

استحوذ الذكاء الاصطناعي في السنوات الأخيرة على الساحة التقنية وأثر على كل الصناعات والقطاعات، بداية من المجالات الإبداعية وصولًا إلى القطاعات المالية، مدفوعًا بالتطور متسارع الخطى للنماذج اللغوية الضخمة Large Language models أو اختصارًا LLMs مثل GPT من شركة OpenAI وجيميناي Gemini من شركة جوجل، فصارت هذه النماذج جزءًا أساسيًا من الأدوات التي يستخدمها مهندسو البرمجيات.
لا يستطيع الجيل الحالي من النماذج اللغوية الضخمة استبدال مهندسي البرمجيات بالطبع، ولكنه يمكنه مساعدتهم في مهام عديدة مثل تحليل الأكواد البرمجية، واكتشاف الأخطاء وتتبعها، وإجراء المهام البسيطة الروتينية. نحاول في هذه المقالة تبسيط تعقيدات استخدام النماذج اللغوية الضخمة واستخدامها في تطبيق عملي لتوليد كود بايثون قادر على التفاعل مع تطبيق خارجي.
ما هي النماذج اللغوية الضخمة Large Language Models
النماذج اللغوية الضخمة هي نماذج تعلم آلي دُربت على كميات ضخمة من البيانات النصية بهدف فهم وتوليد اللغة البشرية، يبنى النموذج اللغوي الضخم عادة باستخدام المحولات transformers والمحولات هي نوع من الشبكات العصبية الاصطناعية تُستخدم بشكل أساسي في معالجة اللغات الطبيعية مثل الترجمة أو الإجابة على الأسئلة وتستخدم أيضًا في تطبيقات مثل معالجة الصور. المميز في المحولات أنها تعتمد على آلية الانتباه الذاتي، مما يجعلها قادرة على التركيز على أجزاء معينة من المدخلات، وهي تقوم على آلية تسمى الانتباه الذاتي self-attention mechanism والتي تعني أن سلسلة المدخلات تعالج بشكل متزامن بدلًا من معالجتها كلمة كلمة، وهذا يتيح للنموذج تحليل جمل كاملة، ويحسن قدرتها على فهم السياق والمعاني الضمنية للكلمات، وفعالة في توليد نصوص قريبة جدًا من الأسلوب البشري.
وكلما زاد عمق الشبكة العصبية الاصطناعية كلما أمكنها تعلم معاني أدق في اللغة، ويتطلب النموذج اللغوي الضخم الحديث كمية هائلة من بيانات التدريب وقد يحتوي مليارات المعاملات parameters وهي عناصر تتغير بالتدريب على البيانات ليتأقلم النموذج على المهمة المراد تعلمها، فزيادة عمق الشبكة يؤدي إلى تحسن في المهام مثل الربط بالأسباب reasoning، على سبيل المثال من أجل تدريب GPT-3 جُمعَت بيانات من المحتوى المنشور في الكتب والإنترنت بلغ حجمها 45 تيرابايت من النصوص المضغوطة، ويحتوي النموذج ما يقارب 175 مليار معامل كي يتمكن من تحقيق هذا المستوى من المعرفة.
وقد ظهرت عدة نماذج لغوية ضخمة حققت تقدمًا ملحوظًا بالإضافة إلى GPT-3 و GPT-4، نذكر منها على سبيل المثال نموذج PaLM 2 من جوجل ونموذج LLaMa 2 من ميتا. ونظرًا لاحتواء بيانات تدريب هذه النماذج على أكواد برمجية بلغات مختلفة فقد أصبحت هذه النماذج اللغوية الضخمة قادرة على توليد الأكواد البرمجية لا المحتوى النصي فحسب، إذ تستطيع النماذج اللغوية الحديثة تحويل الأوامر أو الموجهات prompts المكتوبة باللغة الطبيعية إلى كود بمختلف اللغات والتقنيات، وعلى الرغم من ذلك لن تحقق الاستفادة المرجوة من هذه الميزات القوية إذا لم تمتلك الخبرة التقنية الكافية.
فوائد ومحدويات الأكواد المولدة بنماذج اللغات الضخمة
يتطلب حل المشكلات والمهام المعقدة في الغالب تدخل المطورين البشريين، لكن يمكن للنماذج اللغوية الضخمة أن تعمل كمساعدات ذكية للمطورين وتكتب الأكواد لمهام أقل تعقيدًا، وتسهل التعامل مع المهام التكرارية مما يعزز الإنتاجية ويقلل وقت التطوير في مراحل هندسة البرمجيات خصوصًا في المراحل الأولى من تطوير النماذج الأولية للبرمجيات، كما يمكن أن توفر النماذج اللغوية الضخمة مساعدة كبيرة في تصحيح الكود البرمجي وتشرحه وتساعدنا على إيجاد الأخطاء التي قد يصعب علينا ملاحظتها كبشر.
