Mustafa Suleiman
-
المساهمات
20563 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
496
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
 الصحيح هو إجابة مباشرة في خطوات بدون تفصيل وفي حال سألك عن نقطة معينة فصلها له، وهي تحديد مكان المشكلة لمعرفة هل في الـ Network، الـ Client-side، الـ App Server، أو الـ Database. ثم اذكر له نقاط بسيطة عن كل خطوة، مثلاً في الـ Network و Client من خلال أدوات DevTools في المتصفح سأتفقد هل الـ TTFB مرتفع، في حال ذلك فالمشكلة في الـ Server، أما لو التحميل بطيئ بعد الاستجابة، فالمشكلة في حجم البيانات أو الـ Rendering. وفي الـ App Server لو المشكلة كانت في السيرفر، أراقب الـ Logs وأدوات الـ Profiling لمعرفة هل التأخير بسبب عمليات حسابية ثقيلة أم انتظار خارجي. ولو في الـ Database أراجع الـ Slow Query Logs وهنا أتأكد من أمرين هل الـ Query مكتوب بشكل جيد؟ وهل الجداول تملك الـ Indexing المناسب لمنع المسح الكامل للجدول؟ وفي حال الكود والـ Database بحالة جيدة، أفكر في حلول مثل الـ Caching أو تحويل العملية لـ Background Job.
الصحيح هو إجابة مباشرة في خطوات بدون تفصيل وفي حال سألك عن نقطة معينة فصلها له، وهي تحديد مكان المشكلة لمعرفة هل في الـ Network، الـ Client-side، الـ App Server، أو الـ Database. ثم اذكر له نقاط بسيطة عن كل خطوة، مثلاً في الـ Network و Client من خلال أدوات DevTools في المتصفح سأتفقد هل الـ TTFB مرتفع، في حال ذلك فالمشكلة في الـ Server، أما لو التحميل بطيئ بعد الاستجابة، فالمشكلة في حجم البيانات أو الـ Rendering. وفي الـ App Server لو المشكلة كانت في السيرفر، أراقب الـ Logs وأدوات الـ Profiling لمعرفة هل التأخير بسبب عمليات حسابية ثقيلة أم انتظار خارجي. ولو في الـ Database أراجع الـ Slow Query Logs وهنا أتأكد من أمرين هل الـ Query مكتوب بشكل جيد؟ وهل الجداول تملك الـ Indexing المناسب لمنع المسح الكامل للجدول؟ وفي حال الكود والـ Database بحالة جيدة، أفكر في حلول مثل الـ Caching أو تحويل العملية لـ Background Job. -
سؤالك غير صحيح، ما يجب أن تسأل عنه هو هل ما قمت به صحيح أم لا؟ لا تحاول أبدًا ذكر أشياء لم تقم بها أو ليس لديك الخبرة الكافية بها، فذلك له تأثير معاكس تمامًا لما تريده، ما يجب إظهاره هو أنك تعلم أمور معينة بقدر معين وقادر على تعلم أمور جديدة بشكل مرن عند الحاجة. الصحيح هو أنك حاولت القيام بدور الـ Interviewer قدر الإمكان وأجريت بحث وتعلمت قدر الإمكان قبل القيام بذلك، وحاولت اختيار اختيار المُبرمج المناسب بناءًا على خبرتك الحالية ومن خلال منهجية واضحة بناءًا على بحثك وما تعلمته وليس بشكل عشوائي، بالطبع ليست كافية لكن حاولت تنفيذ المطلوب منك قدر المُستطاع. ولا تقم بذكر إجابات طويلة أبدًا، بل بشكل مباشر وواضح قدر الإمكان. ببساطة ليس شرطًا معرفة عميقة بالتقنيات بالتفصيل ولكن المهم هو وجود أساس برمجي قوي وفهم عميق للمفاهيم الأساسية اللازمة في المجال والتي سيحتاجها في عمله. أيضًا وجود خبرة ومعرفة تتناسب مع متطلبات الوظيفة، فلا يصح اختيار شخص بخبرة بسيطة وأساس قوي لمنصب Senior، حيث الخبرة العملية جراء سنوات العمل لذلك المنصب لازمة. كذلك طريقة التفكير والتحليل والمهارات الغير تقنية Soft Skills.
