

نظرية بت المعلومات (A bit of information theory)
البت هو رقم ثنائي ووحدة معلومات أيضًا، فبت واحد يعني احتمالًا من اثنين إما 0 أو 1، أما وجود بتين يعني وجود 4 تشكيلات محتملة: 00 و 01 و 10 و 11. وإذا كان لديك b بت فهذا يعني وجود 2b قيمة محتملة، حيث يتكون البايت مثلًا من 8 بتات أي 256 (28=256) قيمة محتملة. في الاتجاه المقابل، أي إذا علمت عدد القيم المحتملة ولكنك لا تعلم عدد البتات المناسبة، افترض أنك تريد تخزين حرف واحد من حروف الأبجدية التي تتكون من 26 حرفًا فكم بتًا تحتاج؟ لديك 16 قيمة محتملة ب 4 بتات (24 = 16) وبالتالي هذا غير كافٍ لتخزين 26 حرفًا. وتحصل على 32 قيمة محتملة ب 5 بتات وهو كافٍ لتخزين كل الحروف مع قيم فائضة أيضًا. لذلك إذا أردت الحصول على قيمة واحدة من أصل N قيمة محتملة يجب عليك اختيار أصغر قيمة ل b التي تحقق (2b ≥ N)، وبأخد اللوغاريتم الثنائي للطرفين ينتج (b ≥ log2(N)).
تعطيك نتيجة رمي قطعة نقود بتًا واحدًا من المعلومات (لأن قطعة النقود تملك وجهين وبالتالي احتمالين فقط). أما نتيجة رمي حجر نرد فتعطيك log2(6) بتًا من المعلومات (لأن حجر النرد له ستة أوجه). حيث إذا كان احتمال النتيجة هو 1 من N فذلك يعني أن النتيجة تحوي log2(N) بتًا من المعلومات عمومًا، وإذا كان احتمال النتيجة هو p مثلًا فبذلك تحوي النتيجة log2(p) من المعلومات. تدعى هذه الكمية من المعلومات بالمعلومات الذاتية (self-information) للنتيجة، وهي تقيس مقدار التفاجؤ الذي تسببه تلك النتيجة، ويدعى هذا المقدار أيضًا surprisal. فإذا كان حصانك مشاركًا في سباق خيل على سبيل المثال ويملك فرصةً واحدة للفوز من أصل 16 فرصة ثم يفوز بالفعل، وبالتالي تعطيك تلك النتيجة 4 بتات من المعلومات (log2(16)=4)، أما إذا فاز حصان ما بنسبة 75% من المرات، فيتضمن ذلك الفوز الأخير 0.42 بتًا من المعلومات فقط. حيث تحمل النتائج غير المتوقعة معلومات أكثر، أما عند تأكّدك من حدوث شيء ما فلن يعطيك حدوثه بالفعل إلّا كمية قليلة من المعلومات.
ينبغي عليك أن تكون على معرفة بالتحويل بين عدد البتات الذي نرمز له ب b وعدد القيم N التي تشفّرها (encode) تلك البتات بحيث N=2b.
الذاكرة والتخزين (Memory and storage)
تُحفَظ معظم بيانات عملية ما في الذاكرة الرئيسية (main memory) ريثما تنفّذ تلك العملية، حيث أن الذاكرة الرئيسية هي نوع من الذواكر العشوائية (random access memory وتختصر إلى RAM). الذاكرة الرئيسية هي ذاكرة متطايرة (volatile) على معظم الحواسيب، والتي تعني أن محتوياتها تُفقد عند إغلاق الحاسوب. يملك الحاسوب المكتبي النموذجي ذاكرة تتراوح بين 4 و 8 جيبي بايت وربما أكثر بكثير من ذلك، حيث GiB تشير إلى جيبي بايت وهي 230 بايتًا. إذا قرأت وكتبت عملية ما ملفات فإن هذه الملفات تُخزّن على القرص الصلب (hard disk drive ويختصر إلى HDD) أو على (solid state drive ويختصر إلى SSD). وسائط التخزين هذه غير متطايرة (non-volatile)، لذلك تُستخدم للتخزين طويل الأمد. يحتوي الحاسوب المكتبي حاليًا HDD بسعة تتراوح بين 500 جيجا بايت و 2 تيرا بايت، حيث GB هي جيجا بايت وتقابل 109 بايتًا بينما تشير TB إلى تيرا بايت وتساوي 1012 بايتًا. لابد أنك لاحظت استخدام وحدة النظام الثنائي الجيبي بايت، أي التي تعد الكيلوبايت مثلًا مساويًا 1024 بايتًا أو 210 حيث أساسها العدد 2، لقياس حجم الذاكرة الرئيسية واستخدام وحدتي النظام العشري الجيجا بايت و التيرا بايت، أي التي تعد الكيلو بايت مثلًا مساويًا 1000 بايتًا حيث أساسها العدد 10، لقياس حجم HDD. يقاس حجم الذاكرة بالوحدات الثنائية وحجم القرص الصلب بالوحدات العشرية وذلك لأسباب تاريخية وتقنية، ولكن تُستخدم الجيجا بايت واختصارها GB استخدامًا مبهمًا لذلك يجب أن تنتبه لذلك. يُستخدم مصطلح ذاكرة (memory) أحيانًا للدلالة على HDDs و SSDs و RAM، ولكن خصائص هذه الأجهزة الثلاث مختلفة جدًا. يشار إلى HDDs و SSDs بتخزين دائم (storage).
