

يدعم TCP تجريد تدفق البايت، أي أن برامج التطبيقات تكتب البايت في التدفق، والأمر متروك لبروتوكول TCP لاتخاذ القرار بأن لديه بايتات كافية لإرسال جزء. لكن ما هي العوامل التي تحكم هذا القرار؟ سنتابع في هذا المقال ما تحدثنا عنه في المقال السابق حول بروتوكولات تدفق البايتات الموثوقة بالاعتماد على مثال TCP، وسنكمل الحديث هنا عن هذه البروتوكولات آخذين جانب آلية الإرسال والبدائل.
إذا تجاهلنا إمكانية التحكم في التدفق، أي بفرض أن النافذة مفتوحة على مصراعيها كما هو الحال عند بدء الاتصال لأول مرة، عندئذ يكون لدى بروتوكول TCP ثلاث آليات لبدء إرسال جزء. أولًا، يحتفظ بروتوكول TCP بمتغير، يسمى عادةً حجم الجزء الأقصى maximum segment size أو اختصارًا MSS، ويرسل جزءًا بمجرد أن يجمع بايتاتٍ بحجم MSS من عملية الإرسال. يُضبَط MSS على حجم أكبر جزء يمكن أن يرسله TCP دون التسبب في تجزئة عنوان IP المحلي. أي ضُبِط MSS على أقصى وحدة إرسال maximum transmission unit أو اختصارًا MTU للشبكة المتصلة مباشرة، مطروحًا منها حجم ترويستي TCP و IP. الشيء الثاني الذي ينبّه بروتوكول TCP لإرسال جزء هو أن عملية الإرسال طلبت منه صراحةً القيام بذلك. يدعم بروتوكول TCP العملية push، وتستدعي عملية الإرسال هذه العملية لتفريغ flush المخزن المؤقت للبايتات غير المرسلة بفعالية. المنبّه trigger الأخير لإرسال جزء هو إنطلاق المؤقت timer، حيث يحتوي الجزء الناتج على العديد من البايتات المخزَّنة حاليًا للإرسال. وعلى أية حال لن يكون هذا "المؤقت" كما تتوقعه بالضبط كما سنرى قريبًا.
متلازمة النوافذ الساذجة Silly Window Syndrome
لا يمكننا بالتأكيد تجاهل التحكم في التدفق فقط، والذي يلعب دورًا واضحًا في تقييد المرسل. فإذا كان لدى المرسل بايتات بحجم MSS من البيانات لإرسالها وكانت النافذة مفتوحة على الأقل بهذا القدر، فإن المرسل يرسل جزءًا كاملًا. افترض أن المرسل يجمّع البايتات لإرسالها، ولكن النافذة مغلقة حاليًا. لنفترض الآن وصول ACK يفتح النافذة بفعالية بما يكفي لإرسال المرسل، بحجم MSS / 2 بايت مثلًا. هل يجب على المرسل إرسال جزء نصف ممتلئ أم الانتظار حتى تفتح النافذة بحجم MSS كامل؟ لم تذكر المواصفات الأصلية شيئًا بشأن هذه النقطة، وقررت عمليات التنفيذ الأولي لبروتوكول TCP المضي قدمًا وإرسال جزء نصف كامل، ولكن ليس هناك ما يخبرنا إلى متى سيبقى بهذه الحالة قبل أن تفتح النافذة أكثر.
اتضح أن استراتيجية الاستفادة الكبيرة من أية نافذةٍ متاحة تؤدي إلى حالة تُعرَف الآن باسم متلازمة النوافذ الساذجة، حيث يساعد الشكل التالي على تصور ما يحدث: إذا فكّرت في تدفق TCP على أنه حزامٌ ناقل به حاويات "ممتلئة" أو أجزاء بيانات data segments تسير في اتجاهٍ واحد وحاويات فارغة هي الإشعارات ACKs تسير في الاتجاه العكسي. فإن الأجزاء ذات الحجم MSS تتوافق مع الحاويات الكبيرة والأجزاء ذات الحجم 1 بايت تتوافق مع حاويات صغيرة جدًا. طالما أن المرسل يرسل أجزاءًا بحجم MSS ويرسل المستقبل إشعارات ACKs على الأقل بحجم MSS من البيانات في كل مرة، وبالتالي سيعمل كل شيء جيدًا (كما في القسم أ من الشكل الآتي). لكن ماذا لو اضطر المستقبل إلى تقليل النافذة بحيث لا يتمكن المرسل في وقتٍ ما من إرسال MSS كامل من البيانات؟ إذا ملأ المرسل حاويةً فارغة حجمها أصغر من MSS بمجرد وصولها، فسيرسل المستقبل إشعارًا بهذا العدد الأصغر من البايتات، وبالتالي تظل الحاوية الصغيرة المدخلة في النظام إلى أجلٍ غير مسمى فيه، أي أنها تُملَأ وتُفرَغ على الفور عند كل طرف ولا تُدمَج مطلقًا مع الحاويات المجاورة لإنشاء حاويات أكبر، كما في القسم (ب) من الشكل التالي. اُكتشِف هذا السيناريو عندما وجدت التطبيقات الأولى لبروتوكول TCP نفسها تملأ الشبكة بأجزاء صغيرة.
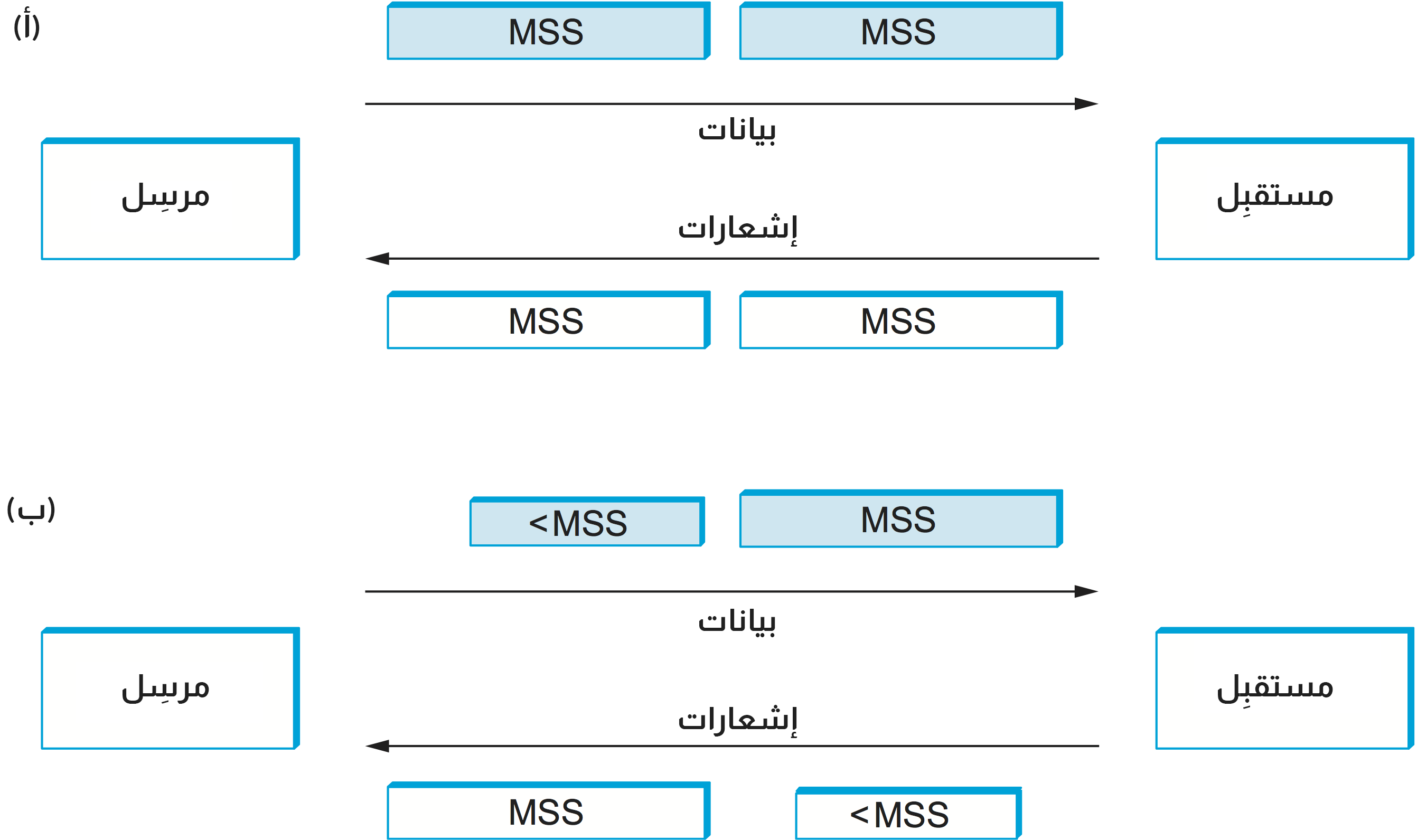
تُعتبر متلازمة النوافذ الساذجة مشكلةً فقط عندما يرسل المرسل جزءًا صغيرًا أو يفتح جهاز الاستقبال النافذة بمقدار صغير. إذا لم يحدث أي من هذين الأمرين، فلن تُدخَل الحاوية الصغيرة مطلقًا في التدفق. من غير الممكن تحريم إرسال مقاطع صغيرة، فقد يقوم التطبيق بعملية push بعد إرسال بايت واحد على سبيل المثال، ولكن من الممكن منع جهاز الاستقبال من إدخال حاوية صغيرة (أي نافذة صغيرة مفتوحة)، حيث يجب أن ينتظر جهاز الاستقبال حيزًا يساوي حجم MSS قبل أن يعلن عن نافذة مفتوحة، وذلك بعد الإعلان عن نافذةٍ صفرية.
