

في هذا المقال من سلسلة تطبيقات عملية على استخدام مكتبة ساي كيت ليرن سنستعرض خطوة بخطوة كيفية تطبيق واحدة من أشهر خوارزميات تعلم الآلة وهي خوارزمية أقرب الجيران k-Nearest Neighbors -أو KNN اختصارًا- لتصنيف الأنواع المختلفة من الأزهار الموجودة ضمن مجموعة بيانات آيرس Iris dataset إحدى أكثر مجموعات البيانات استخدامًا في مجال تعلم الآلة والتي تعرفنا عليها في مقال سابق بعنوان أساسيات تحليل البيانات باستخدام Scikit-Learn.
آلية عمل خوارزمية k-Nearest Neighbors
يمكننا تعريف خوارزمية أقرب جار K-Nearest Neighbors على أنها خوارزمية لا معاملية non-parametric بمعنى أنها لا تملك أوزان أو معاملات تحاول تحسينها كما تتبع خوارزميات ذكاء اصطناعي أخرى، فهي تستخدم في مهام التصنيف Classification وتوقع الانحدار Regression، وفي كلا الحالتين تعتمد على المعلومات المتاحة لدى أقرب k من النقاط المجاورة لمجموعة بيانات التدريب، وتختلف طريقة حساب المخرجات حسب مهمة التعلم.
في حالة التصنيف Classification
يكون خرج النموذج أحد التصنيفات المحددة، ونقرره بناءً على تصويت الأغلبية من عدد k نقطة مجاورة لها حق التصويت أي يسمح لها بالمشاركة في اتخاذ القرار بشأن تصنيف نقطة معينة، ويكون هذا العدد المحدد k من النقاط المجاورة عددًا صحيحًا موجبًا ويفضل أن يكون فرديًا لمنع أي حالات تعادل في التصويت.
من المهم اختيار قيمة k مناسبة في خوارزمية الجار الأقرب، ويفضل أن تكون قيمة صغيرة نسبيًا، فعندما نحدد عدد النقاط المجاورة k=1 سيتأثر قرار النموذج بالضجيج noise في البيانات والنقاط الخارجة outliers وغير المألوفة بشكل كبير، مما يحدث حالة إفراط في التخصيص Overfitting ويضعف قدرته على التعميم لبيانات جديدة، بينما عندما نحدد عدد النقاط المجاورة برقم كبير n يساوي عدد العينات بمجموعة بيانات التدريب سيصبح النموذج أبسط من اللازم وتحدث لديه حالة إفراط في التبسيط Underfitting بالتالي لن يكون قادر على التعبير عن العلاقات المعقدة الموجودة في البيانات وسيأخذ قرارات اعتمادًا على نقاط بعيدة جدًا ولا تؤثر على نقطة الاستفسار الحالية.
في حالة توقع الانحدار Regression
يكون خرج النموذج عدد مستمر ناتج عن أخذ متوسط القيم من عدد محدد k من النقاط المجاورة لتقرير قيمة نقطة الاستفسار الحالية.
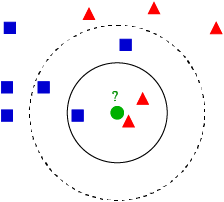
تعرض الصورة السابقة مثالًا على خوارزمية KNN لمهمة التصنيف، وتمثل النقطة الخضراء نقطة الاستفسار الحالية query point والتي نريد تصنيفها إما لصنف المربعات الزرقاء أو المثلثات الحمراء، فإذا قررنا أن عدد النقاط المجاورة k=3 تصبح النقاط الداخلة في القرار هي النقاط المحاطة بالدائرة المتصلة، وكما نرى فالأغلبية في هذا النطاق للمثلثات الحمراء 2 بينما الأقلية هي المربعات الزرقاء 1، بالتالي يمكننا تصنيف نقطة الاستفسار query point بأنها مثلث أحمر، بينما عند زيادة k لتصبح 5 ننظر للنقاط المحاطة بالدائرة المنقطة فنجد أن الأغلبية صارت للمربعات الزرقاء 3 مقابل 2 من المثلثات الحمراء، بالتالي يصبح التصنيف لنقطة الاستفسار مربع أزرق.
