

سننفذ في هذا المقال خوارزميةً بسيطةً لتعلم الآلة بلغة بايثون Python باستخدام مكتبة Scikit-learn، وهذه المكتبة ما هي إلا أداةٌ لتطبيق تعلّم الآلة بلغة البايثون، كما سنستخدم المُصنّف Naive Bayes (NB) مع قاعدة بياناتٍ حقيقية لمعلومات ورم سرطان الثدي، والذي سيتنبأ إذا ما كان الورم خبيثًا أم حميدًا. وفي نهاية هذا المقال ستعرف خطوات وكيفية إنشاء نموذج تنبؤي خاص بك لتَعَلّم الآلة بلغة بايثون.
المتطلبات الرئيسية
قبل البدء بهذا المقال لا بد من تجهيز البيئة المناسبة، وسنستخدم محرر الشيفرات البرمجية Jupyter Notebooks، وهو مفيد جدًا لتجربة وتشغيل الأمثلة الخاصة بتَعَلّم الآلة بطريقةٍ تفاعليةٍ، حيث تستطيع من خلاله تشغيل كتلًا صغيرةً من الشيفرات البرمجية ورؤية النتائج بسرعة، مما سيسهل علينا اختبار الشيفرات البرمجية وتصحيحها.
يُمكنك فتح متصفح الويب والذهاب لموقع المحرر الرسمي jupyter على الوِيب لبدء العمل بسرعة، ومن ثمّ انقر فوق "جرّب المحرر التقليدي Try Classic Notebook"، وستنتقل بعدها لملفٍ جديدٍ بداخل محرر Jupyter Notebooks التفاعلي، وبذلك تجهّز نفسك لكتابة الشيفرة البرمجية بلغة البايثون.
إذا رغبت بمزيدٍ من المعلومات حول محرر الشيفرات البرمجية Jupyter Notebooks وكيفيّة إعداد بيئته الخاصة لكتابة شيفرة بايثون، فيمكنك الاطلاع على: كيفية تهيئة تطبيق المفكرة jupyter notebook للعمل مع لغة البرمجة python.
1. إعداد المشروع
ستحتاج أولًا لتثبيت بعض التبعيات، وذلك لإنشاء مساحة عملٍ للاحتفاظ بملفاتنا قبل أن نتمكن من تطوير برنامج التعرف على الصور، وسنستخدم بيئة بايثون 3.8 الافتراضية لإدارة التبعيات الخاصة بمشروعنا.
سَنُنشئ مجلدًا جديدًا خاصًا بمشروعنا وسندخل إليه هكذا:
mkdir cancer-demo cd cancer-demo
سننفذّ الأمر التالي لإعداد البيئة الافتراضية:
python -m venv cancer-demo
سننفذّ الأمر التالي لتشغيل البيئة الافتراضية في Linux:
source cancer-demo/bin/activate
أما في Windows:
"cancer-demo/Scripts/activate.bat"
سنستخدم إصداراتٍ محددةٍ من هذه المكتبات، من خلال إنشاء ملف requirements.txt في مجلد المشروع، وسيُحدِّد هذا الملف المتطلبات والإصدارات التي سنحتاج إليها.
سنفتح الملف requirements.txt في محرر النصوص، وسنُضيف الأسطر البرمجية التالية، وذلك لتحديد المكتبات التي نريدها وإصداراتها:
jupyter==1.0.0 scikit-learn==1.0
سنحفظ التغييرات التي طرأت على الملف وسنخرج من محرر النصوص، ثم سنُثَبت هذه المكتبات بالأمر التالي:
(cancer-demo) $ pip install -r requirements.txt
بعد تثبيتنا لهذه التبعيات، سنُصبح جاهزين لبدء العمل على مشروعنا.
شغّل محرر الشيفرات البرمجية Jupyter Notebook بمجرد اكتمال عملية التثبيت. هكذا:
(cancer-demo) $ jupyter notebook
أنشئ ملفًا جديدًا في داخل المحرر بالضغط على الزر new واختيار python 3 (ipykernal) وسمه باسم ML Tutorial مثلًا، حيث ستكون في الخلية الأولى للملف عملية استيراد الوِحدة (أو المكتبة) البرمجية scikit-learn (لمزيد من المعلومات حول طريقة استيراد وحدة برمجية في لغة بايثون يمكنك الاطلاع على كيفية استيراد الوحدات في بايثون 3 سبق وأن ناقشنا فيه هذه الفكرة بالتفصيل):
import sklearn
يجب أن يبدو الملف الخاص بك شبيهًا بالملف التالي:
والآن بعد استيرادنا للمكتبة بنجاح، سنبدأ العمل مع مجموعة البيانات لبناء نموذج تعلّم الآلة الخاص بنا.