أحياز العنونة (Address spaces)
يُحدد كل بايت في الذاكرة الرئيسية بعدد صحيح يدعى عنوانًا حقيقيًا (physical address)، حيث تدعى مجموعة العناوين الحقيقية الصالحة بحيز العنونة الحقيقية (physical address space) وتتراوح تلك العناوين بين 0 و N - 1 حيث N هو حجم الذاكرة الرئيسية. أعلى قيمة عنوان صالحة في نظام ب 1 جيبي بايت ذاكرة حقيقية هو 230- 1 ، أي 1,073,741,823 في نظام العد العشري و 0x3f fffff في نظام العد الست عشري حيث تحدد السابقة 0x أنه عدد ست عشري.
توفر معظم أنظمة التشغيل ذاكرةً وهميةً (virtual memory) أيضًا، والتي تعني أن البرامج لا تتعامل أبدًا مع عناوين حقيقية (physical addresses) وليست ملزمة بمعرفة كمية الذاكرة الحقيقية المتوفرة. وبدلًا من ذلك تتعامل البرامج مع الذاكرة الوهمية والتي تتراوح قيمها بين 0 و M - 1، حيث M هو عدد العناوين الوهمية الصالحة. ويحدد نظام التشغيل والعتاد الذي يعمل عليه حجم حيّز العنونة الوهمية.
لا بد أنك سمعت الناس يتحدثون عن نظامي التشغيل 32 بت و 64 بت، حيث يحدد هذان المصطلحان حجم المسجلات والذي هو حجم العنوان الوهمي أيضًا. فيكون العنوان الوهمي 32 بتًا على نظام 32 بت والذي يعني أن حيز العنونة الوهمية يتراوح بين 0 و 0xffff ffff، أي حجم العنونة الوهمية هو 232 بايتًا أو 4 جيبي بايت. أما على نظام 64 بت فحجم حيز العنونة الوهمية هو 264 بايتًا أو 24.10246 بايتًا، أي 16 اكسبي بايت (exbibytes) والذي هو أكبر من حجم الذاكرة الحقيقية الحالية بمليار مرة تقريبًا.
يولّد البرنامج عناوينًا وهمية بكل عملية قراءة أو كتابة في الذاكرة، ويترجمها العتاد إلى عناوين حقيقية بمساعدة نظام التشغيل قبل الوصول إلى الذاكرة الرئيسية، وتقوم هذه الترجمة على أساس per-process أي تعامَل كل عملية باستقلالية عن العمليات الأخرى، حيث حتى لو ولّدت عمليتان نفس العنوان الوهمي فسترتبطان بمواقع مختلفة من الذاكرة الحقيقية. إذًا الذاكرة الوهمية هي إحدى طرق نظام التشغيل لعزل العمليات عن بعضها البعض، حيث لا تستطيع عملية ما الوصول إلى بيانات عملية أخرى، فلا وجود لعنوان وهمي يستطيع توليد ارتباطات (maps) بذاكرة حقيقية مخصصة لعملية أخرى.
أجزاء الذاكرة (Memory segments)
تُنظّم بيانات العملية المُشغّلة ضمن خمسة أجزاء:
- جزء الشيفرة (code segment): ويتضمن نص البرنامج (program text) وهو تعليمات لغة الآلة التي تبني البرنامج.
- الجزء الساكن (static segment): يتضمن القيم غير القابلة للتغيير، قيم السلاسل النصية (string literals) مثلًا، حيث إذا احتوى برنامجك على سلسلة مثلًا "Hello, World" فستُخزَّن هذه الحروف في الجزء الساكن من الذاكرة.