نظرًا لإمكانية استبعاد إمكانية إدخال حاويةٍ صغيرة في التدفق، إلا أننا نحتاج أيضًا إلى آلياتٍ لدمجها. يمكن للمستقبل القيام بذلك عن طريق تأخير ACK، أي إرسال ACK واحد مدمج بدلًا من إرسال عدة رسائلٍ أصغر، ولكن هذا حل جزئي فقط لأن جهاز الاستقبال ليس لديه طريقة لمعرفة المدة التي يمكن فيها تأخير انتظار وصول جزء آخر أو انتظار التطبيق لقراءة المزيد من البيانات (وبالتالي فتح النافذة). يقع الحل النهائي على عاتق المرسل، وهو ما يعيدنا إلى مشكلتنا الأصلية: متى يقرر مرسل TCP إرسال جزءsegment؟
خوارزمية Nagle
بالعودة إلى مرسل TCP، إذا كانت هناك بياناتٌ لإرسالها ولكن النافذة مفتوحة بحجمٍ أقل من حجم MSS، فقد نرغب في الانتظار بعض الوقت قبل إرسال البيانات المتاحة، ولكن السؤال هو كم طول هذه المدة؟ إذا انتظرنا وقتًا طويلًا، فإننا نُضِر بذلك التطبيقات التفاعلية مثل تطبيق Telnet. وإذا لم ننتظر طويلًا بما فيه الكفاية، فإننا نجازف بإرسال مجموعةٍ من الرزم الصغيرة والوقوع في متلازمة النوافذ الساذجة. الجواب هو إدخال مؤقت timer والإرسال عند انتهاء مدته.
يمكننا استخدام مؤقت قائم على النبضات، مثل مؤقت ينطلق كل 100 ميلي ثانية. قدّم Nagle حلًا رائعًا للتوقيت الذاتي. الفكرة هي أنه طالما لدى بروتوكول TCP أي بيانات قيد الإرسال in flight، فإن المرسل سيتلقى في النهاية ACK. يمكن التعامل مع ACK كإطلاق مؤقت، ينبِّه بإرسال المزيد من البيانات. توفر خوارزمية Nagle قاعدة بسيطة وموحدة لاتخاذ قرار بشأن توقيت بدء الإرسال.
When the application produces data to send if both the available data and the window >= MSS send a full segment else if there is unACKed data in flight buffer the new data until an ACK arrives else send all the new data now
من المقبول دائمًا إرسال جزء كامل إذا سمحت النافذة بذلك، كما يحق لك إرسال كمية صغيرة من البيانات على الفور إذا لم يكن هناك أي أجزاء قيد النقل. ولكن إذا كان هناك أي شيء قيد الإرسال، فيجب على المرسل انتظار ACK قبل إرسال الجزء التالي. وبالتالي سيرسل تطبيقٌ تفاعلي مثل Telnet الذي يكتب باستمرار بايتًا واحدًا في المرة الواحدة البياناتِ بمعدل جزء واحد لكل RTT. ستحتوي بعض الأجزاء على بايت واحد، بينما يحتوي البعض الآخر على عدد بايتات بقدر ما كان المستخدم قادرًا على الكتابة في وقت واحد ذهابًا وإيابًا. تسمح واجهة المقبس للتطبيق بإيقاف تشغيل خوارزمية Nagel عن طريق تعيين خيار TCP_NODELAY نظرًا لأن بعض التطبيقات لا يمكنها منح مثل هذا التأخير لكل عملية كتابة تقوم بها لاتصالٍ من نوع TCP، حيث يعني ضبط هذا الخيار إرسال البيانات في أسرع وقتٍ ممكن.
إعادة الإرسال التكيفي Adaptive Retransmission
بما أن بروتوكول TCP يضمن التسليم الموثوق للبيانات، فإنه يعيد إرسال كل جزء إذا لم يُستلَم إشعار ACK خلال فترةٍ زمنية معينة. يضبط بروتوكول TCP هذه المهلة الزمنية كدالة لوقت RTT الذي يتوقعه بين طرفي الاتصال. إن اختيار قيمة المهلة الزمنية المناسبة ليس بهذه السهولة لسوء الحظ، نظرًا لمجال قيم RTT الممكنة بين أي زوجٍ من المضيفين في الإنترنت، بالإضافة إلى الاختلاف في RTT بين نفس المضيفين بمرور الوقت. لمعالجة هذه المشكلة، يستخدم بروتوكول TCP آلية إعادة الإرسال التكيفية. سنقوم بوصف هذه الآلية الآن وتطورها مع مرور الوقت حيث اكتسب مجتمع الإنترنت المزيد من الخبرة باستخدام TCP.
الخوارزمية الأصلية
نبدأ بخوارزمية بسيطة لحساب قيمة المهلة الزمنية timeout بين زوجٍ من المضيفين. هذه هي الخوارزمية التي وُصفت في الأصل في مواصفات بروتوكول TCP، ولكن يمكن استخدامها بواسطة أي بروتوكول طرفٍ إلى طرف end-to-end protocol.
