Mustafa Suleiman
-
المساهمات
20360 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
495
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
 لديك مشكلة في الملفات، فالدالة image_dataset_from_directory تقرأ كل ملف في المجلد، ولو تم قراءة ملف تالف، يتوقف التدريب بأكمله. عليك المرور على جميع الصور في مجلدي Cat و Dog وحذف أي ملف لا يمكن فتحه كصورة صالحة، ومتاح ذلك سهولة من خلال مكتبة Pillow، عن طريق السكريبت التالي، قم بتنفيذه في خلية منفصلة قبل الكود الذي يقوم بإنشاء train_ds و val_ds: import os import PIL from PIL import Image from pathlib import Path cat_path = Path("/kaggle/input/dog-and-cat-classification-dataset/PetImages/Cat") dog_path = Path("/kaggle/input/dog-and-cat-classification-dataset/PetImages/Dog") image_extensions = [".png", ".jpg", ".jpeg"] img_paths = [cat_path, dog_path] for path in img_paths: print(f"Checking directory: {path}") for filepath in path.glob("*"): if filepath.suffix.lower() in image_extensions: try: img = Image.open(filepath) img.verify() except (IOError, SyntaxError, PIL.UnidentifiedImageError) as e: print(f"Deleting corrupt image file: {filepath}") try: os.remove(filepath) except Exception as remove_error: print(f"Could not delete file: {filepath}, Error: {remove_error}") بالطبع عليك تعديل مسار cat_path وdog_path للمسار الصحيح لديك في بيئة Kaggle
لديك مشكلة في الملفات، فالدالة image_dataset_from_directory تقرأ كل ملف في المجلد، ولو تم قراءة ملف تالف، يتوقف التدريب بأكمله. عليك المرور على جميع الصور في مجلدي Cat و Dog وحذف أي ملف لا يمكن فتحه كصورة صالحة، ومتاح ذلك سهولة من خلال مكتبة Pillow، عن طريق السكريبت التالي، قم بتنفيذه في خلية منفصلة قبل الكود الذي يقوم بإنشاء train_ds و val_ds: import os import PIL from PIL import Image from pathlib import Path cat_path = Path("/kaggle/input/dog-and-cat-classification-dataset/PetImages/Cat") dog_path = Path("/kaggle/input/dog-and-cat-classification-dataset/PetImages/Dog") image_extensions = [".png", ".jpg", ".jpeg"] img_paths = [cat_path, dog_path] for path in img_paths: print(f"Checking directory: {path}") for filepath in path.glob("*"): if filepath.suffix.lower() in image_extensions: try: img = Image.open(filepath) img.verify() except (IOError, SyntaxError, PIL.UnidentifiedImageError) as e: print(f"Deleting corrupt image file: {filepath}") try: os.remove(filepath) except Exception as remove_error: print(f"Could not delete file: {filepath}, Error: {remove_error}") بالطبع عليك تعديل مسار cat_path وdog_path للمسار الصحيح لديك في بيئة Kaggle- 9 اجابة
-
- 1
-

-
منصة سنديان التابعة لحسوب عبارة عن منصة بناء مواقع أي Website Builder متكاملة توفر لك كل الأدوات في مكان واحد، وسهلة الاستخدام من قبل المبتدئين، ولا اتطلب أي خبرة تقنية، حيث تعتمد على محرر السحب والإفلات وقوالب جاهزة. متاح أنّ تختار قالب، ثم تعدل النصوص والصور بالسحب والإفلات، وتنشر موقعك في دقائق، أي المنصة مثالية للمواقع التعريفية، المتاجر البسيطة، مواقع الحجوزات. ولن تحتاج إلى شراء استضافة منفصلة، فهي جزء من اشتراكك السنوي في سنديان، أي المنصة تتولى كل شيء، أيضًا توفر نطاق مجاني للسنة الأولى عند الاشتراك في الخطة السنوية، أو يمكنك ربط نطاق اشتريته من مكان آخر بسهولة. ولكنك بحاجة إلى دفع اشتراك سنوي يغطي كل شيء (المنصة، الاستضافة، الدعم