


Mustafa Suleiman
-
المساهمات
20361 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
495
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
عذرًا على أي إزعاج صالحة، تفقدت الدروس وهي تعمل بشكل جيد ويمكن الوصول إليها بدون مشكلة، أرجو حذف الملفات المؤقتة لموقع الأكاديمية بتحديث الصفحة بالضغط على CTRL + F5 في حال استمرت المشكلة أرجو تجربة متصفح آخر، في حال تم المشكلة إذن المشكلة من المتصفح لديكِ ربما يوجد إضافة تسبب المشكلة. لو استمرت إذن يوجد مشكلة في الإنترنت لديكِ، لنقم بتجربة تحميل نسخة الويندوز من البرنامج التالي وتشغيله: https://one.one.one.one/ بعد التثبيت ستجدي أيقونة البرنامج بالضغط على السهم أسفل اليمين في الويندوز، اضغطي على connect للإتصال.
-
 هل قمت بتنفيذ باقي الخطوات؟
هل قمت بتنفيذ باقي الخطوات؟ -
قم بحذف الكاش: php artisan optimize:clear ثم إعادة بناء "خريطة الكلاسات للمشروع، ليتمكن Composer من العثور على الكلاسات الجديدة بشكل صحيح. composer dump-autoload لو استمرت المشكلة، قم بحذف مجلد vendor في مجلد المشروع ثم التثبيت مجددًا. composer install
-
يوجد تعارض مع مكتبة أخرى لديك والتي تتطلب إعتماديات (مكتبات تعتمد عليها لتعمل المكتبة) مختلفة عنها لذا لن يتم تثبيت مكتبات مختلفة لكل مكتبة بالطبع. قم بتحديث جميع الحزم composer update ثم التثبيت: composer require laravel/jetstream
-
أهلاً بكِ، لمتابعة الدورات التي اشتركتي بها، أرجو الضغط على زر دوراتي للوصول إليها: وبخصوص الملفات الخاصة بكل دورة، فالدورة مٌقسمة إلى مسارات وفي بداية كل مسار أي الدرس الأول ستجدين مرفقات لتحميلها خاصة بالملفات الخاصة بالمسار ورابط المستودع الخاص بمشروع المسار في حال توافر ذلك.

- 1 جواب
-
- 1
-

-
المسارات الخاصة بالواجهة الأمامية هي: أساسيات لغة JavaScript أساسيات React.js تطبيق دردشة يشبه WhatsApp (تطبيق الويب من خلال react فقط) تطبيق تعلم اللغات باستخدام Next.js وتقنيات الذكاء الاصطناعي أساسيات TypeScript تطبيقات الويب التقدمية PWA
-
لا مشكلة، فدورة جافاسكريبت دورة ضخمة بها مختلف تقنيات جافاسكريبت المتعلقة بتخصصات مختلفة، لو قمت بدراسة الدورة بشكل كامل ستصبح Full-stack أي ستتعلم MERN Stack والذي يجمع بين الواجهة الأمامية والخلفية، ومتاح أيضًا دراسة جزء من تلك التقنيات فقط، بمعنى دراسة تقنيات الواجهة الأمامية فقط أو الخلفية فقط. بجانب أيضًا تخصص تطوير تطبيقات الهاتف من خلال React Native لو أردت ذلك. لكن لا أنصحك بالجمع بين مجال الويب وبين الهاتف في البداية، React هي الأساس، بمعنى React Native يعتمد على React وهو إطار خاص بالهواتف وليس الويب، لذا عليك التعمق في React أولاً وتعلم Next.js بعد ذلك لأنّ Next خاصة بالويب، في حال أردت التخصص كمطور ويب شامل Full-Stack. وفيما بعد تستطيع تعلم React Native، لكن تعلم تقنيات مختلفة في نفس الوقت هو تشتيت غير مفيد. الفكرة هي أن تعلم الأساسيات لجميع تقنيات جافاسكريبت سيجعلك تظن أنك قادر على تنفيذ مشاريع، وفي الواقع أنت بحاجة إلى التعمق والتركيز على تقنيات محددة فقط لتحسين مستواك بها.