تكمن الفكرة في الاحتفاظ بمتوسط تشغيل RTT ثم حساب المهلة الزمنية كدالة لوقت RTT. يسجل TCP الوقت في كل مرة يرسل فيها جزء بيانات، ويقرأ بروتوكول TCP الوقت مرةً أخرى عند وصول ACK لهذا الجزء، ثم يأخذ الفرق بين هاتين المرتين على أنه SampleRTT. ثم يحسب TCP قيمة EstimatedRTT كمتوسط مرجح بين التقدير estimate السابق وهذه العينة sampleالجديدة، حيث:
EstimatedRTT = alpha x EstimatedRTT + (1 - alpha) x SampleRTT
يُحدَّد المعامل alpha لتنعيم EstimatedRTT. تتتبّع قيمةُ alpha الصغيرة التغييراتِ في RTT ولكن ربما تتأثر بشدة بالتقلبات المؤقتة. ومن ناحيةٍ أخرى، تكون قيمة alpha الكبيرة أكثر استقرارًا ولكن ربما لا تكون سريعة بما يكفي للتكيف مع التغييرات الحقيقية. أوصت مواصفات TCP الأصلية بإعداد قيمة alpha بين 0.8 و 0.9. يستخدم بروتوكول TCP المعامل EstimatedRTT لحساب المهلة الزمنية timeout بطريقة متحفظة إلى حدٍ ما:
TimeOut = 2 x EstimatedRTT
خوارزمية كارن / بارتريدج Karn/Partridge
اُكتشِف عيبٌ واضح في الخوارزمية السابقة البسيطة بعد عدة سنوات من الاستخدام على الإنترنت. كانت المشكلة أن الإشعار ACK لا يُقِر حقًا بالإرسال، بل باستلام البيانات في الحقيقة، أي عندما يُعاد إرسال جزء ثم وصول ACK إلى المرسل، فمن المستحيل تحديد ما إذا كان ينبغي إرفاق هذا الإشعار بالإرسال الأول أو الثاني للجزء بغرض قياس sample RTT. من الضروري معرفة الإرسال الذي سيُربَط به لحساب العينة SampleRTT بدقة. إذا افترضت أن الإشعار ACK للإرسال الأصلي ولكنه كان في الحقيقة للثاني كما هو موضح في الشكل التالي، فإن SampleRTT كبيرةٌ جدًا كما في القسم (أ) من الشكل التالي، وإذا افترضت أن الإشعار ACK للإرسال الثاني ولكنه كان في الواقع للإرسال الأول، فإن عينة SampleRTT صغيرةٌ جدًا كما في القسم (ب) من الشكل التالي:
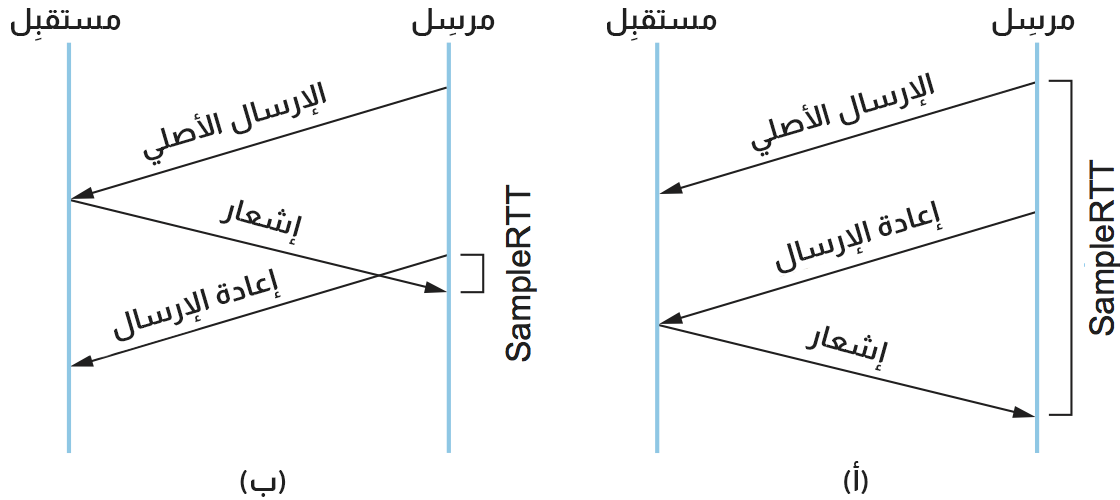
الحل الذي جرى اقتراحه في عام 1987 بسيط جدًا: يتوقف بروتوكول TCP عن أخذ عيناتٍ من RTT عندما يعيد إرسال جزء ما، فهو يقيس SampleRTT فقط للأجزاء التي أُرسلت مرةً واحدة فقط. يُعرف هذا الحل باسم خوارزمية كارن / بارتريدج تيّمنًا بمخترعَيها. يتضمن الإصلاح المقترح أيضًا تغييرًا صغيرًا ثانيًا في آلية مهلة TCP الزمنية. يضبط بروتوكول TCP المهلة التالية لتكون ضعف آخر مهلة في كل مرة يعيد فيها الإرسال، بدلًا من إسنادها إلى آخرEstimatedRTT. اقترح كارن و بارتريدج أن يستخدم بروتوكولُ TCP تراجعًا أسيًا exponential backoff، على غرار ما يفعله إيثرنت. الدافع لاستخدام التراجع الأسي بسيط: الازدحام هو السبب الأكثر احتمالًا لفقدان الأجزاء، مما يعني أن مصدر TCP يجب ألا يتفاعل بقوة مع انقضاء المهلة الزمنية، فكلما انقضت مهلة الاتصال الزمنية، يجب أن يصبح المصدر أكثر حذرًا. سنرى هذه الفكرة مرة أخرى، مجسَّدةً في آلية أعقد لاحقًا.
خوارزمية جاكوبسون / كارلس Jacobson/Karels
قُدّمت خوارزمية كارن / بارتريدج في وقت كان فيه الإنترنت يعاني من مستويات عالية من ازدحام الشبكة، فصُمِّم نهج هذه الخوارزمية لإصلاح بعض أسباب هذا الازدحام، ولكن على الرغم من تقديمها تحسينًا، إلا أنه لم يتم القضاء على الازدحام. اقترح باحثان آخران (جاكوبسون وكارلس) تغييرًا جذريًا في بروتوكول TCP لمحاربة الازدحام في العام التالي (1988). سنركز على هذا الاقتراح المتعلق بتحديد انتهاء المهلة وإعادة إرسال جزء ما.
يجب أن يكون ارتباط آلية المهلة الزمنية بالازدحام واضحًا، فإذا انقضت المهلة في وقت مبكرٍ جدًا، فقد تعيد إرسال جزء بدون داعٍ، والذي يضيف فقط إلى الحِمل على الشبكة. السبب الآخر للحاجة إلى قيمة مهلة دقيقة هو أن المهلة تُؤخَذ للإشارة إلى الازدحام، مما يؤدي إلى تشغيل آلية للتحكم في الازدحام. أخيرًا، لاحظ أنه لا يوجد شيء يتعلق بحساب مهلة جاكوبسون وكارلس الخاص ببروتوكول TCP. يمكن استخدامه من قبل أي بروتوكول من طرفٍ إلى طرف.
تكمن المشكلة الرئيسية في حساب الخوارزمية الأصلية في أنها لا تأخذ في الاعتبار تباين عينات RTT. إذا كان الاختلاف بين العينات صغيرًا، فيمكن الوثوق في EstimatedRTT بصورةٍ أفضل ولا يوجد سبب لضرب هذا التقدير في 2 لحساب المهلة الزمنية. يشير التباين الكبير في العينات من ناحية أخرى إلى أن قيمة المهلة لا ينبغي أن تكون مرتبطة بإحكام شديد بقيمة EstimatedRTT.
بينما في النهج الجديد، يقيس المرسل SampleRTT جديدًا كما كان يتم سابقًا، ثم تُطوى هذه العينة الجديدة في حساب المهلة على النحو التالي:
Difference = SampleRTT - EstimatedRTT EstimatedRTT = EstimatedRTT + ( delta x Difference) Deviation = Deviation + delta (|Difference| - Deviation)
حيث تقع قيمة delta بين 0 و1. أي أننا نحسب كلًا من متوسط وقت RTT والتغير في هذا المتوسط، ثم يحسب TCP قيمة المهلة كدالة لكل من EstimatedRTT وDeviation على النحو التالي:
TimeOut = mu x EstimatedRTT + phi x Deviation
يُعيَّن mu على القيمة 1 وphi على القيمة 4 بناءً على الخبرة. وهكذا تكون TimeOut قريبةً من EstimatedRTT عندما يكون التباين صغيرًا، حيث يؤدي التباين الكبير إلى سيطرة مصطلح الانحراف Deviation على الحساب.
التطبيق Implementation
هناك نقطتان جديرتان بالملاحظة فيما يتعلق بتطبيق المهلات الزمنية في بروتوكول TCP. الأولى هي إمكانية تطبيق حساب EstimatedRTT وDeviation دون استخدام حساب الأعداد العشرية. فبدلًا من ذلك، تُوسَّع العملية الحسابية بالكامل بمقدار 2n، مع اختيار delta لتكون 1/2n. يتيح لنا ذلك إجراء العمليات الحسابية الصحيحة، وتطبيق الضرب والقسمة باستخدام الإزاحات shifts، وبالتالي تحقيق أداءٍ أعلى. يُعطى الحساب الناتج عن طريق جزء الشيفرة التالية، حيث n = 3 (أي delta = 1/8). لاحظ تخزين EstimatedRTT وDeviation في نماذجهما الموسّعَين، بينما قيمة SampleRTT في بداية الشيفرة و TimeOut في النهاية هي قيمٌ حقيقية غير مُوسَّعة. إذا وجدت صعوبة في تتبع الشيفرة، فقد ترغب في محاولة إدخال بعض الأرقام الحقيقية فيها والتحقق من أنها تعطي نفس النتائج مثل المعادلات أعلاه:
{ SampleRTT -= (EstimatedRTT >> 3); EstimatedRTT += SampleRTT; if (SampleRTT < 0) SampleRTT = -SampleRTT; SampleRTT -= (Deviation >> 3); Deviation += SampleRTT; TimeOut = (EstimatedRTT >> 3) + (Deviation >> 1); }
النقطة الثانية هي أن خوارزمية جاكوبسون / كارلس جيدة فقط مثل الساعة المستخدمة لقراءة الوقت الحالي. كانت دقة الساعة كبيرة في تطبيقات يونيكس النموذجية في ذلك الوقت حيث وصلت إلى 500 ميلي ثانية، وذلك أكبر بكثير من متوسط RTT عبر دولة في مكانٍ ما والذي يكون بين 100 و200 ميلي ثانية. لجعل الأمور أسوأ، فحص تطبيق يونيكس لبروتوكول TCP فيما إذا كان يجب أن يحدث انتهاء للمهلة في كل مرة تُحدَّد فيها الساعة 500 ميلي ثانية ولن يأخذ سوى عينةٍ من وقت الذهاب والإياب مرة واحدة لكل RTT. و قد يعني الجمع بين هذين العاملين أن المهلة ستحدث بعد ثانية واحدة من إرسال الجزء. تشتمل توسّعات TCP على آلية تجعل حساب RTT هذا أدق قليلًا.
