

تتمثل إحدى نقاط قوة مكتبة NumPy في إمكانية استخدامها لبناء كائنات جديدة أو لتصنيف كائن ndarray إلى صنف فرعي. هذه العملية السابقة مملة بعض الشيء ولكنها تستحق الجهد لأنها تسمح لك بتحسين كائن ndarray ليناسب مشكلتك.
سندرس في هذا المقال حالتين من العالم الحقيقي (قائمة مقيدة بنوع typed list ومصفوفة مراعية للذاكرة memory-aware array) اللتان تُستخدمان على نطاق واسع في مشروع glumpy، بينما تُعد الحالة الثانية -وهي مصفوفة مضاعفة الدقة double precision array- شائعة في الدراسة الأكاديمية.
القائمة المقيدة بنوع Typed list
تسمى أيضًا المصفوفة غير المنتظمة، وهي قائمة بالعناصر التي تحتوي جميعها على نفس نوع البيانات (بمعنى NumPy). وتوفر كلًا من القائمة وواجهة برمجة تطبيقات ndarray. ولكن نظرًا لأن واجهات برمجة التطبيقات APIs المخصصة قد لا تكون متوافقة في بعض الحالات، علينا تحديد الخيارات. على سبيل المثال فيما يتعلق بالعامل "+" سنختار استخدام NumPy API، إذ تُضاف القيمة إلى كل عنصر على حدة بدلًا من توسيع القائمة عن طريق إلحاق عنصر جديد بها.
>>> l = TypedList([[1,2], [3]]) >>> print(l) [1, 2], [3] >>> print(l+1) [2, 3], [4]
نريد أن نوفر للكائن الجديد إمكانية إدراج العناصر وإنشائها وإزالتها بسلاسة من قائمة API، وهذا ما سنوضحه في الفقرات التالية.
الإنشاء Creation
نظرًا لأن الكائن ديناميكي بحكم التعريف، فمن المهم تقديم تابع إنشاء للأغراض العامة general-purpose قوي بما يكفي لتجنب الاضطرار إلى معالجات لاحقة، إذ تكلف معالجات مثل الإدراج، أو الحذف كثيرًا من العمليات ونحن نسعى إلى تجنبها. إليك اقتراح لإنشاء كائن TypedList:
def __init__(self, data=None, sizes=None, dtype=float) """ Parameters ---------- data : array_like An array, any object exposing the array interface, an object whose __array__ method returns an array, or any (nested) sequence. sizes: int or 1-D array If `itemsize is an integer, N, the array will be divided into elements of size N. If such partition is not possible, an error is raised. If `itemsize` is 1-D array, the array will be divided into elements whose successive sizes will be picked from itemsize. If the sum of itemsize values is different from array size, an error is raised. dtype: np.dtype Any object that can be interpreted as a NumPy data type. """
تسمح واجهة برمجة التطبيقات API هذه بإنشاء قائمة فارغة أو إنشاء قائمة من بعض البيانات الخارجية. لاحظ أنه في الحالة الأخيرة نحتاج إلى تحديد كيفية تقسيم البيانات إلى عدة عناصر أو تقسيمها إلى عناصر بحجم 1، ويمكن أن يكون قسمًا عاديًا (أي أن كل عنصر بطول بيانات 2)، أو قسمًا مخصصًا (أي يجب تقسيم البيانات إلى عناصر بحجم 1 و2 و3 و4 عنصر).
>>> L = TypedList([[0], [1,2], [3,4,5], [6,7,8,9]]) >>> print(L) [ [0] [1 2] [3 4 5] [6 7 8] ] >>> L = TypedList(np.arange(10), [1,2,3,4]) [ [0] [1 2] [3 4 5] [6 7 8] ]
في هذه المرحلة السؤال هو ما إذا كان يجب إنشاء صنف فرعي مشتق من الصنف ndarray، أو استخدام مصفوفة ndarray داخلية لتخزين بياناتنا. في هذه الحالة، ليس من المنطقي استخدام صنف فرعي ndarray لأننا لا نريد تقديم واجهة ndarray. بدلًا من ذلك، سنستخدم مصفوفة ndarray لتخزين بيانات القائمة وسيوفر لنا اختيار هذا التصميم مزيدًا من المرونة.

