

يُعَدّ التعلم المُعزز مجالًا فرعيًا من فروع نظرية التحكم، والتي تُعنى بالتحكم في الأنظمة التي تتغير بمرور الوقت؛ وتشمل عِدّة تطبيقاتٍ من بينها: السيارات ذاتية القيادة، وبعض أنواع الروبوتات مثل الروبوتات المُخصصة للألعاب. وسنستخدم في هذا المقال التعلم المعزز لبناء روبوتٍ لألعاب الفيديو المُخصصة لأجهزة آتاري Atari، حيث لن يُمنح هذا الروبوت إمكانية الوصول إلى المعلومات الداخلية للعبة، وإنما سُيمنح إمكانية الوصول لنتائج اللعبة المعروضة على الشاشة، وكذا المكافآت الناتجة عن هذه اللعبة فقط؛ أي أنه سيرى ما يراه أي شخصٍ سيلعبُ هذه اللعبة.
في مجال تعلّم الآلة، يُعرَّف الروبوت Bot بأنه الوكيل Agent، وسيكون الوكيل بمثابة لاعبٍ في النظام، بحيث يعمل وفقًا لدالة اتخاذ القرار، وهدفنا الأساسي هو تطوير روبوتاتٍ ذكيةٍ من خلال تعليمهم وإمدادهم بقدراتٍ قويةٍ تقدر على اتخاذ القرار.
نعرض، في هذا الدرس، كيفية تدريب روبوت باستخدام التعلم المعزز العميق وفق النموذج الحُر Deep Q-learning للعبة غزاة الفضاء Space Invaders، وهي لعبةٌ مخصصةٌ لجهاز أتاري أركايد Atari Arcade الكلاسيكي.
فهم التعلم المعزز
يكون هدف اللاعب في أي لعبة هو زيادة درجاته، وسنشير في هذا الدرس لنتيجة اللاعب على أنها مكافأته، ولتعظيم المكافأة يجب على اللاعب أن يكون قادرًا على تحسين قدراته في اتخاذ القرارات، وبصيغةٍ أخرى فلسفية، القرار هو عملية النظر إلى اللعبة، أو مراقبة حالة اللعبة، واختيار فعلٍ معينٍ مناسبٍ لهذه الحالة.
يُمكن بشكل عام نمذجة روبوت لاعب في بيئة لعب بسلسلة من الحالات State(ح S) والأفعال Actions (أ A) والمكافآت Rewards (م R): ح.أ.م.ح.أ.م.ح.أ.م… أو بالانكليزية: S,A,R,S,A,R,…
يهدف التعلم إلى اختيار الفعل الأنسب من مجموعة من الأفعال المُمكنة في حالة ما والذي يُمكن أن يؤدي إلى مكافأة كبيرة في النهاية. ليس من الضروري الحصول على مكافأة جيدة في الحالة التالية، بمعنى أن لا يكون الهدف محلي (مكافأة جيدة فورًا) بل أن يكون الهدف استراتيجي (ربح اللعبة مع مكافأة كبيرة في نهاية اللعبة.
أي أننا سنضع في حُسباننا ما يلي:
- عند مشاهدة العديد من الملاحظات حول حالات الروبوت وأفعاله ومكافآته، يمكن للمرء تقدير المكافأة المناسبة لكلّ حالةٍ وفعل معينٍ وذلك حسب النهاية التي آلت إليها اللعبة (أو مرحلة متقدمة منها).
- تُعَد لعبة غزاة الفضاء Space Invaders من الألعاب ذات المكافأة المتأخرة؛ أي أن اللاعب يكافَأ عندما يفجّر أحد الأعداء وليس بمجرد إطلاقه للنار فقط، ومع ذلك فإن قرار اللاعب بإطلاق النار هو الدافع الصحيح للحصول على المكافأة، لذا بطريقةٍ أو بأخرى، يجب أن نتعلم منح الحالة المرتبطة بفعل الإطلاق مكافأةً إيجابيةً.