يجدر التوضيح أن أي أكواد مولدة باستخدام النماذج اللغوية الضخمة تعتبر نقطة للبداية وليس منتجًا نهائيًا وينبغي دائمًا مراجعة الأكواد المولدة واختبارها. والوعي بمحدوديات نماذج اللغات الضخمة، فهي تفتقد لقدرات حل المشكلات والتفكير المنطقي والإبداعي الذي يميزنا كبشر، إضافة إلى احتمال عدم تعرض النماذج للتدريب الكافي الذي يؤهلها للتعامل مع مهام متخصصة مناسبة لنوع معين من المستخدمين أو أطر العمل غير مفتوحة المصدر، وبالتالي يمكن لهذه النماذج اللغوية الضخمة أن تساعد بشكل كبير ولكن سيبقى دور المطور البشري أساسيًا في عملية التطوير بالطبع.
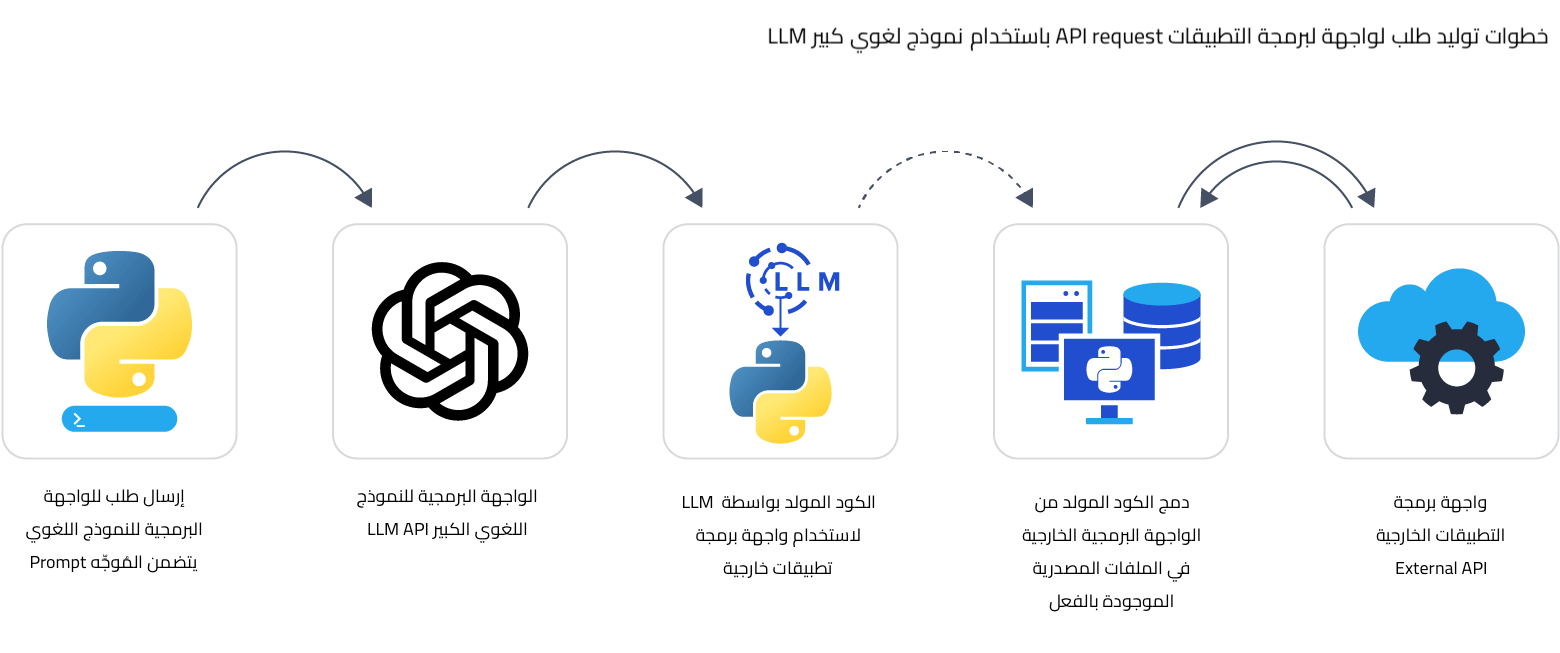
توليد كود برمجي باستخدام نموذج لغوي ضخم: استخدام الواجهة البرمجية للطقس
من أهم مميزات التطبيقات الحديثة قدرتها على التعامل مع مصادر خارجية، إذ يمكن للمطورين إرسال طلبات لهذه المصادر الخارجية من خلال واجهة برمجة التطبيقات API وهي مجموعة من التعليمات أو البروتوكولات التي توفر طريقة موحدة لتواصل التطبيقات فيما بينها.
وتتطلب كتابة الكود البرمجي الذي يستخدم واجهة برمجة التطبيقات قراءة متعمقة لتوثيقات هذه الواجهة، حيث تشرح التوثيقات كافة المتطلبات والتسميات المصطلح عليها، والوظائف والعمليات التي تدعمها، وتنسيق البيانات المرسلة والمستلمة والمتطلبات الأمنية. ويمكن للنموذج اللغوي الضخم تسريع هذه العملية في حال توفرت لديه المعلومات المطلوبة.