سنستخدم لتخزين حد limit لكل عنصر مصفوفة عناصر items، ستهتم بتخزين الموضع (البداية والنهاية) لكل عنصر. توجد حالتان منفصلتان لإنشاء قائمة، هما: لم تُقدم أية بيانات، أو قُدمت بعض البيانات. الحالة الأولى سهلة وتتطلب فقط إنشاء مصفوفتي data_ و items_. لاحظ أن حجم المصفوفتين غير فارغ لأن تغيير حجم المصفوفة سيكون مكلفًا جدًا في كل مرة ندخل عنصر جديد فيها. لذلك من الأفضل حجز بعض المساحة.
الحالة الأولى: لم تُقدّم أية بيانات، فقط dtype.
self._data = np.zeros(512, dtype=dtype) self._items = np.zeros((64,2), dtype=int) self._size = 0 self._count = 0
الحالة الثانية: قُدمت بعض البيانات بالإضافة إلى قائمة بأحجام العناصر.
self._data = np.array(data, copy=False) self._size = data.size self._count = len(sizes) indices = sizes.cumsum() self._items = np.zeros((len(sizes),2),int) self._items[1:,0] += indices[:-1] self._items[0:,1] += indices
الوصول Access
بمجرد الانتهاء من عملية الإنشاء، لا بد من إجراء قليل من الحسابات في كل التوابع وتغيير مفتاح key مختلف عند الحصول على عنصر أو إدراجه أو ضبطه. إليك تعليمات تابع __getitem__، وهو تابع سهل ولكن هناك خطوة سلبية محتملة فيه:
def __getitem__(self, key): if type(key) is int: if key < 0: key += len(self) if key < 0 or key >= len(self): raise IndexError("Tuple index out of range") dstart = self._items[key][0] dstop = self._items[key][1] return self._data[dstart:dstop] elif type(key) is slice: istart, istop, step = key.indices(len(self)) if istart > istop: istart,istop = istop,istart dstart = self._items[istart][0] if istart == istop: dstop = dstart else: dstop = self._items[istop-1][1] return self._data[dstart:dstop] elif isinstance(key,str): return self._data[key][:self._size] elif key is Ellipsis: return self.data else: raise TypeError("List indices must be integers")
تمرين
يُعد تعديل القائمة أكثر تعقيدًا، لأنه يتطلب إدارة الذاكرة بطريقة صحيحة، وبما أن ذلك لا يمثل صعوبة حقيقة، فقد تركنا هذا تمرينًا لك. في حال احتجت إلى مساعدة، يمكنك إلقاء نظرة على التعليمات البرمجية أدناه. كن حذرًا مع الخطوات السلبية ونطاق المفتاح وتوسع المصفوفة. عندما تحتاج المصفوفة الأساسية إلى التوسيع، فمن الأفضل توسيعها أكثر من اللازم لتجنب الحاجة إلى التوسع المستقبلي.
