

هنالك بضعة أدوات يجب توافرها لك في كونك مبرمج أو مهندس تعلم آلة للبدء في برمجة النماذج، وللتسهيل وللتوضيح سنسرد تلك الأدوات بصورة منظمة حتى يسهل عليك قدر الإمكان جمع وربط الأفكار التي قد تكون مشتتة ومشوشة في عقلك أثناء القراءة في موضوع مثل تعلم الآلة.
تتوافر أمور عدة في كل مجال من مجالات صناعة البرمجيات للبدء في العمل، فصناعة برامج الإنترنت تتطلب بدورها وبصورة ضرورية لغة لهيكلة الصفحات هي HTML ولغة لتنسيقها هي CSS ولغة لبرمجة الأنظمة الخلفية مثل لغة PHP أو Python، وبصورة اختيارية لغة تفاعلية للواجهة الأمامية مثل لغة JavaScript، والصورة التي تربط تلك الأدوات واللغات ببعضها البعض، هي ما يدعى بمجال هندسة الويب Web Engineering، ونحن نحاول توضيح الأمر ذاته، عبر ذكر تلك الأدوات الرئيسة والاختيارية في تعلم الآلة والتي من شأنها مساعدتك في ربط الأفكار المتعلقة بتعلم الآلة وبرمجتها.
الأدوات الأساسية الواجب توافرها للبدء في برمجة أي نموذج من نماذج تعلم الآلة هي البيانات والبنية التحتية التقنية والخوارزميات، وسنتحدث في الفقرات الآتية عن كل نقطة من تلك النقاط بشيء من التفصيل.
العلاقة بين البيانات ومجال تعلم الآلة
الأداة الأولى المهمة في تعلم الآلة هي البيانات data، وهي أهم أداة يجب توافرها في نماذج تعلم الآلة، ويتم تمثيل البيانات على هيئة مصفوفات رياضية أثناء وقبل تمريرها إلى خوارزميات تعلم الآلة، ومن السهل تمثيل المصفوفات على هيئة جداول من البيانات، بحيث تحتوي على صفوف وأعمدة، ويكون كل صف عينةً من البيانات تتكون من عدة نقاط، وكل عمود هو خاصية من خواص مجموعة البيانات، إذ تمثل كل خاصية بُعدًا إضافيًا للبيانات، بحيث يكون عدد أبعاد البيانات هو عدد الأعمدة الممثلة للبيانات في صورة جدول، ولمزيد من التوضيح لنأخذ بيانات موظفي شركة ما على سبيل المثال لتجريد تلك المصطلحات السالفة من اللغط.
لدينا في الجدول التالي ثلاث عينات وأربعة أبعاد، وكل خلية من خلايا الجدول هي ما يدعى بنقطة بيانات Data Point .
| الراتب | سنوات الخبرة | مستوى التعليم | العمر |
|---|---|---|---|
| 4000 | 0 | 1 | 20 |
| 6000 | 2 | 2 | 25 |
| 10000 | 10 | 3 | 35 |
كما نرى تحتوي البيانات على ثلاث عينات ونعني هنا ثلاثة موظفين من موظفي الشركة، وكل عينة من تلك العينات لها أربعة أبعاد أو خواص وهي العمر ومستوى التعليم والخبرة والراتب، وما نعنيه بنقطة البيانات هي خلية من خلايا الجدول، أي بعد العينات، إذ يمثل راتب العينة الأخيرة مثلًا نقطة بيانات وقيمتها 10000، كما تمثل عدد سنوات خبرة العينة الأولى نقطة بيانات أخرى وقيمتها صفر وهكذا.
الجدير بالذكر أنّ البعد له أسماء كثيرة قد تسبب لغطًا كبيرًا للمتعلمين، وإن من بينِ أسمائه بعدًا Dimension ومتغيرًا Variable وسمة أو خاصية Attribute وميزة Feature، ولذلك من الضروري عند دراسة أيّ مرجع من مراجع تعلم الآلة وعلوم البيانات أن تعلم أنّ تلك المسميات كلها تشير إلى الشيء ذاته وهو عمود في البيانات بعد تمثيلها على هيئة جدول.
