

المُلكية ownership هي مجموعة من القوانين التي تحدد كيف يُدير برنامج رست استخدام الذاكرة، ويتوجب على جميع البرامج أن تُدير الطريقة التي تستخدم فيها ذاكرة الحاسوب عند تشغيلها. تلجأ بعض لغات البرمجة إلى كانس المهملات garbage collector الذي يتفقد باستمرار الذاكرة غير المُستخدمة بعد الآن أثناء عمل البرنامج، بينما تعطي لغات البرمجة الأخرى مسؤولية تحديد الذاكرة وتحريرها للمبرمج مباشرةً، إلا أن رست تسلك طريقًا آخر ثالثًا؛ ألا وهو أن الذاكرة تُدار عبر نظام ملكية يحتوي على مجموعة من القوانين التي يتفقدها المصرّف، إذ لا يُصرّف البرنامج إذا حدث خرق لأحد هذه القوانين، ولن تبطئ أي من مزايا الملكية برنامجك عند تشغيله.
سيتطلب مفهوم الملكية بعض الوقت للاعتياد عليه بالنظر إلى أنه مفهوم جديد للعديد من المبرمجين، إلا أنك ستجد قوانين نظام الملكية أكثر سهولة بالممارسة وستجدها من البديهيات التي تسمح لك بكتابة شيفرة برمجية آمنة وفعّالة، لذا لا تستسلم.
ستحصل على أساس قوي في فهم المزايا التي تجعل من رست لغة فريدة فور فهمك للملكية، وستتعلم في هذا المقال مفهوم الملكية بكتابة بعض الأمثلة التي تركز على هيكل بيانات data structure شائع جدًا هو السلاسل النصية strings.
المكدس والكومة
لا تطلب معظم لغات البرمجة منك بالتفكير بالمكدس stack والكومة heap بصورةٍ متكررة عادةً، إلا أن هذا الأمر مهم في لغات برمجة النظم مثل رست، إذ يؤثر وجود القيمة في المكدس أو الكومة على سلوك اللغة واتخاذها لبعض القرارات المعينة، وسنصف أجزاءً من نظام الملكية بما يتعلق بالكومة والمكدس لاحقًا، وسنستعرض هنا مفهومي -الكومة والمكدس- ونشرحهما للتحضير لذلك.
يمثل كلًا من المكدس والكومة أجزاءً متاحةً من الذاكرة لشيفرتك البرمجية حتى تستخدمها عند وقت التشغيل runtime، إلا أنهما مُهيكلان بطريقة مختلفة؛ إذ يُخزن المكدس القيم بالترتيب الذي وردت فيه ويُزيل القيم بالترتيب المعاكس، ويُشار إلى ذلك بمصطلح الداخل آخرًا، يخرج أولًا last in, first out. يمكنك التفكير بالمكدس وكأنه كومة من الأطباق، فعندما تضيف المزيد من الأطباق، فإنك تضيفها على قمة الكومة وعندما تريد إزالة طبق فعليك إزالة واحد من القمة، ولا يُمكنك إزالة الأطباق من المنتصف أو من القاع. تُسمى عملية إضافة البيانات بالدفع إلى المكدس pushing onto the stack بينما تُدعى عملية إزالة البيانات بالإزالة من المكدس popping off the stack، ويجب على جميع البيانات المخزنة في المكدس أن تكون من حجم معروف وثابت، بينما تُخزّن البيانات ذات الحجم غير المعروف عند وقت التصريف أو ذات الحجم الممكن أن يتغير في الكومة بدلًا من ذلك.
الكومة هي الأقل تنظيمًا إذ يمكنك طلب مقدار معين من المساحة عند تخزين البيانات إليها، وعندها يجد محدد المساحة memory allocator حيزًا فارغًا في الكومة يتسع للحجم المطلوب، يعلّمه على أنه حيّز قيد الاستعمال، ثم يُعيد مؤشرًا pointer يشير إلى عنوان المساحة المحجوزة، وتدعى هذه العملية بحجز مساحة الكومة allocating on the heap وتُدعى في بعض الأحيان بحجز المساحة فقط (لا تُعد عملية إضافة البيانات إلى المكدس عملية حجز مساحة). بما أن المؤشر الذي يشير إلى الكومة من حجم معروف وثابت، يمكنك تخزينه في المكدس، وعندما تريد البيانات الفعلية من الكومة يجب عليك تتبع المؤشر. فكر بالأمر وكأنه أشبه بالجلوس في مطعم، إذ تصرّح عن عدد الأشخاص في مجموعتك عند دخولك إلى المطعم، ثم يبحث كادر المطعم عن طاولة تتسع للجميع ويقودك إليها، وإذا تأخر شخص ما عن المجموعة يمكنه سؤال كادر المطعم مجددًا ليقوده إلى الطاولة.
الدفع إلى المكدس أسرع من حجز الذاكرة في الكومة، لأن محدد المساحة لا يبحث عن مكان للبيانات الجديدة وموقع البيانات المخزنة، فهو دائمًا على قمة المكدس، بالمثل، يتطلب حجز المساحة في الكومة مزيدًا من العمل، إذ يجب على محدد المساحة البحث عن حيز كبير بما فيه الكفاية ليتسع البيانات ومن ثم حجزها للتحضير لعملية حجز المساحة التالية.