تستند جميع خوارزميات إعادة الإرسال التي ناقشناها إلى مهلات الإشعارات، والتي تشير إلى احتمال فقد جزءٍ ما. لاحظ أن المهلة لا تخبر المرسل فيما إذا اُستلِمت بنجاحٍ أي أجزاءٍ أرسلها بعد فقدان جزء، وذلك لأن إشعارات TCP تراكمية cumulative، أي أنها تحدد فقط الجزء الأخير المُستلم دون أي فجوات سابقة. ينمو استقبال الأجزاء التي تظهر بعد زيادة الفجوة بصورةٍ متكررة كما تؤدي الشبكات الأسرع إلى نوافذ أكبر. إذا أخبرت ACK المرسلَ أيضًا عن الأجزاء اللاحقة، إن وجدت، فقد يكون المرسل أذكى بشأن الأجزاء التي يعيد إرسالها، إضافةً لاستخلاص استنتاجات أفضل حول حالة الازدحام، وإجراء تقديرات RTT أفضل.
اقتباسهناك نقطة أخرى يجب توضيحها حول حساب المُهلات الزمنية timeouts. إنه عمل صعب جدًا لدرجة أنه يوجد RFC كامل مخصصٌ لهذا الموضوع: RFC 6298. والخلاصة هي أنه في بعض الأحيان يتضمن التحديد الكامل للبروتوكول الكثير من التفاصيل بحيث يصبح الخط الفاصل بين المواصفات والتطبيق غير واضح. لقد حدث هذا أكثر من مرة مع بروتوكول TCP، مما دفع البعض إلى القول بأن "التطبيق هو المواصفات". ولكن هذا ليس بالضرورة أمرًا سيئًا طالما أن التطبيق المرجعي مُتاح كبرمجياتٍ مفتوحة المصدر. تشهد الصناعة تزايد في أهمية البرمجيات مفتوحة المصدر مع تزايد أهمية المعايير المفتوحة.
حدود السجلات Record Boundaries
ليس بالضرورة أن يكون عدد البايتات التي يكتبها المرسل نفس عدد البايتات التي قرأها المستقبل نظرًا لأن بروتوكول TCP هو بروتوكول تدفق بايتات، فقد يكتب التطبيق 8 بايتات، ثم 2 بايت، ثم 20 بايت إلى اتصال TCP، بينما يقرأ التطبيق على جانب الاستقبال 5 بايتات في المرة الواحدة داخل حلقة تتكرر 6 مرات. لا يقحم بروتوكول TCP حدود السجلات بين البايتين الثامن والتاسع، ولا بين البايتين العاشر والحادي عشر. هذا على عكس بروتوكول الرسائل الموّجهة، مثل بروتوكول UDP، حيث تكون الرسالة المرسَلة بنفس طول الرسالة المُستلَمة.
يمتلك بروتوكول TCP، على الرغم من كونه بروتوكول تدفق بايتات، ميزتين مختلفتين يمكن للمرسل استخدامهما لإدراج حدود السجلات في تدفق البايتات هذا، وبالتالي إعلام المستقبِل بكيفية تقسيم تدفق البايتات إلى سجلات. (تُعَد القدرة على تحديد حدود السجلات أمرًا مفيدًا في العديد من تطبيقات قواعد البيانات على سبيل المثال) وضُمِّنت هاتان الميزتان في الأصل في بروتوكول TCP لأسباب مختلفة تمامًا، ثم جرى استخدامهما لهذا الغرض بمرور الوقت، وهما:
الآلية الأولى هي ميزة البيانات العاجلة urgent data feature، التي طُبِّقت بواسطة الراية URG وحقل UrgPtr في ترويسة TCP. صُمِّمت آلية البيانات العاجلة في الأصل للسماح للتطبيق المرسِل بإرسال بيانات خارج النطاق إلى نظيره. نعني بعبارة خارج النطاق out-of-band البياناتِ المنفصلة عن تدفق البيانات الطبيعي (أمر مقاطعة عملية جارية بالفعل على سبيل المثال). حُدِّدت هذه البيانات خارج النطاق في الجزء segment باستخدام حقل UrgPtr وكان من المقرر تسليمها إلى عملية الاستلام بمجرد وصولها، حتى لو عنى ذلك تسليمها قبل بيانات ذات رقمٍ تسلسلي سابق. لكن، لم تُستخدَم هذه الميزة بمرور الوقت، لذلك بدلًا من الإشارة إليها ببيانات "عاجلة" ، فقد اُستخدمت للدلالة على بيانات "خاصة"، مثل علامة السجل record marker. طُوِّر هذا الاستخدام لأنه، كما هو الحال مع عملية push، يجب على TCP على الجانب المستلم إبلاغ التطبيق بوصول بيانات عاجلة، أي أن البيانات العاجلة في حد ذاتها ليست مهمة. إنها تشير إلى حقيقة أن عملية الإرسال يمكنها إرسال إشارة فعالة إلى جهاز الاستقبال بأن هناك أمرٌ مهم.
الآلية الثانية لإدخال علامات نهاية السجلات في بايت هي العملية push. صُمِّمت هذه الآلية في الأصل للسماح لعملية الإرسال بإعلام بروتوكول TCP بأنه يجب عليه إرسال أو تفريغ flush أي بايتات جمَّعها لنظيره. يمكن استخدام العملية push لتطبيق حدود السجلات لأن المواصفات تنص على أن بروتوكول TCP يجب أن يرسل أي بيانات مخزَّنة مؤقتًا عند المصدر عندما يقول التطبيق push، ويُعلِم بروتوكول TCP، اختياريًا، التطبيق في الوجهة عند وجود جزء وارد يحتوي على مجموعة الراية PUSH. إذا كان جانب الاستقبال يدعم هذا الخيار (لا تدعم واجهة المقبس هذا الخيار)، فيمكن عندئذٍ استخدام العملية push لتقسيم تدفق TCP إلى سجلات.
برنامج التطبيق حرٌ دائمًا بحشر حدود السجلات دون أي مساعدة من بروتوكول TCP، حيث يمكنه إرسال حقل يشير إلى طول السجل الذي يجب أن يتبعه، أو يمكنه حشر علامات حدود السجل الخاصة به في تدفق البيانات على سبيل المثال.
إضافات بروتوكول TCP
لقد ذكرنا أن هناك إضافات Extensions لبروتوكول TCP تساعد في التخفيف من بعض المشاكل التي واجهها حيث أصبحت الشبكة الأساسية أسرع. صُمِّمت هذه الإضافات ليكون لها تأثيرٌ ضئيل على بروتوكول TCP قدر الإمكان، حيث تُدرَك كخياراتٍ يمكن إضافتها إلى ترويسة TCP. (سبب احتواء ترويسة TCP على حقل HdrLen هو أن الترويسة يمكن أن تكون بطول متغير، يحتوي الجزء المتغير من ترويسة TCP على الخيارات المُضافة). أهمية إضافة هذه الإضافات كخيارات بدلًا من تغيير جوهر ترويسة TCP هو أن المضيفين لا يزالون قادرين على التواصل باستخدام TCP حتى لو لم يقوموا بتطبيق الخيارات، ولكن يمكن للمضيفين الذين يقومون بتطبيق الإضافات الاختيارية الاستفادة منها. يتفق الجانبان على استخدام الخيارات أثناء مرحلة إنشاء اتصال TCP.
تساعد الإضافة الأولى على تحسين آلية ضبط مهلة TCP الزمنية. يمكن لبروتوكول TCP قراءة ساعة النظام الفعلية عندما يكون على وشك إرسال جزء بدلًا من قياس RTT باستخدام حدث قاسٍ coarse-grained، ووضع هذا الوقت (فكر به على أنه علامة زمنية timestamp مؤلفة من 32 بتًا) في ترويسة الجزء، ثم يُرجِع echoes المستقبل هذه العلامة الزمنية مرةً أخرى إلى المرسل في إشعاره، ويطرح المرسل هذه العلامة الزمنية من الوقت الحالي لقياس وقت RTT. يوفر خيار العلامة الزمنية مكانًا مناسبًا لبروتوكول TCP لتخزين سجل وقت إرسال جزء، أي يخزن الوقت في الجزء نفسه. لاحظ أن نقاط النهاية في الاتصال لا تحتاج إلى ساعات متزامنة، حيث تُكتَب العلامة الزمنية وتُقرَأ في نهاية الاتصال نفسها.