جدول البيانات بأكمله في الرياضيات وفي برمجة تعلم الآلة ما هو إلا مصفوفة Matrix ذات بعد يساوي عدد الأعمدة، وكل عمود في الجدول ما هو إلا متجه Vector يحتوي على جزء من المصفوفة، فالمتجهات هي مصفوفات لكنها ذات بعد واحد، أي خاصية واحدة فقط، فسنوات الخبرة للثلاث عينات في الجدول السابق مثلًا هي متجه يحتوي على ثلاثة صفوف وعمود واحد، الصف الأول صفر والثاني اثنان والثالث عشرة، وكذلك الأمر بالنسبة لمستوى التعليم والعمر والراتب، وهكذا. الجدول الآتي هو متجه العمر على سبيل المثال:
| العمر |
|---|
| 20 |
| 25 |
| 35 |
والجدول التالي هو متجه سنوات الخبرة:
| سنوات الخبرة |
|---|
| 0 |
| 2 |
| 10 |
أما الجدول التالي فهو متجه الراتب:
| الراتب |
|---|
| 4000 |
| 6000 |
| 10000 |
يُعَدّ ذلك أمرًا أساسيًا فهمه في البيانات، ففهم البيانات هو أول وأهم الخطوات في سبيل برمجة تعلم الآلة، إذ تُقضَى أكثر أوقات مهندسِي تعلم الآلة في فهم البيانات وتنقيحها قبل إجراء مهمات برمجة نموذج تعلم الآلة، وتستخدِم كل مهمة من مهام تعلم الآلة ذلك النمط من تمثيل البيانات وحتى المعقدة منها مثل النماذج التي تتعامل مع الصور وغيرها حتى وإذا كانت غير واضحة بصورة جلية وبسيطة للمبرمج، ففي التعامل مع الصور تُحوَّل كل صورة إلى مصفوفة من البكسلات Pixels وهكذا.
الجدير بالذكر أنه في التعلم تحت إشراف تُقسَّم المتغيرات أو الأبعاد في البيانات إلى قسمين، بحيث يحتوي القسم الأول على المتغيرات المستقلة Independent Variables وهي تلك المتغيرات التي تعمل على أساس مدخلات للنموذج، والقسم الثاني يحتوي على المتغير التابع Dependant Variable وهو الذي يعمل على أساس خرج في النموذج.
لفهم ذلك لنأخذ بيانات الموظفين السابقة مثالًا ولنقل أننا نريد بناءً على تلك البيانات بناء نموذج تعلم آلة يتوقع راتب الموظف بناءً على عمره ومستوى تعليمه وسنوات خبرته، فتلك المتغيرات هي ما ندعوها بالمتغيرات المستقلة لأن الخرج يعتمد عليها لا العكس وهي على هيئة مصفوفة، وفي مثالنا هذا تتكون المصفوفة من ثلاثة أعمدة وثلاثة صفوف؛ أما المتغير التابع فهو متجه الراتب في ذلك المثال، وهو مصفوفة ذات عمود واحد وثلاثة صفوف، وتكون المتغيرات المستقلة كما يلي:
| سنوات الخبرة | مستوى التعليم | العمر |
|---|---|---|
| 0 | 1 | 20 |
| 2 | 2 | 25 |
| 10 | 3 | 35 |
ويكون المتغير التابع كما يلي:
| الراتب |
|---|
| 4000 |
| 6000 |
| 10000 |
لتدريب نموذج يتوقع راتب الموظفين بناءً على تلك البيانات، فإننا نُمرر مصفوفة المتغيرات المستقلة ومتجه المتغير التابع إلى خوارزمية النموذج ليبني العلاقة بين تلك المتغيرات للوصول إلى القيم المثلى للثوابت الموجودة في المعادلة الجبرية، التي تربط بين المتغيرات المستقلة والمتغير التابع، ثم بعد ذلك نستطيع استخدام تلك المعادلة مع تلك الثوابت التي وصلت الخوارزمية إليها بعد التدريب ليُتوقَّع راتب أيّ موظف جديد.
البنية التحتية التقنية
الأداة الثانية في برمجة تعلم الآلة هي البنية التحتية التقنية، وما نعنيه هنا هو مجموعة الأدوات التقنية الواجب توفرها للبدء في التطبيق العملي في كل مراحله، ويشمل ذلك ما تحتاجه لمعالجة البيانات وتنقيحها وما تحتاجه لرسم البيانات لمساعدتك على فهمها بصورة أفضل وما تحتاجه في معالجة المصفوفات والمتجهات وإجراء العمليات عليهما، …إلخ.
لغات البرمجة المستخدمة في تعلم الآلة
إنّ أول ما نحتاجه في البنية التحتية التقنية هي لغة البرمجة ومع أنّ العمل في مجال تعلم الآلة ممكن باستخدام أيّ لغة من اللغات، إلا أن بعض اللغات قد تدعم العمل على نماذج تعلم الآلة وعلى معالجة البيانات بصورة أفضل وأسهل، ومن ذلك المنطلق وقع اختيارنا على لغة بايثون التي أوردنا شرحها في الفصل الثالث من السلسلة، لكن بايثون ليست اللغة الوحيدة مع ذلك فإن من الاختيارات الأخرى الأكثر شهرةً للتعامل مع البيانات وتعلم الآلة هي لغة R ولغة Matlab ولغة Octave ولغة C++ ولغة JavaScript وغيرها.