بعد أن تعرفنا على آلية عمل الخوارزمية، لنستعرض مجموعة من التدريبات العملية التي تساعدنا على فهم كيفية استخدام هذه الخوارزمية بشكل فعّال باستخدام مكتبة scikit-learn.
فصل مجموعة البيانات
من أولى خطوات التحضير لبناء أي نموذج تعلم آلة هي فصل الخصائص Features وهي البيانات التي نستخدمها لتوقع شيء ما عن الوسوم Labels وهي القيم التي نحاول التنبؤ بها، لنكتب برنامج بايثون لتقسيم مجموعة بيانات أزهار آيرس إلى خصائصها كطول و عرض بتلة الزهرة وسبلتها والتي سنخزنها في متغير X ، والوسوم التي سنخزنها في متغير Y. سيحتوي المتغير X أول أربعة أعمدة بينما يحتوي المتغير Y وسم كل زهرة بفصيلتها مثل Setosa أو Versicolor أو Virginica.
import pandas as pd iris = pd.read_csv("iris.csv") # Idاحذف عمود iris = iris.drop('Id',axis=1) # iloc : تسمح باختيار شريحة من الصفوف والأعمدة # يشير هذا الرمز إلى اختيار جميع العناصر":" X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values print("الخصائص:") print(X) print("\nالوسوم:") print(y)
كما نلاحظ فقد حذفنا في هذه الخطوة عمود المعرف Id من مجموعة البيانات، كونه لا يحمل أي معنى يتعلق بخصائص الأزهار، واستخدامه قد يؤدي لنموذج متحيز وغير دقيق. واستخدمنا التابع iloc لتحديد الخصائص X، والوسوم Y وأخيرًا، طبعنا كلًا من X و Y للتأكد من صحة التقسيم.
عند تنفيذ الكود سنحصل على الخرج التالي:
الخصائص: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] ... [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الوسوم: ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' … 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica']
تقسيم مجموعة البيانات لمجموعة تدريب ومجموعة اختبار
نحتاج لتقسيم البيانات إلى بيانات تدريب training وبيانات اختبار testing حتى نتمكن من معرفة فيما إذا كان النموذج يعمل جيدًا على بيانات جديدة لم يرها من قبل، سنكتب كود لتقسيم مجموعة بيانات آيرس إلى مجموعة تدريب تحتوي 80% من البيانات ومجموعة اختبار تحتوي 20%، بحيث يكون عدد العينات المستخدمة في التدريب هو 120 عينة والمستخدمة في الاختبار 30 عينة، ونطبع كلا المجموعتين.
import pandas as pd from sklearn.model_selection import train_test_split iris = pd.read_csv("iris.csv") # Id احذف العمود iris = iris.drop('Id',axis=1) # iloc : تسمح لنا باختيار شريحة من الصفوف والأعمدة # يشير هذا الرمز إلى اختيار جميع العناصر":" X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسم هذه الدالة مجموعة البيانات عشوائيًا وفقًا للنسب المحددة X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) print("\n70% train data:") print(X_train) print(y_train) print("\n30% test data:") print(X_test) print(y_test)
فصلنا في البداية مجموعة البيانات إلى خاصيات X ووسوم Y كما في فعلنا في التطبيق السابق، ثم استدعينا الدالة train_test_split التي تقسم خاصيات ووسوم المجموعة إلى مجموعة تدريب ومجموعة اختبار، وحددنا نسبة التقسيم باستخدام test_size=0.20 لجعل 20% من مجموعة البيانات مخصصة للاختبار، بينما 80% منها للتدريب، سيجري تقسيم البيانات عشوائيًا في كل مرة نشغل بها الكود.