تعالج الإضافة الثانية مشكلة التفاف wrapping around حقل SequenceNum المكون من 32 بت لبروتوكول TCP في وقت قريب جدًا على شبكة عالية السرعة. يستخدم بروتوكول TCP العلامة الزمنية المؤلفة من 32 بتًا الموصوفة للتو لتوسيع حيز الأرقام التسلسلية بفعالية بدلاً من تحديد حقل رقم تسلسلي جديد مؤلف من 64 بتًا. أي يقرر بروتوكول TCP قبول أو رفض جزء بناءً على معرّف بطول 64 بت يحتوي على حقل SequenceNum بترتيب 32 بت المنخفض والعلامة الزمنية بترتيب 32 بت العالي. بما أن العلامة الزمنية تتزايد دائمًا، فإنها تعمل على التمييز بين تجسبدَين مختلفين لنفس الرقم التسلسلي. لاحظ استخدام العلامة الزمنية في هذا الإعداد فقط للحماية من الالتفاف، حيث لا يُتعامَل معها كجزء من الرقم التسلسلي لغرض طلب البيانات أو الإشعار بوصولها.
تسمح الإضافة الثالثة لبروتوكول TCP بالإعلان عن نافذةٍ أكبر، مما يسمح له بملء الأنابيب ذات جداء (التأخير × حيز النطاق التراسلي) الأكبر والتي تتيحها الشبكات عالية السرعة. تتضمن هذه الإضافة خيارًا يحدد عامل توسيع scaling factor للنافذة المعلن عنها. أي يسمح هذا الخيار لطرفي TCP بالاتفاق على أن حقل AdvertisedWindow يحسب أجزاءًا أكبر (عدد وحدات البيانات ذات 16 بايت الممكن عدم الإقرار بها من قبل المرسل على سبيل المثال) بدلًا من تفسير الرقم الذي يظهر في حقل AdvertisedWindow على أنه يشير إلى عدد البايتات المسموح للمرسل بعدم الإقرار بها. يحدد خيار توسيع النافذة عدد البتات التي يجب على كل جانبٍ إزاحة حقل AdvertisedWindow بها لليسار قبل استخدام محتوياته لحساب نافذة فعالة.
تسمح الإضافة الرابعة لبروتوكول TCP بتوفير إشعاره التراكمي cumulative acknowledgment مع الإشعارات الانتقائية selective acknowledgments لأية أجزاءٍ إضافية جرى استلامها ولكنها ليست متجاورة مع جميع الأجزاء المُستلمة مسبقًا، وهذا هو خيار الإشعار الانتقائي أو SACK. يستمر جهاز الاستقبال بالإقرار أو الإشعار عن الأجزاء بشكلٍ طبيعي عند استخدام خيار SACK، أي لا يتغير معنى حقل Acknowledge، ولكنه يستخدم أيضًا حقولًا اختيارية في الترويسة لإرسال إشعارات وصول أي كتلٍ إضافية من البيانات المستلمة. يتيح ذلك للمرسل إعادة إرسال الأجزاء المفقودة فقط وفقًا للإشعار الانتقائي.
هناك استراتيجيتان مقبولتان فقط للمرسل بدون SACK. تستجيب الاستراتيجية المتشائمة pessimistic لانتهاء المهلة بإعادة إرسال الجزء المنتهية مهلته، وكذلك أي أجزاء سترسَل لاحقًا أيضًا، وتفترض الإستراتيجية المتشائمة الأسوأ والذي هو فقد كل تلك الأجزاء. عيب الاستراتيجية المتشائمة هو أنها قد تعيد إرسال الأجزاء المُستلمة بنجاح في المرة الأولى دون داعٍ. الإستراتيجية الأخرى هي الإستراتيجية المتفائلة optimistic، والتي تستجيب لانتهاء المهلة بإعادة إرسال الجزء المنتهية مهلته فقط. يفترض النهج المتفائل السيناريو الأكثر تفاؤلًا والذي هو فقد جزء segment واحد فقط. عيب الإستراتيجية المتفائلة أنها بطيئة للغاية دون داعٍ، عندما تضيع سلسلة من الأجزاء المتتالية، كما يحدث عندما يكون هناك ازدحام. كما أنها بطيئة نظرًا لعدم القدرة على اكتشاف خسارة كل جزءٍ حتى يتلقى المرسل ACK لإعادة إرسال الجزء السابق، لذلك فهي تستهلك وقت RTT واحدًا لكل جزءٍ حتى يعيد إرسال جميع الأجزاء في السلسلة المفقودة. تتوفر استراتيجية أفضل للمرسل مع خيار SACK وهي: أعد إرسال الأجزاء التي تملأ الفجوات بين الأجزاء التي جرى الإقرار بها انتقائيًا.
بالمناسبة، لا تمثّل هذه الإضافات القصة الكاملة. حيث سنرى بعض الإضافات الأخرى عندما ننظر في كيفية تعامل بروتوكول TCP مع الازدحام. تتعقب هيئة تخصيص أرقام الإنترنت Internet Assigned Numbers Authority أو اختصارًا IANA جميع الخيارات المحددة لبروتوكول TCP (إضافةً للعديد من بروتوكولات الإنترنت الأخرى).
الأداء Performance
تذكر أن في بداية السلسلة قد قدّم المقياسين الكميّين اللذين يجري من خلالِهما تقييم أداء الشبكة وهما: زمن الاستجابة latency والإنتاجية throughput. لا تتأثر هذه المقاييس فقط بالعتاد الأساسي، مثل تأخير الانتشار propagation delay وحيز نطاق الرابط التراسلي link bandwidth، كما هو مذكور في تلك المناقشة، ولكن تتأثر أيضًا بتكاليف البرمجيات الزائدة. يمكننا مناقشة كيفية قياس أداء البروتوكول القائم على البرمجيات بشكل هادف الآن بعد أن أصبح متاحًا لنا رسمًا بيانيًا كاملًا له متضمنًا بروتوكولات نقل بديلة. تكمن أهمية هذه القياسات في أنها تمثل الأداء الذي تراه برامج التطبيق.
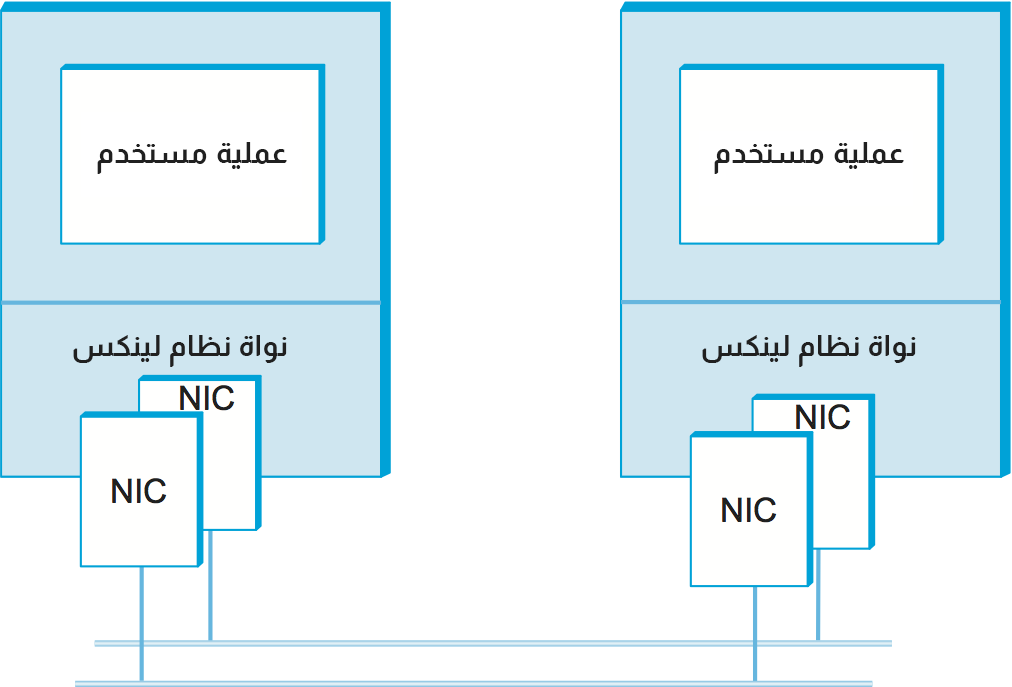
نبدأ، كما ينبغي لأي تقرير لنتائج التجارب، بوصف طريقتنا التجريبية. وهذا يشمل الجهاز المستخدم في التجارب، حيث تحتوي كل محطة عمل على زوج من معالجات Xeon لوحدة المعالجة المركزية بتردد 2.4 جيجاهرتز والتي تعمل بنظام لينوكس في هذه الحالة. يجري استخدام زوج من محوّلات إيثرنت، المسمَّى NIC بطاقة واجهة الشبكة network interface card، على كل جهاز لتمكين سرعات أعلى من 1 جيجابت في الثانية. يمتد الإيثرنت على غرفة جهاز واحدة لذا لا يمثل الانتشار مشكلة، مما يجعل هذا مقياسًا لتكاليف المعالجات / البرمجيات الزائدة. يحاول برنامجُ الاختبار الذي يعمل أعلى واجهة المقبس ببساطة نقلَ البيانات بأسرع ما يمكن من جهازٍ إلى آخر، ويوضح الشكل السابق هذا الإعداد.
