

أدى التطور السريع لنماذج الذكاء الاصطناعي مفتوحة المصدر إلى إمكانية توظيفها في إنتاج نصوص إبداعية بلغات متعددة، ومن بينها اللغة العربية. ومع ذلك، يظل توليد الشعر العربي تحديًا خاصًا نظرًا لخصوصيته الفنية، من أوزان عروضية دقيقة وقوافٍ تتطلب دقة عالية في التوليد التلقائي.
في هذا المقال، سنستعرض كيفية صقل نموذج Gemma، وهو نموذج لغوي مفتوح المصدر من Google، ليكون قادرًا على توليد أبيات شعرية باللغة العربية. سنوضح خطوات تشغيل النموذج وتحضير بيانات التدريب، وأساليب الصقل المعتمدة، ثم نعرض النتائج التي توصلنا إليها، مع اقتراح تحسينات تقرّب النموذج من روح الشعر العربي التقليدي من حيث الوزن والقافية والأسلوب البلاغي.
ما هو نموذج Gemma؟
Gemma هو عائلة من النماذج اللغوية الخفيفة والمفتوحة المصدر، طُوِّرت بواسطة Google DeepMind، وتعتمد على نفس التقنيات البحثية التي بُنِيَت عليها نماذج Gemini. يتميز بقدرات متقدمة في معالجة اللغة الطبيعية NLP، مما يجعله خيارًا قويًا لمجموعة واسعة من المهام اللغوية. يتوفر Gemma بإصدارين رئيسيين، مما يمنح المستخدمين مرونة في توظيفه وفقًا لمتطلبات المهام المختلفة:
الإصدار المضبوط على التعليمات Instruction Tuned - IT: دُرب على تفاعلات لغوية بشرية، مما يجعله مثاليًا للمحادثات والتطبيقات التفاعلية مثل الشات بوت Chatbot والمساعدات الذكية. يتميز هذا الإصدار بقدرته على فهم الأسئلة والاستجابة لها بأسلوب طبيعي وقريب من طريقة تواصل البشر
