

يعد تحليل التباين ANOVA, Analysis of Variance واحدا من أكثر الأدوات شيوعا بالاستخدام في جعبة العاملين بالتحليل الإحصائي، لذا سنقوم في هذه المقالة بتغطية موضوع تنفيذ تحليل التباين باستخدام لغة R وتفسير النتائج التي سنحصل عليها نتيجة تطبيق مثل هكذا تقنية وذلك من وجهة نظر تطبيقية بحتة تبتعد عن التجريد الرياضي وتركز على النواحي العملانية.
كما سبق وأن أشرنا في مقالات سابقة، تعد لغة R من اللغات التي صعد نجمها حديثا وبشكل سريع بمجال البرمجة العلمية في قطاعي الإحصاء والمعلوماتية الحيوية (bioinformatics) حيث باتت معتمدة على نطاق واسع في كثير من الجامعات ومراكز البحث العلمية، وأصبحنا نرى استخدامها والإشارة إليها في المقالات المنشورة بالمجلات العلمية المحكّمة يزداد بشكل طردي ومتسارع، هذا عدى عن حقيقة كونها لغة حرة مفتوحة المصدر يخضع توزيعها لترخيص GPL الشهير. كل ذلك أدى إلى تزايد ما هو متوافر ومتاح على الشابكة (الإنترنت) من مصادر لها على توزع طيف تلك المصادر، فهناك الكتب الإلكترونية والدروس التعليمية وحتى المناهج الأكاديمية والدورات التدريبية إضافة إلى البرامج الجاهزة والمكتوبة بلغة R لتنفيذ هذه المهمة أو تلك، حتى أنها باتت تحظى ببعض الامتياز مقارنة بالعديد من العمالقة في قطاعي البرمجة الرياضياتية العلمية والإحصائية مثل SAS و SPSS وغيرهما، خصوصا من حيث توافر الأمثلة والتطبيقات للطرق والخوارزميات الحديثة، حيث يقاد هذا التوجه في معظمه من طرف الجامعات ممثلة بطلاب الدراسات العليا يحفّزهم على ذلك سهولة بناء الإضافات لهذه اللغة، ويعتبر هذا الأسلوب رغم ما قد يشوبه من نقاط ضعف تتعلق بموثوقية وجودة وغزارة تلك الإضافات الجديدة، والتي تتبع خبرة ومهارة مطوريها وناشريها، لكنها تبقى في القطاع العلمي والأكاديمي أفضل كثيرا من البدائل التجارية التي يعيبها إرتفاع ثمنها من جهة، ومن جهة أخرى بطئ إضافة التحديثات التي تعكس تطور القطاعات العلمية المختلفة، حيث أنها عادة ما تتبع دورة تجارية تتحكم بها الشركات المنتجة.
تستطيع أن تقوم بتحميل لغة R من الموقع الرسمي لها على الرابط http://www.r-project.org، وعملية تنصيب هذه اللغة تخلو من التعقيدات، وبانتهاءها يمكنك تشغيل سطر الأوامر الخاص بها من خلال النقر على أيقونة اللغة على سطح المكتب، إن كل ما نكتبه تاليا سيكون داخل سطر الأوامر هذا، علما أننا نستخدم في كل أمثلتنا إطار البيانات المدعو mtcars والذي يأتي محزوما مع اللغة بشكل إفتراضي، وللحصول على معلومات إضافية عن طبيعة محتوى هذه البيانات يمكنك كتابة الأمر التالي في سطر الأوامرmtcars? ولاختصار طريقة الوصول إلى المعلومات ضمن إطار البيانات ننفذ الأمر (attach(mtcars فنصبح قادرين على استخدام التسمية qsec على سبيل المثال بدلا من استخدام الطريقة المفصلة mtcars$qsec للدلالة على عدد الأميال المقطوعة بغالون البنزين الواحد.