مع ذلك فإنه حتى تاريخ كتابة هذا الفصل لاحظت تفضيل لغة بايثون و R وماتلاب Matlab و Octave على باقي لغات البرمجة من قِبَل مبرمجِي تعلم الآلة وذلك لتوفر مكتبات مساعدة غير متاحة في الكثير من اللغات الأخرى، ولكن بالطبع أكثر لغة مستخدَمة في معالجة البيانات وتعلم الآلة هي بايثون بلا أدنى شك، والتي من أسباب شيوعها هي توفر مكتبات أخرى تساعد على كشط وجمع البيانات من الإنترنت بصورة آلية لاستخدامها في المشاريع.
أيضًا، تُعَد لغة بايثون لغةً عامةً لا تقتصر على مجال بعينه، وإنما تُستخدَم في برمجة الويب وغيرها من المجالات، إذ ستفضِّل شركات برمجيات الويب حتمًا استخدام بايثون لبرمجة نماذج تعلم الآلة في مشروعاتها بدلًا من اللغات الأخرى وذلك لأنها هي ذاتها اللغة التي يمكن عن طريقها برمجة تطبيقات ويب بسلاسة.
تُعَدّ لغة R لغةً مجانيةً ومفتوحة المصدر مثل بايثون، ولكنها مبنية من أجل العمليات الرياضية بصورة أساسية مثل تحليل البيانات والعمليات الإحصائية، إذ تحتوي افتراضيًا على كثير من الدوال التي تؤدي تلك المهام، كما أنها تدعم الكثير من مهام تعلم الآلة؛ أما ماتلاب وأُكتاف Octave، فهما منافستان للغة R من حيث التخصص، ولكن ماتلاب هي لغة تجارية غير مجانية وهي متميزة إلى حد كبير في حل المعادلات الجبرية على وجه الخصوص، ومن ميزاتها أيضًا أنها لغة سهلة التعلم، وهي واسعة الانتشار في الهندسة الكهربائية والهندسة الكيميائية والهندسة المدنية وهندسة الطيران.
مع ذلك/ عادةً لا يستخدِم الكثير من علماء الحاسوب ومهندسو البرمجيات لغة ماتلاب سوى في الأوساط الأكاديمية، فهي لا تستخدَم في الأعمال بصورة كبيرة، لذلك فإنّ العدد الكبير للمساقات الأكاديمية الموجودة على الإنترنت والتي تستخدِم ماتلاب ليس مؤشرًا على وسع انتشار ماتلاب في وسط الأعمال؛ أما لغة Octave فهي ببساطة النسخة المجانية من ماتلاب والتي طُوِّرت عن طريق مساهمات المبرمجين والمطورين حول العالم لتوفير بديل مجاني ومفتوح المصدر لماتلاب.
ناقشنا في الفصل الثالث خيارات كتابة لغة بايثون إما على حاسوبك الخاص أو عبر خدمة Google Colab، وهي تماثل ميزات خدمة أخرى يستخدِمها الكثير من المبرمجين تدعى Jupyter Notebook، وهي خدمة لها واجهة يتم الولوج فيها عبر المتصفح، إذ تُثبَّت على الحاسوب ثم تُشغَّل عبر أمر في الطرفية Terminal أو سطر الأوامر Command Prompt، لكن لكون Google Colab أبسط في التعامل وكونها خدمةً سحابيةً لا تحتاج إلى تثبيت أية مكتبات، فقد فضلنا الإحالة إليها بدلًا من شرح Jupyter Notebook مثل باقي المراجع الأجنبية.
المكتبات البرمجية في تعلم الآلة
يأخذنا هذا إلى الحديث عن المكتبات المهمة في بايثون للتعامل مع علوم البيانات وتعلم الآلة، إذ يجب استخدام مكتبة Numpy للتعامل مع المصفوفات والمتجهات، وللتعامل مع أمور قراءة ملفات البيانات مثل ملفات Excel و CSV، فإن استخدام مكتبة مثل Pandas يُعَدّ أمرًا مهمًا أيضًا، ولتوفير الوقت والجهد في كتابة خوارزميات تعلم الآلة من الصفر يمكن استخدام مكتبة مثل Scikit Learn التي تحتوي على كثير من خوارزميات تعلم الآلة افتراضيًا، إذ يمكن استدعاء واستخدام الدوال المدمجة في المكتبة لإجراء الكثير من الأمور.
