

توفر مكتبة Transformers من منصة Hugging Face العديد من الأدوات المفيدة لبناء وتشغيل النماذج اللغوية الحديثة. ومن بين هذه الأدوات الصنف AutoClass لتحميل النماذج مسبقة التدريب بسهولة، حيث يحمّل AutoClass الإعدادات والأوزان المدربة مسبقًا بما يتناسب مع بنية النموذج، لكن هناك بعض الحالات التي قد نحتاج فيها لتحكم أكبر في معاملات النموذج، وإنشاء نموذج مخصص دون الاعتماد على الصنف AutoClass، وهو ما سنوضحه في هذا المقال.
أهمية بناء نموذج مخصص
يستدل الصنف AutoClass في مكتبة المحوّلات Transformers على بنية النموذج تلقائيًا ويحمّل الضبط Configuration والأوزان المدربة مسبقًا، حيث يوصى باستخدام هذا الصنف لإنتاج شيفرة برمجية مستقلة عن نقاط التحقق Checkpoint، ولكن يمكن للمستخدمين الذين يريدون مزيدًا من التحكم في معاملات النموذج المحددة إنشاء نموذج مخصص باستخدام مكتبة المحولات Transformers من بعض الأصناف الأساسية فقط. يمكن أن يكون ذلك مفيدًا لأي شخص مهتم بدراسة أو تدريب أو تجربة نموذج من مكتبة Transformers من منصة Huggingface، لذا سنتعمق أكثر في إنشاء نموذج مخصص بدون الصنف AutoClass، حيث سنتعلم كيفية:
- تحميل ضبط النموذج وتخصيصه
- إنشاء بنية نموذج
- إنشاء مرمِّز Tokenizer للنص
- إنشاء معالج صور للمهام البصرية
- إنشاء مستخرج ميزات للمهام الصوتية
- إنشاء معالج مهام متعددة الوسائط
الضبط Configuration
يمثّل الضبط Configuration السمات Attributes المحدَّدة للنموذج، حيث يكون لكل ضبط خاص بالنموذج سمات مختلفة، فمثلًا تحتوي جميع نماذج معالجة اللغات الطبيعية NLP على السمات hidden_size و num_attention_heads و num_hidden_layers و vocab_size وتحدّد هذه السمات عدد رؤوس الانتباه Attention Heads أو الطبقات المخفية التي سنبني نموذجًا باستخدامها.
يمكن مطالعة على سمات النموذج DistilBERT من خلال الوصول إلى صنف الضبط DistilBertConfig كما يلي:
>>> from transformers import DistilBertConfig >>> config = DistilBertConfig() >>> print(config) DistilBertConfig { "activation": "gelu", "attention_dropout": 0.1, "dim": 768, "dropout": 0.1, "hidden_dim": 3072, "initializer_range": 0.02, "max_position_embeddings": 512, "model_type": "distilbert", "n_heads": 12, "n_layers": 6, "pad_token_id": 0, "qa_dropout": 0.1, "seq_classif_dropout": 0.2, "sinusoidal_pos_embds": false, "transformers_version": "4.16.2", "vocab_size": 30522 }
يعرض الصنف DistilBertConfig جميع السمات الافتراضية المستخدمة لبناء النموذج DistilBertModel الأساسي، وتكون جميع السمات قابلة للتخصيص، مما يعطينا مساحة للتجريب، فمثلًا يمكننا تخصيص نموذج افتراضي بهدف:
-
تجربة دالة تنشيط مختلفة باستخدام المعامل
activation -
استخدام نسبة تسرب Dropout Ratio أعلى لاحتمالات الانتباه باستخدام المعامل
attention_dropout
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4) >>> print(my_config) DistilBertConfig { "activation": "relu", "attention_dropout": 0.4, "dim": 768, "dropout": 0.1, "hidden_dim": 3072, "initializer_range": 0.02, "max_position_embeddings": 512, "model_type": "distilbert", "n_heads": 12, "n_layers": 6, "pad_token_id": 0, "qa_dropout": 0.1, "seq_classif_dropout": 0.2, "sinusoidal_pos_embds": false, "transformers_version": "4.16.2", "vocab_size": 30522 }
ملاحظة: معدل التسرب Dropout Ratio هو تقنية مفيدة في تدريب الشبكات العصبية تساعد على منع الإفراط في التكيّف من خلال تعطيل بعض الخلايا العصبية عشوائيًا أثناء التدريب، وهذا يزيد قدرة النموذج على التعميم ويجعله أكثر قدرة على التعامل مع بيانات جديدة.
