

تُعرف اللغتان C وC++ بانّ أداءهما عال جدًّا - ويُعزى ذلك في الغالب إلى إمكانية التخصيص المكثّف للشيفرة، إذ يُسمح للمستخدم بتحسين الأداء عبر اختيار بنية الشيفرة وكيفية تنفيذها. وإن أردت تحسين الشيفرة فمن المهم أن تفهمها وتعرف كيفية استخدامها.
وتشمل بعض أخطاء التحسين الشائعة ما يلي:
- التحسين السابق لأوانه: قد يسوء أداء الشيفرات المعقّدة بعد التحسين ممّا يضيع الوقت ويقلل الكفاءة. يجب أن تكون الأولوية هي كتابة شيفرة صحيحة وقابلة للصيانة، وليس شيفرة مُحسَّنة.
- التحسين في الحالات غير المناسبة: إضافة تحميل زائد لأجل حالة احتمال حدوثها 1% لا يستحقّ أن تبطئ لأجله 99% من الحالات الأخرى.
- التحسين المصغّر Micro-optimization: تقوم المُصرِّفات بهذا الأمر بفعالية كبيرة، كما أن التحسين المصغَّر يمكن أن يضرّ بقدرة المُصرِّفات على زيادة تحسين الشيفرة.
وبعض أهداف التحسين النموذجية ما يلي:
- تقليل كمية العمل المطلوبة.
- استخدام خوارزميات / بنيات أكثر فاعلية.
- استغلال العتاد بشكل أفضل.
لكن قد تكون لعمليات التحسين تأثيرات جانبية سلبية، مثل:
- الاستخدام المكثّف للذاكرة.
- تعقيد الشيفرة وصعوبة قراءتها أو صيانتها.
- تعقيد الواجهات البرمجية API وتصميمات الشيفرة.
على أي حال، غالبًا ما يُعدِّل المُصرِّفُ البرنامجَ عند التصريف لتحسين أدائه، وهذا مسموح به وفقًا لقاعدة "كما لو" as-if rule. والتي تسمح بإجراء التغييرات والتحويلات التي لا تغيّر السلوك الملاحظ للبرنامج.
تحسين الصنف الأساسي الفارغ Empty Base Class Optimization
لا يمكن أن يشغل كائن ما أقل من بايت واحد، وإلّا لكانت أعضاء المصفوفات التي تضم عناصر من نفس النوع تحتل العنوان نفسه. لهذا، تكون sizeof(T)>=1 صحيحة دائما. وكذلك لا يمكن أن يكون الصنف المشتق أصغر من صنفه الأساسي base class. لكن إن كان الصنف الأساسي فارغًا، فلن يُضاف حجمه بالضرورة إلى الصنف المشتق:
class Base {}; class Derived: public Base { public: int i; };
وليس من الضروري هنا تخصيص بايت للصنف Base داخل Derived حتى يحتلّ كل كائن -بغض النظر عن نوعه- عنوانًا مميّزًا. وفي حال إجراء تحسين للصنف الأساسي الفارغ -ولم تكن هناك حاجة إلى الحشو padding-، فستكون العبارة sizeof(Derived) ==sizeof(int) صحيحة، أي أنّه لن يُجرى أيّ تخصيص إضافي للصنف الفارغ. هذا ممكن حتّى مع الأصناف الأساسية base classes المتعددة، إذ لا يمكن لعدّة أًصناف أساسية في ++C أن يكون لها نفس النوع، وعليه فلن تنشأ مشكلة من ذلك.
لاحظ أنّه لا يمكن إجراء ذلك إلا إذا كان نوع العضو الأول من Derived مختلفًا عن كلّ الأصناف الأساسية، وهذا يشمل كل الأصناف الأساسية المشتركة بشكل مباشر أو غير مباشر. وإذا كان له نفس نوع أحد أصنافه الأساسية -أو كانت هناك صنف أساسية مشترك)- فيلزم على الأقل تخصيص بايت واحد لضمان ألّا يحتلّ كائنان مختلفان من نفس النوع العنوان نفسه.