2. استيراد مجموعة بيانات Scikit-Learn’s
مجموعة البيانات التي سنتعامل معها في هذا المقال هي قاعدة بيانات الخاصة بتشخيص مرض سرطان الثدي في ولاية ويسكونسن الأمريكية. تتضمن هذه المجموعة من البيانات معلوماتٍ مختلفةٍ حول أورام سرطان الثدي، بالإضافة إلى تصنيفات الأورام سواءً كانت خبيثةً أم حميدةً. كما تحتوي على 569 حالة (أو للدقة بيانات 569 ورمًا)، كما تتضمن معلومات عن 30 ميزة لكلّ ورم، مثل: نصف قطر الورم ونسيجه ونعومته ومساحته.
سنبني نموذجًا لتعلّم الآلة من مجموعة البيانات السابقة باستخدام معلومات الورم فقط للتنبؤ فيما إذا كان الورم خبيثًا أم حميدًا.
يُثَبت مع مكتبة Scikit-learn مجموعات بياناتٍ مختلفةٍ افتراضيًا، ويُمكننا استيرادها لتُصبح متاحةً للاستخدام في بيئتنا مباشرةً، لنفعل ذلك:
from sklearn.datasets import load_breast_cancer # Load dataset data = load_breast_cancer()
سيُمثَل المتغير data ككائنٍ في البايثون، والذي سيعمل مثل عمل القاموس الذي هو نوعٌ مُضمَّنٌ في بايثون، بحيث يربط مفاتيحًا بقيمٍ على هيئة أزواجٍ، وستُؤخذ بالحسبان مفاتيح القاموس، وهي أسماء الحقول المُصنّفة target_names، والقيم الفعلية لها target، وأسماء الميّزات feature_names، والقيم الفعلية لهذه الميزات data.
تُعَد الميّزات جزءًا مهمًا من أي مصنّف، إذ تُمثّل هذه الميزات خصائص مهمةً تصف طبيعة البيانات، كما ستساعدنا في عملية التنبؤ بحالة الورم (ورم الخبيث malignant tumor أو ورم حميد benign tumor)، ومن الميّزات المُفيدة المحتملة في مجموعة بياناتنا هذه، هي حجم الورم ونصف قطره ونسيجه.
أنشئ في الملف نفسه بعد ذلك متغيرات جديدةً لكلّ مجموعةٍ مهمةٍ من هذه المعلومات وأسند لها البيانات:
# تنظيم بياناتنا label_names = data['target_names'] labels = data['target'] feature_names = data['feature_names'] features = data['data']
والآن أصبحت لدينا قوائم لكلّ مجموعةٍ من المعلومات، ولفَهم مجموعة البيانات الخاصة بنا فهمًا صحيحًا ودقيقًا، سنُلقي نظرةً عليها من خلال طباعة حقول الصنف مثل طباعة أول عينةٍ من البيانات، وأسماء ميّزاتها، وقيمها هكذا:
# الاطلاع على بياناتنا print(label_names) print(labels[0]) print(feature_names[0]) print(features[0])
إن نفذّت هذه الشيفرة بطريقةٍ صحيحةٍ فسترى النتائج التالية:
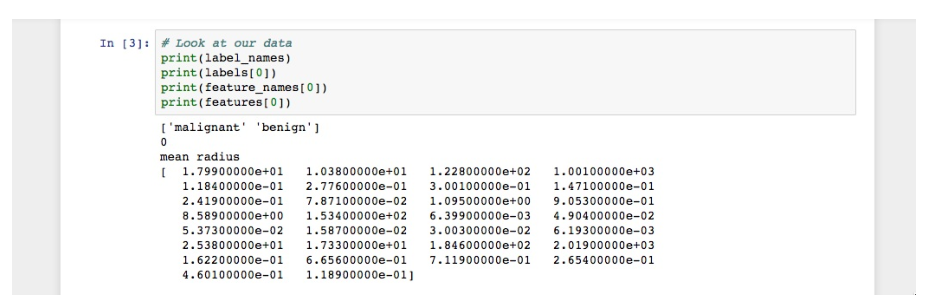
نُلاحظ من الصورة أن أسماء الأصناف الخاصة بنا ستكون خبيث malignant وحميد benign (أي أن الورم سيكون إما خبيثًا أو حميدًا)، والمرتبطة بقيم ثنائية وهي إما 0 أو 1، إذ يُمثّل الرقم 0 أورامًا خبيثة ويُمثّل الرقم 1 أورامًا حميدة، لذا فإن أول مثالٍ للبيانات الموجودة لدينا هو ورمٌ خبيثٌ نصف قطره 1.79900000e+01.
والآن بعد تأكدنا من تحميل بياناتنا تحميلًا صحيحًا في بيئة التنفيذ، سنبدأ العمل مع بياناتنا لبناء مصنّف باستخدام طُرق تعلّم الآلة.
3. تنظيم البيانات في مجموعات
ينبغي عليك دائمًا اختبار النموذج على البيانات غير المرئية، وذلك لتقييم مدى جودة أداء المُصنّف، لهذا قسّم البيانات الخاصة بك إلى جزئين قبل بناء النموذج، بحيث تكون هناك مجموعةٌ للتدريب ومجموعةٌ للاختبار.
تستطيع استخدام المجموعة المخصصة للتدريب من أجل تدريب وتقييم النموذج أثناء مرحلة التطوير. حيث ستمنحك منهجية تنبؤات هذا النموذج المُدرّب على المجموعة المخصصة للاختبار غير المرئية، فكرةً دقيقةً عن أداء النموذج وقوته.
لحسن الحظ، لدى المكتبة Scikit-learn دالة تُدعى train_test_split()، والتي ستقسمُ بياناتك لهذه المجموعات. ولكن يجب أن تستورد هذه الدالة أولًا ومن ثَمّ تستخدمها لتقسيم البيانات:
from sklearn.model_selection import train_test_split # تقسيم بياناتنا train, test, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=42)
ستُقسّمُ هذه الدّالة البيانات بطريقةٍ عشوائيةٍ باستخدام الوسيط test_size. في مثالنا لدينا الآن مجموعةً مخصصةً للاختبار test تُمثّل 33٪ من مجموعة البيانات الأصلية، وسيُشكّل الجزء المتبقي من البيانات المجموعة المخصصة للتدريب train. كما لدينا حقولٌ مخصصةٌ لكلٍ من المتغيرات، سواء أكانت مُخصّصةً للاختبار أو للتدريب، أي train_labels وtest_labels. لنُدرّب الآن نموذجنا الأول.
4. بناء النموذج وتقييمه
هناك العديد من النماذج المُخَصصة لتعلّم الآلة، ولكلّ نموذجٍ منها نقاط قوةٍ وضعفٍ. في هذا المقال، سنُركّز على خوارزمية بسيطةٍ تؤدي عادةً أداءً جيدًا في مهام التصنيف الثنائية، وهي خوارزمية بايز Naive Bayes (NB).
أولًا، سنستورد الوِحدة البرمجية GaussianNB ثم نُهَيّئ النموذج باستخدام الدالة GaussianNB()، بعدها سنُدرّب النموذج من خلال مُلاءمته مع البيانات باستخدام الدالة gnb.fit():
from sklearn.naive_bayes import GaussianNB # تهيئة المصنّف خاصتنا gnb = GaussianNB() # تدريب المصنّف model = gnb.fit(train, train_labels)
بعد أن نُدّرب النموذج سنستخدمه للتنبؤ على المجموعة المخصصة للاختبار، وسننفذ ذلك من خلال الدّالة predict()، والتي ستُعيد مجموعةً من التنبؤات لكلّ نسخة بياناتٍ في المجموعة المخصصة للاختبار، ثم نطبع تنبؤاتنا لِفَهم ما حدده هذا النموذج.