- 4 اجابة
-
- 1
-
-
عليك تثبيت المكتبة من خلال منفذ الأوامر CMDER الخاص بلاراجون، من خلال واجهة لاراجون اضغط على terminal ثم انتقل لمسار مجلد المشروع، ثم تنفيذ أمر تثبيت المكتبة. composer require laravel/jetstream وذلك لأنّ CMDER يتعرف على إصدار PHP الجديد الذي قمت بتحديثه في لاراجون، بسبب وجود متغيرات بيئة خاصة به متوافقة مع لاراجون. وفي حال ظهر لك الخطأ jet-switchable-team مرة أخرى، فقم بتثبيت ميزة الفرق Teams: php artisan jetstream:install livewire --teams ثم تنفيذ: npm install && npm run dev
-
ذلك هو الغرض من منطق البرنامج، تحويل القيمة السالبة التي أدخلها المستخدم لقيمة 0، لو أدخلت قيمة موجبة فلن يحدث شيء، مجرد تمرين ليس أكثر.
-
لأن الشرط الذي يسبقه صحيح، أي لاستبدال القيمة السالبة التي أدخلها المستخدم بالقيمة صفر، وذلك كجزء من منطق البرنامج، ففي البداية تطلب من المستخدم إدخال عدد صحيح، وتم إدخال الرقم -16. فأصبحت قيمة المتغير x هي -16. if x < 0 يتم فحص شرط هل قيمة x (التي هي -16) أصغر من صفر؟ وهي كذلك، إذن يتم تغيير قيمة x إلى 0 وطباعة الرسالة Negative changed to zero
-
يوجد تعارض بين إصدار PHP ومكتبة jetstream، فهو أقدم من الإصدار الذي يتطلبه أحدث إصدار من المكتبة، فهي تتطلب إصدار 8.2.0 أو أحدث. عليك تحميل الإصدار التالي: PHP 8.4 (8.4.12) ثم فك الضغط عن الملف، وسيظهر لك مجلد قم بنقله للمسار التالي: C:\laragon\bin\php ثم اضغط على واجهة لاراجون بزر الفأرة الأيمن واختر php ثم اختر version ثم اختر الإصدار 8.4 وأعد تشغيل خادم apache بالضغط على stop ثم start all.
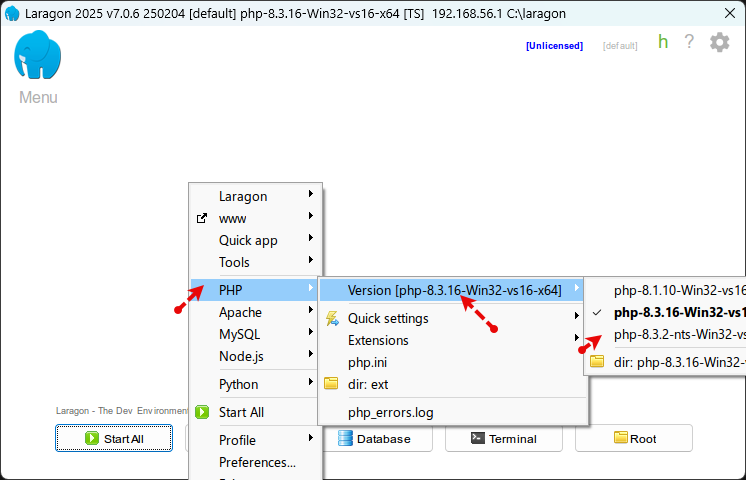
-
لا مشكلة، لكن عند التقدم للإختبار يجب ذكر ما الذي قمت بدراسته وما التخصص الذي اخترته.