الوصول إلى البيانات من الكومة أبطأ من الوصول إلى البيانات من المكدس وذلك لأنه عليك أن تتبع المؤشر لتصل إلى حيز الذاكرة، وتؤدي المعالجات المعاصرة عملها بصورةٍ أسرع إذا انتقلت من مكان إلى آخر ضمن الذاكرة بتواتر أقل. لنبقي على تقليد التشابيه، فكر بالأمر وكأن النادل في المطعم يأخذ الطلبات من العديد من الطاولات، وفي هذه الحالة فمن الأفضل أن يحصل النادل على جميع الطلبات في الطاولة الواحدة قبل أن ينتقل إلى الطاولة التي تليها، فأخذ الطلب من الطاولة (أ) ومن ثم أخذ الطلب من الطاولة (ب) ومن ثم العودة إلى الطاولة (أ) والطاولة (ب) مجددًا عملية أبطأ بكثير، وبالمثل فإن المعالج يستطيع إنجاز عمله بصورةٍ أفضل إذا تعامل مع البيانات القريبة من البيانات الأخرى (كما هو الحال في المكدس) بدلًا من العمل على بيانات بعيدة عن بعضها (مثل الكومة).
عندما تستدعي شيفرتك البرمجية دالةً ما، يُدفع بالقيم المُمررة إليها إلى المكدس (بما فيها المؤشرات إلى البيانات الموجودة في الكومة) إضافةً إلى متغيرات الدالة المحلية، وعندما ينتهي تنفيذ الدالة، تُزال هذه القيم من المكدس.
يتكفل نظام الملكية بتتبع الأجزاء التي تستخدم البيانات من الكومة ضمن شيفرتك البرمجية، وتقليل كمية البيانات المُكررة ضمن الكومة، وإزالة أي بيانات غير مُستخدمة منها حتى لا تنفد من المساحة. عندما تفهم نظام الملكية لن تحتاج للتفكير بالمكدس والكومة كثيرًا، فكل ما عليك معرفته هو أن الهدف من نظام الملكية هو إدارة بيانات الكومة، وسيساعدك هذا الأمر في فهم طريقة عمل هذا النظام.
قوانين الملكية
دعنا نبدأ أولًا بالنظر إلى قوانين الملكية، أبقِ هذه القوانين في ذهنك بينما تقرأ بقية المقال الذي يستعرض أمثلةً توضح هذه القوانين:
- لكل قيمة في رست مالك owner.
- يجب أن يكون لكل قيمة مالك واحد في نقطة معينة من الوقت.
- تُسقط القيمة عندما يخرج المالك من النطاق scope.
نطاق المتغير
الآن وبعد تعرفنا إلى مبادئ رست في المقالات السابقة، لن نُضمّن الشيفرة fn main() { في الأمثلة، لذا إذا كنت تتبع الأمثلة تأكد من أنك تكتب الشيفرة البرمجية داخل دالة main يدويًا، ونتيجةً لذلك ستكون أمثلتنا أقصر بعض الشيء مما سيسمح لنا بالتركيز على التفاصيل المهمة بدلًا من الشيفرة البرمجية النمطية المتكررة.
سننظر إلى نطاق المتغيرات في أول مثال من أمثلة الملكية، والنطاق هو مجال ضمن البرنامج يكون فيه العنصر صالحًا. ألقِ نظرةً على المتغير التالي:
let s = "hello";
يُشير المتغير s إلى السلسلة النصية المجردة، إذ أن قيمة السلسلة النصية مكتوبة بصورةٍ صريحة على أنها نص في برنامجنا، والمتغير هذا صالح من نقطة التصريح عنه إلى نهاية النطاق الحالي. توضح الشيفرة 4-1 البرنامج مع تعليقات توضح مكان صلاحية المتغير s.
{ // المتغير غير صالح هنا إذ لم يُصرّح عنه بعد let s = "hello"; // المتغير صالح من هذه النقطة فصاعدًا // يمكننا استخدام s في العمليات هنا } // انتهى النطاق بحلول هذه النقطة ولا يمكننا استخدام s
[الشيفرة 4-1: متغير والنطاق الذي يكون فيه صالحًا]
بكلمات أخرى، هناك نقطتان مهمتان حاليًا:
-
عندما يصبح المتغير
sضمن النطاق، يصبح صالحًا. - يبقى المتغير صالحًا حتى مغادرته النطاق.
لحد اللحظة، العلاقة بين النطاقات والمتغيرات هي علاقة مشابهة للعلاقة التي تجدها في لغات البرمجة الأخرى، وسنبني على أساس هذا الفهم النوع String.
النوع String
نحتاج نوعًا أكثر تعقيدًا من الأنواع التي غطيناها سابقًا وذلك لتوضيح قوانين الملكية، إذ كانت الأنواع السابقة جميعها من أحجام معروفة ويمكن تخزينها في المكدس وإزالتها عند انتهاء نطاقها، كما أنه من الممكن نسخها بكل سهولة إلى متغير آخر جديد يمثّل نسخةً مستقلةً وذلك إذا احتاج حزءٌ ما من الشيفرة البرمجية استخدام المتغير ذاته ضمن نطاق آخر، إلا أننا بحاجة إلى النظر لأنواع البيانات المخزنة في الكومة حتى نكون قادرين على معرفة ما تفعله رست لتنظيف البيانات هذه ويمثل النوع String مثالًا رائعًا لهذا الاستخدام.
سنركز على أجزاء النوع String التي ترتبط مباشرةً بالملكية، وتنطبق هذه الجوانب أيضًا على أنواع البيانات المعقدة الأخرى سواءٌ كانت هذه الأنواع موجودةً في المكتبة القياسية أو كانت مبنيةً من قبلك، وسنناقش النوع String بتعمّق أكبر لاحقًا.