الإصدار المسبق التدريب Pretrained - PT: لم يخصص لمهام محددة، حيث يعتمد فقط على البيانات الأساسية التي دُرب عليها. وبالتالي، فهو يحتاج إلى ضبط إضافي Fine-Tuning ليتمكن من أداء مهام متخصصة مثل توليد الشعر أو تحليل النصوص. لذا، فإن استخدامه مباشرة دون ضبط قد لا يكون فعالًا في التطبيقات التي تتطلب دقة وتخصصًا أكبر
لماذا اخترنا Gemma؟
اخترنا نموذج Gemma لعدة أسباب رئيسية:
- مفتوح المصدر وقابل للتخصيص: يتيح إمكانية تعديله وضبطه بسهولة، مما يسمح بتكييفه مع الأوزان والقوافي الشعرية في اللغة العربية
- خفيف مقارنة بالنماذج العملاقة، مما يجعله مناسبًا للتشغيل محليًا أو عبر موارد سحابية محدودة
- مرونة في التشغيل، حيث يمكن استخدامه مع Keras, PyTorch, Transformers وغيرها من الأدوات
- دعم لغوي واسع في النسخة الثالثة من النموذج Gemma 3، حيث يدعم أكثر من 140 لغة، بما في ذلك اللغة العربية
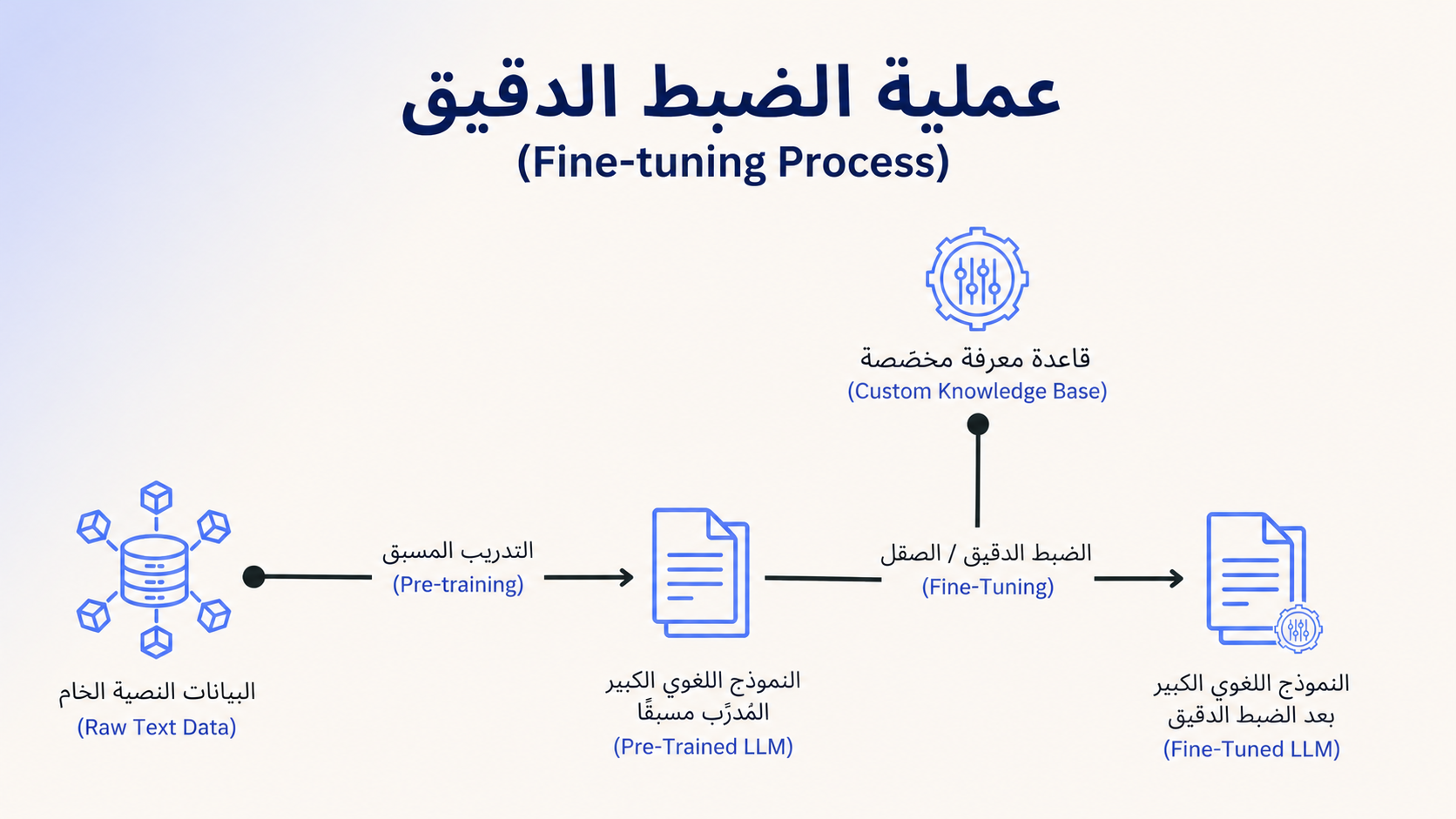
عملية الصقل Fine-Tuning
الصقل Fine-Tuning هو عملية إعادة تدريب نموذج ذكاء اصطناعي مُدرَّب مسبقًا باستخدام مجموعة بيانات متخصصة بهدف تحسين أدائه في مهمة معينة، مثل توليد الشعر العربي. بدلاً من تدريب النموذج من البداية،
يُعدل النموذج ليتناسب مع الأنماط اللغوية والخصائص الخاصة التي يتطلبها السياق المحدد. تبدأ عملية الصقل باستخدام نموذج مدرب مسبقًا يحتوي على معرفة لغوية عامة، ثم يُزود بنصوص شعرية لتمكينه من فهم خصائص الشعر مثل القافية والوزن والأسلوب.