الفني، التحديثات). كذلك أنت مقيد بالأدوات والميزات التي توفرها منصة سنديان، ولا تستطيع إضافة ميزات غير مدعومة، ففريق سنديان هو المسؤول عن صيانة الخوادم، التحديثات الأمنية، وتحديثات المنصة ولن تشغل بالك بشأن الجانب التقني، لكن متاح تخصيص الموقع بتعديل أكواد HTML, CSS, JS لو أردت وتلك ميزة موجهة أكثر للمطورين من أجل تخصيص المواقع للعملاء. وستحصل على دعم فني مباشر من فريق سنديان عبر المحادثة الفورية أو البريد الإلكتروني لمساعدتك في حل المشاكل. بينما WordPress هو نظام إدارة محتوى CMS مفتوح المصدر، أي مجاني تمامًا، وتقوم بتثبيته على أي استضافة تختارها لبناء موقعك، أي تحتاج لشراء استضافة بنفسك، ويجب عليك الاشتراك مع شركة استضافة مثل SiteGround, Bluehost, Hostinger وتثبيت ووردبريس عليها. والواجهة ليست معقدة، لكن تنفيذ ما تريده يتطلب فهم القوالب والإضافات وبعض الإعدادات، ومن خلاله تستطيع بناء أي نوع من المشاريع سواء مدونات ضخمة، متاجر إلكترونية متقدمة عبر WooCommerce، منتديات، مواقع عضوية، شبكات اجتماعية. أيضًأ تحتاج لشراء نطاق بنفسك من شركة مسجلة مثل GoDaddy, Namecheap وربطه بالاستضافة التي اشتريتها. أي البرنامج مجاني، لكنك تدفع للاستضافة والنطاق والقوالب المدفوعة في حال أردت قالب إحترافي، وذلك يوجد إضافات مدفوعة لكن ذلك ليس ضروري بالطبع. ولديك وصول كامل لملفات موقعك وقواعد البيانات، وباستطاعتك تعديل أي شيء وتثبيت آلاف الإضافات لتوسيع وظائف الموقع بلا حدود، وأنت المسؤول عن تحديث نسخة ووردبريس، القوالب، والإضافات، وعمل نسخ احتياطية، وتأمين الموقع، أي بحاجة إلى خبرة تقنية بعض الشيء لإدارة موقعك.
-
بل ستحتاج أولاً إلى إنهاء دورة تطوير واجهات المستخدم، ثم دراسة مسار MERN من خلال دورة جافاسكريبت، وستدرس المسارات التالية: أساسيات لغة JavaScript أساسيات React.js أساسيات Node.js تطبيق دردشة يشبه WhatsApp إنشاء تطبيق أسئلة وأجوبة باستخدام Next.js تطبيق تعلم اللغات باستخدام Next.js وتقنيات الذكاء الاصطناعي تطبيقات الويب التقدمية PWA أساسيات TypeScript بمعنى يجب دراسة الأساسيات أولاً، أي تطوير المشاريع من خلال HTML, CSS, JS وذلك ما نفعله في دورة تطوير واجهة المستخدم، ثم بعد تعلم React وNode.js وNext.js تستطيع العمل على تطوير نفس المشاريع ولكن من خلال التقنيات السابقة، وذلك أفضل لتتفهم الفرق وستكتسب خبرة كبيرة من ذلك. الأفضل العمل على تحويلها إلى مشروع React.js من أجل التدرب على استخدام المكتبة، ثم إنشاء واجهة خلفية من خلال Node.js.
- 9 اجابة
-
- 1
-

-
ليس بتلك الصعوبة، طالما استوعبت المسارات التي قمت بدراستها وتستطيع تنفيذ مشاريع عملية بنفسك مشابهة لما قمت به بالدورة، فلا مشكلة. آلية الإختبار هي كالتالي: بعد إنهاء 4 مسارات من الدورة على الأقل، أو الدورة بالكامل عليك رفع المشاريع التي قمت بها بالدورة على حسابك في github، ثم التحدث لمركز المساعدة وإخبارهم أنك تريد التقدم للإختبار وتوفير روابط المشاريع على github. ثم الإنتظار لبعض الوقت لحين مراجعة المشاريع وسيتم الرد عليك، وتحديد موعد لإجراء مقابلة، وبها يتم: إجراء محادثة صوتيّة لمدة 30 دقيقة يطرح المدرّب عليك أسئلة متعلّقة بالدورة والأمور التي نفّذتها خلالها، وسيتم سؤالك في المسارات التي أنهيتها فقط، لكن بحد أدنى يجب إنهاء 4 مسارات. يحدد لك المدرّب مشروعًا مرتبطًا بما قمت به أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع إلى أسبوعين. إجراء محادثة صوتيّة أخرى لمدّة 30 دقيقة يناقش بها مشروعك وما نفذته وتطرح أسئلة خلالها. إن سارت على جميع الخطوات السابقة بشكل صحيح، تحصل على الشهادة أو يرشدك المدرّب لأماكن القصور ويطلب منك تداركها ثم التواصل معنا من جديد.
