

كتبنا تنفيذًا للواجهة Map باستخدام التعمية hashing في مقالة تنفيذ الخرائط باستخدام التعمية hashing، وتوقَّعنا أن يكون ذلك التنفيذ أسرع لأن القوائم التي يبحث فيها أقصر، ولكن ما يزال ترتيب نمو order of growth ذلك التنفيذ خطّيًّا.
إذا كان هناك عدد مقداره n من المُدْخَلات وعدد مقداره k من الخرائط الفرعية sub-maps، فإن حجم تلك الخرائط يُساوِي n/k في المتوسط، أي ما يزال متناسبًا مع n، ولكننا لو زدنا k مع n، سنتمكَّن من الحدِّ من حجم n/k.
لنفترض على سبيل المثال أننا سنضاعف قيمة k في كلّ مرّةٍ تتجاوز فيها n قيمةَ k. في تلك الحالة، سيكون عدد المُدْخَلات في كلّ خريطةٍ أقلّ من 1 في المتوسط، وأقلّ من 10 على الأغلب بشرط أن تُوزِّع دالّةُ التعميةِ المفاتيحَ بشكلٍ معقول.
إذا كان عدد المُدْخَلات في كلّ خريطةٍ فرعيّةٍ ثابتًا، سنتمكَّن من البحث فيها بزمنٍ ثابت. علاوة على ذلك، يَستغرِق حساب دالة التعمية في العموم زمنًا ثابتًا (قد يعتمد على حجم المفتاح، ولكنه لا يعتمد على عدد المفاتيح). بناءً على ما سبق، ستَستغرِق توابع Map الأساسية أي put و get زمنًا ثابتًا.
سنفحص تفاصيل ذلك في التمرين التالي.
تمرين 9
وفَّرنا التصور المبدئي لجدول تعمية hash table ينمو عند الضرورة في الملف MyHashMap.java. انظر إلى بداية تعريفه:
public class MyHashMap<K, V> extends MyBetterMap<K, V> implements Map<K, V> { // متوسط عدد المُدْخَلات المسموح بها في كل خريطة فرعية قبل إعادة حساب شيفرات التعمية private static final double FACTOR = 1.0; @Override public V put(K key, V value) { V oldValue = super.put(key, value); // تأكّد مما إذا كان عدد العناصر في الخريطة الفرعية قد تجاوز الحد الأقصى if (size() > maps.size() * FACTOR) { rehash(); } return oldValue; } }
يمتدّ الصنف MyHashMap من الصنف MyBetterMap، وبالتالي، فإنه يَرِث التوابع المُعرَّفة فيه. يعيد الصنف MyHashMap تعريفَ التابع put، فيَستدعِي أولًا التابع put في الصنف الأعلى superclass -أي يَستدعِي النسخة المُعرَّفة في الصنف MyBetterMap، ثم يَفحَص ما إذا كان عليه أن يُعيّد حساب شيفرة التعمية. يعيد التابع size عدد المُدْخَلات الكلية n بينما يعيد التابع maps.size عدد الخرائط k.
يُحدّد الثابت FACTOR -الذي يُطلَق عليه اسم عامل الحمولة load factor- العدد الأقصى للمُدْخَلات وسطيًّا في كل خريطة فرعية. إذا تحقَّق الشرط n > k * FACTOR، فهذا يَعنِي أن الشرط n/k > FACTOR مُتحقِّق أيضًا، مما يَعنِي أن عدد المُدْخَلات في كلّ خريطةٍ فرعيّةٍ قد تجاوز الحد الأقصى، ولذلك، يكون علينا استدعاء التابع rehash.
نفِّذ الأمر ant build لتصريف ملفات الشيفرة، ثم نفِّذ الأمر ant MyHashMapTest. ستفشل الاختبارات لأن تنفيذ التابع rehash يُبلِّغ عن اعتراضٍ exception، ودورك هو أن تكمل متن هذا التابع.
إذًا أكمل متن التابع rehash بحيث يُجمِّع المُدْخَلات الموجودة في الجدول. بعد ذلك، عليه أن يضبُط حجم الجدول، ويضيف المُدْخَلات إليه مرةً أخرى. وفَّرنا تابعين مساعدين هما MyBetterMap.makeMaps و MyLinearMap.getEntries. ينبغي أن يُضاعِف حلك عدد الخرائط k في كل مرة يُستدعَى فيها التابع.