-
آلية الإختبار هي كالتالي: بعد إنهاء 4 مسارات من الدورة على الأقل، أو الدورة بالكامل عليك رفع المشاريع التي قمت بها بالدورة على حسابك في github، ثم التحدث لمركز المساعدة وإخبارهم أنك تريد التقدم للإختبار وتوفير روابط المشاريع على github. ثم الإنتظار لبعض الوقت لحين مراجعة المشاريع وسيتم الرد عليك، وتحديد موعد لإجراء مقابلة، وبها يتم: إجراء محادثة صوتيّة لمدة 30 دقيقة يطرح المدرّب عليك أسئلة متعلّقة بالدورة والأمور التي نفّذتها خلالها، وسيتم سؤالك عن المسارات التي درستها فقط. يحدد لك المدرّب مشروعًا مرتبطًا بما قمت به أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع إلى أسبوعين. إجراء محادثة صوتيّة أخرى لمدّة 30 دقيقة يناقش بها مشروعك وما نفذته وتطرح أسئلة خلالها. إن سارت على جميع الخطوات السابقة بشكل صحيح، تحصل على الشهادة أو يرشدك المدرّب لأماكن القصور ويطلب منك تداركها ثم التواصل معنا من جديد. وتستطيع التقدم للإختبار أكثر من مرة لحين اجتيازه، لكن الأفضل الاستعداد له جيدًا لتجنب إضاعة وقتك.
-
لديكِ ملف حجمه كبير وإعدادات git الإفتراضية تمنع رفع مثل تلك الملفات، ولا حاجة لرفع ملفات .pth فهي تحتوي على الأوزان الخاصة بنماذج تعلم الآلة المدربة، فالملف ناتج عن تدريب قمتي به أنتِ بنفسك والكود الذي يولده موجود في المشروع، فمن الأفضل عدم رفعه، وعليكِ رفع الكود فقط، وإضافة إرشادات في ملف README.md تشرح للآخرين كيف يمكنهم تشغيل كود التدريب لتوليد الملف بأنفسهم، أرجو إضافة التالية لملف gitignore: *.pth ثم إزالة الملف من تتبع Git لأنك حاولتي رفع الملف مسبقاً، فهو موجود الآن في منطقة التجهيز staging area، ويجب إزالته من التتبع قبل أن تتمكني من عمل push بنجاح: git rm --cached "Fine Tuning/CLIP/clip_finetuned.pth" ثم تنفيذ: git add . git commit -m "first commit" git push -u origin main
-
يجب أولاً إنشاء ملف باسم: .gitignore وذلك في مجلد المشروع الرئيسي، ووضع التالي به: .env .envrc .venv env/ venv/ ENV/ env.bak/ venv.bak/ .python-version Pipfile.lock .idea/ __pycache__/ # Distribution / packaging .Python build/ develop-eggs/ dist/ downloads/ eggs/ .eggs/ lib/ lib64/ parts/ sdist/ var/ wheels/ share/python-wheels/ *.egg-info/ .installed.cfg *.egg MANIFEST وذلك لتجنب رفع أية مجلدات أو ملفات لا علاقة لها بالكود مثل مجلد env الخاص بالبيئة الإفتراضية. ثم: git init لإنشاء مستودع محلي في مجلد المشروع الرئيسي. ثم تنفيذ الأوامر التالية بالترتيب في مجلد المشروع الرئيسي لرفع المشروع: git add . // ثم git commit -m "first commit" // ثم git branch -M main // ثم git remote add origin رابط المستودع على جيت هب هنا // ثم git push -u origin main لاحظي النقطة في الأمر . git add تعني إضافة جميع محتويات المجلد الرئيسي تمهيدًا لرفعها للمستودع البعيد على جيت هب.