-
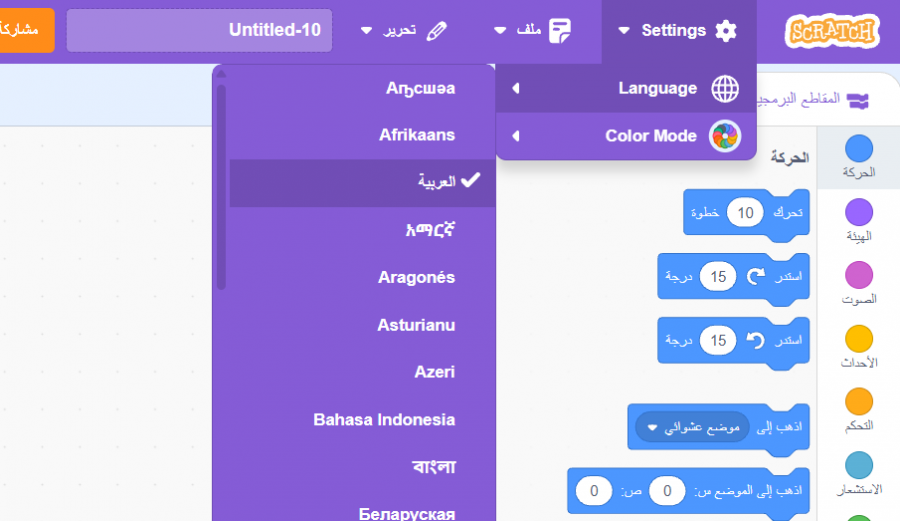
تستطيع تعديل اللغة كما تريد من خلال قائمة settings: وبخصوص سكراتش فيتم الإعتماد عليها في المسار الأول فقط، فدورة علوم الحاسوب تم إعدادها بشكل خاص لكي يتم تأهيلك لتعلم البرمجة، ففي البداية ستتعلم التفكير المنطقي في البرمجة وطريقة كتابة خوارزمية أو خطوات كتابة البرنامج قبل كتابة الكود أي التفكير أولاً، ثم تطبيق الأمر من خلال سكراتش لكون المنصة بسيطة وتوفر لك التعرف على المفاهيم البرمجية بطريقة ممتعة مثل حلقات التكرار والجمل الشرطية والمتغيرات وغيرها. أي لا نتعلم سكراتش بل المفاهيم البرمجية والمنطق البرمجي وكيفية التفكير قبل البدء في كتابة الكود، فتلك هي المرحلة الأهم وليس كتابة الكود. ثم الإنتقال لاستخدام لغة برمجية فعلية مثل بايثون وجافاسكريبت، ولو انتقلت إليهم مباشرًة، ستجد صعوبة في استيعاب المفاهيم البرمجية في حال لم يكن لديك أي خلفية تقنية أو برمجية سابقة.
-
https://flexboxfroggy.com/#ar https://cssgridgarden.com/#ar
-
لا مشكلة، لكل شخص أسلوب مناسب للدراسة ولتلقي المعلومات، فالبعض يتعلم بصريًا مثلك أنت أي بالمشاهدة والاستماع، تحتاج إذن إلى الإعتماد على يوتيوب لمشاهدة شرح إضافي والاستزادة، بجانب التطبيق بشكل عملي وعدم الإكتفاء بالمشاهدة فقط، فالبرمجة تتعلمها بالممارسة لا بالمشاهدة فقط. الفكرة من موسوعة حسوب هي أنها مرجع لمختلف اللغات أي أشبه بمستند رسمي كالذي تجده في المكتبات وإطارات العمل، مع الوقت ستعتاد على هيكل المنصة وطريقة التصفح خلالها، وهو أمر هام للغاية ويتأتى بالممارسة ويصبح أسهل مع الوقت. بإمكانك أيضًا السؤال أسفل أي درس عن الأمور التي تحتاج إيضاح إليها، أو هنا في قسم أسئلة البرمجة.
