

لقد أحدثت النماذج اللغوية الكبيرة LLMs وأشهرها روبوت المحادثة ChatGPT الذي طورته شركة OpenAI ثورة في الكثير من المجالات وأثبتت قدرتها على توليد نصوص تشبه النصوص البشرية، كما سهلت أداء العديد من المهام في مختلف المجالات ومن أبرزها مجال تطوير البرمجيات، فقد وفرت للمطورين والمبرمجين واجهات برمجية APIs تساعدهم في إنشاء تطبيقات ذكاء اصطناعي بسهولة كبيرة. سنتعلم في مقال اليوم كيفية تطوير تطبيق بايثون قادر على فهم نصوص ملف PDF والإجابة على أي أسئلة نطرحها حول محتوى هذا الملف بالاستفادة من ميزات نماذج الذكاء الاصطناعي التي توفرها واجهة برمجة تطبيقات OpenAI API وإطار عمل LangChain، وهو إطار عمل للغة البرمجة بايثون يمكن دمجه في تطبيقاتك لتعزز إمكانيات النماذج اللغوية الكبيرة.
نظرة عامة على التطبيق المطلوب ومتطلباته
نريد تطوير تطبيق بايثون باسم "اسأل PDF" يتيح هذا التطبيق للمستخدم تحميل ملف PDF من جهاز الحاسوب الخاص به، ويسمح له بطرح أي سؤال، ويستخدم تقنيات معالجة اللغة الطبيعية NLP للبحث عن إجابة مناسبة على هذا السؤال بناءً على محتوى الملف ويعرض له الإجابة. يحتاج تنفيذ التطبيق إلى المتطلبات التالية:
- معرفة بأساسيات لغة بايثون وتثبيت بيئة بايثون على الحاسوب المحلي.
- تثبيت أداة pip لتثبيت وإدارة حزم البرمجيات المساندة لبايثون.
- إنشاء حساب على على منصة OpenAI والحصول على مفتاح الواجهة البرمجية OpenAI API key خاص بك.
- معرفة بأساسيات نماذج وأطر عمل الذكاء الاصطناعي واختيار النماذج المناسبة لعمل التطبيق.
- معرفة بطريقة معالجة النصوص باستخدام التضمينات الرقمية ومخازن المتجهات.
ما أهمية التضمينات الرقمية في تطبيقات البحث
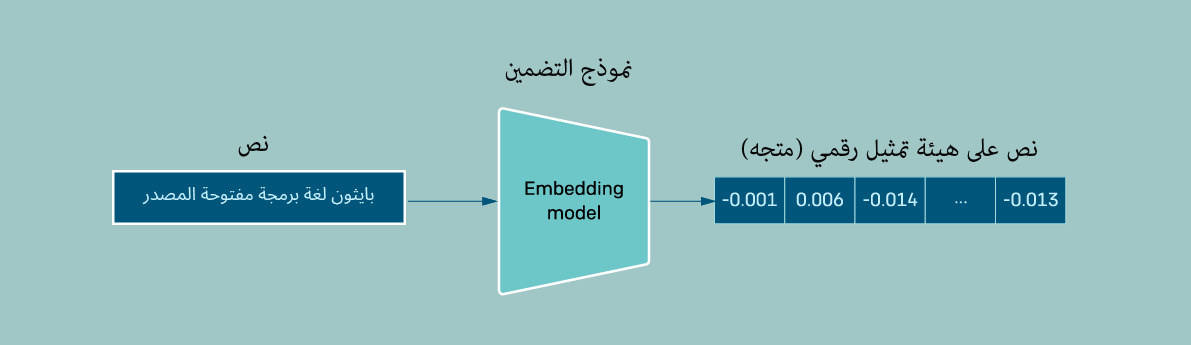
كي نتمكن من إنجاز عملية البحث في ملف pdf نحتاج لإنشاء تضمينات رقمية "Embedding" لكل جزء من أجزاء الملف، فبما أننا سنبحث في ملفات تتضمن الكثير من النصوص، فسنحتاج للاعتماد على تقنية التضمين وهي تقنية تستخدم في معالجة اللغة الطبيعية NLP وتقوم بتمثيل النصوص بشكل أعداد عشرية لتساعدنا على اكتشاف المعنى الدلالي للكلمات والعبارات والجمل بسرعة وفعالية، وتحولها لتنسيق يسهل الوصول إليه والبحث فيه عن المعلومات بدقة وكفاءة، بعدها سنقسم الملف إلى أجزاء صغيرة chunks حجم كل منها مثلًا 1000 حرف، ونفهرس هذه الأجزاء في قاعدة بيانات أو مخزن متجهات vectors حتى نتمكن من استرجاعها بسهولة عندما نريد الإجابة على الأسئلة الموجودة فيه.
بهذه الطريقة ستملك النصوص ذات المحتوى المتشابه لغويًا متجهات متشابهة وبهذا يمكن مقارنة المتجهات والعثور على النصوص المتشابهة بسهولة وسرعة، وعندما نريد الحصول على إجابة لسؤال معين فسوف ننشئ كذلك تضمين رقمي لنص السؤال، ثم نقارن تضمين السؤال مع جميع المتجهات التي خزناها في مخزن المتجهات، ونختار الأكثر تشابهًا بناءً على حسابات رياضية على المتجهات، ثم نمرر تضمين السؤال مع التضمينات الأكثر تشابهًا معه إلى روبوت المحادثة ليولّد لنا الإجابة المناسبة بناءً على هذه المعطيات.
خطوات التطبيق العملي
لننشئ تطبيق واجهة رسومية GUI بلغة بايثون باستخدام المكتبة المدمجة Tkinter يمكننا من خلالها تحميل ملف PDF الذي نريده ثم نبدأ بمعالجة محتواه واستخراج كافة النصوص منه، فبعد تحميل الملف المطلوب سنحول نصوصه إلى تضمينات كما شرحنا سابقًا، ثم سنبدأ بعملية طرح سؤال متعلق بمحتوى الملف. سنحول السؤال كذلك لتضمين أو تمثيل رقمي ونبحث عن كافة المحتوى المشابه له وسنرسل بعد ذلك للواجهة البرمجية ChatGPT API سلسلة تتضمن السؤال وكل المحتوى المرتبط به الذي وجدناه ضمن الملف كمدخلات، ثم سنولّد بناءً على ذلك الإجابة المناسبة بالاستفادة من إمكانيات النماذج اللغوية الكبيرة LLMs. وإليك خطوات القيام بذلك بالتفصيل:
خطوة 1: الحصول على مفتاح API الخاص بك من OpenAI
للحصول على مفتاح API الخاص بك من OpenAI عليك اتباع الخطوات التالية:
- انتقل إلى الصفحة الرسمية لمنصة openai وأنشئ حسابًا جديدًا إذا لم تكن قد أنشأته من قبل ثم سجل الدخول لحسابك.