يمكننا تعديل سمات النموذج المدرَّب مسبقًا في الدالة from_pretrained() كما يلي:
>>> my_config = DistilBertConfig.from_pretrained("distilbert/distilbert-base-uncased", activation="relu", attention_dropout=0.4)
يمكننا حفظ ضبط النموذج باستخدام الدالة save_pretrained() بعد الانتهاء منه كما يلي، ويُخزَّن ملف الضبط الخاص بنا كملف JSON في مجلد الحفظ المحدَّد:
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
يمكننا إعادة استخدام ملف الضبط من خلال تحميله باستخدام الدالة from_pretrained() كما يلي:
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json")
ملاحظة: يمكننا أيضًا حفظ ملف الضبط الخاص بنا على هيئة قاموس Dictionary أو حتى كمجرد فرق بين سمات الضبط المخصصة وسمات الضبط الافتراضية. يمكن الاطلاع على توثيق الضبط على منصة Huggingface لمزيد من التفاصيل.
النموذج Model
سننشئ الآن نموذجًا، حيث يحدّد النموذج أو كما يشار إليه أحيانًا باسم البنية Architecture ما تفعله كل طبقة وما هي العمليات التي تحدث، وتُستخدَم السمات مثل num_hidden_layers من الضبط لتحديد هذه البنية. تتشارك جميع النماذج في الصنف الأساسي PreTrainedModel وبعض التوابع المشتركة مثل تغيير حجم تضمينات الإدخال وتقليم Pruning رؤوس الانتباه الذاتي Self-attention Heads أو تقليل الأجزاء غير الضرورية أو الفائضة من النموذج لتحسين كفاءته. تكون جميع النماذج أيضًا إما الصنف الفرعي torch.nn.Module أو tf.keras.Model أو flax.linen.Module، وهذا يعني أن النماذج متوافقة مع استخدام كل إطار عمل خاص بها.
في حال كنا نستخدم إطار العمل بايتورش Pytorch نحمّل سمات الضبط المخصصة الخاصة بنا في النموذج كما يلي:
>>> from transformers import DistilBertModel >>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/config.json") >>> model = DistilBertModel(my_config)
مما يؤدي لإنشاء نموذج مع قيم عشوائية بدل أوزان مُدرَّبة مسبقًا، ولكننا لن نتمكّن من استخدام هذا النموذج استخدامًا مفيدًا حتى ندرّبه. فالتدريب عملية مكلفة وتستغرق وقتًا طويلًا، لذا يُفضَّل استخدام نموذج مدرب مسبقًا للحصول على نتائج أفضل وأسرع مع استخدام جزء بسيط فقط من الموارد المطلوبة للتدريب، لذا سننشئ نموذجًا مدربًا مسبقًا باستخدام الدالة from_pretrained() كما يلي:
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
يُحمَّل ضبط النموذج الافتراضي تلقائيًا عند تحميل الأوزان المُدرَّبة مسبقًا إذا وفرت مكتبة المحوّلات Transformers هذا النموذج، ولكن لا يزال بإمكاننا وضع سماتنا الخاصة مكان بعض أو جميع سمات ضبط النموذج الافتراضي إذا أردنا ذلك كما يلي:
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
وفي حال استخدمنا إطار العمل تنسرفلو TensorFlow، فحمّل سمات الضبط المخصصة في النموذج كما يلي:
>>> from transformers import TFDistilBertModel >>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json") >>> tf_model = TFDistilBertModel(my_config)
مما يؤدي إلى إنشاء نموذج مع قيم عشوائية بدلًا من أوزان مُدرَّبة مسبقًا، ولكن لن نتمكّن من استخدام هذا النموذج استخدامًا مفيدًا حتى ندربه. إذ يُعَد التدريب عملية مكلفة وتستغرق وقتًا طويلًا، لذا يُفضّل استخدام نموذج مدرّب مسبقًا للحصول على نتائج أفضل وأسرع مع استخدام جزء بسيط فقط من الموارد المطلوبة للتدريب، لذا سننشئ نموذجًا مدربًا مسبقًا باستخدام الدالة from_pretrained() كما يلي:
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
يُحمَّل ضبط النموذج الافتراضي تلقائيًا عند تحميل الأوزان المُدرَّبة مسبقًا إذا وفّرت مكتبة المحوّلات Transformers هذا النموذج، ولكن لا يزال بإمكاننا وضع سماتنا الخاصة مكان بعض أو جميع سمات ضبط النموذج الافتراضي إذا أردنا ذلك كما يلي:
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
رؤوس النماذج Model heads
أصبح لدينا نموذج DistilBERT أساسي يعطي الحالات المخفية Hidden States التي تُمرَّر كدخل إلى رأس النموذج لإنتاج الخرج النهائي. توفر مكتبة المحوّلات Transformers رأس نموذج مختلف لكل مهمة طالما أن النموذج يدعم المهمة، أي لا يمكنك استخدام النموذج DistilBERT لمهمة التحويل من تسلسل إلى آخر Sequence-to-Sequence مثل مهمة الترجمة.