تحليل الصنف MyHashMap
إذا كان عدد المُدْخَلات في أكبرِ خريطةٍ فرعيّةٍ متناسبًا مع n/k، وكانت الزيادة بقيمة k متناسبةً مع n، فإن العديد من التوابع الأساسية في الصنف MyBetterMap تُصبِح ثابتة الزمن:
public boolean containsKey(Object target) {
MyLinearMap<K, V> map = chooseMap(target);
return map.containsKey(target);
}
public V get(Object key) {
MyLinearMap<K, V> map = chooseMap(key);
return map.get(key);
}
public V remove(Object key) {
MyLinearMap<K, V> map = chooseMap(key);
return map.remove(key);
}
يَحسِب كلّ تابعٍ شيفرةَ التعمية للمفتاح، وهو ما يَستغِرق زمنًا ثابتًا، ثم يَستدعِي تابعًا على خريطةٍ فرعيّةٍ، وهو ما يَستغِرق أيضًا زمنًا ثابتًا.
ربما الأمورُ جيدةٌ حتى الآن، ولكن ما يزال من الصعب تحليل أداء التابع الأساسي الآخر put، فهو يَستغرِق زمنًا ثابتًا إذا لم يضطرّ لاستدعاء التابع rehash، ويَستغرِق زمنًا خطيًا إذا اضطرّ لذلك. بتلك الطريقة، يكون هذا التابع مشابهًا للتابع ArrayList.add الذي حللنا أداءه في مقالة "تحليل زمن تشغيل القوائم المُنفَّذة باستخدام مصفوفة".
ولنفس السبب، يتضَّح أن التابع MyHashMap.put يَستغرِق زمنًا ثابتًا إذا حسبنا متوسط زمنِ متتاليةٍ من الاستدعاءات. يعتمد هذا التفسير على التحليل بالتسديد amortized analysis الذي شرحناه في نفس المقالة.
لنفترض أن العدد المبدئيَّ للخرائط الفرعية k يساوي 2، وأن عامل التحميل يساوي 1، والآن، لنفحص الزمن الذي يَستغرِقه التابع put لإضافة متتاليةٍ من المفاتيح. سنَعُدّ عدد المرات التي سنضطرّ خلالها لحساب شيفرة التعمية لمفتاحٍ وإضافته لخريطةٍ فرعيّةٍ، وسيكون ذلك بمنزلةِ وحدةِ عملٍ واحدة.
سيُنفِّذ التابع put عند استدعائه لأوّل مرةٍ وحدة عملٍ واحدةً من وحدات العمل، وسيُنفِّذ أيضًا عند استدعائه في المرة الثانية وحدةَ عملٍ واحدةٍ. أمّا في المرة الثالثة، فسيضطرّ لإعادة حساب شيفرات التعمية، وبالتالي، سيُنفِّذ عدد 2 من وحدات العمل لكي يَحسِب شيفرات تعمية المفاتيح الموجودة بالفعل بالإضافة إلى وحدة عملٍ أخرى لحساب شيفرة تعمية المفتاح الجديد.
والآن، أصبح حجم الجدول 4، وبالتالي، سيُنفِّذ التابع put عند استدعائه في المرة التالية وحدة عملٍ واحدةٍ، ولكن، في المرة التالية التي سيضطرّ خلالها لاستدعاء rehash، فإنه سيُنفِّذ 4 وحدات عملٍ لحساب شيفرات تعميةِ المفاتيح الموجودة ووحدة عملٍ إضافيةٍ للمفتاح الجديد.
تُوضِّح الصورة التالية هذا النمط، حيث يظهر العمل اللازم لحساب شيفرة تعمية مفتاحٍ جديدٍ في الأسفل بينما يَظهَر العمل الإضافي كبرج.
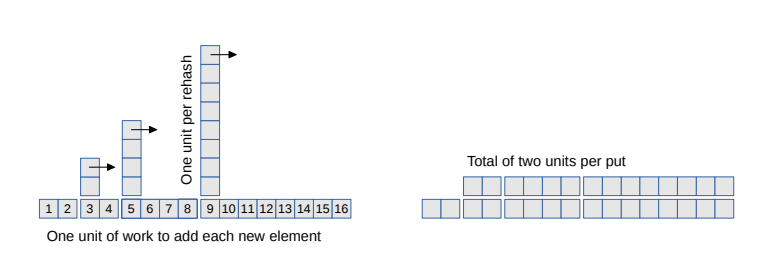
إذا أنزلنا الأبراج كما تقترح الأسهم، سيملأ كلّ واحدٍ منها الفراغ الموجود قبل البرج التالي، وسنحصل على ارتفاعٍ منتظمٍ يساوي 2 وحدة عمل. يُوضِّح ذلك أن متوسط العمل لكل استدعاءٍ للتابع put هو 2 وحدة عمل، مما يَعنِي أنه يَستغرِق زمنًا ثابتًا في المتوسط.