خلال عملية الصقل، يمكن الاستفادة من البيانات المشروحة، حيث يتم إضافة معلومات إضافية مثل نوع الشعر أو اسم الشاعر، مما يساعد النموذج على إنتاج أبيات شعرية دقيقة وملائمة للسياق. على سبيل المثال، قد تكون بيانات التدريب المشروحة كالتالي:
اقتباس
{"input": "اكتب بيتًا من الشعر العمودي في مدح العلم", "output": "العلمُ يبني بيوتًا لا عمادَ لها والجهلُ يهدمُ بيتَ العزّ والشّرفِ"}
يساعد الصقل Fine-Tuning النموذج على فهم الأوزان الشعرية وتكرار الأنماط اللغوية، مما يمكننا من توجيه النموذج لإنشاء شعر بأسلوب معين، مثل الشعر الجاهلي أو الحديث.
هناك نوعان رئيسيان من تقنيات الصقل Fine-Tuning:
- صقل النموذج الكامل Full Fine-Tuning: تُعدل جميع أوزان النموذج بالكامل. يتطلب هذا النوع موارد حسابية كبيرة وقد يستغرق وقتًا طويلًا
- صقل النموذج منخفض الموارد Parameter Efficient Fine-Tuning - PEFT: يُعدل عدد محدود من الأوزان فقط، مما يقلل من استهلاك الذاكرة ويحسن الكفاءة. من الأساليب المشهورة في هذا النوع هي LoRA و QLoRA
تجهيز بيانات التدريب
لتحقيق نتائج مثالية عند صقل نموذج Gemma لتوليد الشعر العربي، من الضروري إعداد مجموعة بيانات غنية ومتنوعة تُلبي الهدف المطلوب. تعتمد نجاح عملية الصقل Fine-Tuning على جودة البيانات وتنظيمها وتنوعها، لذا يجب أولًا تحديد الموضوعات الأساسية للقصائد، مثل وصف الطبيعة أو الغزل أو الفخر أوالرثاء أوالهجاء أو القضايا الاجتماعية والسياسية.
بعد ذلك، تُختار المفردات بعناية ، فقد تكون فصيحة وجزلة كما في الشعر الكلاسيكي، أو حديثة وبسيطة كما في الشعر المعاصر، أو حتى دارجة إذا كان النموذج موجهًا للشعر الشعبي. كما يجب تحديد الأسلوب الشعري، سواء كان الشعر العمودي الموزون وفق بحور الخليل بن أحمد الفراهيدي، أو الشعر الحر الذي يحافظ على الوزن دون التزام بالقافية، أو النثر الشعري الذي يتميز بأسلوب أدبي دون التقيد بالأوزان التقليدية.
لتحسين قدرة النموذج على توليد الشعر بدقة أعلى، يمكن تجهيزه ببيانات تدريب توضّح له النمط الشعري المطلوب. على سبيل المثال، قد نطلب من النموذج كتابة شعر كلاسيكي قريب من أسلوب أحمد شوقي، أو شعر حر قريب من محمود درويش، أو شعر حكمة وفخر قريب من المتنبي، أو شعر سياسي ناقد قريب من أحمد مطر.
بعد تحديد النمط المطلوب، تُنظَّم البيانات على شكل أزواج من المدخلات والمخرجات. يكون المدخل هو الموجّه Prompt، وفيه نكتب التعليمات التي تحدد الموضوع، والأسلوب، ونوع اللغة، والقافية أو الوزن إن وُجدا. أما المخرج فهو poem، أي النص الشعري الذي نريد أن يتعلم النموذج إنتاج ما يشبهه.
اقتباس
{ "prompt": "اكتب لي أبياتًا من الشعر العربي الفصيح عن الفخر، باستخدام مفردات جزلة وقافية منتظمة، بأسلوب الشاعر أبو فراس الحمداني.",
"poem": "سَيَذكُرُني قَومي إِذا جَدَّ جِدُّهُمُ\nوَفي اللَيلَةِ الظَلماءِ يُفتَقَدُ البَدرُ\nفَإِن عِشتُ فَالطَعنُ الَّذي يَعرِفونَهُ\nوَتِلكَ القَنا وَالبيضُ وَالضُمَّرُ الشُقرُ" }{ "prompt": "اكتب لي أبياتًا من الشعر العربي عن القضايا السياسية والاجتماعية، بأسلوب شعر حر، مع استخدام مفردات بسيطة ومباشرة، بأسلوب يشابه أسلوب الشاعر أحمد مطر.", "poem": "ما تهمتي؟\nتهمتك العروبة\nقلت لكم ما تهمتي؟\nقلنا لك العروبة\nيا ناس قولوا غيرها\nأسألكم عن تهمتي ..\nليس عن العقوبة" }
تشغيل وصقل نموذج Gemma
لتنفيذ عملية الصقل Fine-Tuning لنموذج Gemma، سنطبق الخطوات التالية من خلال منصة Kaggle لتسريع عملية التدريب باستخدام GPU أو TPU. سنعمل على تشغيل النموذج باستخدام مكتبة Keras نظرًا لسهولة استخدامها.
