Mustafa Suleiman
-
المساهمات
20356 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
495
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
 الوظائف لا يتم الإعلان عنها هنا، بل تتم من خلال موقع مستقل أو بعيد، ها هي: https://baaeed.com/companies/hsoub/jobs
الوظائف لا يتم الإعلان عنها هنا، بل تتم من خلال موقع مستقل أو بعيد، ها هي: https://baaeed.com/companies/hsoub/jobs -
قم أولاً بتحميل نسخة من الـ Notebook لتفادي حدوث خطأ ويضيع مجهودك، وذلك بالضغط على File بالأعلى ثم Download Notebook. ولحل المشكلة الحفظ قم بتجربة الضغط على السهم بجانب Save Version أعلى اليسار، ثم اختار Save and Run All (Save Version) ثم اكتب Quick Save واضغط Save. إن استمرت المشكلة قم بإعادة تشغيل الجلسة، بالضغط على Run ثم Restart Session، ثم اضغط على file واختار import notebook وقم باختيار الملف الذي قمت بتحميله لاستيراده.
- 2 اجابة
-
- 1
-

-
في الدورة الأفضل استخدام نفس الأدوات التي بالشرح، وفي حال لديك القدرة على استخدام أدوات أخرى ورأيت أنها أفضل فلا مشكلة بالطبع. عامًة عند التطوير محليًا على حاسوبك في البداية الأسهل استخدام Jupyter Notebook وبعد فترة الأفضل استخدام vscode فهو يدعم ميزة Notebook أي مثل Jupyter Notebook لكن بميزات أفضل واحترافي أكثر وأسهل في الاستخدام. لكن عند تدريب نماذج الذكاء الاصطناعي وبحاجة إلى كرت شاشة GPU قوي، الأفضل تطوير المشروع على google colab وهو يعتمد نظام الخلايا كما في Jupyter Notebook، حيث توفر موارد حاسوبية ضخمة لتحليل البيانات وتدريب النماذج بشكل سريع جدًا مقارنًة بحاسوبك.
-
مشاريع التخرج الخاصة بالإختبار في الأكاديمية، يجب تنفيذها بمفردك، عند التقدم للإختبار يُفترض منك الجاهزية لتنفيذ مشروع بنفسك وحل المشاكل التي تواجهك، ولا مشكلة في الحصول على إرشاد لكيفية تنفيذ أمر معين لكن لن يتم تقديم الحل لك بالطبع، مجرد توجيه هنا في قسم أسئلة البرمجة. ففي الواقع العملي لن يوجد أحد مساعدتك عند تنفيذ مشروع لعميل، صحيح؟ وبخصوص الذكاء الاصطناعي، سيتم مناقشتك فيما قمت بتنفيذه، ولو اعتمدت على أدوات مساعدة بنسبة كبيرة فلن تستطيع اجتياز المناقشة وسيظهر بشكل واضح أنك استخدمت أدوات لتنفيذ المشروع دونّ استيعاب منك، وأيضًا ستواجه مشاكل لن تستطيع حلها في اعتمدت عليها بنسبة كبيرة، هي مجرد مساعد لك وليس لاستبدال عقلك ومهاراتك، فما معنى كلمة مبرمج إذن؟
-
المشكلة كيف ستوفر بيانات الكتب الدراسية؟ أي يجب توافرها بشكل رقمي وذلك متاح من المصدر وذلك متاح لدى الجهة المُصدرة للكتب فقط. على ما أعتقد كتب الوزارة متاحة PDF مجاناً على موقع الوزارة، ويوجد كتب خارجية بشكل رقمي. في حال لا يوجد كتب متوفرة لمادة معينى ستحتاج إلى عمل scan للكتاب صفحة صفحة ثم حفظ الصور على الكمبيوتر ومعالجتها من خلال OCR مثلاً لقراءة النصوص كـ Google Lens متوفر بشكل مجاني أو Adobe Scan. ثم تنظيف تلك البيانات ومعالجتها، ثم ستعتمد على تقنية RAG (Retrieval-Augmented Generation) من أجل الإجابة على الأسئلة بناءًا على قاعدة البيانات التي قمت بإنشائها من الكتب. في حال البيانات متوفرة رقميًا من خلال ملفات PDF أو Word حتى لو لم تكن كاملة، فستتخطى الجزء الصعب من المشروع وهو تجميع البيانات. والتطوير محليًا سيتم من خلال Ollama كخادم و LangChain وChromaDB مع llama3.1-8b
-
الحاسوب أي PC لا يتوفر على عتاد للإتصال بالواي فاي بشكل إفتراضي، الأمر يتوقف على نوع وإصدار اللوحة الأم motherboard حيث يوجد إصدارات توفر كرت واي فاي PCIe wifi وبلوتوث أيضًا، لكن بالطبع بتكلفة مرتفعة قليلاً مقارنًة بالإصدار العادي. ولديك لا يتوفر ذلك، ستحتاج إلى شراء كرت واي فاي PCIe wifi، ولا أنصحك بشراء USB Wi-Fi Adapter فالأداء الخاص بتلك القطعة غير جيد وغير مستقر، وكذلك مدى إتصال PCIe wifi أفضل. ما أقصده هو التالي، ويتم تركيبه في اللوحة الأم بداخل الكيسة:

-
للإتصال بقاعدة البيانات محليًا على حاسوبك، ستختار الإتصال عن طريق compass وستحصل على رابط ضعه في البرنامج وسيتم الإتصال. وهو نفس الرابط الذي يجب وضعه في مشروعك في ملف env من أجل الإتصال بقاعدة البيانات، وأيضًا وضع ذلك في متغيرات البيئة على الاستضافة عند نشر المشروع. لكن تأكد من أنّ الرابط يحتوي على كلمة المرور الخاصة بقاعدة البيانات على atlas وليس نجوم ***
-
غير متوفر ذلك، ستحتاج إلى دراسته من مصدر آخر، وللعلم الدورة ليست مختصة بمجال تحليل البيانات.
-
بالطبع من أهم البرامج التي عليك تعلمها في مجال تحليل البيانات، وهو متخصص في تجسيد أو تصوير البيانات، من خلال إنشاء لوحات تحكم Dashboards وتقارير تفاعلية لاستيعاب البيانات المعقدة بسهولة. وللعلم هو جزء من حزمة Microsoft، ومتكامل مع Excel، وSQL Server، وAzure، و SharePoint. ولا يوجد إصدار رسمي يعمل بشكل مباشر على macOS، ستحتاج إلى تشغيل نظام Windows داخل نظام macOS باستخدام برامج المحاكاة ومنها Parallels Desktop وVMware Fusion، أو استخدام النسخة السحابية من خلال المتصفح. البديل لنظام ماك هو Tableau أو Looker Studio.
-
في ووردبريس، توجه إلى الإعدادات ثم عام ثم العضوية، ويجب تفعيل ميزة -يمكن لأي شخص التسجيل-. ثم في إعدادات LearnPress توجه إلى General ثم تفعيل Enable Registration وكذلك Enable Guest Checkout في حال أردت السماح بالشراء للزوار بدون تسجيل. ثم توجه إلى تبويب الصفحات Pages في الإضافة، ويجب تواجد الصفحات التالية: صفحة الدورات. صفحة الملف الشخصي. صفحة الخروج Checkout. صفحة تسجيل الدخول. في حال لم تجدهم، فتوجه إلى خيار الأدوات Tools في إعدادات LearnPress ثم اضغط على Re-install Pages لإنشاء الصفحات المطلوبة تلقائيًا. أيضًا اختر إعداد Payments في LearnPress وتأكد من تفعيل بوابة دفع واحدة على الأقل من التالي: Offline Payment للتجربة والإختبار فقط. PayPal PayPal أو أي بوابة عربية وفي حال تستخدم إضافة LearnPress - WooCommerce Integration، فيجب إعداد وتفعيل إضافة WooCommerce وكذلك إضافة LearnPress - WooCommerce Payment.
-
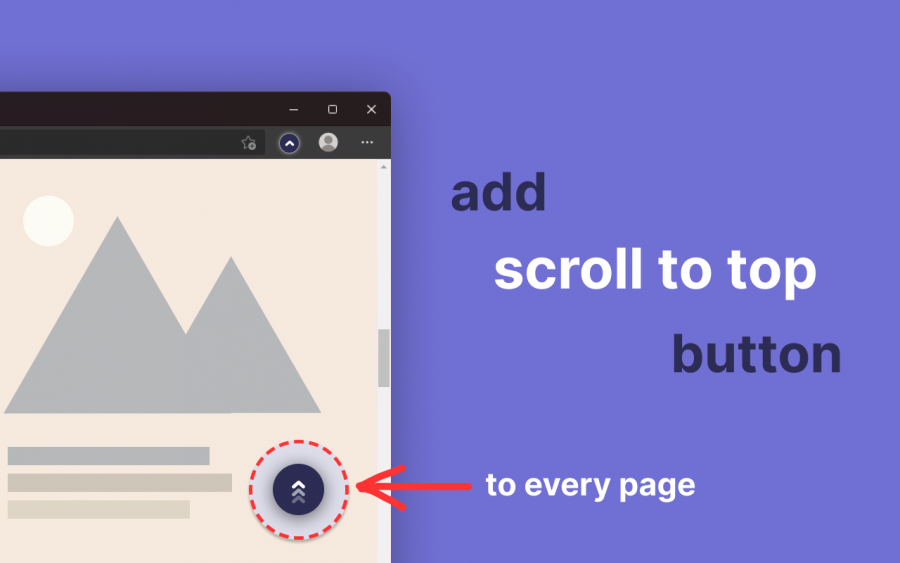
شكرًا على إهتمامك وإقتراحك شادي، سيتم إرساله لقسم التطوير بالأكاديمية، في الوقت الحالي، أرجو تثبيت الإضافة التالية: Scroll To Top وسيظهر لك الزر التالي في الصفحة بعد إعادة التحديث: وعند الضغط عليه سيتم الصعود لأعلى الصفحة، وكذلك يوفر إمكانية النزول لأسفل الصفحة مباشرًة في حال كنت بالأعلى.
- 2 اجابة
-
- 1
-
-
أين يتم تشغيل الملف، فلا يوجد طريقة لتشغيله من خلال github مباشرًة، فهي منصة لعرض وتخزين الكود ونظام تحكم في الإصدارات، ولا تقوم بمهمة تشغيل الكود. ما تقصده هو فتح الملف لرؤية الكود أي عرضه، لكن بالنسبة لملفات jupyter فالمشكلة عند حفظك للملف على جهازك، يتم تخزين معلومات عن الـ Widgets أي الخلايا بطريقة قديمة أو غير مكتملة، ونظام العرض في GitHub يتوقع وجود معلومة محددة اسمها state أي الحالة لكل Widget، ولكنه لم يجدها. أسهل حل هو فتح الملف على حاسوبك من خلال VS Code، ثم من القائمة العلوية، اختار Kernel ثم اختار Restart and Clear Output لإعادة التشغيل ومسح المخرجات التي تظهر نتيجة تشغيل الخلايا. واحفظي الملف مرة أخرى، ورفع الملف الجديد إلى GitHub مرة أخرى.
- 1 جواب
-
- 1
-
-
تلك المشكلة تحدث أحيانًا بالفعل، حيث ستجد رسالة خطأ unable to save your notebook because it may have been modified in another location والحل لتجاوزها هو من خلال تحميل الملف بالضغط على file أعلى اليسار ثم اختر download notebook، ثم أنشيء ملف جديد من خلال استيراد الملف الذي قمت بتحميله للتو وذلك بالضغط على file ثم import notebook.
- 3 اجابة
-
- 1
-
-
سيحدد لك المدرب مشروعًا مرتبطًا بما تعلمته أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع الى أسبوعين. في حال تتوقع تأخير أو تريد مدة أطول، أرجو مناقشة ذلك مع المُدرب المُختص بإختبارك، وسيتم إرشادك، وذلك من خلال مركز المساعدة.
- 1 جواب
-
- 1
-

-
في دالة distribution_values تستخدم المتغير self.mu لكن لم يتم إنشاؤه أو تعيين قيمة له بعد في الكائن v1، فعند تنفيذ v1.plot() يتم استدعاء دالة self.distribution_values() كأول خطوة. ثم دالة distribution_values تعمل على تنفيذ x = np.linspace(self.mu - 4*self.sigma وهي هنا تحتاج إلى قيمة للمتغيرين self.mu و self.sigma. والمكان الوحيد الذي يتم فيه إنشاء هذين المتغيرين هو داخل دالة average()، لكن لم تقم باستدعاء دالة average() قبل استدعاء دالة plot()، يجب استدعائها. كذلك يوجد خطأ إملائي في الدالة البانية __init__ حيث كتبت __int__ وبالتالي لن تعمل ولن يتم تعيين self.column_name1 و self.column_name2. وفي دالة average استخدمت self.col1 بينما في الدالة البانية استخدمت self.column_name1، فيجب توحيد الاسم. وحساب الاحتمال الشرطي غير مكتمل، فهنا p_conditional = 1 - scipy.stats.norm.cdf غير صحيح، فلم تقم باستدعاء الدالة cdf مع معاملاتها، يجب أن تكون p_conditional = 1 - scipy.stats.norm.cdf(0, self.mu, self.sigma ويوجد عدم تطابق أسماء المتغيرات في دالة plot حيث تستخدم self.col1 و self.col2 بينما يجب أن تكون self.column_name1 و self.column_name2. import numpy as np import scipy.stats import matplotlib.pyplot as plt import pandas as pd data_train = pd.DataFrame({ 'V1': np.random.randn(1000), 'forward_returns': np.random.randn(1000) * 0.02 }) class ConditionalProbability: def __init__(self, col1, col2): self.column_name1 = col1 self.column_name2 = col2 def average(self): condition = data_train[self.column_name1] > data_train[self.column_name1].mean() subset = data_train[condition][self.column_name2] self.mu, self.sigma = np.mean(subset), np.std(subset) return self.mu, self.sigma def distribution_values(self): x = np.linspace(self.mu - 4 * self.sigma, self.mu + 4 * self.sigma, 100) pdf = scipy.stats.norm.pdf(x, self.mu, self.sigma) p_conditional = 1 - scipy.stats.norm.cdf(0, self.mu, self.sigma) return x, pdf, p_conditional def plot(self): self.average() x, pdf, p_conditional = self.distribution_values() plt.figure(figsize=(8, 5)) plt.plot(x, pdf, label=f'Distribution of {self.column_name2} (given {self.column_name1} > mean)') plt.fill_between(x, pdf, where=(x > 0), color='orange', alpha=0.4, label=f'Area where returns > 0\nP = {p_conditional:.3f}') plt.axvline(0, color='red', linestyle='--', label='return = 0') plt.title('Conditional Probability Visualization') plt.xlabel('Forward Returns') plt.ylabel('Density') plt.legend() plt.show()
- 4 اجابة
-
- 1
-
-
عليك تعديل قيمة خاصية العرض لعنصر dropdown-column من 100px إلى 100% .dropdown-column { margin-bottom: 15px; width: 100%; }
-
الأهم لديك هو شراء ذاكرة عشوائية إضافية بحجم 16 جيجابايت أو 8 على الأقل، فالنظام يستهلك ما بين 3 إلى 4 جيجا، والبقية للبرامج وخلافه، لذا حاليًا النظام به عنق زجاجة قوي وهي الذاكرة العشوائية. كذلك ستحتاج إلى هارد NVMe SSD وتثبيت النظام عليه، فحاليًا HDD لم يعد مناسب لأنظمة التشغيل، فحتى لو مواصفات الحاسوب لديك مرتفعة ستجد بطيء بسبب وحدة التخزين القديمة وسرعة الكتابة والقراءة المنخفضة.
-
ستحتاج إلى حذف الـ padding لعنصر ul حيث يتم إضافته من قبل بوتستراب ولا حاجة إليه: #venues ul { padding: 0 !important; margin: 0 !important; list-style: none; } كذلك تعديله لعنصر dropdown .dropdown { padding: 20px; position: absolute; top: 100%; right: 100px; width: 200%; background: #fbf8f8; box-shadow: 0 5px 15px rgba(0, 0, 0, 0.1); min-width: 400px; opacity: 0; visibility: hidden; transform: translateY(10px); transition: all 0.3s; } ثم تعديل نسبة استحواذ كل عمود إلى col-md-5 <li class="has-dropdown" id="venues"> <a href="#">VENUES<i class="fas fa-chevron-down"></i></a> <div class="dropdown"> <div class="container-venues"> <div class="row"> <div class="col-md-4"> <div class="dropdown-column"> <h4>Business Courses</h4> <ul> <li><a href="#">Management & Leadership</a></li> <li><a href="#">Innovation & Strategy</a></li> <li><a href="#">Corporate Governance</a></li> </ul> </div> </div> <div class="col-md-4"> <div class="dropdown-column"> <h4>Business Courses</h4> <ul> <li><a href="#">Management & Leadership</a></li> <li><a href="#">Innovation & Strategy</a></li> <li><a href="#">Corporate</a></li> </ul> </div> </div> <div class="col-md-4"> <div class="dropdown-column"> <h4>Business Courses</h4> <ul> <li><a href="#">Management & Leadership</a></li> <li><a href="#">Innovation & Strategy</a></li> <li><a href="#">Corporate Governance</a></li> </ul> </div> </div> <div class="col-md-4"> <div class="dropdown-column"> <h4>Business Courses</h4> <ul> <li><a href="#">Management & Leadership</a></li> <li><a href="#">Innovation & Strategy</a></li> <li><a href="#">Corporate Governance</a></li> </ul> </div> </div> </div> </div> </div> </li>
-
الإختبار غرضه قياس مدى استيعابك فيما قمت بدراسته، لذا يجب معرفة ما هو توجهك وما هدفك وما الذي قمت بتنفيذه، من أجل إختبارك بشكل مناسب لك وتجنب إفتراض أنك قمت بدراسة الدورة كاملة. على ما أعتقد أنك ذكرت دراسة تخصص الواجهة الأمامية فقط، ودرست مسارات معينة، وما المشاريع التي عملت على تنفيذها وهكذا، لذا يجب ذكر ذلك في نقاط مختصرة كالتالي: - - - وبجانب لكل شرطة اذكر النقاط الهامة وبشكل مختصر.
-
الأفضل طرح مشروعك على منصات العمل الحر، حيث ستجد مطورين لديهم خبرة لتنفيذ طلبك، وستطلع على معرض الأعمال الخاص بهم لتقييم الجودة قبل بدء المشروع، وأيضًا سيكون هناك إلتزام بسبب وجود وسيط وهو موقع العمل الحر، ويضمن حقك أيضًا وحق المطور. لديك موقع مستقل وأيضًا خمسات.
-
مواصفات جهاز MSI أفضل بالتأكيد، فجهازك الحالي به كرت Quadro P2000 وهو مخصص لأجهزة الـ Workstation، أي لبرامج التصميم الهندسي CAD وما شابه، لكنه مبني على معمارية قديمة ولا يحتوي على أنوية Tensor. أما RTX 2050 كرت مخصص للألعاب، ولكن مبني على معمارية أحدث Turing، والأهم أحتواءه على أنوية Tensor، وهي وحدات معالجة متخصصة مصممة لتسريع عمليات حساب المصفوفات التي تشكل أساس نماذج التعلم العميق. ومعالج i5-12450H على الرغم من كونه i5، إلا أنه من الجيل الثاني عشر، وفارق الأجيال كبير جدًا لدرجة أنه يتفوق على الـ i7 القديم في كل من أداء النواة الواحدة والأداء متعدد الأنوية بفضل المعمارية الأحدث P-cores و E-cores.
-
بإمكانك التقدم للإختبار الآن لا داعي للقلق.
- 3 اجابة
-
- 2
-
-
-
ليس المطلوب شرح كل شيء في المشروع بل سيتم طرح بعض الأسئلة والمناقشة حول المشاريع التي قمت بتنفيذها لقياس مدى استيعابك لما قمت به وما تم شرحه بالدورة، وليس مجرد تطبيق حرفي مع الشرح بدون استيعاب. ثم اختبار عملي من خلال اسناد مشروع لتنفيذه خلال أسبوع ثم مراجعته لتفقد ما قمت به. آلية الإختبار هي كالتالي: بعد إنهاء 4 مسارات من الدورة على الأقل، أو الدورة بالكامل عليك رفع المشاريع التي قمت بها بالدورة على حسابك في github، ثم التحدث لمركز المساعدة وإخبارهم أنك تريد التقدم للإختبار وتوفير روابط المشاريع على github. ثم الإنتظار لبعض الوقت لحين مراجعة المشاريع وسيتم الرد عليك، وتحديد موعد لإجراء مقابلة، وبها يتم: إجراء محادثة صوتيّة لمدة 30 دقيقة يطرح المدرّب عليك أسئلة متعلّقة بالدورة والأمور التي نفّذتها خلالها. يحدد لك المدرّب مشروعًا مرتبطًا بما قمت به أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع إلى أسبوعين. إجراء محادثة صوتيّة أخرى لمدّة 30 دقيقة يناقش بها مشروعك وما نفذته وتطرح أسئلة خلالها. إن سارت على جميع الخطوات السابقة بشكل صحيح، تحصل على الشهادة أو يرشدك المدرّب لأماكن القصور ويطلب منك تداركها ثم التواصل معنا من جديد.
- 3 اجابة
-
- 1
-
-
لن تتمكن من الإتصال بقاعدة البيانات المحلية فهي تعمل تعمل على حاسوبك فقط، يجب إنشاء قاعدة بيانات على استضافة مثل atlas والإتصال من خلال الرابط الذي ستحصل عليه
-
الأمر ليس له علاقة بـ mongodb compass بل يجب إنشاء قاعدة بيانات على mongodb atlas وستحصل على رابط للإتصال بقاعدة البيانات