-
يجب استيعاب آلية عمل كل منهما أولاً، فباستخدام خاصية position مثل relative, absolute, fixed مع خصائص الإزاحة top, left, right, bottom، فأنت تقوم بتغيير مكان العنصر ضمن تخطيط الصفحة. حيث position: relative تعمل على تحريك العنصر بصريًا من مكانه الأصلي، لكن المتصفح لا يزال يحجز مساحته الأصلية في تدفق الصفحة، والعناصر الأخرى لا تتأثر ولا تملأ الفراغ الذي تركه. بينما position: absolute أو position: fixed يتم إخراج العنصر بالكامل من تدفق الصفحة، والعناصر الأخرى تتصرف وكأنه غير موجود وتملأ مكانه، ويصبح العنصر وكأنه يطفو فوق الصفحة. ونستخدم position: relative تمهيدًا لاستخدام position: absolute حيث يتم تحريك العنصر تبعًا لأقرب عنصر أب له به يمتلك خاصية position: relative. ستحتاج إلى تجربة تلك الخواص عمليًا لتفهم آلية عملهم بشكل واضح، قم بتجربة التالي، اختر اضغط على كل خاصية لترى تأثيرها، وقم بعمل سكرول في الصندوق لتفقد هل تؤثر أي منها عند التحرك صعودًا وهبوطًأ في الصفحة؟ https://developer.mozilla.org/en-US/docs/Web/CSS/position ونستخدم خاصية position من أجل تصميم هيكل الصفحة أي تحديد مكان العناصر في الصفحة، بينما خاصية transform: translate() نستخدمها من أجل تأثيرات الحركة أو أي تغيير بصري لا نريده أي يؤثر على بقية عناصر الصفحة، حيث تلك الخاصية هي جزء من مجموعة التحويلات transform، وهي تعمل في مرحلة لاحقة من عرض الصفحة، لأنّ transform: translate(x, y) تقوم بتحريك العنصر بصريًا فقط دون أن تغير مكانه أو حجمه المحجوز في تخطيط الصفحة، أي بالنسبة للمتصفح، لا يزال العنصر في مكانه الأصلي ضمن تدفق المستند، وكل ما يحدث هو أن المتصفح يقوم برسم العنصر في مكان جديد، ولذلك لا تؤثر إطلاقًا على أماكن العناصر الأخرى المحيطة. قم بتجربة تأثيرها هنا: https://developer.mozilla.org/en-US/docs/Web/CSS/transform-function/translate

- 6 اجابة
-
- 1
-
-
المشاريع الخاصة بجانغو نستخدم بها API بالفعل، فلا يوجد مشروع واجهة خلفية بدون API، الفكرة أننا قمنا بتطوير الواجهة الأمامية أيضًا من خلال جانغو عن طريق محرك القوالب الخاص به، ولو تجاهلت ذلك الجزء، ستجد أننا قمنا بإنشاء API أي مسارات ومتحكمات لمعالجة الطلبات الواردة. أي لو أردت تطوير واجهة خلفية لمشروع آخر من خلال جانغو، تستطيع ذلك لا مشكلة، ستقوم بتطوير المشروع كما فعلنا في الدورة ولكن بدون الجزء الخاص بالواجهة الأمامية. نفس الحال بالنسبة لمشاريع Flask. وفي حال تقصد Django REST Framework فلم يتم التطرق إليه في الدورة، لكنه يعتمد على جانغو لذا بتعلم جانغو فقد تعلمت نسبية كبيرة من ذلك الإطار. ستجد تفصيل هنا:
-
هل فيما بعد عند تنفيذ مشروع لعميل أو من أجل بناء معرض أعمالك ستقوم بنسخ هيكل مشروع ما؟ بالطبع لا، يجب أن تتعلم طريقة تهيئة المشروع وتهيئة بيئة العمل. لكن يجب التفرقة بين الـ Boilerplate وبين تهيئة المشروع، حيث الـ Boilerplate هو هيكل المشروع والأكواد الأساسية اللازمة لإنشاء مشروع react مثلاً، ولا حاجة لفعل ذلك بنفسك، حيث ستقوم بتنفيذ أمر بسيط يقوم بذلك بشكل تلقائي: npm create vite@latest my-react-app -- --template react ما يجب عليك استيعاب هيكل المشروع الذي تم إنشائه وليس تجاهله، بمعنى تستوعب لماذا تم إنشائه بهذا الشكل، لكي تتمكن من التعديل عليه وتطوير المشروع، وتتجنب وضع ملفات في المكان الغير صحيح. بينما مشاريع الويب من خلال HTML, CSS و webpack مثلاً، فتحتاج إلى تعلم كيفية تهيئة المشروع من الصفر، حيث لا يوجد هيكل أساسي لتلك المشاريع، وهي الأساس الذي يُبنى عليه، لذا تعلم الطريقة الصحيحة لهيكلة المشروع والأسلوب المُتعارف عليه وتستطيع التعديل عليه كيفما تريد لكن ليس بالشكل الذي يجعله صعب الفهم من قبل الآخرين.
