

نتناول في هذه السلسلة مجموعة متنوعة من التطبيقات العملية حول تعلم الآلة Machine Learning باستخدام إطار عمل ساي كيت ليرن Scikit-Learn الذي يوفر حزمة من الأدوات البرمجية مفتوحة المصدر تشمل خوارزميات تعلم الآلة كخوارزميات التصنيف Classification وتوقع الانحدار Regression وخوارزميات العنقدة Clustering، وقد صمم هذا الإطار ليعمل بكفاءة مع العديد من مكتبات بايثون القوية مثل NumPy و SciPy.
الهدف من هذه السلسلة إرشاد المبتدئين من خلال مجموعة من التدريبات العملية المكتوبة بلغة بايثون وإطار عمل ساي كيت ليرن Scikit-Learn، فالتطبيق وحل التدريبات واحدة من أفضل طرق التعلم واكتساب المهارات لذا ننصح بمحاولة إيجاد الحل بأنفسكم قبل النظر في الأكواد المرفقة لتحقيق استفادة أفضل.
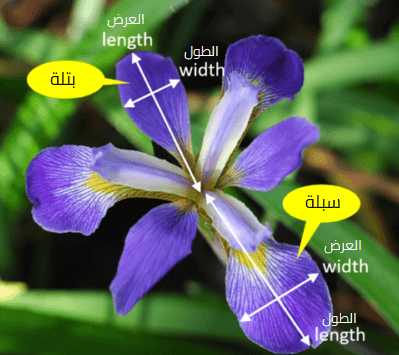
ما هي مجموعة بيانات أزهار آيرس؟
سنستخدم في التطبيقات العملية مجموعة بيانات أزهار آيرس أو السوسن Iris dataset وهي مجموعة بيانات من عدة متغيرات استخدمت بواسطة عالم الإحصاء والأحياء رونالد فيشر في ورقته البحثية لعام 1936، وهي تسمى أيضًا مجموعة بيانات اندرسون نسبة للعالم الذي جمعها ليحلل التغيرات الشكلية بين الفصائل الثلاث لهذه الأزهار.

تتكون مجموعة البيانات من 50 عينة لكل فصيلة من الفصائل الثلاثة للأزهار، وهي Iris setosa و Iris virginica و Iris versicolor وقيست أربعة خصائص لكل عينة وهي:
- طول البتلة Petal length
- عرض البتلة Petal width
- طول السبلة Sepal length
- عرض السبلة Sepal width
وباستخدام هذه التوليفة من الخصائص استطاع فيشر تطوير نموذج تميز خطي Linear discrimination قادر على التفريق بين الفصائل وبعضها.
تطبيقات أساسية باستخدام مكتبة باندا Pandas
سنتعرف على مجموعة من التطبيقات التي تستخدم مكتبة باندا Pandas لتحليل واستكشاف مجموعة البيانات والتي تعد خطوة أساسية في أي مشروع لتعلم الآلة.
تحميل مجموعة البيانات إلى إطار البيانات DataFrame
سنكتب برنامج بلغة برمجة بايثون لتحميل مجموعة بيانات آيرس من ملف csv إلى البنية pandas التي توفرها مكتبة dataframe ونطبع شكل البيانات ونوعها وأول ثلاثة صفوف منها.
import pandas as pd data = pd.read_csv("iris.csv") print("Shape of the data:") print(data.shape) print("\nData Type:") print(type(data)) print("\nFirst 3 rows:") print(data.head(3))
النمط DataFrame هو نمط توفره مكتبة pandas لتنظيم البيانات وتخزينها على هيئة جدول، وقد استوردنا في الكود السابق مكتبة pandas وقرأنا البيانات المطلوبة من الملف iris.csv وخزناها في متغير data من النمط DataFrame، ثم عرضنا عدد الأبعاد -أي عدد الصفوف والأعمدة الموجود في هذا الكائن- باستخدام التابع shape ونوع بياناته باستخدام التابع type وعرضنا أول 3 صفوف من البيانات فقط باستخدام التعليمة data.head(3).