-
الجزء العام (global segment): يتضمن المتغيرات العامة (global variables) والمتغيرات المحلية (local variables) التي يُصرَّح عنها كساكنة
static. -
جزء الكومة (heap segment): يتضمن قطع الذاكرة المخصصة في زمن التشغيل وذلك باستدعاء دالة مكتبة في لغة C هي
mallocفي أغلب الأحيان. - جزء المكدس (stack segment): يتضمن استدعاء المكدس وهو سلسلة من إطارات المكدس (stack frames). يُخصَّص إطار المكدس ليتضمن المعاملات والمتغيرات المحلية الخاصة بالدالة في كل مرة تّستدعى فيها الدالة، ويزال إطار المكدس ذاك التابع لتلك الدالة من المكدس عندما تنتهي الدالة من عملها.
يتشارك المصرِّف مع نظام التشغيل في تحديد ترتيب الأجزاء السابقة، حيث تختلف تفاصيل ذلك الترتيب من نظام تشغيل لآخر ولكن الترتيب الشائع هو:
- يوجد جزء نص البرنامج أو جزء الشيفرة قرب قاع (bottom) الذاكرة أي عند العناوين القريبة من القيمة 0.
- يتواجد الجزء الساكن غالبًا فوق جزء الشيفرة عند عناوين أعلى من عناوين جزء الشيفرة.
- ويتواجد الجزء العام فوق الجزء الساكن غالبًا.
- ويتواجد جزء الكومة فوق الجزء العام وإذا احتاج للتوسع أكثر فسيتوسع إلى عناوين أكبر.
- ويكون جزء المكدس قرب قمة الذاكرة (top of memory) أي قرب العناوين الأعلى في حيز العنونة الوهمية، وإذا احتاج المكدس للتوسع فسيتوسع للأسفل باتجاه عناوين أصغر.
لتعرف ترتيب هذه الأجزاء على نظامك، نفّد البرنامج التالي:
#include <stdio.h> #include <stdlib.h> int global; int main() { int local = 5; void *p = malloc(128); char *s = "Hello, World"; printf("Address of main is %p\n", main); printf("Address of global is %p\n", &global); printf("Address of local is %p\n", &local); printf("p points to %p\n", p); printf("s points to %p\n", s); }
main هو اسم دالة ولكن عند استخدامها كمتغير فهي تشير إلى عنوان أول تعليمة لغة آلة في الدالة main والتي من المتوقع أن تكون في جزء الشيفرة (text segment). أما global فهو متغير عام (global variable) وبالتالي يُتوقع تواجده في الجزء العام (global segment)، و local هو متغير محلي أي يتواجد في جزء المكدس. ترمز s إلى سلسلة نصية (string literal) وهي السلسلة التي تكون جزءًا من البرنامج، على عكس السلسلة التي تُقرَأ من ملف أو التي يدخلها المستخدم. ومن المتوقع أن يكون موقع هذه السلسلة هو الجزء الساكن (static segment)، في حين يكون المؤشر s الذي يشير إلى تلك السلسلة متغيرًا محليًا. أما p فيتضمن العنوان الذي يعيده تنفيذ الدالة malloc حيث أنها تخصص حيزًا في الكومة، وترمز malloc إلى memory allocate أي تخصيص حيز في الذاكرة. يخبر التنسيق التسلسلي format sequence %pالدالة printf بأن تنسق كل عنوان كمؤشر (pointer) فتكون النتيجة عبارة عن عدد ست عشري (hexadecimal).
عند تنفيذ البرنامج السابق سيكون الخرج كما يلي:
Address of main is 0x 40057d Address of global is 0x 60104c Address of local is 0x7ffe6085443c p points to 0x 16c3010 s points to 0x 4006a4
عنوان main هو الأقل كما هو متوقع، ثم يتبعه موقع سلسلة نصية (string literal)، ثم موقع global، وبعده العنوان الذي يشير إليه المؤشر p، ثم عنوان local أخيرًا وهو الأكبر. يتكون عنوان local وهو العنوان الأكبر من 12 رقمًا ست عشريًا حيث يقابل كل رقم ست عشري 4 بتات وبالتالي يتكون هذا العنوان من 48 بتًا، ويدل ذلك أن القسم المُستخدم من حيز العنونة الوهمية هو 248 بايتًا لأن حجم حيز العنونة الوهمية يكون مساويًا 2x بايتًا (تمثل x حجم العنوان الوهمي)، وأكبر عنوان مستخدم في هذا المثال هو 48 بتًا.
