


Mustafa Suleiman
-
المساهمات
20346 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
494
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Mustafa Suleiman
-
لنتحدث بشكل واقعي، أنت لن تصل، يجب وجود هدف واضح وصريح من أجله تتعلم البرمجة، ابحث عنه وضعه أمام عينيك وقم بكتابة عواقب عدم الإلتزام بذلك على ورقة واجعلها بجانبك. بدون هدف لن تتحمل مرارة الرحلة، فتعلم البرمجة ليس بالأمر السهل ويحتاج إلى صبر واستمرار خاصًة في البداية. وذكرت أنّك مشترك في الكثير من الدورات وذلك مفيد وغير مفيد في نفس الوقت، ففي حال الدورات ليست متعلقة ببضعها البعض، إذن أنت تشتت نفسك، يجب تحديد خارطة طريق والتزم بها، لكن لا تقم بتعلم ما تحبه وشغوف به، بل المطلوب في سوق العمل. ابحث على مواقع التوظيف في بلدك عن المهارات المطلوبة في التخصص الذي تريده وليكن back-end مثلاً، ستجد تفصيل هنا:
-
ستحتاجين إلى تعلم تقنية RAG والتي تعتمد على توفير قاعدة بيانات يعود إليها النموذج للبحث عن معلومات تخص السؤال، وذلك ما سنتعلمه في الدورة من خلال lang chain ستجدي ذلك في مسار تطبيقات عملية على النماذج النصية الكبيرة LLMs في قسم تخصيص وصقل نماذج اللغة الكبيرة. بالنسبة لتطوير برنامج للويندوز، فستحتاجين إلى لغة أخرى غير بايثون، واللغة المتخصصة هي C# بجانب إطار .NET الخاص بها، لكن الأفضل تعلم لغة جافاسكريبت ثم تعلم إطار Electrone.js وذلك لأنّ جافاسكريبت لغة خاصة بالويب وستفيدك في حال أردتي تنفيذ مشاريع ويب ونشر تطبيقاتك، وهي أسهل بالطبع من C# و .Net وهناك حل آخر لو أردتي الإعتماد على بايثون فقط، فتخلي عن فكرة برنامج للويندوز، واعملي على تطوير مشروع ويب من خلال Django أو Flask.
-
ليس بيدك سوى محاولة استعادته عن طريق الطرق الرسمية، من خلال الضغط على رابط نسيت كلمة المرور ثم محاولة استعادته بتوفير رقم الهاتف والبريد المرتبطتين بالحساب، وسيتم إرسال كود أو رسالة بريد من أجل استعادة حسابك، وقد يتم سؤالك عن أمور تخص بيانات حسابك. في حال تم تغيير تلك البيانات، ستحتاج إلى التقدم ببلاغ عن سرقة حسابك، وكل منصة لديها آلية لذلك، فمثلاً فيسبوك ستحتاج إلى الإبلاغ من هنا: https://web.facebook.com/help/738660629556925 بالنسبة للمنصات الأخرى، ابحث عن على جوجل عن "my facebook account hacked" واستبدل facebook باسم المنصة وستظهر لك الطريقة المناسبة.