التحسين عن طريق تقليل الشيفرة المنفذة
الأسلوب الأوضح للتحسين هو تقليل الشيفرة المنفّذة، فعادة ما يسرِّع التنفيذَ دون تغيير التعقيد الزمني للشيفرة. لكن رغم أنّ هذه الطريقة تسرّع البرنامج، فلن تظهر فائدتها إلّا في الشيفرات التي تُستدعى كثيرًا.
هذه بعض الأمثلة على تقليل الشيفرات المنفّذة:
إزالة الشيفرات عديمة الفائدة
void func(const A *a); // دالة ما // تخصيص غير ضروري للذاكرة + إلغاء تخصيص النسخة auto a1 = std::make_unique<A>(); func(a1.get()); // استخدام المكدّس يمنع auto a2 = A{}; func(&a2);
الإصدار ≥ C++ 14
منذ الإصدار C++ 14، يُسمح للمُصرِّفات بتحسين هذه الشيفرة لإزالة تخصيص الذاكرة، ومطابقة التحرير matching deallocation.
تنفيذ الشيفرة مرة واحدة فقط
std::map<std::string, std::unique_ptr<A>> lookup; // إدارج/بحث بطيئ // داخل هذه الدالة، سنمر على القاموس مرّتين لأجل البحث عن العنصر، ومرّة ثالثة إن لم يكن موجودا const A *lazyLookupSlow(const std::string &key) { if (lookup.find(key) != lookup.cend()) lookup.emplace_back(key, std::make_unique<A>()); return lookup[key].get(); } // داخل هذه الدالة، سيحصل نفس التأثير الذي يحدث في النسخة الأبطأ لكن مع مضاعفة السرعة // لأنّنا سنمر على القاموس مرة واحدة فقط const A *lazyLookupSlow(const std::string &key) { auto &value = lookup[key]; if (!value) value = std::make_unique<A>(); return value.get(); }
يمكن استخدام أسلوب مشابه للتحسين عبر تنفيذ implement إصدار مستقر من unique:
std::vector<std::string> stableUnique(const std::vector<std::string> &v) { std::vector<std::string> result; std::set<std::string> checkUnique; for (const auto &s : v) { // يُعاد الإدراج إن كان ناجحا، لذلك يمكن أن نعرف ما إذا كان العنصر موجودًا أم لا // هذا يمنع الإدراج، والذي سيمر على القاموس مرّة لكل عنصر فريد // على عناصر مكرّرة v يُكسِبنا هذا حوالي نصف الوقت إن لم تحتو if (checkUnique.insert(s).second) result.push_back(s); } return result; }
منع عمليات إعادة التخصيص والنسخ أو النقل عديمة الفائدة
منعنا في المثال السابق عمليّات البحث في std::set، بيْد أنّ هذا غير كافٍ، فما يزال المتجه std::vector يحتوي على خوارزمية مكلّفة ونامية ستحتاج إلى نقل ذاكرتها، يمكن منع هذا عبر حجز الحجم المناسب.
في المثال التالي، نضمن عدم حدوث أي نسخ أو نقل في المتجه لأن سعته تساوي الحد الأقصى للأعداد التي سندرجها، وإن افترضنا عدم حدوث أي تخصيص من الحجم صفر، وأن تخصيص كتلة كبيرة من الذاكرة يأخذ نفس الوقت الذي يأخذه تخصيص حجم صغير فهذا لن يبطئ البرنامج.
