

إن أكثر المشاكل تحديا في التحليل الإحصائي هي تلك التي نتعامل معها في الحياة العملية بعيدا عن مقاعد الدراسة وتهذيب مسائلها النموذجية، ففي إطار العمل على أرض الواقع غالبا ما نجمع كمية كبيرة إن لم تكن هائلة من البيانات المتعلقة بالقضية المدروسة من كل حدب وصوب ومصدر دون أن نكون على يقين أو معرفة مسبقة أكيدة أيُّها يملك دورا في تفسير ما نراه من نتائج، فكيف بنا إن كنّا نرغب في تقدير مدى تأثير كل منها في توصيف السلوك العام للمنظومة وما يستتبع ذلك من ضرورة استكشاف طبيعة العلاقات والروابط الداخلية ما بين عناصر البيانات المختلفة التي لدينا.
على سبيل المثال إن كان هناك 20 متغير مختلف تم جمعه أو قياسه، فسيكون لدينا بالنتيجة 190 علاقة ارتباط ثنائية محتملة يجب دراستها وأخذها بعين الاعتبار، حيث أن كل واحد من تلك المتغيرات العشرين يجب أن يحسب ارتباطه مع بقية المتغيرات التسع عشر الأخرى واحدا فواحد، ونظرا لأن علاقة الارتباط تعتبر علاقة تبديلية فلا فرق حينها ما بين حساب معامل الارتباط للمتغيرين س و ع أو حسابه بين المتغيرين ع و س، لذا سيكون العدد الكامل هو نصف ناتج جداء العددين 20 و 19 ويساوي 190 كما سبق وأن ذكرنا. من الواضح أن مثل هذا الأسلوب غير عملي أو فعّال كما توحي تطبيقاته النموذجية حينما يكون لدينا بضعة متغيرات فقط، ففي حالتنا هذه سننتهي إلى غابة من الأرقام وشبكة معقدة من العلاقات المحتملة والتي يصعب الإلمام بحجمها ومداها من خلال مجرد النظر والتمحيص في مصفوفة معاملات الارتباط التي سنحصل عليها.
لمثل هكذا حالات وجد تحليل المكونات الرئيسية (Principle Components Analysis (PCA والذي يعد أحد التقنيات المستخدمة لتلخيص البيانات واختصارها، حيث يقوم بتحويل العدد الكبير من المتغيرات المترابطة ضمنا ولو بشكل جزئي إلى مجموعة أصغر بكثير من المتحولات المستقلة التخيلية، وهي تدعى عادة بالمكونات الرئيسية وتحسب أساسا من المتغيرات الأصلية بنسب ومقادير تزيد أو تنقص بحسب دور وتأثير كل منها، لتصف في نهاية المطاف أكبر قدر ممكن من المعلومات الموجودة في المجموعة الأصلية من البيانات التي لدينا.

كما سبق وأن أشرنا في مقالات سابقة، تعد لغة R من اللغات التي صعد نجمها حديثا وبشكل سريع بمجال البرمجة العلمية في قطاعي الإحصاء والمعلوماتية الحيوية (bioinformatics)، حيث باتت معتمدة على نطاق واسع في كثير من الجامعات ومراكز البحث العلمية، وأصبحنا نرى استخدامها والإشارة إليها في المقالات المنشورة بالمجلات العلمية المحكّمة يزداد بشكل طردي ومتسارع، هذا عدى عن حقيقة كونها لغة حرة مفتوحة المصدر يخضع توزيعها لترخيص GPL الشهير. كل ذلك أدى إلى تزايد ما هو متوافر ومتاح على الشابكة (الإنترنت) من مصادر لها على توزع طيف تلك المصادر، فهناك الكتب الإلكترونية والدروس التعليمية وحتى المناهج الأكاديمية والدورات التدريبية إضافة إلى البرامج الجاهزة والمكتوبة بلغة R لتنفيذ هذه المهمة أو تلك، حتى أنها باتت تحظى ببعض الامتياز مقارنة بالعديد من العمالقة في قطاعي البرمجة الرياضياتية العلمية والإحصائية مثل SAS و SPSS وغيرهما، خصوصا من حيث توافر الأمثلة والتطبيقات للطرق والخوارزميات الحديثة، حيث يقاد هذا التوجه في معظمه عن طريق الجامعات ممثلة بطلاب الدراسات العليا يحفّزهم على ذلك سهولة بناء الإضافات في لغة R، ويعتبر هذا الأسلوب رغم ما قد يشوبه من نقاط ضعف تتعلق بموثوقية وجودة وغزارة تلك الإضافات الجديدة، والتي تتبع خبرة ومهارة مطوريها وناشريها، لكنها تبقى في القطاع العلمي والأكاديمي أفضل كثيرا من البدائل التجارية التي يعيبها إرتفاع ثمنها من جهة، ومن جهة أخرى بطئ إضافة التحديثات التي تعكس تطور القطاعات العلمية المختلفة، حيث أنها عادة ما تتبع دورة تجارية تتحكم بها الشركات المنتجة.