حيث يمكن للنموذج اللغوي المساعدة بتوليد الكود البرمجي اللازم لإرسال طلب لواجهة برمجة التطبيقات. وفيما يلي نوضح كيف يمكننا توجيه ChatGPT ليولد كود بلغة البرمجة بايثون لطلب بيانات الطقس من خلال الواجهة البرمجية لتطبيق للطقس OpenWeather API، وسنوضح كيف يمكننا تفادي أخطاء استخدام دوال قديمة deprecated لم تعد مدعومة، وكيف يمكننا إرسال الطلب من خلال الواجهة البرمجية OpenAI API ونختبر تأثير المعاملات على سلوك وأداء النموذج.
ملاحظة: انتبه إلى تكلفة استخدام الواجهة البرمجية للطقس OpenWeather API فهي مجانية لأول 1000 طلب فقط في اليوم الواحد.
تحويل موجهات تشات جي بي تي لطلبات API
يتطلب المثال الذي سنطبقه عرض درجة الحرارة الحالية ووصف حالة الطقس. دعنا نوضح كيف يمكن أن يساعدنا شات جي بي تي ChatGPT في كتابة الكود، سنكتب موجهًا prompt على النحو التالي:
اقتباساكتب كود بايثون باستخدام مكتبة requests لإرسال طلب GET إلى واجهة OpenWeather API للحصول على بيانات الطقس، وذلك عبر نقطة الوصول التالية
http://api.openweathermap.org/data/2.5/weather. يجب أن يتضمن الطلب مفتاح API الخاص بك ضمن الرابط باستخدام المعاملappid. يجب أن تُعيد الواجهة البيانات بتنسيق JSON، ويجب على الكود استخراج درجة الحرارة من البيانات وإعادتها بوحدة الفهرنهايت
سيولد شات جي بي تي ChatGPT هذا الكود ردًا على الموجه السابق:
import requests # استبدل "YOUR_API_KEY" بمفتاح OpenWeather API الخاص بك. api_key = "YOUR_API_KEY" api_url = "http://api.openweathermap.org/data/2.5/weather" # اسم المدينة التي ترغب في الحصول على معلومات الطقس لها. city_name = "London" # المعلمات المطلوبة لإرسال الطلب إلى واجهة API. params = { 'q': city_name, # اسم المدينة 'appid': api_key, # مفتاح API 'units': 'imperial' # استخدم metric للدرجة المئوية أو imperial للفهرنهايت } try: # إرسال طلب GET إلى واجهة API. response = requests.get(api_url, params=params) # التحقق مما إذا كان الطلب ناجحًا if response.status_code == 200: # قراءة وتحليل البيانات المستلمة بصيغة JSON. weather_data = response.json() print("بيانات الطقس لمدينة:", city_name) print("درجة الحرارة:", weather_data['main']['temp'], "°F") print("الوصف:", weather_data['weather'][0]["description"]) else: # طباعة رسالة خطأ إذا لم يكن الطلب ناجحًا. print("خطأ:", response.status_code, response.text) except Exception as e: # التعامل مع أي أخطاء أثناء تنفيذ الكود. print("حدث خطأ:", e)
يمكن أن تلاحظ أنه على الرغم من عدم تحديد الموقع المطلوب للواجهة البرمجية الخاصة بالطقي، فإن الكود المولد يتضمن متغير يسمى city_name وهو مضبوط على قيمة افتراضية هي لندن ويمكن تعديها حسب الطلب، ولا تنسى بالطبع استبدال YOUR_API_KEY بالمفتاح الخاص بك لواجهة برمجة التطبيق للطقس OpenWeather API.