أما بالنسبة لأمور تمثيل البيانات ورسمها، فيمكن استخدام المكتبات الأكثر شيوعًا في بايثون وهما Matplotlib و Seaborn، وقد يظهر لتلك المكتبات مكتبات أخرى منافسة لتكون هي الأكثر شيوعًا واستخدامًا في السنوات القادمة.
بغض النظر عن مستوى النموذج الذي تبرمجه، فإن من أكبر الضروريات أثناء عملك هو تمثيل البيانات عبر أدوات التصور والإظهار Visualization، إذ يعطي تصور البيانات القدرة على فهمها بصورة أكبر، فعن طريقها تستطيع تحديد ما إذا كان لديك بعض العينات الشاذة التي تؤثِّر على النتائج تأثيرًا سلبيًا، وتستطيع أيضًا تحديد وجود مشكلات أخرى، كما تستطيع تحديد أفضل الخوارزميات المناسبة للعمل على البيانات المتاحة، وتستطيع أيضًا تمثيل نتائج الخوارزميات على البيانات، …إلخ.
ذكرنا أن أكثر المكتبات شيوعًا في لغة بايثون لتمثيل البيانات هي Matplotlib و Seaborn، ولكن مع ذلك فقد يظهر لتلك المكتبات مكتبات أخرى منافسة لتكون هي الأكثر شيوعًا واستخدامًا في السنوات القادمة.
تحدثنا في الفصل السابق عن التعلم العميق وأنه أحد فروع تعلم الآلة، وفكرة التعلم العميق هي بناء شبكات عصبية Neural Networks تحاكي تلك الموجودة في دماغنا البشري، وإن للتعلم العميق مكتبات واسعة الاستخدام في بايثون والتي توفر خوارزميات ودوال مهمة، لتسهيل عملية بناء الشبكات العصبية بدلًا من بنائِها من الصفر، وأشهر تلك المكتبات هي تلك التي طُوِّرت في Google وهي مكتبة TensorFlow، وقد أصدرت Google نسخةً منها للغة JavaScript مؤخرًا، ومن مكتبات التعلم العميق مكتبة PyTorch و Theano و Caffe و Chainer، وهي كلها مكتبات متاحة للغة بايثون.
توجد أيضًا مكتبة Keras وهي من أوسع المكتبات استخدامًا في بايثون، إذ تستخدِم إحدى مكتبات التعلم العميق الأخرى المتوفرة في بايثون مع تبسيط كبير لدوالها ووحداتها، فيمكن استخدام Keras مع محرك خلفي آخر مثل Tensorflow أو Theano وغيرهما، ومع ذلك فإنه توجد مكتبات أخرى للغات الأخرى مثل مكتبة DL4J للغة جافا، ومكتبة Microsoft Cognitive Toolkit والتي تتوفر لعدة لغات وهي: بايثون وC# و ++C، كما أنه يمكن إدماجها مع اللغات الأخرى عبر لغتها الخاصة والتي تدعى Brain Script.
يظهر الرسم [4-4] رسمًا بيانيًا من منصة Kaggle تشير إلى أنّ أكثر المكتبات استخدامًا هي مكتبة Sci-kit Learn التي أشرنا إليها؛ أما تلك المنصة فهي أكبر منصة على الإنترنت تجمع علماء البيانات ومهندسِي تعلم الآلة.
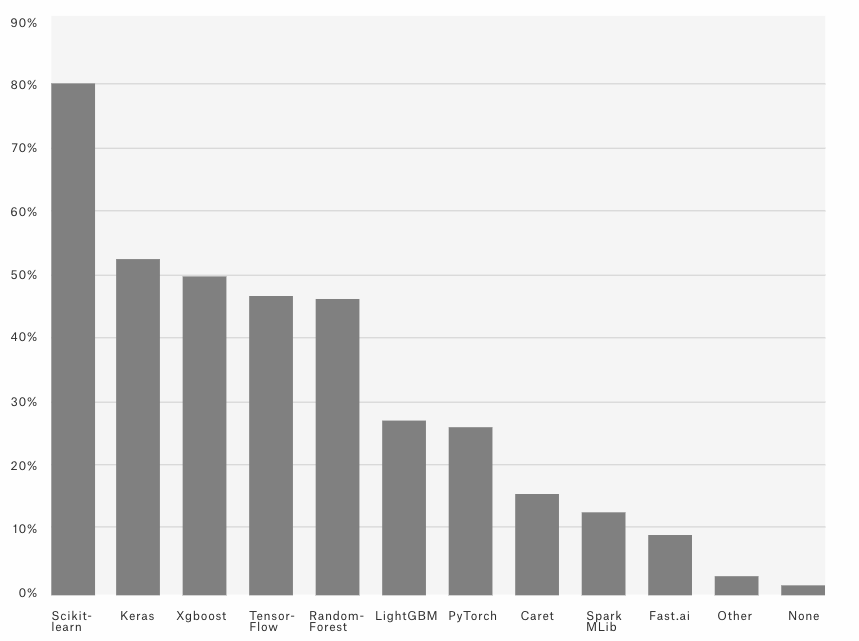
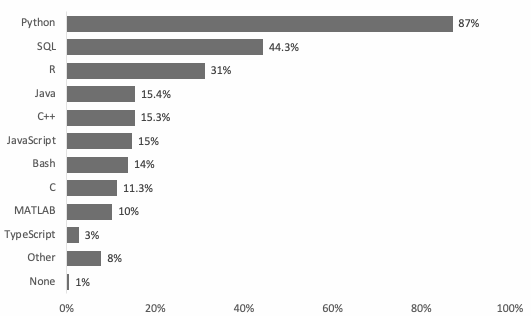
أما الرسم [4-5] فهو رسم بياني آخر من المنصة نفسها يشير إلى أنّ أكثر اللغات التي يستخدمها أعضاؤها يوميًا هي لغة بايثون.