تستطيع أن تقوم بتحميل لغة R من الموقع الرسمي لها على الرابط http://www.r-project.org، وعملية تنصيب هذه اللغة تخلو من التعقيدات، وبانتهاءها يمكنك تشغيل سطر الأوامر الخاص بها من خلال النقر على أيقونة اللغة على سطح المكتب، إن كل ما نكتبه تاليا سيكون داخل سطر الأوامر هذا. تأتي لغة R محزومة مع إطار بيانات افتراضي يدعى mtcars يتضمن بيانات مأخوذة من مجلة Motor Trend لعام 1974 تقارن فيها أحد عشر من مواصفات التصميم والأداء لأكثر من ثلاثين سيارة منتجة في العام 1973، وهي البيانات التي سنستخدمها في كل أمثلتنا ضمن هذه المقالة، للحصول على معلومات إضافية عن طبيعة محتوى هذه البيانات يمكنك كتابة الأمر التالي في سطر الأوامر:
?mtcars
من جهة أخرى يمكنك اختصار طريقة الوصول إلى المعلومات ضمن إطار البيانات هذا عن طريق تنفيذ الأمر:
attach(mtcars)
والذي يجعلنا قادرين على استخدام تسميات مثل mpg بدلا من استخدام الطريقة المفصلة mtcars$mpg للدلالة على عدد الأميال المقطوعة بغالون البنزين الواحد على سبيل المثال.
لنفترض بداية أن لدينا مجموعة من العناصر هي بحسب مثالنا طرازات مختلفة من السيارات حيث توصّف كل واحدة منها بالاعتماد على عدد من الصفات تشمل الوزن والحجم والتسارع وقدرة المحرك الحصانية وعدد الأميال المقطوعة بغالون البنزين الواحد وسواها من صفات (بالإجمال يحتوي إطار البيانات mtcars على 11 صفة مختلفة تخص 32 طراز من السيارات).
?mtcars attach(mtcars) head(mtcars) mpg cyl disp hp drat wt qsec vs am gear carb Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4 Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1 Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1 Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2 Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
لو أننا أردنا دراسة تشابه هذه الطرز من السيارات بحسب واحدة من الصفات المقاسة ولتكن الوزن على سبيل المثال، لأمكننا إنجاز ذلك من خلال تمثيل بياني بسيط على مستقيم الأعداد حيث تتقارب فيه النقاط الممثلة للطرز المتشابهة فيما تتباعد النقاط الممثلة للطرز المختلفة وذلك دوما بحسب الصفة المدروسة (وهي في حالتنا هذه وزن السيارة كما سبق وأن أشرنا). حيث نرى أن طراز مثل تويوتا كورولا والهوندا سيفيك واللوتس متشابهة عند تحديد ذلك بحسب صفة الوزن فقط وفق مثالنا كونها جميعا الأقل وزنا ضمن المجموعة المدروسة، فيما طرز مثل كرايزلر وكاديلاك تتشابه مع بعضها البعض لكنها تقع في الطرف الآخر بحسب صفة الوزن ذاتها حيث أنها من بين الطرز الأكثر وزنا في ما هو موجود لدينا من بيانات.