كي نتمكن من اختبار الكود المولد، نحتاج لأن يكون مفسر interpreter لغة بايثون مثبت على جهازنا، بعد تثبيته يمكن تشغيل الكود محرر أكواد مثل فيجوال ستوديو كود Visual Studio Code أو باستخدام سطر الأوامر Terminal. إليك بيانات الطقس لمدينة لندن المستلمة من الواجهة البرمجية:
بيانات الطقس لمدينة: London °F درجة الحرارة: 50.4 الوصف: overcast clouds
سنحتاج غالبًا لتخزين البيانات التي حصلنا عليها من الواجهة البرمجية، وبالتالي سنحتاج لتحويل البيانات إلى تنسيق محدد مثل XML أو CSV أو استخدام أوامر لغة الاستعلام البنيوية SQL لحفظ البيانات في جداول قاعدة البيانات، لذا سنطلب من النموذج اللغوي مساعدتنا في هذه المهمة عن طريق توليد الكود المناسب لكل تنسيق، فمثلا يمكننا إضافة الجملة التالية للموجه السابق:
اقتباسينبغي أن تكون المخرجات منسقة على هيئة أوامر للغة الاستعلام المهيكل SQL وتخزن البيانات في جدول يسمى
current_weatherوالذي يحتوي الأعمدة التاليةcityوtemperatureوweather_descriptionوأخيرًاupdate_date
سيعيد ChatGPT نفس الكود السابق، ولكن مع إضافة بعض جمل الاستيراد وتحديث تنسيق المخرجات:
# استيراد المكتبات اللازمة import requests import json from datetime import datetime # رابط الواجهة البرمجية api_url = "http://api.openweathermap.org/data/2.5/weather" # إعداد المعاملات المطلوبة للطلب params = { 'q': 'الرياض', # اسم المدينة 'appid': 'مفتاح_API_الخاص_بك', # استبدل بمفتاح API الخاص بك 'units': 'imperial' # تحديد وحدة القياس (الفهرنهايت) } try: # إرسال طلب GET إلى الواجهة البرمجية response = requests.get(api_url, params=params) # التحقق من نجاح الطلب if response.status_code == 200: # تحويل الاستجابة إلى صيغة JSON weather_data = response.json() # استخراج البيانات المهمة city = params['q'] # اسم المدينة temperature = weather_data['main']['temp'] # درجة الحرارة weather_description = weather_data['weather'][0]['description'] # وصف الطقس update_date = datetime.utcnow().strftime('%Y-%m-%d %H:%M:%S') # وقت التحديث # إنشاء أمر SQL لإدخال البيانات في قاعدة البيانات sql_command = f"INSERT INTO current_weather (city, temperature, weather_description, update_date) VALUES ('{city}', {temperature}, '{weather_description}', '{update_date}')" # طباعة أمر SQL print("أمر SQL للإدخال في قاعدة البيانات:") print(sql_command) else: # طباعة رسالة خطأ في حال فشل الطلب print("حدث خطأ في الطلب:", response.status_code, response.text) except Exception as e: # طباعة رسالة خطأ في حال حدوث استثناء print("حدث خطأ أثناء تنفيذ البرنامج:", e)
وسيؤدي تنفيذ الكود السابق لتوليد الأمر التالي بلغة SQL:
INSERT INTO current_weather (city, temperature, weather_description, update_date) VALUES ('London', 53.37, 'broken clouds', '2024-02-06 04:43:35')
ولكن سنرى تحذيرًا ينبهنا إلى عدم استخدام الدالة ()utcnow حيث أنها مهملة deprecated ولن تكون متوفرة في إصدارات قادمة وهذا قد يتسبب في تعطل الكود الخاص بنا في التحديثات المستقبلية:
DeprecationWarning: datetime.datetime.utcnow() is deprecated and scheduled for removal in a future version. Use timezone-aware objects to represent datetimes in UTC: datetime.datetime.now(datetime.UTC).
وكي نمنع ChatGPT من استخدام دوال مهملة deprecated، سنضيف التوجيه التالي:
اقتباسلا تستخدم أي دوال قديمة deprecated من المحتمل إزالتها في التحديثات القادمة.
بعد إضافة هذا السطر، سيبدل ChatGPT الدالة ()utcnow بدالة أخرى كما يلي:
# استخدم الكائن timezone-aware لتحديث التاريخ update_date = datetime.now(timezone.utc).strftime('%Y-%m-%d %H:%M:%S')
يعيد لنا هذا الكود مجددًا أمرًا بلغة SQL ويمكن اختباره في أي محرر استعلامات Query editors لنظام إدارة قواعد البيانات DBMS. وفي حال كنت تولد هذا الكود ضمن تطبيق ويب تقليدي فمن المتوقع تشغيل أمر SQL مباشرة بعد توليده من خلال الواجهة البرمجية وتحديث بيانات قاعدة البيانات في الزمن الحقيقي.
استخدام الواجهة البرمجية OpenAI API بدلًا من شات ChatGPT
تملك العديد من نماذج اللغات الضخمة واجهة برمجة تطبيقات API تمكّن المطور من التفاعل مع النماذج اللغوية الضخمة برمجيًا ودمجها بسلاسة داخل تطبيقاته، سنستفيد من هذه الواجهات البرمجية لإنشاء مساعد ذكي بشكل افتراضي، يوفر لنا هذا المساعد ميزات عديدة مثل إكمال الكود أو توليده من الصفر أو إعادة صياغته وتحسينه.
ويمكن تحسين واجهات المستخدم وتخصيصها من خلال قوالب جاهزة من الموجهات Prompts templates، كما يتيح لنا دمج النماذج اللغوية الضخمة برمجيًا جدولة المهام أو تفعيلها عند تحقق شروط معينة ويسهل أتمتة المساعد الذكي الذي نعمل عليه.
سننفذ في هذا المثال نفس المهمة السابقة وهي طلب معلومات الطقس باستخدام بايثون للتفاعل برمجيًا مع الواجهة البرمجية OpenAI API وتوليد الكود من خلال واجهة المستخدم بدلًا من كتابة موجّه في ChatGPT مباشرة. بداية علينا تثبيت الواجهة البرمجية OpenAI API باستخدام الأمر التالي:
pip install openai
الآن لنتمكن من استخدام الواجهة البرمجية OpenAI API نحتاج لمفتاح الواجهة API key وهو غير مجاني ويتطلب دفع رسوم.