قد تلاحظ أن هذا الإعداد التجريبي لا يمثل ميزة خاصة من حيث العتاد أو سرعة الروابط. لا يتمثل الهدف من هذا القسم في إظهار مدى سرعة تشغيل بروتوكول معين، ولكن لتوضيح المنهجية العامة لقياس أداء البروتوكول والإبلاغ عنه.
يجري اختبار الإنتاجية لمجموعة متنوعة من أحجام الرسائل باستخدام أداة قياس معيارية تسمى TTCP. يوضح الشكل التالي نتائج اختبار الإنتاجية. الشيء الرئيسي الواجب ملاحظته في هذا الرسم البياني هو أن معدل النقل يتحسن مع زيادة حجم الرسائل. وهذا أمرٌ منطقي، حيث تتضمن كل رسالة قدرًا معينًا من الحِمل الزائد، لذا فإن الرسالة الأكبر تعني أن هذا الحِمل يُستهلَك على عددٍ أكبر من البايتات. يُسطَّح منحني سرعة النقل الأعلى من 1 كيلوبايت، وعند هذه النقطة يصبح الحِمل لكل رسالة غير مهم عند مقارنته بالعدد الكبير من البايتات التي يتعين على مكدّس البروتوكول معالجتها.
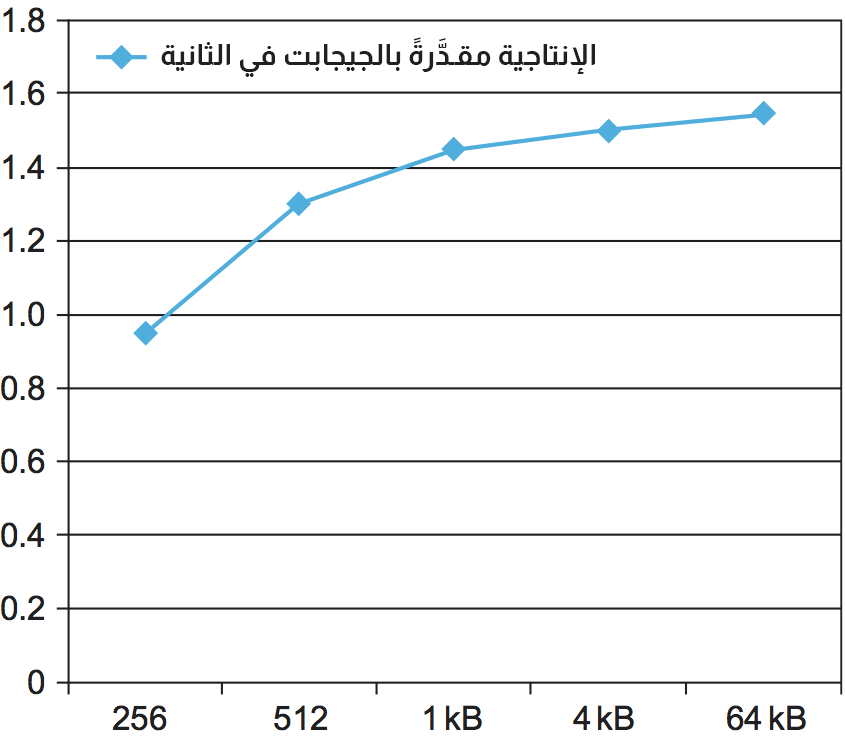
تجدر الإشارة إلى أن الحد الأقصى للإنتاجية أقل من 2 جيجابت في الثانية، وهي سرعة الرابط المتاحة في هذا الإعداد. ستكون هناك حاجة لمزيد من الاختبار وتحليل النتائج لمعرفة مكان الاختناق أو معرفة إذا كان هناك أكثر من عنق زجاجة أو اختناق bottleneck. قد يعطي النظر إلى حِمل وحدة المعالجة المركزية مؤشرًا على ما إذا كانت وحدة المعالجة المركزية هي مكان الاختناق أم أن اللوم يقع على حيز النطاق التراسلي للذاكرة أو أداء محوّل adaptor الشبكة أو بعض المشكلات الأخرى.
نلاحظ أيضًا أن الشبكة في هذا الاختبار "مثالية" بصورةٍ أساسية. لا يوجد أي تأخير أو خسارة تقريبًا، وبالتالي فإن العوامل الوحيدة التي تؤثر على الأداء هي تطبيق بروتوكول TCP إضافةً إلى عتاد وبرمجيات محطة العمل. ولكن نتعامل في معظم الأوقات مع شبكاتٍ بعيدة عن الكمال، ولا سيما روابطنا المقيدة بحيّز النطاق التراسلي وروابط الميل الأخير والروابط اللاسلكية المعرّضة للضياع. نحتاج إلى فهم كيفية تعامل بروتوكول TCP مع الازدحام قبل أن نقّدر تمامًا كيف تؤثر هذه الروابط على أداء TCP.
هدّدت سرعة روابط الشبكة المتزايدة بشكل مطرد بالتقدم على ما يمكن تسليمه إلى التطبيقات في أوقات مختلفة من تاريخ الشبكات. بدأ جهد بحثي كبير في الولايات المتحدة في عام 1989 لبناء "شبكات جيجابت gigabit networks" على سبيل المثال، حيث لم يكن الهدف فقط بناء روابط ومبدلات يمكن تشغيلها بسرعة 1 جيجابت في الثانية أو أعلى، ولكن أيضًا لإيصال هذه الإنتاجية على طول الطريق إلى عملية تطبيقٍ واحدة. كانت هناك بعض المشكلات الحقيقية (كان لابد من تصميم محولات شبكة، وبنيات محطات عمل، وأنظمة تشغيل مع مراعاة إنتاجية النقل من شبكة إلى تطبيق على سبيل المثال) وكذلك بعض المشكلات المُدرَكة التي تبين أنها ليست خطيرة للغاية. وكان على رأس قائمة مثل هذه المشاكل القلقُ من أن بروتوكولات النقل الحالية، وخاصةً بروتوكول TCP، قد لا تكون على مستوى التحدي المتمثل في عمليات الجيجابت.
كما اتضح، كان أداء بروتوكول TCP جيدًا في مواكبة الطلبات المتزايدة للشبكات والتطبيقات عالية السرعة. أحد أهم العوامل هو إدخال توسيع النافذة للتعامل مع منتجات تأخير حيز النطاق التراسلي الأكبر، ولكن غالبًا ما يكون هناك فرقٌ كبير بين الأداء النظري لبروتوكول TCP وما يجري تحقيقه عمليًا. يمكن أن تؤدي المشكلات البسيطة نسبيًا مثل نسخ البيانات مرات أكثر من اللازم أثناء انتقالها من محول الشبكة إلى التطبيق إلى انخفاض الأداء، كما يمكن أن تؤدي ذاكرة التخزين المؤقت غير الكافية إلى انخفاض الأداء عندما يكون منتج تأخير حيز النطاق التراسلي كبيرًا. وديناميكيات TCP معقدة بدرجة كافية، بحيث يمكن للتفاعلات الدقيقة بين سلوك الشبكة وسلوك التطبيق وبروتوكول TCP نفسه تغيير الأداء بصورةٍ كبيرة.
من الجدير بالذكر أن بروتوكول TCP يستمر في الأداء الجيد مع زيادة سرعات الشبكة، ويندفع الباحثون لإيجاد حلول عند حدوث تعارض مع بعض القيود (المرتبطة عادةً بالازدحام أو زيادة منتجات تأخير حيز النطاق التراسلي أو كليهما).
خيارات التصميم البديلة SCTP وQUIC
على الرغم من أن بروتوكول TCP قد أثبت أنه بروتوكول قوي يلبي احتياجات مجموعة واسعة من التطبيقات، إلا أن مساحة تصميم بروتوكولات النقل كبيرة جدًا. ليس بروتوكول TCP بأي حالٍ النقطة الصالحة الوحيدة في مساحة التصميم هذه. نختم مناقشتنا لبروتوكول TCP من خلال النظر في خيارات التصميم البديلة. بينما نقدم شرحًا حول سبب اتخاذ مصممي TCP الخيارات التي قاموا بها، فإننا نلاحظ وجود بروتوكولات أخرى اتخذت خيارات أخرى، وقد يظهر المزيد من هذه البروتوكولات في المستقبل.
هناك صنفان على الأقل من بروتوكولات النقل: البروتوكولات الموجَّهة بالتدفق stream-oriented protocols مثل بروتوكول TCP وبروتوكولات الطلب / الرد request/reply protocols مثل بروتوكول RPC. قسمنا مساحة التصميم ضمنيًا إلى نصفين ووضعنا بروتوكول TCP مباشرةً في نصف عالم البروتوكولات الموجَّهة بالتدفق. يمكننا أيضًا تقسيم البروتوكولات الموجهة بالتدفق إلى مجموعتين، موثوقة reliable وغير موثوقة unreliable، مع احتواء الأولى على بروتوكول TCP والأخيرة أكثر ملاءمة لتطبيقات الفيديو التفاعلية التي تفضل إسقاط أو إهمال إطار بدلًا من تحمّل التأخير المرتبط بإعادة الإرسال.
يُعَد بناء تصنيف لبروتوكول النقل أمرًا مثيرًا للاهتمام ويمكن مواصلته بتفاصيل أكثر، ولكن العالم ليس أبيض وأسود كما قد نحب. افترض ملاءمة بروتوكول TCP كبروتوكول نقل لتطبيقات الطلب / الرد على سبيل المثال. بروتوكول TCP هو بروتوكول ثنائي الاتجاه، لذلك سيكون من السهل فتح اتصال TCP بين العميل والخادم، وإرسال رسالة الطلب في اتجاه واحد، وإرسال رسالة الرد في الاتجاه الآخر، ولكن هناك نوعان من التعقيدات. الأول هو أن بروتوكول TCP هو بروتوكول موجَّهٌ بالبايت وليس بروتوكول موجَّه بالرسائل، وأن تطبيقات الطلب / الرد تتعامل دائمًا مع الرسائل. (سنكتشف مسألة البايتات مقابل الرسائل بتفصيل أكبر بعد قليل). التعقيد الثاني هو أنه في تلك المواقف التي تتلاءم فيها كل من رسالة الطلب ورسالة الرد في رزمة شبكة واحدة، يحتاج بروتوكول الطلب / الرد المصمم جيدًا رزمتان فقط لتطبيق التبادل، بينما يحتاج بروتوكول TCP إلى تسع رزم على الأقل: ثلاث لتأسيس الاتصال، واثنان لتبادل الرسائل، وأربع لإنهاء الاتصال. إذا كانت رسائل الطلب أو الرد كبيرة بما يكفي لأن تتطلب رزم شبكةٍ متعددة (قد يستغرق الأمر 100 رزمة لإرسال إستجابة بحجم 100000 بايت على سبيل المثال)، ستكون التكاليف الزائدة لإعداد الاتصال وإلغائه غير منطقية. ليس الأمر دائمًا أن بروتوكولًا معينًا لا يمكنه دعم وظيفةٍ معينة، ففي بعض الأحيان يكون هناك تصميم أكثر كفاءة من تصميم آخر في ظل ظروف معينة.
ثانيًا، قد تتساءل عن سبب اختيار TCP لتقديم خدمة تدفق بايتات موثوقة بدلًا من خدمة تدفق رسائل موثوقة، حيث تُعتبر الرسائل الخيار الطبيعي لتطبيق قاعدة البيانات الذي يريد تبادل السجلات. هناك إجابتان على هذا السؤال: الأول هو أن البروتوكول الموجَّه بالرسائل يجب أن ينشئ حدًا أعلى لأحجام الرسائل، فالرسالة الطويلة التي بلا حدود هي تدفق بايتات. ستكون هناك تطبيقات تريد إرسال رسائل أكبر بالنسبة إلى أي حجم رسالة يحدده البروتوكول، مما يجعل بروتوكول النقل عديم الفائدة ويجبر التطبيق على تنفيذ خدماته الشبيهة بالنقل. السبب الثاني هو أنه على الرغم من أن البروتوكولات الموجهة بالرسائل هي بالتأكيد أكثر ملاءمة للتطبيقات التي ترغب في إرسال السجلات إلى بعضها البعض، إلا أنه يمكنك بسهولة إدخال حدود السجل في تدفق البايتات لتطبيق هذه الوظيفة.
القرار الثالث الذي اُتخِذ في تصميم TCP هو أنه يسلّم البايتات بناءً على التطبيق. هذا يعني أنه قد يحتفظ بالبايتات التي استلمها مخالفةً للترتيب من الشبكة، في انتظار بعض البايتات المفقودة لملء ثغرة. هذا مفيد للغاية للعديد من التطبيقات ولكن تبين أنه غير مفيد تمامًا إذا كان التطبيق قادرًا على معالجة البيانات المخالفة للترتيب. فلا تحتاج صفحة الويب مثلًا التي تحتوي على كائنات متعددة مضمَّنة إلى تسليم جميع الكائنات بالترتيب قبل البدء في عرض الصفحة. هناك صنف من التطبيقات يفضِّل التعامل مع البيانات المخالفة للترتيب في طبقة التطبيق، مقابل الحصول على البيانات في وقت أقرب عند إسقاط الرزم أو سوء ترتيبها داخل الشبكة. أدت الرغبة في دعم مثل هذه التطبيقات إلى إنشاء بروتوكولي نقل معياريين من IETF. كان أولها بروتوكول SCTP، بروتوكول نقل التحكم في التدفق Stream Control Transmission Protocol. يوفر بروتوكول SCTP خدمة توصيل مُرتَّبة جزئيًا، بدلًا من خدمة TCP المُرتَّبة بدقة. (يتخذ بروتوكول SCTP أيضًا بعض قرارات التصميم الأخرى التي تختلف عن بروتوكول TCP، بما في ذلك اتجاه الرسالة ودعم عناوين IP المتعددة لجلسة واحدة). وحّدت منظمة IETF في الآونة الأخيرة بروتوكولًا محسَّنًا لحركة مرور الويب، يُعرف باسم QUIC.
رابعًا، اختار بروتوكول TCP تطبيق مراحل إعداد / تفكيك صريحة، لكن هذا ليس مطلوبًا، حيث سيكون من الممكن إرسال جميع معاملات الاتصال الضرورية مع رسالة البيانات الأولى في حالة إعداد الاتصال. اختار TCP اتباع نهجٍ أكثر تحفظًا يمنح المتلقي الفرصة لرفض الاتصال قبل وصول أي بيانات. يمكننا إغلاق الاتصال الذي كان غير نشط لفترة طويلة من الزمن بهدوء في حالة التفكيك، ولكن هذا من شأنه أن يعقّد تطبيقات مثل تسجيل الدخول عن بُعد الذي يريد الحفاظ على الاتصال نشطًا لأسابيع في كل مرة، حيث ستُجبَر هذه التطبيقات على إرسال رسائل "keep alive" خارج النطاق للحفاظ على حالة الاتصال عند الطرف الآخر من الاختفاء.
أخيرًا، بروتوكول TCP هو بروتوكول قائم على النافذة window-based، لكن هذا ليس الاحتمال الوحيد. البديل هو التصميم القائم على المعدَّل rate-based design، حيث يخبر المستلمُ المرسلَ بالمعدّل (معبرًا عنه إما بالبايتات أو بالرزم في الثانية) الذي يكون على استعداد لقبول البيانات الواردة إليه، فقد يخبر المتلقي المرسل على سبيل المثال أنه يستطيع استيعاب 100 رزمة في الثانية. هناك ازدواجية مثيرة للاهتمام بين النوافذ والمعدَّل، حيث أن عدد الرزم (البايتات) في النافذة، مقسومًا على RTT، هو المعدل بالضبط. يشير حجم النافذة المكوَّن من 10 رزم و 100 ميلي ثانية RTT على سبيل المثال إلى أنه يُسمح للمرسل بالإرسال بمعدل 100 رزمة في الثانية. يرفع جهاز الاستقبال أو يخفض المعدل الذي يمكن للمرسل الإرسال به بفعالية من خلال زيادة أو تقليل حجم النافذة المعلن عنها. تُرَد هذه المعلومات مرةً أخرى إلى المرسل في حقل AdvertisedWindow من إشعار ACK كل جزء في بروتوكول TCP. تتمثل إحدى المشكلات الرئيسية في البروتوكول المستند إلى المعدل في عدد المرات التي يُرحَّل فيها المعدل المطلوب (والذي قد يتغير بمرور الوقت) إلى المصدر: هل هو لكل رزمة أم مرة واحدة لكل RTT أم عندما يتغير المعدل فقط؟ على الرغم من أننا قد ناقشنا للتو النافذة مقابل المعدل في سياق التحكم في التدفق، إلا أنها قضية متنازع عليها بشدة في سياق التحكم في الازدحام، والتي ستُناقش لاحقًا.
بروتوكول QUIC
أُنشِئ بروتوكول اتصالات إنترنت بروتوكول UDP السريعة Quick UDP Internet Connections أواختصارًا QUIC في Google في عام 2012، ولا يزال يخضع للتوحيد القياسي standardization في منظمة IETF في وقت كتابة هذا الكتاب، ولقد شهد بالفعل قدرًا معتدلًا من النشر (في بعض متصفحات الويب وعدد كبير من مواقع الويب الشائعة). حقيقة أنه كان ناجحًا إلى هذه الدرجة هي في حد ذاتها جزءٌ مثير للاهتمام من قصة QUIC، وكانت قابلية النشر التزامًا رئيسيًا لمصممي البروتوكول.
يأتي الدافع وراء بروتوكول QUIC مباشرةً من النقاط التي أشرنا إليها أعلاه حول بروتوكول TCP: لقد تبين أن بعض قرارات التصميم غير مثالية لمجموعة من التطبيقات التي تعمل عبر بروتوكول TCP، كحركة مرور بروتوكول HTTP (الويب). أصبحت هذه المشكلات أوضح بمرور الوقت، نظرًا لعوامل مثل ظهور الشبكات اللاسلكية ذات زمن الاستجابة العالي، وتوافر شبكات متعددة لجهاز واحد (شبكة Wi-Fi والشبكة الخلوية على سبيل المثال)، والاستخدام المتزايد للتشفير واستيثاق الاتصالات على الويب. تستحق بعض قرارات تصميم بروتوكول QUIC الرئيسية المناقشة في حين أن وصفه الكامل خارج نطاقنا.
إذا كان وقت استجابة الشبكة مرتفعًا (من رتبة مئات الميلي ثانية) فيمكن أن تزيد بسرعة بعض فترات RTT إزعاجًا واضحًا للمستخدم النهائي. يستغرق عادةً إنشاء جلسة HTTP عبر بروتوكول TCP مع تأمين طبقة النقل ثلاث رحلاتٍ ذهابًا وإيابًا (واحدة لتأسيس جلسة TCP واثنتان لإعداد معاملات التشفير) قبل إرسال رسالة HTTP الأولى. أدرك مصممو QUIC أنه يمكن تقليل هذا التأخير (وهو النتيجة المباشرة لنهج متعدد الطبقات لتصميم البروتوكول) بصورةٍ كبيرة إذا دُمِج إعداد الاتصال ومصافحات الأمان المطلوبة وحُسِّن لأدنى حد من وقت الذهاب والإياب.
لاحظ أيضًا كيف قد يؤثر وجود واجهات متعددة للشبكة على التصميم. إذا فقد هاتفك المحمول اتصال Wi-Fi وتحتاج إلى التبديل إلى اتصال خلوي، سيتطلب ذلك عادةً مهلة TCP على اتصالٍ واحد وسلسلة جديدة من المصافحات على الاتصال الآخر. كان جعل الاتصال شيئًا يمكنه الاستمرار عبر اتصالات طبقة الشبكة المختلفة هدفًا تصميميًا آخر لبروتوكول QUIC.
أخيرًا، يُعد نموذج تدفق البايتات الموثوق لبروتوكول TCP تطابقًا ضعيفًا مع طلب صفحة الويب، عند الحاجة إلى جلب العديد من الكائنات ويمكن البدء بعرض الصفحة قبل وصولها جميعًا. أحد الحلول لذلك هو فتح اتصالات TCP متعددة على التوازي، ولكن هذا الأسلوب (الذي اُستخدِم في الأيام الأولى للويب) له مجموعة من العيوب الخاصة به، لا سيما فيما يتعلق بالتحكم في الازدحام.
ومن المثير للاهتمام أنه جرى اتخاذ العديد من قرارات التصميم التي شكّلت تحدياتٍ لنشر بروتوكول نقل جديد بحلول الوقت الذي ظهر فيه QUIC. والجدير بالذكر أن العديد من "الصناديق المتوسطة middleboxes" مثل الجدران النارية firewalls وNAT لديها فهم كافٍ لبروتوكولات النقل المنتشرة على نطاق واسع (TCP وUDP) بحيث لا يمكن الاعتماد عليها لتمرير بروتوكول نقل جديد. ونتيجة لذلك يتواجد بروتوكول QUIC في الواقع فوق بروتوكول UDP، أي أنه بروتوكول نقلٍ يعمل فوق بروتوكول نقل.
يطبّق بروتوكول QUIC إنشاء اتصالٍ سريع مع التشفير والاستيثاق authentication في أول RTT، ويفضّل توفير معرّف اتصال على استمراره عبر التغييرات في الشبكة الأساسية. وهو يدعم تعدد إرسال عدة تدفقات على اتصال نقل واحد، لتجنب توقف رأس الخط الذي قد ينشأ عند إسقاط رزمةٍ واحدة بينما يستمر وصول البيانات المفيدة الأخرى. ويحافظ على خصائص تجنب الازدحام لبروتوكول TCP.
بروتوكول QUIC هو التطور الأكثر إثارة للاهتمام في عالم بروتوكولات النقل. العديد من قيود بروتوكول TCP معروفةٌ منذ عقود، ولكن يمثّل بروتوكول QUIC واحدًا من أنحج الجهود حتى الآن للتركيز على نقطة مختلفة في مساحة التصميم. ويقدم دراسة حالة رائعة في النتائج غير المتوقعة للتصميمات متعددة الطبقات وفي تطور الإنترنت، نظرًا لأنه مستوحى من تجربة بروتوكول HTTP والويب، والتي نشأت بعد فترة طويلة من تأسيس بروتوكول TCP بشكل جيد في الإنترنت.
بروتوكول TCP متعدد المسارات Multipath TCP
ليس من الضروري دائمًا تحديد بروتوكول جديد إذا وجدت أن البروتوكول الحالي لا يخدم حالة استخدام معينة بشكل كافٍ. من الممكن في بعض الأحيان إجراء تغييرات جوهرية في كيفية تطبيق بروتوكول موجود، ولكن تظل وفية للمواصفات الأصلية. يعد بروتوكول Multipath TCP مثالًا على مثل هذه الحالة.
تتمثل فكرة Multipath TCP في توجيه الرزم خلال مسارات متعددة عبر الإنترنت، باستخدام عنوانَي IP مختلفين لإحدى نقاط النهاية على سبيل المثال. يمكن أن يكون هذا مفيدًا بشكل خاص عند تسليم البيانات إلى جهازٍ محمول متصل بكل من شبكة Wi-Fi والشبكة الخلوية (وبالتالي يملك عنوانين IP فريدين). يمكن أن تواجه فقدانًا كبيرًا في الرزمة نظرًا لكون كلتا الشبكتين لاسلكيتين، لذا فإن القدرة على استخدامهما لحمل الرزم يمكن أن تحسّن تجربة المستخدم بصورة كبيرة. الحل هو أن يعيد الجانب المستلم من TCP بناء تدفق البايتات الأصلي بالترتيب قبل تمرير البيانات إلى التطبيق، والذي يظل غير مدرك أنه يجلس على بروتوكول Multipath TCP. (وهذا على عكس التطبيقات التي تفتح عمدًا اتصالين أو أكثر من اتصالات TCP للحصول على أداء أفضل).
يبدو بروتوكول Multipath TCP بسيطًا، ولكنه من الصعب للغاية الحصول عليه بصورةٍ صحيحة لأنه يكسر العديد من الافتراضات حول كيفية تطبيق التحكم في تدفق TCP، وإعادة تجميع الجزء segment بالترتيب، والتحكم في الازدحام. نتركه كتمرينٍ لك لاستكشاف التفاصيل الدقيقة، حيث يُعد القيام بذلك طريقةً رائعة للتأكد من أن فهمك الأساسي لبروتوكول TCP سليم.
ترجمة -وبتصرّف- للقسم Reliable Byte Stream من فصل ProtocolsEnd-to-End من كتاب Computer Networks: A Systems Approach.











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.