- 2 اجابة
-
- 1
-

-
هل المقصود بالصفحة حسابك الشخصي profile أم صفحة page؟ عامًة طالما التطبيق في وضع التطوير فالمنشورات تظهر فقط لمديري التطبيق، ويجب تحويله إلى Live Mode، بالتوجه إلى: https://developers.facebook.com/apps/ ثم أنشئ تطبيق جديد أو استخدم الموجود واختر نوع None طالما ليس تجاري. ثم أضف الصلاحيات التالية بالتوجه إلى App Review في لوحة التحكم ثم Permissions and Features: pages_show_list pages_read_engagement pages_manage_posts ثم تحويل التطبيق إلى Live Mode من Settings واختر Basic وأضف Privacy Policy URL أي سياسة الخصوصية للتطبيق، وشعار للتطبيق وفي أعلى الصفحة حول من Development إلى Live. ولاستخراج الـ Page Access Token عبر Graph API Explorer فتوجه إلىhttps://developers.facebook.com/tools/explorer ثم في الأعلى اختر تطبيقك من القائمة واضغط Generate Access Token. واختر نفس الصلاحيات السابقة، ثم بعد الموافقة، من القائمة المنسدلة User or Page اختر صفحتك حيث سيظهر اسمها.
-
لذلك كنت افكر ، هل باشتراكي في حالتي الراهنة انا اخاطر بفرصة جيدة ؟ الأفضل الدراسة من وقت مُبكر، لكي تكتسب الخبرة اللازمة وأيضًا الإطلاع على مختلف مجالات البرمجة وتحديد التخصص الذي تُفضله، وليس الإنتظار لما بعد الجامعة، وكذلك سيكون لديك مُتسع من الوقت لدراسة الأساسية بشكل مُتعمق والتميز عن نسبة كبيرة ممن ليس لديهم مُتسع من الوقت أو يتكاسلون عن ذلك. وبخصوص شرط الحصول على وظيفة، فتستطيع تأجيل التقدم للإختبار للحصول على الشهادة بعد الإنتهاء من الدورة، وذلك لما بعد تخرجك من الجامعة، فالمدة تبدأ من بعد حصولك اجتيازك للإختبار وحصولك على الشهادة من أكاديمية حسوب.
-
صحيح أية 4 مسارات تريدها، لكن الأهم هو تحقيق فائدة تعود عليك وليس الحصول على الشهادة فقط، فخيار الـ 4 مسارات متاح لمن لديهم خبرة ويريدون دراسة مسارات معينة فقط وليس كامل الدورة، لذا في حال كنت مبتدأ يجب دراسة الدورة بالكامل.
- 4 اجابة
-
- 1
-
-
ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل.