- 4 اجابة
-
- 1
-
-
أول خطوة هي دراسة للسوق، تشمل تحليل المنافسين بالتفصيل، حجم السوق المتوقع، نماذج الأعمال الناجحة والتسعير والاستراتيجيات. ثم عمل validation للفكرة لمدة تترواح ما بين أسبوع إلى أسبوعين، وللقيام بها يجب تحديد الجمهور المستهدف للتأكد أن المشكلة موجودة فعلاً وأن الناس مستعدين لتقبلها أو يوجد احتياج على الأقل، وذلك من خلال محادثات مع 10إلى 20 شخص من الفئة المستهدفة أو استبيانات بسيطة Google Forms أو منشورات في مجموعات متخصصة أو Landing Page بسيط لقياس الاهتمام وترويجه من خلال Facebook وInstagram Ads أو حسب المنصة الموجود بها الفئة المستهدفة. وتجنب التعلق بالفكرة عاطفيًا قبل اختبارها، فهناك مقولة جيدة لذلك Fall in love with the problem, not the solution أي تعلق بالمشكلة وليس الحل. وللعلم قم بالتجربة على فئة مستخدمين آخرين فربما قمت بالأمر بشكل غير صحيح في البداية، ثم تأتي خطوة تحديد القيمة المضافة بمعنى كيف سيحل تطبيقك مشكلة حقيقية؟ وما الذي يميزك عن المنافسين؟ ثم تطوير MVP وهو الحد الأدنى من المنتج ويُركز على الميزات الأساسية فقط ولا تحاول بناء كل شيء من البداية.
- 2 اجابة
-
- 1
-
-
ذلك مثال للتوضيح، بالطبع التطبيقات العملية في باقي المسارات مطلوبة، لكن مثلاً في مسار تحليل البيانات Data Analysis لدينا الأقسام التالية: مدخل التعامل مع البيانات والإحصاء تمثيل البيانات مرئيًا عبر Pandas تحليل البيانات مرئيًا عبر Matplotlib تمثيل البيانات مرئيًا عبر Seaborn وسيتم شرح الأساسيات بأمثلة بسيطة وليس مطلوب منك هنا رفعها، ويوجد بعدها الأقسام التالية للتطبيق العملي: تحليل أداء الطلاب في إحدى المدارس تحليل بيانات متجر إلكتروني لتحسين استراتيجية المبيعات تحليل سلوك العملاء تحليل بيانات الحملات التسويقية لتحسين استراتيجيتها تحليل بيانات حملة تسويقية لبنك للتنبؤ باشتراك العملاء تحليل مبيعات السيارات وهنا مطلوب منك رفع تلك التطبيقات العملية
- 3 اجابة
-
- 1
-
-
ليس المطلوب منك رفع التطبيقات العملية البسيطة، بل المشاريع العملية الكاملة، بمعنى في قسم "استخراج البيانات من الويب Web scraping" يوجد تطبيق عملي ستوظف به ما تعلمته، فذلك مطلوب منك رفعه. وفي مسار "تطبيقات عملية على النماذج النصية الكبيرة LLMs" مطلوب منك التطبيقات التي سنقوم بها في ذلك المسار. بالتالي لتجنب إدخال نفسك في متاهة مفرغة، أرجو إنشاء مجلد للدورة ثم بداخله قم بإنشاء عدّة مجلدات حيث مجلد لكل مسار في الدورة. وبداخل كل مجلد قم بوضع التطبيقات العملية التي قمنا بها في ذلك المسار. ثم رفع المجلد الرئيسي بالكامل بما يحتويه من مجلدات على مستودع GitHub وتوفير الرابط الخاص به عند التقدم للإختبار. وفي حال وجود مشروع به الكثير من الملفات والمجلدات ويحتاج إلى مجلد خاص به مثل مشروع "تخصيص نموذج لغة باستخدام LangChain و OpenAI" هنا تقوم برفع المشروع على مستودع GitHub منفصل خاص به.