يُوضِح الرسم البياني مدى أهمية مضاعفة عدد الخرائط الفرعية k عندما نعيد حساب شيفرات التعمية؛ فلو أضفنا قيمةً ثابتةً إلى k بدلًا من مضاعفتها، ستكون الأبراج قريبة جدًا من بعضها، وستتراكم فوق بعضها، وعندها، لن نحصل على زمن ثابت.
مقايضات
رأينا أن التوابع containsKey و get و remove تَستغرِق زمنًا ثابتًا، وأن التابع put يَستغرِق زمنًا ثابتًا في المتوسط، وهذا أمرٌ رائعٌ بحق، فأداء تلك العمليات هو نفسه تقريبًا بغض النظر عن حجم الجدول.
يَعتمِد تحليلنا لأداء تلك العمليات على نموذج معالجةٍ بسيطٍ تَستغرِق كلّ وحدةٍ عمل فيه نفس مقدار الزمن، ولكن الحواسيب الحقيقية أعقدُ من ذلك بكثير، فتبلغ أقصى سرعتها عندما تتعامل مع هياكل بيانات صغيرة بما يكفي لتُوضَع في الذاكرة المخبئية cache، وتكون أبطأ قليلًا عندما لا يتناسب حجم هياكل البيانات مع الذاكرة المخبئية ولكن مع إمكانية وضعها في الذاكرة، وتكون أبطأ بكثيرٍ إذا لم يتناسب حجم الهياكل حتى مع الذاكرة.
هنالك مشكلةٌ أخرى، وهي أن التعمية لا تكون ذات فائدةٍ في هذا التنفيذ إذا كان المُدْخَل قيمةً وليس مفتاحًا، فالتابع containsValue خطّيٌّ لأنه مضطرّ للبحث في كل الخرائط الفرعية، فليس هناك طريقةٌ فعالةٌ للبحث عن قيمة ما والعثور على مفتاحها المقابل (أو مفاتيحها).
بالإضافة إلى ما سبق، فإن بعض التوابع التي كانت تَستغرِق زمنًا ثابتًا في الصنف MyLinearMap قد أصبحت خطّيّةً. انظر إلى التابع التالي على سبيل المثال:
public void clear() {
for (int i=0; i<maps.size(); i++) {
maps.get(i).clear();
}
}
يضطرّ التابع clear لتفريغ جميع الخرائط الفرعيّةِ التي يتناسب عددها مع n، وبالتالي، هذا التابعُ خطّيٌّ. لحسن الحظ، لا يُستخدَم هذا التابع كثيرًا، ولذا فما يزال هذا التنفيذ مقبولًا في غالبية التطبيقات.
تشخيص الصنف MyHashMap
سنفحص أولًا ما إذا كان التابع MyHashMap.put يستغرق زمنًا خطيًا.
نفِّذ الأمر ant build لتصريف ملفات الشيفرة، ثم نفِّذ الأمر ant ProfileMapPut. يقيس الأمر زمن تشغيل التابع HashMap.put (الذي توفِّره جافا) مع أحجام مختلفةٍ للمشكلة، ويَعرِض زمن التشغيل مع حجم المشكلة بمقياس لوغاريتمي-لوغاريتمي. إذا كانت العملية تستغرق زمنًا ثابتًا، ينبغي أن يكون الزمن الكليُّ لعدد n من العمليات خطيًّا، ونحصل عندها على خطٍّ مستقيمٍ ميله يساوي 1. عندما شغَّلنا تلك الشيفرة، كان الميل المُقدَّر قريبًا من 1، وهو ما يتوافق مع تحليلنا للتابع. ينبغي أن تحصل على نتيجةٍ مشابهة.