-
ما تحتاجه في الرياضيات هو دراسة التالي: الجبر الخطي ودراسة المصفوفات، العمليات الأساسية، الضرب النقطي. ثم التفاضل ودراسة المشتقات، قاعدة السلسلة، التدرج. ثم الإحصاء ودراسة المتوسط، الانحراف المعياري، التوزيعات الأساسية بعد ذلك كلما واجهتك مفاهيم رياضية، توقف وادرسها، مثلاً في درس الدرس "تعلم الآلة Machine Learning - التصنيف باستخدام أشجار القرار - تعلم قواعد التصنيف باستخدام أشجار القرار" ستحتاج إلى دراسة أساسيات الاحتمالات البسيطة واللوغاريتمات ومفهوم المجموع Summation Notation. ستجد هنا تفصيل: وبخصوص الكتاب وعامًة، تعلم الآلة بمثابة جعل الكمبيوتر يتعلم من البيانات لاتخاذ قرارات أو عمل تنبؤات، دون أن تتم برمجته بشكل صريح لكل حالة. ففي البرمجة التقليدية، أنت تكتب قواعد واضحة مثل if/else، وتوفر للكمبيوتر بيانات ليطبق عليها هذه القواعد ويخرج لك بإجابة، وليكن برنامج لمعرفة هل الرقم زوجي أم فردي، حيث القاعدة هي لو باقي قسمة الرقم على 2 يساوي صفر، فهو زوجي. بينما في تعلم الآلة توفر للكمبيوتر بيانات والإجابات الصحيحة المرتبطة بها، وهو بنفسه يستنتج القواعد التي تربط بينها، وتلك القواعد التي يتعلمها تسمى النموذج Model. ويظهر ذلك في برنامج للتعرف على رسائل الـ Spam، ببدلاً من كتابة آلاف القواعد مثل لو الرسالة تحتوي على كلمة مجاناً وعرض خاص وخلافه، أنت فقط توفر آلاف الرسائل مع تصنيفها، أي تلك سبام، وهذه ليست سبام، وهو يتعلم الأنماط بنفسه. أي الانتقال من كتابة القواعد إلى التعلم من الأمثلة. والمكونات الأساسية لأي مشروع تعلم آلة هي: البيانات، وبدون بيانات جيدة، لا يمكن للآلة أن تتعلم شيئ مفيد، فمدخلات سيئة توفر مخرجات سيئة. الخوارزمية وهي طريقة التعلم أو الدماغ الذي سيستخدم البيانات لاستنتاج الأنماط، ويتوفر العديد من الخوارزميات المختلفة، كل منها مناسب لنوع معين من المشاكل. النموذج هو الناتج النهائي لعملية التدريب، وأشبه بكتلة برمجية تحتوي على المعرفة أو القواعد التي استخلصتها الخوارزمية من البيانات، وهو ما ستستخدمه لعمل تنبؤات على بيانات جديدة لم يرها من قبل. وأهم ما يجب معرفته هي الأنواع الرئيسية لتعلم الآلة: التعلم الخاضع للإشراف Supervised Learning التعلم غير الخاضع للإشراف Unsupervised Learning التعلم المعزز Reinforcement Learning تستطيع البحث عنها والتعمق بها.
-
لغة PHP خاصة بالواجهة الخلفية بالفعل، أي هي لغة خاصة بالسيرفر، لكن عن طريق إطار لارافل تستطيع تطوير مشاريع Full-Stack بمعنى الواجهة الأمامية والخلفية معًا، وذلك عن طريق مُحرك القوالب Blade المتوفر في لارافل، وبه تكتب HTML, CSS, JS. لذا الدورة موجهة لتصبح مطور Full-stack فالمشاريع التي بها نعمل على تطوير الواجهة الأمامية والخلفية معًا أي مشروع كامل وليس الواجهة الخلفية فقط. ولا مشكلة لو أردت التركيز على الواجهة الخلفية وتجاهل الجزء الأمامي في الدورة، بمعنى تنفيذ الجزء الخاص بالخادم من إنشاء مسارات ومعالجة الطلبات عن طريق المتحكمات وإدارة قاعدة البيانات وتأمين الخادم. ستجد تفصيل هنا عن الـ Full-stack
