Mustafa Suleiman
-
المساهمات
20366 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
495
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
صحيح، المشروع يعمل بشكل سليم، هل المشكلة تحدث عند تسجيل مستخدم جديد؟ يجب توفير قيمة لمتغير البيئة MONGODB_URL حيث ستحتاج إلى إنشاء قاعدة بيانات على Atlas ثم توفير الرابط الخاص بها وكذلك قيمة JWT_SECRET ستجد أعلى اليمين في صفحة إدارة المشروع في vercel تبويب Settings اضغط عليه ثم اختر Environment Variables وأضف متغير البيئة
-
ربما لديك إعدادات قاعدة البيانات غير صحيحة في ملف env. فلو تم إعداداها على قاعدة sqlite فلن تجد البيانات في mysql DB_CONNECTION=sqlite يجب أن تكون كالتالي: DB_CONNECTION=mysql DB_HOST=127.0.0.1 DB_PORT=3306 DB_DATABASE=اسم_قاعدة_البيانات DB_USERNAME=root DB_PASSWORD= ثم تنفيذ الأمر php artisan config:clear والتهجير والبذر: php artisan migrate:fresh --seed ثم تشغيل الخادم: php artisan serve
-
ستجد build logs وruntime logs عند الضغط على المشروع في vercel ما هي الأخطاء التي تظهر في كل منهما؟
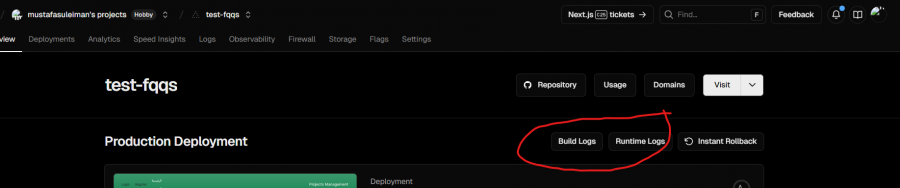
-
لديك خطأ 401 أي عملية غير مُصرح بها، لأن التوكن لم يتم تخزينه بعد تسجيل الدخول، لذا الطلب إلى /api/todos يُرسل بدون Authorization، كذلك يوجد تحذير الـ key وسببه أن دالة createTask تُعيد الجسم الكامل { newTodo, user } بينما الواجهة تتوقع كائن المهمة فقط، فينتج عنصر بدون _id في المصفوفة. في ملف page.tsx يجب حفظ التوكن بعد تسجيل الدخول: if(res?.message){ setError(res?.message); setLoading(false); }else{ alert("تم تسجيل الدخول بنجاح"); localStorage.setItem("token", res.token); // هنا router.push("/home") } كذلك، تعديل createTask لإعادة data.newTodo وللتحقق من الأخطاء: export async function createTask(title:string) { const token = localStorage.getItem("token"); const res = await fetch('http://localhost:3000/api/todos', { method: "POST", headers: { "Content-Type": "application/json", "Authorization": `Bearer ${token ?? ""}` }, body: JSON.stringify({title}), }); if (!res.ok) { const err = await res.json().catch(() => ({})); throw new Error(err?.message || "Request failed"); } const data = await res.json(); return data.newTodo; } كذلك يجب تحويل الـ _id إلى نص عند توليد التوكن فحاليًا أنت تمرر كائن، في ملف app\api\auth\login\route.ts: const token = generateToken(user._id.toString()); ثم شغل الخادم وتوجه إلى الرابط التالي وسجل الدخول: http://localhost:3000/
-

هل مكتبة PyTorch عند استخدامها لبناء الشبكات العصبية الالتفافية (CNN) تجبرني أن أحمّل البيانات وأعالجها فقط من خلالها، وكأنها نظام مغلق مثل منتجات أبل (حيث كل شيء يعمل مع بعضه)، أم يمكنني الاستعانة بمكتبات أخرى مثل cv2 أو os أو غيرها في تجهيز البيانات؟
Mustafa Suleiman رد على سؤال Ali Ahmed55 في علوم الحاسوب