عند تنفيذ الكود، نحصل على الخرج التالي:
Shape of the data: (150, 6) Data Type: <class 'pandas.core.frame.DataFrame'> First 3 rows: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 1 5.1 3.5 1.4 0.2 Iris-setosa 1 2 4.9 3.0 1.4 0.2 Iris-setosa 2 3 4.7 3.2 1.3 0.2 Iris-setosa
استعراض خصائص مجموعات بيانات آيرس
الآن، سكتب برنامج بايثون باستخدام ساي كيت ليرن Scikit-Learn لطباعة مفاتيح الأعمدة Keys وعدد الصفوف وعدد الأعمدة وأسماء الخاصيات والوصف لمجموعة بيانات آيرس.
import pandas as pd iris_data = pd.read_csv("iris.csv") print("\nKeys of Iris dataset:") print(iris_data.keys()) print("\nNumber of rows and columns of Iris dataset:") print(iris_data.shape)
استخدمنا هنا أيضًا بنية DataFrame كما في المثال السابق لتخزين البيانات ضمن متغير باسم iris_data وعرضنا المفاتيح أو أسماء الأعمدة في مجموعة البيانات باستخدام الدالة iris_data.keys() والتي تمثل المتغيرات أو الخصائص المختلفة بيانات الأزهار، وعرضنا أخيرًا عدد الصفوف والأعمدة باستخدام الدالة iris_data.shape.
سنحصل على الخرج التالي من تنفيذ الكود أعلاه:
Keys of Iris dataset:
Index(['Id', 'SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm',
'Species'],
dtype='object')
Number of rows and columns of Iris dataset:
(150, 6)
عرض عدد العينات وعدد القيم المفقودة في مجموعة بيانات آيرس
فيما يلي كود بايثون لمعرفة عدد العينات في مجموعة بيانات الأزهار، وعدد القيم المفقودة فيها.
import pandas as pd iris = pd.read_csv("iris.csv") print(iris.info())
استوردنا مجموعة البيانات بشكل بنية جدول DataFrame وخزناها في متغير باسم iris وطبعنا المعلومات التي نحتاجها باستخدام الدالة iris.info() التي تعرض بعض المعلومات المهمة مثل عدد العينات ونوع العمود الفهرسي Index column وكذلك عدد القيم الفعلية non-null ونوع البيانات لكل عمود، بالإضافة للذاكرة RAM المستهلكة لتخزين البيانات.
نحصل على الخرج التالي من تنفيذ الكود أعلاه:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 150 entries, 0 to 149 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Id 150 non-null int64 1 SepalLengthCm 150 non-null float64 2 SepalWidthCm 150 non-null float64 3 PetalLengthCm 150 non-null float64 4 PetalWidthCm 150 non-null float64 5 Species 150 non-null object dtypes: float64(4), int64(1), object(1) memory usage: 7.2+ KB None
المصفوفات المتناثرة Dense Matrices والمصفوفات عالية الكثافة Dense Matrices باستخدام NumPy و Scipy
سنعمل في هذه الفقرة على إنشاء مصفوفة ثنائية الأبعاد 2D array مليئة بالواحد في كل عناصرها لواقعة على القطر الرئيسي والقيمة الصفر فيما دون ذلك، ثم نحول المصفوفة من نوع NumPy array إلى مصفوفة SciPy sparse matrix أي مصفوفة متناثرة بتنسيق CSR هو أحد تنسيقات مكتبة SciPy لتمثيل المصفوفات.
وتعرف المصفوفة المتناثرة بأنها مصفوفة تحتوي في الغالب على أصفار Sparse matrix، وعلى النقيض تمامًا فإن المصفوفة الي يكون غالب عناصرها قيم لا تساوي الصفر تسمى مصفوفة عالية الكثافة Dense matrix، ويعرف معدل التناثر sparsity على أنه عدد العناصر الصفرية مقسومة على إجمالي العناصر بالمصفوفة، ويساوي أيضًا 1 مطروحًا منه معدل الكثافة Density للمصفوفة، وباستخدام هذه التعريفات يمكننا تصنيف مصفوفة بأنها متناثرة sparse إن كان معدل تناثرها Sparsity أكبر من 0.5.
تكمن فائدة تحويل المصفوفة من NumPy array إلى صيغة مصفوفة متناثرة الصفوف CSR باستخدام SciPy خطوة مفيدة وفعالة وتسرع الوصول إلى العناصر ذات القيمة الفعلية غير الصفرية داخل المصفوفة، حيث تتيح صيغة CSR تخزين المصفوفة بشكل مضغوط دون الحاجة إلى تخزين الأصفار، مما يقلل من استهلاك الذاكرة ويزيد من كفاءة المعالجة.
