

سنتناول في هذه المقالة حل تمرين مقالة تحليل زمن تشغيل القوائم المُنفَّذة باستخدام مصفوفة، ثم نتابع مناقشة تحليل الخوارزميات.
تصنيف توابع الصنف MyLinkedList
تَعرِض الشيفرة التالية تنفيذ التابع indexOf. اقرأها وحاول تحديد ترتيب نمو order of growth التابع قبل المتابعة:
public int indexOf(Object target) { Node node = head; for (int i=0; i<size; i++) { if (equals(target, node.data)) { return i; } node = node.next; } return -1; }
تُسنَد head إلى node أولًا، ويعني هذا أنّ كليهما يشير الآن إلى نفس العقدة. يَعُدّ المُتغيّرُ i هو المُتحكِّم بالحلقة من 0 إلى size-1، ويَستدعِي في كل تكرارٍ التابعَ equals ليفحص ما إذا كان قد وجد القيمة المطلوبة. فإذا وجدها، فسيعيد قيمة i على الفور؛ أما إذا لم يجدها، فسينتقل إلى العقدة التالية ضمن القائمة.
عادةً ما نتأكَّد أولًا مما إذا كانت العقدة التالية لا تحتوي على قيمة فارغة null، ولكن ليس هذا ضروريًا في حالتنا؛ لأن الحلقة تنتهي بمجرد وصولنا إلى نهاية القائمة (بفرض أن قيمة size مُتّسقةٌ مع العدد الفعلي للعقد الموجودة ضمن القائمة).
إذا نفَّذنا الحلقة بالكامل دون العثور على القيمة المطلوبة، فسيعيد التابع القيمة -1.
والآن، ما هو ترتيب نمو هذا التابع؟
-
إننا نستدعِي في كل تكرار التابع
equalsالذي يَستغرِق زمنًا ثابتًا (قد يعتمد على حجمtargetأوdata، ولكنه لا يعتمد على حجم القائمة). تستغرق جميع التعليمات الأخرى ضمن الحلقة زمنًا ثابتًا أيضًا. - تُنفَّذ الحلقة عددًا من المرات مقدراه n لأننا قد نضطّر إلى اجتياز القائمة بالكامل في الحالة الأسوأ.
وبالتالي يتناسب زمن تنفيذ ذلك التابع مع طول القائمة.
والآن، انظر إلى تنفيذ التابع add ذي المعاملين، وحاول تصنيفه قبل متابعة القراءة.
public void add(int index, E element) { if (index == 0) { head = new Node(element, head); } else { Node node = getNode(index-1); node.next = new Node(element, node.next); } size++; }
إذا كان index يُساوِي الصِّفر، فإننا نضيف العقدة الجديدة إلى بداية القائمة، ولهذا علينا أن نُعالِج ذلك مثل حالة خاصة. وبخلاف ذلك سنضطرّ إلى اجتياز القائمة إلى أن نصِل إلى العنصر الموجود في الفهرس index-1، كما سنستخدِم لهذا الهدف التابعَ المساعدَ getNode، وفيما يلي شيفرته:
private Node getNode(int index) { if (index < 0 || index >= size) { throw new IndexOutOfBoundsException(); } Node node = head; for (int i=0; i<index; i++) { node = node.next; } return node; }
يفحص التابع getNode ما إذا كانت قيمة index خارج النطاق المسموح به، فإذا كانت كذلك، فإنه يُبلِّغ عن اعتراض exception؛ أما إذا لم تكن كذلك، فإنه يمرّ عبر عناصر القائمة ويعيد العقدة المطلوبة.
الآن وقد حصلنا على العقدة المطلوبة، نعود إلى التابع add وننشئ عقدةً جديدةً، ونضعها بين العقدتين node وnode.next. قد يساعدك رسم هذه العملية على التأكد من فهمها بوضوح.
والآن، ما هو ترتيب نمو التابع add؟
-
يشبه التابع
getNodeالتابعindexOf، وهو خطّيٌّ لنفس السبب. -
تَستغرِق جميع التعليمات زمنًا ثابتًا سواءٌ قبل استدعاء التابع
getNodeأوبعد استدعائه ضمن التابعadd.
وعليه، يكون التابع add خطيًّا.