رأينا مسبقًا السلاسل النصية المجردة (وهي السلاسل النصية المكتوبة بين علامتي تنصيص " " بصورةٍ صريحة)، إذ تُكتب قيمة السلسلة النصية يدويًا إلى البرنامج. السلاسل النصية المجردة مفيدةٌ إلا أنها غير مناسبة لكل الحالات، مثل تلك التي نريد فيها استخدام النص ويعود السبب في ذلك إلى أنها غير قابلة للتعديل immutable، والسبب الآخر هو أنه لا يمكننا معرفة قيمة كل سلسلة نصية عندما نكتب شيفرتنا البرمجية، فعلى سبيل المثال، ماذا لو أردنا أخذ الدخل من المستخدم وتخزينه؟ تملك رست لمثل هذه الحالات نوع سلسلة نصية آخر يدعى String، ويدير هذا النوع البيانات باستخدام الكومة، وبالتالي يمكنه تخزين كمية غير معروفة من النص عند وقت التصريف. يُمكنك إنشاء String من سلسلة نصية مجردة باستخدام دالة from كما يلي:
let s = String::from("hello");
يسمح لنا عامل النقطتين المزدوجتين :: بتسمية الدالة الجزئية from ضمن فضاء الأسماء namespace وأن تندرج تحت النوع String بدلًا من استخدام اسم مشابه مثل string_from، وسنناقش هذه الطريقة في الكتابة أكثر لاحقًا، بالإضافة للتكلم عن فضاءات الأسماء وإنشائها.
يُمكن تعديل mutate هذا النوع من السلاسل النصية:
let mut s = String::from("hello"); s.push_str(", world!"); // يُضيف ()push_str سلسلةً نصية مجردة إلى النوع String println!("{}", s); // سيطبع هذا السطر `!hello, world`
إذًا، ما الفارق هنا؟ كيف يمكننا تعديل النوع String بينما لا يمكننا تعديل السلاسل النصية المجردة؟ الفارق هنا هو بكيفية تعامل كل من النوعين مع الذاكرة.
الذاكرة وحجزها
نعرف محتويات السلسلة النصية في حال كانت السلسلة النصية مجرّدة عند وقت التصريف، وذلك لأن النص مكتوب في الشيفرة البرمجية بصورةٍ صريحة في الملف النهائي التنفيذي، وهذا السبب في كون السلاسل النصية المجردة سريعة وفعالة، إلا أن هذه الخصائص تأتي من حقيقة أن السلاسل النصية المجردة غير قابلة للتعديل immutable، ولا يمكننا لسوء الحظ أن نضع جزءًا من الذاكرة في الملف التنفيذي الثنائي لكل قطعة من النص، وذلك إذا كان النص ذو حجم غير معلوم عند وقت التصريف كما أن حجمه قد يتغير خلال عمل البرنامج.
نحتاج إلى تحديد مساحة من الذاكرة ضمن الكومة عند استخدام نوع String وذلك لدعم إمكانية تعديله وجعله سلسلةً نصيةً قابلة للزيادة والنقصان، بحيث تكون هذه المساحة التي تخزن البيانات غير معلومة الحجم عند وقت التصريف، وهذا يعني:
- يجب أن تُطلب الذاكرة من مُحدد الذاكرة عند وقت التشغيل.
-
نحتاج طريقة لإعادة الذاكرة إلى محدد الذاكرة عندما ننتهي من استخدام
Stringالخاص بنا.
يُنجز المتطلّب الأول عن طريق استدعاء String::from، إذ تُطلب الذاكرة التي يحتاجها ضمنيًا، وهذا الأمر موجود في معظم لغات البرمجة.
أما المتطلب الثاني فهو مختلفٌ بعض الشيء، إذ يراقب كانس المهملات -أو اختصارًا GC- الذاكرة غير المُستخدمة بعد الآن ويحررها، ولا حاجة للمبرمج بالتفكير بهذا الأمر، بينما تكون مسؤوليتنا في اللغات التي لا تحتوي على كانس المهملات هي العثور على المساحة غير المُستخدمة بعد الآن وأن نستدعي الشيفرة البرمجية بصورةٍ صريحة لتحرير تلك المساحة، كما هو الحال عندما استدعينا شيفرة برمجية لحجزها، ولطالما كانت هذه المهمة صعبة على المبرمجين، فإذا نسينا تحرير الذاكرة فنحن نهدر الذاكرة وإذا حررنا الذاكرة مبكرًا فهذا يعني أن قيمة المتغير أصبحت غير صالحة للاستخدام، بينما نحصل على خطأ إذا حررنا الذاكرة نفسها لأكثر من مرة، إذ علينا استخدام تعليمة allocate واحدة فقط مصحوبةً مع تعليمة free واحدة لكل حيز ذاكرة نستخدمه.
تسلك لغة رست سلوكًا مختلفًا، إذ تُحرر الذاكرة أوتوماتيكيًا عندما يغادر المتغير الذي يملك تلك الذاكرة النطاق. إليك إصدارًا من الشيفرة 4-1 نستخدم فيه النوع String بدلًا من السلسلة النصية المجردة:
{ let s = String::from("hello"); // المتغير s صالح من هذه النقطة فصاعدًا // يمكننا إنجاز العمليات باستخدام المتغير s هنا } // انتهى النطاق ولم يعد المتغير s صالحًا
نستعيد الذاكرة التي يستخدمها String من محدد الذاكرة عندما يخرج المتحول s من النطاق، إذ تستدعي رست دالةً مميزةً بالنيابة عنا عند خروج متحول ما من النطاق وهذه الدالة هي drop، وتُستدعى تلقائيًا عند الوصول إلى قوس الإغلاق المعقوص {.