-
في الوقت الحالي لا تتوفر مُلخصات للدروس، تستطيع الإعتماد على موسوعة حسوب كمرجع، وتستطيع الاستفسار أسفل الدروس في التعليقات عما تحتاجه وسيتم توضيحه لك. الملفات المتوفرة هي ملفات المشروع التي سنعمل عليه خلال المسار، وتستطيع تحميل ذلك من خلال درس المقدمة أو المدخل في بداية المسار. عامًة كل شخص له أسلوب يُناسبه في الدراسة، لكن المهم هو تجنب المشاهدة السلبية وتخصيص وقت أكبر للتطبيق العملي، فالبرمجة عبارة عن تفكير منطقي لحل مشكلة ثم تنفيذ ذلك من خلال كتابة الكود. والبعض يُفضل كتابة مُلخصات لكل شيء، لكن لا أنصحك بذلك، اكتفي فقط بكتابة ملاحظات ومُلخصات ورسومات للأمور النظرية أو معلومة معينة تريد الإحتفاظ بها للعودة إليها للمراجعة. بينما البرمجة نفسها اكتفي بالتطبيق العملي فهو الأهم وبدونه فلا معنى للمُلخصات النظرية مهما كتبت، ببساطة لن تستطيع قيادة سيارة بمشاهدة فيديو صحيح؟
- 6 اجابة
-
- 1
-
-
نفس المشروع العلمي بالفعل وذلك مقصود، حيث سنقوم بتطبيق ما تعلمناه عليه، فالمشروع الأول استخدمنا HTML CSS, JS فقط، وبعد ذلك سنقوم بإضافة إطار عمل بوتستراب وتنسيق الواجهة من خلاله. منذ فترة تم تحديث وحدة إنشاء مشروع شخصي في مسار أساسيات تطوير الويب في دورة تطوير واجهات المستخدم ليواكب أحدث الإصدارات والتقنيات. ويشمل التحديث 10 دروس موزعة على ساعتين وربع، وحدثنا الشرح ليكون أكثر سلاسة وسهولة، وحللنا جميع المشاكل التي كان الطلاب يقعون فيها سابقًا، كما استبدلنا مكتبة jQuery بجافا سكريبت الخالصة، وذلك لأن جافا سكريبت الحديثة أصبحت توفر نفس المزايا وأكثر دون الحاجة إلى تحميل مكتبات إضافية، وهو ما يجعل الكود أخف وأسرع، ويمنح الطلاب فرصة لبناء أساس قوي في لغة أساسية يحتاجونها في كل مشروع احترافي. وأمس تم صدور تحديث آخر، حيث أضفنا مسار جديد بعنوان أطر عمل CSS في دورة واجهات المستخدم، والتحديث يشمل 33 درسًا بمدة 5 ساعات ونصف. و يهدف المسار إلى تدريب الطالب على استخدام أطر عمل CSS لبناء واجهات ويب احترافية وحديثة، مع التركيز على إطار Bootstrap باعتباره واحدًا من أشهر وأكثر الأُطر استخدامًا في عالم تطوير الواجهات. يبدأ المسار بمدخل شامل يوضح لماذا نحتاج أصلًا إلى أطر العمل، وكيف تسهّل عملية التطوير وتسرّع إنتاج واجهات متناسقة ومتجاوبة دون الحاجة إلى كتابة كل شيء من الصفر. وخلال المسار، ستتدرب على فهم أنظمة الشبكات Grid، والمكوّنات الجاهزة، والأدوات المساعدة التي توفّر لك مرونة كبيرة في بناء صفحات حقيقية. كما ستعمل على مشروع عملي متكامل تطبق فيه كل المفاهيم التي تتعلمها خطوة بخطوة.
- 6 اجابة
-
- 1
-

-
مجهود وعزيمة تُشكر عليهما، لكن يجب توجيهم في الطريق الصحيح، ولا داعي لكل ذلك التشاؤم واليأس، فأنت ما زلت في سن صغير وأمامك مُتسع من الوقت -لا تنخدع بذلك الوقت يمر- ما تحتاجه هو التخطيط فقط ثم بذل المجهود بنفس القدر الحالي، فاستمرار السعي يعني حتمية الوصول إن شاء الله. بالنسبة لـ PHP ولارافل فهي مناسبة أكثر لمنصات العمل الحر، بينما لو أردت العمل في شركة فأنصحك بدراسة جافاسكريبت والتقنيات الخاصة بها لتصبح Full-stack أو دراسة C# و .NET وهناك نقطة هامة يجب توضيحها، لا توجد أي دورة في أي مكان توفر لك كل شيء، ستحتاج دائمًا إلى بذل مجهود إضافي بجانبها، في الأكاديمية هنا يتم شرح الأساسيات والتوسع من خلال المشاريع العملية، لذا في مرحلة شرح الأساسيات لو أردت الاستزادة ودراسة المفاهيم المتقدمة وتنفيذ مشروع على جافاسكريبت مثلاً، وذلك ما أنصحك به بالطبع، فعليك بدراسة ذلك من اليوتيوب، ثم العودة هنا واستكمال الدورة. ولا يجب دراسة الدورة بالكامل، طالما تريد تخصص الويب، فيجب التركيز على تقنيات MERN: ويجب أن تتحلى بالصبر ولا تنتظر نتائج سريعة، فالأمر سيستغرق عام من الدراسة وتنفيذ المشاريع لاكتساب خبرة لذا لا تمل سريعًا. وبالنسبة للأمور المالية أو استبدال الدورة، فالأمر يتم من خلال مركز المساعدة.