في حال استخدمنا إطار العمل Pytorch مع مكتبة Transformers، فإن النموذج DistilBertForSequenceClassification مثلًا هو نموذج DistilBERT أساسي مع رأس لتصنيف التسلسل، وهو بمثابة طبقة خطية فوق الخرج المجمَّع. إذًا سننشئ هذا النموذج كما يلي:
>>> from transformers import DistilBertForSequenceClassification >>> model = DistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
يمكننا إعادة استخدام نقطة التحقق السابقة بسهولة لمهمة أخرى من خلال التبديل إلى رأس نموذج مختلف، حيث يمكنك استخدام رأس النموذج DistilBertForQuestionAnswering بالنسبة لمهمة الإجابة على سؤال كما يلي، إذ يشبه رأس الإجابة على سؤال رأس تصنيف التسلسل باستثناء أنه طبقة خطية فوق خرج الحالات المخفية:
>>> from transformers import DistilBertForQuestionAnswering >>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
وإذا كنا تستخدم إطار العمل تنسرفلو TensorFlow، فإن النموذج TFDistilBertForSequenceClassification مثلًا هو نموذج DistilBERT أساسي مع رأس لتصنيف التسلسل، والذي يُعَد طبقة خطية فوق الخرج المجمَّع. إذًا لننشئ هذا النموذج كما يلي:
>>> from transformers import TFDistilBertForSequenceClassification >>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
يمكننا إعادة استخدام نقطة التحقق السابقة بسهولة لمهمة أخرى من خلال التبديل إلى رأس نموذج مختلف، حيث يمكننا استخدام رأس النموذج TFDistilBertForQuestionAnswering بالنسبة لمهمة الإجابة على سؤال كما يلي، إذ يشبه رأس الإجابة على سؤال رأس تصنيف التسلسل باستثناء أنه طبقة خطية فوق خرج الحالات المخفية:
>>> from transformers import TFDistilBertForQuestionAnswering >>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
المرمّز Tokenizer
الصنف الأساسي الأخير الذي نحتاجه قبل استخدام نموذج للبيانات النصية هو المرمّز tokenizer لتحويل النص الأولي إلى موترات Tensors، حيث يوجد نوعان من المرمّزات يمكنك استخدامهما مع مكتبة المحولات Transformers هما:
-
PreTrainedTokenizerوهو تنفيذ لغة بايثون Python للمرمّز -
PreTrainedTokenizerFast: هو مرمّز من مكتبة Tokenizer ويستند إلى لغة رست Rust، وتكون سرعة هذا النوع من المرمّزات ملحوظة وخاصة أثناء الترميز الدفعي Batch Tokenization بسبب تنفيذه باستخدام لغة رست. ويقدّم المرمِّز السريع توابع إضافية مثل ربط الإزاحة Offset Mapping الذي يربط الرموز Tokens بكلماتها أو محارفها الأصلية.
يدعم هذان المرمِّزان التوابع الشائعة مثل التشفير وفك التشفير وإضافة رموز جديدة وإدارة الرموز الخاصة.
ملاحظة: لا تدعم جميع النماذج المرمِّز السريع، لذا ألقِ نظرة على الجدول الموجود في مقال مكتبة المحوّلات Transformers من منصة Hugging Face للتحقق من دعم النموذج للمرمِّز السريع.
