السلام عليكم،
لدي مسألة احاول فيها التنبؤ بالطول الموجي للحركة الزلزالية عند 19 تردد (مثلا كم سيكون طول الموجة عند تردد 0.1, 0.3, 0.5, 0.85, 1...,24 hz) ولدي اربع مدخلات ثلاث منها عددية (قوة الزلزال، المسافة، معامل التربة في الموقع) استُخدم عليها ال (standardization) Standard Scalar والرابع يصف الشرخ الزلزالي وتمت معالجته عن طريق OneHotEcndoer.
هناك ما يقارب 150 زلزال مسجل في قاعدة البيانات وكل زلزال تم رصده على الاقل من 3 مواقع (بعضها اكثر من 3 بكثير) فقمت بتقسيم البيانات بناء على الزلزال وليس على التسجيلات لمنع التسريب الى ثلاث مجموعات 70% تدريب والباقي مناصفة بين الاختبار والتصديق.
ولضمان عدم تأثير حالة خاصة او العدد الكبير لسجلات زلزال معين على جميع الزلازل (فمثلا قد يمتلك زلزال 50 سجل فيؤثر اكثر على قيمة الخسارة بشكل اكبر او قد يمتلك ظاهرة خاصة بسبب نوعية التربة فتؤثر على القيمة الخسارة) تم تعديل دالة الخسارة واضافة شرطين معنيين بقيمة الخسارة.
في البداية MSE اساسي من الشبكة العصبية، الشرط الاول على مستوى الحدث الزلزالي حيث نحسب متوسط الخطأ للتسجيلات التابعة لنفس الزلزال، والثاني على مستوى التسجيل نفسه نحسب متوسط الخطأ عبر قيمة طول الموجة عند 19 تردد.
بالنسبة للشبكة العصبية فهي موضحة ادناه
def build_tunable_model(hp):
inputs = keras.Input(shape=(INPUT_DIM,))
x = inputs
num_layers = hp.Int('num_layers',1, 2, 😎
unit_choices = sorted(set([
INPUT_DIM,
8, 16, 32, 64, 128, 256, 512
]))
for i in range(num_layers):
units = hp.Choice(f"units_{i}", values=unit_choices)
activation = hp.Choice(f'activation_{i}', ['gelu','elu','relu','tanh'])
l2 = hp.Float("l2", 1e-7, 1e-3, sampling="log")
x = layers.Dense(units, activation=activation,
kernel_regularizer=keras.regularizers.l2(l2))(x)
dropout_rate = hp.Float(f'dropout_{i}', 0.0, 0.4, step=0.1)
if dropout_rate > 0:
x = layers.Dropout(dropout_rate)(x)
# Output Layer: 19 Neurons (one per frequency bin)
outputs = layers.Dense(OUTPUT_DIM, activation='linear')(x)
model.compile(
optimizer=keras.optimizers.Adam(learning_rate=lr),
loss=vector_mixed_effects_loss(alpha_event=a_event, alpha_record=a_record, n_targets=OUTPUT_DIM),
metrics=[unpacked_mae]
)
return model
الشبكة في النهاية تكون مكونة من طبقة مخفية واحدة من 128
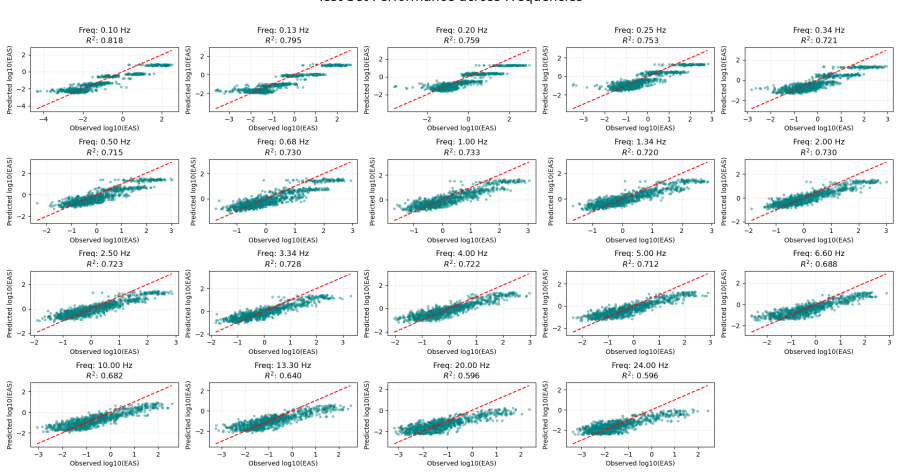
المشكلة تكمن انه عند رسم قيم التنبؤ مقابل القيم الحقيقية لعينة الاختبار، يظهر جليا ان الشبكة غير قادرة على التنبؤ بالقيم الاعلى من موجب وسالب 2 على المقياس اللوجارثمي خصوصا عند الترددات المنخفضة مثل 0.1، ولا استطيع ايجاد سبب لذلك.