- 7 اجابة
-
- 1
-
-
تتوفر الأكواد المصدرية فقط للمشروع الذي نعمل عليه، وأيضًا الملفات التي تحتاجها لتنفيذ المشاريع، وتستطيع الوصول لذلك من خلال رابط أسفل بداية كل درس (المدخل أو المقدمة) في المسارات. بالنسبة للتلخيص فلا يتوفر حاليًا مُلخصات للدروس، تستطيع الاستفسار أسفل الدروس في التعليقات عما تحتاجه وسيتم توضيحه لك. عامًة كل شخص له أسلوب يُناسبه في الدراسة، لكن المهم هو تجنب المشاهدة السلبية وتخصيص وقت أكبر للتطبيق العملي، فالبرمجة عبارة عن تفكير منطقي لحل مشكلة ثم تنفيذ ذلك من خلال كتابة الكود. والبعض يُفضل كتابة مُلخصات لكل شيء، لكن لا أنصحك بذلك، اكتفي فقط بكتابة ملاحظات ومُلخصات ورسومات للأمور النظرية أو معلومة معينة تريد الإحتفاظ بها للعودة إليها للمراجعة. بينما البرمجة نفسها اكتفي بالتطبيق العملي فهو الأهم وبدونه فلا معنى للمُلخصات النظرية مهما كتبت، ببساطة لن تستطيع قيادة سيارة بمشاهدة فيديو صحيح؟
-
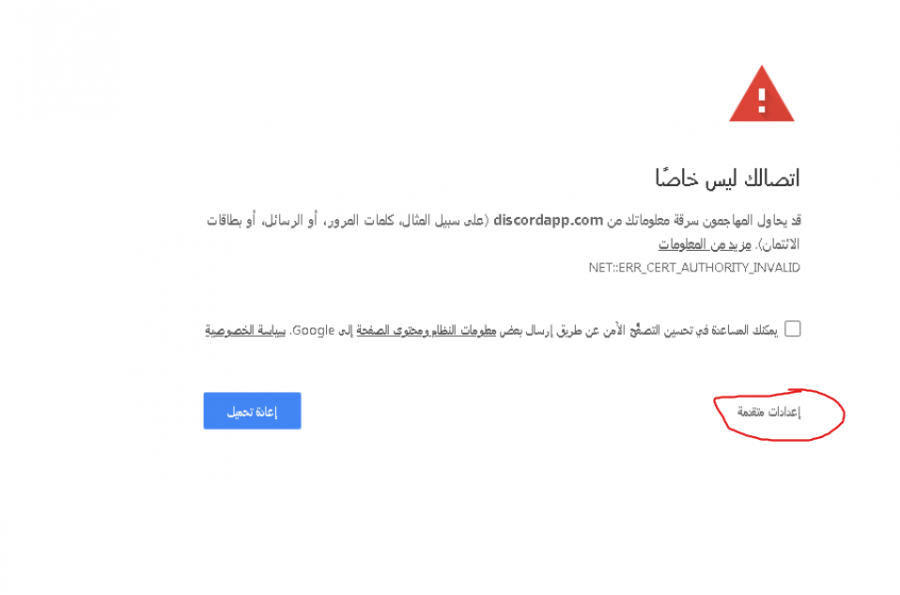
هل الوقت والتاريخ مضبوطين بشكل صحيح على التابلت؟ في حال نعم، إذن المشكلة أنك تستخدم بروكسي من أجل تصفح الإنترنت، ومن الطبيعي أن تظهر تلك التحذيرات. اضغط على إعدادات متقدمة ثم اختر متابعة. وفي حال تخطيت فترة الثانوية، فتستطيع إزالة الحماية الموجودة على التابلت وتصفح الإنترنت بشكل طبيعي.