ملاحظة: يُدعى نمط تحرير الموارد في نهاية دورة حياة العنصر في لغة C++ أحيانًا "اكتساب الموارد هو تهيئتها Resource Acquisition Is Initialization" -أو اختصارًا RAII- ودالة drop في رست هي مشابهة لأنماط RAII التي قد استخدمتها سابقًا.
لهذا النمط تأثير كبير في طريقة كتابة شيفرة رست البرمجية، وقد يبدو بسيطًا للوقت الحالي إلا أن سلوك الشيفرة البرمجية قد يكون غير متوقعًا في الحالات الأكثر تعقيدًا عندما يوجد عدة متغيرات تستخدم البيانات المحجوزة على الكومة، دعنا ننظر إلى بعض من هذه الحالات الآن.
طرق التفاعل مع البيانات والمتغيرات: النقل
يُمكن لعدة متغيرات أن تتفاعل مع نفس البيانات بطرق مختلفة في رست، دعنا ننظر إلى الشيفرة 4-2 على أنها مثال يستخدم عددًا صحيحًا.
let x = 5; let y = x;
[الشيفرة 4-2: إسناد قيمة العدد الصحيح إلى المتغيرين x و y]
يمكنك غالبًا تخمين ما الذي تؤديه الشيفرة البرمجية السابقة: إسناد القيمة 5 إلى x ومن ثم نسخ القيمة x وإسنادها إلى القيمة y، وبالتالي لدينا متغيرين x و y وقيمة كل منهما تساوي إلى 5، وهذا ما يحدث فعلًا، لأن الأعداد الصحيحة هي قيم بسيطة بحجم معروف وثابت وبالتالي يُمكن إضافة القيمتين 5 إلى المكدس.
لننظر الآن إلى إصدار String من الشيفرة السابقة:
let s1 = String::from("hello"); let s2 = s1;
تبدو الشيفرة البرمجية هذه شبيهة بسابقتها، وقد نفترض هنا أنها تعمل بالطريقة ذاتها، ألا وهي: ينسخ السطر الثاني القيمة المخزنة في المتغير s1 ويُسندها إلى s2 إلا أن هذا الأمر غير صحيح.
انظر إلى الشكل 1 لرؤية ما الذي يحصل بدقة للنوع String، إذ يتكون هذا النوع من ثلاثة أجزاء موضحة ضمن الجدول اليساري وهي المؤشر ptr الذي يشير إلى الذاكرة التي تُخزن السلسلة النصية وطول السلسلة النصية len وسعتها capacity، وتُخزّن مجموعة المعلومات هذه في المكدس، بينما يمثّل الجدول اليميني الذاكرة في الكومة التي تخزن محتوى السلسلة النصية.

[شكل 1: مخطط توضيحي لما تبدو عليه الذاكرة عند استخدام String يخزن القيمة "hello" المُسندة إلى s1]
يدل الطول على كمية الذاكرة المُستهلكة بالبايت وهي الحيز الذي يشغله محتوى String، بينما تدل السعة على كمية الذاكرة المستهلكة بالكامل التي تلقّاها String من مُحدد الذاكرة، والفرق بين الطول والسعة مهم، إلا أننا سنهمل السعة لأنها غير مهمة في السياق الحالي.
تُنسخ بيانات String عندما نُسند s1 إلى s2، وهذا يعني أننا ننسخ المؤشر والطول والسعة الموجودين في المكدس ولا ننسخ البيانات الموجودة في الكومة التي يشير إليها المؤشر، بكلمات أخرى، يبدو تمثيل الذاكرة بعد النسخ كما هو موضح في الشكل 2.
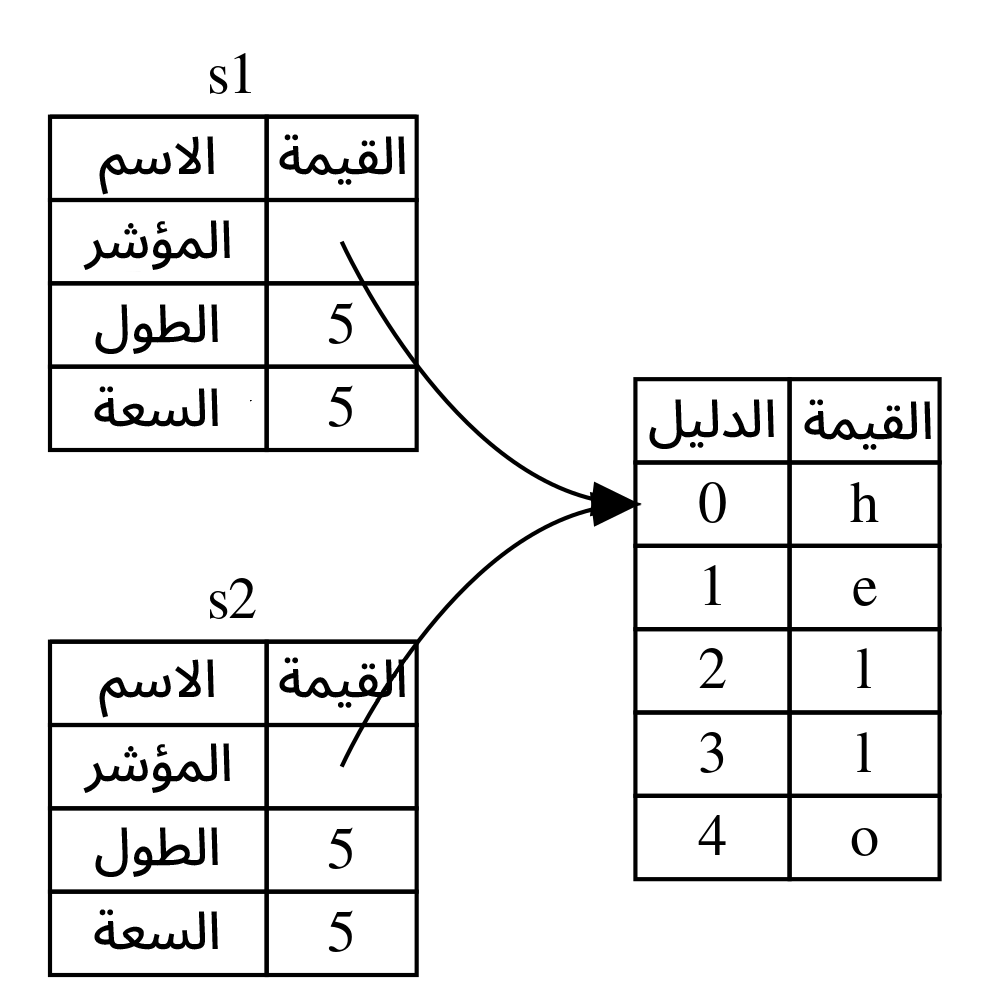
[شكل 2: تمثيل الذاكرة للمتغير s2 الذي يحتوي على نسخة من مؤشر وطول وسعة s1]
تمثيل الذاكرة غير مطابق للشكل 3 وقد ينطبق هذا التمثيل إذا نسخت رست محتويات بيانات الكومة أيضًا، وإذا فعلت رست ذلك، فستكون عملية الإسناد s2 = s1 عمليةً مكلفةً وستؤثر سلبًا على أداء وقت التشغيل إذا كانت البيانات الموجودة في الكومة كبيرة.
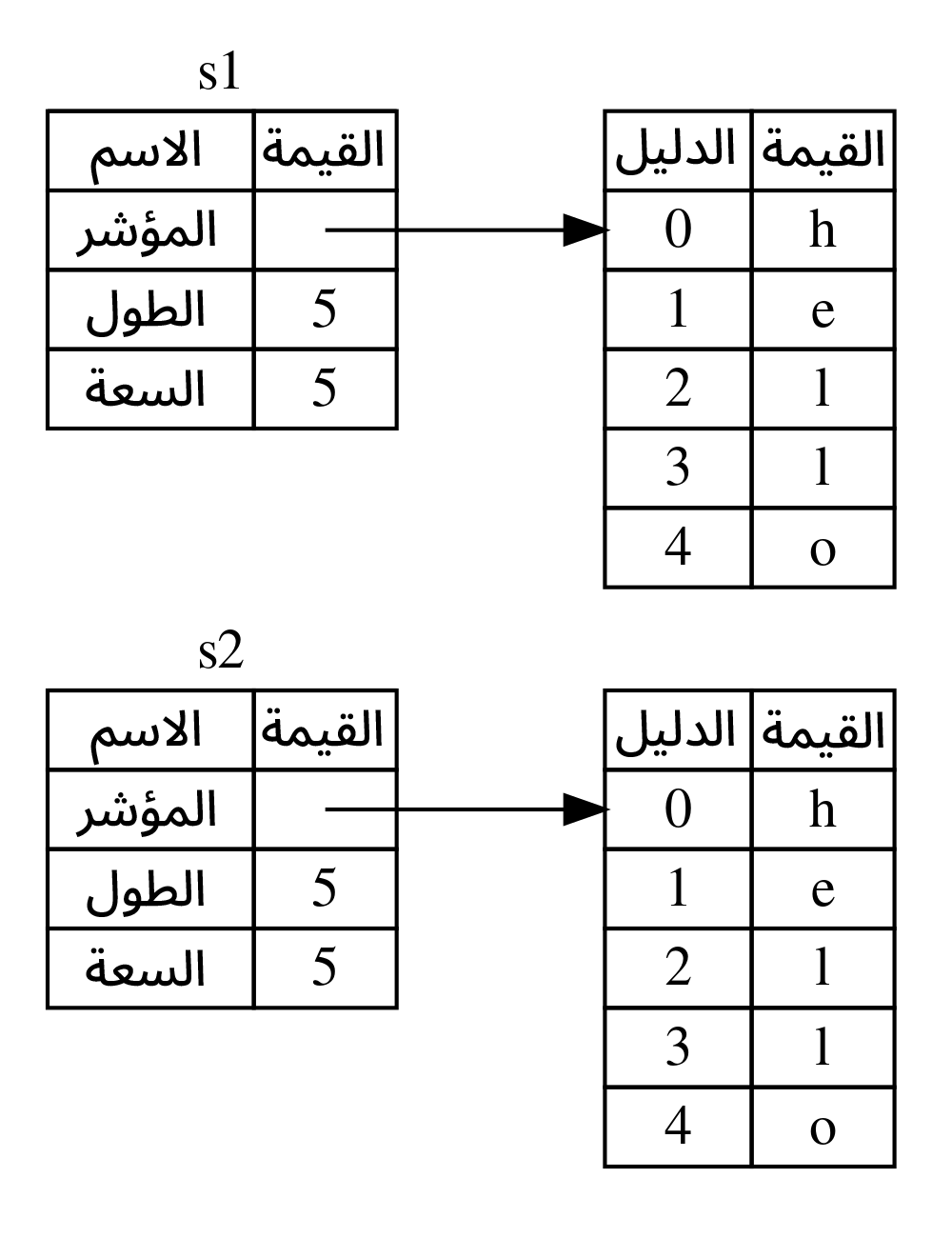
[شكل 3: احتمال آخر لما قد تبدو عليه الذاكرة بعد عملية الإسناد s2 = s1 وذلك إذا نسخت رست محتويات الكومة أيضًا]
قلنا سابقًا أن رست تستدعي الدالة drop تلقائيًا عندما يغادر متغيرٌ ما النطاق، وتحرّر الذاكرة الموجودة في الكومة لذلك المتغير، إلا أن الشكل 2 يوضح أن كلا المؤشرين يشيران إلى الموقع ذاته، ويمثّل هذا مشكلةً واضحة، إذ عندما يغادر كلًا من s1 وs2 النطاق، فهذا يعني أن الذاكرة في الكومة ستُحرّر مرتين، وهذا خطأ تحرير ذاكرة مزدوج double free error شائع، وهو خطأ من أخطاء أمان الذاكرة الذي ذكرناه سابقًا، إذ يؤدي تحرير الذاكرة نفسها مرتين إلى فساد في الذاكرة مما قد يسبب ثغرات أمنية.
تنظر رست إلى s1 بكونه غير صالح بعد السطر let s2 = s1 وذلك لضمان أمان الذاكرة، وبالتالي لا يتوجب على رست تحرير أي شيء عندما يغادر المتحول s1 النطاق. انظر ما الذي يحدث عندما نحاول استخدام s1 بعد إنشاء s2 (لن تعمل الشيفرة البرمجية):
let s1 = String::from("hello"); let s2 = s1; println!("{}, world!", s1);
سنحصل على خطأ شبيه بالخطأ التالي لأن رست يمنعك من استخدام المرجع غير الصالح بعد الآن:
$ cargo run Compiling ownership v0.1.0 (file:///projects/ownership) error[E0382]: borrow of moved value: `s1` --> src/main.rs:5:28 | 2 | let s1 = String::from("hello"); | -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait 3 | let s2 = s1; | -- value moved here 4 | 5 | println!("{}, world!", s1); | ^^ value borrowed here after move | = note: this error originates in the macro `$crate::format_args_nl` (in Nightly builds, run with -Z macro-backtrace for more info) For more information about this error, try `rustc --explain E0382`. error: could not compile `ownership` due to previous error
لعلك سمعت بمصطلح النسخ السطحي shallow copy والنسخ العميق deep copy خلال عملك على لغة برمجة أخرى؛ إذ يُشير مصطلح النسخ السطحي إلى عملية نسخ مؤشر وطول وسعة السلسلة النصية دون البيانات الموجودة في الكومة، إلا أن رست تسمّي هذه العملية بالنقل move لأنها تُزيل صلاحية المتغير الأول. في هذا المثال، نقول أن s1 نُقِلَ إلى s2، والنتيجة الحاصلة موضحة في الشكل 4.
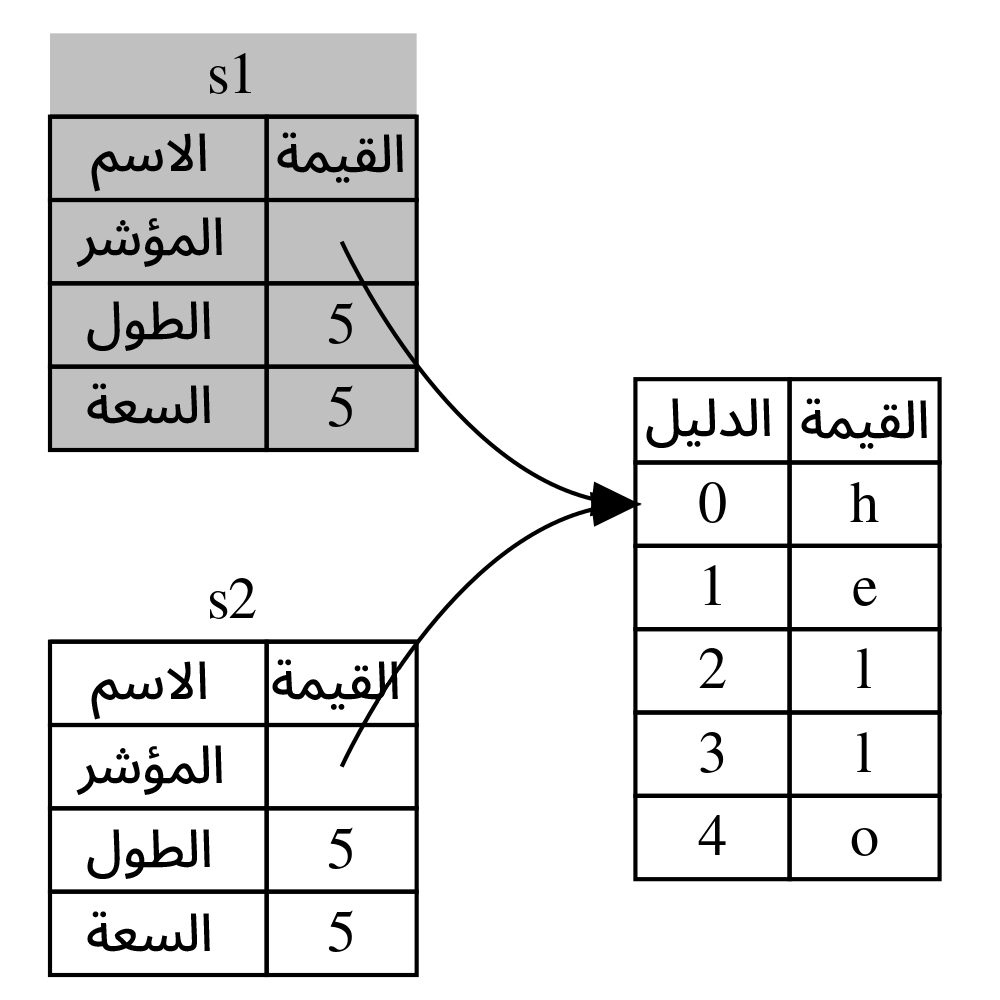
[شكل 4: تمثيل الذاكرة بعد إزالة صلاحية المتغير s1]
يحلّ هذا الأمر مشكلتنا، وذلك بجعل المتغير s2 صالحًا فقط، وعند مغادرته للنطاق فإن المساحة تُحرر بناءً عليه فقط.
إضافةً لما سبق، هناك خيارٌ تصميمي ملمّح إليه بواسطة هذا الحل، ألا وهو أن رست لن تُنشئ نُسَخًا عميقة من بياناتك تلقائيًا، وبالتالي لن يكون أي نسخ تلقائي مكلفًا بالنسبة لأداء وقت التشغيل.
طرق التفاعل مع البيانات والمتغيرات: الاستنساخ
يُمكننا استخدام تابع شائع يدعى clone إذا أردنا نسخ البيانات الموجودة في الكومة التي تعود للنوع String نسخًا عميقًا إضافةً لبيانات المكدس، وسنناقش طريقة كتابة التوابع لاحقًا، إلا أنك غالبًا ما رأيت استخدامًا للتوابع مسبقًا بالنظر إلى أنها شائعة في العديد من لغات البرمجة.
إليك مثالًا عمليًا عن تابع clone:
let s1 = String::from("hello"); let s2 = s1.clone(); println!("s1 = {}, s2 = {}", s1, s2);
تعمل الشيفرة البرمجية بنجاح، وتولد النتيجة الموضحة في الشكل 3، إذ تُنسخ محتويات الكومة.
عند رؤيتك لاستدعاء التابع clone، عليك أن تتوقع تنفيذ شيفرة برمجية إضافية وأن الشيفرة البرمجية ستكون مكلفة التنفيذ، وأن استخدام التابع هو دلالة بصرية أيضًا على حدوث شيء مختلف.
نسخ بيانات المكدس فقط
هناك تفصيلٌ آخر لم نتكلم بخصوصه بعد. تستخدم الشيفرة البرمجية التالية (جزء من الشيفرة 4-2) أعدادًا صحيحة، وهي شيفرة برمجية صالحة:
let x = 5; let y = x; println!("x = {}, y = {}", x, y);
إلا أن الشيفرة البرمجية تبدو مناقضة لما تعلمنا مسبقًا، إذ أن x صالح ولم يُنقل إلى المتغير y على الرغم من عدم استدعائنا للتابع clone.
السبب في هذا هو أن الأنواع المشابهة للأعداد الصحيحة المؤلفة من حجم معروف عند وقت التصريف تُخزن كاملًا في المكدس، ولذلك يمكننا نسخها فعليًا بصورةٍ أسرع، ولا فائدة في منع x من أن يكون صالحًا في هذه الحالة بعد إنشاء المتغير y، وبكلمات أخرى ليس هناك أي فرق بين النسخ السطحي والعميق هنا، لذا لن يُغيّر استدعاء التابع clone أي شيء مقارنةً بالنسخ السطحي الاعتيادي، ولذلك يمكننا الاستغناء عنه.
لدى لغة رست طريقةً مميزةً تدعى سمة trait النسخ Copy، التي تمكّننا من وضعها على الأنواع المخزنة في المكدس كما هو الحال في الأعداد الصحيحة (سنتكلم بالتفصيل عن السمات لاحقًا). إذا استخدم نوعٌ ما السمة Copy، فهذا يعني أن جميع المتغيرات التي تستخدم هذا النوع لن تُنقل وستُنسخ بدلًا من ذلك مما يجعل منها صالحة حتى بعد إسنادها إلى متغير آخر.
لن تسمح لنا رست بتطبيق السمة Copy إذا كان النوع -أو أي من أجزاء النوع- يحتوي على السمة Drop، إذ أننا سنحصل على خطأ وقت التصريف إذا كان النوع بحاجة لشيء مميز للحدوث عند خروج القيمة من النطاق وأضفنا السمة Copy إلى ذلك النوع، إن أردت تعلم المزيد عن إضافة السمة Copy إلى النوع لتطبيقها، ألقِ نظرةً على الملحق (ت) قسم السمات المُشتقة derivable traits.
إذًا، ما هي الأنواع التي تقبل تطبيق السمة Copy؟ يمكنك النظر إلى توثيق النوع للتأكد من ذلك، لكن تنص القاعدة العامة على أن أي مجموعةٍ من القيم البسيطة المُفردة تقبل السمة Copy، إضافةً إلى أي شيء لا يتطلب تحديد الذاكرة، أو ليس أي نوع من أنواع الموارد. إليك بعض الأنواع التي تقبل تطبيق Copy:
-
كل أنواع الأعداد الصحيحة مثل
u32. -
الأنواع البوليانية
boolالتي تحمل القيمتينtrueوfalse. -
جميع أنواع أعداد الفاصلة العشرية مثل
f64. -
نوع المحرف
char. -
الصفوف tuples إذا احتوى الصف فقط على الأنواع التي يمكن تطبيق
Copyعليها، على سبيل المثال يُمكن تطبيقCopyعلى(i32, i32)، بينما لا يمكن تطبيقCopyعلى(i32, String).
الملكية والدوال
تشبه طريقة تمرير قيمة إلى دالة إسناد assign قيمة إلى متغير، إذ أن تمرير القيمة إلى المتغير سينقلها أو ينسخها كما هو الحال عند إسناد القيمة، توضح الشيفرة 4-3 مثالًا عن بعض الطرق التي توضح أين يخرج المتغير من النطاق.
اسم الملف: src/main.rs
fn main() { let s = String::from("hello"); // يدخل المتغير s إلى النطاق takes_ownership(s); // تُنقل قيمة s إلى الدالة ولا تعود صالحة للاستخدام هنا let x = 5; // يدخل المتغير x إلى النطاق makes_copy(x); // يُنقل المتغير x إلى الدالة إلا أن i32 تملك السمة Copy لذا من الممكن استخدام المتغير x بعد هذه النقطة } // يغادر المتحول x خارج النطاق ولا شيء مميز يحدث لأن قيمة s نُقِلَت fn takes_ownership(some_string: String) { // يدخل المتغير some_string إلى النطاق println!("{}", some_string); } // يُغادر المتغير some_string النطاق هنا وتُستدعى drop، وتُحرر الذاكرة الخاصة بالمتغير fn makes_copy(some_integer: i32) { // يدخل المتغير some_integer إلى النطاق println!("{}", some_integer); } // يغادر المتغير some_integer النطاق ولا يحصل أي شيء مثير للاهتمام
[الشيفرة 4-3: استخدام الدوال مع الملكية والنطاق]
ستعرض لنا رست خطأً عند وقت التصريف إذا حاولنا استخدام a بعد استدعاء takes_ownership، ويحمينا هذا التفقد الساكن static من بعض الأخطاء. حاول إضافة شيفرة برمجية تستخدم s و x إلى الدالة main ولاحظ أين يمكنك استخدامهما وأين تمنعك قوانين الملكية من استخدامهما.
القيم المعادة والنطاق
يُمكن أن تحول عملية إعادة القيمة ملكيتها أيضًا، توضح الشيفرة 4-4 مثالًا عن دالة تُعيد قيمة بصورةٍ مشابهة للشيفرة 4-3.
اسم الملف: src/main.rs
fn main() { let s1 = gives_ownership(); // تنقل الدالة gives_ownership قيمتها المُعادة إلى s1 let s2 = String::from("hello"); // يدخل المتغير s2 إلى النطاق let s3 = takes_and_gives_back(s2); // يُنقل المتغير s2 إلى takes_and_gives_back الذي ينقل قيمته المعادة بدوره إلى المتغير s3 } // يُغادر s3 النطاق من هنا ويُحرر من الذاكرة باستخدام drop، ولا يحصل أي شيء للمتغير s2 لأنه نُقل، بينما يغادر s1 النطاق أيضًا ويُحرر من الذاكرة باستخدام drop fn gives_ownership() -> String { // تنقل الدالة gives_ownership قيمتها المعادة إلى الدالة التي استدعتها let some_string = String::from("yours"); // يدخل المتغير some_string إلى النطاق some_string // يُعاد some_string ويُنقل إلى الدالة المُستدعاة } // تأخذ هذه الدالة سلسلة نصية وتُعيد سلسلة نصية أخرى fn takes_and_gives_back(a_string: String) -> String { // يدخل a_string إلى النطاق a_string // يُعاد a_string ويُنقل إلى الدالة المُستدعاة }
[الشيفرة 4-4: تحويل ملكية القيمة المُعادة]
تتبع ملكية المتغير نفس النمط في كل مرة، وهو: "إسناد قيمة إلى متغير آخر ينقلها"، وعندما يخرج متغير يتضمن على بيانات ضمن الكومة من النطاق، تُحرر قيمته باستخدام drop إلا إذا نُقلت ملكية البيانات إلى متغير آخر.
على الرغم من نجاح هذه العملية، إلا أن عملية أخذ الملكية ومن ثم إعادتها عند كل دالة عملية رتيبة بعض الشيء. ماذا لو أردنا أن نسمح لدالة ما باستخدام القيمة دون الحصول على ملكيتها؟ إنه أمر مزعج جدًا أن أي شيء نمرره سيحتاج أيضًا لإعادة تمريره مجددًا إذا أردنا استخدامه من جديد، بالإضافة إلى أي بيانات نحصل عليها ضمن متن الدالة التي قد نحتاج أن نُعيدها أيضًا.
تسمح لنا رست بإعادة عدّة قيم باستخدام مجموعة كما هو موضح في الشيفرة 4-5.
اسم الملف: src/main.rs
fn main() { let s1 = String::from("hello"); let (s2, len) = calculate_length(s1); println!("The length of '{}' is {}.", s2, len); } fn calculate_length(s: String) -> (String, usize) { let length = s.len(); // يُعيد ()len طول السلسلة النصية (s, length) }
[الشيفرة 4-5: إعادة الملكية إلى المعاملات]
هذه العملية طويلة قليلًا وتتطلب كثيرًا من الجهد لشيء يُشاع استخدامه، ولحسن حظنا لدى رست ميزة لاستخدام القيمة دون تحويل ملكيتها وتدعى المراجع references، وسنستعرضها في المقال التالي.
ترجمة -وبتصرف- لقسم من فصل Understanding Ownership من كتاب The Rust Programming Language.










أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.