تعتبر تقنية تحليل التباين تعميما لما سبق وأن تعاملنا معه في اختبار t والذي ينحصر في تحديد معنوية الفروقات فيما بين مجموعتين اثنتين فقط من البيانات، في حين يستطيع تحليل التباين التعامل مع بيانات مقسمة إلى أكثر من مجموعتين بناء على معامل factor أو أكثر، حيث تلعب المعاملات هنا دورا جوهريا في توصيف طريقة تقسيم مجموعة البيانات التي لدينا، وفي المثال الذي سنتناوله في هذه المقالة سنستخدم cyl والذي يشير إلى عدد إسطوانات المحرك كصفة تستخدم للتمييز بين المجموعات، لذا علينا بداية أن نخبر لغة R بضرورة تحويل طبيعة بيانات الشعاع cyl لتصبح معاملة وذلك باستخدام الأمر التالي:
cyl <- factor(cyl)
حيث تجري عملية التحويل ويتم إسناد الشعاع الناتج مجددا إلى ذات التسمية، وحتى نرى طبيعة التغيير التي جرت على cyl يمكننا استخدام التابع summary بالشكل التالي:
> summary(cyl) 4 6 8 11 7 14
والناتج يشير بوضوح إلى وجود ثلاث مجموعات من البيانات بحسب عدد إسطوانات المحرك، فلدينا 11 سيارة بمحركات ذات أربع إسطوانات، و 7 سيارات أخرى بمحركات ذات ستة إسطوانات، إضافة إلى 14 سيارة بمحركات ذات ثمانية إسطوانات.
إن ناتج تنفيذ التابع summary يختلف باختلاف طبيعة شعاع القيم المرسل له، وللمقارنة سنطبق ذات التابع summary على الصفة qsec والتي تمثل المدة اللازمة لقطع مسافة ربع ميل مقدرة بالثواني إنطلاقا من حالة السكون، وهي الصفة التي سندرسها بعد قليل باستخدام تحليل التباين لنرى إن كانت هناك أية فروقات معنوية من حيث الزمن اللازم لقطع مسافة الربع ميل وذلك ما بين فئات المحركات الثلاث والمصنفة بحسب عدد إسطوانات المحرك (أي المحركات بأربع أو ستة أو ثمانية إسطوانات)، إن ناتج تطبيق التابع summary على صفة qsec سيظهر على الشكل التالي:
> summary(qsec) Min. 1st Qu. Median Mean 3rd Qu. Max. 14.50 16.89 17.71 17.85 18.90 22.90
كما ترى فإن التابع عاملها على أنها قيمة مستمرة (وليست متقطعة ذات مستويات محددة كما هي الحال مع المعاملات)، وبالتالي قام التابع summary بعرض القيمة الصغرى والعظمى والوسيط إضافة إلى الربيعين الأول والثالث كتلخيص لهذه الصفة.
ملاحظة: إن قمت بتحويل إحدى الصفات إلى معاملة عن طريق الخطأ باستخدام التابع factor الذي سبق ذكره، فبإمكانك عكس تلك العملية باستخدام الأمر التالي:
x <- as.numeric(x)
هناك العديد من التوابع المفيدة والتي يمكن تطبيقها على المعاملات نذكر منها التابع levels والذي يعيد شعاعا يحوي القيم الفريدة (غير المكررة)، وفي حالة المعاملة cyl سيكون الناتج على الشكل التالي:
> levels(cyl) [1] "4" "6" "8"
كذلك لدينا التابع nlevels والذي يعطي كناتج له عدد المستويات الفريدة للمعاملة المدروسة، وفي حالة cyl سنحصل على الخرج التالي:
> nlevels(cyl) [1] 3
بمعنى وجود ثلاث مستويات أو أنواع مختلفة لعدد الإسطوانات في محركات السيارات ضمن العينة المدروسة. لنقم بداية برؤية طبيعة توزع الصفة qsec بحسب كل مستوى أو قيمة للمعاملة cyl وذلك من خلال المخطط البياني الصندوقي بتطبيق التابع التالي:
boxplot(qsec~cyl, col="gray")
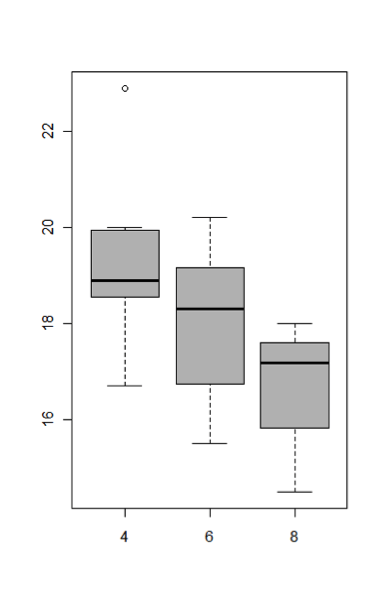
واضح من الشكل المعروض أعلاه وجود فروق معنوية لمقدار الصفة qsec بين مستويات cyl المختلفة، لكننا بحاجة إلى إثبات ذلك بدليل عددي، وهو ما سنحصل عليه من تطبيقنا لتحليل التباين، وللقيام بذلك باستخدام لغة R عليك تنفيذ الأمر التالي (وحفظ ناتج التحليل ضمن اللائحة التي أسميناها هنا في هذا المثال model):
model <- aov(qsec~cyl)
ويعتبر جدول تحليل التباين العنصر الأول والأساسي بنواتج هذا التحليل والذي يمكن الحصول عليه من خلال تمرير اللائحة model إلى التابع summary والذي سيغير من جديد طريقة عرض ناتجه تبعا لنوع الوسيط المرسل له، وفي هذه الحالة سيكون الخرج على الشكل التالي:
> summary(model)
Df Sum Sq Mean Sq F value Pr(>F)
cyl 2 34.606 17.3029 7.7938 0.001955 **
Residuals 29 64.382 2.2201
---
Signif. codes: 0 '***' 0.001 '***' 0.01 '*' 0.05 '.' 0.1 '' 1
سنقوم فيما يلي بشرح مكونات الجدول الناتج حيث أن وظيفة تحليل التباين الأساسية هي قياس كمية التباينات الكلية المقاسة في العينة المدروسة والتي تحسب من العلاقة:
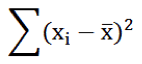
إن الإقرار بمعنوية معاملة ما يتطلب أن تكون التباينات التي تسببت بها أوضح تأثيرا (أي أكبر مقدارا) من تلك التي تتسبب بها المؤثرات المتبقية Residuals والتي تمثل تشويش التجربة، لكن المقارنة ما بين مجموع المربعات هنا هي مقارنة غير عادلة نظرا لكون المقدارين 34.606 و 64.382 يعودان لدرجتي حرية مختلفتين (يوضح مقدار درجة الحرية في العمود Df ضمن الجدول السابق، حيث أن عدد درجات الحرية للمعاملة cyl هو 2 ويحسب من العدد الكلي لقيم cyl الفريدة ناقص واحد، في حين أن العينة المدروسة تضم 32 سيارة فيكون بالتالي عدد درجات الحرية الإجمالي هو 31 أي 32 ناقص واحد، منهما درجتي حرية تم إسنادهما للمعاملة cyl فيتبقى 29 درجة حرية للـ Residuals).
ملاحظة: قد تشير بعض المراجع أو البرمجيات الإحصائية للقيم المتبقية Residuals باستخدام تسمية خطأ التجربة Error كونها تباينات غير مرغوبة يختلف مسببها عن المعاملة المدروسة، لكننا نرى أنه من الأدق تسميتها بالقيم المتبقية كونها لا تعتبر أخطاء بقدر ما هي تباينات تعود لأسباب أخرى خارجة عن نطاق اهتمامنا، في جميع الأحوال كلما صغر هذا المقدار كلما تحسنت دقة نتائجنا.