-
كل عنصر HTML هو بمثابة صندوق، وخاصية display تحدد كيف سيتصرف وكيف سيؤثر على الصناديق التي حوله، وأهم القيم هي: 1- display: block حيث تحول العنصر إلى نوع block والذي يستحوذ على كامل عرض السطر المتاح له ويبدأ دائماً على سطر جديد، وله الخصائص التالية: يمكنك تحديد width و height له. تستطيع تطبيق margin و padding عليه من كل الجهات. يدفع العناصر التي تأتي بعده إلى سطر جديد. 2- display: inline تحول العنصر إلى نوع inline والذي يستحوذ فقط على المساحة التي يحتاجها بقدر المحتوى الذي بداخله، ويبقى على نفس السطر مع العناصر الأخرى. وخصائصه: لا يمكنك تحديد width أو height له حيث يتجاهلهما. margin-top و margin-bottom ليس لهما تأثير. يبقى بجانب العناصر الأخرى في نفس السطر. 3- display: inline-block تحول العنصر إلى مزيد بين النوعين السابقين، بحيث يبقى على نفس السطر مع العناصر الأخرى مثل inline، ولكن تستطيع تحديد width و height و margin و padding له بالكامل مثل block. وتستخدم ذلك في حال تريد عناصر بجانب بعضها البعض ولكن مع التحكم الكامل في أبعادها. ولكن ستعتمد على ما سبق بنسبة قليلة، فحاليًا flexbox وgrid هما الأساس، أي القيم التالية: display: flex display: grid وبالطبع تحتاج إلى دراسة الأساسيات الخاصة بهم لتستطيع استخدامهم بكفاءة. وتوجد قيمة أخيرة وهي . display: none التي تقوم بإزالة العنصر من الصفحة بالكامل وكأنه غير موجود، أي لا تخفيه بل تزيله.
-
عليك باستخدام Laravel Breeze لأنه تم إطلاقها في 2021، وتستخدم مكوناتBlade و Alpine.js وVite، والتصميم الإفتراضي يعتكد على TailwindCSS ويمكن استبداله، ولاستخدام Bootstrap يتطلب الأمر تعديلات تستغرق حوالي 5 إلى 10 دقائق. وتوفر تسجيل دخول، تسجيل مستخدم، إعادة تعيين كلمة المرور، تأكيد البريد، وremember me، ومكوناتBlade قابلة لإعادة الاستخدام، وتنسيق منفصل عن الـ CSS. وبما أنها تعتمد على Vite فالتحميل أسرع، ويتم تقسيم ملفات CSS وJS، وتدعم لارافل 10 وما بعده، وما زالت تحصل على تحديثات مستمرة لكونها مكتبة حديثة. ومن حيث الصيانة فهي أكثر سهولة لأن Breeze يعتمد على الـ components والـ middleware الحديث. بينما Laravel UI تم نشرها في 2019، وتعتمد على قوالب Blade التقليدية وتستخدم Laravel Mix وهي أداة تحزيم قديمة ولم تعد تستخدم، وتعتمد على بوتستراب بشكل إفتراضي أي بخصوص إعداد المشروع فلن تستغرق وقت بسبب إعتمادها على بوتستراب. وتوفر نفس الوظائف، لكن بدون الـ email verification المدمج في Breeze وتستطيع إضافته يدويًا، والقوالب جاهزة ولكنها أحادية أي لا توجد مكونات. وبما أنها تعتمد على Laravel Mix فحجم الملفات أكبر قليلاً والأداء أقل كذلك. وبخصوص الصيانة فتحتاج تعديلات يدوية أكثر عند ترقية لارافل إلى إصدار حديث.
-
لن تستطيع ذلك، الأفلام والمواد الإبداعية محمية بموجب حقوق الطبع والنشر، أي يجب أن يدفع المستخدم للاستفادة منها سواء بالمشاهدة أو الاستخدام، ولن تتمكن من رفع الموقع على Netlify وGitHub بسبب انتهاك حقوق الغير، أي حتى لو تم رفعه سيتم غلقه من قبلهم، وذلك بسبب تطبيق سياسات DMCA وهو قانون أمريكي لحماية الحقوق الرقمية. كل ما يمكنك فعله هو وضع معلومات عن الأفلام وطريقة لمشاهدتها بشكل قانوني. في حال تتساءل عن مواقع الأفلام التي تنشر أفلام مسروقة، فلا يمكن مساعدتك مساعدتك في ذلك بالطبع.
-
في البرمجة المشاهدة شيء والتطبيق العملي شيء آخر تمامًا، بكل صراحة لن تتعلم البرمجة بالمشاهدة فقط، عليك تقسيم الدرس أو الشرح إلى أجزاء طالما مدته طويلة، ثم التوقف والتطبيق. أو لو لديك القدرة، قم بمشاهدة الشرح وتطبيق ما جاء به بالكامل بمفردك، أو التطبيق على مشروع أو تمرين آخر لتوظيف ما تعلمته، المهم هي الممارسة العملية، ستتفاجيء بأمور كثيرة تظن أنك استوعبتها لكن بالتطبيق العملي يظهر عكس ذلك. تفقد التصاميم التالية وحاول تنفيذها من خلال flexbox https://www.frontendmentor.io/challenges?difficulty=1&type=free%2Cfree-plus
- 1 جواب
-
- 1
-
-
في دورة بايثون، يوجد مقدمة وشرح أساسيات بسيطة في مجال تعلم الآلة، فتخصص الدورة هو لغة بايثون وليس تعلم الآلة. بينما دورة الذكاء الاصطناعي فستدرس بها ما يلي: ستتعلم تحليل البيانات على مشاريع عملية، وستتعلم استخلاص المعلومات من مجموعات من البيانات بتحليلها وتصويرها، والتعامل مع مكتبات شهيرة مثل Pandas و Numpy و Matpoltlib و Seaborn. التعامل مع نماذج الذكاء الاصطناعي LLMs الكبيرة مثل GPT من OpenAI مثل ChatGPT ونموذج LLaMA و DeepSeek مع أمثلة عملية عن استخدامها. التعامل مع نماذج الرؤية الحاسوبية باستخدام نماذج الذكاء الاصطناعي الحديثة مثل YOLO وCLIP وVision Transformers، مع صقل Fine-Tuning هذه النماذج لتحقيق أداء أعلى. ستطبق خوارزميات التعلم العميق في تصنيف العناصر، وتدرب شبكات عصبية CNN للتعرف على الصور، وتحلل المشاعر والنصوص وتبني بوت محادثة عبر الشبكات التكرارية RNN، وتطبيقات أخرى عملية عليها. تقنيات نقل التعلم وتدريب النماذج وصقلها Fine-Tuning لتحقيق أداء أعلى في مهام الذكاء الاصطناعي، وستستفيد من النماذج المدربة مسبقًا لتسريع عملية التدريب، وتخصيصها لتلبية احتياجات تطبيقات محددة مثل تصنيف الصور وتحليل النصوص. الخوارزميات التي تستخدم في مهام الانحدار Regressions والتصنيف Classification والتجميع Clustering وغيرها في تعلم الآلة. خوارزميات التعلم الخاضعة للإشراف Supervised learning وخوارزميات التعلم الغير خاضعة للإشراف Unsupervised learning وخوارزميات التعلم المعزز Reinforced learning. ستتعلم هندسة الموجهات Prompt Engineering وضبطها Prompt tuning مع مختلف نماذج LLMs، وكيفية تشغيل Ollama محليًا. ستوظف ما تعلمته من تحليل للبيانات وتعلم الآلة في متجر إلكتروني، بدءًا من جلب البيانات من قاعدة البيانات ثم تحليلها ثم برمجة نماذج الذكاء الاصطناعي ثم دمجها مع المتجر لتقديم أنظمة ذكية للعملاء. كيفية جمع الصور ومعالجتها وتهيئتها لبناء نموذج شبكة عصبية عبر TensorFlow، وستتعلم إنشاء واجهة برمجية API بنفسك لدمج النماذج التي دربتها مع تطبيقاتك. كيفية تصميم أنظمة ذكية تتعلم من التجربة لاتخاذ قرارات مثلى في بيئات ديناميكية، باستخدام تقنيات مثل Q-learning والتعلم العميق. بعد الإنتهاء من الدورة ستنقلك من مستوى شخص لديه أساسيات في تعلم الآلة وهو مستواك الحالي إلى مستوى مهندس تعلم آلة مبتدئ إلى متوسط. أي ستتخرج منها وأنت لست مجرد محلل بيانات بل مطور ذكاء اصطناعي قادر على: تحليل المشكلة وتحديد النهج المناسب سواء تعلم آلة تقليدي، تعلم عميق، استخدام LLM. جمع البيانات ومعالجتها. بناء وتدريب وتخصيص النماذج باستخدام أحدث المكتبات والأدوات بواسطة Transformers أو TensorFlow دمج تلك النماذج في تطبيقات حقيقية عبر واجهات برمجية APIs.
-
ما هو التخصص البرمجي؟ وما هي الاستخدامات الأخرى؟ ففي حال تعلم الآلة فالمواصفات ليس كافية، فالـ GPU المدمج جيد للتعلم، لكن للمشاريع الكبيرة ستحتاج Google Colab Pro أو منصات سحابية أخرى. أيضًا سعة 512GB ستمتلئ مع الـ datasets الكبيرة أو النماذج الضخمة، ستحتاج استخدم Google Colab أو قرص خارجي. لذا تستطيع شراؤه حاليًا والاستفادة منه ثم بيعه وشراء نسخة أفضل فيما بعد، أو التوجه ناحية نظام الويندوز أي لابتوب بنظام ويندوز، فستحصل على مواصفات مرتفعة بنفس السعر. أو في حال ليس لديك مشكلة في دفع اشتراك Google Colab وهي 10$ شهريًا فلا مشكلة.
-
الأمر به مخاطرة بالطبع، وحتى لو طالت المدة يوجد مخاطرة بحظر حساب الشركة أيضًا، فأنظمة Google قوية جدًا في إنشاء بصمة رقمية للمستخدمين من خلال Big Data، بمعنى الربط بين الأجهزة المشتركة (أجهزة الكمبيوتر، الهواتف الذكية) وتسجيل الدخول إلى حساب مطور جديد أو مختلف من جهاز تم استخدامه مسبقاً للوصول إلى حساب تم إنهاؤه هو علامة خطر، بالتالي يمكن للنظام تتبع المعرفات الخاصة بالجهاز. ولو استخدمت نفس الشبكة في منزلك أو شبكة المكتب بنفس عنوان IP الذي تعرض للحظر، وذلك للوصول إلى حسابات مطورين متعددة فبذلك تعرضها لخطر الحظر، حتى استخدام شبكات Wi-Fi العامة أو الشبكات الافتراضية الخاصة (VPNs) محفوفة بالمخاطر أيضًا، فأنت لا تضمن استخدام مطور محظور لنفس الخدمة. والمتصفحات الحديثة توفر الكثير من البيانات منها الخطوط، الإضافات، دقة الشاشة، وكيل المستخدم user-agent، والتي من خلالها يتم إنشاء بصمة فريدة بجانب بيانات أخرى، وذلك يربط الأنشطة عبر حسابات مختلفة حتى بدون ملفات تعريف الارتباط أي الكوكيز. وتوجد حالة مشابهة، ابحث عن Raya Games، حيث تم حظر الحساب الشخصي لموظف سابق منذ ثلاث سنوات، وبعدها تم إنهاء حساب الشركة بسبب الارتباط واستخدام الموظف لحساباتها، تم أيضاً إنهاء حساب Google الشخصي للمالك، وكان الرابط الوحيد هو الوصول المتبقي للموظف السابق إلى تطبيق قديم وغير منشور. ستحتاج إلى استخدام بصمة مختلفة غير متعلقة بالحساب الذي تم حظره، أي جهاز جديد إن أمكن وIP جديد ومتصفح مختلف، ولا تقم بتسجيل الدخول من أي حساب جوجل قمت بتسجيل الدخول به على الجهاز القديم، فجوجل لا تعتمد فقط على الموقع الجغرافي، بل على الـ IP والجهاز، ولو الـ IP الخاص بك في الجزائر، فسيتم التعرف عليه حتى لو كان الحساب مسجلاً في قطر. غير الـ IP من خلال VPN مثل ExpressVPN أو NordVPN لتغيير الـ IP إلى واحد في قطر أو بلد آخر، وفعله دائماً عند الوصول إلى Play Console. ولو أردت استعادة حسابك الشخصي قدم طعناً appeal عبر الرابط في الإشعار مع شرح الظروف وإثبات صدق نيتك، لكن نسبة القبول ضعيفة.
- 1 جواب
-
- 1
-