ستحتاج إلى استخدام دوال PyTorch فقط في حال المعالجة جزء من الرسم البياني ويجب أن يدخل في حساب الـ back-prop كـ RandomCrop يُطبق داخل النموذج نفسه. أو لو تريد أن تتم العملية على الـ GPU مباشرةً، فحينها يجب أن تكون الدوال من مكتبة تورش أو تدعم CUDA. لكن PyTorch قائمة على مبدأ المرونة، بمعنى لا تهتم بكيفية وصول البيانات بل فقط بالشكل النهائي، فالبيانات الخام من أي مصدر وأي شكل، تستطيع معالجتها بأي مكتبة تريد سواء PIL أو panadas ثم تحويلها إلى تحويل إلى torch.Tensor و التدريب في PyTorch. القيد الوحيد هو أن ما يدخل إلى الشبكة في النهاية يجب أن يكون torch.Tensor، أما كل ما يسبق ذلك من قراءة الملفات، المعالجة، الـ augmentation، دمج بيانات إضافية وخلافه فتستطيع إنجازه بأي مكتبة في بايثون. وذلك لأنّ PyTorch مجرد إطار للحوسبة التفاضلية، والـ Autograd يحتاج إلى Tensor لكي يتتبع التدرجات، ولا يهتم بكيفية وصول البيانات إلى الـ Tensor. وجميع التحويلات خارج الرسم البياني كقراءة الصورة أو قصها لا تحتاج إلى أن تكون عمليات torch أصلاً.- 4 اجابة
-
- 1
-

-
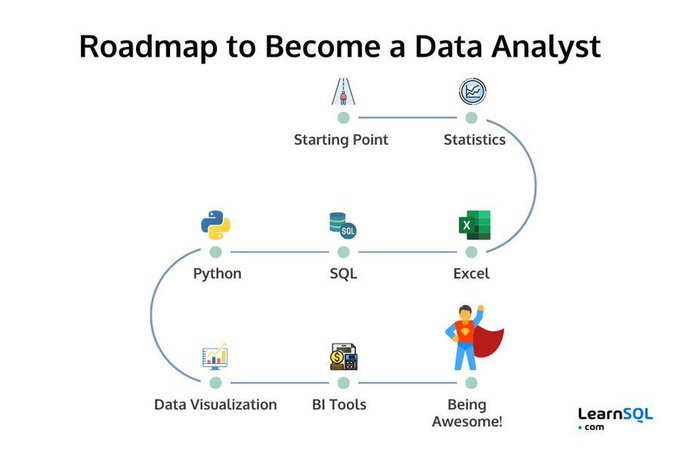
الدورة ليس تخصصها مجال تحليل البيانات، ما ستتعلمه بها هو جزء كبير من الأساسيات اللازمة لذلك المجال، بعد ذلك ستحتاج تعلم أساسيات برنامج الـ Excel، وبالأخص دوال ومعادلات SUM, AVERAGE, VLOOKUP, INDEX, و MATCH. ثم دورة لتعلم الإحصاء والإحتمالات، سواء من Khan Academy أو من مصادر أخرى، ثم دورة أخرى متخصصة في تحليل البيانات باستخدام برنامج الـ Excel. ثم تعلم قواعد البيانات ولغة الـ SQL وقد تعلمت ذلك بالدورة بالفعل، لكن ستحتاج إلى تعلم SQL for Data Analytics للتعمق قليلاً والتعرف على مفاهيم متقدمة منها JOINs بأنواعها، GROUP BY, Window Functions, Subqueries, CTEs، وللعلم معظم مقابلات العمل لمحللي البيانات تتضمن أسئلة SQL متقدمة. الخطوة التالية هي تعلم أحد برامج التحليل والتصوير المرئي للبيانات مثل Power BI أو Tableau أو Google Looker Studio، وأنصحك ببرنامج Power BI فهو المطلوب في سوق العمل. كما أنه يجب عليكِ الاستمرار في التطبيق بكثافة على بيانات حقيقية لتحليلها كلما تقدمت في المسار التعليمي، ومن أشهر المواقع التي يمكنك الحصول منها على بيانات لتقم بتحليلها هو موقع Kaggle الشهير، ولديك أيضًا Data.gov. للتبسيط الصورة التالية جيدة: وفي المرحلة المتقدمة ستحتاج إلى دراسة تعلم الآلة، وذلك ما ستتعلمه بالدورة بالفعل، بالتالي تحتاج إلى دراسة القليل خارج الدورة فيما يخص الأساسيات. ستجد هنا تفصيل لما تحتاجه: https://roadmap.sh/data-analyst
-
الأمر ليس له علاقة بسرعة الكتابة من قريب أو بعيد في مجال البرمجة، فأنت لست كاتب محتوى بل مهندس برمجيات أو مبرمج أيًا كان المُسمى. وظيفتك هي حل مشكلة من خلال البرمجة، أي التفكير والتحليل المنطقي هي المهارة الأهم، وكذلك استيعابك العميق للأساسيات، جودة الكود، قدرتك على التعلم، والخبرة في التقنيات التي تستخدمها أو التخصص الخاص بك سواء مطور واجهة خلفية أو أمامية وخلافه. السرعة والدقة في التنفيذ هي نتاج ما سبق، فالمبتدئين يواجهة صعوبة في التنفيذ بسرعة وبدون أخطاء جسيمة وكذلك جودة الكود أقل، لكن بعد فترة من الممارسة العملية يتم اكتساب تلك الخبرة بطبيعة الحال. لذا يجب العمل على المُسبب الصحيح للبطيء في التنفيذ، والسرعة في الكتابة مجرد مهارة مساعدة، وليست أساسية وتستطيع تطويرها تدريجيًا ولن يسألك أحد عنها في المقابلات. لكن في حال كنت بطيء في استخدام لوحة المفاتيح بشكل عام، فتلك مشكلة، تستطيع حلها بالممارسة الأمر بسيط.