-
من خلال استخدام صورة النموذج كخلفية، بمعنى قبل البدء، قس أبعاد ورقتك بدقة وهما الطول والعرض، ثم في Crystal Reports، توجه إلى File ثم Page Setup. وألغِ تفعيل خيار No Printer، ثم اختر حجم الورقة المناسب، وفي حال الحجم غير قياسي أي ليس A4، فيجب عليك تعريف حجم مخصص Custom Paper Size من إعدادات الطابعة في الويندوز أولاً، ثم اختياره داخل الكريستال ريبورت. واجعل الهوامش Margins مساوية للصفر أو صغيرة جدًا لتتحكم بالمكان.
-
أتفهم ما تُشعر به إبراهيم وشكرًا على شعورك تجاه المدربين، لمساعدتك بشكل أفضل، ما هو عمرك وما هو مجال دراستك الجامعية إن أمكن؟ وكذلك ما هو الوقت المتاح لك للدراسة؟
- 7 اجابة
-
- 1
-
-
الدورة ليس تخصصها مجال تحليل البيانات، ما ستتعلمه بها هو جزء كبير من الأساسيات اللازمة لذلك المجال، بعد ذلك ستحتاج تعلم أساسيات برنامج الـ Excel، وبالأخص دوال ومعادلات SUM, AVERAGE, VLOOKUP, INDEX, و MATCH. ثم دورة لتعلم الإحصاء والإحتمالات، سواء من Khan Academy أو من مصادر أخرى، ثم دورة أخرى متخصصة في تحليل البيانات باستخدام برنامج الـ Excel. ثم تعلم قواعد البيانات ولغة الـ SQL وقد تعلمت ذلك بالدورة بالفعل، لكن ستحتاج إلى تعلم SQL for Data Analytics للتعمق قليلاً والتعرف على مفاهيم متقدمة منها JOINs بأنواعها، GROUP BY, Window Functions, Subqueries, CTEs، وللعلم معظم مقابلات العمل لمحللي البيانات تتضمن أسئلة SQL متقدمة. الخطوة التالية هي تعلم أحد برامج التحليل والتصوير المرئي للبيانات مثل Power BI أو Tableau أو Google Looker Studio، وبالطبع الأفضل برنامج Power BI فهو المطلوب في سوق العمل. كما أنه يجب عليكِ الاستمرار في التطبيق بكثافة على بيانات حقيقية لتحليلها كلما تقدمت في المسار التعليمي، ومن أشهر المواقع التي يمكنك الحصول منها على بيانات لتقم بتحليلها هو موقع Kaggle الشهير، ولديك أيضًا Data.gov. للتبسيط الصورة التالية جيدة: وفي المرحلة المتقدمة ستحتاج إلى دراسة تعلم الآلة، وذلك ما ستتعلمه بالدورة بالفعل، بالتالي تحتاج إلى دراسة القليل خارج الدورة فيما يخص الأساسيات. ستجد هنا تفصيل لما تحتاجه: https://roadmap.sh/data-analyst

- 2 اجابة
-
- 1
-
-
ستجدين أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل.