نبدأ أولًا بتثبيت المكتبات الرئيسية اللازمة لتشغيل النموذج، مثل keras-nlp وkeras:
!pip install -q -U keras-nlp
!pip install -q -U keras
بعد ذلك، نستورد المكتبات التي سنحتاج إليها أثناء عملية التدريب:
import keras
import keras_nlp
import os
-
Keras: مكتبة أساسية لبناء نماذج التعلم العميق -
keras-nlp: مكتبة توفر أدوات ونماذج جاهزة لعمليات الـ NLP -
os: تُستخدم للتعامل مع البيئة وتشغيل أوامر النظام
سوف نختار JAX كخلفية لتشغيل النموذج:
os.environ["KERAS_BACKEND"] = "jax" # Or "torch" or "tensorflow". os.environ["XLA_PYTHON_CLIENT_MEM_FRACTION"] = "0.9"
-
KERAS_BACKEND: تحديد البيئة التي سنستخدمها لتشغيل Keras، حيث إن Keras هو واجهة برمجة تطبيقات عالية المستوى تدعم العديد من أطر العمل للتعلم العميق مثل TensorFlow وJAX وPyTorch -
XLA: يتيح تسريع الحسابات في JAX. الكود يحدد استخدام 90% من الذاكرة المتاحة لتجنب مشاكل تجزئة الذاكرة
ثم نحمل النموذج باستخدام keras_nlp:
gemma_lm = keras_nlp.models.Gemma3CausalLM.from_preset("gemma3_instruct_1b") gemma_lm.summary()
summary: عرض ملخص للنموذج ليتمكن المستخدم من رؤية هيكل النموذج، مثل الطبقات وعدد المعلمات
الخطوة التالية هي تحميل البيانات، حيث نعمل على قراءة ملف JSON الذي يحتوي على بيانات الشعر ونحضرها للنموذج. في هذه العملية، سنستخرج الموجهات prompts والاستجابات من البيانات، ثم نحولها إلى مجموعة بيانات باستخدام مكتبة TensorFlow كالتالي:
import json import tensorflow as tf def prepare_training_data_poetry(json_path): # فتح ملف البيانات مع استخدام ترميز يدعم اللغة العربية with open(json_path, 'r', encoding='utf-8') as file: # قراءة محتوى الملف وتحويله إلى بيانات يمكن التعامل معها في بايثون data = json.load(file) # قائمة لحفظ الموجهات التي تُعطى للنموذج prompts = [] # قائمة لحفظ القصائد أو الأبيات التي تمثل الإجابات المتوقعة responses = [] # المرور على كل مثال تدريبي داخل ملف البيانات for entry in data: # إضافة نص الطلب أو التعليمات إلى قائمة الموجهات prompts.append(entry['prompt']) # إضافة النص الشعري المقابل إلى قائمة الإجابات responses.append(entry['poem']) # إنشاء مجموعة بيانات من الموجهات والإجابات حتى يمكن استخدامها في التدريب dataset = tf.data.Dataset.from_tensor_slices({ "prompts": prompts, "responses": responses }) # خلط البيانات، ثم تقسيمها إلى دفعات صغيرة، ثم تجهيز الدفعات التالية مسبقًا لتسريع التدريب dataset = dataset.shuffle(len(prompts)).batch(1).prefetch(tf.data.AUTOTUNE) # إرجاع البيانات بعد تجهيزها return dataset # تجهيز بيانات التدريب من ملف البيانات الموجود في المسار المحدد training_data = prepare_training_data_poetry('/kaggle/input/arabic-potry/data.json')
-
json.load: قراءة وتحميل البيانات من ملف بصيغة JSON -
Dataset.from_tensor_slice: تحويل القوائم إلى مجموعة بيانات قابلة للاستخدام في التدريب -
shuffle: خلط البيانات بشكل عشوائي
بعد ذلك، نستخدم تقنية LoRA لتحسين التدريب عن طريق تقليل عدد المعاملات التي سوف تُعدل، مما يساعد في تقليل استهلاك الذاكرة مع الحفاظ على الأداء الجيد:
gemma_lm.backbone.enable_lora(rank=64) gemma_lm.summary()
rank=64: يحدد حجم المصفوفات التي سوف تُعدل. قيمة صغيرة تعني تعديلات أبسط وأقل تكلفة، بينما قيمة كبيرة تعني تعديلات أعقد وأكثر تكلفة
ثم، نحدد المعاملات الخاصة بالتدريب مثل تحديد طول السلسلة Sequence length إلى 512 لتقليل استهلاك الذاكرة، واختيار مُحسِّن Optimizer مثل AdamW:
# تحديد الحد الأقصى لطول النص الذي سيدخله النموذج أثناء التدريب # أي أن النموذج سيعالج تسلسلًا لا يتجاوز 512 رمزًا gemma_lm.preprocessor.sequence_length = 512 # إنشاء المحسّن المسؤول عن تحديث أوزان النموذج أثناء التدريب optimizer = keras.optimizers.AdamW( # تحديد سرعة تعلّم النموذج # كلما كانت القيمة صغيرة كان التحديث أبطأ وأكثر استقرارًا