يدخل في نطاق البنية التحتية التقنية أمور أخرى مثل المعدات، وذلك لأن المشروعات الضخمة لا يمكن برمجة نماذجها عبر الحاسوب الشخصي بإمكانياته البسيطة، فعند التعامل مع البيانات الضخمة التي قد تتمثل في عدد من التيرابايت -وهي وحدات قياس سعة تخزين الحاسوب وهي تساوي ألف جيجابايت- أو البيتابايت -أي مليون جيجابايت- إذ سيصبح استخدام خدمات الحوسبة السحابية والحوسبة الموزعة أمرًا لازمًا لأن تدريب مثل تلك النماذج سيتطلب قدرات حاسوبية كبيرة.
الخوارزميات المستخدمة في تعلم الآلة
الخوارزميات هي ثالث الأدوات في تعلم الآلة، وهي أصل الموضوع ولبه، إذ أن تعلم الآلة كما أوردنا ما هو إلا خوارزميات للتعلم من البيانات وخوارزميات لقياس دقة النماذج، …إلخ، ومن الممكن تطبيق تلك الخوارزميات عبر كتابتها من الصفر بأي لغة من لغات البرمجة، لكن الأمر قد يكون معقدًا خاصةً للمبتدئين وإجراء ذلك ليس ضروريًا على الإطلاق، فكما ترى من الفقرة السابقة أنه توجد العديد من المكتبات الجاهزة للاستخدام والتي تحتوي على دوال مدمجة بها أبرز الخوارزميات التي قد تستخدِمها في حياتك المهنية في هذا الحقل.
تُعَدّ خوارزميات تعلم الآلة كثيرةً ومختلفةً، فبعضها متخصص في حل مشكلات التعلم تحت إشراف وبعضها في التعلم دون إشراف وبعضها للتعلم المعزز وللتعلم العميق، …إلخ، وكل خوارزمية من تلك الخوارزميات لها اسم تدعى به، وقد يتخصص مهندس الذكاء الاصطناعي في أحد الفروع دونًا عن غيره، وفي تلك الحالة قد يدرس خوارزميات معينة تُستخدَم في حقله وتخصصه فقط ولا تستخدَم في غيره، ومن تلك التخصصات على سبيل المثال لا الحصر الرؤية الحاسوبية Computer Vision ومعالجة اللغات الطبيعية Natural Language Processing.
تصنَّف الخوارزميات عادةً حسب طريقة عملها، وبالرغم من كون القائمة التالية ليست دقيقةً بصورة مطلقة لأن الكثير من تلك الخوارزميات يمكن تصنيفها إلى صنفين أو أكثر من التصنيفات، إلا أنها قد تعطيك نبذةً عن أشهر الخوارزميات التي قد تراها كثيرًا في مراجع تعلم الآلة، وبالطبع كل تلك الخوارزميات لن تُغطَّى في هذه السلسة ولكن نظرة على تلك الأسماء قد توفر لك جهدًا عند مراجعتك للمراجع الأجنبية.
اقتباسانتبه إلى أنني اجتهدت في ترجمة أسماء الخوارزميات الغريبة منها فإن أخطأت في واحدة أو كان هنالك ترجمة أفضل، فاذكرها بالتعليقات.