plot(wt*0, wt, xlab="", xaxt="n") text(wt*0, wt, row.names(mtcars), cex=0.5, pos=4, col="red") abline(v=0)
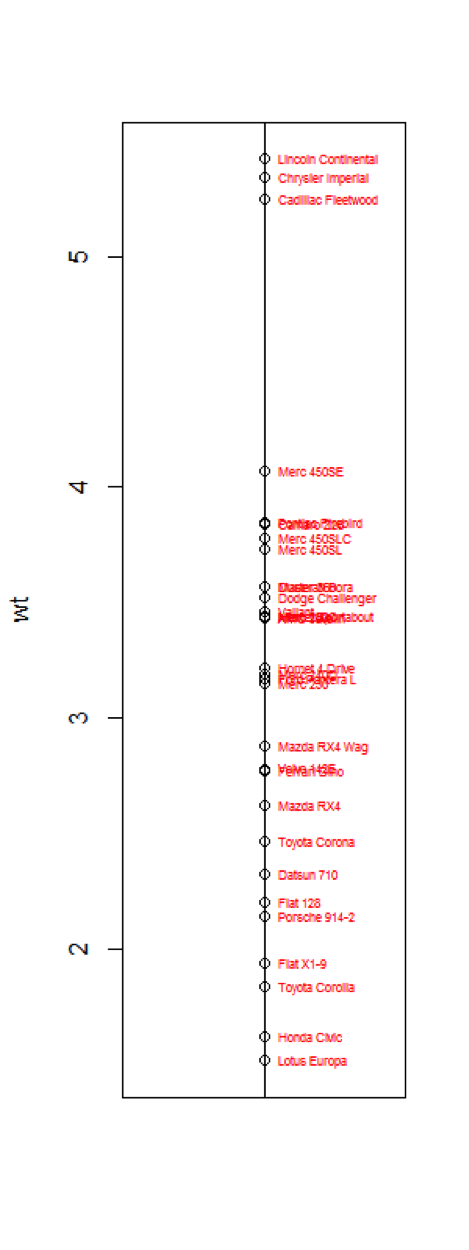
يبقى هذا المنطق سائدا في تحديد ما هو مختلف أو متشابه بأسلوب بياني بسيط حتى وإن كنا نتحدث عن صفتين اثنتين معا في ذات الوقت، كأن نضيف قدرة المحرك الحصانية على سبيل المثال إلى الصورة، إذ عوضا عن إسقاط النقطة الممثلة لكل طراز من السيارات المدروسة على مستقيم الأعداد، نقوم بتمثيلها ضمن مستوي ثنائي الأبعاد سيناته تشير إلى قدرة المحرك الحصانية فيما عيناته تمثل وزن السيارة على سبيل المثال، وهنا يبقى مفهوم التجاور للمتشابهات والتباعد للمختلفات قائما وصحيحا كما هو موضح في الشكل التالي والذي نحصل عليه نتيجة تنفيذ التعليمتين الموضحتين أدناه. عند إلقاء نظرة أكثر تفصيلا بإضافة صفة القدرة الحصانية للمحرك نستطيع حينها التفريق بين طراز اللوتس ذي القدرة الحصانية التي تبلغ تقريبا ضعف ما يملكه طرازي تويوتا كورولا والهوندا سيفيك على الرغم من أنهم جميعا يمتلكون أوزانا متقاربة، تلك الطرز التي كنا نعتبرها متشابهة عند مقارنتها بحسب صفة الوزن فقط كما أسلفنا الذكر سابقا.
plot(hp, wt) text(hp, wt, rownames(mtcars), cex=0.5, pos=4, col="red")
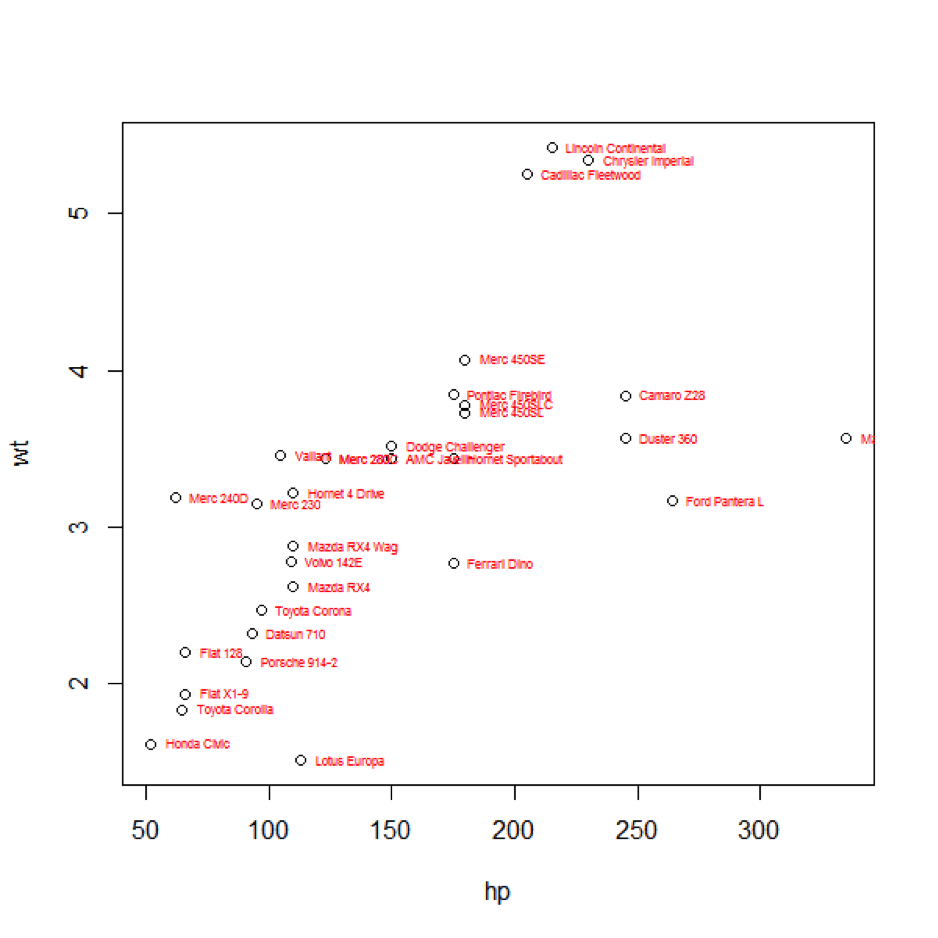
بزيادة عدد الصفات المراد أخذها بعين الاعتبار تبدأ الصورة بالتعقيد، فمع ثلاث صفات نحن بحاجة إلى الرسم في فضاء ثلاثي الأبعاد، أو على أقل تقدير سنحتاج إلى تطبيق بعض الحيل الرياضياتية لعرض هذه البيانات في رسم مسطح كأن نعتمد المخطط البياني الثلاثي Ternary Plot، فيما الحديث عن أربع صفات فما فوق يضع التمثيل البياني خارج إطار ما هو متاح من أساليب لتوصيف البيانات بغرض دراسة التشابه أو الاختلاف فيما بين عناصرها (يمكن في مثل هذه الحالات تطبيق تقنيات أخرى مثل العنقدة الهرمية للوصول إلى تلك الغاية).