- انقر على القسم اAP للدخول لحسابك في صفحة مطوري OpenAI.
- انقر على أيقونة ChatGPT أعلى يمين الصفحة واختر البند API Keys.
- انقر على Create new secret key لإنشاء مفتاح API الخاص بك.
- أدخل اسمًا اختياريًا لمفتاح API للرجوع إليه لاحقًا.
هذا كل ما يلزم لإنشاء مفتاح API الخاص بك من OpenAI. سيبدأ المفتاح بـ sk- انسخه واحفظه في مكان آمن واحرص على عدم مشاركته مع أحد أو كتابته في كود عام، فقد يقوم الآخرون باستخدام مفتاح API الخاص بك ويستهلكون رصيدك المتاح.
ملاحظة: عليك الاشتراك بخطة مدفوعة للاستفادة من واجهة برمجة التطبيقات OpenAI API في تطبيقاتك، وسيكون المبلغ المقتطع بحسب الاستهلاك والنموذج المستخدم، فلكل نموذج تكلفة مختلفة وكلما زادت طلباتك أو عدد الرموز tokens المرسلة والمستقبلة من النموذج كلما زادت فاتورتك، لكن يمكنك في البداية الحصول على رصيد مجاني بقيمة 5 دولار عند الاشتراك حديثًا في المنصة للتجربة.
خطوة 2: إنشاء ملفات تطبيق بايثون اسأل PDF
للقيام بهذه الخطوة يجب أن تكون بيئة بايثون مثبتة على جهازك، ولإنشاء مشروع بايثون جديد، افتح سطر الأوامر (أو الطرفية) في نظام التشغيل وانتقل للمسار المطلوب، وأنشئ مجلدًا جديدًا للمشروع وليكن باسم askpdf، ثم أنشئ ضمنه ملفين الأول ask_pdf.py لإضافة كود الواجهة الرسومية للتطبيق، والثاني ملف .env لإضافة مفتاح الواجهة الرسومية OpenAI API Key اللازمة لعمل التطبيق من خلال كتابة التعليمات التالية تباعًا في سطر الأوامر:
C:\Users\PC>d: D:\>md askpdf D:\>cd askpdf D:\askpdf>touch ask_pdf.py Touching ask_pdf.py D:\askpdf>touch .env Touching .env D:\askpdf>
تثبيت المكتبات اللازمة لعمل التطبيق
يحتاج التطبيق إلى تثبيت العديد من مكتبات ووحدات بايثون الخارجية باستخدام مدير الحزم pip وهي كالتالي:
pip install python-dotenv PyPDF2 langchain langchain-openai langchain-community faiss-cpu
إليك وصفًا موجزًا لكل مكتبة ولماذا استخدمناها في التطبيق:
-
المكتبة python-dotenv لقراءة قيمة المفتاح الذي سأخزنه في الملف
env. - المكتبة PyPDF2 ضرورية للتعامل مع ملف PDF وقراءته محتوياته.
- إطار عمل LangChain ليسهل التعامل مع نموذج text-embedding-ada-002 لتقسيم النصوص، وإنشاء تضمينات وفهارس لها، كما أنه يدعم نموذج GPT-3.5 Turbo Instruct لتوليد إجابات على الأسئلة المطروحة.
- سنستدعي مكتبات langchain و langchain-openai و langchain-community من هذا الإطار وهي مكتبات مفيدة تتكامل مع نماذج OpenAI وتوسع إمكانياتها.
- وأخيرًا سنستخدم مكتبة Faiss وهي مكتبة بايثون يوفرها إطار LangChain تسرع عملية البحث عن التشابه في البيانات النصية دون الحاجة لاستهلاك الكثير من الموارد.
كتابة الكود البرمجي للتطبيق
الخطوة التالية هي إضافة الكود الخاص بالتطبيق، سأفتح الآن مجلد المشروع بمحرر الأكواد VSCode وأكتب بدايةً في ملف إعدادات التطبيق .env قيمة مفتاح الواجهة البرمجية على النحو الآتي:
OPENAI_API_KEY= Your_KEY
وعليك بالطبع استبدال Your_KEY في الكود السابق بالقيمة الفعلية لمفتاحك ليعمل التطبيق بشكل صحيح.

الآن سننتقل للملف الأساسي للتطبيق ask_pdf.py ونستورد بدايةً كافة المكتبات والوظائف اللازمة لعمل التطبيق. ويوضح التعليق ضمن الكود دور كل منها على النحو الآتي:
import os from dotenv import load_dotenv # مكتبات إنشاء الواجهة الرسومية import tkinter as tk from tkinter import filedialog, scrolledtext, ttk from tkinter import font from PIL import Image, ImageTk # قراءة ومعالجة ملفات PDF from PyPDF2 import PdfReader # الواجهة البرمجية OpenAI from langchain_openai import OpenAI from langchain_community.vectorstores import FAISS from langchain_community.callbacks import get_openai_callback from langchain.text_splitter import CharacterTextSplitter from langchain.chains.question_answering import load_qa_chain from langchain_openai import OpenAIEmbeddings
بعدها سننشئ الصنف الأساسي للتطبيق باسم askpdfgui ونعرّف بداخله التابع __init__ لإضافة وتهيئة عناصر الواجهة الرسومية Widgets للتطبيق، ستتضمن الواجهة عناصر متعددة مثل حاويات العناوين Labels وشريط تقدم Progressbar وزِرَّين Buttons الأول لتحميل ملف PDF من الجهاز لذاكرة التطبيق ومعالجته، والثاني للبحث عن إجابة السؤال الذي يكتبه المستخدم ولا يكون هذا الزر مُفعّلًًا إلا بعد اكتمال تحميل ومعالجة الملف.