ملاحظة: يمكن أن تنتبه المصرفات لهذا الأمر وتحذف شيفرة التحقق من الشيفرة المولَّدة.
std::vector<std::string> stableUnique(const std::vector<std::string> &v) { std::vector < std::string > result; result.reserve(v.size()); std::set < std::string > checkUnique; for (const auto &s : v) { // انظر المثال أعلاه if (checkUnique.insert(s).second) result.push_back(s); } return result; }
استخدام حاويات أكفأ
استخدام بنيات البيانات الصحيحة في الوقت المناسب يمكن أن يحسّن التعقيد الزمني للشيفرة، انظر المثال التالي حيث يساوي تعقيد stableUnique هنا (N log(N، حيث N أكبر من عدد العناصر في v:
// log(N) > insert complexity of std::set std::vector<std::string> stableUnique(const std::vector<std::string> &v) { std::vector<std::string> result; std::set<std::string> checkUnique; for (const auto &s : v) { // انظر فقرة التحسين عبر تقليل الشيفرة المنفّذة if (checkUnique.insert(s).second) result.push_back(s); } return result; }
يمكننا تخفيض تعقيد التقديم إلى N عبر استعمال حاوية تستخدم تنفيذًا مختلفًا لتخزين عناصرها، مثل قاموس hash بدلًا من شجرة tree. وهناك أثر جانبي إضافي أيضًا، وهو تقليل استدعاء مُعامل المقارنة على السلاسل النصية، لأنّنا لن نحتاج إلى استدعائها إلّا في حال كانت ستُدرج السلسلة النصية في نفس المجموعة. انظر المثال التالي حيث يكون تعقيد stableUnique مساويًا لـ (N log (N، حيث N أكبر من عدد العناصر في v:
// أكبر من 1 std::unordered_set تعقيد الإدراج في std::vector<std::string> stableUnique(const std::vector<std::string> &v) { std::vector<std::string> result; std::unordered_set<std::string> checkUnique; for (const auto &s : v) { // انظر فقرة التحسين عبر تقليل الشيفرة المنفّذة if (checkUnique.insert(s).second) result.push_back(s); } return result; }
تحسين الكائنات الصغيرة Small Object Optimization
تحسين الكائنات الصغيرة هي تقنية تُستخدم في بنيات البيانات منخفضة المستوى، مثل std::string (يشار إليها أحيانًا باسم تحسين السلاسل النصية القصيرة/الصغيرة)، ويُقصد بها استخدام مساحة مكدّس كمخزن مؤقت buffer بدلًا من استخدام ذاكرة مخصّصة عندما يكون المحتوى صغيرًا بدرجة كافية لتسَعَه المساحة المحجوزة. وسنحاول منع تخصيص مساحة في الكومة heap، لكنّ ثمن هذا هو إضافة حمل إضافي overhead على الذاكرة، وإجراء بعض الحسابات الإضافية.
تعتمد فوائد هذه التقنية على نوع الاستخدام، ويمكن أن تضرّ بالأداء في حال استخدامها بشكل غير صحيح. هذا مثال على ذلك، الطريقة التالية ساذجة لكتابة سلسلة نصية باستخدام هذا التحسين:
#include <cstring> class string final { constexpr static auto SMALL_BUFFER_SIZE = 16; bool _isAllocated{false}; ///< تذكّر إذا كنّا قد خصّصنا الذاكرة char *_buffer{nullptr}; ///< مؤشر يشير إلى المخزن المؤقت الذي نستخدمه char _smallBuffer[SMALL_BUFFER_SIZE]= {'\0'}; ///< SMALL OBJECT مساحة المكدّس المُستخدمة لأجل الكائن الصغير OPTIMIZATION public: ~string() { if (_isAllocated) delete [] _buffer; } explicit string(const char *cStyleString) { auto stringSize = std::strlen(cStyleString); _isAllocated = (stringSize > SMALL_BUFFER_SIZE); if (_isAllocated) _buffer = new char[stringSize]; else _buffer = &_smallBuffer[0]; std::strcpy(_buffer, &cStyleString[0]); } string(string &&rhs) : _isAllocated(rhs._isAllocated) , _buffer(rhs._buffer) , _smallBuffer(rhs._smallBuffer) //< غير ضروري عند التخصيص { if (_isAllocated) { // منع الحذف المزدوج للذاكرة rhs._buffer = nullptr; } else { // نسخ البيانات std::strcpy(_smallBuffer, rhs._smallBuffer); _buffer = &_smallBuffer[0]; } } // حَذفنا التوابع الأخرى، مثل منشئ النسخ ومعامل الإسناد، لأجل تحسين القراءة والوضوح };
كما ترى في الشيفرة أعلاه، فقد أُضيفت بعض التعقيدات الإضافية لمنع تنفيذ بعض عمليات new و delete. وأصبح لدى الصنف مساحة أكبر للذاكرة، وقد لا يستخدَمها إلا في بضع حالات فقط.