ضبط عنصر Setitem
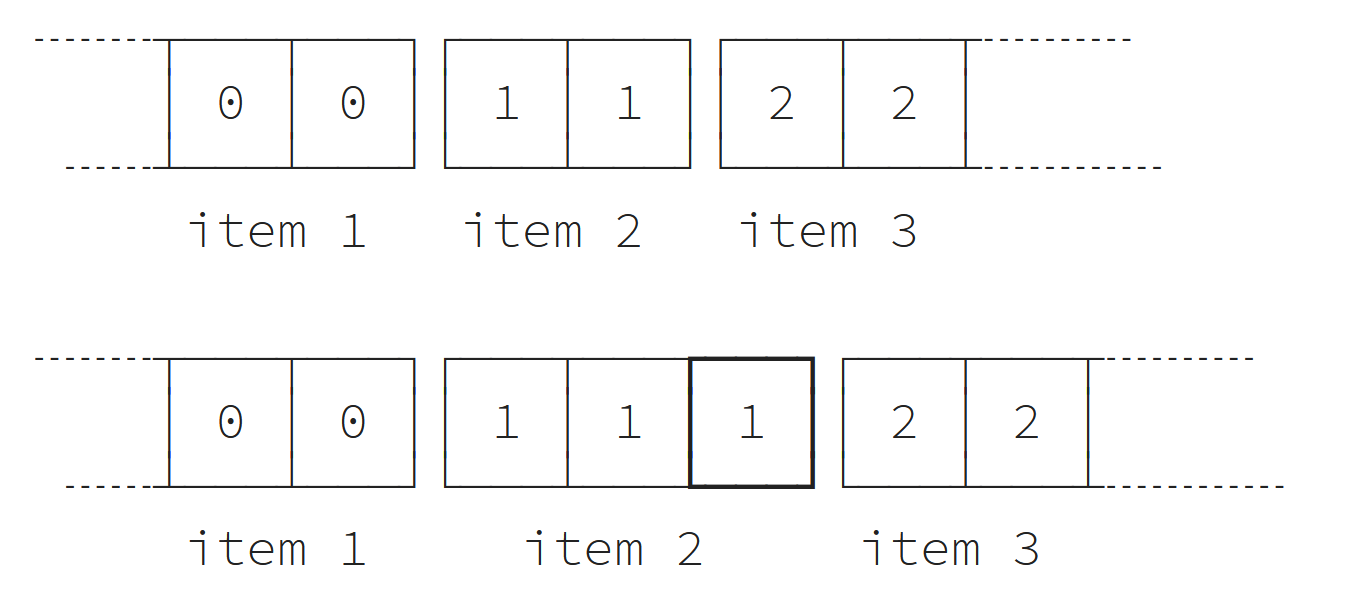
يمكننا ضبط عنصر كما يلي:
L = TypedList([[0,0], [1,1], [0,0]]) L[1] = 1,1,1
حذف عنصر Delitem
يجري حذف عنصر على النحو التالي:
L = TypedList([[0,0], [1,1], [0,0]]) del L[1]

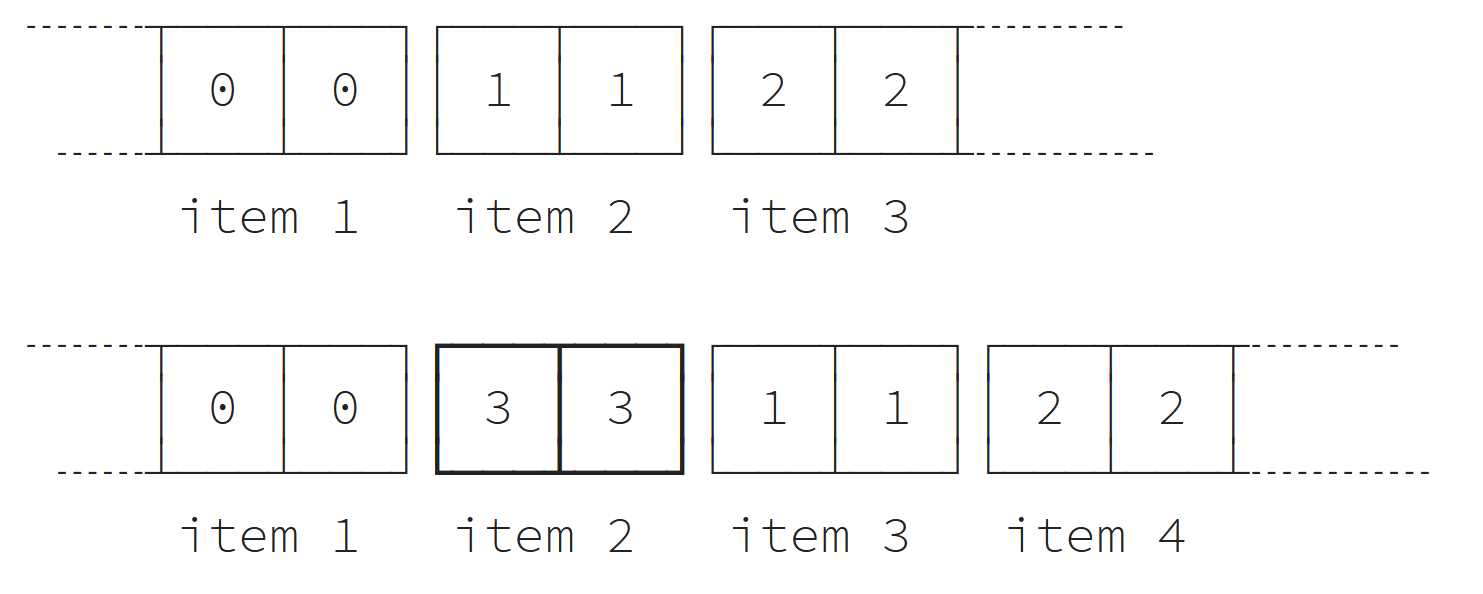
إدراج عنصر insert
يمكننا إضافة عنصر كما يلي:
L = TypedList([[0,0], [1,1], [0,0]]) L.insert(1, [3,3])
مصفوفة مراعية للذاكرة Memory aware array
مكتبة Glumpy
Glumpy هي مكتبة تمثيل مرئي تفاعلي مبنية على OpenGL في بايثون هدفها تسهيل إنشاء عروض مرئية سريعة وقابلة للتطوير وجميلة وتفاعلية وديناميكية. يوضح الشكل التالي محاكاة مجرة حلزونية باستخدام نظرية موجة الكثافة density wave theory:

محاكاة مجرة حلزونية باستخدام نظرية موجة الكثافة.

عرض لنمر باستخدام التجميعات واستدعائين GL.
تعتمد Glumpy على تكامل محكم وسلس مع المصفوفات المعقدة، وهذا يعني أنه يمكنك معالجة بيانات وحدة معالجة الرسومات GPU كما تفعل مع مصفوفات numpy العادية، وستتولى مكتبة Glumpy بقية المهام، وأسرع طريقة لفهم ذلك هي بالمثال التالي:
from glumpy import gloo dtype = [("position", np.float32, 2), # x,y ("color", np.float32, 3)] # r,g,b V = np.zeros((3,3),dtype).view(gloo.VertexBuffer) V["position"][0,0] = 0.0, 0.0 V["position"][1,1] = 0.0, 0.0
V هو VertexBuffer وهو يمثّل GPUData ومصفوفة numpy. عندما يُعدل V، تعتني Glumpy بحساب أصغر كتلة متجاورة من ذاكرة dirty حتى تحميلها على ذاكرة GPU. عندما يُستخدم هذا المخزن المؤقت على وحدة معالجة الرسومات GPU، تتولى Glumpy تحميل منطقة dirty في اللحظات الأخيرة، وهذا يعني أنه في حال عدم استخدامك V فلن يُحمّل أي شيء على وحدة معالجة الرسومات. في الحالة المذكورة أعلاه، تتكون آخر منطقة ذاكرة dirty محسوبة من 88 بايت بدءًا من الإزاحة 0 كما هو موضح أدناه:
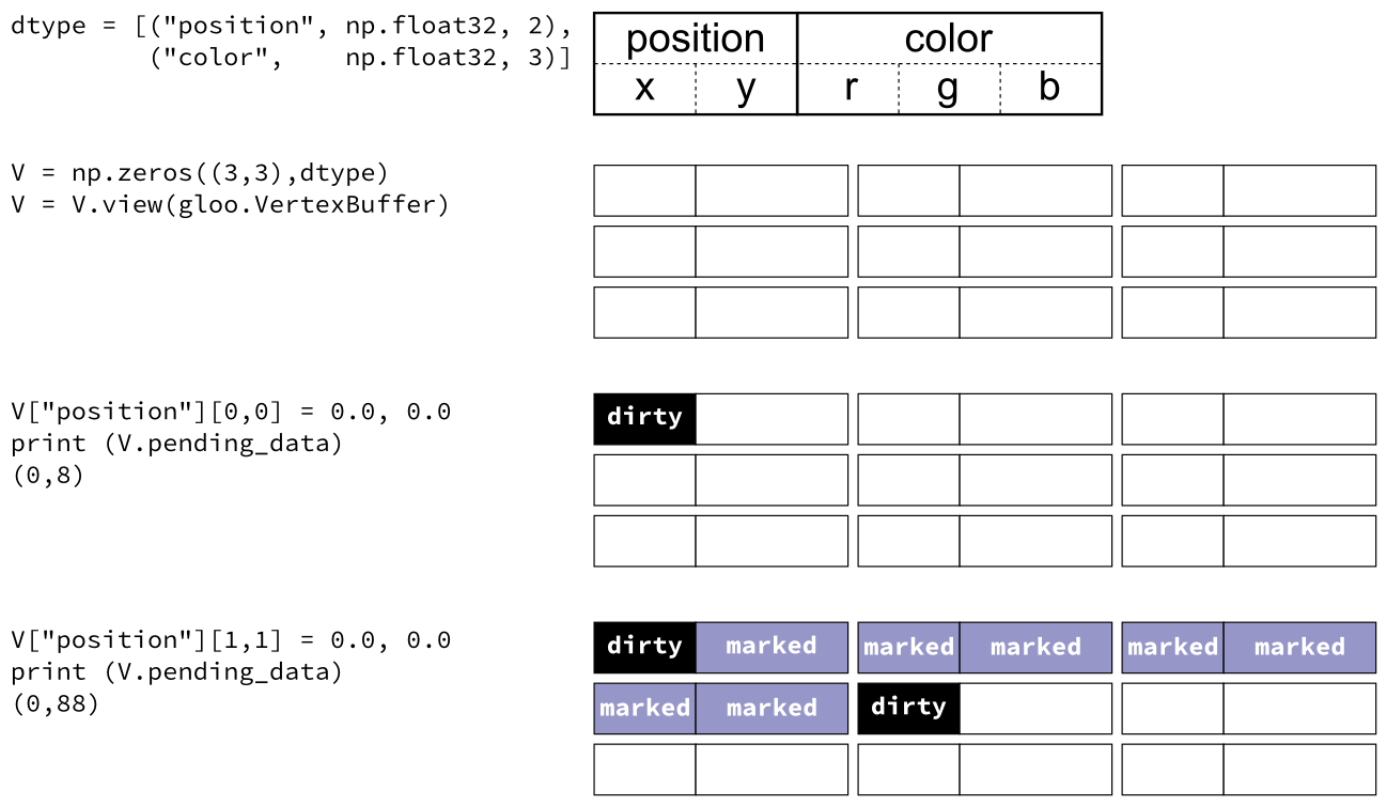
وبالتالي سينتهي الأمر بتحميل Glumpy 88 بايت بينما عُدّل 16 بايت فقط فعليًا. قد تتساءل عما إذا كان هذا هو الأمثل. في الواقع يكون الأمر كذلك في معظم الأوقات، لأن تحميل بعض البيانات إلى مخزن مؤقت يتطلب الكثير من العمليات على جانب GL ولكل استدعاء تكلفة ثابتة.
صنف فرعي من Array
كما هو موضح في توثيق Subclassing ndarray، فإن التصنيف الفرعي ndarray معقد بسبب حقيقة أن الحالات الجديدة لأصناف ndarray يمكن أن تظهر بثلاث طرق مختلفة:
- استدعاء صريح للباني.
- تحويل العرض view casting.
- قالب جديد.