وأخيرًا، لنُلقِ نظرةً على التابع remove:
public E remove(int index) { E element = get(index); if (index == 0) { head = head.next; } else { Node node = getNode(index-1); node.next = node.next.next; } size--; return element; }
يَستدعِي remove التابع get للعثور على العنصر الموجود في الفهرس index ثم عندما يجده يحذف العقدة التي تتضمنه.
إذا كان index يُساوي الصفر، نُعالِج ذلك مثل حالة خاصة. وإذا لم يكن يساوي الصفر فسنذهب إلى العقدة الموجودة في الفهرس index-1، وهي العقدة التي تقع قبل العقدة المستهدفة بالحذف، ونُعدِّل حقل next فيها ليشير مباشرةً إلى العقدة node.next.next، وبذلك نكون قد حذفنا العقدة node.next من القائمة، ومن ثمَّ تُحرّر الذاكرة التي كانت تحتّلها عن طريق الكنس garbage collection. وأخيرًا، يُنقِص التابع قيمة size ويُعيد العنصر المُسترجَع في البداية.
والآن بناءً على ما سبق، ما هو ترتيب نمو التابع remove؟ تَستغرِق جميع التعليمات في ذلك التابع زمنًا ثابتًا باستثناء استدعائه للتابعين get وgetNode اللذين يستغرقان زمنًا خطّيًّا. وبناءً على ذلك يكون التابع remove خطّيًّا هو الآخر.
بعض الأشخاص عندما يرون عمليتين خطّيّتين أن النتيجة الإجمالية ستكون تربيعيّةً، ولكن هذا ليس صحيحًا إلا إذا كانت إحداهما داخل الأخرى؛ أما إذا استُدعِيت إحداهما تلو الأخرى، فستُحسَب المُحصلة بجمع زمنيهما، ولأن كليهما ينتميان إلى المجموعة O(n)، فسينتمي المجموع إلى O(n) أيضًا.
الموازنة بين الصنفين MyArrayList وMyLinkedList
يُلخِّص الجدول التالي الاختلافات بين الصنفين MyArrayList وMyLinkedList. يشير 1 إلى المجموعة O(1) أو الزمن الثابت، بينما يشير n إلى المجموعة O(n) أو الزمن الخطّي:
| MyArrayList | MyLinkedList | |
|---|---|---|
| add (في النهاية) | 1 | n |
| add (في البداية) | n | 1 |
| add (في العموم) | n | n |
| get / set | 1 | n |
| indexOf / lastIndexOf | n | n |
| isEmpty / size | 1 | 1 |
| remove (من النهاية) | 1 | n |
| remove (من البداية) | n | 1 |
| remove (في العموم) | n | n |
في حالتي إضافة عنصر أو حذفه من نهاية القائمة، فإنّ الصنف MyArrayList هو أفضلُ من نظيره MyLinkedList، وكذلك في عمليتي الاسترجاع والتعديل؛ أمّا في حالتي إضافة عنصر أو حذفه من مقدّمة القائمة، فإن الصنف MyLinkedList هو أفضل من نظيره MyArrayList.
يحظى الصنفان بنفس ترتيب النمو بالنسبة للعمليات الأخرى.
إذًا، أيهما أفضل؟ يعتمد ذلك على العمليات التي يُحتمل استخدامها أكثر، وهذا السبب هو الذي يجعل جافا تُوفِّر أكثر من تنفيذٍ implementation وحيد.
التشخيص Profiling
ستحتاج إلى الصنف Profiler في التمرين التالي. يحتوي هذا الصنف على شيفرة بإمكانها أن تُشغِّل تابعًا ما على مشاكلَ ذات أحجامٍ متفاوتةٍ، وتقيس زمن التشغيل لكلٍّ منها، وتَعرِض النتائج.
ستَستخدِم الصنف Profiler لتصنيف أداء التابع add المُعرَّف في كلٍّ من الصنفين ArrayList وLinkedList اللذين تُوفِّرهما لغة جافا.
تُوضِّح الشيفرة التالية طريقة استخدام ذلك الصنف:
public static void profileArrayListAddEnd() { Timeable timeable = new Timeable() { List<String> list; public void setup(int n) { list = new ArrayList<String>(); } public void timeMe(int n) { for (int i=0; i<n; i++) { list.add("a string"); } } }; String title = "ArrayList add end"; Profiler profiler = new Profiler(title, timeable); int startN = 4000; int endMillis = 1000; XYSeries series = profiler.timingLoop(startN, endMillis); profiler.plotResults(series); }
يقيس التابعُ السابقُ الزمنَ الذي يستغرقه تشغيلُ التابعِ add الذي يُضيف عنصرًا جديدًا في نهاية قائمةٍ من النوع ArrayList. سنشرح الشيفرة أولًا ثم نَعرِض النتائج.