بعدها، يمكننا استيراد المكتبة openai وإرسال نفس الموجه المستخدم من قبل مع إزالة الجزء الخاص بتوليد أوامر SQL، كما نحدد النموذج المستخدم GPT-3.5 من خلال الكود التالي:
import openai openai.api_key = "YOUR_API_KEY" # استبدله بمفتاح الواجهة البرمجية الخاص بك response = openai.chat.completions.create( model='gpt-3.5-turbo', max_tokens=1024, temperature=0.3, top_p=0.9, messages = [ {'role': 'system', 'content': 'أنت مساعد ذكي قائم على الذكاء الاصطناعي.'}, {'role': 'user', 'content': "اكتب كود بلغة بايثون باستخدام مكتبة requests لإرسال طلب GET إلى واجهة OpenWeather API للحصول على بيانات الطقس، وذلك عبر نقطة الوصول التالية http://api.openweathermap.org/data/2.5/weather. يجب أن يتضمن الطلب مفتاح API الخاص بك ضمن الرابط باستخدام المعامل appid. يُتوقع أن تُعيد الواجهة البيانات بتنسيق JSON، ويجب على الكود استخراج درجة الحرارة من البيانات وإعادتها بوحدة الفهرنهايت ولا يستخدم أي دوال قديمة غير مستعملة"}, ] response_message = response.choices[0].message.content print(response_message )
سيولد النموذج اللغوي الضخم كود بايثون التالي، والذي يجلب درجات الحرارة لمدينة لندن:
import requests # مفتاح الواجهة البرمجية ونقطة الوصول url = "http://api.openweathermap.org/data/2.5/weather" api_key = "YOUR_API_KEY" # معاملات الاستعلام params = { 'q': 'London,uk', # مثال على المدينة ورمز الدولة. 'appid': api_key } # إرسال طلب GET. response = requests.get(url, params=params) # التحقق مما إذا كان الطلب ناجحاً. if response.status_code == 200: # تحليل استجابة JSON. data = response.json() # طباعة درجة الحرارة بالدرجة المئوية. temperature = data['main']['temp'] - 273.15 print(f"درجة الحرارة في لندن هي {temperature:.2f}°C.") else: print(f"خطأ: {response.status_code}")
لاحظ أننا أزلنا التعليمات الخاصة بتحديد درجات الحرارة بالفهرنهايت لذا لم يحدد النموذج اللغوي الضخم وحدة القياس عند طلب الواجهة البرمجية للطقس، ولكنه اختار حسابها رياضيًا بتحويل الوحدة من الكلفن إلى سلسيوس عند عرض النتائج.
الاستفادة من معاملات النموذج اللغوي الضخم لتحقيق أقصى استفادة
يمكننا ضبط بعض المعاملات عند استخدام الواجهة البرمجية لنماذج الذكاء الاصطناعي والنماذج اللغوية الضخمة من أجل تعديل الردود المولدة منها، فهناك معاملات يمكنها تحديد مستوى العشوائية والإبداع في الردود المولدة كالمعامل Temperature، ومعاملات يمكنها التحكم بتكرار النصوص المولدة مثل Repetition Penalty، بينما تؤثر معاملات أخرى على النص اللغوي المولد مما يساعد على التحكم في جودة الكود الناتج.
في الكود السابق، يمكننا ضبط قيم معاملات GPT في السطر السابع على النحو التالي:
max_tokens=1024, temperature=0.3, top_p=0.9,
| المعامل | الوصف | التأثير على الكود المولد |
|---|---|---|
Temperature
|
يعني درجة الحرارة إذ يتحكم هذا المعامل في عشوائية الردود المولدة، أو درجة الإبداعية في الردود، فالقيمة العالية لهذا المعامل تزيد عشوائية الردود المولدة، بينما القيمة المنخفضة تولد ردودًا واقعية، القيم الممكنة لهذا المعامل بين 0 و 2 والقيمة الافتراضية 0.7 أو 1 بحسب النموذج المستخدم. | ستولد القيمة المنخفضة لهذا المعامل كودًا آمنًا يتبع الأنماط والهياكل المكتسبة خلال عملية التدريب، بينما ستولد القيمة العالية ردودًا أكثر تميزًا وغير اعتيادية مما يرفع من احتمالية الأخطاء والتناقضات البرمجية. |
Max token
|
يحدد هذا المعامل الحد الأقصى لعدد الوحدات النصية tokens المولدة في الاستجابة. إذا ضبطته بقيمة صغيرة، فقد يتسبب ذلك في أن تكون الاستجابة قصيرة جدًا، بينما إذا تم ضبطته بقيمة كبيرة جدًا، قد يؤدي ذلك لاستهلاك عدد كبير من الوحدات النصية المتاحة، مما يزيد من تكلفة الاستخدام | يجب أن يضبط المعامل على قيمة عالية بما يكفي لتغطية جميع الأكواد التي تحتاج إلى توليدها. ويمكنك تقليله إذا كنت ترغب في توليد الكود فقط دون توفير شرح الكود المضاف من النموذج |
top_p
|
يتحكم هذا المعامل في اختيار الكلمات التالية بتقليص نطاق الخيارات المتاحة. إذا منحناه القيمة 0.1 سيقتصر على أفضل 10% من الكلمات الأكثر احتمالاً، مما يزيد الدقة. وإذا منحناه القيمة 0.5 سيوسع الاختيار ليشمل أفضل 50%، مما يعزز التنوع. ويساعد في موازنة الدقة والإبداع في الردوع. |
عند ضبط المعامل بقيمة منخفضة، يصبح الكود المولد أكثر توقعًا وارتباطًا بالسياق، ويجري اختيار الاحتمالات الأكثر ترجيحًا بناءً على السياق الحالي. أما عند زيادة قيمته يزداد التنوع في المخرجات، مما قد يؤدي إلى توليد كود أقل ارتباطًا بالسياق وقد يتسبب في أخطاء أو توليد كود متناقض. |
frequency_penalty
|
يعني عقوبة التكرار إذ يحدّ هذا المعامل من تكرار الكلمات والعبارات في ردود النموذج اللغوي الكبير. عند ضبطه على قيمة عالية، يقلل من تكرار الكلمات أو العبارات التي استخدمها النموذج سابقًا. أما عند ضبطه على قيمة منخفضة، فيسمح للنموذج بتكرار الكلمات والعبارات. حيث تتراوح قيم هذا المعامل من 0 إلى 2. |
تضمن القيمة العالية لهذا المعامل تقليل التكرار في الكود المولد، مما يؤدي لتوليد أكواد أكثر تنوعًا وإبداعًا. ومع ذلك، قد يؤدي ذلك إلى اختيار عناصر أقل كفاءة أو غير صحيحة. من ناحية أخرى، عند خفض قيمته، قد لا يستكشف طرقًا متنوعة للحل. |
presence_penalty
|
يعني عقوبة التواجد ويرتبط هذا المعامل بالمعامل السابق فكلاهما يشجعان على التنوع والتفرد في الكلمات المستخدمة، حيث يعاقب المعامل السابق الوحدات النصية التي استخدمت عدة مرات في النص في حين يعاقب المعامل الحالي الوحدات النصية التي ظهرت من قبل بغض النظر عن مرات التكرار، يتلخص تأثير معامل عقوبة التكرار في أنه يقلل من تكرار الكلمات بينما يركز معامل عقوبة التواجد على استخدام كلمات جديدة بالكليّة، والقيمة الصغرى لهذا المعامل هي 0 أما القيمة العظمى فهي 2. | له تأثير مشابه لعقوبة التكرار، فالقيمة العالية تشجع النموذج على استكشاف حلول بديلة، ولكن قد يصبح الكود المولد أقل كفاءة ومليء بالأخطاء، بينما تسمح القيمة المنخفضة بتكرار الكود مما يؤدي إلى كود أكثر كفاءة واتساقًا، خاصةً عند وجود أنماط متكررة. |
stop
|
دور هذا المعامل هو تحديد نقطة التوقف في عملية توليد النصوص. عند ضبطه مع سلسلة معينة مثل "n/"، سيتوقف النموذج عن توليد النصوص بمجرد أن يصادف هذه السلسلة مما يساعد في التحكم بدقة في نهاية الرد المولد وتحديد متى يجب أن يتوقف النموذج عن إضافة المزيد من الكلمات. |
يمنع هذا المعامل النموذج من توليد أجزاء من الكود لا تتناسب مع السياق أو الوظيفة المطلوبة. يجب أن تكون سلسلة التوقف نقطة منطقية وواضحة لنهاية الكود، مثل نهاية دالة أو نهاية حلقة تكرارية، لضمان توقف النموذج عن توليد المزيد من الكود بشكل مناسب. |
لنختبر كيفية تأثير هذه المعاملات على توليد الكود، سنجرب تعديل معاملات عقوبة التكرار frequency_penalty وعقوبة التواجد presence_penalty .
عند تهيئة عقوبة التكرار frequency_penalty بقيمة مرتفعة وهي 1.5،سينتج النموذج اللغوي الضخم كودًا إضافيًا ليلاقى التوقعات محاولًا تفادي تكرار المخرجات السابقة:
# ... try: # إرسال طلب GET مع المعلمات والحصول على البيانات في تنسيق JSON. response = requests.get(url, params=params) if response.status_code == 200: weather_data = response.json() # طباعة بعض المعلومات المهمة من بيانات الطقس. print("المدينة:", weather_data['name']) print("درجة الحرارة:", weather_data['main']['temp'], "K") except requests.exceptions.RequestException as e: # التعامل مع أي خطأ حدث أثناء الطلب print("خطأ:", e)
عند العمل مع الكود الذي يتعامل مع واجهة برمجية API من المهم أن نلاحظ أن النتائج قد تكون غير متوقعة. ففي الكود السابق، على الرغم من أن إضافة معالجة الأخطاء مفيدة، إلا أننا لم نطلب من النموذج توليد كود يتعامل مع جميع الأخطاء المحتملة بشكل دقيق. لهذا السبب، عند إرسال نفس الطلب مرة أخرى مع نفس المعاملات، قد نحصل على نتائج مختلفة تمامًا. ولضمان استقرار الكود ومعالجته للأخطاء بشكل صحيح، يجب إضافة موجه أولي initial prompt يوجّه النموذج لتوليد الكود مع معالجة الأخطاء بشكل مناسب. بهذا الشكل، يمكن ضمان أن الكود سيكون متسقًا ويعمل كما هو متوقع في جميع الحالات.
يمكننا ضبط المعامل presence_penalty بقيمة عالية ولتكن 2.0 للحصول على تأثير مشابه، حيث يتفادى النموذج تكرار المخرجات السابقة ويرسل طلب جديد للواجهة البرمجية للطقس OpenWeather API من خلال دالة ممرًا لها مفتاح الواجهة البرمجية API key كمعامل كما يلي:
import requests def get_weather(api_key): url = "http://api.openweathermap.org/data/2.5/weather" params = { 'q': 'London,uk', # مثال على المدينة ورمز الدولة. 'appid': api_key } response = requests.get(url, params=params) # إضافة سطر إرسال الطلب if response.status_code == 200: data = response.json() return data else: print("خطأ:", response.status_code) # استبدل "YOUR_API_KEY" بمفتاح الواجهة البرمجية الفعلي من OpenWeather. api_key = "YOUR_API_KEY" weather_data = get_weather(api_key) print(weather_data)
إن إنشاء دالة برمجية مخصصة لطلب الواجهة البرمجية لتطبيق الطقس إضافة مفيدة للكود، ولكن تمرير مفتاح الواجهة من خلال الدالة أمر غريب، فمن المعتاد في أغلب حالات الاستخدام تمرير المدينة city كمعامل للدالة، وهنا يمكننا معالجة هذه المشكلة بتعديل الموجه الأولي.
يتطلب ضبط قيم معاملات نماذج اللغة الضخمة الكثير من التجربة، فبعض النتائج تكون غير متوقعة وبعض التعديلات قد تبدو عديمة التأثير، فتعديل المعاملات لا يمتلك تأثيرًا موحدًا يضمن اتباع أفضل الممارسات في توليد الكود.
دمج النماذج اللغوية الضخمة في ملفات الكود المصدري
بمجرد أن يصبح الكود المولد باستخدام النموذج اللغوي الضخم محسنًا وجاهزًا للعمل، ستكون الخطوة التالية هي دمج الكود الناتج مع الأكواد البرمجية السابقة. لكن قد يؤدي نسخ الكود بشكل مباشر للكود الموجود سابقًا لمشكلات في تنظيم الكود وتنسيقها مما يصعب صيانة وتعديل الكود لاحقًا.
يمكننا تبسيط هذه العملية بتحويل الكود إلى أجزاء قابلة لإعادة الاستخدام مثل دوال برمجية أو كائنات وأصناف برمجية، ويمكننا تحقيق هذا أيضًا باستخدام النموذج اللغوي الضخم ما دامت التعليمات المفصلة للقيام بهذا مرفقةً في الموجه Prompt، ويجب أيضاً تحديد مدخلات هذه الدوال والمخرجات المتوقعة منها.
دعنا نجعل النموذج اللغوي الضخم ينشئ الكائن البرمجي weather الذي يحوي دالة get_weather ، من خلال إضافة الأوامر التالية للموجه:
اقتباسينبغي أن يوضع طلب الواجهة البرمجية OpenWeather API في كائن برمجي يسمى
weatherوالذي يحوي دالة تسمىget_weatherوينبغي تمرير المدينةcityكمدخلات للدالة.
عندها سنحصل على كود بايثون التالي:
import requests class Weather: def __init__(self, api_key): self.api_key = api_key self.temperature = None def get_weather(self, city): url = 'http://api.openweathermap.org/data/2.5/weather' params = { 'q': city, 'appid': self.api_key, 'units': 'imperial' # طلب درجة الحرارة بالفهرنهايت. } response = requests.get(url, params=params) data = response.json() if response.status_code == 200: self.temperature = data['main']['temp'] print(f"درجة الحرارة في {city} هي {self.temperature}°F.") else: print(f"خطأ: {data['message']}") # استبدل "YOUR_API_KEY" بمفتاح الواجهة البرمجية الفعلي من OpenWeather. api_key = "YOUR_API_KEY" weather = Weather(api_key) weather.get_weather('London')
يولّد النموذج دالة قابلة للتشغيل بواسطة الكائن weather، ويمكننا دمج هذا الكائن بتطبيق آخر بكل سهولة، ولكن علينا معالجة الأخطاء التي قد تقع لضمان عدم فشل عمل التطبيق وعدم عرضه لبيانات حساسة أو سرية.
اختبار التطبيق ومعالجة الأخطاء
إن فشل طلبات واجهة البرمجة للتطبيق API أمر شائع في التطبيقات الحقيقية، فيمكن أن تفشل الطلبات لعدة أسباب، لذا لضمان الاعتمادية ينبغي أن يتضمن الكود حالات لمعالجة الأخطاء التي يمكن أن تقع لمنع فشل التطبيق الكامل، في أغلب الأمثلة السابقة كان الكود المولد بواسطة النموذج يحوي شرطًا يختبر رمز الحالة لبروتوكول نقل النص الفائق HTTP ، فالرمز 200 يعبر عن نجاح الطلب بينما أي رمز آخر يعبر عن فشل الطلب أو وجود خطأ ينبغي التعامل معه فيقوم الكود المولد بطباعته، ولكن هذا الشرط لا يأخذ في الاعتبار حالات أخطاء شائعة أخرى مثل انتهاء وقت الطلب timeout أو أخطاء نظام أسماء النطاقات DNS.
لضمان الاعتمادية ينبغي أن يحوي الكود المولد آلية لمعالجة الأخطاء، مثل استخدام try-catch عند إجراء طلب من خلال واجهة برمجة التطبيق API. لذا أضفنا النص التالي للموجه السابق:
اقتباسلمعالجة الأخطاء، استخدم
try-catchعند إرسال طلبات للواجهة البرمجية API، وعليك التأكد أن رمز الحالة لبروتوكول HTTP يساوي 200 فكل شيء على ما يرام أما إن كان رمز مختلف عليك طباعة الخطأ الذي حدث
ولّد هذا التوجيه كود بايثون يحتوي كلتلة try-catch تعالج الأخطاء المحتملة:
class Weather: def __init__(self, api_key): self.api_key = api_key self.temperature = None def get_weather(self, city): try: # بناء عنوان URL للواجهة البرمجية باستخدام المدينة ومفتاح API المقدم. url = "http://api.openweathermap.org/data/2.5/weather" params = {'q': city, 'appid': self.api_key, 'units': 'imperial' # الحصول على درجة الحرارة بالفهرنهايت. } # إرسال طلب GET إلى الواجهة البرمجية. response = requests.get(url, params=params) # التحقق من حالة الاستجابة if response.status_code == 200: # تحليل الاستجابة بتنسيق JSON data = response.json() # استخراج درجة الحرارة بالفهرنهايت من الاستجابة. self.temperature = data['main']['temp'] else: # عرض وصف الخطأ إذا كانت حالة الاستجابة ليست 200. print(f'خطأ: {response.status_code} - {response.json()["message"]}') except requests.exceptions.RequestException as e: # التعامل مع أي استثناءات تحدث أثناء الطلب. print(f'خطأ: {e}')
يعد الكود المولد بواسطة النموذج اللغوي الضخم نقطة بداية جيدة، لكنك ستحتاج في الغالب لتعديلات إضافية لتحصيصه وزيادة الوظائف التي يقوم به، على سبيل المثال من الممكن تسجيل الأخطاء التي تحدث وتنبيه المستخدم من أخطاء الإعدادات التي قد تشمل أخطاء في استيثاق الواجهة البرمجية API authentication error ويمكن للمطورين إضافة واجهة برمجية احتياطية في حالة تعطل الواجهة الأساسية.
بمجرد أن يصبح الكود قادرًا على تأدية وظيفته كما ينبغي، فالخطوة التالية مهمة للتأكد من صموده عند التشغيل الفعلي، وينبغي اختبار كل الوظائف والحالات الممكنة للخطأ، ولضمان اعتمادية قوية يمكننا أتمتة عملية الاختبارات وتقييم الأداء من خلال قياس مؤشرات الأداء المختلفة مثل وقت التشغيل واستخدام ذاكرة الوصول العشوائي واستخدام الموارد الحاسوبية، ستساعدنا هذه المؤشرات على تحديد نقاط الخلل في النظام وتحسين الموجهات prompts وصقل fine-tune معاملات النموذج اللغوي الضخم.
تطور نماذج اللغات الضخمة
تطورت النماذج اللغوية الضخمة لكنها لن تستبدل الخبرة البشرية حاليًا، بل سيقتصر دورها على توليد الكود البرمجي مما يسرّع ويسهّل عملية التطوير كما أنها قادرة على توليد نسخ متنوعة من الكود مما يساعد المطور على اختيار أفضل خيار من بينها، كما يمكنها تولي إنجاز المهام البسيطة والتكرارية لزيادة إنتاجية المطورين، مما يتيح للمطورين التركيز على المهام المعقدة التي تتطلب معرفة متخصصة وتفكير بشري إبداعي.
ترجمة-وبتصرٌّف-للمقال Using an LLM API As an Intelligent Virtual Assistant for Python Development












أفضل التعليقات
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.