learning_rate=5e-5, # تقليل احتمالية حفظ النموذج للبيانات بدل تعلّم الأنماط العامة # وذلك عبر إضافة عقوبة بسيطة على الأوزان الكبيرة weight_decay=0.01, ) # استثناء بعض المتغيرات من عقوبة تقليل الأوزان optimizer.exclude_from_weight_decay(var_names=["bias", "scale"]) # تجهيز النموذج لمرحلة التدريب من خلال تحديد دالة الخطأ والمُحسّن ومقاييس التقييم gemma_lm.compile( # دالة الخطأ المستخدمة في مهام التنبؤ بالكلمة أو الرمز التالي loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), # استخدام المحسّن الذي أنشأناه لتحديث أوزان النموذج optimizer=optimizer, # مقياس لحساب دقة النموذج في اختيار الرمز الصحيح أثناء التدريب weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()], )
-
sequence_length: تحديد الحد الأقصى لطول التسلسل المدخل -
learning_rate=5e-5: معدل التعلم الذي يتحكم في سرعة التحديثات -
weight_decay=0.01: تقليل التأثير الزائد للوزن
وأخيرًا، نبدأ عملية صقل النموذج باستخدام البيانات التي جهزناها:
gemma_lm.fit(training_data, epochs=1)
بعد صقل النموذج، يمكننا حفظ الأوزان التي عُدلت أثناء عملية الصقل Fine-Tuning لتحميلها لاحقًا دون الحاجة لإعادة التدريب، وذلك باستخدام الأمر التالي:
gemma_lm.backbone.save_lora_weights("name.lora.h5")
تجربة أداء النموذج بعد التدريب
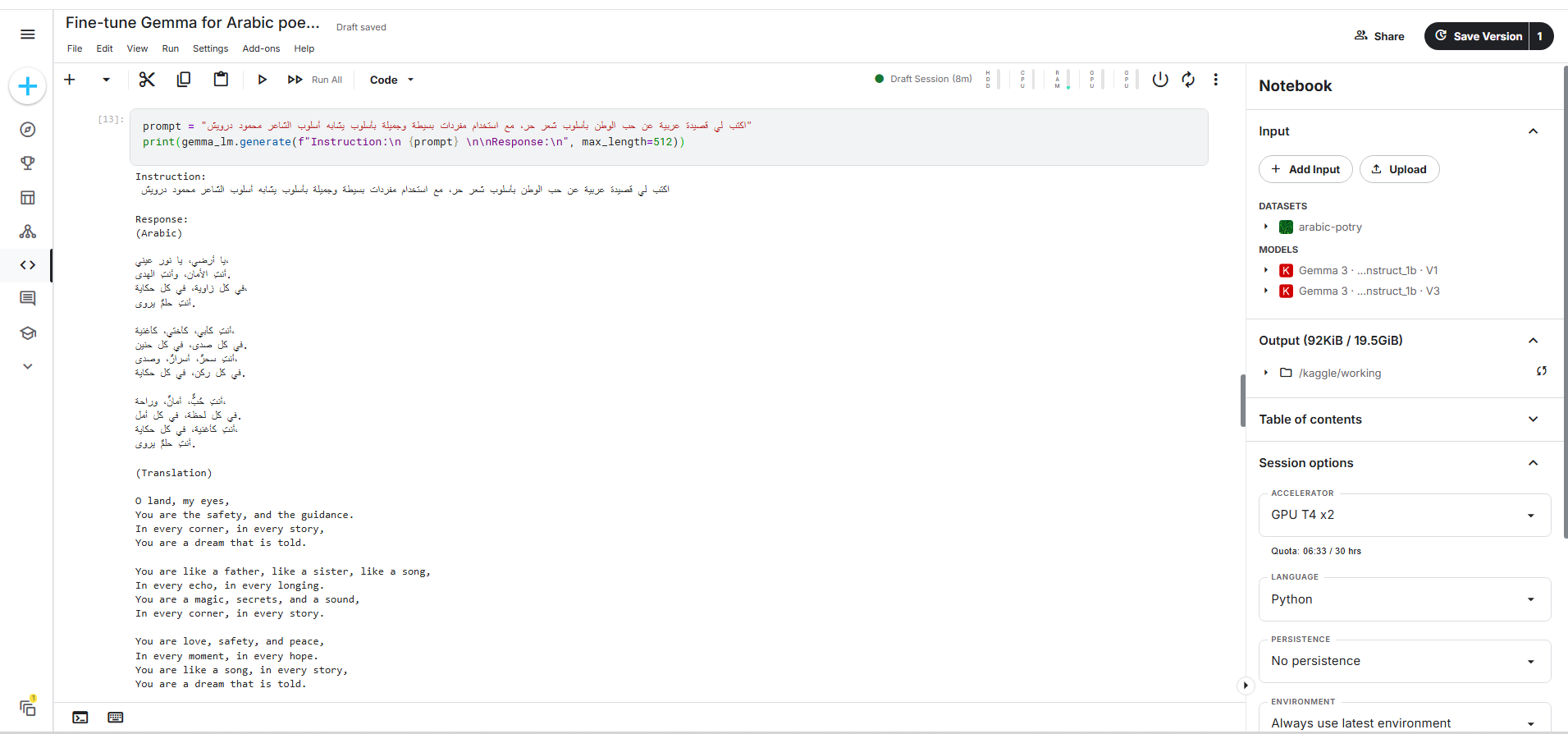
بعد الانتهاء من صقل النموذج على الشعر العربي، أصبح بإمكاننا الآن تجربته عمليًا، وذلك من خلال تقديم تعليمات واضحة تتضمن الوظيفة المطلوبة من النموذج. على سبيل المثال، يمكن استخدام المُوجه التالي prompt:
اقتباسprompt = "اكتب لي قصيدة عربية عن حب الوطن بأسلوب الشعر الحر، مع استخدام مفردات بسيطة وجميلة، وبأسلوب قريب من الشاعر محمود درويش." output = gemma_lm.generate( f"Instruction:\n{prompt}\n\nResponse:\n", max_length=512 ) print(output)
سيحاول النموذج توليد قصيدة تتوافق مع الخصائص المطلوبة، مثل الموضوع والأسلوب.