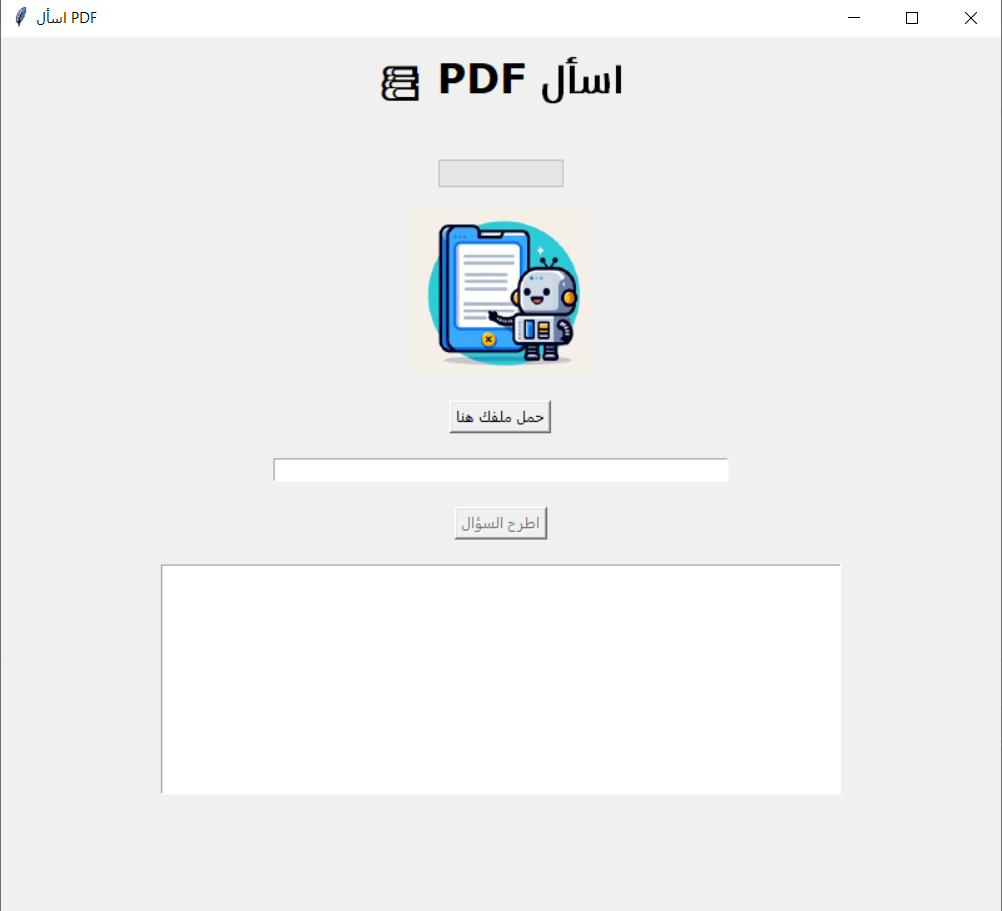
class askpdfgui: def __init__(self, root): self.root = root self.root.title("اسأل PDF") self.root.geometry("800x700") custom_font = font.Font(family="Verdana", size=24, weight="bold") self.label = tk.Label(root, text="? PDF اسأل", font=custom_font) self.label.pack(pady=10) # عرض تقدم حالة تحميل الملف self.progress_label = ttk.Label(root, text="", foreground="green") self.progress_label.pack(pady=5) self.progress_bar = ttk.Progressbar(root, orient="horizontal") self.progress_bar.pack(pady=5) script_dir = os.path.dirname(os.path.abspath(__file__)) image_path = os.path.join(script_dir, "robopdf.png") image = Image.open(image_path) tk_image = ImageTk.PhotoImage(image) self.image_label = tk.Label(root, image=tk_image) self.image_label.image = tk_image self.image_label.pack(pady=10) # إضافة زر تحميل الملف self.upload_button = tk.Button( root, text="حمل ملفك هنا", command=self.upload_pdf ) self.upload_button.pack(pady=10) # حقل نصي لكتابة السؤال self.question_entry = tk.Entry(root, width=60, justify="center") self.question_entry.pack(pady=10) # زر طرح السؤال وإلغاء تفعيله لحين اكتمال معالجة الملف self.ask_button = tk.Button( root, text="اطرح السؤال", command=self.ask_question, state=tk.DISABLED ) self.ask_button.pack(pady=10) # عرض نتيجة السؤال self.result_text = tk.Text(root, wrap=tk.WORD, width=60, height=10) self.result_text.configure(font=("TkDefaultFont", 12)) self.result_text.pack(pady=10, anchor=tk.CENTER)
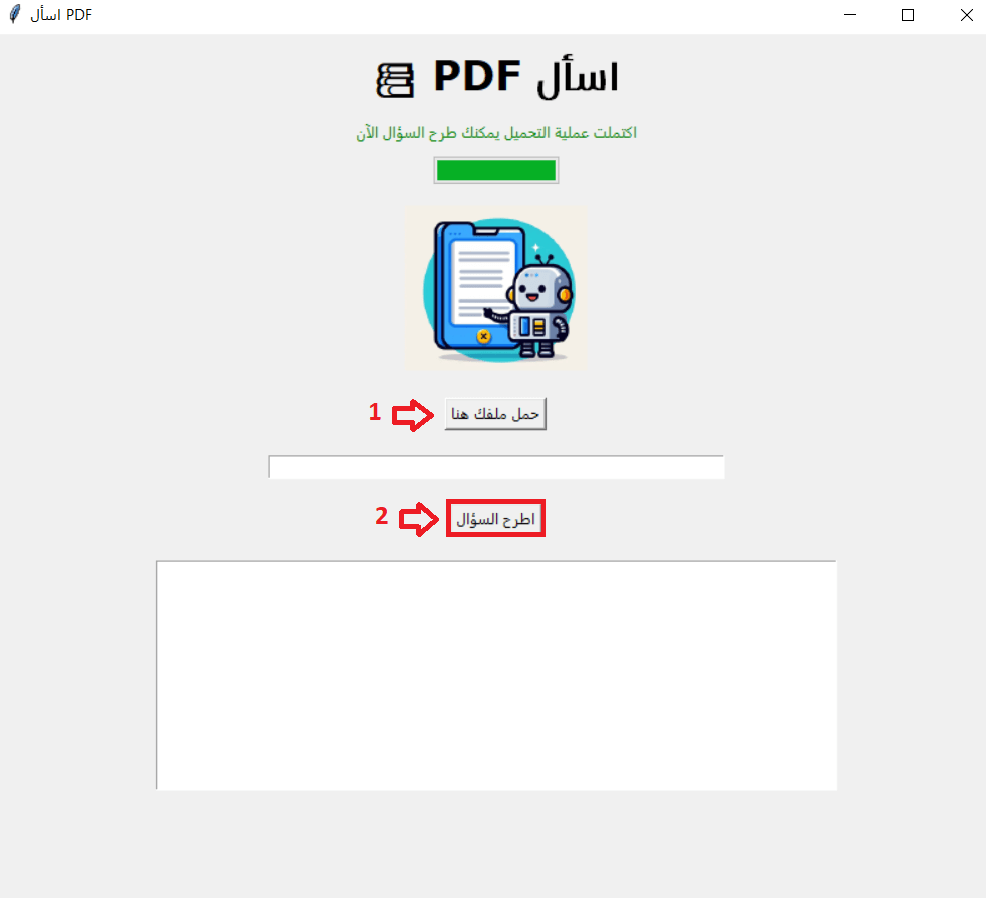
سيكون شكل التطبيق على النحو التالي:
الآن وبعد أن انتيهنا من تصميم واجهة التطبيق وتهيئة خصائص عناصر واجهة المستخدم سنبرمج وظائفه، بداية نحقق كود الدالة upload_pdf التي ستمكن المستخدم من فتح نافذة لتحميل ملف PDF الخاص به لداخل التطبيق كما يلي:
def upload_pdf(self): file_path = filedialog.askopenfilename(filetypes=[("PDF Files", "*.pdf")]) if file_path: self.process_pdf(file_path)
بعد أن يختار المستخدم ملف PDF يستدعى التابع process_pdf الذي يأخذ كوسيط مسار هذا الملف لبدء عملية المعالجة ويستخرج النصوص منه باستخدام الدالة extract_text، ويقسمه إلى أجزاء أو مقاطع أو نصوص بطول 1000 حرف مع تداخل بقيمة 200 حرف بين الأجزاء كي لا يفقد السياق، بمعنى سيكون الجزء الأول من البداية إلى الحرف 1000 أما الجزء الثاني فسيبدأ من الحرف 801 لضمان استمرارية المعنى وعدم فقدان معلومات مهمة بين النصوص المتجاورة.