ومع ذلك فإن حالتنا أبسط لأننا مهتمون فقط بتحويل العرض، لذلك نحتاج فقط إلى تعريف التابع __new__ الذي سيُستدعى عند إنشاء كل نسخة. لذلك ستجهز صنف GPUData بخاصيتين:
-
النطاقات
extents: يمثل هذا النطاق الكامل للعرض نسبيًا بالنسبة للمصفوفة الأساسية، ويُخزّن مثل إزاحة بايت وحجم بايت. -
البيانات المنتظرة
pending_data: يمثل هذا تجاور لمنطقة dirty ويُخزّن مثل (إزاحة البايت، حجم البايت) نسبيًا بالنسبة إلى خاصيةextents.
class GPUData(np.ndarray): def __new__(cls, *args, **kwargs): return np.ndarray.__new__(cls, *args, **kwargs) def __init__(self, *args, **kwargs): pass def __array_finalize__(self, obj): if not isinstance(obj, GPUData): self._extents = 0, self.size*self.itemsize self.__class__.__init__(self) self._pending_data = self._extents else: self._extents = obj._extents
نطاقات الحوسبة
نحتاج في كل مرة يُطلب فيها عرض جزئي للمصفوفة إلى حساب نطاقات هذا العرض الجزئي حتى نتمكن من الوصول إلى المصفوفة الأساسية.
def __getitem__(self, key): Z = np.ndarray.__getitem__(self, key) if not hasattr(Z,'shape') or Z.shape == (): return Z Z._extents = self._compute_extents(Z) return Z def _compute_extents(self, Z): if self.base is not None: base = self.base.__array_interface__['data'][0] view = Z.__array_interface__['data'][0] offset = view - base shape = np.array(Z.shape) - 1 strides = np.array(Z.strides) size = (shape*strides).sum() + Z.itemsize return offset, offset+size else: return 0, self.size*self.itemsize
تعقب البيانات المنتظرة pending data باستمرار
تتمثل إحدى الصعوبات الإضافية في أننا لا نريد أن تتعقب جميع طرق العرض منطقة dirty المُستخدمة ولكن نريد تعقب فقط المصفوفة الأساسية. هذا هو سبب عدم إنشاء نسخة منself._pending_data في الحالة الثانية من تابع __array_finalize__. سنتعامل مع هذا عندما نحتاج إلى تحديث بعض البيانات أثناء استدعاء __setitem__ على سبيل المثال:
def __setitem__(self, key, value): Z = np.ndarray.__getitem__(self, key) if Z.shape == (): key = np.mod(np.array(key)+self.shape, self.shape) offset = self._extents[0]+(key * self.strides).sum() size = Z.itemsize self._add_pending_data(offset, offset+size) key = tuple(key) else: Z._extents = self._compute_extents(Z) self._add_pending_data(Z._extents[0], Z._extents[1]) np.ndarray.__setitem__(self, key, value) def _add_pending_data(self, start, stop): base = self.base if isinstance(base, GPUData): base._add_pending_data(start, stop) else: if self._pending_data is None: self._pending_data = start, stop else: start = min(self._pending_data[0], start) stop = max(self._pending_data[1], stop) self._pending_data = start, stop
الخلاصة
كما هو موضح على موقع ويب NumPy، فإن مكتبة NumPy هي الحزمة الأساسية للحوسبة العلمية باستخدام بايثون، ولكن وكما هو موضح في هذا المقال يتجاوز استخدام نقاط قوة NumPy مجرد حاوية متعددة الأبعاد multi-dimensional container للبيانات العامة.
يمكن استخدام ndarray مثل خاصية خاصة في حالة واحدة (أسلوب TypedList)، أو تصنيفًا فرعيًا مباشرًا لصنف ndarray (أسلوب GPUData) لتتبع الذاكرة في حالات أخرى، وقد وضحنا كيف يمكن أن تتوسع قدرات NumPy لتناسب احتياجات محددة للغاية.
ترجمة -وبتصرّف- للفصل Custom vectorization من كتاب From Python to Numpy لصاحبه Nicolas P. Rougier.








أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.