عند تنفيذ الكود السابق سنحصل على خرج مشابه لما يلي:
الخصائص: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] … [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الوسوم: ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' … 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica'] 70% train data: [[5.6 2.5 3.9 1.1] [5.6 2.9 3.6 1.3] [4.7 3.2 1.6 0.2] [5.4 3.9 1.7 0.4] [5.1 3.8 1.6 0.2] … [4.8 3. 1.4 0.1] [6. 2.7 5.1 1.6] [5.6 2.8 4.9 2. ] [7.7 2.6 6.9 2.3] [7.2 3.6 6.1 2.5] [5.6 3. 4.5 1.5]] ['Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' … 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor'] 30% test data: [[5.5 2.3 4. 1.3] [6.4 3.1 5.5 1.8] [4.8 3. 1.4 0.3] [5. 3.2 1.2 0.2] [5.6 3. 4.1 1.3] … [6.4 2.8 5.6 2.2] [6.9 3.2 5.7 2.3] [6.1 2.6 5.6 1.4] [6.5 3. 5.2 2. ] [4.8 3.1 1.6 0.2]] ['Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa']
ترقيم الفصائل النصية
الأن سنعمل على تطبيق يحوّل فصائل الأزهار في مجموعة بيانات آيرس من أسماء نصية إلى قيم رقمية، ولنفعل ذلك سنحتاج لتحويل كل قيمة إلى رقم ثابت لهذه القيمة، فمثلًا نجعل Iris-setosa:0 و Iris-versicolor:1 و Iris-virginica:2، ثم نطبع مجموعة بيانات التدريب ومجموعة بيانات الاختبار.
import pandas as pd from sklearn.model_selection import train_test_split # LabelEncoder استدعي # والذي سوف نستخدمه لتحويل الفصائل من قيم نصية إلى أرقام ثابته لكل فصيلة from sklearn.preprocessing import LabelEncoder iris = pd.read_csv("iris.csv") # labelEncoder نهيئ الصنف البرمجي le = LabelEncoder() # labelEncoder نستخدم الصنف البرمجي # لتحويل التصنيفات النصية إلى أرقم iris.Species = le.fit_transform(iris.Species) # Id نحذف العمود # حيث لا يحتوي معلومات مهمة للتعلم iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # نقسم مجموعة البيانات إلى مجموعة تدريب ومجموعة اختبار # كل منهما له خصائص ووسوم منفصلة X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) print("\n80% train data:") print(X_train) print(y_train) print("\n20% test data:") print(X_test) print(y_test)
استخدمناLabelEncoder() لنهيئ الكائن le والذي سنستخدمه لتحويل الفصائل النصية categorical classes لأرقام، حيث نرمز لكل صنف أو اسم برقم ثابت لهذا الصنف، ونستدعي هذا الكائن ليطبّق على البيانات باستخدام le.fit_transform(iris.Species) حيث تتعرف هذه الدالة في البداية على الأصناف في عمود Species وتحدد القيم التي ستعطى لكل فصيل category وتسمى هذه العملية fit ويمكن تنفيذها بشكل مستقل، ومن ثم يتم تحويل القيم النصية القديمة إلى الأرقام المقابلة عند تنفيذ عملية transform التي يمكن فصلها لكي تنفّذ بعد عملية fit على أكثر من مجموعة من البيانات التي تتضمن نفس الفصائل، ولكن في كثير من الأحيان نستخدم الدالة التي تدمج الخطوتين معًا.