لكي يتمكَّن الصنف Profiler من أداء عمله، سنحتاج أولًا إلى إنشاء كائنٍ من النوع Timeable. يُوفِّر هذا الكائنُ التابعين setup وtimeMe، حيث يُنفِّذ التابع setup كل ما ينبغي فعله قبل بدء تشغيل المؤقت، وفي هذا المثال سيُنشِئ قائمةً فارغة، أمّا التابع timeMe فيُنفِّذ العملية التي نحاول قياس أدائها. في هذا المثال، سنجعله يُضيف عددًا من العناصر مقداره n إلى القائمة.
لقد عرَّفنا الشيفرة المسؤولة عن إنشاء المتغير timeable ضمن صنفٍ مجهول الاسم anonymous، حيث يُعرِّف ذلك الصنف تنفيذًا جديدًا للواجهة Timeable، ويُنشِئ نسخةً من الصنف الجديد في نفس الوقت. ولكنك على كل حالٍ لست في حاجةٍ إلى معرفة الكثير عنها لحل التمرين التالي، ويُمكِنك نسخ شيفرة المثال وتعديلها.
والآن سننتقل إلى الخطوة التالية، وهي إنشاء كائن من الصنف Profiler مع تمرير معاملين له هما: العنوان title وكائن من النوع Timeable.
يحتوي الصنف Profiler على التابع timingLoop. يستخدم ذلك التابعُ الكائنَ Timeable المُخزَّن مثل متغيِّرِ نُسْخَةٍ instance variable، حيث يَستدعِي تابعه timeMe عدة مراتٍ مع قيم مختلفةٍ لحجم المشكلة n في كل مرة. ويَستقبِل التابع timingLoop المعاملين التاليين:
-
startN: هي قيمةnالتي تبدأ منها الحلقة. -
endMillis: عبارة عن قيمة قصوى بوحدة الميلي ثانية. يزداد زمن التشغيل عندما يُزيد التابعtimingLoopحجم المشكلة، وعندما يتجاوز ذلك الزمنُ القيمةَ القصوى المُحدّدة، فينبغي أن يتوقف التابعtimingLoop.
قد تضطّر إلى ضبط قيم تلك المعاملات عند إجراء تلك التجارب، فإذا كانت قيمة startN ضئيلةً للغاية، فلن يكون زمن التشغيل طويلًا بما يكفي لقياسه بدقّة، وإذا كانت قيمة endMillis صغيرةً للغاية، فقد لا تحصل على بياناتٍ كافيةٍ لاستنباط العلاقة بين حجم المشكلة وزمن التشغيل.
ستجِد تلك الشيفرة -التي ستحتاج إليها في التمرين التالي- في الملف ProfileListAdd.java، والتي حصلنا عند تشغيلها على الخرج التالي:
4000, 3 8000, 0 16000, 1 32000, 2 64000, 3 128000, 6 256000, 18 512000, 30 1024000, 88 2048000, 185 4096000, 242 8192000, 544 16384000, 1325
يُمثِل العمود الأول حجم المشكلة n، أما العمود الثاني فيُمثِل زمن التشغيل بوحدة الميلي ثانية. كما تلاحظ، فالقياسات القليلة الأولى ليست دقيقةً تمامًا وليس لها مدلول حقيقي، ولعلّه كان من الأفضل ضبط قيمة startN إلى 64000.
يُعيد التابعُ timingLoop النتائجَ بهيئة كائن من النوع XYSeries، ويُمثِل متتاليةً تحتوي على القياسات. إذا مرَّرتها إلى التابع plotResults، فإنه يَرسِم شكلًا بيانيًا -مشابها للموجود في الصورة التالية- وسنشرحه طبعًا في القسم التالي.