غالبًا ما سيُحاول ترميزَ القيمة البوليانية _isAllocated داخل المؤشّر _buffer عبر معالجة البتّات من أجل تقليل حجم النُسخة (intel 64 bit: يمكن أن يقلّل الحجم بمقدار 8 بايت)، لكن هذا التحسين غير ممكن إلا إن كانت قواعد المحاذاة الخاصّة بالمنصة معروفة.
حالات الاستخدام
نظرًا لأنّ هذا التحسين يضيف الكثير من التعقيد، فليس من المستحسن استخدامه في كل الأصناف. وستُصادفه غالبًا في بنيات البيانات منخفضة المستوى شائعة الاستخدام.
قد تجد بعض الاستخدامات في std::basic_string<> و std::function<> في تطبيقات implementations المكتبة القياسية الشائعة في C++ 11.
وبما أن هذا التحسين لا يمنع تخصيصات الذاكرة إلا عندما تكون البيانات المُخزّنة أصغر من القيمة المضافة، فستظهر فائدته بالخصوص في الأصناف التي تُستخدم غالبًا مع البيانات الصغيرة. لكن هناك عيب فيه وهو الحاجة إلى جهد إضافي عند تحريك المخزن المؤقت، وهذا يجعل عمليّات النقل أكثر كلفة موازنة بالحالات التي لا يُستخدم المخزن المؤقّت فيها، خاصة عندما يحتوي المخزن المؤقّت على نوع بيانات غير قديم non-POD type.
توسيع التضمين والتضمين
توسيع التضمين Inline expansion، أو التضمين inlining وحسب، هي تقنية تحسين يستخدمها المُصرِّف تقوم على تعويض استدعاء دالة بمتن تلك الدالّة. هذا يقلّل من الحمل الزائد overhead لاستدعاء الدوالّ، ولكن على حساب الذاكرة، إذ أنّ الدالّة قد تُكرّر عدّة مرات.
// :المصدر int process(int value) { return 2 * value; } int foo(int a) { return process(a); } // :البرنامج بعد التضمين int foo(int a) { return 2 * a; // foo() في process() نسخ متن }
تُستخدم تقنية التضمين غالبًا مع الدوال الصغيرة، حيث يكون الحمل الزائد لاستدعاء الدالّة صغيرًا مقارنةً بحجم جسم الدالّة.
تحسين الصنف الأساسي الفارغ Empty base optimization
يجب أن لا يقلّ حجم أي كائن أو عضو من كائن فرعي عن القيمة 1، حتى لو كان ذلك النوع فارغًا (أي حتى لو لم يحتوٍ الصنف class أو البنية struct على أعضاء بيانات غير ساكنة)، وذلك لأجل ضمان أن تكون عناوين الكائنات المختلفة التي تنتمي لنفس النوع مختلفة دائمًا.
بالمقابل، فإنّ القيود على الكائنات الفرعية من الصنف الأساسي base class subobjects أقل بكثير، ويمكن تحسينها بشكل كامل انطلاقًا من مخطط الكائن:
#include <cassert> struct Base {}; // صنف فارغ struct Derived1: Base { int i; }; int main() { // حجم أيّ كائن من صنف فارغ يساوي 1 على الأقل assert(sizeof(Base) == 1); // تطبيق تحسين الصنف الفارغ assert(sizeof(Derived1) == sizeof(int)); }
يُستخدم تحسين الصنف الفارغ عادةً في أصناف المكتبة القياسية الواعية بتخصيص كل من الذاكرة:
-
std::vector. -
std::function. -
std::shared_ptr.