لتصبح عملية المقارنة عادلة ما بين التباينات المقاسة يجب توحيدها وحساب مقدار التباينات التي تتسبب بها كل درجة حرية واحدة لكل من المعاملة cyl والقيم المتبقية Residuals والتي تحسب ببساطة بتقسيم المقدار Sum Sq على عدد درجات الحرية Df لكل بند على حدة، وهو ما يتم عرضه ضمن العمود Mean Sq، هذه المقادير يمكن مقارنتها مباشرة. إحدى طرق المقارنة الأسهل هي حساب نسبة التباين VR, Variance Ratio والتي يشار إليها في الجدول السابق بالتسمية F Value أو ما اصطلح على تسميته بقيمة F المحسوبة.
إن فكرة استخدام نسبة التباين VR تشبه إلى حد بعيد ما نقوم به حين توليف المذياع لاستقبال محطة إذاعية ما، فصوت التشويش في الخلفية لا مفر منه، وهو المقابل لمقدار التباينات المتبقية Residuals في حالة تحليل التباين ANOVA، أما صوت المذيع فيقابل في حالتنا هذه التباينات التي تتسبب بها المعاملة التي ندرسها، ونحن نعتبر الاستقبال واضحا حينما يكون صوت المذيع أعلى بقدر ملحوظ مقارنة بالتشويش الأبيض في الخلفية، لذا كلما زادت نسبة التباين VR زادت فرص ملاحظة وإثبات وجود الفروقات المعنوية.
في حالتنا هذه فإن التباينات التي تسببت بها معاملة عدد الإسطوانات cyl قد كانت أوضح بأكثر من سبعة أضعاف مقارنة بالتباينات العشوائية المتبقية المقاسة والظاهرة في العينة المدروسة، في نهاية المطاف هذا المقدار العددي لا يقدم إجابة حاسمة هل تعتبر هذه الفروقات معنوية أم لا، لذلك يوضح العمود الأخير والمسمى (Pr >F) ما هو احتمال عدم وجود فروقات معنوية ما بين مستويات المعاملة cyl المختلفة (أي أننا نعمل بطريقة نقض الفرض)، فإن كان هذا الاحتمال قليلا بقدر كاف أمكننا رفض هذه الفرضية (عدم وجود فروقات معنوية)، والإقرار بمعنوية الفروقات المقاسة للتباينات فيما بين مستويات المعاملة cyl المدروسة (يعبر عن قيمة الاحتمال برقم يتدرج ما بين 0 والذي يشير إلى الاحتمال المستحيل، و 1 للاحتمال الأكيد. عادة ما يعتبر الحد 0.05 فما دون كافيا للإقرار بوجود فروقات معنوية بمعنى قبول هامش خطأ لا يتجاوز 5%).
بالنسبة للمثال الذي بين أيدينا، من الواضح أن الفروقات ما بين مستويات cyl المختلفة معنوية بدلالة أن المقدار Pr (>F) صغير وهو في حدود 0.002 أي 0.2% وهي نتيجة تدعم ما سبق وأن رأيناه في المخطط الصندوقي بداية هذه المقالة، لكن هذه المرة بشكل عددي مثبت ومتحرر من الأهواء والإنطباعات الشخصية الضبابية.
من الهام ذكره أن تحليل التباين وصحة نتائجه قائم على أربع فرضيات يجب توافرها في البيانات المدروسة وإلا كانت النتائج غير ذات جدوى ولا يصح أن يعتمد عليها من الناحية الإحصائية، هذه الفرضيات الأربع هي التالية (ومجددا سنورد هذه النقاط بإسلوب عملي بعيد عن التعقيدات الرياضياتية قدر المستطاع):
- يجب أن تتبع الأخطاء أو القيم المتبقية التوزع الطبيعي، بمعنى أن الأخطاء أو الفروق الصغيرة عن النموذج المحتسب باستخدام تحليل التباين يجب أن تكون أعلى احتمالا مقارنة بالأخطاء أو الفروقات الواسعة الكبيرة.
ثبات تباين الأخطاء، أي أن مقدار الخطأ يجب أن يكون مستقلا عن المقدار المقاس للصفة المدروسة (وهي في مثالنا qsec)، والخرق الأكثر شيوعا لهذا الشرط يظهر على شكل تباينات أخطاء صغيرة حينما يكون المقدار المقاس صغيرا والعكس بالعكس.