تقوم الفكرة الأساسية في تحليل المكونات الرئيسية PCA على تلخيص أكبر قدر ممكن من التباينات في مجموع الصفات المقاسة والتي تسهم في التمايز ما بين العناصر المدروسة، وذلك من خلال ابتداع عدد من الصفات التخيلية التي تحسب من مجموع الصفات الحقيقية لكن بأوزان متفاوتة تعكس دور كل منها وأهميته في التفريق ما بين تلك العناصر. تعمل خطوات تنفيذ الخوارزمية على حصر أكبر قدر ممكن من التباينات ضمن توليفة الصفة التخيلية الأولى والتي عادة ما يطلق عليها تسمية المكون الرئيسي الأول PC1، كما يتم حساب نسبة مؤوية لهذه الصفة التخيلية التي ابتدعناها تشير إلى الحصّة الكليّة من التباينات التي تم إلتقاطها والتعبير عنها في هذه الصفة التخيلية بالذات، تتابع خوارزمية تحليل المكونات الرئيسية PCA إنجاز عملها بأسلوب يشبه القضم، فبعد أن قامت من خلال ابتداع المكون الرئيسي الأول PC1 التعبير عن أكبر قدر ممكن من التباينات الموجودة ما بين العناصر المدروسة، ولنقل على سبيل المثال أننا استطعنا التعبير عن 60% من خلاله، حينها يأتي الدور على ابتداع المكون الرئيسي الثاني PC2 والذي سيقوم بدوره بمحاولة التعبير عن أكبر قدر ممكن من التباينات المتبقية والتي لم يستطع PC1 التعبير عنها، لذا فإن النسبة التي تمثل ما سيستطيع PC2 التعبير عنه من تباينات هي دوما أقل مما تم التعبير عنه في PC1، وهكذا دواليك بالنسبة لكل من PC3 و PC4 وصولا إلى PCn حيث n هي العدد الكلي للصفات المدروسة، وحينها تصل النسبة الإجمالية (التراكمية) إلى 100%، مع ملاحظة أنه من الممكن أن نصل إلى تلك النسبة قبل ذلك في حال كانت هناك مجموعة جزئية من الصفات المدروسة مستقرأة أو مستخلصة من صفات أخرى داخلة في ذات التحليل (كأن يكون لدينا وزن السيارة بالطن في صفة وبالكيلوغرام في صفة أخرى)، أو حتى لو كانت لدينا مجموعة جزئية من الصفات المدروسة عالية الارتباط فيما بينها لسبب أو لآخر. بمعنى آخر فإن ما نقوم به في هذا الحالة ما هو إلا شكل من أشكال تلخيص كمية المعلومات المقدمة على شكل عدد كبير من الصفات بصورة عدد مقتضب من المكونات الرئيسية (عادة ما نهتم بأول اثنين أو ثلاثة منها)، والتي ما هي إلا عبارة عن صفات تخيلية محسوبة كما سبق وأن أوضحنا بدلالة الصفات الحقيقية لكن بأوزان متفاوتة وضعت وحددّت لكي تعبّر عن أكبر قدر ممكن من التباينات التي تظهر ما بين عناصر المجموعة المدروسة.
بهذا المنطق نرى أن الصفات التي لا تساهم في التفريق ما بين العناصر المختلفة في مجموعة البيانات التي ندرسها (وهي في حالتنا هذه طرز السيارات المختلفة) يكون لها أوزان صغيرة تقترب من الصفر، على نقيض الصفات التي تلعب دورا حاسما في التفريق ما بين العناصر المدروسة حيث يكون لتلك الصفات أوزان ذات مقادير كبيرة تقترب في قيمتها المطلقة من الواحد الصحيح، حيث لا أهمية هنا للإشارة سواء كانت موجبة أم سالبة طالما أن ما نبحث عنه هو وجود التأثير بحد ذاته.
لابد أن تكون قد لاحظت أن قيم الأوزان المستخدمة في تثقيل أي من الصفات الداخلة في حساب المكونات الرئيسية (أي الصفات التخيلية الجديدة المبتدعة والتي تظهر في قسم Rotation ضمن مخرجات التابع prcomp) تتراوح ما بين -1 و +1، لذا فإما أن تكون جميع الصفات المستخدمة في وصف العناصر من ذات الرتبة (كأن تكون العناصر المدروسة هي مجموعة من الطلاب والصفات المستخدمة في دراسة التشابه أو الاختلاف بينهم هي علاماتهم الامتحانية في مجموعة من المواد)، فإن لم يكن الحال كذلك وجب علينا إجراء تقييس للمقادير الخاصة بالصفات الداخلة في التحليل قبل استخدامها في تحليل المكونات الرئيسية نفسه، وإلا ظهرت لدينا الصفة الأكبر قيمة من حيث المقادير المقاسة على أنها الصفة المسيطرة والمؤثرة على التمايز ما بين العناصر وذلك خلافا للصواب (فعلى سبيل المثال إن اختلافا بمقدار 0.5 طن في الوزن ما بين سيارتين يعد هاما في التفريق بينهما بقدر يفوق ما قد يعنيه الاختلاف في قدرة المحرك بمقدار 5 أحصنة على الرغم من أن الرقم 5 هو أكبر بعشرة أضعاف كقيمة مقارنة بالرقم 0.5).
للتقييس طرق وأساليب متعددة منها على سبيل المثال التحويل إلى نسبة مؤية، أو التقييس إلى مجال يتدرج حتى الواحد الصحيح والذي يقابل القيمة العظمى للنطاق الحقيقي للقراءات المعنية، وهو ما يتم من خلال قسمة كافة القيم على مقدار القيمة العظمى تلك، أو يمكننا طرح قيمة المتوسط الحسابي من كافة القراءات وقسمتها على الإنحراف المعياري، فيصبح بالنتيجة المتوسط الحسابي للقراءات الجديدة المحولة هو 0 وانحرافها المعياري هو 1. إن إسناد القيمة TRUE للوسيط scale في التابع prcomp والذي ينفذ تحليل المكونات الرئيسية يطلب إلى الخوارزمية أن تقوم بعملية التقييس على البيانات قبل إجراء التحليل ذاته.
pc <- prcomp(mtcars, scale=TRUE) pc Standard deviations: [1] 2.5706809 1.6280258 0.7919579 0.5192277 0.4727061 0.4599958 [7] 0.3677798 0.3505730 0.2775728 0.2281128 0.1484736 Rotation: PC1 PC2 PC3 PC4 PC5 mpg -0.3625305 0.01612440 -0.22574419 -0.022540255 0.10284468 cyl 0.3739160 0.04374371 -0.17531118 -0.002591838 0.05848381 disp 0.3681852 -0.04932413 -0.06148414 0.256607885 0.39399530 hp 0.3300569 0.24878402 0.14001476 -0.067676157 0.54004744 drat -0.2941514 0.27469408 0.16118879 0.854828743 0.07732727 wt 0.3461033 -0.14303825 0.34181851 0.245899314 -0.07502912 qsec -0.2004563 -0.46337482 0.40316904 0.068076532 -0.16466591 vs -0.3065113 -0.23164699 0.42881517 -0.214848616 0.59953955 am -0.2349429 0.42941765 -0.20576657 -0.030462908 0.08978128 gear -0.2069162 0.46234863 0.28977993 -0.264690521 0.04832960 carb 0.2140177 0.41357106 0.52854459 -0.126789179 -0.36131875
من جهة أخرى نحصل نتيجة تمرير خرج التابع prcomp سابق الذكر إلى تابع عرض وتلخيص النتائج في لغة R أي التابع summary على النسبة المؤية للتباينات التي تم التعبير عنها في كل من المكونات الرئيسية المحسوبة بشكل مستقل أو تراكمي مضافا إلى ما سبقها من مكونات رئيسية، وهو ما يمكن عرضه أيضا بشكل رسومي من خلال تمرير ذات الخرج السابق على تابع الرسم الافتراضي في لغة R وهو التابع plot والذي يظهر تلك النسب المؤية لكل واحد من المكونات الرئيسية ممثلة بالأعمدة ضمن مخطط بياني كما هو موضح أدناه.
summary(pc) Importance of components: PC1 PC2 PC3 PC4 PC5 PC6 Standard deviation 2.5707 1.6280 0.79196 0.51923 0.47271 0.46000 Proportion of Variance 0.6008 0.2409 0.05702 0.02451 0.02031 0.01924 Cumulative Proportion 0.6008 0.8417 0.89873 0.92324 0.94356 0.96279 PC7 PC8 PC9 PC10 PC11 Standard deviation 0.3678 0.35057 0.2776 0.22811 0.1485 Proportion of Variance 0.0123 0.01117 0.0070 0.00473 0.0020 Cumulative Proportion 0.9751 0.98626 0.9933 0.99800 1.0000 plot(pc)
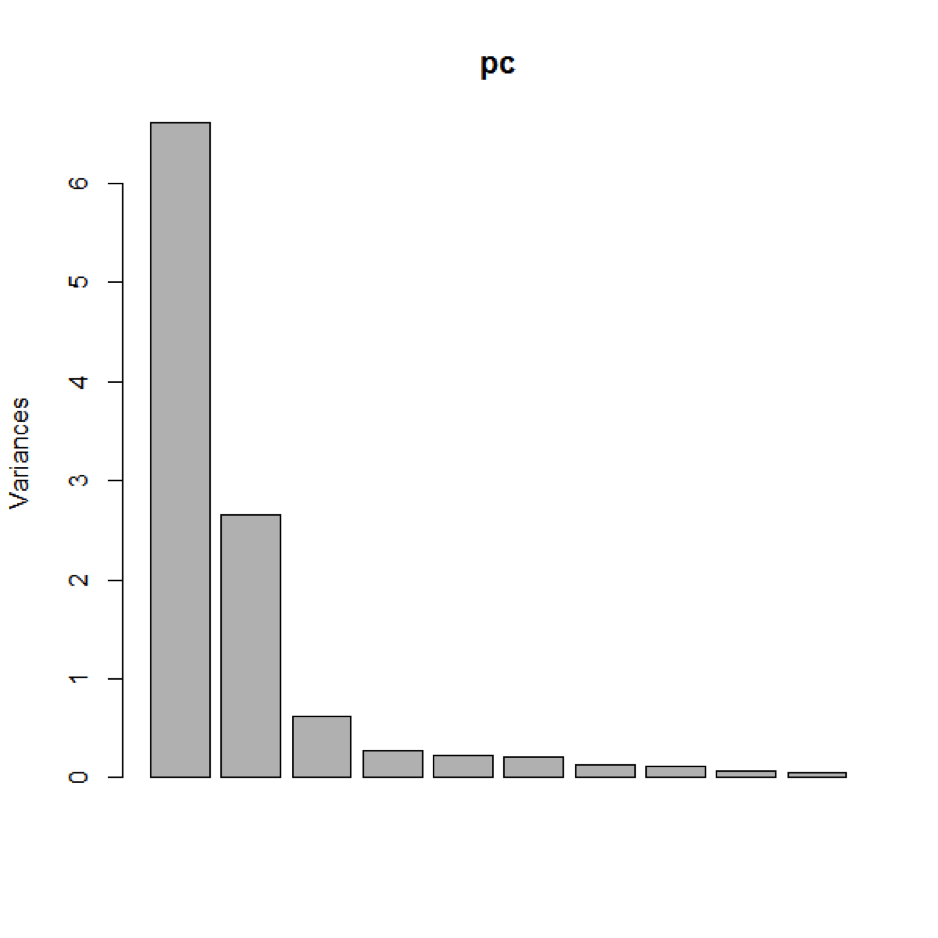
بالعودة إلى التطبيق العملي لهذه التقنية، عادة ما نهتم بأول مكونين رئيسيين فحسب أي PC1 و PC2 والذين يعبران عن أكبر قدر ممكن من التباينات بين العناصر بحسب مجمل الصفات المدروسة والتي يمكن التعبير عنها بمتحولين إثنين فقط، وفي مثالنا يبلغ مجموع هاتين النسبتين 84%، فنحن الآن قادرون على أن نعود إلى استخدام الرسم البياني البسيط على مستوي ثنائي الأبعاد من خلال التعبير عن PC1 على محور السينات و PC2 على محور العينات في مخطط بياني نعلم أنه يعبر عن 84% من التباينات الكلية بحسب كافة الصفات المدروسة (عادة ما تكون أي نسبة تفوق 60% مرضية للكثير من الباحثين)، وهكذا فإن أي نقطتين متجاورتين تمثلان طرازين متشابهين من السيارات. وبالتالي بعد تنفيذ تحليل المكونات الرئيسية PCA باستخدام التابع prcomp يمكننا حفظ النتائج التي نحصل عليها ضمن متحول ما ثم نعيد تمريرها للتابع biplot والذي سيقوم بوظيفة إخراجها بشكل رسومي في مخطط بياني ثنائي الأبعاد سيناته تمثل المكوّن الرئيسي الأول PC1 وعيناته تمثل المكوّن الرئيسي الثاني PC2، حيث يتم إسقاط كل عنصر من البيانات المدروسة وتمثيله على شكل نقطة وحيدة في هذا الفضاء التخيلي ثنائي الأبعاد بعد حساب قيمة كل من مسقطيه PC1 و PC2 من خلال تعويض قيم صفاته الحقيقية في معادلة حساب كل منهما. إن كانت نسب تمثيل كل من PC1 و PC2 متقاربة أمكن لنا تبسيط التعامل مع محاور الإحداثيات على أنها متناظرة، وإلا وجب التنبّه إلى أنّ الفروقات على محور السينات هي أكثر معنوية أو أهمية من فروقات بنفس القدر على المخطط البياني لكن على محور العينات.
biplot(pc, cex=0.75)
.png.bab4905157dbbaa4ec22b88c194ef1ea.png)
بالإضافة إلى ذلك سيظهر لنا هذا المخطط البياني أسهما باللون الأحمر تمثل كل صفة من الصفات الداخلة في تحليل المكونات الرئيسية وهو ما يقدّم لنا المزيد من المعلومات المضافة التي تخص العلاقة ما بين الصفات ذاتها حيث أن تجيب الزاوية (أي قيمة التابع المثلثي cos) ما بين سهمين أي صفتين يمثل قيمة معامل الارتباط بينهما، حيث أن الصفات التي تفصل بين أسهمها زوايا حادة هي صفات بينها ارتباط إيجابي/طردي (أي كلما زادت قيمة الصفة الأولى زادت الثانية والعكس بالعكس، دون أن يدل ذلك بالضرورة على أي علاقة سببية بينهما بل مجرد ارتباط ظاهري)، كما هو الحال بالنسبة لصفتي القدرة الحصانية hp وعدد إسطوانات المحرك cyl، وتزداد قيمة معامل الارتباط بصغر الزاوية حتى إذا انطبق سهما الصفتين على بعضهما البعض كان الارتباط طرديا تاما حيث cos(0) = +1. بشكل مناظر يمكننا استنتاج الصفات المرتبطة مع بعضها البعض لكن بشكل سلبي/عكسي (أي كلما ازدادت قيمة الصفة الأولى نقصت الثانية والعكس بالعكس)، حيث أن الزاوية التي تفصل ما بين السهمين الممثلين للصفتين المقارن بينهما يجب أن تكون زاوية منفرجة، كما هو الحال بالنسبة لصفتي القدرة الحصانية hp وعدد الأميال المقطوعة بغالون البنزين الواحد mpg، وتزداد قيمة معامل الارتباط بازدياد قياس الزاوية وصولا إلى الزاوية المستقيمة والتي يبلغ قياسها 180 درجة (أي أن السهمين يقعان على استقامة واحدة لكن باتجاهين متعاكسين)، وحينها يكون الارتباط هو ارتباط عكسي تام حيث cos(180) = -1. في حين أنّ الصفات التي لها أسهم متعامدة أو قريبة من التعامد (أي أن الزاوية بينهما قريبة من 90 درجة) فهي تشير إلى صفات غير مرتبطة ببعضها البعض أي أنها صفات مستقلة، كما هو الحال بالنسبة لصفتي القدرة الحصانية hp وعدد الغيارات في علبة السرعة gear، حيث أن cos(90) = 0.
كذلك لابد أنك قد لاحظت أن جميع الأسهم في هذا المخطط البياني تظهر متساوية الطول، يعود السبب في ذلك إلى أننا قمنا بإجراء عملية تقييس على البيانات المدخلة قبل تنفيذ تحليل المكونات الرئيسية PCA، وإلا كانت أطوال هذه الأسهم مختلفة وتعبر عن قيمة مساهمة كل واحدة من هذه الصفات في المقدار الكلي للتباينات المقاس ما بين عناصر البيانات المدروسة (في حالة مثالنا إن أهملنا الوسيط scale=TRUE عند استدعاء التابع prcomp لأصبح سهمي الإزاحة/الحجم disp والقدرة الحصانية hp هما وحدهما الطاغيين على المخطط كون الفروقات التي يتسببان بها هي من رتبة العشرات ما بين طرز السيارات المختلفة وتتجاوز بكثير أي صفات أخرى من حيث القيمة المطلقة قبل التقييس، لكن هذا الاستنتاج مضلل ويجب التنبّه إلى ضرورة التقييس في مثل هكذا الحالات).
فائدة أخرى يمكن الحصول عليها من وجود أسهم الصفات المضافة إلى المخطط البياني ثنائي الأبعاد والذي يمثل فيه كل عنصر من عناصر البيانات بنقطة (في حالتنا هذه كل طراز من طرز السيارات المدروسة)، إذ أن كل نقطة موجودة على امتداد أحد الأسهم أو في إتجاهه تعني أن الطراز المقابل لها له قيمة تفوق المتوسط بالنسبة للصفة المعنية المرتبطة بالسهم الذي نقارن معه (تزداد بابتعاد النقطة أكثر فأكثر عن مركز الإحداثيات باتجاه الأطراف)، وبشكل مناظر فإن النقاط الموجودة في الاتجاه المعاكس لسهم الصفة المدروسة وراء مركز الإحداثيات تدل على أن هذا الطراز المعني بتلك النقطة له قيمة أقل من المتوسط العام لهذه الصفة مقارنة بكافة العناصر الموجودة في عينة البيانات المدروسة. بشكل عام نستطيع تمديد السهم ليمثل محورا وهميا خاصا بتلك الصفة بالذات، ومن ثم نستطيع الحصول على تقدير نسبي جيد لقيمة هذه الصفة لكافة العناصر الموجودة من خلال أخذ مساقط من كل نقطة بشكل عامودي على هذا المحور الفرعي/التخيلي. من التدقيق في المخطط البياني الناتج من تحليل المكونات الرئيسية PCA من خلال استدعاء التابع biplot نجد أن صفة mpg التي تمثل عدد الأميال المقطوعة بغالون البنزين الواحد ترتبط بشكل عكسي مع صفات مثل عدد إسطوانات المحرك cyl والحجم disp والوزن مقدرا بالطن wt وهذا يبدو منطقيا، ونرى من خلال ذات المخطط أن سيارة مثل هوندا سيفيك تعد إقتصادية إلى حد بعيد مقارنة بطراز مثل كومارو Z28 والذي يمكن وصفه على أنه واحد من أسوء الطرز المدروسة من جهة استهلاك الوقود، وهي تعد إقتصادية أيضا حتى مقارنة بطرز أخرى مثل فولفو 142E والذي على الرغم من كونه يقطع عدد من الأميال بغالون البنزين الواحد يفوق المتوسط العام لطرز السيارات المدروسة، إلا أنه لا يزال أقل كفاءة من الهوندا سيفيك كما هو موضح بالمخطط البياني.
مراجع للاستزادة:












أفضل التعليقات
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.