عند تنفيذ الكود سنحصل على الخرج التالي:
الخصائص: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] … [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]] الوسوم: ['Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' … 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica'] 70% train data: [[5.6 2.5 3.9 1.1] [5.6 2.9 3.6 1.3] [4.7 3.2 1.6 0.2] [5.4 3.9 1.7 0.4] [5.1 3.8 1.6 0.2] … [5.6 2.8 4.9 2. ] [7.7 2.6 6.9 2.3] [7.2 3.6 6.1 2.5] [5.6 3. 4.5 1.5]] ['Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' … 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor'] 30% test data: [[5.5 2.3 4. 1.3] [6.4 3.1 5.5 1.8] [4.8 3. 1.4 0.3] [5. 3.2 1.2 0.2] [5.6 3. 4.1 1.3] … [6.4 2.8 5.6 2.2] [6.9 3.2 5.7 2.3] [6.1 2.6 5.6 1.4] [6.5 3. 5.2 2. ] [4.8 3.1 1.6 0.2]] ['Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa'] 80% train data: [[7.7 2.8 6.7 2. ] [6.7 3.1 5.6 2.4] [5.7 2.6 3.5 1. ] [6.3 2.8 5.1 1.5] [4.9 3.1 1.5 0.1] … [4.8 3. 1.4 0.3] [6.4 2.9 4.3 1.3] [4.8 3. 1.4 0.1] [5.5 2.6 4.4 1.2] [6.3 2.3 4.4 1.3]] [2 2 1 2 0 0 0 2 2 2 2 2 0 0 2 2 1 2 1 0 1 2 0 1 2 0 1 2 2 0 1 1 1 2 0 1 0 1 0 2 2 2 0 2 1 1 0 2 1 2 1 0 0 1 1 2 0 0 2 1 1 2 0 1 1 0 0 2 0 0 1 1 2 1 0 1 2 2 0 1 0 0 2 0 0 2 0 1 1 2 2 0 0 1 2 0 1 1 1 0 0 1 0 2 2 0 0 0 2 2 0 2 2 0 2 0 1 0 1 1] 20% test data: [[6.8 3.2 5.9 2.3] [5.4 3. 4.5 1.5] [4.3 3. 1.1 0.1] [5.6 3. 4.1 1.3] [6.7 3. 5. 1.7] … [5.8 2.7 3.9 1.2] [6.3 2.5 5. 1.9] [6.3 3.3 4.7 1.6] [5.1 3.7 1.5 0.4] [6.9 3.2 5.7 2.3]] [2 1 0 1 1 0 2 2 2 1 0 2 1 1 1 1 1 2 1 1 1 0 2 0 0 1 2 1 0 2]
بناء نموذج K-Nearest Neighbors باستخدام ساي كيت ليرن Scikit-Learn
لنكتب كود برمجي لجعل نسبة تقسيم مجموعات البيانات 70% لمجموعة التدريب و30% لمجموعة الاختبار، حيث يصبح عدد العينات المستخدمة في التدريب 105 عينة وعدد عينات الاختبار 45، ثم نتوقع باستخدام نموذج KNN تصنيفات الفصائل لمجموعة الاختبار مع تحديد عدد النقاط المجاورة ليكون 5.
import pandas as pd from sklearn.model_selection import train_test_split # نستدعي المُصنف من مكتبة ساي كيت ليرن from sklearn.neighbors import KNeighborsClassifier iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم مجموعات البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30) # KNN Classifier استدعي # القيمة الافتراضية لعدد النقاط المجاورة التي لها حق التصويت هي 5 knn = KNeighborsClassifier(n_neighbors=5) # درب النموذج باستخدام مجموعة بيانات التدريب # في عملية التدريب الخاضع للإشراف يستطيع النموذج أن يستخدم وسم البيانات knn.fit(X_train, y_train) # استخدم النموذج المدرب لتوقع مجموعة بيانات الاختبار print("Response for test dataset:") y_pred = knn.predict(X_test) print(y_pred)
استخدمنا دالة knn.fit(X_train, y_train) لتدريب الكائن الذي يُطبق خوارزمية KNN في مكتبة ساي كيت ليرن، ولتدريب النموذج استخدمنا مجموعة خاصيات التدريب X_train والوسوم المقابلة لها y_train، وأثناء تهيئة الكائن عرفنا بعض الإعدادات والمعاملات مثل عدد النقاط المجاورة n_neighbors، وبعد تدريب النموذج استخدمناه لتوقع وسوم خاصيات مجموعة الاختبار X_test.
عند تنفيذ الكود سنحصل على الخرج التالي:
Response for test dataset: ['Iris-versicolor' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-versicolor' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-versicolor' 'Iris-setosa' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica' 'Iris-setosa' 'Iris-setosa' 'Iris-setosa' 'Iris-virginica' 'Iris-virginica' 'Iris-versicolor' 'Iris-versicolor' 'Iris-virginica' 'Iris-virginica' 'Iris-virginica' 'Iris-setosa' 'Iris-virginica']
نلاحظ أن النموذج استطاع التعامل مع القيم النصية لتصنيفات الفصائل بشكل مباشر، وهذا ليس السائد في نماذج تعلم الآلة حيث أغلبها يتوقع فقط قيمًا رقمية حيث أن أغلب الخوارزميات تقوم بعمليات رياضية، ولكن كما ذكرنا من قبل فإن خوارزمية KNN لا معاملية non-parametric ولا تقوم بأي عمليات رياضية معقدة، فقط عملية التصويت في حالة التصنيف.
نلاحظ أيضًا أن هذا يعمل فقط مع القيم النصية للوسوم وليس للخاصيات أو الأعمدة الأخرى المستخدمة في التدريب، حيث يحتاج النموذج لحساب المسافة بين نقطة الاستفسار query points وبين جميع النقاط في مجموعة التدريب المخزنة في الذاكرة ليستطيع تقرير أقرب k من النقاط المجاورة مسافةً.
اختبار تأثير تغير عدد النقاط المجاورة K في خوارزمية KNN
سنكتب تطبيق لتقسيم مجموعة بيانات آيرس بنسبة 80% لمجموعة بيانات التدريب و20% لمجموعة بيانات الاختبار، ثم ندرب نموذج KNN على مجموعة بيانات التدريب ونحسب دقة النموذج في توقع وسوم مجموعة الاختبار، لنجرب قيمًا مختلفة لعدد النقاط المجاورة من 1 إلى 9 ونحسب دقة النموذج لكل قيمة.
import pandas as pd from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20) # k احسب الدقة لكل قيمة # k=1,2,...,9 for k in range(1, 10): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) print("For k = %d accuracy is"%k,knn.score(X_test,y_test))
أنشأنا حلقة تكرارية حيث نجرب قيمًا مختلفة لعدد النقاط المجاورة k وندرب النموذج ونحسب دقته ونطبعها.
عند تنفيذ الكود سنحصل على الخرج التالي:
For k = 1 accuracy is 0.9666666666666667 For k = 2 accuracy is 0.9666666666666667 For k = 3 accuracy is 0.9666666666666667 For k = 4 accuracy is 0.9333333333333333 For k = 5 accuracy is 0.9666666666666667 For k = 6 accuracy is 0.9666666666666667 For k = 7 accuracy is 0.9666666666666667 For k = 8 accuracy is 0.9333333333333333 For k = 9 accuracy is 0.9666666666666667
رسم بياني لدراسة تأثير تغير عدد النقاط المجاورة K في خوارزمية KNN
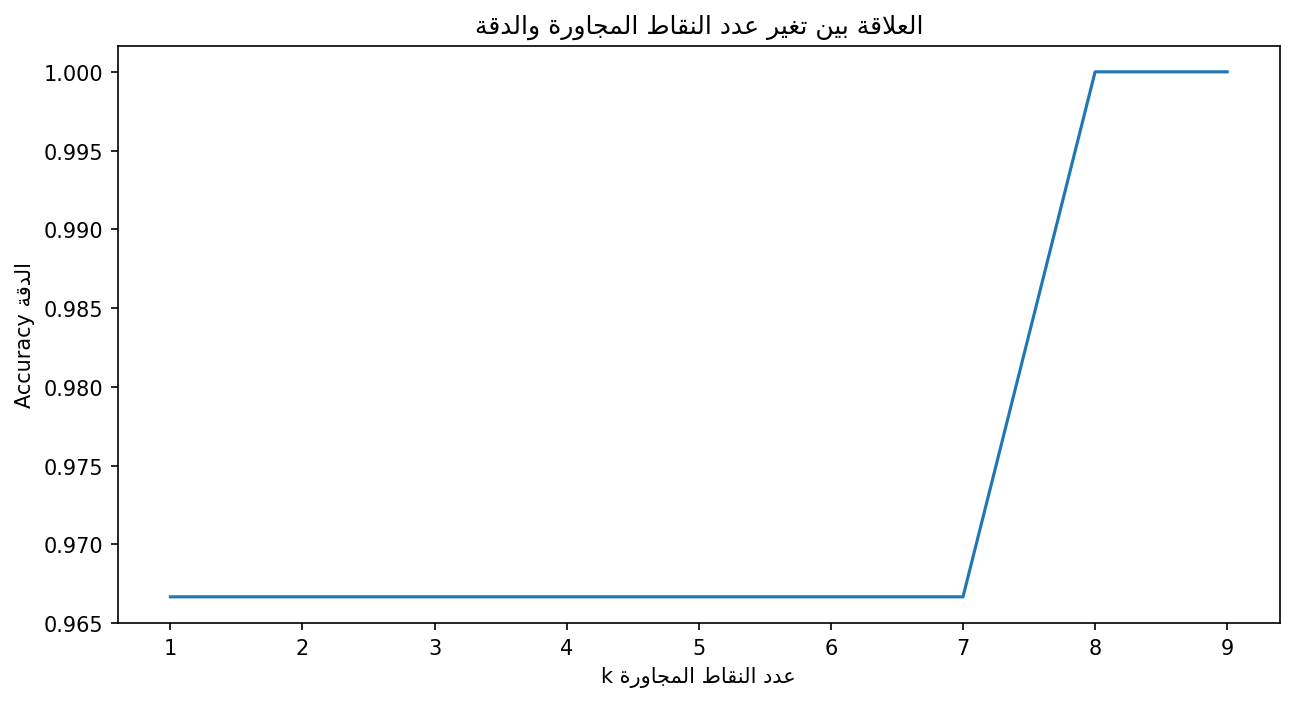
لنقسم الآن مجموعة بيانات آيرس بنسبة 80% لمجموعة بيانات التدريب و20% لمجموعة بيانات الاختبار، ثم ندرب نموذج KNN على مجموعة بيانات التدريب ونحسب دقة النموذج في توقع وسوم مجموعة الاختبار، لنجرب قيمًا مختلفة لعدد النقاط المجاورة من 1 إلى 9 ونحسب لكل قيمة دقة النموذج، ونرسم رسمًا بيانيًا جاعلين محور السينات x للقيم المختلفة لعدد النقاط المجاورة K، بينما محور الصادات y للدقة التي حققها النموذج باستخدام قيمة k.
import pandas as pd import matplotlib.pyplot as plt from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split # لضبط عرض النص العربي from arabic_reshaper import reshape from bidi.algorithm import get_display iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=10) # random_state معامل يضمن ثبات نتيجة التجربة عند تشغيل الكود مرة أخرى # بدون هذا المعامل ستحصل على نتيجة مختلفة بكل مرة تشغل بها الكود # accuracy نعرف قائمة لحفظ القيم الدقة acc = [] # k احسب الدقة لكل قيمة # k=1,2,...,9 for k in range(1, 10): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) score = knn.score(X_test,y_test) acc.append(score) plt.figure(figsize=(10, 5), dpi=150) plt.plot([k for k in range(1, 10)], acc) plt.title(get_display(reshape("العلاقة بين تغير عدد النقاط المجاورة والدقة"))) plt.xlabel(get_display(reshape("k عدد النقاط المجاورة"))) plt.ylabel(get_display(reshape("Accuracy الدقة"))) plt.show()
أنشانا في الكود السابق حلقة تكرارية حيث نجرب قيمًا مختلفة لعدد النقاط المجاورة k وندرب النموذج ونحسب دقته ونطبعها، وقد حفظنا دقة النموذج عند كل نقطة k في القائمة acc لنستخدمها في الرسم البياني، ويمكن أن نلاحظ أننا استخدمنا random_state=10 لتثبيت تقسيم البيانات العشوائي وجعل الكود يخرج نفس الرسم البياني في كل مرة.