استقلالية الخطأ ما بين العينات المدروسة، بمعنى ضرورة عدم وجود انتظام أو نمط معين لمؤثرات أخرى على الصفة المدروسة سوى المعاملة قيد الدراسة، أي أن توزع الأخطاء ما بين العينات يجب أن يكون عشوائيا.
في حال وجود أكثر من معاملة مدروسة، يجب أن يكون ناتج التأثير تلك المعاملات تراكميا.
تتيح لنا لغة R مجموعة من أربع مخططات بيانية تساعدنا على التحقق من معظم الفرضيات الموضحة أعلاه، لذلك سنقوم بداية بالطلب من لغة R أن تقوم بتجهيز نافذة إخراج الرسوم البيانية لتعرض أربع مخططات دفعة واحدة إثنان في كل سطر وذلك من خلال تنفيذ الأمر التالي:
par(mfrow = c(2,2))
بعد ذلك نطلب عرض تلك المخططات باستخدام الأمر التالي (لاحظ أن model هو ذاته اسم اللائحة التي حفظناها كخرج للتابع aov في بداية المقالة):
plot(model)

يمكنك كذلك الحصول على قيم المتوسطات المختلفة والمتعلقة بهذا التحليل عن طريق تنفيذ الأمر التالي:
> model.tables(model, "means")
Tables of means
Grand mean
17.84875
cyl
4 6 8
19.14 17.98 16.77
rep 11.00 7.00 14.00
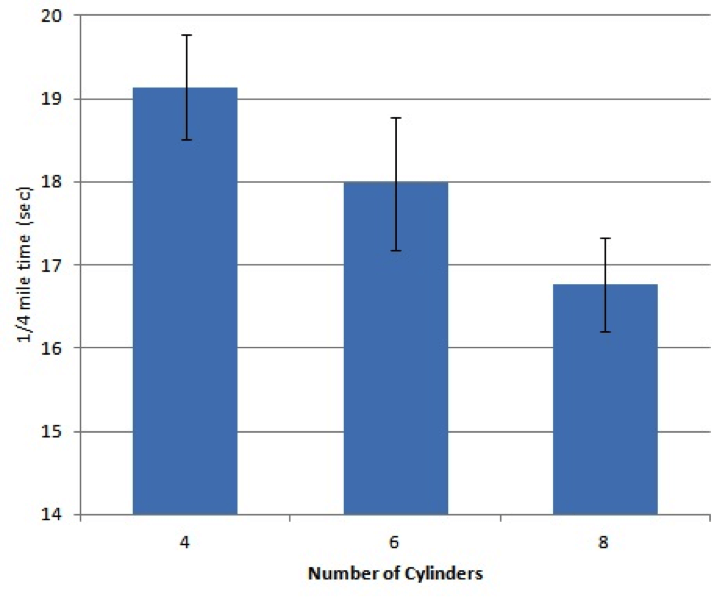
حيث نلاحظ أن المتوسط العام لعينة السيارات المدروسة جميعا يبلغ تقريبا 17.8 ثانية لقطع مسافة الربع ميل الأولى من لحظة بدء التسارع (وهي الصفة التي يشير إليها شعاع القيم qsec)، بمعنى أن أي سيارة من السيارات الـ 32 المدروسة تقطع الربع ميل الأول خلال 17.8 ثانية تقريبا، بعد ذلك نجد جدول متوسطات أكثر تفصيلا يعرض قيمة لكل فئة من فئات السيارات المدروسة والمقسمة بحسب التحليل السابق على أساس عدد الإسطوانات في محركاتها والتي تعبر عنها معاملة cyl كما سبق وأن رأينا، وفي هذه الحالة نرى أن أكثرها بطئا هي الفئة الأولى (ذات المحركات بأربع إسطوانات) حيث تحتاج هذه الفئة بالمتوسط إلى 19.1 ثانية تقريبا (وتضم هذه الفئة 11 سيارة)، تليها فئة السيارات ذات المحركات بستة إسطوانات (وفيها 7 سيارات) حيث يقترب متوسط الزمن اللازم لقطع مسافة الربع ميل الأول لهذه الفئة من المتوسط العام نفسه وبمعدل 18 ثانية تقريبا، لتأتي بعدها فئة السيارات الأعلى تسارعا بمحركاتها ذات الإسطوانات الثمانية والتي لا تحتاج في المتوسط إلى أكثر من 16.8 ثانية لقطع الربع ميل الأول إنطلاقا من حالة السكون (وتضم هذه الفئة 14 سيارة من أصل العينة المدروسة).