هناك عدة تقنيات مختلفة متاحة لتنفيذ مهمة التضمين والفهرسة في تطبيقنا، وقد اعتمدنا في هذا هذا التطبيق على الصنف OpenAIEmbeddings من مكتبة langchain_openai ومررنا قيمة مفتاح الواجهة البرمجية openai_api_key لباني الصنف لأنه سيستخدم هنا النموذج Embading الذي توفره هذه الواجهة لتكوين التضمينات الرقمية وإنشاء المتجهات الخاصة بها بالاستعانة بمكتبة FAISS على النحو التالي:
def process_pdf(self, file_path): self.progress_label.config(text="انتظر اكتمال تحميل ملف PDF...") self.progress_bar.start() self.root.update_idletasks() pdf_reader = PdfReader(file_path) text = "" for page in pdf_reader.pages: text += page.extract_text() # تقسيم نص الملف إلى أجزاء text_splitter = CharacterTextSplitter( separator="\n", chunk_size=1000, chunk_overlap=200, length_function=len ) chunks = text_splitter.split_text(text) # إنشاء تضمينات النصوص embeddings = OpenAIEmbeddings(api_key=openai_api_key) knowledge_base = FAISS.from_texts(chunks, embeddings) self.docs = knowledge_base.similarity_search("")
بالنسبة للسطر الأخير في الكود:
self.docs = knowledge_base.similarity_search("")
سينفذ هذا السطر عملية بحث عن التشابه ويجد أقرب الجمل لسؤالك الذي ستطرحه باستخدام قاعدة بيانات المتجهات knowledge_base ويخزن النتيجة في متغير docs فهذا المتغير يخزن معلومات حول النصوص المتشابهة ودرجة التشابه بين النص أو السؤال الذي تبحث عنه والنص المخزن في قاعدة البيانات، لكن هنا لم نكتب السؤال بعد لذا نخزن نتائج البحث باعتبار السؤال فارغ، لاحقًا عندما ستتم عملية البحث الفعلية سيحدد النصوص المشابهة بشكل أفضل ويحسن عملية البحث.
إليك مثالًا بسيطًا لبنية هذا المتغير، إذا كان السؤال الذي كتبه المستخدم هو "ما فائدة تعلم الذكاء الاصطناعي في تحسين مهارات التطوير" فسوف يحتوي المتغير عندها على قائمة من النصوص التي حصل عليها من الملف مع درجة التشابه مع السؤال المطروح على نحو مشابه للبنية التالية:
self.docs = [ {"text": "تعلم لغات البرمجة يساعد في تطوير مهارات البرمجة", "similarity_score": 0.85}, {"text": "تعلم الذكاء الاصطناعي يحسن من تجربة المستخدم", "similarity_score": 0.92}, # ... وهكذا
تأخذ هذه العملية بعض الوقت لقراءة الملف بالكامل ومعالجته بالاعتماد على حجم الملف وبعد اكتمال تحميل الملف وتحويله لتضمينات وفهرسته بالشكل المطلوب، سيُفعّل زر طرح السؤال إذ يمكن للمستخدم الآن كتابة أي سؤال في الحقل النصي question_entry للإجابة عليه بناءً على المحتوى الذي أنشأه البرنامج.
self.progress_label.config(text="اكتملت عملية التحميل يمكنك طرح السؤال الآن") self.progress_bar.stop() self.progress_bar["value"] = 100 # تمكين زر طرح السؤال self.ask_button["state"] = tk.NORMAL
الخطوة التالية والأخيرة هي تعريف التابع ask_question وهو أهم تابع في تطبيقنا وسنستدعيه بعد كتابة السؤال والنقر على زر طرح السؤال، ليبدأ بالبحث عن إجابة مناسبة على السؤال من محتوى المتغير doc ويرسل الطلب لواجهة OpenAI لتقديم إجابة مناسبة.