-
آلية الإختبار هي كالتالي: بعد إنهاء 4 مسارات من الدورة على الأقل، أو الدورة بالكامل عليكِ رفع المشاريع التي قمتي بها بالدورة على حسابك في github، ثم التحدث لمركز المساعدة وإخبارهم أنك تريدين التقدم للإختبار وتوفير روابط المشاريع على github. ثم الإنتظار لبعض الوقت لحين مراجعة المشاريع وسيتم الرد عليكِ، وتحديد موعد لإجراء مقابلة، وبها يتم: إجراء محادثة صوتيّة لمدة 30 دقيقة يطرح المدرّب عليك أسئلة متعلّقة بالدورة والأمور التي نفّذتيها خلالها. يحدد لكِ المدرّب مشروعًا مرتبطًا بما قمت به أثناء الدورة لتنفيذه خلال فترة محددة تتراوح بين أسبوع إلى أسبوعين. إجراء محادثة صوتيّة أخرى لمدّة 30 دقيقة يناقش بها مشروعك وما نفذتيه وتُطرح أسئلة خلالها. إن سارت على جميع الخطوات السابقة بشكل صحيح، تحصلين على الشهادة أو يرشدك المدرّب لأماكن القصور ويطلب منك تداركها ثم التواصل معنا من جديد. بخصوص المراجعة، حاولي مراجعة الملاحظات والملخصات التي قمتي بها، أي لا تُعيدي تُعد مشاهدة الفيديوهات بالكامل إلا عند الحاجة، أي استخدمي الفيديوهات كمرجع وليس كمراجعة أساسية، أي في حال واجهتي صعوبة في فهم نقطة معينة من ملاحظاتك، عودي إلى الفيديو المحدد لتلك النقطة وشاهده بسرعة x1.5 أو x2 ثم تنفيذ مشروع على كل مسار عملي بالدورة، بحيث توظفين به ما تعلمتيه به أو حتى إعادة تنفيذ لما قمتي به والأمر سيكون سريع تلك المرة، وفي حال كان بطيء إذن المراجعة كانت ضرورية وستستفيدين على أي حال. وفي حال أردتي تمارين برمجية ستجدي ذلك على منصة codewars
-
 ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل. بخصوص المشكلة لديك، فبسبب أنك تستخدم إضافة code runner في vscode والتي تقوم بشكل إفتراضي بتشغيل الكود بداخل تبويب OUTPUT وليس Terminal. لو أردت استخدم code runner قم بإضافة التالي في ملف الإعدادات لتشغيله في التيرمنال كما تم التوضيح: "code-runner.runInTerminal": true ولتصل لمف الإعدادات قم بالضغط على زر F1 ثم ابحث عن settings josn واختر أول خيار وأضف السطر السابق قبل قوس الإغلاق { ثم أضف فاصلة في نهاية السطر الذي يليه كالتالي: ثم اضغط على CTRL + S للحفظ
ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل. بخصوص المشكلة لديك، فبسبب أنك تستخدم إضافة code runner في vscode والتي تقوم بشكل إفتراضي بتشغيل الكود بداخل تبويب OUTPUT وليس Terminal. لو أردت استخدم code runner قم بإضافة التالي في ملف الإعدادات لتشغيله في التيرمنال كما تم التوضيح: "code-runner.runInTerminal": true ولتصل لمف الإعدادات قم بالضغط على زر F1 ثم ابحث عن settings josn واختر أول خيار وأضف السطر السابق قبل قوس الإغلاق { ثم أضف فاصلة في نهاية السطر الذي يليه كالتالي: ثم اضغط على CTRL + S للحفظ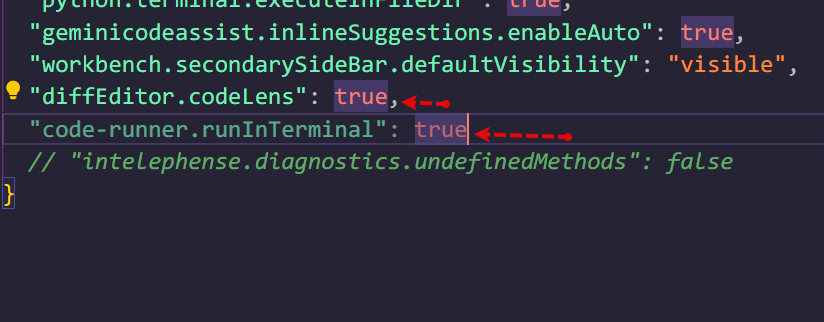
-
حجم الصور لديك كبير، يجب ضغط الصور لتقليص حجمها قبل رفع المشروع على الاستضافة، استخدم الموقع التالي وارفع الصور إليه ثم قم بتحميلها واستبدالها بما لديك في مجلد المشروع: https://imagecompressor.com/
-
أنت لست مُلزم بتعلم لغة واحدة أو إطار واحد، لا تتعلق بالتقنيات، تعلم أن تكون مهندس برمجيات بالتركيز على الأساسيات والتعق بها قدر الإمكان، ثم تعلم تقنية واحدة وتخصص بها واكتسب خبرة، ولتكن .NET ثم بعد سنة بإمكانك توسعة مهاراتك وتعلم لغة وتقنية جديدة، مثل PHP ولارافل. ومن خلال ما سبق ستصبح مطور Full-stack متعدد التقنيات واللغات، وتصبح قادر على تنفيذ نسبة أكبر من المشاريع المعروضة. ولا خلاف على كون PHP ولارافل عليهم طلب بمواقع العمل الحر، لكن أنصحك بالتوجه ناحية .NET لكون PHP مُتشبعة حاليًا وأيضًا المشاريع الخاصة بها صغيرة ورديئة في أغلب الأحيان، لكن لا بأس بها من أجل العمل الحر في حال الطلب أكثر عليها على منصة عمل حر معينة، لذا تفقد المشاريع المعروضة على مستقل وخمسات وقرر بناءًا على ذلك أي لغة وإطار ستتعلمهم أولاً.
-
ملف autoload.php غير موجود داخل مجلد vendor وهو ملف هام لأي مشروع لارافل أو PHP يعتمد على Composer، لأنه يقوم بتحميل جميع المكتبات والتبعيات الخاصة بالمشروع. أولاً تأكد من أنك تقوم بتنفيذ أمر php artisan serve داخل المجلد الذي به ملف composer.json، حاليًا أنت بمسار مجلد CMS لكن ربما بداخله مجلد آخر خاص بالمشروع، لذا تفقد الأمر، وقم بالإنتقال للمسار الصحيح من خلال أمر cd لو استمرت المشكلة قم بحذف ملف composer.lock وأعد تثبيت الحزم: omposer install ثم تشغيل المشروع
-
بشكل افتراضي، يتم البحث عن ملف باسم index.html كملف أساسي لتشغيل مشاريع الويب، بينما لديك باسم index-ar.html قم بتعديل اسمه إلى index.html ثم ادفع التغييرات إلى المستودع.
- 1 جواب
-
- 1
-

-
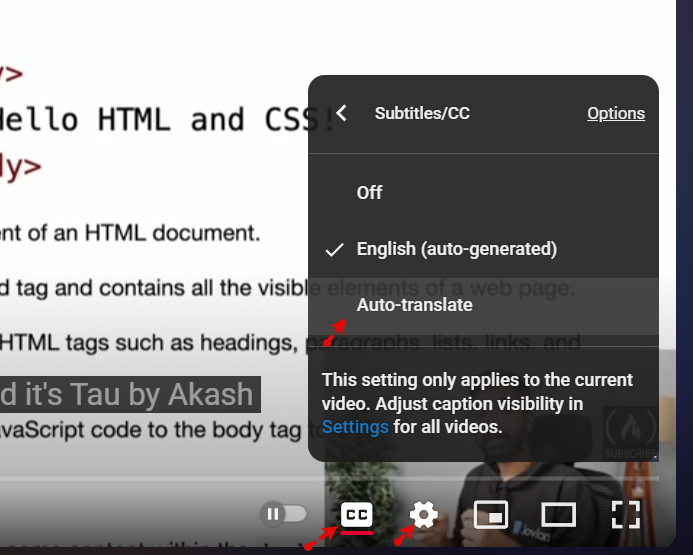
يوجد مشكلة في تلك الميزة حاليًا في يوتيوب عند الترجمة من الإنجليزية للغة أخرى، في العادة ستقوم بالتالي: قم بالضغط على زر cc وسيظهر لك الترجمة بالإنجليزية بشكل إفتراضي، ولتحويلها للعربية، اضغط على أيقونة الترس الخاصة بالإعدادات، ثم اختر subtitles أو الترجمة، ثم اختر auto-translate أي الترجمة التلقائية ثم اختر arabic أو العربية. لكن حاليًا لا تعمل وجاري حل المشكلة، تم ذكر ذلك هنا: https://support.google.com/youtube/thread/367205716/i-haven-t-had-automatic-subtitles-for-a-few-days-now?hl=en ستحتاج إلى الإنتظار لبعض الوقت لحين إصلاح المشكلة، اعتمد على الفيديوهات العربية في الوقت الحالي.
- 2 اجابة
-
- 1
-
-
ستجد أسفل فيديو الدرس في نهاية الصفحة صندوق تعليقات كما هنا، أرجو طرح الأسئلة أسفل الدرس وليس هنا في قسم أسئلة البرمجة حيث نطرح الأسئلة العامة الغير متعلقة بمحتوى الدورة أو الدرس، وذلك لمساعدتك بشكل أفضل.
- 1 جواب
-
- 1
-

-
الأمر ليس له علاقة بنسبة كبيرة، لكن التفكير المنطقي مهارة تنتقل من مجال لآخر بطبيعة الحال وتلك المهارة متوفرة في مجال الهندسة. كذلك سيكون لك الأفضلية في مجال أمن الأنظمة الصناعية ICS وSCADA بسبب استيعابك للدوائر التحكم، الـPLC، وأنظمة الطاقة، لتأمين المصانع ومحطات الطاقة والشبكات الذكية Smart Grid. بجانب أمن الأجهزة، بسبب معرفتك بالإلكترونيات الرقمية والتناظرية تساعدك في مجالات مثل تحليل الهاردوير، الهندسة العكسية، واختبار الاختراق للأجهزة، ستجد ذلك تحت مُسمى Hardware Pen-Testing. أيضًا إنترنت الأشياء IoT والسيارات المتصلة، فالخبرة في الميكروكنترولر والاتصالات اللاسلكية مفيدة لتأمين الأجهزة الذكية والمركبات الكهربائية. ما تحتاج إلى التركيز عليه هو الدراسة الذاتية: أساسيات لغة بايثون CompTIA Network+ الاستيعاب أساسيات الشبكات بشكل عميق، وهو أمر ضروري جداً. CompTIA Security+ هي نقطة الانطلاق في عالم الأمن السيبراني، وتغطي المفاهيم الأساسية والمصطلحات والأدوات. ثم تخصص في مجال معين: CEH (Certified Ethical Hacker) في حال مهتم بالاختراق الأخلاقي. OSCP (Offensive Security Certified Professional) وهي شهادة متقدمة وعملية جداً في مجال اختبار الاختراق. CISSP (Certified Information Systems Security Professional) لو أردت التوجه نحو الجانب الإداري والاستراتيجي وإدارة المخاطر لكن تتطلب خبرة عمل. شهادات SANS/GIAC تعتبر من أقوى الشهادات التقنية وتغطي تخصصات دقيقة جداً.
-
تستطيع استخدام google colab أو kaggle من أجل تدريب النموذج، فالموارد الحاسوبية المجانية التي توفرها كافية لتدريب النموذج بشكل سريع مقارنًة بحاسوبك. في حال استنفدت الموارد المجانية المتاحة لك، حاول تقليل عدد دورات التدريب وحجم البيانات، المهم هو التطبيق بشكل عملي وليس كتابة الكود فقط.
- 2 اجابة
-
- 1
-
-
تستطيع ذلك بالطبع لا مشكلة
- 5 اجابة
-
- 1
-
-
سوق العمل ستحتاج إلى تفقده بنفسك من خلال تفقد الوظائف المعروضة على مواقع التوظيف مثل LinkedIn وIndeed، أي البحث بالكلمات المفتاحية الخاصة بمجال بايثون مثل Python Django Backend Developer وبالنسبة لوسائل الدفع، المتاح هو من خلال باي بال أو من خلال بطاقة إئتمانية تقبل الدفع بالدولار من مصر. أو يمكنك الدفع عن طريق شخص آخر ليشتري لك الدورات التي تريدها، ويوجد بالأكاديمية بطاقة هدية تستطيع استخدام رصيدها لشراء ما تريد، وبالطبع سيشتريها لك شخص آخر. في حال لم تتمكن من الإشتراك، تستطيع مراسلة مركز المساعدة لمناقشة الأمر معهم. بالنسبة لما يمكنك العمل به بعد الإنتهاء من الدورة،: مطور Full-stack لبناء مواقع الويب والمتاجر الإلكترونية أي قادر على تطوير الواجهة الأمامية والخلفية أيضًا من خلال Django و Flask. مطور واجهة خلفية Back-End فقط. مجال تعلم الآلة ولكن هنا أنت بحاجة إلى تعلم المزيد وعدم الإكتفاء بالدورة والأمر بحاجة إلى وقت أكثر من أي مجال آخر. محلل بيانات (Data Analyst )، حيث ستتمكن من استخدام مهارات البرمجة الخاصة بك للتحليل واستخراج البيانات من مصادر متنوعة، ومعالجة البيانات، وإجراء التحليلات الإحصائية والتعلم الآلي باستخدام مكتبات Python مثل pandas و NumPy و scikit-learn. مطور odoo ستجد تفصيل هنا:
-
ليس كل ميزة أو تحديث جديد يجب دراسته أو الإهتمام به في الحال، بمعنى يجب أن تكون تلك الميزة قابلة للاستخدام في مشروع حقيقي، ففي لغة جافاسكريبت يتم إصدار ميزات في الإصدارات الجديدة، لكن ليست مدعومة من المتصفحات وتحتاج إلى وقت لكي تصل لتلك النقطة. نفس الحال بالنسبة للغة CSS، لذا الإلمام هنا بما هو جديد مطلوب بالطبع لتبقى على إطلاع، وأن تعرف أين تجد المعلومات عنه عندما تحتاج إليه لدراسته في الوقت المناسب. أما في حال كان إطار عمل مثل Next.js، هنا تتعلم الميزات الجديدة بالطبع، وتتعرف إلى الفروقات وكيفية تحديث المشاريع القديمة، وفيما سيفيدك التحديث وما الذي يقدمه مقارنًة بالإصدار السابق. ستجد توضيح لذلك في المستند الرسمي للإطار أو المكتبة، فهو أفضل مكان لتتحصل على معلومات منه، وذلك بعد استيعاب الفكرة العامة للميزات الجديدة، وستجد أمثلة للكود Code Snippets لفهم كيفية استخدامها عمليًا. بجانب الشروحات على يوتيوب مثلاً تبحث عن Next.js 15 new features tutorial ومشاهدة مبرمج آخر يطبق الميزة الجديدة أمامك في فيديو مدته 15-20 دقيقة يختصر ساعات من القراءة والتجربة الفردية. ثم تطبيق ذلك عمليًا من خلال مشروع بسيط لتجربة الميزات الجديدة بشكل معزول، أو إضافتها لمشروع قائم لتحسينه والأمر ليس بتلك السهولة حيث يجب توخي الحذر في حال المشروع منشور وله مستخدمين. وللمتابعة، قم بإنشاء حساب على منصة x.com وأيضًا منصة linkedin وقم بمتابعة مطورين مختصين بتقنيات MERN، ولكن اختر بعناية من تقوم بمتابعته، وستبقى على إطلاع بما هو جديد، كذلك متابعة بعض قنوات اليوتيوب المفيدة، وكذلك بعض المواقع المختصة بالبرمجة، والحسابات الرسمية للتقنيات نفسها @nextjs و @reactjs أي العملية هي مزيج من المتابعة السلبية وهي وصول الأخبار إليك عبر تويتر وخلافه والتعلم النشط والمركز من خلال التجربة في مشروع صغير عند ظهور شيء مهم ومفيد لمشاريعك.
- 3 اجابة
-
- 1
-
-
الجزء الخاصة بالواجهة الأمامية ستحتاج به إلى تعلم لغات الويب الأساسية وهي HTML, CSS, JS وقد تعلمت ذلك بالفعل، لكن يجب التعمق بهم وتنفيذ مشاريع من خلالهم وليس دراسة الأساسيات فقط بدون تطبيق، أو الإكتفاء بالتطبيق على نماذج بسيطة ولا مشكلة في البداية، فالتدرج هو المطلوب لكن يجب الإنتقال لتنفيذ مشروع كامل أي موقع كامل. ستجد تمارين هنا للتطبيق عليها: https://www.frontendmentor.io/challenges?difficulty=1&type=free%2Cfree-plus بعد ذلك ستحتاج إلى تعلم إطار tailwind CSS فهو الإطار الإحترافي لتنسيق مشاريع الويب حاليًا، ثم تعلم مكتبة react ثم إطار Next.js والتي من خلالها تستطيع تطوير مشاريع Full-stack بواسطة لغة جافاسكريبت. بعد ذلك تنتقل إلى التعمق في الواجهة الخلفية من خلال Node.js والتي تعتمد على جافاسكريبت، ثم تعلم قاعدة البيانات MongoDB، وبذلك تكون قد تعلمت تقنيات MERN. أو تعلم Django الذي يعتمد على بايثون. وهناك نقطة هامة جدًا، ما تتعلمه يعتمد على سوق العمل، لذا تفقد المهارات المطلوبة أو نوعية المشاريع المعروضة في سوق العمل الذي تستهدفه، ثم تعلم المهارات المطلوبة وليس العكس.
-
الدليل الوحيد الشامل هو المستند الرسمي للمكتبة: https://pandas.pydata.org/docs/ وتستطيع قراءته بالعربية من خلال ترجمة جوجل، اضغط في أي مكان فارغ في الصفحة أثناء تصفح الموقع من خلال جوجل كروم، ثم اختر translate واختر العربية كلغة للترجمة. أو استخدم إضافة DeepTranslate على المتصفح لترجمة الموقع بشكل تلقائي لكن يجب إعداد الإضافة لفعل ذلك. وبالطبع لست بحاجة إلى تعلم كامل المكتبة، بل تعلم ما ستحتاجه في البداية، ثم عند الحاجة قم بالبحث عن ما تريده وتعلمه، أي يجب تعلم التالي أولاً: استيعاب الفرق بين series وdatafram pd.read_csv() pd.read_excel() df.to_csv() df.head() df.tail() df.info() df.describe() df.shape df.columns كيفية اختيار الأعمدة من إطار البيانات df[['col1', 'col2']] واختيار الصفوف أيضًا من خلال .loc[] و .iloc[] واستيعاب الفرق. التصفية الشرطية df[df['Age'] > 25] df.isnull().sum() df.dropna() df.fillna() groupby()
-
عفاك الله، عند مُراسلة مركز المساعدة سيتم الرد عليك لا تقلق بخصوص ذلك، أحيانًا يتأخر الرد بسبب وجود ضغط ليس أكثر، الحل الأول هو أن يتم توفير المحتوى النصي للدورة من قبل مركز المساعدة إن كان هناك سماحية كاستثناء لك بشرط إثبات أن بحاجة إلى الأمر. الحل الآخر هو استخدام قاريء للشاشة، والخيار الأفضل بالنسبة لنظام ويندوز هو NVDA (NonVisual Desktop Access) وبالطبع مجاني ومفتوح المصدر ويدعم اللغة العربية بشكل ممتاز. https://www.nvaccess.org/download/ يوجد أيضًا JAWS ولكنه مدفوع، أما للماك و آيفون فيوجد VoiceOver وهو مدمج في أجهزة