لا يستقيم عرض قيمة متوسط حسابي ما دون ذكر مقدار الخطأ المرتكب في حسابه والذي يشير إلى مقدار تشتت القراءات أو القيم التي حسب منها ذلك المتوسط حول قيمة المتوسط نفسه، ومن المقادير التي تستخدم عادة لهذه الغاية نذكر الخطأ المعياري SE, Standard Error والذي يمكن حسابه في حالة تحليل التباين بقسمة مقدار التبيانات الخاصة بالقيم المتبقية بسبب درجة حرية واحدة (أي المقدار من العمود Mean Sq والسطر Residuals في جدول تحليل التباين) على عدد عينات/تكرارات كل فئة من المعاملة المدروسة، ومن ثم حساب الجذر التربيعي للناتج.
لو كانت بياناتنا متوازنة (بمعنى أن عدد السيارات في كل فئة من فئات المحركات مقسمة بالتساوي بحسب عدد إسطواناتها)، لاستطعنا الحصول على قيمة الخطأ المعياري SE للمتوسطات المحسوبة من خلال إضافة الوسيط se=TRUE إلى التابع model.tables سابق الذكر، لكن الحالة المدروسة في مثالنا ليست متوازنة، وبالتالي علينا حساب الخطأ المعياري يدويا (يمكنك حساب الحد الأدنى والأقصى أو حتى المتوسط) بالطريقة التالية:
SE.min = sqrt (2.2201 / 14) SE.max = sqrt (2.2201 / 7)
لاحظ أن المقدار 2.2201 مأخوذ من جدول تحليل التباين ANOVA الذي عرض سابقا، وأن الرقم 14 يمثل أعلى عدد تكرارات وهو يخص السيارات التي تنتمي لفئة المحركات ذات الإسطوانات الثمانية، أما الرقم 7 فباتت دلالته واضحة فهو يمثل أدنى عدد تكرارات ويعود لفئة المحركات ذات الستة إسطوانات (من الواضح أنه كلما زاد عدد العينات المدروسة إنخفضت قيمة الخطأ المعياري المرتكب في حساب متوسطاتها).
نستطيع إنطلاقا من مقدار الخطأ المعياري SE أن نوجد قيمة SED, Standard Error of Differences والتي تحسب من خلال العلاقة البسيطة التالية:
SED = sqrt(2) * SE
وهي القيمة التي تستخدم عادة لتمثيل الخطأ في مخطط الأعمدة للمتوسطات كما هو موضح بالشكل التالي:
كذلك نستطيع حساب مقدار أقل فرق معنوي LSD, Least Significant Differences وهو يساوي بالتقريب ضعف قيمة SED ويمكن حساب قيمته الدقيقة من خلال المعادلة التالية:
LSD = qt(0.975, Residual df) * SED
تنبع أهمية المقدار LSD من حقيقة أن تحليل التباين يخبرنا فقط إن كانت هناك فروقات معنوية ما بين الفئات المدروسة للمعاملة أم لا، دون أن يوضح أي من تلك الفئات متشابهة وأيها مختلفة، لذا يمكننا استخدام قيمة LSD للمقارنة ما بين المتوسطات المحسوبة لكل واحدة من هذه الفئات، فإن زاد الفرق ما بين متوسطي فئتين عن قيمة LSD نستنتج وجود فروقات معنوية ما بين هاتين الفئتين، وإن لم يكن كذلك فالفارق ما بين متوسطي هاتين الفئتين لا يتجاوز حدود الخطأ المقاس بحسب المعطيات المدروسة.