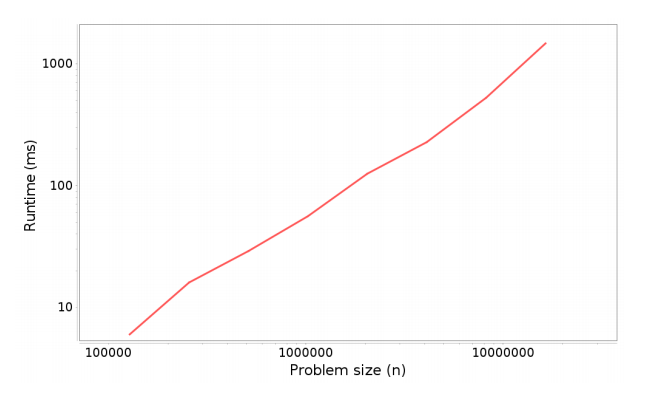
تفسير النتائج
بناءً على فهمنا لكيفية عمل الصنف ArrayList، فإننا نتوقَّع أن يستغرق التابع add زمنًا ثابتًا عندما نضيف عناصرَ إلى نهاية القائمة، وبالتالي ينبغي أن يكون الزمنُ الكلّيُّ لإضافة عددٍ من العناصر مقداره n زمنًا خطيًا.
لكي نختبر صحة تلك النظرية، سنَعرِض تأثير زيادة حجم المشكلة على زمن التشغيل الكلّي. من المفترض أن نحصل على خطٍّ مستقيمٍ على الأقل لأحجام المشكلة الكبيرة بالقدر الكافي لقياس زمن التشغيل بدقة. ويُمكِننا كتابةُ دالّة هذا الخط المستقيم رياضيًّا على النحو التالي:
runtime = a + b*n
حيث يشير a إلى إزاحةِ الخط وهو قيمة ثابتة و b إلى ميل الخط.
في المقابل، إذا كان التابع add خطّيًّا، فسيكون الزمن الكليُّ لتنفيذ عددٍ من الإضافات بمقدار n تربيعيًا. وعندها إذا نظرنا إلى تأثير زيادة حجم المشكلة على زمن التشغيل، فسنتوقَّع الحصول على قطعٍ مكافئٍ parabola، والذي يُمكِن كتابة معادلته رياضيًّا على النحو التالي:
runtime = a + b*n + c*n^2إذا كانت القياسات التي حصلنا عليها دقيقةً فسنتمكَّن بسهولةٍ من التمييز بين الخط المستقيم والقطع المكافئ، أمّا إذا لم تكن دقيقةً تمامًا، فقد يكون تمييز ذلك صعبًا إلى حدٍّ ما، وعندئذٍ يُفضّلُ استخدام مقياس لوغاريتمي-لوغاريتمي log-log لعرض تأثير حجم المشكلة على زمن التشغيل.
ولِنَعرِفَ السببَ، لنفترض أن زمن التشغيل يتناسب مع nk، ولكننا لا نعلم قيمة الأس k. يُمكِننا كتابة تلك العلاقة على النحو التالي:
runtime = a + b*n + … + c*n^k
كما ترى في المعادلة السابقة، فإنّ الأساس ذا الأسِّ الأكبر هو الأهم من بين القيم الكبيرة لحجم المشكلة، وبالتالي يُمكِن تقريبيًّا إهمال باقي الحدود وكتابة العلاقة على النحو التالي:
runtime ≈ c * n^k
حيث نعني بالرمز ≈ "يساوي تقريبًا"، فإذا حسبنا اللوغاريتم لطرفي المعادلة، فستصبح مثل الآتي:
log(runtime) ≈ log(c) + k*log(n)
تعني المعادلة السابقة أنه لو رسمنا زمن التشغيل مقابل حجم المشكلة n باستخدام مقياس لوغاريتمي-لوغاريتمي، فسنرى خطًا مستقيمًا بثابتٍ -يمثل الإزاحة- يساوي log(c) وبميل يساوي k. لا يهمنا الثابت هنا وإنما يهمنا الميل k، فهو الذي يشير إلى ترتيب النمو. وزبدةُ الكلام أنه إذا كانت قيمة k تساوي 1، فالخوارزميةُ خطيّة؛ أما إذا كانت تساوي 2، فالخوارزمية تربيعيّة.
إذا تأمّلنا في الرسم البيانيّ السابق، يُمكِننا أن نُقدِّر قيمة المَيْلِ تقريبيًا، في حين لو استدعينا التابع plotResults، فسيحسب قيمة الميل بتطبيق طريقة المربعات الدنيا least squares fit على القياسات، ثم يَطبَعه. و قد كانت قيمة الميل التي حصل عليها التابع:
Estimated slope = 1.06194352346708
أي تقريبًا يساوي 1. إذًا فالزمنُ الكلّيّ لإجراء عدد مقداره n من الإضافات هو زمن خطي، وزمن كل إضافة منها ثابت كما توقعنا.