تبرز أهمية هذا التحويل بشكل خاص عند إجراء عمليات رياضية أو تحليل بيانات على مصفوفات كبيرة، حيث يسهم تجاهل الأصفار في تسريع الحسابات دون التأثير على النتائج.
import numpy as np from scipy import sparse eye = np.eye(4) print("NumPy array:\n", eye) sparse_matrix = sparse.csr_matrix(eye) print("\nSciPy sparse CSR matrix:\n", sparse_matrix)
بعد أن استوردنا مكتبتي NumPy و SciPy استخدمنا الدالة np.eye() لإنشاء مصفوفة ثنائية الأبعاد تتكون جميع عناصرها من أصفار فيما عدا عناصر القطر الرئيسي للمصفوفة حيث تساوي عناصره الواحد، ومررنا للدالة العدد 4 وهو عدد الصفوف، وثم خزنا الناتج في الكائن eye وطبعنا المصفوفة التي يخزنها الكائن قبل أن تحويلها، واستخدمنا الدالة sparse.csr_matrix(eye) لتحويل المصفوفة للصيغة المضغوطة CSR، وطبعنا الكائن الذي يحتوي المصفوفة الجديدة لنقارن بين الصيغتين.
سنحصل على الخرج التالي من تنفيذ الكود أعلاه:
NumPy array: [[1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]] SciPy sparse CSR matrix: (0, 0) 1.0 (1, 1) 1.0 (2, 2) 1.0 (3, 3) 1.0
نلاحظ أن صيغة CSR لا تعرض كل عناصر المصفوفة، بل تُظهر العناصر التي تحتوي على أرقام غير صفرية فقط. وبما أن المصفوفة تحتوي على 1 في كل موقع قطري سنجد تساوي دليل الصف مع دليل العمود.
عرض الاحصائيات الأساسية عن مجموعة بيانات آيرس باستخدام باندا Pandas
لعرض المعلومات الاحصائية الأساسية عن مجموعة البيانات مثل المتوسط والانحراف المعياري والتوزيع وغيرها من المعلومات نكتب الكود التالي:
import pandas as pd data = pd.read_csv("iris.csv") print(data.describe())
استخدمنا التابع data.describe() للحصول على إحصائيات عن الكائن data من نوع DataFrame، مثل عدد القيم count والمتوسط الحسابي mean والانحراف المعياري standard deviation والتوزيع المئوي percentiles وهي إحصائية تقيس الترتيب النسبي لموقع نقطة في مجموعة البيانات، فمثلًا عند قولنا أن التوزيع المئوي 25% يساوي 38.25 فهذا يعني أن 25% من القيم الموجودة في البيانات أقل من هذا العدد، وتوجد ثلاث توزيعات مئوية أساسية هي 25% و 50% و75% تمثل الأرباع Q1 و Q2 و Q3 على الترتيب، ويعرف Q2 خاصةً بالوسيط median وهو الرقم الوسيط بين مجموعة من القيم المرتبة، وتعرض أيضًا القيمة العظمى لكل عمود، ولا تأخذ هذه الدالة في الاعتبار القيم المفقودة NAN، ولا تعمل إلا على الأعمدة الرقمية Numerical.
نحصل على الخرج التالي من تنفيذ الكود أعلاه:
Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm count 150.000000 150.000000 150.000000 150.000000 150.000000 mean 75.500000 5.843333 3.054000 3.758667 1.198667 std 43.445368 0.828066 0.433594 1.764420 0.763161 min 1.000000 4.300000 2.000000 1.000000 0.100000 25% 38.250000 5.100000 2.800000 1.600000 0.300000 50% 75.500000 5.800000 3.000000 4.350000 1.300000 75% 112.750000 6.400000 3.300000 5.100000 1.800000 max 150.000000 7.900000 4.400000 6.900000 2.500000
معرفة عدد عينات كل نوع Categorical values باستخدام Pandas
لنحصل على عدد عينات كل فصيلة من الفصائل في مجموعة بيانات الأزهار نكتب الكود على النحو التالي:
import pandas as pd data = pd.read_csv("iris.csv") print("Observations of each species:") print(data['Species'].value_counts())
استخدمنا الدالة value_counts() على العمود Species الذي يحتوى وسمًا لكل عينة في مجموعة البيانات، تسمح هذه الدالة بالحصول على عدد العينات في كل تصنيف، بمعنى أخر سنعرف كم عينة تنتمي لكل فصيلة من الأزهار. سنحصل على الخرج التالي من تنفيذ الكود أعلاه:
Observations of each species: Iris-setosa 50 Iris-versicolor 50 Iris-virginica 50 Name: Species, dtype: int64
نلاحظ من الخرج السابق أن البيانات تحتوي على 150 زهرة موزعة بالتساوي على الفصائل الثلاثة.
حذف عمود من DataFrame باستخدام Pandas
لحذف عمود Id وطباعة أول خمسة صفوف حصلنا عليها بعد حذفه نكتب الكود التالي.
import pandas as pd data = pd.read_csv("iris.csv") print("Original Data:") print(data.head()) new_data = data.drop('Id',axis=1) print("After removing id column:") print(new_data.head())
لحذف عمود من بنية DataFrame نستخدم الدالة drop() ونمرر لها اسم العمود المطلوب والمعامل axis وهو معامل يقبل قيمتين إما 0 وتعني أننا نريد حذف عمود، أو 1 والتي تعني أننا نريد حذف صف، ثم نستدعي new_data.head() لعرض أول خمسة صفوف من مجموعة البيانات الجديدة التي حصلنا عليها.
سنحصل على الخرج التالي من تنفيذ الكود أعلاه:
Original Data: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 1 5.1 3.5 1.4 0.2 Iris-setosa 1 2 4.9 3.0 1.4 0.2 Iris-setosa 2 3 4.7 3.2 1.3 0.2 Iris-setosa 3 4 4.6 3.1 1.5 0.2 Iris-setosa 4 5 5.0 3.6 1.4 0.2 Iris-setosa After removing id column: SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa
اختيار شرائح معينة من مجموعة البيانات باستخدام Panda
للوصول إلى أول أربع خلايا من كل صف في مجموعة البيانات المخزنة في بنية DataFrame واستخدم أسماء الأعمدة بالإضافة للفهرس للوصول للخلايا المحددة سنكتب كود بايثون التالي:
import pandas as pd data = pd.read_csv("iris.csv") print("Original Data:") print(data.head()) new_data = data.drop('Id',axis=1) print("After removing id column:") print(new_data.head()) x = data.iloc[:, [1, 2, 3, 4]].values print(x)
يسمح لنا التابع data.iloc[] باختيار شريحة معينة من مجموعة البيانات، حيث نحدد قبل الفاصلة الأولى الصفوف التي نريد أن تدخل في الاختيار، وبعد الفاصلة الأعمدة التي نريد أن تدخل في الاختيار، وفي حالتنا اخترنا عرض قيم جميع الصفوف باستخدام الرمز : والموجودة في أعمدة محددة [1,2,3,4].
سنحصل على الخرج التالي من تنفيذ الكود أعلاه:
Original Data: Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 1 5.1 3.5 1.4 0.2 Iris-setosa 1 2 4.9 3.0 1.4 0.2 Iris-setosa 2 3 4.7 3.2 1.3 0.2 Iris-setosa 3 4 4.6 3.1 1.5 0.2 Iris-setosa 4 5 5.0 3.6 1.4 0.2 Iris-setosa After removing id column: SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] … [6.7 3. 5.2 2.3] [6.3 2.5 5. 1.9] [6.5 3. 5.2 2. ] [6.2 3.4 5.4 2.3] [5.9 3. 5.1 1.8]]
الخاتمة
استكشفنا في هذه المجموعة من التدريبات مجموعة بيانات آيرس، وتعرفنا على خواصها والمعلومات الإحصائية الأساسية عنها، واستعرضنا تطبيقات عملية للتعامل مع بنية DataFrame لتخزين البيانات وتعديلها بطرق مختلفة، يمكن تجربة المزيد من الأكواد لاستكشاف هذه البيانات والتعرف عليها بشكل جيد قبل الانتقال للمقالة القادمة التي سنتدرب بها على إنشاء الرسومات البيانية لفهم العلاقات بين خواص مجموعة بيانات آيرس بشكلٍ مرئي.










أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.