أو غيرها، وذلك لتجنّب شغل أي مساحة تخزين إضافية من قبل عضو مُخصِّص allocator member إذا كان ذلك المُخصّص عديم الحالة stateless. ويمكن تحقيق ذلك عن طريق تخزين أحد أعضاء البيانات المطلوبة، مثل: مؤشّرات begin و end، أو capacity الخاصّة بالمتجهات.
التشخيص Profiling
التشخيص باستخدام gcc وgprof
يتيح لك برنامج التشخيص gprof الخاصّ بـ GNU gprof تشخيص شيفرتك. ولأجل لاستخدامه، عليك إنجاز الخطوات التالية:
- ابنِ التطبيق مع الإعدادات المناسبة لتوليد معلومات التشخيص.
- قم بتوليد معلومات التشخيص عن طريق تشغيل التطبيق المبني.
- اعرض معلومات التشخيص المُولّدة باستخدام أداة gprof.
أضف راية -pg لأجل بناء التطبيق مع إعدادات توليد معلومات التشخيص المناسبة، انظر:
$ gcc -pg *.cpp -o app
أو:
$ gcc -O2 -pg *.cpp -o app
وهكذا دواليك. بمجرد إنشاء التطبيق (نفترض أنّ اسمه app)، نفِّذه كالمعتاد:
$ ./app
من المفروض أن ينتج هذا الأمرُ ملفًّا يُسمّى gmon.out. إن أردت رؤية نتائج التشخيص، نفّذ الأمر التالي:
$ gprof app gmon.out
(لاحظ أننا وقرنا كلًّا من التطبيق وكذلك الخرج الناتج). ويمكنك توجيه الخرج أو إعادة توجيهه:
$ gprof app gmon.out | less
يجب أن تكون نتيجة الأمر الأخير مطبوعة على شكل جدول، ستمثّل صفوفهُ الدوالَّ، أمّا أعمدته فتشير إلى عدد الاستدعاءات، وإجمالي الوقت المستغرق، والوقت الذاتي المستغرق - self time spent - (أي الوقت المستغرق داخل الدالة ما عدا استدعاءات الدوال الداخلية).
إنشاء مخططات الاستدعاءات callgraph بواسطة gperf2dot
بالنسبة للتطبيقات الكبيرة، فقد يصعب فهم تنسيق التشخيص المُستَوي flat execution profiles، لهذا تنتج العديد من أدوات التشخيص رسومًا تخطيطية لتسهيل قراءتها.
تحوّل أداة gperf2dot خرْج النص الذي تنتجه العديد من المُشخِّصات، مثل: Linux perf، وcallgrind، وoprofile إلى رسم تخطيطي، يمكنك استخدام هذه الأداة عن طريق تشغيل المشخّص profiler الذي تعمل به مثل gprof:
# التصريف مع رايات التشخيص g++ *.cpp -pg # توليد بيانات التشخيص ./main # ترجمة بيانات التشخيص إلى نص، وإنشاء صورة gprof ./main | gprof2dot -s | dot -Tpng -o output.png
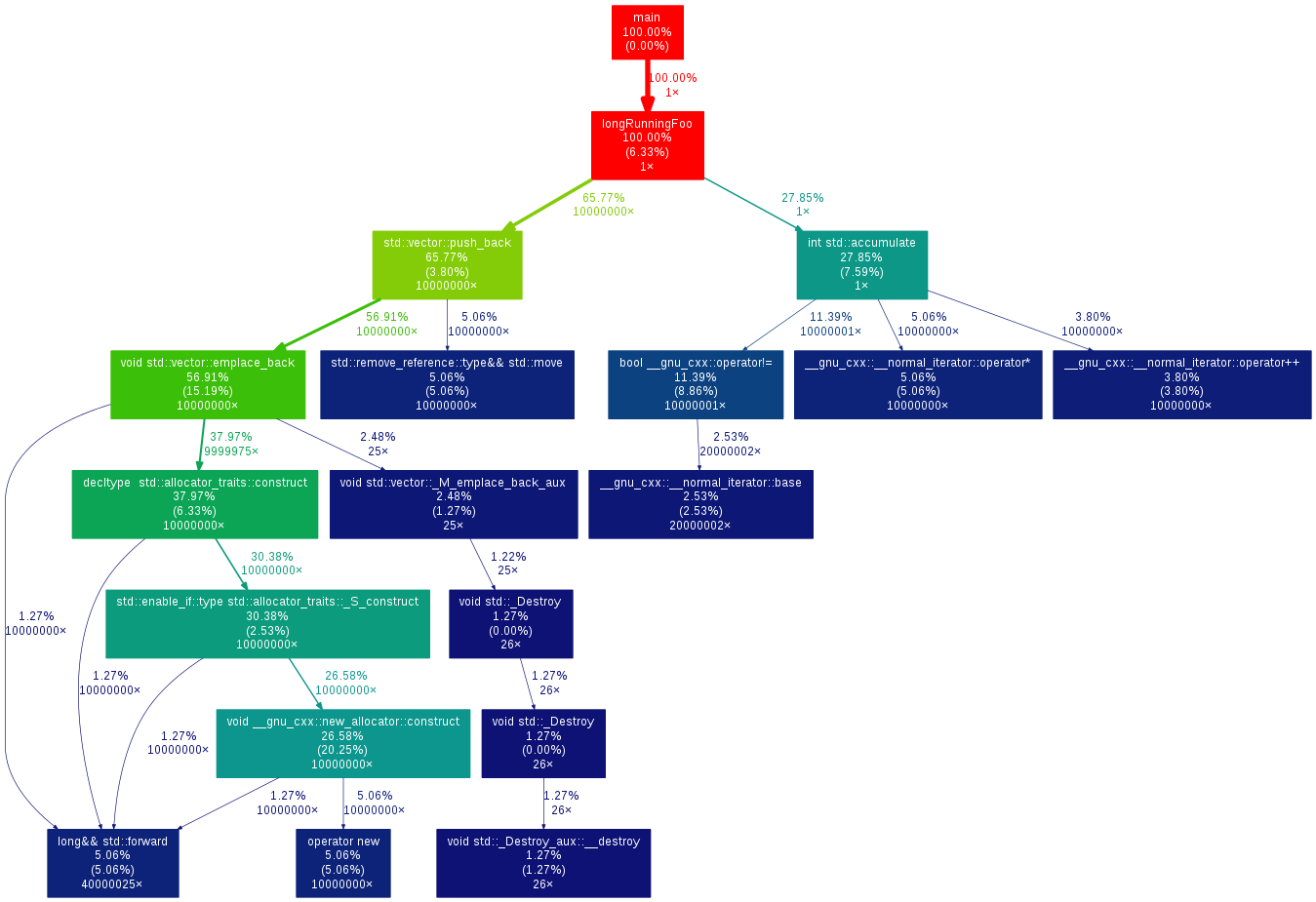
تشخيص استخدام وحدة المعالجة المركزية بواسطة gcc وGoogle Perf
توفّر أدوات Google Perf برنامج تشخيص لوحدة المعالجة المركزية CPU، مع واجهة استخدام سهلة نسبيًا.
لاستخدامها عليك:
- تثبيت أدوات Google Perf .
- تصريف الشيفرة كالمعتاد.