المتطلبات الرئيسية
لإكمال هذا الدرس بنجاحٍ، ستحتاج إلى تجهيز بيئة العمل المكونة من:
- حاسوب يعمل بنظام أوبونتو 18.04، وبذاكرة وصولٍ عشوائيٍ RAM لا تقِل عن 1 غيغابايت، ويجب أن يحتوي الخادم على مستخدمٍ غير مسؤولٍ non-root user وبصلاحيات sudo المُهيّأة مسبقًا، وجدار حمايةٍ مهيئٍ باستخدام UFW. وللمزيد، يمكنك الاطلاع على كيفية التهيئة الأولية لخادم أوبونتو 18.04 أو حاسوب يعمل بنظام ويندوز 10 .
- تثبيت بايثون 3 وإعداد بيئته البرمجية، وبإمكانك معرفة كيفية تثبيت بايثون 3 وإعداد بيئة برمجية على أوبنتو 18.04.
وإذا كنت تستخدم جهازًا محليًا، فيمكنك تثبيت بايثون 3 محليًا خطوةً بخطوة، باطلاعك على كيفية تثبيت بايثون 3 وإعداد بيئته البرمجية على ويندوز 10.
سنحتاج في هذا المشروع إلى المكتبات الأساسية التالية:
- Gym: وهي مكتبة بايثون تجعل الألعاب المختلفة متاحةً للأبحاث، وكذا جميع التبعيات الخاصة بالألعاب المخصصة لأجهزة أتاري، والتي طورتها شركة OpenAI. حيث تقدم مكتبة Gym معاييرًا عامة لكلّ لعبةٍ، وذلك لتمكننا من تقييم أداء الروبوتات والخوارزميات المختلفة بطريقةٍ موحدةٍ.
- Tensorflow: وهي مكتبة التعلم العميق المقدمة من غوغل، تتيح لنا إجراء العمليات الحسابية بطريقةٍ أكثر كفاءةً عن ذي قبل، حيث تؤدي ذلك من خلال بناء دوال رياضيةً باستخدام التجريدات الخاصة بمكتبة Tensorflow تحديدًا ، كما تعمل حصريًا على وِحدة المعالجة الرسومية GPU الخاصة بك.
- NumPy: وهي مكتبة الجبر الخطي.
لإكمال هذا الدرس ستحتاج بيئةً برمجيةً للغة بايثون الإصدار 3.8 سواءً كان محليًا أو بعيدًا. ويجب أن تتضمن هذه البيئة البرمجية مدير الحِزم pip لتثبيت الحِزم، ومُنشئ البيئات الافتراضية venv لإنشاء بيئاتٍ افتراضيةٍ.
قبل البدء بهذا المقال لا بد من تجهيز البيئة المناسبة، وسنستخدم محرر الشيفرات البرمجية Jupyter Notebooks، وهو مفيد جدًا لتجربة وتشغيل الأمثلة الخاصة بتَعَلّم الآلة بطريقةٍ تفاعليةٍ، حيث تستطيع من خلاله تشغيل كتلًا صغيرةً من الشيفرات البرمجية ورؤية النتائج بسرعة، مما سيسهل علينا اختبار الشيفرات البرمجية وتصحيحها.
يُمكنك فتح متصفح الويب والذهاب لموقع المحرر الرسمي jupyter على الوِيب لبدء العمل بسرعة، ومن ثمّ انقر فوق "جرّب المحرر التقليدي Try Classic Notebook"، وستنتقل بعدها لملفٍ جديدٍ بداخل محرر Jupyter Notebooks التفاعلي، وبذلك تجهّز نفسك لكتابة الشيفرة البرمجية بلغة البايثون.
إذا رغبت بمزيدٍ من المعلومات حول محرر الشيفرات البرمجية Jupyter Notebooks وكيفيّة إعداد بيئته الخاصة لكتابة شيفرة بايثون، فيمكنك الاطلاع على: كيفية تهيئة تطبيق المفكرة jupyter notebook للعمل مع لغة البرمجة python.
إعداد المشروع
ستحتاج أولًا لتثبيت بعض التبعيات، وذلك لإنشاء مساحة عملٍ للاحتفاظ بملفاتنا قبل أن نتمكن من تطوير برنامج التعرف على الصور، وسنستخدم بيئة بايثون 3.8 الافتراضية لإدارة التبعيات الخاصة بمشروعنا.