1. خوارزميات الانحدار Regression Algorithms
هي خوارزميات تصنع نماذج تربط بين المتغيرات، والتي تُراجَع دقتها باستمرار عبر تقنيات وطرق قياس الخطأ، وهي خوارزميات تعتمد في الأساس وبصورة كبيرة على علم الإحصاء، وفيما يلي بعض أشهر خوارزميات الانحدار:
- الانحدار الخطي Linear Regression
- الانحدار اللوجستي Logistic Regression
- الانحدار الخطوي Stepwise Regression
- خطوط الانحدار التكيفية متعددة المتغيرات Multivariate Adaptive Regression Splines واختصارًا MARS
- انحدار المربعات الصغرى الاعتيادية Ordinary Least Squares Regression واختصارًا OLSR
- تجانس المخطط المبعثر المقدر محليًا Locally Estimated Scatterplot Smoothing واختصارًا LOESS
2. الخوارزميات المبنية على النماذج Instance-based Algorithms
يهدف هذا النوع من الخوارزميات إلى حل مشكلات اتخاذ القرار بناءً على الأمثلة التي تعلمها النموذج، وتلك الأمثلة بالطبع ضرورية لتدريب النموذج، عادةً يبني ذلك النوع من الخوارزميات قاعدة بيانات تحتوي على أمثلة موجودة مسبقًا مع ما اتُخِذ من قرار ثم تحاول الخوارزمية موازنة البيانات الجديدة مع ما تملكه في قاعدة البيانات لتوقع القرار الأنسب، وفيما يلي أشهر خوارزميات هذا النوع:
- التمثيل الكمي لمتجه التعلم Learning Vector Quantization واختصارًا LVQ
- الجار الأقرب K-nearest neighbor واختصارًا KNN
- الخرائط ذاتية التنظيم Self-Organized Maps واختصارًا SOM
- دعم آلات المتجهات Support Vector Machines واختصارًا SVM
- التعلم الموزون محليًا Locally-Weighted Learning واختصارًا LWL
3. خوارزميات التنظيم Regularization Algorithms
يضم هذا النوع بعض الخوارزميات الإضافية والتي تضاف عادةً إلى خوارزميات الانحدار، وتلك الخوارزميات تقوِّم النماذج بناءً على مستوى بساطتها وتعقيدها، إذ تفضِّل النماذج الأبسط، وفيما يلي قائمة بأكثر تلك الخوارزميات شيوعًا:
- انحدار ريدج Ridge Regression
- أقل انكماش مطلق ومعامل الاختيار Least Absolute Shrinkage and Selection Operator واختصارًا LASSO
- الشبكة المرنة Elastic Net
- انحدار الزاوية الصغرى Least-Angle Regression واختصارًا LARS
4. خوارزميات شجرة القرار Decision Tree
يبني هذا النوع من الخوارزميات نموذج اتخاذ قرارات بناءً على قيم خواص البيانات، فالأمر فيه أشبه بشجرة، إذ تُتَتَبع قيم الخواص حتى الوصول إلى قرار ما، ويُستخدَم هذا النوع من الخوارزميات للتدرب على البيانات الخاصة بمهام التصنيف ومهام التوقع/الانحدار، كما تتميز تلك الخوارزميات بالسرعة والدقة العالية في معظم الأحيان، وفيما يلي بعض من تلك الخوارزميات:
- خوارزمية M5
- قرعة القرار Decision Stump
- أشجار القرار المشروط Conditional Decision Trees
- شجرة التصنيف والانحدار Classification and Regression Tree واختصارًا CART
- ثنائي التفرع التكراري 3 أو Iterative Dichotomiser 3 واختصارًا ID3
- كشف التفاعل التلقائي لمربع تشي Chi-squared Automatic Interaction Detection واختصارًا CHAID
5. خوارزميات مبرهنة بايز Bayesian Algorithms
هذا النوع من الخوارزميات هو الذي يستخدِم مبرهنة بايز Bayes’ Theorem بصورة صريحة لحل مشكلات التصنيف والتوقع / الانحدار، وفيما يلي أكثر خوارزميات هذا النوع انتشارًا:
- خوارزمية Naive Bayes
- خوارزمية Gaussian Naive Bayes
- خوارزمية Naive Bayes متعددة الحدود Multinomial Naive Bayes
- الشبكة البايزية Bayesian Network واختصارًا BN
- مقدِرات متوسطات الاعتماد الواحد Averaged One-Dependence Estimators واختصارًا AODE
- شبكة المعتقدات البايزية Bayesian Belief Network واختصارًا BBN
6. خوارزميات العنقدة Clustering Algorithms
يحاول هذا النوع من الخوارزميات تصنيف وتجميع البيانات المتشابهة إلى أقصى حد لتوفير فهم أفضل للبيانات والخصائص المشتركة بين العينات، وفيما يلي أشهر خوارزميات هذا النوع:
- خوارزمية k-Medians
- خوارزمية k-Means
- تعظيم التوقع Expectation Maximisation واختصارًا EM
- العنقدة الهرمية Hierarchical Clustering
7. خوارزميات تعلم قواعد الترابط Association Rule Learning Algorithms