جرب تنفيذ البرنامج السابق على حاسوبك وشاهد النتائج، أضف استدعاءً آخر للدالة malloc وتحقق فيما إذا أصبح عنوان كومة نظامك أكبر، وأضف أيضًا دالة تطبع عنوان متغير محلي وتحقق إذا أصبح عنوان المكدس يتوسع للأسفل.
يوضح المخطط التالي عملية ترجمة العناوين:
المتغيرات المحلية الساكنة (Static local variables)
تدعى المتغيرات المحلية في المكدس بمتغيرات تلقائية (automatic) لأنها تُخصص تلقائيًا عند استدعاء الدالة وتحرر مواقعها تلقائيًا أيضًا عندما ينتهي تنفيذ الدالة. أما في لغة البرمجة C فيوجد نوع آخر من المتغيرات المحلية، تدعى ساكنة (static)، تخصص مواقعها في الجزء العام (global segment) وتُهيّأ عند بدء تنفيذ البرنامج وتحافظ على قيمتها من استدعاءٍ لآخر للدالة.
تتتبّع الدالة التالية عدد مرات استدعائها على سبيل المثال:
int times_called() { static int counter = 0; counter++; return counter; }
تحدد الكلمة المفتاحية static أن المتغير counter هو متغير محلي ساكن، حيث أن تهيئة المتغير المحلي الساكن تحدث مرة واحدة فقط عند بدء تنفيذ البرنامج، ويخصص موقع المتغير counter في الجزء العام مع المتغيرات العامة وليس في جزء المكدس.
ترجمة العناوين (Address translation)
كيف يُترجم العنوان الوهمي (VA) إلى عنوان حقيقي (PA)؟
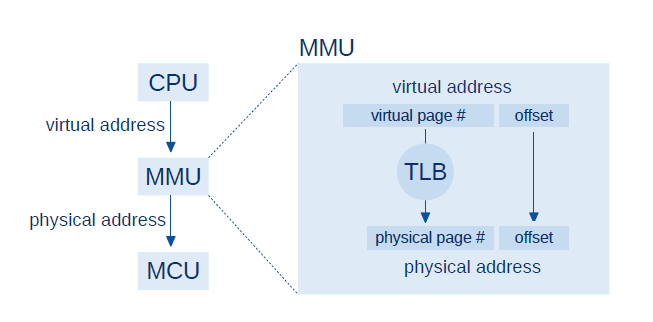
العملية الأساسية لتحقيق ذلك بسيطة، ولكن يمكن أن يكون التنفيذ البسيط أيضًا بطيئًا ويأخذ مساحة أكثر، لذلك يكون التنفيذ الحقيقي أعقد. توفر معظم العمليات وحدة إدارة الذاكرة (memory management unit وتختصر إلى MMU) التي تتموضع بين المعالج CPU والذاكرة الرئيسية وتطبّق ترجمة سريعة بين العناوين الوهمية والعناوين الحقيقية كما يلي:
- يولّد المعالج CPU عنوانًا وهميًا (VA) عندما يقرأ أو يكتب البرنامج متغيرًا .
- تقسّم MMU العنوان الوهمي إلى قسمين هما رقم الصفحة والإزاحة (page number و offset). الصفحة (page) تعني قطعة ذاكرة ويعتمد حجم هذه الصفحة على نظام التشغيل والعتاد ولكن حجوم الصفحات الشائعة هي بين 1 و 4 كيبي بايت.
- تبحث MMU عن رقم الصفحة في مخزَن الترجمة الجانبي المؤقت (translation lookaside buffer)، يُختصر إلى TLB، لتحصل MMU على رقم الصفحة الحقيقي المقابل ثم تدمج رقم الصفحة الحقيقي مع الإزاحة لينتج العنوان الحقيقي PA.
- يمرَّر العنوان الحقيقي إلى الذاكرة الرئيسية التي تقرأ أو تكتب الموقع المطلوب.
يتضمن TLB نسخ بيانات مخبئية من جدول الصفحات (page table) والتي تُخزن في ذاكرة النواة، ويحتوي جدول الصفحات ربطًا بين أرقام الصفحات الوهمية و أرقام الصفحات الحقيقية. وبما أن لكل عملية جدول صفحاتها الخاص لذلك يجب على TLB أن يتأكد من أنه يستخدم مدخلات جدول صفحات العملية التي تنفّذ فقط. لفهم كيف تتم عملية الترجمة افترض أن العنوان الوهمي VA هو 32 بتًا والذاكرة الحقيقية 1 جيبي بايت مقسّمة إلى صفحات وكل صفحة ب 1 كيبي بايت:
- بما أن 1 جيبي بايت هي 230 بايتًا و 1 كيبي بايت هي 210 بايت لذلك يوجد 220 صفحةً حقيقية تدعى أحيانًا إطارات (frames).