-
إضافة مكتبة التشخيص
libprofilerإلى مسار تحميل المكتبات في وقت التشغيل. -
استخدم
pprofلتوليد تشخيص نصّي، أو رسم تخطيطي. مثلّا:
g++ -O3 -std=c++11 main.cpp -o main # تنفيذ المُشخِّص LD_PRELOAD=/usr/local/lib/libprofiler.so CPUPROFILE=main.prof CPUPROFILE_FREQUENCY=100000 ./main
حيث:
-
تشير
CPUPROFILEإلى ملف بيانات التشخيص، و -
تشير
CPUPROFILE_FREQUENCYإلى تردّد عيّنات المشخّص profiler sampling frequency. إن أردت إجراء المعالجة اللاحقة post-process لبيانات التشخيص، فاستخدمpprof، ويمكنك إنشاء تشخيص استدعاءات flat call profile على هيئة نصّ:
$ pprof --text ./main main.prof PROFILE: interrupts/evictions/bytes = 67/15/2016 pprof --text --lines ./main main.prof Using local file ./main. Using local file main.prof. Total: 67 samples 22 32.8% 32.8% 67 100.0% longRunningFoo ??:0 20 29.9% 62.7% 20 29.9% __memmove_ssse3_back /build/eglibc-3GlaMS/eglibc-2.19/string/../sysdeps/x86_64/multiarch/memcpy-ssse3-back.S:1627 4 6.0% 68.7% 4 6.0% __memmove_ssse3_back /build/eglibc-3GlaMS/eglibc-2.19/string/../sysdeps/x86_64/multiarch/memcpy-ssse3-back.S:1619 3 4.5% 73.1% 3 4.5% __random_r /build/eglibc-3GlaMS/eglibc-2.19/stdlib/random_r.c:388 3 4.5% 77.6% 3 4.5% __random_r /build/eglibc-3GlaMS/eglibc-2.19/stdlib/random_r.c:401 2 3.0% 80.6% 2 3.0% __munmap /build/eglibc-3GlaMS/eglibc-2.19/misc/../sysdeps/unix/syscall-template.S:81 2 3.0% 83.6% 12 17.9% __random /build/eglibc-3GlaMS/eglibc-2.19/stdlib/random.c:298 2 3.0% 86.6% 2 3.0% __random_r /build/eglibc-3GlaMS/eglibc-2.19/stdlib/random_r.c:385 2 3.0% 89.6% 2 3.0% rand /build/eglibc-3GlaMS/eglibc-2.19/stdlib/rand.c:26 1 1.5% 91.0% 1 1.5% __memmove_ssse3_back /build/eglibc-3GlaMS/eglibc-2.19/string/../sysdeps/x86_64/multiarch/memcpy-ssse3-back.S:1617 1 1.5% 92.5% 1 1.5% __memmove_ssse3_back /build/eglibc-3GlaMS/eglibc-2.19/string/../sysdeps/x86_64/multiarch/memcpy-ssse3-back.S:1623 1 1.5% 94.0% 1 1.5% __random /build/eglibc-3GlaMS/eglibc-2.19/stdlib/random.c:293 1 1.5% 95.5% 1 1.5% __random /build/eglibc-3GlaMS/eglibc-2.19/stdlib/random.c:296 1 1.5% 97.0% 1 1.5% __random_r /build/eglibc-3GlaMS/eglibc-2.19/stdlib/random_r.c:371 1 1.5% 98.5% 1 1.5% __random_r /build/eglibc-3GlaMS/eglibc-2.19/stdlib/random_r.c:381 1 1.5% 100.0% 1 1.5% rand /build/eglibc-3GlaMS/eglibc-2.19/stdlib/rand.c:28 0 0.0% 100.0% 67 100.0% __libc_start_main /build/eglibc-3GlaMS/eglibc-2.19/csu/libcstart. c:287 0 0.0% 100.0% 67 100.0% _start ??:0 0 0.0% 100.0% 67 100.0% main ??:0 0 0.0% 100.0% 14 20.9% rand /build/eglibc-3GlaMS/eglibc-2.19/stdlib/rand.c:27 0 0.0% 100.0% 27 40.3% std::vector::_M_emplace_back_aux ??:0
أو يمكنك إنشاء رسم تخطيطي في ملف pdf باستخدام الأمر:
pprof --pdf ./main main.prof > out.pdf
هذا الدرس جزء من سلسلة دروس عن C++.
ترجمة -بتصرّف- للفصول:
- Chapter 143: Optimization in C++
- Chapter 144: Optimization
- Chapter 145: Profiling
من كتاب C++ Notes for Professionals












أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.