يحاول هذا النوع من الخوارزميات استخراج القواعد التي تصف العلاقات بين المتغيرات الموجودة في البيانات، إذ يمكن أن تظهر القواعد علاقات ذات فائدة كبيرة في البيانات ذات الأبعاد الكثيرة والتي قد تكون مفيدةً بصورة كبيرة في المشروعات التجارية، وفيما يلي أكثر تلك الخوارزميات شيوعًا:
- خوارزمية ابيروري Apriori algorithm
- خوارزمية إيكلات Eclat algorithm
8. خوارزميات الشبكة العصبية الاصطناعية Artificial Neural Network Algorithms
هذا النوع من الخوارزميات مستلهم من الشبكات العصبية الحيوية الموجودة في دماغ الإنسان، وهي خوارزميات مستخدَمة بكثرة لحل مشاكل التصنيف والتوقع، ولكن ذلك النوع هو بالأحرى مجال فرعي من مجالات تعلم الآلة؛ وذلك لكثرة عدد الخوارزميات واختلافها تبعًا لمشاكلها وتطبيقاتها، وفيما يلي أشهر خوارزميات هذا النوع:
- خوارزمية بيرسبترون Perceptron
- الانتشار الخلفي Back-Propagation
- شبكة هوبفيلد Hopfield Network
- الهبوط التدريجي العشوائي Stochastic Gradient Descent
- خوارزمية بيرسبترون متعددة الطبقات Multilayer Perceptrons واختصارًا MLP
- شبكة وظيفة الأساس الشعاعي Radial Basis Function Network واختصارًا RBFN
9. خوارزميات التعلم العميق Deep Learning Algorithms
لقد فرقنا بين خوارزميات التعلم العميق وخوارزميات الشبكات العصبية لكون خوارزميات التعلم العميق هي النسخة الأحدث والمطوَّرة من خوارزميات الشبكات العصبية، فذلك النوع من الخوارزميات يعنى بتطوير الشبكات العصبية الأكثر تعقيدًا من نظيراتها الأخرى، فهي تعمل على تطوير شبكات معقدة تتعامل مع بيانات ضخمة ومعقدة مثل الصور والصوتيات والنصوص والمقاطع المرئية ونحوها، وفيما يلي مجموعة من أشهر خوارزميات التعلم العميق:
- الشبكات العصبية التلافيفية Convolutional Neural Network واختصارًا CNN
- شبكات الذاكرة طويلة-قصيرة المدى Long Short-Term Memory Networks واختصارًا LSTMs
- المشفرات الآلية المرصوصة Stacked Auto-Encoders
- الشبكات العصبية المتكررة Recurrent Neural Networks واختصارًا RNN
- شبكة المعتقد العميق Deep Belief Networks واختصارًا DBN
- آلة بولتزمان العميقة Deep Boltzmann Machine واختصارًا DBM
10. خوارزميات تقليص الأبعاد Dimensionality Reduction Algorithms
تقلِّص هذه الخوارزميات أبعاد البيانات لمحاولة تصنيف وتجميع البيانات المتشابهة تمامًا مثل خوارزميات العنقدة، وتلك الخوارزميات مفيدة في فهم البيانات بصورة أفضل حتى يُعدَّل على البيانات قبل استخدامها مرةً أخرى في خوارزميات أخرى، كما تستخدَم لحل مشاكل التصنيف أو التوقع، وفيما يلي قائمة بأوسع خوارزميات هذا النوع استخدامًا:
- تحليل المكون الرئيسي Principal Component Analysis واختصارًا PCA
- انحدار المكون الرئيسي Principal Component Regression واختصارًا PCR
- انحدار المربعات الصغرى الجزئي Partial Least Squares Regression واختصارًا PLSR
- رسم خرائط سامون Sammon Mapping
- مطاردة الإسقاط /التنبؤ Projection Pursuit
- التحجيم متعدد الأبعاد Multidimensional Scaling واختصارًا MDS
- تحليل التمييز الخطي Linear Discriminant Analysis واختصارًا LDA
- تحليل التمييز الخليط Mixture Discriminant Analysis واختصارًا MDA
- تحليل التمييز المرن Flexible Discriminant Analysis واختصارًا FDA
- تحليل التمييز التربيعي Quadratic Discriminant Analysis واختصارًا QDA
11. خوارزميات الفرقة/المجموعة الواحدة Ensemble Algorithms
تجمع هذه الخوارزميات نتائج نماذج مختلفة ضعيفة في نتيجة واحدة، إذ يُدرَّب كل نموذج عليها بصورة مستقلة ثم تجمع هذه الخوارزمية تلك التوقعات لتكوين توقع واحد جديد شامل، وفيما يلي قائمة من أبرز هذا النوع من الخوارزميات:
- التعزيز Boosting
- خوارزمية تجميع Bootstrap وهي بالإنجليزية Bootstrap aggregating أو تسمى في كثير من الأحوال بالتعبئة Bagging
- خوارزمية AdaBoost
- الغابة العشوائية Random Forest
- التعميم المرصوص/المكدس Stacked Generalization ويدعى أحيانًا التراص Stacking
- خوارزمية المتوسط الموزون Weighted Average وأحيانًا تدعى المزج Blending
- أشجار الانحدار المعزز بالتدرج Gradient Boosted Regression Trees والذي يدعى أحيانًا GBRT اختصارًا في بعض المراجع
- آلات تعزيز التدرج Gradient Boosting Machines وتدعى أحيانًا GBM اختصارًا.