-
لا علاقة لمجال المحاسبة بالبرمجة، الأمر سيفيدك فقط عند العمل على مشاريع محاسبية مثل أنظمة ERP، أو Fintech، أو مشاريع متعلقة بإدخال قيود، مطابقة حسابات، إعداد تقارير. ولديك أفضلية في العمل في شركة ناشئة تبني تطبيق لإدارة المصاريف الشخصية، أو تطوير أنظمة دفع إلكتروني، أو منصات إقراض، أو برامج لإدارة الاستثمار، لأنك مستوعب للوائح المالية والمبادئ المحاسبية التي يجب أن يلتزم بها أي منتج مالي. لكن الفكرة أنه بعد تخرجك تنسى ما درسته إلا في حال كنت ترغب التخصص في مجال المحاسبة والبحث عن وظيفة بها، لذا الشركات التي بحاجة إلى محاسب، سترى أنك مشتت بين المجالين، والشركات التي بحاجة غلى مبرمج، سترى أن خبرتك البرمجية ليست كافية. لذا الحل الأنسب في حال تريد البرمجة هو التعمق بها، وأيضًا التعمق في مشاريع Fintech. أو التركيز على تعلم بايثون وOdoo لتصبح متخصص ERP.
-
أرفق المشروع لديك مع أحدث تعديل لتفقده
-
توقيع الدوال في [id]/route.ts غير صحيح قمت بتعريفها كـ PATCH(request, params) وDELETE(request, params) بدلًا من PATCH(request, { params }) وDELETE(request, { params }). بالتالي params.id يصبح undefined، عند إنشاء مشروع Next.js (App Router)، فدوال المسارات الديناميكية تستقبل params داخل كائن ثانٍ بشكل هيكلي، والتوقيع الصحيح هو (request, { params }) وليس (request, params) import { connectDB } from "@/app/libs/connectDB"; import { NextRequest, NextResponse } from "next/server"; import jwt from 'jsonwebtoken'; import User from "@/app/models/User"; import Todos from "@/app/models/Todos"; import mongoose from "mongoose"; type Params = { id: string; } export async function GET(request:NextRequest, {params} : {params: Params }){ try{ await connectDB(); const authHeader = request.headers.get("authorization"); if(!authHeader || !authHeader.startsWith("Bearer ")){ return NextResponse.json({error: "Unauthorized"}, {status:401}) } const token = authHeader.split(" ")[1]; const decoded = jwt.verify(token , process.env.JWT_SECRET); const userId = (decoded as {userId?: string}).userId; if(!userId){ return NextResponse.json({error: "Unauthorized"}, {status:401}) } const user = await User.findById(userId); if(!user){ return NextResponse.json({error: "User not found!"}, {status: 404}); } if (!mongoose.Types.ObjectId.isValid(params.id)) { return NextResponse.json({ error: "Invalid id" }, { status: 400 }); } const task = await Todos.findOne({_id: params.id , userId}); if(!task){ return NextResponse.json({error: "Task not found"}, {status: 404}); } return NextResponse.json({task}) }catch(e:any){ return NextResponse.json({error: e.message}, {status:500}) } } export async function PATCH(request:NextRequest, { params }: { params: Params }){ try{ await connectDB(); const {title , content} = await request.json(); const authHeader = request.headers.get("authorization"); if(!authHeader || !authHeader.startsWith("Bearer ")){ return NextResponse.json({error: "Unauthorized"}, {status:401}) } const token = authHeader.split(" ")[1]; const decoded = jwt.verify(token , process.env.JWT_SECRET) const userId = (decoded as {userId?: string}).userId; if(!userId){ return NextResponse.json({error: "Unauthorized"}, {status:401}) } const user = await User.findById(userId).select("-password"); if(!user){ return NextResponse.json({error: "User not found!"}, {status: 404}); } if (!mongoose.Types.ObjectId.isValid(params.id)) { return NextResponse.json({ error: "Invalid id" }, { status: 400 }); } const taskUpdate = await Todos.findOneAndUpdate( {_id: params.id , userId}, { title , content }, {new: true} ); if(!taskUpdate){ return NextResponse.json({error: "Task not found"}, {status: 404}); } return NextResponse.json(taskUpdate); }catch(e:any){ return NextResponse.json({error: e.message}, {status:500}) } } export async function DELETE(request:NextRequest, { params }: { params: Params }){ try{ await connectDB(); const authHeader = request.headers.get("authorization"); if(!authHeader || !authHeader.startsWith("Bearer ")){ return NextResponse.json({error: "Unauthorized"}, {status:401}) } const token = authHeader.split(" ")[1]; const decoded = jwt.verify(token , process.env.JWT_SECRET); const userId = (decoded as {userId?: string}).userId; if(!userId){ return NextResponse.json({error: "Unauthorized"}, {status:401}) } const user = await User.findById(userId); if(!user){ return NextResponse.json({error: "User not found!"}, {status: 404}); } if (!mongoose.Types.ObjectId.isValid(params.id)) { return NextResponse.json({ error: "Invalid id" }, { status: 400 }); } const taskDelete = await Todos.findOneAndDelete({_id: params.id, userId}); if(!taskDelete){ return NextResponse.json({error: "Task not found"}, {status: 404}); } return NextResponse.json(taskDelete); }catch(e:any){ return NextResponse.json({error: e.message}, {status:500}) } }