-
جيد، لكن لم تقم بمعالجة البيانات أي تنظيفها، فالنصوص تحتوي على شرطات سفلية _ ومسافات زائدة ورموز مثل - أو . أو أقواس) وهي تشوش على النموذج وتجعله يظن أن النصوص مختلفة. أيضًا استخدام حلقتين متداخلتين أمر غير عملي وبطيء، كما أن المخرجات تكون مجرد أزواج يصعب تتبعها. تتوفر دالة جاهزة في مكتبة sentence-transformers تسمى paraphrase_mining لاستخراج الجمل المتشابهة بسرعة فائقة وترتيبها حسب نسبة التطابق. import pandas as pd import re from sentence_transformers import SentenceTransformer, util def clean_text(text): if not isinstance(text, str): return "" text = re.sub(r'[^\w\s]', ' ', text) text = text.replace('_', ' ') text = " ".join(text.lower().split()) return text file_path = "files/similar_services.xlsx" try: df = pd.read_excel(file_path) except Exception as e: print(f"Error loading file: {e}") exit() if 'name' not in df.columns: target_column = df.columns[2] else: target_column = 'name' print(f"Processing column: {target_column}") services_original = df[target_column].astype(str).tolist() services_cleaned = [clean_text(txt) for txt in services_original] print("Loading Model...") model = SentenceTransformer("sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2") print("Calculating Similarity...") matches = util.paraphrase_mining(model, services_cleaned, show_progress_bar=True, top_k=10) threshold = 0.75 output_data = [] for score, i, j in matches: if score >= threshold: if i != j: output_data.append({ "Service_ID_1": i + 2, "Service_Text_1": services_original[i], "Service_ID_2": j + 2, "Service_Text_2": services_original[j], "Similarity_Score": round(score * 100, 2) }) result_df = pd.read_json(pd.io.json.json_normalize(output_data).to_json()) if not result_df.empty: result_df.to_excel("similar_services_final.xlsx", index=False) print(f"Done! Found {len(result_df)} similar pairs. Saved to 'similar_services_final.xlsx'") else: print("No similar services found with the current threshold.") نسبة التشابه Threshold جعلتها 0.75، لأنّ أحيانًا الترجمة أو اختلاف ترتيب الكلمات مثل خلع ضرس و ضرس خلع يعطي نسبة أقل من 0.80، لذا 0.75 ستظهر لك نتائج شاملة أكثر، وتستطيع حذف غير المناسب من ملف الإكسل الناتج. لو وجدت أن النتائج لا تزال غير دقيقة بنسبة 100%، فالسبب غالبًا هو تكرار المعنى بكلمات مختلفة، لذا استخدم ميزة Community Detection أي اكتشاف المجموعات والتي تقوم بتجميع الخدمات المتشابهة في مجموعات Cluster بدلاً من أزواج. مثلاً تجميع لك كل خدمات الحشوات مع بعض في مجموعة واحدة، قم بتجربة الكود التالي بعد تحميل الموديل: embeddings = model.encode(services_cleaned) clusters = util.community_detection(embeddings, min_community_size=2, threshold=0.75) for i, cluster in enumerate(clusters): print(f"\nGroup {i+1}:") for sentence_id in cluster: print("\t", services_original[sentence_id])
-
يتوفر React وNext.js وذلك في دورة جافاسكريبت، لكن Angular لا يتوفر شرح لها بدورة الأكاديمية، والمشترك بينهما هو لغة جافاسكريبت، وأيضًا المفاهيم التالية: مفهوم المكونات إدارة الحالة تطبيقات الصفحة الواحدة SPA Server-Side Rendering (SSR) لذا في حال تعلمت react وNext.js ستجد أن تعلم أنجولار أصبح أسهل، عامًة يوجد شرح نصي فقط من خلال المقالات البرمجية بالأكاديمية: مقالات Angular بالأكاديمية
-
هل ما تريده سيتم من خلال كتابة سكريبت بايثون أم بدون برمجة؟ أي تريد أن يتم الأمر بشكل تلقائي، أم هو ملف واحد فقط تريد العمل عليه واستخلاص معلومات منه؟
-
يتم تحديث الدورة بشكل مستمر، وحاليًا ستتعلم جزء كبير من الأساسيات في الدورة اللازمة لتطوير AI Agents. بجانب أن مسار التعلم المعزز Reinforcement Learning قائم بالكامل على فكرة وجود Agent يتفاعل مع بيئة ويتخذ قرارات للحصول على مكافأة، وهنا ستتعلم كيف يبني الوكيل استراتيجيته بنفسه. وفي مسار تطبيقات عملية على النماذج النصية الكبيرة LLMs، يتم شرح كيفية تطوير وكلاء بالنهج الحديث، حيث التوجه حاليًا هو بناء وكلاء أذكياء Autonomous Agents باستخدام النماذج اللغوية مثل GPT كعقل للمفكر، واستخدام أدوات لتنفيذ المهام مثل استخدام LangChain. وفي مسار تطوير نماذج ذكاء اصطناعي لمتجر إلكتروني، يتم التطبيق بشكل عملي من خلال شرح كيفية بناء Chatbot أو وكيل خدمة عملاء ذكي، وهو أحد أشهر أنواع الـ AI Agents.