عدِّل الصنف ProfileMapPut.java لكي يُشخِّص التنفيذ MyHashMap الخاص بك وليس تنفيذ الجافا HashMap. شغِّل شيفرة التشخيص مرةً أخرى، وافحص ما إذا كان الميل قريبًا من 1. قد تضطرّ إلى تعديل قيم startN و endMillis لكي تعثر على نطاقٍ مناسبٍ من أحجام المشكلة يبلغ زمن تشغيلها أجزاءَ صغيرةً من الثانية، وفي نفس الوقت لا يتعدى بضعة آلاف.
عندما شغّلنا تلك الشيفرة، وجدنا أن الميلَ يساوي 1.7 تقريبًا، مما يشير إلى أن ذلك التنفيذ لا يستغرق زمنًا ثابتًا. في الحقيقة، هو يحتوي على خطأٍ برمجيٍّ مُتعلِّقٍ بالأداء.
عليك أن تعثر على ذلك الخطأِ وتصلحَه وتتأكَّد من أن التابع put يستغرق زمنًا ثابتًا كما كنا نتوقّع قبل أن تنتقل إلى القسم التالي.
إصلاح الصنف MyHashMap
تتمثل مشكلة الصنف MyHashMap بالتابع size الموروث من الصنف MyBetterMap. انظر إلى شيفرته فيما يلي:
public int size() { int total = 0; for (MyLinearMap<K, V> map: maps) { total += map.size(); } return total; }
كما ترى يضطرّ التابع للمرور عبر جميع الخرائط الفرعية لكي يحسب الحجم الكلّيّ. نظرًا لأننا نزيد عدد الخرائط الفرعية k بزيادة عدد المُدْخَلات n، فإن k يتناسب مع n، ولذلك، يستغرق تنفيذ التابع size زمنًا خطّيًّا.
يجعل ذلك التابع put خطّيًّا أيضًا لأنه يَستخدِم التابع size كما هو مُبيَّنٌ في الشيفرة التالية:
public V put(K key, V value) { V oldValue = super.put(key, value); if (size() > maps.size() * FACTOR) { rehash(); } return oldValue; }
إذا تركنا التابع size خطّيًّا، فإننا نهدر كل ما فعلناه لجعل التابع put ثابتَ الزمن.
لحسن الحظ، هناك حلٌّ بسيطٌ رأيناه من قبل، وهو أننا سنحتفظ بعدد المُدْخَلات ضمن متغير نسخة instance variable، وسنُحدِّثه كلما استدعينا تابعًا يُجرِي تعديلًا عليه.
ستجد الحل في مستودع الكتاب في الملف MyFixedHashMap.java. انظر إلى بداية تعريف الصنف:
public class MyFixedHashMap<K, V> extends MyHashMap<K, V> implements Map<K, V> { private int size = 0; public void clear() { super.clear(); size = 0; }
بدلًا من تعديل الصنف MyHashMap، عرَّفنا صنفًا جديدًا يمتدّ منه، وأضفنا إليه متغير النسخة size، وضبطنا قيمتَه المبدئيَّة إلى صفر.
أجرينا أيضًا تعديلًا بسيطًا على التابع clear. استدعينا أولًا نسخة clear المُعرَّفة في الصنف الأعلى (لتفريغ الخرائط الفرعية)، ثم حدثنا قيمة size.
كانت التعديلات على التابعين remove و put أعقد قليلًا؛ لأننا عندما نستدعي نسخها في الصنف الأعلى، فإننا لا نستطيع معرفة ما إذا كان حجم الخرائط الفرعيّة قد تغيّر أم لا. تُوضِّح الشيفرة التالية الطريقة التي حاولنا بها معالجة تلك المشكلة:
public V remove(Object key) { MyLinearMap<K, V> map = chooseMap(key); size -= map.size(); V oldValue = map.remove(key); size += map.size(); return oldValue; }
يَستخدِم التابعُ remove التابعَ chooseMap لكي يعثر على الخريطة المناسبة، ثم يَطرَح حجمها. بعد ذلك، يَستدعِي تابع الخريطة الفرعية remove الذي قد يُغيّر حجم الخريطة، حيث يعتمد ذلك على ما إذا كان قد وجد المفتاح فيها أم لا، ثم يضيف الحجم الجديد للخريطة الفرعية إلى size، وبالتالي تصبح القيمة النهائية صحيحة.
