

أصبح الذكاء الاصطناعي أداةً قويةً لمساعدة المطورين في كتابة الأكواد البرمجية بسرعة ودقة، لا سيما بعد ظهور نماذج متخصصة مدرّبة على المحتوى البرمجي. سنشرح في مقال اليوم طريقة الاستفادة من نموذج كود لاما Code Llama القوي لكتابة أكواد SQL متنوعة بسهولة باستخدام أوامر بلغة طبيعية، مما يعزز الإنتاجية ويوفر وقت المطورين، وختامًا سنوضح أهم التحديات التي ستواجهنا عند الاعتماد على الذكاء الاصطناعي لكتابة الكود البرمجي وكيفية التعامل معها.
ما هو Code Llama
كود لاما Code Llama هو نموذج ذكاء اصطناعي مفتوح المصدر طورته شركة Meta في أغسطس 2023، وهو يعتمد على نموذج Llama 2 مع تحسينات مخصصة لمعالجة وتوليد الأكواد البرمجية. فقد دُرّب هذا النموذج على مجموعات بيانات كبيرة في مختلف مجالات البرمجة، ما جعل منه أداة قوية لدعم المطورين في كتابة الأكواد وتحسينها وتسريع عمليات التطوير، يعتمد هذا النموذج على بنية المحوّلات Transformer لفهم السياق الكامل للكود البرمجي بدقة، ومعرفة العلاقة بين كل كلمة أو جزء في الكود، مما يساعده على إنشاء أكواد برمجية متوافقة مع مختلف المتطلبات.
يدعم نموذج Code Llama تطوير البرمجيات باستخدام عدة لغات برمجة من بينها بايثون وجافا و PHP و Bash و SQL وغيرها، مما يجعله مناسبًا لمجالات وتطبيقات متنوعة كما يستطيع فهم المدخلات النصية، بما في ذلك تعليمات مكتوبة بلغة طبيعية على غرار: اكتب لي استعلام بلغة SQL يجلب جميع المستخدمين الذين سجلوا في الدورات خلال الشهر الماضي، كما يمكن أن نوفر للنموذج أجزاء من كود SQL غير مكتمل ونطلب منه إكماله بطريقة صحيحة، أو تحسينه وجعله أكثر احترافية.
إصدارات Code Llama
يوفر Code Llama عدة إصدارات لتلبية احتياجات مختلفة في مجال البرمجة وفيما يلي شرح موجز لكل إصدار:
- Code Llama: الإصدار الأساسي العام المصمم لتوليد الأكواد البرمجية بمختلف لغات البرمجة
- Code Llama - Python: إصدار متخصص في لغة كتابة أكواد للغة بايثون Python
- Code Llama - Instruct: إصدار مُدرَّب لفهم التعليمات النصية الطبيعية بدقة كبيرة
توضح الصورة التالية مراحل تدريب وتطوير الإصدارات المختلفة لنموذج Code Llama بالاعتماد على Llama 2 كنموذج أساسي، واستخدم أحجام معاملات parameters مختلفة.
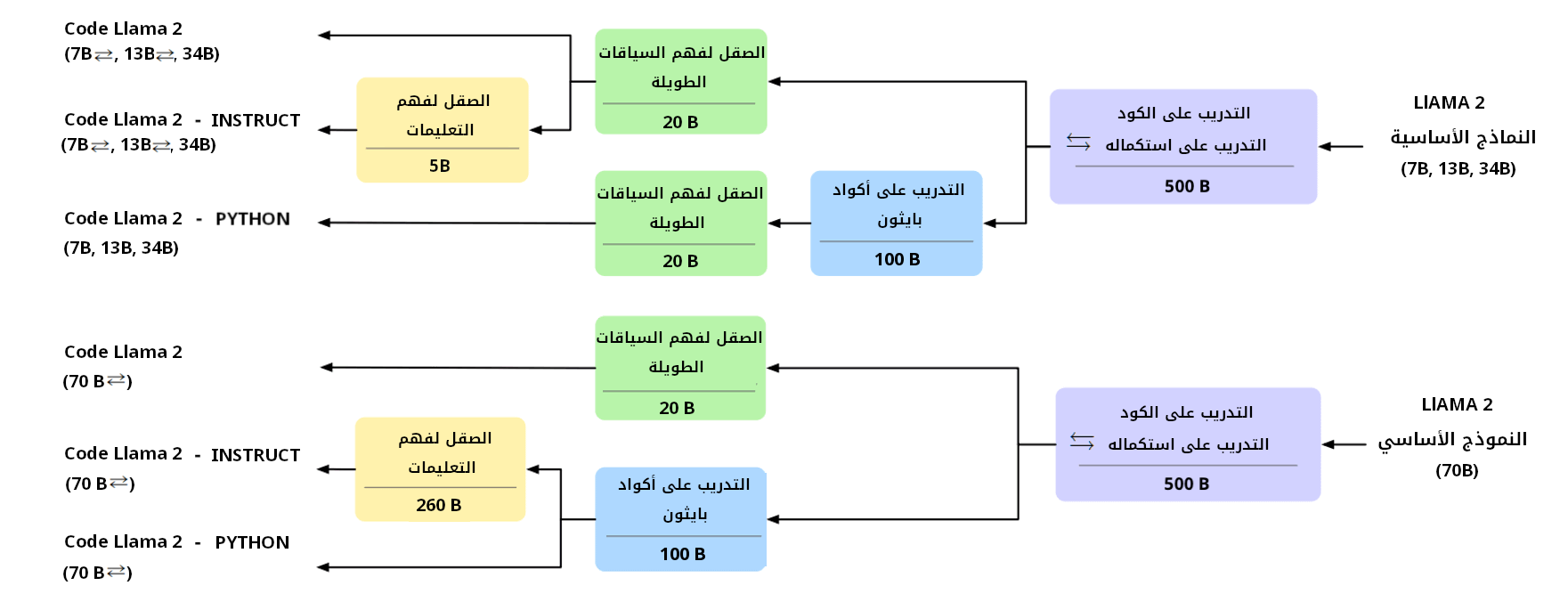
سنشرح في الفقرات التالية خطوات استخدام نموذج Code Llama لتوليد أكواد SQL، مع توفير أمثلة عملية توضح حالات استخدامه.
طريقة إعداد واستخدام Code Llama
يمكن تشغيل نموذج كود لاما Code Llama محليًا على جهازنا، ومن الجدير بالذكر أن تشغيل النموذج قد يتطلب موارد حاسوبية عالية، لذا إذا كان جهازنا المحلي لا يدعم ذلك، فيمكننا استخدام منصات سحابية مثل Google Colab أو Kaggle Notebook والتي توفر بيئة عمل بموارد قوية.
كما يمكننا الاستعانة بالواجهة البرمجية التي توفرها منصة Hugging Face والتي تتيح لنا استخدام نماذج الذكاء الاصطناعي لتوليد وتحسين الأكواد البرمجية بسهولة وفعالية كما سنوضح في الفقرات التالية.
استخدام Code Llama عبر Hugging Face API
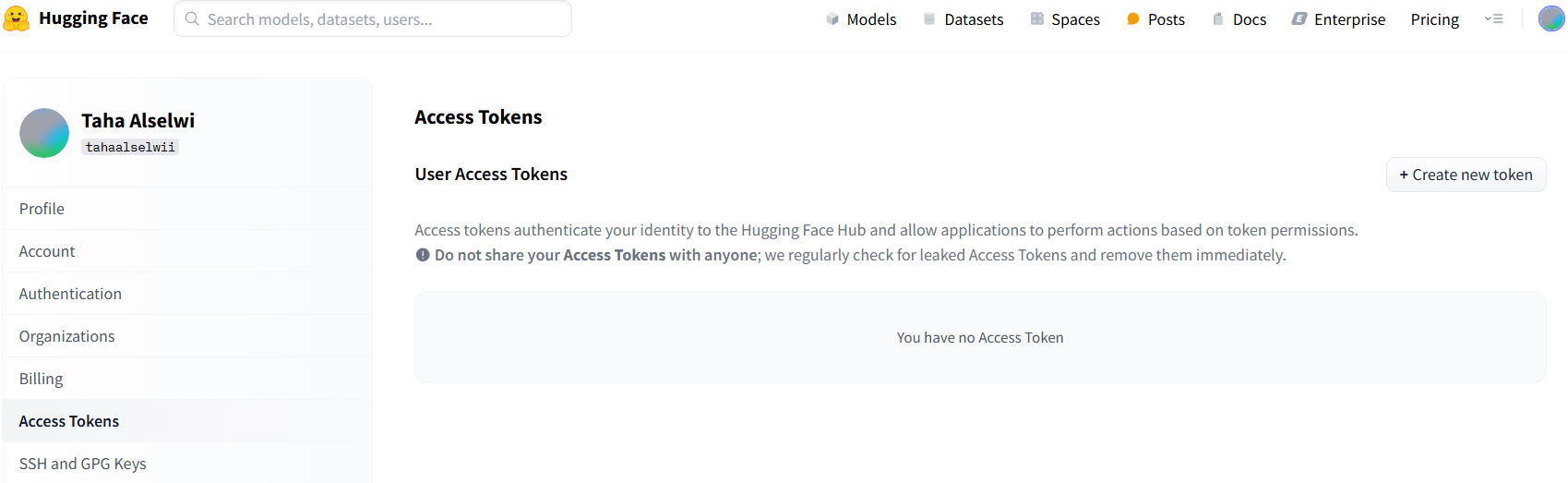
يمكننا استخدام النموذج بسهولة من خلال الواجهة البرمجية Hugging Face API التي تتيح استدعاء النموذج وتوليد الأكواد المطلوبة. لإعداد واستخدام Hugging Face API، نحتاج بدايةً للحصول على مفتاح الوصول Token من منصة Hugging Face. لذا ننتقل إلى صفحة Hugging Face Tokens، ثم نضغط على Create new token كما توضح في الصورة التالية:
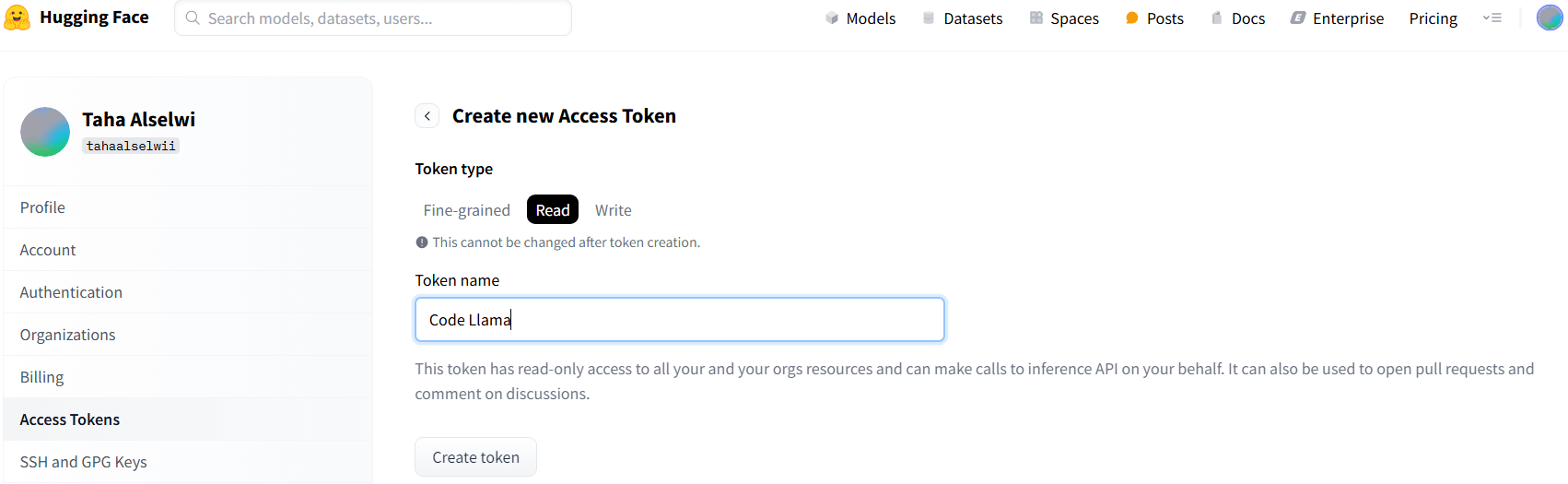
بعد ذلك، نحدد الصلاحية Read ثم نُدخل اسمًا مخصصًا في خانة Token name كما يلي:
بعد ذلك نضغط على زر Create token لتوليد مفتاح الواجهة البرمجية، وننسخه بالنقر على زر Cpoy ونحفظ المفتاح الناتج في مكان آمن.
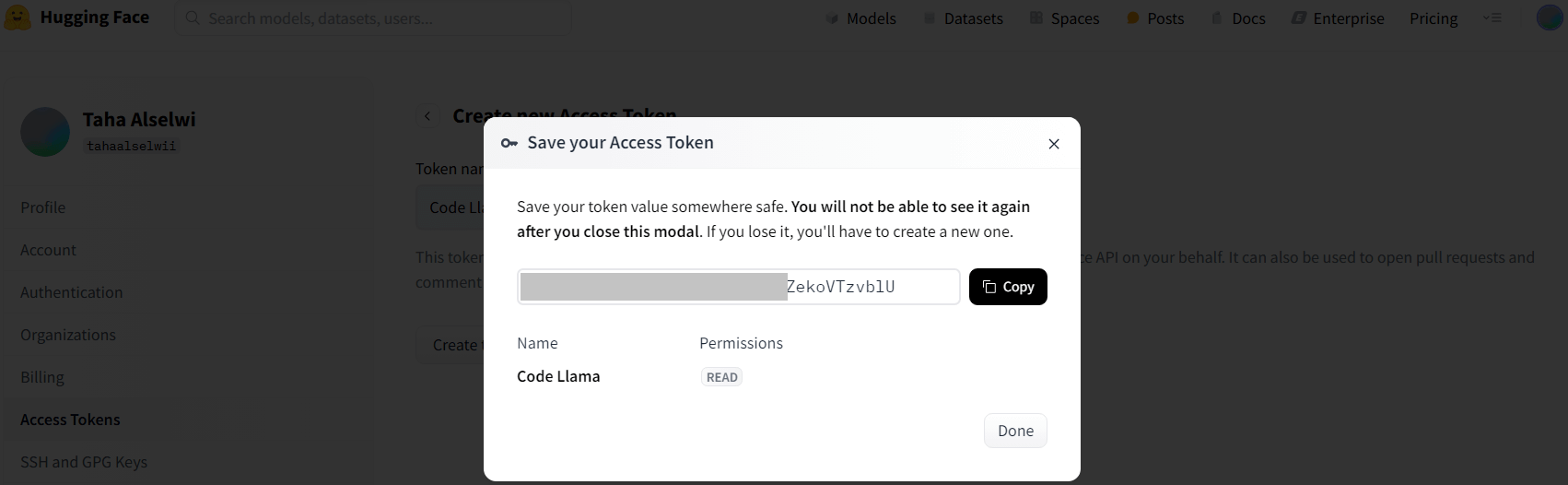
ملاحظة: من الضروري عدم مشاركة هذا المفتاح مع أي شخص لضمان أمان حسابنا.
بعد الحصول على المفتاح API Token، يمكننا الآن إرسال طلب إلى الواجهة البرمجية، سنستخدم على سبيل المثال مكتبة requests في بايثون لنرسل طلب POST متضمنًا المُوجّه prompt المطلوب. كما نحتاج لتحديد عنوان النموذج الذي سنرسل إليه الطلب API_URL، مع تضمين مفتاح الوصول في الطلب كما يلي:
# استيراد المكتبة import requests # رابط النموذج API_URL = "https://api-inference.huggingface.co/models/codellama/CodeLlama-34b-Instruct-hf" # نستبدل المفتاح التالي بالمفتاح الذي حصلنا عليه headers = {"Authorization": "Bearer hf_XXXXXXXXXXXXXXXXXXXX"}
بعد ذلك، سنُعرّف المُوجّه prompt الذي سنرسله للنموذج والمكتوب بلغة طبيعية كي ينتج لنا استعلام بلغة SQL. على سبيل المثال سنجرب كتابة استعلام SQL يجلب لنا جميع المستخدمين المسجلين في الأيام السبعة الأخيرة، مع ترتيبهم تنازليًا حسب تاريخ التسجيل على النحو التالي:
prompt = """ [SYSTEM]: أنت نموذج ذكاء اصطناعي متخصص في تحويل استعلامات اللغة الطبيعية إلى SQL. سيتم إعطاؤك استفسارات بلغة طبيعية، ومهمتك هي توليد استعلام SQL. [USER]: لدي قاعدة بيانات تحتوي على جدول باسم users به الأعمدة التالية: - user_id - user_name - email - created_at اكتب استعلام يجلب جميع المستخدمين المسجلين في آخر 7 أيام، مع ترتيبهم حسب تاريخ التسجيل من الأحدث إلى الأقدم. [ASSISTANT]: """
لإرسال هذا الطلب إلى النموذج واستقبال الرد، سننشئ دالة query تتضمن المُوجّه ثم تعيد الاستجابة:
# دالة لإرسال الطلب إلى النموذج واستقبال الرد def query(payload): response = requests.post(API_URL, headers=headers, json=payload) return response.json() # استدعاء الدالة والحصول على الاستجابة output = query({"inputs": prompt}) output = output[0]['generated_text'] # طباعة الكود الذي تم توليده print(output.split("[ASSISTANT]:")[1])
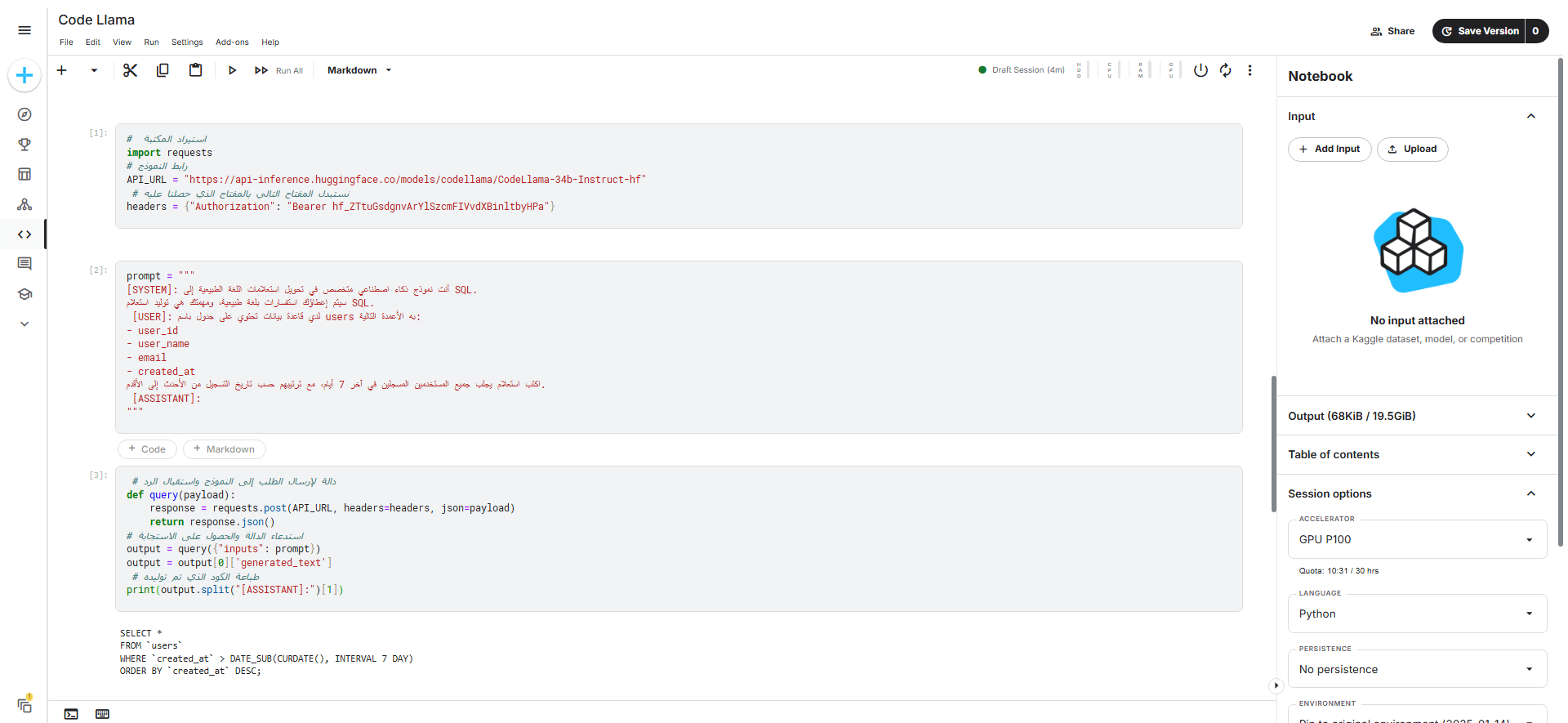
بعد إرسال الطلب، سيُحلل النموذج الطلب ويُولد لنا استعلام SQL كما في المثال التالي:
SELECT * FROM users WHERE created_at >= DATE_SUB(NOW(), INTERVAL 7 DAY) ORDER BY created_at DESC;
توضح الصورة التالية نتيجة تنفيذ الكود ضمن المنصة السحابية Kaggle Notebook:
استخدام Code Llama عبر التثبيت المباشر
يمكننا الاستفادة من إمكانيات النموذج واستخدامه مباشرةً دون الحاجة إلى الاتصال بواجهة برمجية خارجية مما يضمن لنا التحكم الكامل بالنموذج وضبطه بالطريقة المناسبة لنا.
سنحتاج أولًا لاستيراد المكتبات اللازمة لتحميل واستخدام النموذج، حيث سنستخدم هنا النموذج CodeLlama-7b-Instruct-hf، ثم سنعرّف كائن tokenizer لتحميل محوًلات للنموذج المدرب كما يلي:
# استيراد المكتبات اللازمة import torch import transformers from transformers import AutoTokenizer # تحديد اسم النموذج المراد تحميله model = "codellama/CodeLlama-7b-Instruct-hf" # تحميل المحول الخاص بالنموذج tokenizer = AutoTokenizer.from_pretrained(model)
الخطوة التالية هي إنشاء خط أنابيب pipeline لإعداد نموذجنا واستخدامه في توليد الأكواد. سنحدد بدايةً المهمة الأساسية التي نريد من النموذج تنفيذها وهي توليد النصوص text-generation، ثم نحدد ما النموذج المراد استخدامه، ونستخدم بيانات بدقة منخفضة float16 لتسريع الحسابات وتقليل استهلاك الذاكرة، ونقرر ما هو الجهاز المناسب الذي سيعمل عليه النموذج مثل GPU أو CPU كما يلي:
pipeline = transformers.pipeline( "text-generation", model=model, torch_dtype=torch.float16, device_map="auto", )
ملاحظة: تعني القيمة auto الممررة إلى نوع الجهاز device_map بأن النظام هو من سيحدد الجهاز الأفضل بشكل تلقائي بناءً على الموارد المتاحة.
لنحدد الآن المُوجّه الذي سنمرره للنموذج كما يلي:
prompt = ''' [SYSTEM]: أنت نموذج ذكاء اصطناعي متخصص في تحويل استعلامات اللغة الطبيعية إلى SQL. سيتم إعطاؤك استفسارات بلغة طبيعية، ومهمتك هي توليد استعلام SQL الصحيح. لا تضف أي معلومات أخرى بعد توليد الاستعلام [USER]: لدي قاعدة بيانات تحتوي على جدول باسم orders به الأعمدة التالية: - order_id - user_id - product_name - order_date - quantity اكتب استعلامًا يعرض مجموع الكميات المطلوبة لكل منتج، مرتبة حسب الكمية من الأكبر إلى الأصغر. [ASSISTANT]: '''
ثم نكتب كود يستخدم خط الأنابيب pipeline لتنفيذ النموذج:
# تنفيذ النموذج لتوليد الأكواد بناءً على المُوجّه المعطى sequences = pipeline( text_inputs=prompt, do_sample=True, top_k=1, temperature=0.1, top_p=1, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id, max_length=1000, )
استخدمنا في الكود السابق عدة معاملات لضبط النموذج، دعونا نشرح دور كل متغير وأهميته لتوليد استعلام SQL:
-
text_inputs=prompt: تمرير الموجّه المكتوب بلغة طبيعية للنموذج لتحويله إلى استعلام SQL -
do_sample=True: تمكين التوليد العشوائي للنصوص لتوليد استعلامات متنوعة -
top_k=1: اختيار أعلى احتمالية للكلمة التالية -
temperature=0.1: تقليل العشوائية لجعل النتائج أكثر دقة -
top_p=1: استخدام طريقة التصفية العليا لضبط التوليد، وهو يساعد في اختيار الكلمات الأكثر احتمالاً بناءً على المعطيات -
num_return_sequences=1: تعيين عدد النصوص أو الاستجابات المولدة -
eostokenid=tokenizer.eostokenid: تحديد رمز نهاية الجملة لمنع التوليد غير المحدود للنصوص -
max_length=1000: يحدد الحد الأقصى لطول النص المولد
أخيرًا لنطبع الأكواد المولدة بكتابة الكود التالي:
for seq in sequences: output = seq['generated_text'].split("[ASSISTANT]:")[1] print(output)
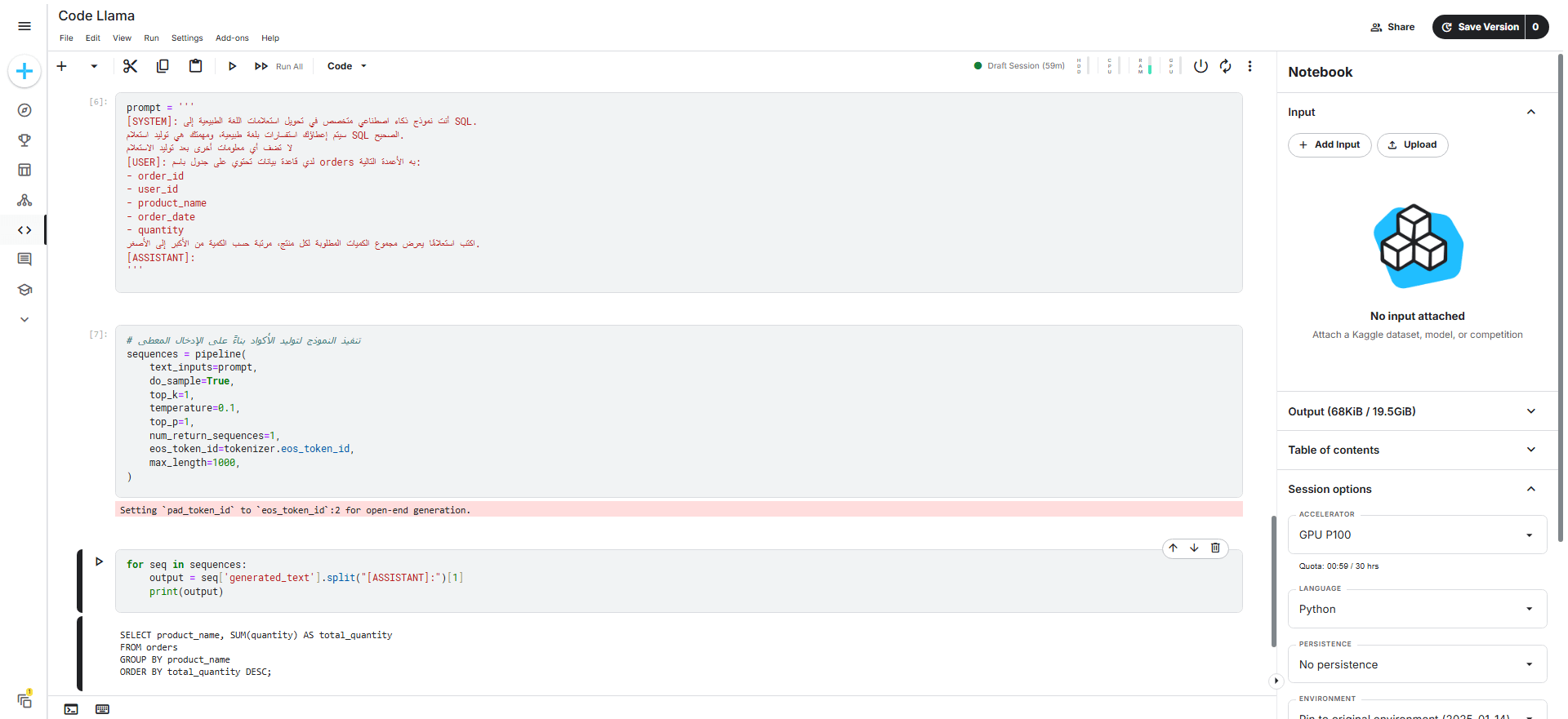
سيولد النموذج استعلام SQL بناءً على المُوجّه prompt المُمرّر له كما يلي:
SELECT product_name, SUM(quantity) AS total_quantity FROM orders GROUP BY product_name ORDER BY total_quantity DESC;
فيما يلي صورة توضح نتيجة التنفيذ:
توليد استعلامات SQL وتنفيذها على قاعد بيانات حقيقية
دعونا الآن نستخدم Code Llama عبر الواجهة البرمجية Hugging Face API لتحويل استفسارات اللغة الطبيعية إلى استعلامات SQL، ثم تنفيذها على قاعدة بيانات حقيقية. سنبدأ بتنزيل قاعدة بيانات Chinook من GitHub، ومن ثم سنستخرج معلومات الجداول المتوفرة. بعد ذلك، سنُمرّر هيكل قاعدة البيانات مع استفسار محدد إلى النموذج، والذي سيعمل على توليد استعلام SQL تلقائيًا. أخيرًا، سننفذ الاستعلام على قاعدة البيانات ونستعرض النتائج.
في البداية، سنثبت المكتبات الضرورية:
!pip install langchain_community
بعدها، سنعمل على إعداد Code Llama عبر Hugging Face API:
# استيراد المكتبة import requests # رابط النموذج API_URL = "https://api-inference.huggingface.co/models/codellama/CodeLlama-34b-Instruct-hf" # استبدل المفتاح التالي بالمفتاح الذي حصلت عليه API_KEY = "hf_XXXXXXXXXXXXXXXXXXXX" headers = {"Authorization": f"Bearer {API_KEY}"} # دالة لاستدعاء النموذج عبر API def query_llama(prompt): response = requests.post(API_URL, headers=headers, json={"inputs": prompt}) return response.json()[0]['generated_text']
نبدأ بعدها بإعداد قاعدة البيانات واستخراج هيكلها:
# استيراد المكتبات اللازمة import requests from langchain_community.utilities import SQLDatabase # رابط قاعدة البيانات على GitHub url = "https://github.com/lerocha/chinook-database/raw/master/ChinookDatabase/DataSources/Chinook_Sqlite.sqlite" # تحديد مسار حفظ قاعدة البيانات db_path = "/content/Chinook.db" # تنزيل قاعدة البيانات من GitHub response = requests.get(url) if response.status_code == 200: with open(db_path, "wb") as f: f.write(response.content) # الاتصال بقاعدة البيانات عبر LangChain db = SQLDatabase.from_uri(f"sqlite:///{db_path}") # عرض أسماء الجداول المتاحة print("📌 الجداول المتاحة في قاعدة البيانات:") print(db.get_usable_table_names()) # استخراج معلومات الجداول من قاعدة البيانات db_schema = db.table_info
سنحصل على الجداول التالية:
📌 الجداول المتاحة في قاعدة البيانات: ['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
نحن جاهزون الأن لتوليد استعلام SQL وتطبيقه على قاعدة البيانات:
# تحديد الإدخال الذي سيتم تمريره للنموذج user_query = "اكتب استعلامًا يجلب أسماء 5 عملاء من قاعدة البيانات" prompt = f''' [SYSTEM]: أنت نموذج ذكاء اصطناعي متخصص في تحويل استعلامات اللغة الطبيعية إلى SQL. سيتم إعطاؤك استفسارات بلغة طبيعية، ومهمتك هي توليد استعلام SQL. [USER]: لدي قاعدة بيانات تحتوي على {db_schema} {user_query} [ASSISTANT]: ''' # توليد استعلام SQL sql_query = query_llama(prompt) sql_query = sql_query.split("[ASSISTANT]:")[1] print("🔹 الاستعلام الذي تم توليده:") print(sql_query) # تنفيذ الاستعلام على قاعدة البيانات result = db.run(sql_query) print("\n🔹 النتيجة:\n") print(result)
سنحصل على استعلام بلغة SQL يعرض أول خمسة أسماء من جدول العملاء، وتعرض النتيجة الموافقة لهذا الاستعلام وفق قاعدة البيانات:
🔹 الاستعلام الذي تم توليده: SELECT firstname FROM customer LIMIT 5; 🔹 النتيجة: [('Luís',), ('Leonie',), ('François',), ('Bjørn',), ('František',)]
نلاحظ في الصورة التالية نتيجة التنفيذ بالكامل:

تحديات وحلول توليد استعلامات SQL بالذكاء الاصطناعي
يواجه توليد استعلامات SQL باستخدام تقنيات الذكاء الاصطناعي عددًا من التحديات، ولكن يمكن تجاوزها من خلال تبني حلول مبتكرة وتخصيص النموذج وفقًا للمتطلبات. فيما يلي أبرز التحديات والحلول المقترحة:
تنوع صياغة SQL
توجد بعض الاختلافات في أسلوب كتابة أكواد SQL المستخدمة في أنظمة إدارة قواعد البيانات العلاقية مثل MySQL وOracle وPostgreSQL، لذا نحتاج لتخصيص عملية توليد الاستعلامات بحيث تتناسب مع النظام المستهدف، وتلتزم باستخدام الصيغة الصحيحة. يمكن تحقيق ذلك من خلال تدريب النماذج على عينات من كل صيغة، أو إضافة مدخلات سياقية تحدد النظام المطلوب.
نقص في سياق البيانات
تفتقر بعض الاستعلامات المولدة من إدخالات اللغة الطبيعية إلى المعلومات السياقية الضرورية، مثلًا لو طلبنا كتابة استعلام عن المبيعات لهذا العام فقد لا يعرف النموذج ما هو اسم جدول المبيعات بالضبط، واسم العمود الذي يحتوي على إجمالي المبيعات، ولحل هذه المشكلة، يمكن تعزيز السياق عن طريق إدراج معلومات إضافية مثل البيانات الوصفية لقاعدة البيانات metadata وسجل جلسة المستخدم لمساعدة النموذج على فهم السياق وتوليد استعلامات صحيحة.
معالجة الأخطاء
من المحتمل أن ينتج عن توليد استعلامات SQL بعض الأخطاء في الكود، مما يتطلب وجود آلية لتقديم تغذية راجعة للمستخدم لتصحيحها. لحل هذه المشكلة، يمكن إنشاء واجهة مستخدم تفاعلية تشرح الأخطاء المحتملة وتقدم اقتراحات للتصحيح. بالإضافة إلى ذلك، يمكن استخدام ملاحظات المستخدم لتحسين النموذج وتدريبه على تجنب الأخطاء في المستقبل.
الخاتمة
إلى هنا نكون قد وصلنا لنهاية مقالنا الذي شرحنا فيه كيف يمكن للذكاء الاصطناعي من خلال نموذج Code Llama، أن يسهم في تبسيط وتسريع عملية كتابة استعلامات SQL بدقة وكفاءة عالية. واستعرضنا كيفية إعداد النموذج سواء عبر واجهة برمجة التطبيقات API أو بالتثبيت المباشر على الأجهزة أو عبر بيئات الحوسبة السحابية، مما يوفر مرونة كبيرة للمطورين في اختيار البيئة التي تناسب احتياجاتهم. كما ناقشنا التحديات المتعلقة بتنوع لهجات SQL وتعقيد الاستعلامات، وكيف يمكن تجاوزها باستخدام أساليب متقدمة لتخصيص الاستعلامات ومعالجة الأخطاء.











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.