عند تنفيذ الكود سنحصل على الرسم البياني التالي:
مقارنة أداء النموذج بين مجموعة بيانات التدريب ومجموعة بيانات الاختبار
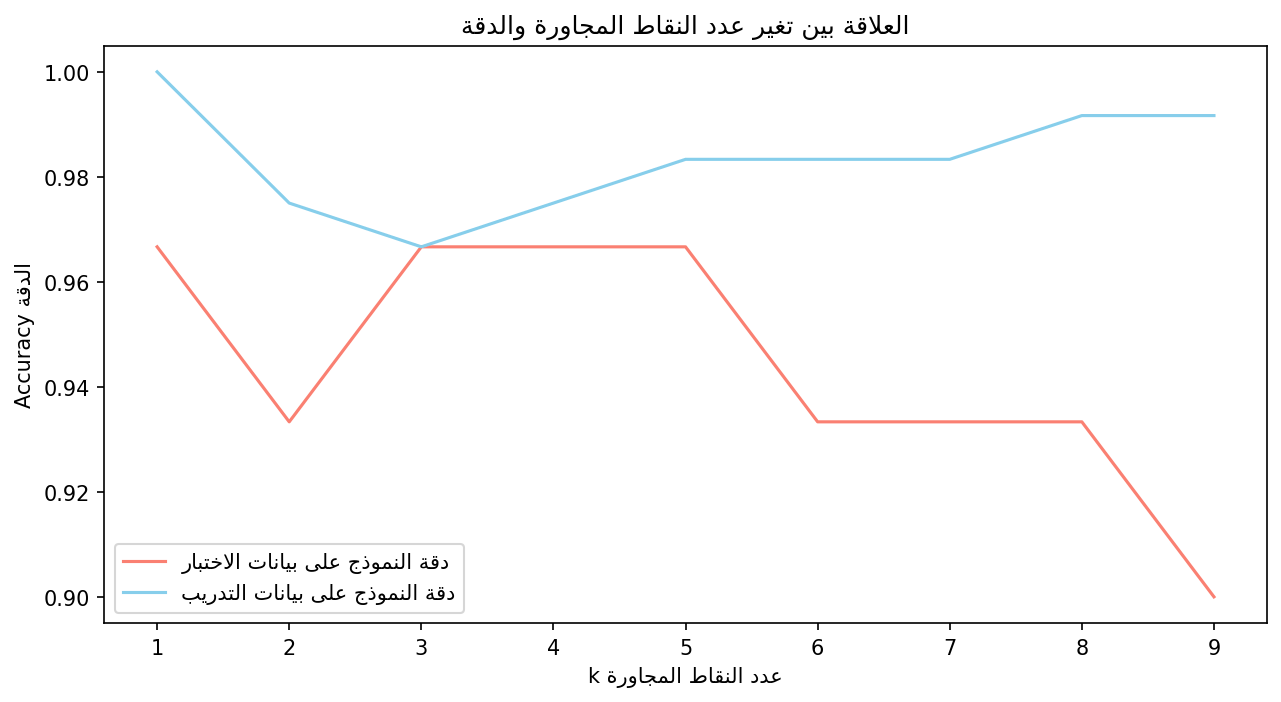
سنكتب برنامج لتقسيم مجموعة بيانات آيرس بنسبة 80% لمجموعة بيانات التدريب و20% لمجموعة بيانات الاختبار، ثم درب نموذج KNN على مجموعة بيانات التدريب ونحسب دقة النموذج في توقع وسوم مجموعة الاختبار، وكذلك دقته في توقع وسوم مجموعة التدريب، لنجرب قيمًا مختلفة لعدد النقاط المجاورة من 1 إلى 9 ونحسب لكل قيمة دقة النموذج، ونرسم رسمًا بيانيًا جاعلين محور السينات x للقيم المختلفة لعدد النقاط المجاورة K، بينما محور الصادات y للدقة التي حققها النموذج باستخدام قيمة k، سنستخدم هذا الرسم البياني للمقارنة بين أداء النموذج على مجموعة التدريب أمام أدائه على مجموعة الاختبار.