-
يتوفر بالفعل محتوى عن ذلك بالدورة، في المسارات التالية: تطبيقات عملية على النماذج النصية الكبيرة LLMs، فالنماذج اللغوية الكبيرة LLMs هي حاليًا أشهر أشكال الذكاء الاصطناعي التوليدي وتقوم بتوليد النصوص والأكواد. تطبيقات عملية باستخدام المحوّلات Transformers، وهو مسار أساسي أيضًا، لأن معمارية المحوّلات هي البنية التحتية التي تعمل عليها معظم النماذج التوليدية الحديثة مثل GPT و BERT. التعلم العميق Deep Learning، يتضمن شرح للمفاهيم النظرية للنماذج التوليدية كالشبكات التنافسية التوليدية GANs والمشفرات التلقائية المتغيرة VAEs.
-
fetch ليس الغرض منها تحديد كمية البيانات، فالمتحكم هو المسؤول الأول والأساسي عن تلك العملية، حيث أن fetch هي مجرد وسيلة نقل للطلب من المتصفح إلى الخادم، ولا تملك أي صلاحية للوصول المباشر إلى قاعدة البيانات أو التحكم في كيفية استرجاع البيانات منها. يتوجب عليك كتابة المنطق الخاص بتقسيم البيانات داخل المتحكم في الواجهة الخلفية، لأنّ عملية جلب البيانات تعتمد على استعلامات SQL أو NoSQL التي يتم تنفيذها على الخادم، فالمتصفح يرسل فقط الرغبة في الحصول على عدد معين عبر Query Parameters، ويجب على الخادم أن يفهم تلك الرغبة وينفذها. بمعنى تبدأ العملية عندما تقوم بإرسال الطلب عبر fetch بتمرير المعايير مثل ?limit=10 ضمن الرابط، والتي يستقبلها المتحكم ويقوم بقراءة تلك القيم ومعالجتها، ثم دمجها داخل استعلام قاعدة البيانات باستخدام أوامر مثل LIMIT و OFFSET، وبالتالي يتم استخراج العشرة صفوف المطلوبة فقط من القرص الصلب للخادم وإرسالها عبر الشبكة. وفي حال لا يوجد ذاك المنطق في الخلفية، فسيقوم الخادم بتجاهل تلك المعاملات المرسلة في الرابط، وسيعيد كامل محتوى الجدول في قاعدة البيانات، بالتالي fetch ستقوم بتحميل حجم بيانات ضخم، ويتدهور الأداء حتى لو قمت بعرض جزء صغير منها لاحقاً بواسطة جافاسكريبت، فالهدف الأساسي هو تقليل البيانات المنقولة عبر الشبكة وليس فقط تقليل المعروض على الشاشة.