سَنُنشئ مجلدًا جديدًا خاصًا بمشروعنا وسندخل إليه هكذا:
mkdir qlearning-demo cd qlearning-demo
سننفذّ الأمر التالي لإنشاء البيئة الافتراضية:
python -m venv qlearning-demo
ومن ثم الأمر التالي في Linux لتنشيط البيئة الافتراضية:
source qlearning-demo/bin/activate
أما في Windows، فيكون أمر التنشيط:
"qlearning-demo/Scripts/activate.bat"
سنستخدم إصداراتٍ محددةٍ من هذه المكتبات، من خلال إنشاء ملف requirements.txt في مجلد المشروع، وسيُحدِّد هذا الملف المتطلبات والإصدارات التي سنحتاج إليها.
نفتح الملف requirements.txt في محرر النصوص، ونُضيف الأسطر التالية، وذلك لتحديد المكتبات التي نريدها وإصداراتها:
tensorflow==2.6.0 numpy==1.19.5 cmake==3.21.4 tf-slim==1.1.0 atari-py==0.2.6 gym==0.19.0 matplotlib==3.5.0 PyVirtualDisplay==2.2 jupyter keras==2.6.* gym[all] PyVirtualDisplay
سنحفظ التغييرات التي طرأت على الملف وسنخرج من محرر النصوص، ثم سنُثَبت هذه المكتبات بالأمر التالي:
(qlearning-demo) $ pip install -r requirements.txt
بعد تثبيتنا لهذه التبعيات، سنُصبح جاهزين لبدء العمل على مشروعنا.
كتابة الشيفرة البرمجية
شغّل محرر الشيفرات البرمجية Jupyter Notebook بمجرد اكتمال عملية التثبيت. هكذا:
(qlearning-demo) $ jupyter notebook
أنشئ ملفًا جديدًا في داخل المحرر بالضغط على الزر new واختيار python 3 (ipykernal) وسمه باسم main مثلًا، حيث ستكون في الخلية الأولى للملف عملية استيراد الوِحدات (أو المكتبات) البرمجية اللازمة. (لمزيد من المعلومات حول طريقة استيراد وحدة برمجية في لغة بايثون يمكنك الاطلاع على كيفية استيراد الوحدات في بايثون 3 سبق وأن ناقشنا فيه هذه الفكرة بالتفصيل).
نقوم أولًا بتثبيت مكتبة مساعدة في نمذجة الحركات الفيزيائية:
تثبيت محرك المحاكاة الفيزيائية # !curl https://mujoco.org/download/mujoco210-linux-x86_64.tar.gz --output mujoco210-linux-x86_64.tar.gz !tar -xf mujoco210-linux-x86_64.tar.gz import os إضافة متغير يدل على مسار المحرك# os.environ['MUJOCO_PY_MUJOCO_PATH'] = "/content/mujoco210"
ثم نقوم باستيراد جميع المكتبات اللازمة:
# مكتبة العمليات الرياضية import numpy as np # مكتبات الألعاب import gym from gym import logger as gymlogger from gym.wrappers import Monitor # مكتبات التعلم العميق import tensorflow as tf import tf_slim # مكتبة للرسوميات import matplotlib.pyplot as plt %matplotlib inline # تفعيل توافقية نسخ مكتبة التعلم العميق tf.compat.v1.disable_eager_execution() # مكتبة لاستخدام القائمة مفتوحة الطرفين from collections import deque, Counter # مكتبة للمسارات import glob # مكتبة دخل-خرج import io # مكتبة ترميز 64 import base64 # مكتبة عرض HTML from IPython.display import HTML
نُنشئ بيئة لعبة غزاة الفضاء SpaceInvaders-v0 باستخدام الدالة gym.make. نستخدم الخاصية action_space.n لبيئة اللعبة لمعرفة عدد الأفعال الممكنة في اللعبة، ونستخدم الدالة get_action_meanings للحصول على أسماء هذه الأفعال الممكنة:
# تهيئة بيئة عمل اللعبة env = gym.make("SpaceInvaders-v0") # معاينة عدد الأفعال الممكنة n_outputs = env.action_space.n print(n_outputs) # معاينة أسماء الأفعال الممكنة print(env.get_action_meanings())
يُبين ناتج التنفيذ عدد الأفعال الممكنة في اللعبة وأسمائها:
6 ['NOOP', 'FIRE', 'RIGHT', 'LEFT', 'RIGHTFIRE', 'LEFTFIRE']
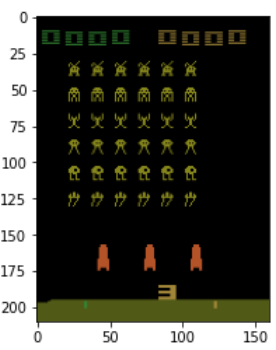
يُمكن طباعة شاشة اللعبة الأولية وذلك بعد استدعاء دالة التهيئة الأولية لبيئة اللعبة reset:
# التهيئة الأولية state = env.reset() # معاينة الوضع الأولي للعبة plt.imshow(state)
مما يُعطي صورة شاشة اللعبة التالية:
نستخدم فيما يلي الدالة الأساسية env.step، والتي تُعيد القيم التالية:
- الحالة state: وهي الحالة الجديدة للعبة بعد تطبيق فعلٍ معينٍ.