import pandas as pd import matplotlib.pyplot as plt from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split # لضبط عرض النص العربي from arabic_reshaper import reshape from bidi.algorithm import get_display iris = pd.read_csv("iris.csv") iris = iris.drop('Id',axis=1) X = iris.iloc[:, :-1].values y = iris.iloc[:, 4].values # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=21) # random_state معامل يضمن ثبات نتيجة التجربة عند تشغيل الكود مرة أخرى # بدون هذا المعامل ستحصل على نتيجة مختلفة بكل مرة تشغل بها الكود # accuracy نعرف قائمة لحفظ القيم الدقة test_acc = [] train_acc = [] # k احسب الدقة لكل قيمة # k=1,2,...,9 for k in range(1, 10): knn = KNeighborsClassifier(n_neighbors=k) knn.fit(X_train, y_train) test_score = knn.score(X_test,y_test) train_score = knn.score(X_train, y_train) test_acc.append(test_score) train_acc.append(train_score) plt.figure(figsize=(10, 5), dpi=150) plt.plot([k for k in range(1, 10)], test_acc, label=get_display(reshape("دقة النموذج على بيانات الاختبار")), color='salmon') plt.plot([k for k in range(1, 10)], train_acc, label=get_display(reshape("دقة النموذج على بيانات التدريب")), color="skyblue") plt.title(get_display(reshape("العلاقة بين تغير عدد النقاط المجاورة والدقة"))) plt.xlabel(get_display(reshape("k عدد النقاط المجاورة"))) plt.ylabel(get_display(reshape("Accuracy الدقة"))) plt.legend() plt.show()
يختلف هذا التدريب عن السابق في أنه يحسب الدقة على مجموعة التدريب ومجموعة الاختبار وهي استراتيجية شائعة تستخدم لاختبار مدى قدرة النموذج على التعميم generalization، حيث لا ينبغي أن يكون الفرق المطلق بين أداء النموذج على مجموعة التدريب ومجموعة الاختبار كبيرًا، فأن كان أداء النموذج جيد جدًا في مجموعة التدريب وسيئ للغاية فهذا النموذج ليس قابلًا للاستخدام في العالم الحقيقي على البيانات التي لم يرها من قبل، يمكن تشبيه هذه الحالة بالطالب الذي حفظ أسئلة الاختبار وعند تخرجه ليواجه المشاكل الحقيقية فشل فشلًا ذريعًا لأنه في واقع الأمر حفظ البيانات ولم يتعلم منها وتعرف هذه الحالة بالمسايرة المفرطة أو فرط التخصيص overfitting، وفي الحالة التي يكون أداء النموذج سئيًا على كل من مجموعة بيانات الاختبار والتدريب فتعرف هذه الحالة بقلة التخصيص underfitting وهي بساطة النموذج لدرجة تمنعه من تعلم الأنماط المعقدة الموجودة في مجموعة البيانات.
عند تنفيذ الكود سنحصل على الرسم البياني التالي:
الخاتمة
تناولنا في المقال الثالث من سلسلة تطبيقات ساي كيت ليرن مجموعة تدريبات على خوارزمية أقرب الجيران K-Nearest Neighbors واستخدمناها لتصنيف فصائل أزهار آيرس، ودرسنا كيفية تقسيم البيانات لمجموعة تدريب ومجموعة اختبار مع تقييم النموذج وحساب دقة التوقعات،كما تعرفنا على تأثير عدد النقاط المجاورة في هذه الخوارزمية، سنتدرب في المقال القادم على استخدام خوارزمية الانحدار اللوجيستي Logistic Regression وهي أيضًا خوارزمية أساسية من خوازرميات التصنيف Classification وتستخدم في مهام عديدة مثل تشخيص الأمراض وتصنيف رسائل البريد.











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.