- 3 اجابة
-
- 1
-
-
الأمر مختلف من شخص لآخر، بمعنى خلفيته السابقة وهل يبدأ من الصفر أم لا، والوقت المخصص للدراسة بشكل يومي، ومدى قدرة الشخص على الاستيعاب فهناك فروق فردية بالطبع، أيضًا طريقته في المذاكرة فلكل شخص أسلوب يناسبه. إذا كنت متفرغ فأنصحك بتخصيص 6 إلى 10 ساعات يوميًا للمذاكرة، أما إذا كنت غير متفرغ فيمكنك تخصيص 3 ساعات يوميًا للمذاكرة أو ساعتان حيث أن أقل من ذلك لا يعتبر وقت كافي. وكلما زدت في الوقت والإجتهاد كان أفضل لك، ولكن ذلك لا يعني أن تخصص 10 ساعات لمشاهدة الفيديوهات بل خليط ما بين المشاهدة ثم الكتابة وراء المدرب أو بمفردك ومحاولة التغيير في الكود الذي كتبه المدرب وخلق تحدي بسيط لك وأيضًا البحث عن حل للمشاكل التي تواجهك من خلال القراءة أو مشاهدة فيديو على اليوتيوب مثلاً ولكن حاول البحث والقراءة أولاً. فلا تعود نفسك على رؤية الحل مباشرًة فعند البحث ستجد معلومات كثيرة أنت بحاجة إليها في البداية، وأيضًا ستكتشف المصادر الخاصة بالمعلومات والأدوات. أي أن الوقت اللازم يتوقف عليك أنت، فالبعض قد ينهي الدورة بشكل سريع لكن هل حقق الاستفادة المرجوة فعلاً؟ وهناك نصيحة، في البداية عليك أن تسير ببطيء من أجل الإسراع لاحقًا لا العكس، حيث أن الأساسيات هي ما ستوفر لك التعلم بشكل أسرع مستقبلاً وتجنب التخبط والتشتت. وستجد هنا تفصيل بخصوص مدة الدراسة: وتفصيل أيضًا بخصوص طريقة الدراسة:
-
المُلخصات الخاصة بالدروس غير متاحة للحفاظ على محتوى الدورة من النشر، لكن يوجد موسوعة حسوب وبها تفصيل أو مُلخص لكل ما تريد: https://wiki.hsoub.com أيضًا تستطيع البحث على جوجل عن Python Cheatsheet مثلاً وستجد مُلخصات لكن بالإنجليزية. وستجد إفادة بخصوص تدوين الملاحظات للمراجعة:
-
بالفعل يوجد عُطل عام في الوقت الحالي، نعتذر لك تايم على الإزعاج، سيتم حلها بأسرع وقت لا تقلق، الإدارة على علم بذلك.
- 3 اجابة
-
- 1
-
-
يوجد عُطل عام في الوقت الحالي، نعتذر لك طاهر على الإزعاج، سيتم حلها بأسرع وقت لا تقلق، الإدارة على علم بذلك
- 4 اجابة
-
- 1
-
-
في حال سؤالك خاص بمشكلة "عذرًا، هنالك مشكلة ما! حدث خطا ما. حاول مرة أخرى لاحقا. فيوجد عُطل عام في الوقت الحالي، نعتذر لك أحمد على الإزعاج، سيتم حلها بأسرع وقت لا تقلق، الإدارة على علم بذلك.
-
بالفعل يوجد عُطل عام في الوقت الحالي، نعتذر لك أحمد على الإزعاج، سيتم حلها بأسرع وقت لا تقلق، الإدارة على علم بذلك.
- 2 اجابة
-
- 1
-
-
بالفعل لم يعد القسم موجود، تم تحديث مسار أساسيات الويب، حيث استبدلنا مكتبة jQuery بجافا سكريبت الخالصة، وذلك لأن جافا سكريبت الحديثة أصبحت توفر نفس المزايا وأكثر دون الحاجة إلى تحميل مكتبات إضافية، وهو ما يجعل الكود أخف وأسرع، ويمنح الطلاب فرصة لبناء أساس قوي في لغة أساسية يحتاجونها في كل مشروع احترافي. أيضًا تم تحديث قسم إنشاء مشروع شخصي في مسار أساسيات تطوير الويب في دورة تطوير واجهات المستخدم ليواكب أحدث الإصدارات والتقنيات.