استخدِم الدالة predict() مع مجموعة البيانات المخصصة للاختبار test واطبع النتائج:
# بناء التوقعات preds = gnb.predict(test) print(preds)
عند تنفيذك للشيفرة البرمجية تنفيذًا صحيحًا سترى النتائج التالية:
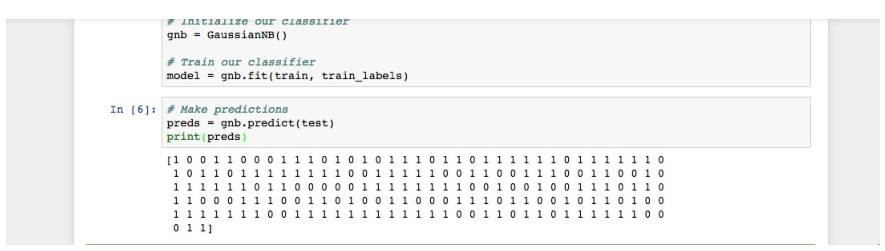
فكما ترى، أعادت الدالة predict() مصفوفةً ثُنائية القيم إما 0 أو 1، حيث تُمثل القيم المتوقعة لصنف الورم (خبيث أم حميد).
والآن بعد أن حصلنا على توقعاتنا، لِنُقيِّم مدى جودة أداء هذا المُصنّف.
5. تقييم دقة النموذج
نُقّيم دقة القيم المتوقَّعة لنموذجنا باستخدام مصفوفة التصنيفات الناتجة للأصناف الحقيقية التي لدينا، وذلك من خلال موازنة المصفوفتين test_labels وpreds باستخدام الدالة accuracy_score() التابعة للمكتبة Scikit-learn، وذلك لتحديد دِقة المُصنّف.
from sklearn.metrics import accuracy_score # تقييم الدقة print(accuracy_score(test_labels, preds))
سترى النتائج التالية:

كما ترى في النتيجة، فإن المُصنّف NB دقيقٌ بنسبة 94.15٪. وهذا يعني أن المُصنِّف قادرٌ على التنبؤ الصحيح فيما إذا كان الورم خبيثًا أو حميدًا بنسبة 94.15٪ من الحالات الكُليّة. كما تُشير هذه النتائج إلى أن مجموعة الميّزات المُكونة من 30 ميزة هي مؤشراتٍ جيدةٍ لصنف الورم.
بهذا تكون قد نجحت في إنشاء مصنِّفك الأول الذي يعتمد في عمله على طرق تعلّم الآلة، والآن لنعد تنظيم الشيفرة البرمجية بوضع جميع عمليات الاستيراد في أعلى الملف، إذ يجب أن تبدو النسخة النهائية من الشيفرة البرمجية خاصتك شبيةً بهذه الشيفرة:
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.naive_bayes import GaussianNB from sklearn.metrics import accuracy_score # تحميل البيانات data = load_breast_cancer() # تنظيم البيانات label_names = data['target_names'] labels = data['target'] feature_names = data['feature_names'] features = data['data'] # الاطلاع على البيانات print(label_names) print('Class label = ', labels[0]) print(feature_names) print(features[0]) # تقسيم البيانات train, test, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=42) # تهيئة المصنّف gnb = GaussianNB() # تدريب المصنّف model = gnb.fit(train, train_labels) # بناء التوقعات preds = gnb.predict(test) print(preds) # تقييم الدقة print(accuracy_score(test_labels, preds))
والآن بإمكانك إكمال العمل على الشيفرة البرمجية، وتحسين عمل المُصنّف وتوسيعه، وكذا تجربة هذا المصنّف مع مجموعاتٍ فرعيةٍ مختلفةٍ من الميزات، أو حتى تجربة خوارزمياتٍ مختلفةٍ تمامًا.
تستطيع الاطلاع على الموقع الرسمي لمكتبة Scikit-Learn لمزيدٍ من الأفكار حول تطبيق تعلّم الآلة مع البيانات لبناء شيءٍ مفيدٍ.
الخلاصة
لقد تعلمنا في هذا المقال كيفية إنشاء مُصنّف بالاعتماد على تعلّم الآلة بلغة بايثون باستخدام المكتبة Scikit-learn، والآن بإمكانك تحميل البيانات في بيئةٍ برمجيةٍ وتنظيمها وتدريبها، وكذا التنبؤ بأشياء بناءً عليها، وتقييم دِقّة المُصنّفات الناتجة.
نتمنى أن تُساعدك هذه الخطوات في تسهيل طريقة العمل مع بياناتك الخاصة بلغة بايثون.
ترجمة -وبتصرف- للفصل How To Build a Machine Learning Classifier in Python with Scikit-learn من كتاب Python Machine Learning Projects لكاتبه Michelle Morales.





أفضل التعليقات
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.