-
بسبب أنك أرسلت طلب للمسار GET /api/auth/todos/id مع قيمة نصية للـ id وليس رقم من نوع ObjectId أي 24 حرف سداسي. فمكتبة Mongoose تعمل على تحويل الـ id إلى ObjectId لذا يجب تمرير قيمة صحيحة. لذا مرر معرف todo الصحيح في الـ URL بدل "id"، أي كالتالي /api/auth/todos/66f6a6b13f0d8b1a2c1c1234 ثم إضافة تحقق من صلاحية المعرف قبل الاستعلام لتجنب خطأ 500 وإرجاع 400 في حال المعرف غير الصحيح. أيضًا عند إنشاء مشروع Next.js (App Router)، فدوال المسارات الديناميكية تستقبل params داخل كائن ثانٍ بشكل هيكلي، والتوقيع الصحيح هو: (request, { params }) وليس (request, params) ليصبح ملف route.ts: import { connectDB } from "@/app/libs/connectDB"; import { NextRequest, NextResponse } from "next/server"; import jwt from 'jsonwebtoken'; import User from "@/app/models/User"; import Todos from "@/app/models/Todos"; import mongoose from "mongoose"; type Params = { id: string; } export async function GET(request:NextRequest, {params} : {params: Params }){ try{ await connectDB(); const authHeader = request.headers.get("authorization"); if(!authHeader || !authHeader.startsWith("Bearer ")){ return NextResponse.json({error: "Unauthorized"}, {status:401}) } const token = authHeader.split(" ")[1]; const decoded = jwt.verify(token , process.env.JWT_SECRET); const userId = (decoded as {userId?: string}).userId; if(!userId){ return NextResponse.json({error: "Unauthorized"}, {status:401}) } const user = await User.findById(userId); if(!user){ return NextResponse.json({error: "User not found!"}, {status: 404}); } if (!mongoose.Types.ObjectId.isValid(params.id)) { return NextResponse.json({ error: "Invalid id" }, { status: 400 }); } const task = await Todos.findOne({_id: params.id , userId}); if(!task){ return NextResponse.json({error: "Task not found"}, {status: 404}); } return NextResponse.json({task}) }catch(e:any){ return NextResponse.json({error: e.message}, {status:500}) } } export async function PATCH(request:NextRequest, { params }: { params: Params }){ try{ await connectDB(); const {title , content} = await request.json(); const authHeader = request.headers.get("authorization"); if(!authHeader || !authHeader.startsWith("Bearer ")){ return NextResponse.json({error: "Unauthorized"}, {status:401}) } const token = authHeader.split(" ")[1]; const decoded = jwt.verify(token , process.env.JWT_SECRET) const userId = (decoded as {userId?: string}).userId; if(!userId){ return NextResponse.json({error: "Unauthorized"}, {status:401}) } const user = await User.findById(userId).select("-password"); if(!user){ return NextResponse.json({error: "User not found!"}, {status: 404}); } if (!mongoose.Types.ObjectId.isValid(params.id)) { return NextResponse.json({ error: "Invalid id" }, { status: 400 }); } const taskUpdate = await Todos.findOneAndUpdate( {_id: params.id , userId}, { title , content }, {new: true} ); if(!taskUpdate){ return NextResponse.json({error: "Task not found"}, {status: 404}); } return NextResponse.json(taskUpdate); }catch(e:any){ return NextResponse.json({error: e.message}, {status:500}) } } export async function DELETE(request:NextRequest, { params }: { params: Params }){ try{ await connectDB(); const authHeader = request.headers.get("authorization"); if(!authHeader || !authHeader.startsWith("Bearer ")){ return NextResponse.json({error: "Unauthorized"}, {status:401}) } const token = authHeader.split(" ")[1]; const decoded = jwt.verify(token , process.env.JWT_SECRET); const userId = (decoded as {userId?: string}).userId; if(!userId){ return NextResponse.json({error: "Unauthorized"}, {status:401}) } const user = await User.findById(userId); if(!user){ return NextResponse.json({error: "User not found!"}, {status: 404}); } if (!mongoose.Types.ObjectId.isValid(params.id)) { return NextResponse.json({ error: "Invalid id" }, { status: 400 }); } const taskDelete = await Todos.findOneAndDelete({_id: params.id, userId}); if(!taskDelete){ return NextResponse.json({error: "Task not found"}, {status: 404}); } return NextResponse.json(taskDelete); }catch(e:any){ return NextResponse.json({error: e.message}, {status:500}) } }
-
ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل.