-
كافية لا مشكلة، والأفضل دائمًا هو التعمق في الأساسيات قبل الإنتقال لتعلم أي تقنية، أتفهم رغتبك في الإنتقال سريعًا بين المسارات، لكن ذلك لن يعود بالفائدة عليك، حاول تجنب ذلك، والتوقف للتعمق لبعض الوقت وتنفيذ مشاريع من خلال اللغة الأساسية وهي جافاسكريبت، ثم الإنتقال لتعلم اللغة. وللتسهيل عليك، تعلم دوال المصفوفات الحديثة: map filter find reduce ميزات ES6+ الحديثة: Destructuring التفكيك للمصفوفات والكائنات Spread Operator عامل النشر مفهوم الوحدات Modules أي import و export قالب النص template literal وبعد ذلك قم ببناء مشروع من خلال جافاسكريبت، ثم انتقل لتعلم React.
- 3 اجابة
-
- 1
-
-
صحيح تنفيذه من خلال اللغات الأساسية أولاً، والأفضل الإعتماد على CSS في البداية للتعمق بها، ثم استخدام بوتستراب بعد ذلك. ثم استخدام تقنية React ثانيًا.
-
صحيح، استبدلنا مكتبة jQuery بجافا سكريبت الخالصة، وذلك لأن جافا سكريبت الحديثة أصبحت توفر نفس المزايا وأكثر دون الحاجة إلى تحميل مكتبات إضافية، وهو ما يجعل الكود أخف وأسرع، ويمنح الطلاب فرصة لبناء أساس قوي في لغة أساسية يحتاجونها في كل مشروع احترافي. أيضًا تم تحديث قسم إنشاء مشروع شخصي في مسار أساسيات تطوير الويب في دورة تطوير واجهات المستخدم ليواكب أحدث الإصدارات والتقنيات. خطوة ممتازة، لكن يجب تنفيذ تلك المشاريع أولاً من خلال HTML, CSS أو بوتستراب
-
خيار جيد أيضًا، التحديثات الأمنية بها ممتدة حتى 2027 لكونها نسخة مخصصة للأجهزة الحساسة مثل الـ ATM أو الأجهزة الطبية، وبها نفس ميزات ويندوز 10 pro
- 4 اجابة
-
- 1
-
-
لستّ بحاجة إلى مواصفات مرتفعة، فواجهات المستخدم ليست بحاجة إلى برامج حاليًا، فلديك منصة أو موقع Figma وهي الأداة المعتمدة الآن لتصميم واجهات المستخدم. ما تحتاج إلى التركيز عليه، هو رامات بحجم 16 جيجابايت على الأقل، وهارد SSD بحجم 256 جيجابايت على الأقل، وبالنسبة للمعالج ركز على معالج متعدد الأنوية، وفي حال الميزانية منخفضة تستطيع شراء معالج من نوع APU والذي يوفر لك كرت شاشة مدمج لحين توفر ميزانية لشراء كرت شاشة خارجي مناسب.
-
أمامك خيارين، الأول شراء Extended Security Updates حيث مايكروسوفت أعلنت أنها ستوفر للمستخدمين العاديين وليس فقط الشركات خيار شراء تحديثات الأمان الممتدة Extended Security Updates لمدة تصل إلى ثلاث سنوات بعد انتهاء الدعم الرسمي. أي بعد أكتوبر 2025، ستتمكن من دفع اشتراك سنوي 30 دولار لمايكروسوفت، ومقابله سيستمر جهازك في تلقي التحديثات الأمنية الهامة فقط ولن تحصل على تحديثات الميزات الجديدة. والأسهل هو التحديث لويندوز 11، ثم تغيير شكل الواجهة لتبدوا مثل واجهة ويندوز 10، هناك أدوات مثل StartAllBack أو Start11 متخصصان في إعادة قائمة ابدأ وشريط المهام إلى شكل ويندوز 10، وتستطيع يمكنك نقل شريط المهام إلى اليسار، وإلغاء تجميع النوافذ، وإعادة قائمة ابدأ المعتادة. أيضًا أداة ExplorerPatcher تعيد مدير الملفات File Explorer وشريط المهام والعديد من جوانب النظام إلى واجهة ويندوز 10.
-
npm run build هو خاص بالواجهة الأمامية، بالنسبة للواجهة الخلفية: أمر build: cd server && npm i و أمر Start: cd server && npm start وما سبق على إفتراض أنّ المستودع به مجلدين server و client.