أعدنا كتابة التابع put باتباع نفس الأسلوب:
public V put(K key, V value) { MyLinearMap<K, V> map = chooseMap(key); size -= map.size(); V oldValue = map.put(key, value); size += map.size(); if (size() > maps.size() * FACTOR) { size = 0; rehash(); } return oldValue; }
واجهنا نفس المشكلة هنا: عندما استدعينا تابع الخريطة الفرعية put، فإننا لا نعرف ما إذا كان قد أضاف مدخلًا جديدًا أم لا، ولذلك استخدمنا نفس الحل، أي بطرح الحجم القديم، ثم إضافة الحجم الجديد.
والآن، أصبح تنفيذ التابع size بسيطًا:
public int size() { return size; }
ويستغرق زمنًا ثابتًا بوضوح.
عندما شخَّصنا أداء هذا الحل، وجدنا أن الزمنَ الكلّيَّ لإضافة عدد n من المفاتيح يتناسب مع n، ويعني ذلك أن كلّ استدعاءٍ للتابع put يستغرق زمنًا ثابتًا كما هو مُتوقّع.
مخططات أصناف UML
كان أحد التحديات التي واجهناها عند العمل مع شيفرة هذا المقال هو وجود عددٍ كبيرٍ من الأصناف التي يعتمد بعضها على بعض. انظر إلى العلاقات بين تلك الأصناف:
-
MyLinearMapيحتوي علىLinkedListويُنفِّذMap. -
MyBetterMapيحتوي على الكثير من كائنات الصنفMyLinearMapويُنفِّذMap. -
MyHashMapيمتد من الصنفMyBetterMap، ولذلك يحتوي على كائناتٍ تنتمي إلى الصنفMyLinearMapويُنفِّذMap. -
MyFixedHashMapيمتد من الصنفMyHashMapويُنفِّذMap.
لتسهيلِ فهمِ هذا النوع من العلاقات، يلجأ مهندسو البرمجيات إلى استخدامِ مخططاتِ أصنافِ UML -اختصارً إلى لغة النمذجة الموحدة Unified Modeling Language. تُعدّ مخططات الأصناف class diagram واحدةً من المعايير الرسومية التي تُعرِّفها UML.
يُمثَّل كل صنفٍ في تلك المخططات بصندوق، بينما تُمثَل العلاقات بين الأصناف بأسهم. تَعرِض الصورة التالية مخطط أصناف UML للأصناف المُستخدَمة في التمرين السابق، وهي مُولَّدةٌ تلقائيًّا باستخدام أداة yUML المتاحة عبر الإنترنت.
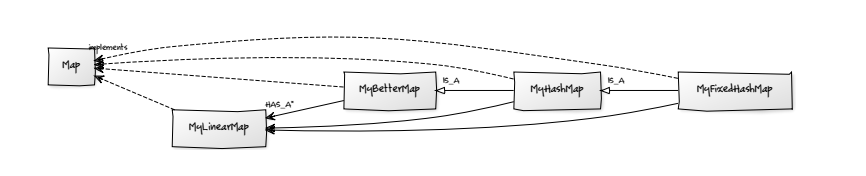
تُمثَّل العلاقات المختلفة بأنواعٍ مختلفة من الأسهم:
-
تشير الأسهم ذات الرؤوس الصلبة إلى علاقات من نوع HAS-A. على سبيل المثال، تحتوي كلّ نسخةٍ من الصنف
MyBetterMapعلى نسخٍ متعددةٍ من الصنفMyLinearMap، ولذلك هي متصلة بأسهم صلبة. -
تشير الأسهم ذات الرؤوس المجوفةِ والخطوطِ الصلبة إلى علاقات من نوع IS-A. على سبيل المثال، يمتد الصنف
MyHashMapمن الصنفMyBetterMap، ولذلك ستجدهما موصولين بسهم IS-A. - تشير الأسهم ذات الرؤوس المجوّفة والخطوط المتقطّعة إلى أن الصنف يُنفِّذ واجهة. تُنفِّذ جميع الأصناف في هذا المخطط الواجهةَ Map.
تُوفِّر مخططات أصناف UML طريقةً موجزةً لتوضيح الكثير من المعلومات عن مجموعةٍ من الأصناف، وتُستخدَم عادةً في مراحل التصميم للإشارة إلى تصاميمَ بديلة، وفي مراحل التنفيذ لمشاركة التصور العام عن المشروع، وفي مراحل النشر لتوثيق التصميم.
ترجمة -بتصرّف- للفصل Chapter 11: HashMap من كتاب Think Data Structures: Algorithms and Information Retrieval in Java.











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.