-
لا داعي للتردد، المهم هو القدرة على تنفيذ مشاريع، وتستطيع إعادة الإختبار لحين إجتيازه، لكن الأفضل الاستعداد
-
أهم نقطة يجب التركيز عليها هي القدرة على تنفيذ مشاريع بنفسك حتى لو بنسبة 70%، والمشروع المُسند إليك لن يكون معقد لتلك الدرجة، لكن يجب أن تمتلك القدرة على استيعاب المطلوب وتقسيم ذلك إلى مهام والعمل على تنفيذها لإنهاء المشروع، أي الربط ما بين تعلمته والتطبيق العملي، وليس التركيز على الجانب النظري أو المشاهدة. آلية الإختبار هي كالتالي: بعد إنهاء 4 مسارات من الدورة على الأقل، أو الدورة بالكامل عليك رفع المشاريع التي قمت بها بالدورة على حسابك في github، ثم التحدث لمركز المساعدة وإخبارهم أنك تريد التقدم للإختبار وتوفير روابط المشاريع على github. ثم الإنتظار لبعض الوقت لحين مراجعة المشاريع وسيتم الرد عليك، وتحديد موعد لإجراء مقابلة، وبها يتم: إجراء محادثة صوتيّة لمدة 30 دقيقة يطرح المدرّب عليك أسئلة متعلّقة بالدورة والأمور التي نفّذتها خلالها. يحدد لك المدرّب مشروعًا مرتبطًا بما قمت به أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع إلى أسبوعين. إجراء محادثة صوتيّة أخرى لمدّة 30 دقيقة يناقش بها مشروعك وما نفذته وتطرح أسئلة خلالها. إن سارت على جميع الخطوات السابقة بشكل صحيح، تحصل على الشهادة أو يرشدك المدرّب لأماكن القصور ويطلب منك تداركها ثم التواصل معنا من جديد. في حال قمت بتدوين ملاحظات أثناء دراستك للدورة فاعتمد عليها للمراجعة، ثم حاول تنفيذ مشروع من خلال Next.js للمراجعة على ما تعلمته. وعليك استيعاب كيف يتواصل تطبيق React (الواجهة الأمامية) مع خادم Node.js (الواجهة الخلفية)؟ كيف يتم إرسال واستقبال البيانات (API calls)؟ كيف يمكن استخدام TypeScript في كل من React و Node.js لتحسين الكود؟ كيف يمكن لـ GraphQL أن تكون بديلاً لـ REST API في ذلك التواصل؟ وذلك في حال درست الواجهة الأمامية والخلفية. وابحث عبر الإنترنت عن JavaScript assessment questions أو React quiz أو Node.js interview questions، لتكون فكرة عن نوعية الأسئلة التي ستواجهها بالإمتحان، وبالطبع الإختبار بالأكاديمية سيكون شفهيًا ثم اسناد مشروع إليك.
-
في حال أردت إنشاء واجهة إنجليزية، فأبسط طريقة بالنسبة للمواقع الثابتة static والتي تتكون من ملف واحد كما لديك وهو index.html، هي من خلال إنشاء ملف html آخر مُنفصل index-en.html ثم ترجمة ما به واستخدام نسخة LTR من بوتستراب وهي النسخة العادية، ثم تعديل التنسيقات بما يُناسب تلك الواجهة وتخصيص ملف Style-en.css مُنفصل في حال هناك الكثير من التخصيصات. ووضع زر في كل ملف للتحويل للواجهة الأخرى كالتالي: <a href="index-en.html">English</a>
-
ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل.
-
ربما حجم الصورة كبير، فالصو الملتقطة بالكاميرا أو المختارة من المعرض، دقتها عالية جداً مثلاً 4000x3000 بكسل، وعند تحميلها في الذاكرة كـ Bitmap، تستهلك مساحة كبيرة. أو تمرر الصورة كـ Bitmap كامل بين صفحة 2 وصفحة 3 عبر Intent Extras، فتواجه خطأ TransactionTooLargeException. لذا قبل إرسال الصورة إلى Gemini API، يجب تصغير حجمها وضغطها، فنماذج Gemini لا تحتاج إلى صور بدقة 4K للتعرف عليها، يكفي دقة 720p أو 1080p. وإليك مثال: import android.graphics.Bitmap import android.graphics.BitmapFactory import java.io.ByteArrayOutputStream fun resizeAndCompressImage(bitmap: Bitmap, maxDimension: Int = 1024, quality: Int = 80): Bitmap { val originalWidth = bitmap.width val originalHeight = bitmap.height var resizedWidth = originalWidth var resizedHeight = originalHeight // Resize the image (تصغير الأبعاد) if (originalHeight > maxDimension || originalWidth > maxDimension) { if (originalWidth > originalHeight) { resizedWidth = maxDimension resizedHeight = (resizedWidth * originalHeight / originalWidth.toFloat()).toInt() } else { resizedHeight = maxDimension resizedWidth = (resizedHeight * originalWidth / originalHeight.toFloat()).toInt() } } val resizedBitmap = Bitmap.createScaledBitmap(bitmap, resizedWidth, resizedHeight, false) // Compress the image (ضغط الجودة) val outputStream = ByteArrayOutputStream() resizedBitmap.compress(Bitmap.CompressFormat.JPEG, quality, outputStream) val compressedBytes = outputStream.toByteArray() return BitmapFactory.decodeByteArray(compressedBytes, 0, compressedBytes.size) } val originalBitmap: Bitmap = // الصورة الأصلية val optimizedBitmap = resizeAndCompressImage(originalBitmap) كذلك يجب أن تتم كل عمليات معالجة الصورة والاتصال بالـ API في thread خلفي لتجنب تجميد واجهة المستخدم، وأفضل طريقة للقيام بذلك في أندرويد هي بواسطة Coroutines import androidx.lifecycle.ViewModel import androidx.lifecycle.viewModelScope import com.google.ai.client.generativeai.GenerativeModel import com.google.ai.client.generativeai.type.content import kotlinx.coroutines.Dispatchers import kotlinx.coroutines.launch import kotlinx.coroutines.withContext import android.graphics.Bitmap class ChatViewModel : ViewModel() { private val generativeModel: GenerativeModel = // تهيئة النموذج هنا fun analyzeImage(prompt: String, image: Bitmap) { viewModelScope.launch { try { val optimizedImage = withContext(Dispatchers.Default) { resizeAndCompressImage(image, maxDimension = 768, quality = 75) } val inputContent = content { image(optimizedImage) text(prompt) } val response = generativeModel.generateContent(inputContent) withContext(Dispatchers.Main) { _chatResponse.value = response.text } } catch (e: Exception) { withContext(Dispatchers.Main) { } } } } } ولا تقم بتمرير الـ Bitmap مباشرة، بل تمرير مسار URI للصورة كـ String من صفحة 1 إلى 2 ثم إلى 3، وفي صفحة 3، قم بقراءة الـ Bitmap من الـ URI ثم قم بمعالجته وإرساله. وبعد التصنيف في صفحة 1، قم بحفظ النسخة المصغرة في ذاكرة التخزين المؤقت للتطبيق ومرر مسار الملف الجديد إلى الصفحات التالية. النموذج المحلي سيعمل على جهاز المستخدم للتصنيف الأولي، لكن مهمة الشات مع Gemini تستطيع نقلها إلى الخادم باستخدام Cloud Functions for Firebase والتي هي أساس Firebase AI Extensions و Genkit. أي في التطبيق سيقوم المستخدم بتصنيف الصورة باستخدام النموذج المحلي، وعند الانتقال لصفحة الشات، ثم يعمل التطبيق على رفع الصورة المُصغّرة إلى Cloud Storage for Firebase. وعند كتابة المستخدم لسؤال، سيقوم التطبيق بإرساله ورابط الصورة في Cloud Storage إلى Cloud Function. وفي الخادم Firebase Cloud Function سيتم تفعيل الـ Function عند استدعائها من التطبيق، سواء مكتوبة بـ Node.js وTypeScript أو Python لتستقبل السؤال ورابط الصورة. ثم تقوم باستدعاء Gemini API من الخادم وذلك أفضل من حيث الأمان، ثم تستقبل الرد من Gemini، ثم إرسال الرد مرة أخرى إلى التطبيق، إما مباشرة كرد على الاستدعاء أو عن طريق كتابته في Firestore أو Realtime Database حيث يستمع التطبيق للتحديثات.
- 2 اجابة
-
- 1
-

-
ليس بنفس الطريقة التي تبرمجه بها بلغة C++ في Arduino ثم عمل محاكاة كاملة للكود في بروتيوس، ولكن، يوجد حل بديل عملي يسمح لك باستخدام بايثون للتحكم في الدائرة التي تتم محاكاتها في بروتيوس. المشكلة أنّ بايثون هي لغة يتم تفسيرها Interpreted للغة الآلة، بالتالي تحتاج إلى بيئة تشغيل وهو مُفسر بايثون لترجمة الأوامر إلى لغة الآلة لحظة بلحظة، أي المفسر نفسه يحتاج إلى موارد كبيرة من RAM وذاكرة تخزين. ومتحكم ATmega328p الموجود في أردوينو أونو هو متحكم 8-بت بموارد محدودة جدًا وهي ذاكرة فلاش 32 كيلوبايت لتخزين الكود، وذاكرة SRAM كيلوبايت فقط لتخزين المتغيرات أثناء التشغيل، وبالطبع تلك الموارد لا تكفي إطلاقاً لتشغيل مفسر بايثون. وربما سمعت عن مشاريع مثل MicroPython، وهي نسخة مصغرة من بايثون مصممة للعمل على المتحكمات الدقيقة، ولكن حتى تلك النسخ تتطلب متحكمات أقوى بكثير 32-بت مثل ESP32, ESP8266, Raspberry Pi Pico, أو سلسلة STM32 التي تمتلك ذاكرة RAM وفلاش أكبر بعشرات أو مئات المرات من ATmega328p. لذا دمج بايثون مع الأردوينو أو أي متحكم آخر، ومحاكاتها بشكل ممتاز في بروتيوس، عليك تقسيم المهام، بحيث المتحكم ATmega328p تتم برمجته بلغة C++ فيArduino ليقوم بالمهام البسيطة والمباشرة، ليصبح تابع يستقبل الأوامر عبر المنفذ التسلسلي Serial Port وينفذها، وليكن مثلاً أشعل الليد، اقرأ قيمة الحساس، أرسل لي قيمة الجهد وهكذا. ثم الكمبيوتر وهو المُستضيف Host، ستقوم بإنشاء سكربت بايثون به يحتوي على المنطق المعقد، واجهات المستخدم، معالجة البيانات، أو اتخاذ القرارات، وسيقوم بإرسال الأوامر إلى المتحكم عبر المنفذ التسلسلي.