- المكافأة reward: وهي الزيادة في الدرجة المترتبة عن فعلٍ معينٍ. وفي نمط الألعاب المعتمدة على النقاط، يكون هدف اللاعب هو تعظيم المكافأة الإجمالية، بزيادة مجموع النقاط لأقصى درجةٍ ممكنةٍ.
-
حالة انتهاء اللعبة done: تأخذ القيمة
trueعندما يخسر اللاعب ويفقد جميع الفرص المتاحة له. - المعلومات info: وهي المعلومات الجانبية، وسنتجاوز شرحها حاليًا.
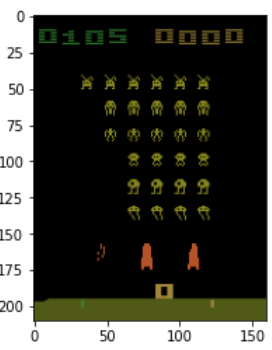
نشرح مبدأ اللعبة عبر الشيفرة التالية والتي تدخل في حلقة تُبقي اللعبة مستمرة إلى أن يخسر اللاعب بموته. تختار الدالة sample أحد الأفعال الستة الممكنة بشكل عشوائي. يؤدي تنفيذ الفعل (باستخدام الدالة step) إلى الانتقال إلى حالة جديدة مع مكافأة ممكنة في بعض الحالات. تنتهي اللعبة بموت اللاعب (done=true).
env.reset() # المكافأة الإجمالية episode_reward = 0 while True: # اختيار فعل بشكل عشوائي action = env.action_space.sample() # تنفيذ الفعل # الانتقال لحالة جديدة state, reward, done, info = env.step(action) if (reward>0): # طباعة القيم في حال مكافأة أكبر من الصفر print(env.get_action_meanings()[action]," ==> ", reward, " ,(",episode_reward,")" ) # إضافة مكافأة الفعل للمكافأة الإجمالية episode_reward += reward # اختبار نهاية اللعبة if done: # طباعة المكافأة النهائية print('Reward: %s' % episode_reward) break # معاينة الوضع النهائي للعبة plt.imshow(state) plt.show()
يكون الخرج مثلًا:
FIRE ==> 5.0 ,( 0.0 ) NOOP ==> 5.0 ,( 5.0 ) RIGHTFIRE ==> 10.0 ,( 10.0 ) RIGHT ==> 15.0 ,( 20.0 ) RIGHT ==> 20.0 ,( 35.0 ) FIRE ==> 25.0 ,( 55.0 ) RIGHT ==> 10.0 ,( 80.0 ) RIGHTFIRE ==> 15.0 ,( 90.0 ) Reward: 105.0
كما تُبين واجهة اللعبة:
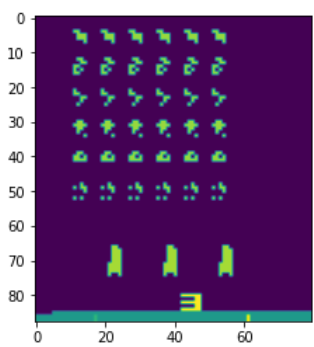
نحتاج إلى إجراء معالجة أولية لصور اللعبة (والتي ستكون لاحقًا دخلًا لشبكات التعلم العصبية)، ولذا نُعرّف الدالة التالية والتي تقتطع الجزء الهام من صورة اللعبة وتُنفّذ بعض عمليات المعالجة عليها:
def preprocess_state(state): # تحجيم الصورة واقتطاع الجزء الهام منها img = state[25:201:2, ::2] # تحويل الصورة إلى درجات الرمادي img = img.mean(axis=2) color = np.array([210, 164, 74]).mean() # تحسين التباين في الصورة img[img==color] = 0 # تطبيع القيم من -1 إلى +1 img = (img - 128) / 128 - 1 return img.reshape(88,80)
نستدعي الدالة السابقة مثلًا على صورة بداية اللعبة لنعاين ناتج المعالجة:
# التهيئة الأولية state = env.reset() # معاينة الصورة بعد عمليات التهيئة state_preprocessed = preprocess_state(state).reshape(88,80) print(state.shape) print(state_preprocessed.shape) plt.imshow(state_preprocessed) plt.show()
يكون الخرج:
(210, 160, 3) (88, 80)
والصورة المُعالجة:
نُعرّف فيما يلي الدالة stack_frames والتي تُجهز قائمة من الصور عددها (4 مثلًا)، نخزن العدد ضمن المتغير stack_size. تحوي القائمة نفس صورة البداية مكررة العدد نفسه stack_size مرة عند بداية كل حلقة episode لعب.