السؤال
عبدالرحمن_
السلام عليكم،
لدي مسألة احاول فيها التنبؤ بالطول الموجي للحركة الزلزالية عند 19 تردد (مثلا كم سيكون طول الموجة عند تردد 0.1, 0.3, 0.5, 0.85, 1...,24 hz) ولدي اربع مدخلات ثلاث منها عددية (قوة الزلزال، المسافة، معامل التربة في الموقع) استُخدم عليها ال (standardization) Standard Scalar والرابع يصف الشرخ الزلزالي وتمت معالجته عن طريق OneHotEcndoer.
هناك ما يقارب 150 زلزال مسجل في قاعدة البيانات وكل زلزال تم رصده على الاقل من 3 مواقع (بعضها اكثر من 3 بكثير) فقمت بتقسيم البيانات بناء على الزلزال وليس على التسجيلات لمنع التسريب الى ثلاث مجموعات 70% تدريب والباقي مناصفة بين الاختبار والتصديق.
ولضمان عدم تأثير حالة خاصة او العدد الكبير لسجلات زلزال معين على جميع الزلازل (فمثلا قد يمتلك زلزال 50 سجل فيؤثر اكثر على قيمة الخسارة بشكل اكبر او قد يمتلك ظاهرة خاصة بسبب نوعية التربة فتؤثر على القيمة الخسارة) تم تعديل دالة الخسارة واضافة شرطين معنيين بقيمة الخسارة.
في البداية MSE اساسي من الشبكة العصبية، الشرط الاول على مستوى الحدث الزلزالي حيث نحسب متوسط الخطأ للتسجيلات التابعة لنفس الزلزال، والثاني على مستوى التسجيل نفسه نحسب متوسط الخطأ عبر قيمة طول الموجة عند 19 تردد.
بالنسبة للشبكة العصبية فهي موضحة ادناه
def build_tunable_model(hp):
inputs = keras.Input(shape=(INPUT_DIM,))
x = inputs
num_layers = hp.Int('num_layers',1, 2, 😎
unit_choices = sorted(set([
INPUT_DIM,
8, 16, 32, 64, 128, 256, 512
]))
for i in range(num_layers):
units = hp.Choice(f"units_{i}", values=unit_choices)
activation = hp.Choice(f'activation_{i}', ['gelu','elu','relu','tanh'])
l2 = hp.Float("l2", 1e-7, 1e-3, sampling="log")
x = layers.Dense(units, activation=activation,
kernel_regularizer=keras.regularizers.l2(l2))(x)
dropout_rate = hp.Float(f'dropout_{i}', 0.0, 0.4, step=0.1)
if dropout_rate > 0:
x = layers.Dropout(dropout_rate)(x)
# Output Layer: 19 Neurons (one per frequency bin)
outputs = layers.Dense(OUTPUT_DIM, activation='linear')(x)
model = keras.Model(inputs, outputs)
lr = hp.Float('learning_rate', 1e-4, 1e-2, sampling='log')
a_event = hp.Float('alpha_event', 1e-3, 1.0, sampling='log')
a_record = hp.Float('alpha_record', 1e-3, 1.0, sampling='log')
model.compile(
optimizer=keras.optimizers.Adam(learning_rate=lr),
loss=vector_mixed_effects_loss(alpha_event=a_event, alpha_record=a_record, n_targets=OUTPUT_DIM),
metrics=[unpacked_mae]
)
return model
الشبكة في النهاية تكون مكونة من طبقة مخفية واحدة من 128
المشكلة تكمن انه عند رسم قيم التنبؤ مقابل القيم الحقيقية لعينة الاختبار، يظهر جليا ان الشبكة غير قادرة على التنبؤ بالقيم الاعلى من موجب وسالب 2 على المقياس اللوجارثمي خصوصا عند الترددات المنخفضة مثل 0.1، ولا استطيع ايجاد سبب لذلك.
تم التعديل في بواسطة عبدالرحمن_2 أجوبة على هذا السؤال
Recommended Posts
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.