يمكنك إنشاء مرمّز من ملف المفردات vocabulary الخاص بنا كما يلي لإنشاء خاص مرمّز بنا:
>>> from transformers import DistilBertTokenizer >>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
يجب أن نتذكر أن المفردات القادمة من المرمّز المخصَّص ستكون مختلفة عن المفردات التي يولّدها مرمّز النموذج المُدرَّب مسبقًا، لذا سنحتاج لاستخدام مفردات نموذج مدرب مسبقًا إذا استخدمنا نموذج مُدرَّب مسبقًا، وإلّا لن يكون للدخل أي معنى. لننشئ مرمّز باستخدام مفردات نموذج مدرب مسبقًا باستخدام الصنف DistilBertTokenizer كما يلي:
>>> from transformers import DistilBertTokenizer >>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
ولننشئ مرمّز سريع باستخدام الصنف DistilBertTokenizerFast كما يلي:
>>> from transformers import DistilBertTokenizerFast >>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert/distilbert-base-uncased")
ملاحظة: سيحاول الصنف AutoTokenizer افتراضيًا تحميل مرمّز سريع، ولكن يمكنك تعطيل هذا السلوك من خلال ضبط القيمة use_fast=False في الدالة from_pretrained.
معالج الصور Image Processor
يعالج معالج الصور المدخلات البصرية، وهو يرث الصنف ImageProcessingMixin الأساسي، ويمكن استخدامه من خلال إنشاء معالج صور مرتبط بالنموذج الذي تستخدمه، فمثلًا يمكننا إنشاء صنف ViTImageProcessor افتراضي كما يلي، إذا كنا نستخدم النموذج ViT أو المحوّل البصري Vision Transformer لتصنيف الصور:
>>> from transformers import ViTImageProcessor >>> vit_extractor = ViTImageProcessor() >>> print(vit_extractor) ViTImageProcessor { "do_normalize": true, "do_resize": true, "image_processor_type": "ViTImageProcessor", "image_mean": [ 0.5, 0.5, 0.5 ], "image_std": [ 0.5, 0.5, 0.5 ], "resample": 2, "size": 224 }
ملاحظة: إن لم نكن نريد تخصيص أيّ شيء، فما علينا سوى استخدام التابع from_pretrained لتحميل معاملات معالج الصور الافتراضية للنموذج.
لنعدّل الآن أحد معاملات الصنف ViTImageProcessor لإنشاء معالج الصور المخصَّص كما يلي:
>>> from transformers import ViTImageProcessor >>> my_vit_extractor = ViTImageProcessor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3]) >>> print(my_vit_extractor) ViTImageProcessor { "do_normalize": false, "do_resize": true, "image_processor_type": "ViTImageProcessor", "image_mean": [ 0.3, 0.3, 0.3 ], "image_std": [ 0.5, 0.5, 0.5 ], "resample": "PIL.Image.BOX", "size": 224 }
العمود الفقري Backbone
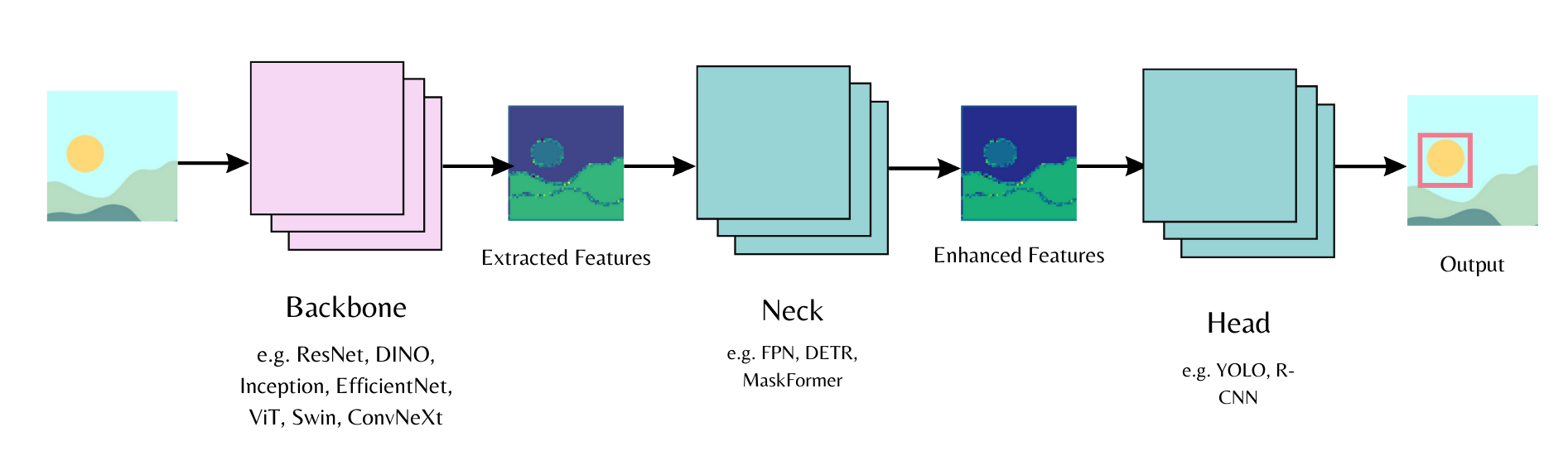
تتكون نماذج الرؤية الحاسوبية من العمود الفقري Backbone والعنق Neck والرأس Head، حيث يستخرج العمود الفقري الميزات Features من صورة الدخل، ويجمع العنق الميزات المستخرجة ويحسّنها، ويُستخدم الرأس للمهمة الرئيسية مثل اكتشاف الكائنات. دعنا نبدأ بتهيئة العمود الفقري في ضبط النموذج ونحدد تحميل أوزان مدرَّبة مسبقًا أو تحميل أوزان مُهيَّأة عشوائيًا، ثم يمكننا تمرير ضبط النموذج إلى الرأس.
إذا أردنا مثلًا تحميل العمود الفقري ResNet في النموذج MaskFormer باستخدام رأس تقسيم أجزاء الصورة كما يلي:
<hfoptions id="backbone"> <hfoption id="pretrained weights">
فيجب ضبط القيمة use_pretrained_backbone=True لتحميل أوزان ResNet المدرَّبة مسبقًا للعمود الفقري كما يلي:
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation config = MaskFormerConfig(backbone="microsoft/resnet-50", use_pretrained_backbone=True) # ضبط العمود الفقري والعنق model = MaskFormerForInstanceSegmentation(config) # الرأس
وإذا أردنا تحميل العمود الفقري ResNet في النموذج MaskFormer باستخدام رأس تقسيم أجزاء الصورة كما يلي:
</hfoption> <hfoption id="random weights">
فيجب ضبط القيمة use_pretrained_backbone=False لتهيئة العمود الفقري ResNet عشوائيًا كما يلي:
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation config = MaskFormerConfig(backbone="microsoft/resnet-50", use_pretrained_backbone=False) # ضبط العمود الفقري والعنق model = MaskFormerForInstanceSegmentation(config) # الرأس
يمكن أيضًا تحميل ضبط العمود الفقري بطريقة منفصلة ثم تمريره إلى ضبط النموذج كما يلي:
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation, ResNetConfig backbone_config = ResNetConfig() config = MaskFormerConfig(backbone_config=backbone_config) model = MaskFormerForInstanceSegmentation(config)
تُحمَّل نماذج المكتبة timm ضمن نموذج كما يلي باستخدام القيمة use_timm_backbone=True أو باستخدام الصنف TimmBackbone والصنف TimmBackboneConfig:
</hfoption> </hfoptions id="timm backbone">
لذا سنستخدم القيمة use_timm_backbone=True و use_pretrained_backbone=True لتحميل أوزان timm المدرَّبة مسبقًا للعمود الفقري كما يلي:
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation config = MaskFormerConfig(backbone="resnet50", use_pretrained_backbone=True, use_timm_backbone=True) # ضبط العمود الفقري والعنق model = MaskFormerForInstanceSegmentation(config) # الرأس
ولنضبط الآن القيمة use_timm_backbone=True و use_pretrained_backbone=False لتحميل العمود الفقري timm المهيَّأ عشوائيًا كما يلي:
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation config = MaskFormerConfig(backbone="resnet50", use_pretrained_backbone=False, use_timm_backbone=True) # ضبط العمود الفقري والعنق model = MaskFormerForInstanceSegmentation(config) # الرأس
يمكننا أيضًا تحميل ضبط العمود الفقري واستخدامه لإنشاء الصنف TimmBackbone أو تمريره إلى ضبط النموذج، حيث ستحمّل الأعمدة الفقرية Timm الأوزان المدرَّبة مسبقًا افتراضيًا، لذا سنضبط القيمة use_pretrained_backbone=False لتحميل الأوزان المُهيَّأة عشوائيًا كما يلي:
from transformers import TimmBackboneConfig, TimmBackbone backbone_config = TimmBackboneConfig("resnet50", use_pretrained_backbone=False) # إنشاء صنف العمود الفقري backbone = TimmBackbone(config=backbone_config) # إنشاء نموذج باستخدام العمود الفقري timm from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation config = MaskFormerConfig(backbone_config=backbone_config) model = MaskFormerForInstanceSegmentation(config)