آبل ويعمل بشكل ممتاز. بالنسبة لمحرر الأكواد اعتمد علىVisual Studio Code (VS Code) لأنّ فريق مايكروسوفت بذل جهد كبير لجعله متوافق تمامًا مع قارئات الشاشة، وسيقرأ لك قارئ الشاشة المسافات البادئة (Indentation) ووالأقواس والرموز وكل تفاصيل الكود. والمدرب في الدورة يشرح ما يفعله، سيقول مثلاً الآن سنقوم بإنشاء دالة جديدة اسمها calculate_price تأخذ معاملين، quantity و item_price، فالشرح الصوتي هو دليلك الأساسي. ولا تستمع للدرس كاملاً دفعة واحدة، استمع لشرح فكرة أو كتابة بضعة أسطر، ثم أوقف الفيديو مؤقتاً، وانتقل إلى محرر الأكواد، وحاول كتابة نفس الكود بنفسك، لترسيخ المعلومة، وقارئ الشاشة سيساعدك على التأكد من أنك كتبت كل شيء بشكل صحيح (الأقواس، الفواصل، المسافات البادئة).
-
ستقومين بتفقد حجم المجلدات والملفات في مجلد المشروع، تستطيعي الوقوف بمؤشر الفأرة فوق الملف أو المجلد وسيتم إظهار مساحته، أو الضغط عليه بزر الفأرة الأيمن ثم اختاري properties. غالبًا مجلد scraped_data هو الذي يسبب المشكلة، لنقم بوضعه في ملف gitignore كالتالي: scraped_data/ ثم تنفيذ git rm --cached -r . ثم: إعادة رفع المشروع: git add . git commit "first commit" git push
-
يوجد ملف بحجم كبير 400 ميجابايت، وذلك غير مسموح بشكل إفتراضي على github، يجب إضافة الملفات كبيرة حجم إلى ملف gitignore لتجاهلها وتجنب رفعها. هل الصور هي سبب الحجم الكبير للمشروع أم يوجد ملف لنموذج تم تدريبه؟
-
بالنسبة لملفات csv لعرضها يجب الضغط على رابط view raw بالنسبة لملفات jupyter فالمشكلة عند حفظك للملف على جهازك، تم تخزين معلومات عن الـ Widgets بطريقة قديمة أو غير مكتملة، ونظام العرض في GitHub يتوقع وجود معلومة محددة اسمها state أي الحالة لكل Widget، ولكنه لم يجدها. أسهل حل قومي بفتحها على حاسوبك من خلال VS Code، ثم من القائمة العلوية، اختاري Kernel ثم اختاري Restart and Clear Output لإعادة التشغيل ومسح المخرجات التي تظهر نتيجة تشغيل الخلايا. واحفظي الملف مرة أخرى، ورفع الملف الجديد إلى GitHub مرة أخرى: git add . git commit "clearing Jupyter Notebook output" git push
- 1 جواب
-
- 1
-
-
عذرًا على أي إزعاج صالحة، تفقدت الدروس وهي تعمل بشكل جيد ويمكن الوصول إليها بدون مشكلة، أرجو حذف الملفات المؤقتة لموقع الأكاديمية بتحديث الصفحة بالضغط على CTRL + F5 في حال استمرت المشكلة أرجو تجربة متصفح آخر، في حال تم المشكلة إذن المشكلة من المتصفح لديكِ ربما يوجد إضافة تسبب المشكلة. لو استمرت إذن يوجد مشكلة في الإنترنت لديكِ، لنقم بتجربة تحميل نسخة الويندوز من البرنامج التالي وتشغيله: https://one.one.one.one/ بعد التثبيت ستجدي أيقونة البرنامج بالضغط على السهم أسفل اليمين في الويندوز، اضغطي على connect للإتصال.