-
هناك ثلاث ركائز أساسية وهي Effectiveness و Efficiency و Satisfaction، والتي تعني قياس قدرة المستخدم على إكمال المهام بدقة، والموارد أو الوقت المستغرق لذلك، ومدى رضا المستخدم عن التجربة، ولتطبيق تلك المعايير عمليًا وفي وقت قصير، يتعين عليك البدء بإجراء Heuristic Evaluation سريع، حيث تقوم بمراجعة واجهات التطبيق بنفسك أو بمساعدة خبير بناءً على قواعد Jakob Nielsen العشر لسهولة الاستخدام قبل إطلاق التطبيق للمستخدمين، وسيساعدك ذلك على اكتشاف الأخطاء البديهية في واجهة المستخدم وتصحيحها مبكراً مما يوفر الوقت لاحقاً. عند الانتقال لمرحلة الاختبار مع المستخدمين الفعليين، فأسلوب Guerrilla Usability Testing هو الأنسب لمشاريع التخرج نظراً لقلة تكلفته وسرعته. ولتعزيز دقة النتائج رقمياً، يجب عليك دمج أدوات التحليل البرمجية مثل Firebase Analytics داخل الكود المصدري للتطبيق، والذي يحتوي على دوال برمجية تقوم بتتبع سلوك المستخدم تلقائيًا. ولقياس المعيار الثالث وهو Satisfaction، استخدم مقياس System Usability Scale المعروف اختصاراً بـ SUS، والذي يعتبر المعيار الصناعي الأسرع والأكثر موثوقية، ويتكون من عشرة أسئلة قصيرة تعرض على المستخدم بعد انتهاء التجربة مباشرة عبر Dialog بسيط داخل التطبيق أو استبيان خارجي. وتتمحور الأسئلة حول مدى تعقيد النظام وحاجة المستخدم للدعم الفني، ثم يتم حساب النتيجة النهائية وفق معادلة خاصة لتعطي رقماً من 100، ولو تجاوزت النتيجة 68 يعتبر تطبيقك قابلاً للاستخدام بمستوى جيد، أما إن قلت عن ذلك فيدل على وجود مشاكل جوهرية في تجربة المستخدم تحتاج لإعادة نظر.
- 1 جواب
-
- 1
-
-
بالطبع يجب استدعاء fetch كل مرة تصل فيها إلى نهاية الصفحة أو بالقرب منها حسب تصميم الصفحة لديك، والأفضل بالقرب منها وذلك بالإعتماد على Intersection Observer API في المتصفح. لا تقم أبدًا بجلب كل البيانات، فذلك من شأنه التأثير على الأداء بشكل كبير، وأيضًا استهلاك الموارد بدون داعٍ. من خلال CORS وهي آلية أمان مدمجة في المتصفحات تمنع أي موقع أو أصل - Origin من طلب موارد من موقع آخر إلا إذا سمح الموقع الآخر بذلك صراحًة، والأصل يتكون من البروتوكول، اسم النطاق والمنفذ. أي بتحديد النطاقات المسموح لها بالإتصال بالخادم وتمرير ذلك إلى مكتبة CORS وذلك بالنسبة لجافاسكريبت، أما في PHP فتتحقق من جود الـ origin في الطلب.
- 1 جواب
-
- 1
-
-
ما هو تخصصك؟ هل تنوي استخدامه لدراسة الفيزياء أم تنوي دراسة مجال الذكاء اصطناعي وتسأل عن الأساسيات المطلوبة؟ عامًة لست بحاجة إلى دراسة الفيزياء، بل أساسيات الرياضيات: ابدء بالجبر الخطي ودراسة المصفوفات، العمليات الأساسية، الضرب النقطي. ثم التفاضل ودراسة المشتقات، قاعدة السلسلة، التدرج. ثم الإحصاء ودراسة المتوسط، الانحراف المعياري، التوزيعات الأساسية بعد ذلك كلما واجهتك مفاهيم رياضية، توقف وادرسها. ستجد تفصيل هنا: