Mustafa Suleiman
-
المساهمات
20171 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
489
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
محتوى المسار تم استبداله في التحديثات الجديدة التي طرأت على الدورة لذا لم يعد حاجة إليه، حيث مسار تطبيق تعلم اللغات باستخدام Next.js وتقنيات الذكاء الاصطناعي يشرح أيضًا أساسيات Next.js
-
 أتفهم ما الصعوبات التي تواجهها عند تنفيذ أول مشروع واقعي لك بدون توجيه، وما تمر به حاليًا هو ما ستتعلم منه لاحقًا، أي ذلك الشعور بعدم الأريحية والقلق حاول عدم الإنزعاج منه ولا داعي للقلق ما تمر به طبيعي، عند مواجهة مشكلة لا تقوم بالتركيز عليها فقط، بل دعك منها وفكر في الأسباب أي اعتنق عقلية التفكير المنطقي عند حدوث مشكلة، اعزل الكود الخاص بتلك الميزة وتفقد ما الذي يسبب تلك المشكلة واعمل على جزء جزء كما ذكرت لك هنا: بخصوص الذكاء الاصطناعي، لا يهم ما هي الأداة التي ستستخدمها، المهم هو أن تستوعب ما تقوم به وليس مجرد نسخ ولصق ومحاكاة لما تشاهده دون استيعاب، بحيث تصبح قادر على تنفيذ مشاريع بنفسك أو التطوير على مشروع قائم أو حل المشاكل التي ستواجهك، لذا وظف أي أداة في متناول يديك لتصبح مبرمج أفضل وليس مجرد مستخدم آخر للأداة.
أتفهم ما الصعوبات التي تواجهها عند تنفيذ أول مشروع واقعي لك بدون توجيه، وما تمر به حاليًا هو ما ستتعلم منه لاحقًا، أي ذلك الشعور بعدم الأريحية والقلق حاول عدم الإنزعاج منه ولا داعي للقلق ما تمر به طبيعي، عند مواجهة مشكلة لا تقوم بالتركيز عليها فقط، بل دعك منها وفكر في الأسباب أي اعتنق عقلية التفكير المنطقي عند حدوث مشكلة، اعزل الكود الخاص بتلك الميزة وتفقد ما الذي يسبب تلك المشكلة واعمل على جزء جزء كما ذكرت لك هنا: بخصوص الذكاء الاصطناعي، لا يهم ما هي الأداة التي ستستخدمها، المهم هو أن تستوعب ما تقوم به وليس مجرد نسخ ولصق ومحاكاة لما تشاهده دون استيعاب، بحيث تصبح قادر على تنفيذ مشاريع بنفسك أو التطوير على مشروع قائم أو حل المشاكل التي ستواجهك، لذا وظف أي أداة في متناول يديك لتصبح مبرمج أفضل وليس مجرد مستخدم آخر للأداة. -
مشروع التخرج يتم اسناده إليك لتنفيذه من قبلك فقط، وذلك لقياس مدى استيعابك لما تم تنفيذه في الدورة وأيضًا للحصول على مزايا ما بعد الدورة نتيجة اجتيازك للإختبار كما هو موضح في وصف الدورة، والأمر محاكاة للواقع العملي بحيث يُسند إليك عميل مشروع ويطلب منك تنفيذه، لذا ستكون بمفردك. عند مواجهة مشكلة، توقف عن التفكير بالمشكلة نفسها، وفكر في المنطق المختص بتنفيذ تلك الميزة التي يظهر بها مشكلة، بحيث تعود للبداية: بدءًا من إرسال الطلب لتتفقد المسار هل هو صحيح؟ هل يوجد مشكلة في الملفات أو المجلدات والأسماء الخاصة بها أو مساراتها؟ أو هل الملفات أو المجلدات التي تستخدمها في الكود موجودة بالفعل؟ هل المتحكم يُعالج الطلب بشكل صحيح؟ وهل يوجد مشكلة في المصادقة؟ هل يوجد مشكلة في الاستيرادات؟ سواء غير صحيحة أو مكررة؟ هل قمت بكتابة ميثود أو متغير بشكل غير صحيح أي خطأ في الـ syntax؟ هل مررت قيم غير صحيحة؟ استخدم console.log لتفقد القيم والنتائج ،كذلك try catch وطباعة الخطا في catch من خلال console.log
-
بإمكانك استخدام قالب notion التالي من أجل تنظيم ومتابعة تقدمك الدراسي بالدورات: Course Planner, Schedule & Learning Progress ستقوم بتعديل أسماءء الـ topics بأسماء المسارات الخاصة بالدورة هنا، ثم إضافة الدروس وعند الإنتهاء من درس تُحدده كمُنتهي. أو تستطيع استخدام google keep أو Todoist لتنفيذ نفس الأمر. وبخصوص نصائح لدراسة الدورة، فلم تقم بذكر ما هي الدورة التي قمت بدراستها، وما الغرض من تعلمك للبرمجة؟ وما هو الوقت المتاح لك وما هو عمرك الحالي؟
-
المشكلة ليست في فكرة الـ Hash Table نفسها، بل في دالة التجزئة التي استخدمتها وحجم الجدول الصغير، فالدالة ليست جيدة: short hash = toupper(vocabulary[0]) - 'A'; لأنها تعتمد فقط على الحرف الأول من الكلمة، بالتالي كل الكلمات التي تبدأ بنفس الحرف مثل Apple, Ant, Art, Around وستذهب إلى نفس الـ Bucket أي نفس الخانة في المصفوفة dictionary، وفي اللغة الإنجليزية، هناك حروف تبدأ بها كلمات كثيرة جداً مثل S, T, A وحروف أخرى نادرة كـ X, Z, Q، لذا سيحدث تكتل أي Clustering فبعض الـ Buckets ستحتوي على Linked Lists طويلة جدًا. وعند البحث عن كلمة تبدأ بحرف شائع، ستضطر للمرور على قائمة طويلة، ويصبح أداء البحث يقترب من O(n) في أسوأ الحالات، ويلغي الفائدة من استخدام الـ Hash Table. أيضًا حجم الجدول صغير، فلديك 26 Bucket فقط، وهو عدد قليل جدًا بالنسبة لقاموس ضخم يحتوي على آلاف الكلمات. وبالنسبة للتقسيم فالأفضل للكلمات يعتمد بشكل مباشر على العملية التي تتم على الكلمات أي دالة التجزئة، والجيد منها يعمل على توزيع الكلمات بشكل عشوائي ومتساوٍا قدر الإمكان على جميع الـ Buckets المتاحة، ولفعل ذلك يجب أن تضع في الاعتبار الكلمة بأكملها، وليس فقط الحرف الأول. بيحث نفس الكلمة يجب أن تعطي نفس قيمة الـ Hash في كل مرة، وتعتمد على كل حروف الكلمة وأي تغيير بسيط في الكلمة مثل cat و car يؤدي إلى قيمة Hash مختلفة. وأن توزع الكلمات بشكل متساوٍا على الـ Buckets المتاحة لتجنب التكتل. مثال بسيط للتوضيح مع الوضع في الإعتبار ما سبق، وهي دالة تستقبل مجموع قيم ASCII لكل الحروف في الكلمة. unsigned int hash(const char* word, unsigned int N) { unsigned int sum = 0; for (int i = 0; word[i] != '\0'; i++) { sum += word[i]; } return sum % N; } لكن ما زالت ليس جيدة كفاية، فالكلمتان cat و act لهما نفس الحروف وبالتالي ستحصلان على نفس قيمة الـ Hash وذاك يسمى تصادم - Collision. وذلك ما تم تحسينه في الدالة التالية: unsigned int hash_djb2(const char *word, unsigned int N) { unsigned long hash_value = 5381; int c; while ((c = *word++)) { hash_value = ((hash_value << 5) + hash_value) + c; } return hash_value % N; } توفر قيم مختلفة لكلمتي cat و act، وستوزع الكلمات بشكل ممتاز. بعد الدالة السابقة لم يعد من المنطقي استخدام جدول بحجم 26 فقط، فلو القاموس يحتوي على 140,000 كلمة، فالأفضل استخدام جدول بحجم كبير لتقليل احتمالية التصادمات وجعل القوائم المتصلة قصيرة جدًا. أي بدلاً من تعريف الجدول هكذا: #define ALPHABETS 26 node* dictionary[ALPHABETS] = {NULL}; نقوم بتعريفه بحجم أكبر بكثير، وكقاعدة عامة حجم الجدول يكون عدد أولي قريب من عدد العناصر التي تتوقع تخزينها أو أكبر، لأنّ استخدام عدد أولي يساعد في تحسين التوزيع عند استخدام عملية باقي القسمة %. #define N_BUCKETS 10007 node* dictionary[N_BUCKETS] = {NULL}; وبالتالي بدلاً من حساب الـ Hash بناءًا على الحرف الأول، نستخدم الدالة الجديدة: for (int i = 0; i < n_of_words; i++) { string vocabulary = get_string("Word: "); // بدلاً من // short hash = toupper(vocabulary[0]) - 'A'; unsigned int hash_index = hash_djb2(vocabulary, N_BUCKETS); insert_node(&dictionary[hash_index], vocabulary); }
- 3 اجابة
-
- 1
-

-
في البداية كل ما تحتاجه بخصوص github هي الأساسيات، والأمر ليس بالصعوبة التي تتصورها، فالأمر يبدوا أنه معقد لكن على العكس تمامًا بعد أن تستوعب الأساسيات. ببساطة، Git نظام للتحكم في الإصدارات Version Control أي هو التقنية أو النظام نفسه، بينما GitHub منصة سحابية أي استضافة للمشاريع باستخدام Git أي منصة سحابية لاستضافة المشاريع. وستقوم بإنشاء مستودع Git محلي على حاسوبك، ثم دفع أي رفع المشروع إلى المستودع البعيد remote على github. وهناك مصطلحات ضرورية وهي: Repository مستودع والمقصود به هو مجلد المشروع. Commit يعني حفظ التغييرات مع رسالة تصف ما قمت به. Branch فرع وهو نسخة موازية لمستودع المشروع تستطيع به إنشاء نسخة منفصلة عن المشروع. Pull Request يعني طلب دمج التغييرات مع ما هو موجود في مستودع المشروع. Clone نسخ المشروع من مستودلجهازك Fork: نسخ مشروع شخص آخر لحسابك وخطوات التثبيت والإعداد لـ GIT على حاسوبك، وستجدها هنا: بجانب الأوامر الأساسية،وهي إنشاء مستودع جديد محلي على حاسوبك: git init git add . git commit -m "first commit" و git push لرفع التغييرات للسحابة على منصة github. وهناك أوامر أخرى من الأفضل الإلمام بها لحين الحاجة:
-
كمطور واجهة أمامية فذلك الجزء ليس من اختصاصك بل من اختصاص مصمم واجهات المستخدم، لكن يجب الإلمام بالأساسيات الخاصة به لتصبح قادر على التعديل متى أردت وإبداء رأيك في التصميم واقتراح أمر ما على المصمم من وجهة نظرك، أو حتى تصميم واجهة جيدة عند العمل على مشاريعك، ستفاجيء بمقدار التحسن في تصميم الواجهة الذي تقوم به في مشروع خاص بك عند الإلمام بالأساسيات أي على دراية بما تقوم به وليس بشكل عشوائي. أيضًا عند العمل على مواقع العمل الحر، ستضطر أحيانًا إلى تصميم وتطوير المشروع بنفسك، لذا يجب أن تكون على جاهزية لتنفيذ المطلوب وبالطبع هناك تكلفة إضافية بجانب البرمجة. على الأقل تعلم ما يلي: التسلسل الهرمي البصري Visual Hierarchy وهو ترتيب العناصر لتوجيه عين المستخدم إلى الأهم أولاً. التباين Contrast الخاص باستخدام الألوان والأحجام والأوزان لجعل العناصر قابلة للقراءة والتمييز. المساحة البيضاء White Space وNegative Space لاستخدام الفراغ لتنظيم المحتوى وتجنب ازدحام الواجهة. المحاذاة Alignment لتنظيم العناصر على شبكة Grid وهمية لجعل التصميم يبدو مرتب ومنظم. التكرار أي إعادة استخدام نفس الأنماط (الألوان، الخطوط، الأزرار) للحفاظ على الاتساق. نظرية الألوان Color Theory لاستيعاب أساسيات تناسق الألوان وكيفية استخدامها للتأثير على شعور المستخدم. Typography لاختيار الخطوط وأحجامها وأوزانها لضمان سهولة القراءة وتحسين تجربة المستخدم. وإليك مصادر لتعلم الأساسيات: وتعلم Figma وأساسيات الـ UI/UX من القنوات التالية: Ahmad Sekmani Anas Rafaat | أنس رأفت
-
في الواقع العملي لا يتم استخدام المصطلحات العربية بالفعل، اللغة الإنجليزية هي لغة البرمجة، لكن الدارسين بالأكاديمية لغتهم الأولى هي العربية لذا المحتوى موجه لهم في المقام الأول ويتم في معظم الدروس توضيح المصطلح بالإنجليزية أيضًا، وفي حال لم يتم ذكر ذلك، أرجو الاستعانة بموسوعة حسوب وابحث عن المصطلح وستجده بالعربية والإنجليزية. وفي حال واجهت صعوبة في استيعاب مصطلح ما، تستطيع الاستفسار أسفل الدروس وسيتم توضيحه لك، ويجب معرفة المصطلح بالعريبة والإنجليزية حتى تتمكن من البحث عنه بالرغم من أنّ الإنجليزية أهم بالطبع لكون المصادر أغلبها بالإنجليزية ولن تحتاج العربية إلا في حال شرح أمر ما لشخص آخر أو للفريق وحتى في تلك الحالة يتم استخدام المصطلحات الإنجليزية. وعامًة ستجد مصطلحات متكررة ومستخدمة في أغلب البرمجة ها هي: متغير - Variable: مكان في الذاكرة لتخزين البيانات. نوع البيانات - Data Type: يحدد نوع البيانات التي يمكن تخزينها في المتغير (مثل: نص، عدد صحيح، عدد عشري). عامل - Operator: رمز أو كلمة تستخدم لتنفيذ عملية على البيانات (مثل: + للجمع، - للطرح). تعبير - Expression: مجموعة من المتغيرات والعوامل التي تُرجع قيمة. شرط - Condition: تعبير منطقي يُرجع إما صحيح أو خطأ. جملة - Statement: سطر من التعليمات البرمجية التي تُنفذ مهمة محددة. كتلة - Block: مجموعة من الجمل التي تُنفذ معًا. دالة - Function: مجموعة من التعليمات البرمجية التي تُنفذ مهمة محددة وتُعيد قيمة. معامل - Parameter: قيمة تُمرر إلى دالة عند استدعائها. مصفوفة - Array: مجموعة من البيانات من نفس النوع مخزنة في مكان واحد. حلقة - Loop: تُستخدم لتكرار مجموعة من التعليمات البرمجية عدة مرات. مصفوفة ترابطية - Associative Array / Dictionary: مجموعة من البيانات مخزنة كأزواج من المفتاح والقيمة. كائن - Object: كيان يجمع بين البيانات والوظائف التي تعمل على هذه البيانات. فئة - Class: قالب لإنشاء الكائنات. وراثة - Inheritance: آلية تسمح لفئة ما بوراثة خصائص وصفات فئة أخرى. تعدد الأشكال - Polymorphism: القدرة على استخدام نفس الاسم لوظائف مختلفة في سياقات مختلفة. ملف - File: مجموعة من البيانات المخزنة على وسيط تخزين دائم. استثناء - Exception: حدث غير طبيعي يحدث أثناء تنفيذ البرنامج. معالجة الاستثناءات - Exception Handling: آلية للتعامل مع الاستثناءات ومنع تعطل البرنامج. وبالنسبة للمصطلحات الخاصة ببايثون: وحدة - Module: ملف يحتوي على تعليمات برمجية بايثون يمكن استخدامه في برامج أخرى. حزمة - Package: مجموعة من الوحدات النمطية. قائمة - List: مجموعة مرتبة من العناصر قابلة للتغيير. مجموعة - Tuple: مجموعة مرتبة من العناصر غير قابلة للتغيير. مجموعة - Set: مجموعة غير مرتبة من العناصر الفريدة. قاموس - Dictionary: مجموعة غير مرتبة من أزواج المفتاح والقيمة. تعليمة استيراد - Import Statement: تُستخدم لاستيراد وحدات أو حزم في البرنامج. ديكوريتور - Decorator: دالة تُعدل سلوك دالة أخرى. مولد - Generator: دالة تُعيد سلسلة من القيم. استدعاء ذاتي - Recursion: عندما تستدعي الدالة نفسها داخل تعريفها. تعبير لامبدا - Lambda Expression: دالة مجهولة تُعرّف وتُستخدم في سطر واحد. استيعاب القائمة - List Comprehension: طريقة لإنشاء قائمة جديدة من قائمة موجودة في سطر واحد. استيعاب المجموعة - Set Comprehension: طريقة لإنشاء مجموعة جديدة من مجموعة موجودة في سطر واحد. استيعاب القاموس - Dictionary Comprehension: طريقة لإنشاء قاموس جديد من قاموس موجود في سطر واحد. إدارة الحزم - Package Management: عملية تثبيت وتحديث وإزالة الحزم. بيئة افتراضية - Virtual Environment: بيئة معزولة لتشغيل مشروع بايثون بتبعياته الخاصة.
- 2 اجابة
-
- 1
-
-
الوظائف لا يتم الإعلان عنها هنا، بل تتم من خلال موقع مستقل أو بعيد، ها هي: https://baaeed.com/companies/hsoub/jobs
-
قم أولاً بتحميل نسخة من الـ Notebook لتفادي حدوث خطأ ويضيع مجهودك، وذلك بالضغط على File بالأعلى ثم Download Notebook. ولحل المشكلة الحفظ قم بتجربة الضغط على السهم بجانب Save Version أعلى اليسار، ثم اختار Save and Run All (Save Version) ثم اكتب Quick Save واضغط Save. إن استمرت المشكلة قم بإعادة تشغيل الجلسة، بالضغط على Run ثم Restart Session، ثم اضغط على file واختار import notebook وقم باختيار الملف الذي قمت بتحميله لاستيراده.
- 2 اجابة
-
- 1
-
-
في الدورة الأفضل استخدام نفس الأدوات التي بالشرح، وفي حال لديك القدرة على استخدام أدوات أخرى ورأيت أنها أفضل فلا مشكلة بالطبع. عامًة عند التطوير محليًا على حاسوبك في البداية الأسهل استخدام Jupyter Notebook وبعد فترة الأفضل استخدام vscode فهو يدعم ميزة Notebook أي مثل Jupyter Notebook لكن بميزات أفضل واحترافي أكثر وأسهل في الاستخدام. لكن عند تدريب نماذج الذكاء الاصطناعي وبحاجة إلى كرت شاشة GPU قوي، الأفضل تطوير المشروع على google colab وهو يعتمد نظام الخلايا كما في Jupyter Notebook، حيث توفر موارد حاسوبية ضخمة لتحليل البيانات وتدريب النماذج بشكل سريع جدًا مقارنًة بحاسوبك.
-
مشاريع التخرج الخاصة بالإختبار في الأكاديمية، يجب تنفيذها بمفردك، عند التقدم للإختبار يُفترض منك الجاهزية لتنفيذ مشروع بنفسك وحل المشاكل التي تواجهك، ولا مشكلة في الحصول على إرشاد لكيفية تنفيذ أمر معين لكن لن يتم تقديم الحل لك بالطبع، مجرد توجيه هنا في قسم أسئلة البرمجة. ففي الواقع العملي لن يوجد أحد مساعدتك عند تنفيذ مشروع لعميل، صحيح؟ وبخصوص الذكاء الاصطناعي، سيتم مناقشتك فيما قمت بتنفيذه، ولو اعتمدت على أدوات مساعدة بنسبة كبيرة فلن تستطيع اجتياز المناقشة وسيظهر بشكل واضح أنك استخدمت أدوات لتنفيذ المشروع دونّ استيعاب منك، وأيضًا ستواجه مشاكل لن تستطيع حلها في اعتمدت عليها بنسبة كبيرة، هي مجرد مساعد لك وليس لاستبدال عقلك ومهاراتك، فما معنى كلمة مبرمج إذن؟
-
المشكلة كيف ستوفر بيانات الكتب الدراسية؟ أي يجب توافرها بشكل رقمي وذلك متاح من المصدر وذلك متاح لدى الجهة المُصدرة للكتب فقط. على ما أعتقد كتب الوزارة متاحة PDF مجاناً على موقع الوزارة، ويوجد كتب خارجية بشكل رقمي. في حال لا يوجد كتب متوفرة لمادة معينى ستحتاج إلى عمل scan للكتاب صفحة صفحة ثم حفظ الصور على الكمبيوتر ومعالجتها من خلال OCR مثلاً لقراءة النصوص كـ Google Lens متوفر بشكل مجاني أو Adobe Scan. ثم تنظيف تلك البيانات ومعالجتها، ثم ستعتمد على تقنية RAG (Retrieval-Augmented Generation) من أجل الإجابة على الأسئلة بناءًا على قاعدة البيانات التي قمت بإنشائها من الكتب. في حال البيانات متوفرة رقميًا من خلال ملفات PDF أو Word حتى لو لم تكن كاملة، فستتخطى الجزء الصعب من المشروع وهو تجميع البيانات. والتطوير محليًا سيتم من خلال Ollama كخادم و LangChain وChromaDB مع llama3.1-8b
-
الحاسوب أي PC لا يتوفر على عتاد للإتصال بالواي فاي بشكل إفتراضي، الأمر يتوقف على نوع وإصدار اللوحة الأم motherboard حيث يوجد إصدارات توفر كرت واي فاي PCIe wifi وبلوتوث أيضًا، لكن بالطبع بتكلفة مرتفعة قليلاً مقارنًة بالإصدار العادي. ولديك لا يتوفر ذلك، ستحتاج إلى شراء كرت واي فاي PCIe wifi، ولا أنصحك بشراء USB Wi-Fi Adapter فالأداء الخاص بتلك القطعة غير جيد وغير مستقر، وكذلك مدى إتصال PCIe wifi أفضل. ما أقصده هو التالي، ويتم تركيبه في اللوحة الأم بداخل الكيسة:

-
للإتصال بقاعدة البيانات محليًا على حاسوبك، ستختار الإتصال عن طريق compass وستحصل على رابط ضعه في البرنامج وسيتم الإتصال. وهو نفس الرابط الذي يجب وضعه في مشروعك في ملف env من أجل الإتصال بقاعدة البيانات، وأيضًا وضع ذلك في متغيرات البيئة على الاستضافة عند نشر المشروع. لكن تأكد من أنّ الرابط يحتوي على كلمة المرور الخاصة بقاعدة البيانات على atlas وليس نجوم ***
-
غير متوفر ذلك، ستحتاج إلى دراسته من مصدر آخر، وللعلم الدورة ليست مختصة بمجال تحليل البيانات.
-
بالطبع من أهم البرامج التي عليك تعلمها في مجال تحليل البيانات، وهو متخصص في تجسيد أو تصوير البيانات، من خلال إنشاء لوحات تحكم Dashboards وتقارير تفاعلية لاستيعاب البيانات المعقدة بسهولة. وللعلم هو جزء من حزمة Microsoft، ومتكامل مع Excel، وSQL Server، وAzure، و SharePoint. ولا يوجد إصدار رسمي يعمل بشكل مباشر على macOS، ستحتاج إلى تشغيل نظام Windows داخل نظام macOS باستخدام برامج المحاكاة ومنها Parallels Desktop وVMware Fusion، أو استخدام النسخة السحابية من خلال المتصفح. البديل لنظام ماك هو Tableau أو Looker Studio.
-
في ووردبريس، توجه إلى الإعدادات ثم عام ثم العضوية، ويجب تفعيل ميزة -يمكن لأي شخص التسجيل-. ثم في إعدادات LearnPress توجه إلى General ثم تفعيل Enable Registration وكذلك Enable Guest Checkout في حال أردت السماح بالشراء للزوار بدون تسجيل. ثم توجه إلى تبويب الصفحات Pages في الإضافة، ويجب تواجد الصفحات التالية: صفحة الدورات. صفحة الملف الشخصي. صفحة الخروج Checkout. صفحة تسجيل الدخول. في حال لم تجدهم، فتوجه إلى خيار الأدوات Tools في إعدادات LearnPress ثم اضغط على Re-install Pages لإنشاء الصفحات المطلوبة تلقائيًا. أيضًا اختر إعداد Payments في LearnPress وتأكد من تفعيل بوابة دفع واحدة على الأقل من التالي: Offline Payment للتجربة والإختبار فقط. PayPal PayPal أو أي بوابة عربية وفي حال تستخدم إضافة LearnPress - WooCommerce Integration، فيجب إعداد وتفعيل إضافة WooCommerce وكذلك إضافة LearnPress - WooCommerce Payment.
-
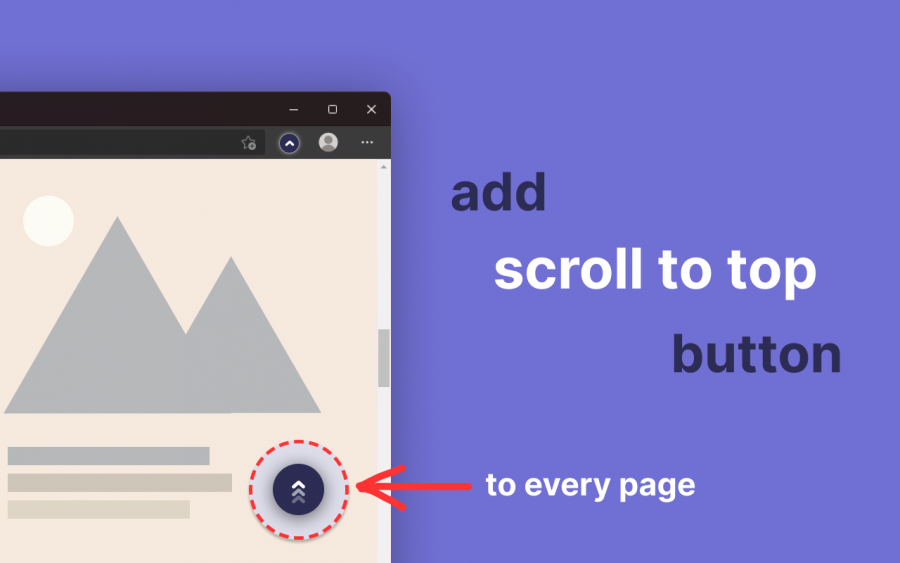
شكرًا على إهتمامك وإقتراحك شادي، سيتم إرساله لقسم التطوير بالأكاديمية، في الوقت الحالي، أرجو تثبيت الإضافة التالية: Scroll To Top وسيظهر لك الزر التالي في الصفحة بعد إعادة التحديث: وعند الضغط عليه سيتم الصعود لأعلى الصفحة، وكذلك يوفر إمكانية النزول لأسفل الصفحة مباشرًة في حال كنت بالأعلى.
- 2 اجابة
-
- 1
-
-
أين يتم تشغيل الملف، فلا يوجد طريقة لتشغيله من خلال github مباشرًة، فهي منصة لعرض وتخزين الكود ونظام تحكم في الإصدارات، ولا تقوم بمهمة تشغيل الكود. ما تقصده هو فتح الملف لرؤية الكود أي عرضه، لكن بالنسبة لملفات jupyter فالمشكلة عند حفظك للملف على جهازك، يتم تخزين معلومات عن الـ Widgets أي الخلايا بطريقة قديمة أو غير مكتملة، ونظام العرض في GitHub يتوقع وجود معلومة محددة اسمها state أي الحالة لكل Widget، ولكنه لم يجدها. أسهل حل هو فتح الملف على حاسوبك من خلال VS Code، ثم من القائمة العلوية، اختار Kernel ثم اختار Restart and Clear Output لإعادة التشغيل ومسح المخرجات التي تظهر نتيجة تشغيل الخلايا. واحفظي الملف مرة أخرى، ورفع الملف الجديد إلى GitHub مرة أخرى.
- 1 جواب
-
- 1
-
-
تلك المشكلة تحدث أحيانًا بالفعل، حيث ستجد رسالة خطأ unable to save your notebook because it may have been modified in another location والحل لتجاوزها هو من خلال تحميل الملف بالضغط على file أعلى اليسار ثم اختر download notebook، ثم أنشيء ملف جديد من خلال استيراد الملف الذي قمت بتحميله للتو وذلك بالضغط على file ثم import notebook.
- 3 اجابة
-
- 1
-
-
سيحدد لك المدرب مشروعًا مرتبطًا بما تعلمته أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع الى أسبوعين. في حال تتوقع تأخير أو تريد مدة أطول، أرجو مناقشة ذلك مع المُدرب المُختص بإختبارك، وسيتم إرشادك، وذلك من خلال مركز المساعدة.
- 1 جواب
-
- 1
-

-
في دالة distribution_values تستخدم المتغير self.mu لكن لم يتم إنشاؤه أو تعيين قيمة له بعد في الكائن v1، فعند تنفيذ v1.plot() يتم استدعاء دالة self.distribution_values() كأول خطوة. ثم دالة distribution_values تعمل على تنفيذ x = np.linspace(self.mu - 4*self.sigma وهي هنا تحتاج إلى قيمة للمتغيرين self.mu و self.sigma. والمكان الوحيد الذي يتم فيه إنشاء هذين المتغيرين هو داخل دالة average()، لكن لم تقم باستدعاء دالة average() قبل استدعاء دالة plot()، يجب استدعائها. كذلك يوجد خطأ إملائي في الدالة البانية __init__ حيث كتبت __int__ وبالتالي لن تعمل ولن يتم تعيين self.column_name1 و self.column_name2. وفي دالة average استخدمت self.col1 بينما في الدالة البانية استخدمت self.column_name1، فيجب توحيد الاسم. وحساب الاحتمال الشرطي غير مكتمل، فهنا p_conditional = 1 - scipy.stats.norm.cdf غير صحيح، فلم تقم باستدعاء الدالة cdf مع معاملاتها، يجب أن تكون p_conditional = 1 - scipy.stats.norm.cdf(0, self.mu, self.sigma ويوجد عدم تطابق أسماء المتغيرات في دالة plot حيث تستخدم self.col1 و self.col2 بينما يجب أن تكون self.column_name1 و self.column_name2. import numpy as np import scipy.stats import matplotlib.pyplot as plt import pandas as pd data_train = pd.DataFrame({ 'V1': np.random.randn(1000), 'forward_returns': np.random.randn(1000) * 0.02 }) class ConditionalProbability: def __init__(self, col1, col2): self.column_name1 = col1 self.column_name2 = col2 def average(self): condition = data_train[self.column_name1] > data_train[self.column_name1].mean() subset = data_train[condition][self.column_name2] self.mu, self.sigma = np.mean(subset), np.std(subset) return self.mu, self.sigma def distribution_values(self): x = np.linspace(self.mu - 4 * self.sigma, self.mu + 4 * self.sigma, 100) pdf = scipy.stats.norm.pdf(x, self.mu, self.sigma) p_conditional = 1 - scipy.stats.norm.cdf(0, self.mu, self.sigma) return x, pdf, p_conditional def plot(self): self.average() x, pdf, p_conditional = self.distribution_values() plt.figure(figsize=(8, 5)) plt.plot(x, pdf, label=f'Distribution of {self.column_name2} (given {self.column_name1} > mean)') plt.fill_between(x, pdf, where=(x > 0), color='orange', alpha=0.4, label=f'Area where returns > 0\nP = {p_conditional:.3f}') plt.axvline(0, color='red', linestyle='--', label='return = 0') plt.title('Conditional Probability Visualization') plt.xlabel('Forward Returns') plt.ylabel('Density') plt.legend() plt.show()
- 4 اجابة
-
- 1
-
-
عليك تعديل قيمة خاصية العرض لعنصر dropdown-column من 100px إلى 100% .dropdown-column { margin-bottom: 15px; width: 100%; }
-
الأهم لديك هو شراء ذاكرة عشوائية إضافية بحجم 16 جيجابايت أو 8 على الأقل، فالنظام يستهلك ما بين 3 إلى 4 جيجا، والبقية للبرامج وخلافه، لذا حاليًا النظام به عنق زجاجة قوي وهي الذاكرة العشوائية. كذلك ستحتاج إلى هارد NVMe SSD وتثبيت النظام عليه، فحاليًا HDD لم يعد مناسب لأنظمة التشغيل، فحتى لو مواصفات الحاسوب لديك مرتفعة ستجد بطيء بسبب وحدة التخزين القديمة وسرعة الكتابة والقراءة المنخفضة.