يمكن أيضًا تحسين جودة المخرجات عبر استخدام تقنية Few-shot Prompting، حيث يتم إرسال التعليمات إلى النموذج مرفقةً بأمثلة توضح المطلوب بدقة. هذا يساعد النموذج على التقاط النمط والأسلوب المستهدف. المثال التالي يوضح ذلك:
prompt = """ أنت نموذج ذكاء اصطناعي متخصص في كتابة الشعر العربي بأسلوب المتنبي. اكتب أبياتًا شعرية تعبر عن الفخر، الطموح، القوة، والحكمة بأسلوب المتنبي. ### مثال : **المدخل:** "اكتب لي أبياتًا عن الطموح والسعي وراء المجد بأسلوب المتنبي." **المخرج:** "إِذا غامَرتَ في شَرَفٍ مَرومِ فَلا تَقنَع بِما دونَ النُجومِ فَطَعمُ المَوتِ في أَمرٍ صَغيرٍ كَطَعمِ المَوتِ في أَمرٍ عَظيمِ" الآن، أكمل وفقًا لنفس النمط: **المدخل:** "اكتب لي أبياتًا من الشعر العمودي عن الحكمة بأسلوب المتنبي." **المخرج:** """ result = gemma_lm.generate(f"Instruction:\n {prompt} \n\nResponse:\n", max_length=512) print(result.split("Response:")[1])
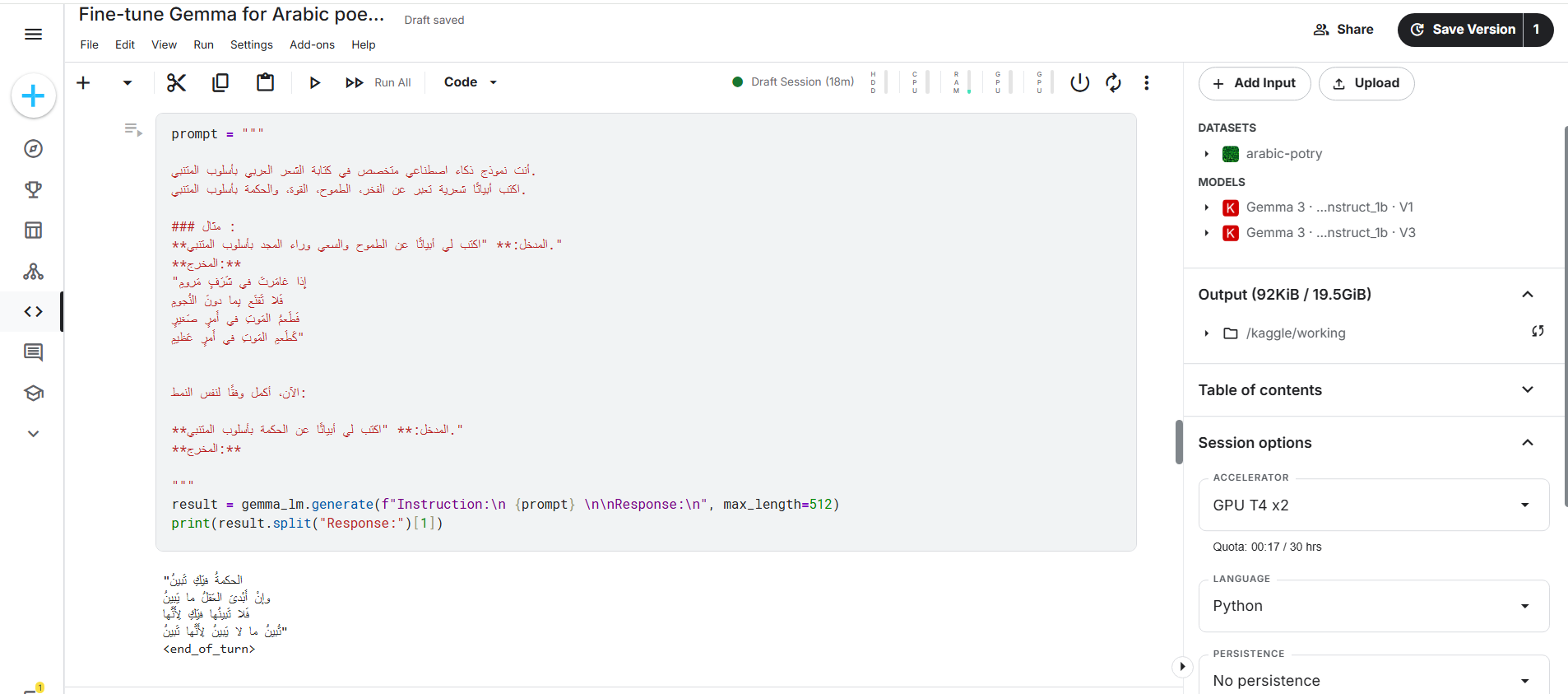
من خلال تحليل النتائج، يمكن ملاحظة أن جودة الأبيات التي يولدها النموذج لا ترقى في كثير من الأحيان إلى المستوى المتوقع من حيث المعنى و الوزن و الأسلوب والبلاغة. وهذا يشير إلى أن نماذج الذكاء الاصطناعي لا تزال تعاني من جوانب قصور واضحة في توليد الشعر العربي، لا سيما عند محاولة محاكاة الأساليب الكلاسيكية مثل أسلوب المتنبي. في الفقرة التالية، سنتناول مجموعة من الحلول والاقتراحات التي قد تسهم في تحسين أداء هذه النماذج، وتمكينها من توليد نصوص شعرية أكثر جودة واحترافية.
نصائح لتحسين الأداء
لتحقيق نتائج أفضل في توليد الشعر العربي بأساليب مختلفة، يمكننا اتباع عدة استراتيجيات:
تحسين وتنويع بيانات التدريب
- زيادة حجم بيانات التدريب: جمع المزيد من القصائد بأساليب شعراء مختلفين يساعد في تغطية نطاق أوسع من الأنماط الشعرية
- تنويع البيانات: من المهم تضمين أنواع مختلفة من الشعر، مثل الشعر العمودي والشعر الحر، لضمان قدرة النموذج على توليد أشكال متعددة من الشعر
- تحسين جودة البيانات: مراجعة البيانات يدويًا أو استخدام تقنيات التنظيف والتصفية يمكن أن يساعد في إزالة الأخطاء أو العبارات غير الطبيعية
استخدام نموذج أكبر
يمكن تحسين جودة توليد الشعر العربي من خلال تجربة إصدارات أكبر من النموذج، مثل استخدام gemma3_12b بدلًا من gemma3_1b، لأن النماذج الأكبر تمتلك قدرة أعلى على فهم الأنماط اللغوية والأسلوبية المعقدة، وتمثيل العلاقات الدقيقة داخل النصوص الشعرية. هذا قد يساعد النموذج على إنتاج قصائد أكثر تماسكًا من حيث المعنى والصياغة والإيقاع.
كما يمكن تجربة نماذج لغوية أخرى متقدمة، مثل Qwen، وإعادة صقلها على مجموعة مختارة من الدواوين العربية الكلاسيكية والحديثة. من المتوقع أن يساعد ذلك النموذج على التقاط الخصائص الأسلوبية والإيقاعية للشعر العربي بشكل أفضل، وتحسين قدرته على توليد نصوص شعرية أقرب إلى طبيعة الشعر العربي من حيث اللغة والصورة والمعنى.
تحسين المعاملات الخاصة بالتدريب
-
زيادة قيمة LoRA Rank: إذا كان النموذج الحالي يستخدم
rank=64، يمكن زيادة هذه القيمة إلىrank=128أو أكثر للحصول على ضبط أدق وأداء أفضل - زيادة قيمة Rank قد تساعد في تحسين قدرة النموذج على تخصيص الأوزان بشكل أفضل أثناء عملية الصقل Fine-Tuning
-
تدريب النموذج على عدد أكبر من Epochs: يمكن تجربة قيم أعلى مثل
epochs=5للمساعدة في تثبيت الأنماط الشعرية داخل النموذج بشكل أكثر فعالية
الخاتمة
في هذا المقال، عملنا على صقل نموذج Gemma لإنتاج الشعر العربي. استعرضنا كيفية تحضير البيانات وطرق الصقل المختلفة، كما ناقشنا عدة استراتيجيات لتعزيز دقة النموذج، مثل زيادة حجم البيانات واستخدام نماذج أكبر وتحسين معلمات التدريب لتحسين الأداء وتحقيق نتائج أفضل في توليد الشعر العربي.
اقرأ أيضًا
- طريقة الصقل Fine-Tune لنموذج ذكاء اصطناعي مُدرَّب مُسبقًا
- المعالجة المُسبقة للبيانات قبل تمريرها لنماذج الذكاء الاصطناعي
- نظرة عامة على الصنف Trainer في مكتبة المحولات Transformers
- مشاركة نموذج ذكاء اصطناعي على منصة Hugging Face
المراجع











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.