اقتباسنقطة مهمة إذا رأيت خطًا مستقيمًا في رسمة مشابهة للرسمة السابقة، فهذا لا يَعنِي بالضرورة أن الخوارزميّة خطّيّة. إذا كان زمن التشغيل متناسبًا مع nk لأي أس k، فمن المتوقع أن نرى خطًا مستقيمًا ميله يساوي k. فإذا كان الميل أقرب للواحد الصحيح، فمن المُرجَّح أن تكون الخوارزمية خطية؛ أما إذا كان أقرب لاثنين، فيُحتمَل أن تكون تربيعية.
تمرين 4
ستجد ملفات الشيفرة المطلوبة لهذا التمرين في مستودع الكتاب.
-
Profiler.java: يحتوي على تنفيذ الصنفProfilerالذي شرحناه فيما سبق. ستَستخدِم ذلك الصنف، ولن تحتاج لفهم طريقة عمله، ومع ذلك يُمكِنك الاطلاع على شيفرته إن أردت. -
ProfileListAdd.java: يحتوي على شيفرة تشغيل التمرين، بما في ذلك المثال العلوي الذي شخَّصنا خلاله التابعArrayList.add. ستُعدِّل هذا الملف لتُجرِي التشخيص على القليل من التوابع الأخرى.
ستجد ملف البناء build.xml في المجلد code أيضًا.
نفِّذ الأمر ant ProfileListAdd لكي تُشغِّل الملف ProfileListAdd.java. ينبغي أن تحصل على نتائج مشابهة للصورة المُرفقة في الأعلى، ولكنك قد تضطّر إلى ضبط قيمة المعاملين startN وendMillis. ينبغي أن يكون الميل المُقدَّر قريبًا من 1، مما يَعني أن تنفيذ عدد n من عمليات الإضافة يستغرق زمنًا متناسبًا مع n مرفوعة للأس 1، أي ينتمي إلى المجموعة O(n).
ستجد تابعًا فارغًا في الملف ProfileListAdd.java اسمه كالآتي:
profileArrayListAddBeginning
عندها املأه بشيفرةٍ تفحص التابع ArrayList.add جاعلًا إياه يُضيِف العنصر الجديد دائمًا إلى بداية القائمة. إذا نَسخَت شيفرة التابع profileArrayListAddEnd، فستحتاج فقط إلى إجراء القليل من التعديلات. في الأخير، أضف سطرًا ضمن التابع main لاستدعاء تلك الدالة.
نفِّذ الأمر ant ProfileListAdd مرةً أخرى وفسِّر النتائج. بناءً على فهمنا لطريقة عمل الصنف ArrayList، فإننا نتوقَّع أن تَستغرِق عملية الإضافة الواحدة زمنًا خطيًا، وبالتالي سيكون الزمن الكلي الذي يَستغرِقه عدد مقداره n من الإضافات تربيعيًا. إن كان ذلك صحيحًا، فإن الميل المُقدَّر للخط بمقياس لوغاريتمي-لوغاريتمي ينبغي أن يكون قريبًا من 2.
بعد ذلك، وازن ذلك الأداء مع أداء الصنف LinkedList. املأ متن التابع الآتي واستخدمه لتصنيف التابع LinkedList.add بينما يُضيِف عنصرًا جديدًا إلى بداية القائمة:
profileLinkedListAddBeginning
أخيرًا، املأ متن التابع profileLinkedListAddEnd، واِستخدَمه لتصنيف التابع LinkedList.add بينما يُضيِف عنصرًا جديدًا إلى نهاية القائمة. ما الأداء الذي تتوقعه؟ وهل تتوافق النتائج مع تلك التوقعات؟
سنَعرِض النتائج ونجيب على تلك الأسئلة في المقالة التالية.
ترجمة -بتصرّف- للفصل Chapter 4: LinkedList من كتاب Think Data Structures: Algorithms and Information Retrieval in Java.
اقرأ أيضًا
- المقال التالي: تحليل زمن تشغيل القوائم المنفذة باستخدام قائمة ازدواجية الترابط
- المقال السابق: تحليل زمن تشغيل القوائم المنفذة باستخدام مصفوفة











أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.