def ask_question(self): user_question = self.question_entry.get() if user_question: llm = OpenAI(model="gpt-3.5-turbo-instruct", api_key=openai_api_key, temperature=0.0) chain = load_qa_chain(llm, chain_type="stuff") with get_openai_callback(): response = chain.run(input_documents=self.docs, question=user_question) print(response) # عرض الإجابة على السؤال self.result_text.tag_configure("center", justify="center") # مسح أي نص قديم إن وجد self.result_text.delete("1.0", tk.END) self.result_text.insert(tk.END, response, "center")
كما هو موضح في الكود أعلاه سيحصل التابع على نص السؤال الذي أدخله المستخدم في الحقل النصي question_entry ثم يخزنه في المتغير user_question ويمرر مدخلات المستخدم إلى النموذج gpt-3.5-turbo-instruct لتوليد الإجابة، وهنا نحتاج كذلك لإدخال قيمة المفتاح openai_api_key لإنشاء اتصال مع واجهة برمجة تطبيقات OpenAI ولتخصيص أي وسطاء نحتاجها لتخصيص إجابة النموذج وأهم هذه الوسطاء temperature الذي يحدد درجة دقة السؤال. ويفضل في حالة تطبيقنا أن تبقى قيمته صفر للحصول على إجابات منطقية وحتمية تلتزم بمحتوى الملف، وعدم ترك النموذج يبدع ويؤلف إجابات لا صلة لها بالسياق وسنوضح المزيد عنه لاحقًا عن تجربة تنفيذ التطبيق.
بعدها نستدعي الدالة load_qa_chain التي تنشئ سلسلةً نصيةً من نوع stuff لترسلها كمطالبة إلى الواجهة البرمجية OpenAI التي تفهم بدورها الطلب الذي أرسلناه وتعيد لنا الإجابة المناسبة response. ملاحظة: يحدد نوع السلسلة chain_type طريقة تمرير المستندات إلى النموذج اللغوي الكبير LLM وهنا مررنا القيمة ليكون stuff التي ترسل جميع المستندات في طلب واحد للواجهة البرمجية وهي تناسب حالة التعامل مع مستند واحد أو عدة مستندات صغيرة الحجم وتتضمن نفس طبيعة المحتوى، وهناك طرق أخرى هي
Map-reduce تفيد في حال التعامل مع مستندات كبيرة هي تلخص كل مستند على حدا ثم تجمع التلخيصات في ملخص نهائي.
أخيرًا نكتب كود تشغيل التطبيق كبرنامج رئيسي من خلال تحميل بيانات مفتاح OpenAI API من ملف .env وفحص فيما إذا كان المفتاح قد تم تعيينه أم لا، والبدء بإنشاء واجهة المستخدم الرسومية وتشغيل التطبيق حتى يتم إغلاق النافذة.
if __name__ == "__main__": load_dotenv() openai_api_key = os.getenv("OPENAI_API_KEY") if openai_api_key is None: print( "OpenAI API تأكد من تعيين قيمة مفتاح" ) else: root = tk.Tk() app = askpdfgui(root) root.mainloop()
تجربة عمل التطبيق
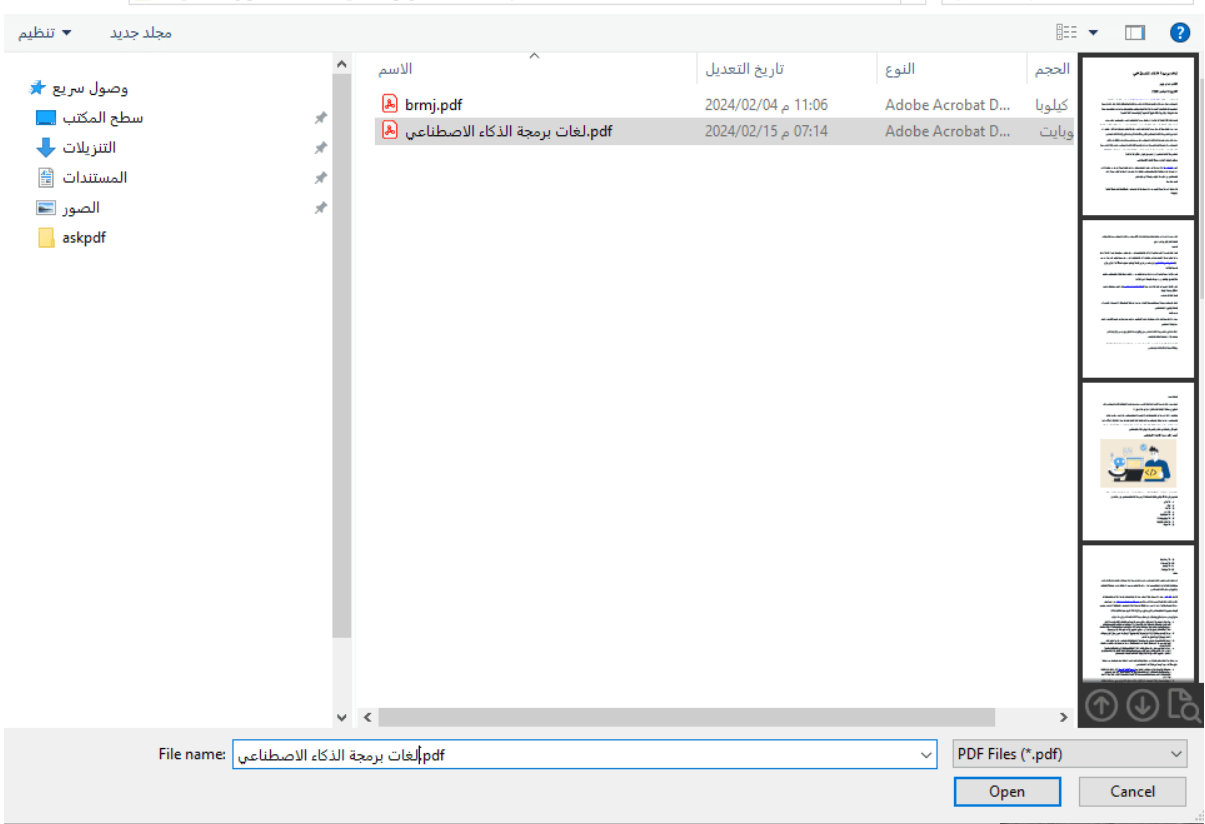
لننفذ الآن كود التطبيق ونختبر آلية عمله: انتقل لمسار وجود التطبيق واكتب الأمر python ask_pdf.py في سطر الأوامر أو الطرفية لتشغيله، ستظهر لك الواجهة الأولية ولتجربة التطبيق سأنقر على زر "حمل ملفك هنا"
يمكن تحميل أي ملف pdf خاص بك في التطبيق، وفي حالتي سأختار ملف يتحدث عن لغات برمجة الذكاء الاصطناعي كما يلي:
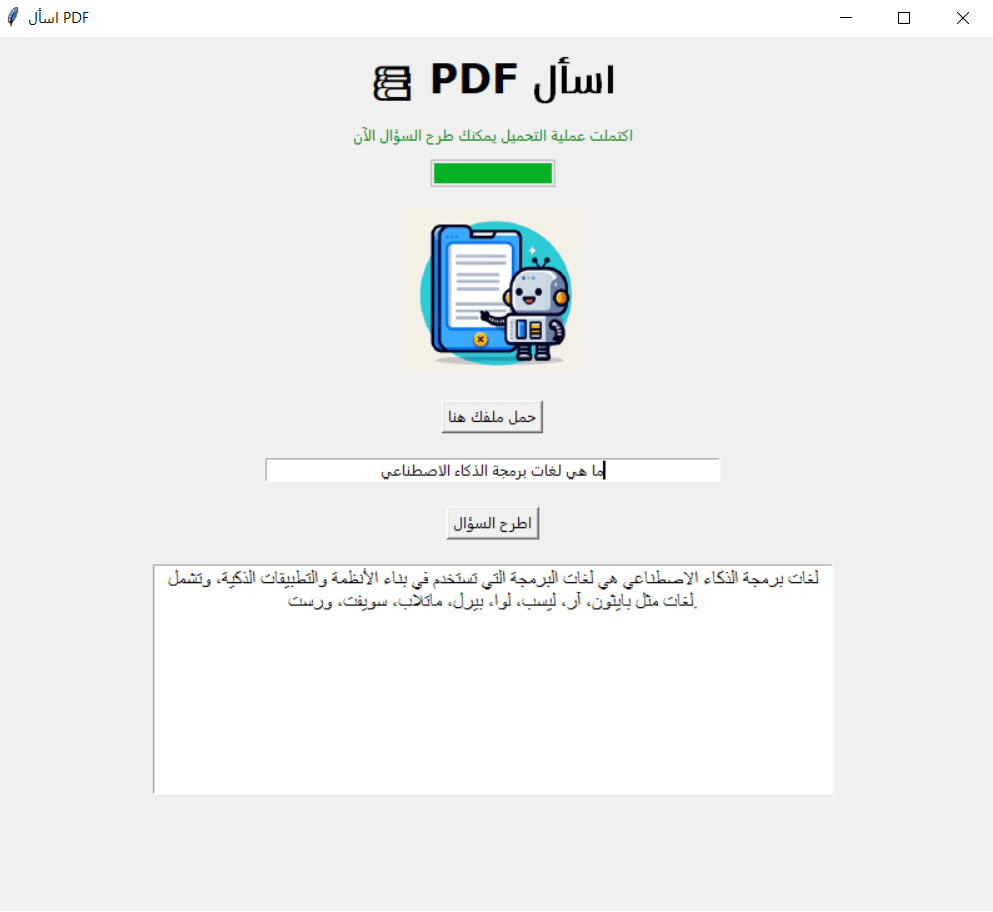
بعد اكتمال عملية التحميل سأطرح السؤال التالي: "ما هي لغات برمجة الذكاء الاصطناعي؟" وسأحصل على الإجابة كما هو موضح في الصورة التالية:
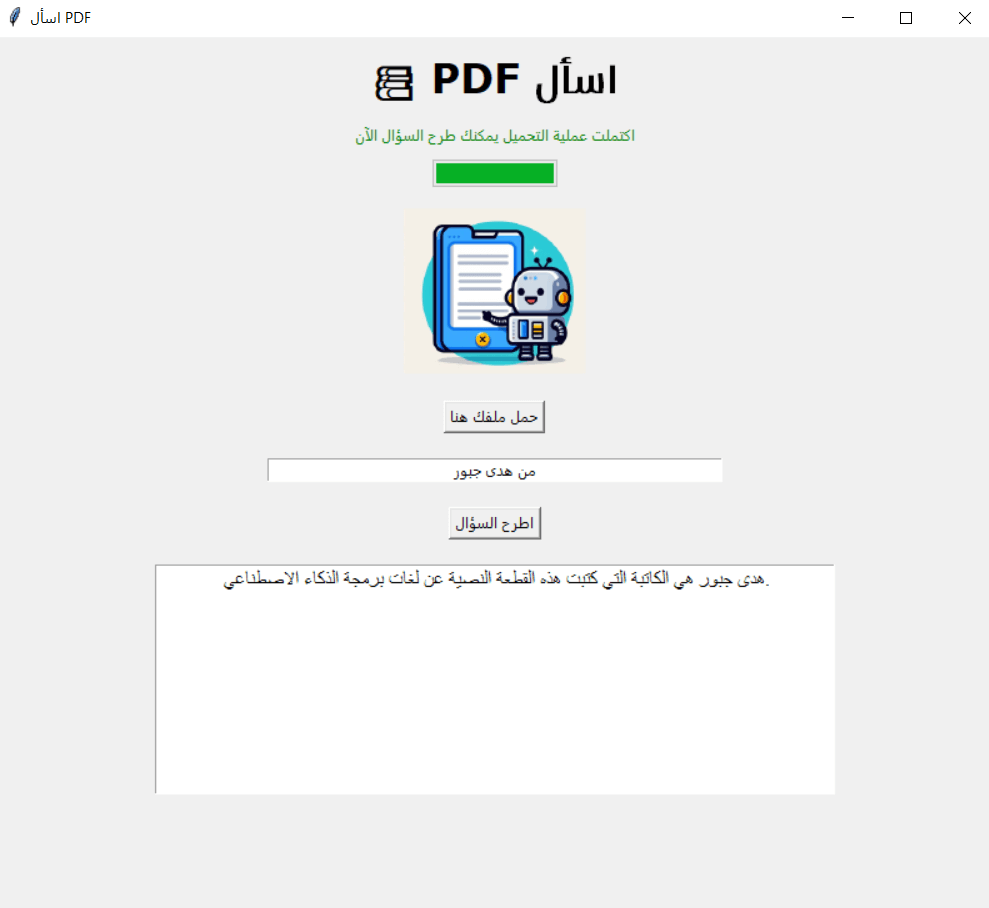
كما يمكن طرح أي أسئلة أخرى حول الملف مثل اسم الكاتب أو تاريخ نشره وسيتمكن من الإجابة كما توضح الصورة أدناه:
الآن لو طرحت سؤالًا لا علاقة له بمحتوى هذا الملف مثل "من اخترع المصباح الكهربائي" ستكون النتيجة كما يلي:
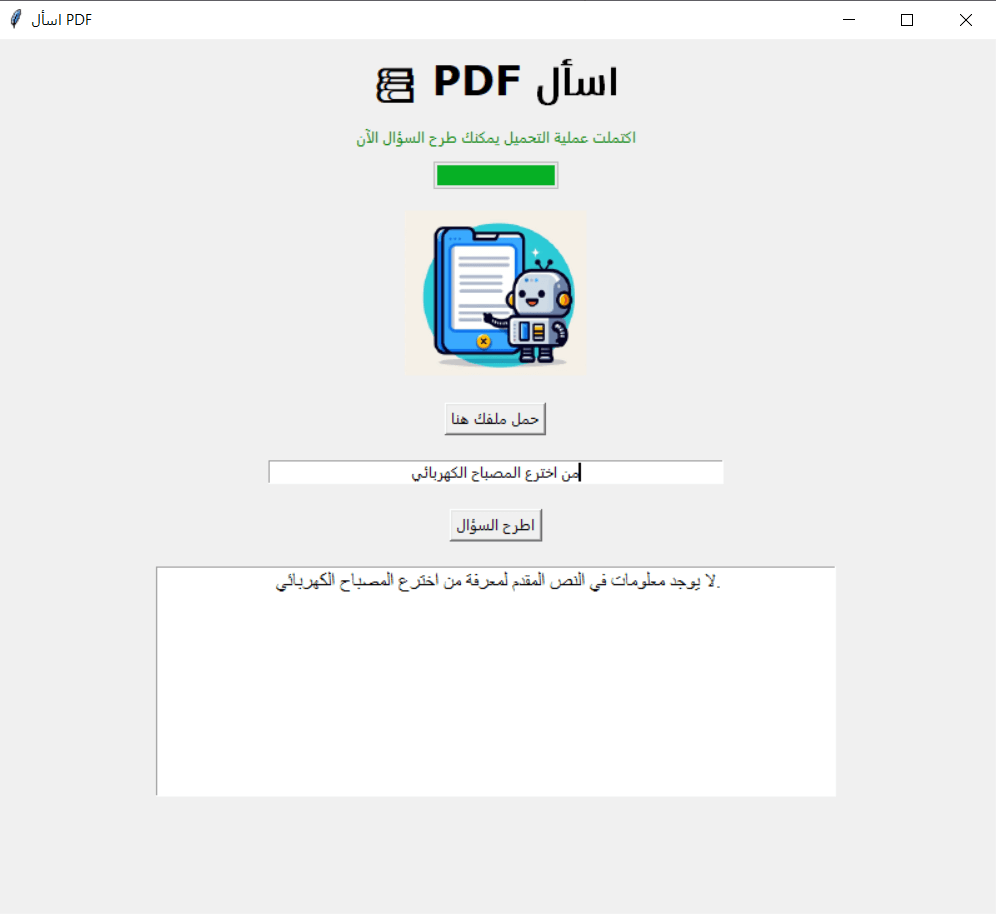
تأثير الوسيط Temperature على دقة نتائج التطبيق
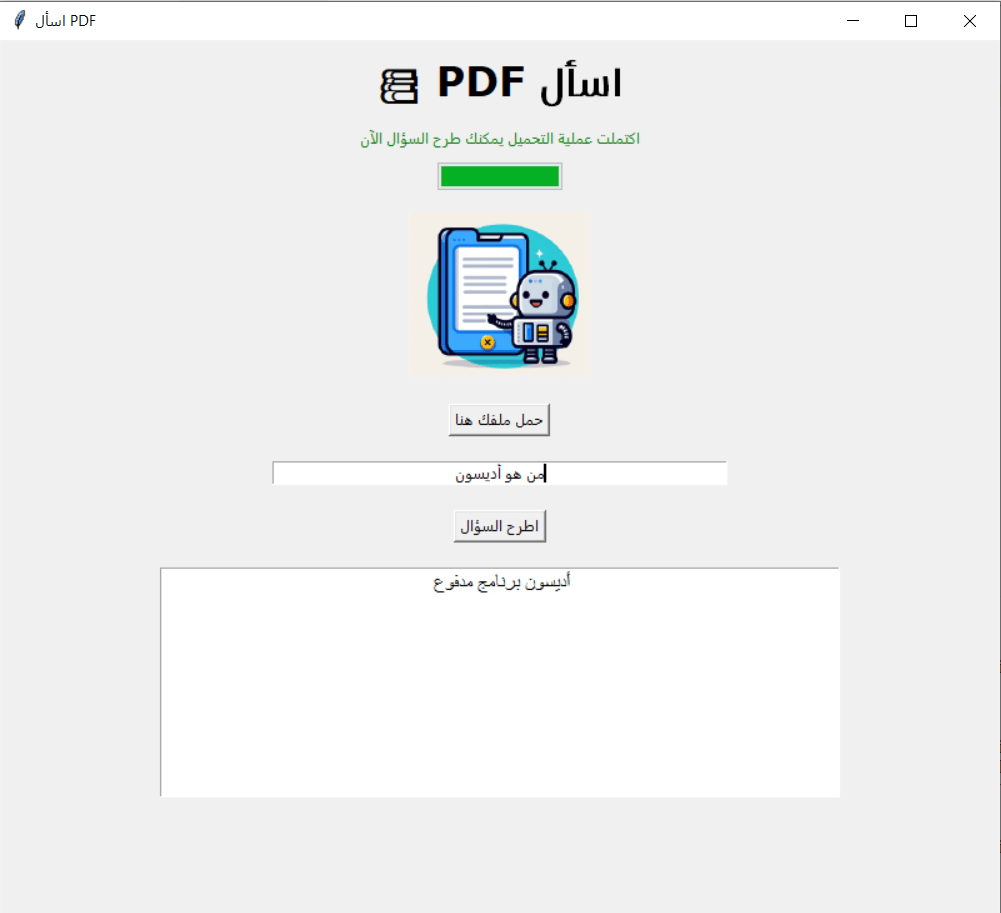
يستخدم المعامل أو الوسيط temperature كما وضحت سابقًا للتحكم في دقة أو عشوائية النتائج التي تعيدها نماذج واجهة برمجة تطبيقات OpenAI وتتراوح قيمة هذا الوسيط بين 0 و 2، فعند ضبط درجة الدقة على قيم قريبة من الصفر ستحصل على نتائج واقعية وذات صلة بالطلب وحين تضبطه على قيم قريبة من 2 ستحصل على نتائج أكثر إبداعًا لكنها قد تكون غير دقيقة ولا صلة لها بالسؤال. لذا عليك تعديل قيمة هذا المعامل بما يتناسب مع طبيعة تطبيقك، وهل يحتاج للدقة كما في حال تطبيقنا الذي يبحث عن النتائج الموافقة للسؤال، أم يسمح فيه الإبداع والابتكار كتطبيقات تأليف القصص والروايات. سأجرب على سبيل المثال تغير درجة الحرارة في الكود السابق وجعلها مثلًا 1.5 وأحمّل الملف نفسه واطرح سؤال "من هو أديسون؟" مثلًا ستكون النتيجة غير منطقية كما يلي!
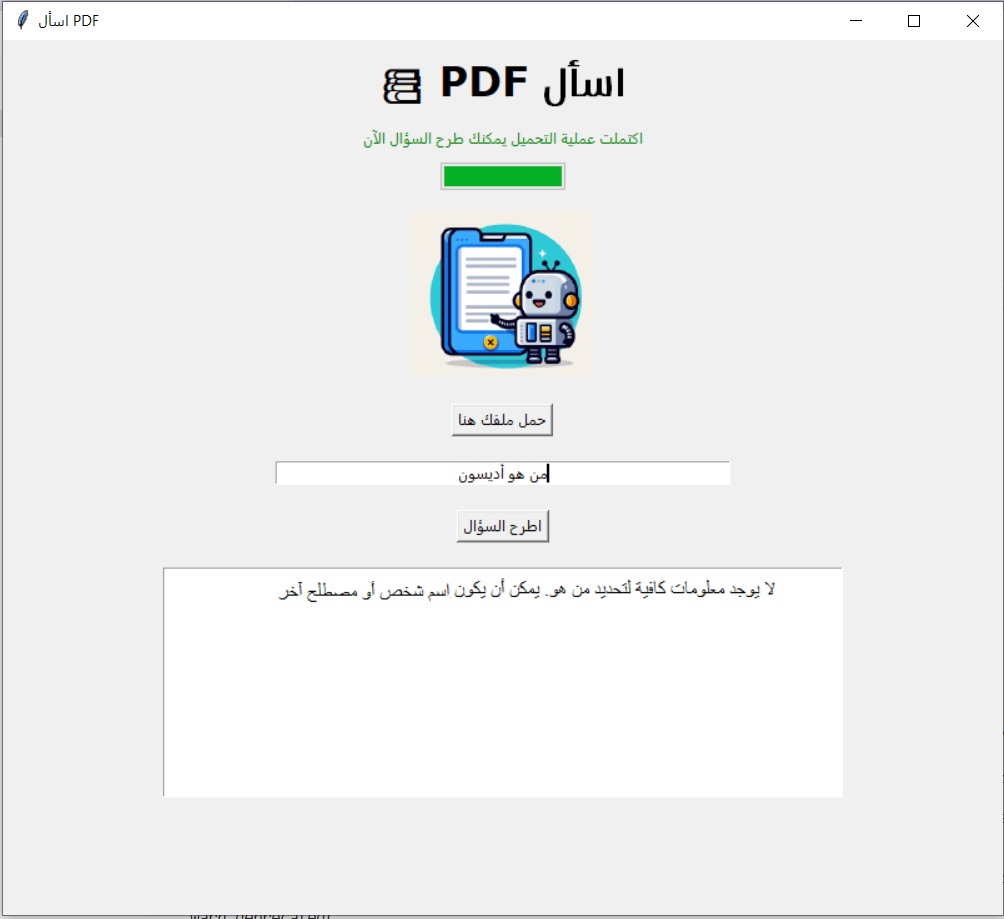
أما عند إعادة ضبطه بالقيمة 0 فسيجيب التطبيق بأنه لا يملك معلومات عن أديسون وفق الملف الذي وفرته له.
قيود على عدد الرموز Tokens في التطبيق
يمكنك تجربة التطبيق على أي ملف pdf خاص بك، لكن تملك نماذج من OpenAI API حدًا أقصى لعدد الرموز Token Limits التي تمثل إجمالي طول المدخلات التي تستقبلها والنتائج التي تولدها وفي حالة النموذج gpt-3.5-turbo-instruct المستخدم في الكود فالعدد الأقصى هو 4096 رمزًا، وبالتالي قد تحصل على الخطأ التالي عند تحميل ملفات كبيرة وتجاوز إجمالي الرموز في دخل وخرج النموذج هذا العدد، ومن الإجراءات الممكنة لتجاوز هذه القيود، تحديد قيمة المعامل max_tokens للنموذج كي تحدد له طول الرد الذي سينتج وتمنعه من إنشاء محتوى طويل جدًا أو تقصير نص الطلب أو السؤال قدر المستطاع.

كما تحدد بعض النماذج سرعة معالجة الرموز في الدقيقة الواحدة، فالحد الأقصى المسموح به للتضمينات في نموذج text-embedding-ada-002 هو 15000 رمز في الدقيقة، وبالتالي إذا استخدمت ملفات pdf كبيرة تتجاوز هذه الحدود فسوف تحصل على كذلك أخطاء في التنفيذ بسبب القيود التي تفرضها الواجهة البرمجية ولحلها عليك رفع خطة الاشتراك في الواجهة البرمجية.

الخلاصة
بهذا نكون قد وصلنا لنهاية مقالنا، الذي شرحنا فيه خطوات إنشاء تطبيق بايثون يستفيد من واجهة برمجة تطبيقات OpenAI لتحميل ملف PDF وطرح أسئلة حوله وتوليد إجابات عليها من محتوى الملف، وهناك بالطبع الكثير من الأفكار الأخرى التي يمكنك الاستفادة منها من النماذج اللغوية الكبيرة LLMs في تطوير تطبيقات متقدمة في مجال الذكاء الاصطناعي، أطلق العنان لإبداعك واستفد من قوة هذه النماذج وإمكانياتها الهائلة.
اقرأ أيضًا
- تطوير تطبيق "وصفة" لاقتراح الوجبات باستخدام ChatGPT و DALL-E في PHP
- تطوير تطبيق "اختبرني" باستخدام ChatGPT ولغة جافاسكربت مع Node.js
- إعداد بيئة العمل للمشاريع مع بايثون
- اكتشاف دلالات الأخطاء في شيفرات لغة بايثون
كود التطبيق






أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.