وبالرغم من وجود الكثير من الخوارزميات الأخرى، إلا أن ذلك يغطي معظم ما يراه مهندس تعلم الآلة من الخوارزميات في عمله اليومي في وقتنا الحاضر، وأغلب الظن أنّ القوائم السابقة ستزيد وتتغير بصورة كبيرة خلال السنوات القادمة، إذ أنّ الأعمال البحثية في كثير من جامعات وشركات العالم قائمة وفي تنافس شديد ومتسارع.
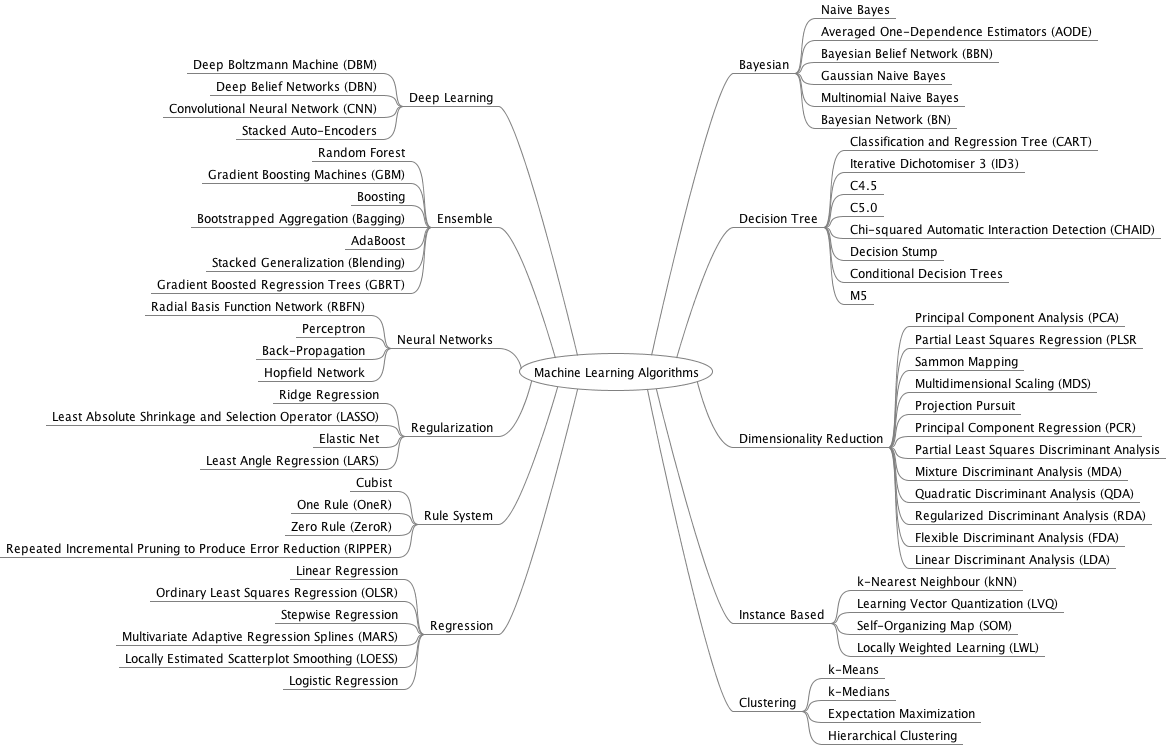
إليك الصورة التالية التي تجمع كل خوارزميات تعلم الآلة في مكان واحد لتبقى لك مرجعًا:






أفضل التعليقات
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.