مستخرج الميزات Feature Extractor
يعالج مستخرج الميزات المدخلات الصوتية، وهو يرث الصنف FeatureExtractionMixin الأساسي، ويمكن أن يرث أيضًا الصنف SequenceFeatureExtractor لمعالجة المدخلات الصوتية. لننشئ الآن مستخرج ميزات مرتبط بالنموذج الذي تستخدمه مثل إنشاء صنف Wav2Vec2FeatureExtractor افتراضي كما يلي إذا كنت تستخدم النموذج Wav2Vec2 لتصنيف الأصوات:
>>> from transformers import Wav2Vec2FeatureExtractor >>> w2v2_extractor = Wav2Vec2FeatureExtractor() >>> print(w2v2_extractor) Wav2Vec2FeatureExtractor { "do_normalize": true, "feature_extractor_type": "Wav2Vec2FeatureExtractor", "feature_size": 1, "padding_side": "right", "padding_value": 0.0, "return_attention_mask": false, "sampling_rate": 16000 }
ملاحظة: إن لم نكن نرغب بتخصيص أيّ شيء، فما علينا سوى استخدام التابع from_pretrained لتحميل معاملات مستخرج الميزات الافتراضية الخاصة بالنموذج.
لنعدّل الآن أحد معاملات الصنف Wav2Vec2FeatureExtractor لإنشاء مستخرج الميزات المخصَّص الخاص بنا كما يلي:
>>> from transformers import Wav2Vec2FeatureExtractor >>> w2v2_extractor = Wav2Vec2FeatureExtractor(sampling_rate=8000, do_normalize=False) >>> print(w2v2_extractor) Wav2Vec2FeatureExtractor { "do_normalize": false, "feature_extractor_type": "Wav2Vec2FeatureExtractor", "feature_size": 1, "padding_side": "right", "padding_value": 0.0, "return_attention_mask": false, "sampling_rate": 8000 }
المعالج Processor
تقدم مكتبة المحوِّلات Transformers صنف المعالج الذي يغلِّف أصناف المعالجة مثل مستخرج الميزات والمرمِّز في كائن واحد بالنسبة للنماذج التي تدعم المهام متعددة الوسائط. لنستخدم مثلًا الصنف Wav2Vec2Processor لمهمة التعرّف التلقائي على الكلام Automatic Speech Recognition أو ASR اختصارًا، والتي تحوّل الصوت إلى نص، لذا ستحتاج إلى مستخرج ميزات ومرمّز.
لننشئ أولًا مستخرج ميزات للتعامل مع المدخلات الصوتية كما يلي:
>>> from transformers import Wav2Vec2FeatureExtractor >>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
ثم ننشئ مرمّز للتعامل مع المدخلات النصية كما يلي:
>>> from transformers import Wav2Vec2CTCTokenizer >>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
ثم ندمج مستخرج الميزات والمرمّز في الصنف Wav2Vec2Processor كما يلي:
>>> from transformers import Wav2Vec2Processor >>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
الخلاصة
يمكننا إنشاء أي من النماذج التي تدعمها مكتبة المحولات Transformers من منصة Huggingface باستخدام صنفين أساسيين للضبط والنموذج وصنف إضافي للمعالجة المسبَقة مثل مرمِّز أو معالج صور أو مُستخرج ميزات أو معالج، وتكون هذه الأصناف الأساسية قابلة للضبط، مما يسمح لنا باستخدام السمات المحدَّدة التي نريدها، ويمكن بسهولة إعداد نموذج للتدريب أو تعديل نموذج مُدرَّب مسبقًا لصقله Fine-tune.
ترجمة -وبتصرّف- للقسم Create a custom architecture من توثيقات Hugging Face.











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.