- حجم حيز العنونة الوهمية هو 232 بايتًا وحجم الصفحة هو 210 بايتًا لذلك يوجد 222 صفحة وهمية.
- يحدد حجم الصفحة حجمَ الإزاحة وفي هذا المثال حجم الصفحة هو 210 بايتًا لذلك يتطلب 10 بتات لتحديد بايت من الصفحة.
- وإذا كان العنوان الوهمي 32 بتًا والإزاحة 10 بت فتشكّل ال22 بتًا المتبقية رقم الصفحة الوهمية.
- وبما أنه يوجد 220 صفحة حقيقية فكل رقم صفحة حقيقية هو 20 بتًا وأضف عليها إزاحة ب 10 بت فتكون العناوين الحقيقية الناتجة ب 30 بتًا.
يبدو كل شيء معقولًا حتى الآن، ولكن التنفيذ الأبسط لجدول الصفحات هو مصفوفة بمدخلة واحدة لكل صفحة وهمية، وتتضمن كل مدخلة رقم الصفحة الفعلية وهي 20 بتًا في هذا المثال، بالإضافة إلى بعض المعلومات الإضافية لكل إطار أو صفحة حقيقية، وبالتالي من 3 إلى 4 بايتات لكل مدخلة من الجدول ولكن مع 222 صفحة وهمية يكون حجم جدول الصفحات 224 بايتًا أو 16 ميبي بايت. تحتاج كل عمليةٍ إلى جدول صفحات خاص بها لذلك إذا تضمن النظام 256 عملية مشغّلة فهو يحتاج 232 بايتًا أو 4 جيبي بايت لتخزين جداول الصفحات فقط! وذلك مع عناوين وهمية ب 32 بتًا وبالتالي مع عناوين وهمية ب 48 و 64 بتًا سيكون حجم تخزين جداول الصفحات كبيرًا جدًا. لا نحتاج لتلك المساحة كلها لتخزين جدول الصفحات لحسن الحظ، لأن معظم العمليات لا تستخدم إلا جزءًا صغيرًا من حيز العنونة الوهمية الخاص بها، وإذا لم تستخدم العملية صفحةً وهمية فلا داعي لإنشاء مدخلة لها في جدول الصفحات.
يمكن القول بأن جداول الصفحات قليلة الكثافة (أو مخوَّخَة sparse) والتي تطبيقها باستخدام التنفيذات البسيطة، مثل مصفوفة مدخلات جدول الصفحات، هو أمر سيء. ولكن يمكن تنفيذ المصفوفات قليلة الكثافة أو المخوَّخَة (sparse arrays) بطرق أخرى أفضل لحسن الحظ. فأحد الخيارات هو جدول صفحات متعدد المستويات (multilevel page table) الذي تستخدمه العديد من أنظمة التشغيل، Linux مثلًا. الخيار الآخر هو الجدول الترابطي (associative table) الذي تتضمن كل مدخلة من مدخلاته رقم الصفحة الحقيقية والوهمية. يمكن أن يكون البحث في الجدول الترابطي بطيئًا برمجيًا، أما عتاديًا يكون البحث في كامل الجدول على التوازي (parallel)، لذلك تستخدم المصفوفات المترابطة (associative arrays) غالبًا في تمثيل مدخلات جدول الصفحات في TLB. يمكنك قراءة المزيد عن ذلك من خلال: https://en.wikipedia.org/wiki/Page_table
كما ذُكر سابقًا أن نظام التشغيل قادر على مقاطعة أية عملية مُشغّلة ويحفظ حالتها ثم يشغّل عملية أخرى. تدعى هذه الآلية بتحويل السياق (context switch). وبما أن كل عملية تملك جدول الصفحات الخاص بها فيجب على نظام التشغيل بالتعاون مع MMU أن يتأكد من أن كل عملية تحدث على جدول الصفحات الصحيح. وفي الآلات القديمة كان ينبغي أن تُستبدل معلومات جدول الصفحات الموجودة في MMU خلال كل عملية تحويل سياق، وبذلك كانت التكلفة باهظة. أما في الأنظمة الجديدة فإن كل مدخلة في جدول الصفحات ضمن MMU تتضمن معرّف عملية (process ID) لذلك يمكن أن تكون جداول صفحات عمليات متعددة موجودة في نفس الوقت في MMU.
ترجمة -وبتصرّف- للفصل Virtual memory من كتاب Think OS A Brief Introduction to Operating Systems












أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.