريدات المحايدة (13%) مما قد يؤدي إلى انحراف نتائج التعلم نحو القطبية الموجبة. يُمكن تلافي ذلك عن طريق الموازنة بين هذه الصفوف الثلاثة.
نحسب في الشيفرة التالية عدد التغريدات الموجبة والسالبة والمحايدة ونسبها:
# حساب أوزان القطبيات posCount=0 negCount=0 neuCount=0 # حساب عدد التغريدات الموجبة والسالبة والمحايدة for index, row in tweets.iterrows(): if row['polarity']=='negative': negCount=negCount+1 elif row['polarity']=='positive': posCount=posCount+1 else: neuCount=neuCount+1 print(negCount, neuCount, posCount) total=posCount+ negCount+ neuCount # حساب النسب weight_for_0 = (1 / negCount) * (total / 3.0) weight_for_1 = (1 / neuCount) * (total / 3.0) weight_for_2 = (1 / posCount) * (total / 3.0) print(weight_for_0, weight_for_1, weight_for_2) class_weight = {0: weight_for_0, 1: weight_for_1, 2:weight_for_2}
يكون ناتج طباعة هذه الأوزان ما يلي (لا حظ الوزن الأصغر للتغريدات الموجبة):
2.4954429456799123 2.504573728503476 0.45454545454545453
بناء نموذج التعلم النهائي
نستخدم الدالة KerasClassifier من scikit لبناء المُصنف مع الدالة السابقة create_model :
# مكتبة التصنيف from keras.wrappers.scikit_learn import KerasClassifier # إنشاء النموذج مع قيم المعاملات المترفعة الأمثلية model = KerasClassifier(build_fn = create_model, # معاملات النموذج dropout_rate = 0.2, embed_dim = 32, hidden_unit = 64, optimizers = Adam, learning_rate = 0.001, # معاملات التدريب epochs=10, batch_size=256, # نسبة بيانات التقييم validation_split = 0.1) # ملائمة النموذج مع بيانات التدريب # مع موازنة الصفوف الثلاثة model_prediction = model.fit(X_train, y_train, class_weight=class_weight)
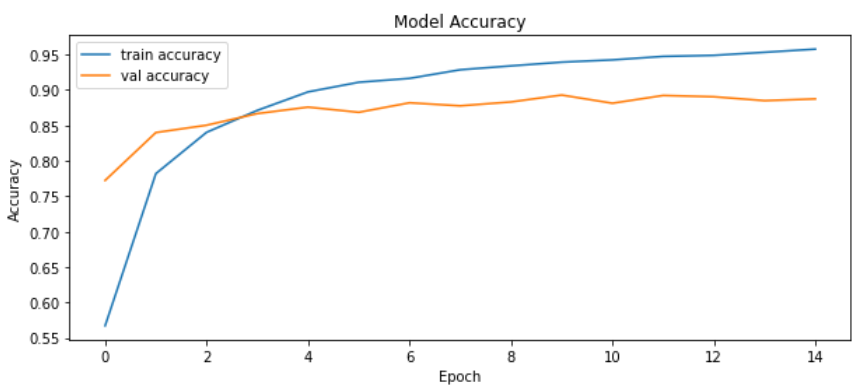
يُمكن الآن رسم منحني الدقة accuracy لكل من بيانات التدريب والتقييم (لاحظ أننا في الشيفرة السابقة احتفاظنا بنسبة 10% من بيانات التدريب للتقييم):
# معاينة دقة النموذج # التدريب والتقييم fig, ax = plt.subplots(figsize = (10, 4)) ax.plot(model_prediction.history['accuracy'], label = 'train accuracy') ax.plot(model_prediction.history['val_accuracy'], label = 'val accuracy') ax.set_title('Model Accuracy') ax.set_xlabel('Epoch') ax.set_ylabel('Accuracy') ax.legend(loc = 'upper left') plt.show()
يكون للمنحني الشكل التالي:
حساب مقاييس الأداء
يُمكن الآن حساب مقاييس الأداء المعروفة في مسائل التصنيف (الصحة Accuracy، الدقة Precision، الاستذكار Recall، المقياس F1) للنموذج المتعلم باستخدام الشيفرة التالية:
# مقاييس الأداء # مقياس الصحة from sklearn.metrics import accuracy_score # مقياس الدقة from sklearn.metrics import precision_score # مقياس الاستذكار from sklearn.metrics import recall_score # f1 from sklearn.metrics import f1_score # مصفوفة الارتباك from sklearn.metrics import confusion_matrix # تصنيف بيانات الاختبار y_pred = model.predict(X_test) # حساب مقاييس الأداء accuracy = accuracy_score(y_test, y_pred) precision=precision_score(y_test, y_pred , average='weighted') recall= recall_score(y_test, y_pred, zero_division=1, average='weighted') f1= f1_score(y_test, y_pred, zero_division=1, average='weighted') print('Model Accuracy on Test Data:', accuracy*100) print('Model Precision on Test Data:', precision*100) print('Model Recall on Test Data:', recall*100) print('Model F1 on Test Data:', f1*100) confusion_matrix(y_test, y_pred)
تكون النتائج (لاحظ ارتفاع جميع المقاييس مما يعني جودة المُصنف):
Model Accuracy on Test Data: 90.1144387630874 Model Precision on Test Data: 90.90281584915091 Model Recall on Test Data: 90.1144387630874 Model F1 on Test Data: 90.32645671662543 array([[ 366, 129, 24], [ 53, 444, 62], [ 20, 118, 2891]], dtype=int64)
يُمكن رسم مصفوفة الارتباك confusion matrix بشكل أوضح باستخدام المكتبة seaborn:
# رسم مصفوفة الارتباك import seaborn as sns sns.set(style = 'whitegrid') fig, ax = plt.subplots(figsize = (8,6)) sns.heatmap(confusion_matrix(y_true = y_test, y_pred = y_pred), fmt = 'g', annot = True) ax.xaxis.set_label_position('top') ax.xaxis.set_ticks_position('top') ax.set_xlabel('Prediction', fontsize = 14) ax.set_xticklabels(['negative (0)', 'neutral (1)', 'positive (2)']) ax.set_ylabel('Actual', fontsize = 14) ax.set_yticklabels(['negative (0)', 'neutral (1)', 'positive (2)']) plt.show()
مما يُظهر:
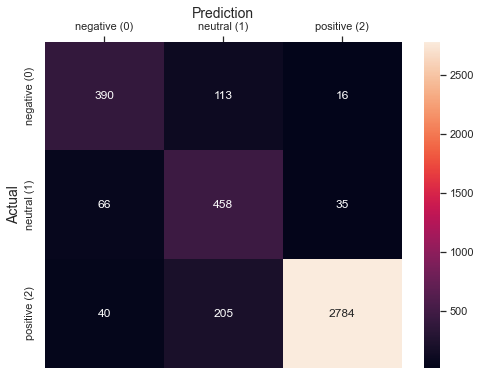
يُمكن حساب بعض مقاييس الأداء الأخرى المُستخدمة في حالة وجود أكثر من صف في المسألة (Micro, Macro, Weighted):
# مقاييس الأداء في حالة أكثر من صفين print('\nAccuracy: {:.2f}\n'.format(accuracy_score(y_test, y_pred))) print('Micro Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='micro'))) print('Micro Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='micro'))) print('Micro F1-score: {:.2f}\n'.format(f1_score(y_test, y_pred, average='micro'))) print('Macro Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='macro'))) print('Macro Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='macro'))) print('Macro F1-score: {:.2f}\n'.format(f1_score(y_test, y_pred, average='macro'))) print('Weighted Precision: {:.2f}'.format(precision_score(y_test, y_pred, average='weighted'))) print('Weighted Recall: {:.2f}'.format(recall_score(y_test, y_pred, average='weighted'))) print('Weighted F1-score: {:.2f}'.format(f1_score(y_test, y_pred, average='weighted'))) # تقرير التصنيف from sklearn.metrics import classification_report print('\nClassification Report\n') print(classification_report(y_test, y_pred, target_names=['Class 1', 'Class 2', 'Class 3']))
مما يُعطي (لاحظ ارتفاع جميع المقاييس مما يعني جودة المُصنف):
Accuracy: 0.88 Micro Precision: 0.88 Micro Recall: 0.88 Micro F1-score: 0.88 Macro Precision: 0.79 Macro Recall: 0.83 Macro F1-score: 0.80 Weighted Precision: 0.90 Weighted Recall: 0.88 Weighted F1-score: 0.89 Classification Report precision recall f1-score support Class 1 0.79 0.75 0.77 519 Class 2 0.59 0.82 0.69 559 Class 3 0.98 0.92 0.95 3029 accuracy 0.88 4107 macro avg 0.79 0.83 0.80 4107 weighted avg 0.90 0.88 0.89 4107
يُمكن أيضًا اختيار مجموعة تغريدات عشوائية جديدة وتصنيفها وحفظ النتائج في ملف results.csv:
# تصنيف مجموعة اختبار text_clean = tweets['tweet_clean'] text_train, text_test = train_test_split(text_clean, test_size = 0.2, random_state = 0) result_test = pd.DataFrame(data = zip(text_test, y_pred), columns = ['text', 'polarity']) polarity_decode = {0 : 'Negative', 1 : 'Neutral', 2 : 'Positive'} result_test['polarity'] = result_test['polarity'].map(polarity_decode) pd.set_option('max_colwidth', 300) # حفظ النتائج result_test.to_csv("results.csv") result_test
تكون النتائج مثلًا:

الخلاصة
عرضنا في هذه المقالة خطوات بناء نموذج تعلّم لتصنيف النصوص العربية إلى موجبة وسالبة ومحايدة.
يُمكن تجربة المثال كاملًا من موقع Google Colab، ولا تنسى الاطلاع على مجموعة البيانات المتوفرة الخاصة بهذا المقال.












أفضل التعليقات
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.