-
قم أولاً بحذف الإعدادات والملفات المؤقتة: php artisan optimize:clear ثم أعد التثبيت: php artisan jetstream:install livewire --teams ثم نشر ملفات Jetstream من جديد php artisan vendor:publish --tag=jetstream-views --force و: php artisan migrate ثم تنفيذ: php artisan optimize:clear
-
ستقوم بالبحث عن المفهوم الذي تجد صعوبة في استيعابه، ستجد شروحات مختلفة حوله، سواء بالعربية أو الإنجليزية، والأفضل البحث بالإنجليزية بالطبع. ولا تحاول فهم الدرس بأكمله دفعة واحدة، قسّمه إلى أصغر أجزاء ممكنة واسأل نفسك ما هي الفكرة الأساسية هنا أو ما هو المصطلح الذي لم أفهمه؟ وفي الغالب سبب صعوبة فهم مفهوم متقدم هو ضعف في فهم الأساسيات التي بُني عليها، لذا عد إليها وراجعها أو تعلمها، وحاول الربط بين النظري والعملي. أيضًا تجنب اللجوء لأدواء الذكاء الاصطناعي مباشرًة وخاصًة في بداية مرحلة التعلم، فأنت بحاجة إلى تفقد المصادر الخاصة بالمعلومات وأثناء ذلك تكتشف أمور جديدة، وقد تجد أحد قنوات اليوتيوب المفيدة التي لم تكن تعلم بوجودها، أو مرجع مفيد بها معلومات قيمة وهكذا. بعد ذلك تستطيع الاستعانة بأي أدوات تريدها، وبشكل واقعي الأمر صعب ومغري، لكن حاول مقاومة ذلك. لا تنسى أيضًا المستند الرسمي، فهو المصدر الأساسي للمعلومات، لكن بعض المستندات معقدة وغير مفهومة، هنا قم بالبحث عن المعلومة في مكانٍ آخر مثل شرح على اليوتيوب أو مقال، ثم استعن بأدوات الذكاء الاصطناعي والذي بالطبع يُخطيء أحيانًا لذا لا تثق به 100% فهو مجرد نموذج تعلم آلة تدرب على البيانات الموجودة على الإنترنت ويعرض لك معلومة بناءًا على احتمالية أنها صحيحة فهو مبني على مفاهيم الإحتمالات في الرياضيات.
-
تجنب رفع المشاريع مع مجلد node_modules. المشكلة ليست في Next.js نفسه بل بسبب انتقال الكود من السيرفر إلى المتصفح، أي في مرحلة الـ Hydration. ففي React كل شيء يحدث في المتصفح، بمعنى يحصل على ملف جافاكسريبت، ثم React تقوم ببناء الصفحة بأكملها، لذا منذ اللحظة الأولى، تعرف React حجم الشاشة ويمكنها تطبيق الأنماط المتجاوبة فورًا. أما في Next.js فالأمر يتم من جهة الخادم أولاً، حيث يبني نسخة HTML أولية من الصفحة ويرسلها إلى المتصفح، المشكلة الخادم لا يعرف أي شيء عن المتصفح بعد، أي لا يعرف حجم الشاشة، أو عرض النافذة، لذا، يقوم ببناء الصفحة بناءًا على افتراض معين وهي نسخة سطح المكتب. بعد ذلك يستقبل المتصفح ملف الـ HTML ويعرضه فورًا وذلك سبب كون Next.js سريع في العرض الأولي، ثم يبدأ المتصفح في تحميل ملفات جافاسكريبت. ثم يلي ذلك مرحلة الـ Hydration والتي تقوم بها React بالاستحواذ على الـ HTML الذي أرسله الخادم وحقن جافاسكريبت به ليصبح تفاعلي، أي تستوعب React أنها تعمل الآن في المتصفح، وتحصل على حجم الشاشة الحقيقي، وتحديث الواجهة لتتطابق مع ذلك الحجم. وبسبب ما سبق تظهر مشكلة في بعض المكتبات مكتبات الـ Sliders, Carousels, أو الرسوم البيانية والتي تعتمد بشكل كبير على كائن window عند تهيئتها، ولو حاولت استيرادها وتشغيلها على الخادم، ستسبب مشاكل لأن كائن window غير موجود هناك. ولديك مكتبات aos للتحريكات عند التمرير، و swiper للسلايدر تقوم بحقن الأنماط الخاصة بها في الصفحة عند تشغيلها على المتصفح، لكن الخادم يرسل صفحة HTML بدون تلك الأنماط، وعند تحميل وتشغيل ملفات جافاسكريبت في المتصفح، تبدأ تلك المكتبات بالعمل وتضيف الأنماط اللازمة، بالتالي الصفحة تبدو متجاوبة فجأة. يجب أن تستورد ملفات CSS الخاصة بها مباشرة في ملف التنسيق الرئيسي للمشروع layout.tsx، لتضمين الأنماط في ملف CSS الرئيسي الذي يتم تحميله مع الصفحة من البداية، ويصبح التطبيق متجاوب فورًا عند عرض الصفحة. import 'aos/dist/aos.css'; import 'swiper/css'; import 'swiper/css/pagination'; import 'swiper/css/navigation';
-
مفهوم هندسة البرمجيات أشمل لكونه تطبيق لمبادئ الهندسة لإدارة دورة حياة البرمجيات كاملة، من تحليل المتطلبات، التخطيط، التصميم، التطوير، الاختبار، الإطلاق، التشغيل والصيانة، والجودة والإدارة. أي يهتم بالعمليات والمنهجيات والتي تسمى تقنيًا Agile وDevOps، كذل إدارة المخاطر، القياسات، الأدوات وسير العمل. بينما تصميم البرمجيات هو بمثابة مرحلة داخل هندسة البرمجيات، ويختص بكيف سيُبنى النظام داخليًا، ويشمل ذلك التصميم المعماري عالي المستوى حيث يتم النظر للمشروع بنظرة عامة لإختيار المعمارية المناسبة، ثم التصميم التفصيلي بالغوص في تفاصيل واجهات المكونات، نماذج البيانات، الخوارزميات، أنماط التصميم مثل MVC وObserver، مع مراعاة القيود غير الوظيفية كالأداء والأمان والقابلية للتوسع.
- 3 اجابة
-
- 1
-
-
لا مشكلة تستطيع استخدامها، وفي ظهرت مشكلة في التنسيقات، فقم بإضافة كلاس بوتستراب img-fluid إلى عنصر الصورة <img> والذي يُطبق تنسيق max-width: 100% على الصورة، لكلي لا تتجاوز عرض العنصر الأب الذي يحتويها. وكذلك height: auto للحفاظ على نسبة أبعاد الصورة الأصلية. لكن لو أردن إنشاء بطاقات Cards بارتفاع ثابت أي يوجد عدة بطاقات وتريد أن يكون لها نفس الارتفاع، فقم تحديد height للعنصر الأب الذي يحتوي الصورة، ثم استخدام خصائص CSS للتحكم في كيفية ظهور الصورة داخل هذا الحيز مثل object-fit: cover
-
الأفضل تجنب القوالب الجاهزة التي يكتبها أغلب الأشخاص على تلك المنصة، فأنا شخصيًا أنزعج من ذلك، الأفضل باختصار توضيح ما تعلمته خلال تنفيذك للمشروع، وكمثال ابدأ بتحدٍا واجهته أو فكرة رئيسية تعلمتها بمعنى شيء يثير الفضول لو أردت، ثم اذكر ما هو المشروع باختصار شديد، وتحدث عن المهارات أو المفاهيم التي استوعبتها حقاً أثناء العمل، وتذكر الإختصار مع الدقة مهم. ثم شكر طبيعي غير متكلف، بذكر الأكاديمية كجزء من رحلة التعلم. وقم بنشر رابط لحي لتفقد المشروع واطلب ممن لديهم وقت مراجعته وإخبارك بأية ملاحظات أو نصائح.
- 1 جواب
-
- 1
-
-
تعلم الأساسيات للواجهة الخلفية في الوقت الحالي، أقصد أساسيات Node.js فهي لازمة من أجل استيعاب ما تقوم في إطار Next.js فحاليًا أنت تستخدمه بدون استيعاب، ولا تتجاهل تعلم أساسيات SQL وقواعد البيانات. بعد ذلك انتقل لتعلم كيفية تطوير مشروع كامل أي Full-stack بواسطة Next.js وبعد تنفيذ أكثر من مشروع، قم بالتعمق أكثر في الواجهة الخلفية وتعلم المفاهيم الـ advanced أي المتقدمة وتنفيذ مشاريع متقدمة كذلك بواسطة Node.js وExpress.js. وبعدها تستطيع الاستمرار في تطوير مشاريع كاملة من خلال Next.js وفي حال واجهت صعوبة في أمر ما فقم بالبحث عنه وتعلمه، سواء في الواجهة الأمامية أو الخلفية.