كما وجدنا سابقا فإن تحليل التباين قد أظهر لنا بما لا يدع مجالا للشك أن هناك فروقا معنوية بالزمن اللازم لقطع الربع ميل الأول ما بين الفئات الثلاث لمحركات السيارات بحسب عدد إسطواناتها، لكنه كما أوضحنا يقف عند هذا الحد ولا يخبرنا أي الفئات متشابهة وأيها مختلفة، فهذه الفروق التي نجدها بين المتوسطات المحسوبة قد تكون معنوية وقد تكون ضمن هامش خطأ التجربة! فليست كل السيارات التي تدفعها محركات بأربعة إسطوانات تقطع الربع ميل الأول خلال 19.1 ثانية فهناك تباين فيما بين السيارات ضمن هذه الفئة، بمعنى أن بعضها قد يكون أسرع قليلا من هذا الزمن وبعضها الآخر أبطئ، والمتوسط المعروض ما هو إلا تمثيل لمركز المجموعة، ومعنوية الفروق التي ظهرت نتيجة تحليل التباين السابق تعني أنه لدينا على الأقل فئة واحدة تختلف عن باقي الفئات، ولا تشترط أن تكون جميع تلك الفئات مختلفة معنويا عن بعضها البعض مثنى مثنى.
لذا فإن الخطوة التالية بعد اكتشاف وجود فروقات معنوية هو إجراء مقارنات متعددة Multiple Comparison لكل فئات المعاملة الممكنة مثنى مثنى وتقرير أيها معنوي وأيها لا تتجاوز الفروقات الظاهرة بين متوسطاته هامش خطأ التجربة، لإنجاز ذلك لدينا العديد من الاختبارات الممكنة أحدها يدعى اختبار Tukey وهو ما سنوضح طريقة استخدامه فيما يلي:
> mc <- TurkeyHSD(model, "cyl", ordered=TRUE)
> mc
Turkey multiple comparisons of means
95% family-wise confidence level
factor levels have been ordered
Fit: aov(formula = qsec ~ cyl)
$cyl
diff lwr upr p adj
4-6 1.205000 -0.4983980 2.908398 0.2053353
4-8 2.365130 0.8825122 3.847748 0.0013300
4-6 1.160130 -0.6190113 2.939271 0.2574564
يوضح الجدول الناتج جميع الأزواج الممكنة بين فئات المعاملة cyl الثلاث، موضحا إلى جانب كل منها الفرق ما بين متوسطات تلك الفئات ضمن العمود diff، وهنا أرغب بالتذكير أننا لا نتعامل في الإحصاء مع حقائق مطلقة ومثبتة لا تقبل الشك، بل نتعامل مع متوسطات وهوامش خطأ وعدم يقين، لذلك وإن كان الفرق بين متوسطي الزمنين اللازمين لقطع مسافة الربع ميل للسيارات بمحركات ذات ستة وثمانية إسطوانات هو 1.2 ثانية تقريبا، إلا أن هذا التقدير يحتمل هامشا من الخطأ يحدده إختبار Tukey بحدين أدنى lwr وأعلى upr يتراوح بين ناقص 0.5 ثانية (أي إحتمال وجود سيارة بمحرك ذي ستة إسطوانات أسرع بنصف ثانية من سيارة أخرى بمحرك ذي ثمانية إسطوانات) و 2.9 ثانية تقريبا لصالح السيارات بمحركات ذات ثمانية إسطوانات، ونرى في هذه الحالة وجود تداخل ما بين هاتين الفئتين من السيارات، لذا لا نستطيع الجزم بأن الفروقات التي رأيناها ما بين متوسطي الفئتين تعد معنوية، وهو ما يوضحه العمود الأخير الذي يمثل احتمال تشابه هاتين الفئتين المدروستين وهو في هذه الحالة 0.2 تقريبا أي 20% وبالتالي هو إحتمال أعلى من أن يتم تجاهله وبالتالي رفض فرضية التشابه.
في اختبار Tukey نعتبر أن الفئتين المدروستين يوجد بينهما فروق معنوية حينما تكون قيمة الاحتمال الوارد في العمود الأخير للزوج المعني لا تتجاوز 0.05 (أي أن هامش الخطأ لا يتجاوز 5%)، وحينها سنجد أن المجال المحصور ما بين القيمتين lwr و upr لا يتضمن الصفر بين حديه، وهي الحال بين فئتي السيارات المزودة بمحركات ذات أربع وثمانية إسطوانات، حيث أن فرق الزمن بين متوسطيهما يتجاوز 2.3 ثانية، وهو يقارب في حدوده الدنيا 0.9 ثانية ويمكن أن يصل في حدوده العظمى إلى 3.8 ثانية تقريبا، كما أن إحتمال التشابه في هذه الحالة هو في حدود 0.001 أي 0.1% تقريبا، وبالتالي عملا بإسلوب نقض الفرض نقر بأن هاتين الفئتين غير متشابهتين وبالتالي هناك فروق معنوية فيما بينهما.
يمكن عرض نتائج إختبار Tukey للمقارنات المتعددة بشكل رسومي يسهل قراءته وذلك باستخدام الأمر التالي:
plot(mc)
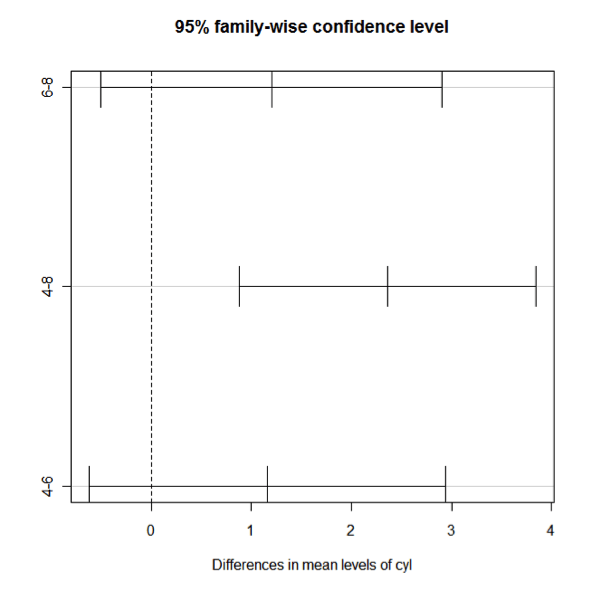
حيث أن الزوج الذي يتقاطع فيه محور العينات (أي عند القيمة 0 على محور السينات، وهو الخط المنقط الظاهر على المخطط) مع الخط الممثل لذلك الزوج والذي يحدد المجال بين قيمتي الحد الأدنى والأعلى يشير إلى عدم وجود فروق معنوية بين قطبيه.
إن قيمة الخطأ المعياري SE, Standard Error المرتكب في حساب المتوسطات هو مقدار له ذات واحدة قياس القيم المقروءة والمتوسطات المحسوبة، لذا يصعب علينا تحديد مدى هامشية أو فداحة تلك الأخطاء من مجرد النظر إلى مقدار SE، فعشر غرامات خطأ في قياس الوزن عند البقال تكاد لا تذكر في حين أنها عند الجواهرجي كارثية، لذا عادة ما نقوم بحساب معامل الاختلاف CV%, Coefficient of Variation وهو كما نرى نسبة مؤية مستقلة عن واحدات القياس وتحسب من ناتج قسمة الجذر التربيعي لقيمة Mean Sq الخاصة بالقيم المتبقية Residuals على المتوسط العام، أي أنه في حالتنا هذه يمكن حساب قيمة معامل الاختلاف CV% بالطريقة التالية:
> CV <- sqrt(2.2201) / 17.84875 > CV [1] 0.08347924
أي أن معامل الإختلاف في هذه الحالة هو في حدود 8.3% (بعد أن نضرب العدد الناتج بـ 100). وهكذا أصبحنا قادرين على التعبير عن الخطأ نسبة للمقادير التي نقيسها بمتوسطاتنا.
لائحة المراجع:











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.