لاحظ أننا نستخدم البنية الخاصة في بايثون المدعوة deque (قائمة مفتوحة الطرفين) والتي يُمكن لنا الإضافة عليها والحذف منها وذلك من طرفيها.
# نستخدم 4 صور متعاقبة لملاحقة الحركة stack_size = 4 # تهيئة قائمة مفتوحة الطرفين # تحوي أربعة صور ذات قيم 0 stacked_frames = deque([np.zeros((88,80), dtype=np.int) for i in range(stack_size)], maxlen=stack_size) def stack_frames(stacked_frames, state, is_new_episode): # المعالجة الأولية للصورة frame = preprocess_state(state) # حلقة جديدة if is_new_episode: # مسح الصور السابقة المكدّسة stacked_frames = deque([np.zeros((88,80), dtype=np.int) for i in range(stack_size)], maxlen=stack_size) # تكرار الصورة المعالجة في كل حلقة جديدة من اللعبة for i in range(stack_size): stacked_frames.append(frame) # تكديس الصور stacked_state = np.stack(stacked_frames, axis=2) else: # بما أن القائمة مفتوحة الطرفين تضيف من أقصى اليمين # نُحضر الصورة أقصى اليمين frame=stacked_frames[-1] # إضافة الصورة stacked_frames.append(frame) # إنشاء الحالة stacked_state = np.stack(stacked_frames, axis=2) return stacked_state, stacked_frames
نُعرّف شبكة عصبية مؤلفة من ست طبقات: ثلاثة طبقات تلافيفية، تليها طبقة مسطحة flatten، ومن ثم طبقة موصولة بشكل كامل fully connected، تليها طبقة الخرج.
def q_network(X, name_scope): # تهيئة الطبقات initializer = tf.compat.v1.keras.initializers.VarianceScaling(scale=2.0) with tf.compat.v1.variable_scope(name_scope) as scope: # تهيئة الطبقات التلافيفية layer_1 = tf_slim.conv2d(X, num_outputs=32, kernel_size=(8,8), stride=4, padding='SAME', weights_initializer=initializer) tf.compat.v1.summary.histogram('layer_1',layer_1) layer_2 = tf_slim.conv2d(layer_1, num_outputs=64, kernel_size=(4,4), stride=2, padding='SAME', weights_initializer=initializer) tf.compat.v1.summary.histogram('layer_2',layer_2) layer_3 = tf_slim.conv2d(layer_2, num_outputs=64, kernel_size=(3,3), stride=1, padding='SAME', weights_initializer=initializer) tf.compat.v1.summary.histogram('layer_3',layer_3) # تسطيح نتيجة الطبقة الثالثة قبل تمريرها إلى الطبقة # التالية الموصولة بشكل كامل flat = tf_slim.flatten(layer_3) # إدراج الطبقة الموصولة بشكل كامل fc = tf_slim.fully_connected(flat, num_outputs=128, weights_initializer=initializer) tf.compat.v1.summary.histogram('fc',fc) # إضافة طبقة الخرج النهائية output = tf_slim.fully_connected(fc, num_outputs=n_outputs, activation_fn=None, weights_initializer=initializer) tf.compat.v1.summary.histogram('output',output) # تخزين معاملات الشبكة كأوزان vars = {v.name[len(scope.name):]: v for v in tf.compat.v1.get_collection(key=tf.compat.v1.GraphKeys.TRAINABLE_VARIABLES, scope=scope.name)} # إرجاع كل من المتغيرات والخرج #Return both variables and outputs together return vars, output
نُعرّف الدالة epsilon_greedy لتنفيذ السياسة المدعوة بسياسة إبسلون الشرهة epsilon greedy policy والتي تختار أفضل فعل باحتمال "1 - إبسلون" أو أي فعل آخر عشوائي باحتمال إبسلون.
لاحظ أننا نُخفّض قيمة إبسلون مع مرور الوقت (زيادة عدد الخطوات) كي تستخدم هذه السياسة الأفعال الجيدة فقط.
epsilon = 0.5 eps_min = 0.05 eps_max = 1.0 eps_decay_steps = 500000 def epsilon_greedy(action, step): p = np.random.random(1).squeeze() # متحهة أحادية epsilon = max(eps_min, eps_max - (eps_max-eps_min) * step/eps_decay_steps) if p < epsilon: return np.random.randint(n_outputs) else: return action
نهيئ فيما يلي ذاكرة تخزين مؤقت من النمط قائمة مفتوحة الطرفين deque لنضع فيها معلومات اللعب من الشكل SARSA.
نُخزّن كل خبرة الروبوت أي (الحالة، الفعل، المكافأة) state, action, rewards في الذاكرة المؤقتة وهي الخبرة المكتسبة المفيدة عند إعادة اللعب experience replay buffer ونقوم لاحقًا بأخذ عينات منها y-values لتوليد القيم التي سنُدرب الشبكة عليها:
buffer_len = 20000 # نستخدم لذاكرة التخزين المؤقت قائمة مفتوحة الطرفين exp_buffer = deque(maxlen=buffer_len)
نُعرّف الدالة sample_memories التي تنتقي مجموعة عشوائية من تجارب التدريب:
# اختيار مجموعة عشوائية من تجارب التدريب # بطول حجم دفعة التدريب def sample_memories(batch_size): perm_batch = np.random.permutation(len(exp_buffer))[:batch_size] mem = np.array(exp_buffer)[perm_batch] return mem[:,0], mem[:,1], mem[:,2], mem[:,3], mem[:,4]
نُعرّف فيما يلي جميع المعاملات المُترفعة hyperparameters للشبكة مع قيمها. اخترنا هذه القيم بعد بناًء على الخبرة في الشبكات العصبية وبعد العديد من التجارب.
num_episodes = 2000 batch_size = 48 input_shape = (None, 88, 80, 1) learning_rate = 0.001 # التعديل لملائمة الصور المكدّسة X_shape = (None, 88, 80, 4) discount_factor = 0.97 global_step = 0 copy_steps = 100 steps_train = 4 start_steps = 2000
نُعرّف حاوية الدخل X:
tf.compat.v1.reset_default_graph() # تعريف حاوية دخل الشبكة العصبية أي حالة اللعبة X = tf.compat.v1.placeholder(tf.float32, shape=X_shape) # تعريف متغير بولياني لقلب حالة التدريب in_training_mode = tf.compat.v1.placeholder(tf.bool)
نبني فيما يلي شبكتين: الشبكة الأولية والشبكة الهدف مما يسمح بتوليد البيانات والتدريب بشكل متزامن:
# بناء الشبكة التي تولد جميع قيم التعلم لجميع الأفعال في الحالة mainQ, mainQ_outputs = q_network(X, 'mainQ') # بشكل مشابهة نبني الشبكة الهدف لقيم التعلم targetQ, targetQ_outputs = q_network(X, 'targetQ') # تعريف حاوية قيم الأفعال X_action = tf.compat.v1.placeholder(tf.int32, shape=(None,)) Q_action = tf.reduce_sum(input_tensor=targetQ_outputs * tf.one_hot(X_action, n_outputs), axis=-1, keepdims=True) # نسخ قيم معاملات الشبكة إلى الشبكة الهدف copy_op = [tf.compat.v1.assign(main_name, targetQ[var_name]) for var_name, main_name in mainQ.items()] copy_target_to_main = tf.group(*copy_op)
نُعرّف فيما يلي الخرج ونقوم بحساب الخسارة:
# تعريف حاوبة الخرج y = tf.compat.v1.placeholder(tf.float32, shape=(None,1)) # حساب الخسارة والتي هي الفرق بين القيمة الحقيقية والقيمة المتوقعة loss = tf.reduce_mean(input_tensor=tf.square(y - Q_action)) # تحسين الخسارة optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate) training_op = optimizer.minimize(loss)
نبدأ الآن جلسة Tensorflow ونُشغّل النموذج model:
- نُجري أولًا المعالجة الأولية لصورة شاشة اللعب ومن ثم نُمرر الناتج (الحالة s) إلى الشبكة العصبية DQN والتي تُعيد جميع قيم التعلم Q-values.
- نختار أحد الأفعال a باستخدام سياسة إبسلون الجشعة.
- نُنفذ الفعل a على الحالة s وننتقل إلى حالة جديدة snew مع حصولنا على مكافأة (تكون الحالة الجديدة هي الصورة المعالجة لشاشة اللعب التالية)
- نُخزّن هذا الانتقال في الذاكرة المؤقتة على الشكل ,a,r,snew>
- ننتقي بعض الانتقالات من الذاكرة العشوائية ونحسب الخسارة.
- نُعدّل معاملات الشبكة لتخفيض الخسارة.
- ننسخ أوزان شبكة التدريب إلى الشبكة الفعلية.
- نكرر الخطوات السابقة عددًا من المرات (num_episodes).
with tf.compat.v1.Session() as sess: init = tf.compat.v1.global_variables_initializer() init.run() # من أجل كل دورة history = [] for i in range(num_episodes): done = False obs = env.reset() epoch = 0 episodic_reward = 0 actions_counter = Counter() episodic_loss = [] # تكديس الصور في الخطوة الأولى obs,stacked_frames= stack_frames(stacked_frames,obs,True) # الدوران طالما لم نصل للحالة النهائية while not done: # توليد البيانات باستخدام الشبكة غير المدربة # إدخال صورة اللعبة والحصول على قيم التعلم # من أجل كل فعل actions = mainQ_outputs.eval(feed_dict={X:[obs], in_training_mode:False}) # اختيار الفعل action = np.argmax(actions, axis=-1) actions_counter[str(action)] += 1 # استخدام سياسة ابسلون الشرهة لاختيار الفعل action = epsilon_greedy(action, global_step) # تنفيذ الفعل # والانتقال للحالة التالية وحساب المكافأة next_obs, reward, done, _ = env.step(action) # تكديس مابين الدورات next_obs, stacked_frames = stack_frames(stacked_frames, next_obs, False) # تخزين الانتقال كتجربة في # الذاكرة المؤقتة لإعادة اللعب exp_buffer.append([obs, action, next_obs, reward, done]) # تدريب الشبكة من الذاكرة المؤقتة لإعادة اللعب بعد عدة خطوات معينة if global_step % steps_train == 0 and global_step > start_steps: # تحوي الذاكرة المؤقتة لإعادة اللعب # كل ما تمت معالجته وتكديسه # mem[:,0], mem[:,1], mem[:,2], mem[:,3], mem[:,4] o_obs, o_act, o_next_obs, o_rew, o_done = sample_memories(batch_size) # الحالات o_obs = [x for x in o_obs] # الحالات التالية o_next_obs = [x for x in o_next_obs] # الأفعال التالية next_act = mainQ_outputs.eval(feed_dict={X:o_next_obs, in_training_mode:False}) # المكافآت y_batch = o_rew + discount_factor * np.max(next_act, axis=-1) * (1-o_done) train_loss, _ = sess.run([loss, training_op], feed_dict={X:o_obs, y:np.expand_dims(y_batch, axis=-1), X_action:o_act, in_training_mode:True}) episodic_loss.append(train_loss) # نسخ أوزان الشبكة الرئيسية إلى الشبكة الهدف if (global_step+1) % copy_steps == 0 and global_step > start_steps: copy_target_to_main.run() obs = next_obs epoch += 1 global_step += 1 episodic_reward += reward next_obs=np.zeros(obs.shape) exp_buffer.append([obs, action, next_obs, reward, done]) obs= env.reset() obs,stacked_frames= stack_frames(stacked_frames,obs,True) history.append(episodic_reward) print('Epochs per episode:', epoch, 'Episode Reward:', episodic_reward,"Episode number:", len(history))
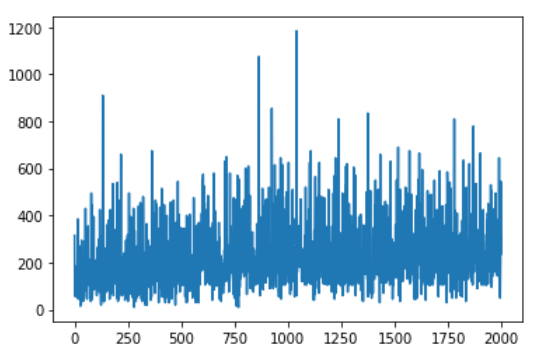
نرسم المكافآت وفق الحلقات:
plt.plot(history) plt.show()
مما يُعطي مثلًا:
يُمكن في النهاية معاينة أداء الروبوت وتسجيل فيديو للعبة:
# تسجيل فيديو بهدف التقييم gymlogger.set_level(40) def show_video(): # مسار ملف الفيديو mp4list = glob.glob('video/*.mp4') # التأكد من وجود الفيديو if len(mp4list) > 0: mp4 = mp4list[0] # فتح ملف الفيديو video = io.open(mp4, 'r+b').read() # التحويل لكود 64 encoded = base64.b64encode(video) # عرض الفيديو في حالة حاسوب محلي # HTML بتوليد ipythondisplay.display(HTML(data='''<video alt="test" autoplay loop controls style="height: 400px;"> <source src="data:video/mp4;base64,{0}" type="video/mp4" /> </video>'''.format(encoded.decode('ascii')))) else: print("Could not find video") def wrap_env(env): env = Monitor(env, './video', force=True) return env # تقييم النموذج environment = wrap_env(gym.make('SpaceInvaders-v0')) done = False observation = environment.reset() new_observation = observation prev_input = None with tf.compat.v1.Session() as sess: init.run() observation, stacked_frames = stack_frames(stacked_frames, observation, True) while True: # الحصول على قيم التعلم actions = mainQ_outputs.eval(feed_dict={X:[observation], in_training_mode:False}) # الحصول على الفعل action = np.argmax(actions, axis=-1) actions_counter[str(action)] += 1 # اختيار الفعل باستخدام سياسة إبسلون الشرهة action = epsilon_greedy(action, global_step) # يجب إضافة التعليمة التالية على حاسوب محلي # environment.render() new_observation, stacked_frames = stack_frames(stacked_frames, new_observation, False) observation = new_observation # تنفيذ الفعل و الانتقال للخطوة التالية new_observation, reward, done, _ = environment.step(action) if done: break environment.close()
يُمكن أن يكون الفيديو مثلًا:

الخلاصة
بنينا في هذا الدرس روبوتًا يلعب لعبة غزو الفضاء وذلك باستخدام التعلم المعزز العميق وفق النموذج الحُر Deep Q-learnin.
السؤال الطبيعي الذي سيخطر ببالنا هو، هل يمكننا بناء روبوتاتٍ لألعابٍ أكثر تعقيدًا مثل لعبة StarCraft 2؟ فكما اتضح لنا، إن هذا سؤالٌ بحثيٌ معلقٌ ومدعومٌ بأدواتٍ مفتوحة المصدر من شركاتٍ كبيرةٍ مثل غوغل Google وديب مايند DeepMind وشركة بليزارد Blizzard. فإذا كانت هذه المشاكل تهمك فعلًا، فيمكنك الاطلاع على المشاكل الحالية التي يواجهونها.
يُمكن تجربة المثال كاملًا من موقع Google Colab من الرابط.
المصادر
- Optimized Space Invaders using Deep Q-learning: An Implementation in Tensorflow 2.0
- Getting Started with Gym
- https://gym.openai.com/envs/SpaceInvaders-v0/
- Python Machine Learning Projects.








أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.